{
"cells": [
{
"cell_type": "code",
"execution_count": 1,
"metadata": {},
"outputs": [],
"source": [
"# You must run this cell, but you can ignore its contents.\n",
"\n",
"import hashlib\n",
"\n",
"def ads_hash(ty):\n",
" \"\"\"Return a unique string for input\"\"\"\n",
" ty_str = str(ty).encode()\n",
" m = hashlib.sha256()\n",
" m.update(ty_str)\n",
" return m.hexdigest()[:10]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# transcriptome clustering analysis\n",
"\n",
"In this exercise, you are going to analyze the results of an experiment in which the RNA was sequenced (a \"transcriptome\" was made) for many cells in cell culture. We expect that the total number of cell types is rather limited, although we sequenced many individual cells.\n",
"\n",
"The data here is fake, but the analysis methods are real and are in heavy use across lots of different labs and can be applied to many other types of problems beyond RNA sequencing data."
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {},
"outputs": [],
"source": [
"import pandas as pd\n",
"from sklearn.decomposition import PCA\n",
"import numpy as np\n",
"\n",
"import matplotlib.pyplot as plt\n",
"import seaborn as sns"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We are given a dataset where the RNA expression levels of 50 genes from each of many cells was quantified. The data is in the file `RNAseq_data_50genes.csv`. Let's read this into a pandas DataFrame."
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {},
"outputs": [],
"source": [
"df = pd.read_csv('RNAseq_data_50genes.csv')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now let's have a first look at this data."
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"
\n",
"\n",
"
\n",
" \n",
"
\n",
"
\n",
"
gene 0
\n",
"
gene 1
\n",
"
gene 2
\n",
"
gene 3
\n",
"
gene 4
\n",
"
gene 5
\n",
"
gene 6
\n",
"
gene 7
\n",
"
gene 8
\n",
"
gene 9
\n",
"
...
\n",
"
gene 40
\n",
"
gene 41
\n",
"
gene 42
\n",
"
gene 43
\n",
"
gene 44
\n",
"
gene 45
\n",
"
gene 46
\n",
"
gene 47
\n",
"
gene 48
\n",
"
gene 49
\n",
"
\n",
" \n",
" \n",
"
\n",
"
0
\n",
"
2377
\n",
"
2886
\n",
"
1524
\n",
"
2235
\n",
"
2472
\n",
"
1256
\n",
"
1006
\n",
"
1902
\n",
"
911
\n",
"
2285
\n",
"
...
\n",
"
0
\n",
"
1115
\n",
"
1381
\n",
"
2226
\n",
"
1810
\n",
"
2124
\n",
"
1479
\n",
"
719
\n",
"
0
\n",
"
529
\n",
"
\n",
"
\n",
"
1
\n",
"
1251
\n",
"
948
\n",
"
3038
\n",
"
3857
\n",
"
1971
\n",
"
1761
\n",
"
2371
\n",
"
632
\n",
"
1705
\n",
"
2251
\n",
"
...
\n",
"
954
\n",
"
1874
\n",
"
527
\n",
"
1783
\n",
"
1922
\n",
"
1029
\n",
"
173
\n",
"
2267
\n",
"
1078
\n",
"
1343
\n",
"
\n",
"
\n",
"
2
\n",
"
2650
\n",
"
1643
\n",
"
1560
\n",
"
2545
\n",
"
1689
\n",
"
1072
\n",
"
1999
\n",
"
1707
\n",
"
579
\n",
"
1655
\n",
"
...
\n",
"
589
\n",
"
409
\n",
"
967
\n",
"
1762
\n",
"
1789
\n",
"
2424
\n",
"
494
\n",
"
1680
\n",
"
0
\n",
"
1283
\n",
"
\n",
"
\n",
"
3
\n",
"
1622
\n",
"
1581
\n",
"
1333
\n",
"
2218
\n",
"
2346
\n",
"
342
\n",
"
1534
\n",
"
1571
\n",
"
456
\n",
"
187
\n",
"
...
\n",
"
2535
\n",
"
1524
\n",
"
236
\n",
"
1343
\n",
"
1089
\n",
"
1429
\n",
"
930
\n",
"
1415
\n",
"
173
\n",
"
1153
\n",
"
\n",
"
\n",
"
4
\n",
"
1863
\n",
"
993
\n",
"
1225
\n",
"
1318
\n",
"
1854
\n",
"
0
\n",
"
1461
\n",
"
634
\n",
"
663
\n",
"
0
\n",
"
...
\n",
"
1882
\n",
"
1072
\n",
"
0
\n",
"
3040
\n",
"
1031
\n",
"
553
\n",
"
1468
\n",
"
2100
\n",
"
0
\n",
"
1001
\n",
"
\n",
" \n",
"
\n",
"
5 rows × 50 columns
\n",
"
"
],
"text/plain": [
" gene 0 gene 1 gene 2 gene 3 gene 4 gene 5 gene 6 gene 7 gene 8 \\\n",
"0 2377 2886 1524 2235 2472 1256 1006 1902 911 \n",
"1 1251 948 3038 3857 1971 1761 2371 632 1705 \n",
"2 2650 1643 1560 2545 1689 1072 1999 1707 579 \n",
"3 1622 1581 1333 2218 2346 342 1534 1571 456 \n",
"4 1863 993 1225 1318 1854 0 1461 634 663 \n",
"\n",
" gene 9 ... gene 40 gene 41 gene 42 gene 43 gene 44 gene 45 gene 46 \\\n",
"0 2285 ... 0 1115 1381 2226 1810 2124 1479 \n",
"1 2251 ... 954 1874 527 1783 1922 1029 173 \n",
"2 1655 ... 589 409 967 1762 1789 2424 494 \n",
"3 187 ... 2535 1524 236 1343 1089 1429 930 \n",
"4 0 ... 1882 1072 0 3040 1031 553 1468 \n",
"\n",
" gene 47 gene 48 gene 49 \n",
"0 719 0 529 \n",
"1 2267 1078 1343 \n",
"2 1680 0 1283 \n",
"3 1415 173 1153 \n",
"4 2100 0 1001 \n",
"\n",
"[5 rows x 50 columns]"
]
},
"execution_count": 4,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"df.head()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Q1 Understanding the raw data.\n",
"\n",
"In the first row (with index 0), how many reads were made of gene 0? Put the answer in the variable `n_reads_sample0_gene0`."
]
},
{
"cell_type": "code",
"execution_count": 5,
"metadata": {
"nbgrader": {
"grade": false,
"grade_id": "cell-867448dc531b9577",
"locked": false,
"schema_version": 3,
"solution": true,
"task": false
}
},
"outputs": [],
"source": [
"# Type your answer here and then run this and the following cell.\n",
"n_reads_sample0_gene0 = 2377"
]
},
{
"cell_type": "code",
"execution_count": 6,
"metadata": {
"nbgrader": {
"grade": true,
"grade_id": "cell-927c0add61a309ae",
"locked": true,
"points": 1,
"schema_version": 3,
"solution": false,
"task": false
}
},
"outputs": [],
"source": [
"# This is a test of the above, do not change this code.\n",
"assert type(n_reads_sample0_gene0)==int\n",
"assert ads_hash(n_reads_sample0_gene0)=='1a5de96b83'"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"How many total cells were sequenced? This is the number of rows in the dataframe. Put this in the variable `n_cells_sequenced`."
]
},
{
"cell_type": "code",
"execution_count": 7,
"metadata": {
"nbgrader": {
"grade": false,
"grade_id": "cell-190def2eb393c7e4",
"locked": false,
"schema_version": 3,
"solution": true,
"task": false
}
},
"outputs": [],
"source": [
"# Type your answer here and then run this and the following cell.\n",
"n_cells_sequenced = len(df)"
]
},
{
"cell_type": "code",
"execution_count": 8,
"metadata": {
"nbgrader": {
"grade": true,
"grade_id": "cell-c04f0d4317e6abfe",
"locked": true,
"points": 1,
"schema_version": 3,
"solution": false,
"task": false
}
},
"outputs": [],
"source": [
"# This is a test of the above, do not change this code.\n",
"assert type(n_cells_sequenced)==int\n",
"assert ads_hash(n_cells_sequenced)=='284b7e6d78'"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"How many genes do we have in our dataset? This is actually the dimensionality of our dataset. We are counting reads for each of these genes, so if we have N genes, we have an N dimensional dataset. Put your answer in the variable `n_dim`."
]
},
{
"cell_type": "code",
"execution_count": 9,
"metadata": {
"nbgrader": {
"grade": false,
"grade_id": "cell-866e97e764ad0ed7",
"locked": false,
"schema_version": 3,
"solution": true,
"task": false
}
},
"outputs": [],
"source": [
"# Type your answer here and then run this and the following cell.\n",
"n_dim = 50"
]
},
{
"cell_type": "code",
"execution_count": 10,
"metadata": {
"nbgrader": {
"grade": true,
"grade_id": "cell-b28c7b470e97c1de",
"locked": true,
"points": 1,
"schema_version": 3,
"solution": false,
"task": false
}
},
"outputs": [],
"source": [
"# This is a test of the above, do not change this code.\n",
"assert type(n_dim)==int\n",
"assert ads_hash(n_dim)=='1a6562590e'"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Quickly plotting pandas DataFrames with seaborn\n",
"\n",
"Several lectures ago, we discussed seaborn we are are going to use it below to make a plot with our transcriptomic data. Let's first practice with a simple dataset:"
]
},
{
"cell_type": "code",
"execution_count": 11,
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"
\n",
"\n",
"
\n",
" \n",
"
\n",
"
\n",
"
column 1
\n",
"
column 2
\n",
"
\n",
" \n",
" \n",
"
\n",
"
0
\n",
"
1
\n",
"
1
\n",
"
\n",
"
\n",
"
1
\n",
"
2
\n",
"
5
\n",
"
\n",
"
\n",
"
2
\n",
"
3
\n",
"
5
\n",
"
\n",
"
\n",
"
3
\n",
"
4
\n",
"
2
\n",
"
\n",
"
\n",
"
4
\n",
"
5
\n",
"
2
\n",
"
\n",
" \n",
"
\n",
"
"
],
"text/plain": [
" column 1 column 2\n",
"0 1 1\n",
"1 2 5\n",
"2 3 5\n",
"3 4 2\n",
"4 5 2"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAjcAAAGwCAYAAABVdURTAAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjkuMiwgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy8hTgPZAAAACXBIWXMAAA9hAAAPYQGoP6dpAAAsxklEQVR4nO3df3CU5b3//9diIAmQXX6FZDMEAUXQQJAJnJJWkRILGk2lzZkeWwcBlWMKokIZ09jxV20nMMdTkYMDovgjpsJMjWgQf0A9yWKZMAMaBBUoQpQ0Jsacym4SZBPg/v7RT/brkk3YDZvs7uXzMXPP9L7u6959X16196v3fe0dm2VZlgAAAAzRL9IFAAAAhBPhBgAAGIVwAwAAjEK4AQAARiHcAAAAoxBuAACAUQg3AADAKHGRLqCvnTt3Tl9++aWSkpJks9kiXQ4AAAiCZVlqbm5WWlqa+vXr/t7M9y7cfPnll0pPT490GQAAoAdqa2s1atSobvt878JNUlKSpH/9w7Hb7RGuBgAABMPj8Sg9Pd13He/O9y7cdDyKstvthBsAAGJMMEtKWFAMAACMQrgBAABGIdwAAACjEG4AAIBRCDcAAMAohBsAAGAUwg0AADAK4QYAABiFcAMAAIxCuAEAAEaJaLh59NFHZbPZ/LbU1NRuz3G5XMrKylJCQoLGjRunDRs29FG1MJ37VJuONbao+sQ3OvZ1i9yn2iJdEkLA/AHoEPG/LZWRkaG//vWvvv1LLrmky741NTXKzc3V4sWLVVpaqt27d2vJkiVKTk5Wfn5+X5QLQ3158lsVlh3Q+0ebfG0zx4/QqvxMpQ1JjGBlCAbzB+C7Iv5YKi4uTqmpqb4tOTm5y74bNmzQ6NGjtWbNGl155ZW66667dMcdd+iJJ57ow4phGveptk4XRknadbRJvy07wB2AKMf8AThfxMPN0aNHlZaWprFjx+rWW2/V8ePHu+xbVVWlOXPm+LXNnTtX+/btU3t7e8BzvF6vPB6P3wZ8V1NLW6cLY4ddR5vU1MLFMZoxfwDOF9Fw84Mf/EAlJSV699139eyzz6qhoUE//OEP9X//938B+zc0NCglJcWvLSUlRWfOnFFTU+D/cSsuLpbD4fBt6enpYR8HYpvndOBg3KH5AscRWcwfgPNFNNzceOONys/P1+TJk3X99ddr+/btkqSXXnqpy3NsNpvfvmVZAds7FBUVye12+7ba2towVQ9T2BP6d3s86QLHEVnMH4DzRfyx1HcNGjRIkydP1tGjRwMeT01NVUNDg19bY2Oj4uLiNHz48IDnxMfHy263+23Ad40YPEAzx48IeGzm+BEaMXhAH1eEUDB/AM4XVeHG6/Xq0KFDcjqdAY9nZ2dr586dfm07duzQtGnT1L8//+8MPeMYOECr8jM7XSBnjh+h1fmZcgzk4hjNmD8A57NZHc91ImDlypXKy8vT6NGj1djYqD/84Q9yuVw6ePCgLr30UhUVFamurk4lJSWS/vVT8EmTJunuu+/W4sWLVVVVpYKCAm3evDnon4J7PB45HA653W7u4sCP+1Sbmlra1Hy6XUkJ/TVi8AAujDGE+QPMFsr1O6LvufnHP/6hX/7yl2pqalJycrJmzJihPXv26NJLL5Uk1dfX68SJE77+Y8eO1VtvvaXly5fr6aefVlpamtauXcs7bhAWjoFcDGMZ8wegQ0Tv3EQCd24AAIg9oVy/o2rNDQAAwMUi3AAAAKMQbgAAgFEINwAAwCiEGwAAYBTCDQAAMArhBgAAGIVwAwAAjEK4AQAARiHcAAAAoxBuAACAUQg3AADAKIQbAABgFMINAAAwCuEGAAAYhXADAACMQrgBAABGIdwAAACjEG4AAIBRCDcAAMAohBsAAGAUwg0AADAK4QYAABiFcAMAAIxCuAEAAEYh3AAAAKMQbgAAgFEINwAAwCiEGwAAYBTCDQAAMArhBgAAGCVqwk1xcbFsNpvuv//+LvtUVlbKZrN12g4fPtx3hQIAgKgWF+kCJGnv3r3auHGjMjMzg+p/5MgR2e12335ycnJvlQYAAGJMxO/ctLS06LbbbtOzzz6roUOHBnXOyJEjlZqa6tsuueSSXq4SAADEioiHm6VLl+qmm27S9ddfH/Q5U6dOldPpVE5OjioqKrrt6/V65fF4/DYAAGCuiD6W2rJliz788EPt3bs3qP5Op1MbN25UVlaWvF6vXn75ZeXk5KiyslIzZ84MeE5xcbEee+yxcJYNAACimM2yLCsSX1xbW6tp06Zpx44dmjJliiRp1qxZuvrqq7VmzZqgPycvL082m03l5eUBj3u9Xnm9Xt++x+NRenq63G6337odAAAQvTwejxwOR1DX74g9lvrggw/U2NiorKwsxcXFKS4uTi6XS2vXrlVcXJzOnj0b1OfMmDFDR48e7fJ4fHy87Ha73wYAAMwVscdSOTk5OnjwoF/bokWLNHHiRBUWFga9SLi6ulpOp7M3SgQAADEoYuEmKSlJkyZN8msbNGiQhg8f7msvKipSXV2dSkpKJElr1qzRmDFjlJGRoba2NpWWlqqsrExlZWV9Xj8AAIhOUfGem67U19frxIkTvv22tjatXLlSdXV1SkxMVEZGhrZv367c3NwIVgkAAKJJxBYUR0ooC5IAAEB0iIkFxQAAAL2BcAMAAIxCuAEAAEYh3AAAAKMQbgAAgFEINwAAwCiEGwAAYBTCDQAAMArhBgAAGIVwAwAAjEK4AQAARiHcAAAAoxBuAACAUQg3AADAKIQbAABgFMINAAAwCuEGAAAYhXADAACMQrgBAABGIdwAAACjEG4AAIBRCDcAAMAohBsAAGAUwg0AADAK4QYAABiFcAMAAIxCuAEAAEYh3AAAAKMQbgAAgFEINwAAwCiEGwAAYJSoCTfFxcWy2Wy6//77u+3ncrmUlZWlhIQEjRs3Ths2bOibAgEAQEyIinCzd+9ebdy4UZmZmd32q6mpUW5urq699lpVV1frwQcf1L333quysrI+qhQAAES7iIeblpYW3XbbbXr22Wc1dOjQbvtu2LBBo0eP1po1a3TllVfqrrvu0h133KEnnniij6oFAADRLuLhZunSpbrpppt0/fXXX7BvVVWV5syZ49c2d+5c7du3T+3t7QHP8Xq98ng8fhsAADBXRMPNli1b9OGHH6q4uDio/g0NDUpJSfFrS0lJ0ZkzZ9TU1BTwnOLiYjkcDt+Wnp5+0XUDAIDoFbFwU1tbq/vuu0+lpaVKSEgI+jybzea3b1lWwPYORUVFcrvdvq22trbnRQMAgKgXF6kv/uCDD9TY2KisrCxf29mzZ7Vr1y6tW7dOXq9Xl1xyid85qampamho8GtrbGxUXFychg8fHvB74uPjFR8fH/4BAACAqBSxcJOTk6ODBw/6tS1atEgTJ05UYWFhp2AjSdnZ2dq2bZtf244dOzRt2jT179+/V+sFAACxIWLhJikpSZMmTfJrGzRokIYPH+5rLyoqUl1dnUpKSiRJBQUFWrdunVasWKHFixerqqpKmzZt0ubNm/u8fgAAEJ0i/mup7tTX1+vEiRO+/bFjx+qtt95SZWWlrr76aj3++ONau3at8vPzI1glAACIJjarY0Xu94TH45HD4ZDb7Zbdbo90OQAAIAihXL+j+s4NAABAqAg3AADAKIQbAABgFMINAAAwCuEGAAAYhXADAACMQrgBAABGIdwAAACjEG4AAIBRCDcAAMAohBsAAGAUwg0AADAK4QYAABiFcAMAAIxCuAEAAEYh3AAAAKMQbgAAgFEINwAAwCiEGwAAYBTCDQAAMArhBgAAGIVwAwAAjEK4AQAARiHcAAAAoxBuAACAUQg3AADAKIQbAABgFMINAAAwCuEGAAAYhXADAACMQrgBAABGiWi4Wb9+vTIzM2W322W325Wdna233367y/6VlZWy2WydtsOHD/dh1QAAIJrFRfLLR40apVWrVunyyy+XJL300ku65ZZbVF1drYyMjC7PO3LkiOx2u28/OTm512sFAACxIaLhJi8vz2//j3/8o9avX689e/Z0G25GjhypIUOG9HJ1AAAgFkXNmpuzZ89qy5Ytam1tVXZ2drd9p06dKqfTqZycHFVUVHTb1+v1yuPx+G0AAMBcEQ83Bw8e1ODBgxUfH6+CggJt3bpVV111VcC+TqdTGzduVFlZmV577TVNmDBBOTk52rVrV5efX1xcLIfD4dvS09N7aygAACAK2CzLsiJZQFtbm06cOKGTJ0+qrKxMzz33nFwuV5cB53x5eXmy2WwqLy8PeNzr9crr9fr2PR6P0tPT5Xa7/dbtAACA6OXxeORwOIK6fkd0zY0kDRgwwLegeNq0adq7d6+eeuopPfPMM0GdP2PGDJWWlnZ5PD4+XvHx8WGpFQAARL+IP5Y6n2VZfndaLqS6ulpOp7MXKwIAALEkonduHnzwQd14441KT09Xc3OztmzZosrKSr3zzjuSpKKiItXV1amkpESStGbNGo0ZM0YZGRlqa2tTaWmpysrKVFZWFslhAACAKBLRcPPVV19p/vz5qq+vl8PhUGZmpt555x395Cc/kSTV19frxIkTvv5tbW1auXKl6urqlJiYqIyMDG3fvl25ubmRGgIAAIgyEV9Q3NdCWZAEAACiQyjX76hbcwMAAHAxCDcAAMAohBsAAGAUwg0AADAK4QYAABiFcAMAAIwSUrjZvn277rrrLj3wwAM6fPiw37FvvvlGs2fPDmtxAAAAoQo63Lzyyiu65ZZb1NDQoKqqKk2dOlV//vOffcfb2trkcrl6pUgAAIBgBf2G4ieeeEJPPvmkli1bJkl69dVXtWjRIp0+fVp33nlnrxUIAAAQiqDDzd///nfdfPPNvv1///d/14gRI/TTn/5U7e3t+tnPftYrBQIAAIQi6HBjt9v11VdfaezYsb62WbNmadu2bbr55pv1j3/8o1cKBAAACEXQa27+7d/+TW+//Xan9uuuu07btm3TmjVrwlkXAABAjwQdbpYvX66EhISAx2bNmqU333xTt99+e9gKAwAA6An+KjgAAIh6/FVwAADwvUW4AQAARiHcAAAAoxBuAACAUQg3AADAKEG/xK9Da2urVq1apffee0+NjY06d+6c3/Hjx4+HrTgAAIBQhRxu7rrrLrlcLs2fP19Op1M2m6036gIAAOiRkMPN22+/re3bt+tHP/pRb9QDAABwUUJeczN06FANGzasN2oBAAC4aCGHm8cff1wPP/ywTp061Rv1AAAAXJSQH0v993//t44dO6aUlBSNGTNG/fv39zv+4Ycfhq04AACAUIUcbubNm9cLZQAAAIQHfzgTAABEvVCu3yHfufmulpaWTu+5ITAAAIBICnlBcU1NjW666SYNGjRIDodDQ4cO1dChQzVkyBANHTq0N2oEAAAIWsh3bm677TZJ0vPPP6+UlBRe4gcAAKJKyOHmwIED+uCDDzRhwoTeqAcAAOCihPxYavr06aqtrQ3Ll69fv16ZmZmy2+2y2+3Kzs7W22+/3e05LpdLWVlZSkhI0Lhx47Rhw4aw1AIAAMwQ8p2b5557TgUFBaqrq9OkSZM6vecmMzMz6M8aNWqUVq1apcsvv1yS9NJLL+mWW25RdXW1MjIyOvWvqalRbm6uFi9erNLSUu3evVtLlixRcnKy8vPzQx0KAAAwUMg/Bd+zZ49+9atf6fPPP///P8Rmk2VZstlsOnv27EUVNGzYMP3Xf/2X7rzzzk7HCgsLVV5erkOHDvnaCgoK9NFHH6mqqiqoz+en4AAAxJ5e/Sn4HXfcoalTp2rz5s1hXVB89uxZ/eUvf1Fra6uys7MD9qmqqtKcOXP82ubOnatNmzapvb29010kSfJ6vfJ6vb59j8cTlnoBAEB0CjncfPHFFyovL/c9SrpYBw8eVHZ2tk6fPq3Bgwdr69atuuqqqwL2bWhoUEpKil9bSkqKzpw5o6amJjmdzk7nFBcX67HHHgtLrQAAIPqFvKB49uzZ+uijj8JWwIQJE7R//37t2bNHv/71r7VgwQJ9+umnXfY//05Rx1O1ru4gFRUVye12+7ZwLYYGAADRKeQ7N3l5eVq+fLkOHjyoyZMnd3oU9NOf/jSkzxswYIDvLtC0adO0d+9ePfXUU3rmmWc69U1NTVVDQ4NfW2Njo+Li4jR8+PCAnx8fH6/4+PiQagIAALEr5HBTUFAgSfr973/f6Vg4FhRbluW3Rua7srOztW3bNr+2HTt2aNq0aQHX2wAAgO+fkB9LnTt3rsst1GDz4IMP6v3339fnn3+ugwcP6ne/+50qKyt9b0EuKirS7bff7utfUFCgL774QitWrNChQ4f0/PPPa9OmTVq5cmWowwAAAIa6qD+cebG++uorzZ8/X/X19XI4HMrMzNQ777yjn/zkJ5Kk+vp6nThxwtd/7Nixeuutt7R8+XI9/fTTSktL09q1a3nHDQAA8An5PTeBHkd918MPP3xRBfU23nMDAEDs6dX33GzdutVvv729XTU1NYqLi9Nll10W9eEGAACYLeRwU11d3anN4/Fo4cKF+tnPfhaWogAAAHoq5AXFgdjtdv3+97/XQw89FI6PAwAA6LGwhBtJOnnypNxud7g+DgAAoEdCfiy1du1av33LslRfX6+XX35ZN9xwQ9gKAwAA6ImQw82TTz7pt9+vXz8lJydrwYIFKioqClthAAAAPRFyuKmpqemNOgAAAMIibGtuAAAAokFQd25+/vOfB/2Br732Wo+LAQAAuFhBhRuHw9HbdQAAAIRFUOHmhRde6O06AAAAwqLHfzjz66+/1pEjR2Sz2XTFFVcoOTk5nHUBAAD0SMgLiltbW3XHHXfI6XRq5syZuvbaa5WWlqY777xTp06d6o0aAQAAghZyuFmxYoVcLpe2bdumkydP6uTJk3rjjTfkcrn0m9/8pjdqBAAACJrNsiwrlBNGjBihV199VbNmzfJrr6io0C9+8Qt9/fXX4awv7EL5k+kAACA6hHL9DvnOzalTp5SSktKpfeTIkTyWAgAAERdyuMnOztYjjzyi06dP+9q+/fZbPfbYY8rOzg5rcQAAAKEK+ddSTz31lG644QaNGjVKU6ZMkc1m0/79+5WQkKB33323N2oEAAAIWshrbqR/3akpLS3V4cOHZVmWrrrqKt12221KTEzsjRrDijU3AADEnlCu3z16z01iYqIWL17co+IAAAB6U8hrboqLi/X88893an/++ee1evXqsBQFAADQUyGHm2eeeUYTJ07s1J6RkaENGzaEpSgAAICeCjncNDQ0yOl0dmpPTk5WfX19WIoCAADoqZDDTXp6unbv3t2pfffu3UpLSwtLUQAAAD0V8oLiu+66S/fff7/a29s1e/ZsSdJ7772nBx54gD+/AAAAIi7kcPPAAw/on//8p5YsWaK2tjZJUkJCggoLC1VUVBT2AgEAAELRo/fcSFJLS4sOHTqkxMREjR8/XvHx8eGurVfwnhsAAGJPr7/nRpIGDx6s6dOn9/R0AACAXhHygmIAAIBoRrgBAABGIdwAAACjRDTcFBcXa/r06UpKStLIkSM1b948HTlypNtzKisrZbPZOm2HDx/uo6oBAEA0i2i4cblcWrp0qfbs2aOdO3fqzJkzmjNnjlpbWy947pEjR1RfX+/bxo8f3wcVAwCAaNfjX0uFwzvvvOO3/8ILL2jkyJH64IMPNHPmzG7PHTlypIYMGdKL1QEAgFgUVWtu3G63JGnYsGEX7Dt16lQ5nU7l5OSooqKiy35er1cej8dvAwAA5oqacGNZllasWKFrrrlGkyZN6rKf0+nUxo0bVVZWptdee00TJkxQTk6Odu3aFbB/cXGxHA6Hb0tPT++tIQAAgCjQ4zcUh9vSpUu1fft2/e1vf9OoUaNCOjcvL082m03l5eWdjnm9Xnm9Xt++x+NReno6bygGACCGhPKG4qi4c7Ns2TKVl5eroqIi5GAjSTNmzNDRo0cDHouPj5fdbvfbAACAuSK6oNiyLC1btkxbt25VZWWlxo4d26PPqa6ultPpDHN1AAAgFkU03CxdulSvvPKK3njjDSUlJamhoUGS5HA4lJiYKEkqKipSXV2dSkpKJElr1qzRmDFjlJGRoba2NpWWlqqsrExlZWURGwcAAIgeEQ0369evlyTNmjXLr/2FF17QwoULJUn19fU6ceKE71hbW5tWrlypuro6JSYmKiMjQ9u3b1dubm5flQ0AAKJY1Cwo7iuhLEgCAADRIeYWFAMAAIQL4QYAABiFcAMAAIxCuAEAAEYh3AAAAKMQbgAAgFEINwAAwCiEGwAAYBTCDQAAMArhBgAAGIVwAwAAjEK4AQAARiHcAAAAoxBuAACAUQg3AADAKIQbAABgFMINAAAwCuEGAAAYhXADAACMQrgBAABGIdwAAACjEG4AAIBRCDcAAMAohBsAAGAUwg0AADAK4QYAABiFcAMAAIxCuAEAAEYh3AAAAKMQbgAAgFEINwAAwCgRDTfFxcWaPn26kpKSNHLkSM2bN09Hjhy54Hkul0tZWVlKSEjQuHHjtGHDhj6oFgDQm9yn2nSssUXVJ77Rsa9b5D7VFumSEKJomcO4iHzr/+NyubR06VJNnz5dZ86c0e9+9zvNmTNHn376qQYNGhTwnJqaGuXm5mrx4sUqLS3V7t27tWTJEiUnJys/P7+PRwAACIcvT36rwrIDev9ok69t5vgRWpWfqbQhiRGsDMGKpjm0WZZl9ek3duPrr7/WyJEj5XK5NHPmzIB9CgsLVV5erkOHDvnaCgoK9NFHH6mqquqC3+HxeORwOOR2u2W328NWOwCgZ9yn2nTP5mq/i2KHmeNH6H9+OVWOgQMiUBmC1RdzGMr1O6rW3LjdbknSsGHDuuxTVVWlOXPm+LXNnTtX+/btU3t7e6f+Xq9XHo/HbwMARI+mlraAF0VJ2nW0SU0tPJ6KdtE2h1ETbizL0ooVK3TNNddo0qRJXfZraGhQSkqKX1tKSorOnDmjpqbO/2CLi4vlcDh8W3p6ethrBwD0nOd05/9j+l3NFziOyIu2OYyacHPPPffowIED2rx58wX72mw2v/2OJ2vnt0tSUVGR3G63b6utrQ1PwQCAsLAn9O/2eNIFjiPyom0OoyLcLFu2TOXl5aqoqNCoUaO67ZuamqqGhga/tsbGRsXFxWn48OGd+sfHx8tut/ttAIDoMWLwAM0cPyLgsZnjR2jEYNbbRLtom8OIhhvLsnTPPffotdde0//+7/9q7NixFzwnOztbO3fu9GvbsWOHpk2bpv79SfcAEGscAwdoVX5mp4vjzPEjtDo/k8XEMSDa5jCiv5ZasmSJXnnlFb3xxhuaMGGCr93hcCgx8V8/GysqKlJdXZ1KSkok/eun4JMmTdLdd9+txYsXq6qqSgUFBdq8eXNQPwXn11IAEJ3cp9rU1NKm5tPtSkrorxGDBxBsYkxvzmEo1++IhptAa2Qk6YUXXtDChQslSQsXLtTnn3+uyspK33GXy6Xly5frk08+UVpamgoLC1VQUBDUdxJuAACIPTETbiKBcAMAQOyJ2ffcAAAAXCzCDQAAMArhBgAAGIVwAwAAjEK4AQAARiHcAAAAoxBuAACAUQg3AADAKIQbAABgFMINAAAwCuEGAAAYhXADAACMQrgBAABGIdwAAACjEG4AAIBRCDcAAMAohBsAAGAUwg0AADAK4QYAABiFcAMAAIxCuAEAAEYh3AAAAKMQbgAAgFEINwAAwCiEGwAAYBTCDQAAMArhBgAAGIVwAwAAjEK4AQAARiHcAAAAoxBuAACAUSIabnbt2qW8vDylpaXJZrPp9ddf77Z/ZWWlbDZbp+3w4cN9UzAAAIh6cZH88tbWVk2ZMkWLFi1Sfn5+0OcdOXJEdrvdt5+cnNwb5QEAgBgU0XBz44036sYbbwz5vJEjR2rIkCHhLwgAAMS8mFxzM3XqVDmdTuXk5KiioqLbvl6vVx6Px28DAADmiqlw43Q6tXHjRpWVlem1117ThAkTlJOTo127dnV5TnFxsRwOh29LT0/vw4oBAEBfs1mWZUW6CEmy2WzaunWr5s2bF9J5eXl5stlsKi8vD3jc6/XK6/X69j0ej9LT0+V2u/3W7QAAgOjl8XjkcDiCun7H1J2bQGbMmKGjR492eTw+Pl52u91vAwAA5or5cFNdXS2n0xnpMgAAQJSI6K+lWlpa9Nlnn/n2a2pqtH//fg0bNkyjR49WUVGR6urqVFJSIklas2aNxowZo4yMDLW1tam0tFRlZWUqKyuL1BAAAECUiWi42bdvn3784x/79lesWCFJWrBggV588UXV19frxIkTvuNtbW1auXKl6urqlJiYqIyMDG3fvl25ubl9XjsAAIhOUbOguK+EsiAJAABEh+/VgmIAAIDvItwAAACjEG4AAIBRCDcAAMAohBsAAGAUwg0AADAK4QYAABiFcAMAAIxCuAEAAEYh3AAAAKMQbgAAgFEINwAAwCiEGwAAYBTCDQAAMArhBgAAGIVwAwAAjEK4AQAARiHcAAAAoxBuAACAUQg3AADAKIQbAABgFMINAAAwCuEGAAAYhXADAACMQrgBAABGIdwAAACjEG4AAIBRCDcAAMAohBsAAGAUwg0AADAK4QYAABglouFm165dysvLU1pammw2m15//fULnuNyuZSVlaWEhASNGzdOGzZs6P1Cg+A+1aZjjS2qPvGNjn3dIveptkiXBADA91JcJL+8tbVVU6ZM0aJFi5Sfn3/B/jU1NcrNzdXixYtVWlqq3bt3a8mSJUpOTg7q/N7y5clvVVh2QO8fbfK1zRw/QqvyM5U2JDFidQEA8H1ksyzLinQRkmSz2bR161bNmzevyz6FhYUqLy/XoUOHfG0FBQX66KOPVFVVFdT3eDweORwOud1u2e32iy1b7lNtumdztV+w6TBz/Aj9zy+nyjFwwEV/DwAA32ehXL9jas1NVVWV5syZ49c2d+5c7du3T+3t7QHP8Xq98ng8fls4NbW0BQw2krTraJOaWng8BQBAX4qpcNPQ0KCUlBS/tpSUFJ05c0ZNTYEDRnFxsRwOh29LT08Pa02e04FDVYfmCxwHAADhFVPhRvrX46vv6niqdn57h6KiIrndbt9WW1sb1nrsCf27PZ50geMAACC8IrqgOFSpqalqaGjwa2tsbFRcXJyGDx8e8Jz4+HjFx8f3Wk0jBg/QzPEjtKuLNTcjBrPeBgCAvhRTd26ys7O1c+dOv7YdO3Zo2rRp6t8/MndIHAMHaFV+pmaOH+HXPnP8CK3Oz2QxMQAAfSyid25aWlr02Wef+fZramq0f/9+DRs2TKNHj1ZRUZHq6upUUlIi6V+/jFq3bp1WrFihxYsXq6qqSps2bdLmzZsjNQRJUtqQRP3PL6eqqaVNzafblZTQXyMGDyDYAAAQARENN/v27dOPf/xj3/6KFSskSQsWLNCLL76o+vp6nThxwnd87Nixeuutt7R8+XI9/fTTSktL09q1ayP6jpsOjoGEGQAAokHUvOemr4T7PTcAAKD3GfueGwAAgAsh3AAAAKMQbgAAgFEINwAAwCiEGwAAYBTCDQAAMArhBgAAGIVwAwAAjEK4AQAARompvwoeDh0vZPZ4PBGuBAAABKvjuh3MH1b43oWb5uZmSVJ6enqEKwEAAKFqbm6Ww+Hots/37m9LnTt3Tl9++aWSkpJks9nC+tkej0fp6emqra018u9WmT4+yfwxMr7YZ/oYGV/s660xWpal5uZmpaWlqV+/7lfVfO/u3PTr10+jRo3q1e+w2+3G/pdWMn98kvljZHyxz/QxMr7Y1xtjvNAdmw4sKAYAAEYh3AAAAKMQbsIoPj5ejzzyiOLj4yNdSq8wfXyS+WNkfLHP9DEyvtgXDWP83i0oBgAAZuPODQAAMArhBgAAGIVwAwAAjEK4AQAARiHcBGnXrl3Ky8tTWlqabDabXn/99Que43K5lJWVpYSEBI0bN04bNmzo/UIvQqhjrKyslM1m67QdPny4bwoOUXFxsaZPn66kpCSNHDlS8+bN05EjRy54XqzMY0/GF0tzuH79emVmZvpeDJadna23336723NiZe46hDrGWJq/QIqLi2Wz2XT//fd32y/W5rFDMOOLtTl89NFHO9Wampra7TmRmD/CTZBaW1s1ZcoUrVu3Lqj+NTU1ys3N1bXXXqvq6mo9+OCDuvfee1VWVtbLlfZcqGPscOTIEdXX1/u28ePH91KFF8flcmnp0qXas2ePdu7cqTNnzmjOnDlqbW3t8pxYmseejK9DLMzhqFGjtGrVKu3bt0/79u3T7Nmzdcstt+iTTz4J2D+W5q5DqGPsEAvzd769e/dq48aNyszM7LZfLM6jFPz4OsTSHGZkZPjVevDgwS77Rmz+LIRMkrV169Zu+zzwwAPWxIkT/druvvtua8aMGb1YWfgEM8aKigpLkvXNN9/0SU3h1tjYaEmyXC5Xl31ieR6DGV+sz+HQoUOt5557LuCxWJ677+pujLE6f83Nzdb48eOtnTt3Wtddd5113333ddk3FucxlPHF2hw+8sgj1pQpU4LuH6n5485NL6mqqtKcOXP82ubOnat9+/apvb09QlX1jqlTp8rpdConJ0cVFRWRLidobrdbkjRs2LAu+8TyPAYzvg6xNodnz57Vli1b1Nraquzs7IB9YnnupODG2CHW5m/p0qW66aabdP3111+wbyzOYyjj6xBLc3j06FGlpaVp7NixuvXWW3X8+PEu+0Zq/r53fzizrzQ0NCglJcWvLSUlRWfOnFFTU5OcTmeEKgsfp9OpjRs3KisrS16vVy+//LJycnJUWVmpmTNnRrq8blmWpRUrVuiaa67RpEmTuuwXq/MY7PhibQ4PHjyo7OxsnT59WoMHD9bWrVt11VVXBewbq3MXyhhjbf4kacuWLfrwww+1d+/eoPrH2jyGOr5Ym8Mf/OAHKikp0RVXXKGvvvpKf/jDH/TDH/5Qn3zyiYYPH96pf6Tmj3DTi2w2m9++9f9eBn1+e6yaMGGCJkyY4NvPzs5WbW2tnnjiiaj8l/K77rnnHh04cEB/+9vfLtg3Fucx2PHF2hxOmDBB+/fv18mTJ1VWVqYFCxbI5XJ1efGPxbkLZYyxNn+1tbW67777tGPHDiUkJAR9XqzMY0/GF2tzeOONN/r+8+TJk5Wdna3LLrtML730klasWBHwnEjMH4+leklqaqoaGhr82hobGxUXFxcw3ZpixowZOnr0aKTL6NayZctUXl6uiooKjRo1qtu+sTiPoYwvkGiewwEDBujyyy/XtGnTVFxcrClTpuipp54K2DcW504KbYyBRPP8ffDBB2psbFRWVpbi4uIUFxcnl8ultWvXKi4uTmfPnu10TizNY0/GF0g0z+H5Bg0apMmTJ3dZb6Tmjzs3vSQ7O1vbtm3za9uxY4emTZum/v37R6iq3lddXR11t4k7WJalZcuWaevWraqsrNTYsWMveE4szWNPxhdINM/h+SzLktfrDXgsluauO92NMZBonr+cnJxOv6xZtGiRJk6cqMLCQl1yySWdzomleezJ+AKJ5jk8n9fr1aFDh3TttdcGPB6x+evV5coGaW5utqqrq63q6mpLkvWnP/3Jqq6utr744gvLsizrt7/9rTV//nxf/+PHj1sDBw60li9fbn366afWpk2brP79+1uvvvpqpIZwQaGO8cknn7S2bt1q/f3vf7c+/vhj67e//a0lySorK4vUELr161//2nI4HFZlZaVVX1/v206dOuXrE8vz2JPxxdIcFhUVWbt27bJqamqsAwcOWA8++KDVr18/a8eOHZZlxfbcdQh1jLE0f105/9dEJszjd11ofLE2h7/5zW+syspK6/jx49aePXusm2++2UpKSrI+//xzy7KiZ/4IN0Hq+Lne+duCBQssy7KsBQsWWNddd53fOZWVldbUqVOtAQMGWGPGjLHWr1/f94WHINQxrl692rrsssushIQEa+jQodY111xjbd++PTLFByHQ2CRZL7zwgq9PLM9jT8YXS3N4xx13WJdeeqk1YMAAKzk52crJyfFd9C0rtueuQ6hjjKX568r5F38T5vG7LjS+WJvD//iP/7CcTqfVv39/Ky0tzfr5z39uffLJJ77j0TJ/Nsv6fyt7AAAADMCCYgAAYBTCDQAAMArhBgAAGIVwAwAAjEK4AQAARiHcAAAAoxBuAACAUQg3AADAKIQbAFFn4cKFmjdvXqTLABCjCDcAEILTp09r4cKFmjx5suLi4ghhQBQi3ABACM6ePavExETde++9uv766yNdDoAACDcAwu7cuXNavXq1Lr/8csXHx2v06NH64x//6Dt+8OBBzZ49W4mJiRo+fLj+8z//Uy0tLV1+3pgxY7RmzRq/tquvvlqPPvqob99ms+mZZ57RzTffrIEDB+rKK69UVVWVPvvsM82aNUuDBg1Sdna2jh075jvn0Ucf1dVXX62XX35ZY8aMkcPh0K233qrm5uYuaxk0aJDWr1+vxYsXKzU1NfR/OAB6HeEGQNgVFRVp9erVeuihh/Tpp5/qlVdeUUpKiiTp1KlTuuGGGzR06FDt3btXf/nLX/TXv/5V99xzz0V/7+OPP67bb79d+/fv18SJE/WrX/1Kd999t4qKirRv3z5J6vQ9x44d0+uvv64333xTb775plwul1atWnXRtQCInLhIFwDALM3NzXrqqae0bt06LViwQJJ02WWX6ZprrpEk/fnPf9a3336rkpISDRo0SJK0bt065eXlafXq1b4Q1BOLFi3SL37xC0lSYWGhsrOz9dBDD2nu3LmSpPvuu0+LFi3yO+fcuXN68cUXlZSUJEmaP3++3nvvPb87TQBiC3duAITVoUOH5PV6lZOT0+XxKVOm+IKNJP3oRz/SuXPndOTIkYv67szMTN9/7ghJkydP9ms7ffq0PB6Pr23MmDG+YCNJTqdTjY2NF1UHgMgi3AAIq8TExG6PW5Ylm80W8FhX7f369ZNlWX5t7e3tnfr179+/02cFajt37lzAczr6fPc4gNhDuAEQVuPHj1diYqLee++9gMevuuoq7d+/X62trb623bt3q1+/frriiisCnpOcnKz6+nrfvsfjUU1NTXgLB2AMwg2AsEpISFBhYaEeeOABlZSU6NixY9qzZ482bdokSbrtttuUkJCgBQsW6OOPP1ZFRYWWLVum+fPnd7neZvbs2Xr55Zf1/vvv6+OPP9aCBQt0ySWX9OWw/Hz66afav3+//vnPf8rtdmv//v3av39/xOoB4I8FxQDC7qGHHlJcXJwefvhhffnll3I6nSooKJAkDRw4UO+++67uu+8+TZ8+XQMHDlR+fr7+9Kc/dfl5RUVFOn78uG6++WY5HA49/vjjEb1zk5ubqy+++MK3P3XqVEnq9OgMQGTYLP5tBAAABuGxFAAAMArhBgAAGIVwAwAAjEK4AQAARiHcAAAAoxBuAACAUQg3AADAKIQbAABgFMINAAAwCuEGAAAYhXADAACM8v8BgW4+1zXJBXcAAAAASUVORK5CYII=",
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"simple_df = pd.DataFrame(data={'column 1':[1,2,3,4,5], 'column 2':[1,5,5,2,2]})\n",
"display(simple_df)\n",
"sns.scatterplot(data=simple_df, x='column 1', y='column 2');"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Q2 Visualizing the raw data\n",
"\n",
"Now let's use seaborn to make a quick plot of the data (stored as a Pandas DataFrame in the variable `df`). Use the seaborn `scatterplot` function to make a plot like the following. Your plot should include the X and Y axes labels. You need only a single line of code for this.\n",
"\n",
"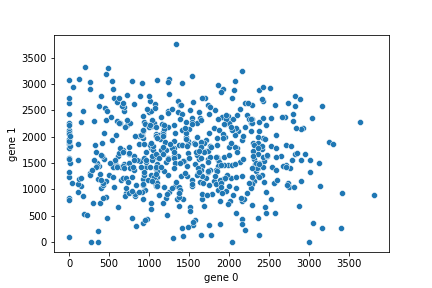."
]
},
{
"cell_type": "code",
"execution_count": 12,
"metadata": {
"nbgrader": {
"grade": true,
"grade_id": "cell-3eb44d7a59e553d8",
"locked": false,
"points": 1,
"schema_version": 3,
"solution": true,
"task": false
}
},
"outputs": [
{
"data": {
"text/plain": [
""
]
},
"execution_count": 12,
"metadata": {},
"output_type": "execute_result"
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAkQAAAGwCAYAAABIC3rIAAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjkuMiwgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy8hTgPZAAAACXBIWXMAAA9hAAAPYQGoP6dpAACm8ElEQVR4nO29eXxTdb7//0rTJm26pBvdpK2VFgVbEEERCoKgCFqR5aoD/rggDOpFYLjAVVFRXAZcxhUGx+vIMi7gd66C4jjMoIxIQUSwDqsMBQQcWkprm9KmTdr0/P6o55jlrMlJzknyfj4ePB40OUk+n7N8Pq/Pe/sYGIZhQBAEQRAEEcXEaN0AgiAIgiAIrSFBRBAEQRBE1EOCiCAIgiCIqIcEEUEQBEEQUQ8JIoIgCIIgoh4SRARBEARBRD0kiAiCIAiCiHpitW5AuNDV1YVz584hOTkZBoNB6+YQBEEQBCEDhmFw8eJF5OXlISZG2A5Egkgm586dQ35+vtbNIAiCIAjCD86ePYuePXsKvk+CSCbJyckAuk9oSkqKxq0hCIIgCEIOzc3NyM/P5+ZxIUgQyYR1k6WkpJAgIgiCIIgwQyrchYKqCYIgCIKIekgQEQRBEAQR9ZAgIgiCIAgi6iFBRBAEQRBE1EOCiCAIgiCIqIcEEUEQBEEQUQ8JIoIgCIIgoh4SRARBEARBRD0kiAiCIAiCiHpIEBEEQRAEEfXQ1h0EEYXY7E7UtzjR3N6BlIQ4ZCaaYLWYtG4WQRCEZpAgIogo41xTGx764AB2Hq/nXru+JBPPTu6HvNQEDVtGEAShHeQyI4gowmZ3+oghAPjyeD0e/uAAbHanRi0jCILQFhJEBBFF1Lc4fcQQy5fH61HfQoKIIIjohAQRQUQRze0dou9flHifIAgiUiFBRBBRREp8nOj7yRLvEwRBRCokiAgiishMMuH6kkze964vyURmEmWaEQQRnZAgIogowmox4dnJ/XxE0fUlmXhucj9KvScIImqhtHuCiDLyUhOwcsoA1Lc4cbG9A8nxcchMojpEBEFENySICCIKsVpIABEEQbhDLjOCIAiCIKIeEkQEQRAEQUQ9JIgIgiAIgoh6SBARBEEQBBH1kCAiCIIgCCLqIUFEEARBEETUQ4KIIAiCIIiohwQRQRAEQRBRDwkigiAIgiCiHhJEBEEQBEFEPSSICIIgCIKIekgQEQRBEAQR9ZAgIgiCIAgi6tFUEL3++uvo168fUlJSkJKSgiFDhuCvf/0r9/6MGTNgMBg8/l133XUe3+FwODBv3jxkZmYiMTER48ePx48//uhxTGNjI6ZNmwar1Qqr1Ypp06ahqakpFF0kCIIgCCIM0FQQ9ezZE88++yz27duHffv2YdSoUbj99ttx+PBh7pixY8eipqaG+/fpp596fMeCBQuwadMmbNy4EZWVlWhpaUFFRQVcLhd3zNSpU/Hdd99h69at2Lp1K7777jtMmzYtZP0kCIIgCELfGBiGYbRuhDvp6el44YUXMGvWLMyYMQNNTU3YvHkz77E2mw09evTA22+/jbvuugsAcO7cOeTn5+PTTz/FzTffjKNHj6Jv377Ys2cPBg8eDADYs2cPhgwZgu+//x6XX34573c7HA44HA7u7+bmZuTn58NmsyElJUXdThMEQRAEERSam5thtVol52/dxBC5XC5s3LgRra2tGDJkCPf6F198gaysLPTu3RuzZ89GXV0d997+/fvR0dGBMWPGcK/l5eWhtLQUu3fvBgB89dVXsFqtnBgCgOuuuw5Wq5U7ho8VK1ZwLjar1Yr8/Hw1u0sQBEEQhI7QXBAdPHgQSUlJMJvNuP/++7Fp0yb07dsXADBu3Di8++672L59O1588UV88803GDVqFGe5qa2thclkQlpamsd3Zmdno7a2ljsmKyvL53ezsrK4Y/hYsmQJbDYb9+/s2bNqdZkgCIIgCJ0Rq3UDLr/8cnz33XdoamrCBx98gOnTp2PHjh3o27cv5wYDgNLSUgwaNAiFhYX4y1/+gkmTJgl+J8MwMBgM3N/u/xc6xhuz2Qyz2exnrwiCIAiCCCc0txCZTCYUFxdj0KBBWLFiBfr3749XX32V99jc3FwUFhbi+PHjAICcnBw4nU40NjZ6HFdXV4fs7GzumPPnz/t814ULF7hjCIIgCIKIbjQXRN4wDOMRzOxOQ0MDzp49i9zcXADAwIEDERcXh23btnHH1NTU4NChQxg6dCgAYMiQIbDZbNi7dy93zNdffw2bzcYdQxAEQRBEdKOpy+yRRx7BuHHjkJ+fj4sXL2Ljxo344osvsHXrVrS0tGDZsmWYPHkycnNz8cMPP+CRRx5BZmYmJk6cCACwWq2YNWsWFi1ahIyMDKSnp2Px4sUoKyvDjTfeCADo06cPxo4di9mzZ+ONN94AANx7772oqKgQzDAjCIIgCCK60FQQnT9/HtOmTUNNTQ2sViv69euHrVu34qabbkJbWxsOHjyIP/3pT2hqakJubi5uuOEGvP/++0hOTua+4+WXX0ZsbCzuvPNOtLW1YfTo0Vi3bh2MRiN3zLvvvov58+dz2Wjjx4/HqlWrQt5fgiAIgiD0ie7qEOkVuXUMCIIgCILQD2FXh4ggCIIgCEIrSBARBEEQBBH1kCAiCIIgCCLqIUFEEARBEETUo3mlaiJ42OxO1Lc40dzegZSEOGQmmmC1mLRuFkEQBEHoDhJEEcq5pjY89MEB7Dxez712fUkmnp3cD3mpCRq2jCAIgiD0B7nMIhCb3ekjhgDgy+P1ePiDA7DZnRq1jCAIgiD0CVmIIpD6FqePGGL58ng96lucIXOdkduOIAiCCAdIEEUgze0dou9flHhfLchtRxAEQYQL5DKLQFLi40TfT5Z4Xw3IbUcQBEGEEySIIpDMJBOuL8nkfe/6kkxkJgXfZSXHbUcQ0YzN7sSJuhZUnWnEiQsttEggCI0hl1kEYrWY8Ozkfnj4gwP40std9dzkfiGJ4dGL244g9Ai5kwlCf5AgilDyUhOwcsoA1Lc4cbG9A8nxcchMCl1Asx7cdgShR6TcySunDKDEA4LQABJEEYzVol1GF+u2+5LHbRYqtx1B6BE9ZYESBPELFENEBAXWbecdyxRKtx1B6BFyJxOEPiELERE0tHbbEYQeIXcyQegTEkREUNHSbUcQeoTcyQShT8hlRgQFSikmCH7InUwQ+oQsRITqUEoxQYhD7mSC0B9kISJUhSpUE4Q8rBYTemUl4aqCNPTKSiIxRBAaQxYiQlUopZgAaFNfgiDCDxJEhKpQSjFBLlOCIMIRcpkRqkIpxdENuUwJgghXSBARqqKHjWUJ7aBNfQmCCFdIEBGqQinF2qGHUgfkMiUIIlyhGKIwRO8Bq5RSHHr0ErdDLlOCIMIVEkRhhl4mPimoQrUyAhG5eto9naowEwQRrpAg0hClk6CeJr5wRY/WtUBFrp5KHbAu04c/OOAhishlShCE3iFBpBH+TIJ6mvjUINTiRI/WNTVErt7idqLZZapHwU0QhDxIEGmAv5OgmhOf1gN3qMWJXq1raojcdIsJb00fBEdnF+LjjPj2TCPWVJ6C3ekCoE3cTjS6TPUouAmCkA8JIg3wdxJUK2BV64FbC3GiV+taoCL3XFMbHtt8CDurf+lbeXEGXpsyAPM3VGFQYRrF7YQAvQpugiDkQ4JIA/ydBNUIWNXDwK2FOFHDuhYMq1ogIpe7ltWe53JXdQMAYGlFX4zs3cPvNmptRQwn9Cq4CYKQDwkiDfB3ElQjYFUPA7cWMS+BWteCZVULROSKXctd1Q1YdtuVyPWzbVpbEcMNvcVxEQShHCrMqAGBVHNmA1Y/XzgCm+cMxecLR2DllAGyJz49DNxa1KoJ5JwHczuKQApZSl3LVkenX22i7TeUQ/WXCCL80VQQvf766+jXrx9SUlKQkpKCIUOG4K9//Sv3PsMwWLZsGfLy8pCQkICRI0fi8OHDHt/hcDgwb948ZGZmIjExEePHj8ePP/7ocUxjYyOmTZsGq9UKq9WKadOmoampKRRd5CXQas5Wiwm9spJwVUEaemUlKbLo6GHg1mJ7j0DOebC3o/BX5AbrWtL2G8qhLWsIIvzR1GXWs2dPPPvssyguLgYArF+/Hrfffjuqqqpw5ZVX4vnnn8dLL72EdevWoXfv3njmmWdw00034dixY0hOTgYALFiwAFu2bMHGjRuRkZGBRYsWoaKiAvv374fRaAQATJ06FT/++CO2bt0KALj33nsxbdo0bNmyRZuOQ7vUZD0UztOqVo2/5zwUVjV/srKCdS31YEUMFsGKi6L6SwQR/hgYhmG0boQ76enpeOGFFzBz5kzk5eVhwYIFeOihhwB0W4Oys7Px3HPP4b777oPNZkOPHj3w9ttv46677gIAnDt3Dvn5+fj0009x88034+jRo+jbty/27NmDwYMHAwD27NmDIUOG4Pvvv8fll1/O2w6HwwGHw8H93dzcjPz8fNhsNqSkpAT5LASXc01tggO3vzEn/sBOTnqvVXOirgWjX9oh+P7nC0egV1ZSCFv0C8G4lnrubyCEIi4qXO5pgogmmpubYbVaJedv3QRVu1wu/PnPf0ZrayuGDBmCU6dOoba2FmPGjOGOMZvNGDFiBHbv3o377rsP+/fvR0dHh8cxeXl5KC0txe7du3HzzTfjq6++gtVq5cQQAFx33XWwWq3YvXu3oCBasWIFnnzyyeB1WEP0UjgvXGrV6MGqJkQwrqWe++svocquDJd7miAIXzQPqj548CCSkpJgNptx//33Y9OmTejbty9qa2sBANnZ2R7HZ2dnc+/V1tbCZDIhLS1N9JisrCyf383KyuKO4WPJkiWw2Wzcv7NnzwbUT70RSBxStBFozFewUfta6r2//kBxUQRBSKG5hejyyy/Hd999h6amJnzwwQeYPn06duz4xVxvMBg8jmcYxuc1b7yP4Tte6nvMZjPMZrPcbqgK1X/RH3qxqoWKSOtvJMdF+QONMQThi+aCyGQycUHVgwYNwjfffINXX32Vixuqra1Fbm4ud3xdXR1nNcrJyYHT6URjY6OHlaiurg5Dhw7ljjl//rzP7164cMHH+qQHqP6Lfok2d0gk9VcP2ZV6QckYQ8KJiCY0d5l5wzAMHA4HioqKkJOTg23btnHvOZ1O7NixgxM7AwcORFxcnMcxNTU1OHToEHfMkCFDYLPZsHfvXu6Yr7/+GjabjTtGL4S6/ovN7sSJuhZUnWnEiQstmtWX0Us7iMhFblp8pN+LSsaYc01tmLuhCqNf2oGJq3dj9Is7MG9DFc41tYW62QQREjS1ED3yyCMYN24c8vPzcfHiRWzcuBFffPEFtm7dCoPBgAULFmD58uUoKSlBSUkJli9fDovFgqlTpwIArFYrZs2ahUWLFiEjIwPp6elYvHgxysrKcOONNwIA+vTpg7Fjx2L27Nl44403AHSn3VdUVAgGVGtFKKtI68USpZd2EJGNnLT4aLgX5Y4xetjihyBCjaaC6Pz585g2bRpqampgtVrRr18/bN26FTfddBMA4MEHH0RbWxvmzJmDxsZGDB48GH//+9+5GkQA8PLLLyM2NhZ33nkn2traMHr0aKxbt46rQQQA7777LubPn89lo40fPx6rVq0KbWdlEKo4B70MdnppBxEdiMVFqXEv6tW95N6uzi7xKivsGKOHLX4IItRoKojeeust0fcNBgOWLVuGZcuWCR4THx+PlStXYuXKlYLHpKen45133vG3mSEjVHEOehns9NIOInoQiosK9F7Uq3XJu11vTR8kejw7xlAQOhGN6C6GKJoJVfl/vQx2emkHQQRyL+p17ze+dlWdbUJ5cQbv8e5jDAWhE9EICSIdEar6L3oZ7PTSDoII5F7Ua40jvnatqTyFe8qLfESR9xhDe7MR0YjmafeEJ6Go/6KXSsR6aQcRvbDxNbY2JzbMHoxdJxqwpvIU7E4Xd4zUvahXSydfu+xOF+ZvqMLMYUV49JY+cHZ28Y4xtDcbEY2QINIhwa7/opfBTi/tIKITvrifYcUZeG3KAMzfUAW70yXrXtSrpVOoXXanC6u2V2PiVZegb55V8PORVpyTIKQgQRSl6GWw00s7iOhCKO6nsroBBoMBHz1QjhiDQda9qFdLpxrtiqTinAQhBQmiKEYvg51e2hHu6DXtW4+Ixf3sPF6PGIMBvbKSZH2XXi2dem0XQegVEkRERBJt4kCvad96Re24H71aOvXaLoLQIySIiIgj2sQBFbhUTjDifvRq6dRruwhCb1DaPRFRqF0TJhz2ttJr2reeobTy8CUcnkkiPCELEeEXenVJqVn92l9LU6jPjV7TvvUMxdeEJ9Fm/SVCCwkiQjF6HpTUEgf+uqG0ODd6TfvWOxRfE16Qa5gINuQyIxQRrG0K1DKDqyUO/HFDabWFA7l//MdqMaFXVhKuKkhDr6wkmlB1DLmGiWBDFiIN0avbSYxgbMgqx6oi91ypVRPGH0uTVpvVRpL7h+86A9DtcxKOz3C4Qq5hItiQINIIPbudxFB7UJJjBm91umSfK7XEgT+WJi0H7Ehw//A9E8NLMvHADcWYue4bbjsNvTwn4foMhyvkGiaCDQkiDQhnX7jag5KUVaXJ3oHHPjqk6FypIQ78sTRpPWCHc3q10DOx83g9uhgGM4cVYdX2agD6eE7C+RkOV6uWkmcyXPtIaAsJIg3QyrWiBmpvUyBlVWl1dvp1rgIVB/5YmvS6hUM4IPZM7KpuwMzyIo/XtH5OwvUZDmerltxnMpz7SGgLCSINCGdfuNrxKlJWlVa3Xcf50JMbSujcDC/JxBPjr0RDq5M7jvBE6plwdHb5vKblcxKOz3A4W7VYpJ7JSOgjoR0kiDRAa9dKoKgZryJlVUlNCC83lPu5aWpzwtHRhd0nG3Dbykpu93S9rVT14F6QeibMsb4JsVo+J+H4DIerVcsbsWcyUvpIaAMJIg2IBNeKWvEqUhYni8kYdueKPS/LthzW/UpVL+4FsWeivDgDVWebPF7T+tqH4zMsZdVqagv/tPVwtNwR+oHqEGkAKwK8a8eEY5q0GrBWlc8XjsDmOUOxfdEIvHBHf9idLvzQ0Iqnbi8Nu3MVDjVTglk3SWldKaFnYnhJJuaNKsGaylPca3q49uH4DEtZtRwdXWG/DUY4Wu4I/UAWIo3IS03AC3f0R2OrE83tnUhJiEWaxYTslHitm6YJ7hanc01tWPznf3ITtcVkxNKKvnj01j5oc7rCIqU8HFaqwXIv+Gt1EnLFAsCWucN0V04gGKUO3N2X1oQ4JJpj0dLeqYo7MzPJhOElmbzXvLw4A7tPNiA7JV7TzL1AXbfhaLkj9AMJIo3Qi6tCb/BZLexOF5Z8eBDXl2T6uJr0EP/CRzisVIMh2gINahVyxerhmvKhZqkD9zHBYjLitSkDsHbXKeyqbuCOCWSMsFpMWDb+Sjz+0SGP7ywvzsA95UWYv6EKN16RpUpflKLWeBhJRUqJ0EOCSAMoE0IYJVYLPYtKOStVrcVcMEQbBbX6h/eYMHNYkY8YAgIfIwwABhSkYWZ5ERydXTDHxqDqbBPmb6iC/Wfra6hRezyMhCKlhDaQINIAmjSEkWu1UGsQDZYoEVupPj+5n6Lq28EiGO6FcHAV6hHvMWFAfipXiNKbQMaIjEQTDpxt4v1urVxKwRgPw7lIKaEdJIg0gCYNYeRaLdQYRINtYRKLiZm7oUpzC6G7aNt3uhEzhxVhQH4qjAYDCjMsqLvowMn6VkVCMRxchXrEe0zgq7vkjq2tAyfqWhQL+WC4lAJdVNB4SOgFEkQaQJOGMHJdTT9JZMNIDaKhclvyrVRP1LXoxkLIirZGeweWbj6INZWn8NqUAXjMK85ErlAMRVCr1q7GYOA9JvDVXXKnvcOFSa/v5v5WIuTVdCmpsaiIxPEwEu/RaIDS7jWAnTT40HsmhNJ0aqVIpTPbnS7M3VCF5jZxwSM1iGqZFq/HFfHSjw5hZ3WDZOyKv+nzagW1nmtqw9wNVRj90g5MXL0bo1/cgXkbqnCuqS2g79Ua7zGh6mwTyoszeI8d9nNGmDtKSyVYLSb0ykrCVQVp6JWV5LdlSI2yDUrHw2CPQYESqfdoNEAWIg0I10yIUAUxy3E19c9PRXlxhs/EzbZJSlRqKUr0tiJ2F4dqxK4EK6jVewK2mIycm+9oTTNaHZ3ISjbr9vkRw3tMYC11BgCVbvf48JJMTB96KeZvqPL5jlBbF9WK/VEyHuo5kQKghJlwhwSRRoRbJkSoH3QpVxM7YQDwSSGec0Mx7E4XrBbh79dSlGQmmbBiUhmyks1wdHYhPs6Ib880Yk3lKQwqTAu5hdBdHErFrsgVisEIanWfgN3T0t0FnJ4mR6V4jwkpCXF48c6r0NLeyY0RLobBhN/vgl1gj79QWhfVXFTIGQ/DQWxQwkx4Q4JIQ8IpE0LJgx4s/7n7AGx3ujB/QxVmDiviUoh7piXg70fOY+a6bzCoME10gNSygFur04VPD9RgZ/Uvv11enIE1M67BpekWTfcRk4pd0TKew/36BystXWv4xoTslF/+f6KuRVAMAaG9PmovKqTGw3AQG3p0hxPyoRgiQhZyH/Rg+s+9B2C704VV26sxa/0+zHn3W1y46MCq7dWwO12ScUBabb3ArXKrPQf2XdUNWP2PaiSYjEH5XTHcYzjEYle0jm9zv/4D8lN53aWAfrZG4SPQ+Bc9xR+Gui3hIDb05g4nlEEWIkIWch70YJu0lW4AKjVAqum2lGsVC/UqV0673GM4hFyReohvc7/+arn2Qoka8S96ij8MdVvCQWzQ1iHhDQkiQhZyHvRgT/ZCA7D71gPuyBkg1XBbKpnoQrnKVdIud3HY6ujA8gllcLq60OrolCUUQ5Fm7H799eza40PNxYKe4g9D2ZZwEBt6EqyEcjQVRCtWrMCHH36I77//HgkJCRg6dCiee+45XH755dwxM2bMwPr16z0+N3jwYOzZs4f72+FwYPHixdiwYQPa2towevRorF69Gj179uSOaWxsxPz58/Hxxx8DAMaPH4+VK1ciNTU1uJ2MEOQ86CfrW0W/Q43J3n0AtrV1oL3Dhd0nG7itB9zbFYoBUulEF6pVrj8TsL/iMJSZP+z1b7J3CG5UqpetUdxRe7Ggp/jDULUlXMSGngQroQxNBdGOHTvwwAMP4JprrkFnZyceffRRjBkzBkeOHEFiYiJ33NixY7F27Vrub5PJ88ZasGABtmzZgo0bNyIjIwOLFi1CRUUF9u/fD6OxOyZj6tSp+PHHH7F161YAwL333otp06Zhy5YtIehpZCD1oLtP9u4p0WwmVZpKA4L7AHymoRXfnWn0EEPDijPwzITSkAxASie6UK1yQ+Wa0yLzh73+z4lMjnanCw/qKD07HOJfwoFwERt6EqyEfDQVRKw4YVm7di2ysrKwf/9+XH/99dzrZrMZOTk5vN9hs9nw1ltv4e2338aNN94IAHjnnXeQn5+Pzz77DDfffDOOHj2KrVu3Ys+ePRg8eDAA4M0338SQIUNw7NgxD4tUuBPsVbHYg85O9vtON4YkJdpmd+KpT47gqoI03OO1WeXTnxzB7+7oH/RBSWqi49tiIRirXO/rbmuTV8k70PtFy8wfvW+N4k44xL+ECyQ2iGChqxgim80GAEhPT/d4/YsvvkBWVhZSU1MxYsQI/Pa3v0VWVhYAYP/+/ejo6MCYMWO44/Py8lBaWordu3fj5ptvxldffQWr1cqJIQC47rrrYLVasXv3bl5B5HA44HA4uL+bm5tV7Wsw0LpoGWvS3vGvCyFJia5vceKzo3X47Gid4PvBHjilJjq+LRaem9xP1VUu33V/79eDRT7RPQGrcb8EavkIVJDpfWsUlnCIfyGIaEc3afcMw2DhwoUYNmwYSktLudfHjRuHd999F9u3b8eLL76Ib775BqNGjeLESm1tLUwmE9LS0jy+Lzs7G7W1tdwxrIByJysrizvGmxUrVsBqtXL/8vPz1epqUFCrjH6g5KUmYFBhWkhSovXghhBLPRbaYuGhDw4AQMBbJwDd1/3xjw6hf34q3po+CKvvvhprZlyDtg4XhomkzyfFx6pyvwRi+QhWiQY93BfeaFXmgSAI+ejGQjR37lwcOHAAlZWVHq/fdddd3P9LS0sxaNAgFBYW4i9/+QsmTZok+H0Mw8BgMHB/u/9f6Bh3lixZgoULF3J/Nzc361oU6aloWYujU/R9tSYkPbghhAI9hxdnYnp58LdYaGh14lfXFvi4J0dd0QNLK67EM3854mMBem5yP7Q6OlW5X/y1fAQz9kgP9wUf4RL/QhDRii4E0bx58/Dxxx/jyy+/9MgM4yM3NxeFhYU4fvw4ACAnJwdOpxONjY0eVqK6ujoMHTqUO+b8+fM+33XhwgVkZ2fz/o7ZbIbZbPa3S7JQM95HT6viUE1IenFDsBNdja0dJ+tbYY6NQXqiCXf/8eugb7HQ2cXwuie3f38BAPD07VfC1QWfCbjqTKPo97Y6OhTXMFISExWogBdrm17uCz4o/oUg9IumgohhGMybNw+bNm3CF198gaKiIsnPNDQ04OzZs8jNzQUADBw4EHFxcdi2bRvuvPNOAEBNTQ0OHTqE559/HgAwZMgQ2Gw27N27F9deey0A4Ouvv4bNZuNEU6hRO95HT6viUE1IekrDZcsOzHn3WwDAW9MHhWSLha4uRtA9uf37C3jw5i5ckZvi857Y/WIxGZGSYPIJTJZTw0iu5SMQAS/17OjpviDUQ09lFIjIRFNB9MADD+C9997DRx99hOTkZC6ex2q1IiEhAS0tLVi2bBkmT56M3Nxc/PDDD3jkkUeQmZmJiRMncsfOmjULixYtQkZGBtLT07F48WKUlZVxWWd9+vTB2LFjMXv2bLzxxhsAutPuKyoqNMkwC4a7QE+r4lBOSHpyQ7iLDHYLDD6xoub1sDvF3ZNCokzsflla0RdLNx/y2V5EzRpG/gp4uc+OWvcFTcL6QOuEESI60FQQvf766wCAkSNHery+du1azJgxA0ajEQcPHsSf/vQnNDU1ITc3FzfccAPef/99JCcnc8e//PLLiI2NxZ133skVZly3bh1XgwgA3n33XcyfP5/LRhs/fjxWrVoV/E7yEIx4H72tikMpVELphpDrqgnVFhjWBPHvsSbwCwux++XqglQs+fAg7+fUin/yV8AreXYCvS/4JuHhJZlYNv5KGABkyBRH/ooqEmPdhMMu90RkYGAYhtG6EeFAc3MzrFYrbDYbUlJ8XRBKqDrTiImrdwu+v3nOUFxVkCb4vhjsIKq1tSQSkbNKPdfUxokMtjjl0MsyYI6LQWqCSfXrYbM7MW9DlaCwkJos+O6Xk/WtQbs/3XE/V+5tfm5yP+QKrPqD8ezwCQ+Av5YR0L1VzICCNBw42yRpofDXskEWkV84UdeC0S/tEHz/84Uj0CsrKYQtIsINufO3LoKqo41gxvuEQ9BmOK58Q+2qYX8zWEHN7p/3PiYlXjzlXq34J3/OldrPjpDwePTWPoKWqF3VDZhZXoRV26tFLRT+WjYi0SISyDOvp4QRIrIhQaQBeor3CTXhuvINpasG8H9jVjUsg6G8P5WeKzXbJiY8pjeK10JydHZxxwq5EP11jYeihEYoFyVC9/Lyid0bCNvaxNugp4QRIrLRTWHGaCJai7TppXikP4RylerPebJaTKoUemS/S6/3p5ptExMeUphjfxk6ha69v/dMsO+1YBXE5EP0Xv7wAD6s+rdkG8SKn0b6ApIILWQh0gg9ZUeFCj0Vj1RKKFepejhPgd6fSiwQSq0Vaj07YsKj6mwThpdkCsYQVZ1t4v4Wuvb+3jPen/PeKDnBbMT55na0tHf6FajtrxvPH4uS2L1cWd2Ae8p/KbUi1AatEkbC0bVPBAYJIg0Jh3gfNQnnWIBQupG0Ok98E4A/wapK3H3+ulD9fXbc+5hgMmLuqGKsqTzlU55g494z+OD+oXjso0MebSsvzsA95UVcBfKb+mQhKT7WZwNfq8Xk9z3j/jmLychtlLym8hTuvf4y5Kcn4NC/bTAYDPj2TCPWVJ7CoMI0WW5nf8R2IG5uqXuZdT1KtSHUC8hwde0TgUGCiAgKfJNrKKwswVrVBbJKVdomLWIm1JoAlFgg3I/1toKcbmiFMcaA7JR4dToI/j4OK87Aa1MGYP6GKk4UWUxGrJp6NZ7+5Aj656dixtBL4ejsgjUhDsnxsZi57hvYnS7c1CcLSyv6YvGf/yl43vy5Z9zvtX75qVi76xSqzjThtSkDsG7XKbzy2XHu2HK39ssJuFYqtgMN8Ja6l91dj0JtYAnVAjISg9oJeZAgIlRHaHJdMaksqFaWYK/q/Fml+tOmUAfdqzkBKLFAsMe6W0Hc92Mb/rNwUOPaCfWx8ucaUTOHFXG/vbSiL36/vRo7q+vx2fd1HscPL8nEhtnXAQDiY2PwyKaD2Fntu4Eve978tWy4bwezans15o4q5t2iZZdX+6XcqUrFdqDuW7F72dv1KNSGUKMHlzWhDRRUTaiK2OS67OPDWD6xTHZArM3uxIm6FlSdacSJCy2iQdehCthWErzsb5tCHdQsZwKQixILBHvszGFFvJP9ThWvnVQsS0VZLjbPGYrPF47AoMI0nyrd7m3qYhg89ckR/KuuxUcMsbifN38D3q0WE9o6uq1WA/JTBbdo2VXdgAH5qQCk3alKA5QDdd8K3cvDfnY9rqk8JdmGUBPOrn0iMMhCRHgQqMtJbOLZdrQOS27pI2vFrNSyosdVXSBtCmXMhJoTgDUhDnNHFXOur/g4IxfnYne6PFb/rLViQH6qh2XIHbWunVQf2ztcXEFHqY1vf2xsw87j9ZhybYHocWpMnOw58o618YZ9n8+64v1Mr5hUhmUfH8a2o79Yv4TEthruW757OT4uBss+PuwRuyUl+EMV5Exp/tELCaIIQK2BQg2Xk9TE09zWgct6BGZZ4XPhaLGqkzrvaqyuQyHilEwAUn02GWNQdabRQ+CwcS7v7z3jsfpnrRVSk72awkIIPqEmBV/8i9B3+gt7jqR+yxwbw2tdEasBtOSWPmhuExfbarlv+e7l393RX7bgD2WQczTXiZNLpGbgkSAKc7QIhhVDjdWVu2XFO9g2Ps6In1p/cUXI/d1EM38mkL/IOe9SbTLFxuDEhRbNBxO5E4BUn212J5ZsOsgb52IA8PzkfgDgcR1WTCrDmZ/sou1TU1jImeTEjh1ekokeyWasvvtqZCXHY3hxBq/bTK2Jk3U57fjXBcHNgsuLM1B30eFjXRF7ph/ZdBArpwzAZT3EswiDmfIuV/CHOshZqzT/cCGSM/BIEGlIoCpbq2BYMdRYXbGWFcFg2+IMPDCqBIXpFm7PK6lJbN/pRo8NSwN5gOWed6mA0k8P1WLV9mrNBxM5E4CcPovdQ9+eaYLTxeAhr/3BWGuFUM0ftYWFnElO6NjhJZl4YGQxfvW/e2B3umAxGfHW9EEADB4xR2pPnHmpCbilNAdDLsvAUq8yAMNLMvHU7Vci0RSLLK+MPLWeaa1rpmnhDte6z3ol0jPwSBBphBoqW82BQi2XkxqrK9ayIhhsW92ALgAV/fJwS2kOt9IU+t05NxRj5rpvPL4jkAfYPTvK23r17ZlGNLQ6RdvkXctGD4OJ1AQg515zF7Le54VhGDzzyWHegfTJLYexYmIZHtl0MKgrciWTnPexieZY7DvdiJnrv+HiXuxOF2at34fHbu2D39xYAltbBwrSLchKNqt+Ha0WE+xOF8b3z8ODYy9HXbMDQHcByVtfq+StQ6RqbJiGNdO0CnKOtjpxctBjrKaakCDSALVUtpoDhZqBhIGurljLiliwLbvBpvsDyPe7sTEGjHttp0/hPcD/B7i5vUPQelVenIGJAy7h/k40GbG0oi+a2jqQaDKis4vBP47VedS9EWtLKH31YhOAnHstJT5OxKqXienll2L3yZ98roWSYPtAkTPJ2exO1F10cNcsLdGEDleXh4WRxe504ZFNh/Derwejb24KZ7FUG5vdiQc/OID++anY/N2/fRYJfGOHmrFhWkJBzvoh0jPwSBBpQH2LE/tPNwpm48idpNUcKNQOJAxkdcVaVo7WNIse5+js8nkAvYOaO7sYXjHE4s8DnBIfJ2i92lXdgGUfH8aqKQPQ6nT5CF/WOiSnLd5WRMvP4urqglTYnS7FE1cgk56cey0zyYSlFX0FrHr16ALjUe/HHTnB9qHgXFMbHvq/Ax4usPLiDDxRcSUsJqPgvRQfZwyaGAJ+WZnPGHqp7Iw8tWLDtIaCnPVDpItTqkOkAS2ODrw2ZQCqzjRi1vp9mPPut5i57htUnWnEa1MGoNUhb5JWc9PDUNe+kSIvNQEF6RbRY8yxMT4PoPfGlc1t4ufSnwc4M8mEoZfxB7gC3bVqfmp14qH/+6ePFXBXdQPW7jqFmcN8RZH3it1bDL02ZQA+OXAON7+yU/GmnIFu6CnnXrNaTLi6QF69HG/0MJDa7E4fMQR0t/vpT47wXjMWa0Jw28+uzJVk5Ml5psNhw2W9jU3RTKRvtEsWIg1ITTDh+b8dE6w6u3xCmazvUTsbQm+BhFnJZtGg5LqLDgwqTONe4xvcq842CWbn+PsAWy0mmCTSoC86OgWL9rHuPneGe7XF21cvZJGS42ZVw0Ur914Ts8YB/BO6XgbS+hancEHG6nrcP7IXr3UmFO1nV+ZKU/3ViA3Tg+DQ29gUrUR6Bh4JIg1wurpEV9FOl/gq0B21Bwo9BRKyDx+f22neqBJcmm7h2mqzO1Fja8eUawtwT3kR535cU3kKr00ZAAAe5zzQBzhN5HMWkxHtHeLX0Onq4lymANAzzdMa5u2rD6R4YSizjaRM6qlelhQ9DaRS8RHGGAOXDccGjg+9LAPm2BjU85SCUBN2Ze6PwA80Nkwv6GlsimYiWZySINKAFken6PutEu97E8kDRV5qAlZNGYC6iw7Y2rqDmRNNsUi1xHF95ouBcN/0cv6GKswcVoRHb+kDZ2eXKg+wUFwDm4rdISFqizIS8d6e0x4ixz1uw1tYSLlKbG0dgnWW1Jr05MQgScV79MpKwucLR+hyIJUSc3anC8/cXgoXw4ABsOyjQ4LXz594LbHPsIuDJz46xMWgqSHwwzkmRM+B4JFOpM45JIg0IJwHIS0Qe/iE3EHem16u2l6NiVddgr55VtXaxGc6fuzWPlj9j2r0L0gTXMkPL87At2caRTcF9RYWUq6S9g4XJr2+m/tbTFx5I+d+kxt4K2VSz06JR3aK5M8FhL8TpVTdqPPN7RhYkAoAmLuhSvD6rZhUhoc/PKgoSFnO+c1LTcDv7uiPhlYnlt12JVw/JwxYE/wXluEasKz3QHAiPCFBpAHhOgjpETF3kHusTjDOq7fpOD7OiBZHJx7ZdAj7zzTxuuqGF2di6W19MeH3u3i/k3Vh9cpK8hAWYq6SYcUZ2H1SvrhyR855kYpBeuGO/mhp7/QQIFqZ1AOZKOW6aE/UtYi6IE832BXFaymJ8VJ7ZR6OMSFyz5e7ME4yx8JkjEFTmxNJ8WRNIvghQaQB4TgI6RUpd5Cjsyuo59V9grLZndh3untjULvTxbnqZpYXwdHZBXNsDNITTThV3yqrFIC74Gp1dOA/ru7JW6n4nvJLMfe9Kp/vERJXLHLPi1QM0om6Fkz949ce3/vs5H7olSW+LYTaqBE8LsdFK3XPNQlkNgrFa2kd2BxuMSFyzpdYyYspb37NW8iSIEgQaUReagJeuKM/GludaG7vREpCLNIsJmR7ld8nxJFyB12Wmah6BWghl4zVYkLPtF8GWLvT5RMI/db0QYiNMYh+v7sLy11w1TS14ZayXMwYeiknsOouOmCA8PfxiSulk55SAaBV5W25wkLKpSZlhZG65+LjjILv8cVr6SGwOZxiQqTOl62tA8u2+FZF93aja10dntAfJIg0gnzg6iDlDsq1xqs64Eldt5yUeNE91QrSLTAZYxS7sNhKxXwTfnlxhmDBQyFxJQdWOMjZad0bLVK2pSbKVkeHKs+d2D03rDgDmUkmwSKOfPFaFFOoDKnzZTEZZbnR9VRWgNAHVJhRA8KhGFq4EMqibXKum1h7np/cDyXZySjMTFTcZqlYKb6Ch4HETbkXcvz0UC3KizN4jysvzkDV2Sbe90Kdsi01UVoTTKo8d1aLCcsnlmGY1zkpL87AjPIivPrZv3iLOA4vyUSs0eDzO8EsdmezO3GirgVVZxpx4kJLRIwtUucrRsIC656xqaeyAoT2kIVIA7SOGYg0QhUDIfe6yWmP0jbb2pRNZIEIQm/hJ1TLaXhJJqYPvZTbpNabUFs2pKyFTleXas+d09WFqwrScI9bfFjV2SZuj7qZwy7z2sstA9OHXopxr+70iV9RGlMoN4suUq3QUuerrUO8OKi7RZOsb4Q7JIg0gN0clG+n9DWVp2jV4gehiIFQEushpz1y23yuqU2y0GNBukW1+j7ews87QNyaEIc0iwlJ8bF4bNNBXteQFtmSUhNlbXO76OeVPHe2tg7BQpkA4GIYvDV9ECeWeiSb8av/3QO708UbYyVXIMsVOWptIK1XxM6Xze4ULZ/AWjQpo5fwhgSRBlgT4gR3Sn9tygCkBHlfpGASycXSkszij0uixPv+wE5s/fNTRSsUZyWbVTvPfMLP7nRhTWX3Hmy3lOZ0H2MAlo2/EkD3jvXu7QlFtiTfvSY2UUptK6LEWiDlnuvo7MKs9fsAdD/XAwrSPH6fzyIlJZCViJxosEILnS8hYcxmmc3fUEUZvQQvqo3gZ8+exRNPPIE1a9ao9ZURS6I5VnCndAOAF++8SpN2BUqkmuhZTMYYQVFSXpwBk1H9kDx2Yjta04w1M67BxfZO2No6OIvi9zXNePr2UtkDuxzByjfZs5vLeov460sysXxiGZbc0gfNbaFL2Za61/h+X836X1JFHFkrhPsk7I1SS7ASkaOHzDUt8RbGiT/XIbK1ObFl7jBdlxUgtEM1QfTTTz9h/fr1JIhk0NLeiaozTdxeVt4us5b2zqBX81WbSDfRA0BTm5N32wR20uuO80lU9TdZ9+qzk/vhua3f+xR5fGrClciVKTblCla+yV5sc9lHNh3EyikDcFmP0NQd8vdeE3OpPT+5HwAIbn+i5Lueur0UzW1OVJTl4pODNVxckTdK41eUiBzKXBOyIKn7fBKRhWxB9PHHH4u+f/LkyYAbEy20ODpEXWatjvBbvalpoter2y3JHIcpb37tU2yRDabdMneYou+Ta60REiM7q+vx+EeHsUqG2FRaDdl7sg9kc1m1CeReE3KptTpd3dtxKLBuisf9JMJmd+LA2SbVYqyUiByqhk8QypEtiCZMmACDwQCGYQSPMRjE0x2JblITTHj+b8d4XWYAsHxCmRbNCgi1TPR6dbvZ7E4YY4CBhWm8wkDpJCPUz+cm94PFZPTYcuDGPtmCYmSnTDGiVER4T/YdXcLPPRBaF0yg95q35SAQ6yafFcJd6D52a1/sP9OIpz85wgkjf+NXlIicUFfD1+sihiCUIFsQ5ebm4ve//z0mTJjA+/53332HgQMHqtWuiMbp6uKNQwG6RZFTYqd0PaKGiV6vbrdzTW146P8OYP+ZRrw2ZQC6GCagncaF+rnvdCNO/2TH77dXY2f1L++9NX2Q6PfJESP+iAj3yf5EXYvo50PpglHbHaSmdVNI6H46fzia25xINPvGWMkVE0pFTqjKUeh1EUMQSpEtiAYOHIhvv/1WUBBJWY+IX2hxdHL/50u/D0fUMNFrlRnDNyGx7XExDJ7ecpjb2dw9/RwAMpLMyLXGK9pyhe1nZpIJz03uh6wUM1raXbAmxKK5vQNHa5s9jo+NiRGMN7M7XbIEQKAiQk8uGLXbopZ1U0zQP/7RIV5Br1RMKBU5wS5HoddFDEH4g+y0mP/5n//B0KFDBd8vLi7GP/7xD0U/vmLFClxzzTVITk5GVlYWJkyYgGPHjnkcwzAMli1bhry8PCQkJGDkyJE4fPiwxzEOhwPz5s1DZmYmEhMTMX78ePz4448exzQ2NmLatGmwWq2wWq2YNm0ampqaFLVXLdjJic3cqTrTiFnr92HOu99i5rpv8NQnR3CuqU2TtvmLGhWjtciMca/IPHH1box+cQfmbqjC0dqLuG1VJc7+ZOfEEPDL/mSz1u/DrPX70NDiQJPC6r/N7R3ITDLh3V9fhzW7TuG2lbsw5c09uOW1SqzaXo13f30dN6lbTEbkWuN97pGqn61Vo6/ogaR46XVNoNWQQ1kRXAq126KWxUmOoHfH34r1VosJvbKScFVBGnplJQkX8wxBlWqlfSYIPSPbQjR8+HDR9xMTEzFixAhFP75jxw488MADuOaaa9DZ2YlHH30UY8aMwZEjR5CY2J0N8Pzzz+Oll17CunXr0Lt3bzzzzDO46aabcOzYMSQnJwMAFixYgC1btmDjxo3IyMjAokWLUFFRgf3798No7La4TJ06FT/++CO2bt0KALj33nsxbdo0bNmyRVGb1YCdnPrlp/IHy4bp6ipQE32oM2OEJqSdx+vRxTCYOazIo8w/H47OLvy7qQ05KfL3TEuJj8Nzk/vhqU8O+1z7yuoGPP3JYTw3uR9mrd+HmcOK8DTPcWyJhgfHXoFWN4ujEGrElBgAjCvLxXSvzWWVoFasieJK3yK/K2ZxGl6SCRfD4MSFFsm2KhX0wbSIhsqNFe3p/URkoWlhRlacsKxduxZZWVnYv38/rr/+ejAMg1deeQWPPvooJk2aBABYv349srOz8d577+G+++6DzWbDW2+9hbfffhs33ngjAOCdd95Bfn4+PvvsM9x88804evQotm7dij179mDw4MEAgDfffBNDhgzBsWPHcPnll4e03+zk9EN9q24yd9QiEBN9qN0yUvuDsW4xMdgqxA2t8q9VZpIJ7R0u7KpuEKxYnmM1AxDP7qqsbsDMFie6JAKeWQIRrGKby15fkilLvKs9SSup9C1Vs2jFpDKcbrCjya3G09FzNkwZXIgJv98Fu9Ml2Valgj5YYkKuG0sNcUrp/UQkoavNXW02GwAgPT0dAHDq1CnU1tZizJgx3DFmsxkjRozA7t27AQD79+9HR0eHxzF5eXkoLS3ljvnqq69gtVo5MQQA1113HaxWK3eMNw6HA83NzR7/1CQvNQHxceKnP9pWV6F2y0hNSI7OLlSdbcJwkY1Nzze34+CPNrhkihKgu5+tzk5Bl2nVmUaYY2NhMRklLVTtHfJiiNx/W467xZv6Fif2n27E3FHFeGv6IKy++2qsmXEN5o4qxr7TjZKuEa02NJbzu+ea2vDwhwcx9Y9fc9fgn2eaMG90bzz8wQEuO0yqrUrdksESE3IsT6yr+LZVlfj8+zr8UN+Kfacb8a/ai4quRTA3piWIUKObrTsYhsHChQsxbNgwlJaWAgBqa2sBANnZ2R7HZmdn4/Tp09wxJpMJaWlpPsewn6+trUVWVpbPb2ZlZXHHeLNixQo8+eSTgXVKAqkBLxpXV6HKjAGkJyRzbAzWVJ7CqqkDAIPBY5IpL87A3BtK0N7hwgPvfYsP/0s4vk7ot4XqC+2qbsCTWw5j473XSX5PakJcSCadQGtnaRUwL/W7TfYOPPbRIV+3aXU9usDgV9cWePRXrK1K3ZLBsohKCX1bWweWbTmM/acbBauPy7XahTq9nyCCiW4E0dy5c3HgwAFUVlb6vOdd34hhGMmaR97H8B0v9j1LlizBwoULub+bm5uRn58v+ptKONfUhn2nG0X3p4rW1VUoNmoF5G2/YHe6MPe9Kvz5/iH4zWgXOrsYWEzdcWn/OFaHN3achN3pktwny5u0RBOGXJYhWl9oxtBLUXW2SfAeGVacgcIMS0jOVaC1s7SKNZH63VZnp2K3qVhblQh6q8XUve3JpoO89aj8va5SQt9iMmLn8XrMHVUsWH1cSQxjKBcxBBFMdCGI5s2bh48//hhffvklevbsyb2ek5MDoNvCk5uby71eV1fHWY1ycnLgdDrR2NjoYSWqq6vjsuJycnJw/vx5n9+9cOGCj/WJxWw2w2w2B945HlgzPrtCAxBQXZtwRetibkKr2+ElmXjghmLMXPcNgO7Msua2Dkx582vh71K4IW92SjzO/mQXPcbR2YU1lad475HhJZlYMbEMl6RZZP1eoOc60NpZgbqH/G2/1O+2SghZPpelVFuVxDYt23IY/fNTMePnQPXUhDgUZlhkb8fCh5TlKSamexGoZvXxUC1iCCKY+CWI3n77bfzhD3/AqVOn8NVXX6GwsBCvvPIKioqKcPvtt8v+HoZhMG/ePGzatAlffPEFioo8V2NFRUXIycnBtm3bMGBA96TgdDqxY8cOPPfccwC66yPFxcVh27ZtuPPOOwEANTU1OHToEJ5//nkAwJAhQ2Cz2bB3715ce+21AICvv/4aNptNtJRAsGDjMWYOK0KswYDFYy7Hw+Ni0Gh3otPFoFdmYkADYjigl2JuQqtbANgydxj3WlJ8rOrujTSJCcQcGwO70+VR+8iaEIc0i0nRClyNc90ikckmlekWiHsokPZL/W6qhJA1x3rG+alluXWPbfrsaJ3PbwSSYSrlxmrr6BaBUvFp0RbDSBCKg6pff/11LFy4ELfccguamprgcnU/XKmpqXjllVcUfdcDDzyAd955B++99x6Sk5NRW1uL2tpatLV11+AxGAxYsGABli9fjk2bNuHQoUOYMWMGLBYLpk6dCgCwWq2YNWsWFi1ahM8//xxVVVX4//6//w9lZWVc1lmfPn0wduxYzJ49G3v27MGePXswe/ZsVFRUhDzDDAAutju5YNoZ677BxNW7cdvKSryx4wS6GAaNQQow1QtaBdgKwRdo7P1adkq86gHfYgGp7jumu9c+MhkNyEwyob7FKau+jFrnWsrSYoqNEW2LnIB5vro5gbZf6nezks2C12CY2zXwbmugBLt+Dyv0P184ApvnDMXnC0dg5ZQByE1NQEZi933nLfa8icYYRiK6UWwhWrlyJd58801MmDABzz77LPf6oEGDsHjxYkXf9frrrwMARo4c6fH62rVrMWPGDADAgw8+iLa2NsyZMweNjY0YPHgw/v73v3M1iADg5ZdfRmxsLO688060tbVh9OjRWLduHVeDCADeffddzJ8/n8tGGz9+PFatWqWovWphTTDhhb//SzAe45nbS7VoVsjQKsA2UNSOlRBayZcXZ+Ce8iLM31DlcbzFZERKgknRJqRqnWupeKtPD9Vi1fZqv6ssC1mBnrq9FPtPNwbUfqnrJmRNWT6xDE5XF268Ikv1uJhQxFQJubHY+27Hvy5QDKPGaB02QHhiYBTut5GQkIDvv/8ehYWFSE5Oxj//+U9cdtllOH78OPr168dZdyKN5uZmWK1W2Gw2pKSkBPRd39c0Y+yrOwXf3/qb4bgiN7DfCBX+PNBVZxoxcTV/uQMA2DxnKK4qSBN8P5yQc37YYy62dyDRHIt9pz03A2VZMakMnx6o8djnjEXIzaLmuT7X1CYq3tw3L1VS68Zmd/qIPJbhJZnoLxLrota94n4NQhEUfKKuBaNf2iH4/ucLR6BXVpLk94idX6lzb7M70WjvwFKvLDvWEhbpbnut0UvYQDQgd/5WbCEqKirCd999h8LCQo/X//rXv6Jv377KWxqFSMVjSL2vF/x9oKOlmJvc8+O9kk80x+KvhWk+FourC1Kx5MODvL8lZC1R81y7W1oa7U7Y2jpQdbbJQwy5t6XV6ZLVfzEr1s7j9Xhw7OXom5vis4eb0vaL4U9QcCCrezVS7oXur+cm9wMDSJ57ts+rKEMs5NAecPpEsSD6n//5HzzwwANob28HwzDYu3cvNmzYgBUrVuCPf/xjMNoYcSSZxU+71Pt6MLMG8kDraaPQYBHI+RFy8ZysbxX9zVZHh8+9kRQfi5v6ZGGbV+Au4N+5ZifRf55tRNXZJgzIT8Xv7ujvI1bYWjc7j9f7VOM+3dAKY4yB2xBXyn109qc2zHn3WwC/1D2av6EKgwrTNLtXAl3dB1q/R+z++uJfF3gtiUL3HmWIhR6xRcC+041osndoPsZHI4oF0T333IPOzk48+OCDsNvtmDp1Ki655BK8+uqr+NWvfhWMNkYcMTEGQd99eXEGjDHCNZb0YmYNJDYlXIq5yXE5CL0faOwO3ySVEi8caCsWX/TMhO6YNHdRFOi5tiaYUHWmkbdI4/wNVVytG7Yat3fxv+E//35eaoKsApks7DOztKIvRvbuIbv9ai4i1FrdBxKTJnZ/ZSWbed2qbBv1GqMXTQgtAtjn5bHNBz02lSZXWmjwK+1+9uzZmD17Nurr69HV1cVbBZoQJjbGgHt+LvjmLorYeAwhQRQqM6ucySPQoFC9F3OTEp5S7wcjaFbMsra0oi+Wbj7EaxV4bPMhvHBHfzw8rpP3XPNdbwCou+hAU1sHEk1GJJpjkZoQx8UFLd18SDApYGlFX67WjVA1bvcNjJPiYzGsOAOVAgsE90wv9neW3Xal7BgXtRcRaiYF+GudEbu/wimdXg/Wbi0QWgQIPS/kSgsNARVmzMzkT1clxEk0x2LD16cxoCANM8uLuJ3Dq842YePXZ/DUBP4ss1BkZ8mdPNSITdGrqV5KeL5wR39JYSo3TV3JBCBmWZOKL2pp7+QN0vW+3haTEWtmXIPfbz/usUItL87AvFElKEy3oL3Dhf4FqZhRfqnHhrRrKrsH8scr+iJWQfE/gwGYUV4EBvwLBO9sO0C67hFLMBYRetjh3f3+8nZJFqRbMHdUsUeslfuxaRYTTtS1KBIhwRAucsaaSBVMQosbNYtlEspRLIjOnz+PxYsX4/PPP0ddXR28k9TYukSEMK2OTkwZXMi7L9Q95UV4/KNDeOr2Up/Va7AHYiWTRyTHAUkJz8ZWaWGaYDKKWj3kpKnz4W98Ed+9wXe9Zw4rwsrtxwWtPxOuugSDLk0TdZe1OV3IyYzH9SWZsqwVDOBRfNLR2YX89AT87fB5n4BtFlZwS02YwVhE6CEpgH3+9gnsRzbM7Xqw548Vu495WRKl7sFguOnljDVyg/LDEaHFjRR6su5FIooF0YwZM3DmzBksXboUubm5knuKEb7Y2jowf0MVVk4ZgDkji2Fr6+AsROwA5uz0Xb0GeyBWMnmEQxyQv6tLKeHZ3C5unbjY3oHOri5ZVg8llgrv/hRlJnKfEYsvAvjvDb7rLbZC3VXdgIfGXoHHRdxlM4cVITk+jrs/fpAQasnxcTAY4GHhiI8zoq7ZgSPnbLxiiBXccibqULsury/JRFJ8rGILjFLcawnxuVgq3a4Hez0fu7WPj+UPEL8Hg+Wm93fT3UhyHfEtbrokquBESgauXlEsiCorK7Fz505cddVVQWhOdJASH8cN9Hf/kX9/LL7Va7CtMkonDz3HAQWyqpUSninx4o9NcnwcGlqdHlaPRHMsWh2domnqYudNqj/+3Bt811vKogPAZ0Jl2VXdgAdGFnO/lZeaAGOMAcNLMnknP7ZdF9s7eS1Oj1dcCQOAz7+/4PGZ5yb3A/BLWrlYFpvaiwib3YmGVieeGH8lln18mDeA/dFNBz224wiWVSMvNQGDCtMEXaWV1Q14aNwV6JubAnNsDDKSzHhk0yHeY4XuwWC56QPZdDeSXEfeYQM2uzNiLe/hgGJBlJ+f7+MmI5SRmWTCTX2yEGcUL53vLUCCbZXxZ/IIVRyQEmtPoKtaKXGRligtPjpcXdyWGwCw+u6rudRxPsQsFXL7I3Vv+KTk85R3kNrOwe4Qd4mb42I8zm12SjyeE2kXACzZdJDX4vT0J4fx7OR+eOSWLh/BfaKuRVYWm5qLCHdRyoqw/xrRC+a4GKQmmJAUH+sjhoDu6/TQBwfwuzv6c6UG1EKqZhlbsuD6kkz8ZnSJ6LF896CkcOEp9SDHIhbopruR6joKB8t7JKNYEL3yyit4+OGH8cYbb+DSSy8NQpMiH6vFhKUVfXG2UbyqN58ACaZVRq9xQUqtPWqkvIsNSuy+ZmKDVntnl0cMUSD7Rsntj/e9kWiOhckYg7qL7bjY3on9ZzwrYK+YVOZjvak62yRaEiLeZPR53Z3UBN/zKnbPssKGj8rqBjg6uniDwdmJWk4WmxoTjLcoZcUuGwfG9s9bDLm350RdC1xdjKqWIiFhwQq2osxE/Pn+IUhNiIPJGAOLycjrhgT470Ex4eLPVjIsgW66G8muIz1b3iMdxYLorrvugt1uR69evWCxWBAX53lj/vTTT6o1LlKx2Z14dPMh9M9P9WsvoWBZZfS4OvHH2qNG3IjUoCT1fnZKPH47sQyPbjqIyuoGUaEhJTaV9Ie9N/hEZLlXoO3TnxzBmhnXwABw13tN5SmsmXENYgwGn8/OG1WCLD9Fs9A96++1YidqOVk5vbKSAp5g5IhSqb40tXWoHv/CJyyErGbXl2RizYxrMHPdNz6iSOja+VvqQaqfUmONxWTU5eIsVOg1AzfS8ctCRAQGO7ju/zlDBPAMvB2uoQDR2+pEaiKqsbXjZH2rh6lerbgRqUFJ6n1XF4OrCtJwT3kRXAyDiVddwlVvZhETm6wrQql1SUhE7vIKtLU7XZi57hv8df5wdHYxHtd71ZQBqLvogK2tAxaTEYmmWKRa4lQXzf5eK3ailltzJ9AJRo5wk1NgUu34F77rIVbLhgGw9NY+WOIWSzSsOAPPTCjlbVMgpR6k+unvprvkOiKChWJBNH369GC0I6pgB1e70+WTbmyOjUFBukXTjRX1tDqRmohO1rdysTmsqV4vrj9bWwdWba/mVuy//fQI+uenYsbQ7vo9qQlxKMzgv9buFp65o4oFrUvDSzIRazTAZv9l8hETkbuqGzDz56KgQPc92Gh38m6QKnQPqCma/b1WSrLY1ECOcBPri3uBSbXjX7yvR3ycUdBqtvN4PX4zugRvTR/kUf/s6U+O4Hd39Oe9hmqWevBGbKzR2+KMiHz8Ksx44sQJrF27FidOnMCrr76KrKwsbN26Ffn5+bjyyivVbmPE4T64ugfesny+cESom6RblGzr4G6q18Pqkm27+4p9u1vGFNsmb9eCt4VnTeUpXktieXEGpg+9FONe3YlBhWmyq2R7W1X8EQ1qiuZHb+2D6Y1tMBgMXIHHQYVpHteKtZa1ODqQajHB2dmFFkcn8lLjJbPY1ECOcGNFGp+r0r3UgprxL3ylGKSESt1FB2+Av9R2O0q2kgHU6aeeFmdE5KNYEO3YsQPjxo1DeXk5vvzyS/z2t79FVlYWDhw4gD/+8Y/4v//7v2C0M6LQiwVDCj1UiZW76mZRM25ELkLniW270uqz3hYeb0tikjkWLV4p/FJVst1T0xNNsVgz4xp8e6YRx2qaQ2cxcztP1p+DfJdsOujR1+Elmfh0/nCkWbr7cKKuBY12JzpcXfj61E/o3zMVz//tGCcM2WKDAGS7Iv1BrqswLzUBv7ujP07UtaCJp76Yms+3ULLBo7f2Ef2ckAtWqeUqXMYxgpCLYkH08MMP45lnnsHChQuRnJzMvX7DDTfg1VdfVbVxkYoeg5e90csmsnznymIyYumtfTCgIA1N9g6MvTIH55vb8dAHBzgBxH422OdS6jw9O7kfjtY0i36H90TEZ+GRk8LPiivviUooyHZYcQaWTywLyf3mfZ7mjipG1ZlG3uywxz86hBWTyvDwh15iqTgDg4vSUXWmiXuNjYNaWtEXj1f0RaujM2jiV64LJzslHq4uBg9/cAD7Tjd2V//+2cKXn2ZRpS1iyQbjzjQpWkSwKLXohMM4RhBKUCyIDh48iPfee8/n9R49eqChgb9gG+GLnv3jodpEVi7u56rV0YHkhDg8vvmQT2Dou7++Dnf/cU/IUnLlnKe81ATJfbe826vETejNxfYO9MpK8piohIJsK6sb8NjmQ0G/nnznScpqdrrB7nNed1Y3oAue1ZeBblG05MOD+HzhCN5YKDWRK7LZe7bR3oGlmw/6ZHsFurAQixN7+pMj+HT+cDz+0SEfoTLnhmLMXPeNz2f8tejoYRzTgyWbiAwUC6LU1FTU1NSgqKjI4/WqqipccsklqjUsGtCrfzwUm8j6S3ycEY9vPuRTLbny50J+q6Ze7TGwB3OwlHuespLNvKnRM4cVYehlGbC1OT02ehVzRQwvyRRc4QO/iCv3icrR6RunxtdOf5BzfvnOk1R2WFMbv/vGOyjcHT0W61v6ke+9qsbCQixOzO50obnNyStU7E4XBhWmqWrR0XIc04slm4gMFAuiqVOn4qGHHsKf//xnGAwGdHV1YdeuXVi8eDH+8z//MxhtJEKMHnbzdsd90Htr+iDBrSMqqxvw6K19ucE52IOl3PPk7VoQqxPj7mpzP54VT6bYGHS6uivFe+9m7r3KZyeqqjONstqpFLnnl+88SZUSEHtfSEzprVhfMBcWUlbEBFMsr1C1WqC5RSdQWBHuYhg8veWwYsFJFiVCCMWC6Le//S1mzJiBSy65BAzDoG/fvnC5XJg6dSoee+yxYLSRCDF62M2bxdvdIl13ppP3cyxquv2UnCd3i00Xw+CpLYd568Q89MEBPDOhFKkJcVg5ZQAaWp1gACz76JDobuZiq/xgXE8l55fv98UKVUpZwfjEkh6DeIO5sJCyIu473ehRI8hdqOrVMi0HuYsjIcFJFiVCDPFlGg9xcXF499138a9//Qv/7//9P7zzzjv4/vvv8fbbb8NoFC/rT4QH7GDLh/vEY7M7caKuBVVnGnHiQgtsdvE0XH/wXmVLWRbYjVflrM4DRe55YrFaTOiVldRdBVpgIN95vB7VdS2Yt6EKrU4XMhJN3ZuI8rgI1+/+AR89UI7PF47AyikDBGtXKW2nHJScX77fX1N5CveUF2FYcYZPe1ZMLMMxgUD04cWZON/c7vOZUATxKr3fg7mwYK2O3uf1+pJMPHBDMZ7+5IjH66xQlWpzKJ5pf1G+OPIUnFIiXk99JbTBrzpEANCrVy/06tVLzbYQOkFO9gjfSmv4z5NZz3R1MmkAwNbmOUiJWRaGFWcgLdHE+znf7w3c7edvlo2cOkHsIL20oq+g8Nh5vB4xBgPvXl9qtFMMpduJeP++3enCe1+fxoNjr8ADjk6YYrs3SGXdN0/eXgpHp2d7h5dk4snxVyLWYMC2/74+qBll3vhjWQh2WnqiyYilFX3R1NaBJJMRFlMsDADGvraTd78yKTddsKwnarmolC6OvAWnnmMjCX2gWBAtXLiQ93WDwYD4+HgUFxfj9ttvR3p6esCNI7RDLHtEaKW183g9Hv7wAJ6b3A+XqJBefK6pDe0dnqtAoSKFbAo5u5u4xSR+a1t+3qQ00MFabpaN++8kSGyQyg70Xx6vFwwuZpHrdslLTcALd/RHY6sTze2dSEmIRZrFhOyU+KDsVu49GbG/712f51f/u4dz+bm72fSQvcTir/s1mGnpQuLlifHihXGF7pdguZjVFFneIlzp/oB6i40k9IdiQVRVVYVvv/0WLpcLl19+ORiGwfHjx2E0GnHFFVdg9erVWLRoESorK9G3b99gtJkIEUKxBmIrrcrqBpxusCPJHBvQgM8O0N4b4LoXKXxgZDHiYmOQbI5FWqKJE0MAEBNjEN213RhjUG2wlorJ4KvBM6w4A5UCbXOPn0mUEE9y3S5CfX1mQime+uSIxy7tauxWzmf9aGnvxNQ/fs37fXwrdDmxLlJiTqnY4zs+EMtCMISdmHhZ9vFhn7IE7rD3i3c/u7oYv/sodI7VFlneIlxocSQkOPUUG0noE8WCiLX+rF27FikpKQCA5uZmzJo1C8OGDcPs2bMxdepU/Pd//zf+9re/qd5gQnvk7OodqPlZbANcu9OFf55twt3XFgjGzcTGGHDPz+nZ3ttd3FNeBLMxJiS1lvgmBfeB3F0UDS/OxNLb+uKvh2pgMRlhd7qQaIoN2O0iNjE9sukgripI8xBEauxWzvc5tVfoUoJWyK379O2lSPt5o1o53zd/dElA7VY7iFlMoO08Xo//GtGLVxCx9wtfP9/99WDR3xRyMYtdg/YOl6ouKm8R7r04io8zwpogLDipsjYhhWJB9MILL2Dbtm2cGAKAlJQULFu2DGPGjMFvfvMbPP744xgzZoyqDY1EwjX9U07hwEDNz4FugJuRaMKKT49iQEGax+eqzjbh/b1n8ODYK0IST8A3ebn36ZFb+6KmqQ1Atwtg6pt7sPCm3nj/vutw4aIDHV1dWD6xDI9sOui326Wh1emxqWx8nJHbM6yyuoETju4o2a28yd6BVmcnWp0upCbEce5Ib8TuG4vJiDSLCSfqWmQ9D1LWhxfu6C/o1n1080FU9MvDiN49OCuY2PfdP0I8VjLUlgUpYWmOi/GZ+Nn7BQBvP1MS5LmY3ZG6Bo9ViHsIlI4RQrFoByQWR2KfB6iyNvELigWRzWZDXV2djzvswoULaG7uzgxJTU2F00kR+2LUNLXhi39dQFayGY7OLjTaO7D31E8Y2buHpjvdyyEzySS4oSbr8qnol+uxA7tSAt0Alw3MffiDAz61fp6b3A+1XplK3sgZrOUIWqHJi+3TgPxUzFq/D4DnFhuPuFXhvqlPFlZMKkN7Rxev20WqHQyAqjONHueh3C1tXyhbR845aHW68NhHh2S5HYVW6Ox+ZI9tPoSd1fLcl1JurMZW4ffZ4o7uVjCx79t9siEkG8jKRWpBkppgEnTTnahr4e1Hp4uRdDF7I3UNuroY0Xb6IyQDdUHqKTaN0B9+ucxmzpyJF198Eddccw0MBgP27t2LxYsXY8KECQCAvXv3onfv3mq3NWKw2Z04/ZMdnxw45+POKcpMhMVk1PUDarWYsGJiGR7+8ICHy4d1R7339WkAwIGzTX5nqKhh3hYb/PiycNyRGqzlxh9JTV7uCG2xse1oHRydXVg5ZYBPRtm5pjY8/tEhXJGbggH5qaixtaPOEoeCdAsuSbPAZndi2UeHfL6T/XvmsCLBbB2pc6A0RkRohf7YrX3w++3HZRfYs9md+EkiRbq5XXy7FDaTj7WCiVld1lSewpZ5w/Dkx4eDYllQaimWqkGUFB8r6KYT6qfN3iHqYuYTRFKWKjZYXm0XVaAuyHCuw0QEF8WC6I033sB///d/41e/+hU6O7sHndjYWEyfPh0vv/wyAOCKK67AH//4R3VbGkE02TuwcvtxwUlq+QTxDTf14GrrmW7Bc5P74XSD3SNr6L2vT2Pq4EKuYKDSeBz3vj12a1/sP9OIpz85wgkYpZOQ0OCXmWTCikllnIXO3Y00qDBNdLB2FwLuu8g7OrtwuqEVxhgDF+AtOnl5BVBL7e/l7cKy2Z14/KND+NW1Bbwbtz47qR+cri7Bmke7qhswZ2QxvjopL0vHG3+CjfmyzawJcR4WMbHvYYXojKGXiraNrUclBCsCWSuYmHC1O10wIDgVnv0J7BcSluXFGZg+9FI8tukgnry9lPfzQv3cd6YRR87ZBF3Mv7ujv+zv4tqZEBd2Lio9jK2EdigWRElJSXjzzTfx8ssv4+TJk2AYBr169UJS0i8r16uuukrNNkYcrc5OXtM00D1JtTqFV7fBrrSqZEC4JM2CJHMsamztOFnfigH5qQDAiSFAWTyOUN8+nT8czW1OJJrVM2+3Ol349ECNh4umvDgDa2Zcg9yUePzQ0IqkVqfo3lxCW3AM/3nAZ6sCPzOhFI9sOuhhTRtWnIEnby9FxcpK7jWlhebqW5y4IjdFcOPWJZsOYqlEHIc5NsanCKL3hCV0T/gbJO2dbbb67qtlfY+7EPXOPvRuf1qiuBDNSo7H3FHFSEnontSlLJIZ3NYX6k2OgWRhCZUxYJ89Ryf/54X6uabyFNbMuAar/1HN62L2N0jZahF23yk5T/6IFKWfoyrWhN+FGZOSktCvXz812xI1tEq4a4TcOcHejsLf1erJ+lbMefdbwe+VG48j1LfHP1J3R3but6o9f2tXdQNiAAy8NB2vfHYcgPjeXEIurp1u1wMAnvrkCK4qSMM9XivvfT/8hIEFqZwFR2mhueb2DlGr0k4ZcRxpFhN+d0d/wQlL7J7wN43ZW0jJ7be7RUoq5To7JV7YilJehLv+9ytcXZCKXw3KB6BNwG2ghQKVljEAhPs5sDAN+Qrja+Ses0CEpL8iRennQrHVD6F//BZEhP+kJkibmvkIZqXVQAYENep7hLKKrGjacnUDZrhlXbH7iy2t6AtjjAGZiSauv3JcXADw2dE6j7R2FovJiL/MG4bHPz6MncfrFReaS4mPQ41NPDhcThyH0IRlszux418XMGPopZhybYGHW5HN5PInRsT7fpHb7xZHB+aOKubck0aDATPLizB72GWwd7hwaYYFl/xslQN+iSGrbW7Hj42/ZPKxVpTK6gY8sukgd2+HOuA20DIE/n4+LzUBKyaV+bi7l205jCdvL5WsfO79XcE6Z/6OSf58jqpYEwAJIk3ISjYLZq0ML8lEVrKZ93PBrLQayICgRgB0KKvIytk6w52dx+tx9ic7Zq3f173X1qQyXF+SKcvFJWafsTtduNjegVU/Tyitjg78x9U98fhHh2RZKZLiY1EosU1KIHEcjfYO3sB/Njut1dHp13d73y9yC+xZE0y82XL3lBdh8Z//iS1zh/FaROpbnFwmH9AtRN2FVc3PGYesMAzmxKekYrnUQsLfhYjN7sTDHx7kfd6FXG1iBOuc+Tsm+fM5qmJNACSINMFqMeE5nomELRonRDArrUoNCI12J6rONPL64pW4G4T8+sHqG9/vyamj5A0rfthqwMsnluHMT3bR70k0xyLG4Jud43lMnM+EImfFzboEpGJp/I3jsNmdWLr5oGh2WnNbBy7rkaT4u73vF7Yu09KKvni8oi/anC7e0gJLNwtnyy2t6CsovN3vbaG4r1DEiiipWC5nISFnIcJ3/zeIlCTQkzXEX5Hiz+cCHX8oGDsy0FQQffnll3jhhRewf/9+1NTUYNOmTVzqPgDMmDED69ev9/jM4MGDsWfPHu5vh8OBxYsXY8OGDWhra8Po0aOxevVq9OzZkzumsbER8+fPx8cffwwAGD9+PFauXInU1NSg9k8MIXP+La/txKDCNEV1XIDA66FIDQi2tg5ulc03ecgxnYv59YPRN6HfYy08fL/lvXUGi7tI2na0Dktu6YP8tAQML870iUViv8dkjEGqJU5xv6RW3O4uAb5K3ux3e8dxsDS3dwAG+Lzubb3oX5CG/WeafGLa2Do+7CThj4VAqaulvsXJe57Z9jxe0VeWS1co7ivYsSJKKpbLjVvyFpZsxuPQyzJgjo3B+WYHb5bmE+Ov5Cqh86EXa4i/IsWfzwUy/lAwduSgqSBqbW1F//79cc8992Dy5Mm8x4wdOxZr167l/jaZPG/MBQsWYMuWLdi4cSMyMjKwaNEiVFRUYP/+/TAau03SU6dOxY8//oitW7cCAO69915MmzYNW7ZsCVLP5PPMX44GXMdFjcBPsQHBWySItU+oDVJ+/RWTyjDnhmK4GMZjshou0Td/9lFiLTze1Z+HFWdgRnkR5m+oEu0/ADS3dcBgAKaXX4ouMLy1W2xtThRmJsq6ZkpWmO4uAb5K3pdlJiLXGi9bjAptc+HuHuObPAMtSKhESEmt+ttEEhXc722lpQ38Qa5Vxv3aPXZrX7R3+FrGpGCFZUOrEwyAZR8d8ujfqCt6YOO916G+xYn2Dhfi44zYe+on3DfiMry87Tjvd+plTy9/RYo/n/N3bKVg7MhCU0E0btw4jBs3TvQYs9mMnJwc3vdsNhveeustvP3227jxxhsBAO+88w7y8/Px2Wef4eabb8bRo0exdetW7NmzB4MHd+/X8+abb2LIkCE4duwYLr/8cnU7pQB/67gEI4hRrLbJPTwiQenkIdXX0w12/PpP+3y26Ki76BDcCkJskm9zCu+jxFp4vM9jfFwMln182GPyF+o/O2lMefNrnzazgbtb5g4DIH3NlK4wvcWBdyXvzXOG+lh+/Nnmwt095i0ieqYlKLrnAnUpBOLScL+3veO+vOtIOV0unG9uR6ujE7Y25W0V24WezyrDXrsbr8jCVQVpsn6Dr3/tnV1Y/P++86g5ZTEZMXVwIZ7b+r2PYH/ytivxxo6TPu3R055e/ooUfz/nz9hKwdiRhe5jiL744gtkZWUhNTUVI0aMwG9/+1tkZWUBAPbv34+Ojg6PfdPy8vJQWlqK3bt34+abb8ZXX30Fq9XKiSEAuO6662C1WrF7925BQeRwOOBwOLi/2W1J1MRfH3mwghi9BwRTbAw+PVQraCFQYlqXsyEs3xYdAHDtpek+/ZWa5BfcKL4hJxv/4v29bAq6ra0D7R0u7D7Z4NN/90ljUGGa6EaaLGKZXEpXmErFgRrbXLhzfUkmcn4uPCkHNVwKgbpU2XvbPStPKJ7I3VLIZuk9O7kfEk1GQWtkfYsTLobB01sO81bclrsLvT+ca2rDD/WtPr8r5B7cVd2AJz85gqUVfbHkw4Pc61oUTJQSyv4uAP39nNKxlYKxIwtdC6Jx48bhjjvuQGFhIU6dOoWlS5di1KhR2L9/P8xmM2pra2EymZCW5rmyys7ORm1tLQCgtraWE1DuZGVlccfwsWLFCjz55JPqdsiLYAZJ+4v7gHDyQguA7iBf72rO9p8DX+WiJJDZZ9Xe6fLZF01sw9Ivj9fjkVv6iP6eUNvd+3+uqQ1/2HHCRwy5TxqBujD9WWEqFQdSg7acbS7cv1/JpOmP4BOaJAM91+wx7LkTEgyV1Q1g8ItljC29cEtZroeAuKlPFpZW9MWjm7v3cntr+iDBquBydqH3B/b8Trm2wOc9qRpVj1f0xecLR2i2p5dcoezvAjDYGYOAPsdwwn90LYjuuusu7v+lpaUYNGgQCgsL8Ze//AWTJk0S/BzDMDC4ZfcYeDJ9vI/xZsmSJVi4cCH3d3NzM/Lz85V2QZRgBkmrgckYI7gp6Ma9ZxBrNMjewFVq/yU2RkduFpDUhqXGGENQ90JTcowY/qwwlYoDqUFbapuLyzITsXnOUI++yXWBKRV8UpOkGu7iR2/tg+mNbchKiRcUDN6WsZ3H6322C7k8NwVLNv2SiSdVhkFsF3p/J272/PJtZSLVnlZHp99uOn9h7xtbmxOOzi70z0/F/tONHpXtwyn2Ru9jOKEMXQsib3Jzc1FYWIjjx7uDAXNycuB0OtHY2OhhJaqrq8PQoUO5Y86fP+/zXRcuXEB2drbgb5nNZpjN/PWA1CKYQdKBYrM7PQZ7ll3VDTAAeHDsFRj3qnBGnDdifX1mYhnONdrRNzcF+WkWvPLZMY89lVjrzxMfHeL2VJLasNQYY1Dl3MrJzmJhAO59uQiJFdZKFh9n5C13oEQcSA3aYttcXF+SqThA2x0lgk+uNcnf58K73VJbhngLCu+/vS0wUhW3xXah9xf2/PIVt5RqT6I5FifqWkKWKu59/i0mIx67tQ/ev+86/NjYBnPsL1becIm90fMYTignrARRQ0MDzp49i9zcXADAwIEDERcXh23btuHOO+8EANTU1ODQoUN4/vnnAQBDhgyBzWbD3r17ce211wIAvv76a9hsNk40aUmoq+PKRcwlVVndgJktTtidLkUrOr6+xsfF4ImPD3OVnNfNuAZTBhf6WIjY4OYLLQ50uhjRDUsfGFnM7T21csoANNk70OrsRKvThdSEOFhMRtkWDn+ys9jB0CIQc+JOUnws3vv1YDS1dXDneOPeM3h2cj9JK5lccSA1aAttcyFUR0qJC0yJSyHUldilBIP3+95/ewskORW31XbjsOeXr7hl1dkmwTpHw0syse90o08MkdTiJpB9xbzFEGsJdt/Yl7XytjrCJ/ZGr2M4oRxNBVFLSwuqq38Z8E+dOoXvvvsO6enpSE9Px7JlyzB58mTk5ubihx9+wCOPPILMzExMnDgRAGC1WjFr1iwsWrQIGRkZSE9Px+LFi1FWVsZlnfXp0wdjx47F7Nmz8cYbbwDoTruvqKjQNMPMnVD4upUi5ZJq7/glrkbJZOXeV5vdibkbqjwmKaslDr/7+zFB689DY6/g6jZ5xxqxgiLBFMP9RqvThcc+OuQxEK+ZcQ1+v73ao64N32Tgb3bWvtONOP2TXfI3hFLd18y4Bs97ZQa5/64/7gR2M9DGViea2zuRkhCLNIsJ2T8HR8sd1JWKFiUuhVBXYhcTMN6lFvhKL3gLJLkVt9XA3fW0YfZg7DrRgIc/OIBfXVvAWVbTLXG4c1A+HvMqL3F9SSbm3FCMmeu+8fhOqfsrkOB47/MvFvANAL+dUBpS61Wg6HEMJ5SjqSDat28fbrjhBu5vNmZn+vTpeP3113Hw4EH86U9/QlNTE3Jzc3HDDTfg/fffR3JyMveZl19+GbGxsbjzzju5wozr1q3jahABwLvvvov58+dz2Wjjx4/HqlWrQtTL8MNmd0q6pLwnA38mK75JKtZo4J2g2N83GLonIqFYo/LiDPzH1T25fngP4DOHFWHl9uOyxIa/2VlyfgOAYKp7S3sn76qe/Q5/LCVyJjM5g7pS0cJnnbKYjFha0RdXF6TiZH0rUhKc3ROexB5/aldiFxIw3vWohASEtwXGva7QAyOLER9nhDVBfWsB37UcVpyBZyf349q8tKIvevVIxIWL7Vh225VwdnXB7nDBmhCH2BgDxr22kzdzVOj+CrTejvf5Fwv43lXdgKa2Tkz4/S7uNSp0SIQCTQXRyJEjwTDCuz397W9/k/yO+Ph4rFy5EitXrhQ8Jj09He+8845fbYxGuqsCC4uSOSOL8dVJz/f9maz4JqnGVqktRDpQdbYJj93aR3CF+fhHhzhrh/cArqQwn7/ZWXI3fRUSW01t6lpK1Cwe509Wjbv1qdXRgZQEE5ZuPuTjrlk+sQw39cnCNp6NcINRid1dwCx1K4yYFB+LVkcn3vv1YM5SZne6MKgwzcPScqymGcsnluGxzb/sPWd3unDgbBPuvrYAuUGYvIWuZWV1AwwGAz56oBxxxhif81tenIF5o0pgMRlR29wuWKUa4L+/AnVnep9/qYDvGlubz2+EU7A1EZ6EVQwRERy84wJcDCNa2t8YY8CaylPc3/5OVnyTVGeX2HaoQKeLwZrKU3j/vus8Yg/cYQdoPkEjNRDb3MSIv9lZgW76KhXbolR8qhmb429WDWt94tyk1b7i7JFNB7FiUhkcnV0hq8TOCpjZw4pEv99qEd5jLpTxI2LXkn196eZDPueXXThU9MvDoELxzDK++0tscWAxGdHFMKIuLu/zL3WPm4y+71OhQyLYkCCKcvjM78NLMkW3bLA7XR57I/k7WWUmmTC8JNPjt7890yga1/Htme4UXTaOSIiL7R28gkZqIG7vcOFcUxvyUhP8zs6SI2i6RCyjVWebfM6L++8qFZ9qxuYEmlUjJc5sbR1YWtEXJmMMbG1OJJp9BYa7gE8yx8JkjEFTmxNJ8b4Tsfuxj93al3dvLyV1jPiOC2X8iNS1tLV1iO75NrO8CCajb/o/i9D9JZYN+dqUAXjKqyAlnzvW/b5REr/lDhU6JIIJCaIoRsj8vvN4PRiG4a2se31JJnrx1KXxB6vFhBUTy/Dwhwe4OIw1lafw1vRBiIHBJyDZPY6DbwXpDts274FfaiDefbIBf9hxgjPN+5OdVXfRISlomuwdgu34/pwNz0woxVI3Vwz72eUTy9DQ6vw59kZesKnaxeMCyaqRmtB/aLBjzrvfCsaMCAWi31NehClvfu1RBsL9WPeNT/8081okmo2wxMUi1RIXVhYHqWsptM0Ni6OzC7Y2p2JRK7Q4ULJZrrfr9D+u7onHP/K8x4eXZGL60Et9tsphoUKHRDAhQRTFiK3WK3+OFfJO+35ucj/kpiagEImqtKFnugXPTe6H0w12NLV1wBwbg70//ITxV+XhsYo+aHO6eOM45KY4ew/8aypPYc2MaxBjMPBOqqxVjDXNC03+ADgXAZ9FY0TvHqITzg8NrZg1rMhH+JUXZ2DW8F7o6mIkSxSw3ykVbBqM4nH+WkXkViznm1CFBLz3nmveGYBSxT6tFsXd0Aypa5kQJy6IzLExSDTHKRa1QouDoZdlKNos1/u+8W5DUnwsHtt0kNcyTYUOiWBjYMSimgmO5uZmWK1W2Gw2pKSkaN0cVag604iJq3cLvv/hfw2FNSEuJLERrGtD6rfY49jgXO8VprtoE/vu8xcdOPuT3WNDVnZLEqB7g1ShKr5y04/F+nSirgWfHDyHHklmZKfE+7RjYGEaVnmJAe8SBe6/LRVseq6pTVCgBSP4Vwib3Yl5G6qw73SjT8mEWlsbLrQ4PHZh/3zhCPTKSgLQfc5Gv7RD8LvXzLiGsyBu/c1wjH11JwBg7qhiVJ1pFBTP4Raoy3cth5dk4oEbivH1qQbsO/UTb1JEeXEGKvrl4ZbSnIDqObnf07Y2Jya9/pXg8WLPkRBa3quBbkJM6BO58zdZiDRE64cvySx++a0JcdxkFGyUFBkUW2HyCSm+765vcWLW+n2CvyNkmleSsSXWp8wkE64pTMfUP37N+/5Or9V1oIHReikeZ7WYui2CP9mxcvtxD+vC8OJM3DPsUo+Afo9K1m1O0e+ONf5SJtw9A1BJZmE44H0tE82x3QLzZzG4auoAgMfyOG9UCS5NtwTUV+97+kRdi+jx/ri4tLpX1diEmAhvSBBphNYP37mmNuw7LRzAHC7maX9dN/66kdTK2LJaTDBJBF+7iwE1AqMDDf5VS8B3MQx+z1OnaWd1PbrgGbvmPqFaTOLDVZrll2PdMwDlZP2FG+7X8kRdi0eK/dz3qnDv9ZfhNzeWoLOLQXJ8LJJMwYmXCtZeXqEudKhmaQoifCFBpAFaP3zs7+8/3eh3ZV2trVuB4m+2lJoZW+mJJswdVexTaZt13bmLAa131VZLwNvsTpxusIvWuWI3VfWeUGNiDKIB8Z0uhvucewag2mUM9Ib3PWl3uvDKZ8fxymfdrsfNc4aiME+dmD9vImUvr2BuG0OEDySINEDrh899n7LOLgYPj+0DR6cLF1ocMBljUNwjSdRXr7V1Sy38Mc0rFSZiwtFkjBHcHuX9vWc8xIDUSjw2xsC7CawaqCngG1qdkrWmHJ1dvBNqbIwB9/wsltxFERsQb7N38GYAygnAD2e0Fst6cccGQjC3jSHCBxJEGqD1wye0T9k95UWYt6EK7/16sGAWWSCTox6tSkpN80pcBGLCMdFkxJJNB3krbRsAHzEgtBIf/nM5AvetGNQWp2oKeAbdhT3FuCwzkfc+ykg0YcWnRzGgII3br4sNRN+49wyW3tqXN827odWJiQMuwbKPD/NuwivVdj3et+4odVsFoz/hvpeX1qKS0AckiDRAy4dPzj5lYr/v7+QYKVYlq8WEZyaU4pFNBz32GxtWnIFnJpRKpoizwnFpRV/RkgftHb5xL2LBtO5pyoG6Xr0nTKlg5ka7Eza7tChi773+BWmCFpvhJZnItcYLFkB88vZSPPzBAcFyEGL9+N0d/dHq6ERzm3wrRjjct0rcVuHQHy0IViwUEV6QINIALR8+qX3KHhhZLPr7/li3tI6ZUhOb3YmnPjmCqwrScI+XleLpT47gd3f0h9VikhSO/u5XJhZM6/0bam0C+96vB4t+xtbWgXkbqiQnVfbe23+miTd2bXhxJn4rUXhSrntGbOK/rIe8zMlgW0PVtNR4n5eUhDgkmmPR0t7JuVKTzLER8xyqTaTEQhGBQYJIA7R8+KQEjTkuRtUYGkDYqmQxGdEvPxU1tnZFlZcDIdBJqL7Fic+O1nkUR/R+32oxSZ7nRImKwgkS7wPqu16FBMDukw0eu7q7w26zIGdSZdvrvqmqu+urZ1oCntoiXXhSyj2jlgAPpjU0GJYa9/NyrqkNi//8T+x3q/eUZI7FPeVF6J+f6lFzS6o/0UIkxEIRgUGCSCPyUhPwwh390djqRHN7J1ISYpFmMSE7JV7R9yid4KUETWqC+MPvj3WLb+KWqh4sZ1JQ2nc1JiG5IkRs76eZw4qQEGcU3N6je8+2JuSk8LuOWNR2vQoJgDWVp/DalAEwiFT3BqQnVff22p0un9pA7/16sI/Q9Md6oVbMU7CsoQACFmxi9753Fqn3M8YG7nvvVUiBw+EfC0UEBgkijVBjcvbnOwJ11/lj3eKbuJXsgcSH0r6rZTWQK0L4zrO7CGRFRhfD8GZMzd9QhWsvTRdtk9quVyEBwFp0PnqgHB2uLvzQYOfchEomVbH2Di/JxO6T/K7cL4/Xo+6iQ7b4VctylmaJw1vTB/GWRACA+DijT2afHDEGICDBJnXvs22YO6qY9xnz3uqEhQKHiWiHBJEGqDE5+/sdarjrlJqW+SbCQKoHC/V93+lG7PjXBQwqTEOLo1PxRCWn70nxsbJ2ouc7z94i0N1tBHRXBv/iXxc4kSE1cavtehUTe3anCzEGA8yxRsx591vB48QmVbH2PjH+Sty2slLws2d+sntUFhcTv2pYzs40tGLp5kMe8XbulpWrC1LxycEa7h5m2yNHjEntlSR23eU892wbxJ4x93pPbPspcJiIdkgQaYAak3PdRYff3+GPr5zPRC93Ww++iTCQ6sF858/d+uIeaMxOVC2OwK0G55ra8PhHhzB96KU+lh0+EeJ9nuPjjB4TlLfb6K3pgxSv2NWMe5BrcQrEKiXU3oZWJ++GnkKICX9/LWfsPe7q6sLTnxzxST5gr/fSW/ugR0q8x47s7tmDYsi5poFmebKCUOoZY9+nwGGC6IYEkQYEatI/19SGMz/ZA/oOJb5ybxO9xWTE0oq+uLogFXanS1b8Dp84EENsUuBLA5dywT19e6nfvwd4rsx3n2jwCAhO/XnPt+yUeFHhWHWmUfQ33CcwJSt2teIe5FqcpI6Riu0Saq+QiGEDt70REv5y++HezkRTLPafacTTnxzByikDRDMxH72lL/7jD7t9BNyXx+thMsYEVVTKGTuKMhNxfUmmZIXuSzMs+HzhCFUDh/Ves4kgxCBBpAGBmPTZiXnG0Ev9/g4leJvopSwxeakJgoOi+0Roszv9mhTONbXx1uiRcsE5XV0BWTbcV+Z8AcHbF42QjO2Quu7sBKblil2OxUnsGH9j48QKT04feqmHNcYdIeEv1Q++drIuMadL3LJia+sQtGbZ2pyqiEoh5Iwd7Lnc8a8LohW6L0lNUPUe01uNIxJnhFJIEGlAIMGw7MTcPz81JNsReJvopSwxKyaV4eEPD0oOiv7Ev7DijK/vUu6BVkdnQPE2UitzVxcjGNvxxEeH8MzEMnQxDN6aPggGg8EnQHd4SSaKMhKxY/HIoGzCqQQ5Fie+YwKNjeMTMbExBo8q3N4ICX85WVje7WTvp/++sbdo35Piha2biea4gEWlGFKB6bFGA2x2J/JSE3BLaQ6GXJaBpR8d8qtCtxL0VmtMb+KMCA9IEGlAIMGw7MTMZikBXsXtVB7svIWAlCXmdINd9qCodFJgxRnfprRyNvAMJN5GamXu6mIEay3ddW0BFv+/7wQDdAcUpGL60EtRsaoSgwrT8OzkfrBaJJukO9SIjfMWWja7E4MK0xQtHuRmYfGxq7oBD42NEVxsDCvOQKuDX5x5B9X7IyqlEBo7yoszMH3opRj36k7uHsr72QK0KgS1dbTen9EdvYkzInwgQaQR/k7O7MQsVNxOamNWpXgLASlLjFAFZrF4D7mDk1hhvx7JZo/sL7bez4D8VABAF8Nw20sEI+DY7uzk/ZyQRW1XdQNiYMDGe6/D34+c5zLLQjFoB8uV4G9snFh7lC4elGRhCVFja+fdRHZYcQaWTyzjjRMKpZuTHTvqLjq4WEL3Egje95DYPa/WvaD1/ozu6EmcEeEFCSINEXI7iA1Q7hOzdyzL9SWZXOE3tfAWAlKWmJ5pCVgz4xoflxAQ+KAoVtjPYjLi0/nD8fhHh7BPoCBdICZzqYlZyKUjZlHbWV2PB3E5bu6bg5G9e+BCiwPm2O56Nw2twRm0g+lK8Cc2Tk57lCwelGRhuYtm91pDZmMM5rz3LWYOK8IDI4sRFxuDZHMs0hJ/KZwa6orGfOOCMcbgUYqAr6/BLlTKoqfNUfUkzojwggSRjpAzQKlde0YK79+rOtsk6E4oL87A34+cx6rt1bzVcAMdFMWsNIMK05BmicPKKQPQZO/AY5t9d5IP1PoiNjELBYlLxjY5XVi5/bhPccaJAy5R3D4pgu1K8GfXde/2sNu5/FDfilpbG6wWk0dQvhRys7Bu6pOFu64t8BHNw4ozcGOfbADAgbNNuPvaAl6LaygrGguNC0+MvxIWk1FQjAdaz0hOLTRWpKUnBl4kVC1rlZ7EGRFekCDSCXIHKJvdifYOFx6r6IsuhoHd4YI1IbgrVHch0OrowH9c3ROPf3TIJ4bBfRsH72q4agR6yxWDYhvYqmUyZwDAIN221ATp2CM+d9qyjw9jlcpus2C7EpSKde/2qLGdi/tkyGcBSvtZyCwbfyUe/OCAz7mvrG6AwXAMf50/XPPgdkB8XFj28WG8++vBaLR38FpkA61npMS6ZDEZsWbGNWAAvwK41bRW0c71hL+QINIJcgaoVqdLcNAI9sDtvSJmBVKj3QlbWwfvNg5sNVw1rVdy3CfBiGUBpAdtvrYlxccKZwUVZ+Irge0qdgYh1iEUrgQle/R5t0fpdi5814udDKXcpu0dXbxWTqD73Hd2MZqLIUB8XNh5vB4zhl6KWev3+Vhk1ahnJASfSLM7XZi57hssreiLxyv6otXRKduVqLblMtRWdCJyIEGkE6QGKFtbB5ZtOaybzAlWIFWdaRSMYwC6t6NQu21S7opgxLLIHbT52iaUFfRYRR9MXL1bsJ1qxzqEwpWgZKXv3R4l27mI/c5zk/vhi39dEBVXC24sEe2HXuJMpMYF1iXrbpE9cLZJlXpGQgiJNLvThSUfHsTnC0fgqoI00e93p8negRlDL8WUawt89ozz13JJO9cT/iAeIUuEDKkBymIyyto0MtRItTtNQrwEA9ZKwIfcWBbgl8mTtUT4e/7ZwfnzhSPwf/cPwVvTB2FAQRpqmtpFt6tQO9aB3YeNDzVcCXLOozve10nudi5Sv2MxGTGoME3QAvTl8XpYTOJrQaniqCfqWlB1phEnLrT49EtN5BbzBLpFUUVZLlZOGSCZaar0GXFHTUvjuaY2PLb5IGat34c5736Lmeu+QdWZbuuexWRU/H3uWC3dVeKvKkhDr6wkEkOEJGQh0glSfu+YGAPPp36h0e702Xk7FGQmmQQ3Ox2ukb8+0FgWd1ixE+gkwFqObHYn5m2owpfHu3cjLy/OQNWZJp9Yl/PN7aqeO6X7sPmD0rgU7+skp5aU3N9pcfCXQWAxxhj8rpQeyoJ/YuMC35Ym7R0uWdcxELeSWpZGTtgK7BnHxh+GQxA0VcWODEgQ6QSpAaqtQ3zjS1tbB+e6CnVF1gduKPaZZMuLM/DADcWyv0PtAUWJyVyO2Ekyiz8qiRLvs7hf5zWVp/D7qVcjPi4Gq/5R7eEuGl6cieHFmaoMqnL3YQsUqfPYxLMHnft16mIYQXHtLlLkXC+pSdsYY+Bca1nJZg8hekPvHrznXYuCf2KFGN2TGFiUiIdgVMtWYmmUKpDJxh+6f58ehQdVxY4cSBDpCH/SugHflWIo44rqW5yYue4bnwKRVWebMHPdN9gyd1hIM0zckZsaLWfFGxtjEC03YDLK9z6z17nG1g5HZxd+97fvfb53Z3U9lmw66JNp5s+EILYPm8VkxF/nD8eJupagpzs7Orq44pjuuF+n52RYLeRcL6lJOyPRhFanC58eqMHOas/fGtG7B+/3alXwz31caGpzIj7WCKerC81tnZg5rIiLt/HH7almtWyllkYpYZtkjsWKSWWy4sa0Eh5UFTuyIEGkM4QGKKUrxVBVZG1u7+Dd7JRFypWk5oDi7+pRzor3h4ZW3urF7Pm3tTkBJMpqJ9B9PU/Wt+KnVuESAd6ZZv5MCDa7E45OF1bffbVPwCqb5v7Y5oMebQgk3VnIwlNenIHdJxuQnRIvek3kWC3kXC+pSRvAz+4a+fedErep2pYMq6VbwC3bcpx3Q9r3957BU7eXhmzyVSNoWUrYtjg6seTDg3h2cj8kmoy6FB5UFTuyIEEURngPQqbYGHx6qNYn3Z0l2JkyNrsTCXHCG10C0iZ8tQaUQFaPcla8SS1OTHnza15L2PwNVdgyd5hkG71JiY9Dja1d9Bi5gcR8E4LYju7s1idK0tylYOv7PP7RIV7ROH9DFW68IkvW94j9rlwLhdikfaKuRfF9Jzd2JhiWDLENaWMMBvzujv6quD2VEGhxSjnxUey9uLSiry6FB1XFjixIEIUZ7oPQiboWQcsMENyKrOygz7fzPIscE74aA4oaViapFW9mkgmDCtN4z7e/GVqZSSacb5Y3ySoVjlI7urNB3HLT3OViADCgII1XNNqdLtXuSbkWCqFJ25/7To5lKlguFKl6RC3tnchOUfy1miLX6v3l8XrBPRJZtBIeVBU7stA07f7LL7/Ebbfdhry8PBgMBmzevNnjfYZhsGzZMuTl5SEhIQEjR47E4cOHPY5xOByYN28eMjMzkZiYiPHjx+PHH3/0OKaxsRHTpk2D1WqF1WrFtGnT0NTUFOTeBZ9AUmcDwX3QX1N5CveUF6G8OMPn9+XEE6gxoASSEu+OWJouO3h7n+9AMrSsFhMKMywY5nXu3L9bSSCxO1IBq+ymt0q+Uw4ZiSYcONvEpVHPWr8Pq7ZX+x3jIoY/adVsyrzcjDbv35O6B9S6F72JVEsEK2w/nT8Mq+++mitJ4W31TjQFZokOFlqNwURw0NRC1Nraiv79++Oee+7B5MmTfd5//vnn8dJLL2HdunXo3bs3nnnmGdx00004duwYkpOTAQALFizAli1bsHHjRmRkZGDRokWoqKjA/v37YTR2P0RTp07Fjz/+iK1btwIA7r33XkybNg1btmwJXWeDgFYVWb2DdL13nr8sMxG5VvFYERY1MlZCFdvhbZVINMfCZIxB3cV22DtcfsWJXJJmwbOT+mHJpoOiWx4oFY5S58SaEAer17YiPltdmIy8QdCi36vjKsHuriy25IFSy6aUZSpYwiWSLRGskJzz7reCxySahCu+ayk89Hy/E8rRVBCNGzcO48aN432PYRi88sorePTRRzFp0iQAwPr165GdnY333nsP9913H2w2G9566y28/fbbuPHGGwEA77zzDvLz8/HZZ5/h5ptvxtGjR7F161bs2bMHgwcPBgC8+eabGDJkCI4dO4bLL7+c9/cdDgccDgf3d3Nzs5pdVw0tKrJ6D/reQdWb5wyV/ftqDCihjO1gXTBqxon0TLdglQqBxO7IKZjp/p1q7CPGoscqwd6urDWVp/DalAEAIFiTSUg8i8XOBEu4RPr+XFL9S7XE6VZ46PF+J/xDtzFEp06dQm1tLcaMGcO9ZjabMWLECOzevRv33Xcf9u/fj46ODo9j8vLyUFpait27d+Pmm2/GV199BavVyokhALjuuutgtVqxe/duQUG0YsUKPPnkk8HroIoEGtyoFLUH/UAHlFDEdrhPjknmWOw73Yj9pxv9+i4+1AokZlGaidUvP1X1AGs9TQjerixvy6Y1IY4TiYEI3mAJl1BYIrSs8SOnf1YLdCs89Ha/E/6hW0FUW1sLAMjOzvZ4PTs7G6dPn+aOMZlMSEtL8zmG/XxtbS2ysnwzW7Kysrhj+FiyZAkWLlzI/d3c3Iz8/Hz/OqMieihMFoxBP5ABRc5g6k9WEXuuG+1OdLi6sOtEA5ey7r2ZptR3qYGUcHS/N6wJcVg+sQyPbDooKxOrxtaueoC1nuBzZblbNjfPGYpeWUkAAgvSD6ZwCaYlQg81fuT0j4QHEUx0K4hYDAbPLSsYhvF5zRvvY/iOl/oes9kMs9mssLXBRQ+DFqBPv7nasR1SKeve2wuIfZeaCE0IfO29qU8WVkwqQ3tHl2Qm1okLLaK/G65BuyxiVk2LyYi0n0Vzc3sHEkxG9M9Pxf7TjT7lLOSIw2AKl2AIAj0VFyTB4z96WCyHO7oVRDk5OQC6LTy5ubnc63V1dZzVKCcnB06nE42NjR5Worq6OgwdOpQ75vz58z7ff+HCBR/rk57R06AF6NNv7v7bLY4OxBoNqLvoQIujEwkKslTkpKyv2l7NbS8g9l2hQKi9247WwdHZhZVTBnDWDz5qmtoQH2fEW9MHcVtYuBdwBELbp2AM7EJWTYvJiDUzrsFjmw95FGkUsgAC8sRhoBN7KCc3Ki4Y/uhlsRzu6FYQFRUVIScnB9u2bcOAAd3Bj06nEzt27MBzzz0HABg4cCDi4uKwbds23HnnnQCAmpoaHDp0CM8//zwAYMiQIbDZbNi7dy+uvfZaAMDXX38Nm83GiaZwQI+Dlt5Wc+ygsP90927Zz//tGCdi5o4qxrDiDFTKyCqSs8cSi/cO7VoEuDbZOzBj6KWYcm2Bj5iRujdsdidO/2THqu3HPc6NuyAYVJgWsj4FcxsXPqvm0oq++P32ap+K1WIWwGCLw1BPbpGa0h8t6G2xHM5oKohaWlpQXf3LYHPq1Cl89913SE9PR0FBARYsWIDly5ejpKQEJSUlWL58OSwWC6ZOnQoAsFqtmDVrFhYtWoSMjAykp6dj8eLFKCsr47LO+vTpg7Fjx2L27Nl44403AHSn3VdUVAgGVOsRGrTEcR8U5o4q9gkQds8qqvTKKlo+sQwNrU6crG9FSkLcz9twCOMugtzr2ajhMlRqGTjX1Oaz9Ya3dUPs3miyd2Dl9uM+wdTs30sr+mKkwGanaqPGwC52/visml0MgyUfHuT9Lj4LoJDgVcuio8XkFskp/dGAHhfL4Yqmgmjfvn244YYbuL/ZIObp06dj3bp1ePDBB9HW1oY5c+agsbERgwcPxt///neuBhEAvPzyy4iNjcWdd96JtrY2jB49GuvWreNqEAHAu+++i/nz53PZaOPHj8eqVatC1Et1oEFLHPdBga8Cs3tW0WO39kV7R3fV5Pi4GDzx8WF8drSOO/a9Xw+GGKwIur4kE8U9krB5zlBVXIZKLQPc5CkgZljrhti90ers5K3Fw37P0lv7IjdEJnexgX3f6UY02TtERYec8+dt1aw645kp6I27+BUSvGpadLSY3CI9pT/SiYTFsl7inzQVRCNHjgTDMILvGwwGLFu2DMuWLRM8Jj4+HitXrsTKlSsFj0lPT8c777wTSFM1R+6gpZcbK9S0ODowd1QxBuSnwmLiv63ZrKIbr8jCVQVpsNmdmLuhymcC2n2yQdC9xu6xxE6OuakJKFSwqasQ/lgG5Lj2pCa0Vp498NxpcXTK7EHgCA3scjah9deyIrXQuCwzUVTwqm3R0WJy02OSBCGfcF8s6yn+SbcxRIQncgYtPd1YocaaYELVmUas2l6Nt6YPEj1Wan8w1r1mMBg83h9ekoknx18JAJg9rEjVicIfy4DU5AlAckJLTRAfLL2rWQcToYFdzia0/lpWpBYaUhXX1bboaDW56TFJgpBHOFv49Bb/RIIojBAbtPR2Y4XSUmWzO7F08y87rFedbZK1LYNQrBDrXts8pxzGGENIJgh/LANSk2dBukXS3ZWVbMbwkkzeSX14SSaykkNXekJoYJezCa2/lpVArSNqW3S0nNz0liRByCOcLXx6i38iQRRmCA1aerqxQm2pqm9xemQJydmWAYCgaw3oFkVdDIPeWcmCx6iJP5YBqclTjpixWkx4bnI/n+s1vCQTz4d4MBUa2KW42N4RkGUlEOuI2hadcJ7cCO0IVwuf3uKfSBBpiJpWFK1vLLYvtjYnHJ1dPoXtgmmp4ttbzX1bhuT4OGQkmnwGiJgYg6Alqbw4A8YY8QKgauKvZeCp20ux9KNDohvDSmEAcEtZLmYMvRSOzi6YY2NQd9Eh+blgIJQJJgY7+AdiWfHXOhIMi064Tm6EtoSjhU9v8U8kiDRCbSuKljeWVFVnd1EUDEsVX9/dt2X4fOEI3sKEsTEG3PNzWvUur7T1e8qLBAVRMNyBSi0D7jWXZg4rwoyhlwIAeqYlICdFPO7Fuy8P8rha2d9++vZS/GR3hjRA33tgt9mdivZlC6Vlxd/f5buHAHi+lmQSLahJEOGO3uKfDIxYmhfB0dzcDKvVCpvNhpSUlIC+Syi7Cei+CfyxotjsTszbUCV4YwUrhkisL+XFGRhQkOYR/7F5zlBcVZDmc2ygbfCn7za7E4v//E9cnpuCAfmpnHWk6mwTjtU043d39A9qirVQX6QsA2rdPza7EzW2dox9dafgMW9NH4RZ6/dx3x3sAH0hsXmuqU1QdLjHSck5f8Fst5zf5buHhpdk4oEbijFz3TfcAkJPCRHRmr1KBB+5z3YgyJ2/yUKkAcGI99FqhaykqjMQHEuVv323Wkx48vZSPPzBAQ/RJvS5UASuyzF7q3H/sJPylGsLRI9zr8MT7AB9KbEpx42kldtA7u8K3UM7j9eji2E8KmPrpdJwNGevEsFHTy5iEkQa0NzeAYvJiJnDijjLhPuWC/7G+2hxY0nFLnkXtguWCdTfviv5nF4C1wONF3OflFlXmxDulbiB4PVTrtgMd6uE0gWE1pWG9Za9SkQmenm2SRBpgDUhDq9NGYC1u055WCbYuJuUAGq/hPrGkopdcq/qHOwsGX/7LvdzWgeuswQaL+Y+KYuVKGCLUHoTjH5qITa1cAMpWUCwaFlpWC+LAIIIBSSINCDRHMtbaG5XdQMMAF688ypN2uUPYkFxw0syUZBuwecLR0REloxeMiICDUR0n5SFShSwgeXzN1T5fD4Y/Qy12AzEDRSIkJK7gHBHy0rDelkEEEQoIEGkAS3twvtHVVY3oKW9E9mBxW2HDKn4nVDtgxUK9JIREWi8mPuk7F2iwNHZhct6JKLqTJNHhqD7bwSjn6EUm4G4gQKNpxG7h/gsclpXGtbLIoAgQgEJIg3Q46orkFWvnoLigok/QiRYbplAzrn3pOxeooDNUkvp3QN/LUwLWYB+KMWmv24gNeJprBYTlk8sw8MfHvDYK294cSbm3FCMWeu/4V7TQzFGvSwCCCIUUNq9TNRMuz9R14LRL+0QfF+obk6wULLqpfRb+SnWambnqH3e5aS6hjqFPRTpt0D3DvcTV+8WfJ+vNARbouBkfatHAoS7BU3uc3vyQgs+rPq3R6mHg/+2wWAASvOssCbEIc3iW0hUK0J1XQgiWFDavY7R06pLyaqX0m+7kROErWZ2TjDOuxwLU6gD9ENlaVTqBpJbeFSuZdfW1iG4NxvQLcj0VJAxWizABOEbwUcEHdb1cn1JpsfrWpjI5bgPAOkJ3mbn3yg1WpF7XqUI5nm3WrorIV9VkIZeWUm6mOBC0SZ2QcKH94JE6Pzvqm7A2l2nMHPYL2nycuNpwjEuR4/3CkGoDVmINEIvqy658UyUfqsMteLE6Lyrj5JYMLl1g5RYdtWwEJPrmiDUhwSRhuihGJXc1aoeA8H1jFpWADrvwUHugkRO3SCllt1AswTJdU0QwYEEUZQjd7UajmZ+LVErTiwU512v1oZgt0vOgkTq/F+WmehXtWZ/LcRUOVocvd7LRHhAgijKkbta1SoQPFwHOLX2lgv2eVfL2hCMLDg9WEGkzn+uNd7vfvpjISYXqjB6uWeI8IXS7mWiZtq9HpGTYh3q9NtIGODUSF0P1nm32Z2Yu6GKd4Jl6xHJaava10mtdqmFntLO/SkZIEW4Ljrc0ds9Q+gLSrsnFCFntRrKQPBIcQ2oEScWrPOuhrUhGNdJb1YQvSRAAOq7UCNh0QHo754hwhMSRIQiQhUIHkkDnBor8GCcdzUCtoNxnfQYSK6HBAhAXRdqpCw6AH3eM0T4QYKI0CWRMsDpeQWuhrUhGNeJAviFUSs2DYisRQfdM4QakCAidEkkDHB6X4GrYW0IxnXSUyV3PaKWCy9SFh0A3TOEOlClakKXKKkmrFfUqlYdLNSomB6M66SnSu56RY3K0ZGw6GChe4ZQA7IQEbpETdeAVoTDCjxQa4PVYsJzk/vhi39dQFayGY7OLsTHGXG+uR039O7h93XSUyBzpBJpVhW6Z4hAIUFE6JZwH+DCZQUeaMAwA+DTAzXYWe0pXEf07qFpuwhxImHR4Q3dM0QgkCAidE04D3CRtgLng4uTqtZnnBQhTrgvOghCTSiGiCCCRDTENeg9ToqQhnayJ4huyEIUgURC5dlIIdJX4OEQJ6UF4fgM+tPmcOwnQQhBgijC0HPdm2glnN1+UoRLnFQoCcdn0J82h2M/CUIMcplFEFJ1b2x2cl9EGja7EyfqWlB1phEnLrSE/BpHQnkENQnHZ9CfNodjPwlCCrIQRRBC8RwWkxH98lNRY2vHyfpWMm1HCHpYoUdiplIghGP1Z3/aHI79JAgpSBBFEHzxHBaTEa9NGYC1u05h1fZq7nUybYc3eqqCHelxUkoIx5gqf9ocjv0kCCl07TJbtmwZDAaDx7+cnBzufYZhsGzZMuTl5SEhIQEjR47E4cOHPb7D4XBg3rx5yMzMRGJiIsaPH48ff/wx1F0JCXzxHDOHFWHtrlPYVd3g8TqZtsMbvWV3UaZSN+EYU+VPm8OxnwQhha4FEQBceeWVqKmp4f4dPHiQe+/555/HSy+9hFWrVuGbb75BTk4ObrrpJly8eJE7ZsGCBdi0aRM2btyIyspKtLS0oKKiAi6XS4vuBBW+eI4B+ak+YoiF0qLDF1qh65NwjKnyp83h2E+CkEL3gig2NhY5OTncvx49uqvfMgyDV155BY8++igmTZqE0tJSrF+/Hna7He+99x4AwGaz4a233sKLL76IG2+8EQMGDMA777yDgwcP4rPPPhP9XYfDgebmZo9/eoev7o2js0v0MzRxhie0Qtcn4Vh7yp82h2M/CUIK3ccQHT9+HHl5eTCbzRg8eDCWL1+Oyy67DKdOnUJtbS3GjBnDHWs2mzFixAjs3r0b9913H/bv34+Ojg6PY/Ly8lBaWordu3fj5ptvFvzdFStW4Mknnwxq34KBdzxHfJxR9HiaOMOTaKiCHa7oJaZKSY0gf9qsl34ShFroWhANHjwYf/rTn9C7d2+cP38ezzzzDIYOHYrDhw+jtrYWAJCdne3xmezsbJw+fRoAUFtbC5PJhLS0NJ9j2M8LsWTJEixcuJD7u7m5Gfn5+Wp0K+i4172x2Z2aTpx6LNymxzYphbK79I3Wtaf8yUD0p81a95Mg1ETXgmjcuHHc/8vKyjBkyBD06tUL69evx3XXXQcAMBgMHp9hGMbnNW/kHGM2m2E2m/1suX7QcuLUQ1p4qNqkhciiFXr4E4z7Rk8ZiAQRTuhaEHmTmJiIsrIyHD9+HBMmTADQbQXKzc3ljqmrq+OsRjk5OXA6nWhsbPSwEtXV1WHo0KEhbbuWaDFx6nFQDlabtBR+4bJCjwSrnNoE676hGkEE4R+6D6p2x+Fw4OjRo8jNzUVRURFycnKwbds27n2n04kdO3ZwYmfgwIGIi4vzOKampgaHDh2KKkEEhD4tWm9p4UBw2nS+uR0/1LdiyrUFWDPjGswdVQyLyUhlDdw419SGuRuqMPqlHZi4ejdGv7gD8zZU4VxTm9ZN04xgVnqmDESC8A9dW4gWL16M2267DQUFBairq8MzzzyD5uZmTJ8+HQaDAQsWLMDy5ctRUlKCkpISLF++HBaLBVOnTgUAWK1WzJo1C4sWLUJGRgbS09OxePFilJWV4cYbb9S4d5GNHgdltdt0rqkND/3fP7HTraxBeXEGXpsyAPM3VNFqHPq0FOqBYFpxKAORIPxD14Loxx9/xJQpU1BfX48ePXrguuuuw549e1BYWAgAePDBB9HW1oY5c+agsbERgwcPxt///nckJydz3/Hyyy8jNjYWd955J9ra2jB69GisW7cORqN49hURGHoclNVsEzfRe9V4Yms+zRxWhFXbq6N+NU7uG36CuWCgDESC8A9dC6KNGzeKvm8wGLBs2TIsW7ZM8Jj4+HisXLkSK1euVLl1hBh6HJTVbJPYRL+rugEzy4sARO9qnI0Zamh1Ys2Ma/DtmUasqTwFu9OzIGq0CsZgLhgoA5Eg/EPXgogIX/Q4KKvVJpvdiZ8kYjwcnV1RuxrnCxZ2dyW6i6JoFYzBXjBQBqI6UDJAdGFgGIbRuhHhQHNzM6xWK2w2G1JSUrRuTtjADih6GpQDaRM72c8Yeilmrd8neNx7vx6MosxE5EbZ5rk2uxNzN1TxWs/KizMwoCCN22T4+pLMqI0hArrvJSFxHm33jR7RY9kQwj/kzt9kISKCih7Twv1tk3uAcP/8VJQXZ/DuEze8JBO9spKQnRKvRnPDCrmuRHLfkBVHz1AyQHRCgoggZOI+2a+pPIXXpgwAAA9RxE700SiGAOlg4eT4OHy+cIQuJn49uUMYABCvFUuEEEoGiE5IEBGETNwne7vThfkbqjBzWBFmlhfB0dmFSzMsuCQ1IaoHSqlg4YzE7npYgRKomNGDO0QPbSD40WPZECL4kCAiCMibYL0ne7vTxcXDAMDnC0dEtRgCQpNdGKiQ0IM7RA9tIITRY9kQIviEVaVqgggGcisps5M9H9GaUeYNm8k33Os8lRdnYM4NxT5p90pRo8KzHqqo66ENhDD0rEcnJIiIqEbJBMtO9t4DJQUIe5JoMuKWsly8NX0QVt99Nd6aPggDCtIwc903eCjAbSnUEBJ6cIfooQ2EMPSsRyfkMiOiGqXBk5QZ9AtCbsb6FieWfHiQ9zOBBqSqIST04A7RQxsIccLtWddTkkC4QoKIiGr8mWD1WEpAbaQGV7E4nhZH8KwfaggJPVRR10MbCGkCKdERSnFCAfrqQC4zIqqhlbovUjFVUm7G1ATxgT+Qc6pGbIce3CF6aAMRHOTGJKqFGnF1RDdkISKiGlqpeyIn+0nKzeh0dQXtnKq1/Yoe3CF6aAOhLlpkD1LNJPUgQURENXrcc01L5AyuUm7GVkdnUM+pWkJCD65PPbSBUA8txAkF6KsHCSIi6qGV+i/IGVzluBmDfU4jUUhQUGz4o4U4Ibe/epAgIiSJhoE6EidYf5AzuMp1M9I5lQ8FxUYGWogTcvurBwVVE6KEOkCQ0BY5QcsUEKwuFBQbOWhR0JGeR/UwMAzDaN2IcKC5uRlWqxU2mw0pKSlaNyck2OxOzN1QxesTv74kk7YXiFDONbUJxv/kulkrWMthtLsZA+VEXQtGv7RD8P3PF45QZf83IjTIfX7Uhp5HYeTO3+QyIwSh7IXoRG78D7nE1IGCYiMLrWIS6XkMHBJEhCA0UEcvNLiGDgqKjTzo+QlPKIaIEIQGaoIIPrSRKEHoAxJEhCA0UBOhxGZ34kRdC6rONOLEhZaoCSYOdlBstJ5XglAKBVXLJBqDqgHtAgSJ6CKQtPNIKQsRjKBYSucnCPnzNwkimUSrIAIoe4EILoFkM9KELwxliRJEN5RlRqgGBQhGJ6GyvPibzajFvlHhBGWJEoQySBBpSKSY+onII5SWF3+zGWnCF4eyRAlCGSSINIJM/UQoUSK+Q2158TebkSZ8cShLlCCUQVlmGkCl+olQonT7FTmWFzXxN5uRJnxxKEuUIJRBgkgDQj3hENGLP+I71JYXf9POacIXh/a4IghlkMtMA8jUT4QKf+JstLC8+LPdATvhC5WFoAlfu20kCCIcIUGkAWTqJ0KFP+Kbtbx8KZCuHSzLiz/ZjDThS0NZogQhD3KZaQCZ+olQ4Y/4DjdXi9ViQq+sJFxVkIZeWUm6ax9BEOEBWYg0gEz9RKjw19pDlheCIKINqlQtk2BUqqYK0EQooO1XCIKIZqhSNQ+rV6/GCy+8gJqaGlx55ZV45ZVXMHz4cM3ao7VvX2ltGioiGZ6QtSe40LMRGdB1JKJGEL3//vtYsGABVq9ejfLycrzxxhsYN24cjhw5goKCAq2bF3KUFIakIpLhj9biO1KhZyMyoOtIAFHkMhs8eDCuvvpqvP7669xrffr0wYQJE7BixQrJz0fS5q5KNn2kDSIJgh96NiIDuo6Rj9z5OyqyzJxOJ/bv348xY8Z4vD5mzBjs3r2b9zMOhwPNzc0e/yIFJYUhqYgkQfBDz0ZkQNeRYIkKQVRfXw+Xy4Xs7GyP17Ozs1FbW8v7mRUrVsBqtXL/8vPzQ9HUkKCkNg0VkSQIfujZiAzoOhIsUSGIWAwGg8ffDMP4vMayZMkS2Gw27t/Zs2dD0cSQoKQ2DRWRJAh+6NmIDOg6EixRIYgyMzNhNBp9rEF1dXU+ViMWs9mMlJQUj3+RgpLCkFREkiD4oWcjMqDrSLBEhSAymUwYOHAgtm3b5vH6tm3bMHToUI1apR1KKhGHW9VigggV9GxEBnQdCZaoyTJ7//33MW3aNPzhD3/AkCFD8L//+7948803cfjwYRQWFkp+PpKyzFiUFIakIpIEwQ89G5EBXcfIhQozenHXXXehoaEBTz31FGpqalBaWopPP/1UlhiKVJTUpqE6NgTBDz0bkQFdRyJqLESBEokWIoIgCIKIdKgOEUEQBEEQhExIEBEEQRAEEfWQICIIgiAIIuohQUQQBEEQRNRDgoggCIIgiKiHBBFBEARBEFEPCSKCIAiCIKIeEkQEQRAEQUQ9JIgIgiAIgoh6ombrjkBhC3o3Nzdr3BKCIAiCIOTCzttSG3OQIJLJxYsXAQD5+fkat4QgCIIgCKVcvHgRVqtV8H3ay0wmXV1dOHfuHJKTk2EwGFT73ubmZuTn5+Ps2bNRsUdaNPWX+hqZUF8jl2jqbzT1lWEYXLx4EXl5eYiJEY4UIguRTGJiYtCzZ8+gfX9KSkrE35TuRFN/qa+RCfU1comm/kZLX8UsQywUVE0QBEEQRNRDgoggCIIgiKiHBJHGmM1mPPHEEzCbzVo3JSREU3+pr5EJ9TVyiab+RlNf5UJB1QRBEARBRD1kISIIgiAIIuohQUQQBEEQRNRDgoggCIIgiKiHBBFBEARBEFEPCSKNWb16NYqKihAfH4+BAwdi586dWjdJEcuWLYPBYPD4l5OTw73PMAyWLVuGvLw8JCQkYOTIkTh8+LDHdzgcDsybNw+ZmZlITEzE+PHj8eOPP4a6K7x8+eWXuO2225CXlweDwYDNmzd7vK9W/xobGzFt2jRYrVZYrVZMmzYNTU1NQe6dJ1J9nTFjhs+1vu666zyOCYe+rlixAtdccw2Sk5ORlZWFCRMm4NixYx7HRNJ1ldPfSLm2r7/+Ovr168cVGxwyZAj++te/cu9H0nWV6mukXNOQwhCasXHjRiYuLo558803mSNHjjC/+c1vmMTEROb06dNaN002TzzxBHPllVcyNTU13L+6ujru/WeffZZJTk5mPvjgA+bgwYPMXXfdxeTm5jLNzc3cMffffz9zySWXMNu2bWO+/fZb5oYbbmD69+/PdHZ2atElDz799FPm0UcfZT744AMGALNp0yaP99Xq39ixY5nS0lJm9+7dzO7du5nS0lKmoqIiVN1kGEa6r9OnT2fGjh3rca0bGho8jgmHvt58883M2rVrmUOHDjHfffcdc+uttzIFBQVMS0sLd0wkXVc5/Y2Ua/vxxx8zf/nLX5hjx44xx44dYx555BEmLi6OOXToEMMwkXVdpfoaKdc0lJAg0pBrr72Wuf/++z1eu+KKK5iHH35YoxYp54knnmD69+/P+15XVxeTk5PDPPvss9xr7e3tjNVqZf7whz8wDMMwTU1NTFxcHLNx40bumH//+99MTEwMs3Xr1qC2XSneIkGt/h05coQBwOzZs4c75quvvmIAMN9//32Qe8WPkCC6/fbbBT8Trn2tq6tjADA7duxgGCayryvD+PaXYSL32jIMw6SlpTF//OMfI/66MswvfWWYyL6mwYJcZhrhdDqxf/9+jBkzxuP1MWPGYPfu3Rq1yj+OHz+OvLw8FBUV4Ve/+hVOnjwJADh16hRqa2s9+mg2mzFixAiuj/v370dHR4fHMXl5eSgtLdX9eVCrf1999RWsVisGDx7MHXPdddfBarXq7hx88cUXyMrKQu/evTF79mzU1dVx74VrX202GwAgPT0dQORfV+/+skTatXW5XNi4cSNaW1sxZMiQiL6u3n1libRrGmxoc1eNqK+vh8vlQnZ2tsfr2dnZqK2t1ahVyhk8eDD+9Kc/oXfv3jh//jyeeeYZDB06FIcPH+b6wdfH06dPAwBqa2thMpmQlpbmc4zez4Na/autrUVWVpbP92dlZenqHIwbNw533HEHCgsLcerUKSxduhSjRo3C/v37YTabw7KvDMNg4cKFGDZsGEpLSwFE9nXl6y8QWdf24MGDGDJkCNrb25GUlIRNmzahb9++3AQeSddVqK9AZF3TUEGCSGMMBoPH3wzD+LymZ8aNG8f9v6ysDEOGDEGvXr2wfv16LoDPnz6G03lQo398x+vtHNx1113c/0tLSzFo0CAUFhbiL3/5CyZNmiT4OT33de7cuThw4AAqKyt93ovE6yrU30i6tpdffjm+++47NDU14YMPPsD06dOxY8cOwTaG83UV6mvfvn0j6pqGCnKZaURmZiaMRqOPyq6rq/NZwYQTiYmJKCsrw/Hjx7lsM7E+5uTkwOl0orGxUfAYvaJW/3JycnD+/Hmf779w4YKuz0Fubi4KCwtx/PhxAOHX13nz5uHjjz/GP/7xD/Ts2ZN7PVKvq1B/+Qjna2symVBcXIxBgwZhxYoV6N+/P1599dWIvK5CfeUjnK9pqCBBpBEmkwkDBw7Etm3bPF7ftm0bhg4dqlGrAsfhcODo0aPIzc1FUVERcnJyPProdDqxY8cOro8DBw5EXFycxzE1NTU4dOiQ7s+DWv0bMmQIbDYb9u7dyx3z9ddfw2az6focNDQ04OzZs8jNzQUQPn1lGAZz587Fhx9+iO3bt6OoqMjj/Ui7rlL95SNcry0fDMPA4XBE3HXlg+0rH5F0TYNG6OK3CW/YtPu33nqLOXLkCLNgwQImMTGR+eGHH7RummwWLVrEfPHFF8zJkyeZPXv2MBUVFUxycjLXh2effZaxWq3Mhx9+yBw8eJCZMmUKb5prz549mc8++4z59ttvmVGjRukm7f7ixYtMVVUVU1VVxQBgXnrpJaaqqoorjaBW/8aOHcv069eP+eqrr5ivvvqKKSsrC3lqq1hfL168yCxatIjZvXs3c+rUKeYf//gHM2TIEOaSSy4Ju77+13/9F2O1WpkvvvjCIyXZbrdzx0TSdZXqbyRd2yVLljBffvklc+rUKebAgQPMI488wsTExDB///vfGYaJrOsq1tdIuqahhASRxvz+979nCgsLGZPJxFx99dUeqbDhAFvHIy4ujsnLy2MmTZrEHD58mHu/q6uLeeKJJ5icnBzGbDYz119/PXPw4EGP72hra2Pmzp3LpKenMwkJCUxFRQVz5syZUHeFl3/84x8MAJ9/06dPZxhGvf41NDQwd999N5OcnMwkJyczd999N9PY2BiiXnYj1le73c6MGTOG6dGjBxMXF8cUFBQw06dP9+lHOPSVr48AmLVr13LHRNJ1lepvJF3bmTNncuNpjx49mNGjR3NiiGEi67qK9TWSrmkoMTAMw4TOHkUQBEEQBKE/KIaIIAiCIIiohwQRQRAEQRBRDwkigiAIgiCiHhJEBEEQBEFEPSSICIIgCIKIekgQEQRBEAQR9ZAgIgiCIAgi6iFBRBAEQRBE1EOCiCAIgiCIqIcEEUEQhEqsXr0aRUVFiI+Px8CBA7Fz506tm0QQhExIEBEEQajA+++/jwULFuDRRx9FVVUVhg8fjnHjxuHMmTNaN40gCBmQICIIImy4ePEi7r77biQmJiI3Nxcvv/wyRo4ciQULFnDHOJ1OPPjgg7jkkkuQmJiIwYMH44svvuDeX7duHVJTU/G3v/0Nffr0QVJSEsaOHYuamhqP31q7di369OmD+Ph4XHHFFVi9erVo21566SXMmjULv/71r9GnTx+88soryM/Px+uvv67mKSAIIkiQICIIImxYuHAhdu3ahY8//hjbtm3Dzp078e2333occ88992DXrl3YuHEjDhw4gDvuuANjx47F8ePHuWPsdjt+97vf4e2338aXX36JM2fOYPHixdz7b775Jh599FH89re/xdGjR7F8+XIsXboU69ev522X0+nE/v37MWbMGI/Xx4wZg927d6t4BgiCCBaxWjeAIAhCDhcvXsT69evx3nvvYfTo0QC6rTh5eXncMSdOnMCGDRvw448/cq8vXrwYW7duxdq1a7F8+XIAQEdHB/7whz+gV69eAIC5c+fiqaee4r7n6aefxosvvohJkyYBAIqKinDkyBG88cYbmD59uk/b6uvr4XK5kJ2d7fF6dnY2amtrVTwLBEEECxJEBEGEBSdPnkRHRweuvfZa7jWr1YrLL7+c+/vbb78FwzDo3bu3x2cdDgcyMjK4vy0WCyeGACA3Nxd1dXUAgAsXLuDs2bOYNWsWZs+ezR3T2dkJq9Uq2kaDweDxN8MwPq8RBKFPSBARBBEWMAwDgF90sHR1dcFoNGL//v0wGo0exyUlJXH/j4uL83jPYDBw39PV1QWg2202ePBgj+O8v5MlMzMTRqPRxxpUV1fnYzUiCEKfUAwRQRBhQa9evRAXF4e9e/dyrzU3N3vEBg0YMAAulwt1dXUoLi72+JeTkyPrd7Kzs3HJJZfg5MmTPt9RVFTE+xmTyYSBAwdi27ZtHq9v27YNQ4cO9aO3BEGEGrIQEQQRFiQnJ2P69On4n//5H6SnpyMrKwtPPPEEYmJiOKtR7969cffdd+M///M/8eKLL2LAgAGor6/H9u3bUVZWhltuuUXWby1btgzz589HSkoKxo0bB4fDgX379qGxsRELFy7k/czChQsxbdo0DBo0CEOGDMH//u//4syZM7j//vtVOwcEQQQPEkQEQYQNL730Eu6//35UVFQgJSUFDz74IM6ePYv4+HjumLVr1+KZZ57BokWL8O9//xsZGRkYMmSIbDEEAL/+9a9hsVjwwgsv4MEHH0RiYiLKyso80vu9ueuuu9DQ0ICnnnoKNTU1KC0txaefforCwsJAukwQRIgwMO4OeIIgiDCitbUVl1xyCV588UXMmjVL6+YQBBHGkIWIIIiwoaqqCt9//z2uvfZa2Gw2LlX+9ttv17hlBEGEOySICIIIK373u9/h2LFjXCDzzp07kZmZqXWzCIIIc8hlRhAEQRBE1ENp9wRBEARBRD0kiAiCIAiCiHpIEBEEQRAEEfWQICIIgiAIIuohQUQQBEEQRNRDgoggCIIgiKiHBBFBEARBEFEPCSKCIAiCIKKe/x8faJB5UDn8VQAAAABJRU5ErkJggg==",
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"# Type your answer here. It should make a plot just like above.\n",
"sns.scatterplot(data=df, x='gene 0', y='gene 1')\n",
"# plt.savefig('scatterplot.png')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# first impressions of the data\n",
"\n",
"So, how does our data look? At first glance it looks... like a bunch of random numbers with no real structure! But could there be some structure? For example, above we learned that although many cells have been sequenced, we expect these are from only a very limited number of cell types.\n",
"\n",
"How can we figure out something about these cell types?\n",
"\n",
"Let's make use of principal component analysis (PCA) and clustering from scikit-learn as some of the first tools in our toolkit."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Converting to plain numpy\n",
"\n",
"While Pandas is very convenient for many things, scikit learn uses plain numpy arrays and generally works best when the datatype is a floating point number rather than an integer. Let's do this conversion now and call our data `X`. (We also `copy()` this to a new numpy array to ensure it is contiguous in memory.)"
]
},
{
"cell_type": "code",
"execution_count": 13,
"metadata": {},
"outputs": [],
"source": [
"X = df.to_numpy(dtype=np.float64).copy()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## PCA\n",
"\n",
"Let's first run PCA on our data."
]
},
{
"cell_type": "code",
"execution_count": 14,
"metadata": {},
"outputs": [],
"source": [
"from sklearn.decomposition import PCA\n",
"pca = PCA().fit(X)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The results of our analysis are stored in the variable `pca`. We can use this to project our original 50 dimensional data into its principle components and plot just the first two dimensions in this principle component space."
]
},
{
"cell_type": "code",
"execution_count": 15,
"metadata": {},
"outputs": [],
"source": [
"projected = pca.transform(X)"
]
},
{
"cell_type": "code",
"execution_count": 16,
"metadata": {},
"outputs": [
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAlAAAAGwCAYAAABmTltaAAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjkuMiwgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy8hTgPZAAAACXBIWXMAAA9hAAAPYQGoP6dpAACA5UlEQVR4nO3dfXwU5bk//s8kkBAirAkBkkAwAXny8CigBBCIVh5EOVhawXgoWEURkVKkEOivLXrEBKrWFsQHpNrjA3C+BbRWodCDEkMAAwYJIlBpQoAkQjRsEGKCyf37I+y6OzuzO7M7szu7+bxfL88pm9ndmU1m55rrvu7rloQQAkRERESkWVSod4CIiIgo3DCAIiIiItKJARQRERGRTgygiIiIiHRiAEVERESkEwMoIiIiIp0YQBERERHp1CrUOxCJmpqaUFFRgXbt2kGSpFDvDhEREWkghMDFixeRmpqKqCjvOSYGUCaoqKhAWlpaqHeDiIiI/HD69Gl07drV6zYMoEzQrl07AM2/gPbt24d4b4iIiEiL2tpapKWlOa/j3jCAMoFj2K59+/YMoIiIiMKMlvIbFpETERER6cQAioiIiEgnBlBEREREOjGAIiIiItKJARQRERGRTgygiIiIiHRiAEVERESkEwMoIiIiIp0YQBERERHpxACKiIiISCcGUEREREQ6MYAisoBKex0KT1aj0l4X6l0hIiINuJgwUYhtKirH0i0laBJAlATk/rg/pg3rFurdIiIiL5iBIgqhSnudM3gCgCYBLNtyhJkoIiKLYwaKKAQq7XUorb6Er7+tdwZPDo1CoKz6MlJscaHZOSIi8okBFIUtRxCSkRQfVsGGfMhOAuAaQ0VLEtKT2oZq94iISAMGUBSWwrVuSGnITpKAKAE0oTl4evrH/cIqICQiaokYQFHYUasbGt2rY9ADDy1ZMNdtDp6q8RiyEwJYkz0YifGxSE9qy+CJiCgMhE0R+YsvvogBAwagffv2aN++PTIzM7Ft2zbnz4UQWL58OVJTUxEXF4exY8fi888/d3uN+vp6PPbYY0hKSkJ8fDwmT56MM2fOuG1TU1ODGTNmwGazwWazYcaMGbhw4UIwDpE0Kq2+pFo3FEybisoxMm8Xstftx8i8XdhUVO51mxG5uzDv7WKPbaIlCTdel4DMHh0YPBERhYmwCaC6du2KvLw8HDhwAAcOHMCtt96K//zP/3QGSatWrcJzzz2HNWvWoKioCMnJybj99ttx8eJF52ssWLAAW7duxcaNG1FQUIBvv/0Wd955JxobG53bZGdn49ChQ9i+fTu2b9+OQ4cOYcaMGUE/XlKXkRSPKMn9sWDXDWmZPSffRii8TpQEU4fs2F+KiMgckhBC6Xs9LCQmJuL3v/89fv7znyM1NRULFizAkiVLADRnmzp37oyVK1fi4Ycfht1uR8eOHfHGG29g2rRpAICKigqkpaXhgw8+wPjx4/HFF1/ghhtuwL59+3DzzTcDAPbt24fMzEwcO3YMvXv31rRftbW1sNlssNvtaN++vTkH38JtKirHsi1H0CiEs24omDVQhSerkb1uv8fjG2YPR2aPDl63cbXm3sG4c2CqKfsYrnViREShouf6HTYZKFeNjY3YuHEjLl26hMzMTJSWlqKqqgrjxo1zbhMbG4sxY8agsLAQAHDw4EFcuXLFbZvU1FT069fPuc3evXths9mcwRMADB8+HDabzbmNkvr6etTW1rr9R+aaNqwbCnKysGH2cBTkZCkGBmZmX7RkwZS2kW8/JD3B8H0DWk5/KWbYiChUwiqAKikpwTXXXIPY2FjMmTMHW7duxQ033ICqqioAQOfOnd2279y5s/NnVVVViImJQUJCgtdtOnXq5PG+nTp1cm6jJDc311kzZbPZkJaWFtBxkjYptjjFuqFKex1WvH/UZ31SoO+d++P+iJaaIySl2XPybaSrLQvUtveXUhBhlToxM2mpQSMiMktYzcLr3bs3Dh06hAsXLmDz5s2YOXMmdu/e7fy5JLnf7gshPB6Tk2+jtL2v11m6dCkWLlzo/HdtbS2DKD8F2ttpU1E5cjaXuNUbmTVLb9qwbhjdqyPKqi+rzp6TbwPA6/Z6qQ3TObJfrkFUJPWXstJMTCJqmcIqgIqJicH1118PABg6dCiKiorwxz/+0Vn3VFVVhZSUFOf2586dc2alkpOT0dDQgJqaGrcs1Llz5zBixAjnNl999ZXH+54/f94ju+UqNjYWsbGxgR9gCxdozY7joqpU1GdWd+8UW5zP15RvY9Q++Aoicn/c36NOLFKCC28Ztkg5RiKytrAawpMTQqC+vh4ZGRlITk7Gzp07nT9raGjA7t27ncHRkCFD0Lp1a7dtKisrceTIEec2mZmZsNvt+OSTT5zb7N+/H3a73bkNmcOImh2li6pDJGVfHHwN02mpEwtXVpiJSUQtW9hkoJYtW4aJEyciLS0NFy9exMaNG/HRRx9h+/btkCQJCxYswNNPP42ePXuiZ8+eePrpp9G2bVtkZ2cDAGw2Gx544AE8/vjj6NChAxITE7Fo0SL0798fP/rRjwAAffv2xYQJEzB79my8/PLLAICHHnoId955p+YZeOQfIzIKSsNWgPmtAkJFyzCdlgxZOIr0DBsRWV/YBFBfffUVZsyYgcrKSthsNgwYMADbt2/H7bffDgBYvHgx6urqMHfuXNTU1ODmm2/Gjh070K5dO+dr/OEPf0CrVq1wzz33oK6uDrfddhtef/11REdHO7d56623MH/+fOdsvcmTJ2PNmjXBPdgWyIiaHflFNQrAg6MzcP/IjIi8sLb0IEJLDRoRkVnCug+UVbEPlH+M6u1Uaa9rURfVlna8RERm0XP9ZgBlAgZQ/tMaDAQ6W4+IiEhOz/U7bIbwqGXQUrPDDttERBRqYT0Lj1qeSO+wzc7aREThgRkoAhD6ITGt7x/J/X+YWSMiCh8MoCjkF2497x+pHbat2Fk71EE1EZGVcQivhQv1kJje99eyBl04MnrtukCHArnOHBGRd8xAtXChHhLz5/0D7f9jxcyKkZk1o5bEsVI2jIjIapiBauFCvSSGv++fYotDZo8Oui/oVs2sGJVZM2tJnECyYUREkYgBVAsX6iGxYL5/qIcrfTFi7Tojgp9QB9VEROGAQ3gU8iUxgvX+oR6u1CLQtevMWBInUurMiIiMxACKAIR+0dlgvH+kzuBzZVTwE+qgmojI6hhAUYvRUjIrRgU/oQ6qiYisjAEUtShmZ1asMsOPwQ8RkbkYQFGLY1ZwEeqGpEREFDychUdhz4j14wJ9DavP8CMiImMxA0VhzYisjxGvEQ4z/IiIyDjMQFHYMiLrY1TmKCMpHrLWSW4z/LRmuIzIphERkfmYgaKwVGmvw98PVwSc9Qkkc+RaMJ5/4rzbzyTAOcNPa4aLNVREROGDARSFHddAQ05vXyd/e0O57oMj8+S6O5IEjO7VUfO6ckauP2eVmYBERJGMQ3gUVuSBhit/+jr5s5SMfB8E3IMnoDkAKqu+rHlpFaPWn7PqWn9ERJGGGSgKK0qBBgD8ZlJf3DEgxa+Mi97eUGr7IHf4zAVMHpSqKcNlRJd0I7NYRETkHTNQFFbUFrr1N3hySLHFIbNHB02vobQP8gJyAFi1/TgAaMpwGbGosloW6/3DlSxKJyIymCSE0HAvTXrU1tbCZrPBbrejffv2od6dsFZpr8PBUzUQQmBoeqKzKFu+HEuwi63l+/DAqHS88nGpx3YbZg9HZo8OqLTXacpwad1O7bkj83YpZse0FqWzfoqIWjI9128GUCZgAGWMTUXlyNlc4qwvkgDkTW0OAgIJNIziug8APIKXaElCQU5WUPfPNbCT87U/SrMAR/fqyICKKEzwBihwDKBCjAFU4NSyKVEA9iy9NahfDq5fSgBUv6D0ZMbkX3RKmbZA9vf9w5V46v0vPH7myIgpPUf+eUtonk3ItgpE1sc2KMbQc/1mETlZklqhdhPg1qPJ7DsutXYFSl9QWovR5V90dw/ugi2fnlXMtPkjxRaHSQNS8PQHX2guSlf6vAUAwYJ0IsvjBJLQYBE5WZJSoTbQ/AfrCALMnrLvrV2BWsdyX8XoSl90m12CJ8f7LN1cElDht96idLXP25U/bRWIyHxGtUEhfRhAkSU5AgDJ5aIuAcid2t855GX24r2+2hX48wWltQWCI9MWiGnDuqEgJwsbZg9HQU6W14yWPOCKgufMQr1tFYgoONRmJ/N8NReH8MiyHENin56qgRDAkPQEZwYlGIv3KvVmcuX4gtIzjOjrNV21jVG+v9Hzfim2OM2fh3wIMv/EeY+aLg4HEFmP4waI52twMYAiS2uu5/H8EjCi8aSW93b9UpIAQGquC3J8QeWfOK+rcNPxmq6zC9VcbmjyeOzl3SeRt+2Yah1WoFwDLr0NRokodHi+Bh8DKApLwbrjkn8pAVBtXaC1cHN0r46QpB8KtJUoBYMv559E7rZjzn8rvZ/RRfV6MlhEFFo8X4OLARSFrdG9OuKP9w4CZMN7RpN/KTn+d+HJar+GEdXqoKLQXPukFAxW2uuQ5xI8Kb0fpzFTpGA/IwoHDKAoLAU7WFD6Qvd3GFHtea/87EaUVl/GsPQEDExLcHtOafUlxYyVY1aiWdOYeSGjYOONAIULzsIjD5X2OhSerLbM+mny/QnGDDxXau0S/F2/Tul5UwanYvb/HMRT73+Bu9cWerRkyEiKV1xvb8nEPkixxXktqvf392l2mwgiuWCf20SBYAaK3ATz7k9LdkNpf9IS25o+A891H71ldtQKN30dm+vz2sZEYcoLhW49pnK2lPjMHkkAJg9KBaCe1Tp85gLue3Wf7t8nG/NRKARjdi2RUZiBIqdg3f1V2uuw4v2jPrMbavsTHxPtkY2RJJjS80RLgzrX5pmV9jo8/f5RjMj1nblxPO90TZ3HjDwhgE9P1TizRwfKvvHcBj/0ilLKai2e2Bsrtx/z6/fJxnwUClbpZ2S1LDxZU9gEULm5uRg2bBjatWuHTp06YcqUKTh+/LjbNkIILF++HKmpqYiLi8PYsWPx+eefu21TX1+Pxx57DElJSYiPj8fkyZNx5swZt21qamowY8YM2Gw22Gw2zJgxAxcuXDD7EEMuGBfNTUXlGJG7C+s+LvV5YVfbnzMKAYfPngB+0vOF7hjyeuXjUp8dy12pLUe558uvnUHm/A2HfDa2lDfO7N/F5vfv0yoXMmpZ/B0WNxKHrkmrsAmgdu/ejUcffRT79u3Dzp078f3332PcuHG4dOmSc5tVq1bhueeew5o1a1BUVITk5GTcfvvtuHjxonObBQsWYOvWrdi4cSMKCgrw7bff4s4770RjY6Nzm+zsbBw6dAjbt2/H9u3bcejQIcyYMSOox2sGX3dVZl80HRklpXBBqV5HbX/2fFnt8XzXbIz8PQO5k8w/cd6teFuSoPiFLs+WufIVtAxNT1Ssb9pYVK64jAygfmFxzYYF8vu0woWMWiY9HfSNxhos0iNsaqC2b9/u9u/XXnsNnTp1wsGDBzF69GgIIfD888/j17/+NX784x8DAP7yl7+gc+fOePvtt/Hwww/Dbrdj/fr1eOONN/CjH/0IAPDmm28iLS0N//znPzF+/Hh88cUX2L59O/bt24ebb74ZALBu3TpkZmbi+PHj6N27t8e+1dfXo76+3vnv2tpasz4Gv2mpbTK7t5K3ZUzU6nXk+7N4QvOwlJzrGnl6jhlQr1dSCvgk0dw+Qf48X8fmLWhJscUhZ2KfHxpkAnjwlgy88nGpx7YSgDXZg3Hjdb7bNgT6+2RjPgqVUPUzYg0W6RE2AZSc3W4HACQmJgIASktLUVVVhXHjxjm3iY2NxZgxY1BYWIiHH34YBw8exJUrV9y2SU1NRb9+/VBYWIjx48dj7969sNlszuAJAIYPHw6bzYbCwkLFACo3NxdPPPGEWYcaMD0FwWZeNNWWMYmS0Fyvs82zXqcgJwsFOVnO/VELVB4cnaEY/Pg6Zm9BltJ7Odaok3cgXzKhj/KxQTlj5WpTUTlWbm8OniSpeWbd5IGpWFdQ6tG6QABIjI8NWhDExnzUkgRjhQOKHGEzhOdKCIGFCxdi1KhR6NevHwCgqqoKANC5c2e3bTt37uz8WVVVFWJiYpCQkOB1m06dOnm8Z6dOnZzbyC1duhR2u9353+nTpwM7QIPprW1yHQYyknxYSAKQfXMa9uTc6rVex9ewVJQE3D8yw+0xLcfsK12v1DogWpLQNibK43mrth/Hkol9fliMVwIeuqU79iy9FdOGdVMdSpTvgxDAqm3NtX05E/t4fIb+fJmb9fskijQcuiY9wjIDNW/ePBw+fBgFBQUeP5Mk90ueEMLjMTn5Nkrbe3ud2NhYxMbGatn1kLDSXdW0Yd1w4fIV53DVxk9OY2DXazG6V0dN+6h1WErLMftK1+efOO/2MwnN2aRLDY2KzxvQ5Vq3bJljn17Ov7p+ncYsl2MfHh7dAxBozsxB/5c5m2AS6ceha9Iq7AKoxx57DH/729+Qn5+Prl27Oh9PTk4G0JxBSklJcT5+7tw5Z1YqOTkZDQ0NqKmpcctCnTt3DiNGjHBu89VXX3m87/nz5z2yW+EiWOvGablgV9rrnMNVQHOAs3RLCfbk3Kp5H7V8wWk5Zm9BlmL9k/RD/ZPa8+RDXi/v9r5+na9A7+ExPTB5UKruL3N2cybyH4euSYuwCaCEEHjsscewdetWfPTRR8jIcB+yycjIQHJyMnbu3InBgwcDABoaGrB7926sXLkSADBkyBC0bt0aO3fuxD333AMAqKysxJEjR7Bq1SoAQGZmJux2Oz755BPcdNNNAID9+/fDbrc7g6xwZPZdldYLtmJdkQBe21OKZXfcoHkftXzB+TrmFFsclkzoo5jhUVrnrkk01z9l9uigKdjTsn6dlkBP75e5GU0wmc0iInIXNgHUo48+irfffhvvvvsu2rVr56xHstlsiIuLgyRJWLBgAZ5++mn07NkTPXv2xNNPP422bdsiOzvbue0DDzyAxx9/HB06dEBiYiIWLVqE/v37O2fl9e3bFxMmTMDs2bPx8ssvAwAeeugh3HnnnYoF5OHErLsqPRdstULyV/NLcf/IDMP30dvrOYq3m9CcXVo8sbcz6POVGdISkJZWX1Js2RAla/o5bVg39Eluh6KyGsV18PQyeiaRa3Asobk26+ExPQLaRyKicBc2ReQvvvgi7HY7xo4di5SUFOd/mzZtcm6zePFiLFiwAHPnzsXQoUNx9uxZ7NixA+3atXNu84c//AFTpkzBPffcg5EjR6Jt27Z47733EB0d7dzmrbfeQv/+/TFu3DiMGzcOAwYMwBtvvBHU4w0neorUU2xxeGBUhsfjjtltRvLWA0qteNuxrWJn7wm9UVp9CZ+drkHhyeZeVN6Ks5UK3oEf1q9z2FRUjrvXFqqug6eXkf28PD4nALnbjuHl/JMB7SMRUbiThFobZPJbbW0tbDYb7HY72rdvH+rdMV2lvQ4j83Z5ZGsKcrIUg4tKex1G5O7yaAyptr0/fA0pFp6sRva6/R7P2zB7ODJ7dHDb17Lqyzh89oJbmwVAW23RpqJy5/BcFJqDJ9fsjdbPTu8Qmuv7OoYF/amBUvucoiRgT86tzuVrOLxHRJFAz/U7bIbwyLr0Fqmn2OKQN9W8onalIcWlssV5tc5MdGzvaPDpSkttka+hPi3Dbf4UhOupefMWADlaOcjvshz1YPJ+WCxWp0jEmwRSwgCKDKG3SN3MonZfheqAvqDPW5dxLbVF3uqwfAVygRSEu76v2gXAV3Dm6JKeKyuGV+uHFWixOpGDVYIWzmglNQygyDB6C8DNKmpXy5q4FqoDzS0Jnp8+EFGS5HVpFLXCdyCwflqOC8SSiX2wattxxUDOiIJwtQuA1uDs4TE9AAnOIUzHPqr1w+KyFxQoqwQtZsxopcjBAIosxai7TqWEkaNQPcUWp+sLWp6tcghk6FH+/ksm9MGArtd6ZOMCbYLq7QJwoOwbzQHQw6N7YPJA935UlfY6yzRopchhpaCFa+ORNwygyDKMuussrb6k+LijfYA/X9CuQ45tY6JwuaHJ76FHpfdftf24YhF9oE1Q1S4Ar+0pxasKixV7C4DkGcNgNWillsVKQYuVVnEg62EARZZg5F2n2pCbo32AUpPMQGuZ5MfiLYum9wIRSL2Y0mcRJQHr8ks9snRaFj42ct+IlFgpaAmHmwSr1Iq1RAygyBKMvOuUf+lJAOaO7dG8thyM/4J2/QLTMivNn/f3t15M6QLw81HpWKeQfVqdPRiTBqT69R784iajWC1osfJNglVqxVoqBlBkCUYHNdOGdcOFuivORXxf3H0S3Tq0xbRh3Qz9gpZ36Qbgts6fUhZN7f2B5r5LRt9Jyi8AALC+oNTjs77xusA6oBMZxWpBixVvEj47XYOcLSUQIawVa+nZLwZQZAlG33VW2uuw8mrwBHh+uRjxBa3UpVtOLYsmf//8E+edDTXNuJOUXwCsdIdPpMSKQUsoyTPdOZtLPL5zjKoV0xIYMfvFAIoMFOjdiJF3nVqGBAP9gvbWH8pBS1F2MGcdOX5Ho3t1REFOlmXu8IlInTxYEUL5hs2IWjEtgZGVZkqGEgMoMoRRdyNG3XUGoxBV6T0kNC9M7NovydfxBGvWEe8YKVRa+lCPEq2fiVKwoiRK0j8JRMt7KQVGer6zIvl3zwCKAmbFu5FgFKKqvYfeLFowgj0r/o6oZQjHwN3si76ez0RLpjsKwNa5IzAwLbA6Rq2BkdbvrHD83evBAIoCpnbSHSyrwZ0DQ3dxDkYh6uheHfHHewcBAhiSnuA2PKiV3mDPny93K/XWoZYjHAN3sy/6ej8TxUy3BEiiuTmw4/si0OBJ7b3U1gj19Z0Vjr97vRhAUcDU+i7N31iMSw3fY3SvjiFL4ZpZiBroF61rIKQ12PP3Pa3UW4dajnAL3INx0df7mejNdAeSPdNzM2fEQunhjgEUBcxx0i3dXIIml8ebBJCzpQS4WvAYSSncQL9o1QIhvbUQehYW5sw7Cja1Rq6ugbtVamQq7XX4++EKTRf9QPbZn5sZtWBF/t5GZM/0ZO693aC2hJs2BlBkiGnDuiE+thXmvV3s9rjL0nFhm8JV+rIM5O7K30Ao0Ds6f4Y0rXJxo/DkCNxd+xUJAeSfOI9pw7pZpkbGdT/k5Bf9QPfZ35sZX9l0I7NnRmTuW8JNGwMoMsyQ6xIUh/JchVsKV+3LMpC7K38DISPu6PR8MZpxcWNA1vKM7tXRbc69QPOFvU9yO68X/GD9rcgDD1fyi76/QYr8WMyoz7TikJnVGqIajQEUGUZ+x6HUryScUri+viz9vbvyNxBS+nx/Pio9gCNUZ0YtiFWyDRRcpdWXFBs+FpXVqF7wtSyJZOT+KQVPv5nUF3cMSPF7+r6Dt+F6IwMKqw6ZRXJD1KhQ7wBFlmnDuqEgJwsbZg/HnpxbkTe1P6Kl5kVOwi2F6+3LEnA/1oKcLIzu1RGFJ6tRaa/z+rqOQMifz8Xxng+NzoAQwLqPSzEybxc2FZX7d5AqfB27XmoBma/PisKf48LuKgpAbKsoyB5GtCShbUxUUP9WlPYvWpI8gidv26oFKcH8uw/ke4X8wwwUGc71jsOKKVytQwNa7ugcx6o3uxLo5/Lqx6U+19wLhNF3s1YcXqDgkGdOJTRnpX/z7ufNjWev/ttxwb/U0BjUvxU92WS9medg/91b8fs2kjGAItOFKoWrFCjpCXS0fln6O9zlWpDu+m9fgvGlbHQBqFWHFyg4HBf2g2U1mL+x2G39yCgJWD19sLOPWqW9Luh/K3oCDz3bhuLvPpKHzKyGARRZmr+FpEqB0uheHXUHOlq+LP0NaALp6eS4a3cw40vZyLvZljAjh7xLscUh8RrPc6VJAB2uiXWbmh+sWj/5/mltXqs1SPE4FgAPBOFYKDgYQJFl+RtgqGWE/njvIL8CHV9flv7cZQZSpJ1/4rzbvyUEvgaWGiPvZjm8QFrPFcffymt7SrEuvxTrPi7F+oLSkEw8CHTyg/NYCsrwasG/8crHpXg1RMdCxmIROVlSIMWXahkhXP0CdGVE5saf4k1/i7Qdn4vrUyXp6lTxMJBii0Nmjw4MnlooveeKUq1foAXYlfY6TZM9HNsaVQT+asG/3V5n6ZYSfHa6RvfrkHUwA9UChGPvnUDqfNTucoekJ5g2jKQ3u6Ina+X6+1P6XJoEAqp/Cse/DwpfWs8VM2r99GaT/F3nU35OqZ23U14oRN5UZqLCFQOoCOR68gazn4qRAim+9FZvY8YwkuPzjo+JhvDoeKN/H13Jv/CXTOxjaFEqezNRKGgZGja6APuz0zVuHdG1DJv7WudT6VxRq79Ueh1HU1H5PvCmJjxIQght3/ikWW1tLWw2G+x2O9q3bx/U95afvEqNLAtyskJ6Umr9cthUVO4RYOhdrNfsehulJSD01mup7WOlvQ4j83Z5XEAWT+iNVduP+/25+Hr9UP99EDkE+h3g+jo5m0sUb282zB6OzB4dvD5Xvs4noHyueDunXG9mve0Db2pCS8/1mxmoCKI0Xi8X6t47er4cAs0WmT2dV20JCL2L/KrdeaoNHwzoei0KcrK8fi5agtRQ9GbinXXL5O/v3YiMsVLdoKu2Md5LgdXW+VQ6V7ydU9OGdUOf5HaY8kKh6gxao1YA4HkWHAygIojakgSu/EmBG3Uy+vPlYOWeJt4+b72BSKW9Dq8VNM82cvTGWTJBfbjO2+fycv5J5G07BuEjSA12jxotwTO/+COPEYvvBvK34Ot78XKDPLfkSWmdT6Vzxdc5NTAtAXlT1YfujbipYQYreBhARRClk1eSAEkATfCvtb+RJ2OkdaNWq48A9AUim4rK3WozgObXXLX9OJZM7INV245rLnp/efdJ5G475vY6akFqMHszeQuegea/jZIzdqzcfoxf/BHEyDUV/Q2uAzlPXd9Ty7mi5ZzyllWLj4mGdLX0Qus+yvfX6DUsSR0DqAiidvL6mwI3+mTUm/GwejZC/nk76AlEKu11qrUZjUJgQBffw3Wur5XnEjy5vo5akBqs3kxqwbOjN04gw6BkXUbdNLneyEkAZt+SgftHZTjfIz4mGuXfXIYkSRhyXYLba/t7nirdPGo5F7WcU0pZNcf7yYMnPTc1kXaTanUMoCKM2snrz8lj9MmoJ+OhNfNlVpCl9XUddQ1FZTXISGqLtjGtdQUiB0/VqNZmaBmuc6W06j3Q/Pl5u4N1vL6jP478mI34jJWC5yhAMXhy4Bd/+FD7G1H8vUtA9bffodJep/kmw/VGTgB45ePm4W7Hv11JgEdrANfvxbYxUbjc0OQ8t5T2Xe3msSAny2vBuYPeYUelesooAFvmZmJgWoLm1zF7WN7qN7XBxgAqAhlVN+RvryJfAYevuzOtmS+zxvr1vK7Stlq+YB3UJsH6011cbahiycQ+Pl9H7ZiN+oyVgucHRqXjlasXQSVcKy88ePsbcfzeXbNHQgCPbTik+e9JrYZJ7cZDoLlJpfz7wrXOyPE9pdQmpH8XG7651BDUTI5inyj4rs9SWmLGrGF51lZ5YgBFqvztVeTrxPIV4GnJfJk11q/ndY3Yh6HpiR7r2kkA3nl0hK47T0B53a0lE/vg4dE9vD5P7Tj6JLcz9DOWB88A8GpBqWptCtfKsz6t54DjPsH1V63178lbDZMapeaySsHSym3H3PY994PmIXDp6n9qs+WMpnaMh89eUL0hU/veNavXHWurPDGAIq98nYxmnFhaMl9mjfXreV0j9iHFFoe8qf2dfWaiAORO7a87eHLw58tT7TiKymoM/4zlwbM8QF88sTcGdLmWa+WFCV/ngK8WAlrXosz9cX/FXkxq5MPWSt9TeR8c85rFkq6+TpMwP6BPscVhyYQ+bhNAAGDVtuOYPDBV9/eu0bOXWVuljAEU+eTtZDTjxPKV+aq01+GbSw2m3CHqGbY0qt7A6DtGvV+eascxLF196rZRtRBcYDi8+ToHfLUQ0Hq+yBfkbRLNM4whFGqgrmZjXP+WlPbDV0JLAFg9fTA6XBOLtjFRuNTQqLluyx/9u9o8HtN78+ZriRl/BbvlSbgIq8WE8/PzcddddyE1NRWSJOGdd95x+7kQAsuXL0dqairi4uIwduxYfP75527b1NfX47HHHkNSUhLi4+MxefJknDlzxm2bmpoazJgxAzabDTabDTNmzMCFCxdMPjpt9CyEGQyOE8uVESfWtGHdUJCThQ2zh6MgJ8s5JLipqBwj83Y5m9o53tqoO0RH8KZ1sdMHR2U4T6JA9iHFpn+RXaP+FtSOeWBaguLj+SfOY2TeLmSv24+Rebuwqag84PfnAsPhydf5ovT94KD3fEmxxWHZpL7Yk3MrNswejsKcW1G4tPl/v/voCKy5dzBeyB6MwpxbPUoIMpLiobIbqhzrZ5Z/cwl3ry007O9djaOFgXwfvN28yc3fWGzK/un9Xmwpwmopl23btmHPnj248cYbMXXqVGzduhVTpkxx/nzlypVYsWIFXn/9dfTq1QtPPfUU8vPzcfz4cbRr1w4A8Mgjj+C9997D66+/jg4dOuDxxx/HN998g4MHDyI6OhoAMHHiRJw5cwavvPIKAOChhx5Ceno63nvvPU37adZSLlYt4jNquQVflJZJiJKAP00fjCHpCYaezL6WgZH/Lh4c1R33j0oHgKDMUjHjb6HSXoeDZTWABLep4K6fBQAu/0IevJ0v8u+HxRN6Y0BX44ZptWZDn37/qNdJC64cQ+mje3VU/M7Zk3Or2/kR6DmvtCSUr+9SPUvMGCUYy2OFmp7rd1gFUK4kSXILoIQQSE1NxYIFC7BkyRIAzdmmzp07Y+XKlXj44Ydht9vRsWNHvPHGG5g2bRoAoKKiAmlpafjggw8wfvx4fPHFF7jhhhuwb98+3HzzzQCAffv2ITMzE8eOHUPv3r099qW+vh719fXOf9fW1iItLc3QAMrq65YF48QqPFmN7HX7PR73tZaV0VTXqJvY21mUamaAa9bfgpagzCq/AwovZn0/6LmRUDpv1LyQPRiTBqSq/r0/NDoDy+64we8bGdegC/C8KYkCsFXDRJK/H67wWGIGAP6/SX0xaUCKJa4N4UZPABVWQ3jelJaWoqqqCuPGjXM+FhsbizFjxqCwsBAAcPDgQVy5csVtm9TUVPTr18+5zd69e2Gz2ZzBEwAMHz4cNpvNuY1cbm6uc7jPZrMhLS3N+OPzUmtkBcEYgjJruFAvtd9FnmxGz7ItR0wZavVW/+AvtaJU+f5b5XdA3lltqN+MYVpvf7NKx59ii8Pdg7u4vUa/VM8LpCQBN17XHLiUnLUrvver+aX47HSNpnNG7uXdJzEi94ch8D8rzETV0sIA+GGJGbmn3v/C1OFGahYxAVRVVRUAoHPnzm6Pd+7c2fmzqqoqxMTEICEhwes2nTp18nj9Tp06ObeRW7p0Kex2u/O/06dPB3w8cpF24XLUMumpK9AyDh+MC4fS7yIK7ssvAOYFuGbUP2gN0FkLYX3+nFtWoef89dbdXun4K+112Fp81m37o5W1ni8sftiXlQqd/YHmAMfbLFU1L+c3L7XkeFqTANYXlHrUZ2n9bpefj277aOJNHDWLuFl4kuwPSQjh8ZicfBul7b29TmxsLGJjY/3YW+3MbJAWbIG0PvA2aytYNWJKv4vFE3o3L+Drsp3kowN4oO8vr38IpIWEnlk2nDlnXeHcr0fvcJzSTFx5d3vX41dsVqnSoLOs+jIEhOpwn69Zqmr7rLTUUpNoHhJc/3GZ7u/2Snsd0hLbYsvcTBSV1eCp979w+zlbDZgrYgKo5ORkAM0ZpJSUFOfj586dc2alkpOT0dDQgJqaGrcs1Llz5zBixAjnNl999ZXH658/f94juxVsVr1w6S2iDLT1gdI0fX8uHIEUfyo1hfT4cvRSaxFo4em0Yd0QH9vKo/7B3y9MvQG60X1myBjh2q9Hz/krXxfPEUSpdbdvFAKfnqpBkxCKy8oIod4ORam5ZRSaVwno1L4NHhyVgVc/LtW0WHtp9SWPLLXj9e4fmYH7R2bo+m73aAw6oQ9bDQRZxARQGRkZSE5Oxs6dOzF48GAAQENDA3bv3o2VK1cCAIYMGYLWrVtj586duOeeewAAlZWVOHLkCFatWgUAyMzMhN1uxyeffIKbbroJALB//37Y7XZnkBVKVrtw+ZP18ZXtkBdYagk09F44jMhWuf4uCk9We8RLjjtZfzu3q63R5XjMUf9g1BdmKAJ0rq1lrHDt16P1/FVaFy9Kau7XNCS9+aZY3t1ekoB5bxc7m2NKV4MmR8ADQPXGwa2zv8tsW0crD8c5/NDVx/3pqO661JLWc0Ap4Fy1/TiWTOyDVduOh/0oRbgIqwDq22+/xZdffun8d2lpKQ4dOoTExER069YNCxYswNNPP42ePXuiZ8+eePrpp9G2bVtkZ2cDAGw2Gx544AE8/vjj6NChAxITE7Fo0SL0798fP/rRjwAAffv2xYQJEzB79my8/PLLAJrbGNx5552KM/Baskp7HXI2l7iN52sZLvCW7ZDfXQI/fEl6C3L0rtsXiu7pet5bKcgC4PGY0cO6wQzQrdqWI5yF61C/1vNHbRiuwzWxqkGP6/bi6v95IXswbnRp1aF24+C6WPiw9AQMTEtQPIfXF5Q625gAyjcG8t+NYzkZX0stKTlQ9o1iwDmgy7UoyMmy3ChFpAqrAOrAgQPIyspy/nvhwoUAgJkzZ+L111/H4sWLUVdXh7lz56KmpgY333wzduzY4ewBBQB/+MMf0KpVK9xzzz2oq6vDbbfdhtdff93ZAwoA3nrrLcyfP985W2/y5MlYs2ZNkI4yfPy5oNQj66J1uEAp26F0d+ngK8jR0r3c8YUWiu7pjn34++EKn++t9AW9dEuJ21CD47E/Th+ELXMz3VaXDwfhXKtjdVoX7LZS5k9r4Kcl0HI9/i/PX8Rv3nFvpuz6nq7/W2umOi2xrddz2NuNgRFZXsfryzk+B7USByv9viNFWAVQY8eOVV29Hmgu/l6+fDmWL1+uuk2bNm2wevVqrF69WnWbxMREvPnmm4HsasSrtNdhfUGpx+NR0F44LT/RfS374CvIUftyMrJWwNsXkdYCdzkt6/wpPa9JuK9qH059mMK1VidceMskWjXzpyW40BpoOY6/+tvvFN9LS/dDxRuZzSV4Ysp/KNZSOZY48nVjEEiWV/76zvcHVG8Y80+ct+TvOxKEVQBF1qEW7Dw4OsPQYTBXWoIc+ZeTkbUCWi48Wgrc5cckf2+lz0Gp2NXBiOxNsO9Qw7VWJ9xZPfOnJbjQk8UZmp7oMVNPApz1Ut4o3sgA+M07n7sVrwPN52b+ifM+s1OBUvveXX218SfgWWQPQHeZBWkTMX2gKLgUeyFJzbNJ/CXvaeIo+AT87zeklulw1ArI19pTo7XRpNLzlIbtAOA3k/oqvrdSr6XcH/dH3lTlfi+OY/K351Qo+gaxn1RohLohr5HrN2ppzJlii0Pe1P7OC10UgLyp/Z0lA972xds6fgLuQZlA8/dBfEy0ar8+I45drR+go/GnUhmEWpkFBY4ZKPKLWcWqSu0BAqkX8Jbp0JNK92fIyduwXRSAO7wstaB2lz26V0f83xdf4f9TqOtoG6P/fiiUGQmrtuWIZKHM/IVq6FDp70xpXxy9ohxZWPl3nC+NQuByQ5Pi96JRw2i+vnd9lUEA+n7frJ3yjgEU+c2sC6A8sAl0VpkRgZ7eC4+3YTug+a4w/8R5r1+irl+Kjn+n2OLQveM1ittrWfpBLtS1SFZryxHpQjVLz+hA3duFXW0GnLdJGjlbSgDhOePX8R13sKwG8zcWew1OHN8HmT06eNwEuq51F+ixe/ve9VUGIUnQ/Pu2aq2clTCAooCEwwUwkEDP9ctYz4XH152gI+Xv7UtU7QvMyCwCa5FaHm/ng1kZByMDdW/Zo5KzdtUFvR3H9s2lBo99cU0wyQOcFFsc7hwYh0sN33u9KZoyOFUxYCs8WW3KrF8tRfZykmjOYvti9Vo5q2AARS2CP4Ge0he11h4rvu4EAe9for6+wIzKIoQqI0GhpXQ+mJlx0BKoawnefGWPXLmeM65DaPICcCVK5+boXh1x18AUvHuoUvE57xRXYNH43h77Hh8T7Wze6aBntrJejgD5/cOVHku7NEG5ua9cqDPT4YIBFLUYeu6u1QKYgpwsTe0C5IFJFDwLOr1lenx9gRmZRWAtUsvl+FuJj4k2NePgK1DXGrwpnRfeypMcy7jIC6sl/LBMi6/lXBz759o0WO295AGG47jk+6hlCD8QKbY4TBqQgqc/+EJXdtn174GZad8YQFGLoPfu2og7MHlgkn/ivOZMj5Y7diOzCOEwFEvGcpvuLnkGIlr/3rUG7KN7dcTz0wci6uqsMW81SWrBm5bMrqtoSUKT8FwUWKB5+ZcO18T6PDcd++frLZUyampDflqG8APlcRMnAT936ZYuJ//uuHtwF7xTXMHMtBcMoCji+TOe729tkPxi4hqY6Mn0+DO0xroF0spjurvKTFFfMzu1BuzettNzsyI/L6SrY3FKwY3jnBmanqh4Lg9JT/B5bnprQ+JKgmdxtr+NgV2zQJcaGp3/P5BFz1/bU4p1+aVY93Ep1heUevyelL473imuCMtVDoKJARQFRSinw/qTTfIngPG30aYavUNrrFsgrdQu7lForpPB1f9/99pCr4tdawnYfW2n92Zl2rBuuHD5CvK2HYMQngsEL57QGwO6Xut2zujpXu7grQ2JnCR5Fmf70xjYa+uTAOrSXv241GszTbXvjssNTWG1wkGwMYAi04V6Oqy/2SQ9AYxZ2R89ARdn1JFWan8rr/zsRjz4PwedGSlvf8daA3Zf2+m5Wam01+FA2TdYuf3YD13AAUQJYI1sgWBXetcHBKAayCgVoDcJz+Jsj2zZ1Sc7Aj2ltTK9BWz+fqdo+T3pWQydfaF+wACKTBXKYSV/WxAoPT8csj9KF6LFE3u79ZEiAtQzrHExrTTXQmm96OpdAFgtwPGWnWkCkBgf63NYXGvLkAdHZaiuHjA0PQF3ry3UdKOipzGwliaY/nynxMdEKz7uOjyrJYgN9Y2wFTGAIlOFKrAIpAWB2vO9fVmYkf2RB3BaAjrXL+zDZy6o9sQhUgpaKu11mv+OtWaO9GyntX2BXCDnmtJN3qsflyp+Do7VA/TckMmPy/E5F56sdjuXtRTI+3OclxoaFR+XN971NbOX9ZWeGECRqUIxrBRoCwJ/vyweHJWBVz8uRRMCX9tNaUbM1uKzmoIhx3ve9+o+fuGRV0oXdz3BgdZh7kBbZXjLzgR6rh08VePx2k0AHhrVHesLShU/B3+Ox3EDpNbsM8UWhwdGZWDdx6WKz1cqVNdCz3ewWhBrhQy7FTGAIlP5U4wdqEBPdr3Plwc7D43qjvtHpXu9m/aWSVIK4DZ/etb5cy3BEL/wyF96gwOtdXq+tvN2XigFAVEAVnupe9LC0d9JLlqScP+odNw/Kl31c5Afj3z2nOtxqA0/ys/ln3sJoDR2bvCQYovDkol9nEGbP9/BrK9UxgCKTBfsRo2Bnux6nq8U7KwvKMX9Kv1WtAwNGlELwS880kupBUcw3gfwfV6o3YhNGpCq+71cf6bU3ylKtl6cls/h5d0nm2cFyl7HscyMt+FHeUH9yqn9VZt2+pNF3lRU7gyeJACLJ/TWPZQfihvhcMAAioLCdbqs67/Neq9ATnY9z9eT6dE6NGhELQS/8EiPYBUIq61j5xowNInm5Vnk54XeGzFfx6R2o/Kn6YNx50DvgZmrl/NPInfbMY/HHef389MH6jqXHce5YX85/rTrS7dt9WaRPfp9AVi1/TgmD0rV/V1gtRULrDAjkAEUBYW3BUDNOAECPdm1Pl/P9F+lhnxKX4hKwc+Uwam6uwJb7QuPrClYBcJq77N88g0e2RYhgE9P1WDSAO2F5lrey/WY1M7dIekJuo4pTyF4cmjuAC6p3hB5K6i/9+ZuWPPhlwFlkY0eyjczM6mHVWYEMoAi0ykuALq5BJLLWlRmnAB6ay68dRH39h56pv8q+fpSPSrtdT7vtheN7607GLLKFx5ZV7Dq5dTe5/zFesXtva1x5+97uR6T/Nz1tdSJ2vt428/oq8vWeLQXUWj2KWdEFjkSh/KtNCOQARSZTnEBUEBTsz6zBDLLTU7P9F8l894uVq37kGemGAyR0Yy+yKoNrai9z219O2H1ri/dslASoCsTJKf1mLQudaLnfVzfzxHw+JsNDjSLHKyh/GAOp1lpgoz3hY6IDOD4kvHGcQIEg9osN/kdTaW9TvNrptjikNmjg8cJrKUg3N/3JDKC4yIbLTWfpIFcZDcVlWNk3i5kr9uPkXm7sKmo3Of7DExLQN7U/h6vlX/ivJ9HpP+YlJY60XIuyt8nSgIezeqBDbOHoyAny+OGSOk7Qo2jVxQAXc+TmzasGwpyshT3yQjefudmULqehCqrxgwUmc4jVY6rGSiXbYJ5ApjV8RfwvBPTs3o82wxQqBhRL6dlaEXtfUb36uh2nggEnpXWekx6J4LIMy1m1BoaXeNjVvY6FMNpVpogwwCKgkL+JZN/4nzITgCzOv6qfemprYdlxHsSGSXQi6zWQETpfYwalvGnjlHrcJ+voEb43anJ8xisUuPjS6iG06wyQYYBFAWN65dZKE8Axx3M0s0laFL4eRT0d/z19qWnth7W4bMXsGrb8ZDfRfnLCtOIyToCqaXS+1x/ekmp0ZLR8HZ+5584b2i2SC0oOVhWgzsHWus8C2WRuhVqQhlAUciE8gSYNqwb4mNbYd7bxR4/W5092GeDPjktK87L78Ize3TA5IGpIb+L8odVphGTdQQytKLnuWotUQLJ2vi6ofMW1BidLVLLkM/fWIxLDd9b6jyz0nBaKDCAIlMEkp0IVmZjyHUJindPN16nf/aPv3diVriL0iuYQwzMcoWXQDLLWp6r9rf3x3sHBTyU5DgXtS70Gy1JgEKgE+gQllqG3KpDeVYZTgsFBlBkuECyE8HMbBh599SS7sSCVffALFd4CuSmQP5ceQCt9reHq38jgQ4lqf3NqZ3fajdhgQ5hqWXIrTrRJBxvBI3AAIoMFUh2IhTFk0bePVnpTszMzE0w6h7CqZCWzKE2VKfWPTzQGxilv7mlLkvKqJ3fRryv0rlqVnBGxmEARYYKJDsRqhkdRt49WeFOzOzMTTCybVZqlkfBpxZAF+Rkqf7t+XMD4xq8KP3NNQngtT2lWHbHDQCUz+/RvTri+ekDEXV1+F/P36fruSoBmH5TGubf1tP5Pi0lqx2uGECRoYyeiRMF8I5Lh2BlbszOtkXiEhSknbcA2tvfnp4bGPmNxtyxPRS3W5dfivtHZmguaHfcrPjKAist9Lvhk9PY8MlprJza/DpWymqTJ3YiJ8M4vjCWTOjjV1djxx2Xa5NZgcA6Erc03i48RnPMJDTjS93xt2BEd2wKDkfxtZ5u+o7nfHa6xu25vrpNB/q3p3Sjsfajk4rbCkDx/FG7Wam012nqzu2toe/SzSXOz8LM84wCwwwUGUJ+J7ZkYh8M6OJ9sUwlo3t1hOTSaNKIjsQtSSRlbnj3HT78GTZWWmRbrQGt0QG02nCdBHi0w5QAtI3xzDUE2togIyle8f0AoAngcHUYYAaKAqZ0J7Zq23G/LnrBzKBEokjL3PDu2/q8ZWLk2zmyTGqLbLs+18w13NQyXDkT+0CSPS4A3L220COLpPYa3lobuEqxxSFnYh/F/WPpQnhgBooCZmTBbyRlUEKFmRsKJi3nvzxDNf2mbqrDV94a0BpFrUB72rBuGN49Ee8eqsCf95Q5t1fKIslfI0oCFk/srXn2XKW9Dv272jAvqwde+PCkMxMlAcid2p/nbRhgAEUB0xP0+Cqs5MwTY1hhNiBFDm/nra/zXylD9fZ+z5ogpefq2Q+9lG40lIYVHeRBYaW9DmmJbTFnTHes/egkmgSwctsxXBvX2ud3mDygzJnYB10T4iAEMCRd30w+Ch1JCKVlTQkA1q5di9///veorKzEf/zHf+D555/HLbfc4vN5tbW1sNlssNvtaN++fRD2NPQ2FZUr3s3Jt9FaJ1Fpr2MGhcgCtJy33s7/wpPVyF63X9N7qX13aN2PQFTa6zAyb5dqZixaklCQk+Uz0HJsB8DjO6zSXocDZd/gFxsPeQScjtem0NJz/WYGSsWmTZuwYMECrF27FiNHjsTLL7+MiRMn4ujRo+jWjd2Q5XwNG+mdXu9vBoVLfxAZR+t56+38V1vbzdV//+d/4PpO7XQv4WLk5BJvs+Jcs0hq9VsOjkyVvHZPT3aLwgMDKBXPPfccHnjgATz44IMAgOeffx7/+Mc/8OKLLyI3NzfEe2dN3oKeYDRGDOXSHwzcKBLpOW/Vzn/5sLxctCThRzd09nreBOP7Q7EPnQT8afpgt2E1b4EWoF7v5C3oApRn+pG1MYBS0NDQgIMHDyInJ8ft8XHjxqGwsNBj+/r6etTX1zv/XVtba/o+hhuzi8NDufQH12yjSGXUeeuaoTp85gJWbT+uq8YxGJNL1Oov7xyY6nNfHKIkKB6Pr6ALAC43NHnfgCyHAZSC6upqNDY2onPnzm6Pd+7cGVVVVR7b5+bm4oknngjW7oUls4vDQ7X0B9dso0giz6Qaed46Xi+zRwdMHpSqq8bRqP3wlSnWOoP1gVEZWF9Q2tw7yrVvnUqQ5GsY0+ibSWbDg4MBlBeSrCGIEMLjMQBYunQpFi5c6Px3bW0t0tLSTN+/cGPm9PpQtT+w8ppt/CIlPdQyqd7OW3//xvypcVTaDz3vrzVT7G3f5GvXZd+chg37Tzt/LtDcRTw+thWGuKyL520Y08ibSWbDg4sBlIKkpCRER0d7ZJvOnTvnkZUCgNjYWMTGxgZr98JasPu6mB04WLVvFb9ISQ9fmVSl8zYUf2Ou+6F3Vm+gmWKltes2fnLao5N4E4B5bxd77NO0Yd1woe4K8rYdg7i6zw+O6o77R6Ub8j3FbHjwsWpNQUxMDIYMGYKdO3e6Pb5z506MGDEiRHtFvpjZuViNFTt/a+0MTeSgdwUAf7qPG0nv+x8o+0b1+LTuo7flX5TI96nSXoeVV4Mnx8/XF5R67Ku/nxVXcQg+ZqBULFy4EDNmzMDQoUORmZmJV155BeXl5ZgzZ06od428CEUDSat1/rbysCJZk95Mqtrf2KenajBpgP4MkZyvoTl/up/L152LliQcPnMB9726T9M+qn1Giyf0dhbFy7nuk7fP7Nv68wFn86yaDY9kzECpmDZtGp5//nk8+eSTGDRoEPLz8/HBBx/guuuuC/WukQVZac02XyvZE8npzaQq/Y0BzUNXm4rKA8pQbSoqx8i8Xchetx8j83Z5rEGn9v6+up9D+uGCFy1JWDyxN1ZuP6Y5U6v2GT08pgcKcrKw5t7BXvfJ22eWsznwjLEVs+GRjp3ITdASO5GTb8Es6tbSGZ5ITs8KAGqNIaMAPDHlP/Cbdz73eM6G2cOR2aODx/MdWZfRvTp6dANX69LtT/fzF7IHIzE+FulJbVFafUlxG9d9VOLtM/J13nlrpql3P/zZP/KNnciJLCbYBbdWG1Y0EmcXmkfPEPi0Yd3QNiYaj2045PZ4E4DfvvO54pCZtwzRsi1H8Md7B2keftbb/TxaknDjde7rzPkz5OXtM/J13ql9ZnKBZIwd++fI7vE8MQ8DKCKThWp2TCQuKNySZheGQ6A4ND1Rsb+RQHN/pCjRHFDJh5PU6oEg9AU1WrufKw1nmTVz19d5p/SZSRIgqXxW/mhJ50koMYAiMhmLuo3RkqZph8sF0BGELN1cAnkfbSGANS5DZloyREPSEwwLarRkYeXbADA9a6MWuBmVMW5J50moMYAiMhlnxxijpQSi4XYBnDasG/okt8OUtYVunbjlQ2byjJpaoGTk8LOWLKxjm2AGrWrHaMTvt6WcJ1agO4D67LPP8N577yExMRH33HMPkpKSnD+rra3FggUL8Oc//9nQnSQKZ6Fq8hlpWkogGo4XwIFpCcjz8jeuFpyoBUrBHn4ORdBq1jG2lPPECnTNwtuxYwfuuusu9OzZExcvXsTly5fxv//7v8jKygIAfPXVV0hNTUVjY6NpOxwOOAuPlHB2TOBawuzCSnud5ploVqP0Nx4Ox6M2a0/vTDir1K21hPPELKbNwlu+fDkWLVqEFStWQAiBZ555BpMnT8b/+3//DxMmTAhop4kiXSQWdQdbJM8udAjnjKXS37hRGTUzgxMjsjabisqRs7kEV1tOIW9q6OrWWsJ5YgW6AqjPP/8cb7zxBoDmhXZ/9atfoWvXrvjJT36CDRs24KabbjJlJ4mIHFpCIBpJF0CjghMz65MCDVor7XXO4AlonoWYs7kkpHVrLeE8CTVdAVRsbCwuXLjg9ti9996LqKgoTJ8+Hc8++6yR+0ZE1GJFygXQiOAkGPVJgQStB8q+8VhUWAA4WFaDOweG/++QlOkKoAYNGoQPP/wQQ4YMcXt82rRpaGpqwsyZMw3dOSIiCn+BBCf+DAF6G+7z9jN/g1ZJUl5SWOVhihC6AqhHHnkE+fn5ij+79957AQCvvPJK4HtFREQRxd/gRO8QoLfhPrOGAodcl+DReV2SgBuvSwj4tcm6uBaeCTgLj4jIOFpnlXmb8QfA1NmA4dL8lLwzbRZeTU0N3nzzTcycOdPjhe12O/7nf/5H8WdERET+0joE6G24T0CY2l8rkgr/SZsoPRuvWbMG+fn5igGSzWbDxx9/jNWrVxu2c0REREDzEGBmjw5eAxPHcJ+rKABfX6pHfEy0x8+MbjCpZR8pcugKoDZv3ow5c+ao/vzhhx/GX//614B3ioiISC/HjL/oq9XbjrqkeW8X4+61hbh7cBfnz4LdX6vSXofCk9WotNcF5f3IfLqG8E6ePImePXuq/rxnz544efJkwDtFRETkD8dQ2sGyGszfWOzW/uCd4gpsmZuJyw1NQR1mY31UZNKVgYqOjkZFRYXqzysqKhAVpesliYgowoQ625Jii0PiNTGKNU+XG5qCOsym1seKmajwpysDNXjwYLzzzjsYPny44s+3bt2KwYMHG7JjREQUfqySbbHKorrhuDg0aaMrXTRv3jw8++yzWLNmjduCwY2NjVi9ejX+8Ic/4NFHHzV8J4mIyPqslG2R10OFak3BkjN2j8dCEciR8XRloKZOnYrFixdj/vz5+PWvf43u3btDkiScPHkS3377LX71q1/hJz/5iVn7StTiWGV1dyItrJZtCXVrgUp7HVZuP+bx+OKJvXk+RwBdARQArFixAlOmTMFbb72Ff/3rXxBCYPTo0cjOzuZiwkQq/AmErDIUQpHJjODcKsNmrkK5pqBSQAkAA7pcG/R9IePpCqAuX76MX/3qV3jnnXdw5coV3HbbbVi9ejWSkpLM2j+isOdPIBSsBVSpZTIrOA904eBIY8WAkoyjqwbqd7/7HV5//XVMmjQJ9957L/75z3/ikUceMWvfiMKevzUh3oZCiAJhdp3StGHdUJCThQ2zh6MgJ6tFZ02tUodF5tCVgdqyZQvWr1+P6dOnAwDuu+8+jBw5Eo2NjYiOjjZlB4nCmb81IbxzJbMEo04plMNmVhPqOiwyj64M1OnTp3HLLbc4/33TTTehVatWXntDEbVkSktLaAmEeOdKZvH3b5L8xyVeIpOuDFRjYyNiYmLcX6BVK3z//feG7hRRpAikJoR3rqSVnoJw1ikRGUMSQijMEVAWFRWFiRMnIjY21vnYe++9h1tvvRXx8fHOx7Zs2WLsXoaZ2tpa2Gw22O12xYWXqeWptNcxECJT+FsQ3pL/JtkehNTouX7rykDNnDnT47H/+q//0rd3RC0Qa0LIDIHM1mypf5NsD0JG0RVAvfbaa2btBxGR4czONIQ6k2G1xpVWx/YgZCTdjTSJiAIRrKDD7EyDFTIZnK2pDwNOMpKuWXhERIHYVFSOkXm7kL1uP0bm7cKmonJT3sfsXkdWWvPtgVEZzll1LAj3jjMQyUgMoIgoKIIZdJjdiNQKjU4dwei6j0shBPDQ6IwW37jSF7YHISNxCI+IgiKYwydah7b8HU4M9dCZPBgVANZ/XIb7R2YE5f3DGduDkFGYgSIinyrtdSg8WR1QtiiYwydaMg2BDCeGOpNhhQxYOGNjSzICM1BE5JVRxdLBbuDoLdNgxGysUGYyQp0BIyIGUETkhdHTvo0KOrQOvan1OjJqODFUvZTYTZwo9MJmCG/FihUYMWIE2rZti2uvvVZxm/Lyctx1112Ij49HUlIS5s+fj4aGBrdtSkpKMGbMGMTFxaFLly548sknIW/Gvnv3bgwZMgRt2rRB9+7d8dJLL5l1WESWZsZQUaDDJ0bM5IuE2VjThnVDQU4WNswezuJxohAImwCqoaEBP/3pT/HII48o/ryxsRGTJk3CpUuXUFBQgI0bN2Lz5s14/PHHndvU1tbi9ttvR2pqKoqKirB69Wo888wzeO6555zblJaW4o477sAtt9yC4uJiLFu2DPPnz8fmzZtNP0Yiq7FaoGHUTL5Q1zAZhbU8RKETNkN4TzzxBADg9ddfV/z5jh07cPToUZw+fRqpqakAgGeffRazZs3CihUr0L59e7z11lv47rvv8PrrryM2Nhb9+vXDiRMn8Nxzz2HhwoWQJAkvvfQSunXrhueffx4A0LdvXxw4cADPPPMMpk6dGoxDJbIMqw0VGTmTj7OxiCgQYRNA+bJ3717069fPGTwBwPjx41FfX4+DBw8iKysLe/fuxZgxY9wWQx4/fjyWLl2KsrIyZGRkYO/evRg3bpzba48fPx7r16/HlStX0Lp1a4/3rq+vR319vfPftbW1JhwhUWhYKdAwuni6pa4HR0SBC5shPF+qqqrQuXNnt8cSEhIQExODqqoq1W0c//a1zffff4/q6mrF987NzYXNZnP+l5aWZsgxEVmFVYaKImXojYjCX0gDqOXLl0OSJK//HThwQPPrSZLk8ZgQwu1x+TaOAnK927haunQp7Ha787/Tp09r3mci0ofF00RkBSEdwps3bx6mT5/udZv09HRNr5WcnIz9+/e7PVZTU4MrV644M0rJycnOTJPDuXPnAMDnNq1atUKHDh0U3zs2NtZtWJCIzMWhNyIKtZAGUElJSUhKSjLktTIzM7FixQpUVlYiJSUFQHNheWxsLIYMGeLcZtmyZWhoaEBMTIxzm9TUVGeglpmZiffee8/ttXfs2IGhQ4cq1j8RERFRyxM2NVDl5eU4dOgQysvL0djYiEOHDuHQoUP49ttvAQDjxo3DDTfcgBkzZqC4uBj/93//h0WLFmH27Nlo3749ACA7OxuxsbGYNWsWjhw5gq1bt+Lpp592zsADgDlz5uDUqVNYuHAhvvjiC/z5z3/G+vXrsWjRopAdO1GkMWJpGCIr49945JOEvIukRc2aNQt/+ctfPB7/8MMPMXbsWADNQdbcuXOxa9cuxMXFITs7G88884zb8FpJSQkeffRRfPLJJ0hISMCcOXPw29/+1q2+affu3fjlL3+Jzz//HKmpqViyZAnmzJmjeV9ra2ths9lgt9udwRtRJNOzKK9RS8NEOn8XOqbQ4994+NJz/Q6bACqcMICilkTPxaLSXoeRebs82hAU5GQxSHDBC3D44t94eNNz/Q6bITwish69ncHNWBom0hjVbZ1Cg3/jLQcDKCLym9aLhaMeJD4m2vSlYaxee+Jr/3gBDm9WW/6IzBMxnciJKPi0dAaXD0fdPbgL3imuMGVpGKsPfWnZP6O7rVNwWW35IzIPa6BMwBooakk2FZV7XCwcQYFaPciWuZm43NBk6NIwVq890bN/3j5TCg+V9jpLLH9E+ui5fjMDRUQB8bZWntpw1OWGJmT2UG5M669AFxo2e9abnv2z0vqD5B82e418DKCIKGBqF4tgDkcF8l7BGPrTu3+8ABNZG4vIiShgaoXRwVz819/3CtasNy6ETBRZmIEiooD4yt4EczjKn/cKdOjP7P0jImtiAEUUBFrqa7TW4FipQ7Va9mZ0r45u+xbM4Si97xXsWW8cmiOKDAygiEympb5Gaw2O1abpBzN7YxZOOycifzCAIjKRlgyN1iyO1u3kPjtdg0/KvsFN6YkYmJZg6PFFSs8iDq0RkV4MoIhMpCVDozWL40+25/H/PYTNn551/nvqjV3w7D2D/D4euUjK3nBojYj0YABFZCItGRqtWRy92Z7PTte4BU8AsPnTs/hZ5nWGZqKMyt5YqbaLiMgXtjEgMpGWqetap7frnQb/Sdk3io8fKKsB4N+acd7aFWT26OB34PNy/kmMyNuF7HX7MTJvFzYVlfv1Olr21aznEVHLwqVcTMClXEhOy7IOWpd+0LrdZ6dr8J8vFHo8/u6jI3Cs6qLuYnSzCthf3n0SuduOuT0W6BIs/u6r1Yr0iSi49Fy/mYEiCgItGRqtWRyt2w1MS8DUG7u4PTb1xi7o1L6N7saRZjWbrLTXIU8WPAE/1Hb5+5r+7KvW54Vzhiqc953IalgDRRTBnr1nEH6WeR0OlNVgaHoCBqYloPBkte5i9ANl3xjarsBR7/T1t/VQSoFHSfB7Jp+/rRW0PC+cM1ThvO9EVsQAiijCDUxLcCsa11uM7rjwyvnbrkB+IZcAjyBqycQ+fg/f+dtawdfz/G0jYQXhvO9EVsUhPKIWRk8xuvzC6xAFeC1gVxsqUrqQQ/rhiygKwNKJffDw6B5BOT65B0ZlIKr5aR7P85ahsrpw3nciq2IGiqgF0tp6QOnCCwCrswdj0oBUxefIM0xLJvZB/y42ZCTFK76eEMCa7MFIjI81rIml3tYKrvssAXhodAbuH5nh9rxwbhoazvtOZFUMoIhaKC2NI9UuvDdep9xHSinDlPtBc5F4lAQsmdDH4/Wi0DyEZ3QHcK2NMeX7LACs/7gM94/McNvmtYJSt/2WJO9ZOCuJpIanRFbBAIrIYqzUUFLvhVctYwU0B02rth/Hkol9sGrbcTQK4ax/mvd2cVAKmyvtdThQ9g0kScKQ6xKQYovzWTzump1yJQlgdK+Opu2r0bhcDZGxGEARWYgVZ0rpufAqZaxcNQqBAV2uRUFOFg6W1WD+xuKgFTZvKipHzuYSZ8G6BCBvan+M7tVRdXhLrQYMAJqAsFo0GeByNURGYhE5kUV460MU6v49enpUuRZwyzkCkxRbHBKviQlaYXOlvQ5LXIInoDnz5ZhdqFZ07i2jxhoiopaNGSgii1AbSnqtoAyvFvw7ZFkpvUOKrhmrw2cuYNX2427DfwBQeLIa8THRQStsPniqRvHxJtGcRVLLsqll1HzNQiSiyMcAisgilC7WUYAzeAKC379Hy5CiUoDlGCrK7NEBkwelOgOT/BPnMTJvl/P17h7cBe8UV6BRCERJwOKJvU05LrUVq1wbdioNb8lrwKIk4MFR3XH/qHSPba1Uu0ZE5mMARWQRSgXbD4xKxysfl7ptF0gHcFeOC358TDQuNTR6XPi1NF/UEmA5AhOl13unuAJzxnTH2o9OokkAK7cdw7VxrQ3PsA1NT/TZsFMtABrdqyOenz4QUVdnHyp97lasXSMiczGAIrIQ+VASALwqmz5vxDCX0swy+YXf1+w0vd2t1V5v7UcnnYGNWRm2FFsccib2Qd62Y7jauxM5Lg071QIgrRk4dvkmanlYRE5kMa4F24F01VajNrNMvniuY0jRlWvwpre7tdLrAZ5ZITMKyTcVlWPl9qvBkwTk3NEHD49pDp7UAqDPTtdoWlyYXb6JWiYGUEQWojTbbtqwbijIycKG2cNRkJMV8NCQt5lljULg/cOVqLTX+QzefAVYcim2OCyZ0Mfn/hldSO7RKFMAq7Ydd37GagFQUVmNpsBI7+fgul+hnFlJRIHhEB6RRXgbLjKyf4+vXk1Pvf8Fnv7gC+f7q/WA8iiwBrB4gvci8P5dbYqPR6G5r5IZHbJ9DUWqdVsflp6gaZagP12+WTNFFP4YQBFZQDDraBwXfLUGkUrvr7YP04Z1w4W6K8jbdqy5CHz7MVzbVr0IXC1Y2TI3E5cbmhQbdQY6u83XOnBqAdDAtASPAHHasK745xdfIaFtjLOTueNz0NpslDVTRJGBARSRimBOS/eVJTHatGHd0DYmGo9tOKS6jZb3r7TXYeW2YxAagwFvwYoSIzI1WjJEagGQ4/HXCsrwysf/xtufnHY+x9HJXG+WMNi/ayIyBwMoIgXBHmLxlSUxQ7fEtpAkQKVFkttyJmqBpD/BgNZsjZGZGi3v6S0AeuXjf3s85uhkrnd/QvG7JiLjsYicSMbbkipmMWO2nZpKex1WvH8Ud68tdAueJKk5q+L6/o7Gl9nr9mNk3i5sKip3ey1/C6i1LA1j9Ow2pffUUsit1sUc+KGTuRaO9wLUl44hovDBDBSRTKiGWPTU0bjSM9QoX1DXIQrA1rkj0Kl9G7ceVI6u4YByBsifAmqtzM7UaM0yqnUxB9w7met9r4KcLN2/ayKyjrDIQJWVleGBBx5ARkYG4uLi0KNHD/zud79DQ0OD23bl5eW46667EB8fj6SkJMyfP99jm5KSEowZMwZxcXHo0qULnnzySY8vyN27d2PIkCFo06YNunfvjpdeesn0YyTr8DerYgSti/Y6bCoq95ohcuXIrCmFA00ALjc0ub2/1gyQ0W0WHMzMyunJMjq6mMtJaA6EHE1F1TJZau8FwOfvmq0OiKwrLDJQx44dQ1NTE15++WVcf/31OHLkCGbPno1Lly7hmWeeAQA0NjZi0qRJ6NixIwoKCvD1119j5syZEEJg9erVAIDa2lrcfvvtyMrKQlFREU6cOIFZs2YhPj4ejz/+OACgtLQUd9xxB2bPno0333wTe/bswdy5c9GxY0dMnTo1ZJ8BBY+ZWRUjGdEJ3EEpQNSTATKyzYIrf7NyvujJMqbY4pA3tT+Wbi5B09XHsm9Kw2O39USKLc5nJsvfjCZbHRBZW1gEUBMmTMCECROc/+7evTuOHz+OF1980RlA7dixA0ePHsXp06eRmpoKAHj22Wcxa9YsrFixAu3bt8dbb72F7777Dq+//jpiY2PRr18/nDhxAs899xwWLlwISZLw0ksvoVu3bnj++ecBAH379sWBAwfwzDPPMIAKolAvzGrWhdtIWpZacf0M1fo/RUlQDBCtEkiaEZz5Cg7ln53a34OWINafoUi2OiCyvrAIoJTY7XYkJiY6/713717069fPGTwBwPjx41FfX4+DBw8iKysLe/fuxZgxYxAbG+u2zdKlS1FWVoaMjAzs3bsX48aNc3uv8ePHY/369bhy5Qpat27tsS/19fWor693/ru2ttbIQ21xrHLnrfXCHapgz9uFWe0zlPc1enB0Bib1T8GlhkZn93FXegPJQD+LYH2W3oJDtc9O6e9BLYh9/3AlJg1IcVuOR08gylYHRNYXlgHUyZMnsXr1ajz77LPOx6qqqtC5c2e37RISEhATE4OqqirnNunp6W7bOJ5TVVWFjIwMxdfp3Lkzvv/+e1RXVyMlJcVjf3Jzc/HEE08YcWgtXrjdeQcz2JMHF2oXZgCqn6E8IMo/cR53ry302H+l9zL7s5A/f8nEPujfxeYRTBkVZCkFh3r//tSyevJu7noDUbY6ILK+kAZQy5cv9xl4FBUVYejQoc5/V1RUYMKECfjpT3+KBx980G1bSfIs9RRCuD0u38ZRQK53G1dLly7FwoULnf+ura1FWlqa1+MiZeF05x1osKd39pxScKJ0YX7vs7NeP0PHf2r7f+HyFazcfkxXIPTZ6Rq32X3+fBbyfcn94BiA5mLt2bdk4P5RGcg/cd7QgFUeHOr9+5MHsa6Uurlr/Rv2lbUK9RA3EYU4gJo3bx6mT5/udRvXjFFFRQWysrKQmZmJV155xW275ORk7N+/3+2xmpoaXLlyxZlRSk5OdmajHM6dOwcAPrdp1aoVOnTooLiPsbGxbsOC5L9wuvMOJNjTk63xFai5Xpgdryun9Bmq7X/etmO6AqFNReXIUZjd560eS+7gKc+Fex0EgFc+LsW6glJAwO8gTQt//v4cQez7hyvx1PtfuP0skOBfLWtllSFuopYupG0MkpKS0KdPH6//tWnTBgBw9uxZjB07FjfeeCNee+01REW573pmZiaOHDmCyspK52M7duxAbGwshgwZ4twmPz/frbXBjh07kJqa6gzUMjMzsXPnTrfX3rFjB4YOHapY/0TGCmZDyUD52+5Ab6NOre0E5K/rEAXlInGl/Y+SoBoIeTsWpVZJrvVYrq0WXs4/6TY1f1NROR57u1jx9V0JoW/ffFFqEeDv31+KLQ6TBqQY3v5C3tYiFE1eiUhZWNRAVVRUYOzYsejWrRueeeYZnD9/3vmz5ORkAMC4ceNwww03YMaMGfj973+Pb775BosWLcLs2bPRvn17AEB2djaeeOIJzJo1C8uWLcO//vUvPP300/jtb3/rHJ6bM2cO1qxZg4ULF2L27NnYu3cv1q9fjw0bNgT/wFuocJgBB/g/S01v5kprVkStTcHq7MGYNCDV43Gl/Z8ztjvWfnjSI1DZ8+V5ZPbwzMCqvacjaAM867EcQ3NRErBkQh+s3H5MsTeVFv4GKN6yOP7+/QVj1mI4DXETRbqwCKB27NiBL7/8El9++SW6du3q9jNHfVJ0dDTef/99zJ07FyNHjkRcXByys7OdbQ4AwGazYefOnXj00UcxdOhQJCQkYOHChW71SxkZGfjggw/wy1/+Ei+88AJSU1Pxpz/9iS0MgsysvkJG8+diqzUgch320nJhVnvdG69TXqhXvv+Hz15oXhhYYbs1H55Euzat8fCYHj7fM0pq7mo+MC0BhSerVYfmmgSwctsxZ28lLSQJzmE8tcwa4L1GSEvtmr9/f4EE/1rqmsJpiJso0knC2zoF5Jfa2lrYbDbY7XZn9ovI1aaico+AyLWORSlDouXC7Ot11VTa69yWbVESBWDP0ls93tvbe2p5XbUFjaMA3HtzN2z4pBxNojlQmDI4FVuLz3qt//FVI1R4shrZ6/ZDbsPs4YpZNjkzCrj11DW9nH+yOfAU0PU7DgSL1qml0HP9ZgBlAgZQpEWlvU4xIFIKOqIlCQU5WZpntOnt2/T1t/V4bMMhn6+tFmR4e0/XAEsuWpLwyNjueOGjk4pB1IbZw5Ge1BZl1ZfRNibK2XLB9fmun4vSZ+eaEVPbRuvna0YBt579cX1/CUDOxD4eWUGjsWidWhI91++wWAuPKBKprXuntWhc7+vKuRZ3/2LjIcX13uQOn72g+p7pSW1RWn3Jo6DZda28pRP7uBVoTxmcirUqwZNjaMpxPJcaGn1+LkqfXZMAprxQ6Fwn0N9CcbMKuP2dJCAArNp+3NQCchatE6kLixooopZErc6lbUwUCk9WGzKMonRhlCQgSjQvLBwtSRjdKwkfHj/v9rxV245j8sBUr5kRpSyFo6Yos0cHTB6UqppRcj1eR1DjyJLFx0T7rP8pOWNXPF4B9zonf2qVXisoNaWAO5BJAmYXkLNonUgdAygii1GazTVlcKpix3B/KV0YhQD+e8p/4LsrTRiWnoBLDY0eAZTSxVNvQ1FHMKVWYP6bSX1xx9VlUOSB2d2Du+Cd4grV5pIrtx9TPWb5vjv+f2n1Jbd/K6m012Hdx6Uej0dJUCzg1lMzpHX2XigKyFm0TqSOARSRBblmSOSZGiMaSCpdGCUJ+M07nzfPcLvaYsCIzIhaMKF2cXYET0qB2TvFFdgyNxOXG5o8MkdqLRXU9l1PbU9p9SXF2YkPjuquOxunREtGLBhtEqzwnkThggEUkUV5y9QEOowivzBGSe6NKptEc33Nkol9sGrbcb8zI96CiRRbXHMfqKutDOSvrxaYnampQ0J8jMcxZSTF42qXAw9K2apA17yLAnD/qHS37QJZ3se1dYJa0BmKHmnh0peNKNgYQBFZgLchH3/6Rmm5yLleGKu//c5jFl6jEBjQ5VoU5GT5vHhOvykNG/afhsAPwQqgvqixY3hu5fbm4EmSgMUTe7tlatSyZPPeLnZmyVwXPz54qkYxeHohezBuvC7B0DXv1IJJI2qGtNaT6RFoG4Jw6ctGFEwMoIhCTMsF09fF29+p5o4LY6W9TjVI83bx3FRU7raIMAAsntAcCHnLnAHuwZUQngXqWrJky7YcwYW6K86+SEoS42MNqSfSkokJtGZILYPVJ7kdLjU0+hUAsQ0BkTnYxoAohCrtdcjZ7H7BzNlS4rUVQEFOltsF0Iip5o5gxfGFoNTlW752nHMdPNlrrdx2DJX2OsTHRCu+V9uYKM1T912P+4/TBymuhZfnJXhSC14CWfPOW4uIQNdyVPtcpqwtdK4l6GjHoAXbEBCZhxkoohBSGnYSAvj0VA0mDXC/6Kplggydau4oIpI1hVLKYqQltlUMXJoAlFVfhlBZ4e5yQ5OuTI23LFkU4DV48ha8mFXbE8jrKn0uwA+d2vVOIGAbAiLzMANFFEJqCwHoWR/AcdF1pXequbdMhdrPHH2Z5KLQPLXf2375k6lRes6SiX083iNKAtbcO9gjU6f2mlqajurl7+vKj1HpC1pPU1Uj/jaISBkzUEQhNDQ90WPmmARgSLr6AsByeqaaqxUTe8tUCAjFn11uaELuj/sjZ0uJM+CTAORO7e98bW/75U+mRuk517Zt7fEedw5M1fz5WY23FhaAvgCIbQiIzMMAishgepso5k3tj6WbS5pnowF48JYM3e85bVg39Eluh6KyGgxLT3Cu++bq5d0nkbftmMcMNsB38bPazzJ7dMDoXh3x6akaCNEc+Lke8+heHfHHewcBCj9zHL8/WZpQT+03m+sxBhoAReLnQ2QFXEzYBFxMuOXyd8ZTpb0Or+0pxbr8UsUAJ9D3fTn/JHI/cO/SLV+w1nXR3ygAS1wWqnX9meMi7mvfwmH2V6DT+4NFzwLRROQ/PddvBlAmYADVMlXa6zAyb5dHpsY1SAnFcyvtdcjM3aX43A2zhyOzRwfnv1/Ov5qlUgh69FzEAzkeLdQCHz0BkVKAN7pXR4/nh0uQRUSB03P95hAekUECmfGk57nyC7qv5/65wHMNN+CHYm/X1115NXgCPGd86Vk7zszZX2qZLT0ZL6XC+JwtJcDVPlOO5wOwfBaNiEKDARSRQQJpoqj1uUoZotG9Oqo+t9Jeh/UqAdSSiX00F5IDwJ8LSrG+oFRTMKG49InLwrv+ZnXUZgQmXRPjVszua7q/2mLKDk3CvdGnltckopaFbQyIDKJlar68GaWe5768u7mOSR4kAFB9rtoCu9k3pznrmxzUprwfPnMBmbm7sO7jUrfAZenmEnx2usbrZyG5vJ4QQP6J89hUVI6Rebv8agypFuQ98JeDHq0fGoXAwTLl/VM6Vjmlz01PCwEiimysgTIBa6Aii95siVqtkJYhJrXnVtrrMCJ3l2JrSkcdk9JzlWqRoiRgT86tisciLxZfPLE38j44ptISs3ltujyVTJTSPkeheYjMrW2DBBTm3AoAPj9npePxxlumzK1oXrZMjOrrAdizVPmzI6LwxxooIoP4M5NMaWq+2tCTfDjIW7dxpYu767CY0nP19gGST3k/UPaN16BCeBnWUtrnJpXXWLPrS2z4pNz5OT8wKgM/H5Xh83iUuna7vZ+X/ZMfa/6J8z5f98HRnvvkigXnRC0HAygiFVqDHi0CLapWW+JDXsekxFcfIPlF3zUQkyQf41xejkNpn+VNQx3e3l/utkjwuo9L8erHpcib6hmw+mo0qXX/APeg09frRknA/SPVe3SFQ9sGIjIOa6AooqnVHGmhdcFbLQJdUkNpiY+lE/vg4dE9vD/R5flKS4v4qkcacl2CfFk8D65ZMG/7HC1JyJnYR/H1lOIfAfWFbx3HMzAtweNzkb++3s9Z6XWjJQm5P+6vGqxy0V6ilocZKIpYgWYEAplVJ2fEkhpGd5TWkmFzdkqXzUhz9eCo7roW7L22bWtn53VHw05Hh3Q5LVk6b0NxgSxdoufz5qK9RC0PAyiKSFqH37zVrBi9jpgRAZA/S5+oUbvof3qqBpMGeC6V8umpGsx7u9ijKPz+Uek+99nxfq6v5/gcACBv2zHF52oNWNWG4gINNLV+3kYG20QUHhhAUUTSkhHQkqHSczHWUkBsZAAUKLW6qnlvF+Pb+u/dPosUWxwmDYjDt/Xf6w4o1T5nx/MKT1YrF8gDfgeswf6cuWgvUcvDNgYmYBuD0NOyvImRS40YUUAcihlcrvvtyttnYdSSLkBzoBsfE61YsL117gjFRZGtjGvWEYU3tjGgFs9XRsDImhUjZuuFagbXtGHd0DYmGo9tOOT2uNaZa76ofc6v7WmeZec43rsHd8E7xRXOhYwfHJWBTu3b+HlUoWOlDCMRmYsBFEUsb8NvRtasBBqMGdkuwfF6ejJZQ9MTTavfUVvSZV1+qVvbgneKK7BlbibeP1yFVwv+jVc+LsWrBaWmBJLyz4e9m4jIHwygKKKpZQSMrFkpOWv3eExPAGJkNszfxp9m1e+k2OJw9+Au2PzpWedjo65PQv6/qt22axQCZ2rq8GrBvw0LJJXIP5+7B3fB1uKz7N1ERLoxgKIWy4jZWpX2OqxUmEG2eEJvza9nVDYskEyW0S0SXPdpa/FZt8cK/lWteLxNQpjaCkDp83EN7LhYMBHpwUaa1KKpNZjUSm2x3gFdr9W1D74WEvZ3X/Q0/gz0s9C6T01o7h3leryLJ/bG3pNfezzfyFYAar8rV1wsmIi0YgaKKABGZY+MyACp1Rv961wtvr5UjyHXJQQ9s6L2+dw/Kh33j0pHWfVlHD5zQXXBYj2ZPH/2RS5KAtrGBPe+kjVYROGJGSiiABiVPXK8ViAZIPm+SFeDhd++exTz3i7GiFzPpVrM5u3zSbHFIT2pLVZuVw6eAH2ZPH/2ZeqNXZz/Bpo/r7vXFgbtc/K1lA4RWRf7QJmAfaDCl7/ZACv1/6m01+HTUzV49O1ij59FScCenFuDvo9qn0/hyWpkr9uv+By9fbm0/u7k+/LZ6RpMeaHQLYgLpCeYVkb3IiOiwLEPFJEfAunFZKX+Pym2OCTEX1L8WZNASNZnU/t81IbVoiR9Xcj1/O7k+3KpodEjAxaMdey4fh5ReOMQHhHUZ7BV2utCu2N+ykiKh6TweJQES63PJh9WiwLw0OgM7Mm5VXPwGujvzhHEuQrGOnahel8iMkbYBFCTJ09Gt27d0KZNG6SkpGDGjBmoqKhw26a8vBx33XUX4uPjkZSUhPnz56OhocFtm5KSEowZMwZxcXHo0qULnnzySchHMXfv3o0hQ4agTZs26N69O1566SXTj49CK9AZbFaTYotD3tT+bkGUdDUzY7XsxrRh3VCQk4UNs4djz9JbseyOG3TtoxGzD42qY9MjVO9LRMYImyG8rKwsLFu2DCkpKTh79iwWLVqEn/zkJygsLAQANDY2YtKkSejYsSMKCgrw9ddfY+bMmRBCYPXq1QCaxzZvv/12ZGVloaioCCdOnMCsWbMQHx+Pxx9/HABQWlqKO+64A7Nnz8abb76JPXv2YO7cuejYsSOmTp0asuMncxnZmdwqHDP7DpbVQJKAG0MwC08rX0Og3uqbjPjdmdUHy6rvS0SBC9si8r/97W+YMmUK6uvr0bp1a2zbtg133nknTp8+jdTUVADAxo0bMWvWLJw7dw7t27fHiy++iKVLl+Krr75CbGwsACAvLw+rV6/GmTNnIEkSlixZgr/97W/44osvnO81Z84cfPbZZ9i7d6/ivtTX16O+vt7579raWqSlpbGIPMxsKir36MbNrtShp6W+ib87IjJCxBeRf/PNN3jrrbcwYsQItG7dGgCwd+9e9OvXzxk8AcD48eNRX1+PgwcPIisrC3v37sWYMWOcwZNjm6VLl6KsrAwZGRnYu3cvxo0b5/Z+48ePx/r163HlyhXn+7nKzc3FE088YdLRUrAEmg1gPx/jae2uzkwOEQVb2NRAAcCSJUsQHx+PDh06oLy8HO+++67zZ1VVVejcubPb9gkJCYiJiUFVVZXqNo5/+9rm+++/R3W1+/pdDkuXLoXdbnf+d/r06cAOlELG315M7OdjDj31TWZ0UiciUhPSAGr58uWQJMnrfwcOHHBu/6tf/QrFxcXYsWMHoqOj8bOf/cytAFySPOcdCSHcHpdv43i+3m1cxcbGon379m7/UcsRaTP4rIQz1YjIqkI6hDdv3jxMnz7d6zbp6enO/52UlISkpCT06tULffv2RVpaGvbt24fMzEwkJydj/373hnw1NTW4cuWKM6OUnJzszDQ5nDt3DgB8btOqVSt06NDBr+OkyMZ+PuZxzFST1zfxcyWiUAtpAOUIiPzhyAo5irczMzOxYsUKVFZWIiUlBQCwY8cOxMbGYsiQIc5tli1bhoaGBsTExDi3SU1NdQZqmZmZeO+999zea8eOHRg6dKhi/RNRJM7gsxLWNxGRFYVFDdQnn3yCNWvW4NChQzh16hQ+/PBDZGdno0ePHsjMzAQAjBs3DjfccANmzJiB4uJi/N///R8WLVqE2bNnO4fUsrOzERsbi1mzZuHIkSPYunUrnn76aSxcuNA5PDdnzhycOnUKCxcuxBdffIE///nPWL9+PRYtWhSy4ydrYz8f87G+iYgsR4SBw4cPi6ysLJGYmChiY2NFenq6mDNnjjhz5ozbdqdOnRKTJk0ScXFxIjExUcybN0989913Hq91yy23iNjYWJGcnCyWL18umpqa3Lb56KOPxODBg0VMTIxIT08XL774oq79tdvtAoCw2+3+HTBZQsWFy2LPl+dFxYXLmrcv/LJa8/ZERGQteq7fYdsHysq4mHD4C2RdPCIiCk96rt9hMYRHFEycVUdERL4wgCKSibR18YiIyHgMoIhkWkrvoUp7HQpPVitm1rz9jIiIwnQpFyIztYTeQ95qvFj/Ff64rBCR+VhEbgIWkUeGSntdRPYeqrTXYWTeLo++VQU5WQCg+rNI+gyMZqWAhQEwkf8ifjFhomBIscWZejHUc9E18gLtrcZLQLCruk5WCli0Lr5MRIFjAEUUAnouukZfoH11TmdXde2sFrBwWSGi4GEROVGQ6WmTYEZLBW+d09lVXR+rzdhsKRMgiKyAGSiiINOTJTAro+BtfTmuPaed1dZBbAkTIIisggEUUZDpueiaeYH2VuNlpfovK7NiwMIAmCg4OAvPBJyFR75sKir3uOh6q4HSum04sFLRtVEidcYmUUuj5/rNAMoEDKBICz0X3Ui5QHtroRDOx0VEkYFtDIjCgJ5hMrOH1IKFs8SIKFJwFh4RBQ1niRFRpGAARURBwzYJRBQpOIRHREHFWWJEFAkYQBFR0EVKTRcRtVwcwiMiIiLSiQEUERERkU4MoIiIiIh0YgBFREREpBMDKCIiIiKdGEARERER6cQAioiIiEgnBlBEREREOjGAIvKh0l6HwpPVqLTXhXpXiIjIItiJnMiLTUXlWLqlBE0CiJKA3B/3x7Rh3UK9W0REFGLMQBGpqLTXOYMnAGgSwLItR5iJIiIiBlBEakqrLzmDJ4dGIVBWfTk0O0RERJbBAIpIRUZSPKIk98eiJQnpSW1Ds0NERGQZDKCIVKTY4pD74/6IlpqjqGhJwtM/7ocUW1yI94yIiEKNReREXkwb1g2je3VEWfVlpCe1ZfBEREQAGEAR+ZRii2PgREREbjiER0RERKQTAygiIiIinRhAEREREekUdgFUfX09Bg0aBEmScOjQIbeflZeX46677kJ8fDySkpIwf/58NDQ0uG1TUlKCMWPGIC4uDl26dMGTTz4JIdyb/ezevRtDhgxBmzZt0L17d7z00ktmHxYRERGFkbArIl+8eDFSU1Px2WefuT3e2NiISZMmoWPHjigoKMDXX3+NmTNnQgiB1atXAwBqa2tx++23IysrC0VFRThx4gRmzZqF+Ph4PP744wCA0tJS3HHHHZg9ezbefPNN7NmzB3PnzkXHjh0xderUoB8vUUtXaa9DafUlZCTFs5ifiCwjrAKobdu2YceOHdi8eTO2bdvm9rMdO3bg6NGjOH36NFJTUwEAzz77LGbNmoUVK1agffv2eOutt/Ddd9/h9ddfR2xsLPr164cTJ07gueeew8KFCyFJEl566SV069YNzz//PACgb9++OHDgAJ555hnVAKq+vh719fXOf9fW1przARC1MFyLkIisKmyG8L766ivMnj0bb7zxBtq29ewEvXfvXvTr188ZPAHA+PHjUV9fj4MHDzq3GTNmDGJjY922qaioQFlZmXObcePGub32+PHjceDAAVy5ckVx33Jzc2Gz2Zz/paWlBXq4RC0e1yIkIisLiwBKCIFZs2Zhzpw5GDp0qOI2VVVV6Ny5s9tjCQkJiImJQVVVleo2jn/72ub7779HdXW14nsvXboUdrvd+d/p06f1HyQRueFahERkZSENoJYvXw5Jkrz+d+DAAaxevRq1tbVYunSp19eTJMnjMSGE2+PybRwF5Hq3cRUbG4v27du7/UdEgeFahERkZSGtgZo3bx6mT5/udZv09HQ89dRT2Ldvn9vQGwAMHToU9913H/7yl78gOTkZ+/fvd/t5TU0Nrly54swoJScnOzNNDufOnQMAn9u0atUKHTp00H+QROQXx1qEy7YcQaMQXIuQiCwlpAFUUlISkpKSfG73pz/9CU899ZTz3xUVFRg/fjw2bdqEm2++GQCQmZmJFStWoLKyEikpKQCaC8tjY2MxZMgQ5zbLli1DQ0MDYmJinNukpqYiPT3duc17773n9v47duzA0KFD0bp164CPmYi041qERGRVkpA3QQoDZWVlyMjIQHFxMQYNGgSguY3BoEGD0LlzZ/z+97/HN998g1mzZmHKlCnONgZ2ux29e/fGrbfeimXLluFf//oXZs2ahd/+9rdubQz69euHhx9+GLNnz8bevXsxZ84cbNiwQXMbg9raWthsNtjtdg7nERERhQk91++wKCLXIjo6Gu+//z7atGmDkSNH4p577sGUKVPwzDPPOLex2WzYuXMnzpw5g6FDh2Lu3LlYuHAhFi5c6NwmIyMDH3zwAT766CMMGjQI//3f/40//elP7AFFRERETmGZgbI6ZqCIiIjCT4vMQBEREREFCwMoIiIiIp0YQBERERHpxACKiIiISCcGUEREREQ6MYAiIiIi0okBFBEREZFODKCIiIiIdGIARURERKRTSBcTjlSO5u61tbUh3hMiIiLSynHd1rJICwMoE1y8eBEAkJaWFuI9ISIiIr0uXrwIm83mdRuuhWeCpqYmVFRUoF27dpAkyfl4bW0t0tLScPr06YhcI4/HF954fOGNxxfeeHzWIITAxYsXkZqaiqgo71VOzECZICoqCl27dlX9efv27S39BxQoHl944/GFNx5feOPxhZ6vzJMDi8iJiIiIdGIARURERKQTA6ggio2Nxe9+9zvExsaGeldMweMLbzy+8MbjC288vvDDInIiIiIinZiBIiIiItKJARQRERGRTgygiIiIiHRiAEVERESkEwMoA9XX12PQoEGQJAmHDh1y+1l5eTnuuusuxMfHIykpCfPnz0dDQ4PbNiUlJRgzZgzi4uLQpUsXPPnkkx7r8ezevRtDhgxBmzZt0L17d7z00ktmHxYmT56Mbt26oU2bNkhJScGMGTNQUVEREcdXVlaGBx54ABkZGYiLi0OPHj3wu9/9zmPfw/X4AGDFihUYMWIE2rZti2uvvVZxm3A+Pq3Wrl2LjIwMtGnTBkOGDMHHH38c6l3ykJ+fj7vuugupqamQJAnvvPOO28+FEFi+fDlSU1MRFxeHsWPH4vPPP3fbpr6+Ho899hiSkpIQHx+PyZMn48yZM27b1NTUYMaMGbDZbLDZbJgxYwYuXLhg8tEBubm5GDZsGNq1a4dOnTphypQpOH78uNs24XyML774IgYMGOBsFpmZmYlt27ZFxLHJ5ebmQpIkLFiwwPlYJB2fJoIMM3/+fDFx4kQBQBQXFzsf//7770W/fv1EVlaW+PTTT8XOnTtFamqqmDdvnnMbu90uOnfuLKZPny5KSkrE5s2bRbt27cQzzzzj3Obf//63aNu2rfjFL34hjh49KtatWydat24t/vrXv5p6XM8995zYu3evKCsrE3v27BGZmZkiMzMzIo5v27ZtYtasWeIf//iHOHnypHj33XdFp06dxOOPPx4RxyeEEL/97W/Fc889JxYuXChsNpvHz8P9+LTYuHGjaN26tVi3bp04evSo+MUvfiHi4+PFqVOnQr1rbj744APx61//WmzevFkAEFu3bnX7eV5enmjXrp3YvHmzKCkpEdOmTRMpKSmitrbWuc2cOXNEly5dxM6dO8Wnn34qsrKyxMCBA8X333/v3GbChAmiX79+orCwUBQWFop+/fqJO++80/TjGz9+vHjttdfEkSNHxKFDh8SkSZNEt27dxLfffhsRx/i3v/1NvP/+++L48ePi+PHjYtmyZaJ169biyJEjYX9srj755BORnp4uBgwYIH7xi184H4+U49OKAZRBPvjgA9GnTx/x+eefewRQH3zwgYiKihJnz551PrZhwwYRGxsr7Ha7EEKItWvXCpvNJr777jvnNrm5uSI1NVU0NTUJIYRYvHix6NOnj9v7Pvzww2L48OEmHpmnd999V0iSJBoaGoQQkXd8q1atEhkZGc5/R8rxvfbaa4oBVKQcnzc33XSTmDNnjttjffr0ETk5OSHaI9/kAVRTU5NITk4WeXl5zse+++47YbPZxEsvvSSEEOLChQuidevWYuPGjc5tzp49K6KiosT27duFEEIcPXpUABD79u1zbrN3714BQBw7dszko3J37tw5AUDs3r1bCBGZx5iQkCBeffXViDm2ixcvip49e4qdO3eKMWPGOAOoSDk+PTiEZ4CvvvoKs2fPxhtvvIG2bdt6/Hzv3r3o168fUlNTnY+NHz8e9fX1OHjwoHObMWPGuDUZGz9+PCoqKlBWVubcZty4cW6vPX78eBw4cABXrlwx4cg8ffPNN3jrrbcwYsQItG7d2rlfkXJ8AGC325GYmOj8d6Qdn1ykH19DQwMOHjzosW/jxo1DYWFhiPZKv9LSUlRVVbkdR2xsLMaMGeM8joMHD+LKlStu26SmpqJfv37Obfbu3QubzYabb77Zuc3w4cNhs9mC/nnY7XYAcJ5vkXSMjY2N2LhxIy5duoTMzMyIObZHH30UkyZNwo9+9CO3xyPl+PRgABUgIQRmzZqFOXPmYOjQoYrbVFVVoXPnzm6PJSQkICYmBlVVVarbOP7ta5vvv/8e1dXVhhyPmiVLliA+Ph4dOnRAeXk53n33XefPIuH4HE6ePInVq1djzpw5zsci6fiURPrxVVdXo7GxUXHfHPseDhz76u04qqqqEBMTg4SEBK/bdOrUyeP1O3XqFNTPQwiBhQsXYtSoUejXr59z3xz76yqcjrGkpATXXHMNYmNjMWfOHGzduhU33HBDRBzbxo0b8emnnyI3N9fjZ5FwfHoxgFKxfPlySJLk9b8DBw5g9erVqK2txdKlS72+niRJHo8JIdwel28jrhbo6t3GyONz+NWvfoXi4mLs2LED0dHR+NnPfuZWQBzuxwcAFRUVmDBhAn7605/iwQcfdPtZJByfN1Y7PjMo7ZsV9ksvf47D1+9S6+sYad68eTh8+DA2bNjg8bNwPsbevXvj0KFD2LdvHx555BHMnDkTR48eVd2vcDm206dP4xe/+AXefPNNtGnTRnW7cD0+f7QK9Q5Y1bx58zB9+nSv26Snp+Opp57Cvn37PNb3GTp0KO677z785S9/QXJyMvbv3+/285qaGly5csUZrScnJ3tE1+fOnQMAn9u0atUKHTp0MOX4HJKSkpCUlIRevXqhb9++SEtLw759+5CZmRkRx1dRUYGsrCxkZmbilVdecdsuEo7PGysen5GSkpIQHR2tuG/yu2UrS05OBtB8h56SkuJ83PU4kpOT0dDQgJqaGre7/HPnzmHEiBHObb766iuP1z9//nzQPo/HHnsMf/vb35Cfn4+uXbs6H4+EY4yJicH1118PoPk6UFRUhD/+8Y9YsmQJgPA9toMHD+LcuXMYMmSI87HGxkbk5+djzZo1ztmU4Xp8fglOqVXkOnXqlCgpKXH+949//EMAEH/961/F6dOnhRA/FOlWVFQ4n7dx40aPIt1rr71W1NfXO7fJy8vzKNLt27ev2/vPmTMn6EW65eXlAoD48MMPhRDhf3xnzpwRPXv2FNOnT3ebCeIQ7sfn4KuIPNyPz5ubbrpJPPLII26P9e3bNyyLyFeuXOl8rL6+XrFId9OmTc5tKioqFIt09+/f79xm3759QSnSbWpqEo8++qhITU0VJ06cUPx5uB+j3K233ipmzpwZ9sdWW1vrdq0rKSkRQ4cOFf/1X/8lSkpKwv74/MEAymClpaWqbQxuu+028emnn4p//vOfomvXrm7TxC9cuCA6d+4s7r33XlFSUiK2bNki2rdvrzhN/Je//KU4evSoWL9+venTxPfv3y9Wr14tiouLRVlZmdi1a5cYNWqU6NGjh3NGVjgf39mzZ8X1118vbr31VnHmzBlRWVnp/M8hnI9PiOYgv7i4WDzxxBPimmuuEcXFxaK4uFhcvHgxIo5PC0cbg/Xr14ujR4+KBQsWiPj4eFFWVhbqXXNz8eJF5+8HgHjuuedEcXGxs91CXl6esNlsYsuWLaKkpETce++9itPEu3btKv75z3+KTz/9VNx6662K08QHDBgg9u7dK/bu3Sv69+8flGnijzzyiLDZbOKjjz5yO9cuX77s3Cacj3Hp0qUiPz9flJaWisOHD4tly5aJqKgosWPHjrA/NiWus/CEiLzj84UBlMGUAighmi9ikyZNEnFxcSIxMVHMmzfPbUq4EEIcPnxY3HLLLSI2NlYkJyeL5cuXO+/uHT766CMxePBgERMTI9LT08WLL75o6vEcPnxYZGVlicTERBEbGyvS09PFnDlzxJkzZyLi+F577TUBQPG/SDg+IYSYOXOm4vE5MojhfnxavfDCC+K6664TMTEx4sYbb3ROnbeSDz/8UPF3NXPmTCFEc4bmd7/7nUhOThaxsbFi9OjRoqSkxO016urqxLx580RiYqKIi4sTd955pygvL3fb5uuvvxb33XefaNeunWjXrp247777RE1NjenHp3auvfbaa85twvkYf/7znzv/xjp27Chuu+02Z/AU7semRB5ARdrx+SIJIWslTERERERecRYeERERkU4MoIiIiIh0YgBFREREpBMDKCIiIiKdGEARERER6cQAioiIiEgnBlBEREREOjGAIiIiItKJARQRERGRTgygiKjFmzVrFiRJgiRJaN26Nbp3745Fixbh0qVLzm02b96MsWPHwmaz4ZprrsGAAQPw5JNP4ptvvgEAVFZWIjs7G71790ZUVBQWLFgQoqMhomBgAEVEBGDChAmorKzEv//9bzz11FNYu3YtFi1aBAD49a9/jWnTpmHYsGHYtm0bjhw5gmeffRafffYZ3njjDQBAfX09OnbsiF//+tcYOHBgKA+FiIKAa+ERUYs3a9YsXLhwAe+8847zsdmzZ+Pvf/873n33Xdx88814/vnn8Ytf/MLjuRcuXMC1117r9tjYsWMxaNAgPP/88+buOBGFDDNQREQK4uLicOXKFbz11lu45pprMHfuXMXt5METEbUMDKCIiGQ++eQTvP3227jtttvwr3/9C927d0fr1q1DvVtEZCEMoIiIAPz973/HNddcgzZt2iAzMxOjR4/G6tWrIYSAJEmh3j0isphWod4BIiIryMrKwosvvojWrVsjNTXVmXHq1asXCgoKcOXKFWahiMiJGSgiIgDx8fG4/vrrcd1117kFStnZ2fj222+xdu1axedduHAhSHtIRFbCDBQRkRc333wzFi9ejMcffxxnz57F3XffjdTUVHz55Zd46aWXMGrUKOfsvEOHDgEAvv32W5w/fx6HDh1CTEwMbrjhhhAeARGZgW0MiKjFU2pjIPe///u/eOGFF1BcXIympib06NEDP/nJT/DYY485Z+Ip1Updd911KCsrM2fHiShkGEARERER6cQaKCIiIiKdGEARERER6cQAioiIiEgnBlBEREREOjGAIiIiItKJARQRERGRTgygiIiIiHRiAEVERESkEwMoIiIiIp0YQBERERHpxACKiIiISKf/H5lgD1eltUXFAAAAAElFTkSuQmCC",
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"plt.plot(projected[:,0], projected[:,1],'.')\n",
"plt.xlabel('PC1')\n",
"plt.ylabel('PC2');"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Structure in the PCA space\n",
"\n",
"Now, what do you notice about the data in this PCA space?\n",
"\n",
"Now, instead of looking like a structure-free blob, we seem to have some structure. What kind of structure do we have?\n",
"\n",
"\"3 clusters\", I hope you are thinking. Biologically speaking, we are now guessing that there were this many cell types in our original sample.\n",
"\n",
"## PCA explained variance\n",
"\n",
"One of the first questions about PCA is how much of the variance in our data are \"explained\" by the first N components of the projected data. Let's plot this."
]
},
{
"cell_type": "code",
"execution_count": 17,
"metadata": {},
"outputs": [
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAjcAAAGwCAYAAABVdURTAAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjkuMiwgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy8hTgPZAAAACXBIWXMAAA9hAAAPYQGoP6dpAABUVUlEQVR4nO3deVhU5d8G8Puw7yO7gAi44wIuuOCSO0a+tlhpWS5lpaWpWZq0/NSyMC2zMlNbtMXUTGw1lVxzK0RUxA0VxGUQQZxBdmae9w9jchzUOTjDwHB/rovrcs45c+bLieT2WSUhhAARERGRlbCxdAFEREREpsRwQ0RERFaF4YaIiIisCsMNERERWRWGGyIiIrIqDDdERERkVRhuiIiIyKrYWbqAmqbVanHx4kW4u7tDkiRLl0NERERGEEKgoKAAgYGBsLG5fdtMvQs3Fy9eRHBwsKXLICIiomo4d+4cGjVqdNtr6l24cXd3B3D94Xh4eFi4GiIiIjKGWq1GcHCw7vf47dS7cFPZFeXh4cFwQ0REVMcYM6SEA4qJiIjIqjDcEBERkVVhuCEiIiKrwnBDREREVoXhhoiIiKwKww0RERFZFYYbIiIisioMN0RERGRVGG6IiIjIqjDcEBERkVWxaLjZuXMnhgwZgsDAQEiShJ9++umO79mxYwc6deoEJycnNGnSBEuWLDF/oURERFRnWDTcFBYWIjIyEosWLTLq+oyMDNx3333o1asXUlJS8Nprr2HSpElYt26dmSslIiIiYyhVxdhzOhdKVbHFarDoxpmxsbGIjY01+volS5agcePGWLhwIQAgPDwc+/fvx/vvv4+HH37YTFUSERERcD24ZOQWIszHFQEKZ4Pzq/7JwuvrU6EVgI0ExA9th+GdG9d4nXVqV/C9e/ciJiZG79igQYPw5Zdfory8HPb29gbvKS0tRWlpqe61Wq02e51ERER1yZ1CC6AfXCQA/xcRgIAGzlCqSpCtKsa5/GJkq0p012sF8FrCEdzTwveW9zSXOhVusrOz4e/vr3fM398fFRUVyM3NRUBAgMF74uPjMXv27JoqkYiIqE5Zk5SFuIT/WlteiWmJtkEKnL1ShLO5hcjMK8LpywXIyC3SvUcA+PWw8o731giBzNwihps7kSRJ77UQosrjleLi4jB16lTda7VajeDgYPMVSEREVIvc3Cqj1QpcVBUjM7cIB8/l44PNJyH+vVYrgHmbThh97/vaNkTHEE8EKJxhbyth/HfJ0Ir/zttKEkJ9XEz7DRmhToWbhg0bIjs7W+9YTk4O7Ozs4O3tXeV7HB0d4ejoWBPlERER1ajbdScVlVVg8bbT+HTbKV148fdwxNWicpRWaG9730aeTmjVUIFQbxeEeLvA3ckeU384aBBc3hzSWu9z44e2w2sJR6ARAraShHeHtq3xVhugjoWb6Oho/Prrr3rHNm/ejKioqCrH2xAREVmrG7uTJAl4tFMjeLo6IP3SNZy8VIDz+YazlS6pr49BtbeVEOLtioYeTth9Khc3ZBbYSsDa8d0NQklpheaOwWV458a4p4UvMnOLEOrjYpFgA1g43Fy7dg2nTp3Svc7IyMDBgwfh5eWFxo0bIy4uDhcuXMA333wDABg/fjwWLVqEqVOn4tlnn8XevXvx5ZdfYtWqVZb6FoiIiMyiqu6ks1eKcCJbjX8yruCr3Zm6a4UAfth/3qj7fjS8PQZHBMDO9vpqMGuSsoxqbTE2uAQonC0WaipZNNzs378fffv21b2uHBszevRorFixAkqlEllZWbrzYWFh2LBhA1566SV8+umnCAwMxMcff8xp4EREZFVW7MnA7F+P4t9hpWjk6Yy8a2UoLtfc9n0Dw/1xTwsfNPd3h8LZHoM//sugK6lLEy9dsAHktbbUhuBiDElUjsitJ9RqNRQKBVQqFTw8PCxdDhER1UM3tsrY2dgg7aIKaRfVSLuowqFzV3HhakmV73O0s0ELf3c09nLGhtTsm7qTJOya0VcvfFTVKmOJdWdMQc7v7zo15oaIiKg2u9N6MXnXSvHJ1nR8vecs5LYsfDAsEg+2D4KtzfXZwcZ0J9WWMTA1jeGGiIjIBG5eL+atB9oiPMAdKVlXcei8CgfP5ePclaq3JGjs5Yz2wZ5oE+iBgAZOmLLacGZS96beumAD1K0xMDWN4YaIiOguXbxapAs2wPX1Yt746YjR73/v4UhEN/1vSZPisjvPTALqZ3AxBsMNERGREW7scvJxc8TRi2rsP5uP5LNXsOdUnl5LSyUPJzt0CfNC++AGaB/sCT8PR9y7cOcdF7qrr91JpsJwQ0REdAdf78nErF/TdLOX7GwlVGhuP2rGRgI2TumFwAb6wcXYhe7YKlN9DDdERFTv3TwQuKCkHPsz87EvIw87T+bimFJ/0+UKjYC7kx06h3qhU4gnokI8kZ5zDTN/TtMLLTcHG4CtMjWB4YaIiOo1vZV+AQR5OuPi1eIqu5lutPTJTujezEf3umsTb/QP97Oq9WLqKoYbIiKyalVNzy6r0OJAVj42HcnG8j2ZumsFoNu2IMTbBV3DvNDS3x3vbDhmME4mzNfV4LMYWmoHhhsiIrJaN++/dF/bABSWVeDvM1duu9rvpyM6YHBEoO61m5NdrdgQkozDcENERFbpyAUVZqxL1S2WJwTwe6pSd97HzQEdG3si8eglg5V+O4Z46t2L42TqFoYbIiKqs27scvJ2dUTy2XzsOHkZO09extGbBgFXerJbYzzRNQQt/d1hYyMZvXEku5zqDoYbIiKqk27scgIAB1sJZXeYnm0rSZjQt5leSGGrjPVhuCEiojpDoxU4kJWPnw5ewMp9WXrnyjQCni726NPSD71b+KJncx9sOXaJrTL1EMMNERHVOjd2N7k52uGv9Fz8eewSth3PQX5R+S3f9+mIjnrTs9kqUz8x3BARUa1yc3eTrQTc2Nvk4WSHbk28qxwIzOnZBDDcEBFRLXH68jWs3X8OS3ac0TuuEUCwpzMGtWmI/uH+iAr1hL2tjdEDgan+YbghIqIaVdnlFOrtgiuF5dh4JBub0rKRnnPtlu+Z94j+rtkAu5zo1hhuiIioxqz6JwuvrU/VbUB5I3tbCR0be+KfjCsG3U0375pdiV1OVBWGGyIiMishBI5cUGNVUha+/zvL4Hyflr54sH0Q+rbyg8LZnt1NdNcYboiIyGRunOWkLq7Ar4cu4rfDF5GZV3TL94y7p6lelxO7m+huMdwQEZFJ3DzL6UZO9jbo3tQH247nGNXlxO4muhsMN0REdFdUReVY+c9ZzNt4wuBcz2Y+eDSqEQaE+8PV0Y5dTlQjGG6IiMgoN3Y5+bg5YufJy0g4cAGJxy6hrEJb5Xsm9G3GLieqcQw3RER0Rzd2OUkAXB1tca1UozvfxMcVGbmF7HKiWoHhhoiIbuu4Uo0Z61J1wUUAuFaqQQNnewzt2AhDOwahTaAHfth/jl1OVCsw3BARkQGtVmDvmTysTjqHP1KVqGqv7UUjOqBnc1/da3Y5UW3BcENERLrxNG4OdtiZfhlr9p/DuSvFt7zeVpLQ1M/N4Di7nKg2YLghIqrnvv/7LF5ff8Sgdcbd0Q4PdAjEY50bI+2iil1OVGcw3BAR1VPn84vw5V8ZWL4n0+Dcm4PDMaJrCJwdbAEAbYMU7HKiOoPhhojIit04fTtA4YwKjRZbj+dg1T9Z2H7ycpV7PAFA60CFLthUYpcT1RUMN0REVurG6ds2EtC3pR+OXFThkrpUd01UaAMkZ141eqNKorqA4YaIyAopVcV6WyFoBbDleA4AwMvVAY92aoTHujRGmI8rVw0mq8NwQ0RkZQpKyvHZ9tNV7vE0qV8zTOjXDI52/3U5cQo3WRuGGyKiOurm8TRnLl/DN3vPYu3+cygs0xhcbytJeLxrY71gU4njaciaMNwQEdVBetshSEALPzecuHRNd76ZnxvaBnrgl0MXoRVgdxPVKww3RER1zM3jaYSALtgMCPfDmO5h6NHMG5Ik4dXYVuxuonqH4YaIqA45m1eIuRuOVzmeZuHwSDzYoZHeMXY3UX3EcENEVAvdOJ6moYcT9pzOw/LdGdhyPKfKtWlsJQldm3jXfKFEtRDDDRFRLaM3ngaAn4ej3to0fVr6IszHFd/syYSG42mIDDDcEBHVIgbjaQBcUpfCyd4Gw6KCMbp7KJr6Xt+w8rl7mnA8DVEVGG6IiGqJzNxCvP3b0SrH0ywa0REDwv31jnE8DVHVGG6IiCws9bwKS3acxh9HlFUGG1tJQptAj5ovjKiOYrghIqphSlUxMi4XIrewFD8knceuU7m6c31b+qJlQ3d8vvMMx9MQVRPDDRFRDVr1TxZeS0jV36jSRsL9kYEY17sJWjW83kIzunsox9MQVRPDDRFRDdBoBb7bl4mZvxzVOy4B+GFcN3QK8dI7zvE0RNXHcENEZEYVGi1+OXQRi7aewpncQoPzAkBZRRUDbYio2hhuiIhMqHLxvUaezth35go+3XYKZ/OKAADuTna4VlKh3yUlSQj1cbFMsURWiuGGiMhEblx870Zerg54plcYRkWH4vfDF/FawhFohOBgYSIzYbghIjKBrCuFmLFOf6AwAEzs2xTP92kGV8frf90O79wY97Tw5WBhIjNiuCEiugsVGi0SUi5g/qbjBsEGAHo089UFm0ocLExkXgw3RETVoNEK/HLoAj76Mx2Z/46puRnH0xBZBsMNEZERKgcKh3i5IOXcVSz8Mx2ncq4BuD6mZnzvJnC2t8OsX9I4nobIwhhuiIju4FYDhRXO9njuniYY3T0Ubv92PQ1o7cfxNEQWxnBDRHQbSlUxZiSkQtwUbMb2DMXkAS3g4WSvd5zjaYgsz8bSBRAR1VbHlGqM+zbZINgAwIDwhgbBhohqB7bcEBHd5Hx+ERZsPon1By9UGWw4UJiodqt2uCkrK0NGRgaaNm0KOztmJCKquyoHC3u5OGDdgfP4es9ZlGm0AIDBEQEID/DAh5tPcqAwUR0hO5UUFRXhxRdfxNdffw0AOHnyJJo0aYJJkyYhMDAQM2bMMHmRRETmcqvBwt2aeCEuNhyRwQ0AAA93DOJAYaI6QvaYm7i4OBw6dAjbt2+Hk5OT7viAAQOwZs0akxZHRGROF/KLMGOdYbD5YFgkVj3bTRdsgOsDhaObejPYENUBsltufvrpJ6xZswbdunWDJEm6461bt8bp06dNWhwRkbnsz7yCV9cdrnJV4UCFs97fb0RUt8gON5cvX4afn5/B8cLCQv5lQES13rkrRZi78Th+P6ys8jwHCxPVfbK7pTp37ozff/9d97oy0Hz++eeIjo42XWVERCagVBVjz+lcpF8qwNw/jqP/Bzvw+2ElbCTg8S7BeH1wOGz//XuMg4WJrIPslpv4+Hjce++9OHr0KCoqKvDRRx8hLS0Ne/fuxY4dO8xRIxFRtdxqsHCPZt54Y3BrhAd4AAD+LyKAg4WJrIjslpvu3btj9+7dKCoqQtOmTbF582b4+/tj79696NSpkzlqJCKSrXJl4ZuDzfxHIvDd2K66YANwsDCRtanWAjXt2rXTTQUnIqptzuYV4uUfDlW5AF8jTxeODySycrLDzYYNG2Bra4tBgwbpHd+0aRO0Wi1iY2NNVhwRkRzXSivw6bZT+PKvDN0ifDfiYGGi+kF2t9SMGTOg0WgMjgshuIAfEdWoysHCF/KL8GPyefR9fzs+234aZRotejX3wdSBzTlYmKgekt1yk56ejtatWxscb9WqFU6dOiW7gMWLF2P+/PlQKpVo06YNFi5ciF69et3y+pUrV2LevHlIT0+HQqHAvffei/fffx/e3t6yP5uI6q5bDRYO9XbBG4Nbo3+4HyRJwqNRwRwsTFTPyG65USgUOHPmjMHxU6dOwdXVVda91qxZgylTpuD1119HSkoKevXqhdjYWGRlZVV5/a5duzBq1CiMHTsWaWlpWLt2LZKSkvDMM8/I/TaIqA5TqoqrDDYT+jTFppfuwYDW/rpxNRwsTFT/yA43999/P6ZMmaK3GvGpU6fw8ssv4/7775d1rwULFmDs2LF45plnEB4ejoULFyI4OBifffZZldfv27cPoaGhmDRpEsLCwtCzZ0+MGzcO+/fvl/ttEFEdVVqhwcI/0w2CDQD0bO4LRzvbmi+KiGoV2eFm/vz5cHV1RatWrRAWFoawsDCEh4fD29sb77//vtH3KSsrQ3JyMmJiYvSOx8TEYM+ePVW+p3v37jh//jw2bNgAIQQuXbqEH3/8EYMHD77l55SWlkKtVut9EVHdtPX4JQz6cCfWJJ0zOMfBwkRUSfaYG4VCgT179iAxMRGHDh2Cs7MzIiIicM8998i6T25uLjQaDfz9/fWO+/v7Izs7u8r3dO/eHStXrsTw4cNRUlKCiooK3H///fjkk09u+Tnx8fGYPXu2rNqIqHbJyC3E278dxdbjOQAAX3dH9G3pi3XJ56ERHCxMRPokIapaCcL8Ll68iKCgIOzZs0dv24Z33nkH3377LY4fP27wnqNHj2LAgAF46aWXMGjQICiVSkybNg2dO3fGl19+WeXnlJaWorS0VPdarVYjODgYKpUKHh4eVb6HiCxPqSrGMaUaW49fxpqkLJRrBOxtJTzdIwwv9m8ON0c7KFXFHCxMVE+o1WooFAqjfn9XaxG/LVu2YMuWLcjJyYFWq7+WxFdffWXUPXx8fGBra2vQSpOTk2PQmlMpPj4ePXr0wLRp0wAAERERcHV1Ra9evTBnzhwEBAQYvMfR0RGOjo5G1UREtcPqf67PhLrxX173tPDFzCGt0dTXTXcsQOHMUENEBmSPuZk9ezZiYmKwZcsW5ObmIj8/X+/LWA4ODujUqRMSExP1jicmJqJ79+5VvqeoqAg2Nvol29peHzxooQYoIjKxPadyMeOmYGMjAXOHttULNkREtyK75WbJkiVYsWIFRo4cedcfPnXqVIwcORJRUVGIjo7GsmXLkJWVhfHjxwMA4uLicOHCBXzzzTcAgCFDhuDZZ5/FZ599puuWmjJlCrp06YLAwMC7roeILKe4TIOPt6Zj6Y7TBue0AjibV4zABhwwTER3JjvclJWV3bJlRa7hw4cjLy8Pb731FpRKJdq2bYsNGzYgJCQEAKBUKvXWvBkzZgwKCgqwaNEivPzyy2jQoAH69euH9957zyT1EJFlbDl2Cf/7OQ0XrhZXeZ4zoYhIDtkDil999VW4ubnhzTffNFdNZiVnQBIRmZ5SVYyM3EKE+bhCK4DZv6Rh89FLAIBAhRNm3t8G+YVleH39EWiE0M2EGt65sYUrJyJLMuuA4pKSEixbtgx//vknIiIiYG9vr3d+wYIFcm9JRPXEjVsmSADsbCWUawTsbCSM7RWGyf2bw8Xh+l9LvVv6ciYUEVWL7HBz+PBhtG/fHgBw5MgRvXOVy50TEd3s5i0TBIByjUD7Rg3w3iMRaNnQXe96zoQiouqSHW62bdtmjjqIyModU6qr3DLh1diWBsGGiOhuyJ4KTkQk1/YTOXgt4YjB8esDheVtuEtEdCfVWsQvKSkJa9euRVZWFsrKyvTOJSQkmKQwIqr78gvL8PZvR5GQcgEA4OliD1VxObTcMoGIzEh2uFm9ejVGjRqFmJgYJCYmIiYmBunp6cjOzsZDDz1kjhqJqI6onAkV6u2C5LNXMeuXNOQVlkGSgKe6h+GVQS2gKi7nQGEiMivZ4ebdd9/Fhx9+iAkTJsDd3R0fffQRwsLCMG7cuCq3PyCi+uHGmVA3auHvhrkPR6BjY08AgIuDHUMNEZmV7DE3p0+fxuDBgwFc37epsLAQkiThpZdewrJly0xeIBHVfjfPhKo0tmcofnuxly7YEBHVBNnhxsvLCwUFBQCAoKAg3XTwq1evoqioyLTVEVGd8M+ZK1XOhBoQ3hAOdpy3QEQ1S3a3VK9evZCYmIh27dph2LBhmDx5MrZu3YrExET079/fHDUSUS2l1Qp89/dZvLvhmME5bplARJYiO9wsWrQIJSUlAK5vbGlvb49du3Zh6NChdXZLBiKSLzO3EK+uO4y/M64AAMK8XXH2SiFnQhGRxcneW6qu495SRNVTOROqsZcLNqVdwvxNx1FSroWLgy1evbcVRnYLwaWCEs6EIiKzMPneUmq1WncjtVp922sZGIisz61mQnVv6o33Ho5AsNf17idumUBEtYFR4cbT0xNKpRJ+fn5o0KBBlXtICSEgSRI0Go3JiyQiy7nVTKjp97bE872bck85Iqp1jAo3W7duhZeXFwDuLUVU39xqJlSHYE8GGyKqlYwKN7179wYAVFRUYPv27Xj66acRHBxs1sKIyLKEEEg4cAFv/nyrPaE4E4qIaidZC1DY2dnh/fffZ9cTkZW7UliGF1YewMtrD6GoTIMQLxfY/NtIw5lQRFTbyZ4K3r9/f2zfvh1jxowxQzlEZGnbT+Rg2o+HcbmgFHY2El4a2ALjezdFDmdCEVEdITvcxMbGIi4uDkeOHEGnTp3g6uqqd/7+++83WXFEVDOUqmKcUBbgl0MXdTt4N/Nzw8Lh7dE2SAGAM6GIqO6Qvc6Njc2te7LqwmwprnNDpG9NUhZmJKTixr8JxnQPxYzYVnCyt7VcYURENzD5Ojc30mq11S6MiGqX8/lFmLEuFTf+C8dGAsb1bsJgQ0R1Fne0I6qnslUleO6bZNzcdKsVQGYuN8ElorpLdssNABQWFmLHjh3IyspCWVmZ3rlJkyaZpDAiMp/NadmYvu4wrhaVG5zjNG8iqutkh5uUlBTcd999KCoqQmFhIby8vJCbmwsXFxf4+fkx3BDVYiXlGrzz+zF8u+8sAKBtkAfubdMQHyamQyMEp3kTkVWQHW5eeuklDBkyBJ999hkaNGiAffv2wd7eHk8++SQmT55sjhqJyAROZBfgxVUHcPLSNQDAs73CMG1QKzjY2eDhTo04zZuIrIbscHPw4EEsXboUtra2sLW1RWlpKZo0aYJ58+Zh9OjRGDp0qDnqJKJquni1CMt2ZmDl32dRrhHwcXPEgmGRuKeFr+4aTvMmImsiO9zY29vr9pPx9/dHVlYWwsPDoVAokJWVZfICiaj6lu/OwOxfj+pet/R3w8pnu8HHzdGCVRERmZfscNOhQwfs378fLVq0QN++ffG///0Pubm5+Pbbb9GuXTtz1EhE1bDjRI5esAGAUznXUK7hcg5EZN1kTwV/9913ERAQAAB4++234e3tjeeffx45OTlYtmyZyQskIvl+SrmAZ77Zb3Bcw2neRFQPyG65iYqK0v3Z19cXGzZsMGlBRFR95Rot3t1wDMt3Z1Z5ntO8iag+kN1yM3v2bJw+fdoctRDRXbhcUIonvvhbF2xe7NcM8UPbwfbfMXKc5k1E9YXsvaUiIiKQlpaGzp0748knn8Tw4cPh6+t75zfWEtxbiqzRgax8PP9dMi6pS+HmaIcPhkViUJuGAK5vislp3kRU18n5/S073ABAWloaVq5cidWrV+P8+fMYMGAAnnzySTz44INwcandTd4MN2QtlKpiZOQW4tA5FT5MPIkyjRZNfV2xdGQUmvm5Wbo8IiKTMnu4udHu3bvx/fffY+3atSgpKYFarb6b25kdww1ZgzVJWYhLSIX2hv97723TEO8Pi4SbY7V2VSEiqtXk/P6+640zXV1d4ezsDAcHB5SXG+5TQ0SmpVQVGwQbCcD/hoQz2BARoZrhJiMjA++88w5at26NqKgoHDhwALNmzUJ2drap6yOim2w8kq0XbABAADibV2yReoiIahvZ/8yLjo7GP//8g3bt2uGpp57CiBEjEBQUZI7aiOgGQgh8t+8s5vx21OAcp3gTEf1Hdrjp27cvvvjiC7Rp08Yc9RBRFUrKNfjfz0fww/7zAIB2jRRIu6CCVnCKNxHRze56QHFdwwHFVNdkq0ow7rtkHDp3FTYSMP3eVhh3TxNkq0s4xZuI6g05v785+pCoFqqc5q0uLscbP6Uh91opFM72+OTxDrrdvLmTNxFR1RhuiGqZqqZ5t2rojmUjo9DYm+NqiIju5K6nghOR6dxqmvfiJzoy2BARGYnhhqgWOXJBXeU070vqUovUQ0RUFxnVLXX48GGjbxgREVHtYojqs3NXivDO75zmTUR0t4wKN+3bt4ckSRBCQPp3h+Fb0Wg0JimMqD45dO4qxn69H7nXSuHhZIdrpRWc5k1EVE1GhZuMjAzdn1NSUvDKK69g2rRpiI6OBgDs3bsXH3zwAebNm2eeKoms2MYj2ZiyJgUl5VqEB3jgqzFRAMBp3kRE1WRUuAkJCdH9+dFHH8XHH3+M++67T3csIiICwcHBePPNN/Hggw+avEgiaySEwBd/ZeDdP45BCKBPS18sGtFRtz8UQw0RUfXIngqempqKsLAwg+NhYWE4etRwvAAR6VOqinEq5xoSDpzH+pSLAIAnuzXGrCFtYGfLMf5ERHdLdrgJDw/HnDlz8OWXX8LJyQkAUFpaijlz5iA8PNzkBRJZk6rWsHljcDjG9gy743g2IiIyjuxws2TJEgwZMgTBwcGIjIwEABw6dAiSJOG3334zeYFE1qKqNWxsJGBwRACDDRGRCckON126dEFGRga+++47HD9+HEIIDB8+HCNGjICrq6s5aiSyCrvTcw3WsNGK6wOHOb6GiMh0qrX9gouLC5577jlT10JktZIyr2D2b1zDhoioJlRr9OK3336Lnj17IjAwEGfPngUAfPjhh/j5559NWhyRNdh4RIknvvgbBSUVaOzlDJt/e6C4hg0RkXnIDjefffYZpk6ditjYWOTn5+sW7fP09MTChQtNXR9Rnfb1nkw8v/IAyiq0GBDuj01TemP3jH5Y9Ww37JrRF8M7N7Z0iUREVkd2uPnkk0/w+eef4/XXX4ed3X+9WlFRUUhNTTVpcUR1lVYrMPeP45j5SxqEAEZ0bYwlT3aEs4MtAhTOiG7qzRYbIiIzkT3mJiMjAx06dDA47ujoiMLCQpMURVRXKVXFSL90Dd//nYWNadkAgFdiWmBC32acEUVEVENkh5uwsDAcPHhQb9ViAPjjjz/QunVrkxVGVNfcvIaNJAHzHo7Ao1HBli2MiKiekR1upk2bhgkTJqCkpARCCPzzzz9YtWoV4uPj8cUXX5ijRqJar6o1bCQAPZv7WKwmIqL6Sna4eeqpp1BRUYHp06ejqKgII0aMQFBQED766CM89thj5qiRqNb758wVrmFDRFRLVGudm2effRbPPvsscnNzodVq4efnZ+q6iOqM9EsFePt3rmFDRFRbVCvcVPLxYZM71W+Hzl3FmOX/IL+oHH7ujsi9Vgqt4Bo2RESWJDvcXLp0Ca+88gq2bNmCnJwcCKHfFl+57g2Rtdt7Og/PfJ2EwjINIhspsOKpLiip0CAztwihPi4MNkREFiI73IwZMwZZWVl48803ERDADf+ofvrz6CW88P31xfmim3jj89FRcHO8/r8TQw0RkWXJDje7du3CX3/9hfbt25uhHKLab33Kebyy9jA0WoGBrf3xyeMd4GRva+myiIjoX7LDTXBwsEFXFFF9oFQVY+mOM1ixJxMAMLRjEOY9HAE722pt0UZERGYi+2/lhQsXYsaMGcjMzDRDOUS10+p/stA9fqsu2HRv6o33H4lksCEiqoVkt9wMHz4cRUVFaNq0KVxcXGBvb693/sqVKyYrjqg2uHi1CHEJqbixvfLvM3m4VFDC8TVERLWQ7HBj6p2/Fy9ejPnz50OpVKJNmzZYuHAhevXqdcvrS0tL8dZbb+G7775DdnY2GjVqhNdffx1PP/20SesiAgAhBN7+9Rhu7ojVcIE+IqJaS3a4GT16tMk+fM2aNZgyZQoWL16MHj16YOnSpYiNjcXRo0fRuHHjKt8zbNgwXLp0CV9++SWaNWuGnJwcVFRUmKwmokparcDMX9Lwx78bYN6IC/QREdVekjBidLBarYaHh4fuz7dTeZ0xunbtio4dO+Kzzz7THQsPD8eDDz6I+Ph4g+s3btyIxx57DGfOnIGXl5dRn1FaWorS0lLda7VajeDgYKhUKlm1Uv2i1Qq8/lMqVv1zDpIEPNyhEdanXIBGCN0CfcM7Vx3AiYjI9NRqNRQKhVG/v41qufH09IRSqYSfnx8aNGhQ5do2QghIkmT0In5lZWVITk7GjBkz9I7HxMRgz549Vb7nl19+QVRUFObNm4dvv/0Wrq6uuP/++/H222/D2bnq7oH4+HjMnj3bqJqIAECjFXh13WH8mHweNhLw/qORGNqxEV4e1IIL9BER1QFGhZutW7fqWkq2bdtmkg/Ozc2FRqOBv7+/3nF/f39kZxt2AwDAmTNnsGvXLjg5OWH9+vXIzc3FCy+8gCtXruCrr76q8j1xcXGYOnWq7nVlyw1RVSo0Wry89hB+PngRtjYSFgyLxAPtgwBcX5yPoYaIqPYzKtz07t27yj+bws2tQJUtQFXRarWQJAkrV66EQqEAACxYsACPPPIIPv300ypbbxwdHeHo6GjSmsk6lWu0mLL6IH5PVcLORsLHj3fAfe0CLF0WERHJVO2NM4uKipCVlYWysjK94xEREUa938fHB7a2tgatNDk5OQatOZUCAgIQFBSkCzbA9TE6QgicP38ezZs3l/ldEF1fnC/90jV88dcZ7EzPhb2thE9HdERMm4aWLo2IiKpBdri5fPkynnrqKfzxxx9Vnjd2zI2DgwM6deqExMREPPTQQ7rjiYmJeOCBB6p8T48ePbB27Vpcu3YNbm5uAICTJ0/CxsYGjRo1kvmdEAFrkrIQl5AK7b/D6m1tJCwbGYW+rfwsWxgREVWb7OVVp0yZgvz8fOzbtw/Ozs7YuHEjvv76azRv3hy//PKLrHtNnToVX3zxBb766iscO3YML730ErKysjB+/HgA18fLjBo1Snf9iBEj4O3tjaeeegpHjx7Fzp07MW3aNDz99NO3HFBMdCtKVbFesAGud4u2CnC3XFFERHTXZLfcbN26FT///DM6d+4MGxsbhISEYODAgfDw8EB8fDwGDx5s9L2GDx+OvLw8vPXWW1AqlWjbti02bNiAkJAQAIBSqURWVpbuejc3NyQmJuLFF19EVFQUvL29MWzYMMyZM0fut0GEUznX9IINAGi5OB8RUZ1n1Do3N/Lw8MDhw4cRGhqK0NBQrFy5Ej169EBGRgbatGmDoqIic9VqEnLmyZP10mgFnvtmP7Ycz9E7bitJ2DWjL8MNEVEtI+f3t+xuqZYtW+LEiRMAgPbt22Pp0qW4cOEClixZgoAAziyh2k+rFZj24yFsOZ4DWwmw+XdyXuXifAw2RER1m+xuqSlTpkCpVAIAZs6ciUGDBmHlypVwcHDAihUrTF0fkUkJcX3l4YQDF2BrI+HTER0QGdyAi/MREVkR2d1SNysqKsLx48fRuHFj+Pj4mKous2G3VP0lhMDsX49ixZ5M2EjAwsc64P7IQEuXRURERjD59gu34+Ligo4dO97tbYjMSgiB+D+OY8WeTADAvEciGWyIiKyUUeHmxu0L7mTBggXVLobI1JSqYmTkFiIx7RKW/xts3n2oHR7pxHWRiIislVHhJiUlxaib3WrbBCJLuHmBPgCYOaQ1RnTlbt5ERNbMqHBjqs0yiWpKVQv0SQDubcstFYiIrJ3sqeA3OnfuHM6fP2+qWohMJiO30GCBPoHrC/QREZF1kx1uKioq8Oabb0KhUCA0NBQhISFQKBR44403UF5ebo4aiWQ7f6XY4JitJCHUx8UC1RARUU2SPVtq4sSJWL9+PebNm4fo6GgAwN69ezFr1izk5uZiyZIlJi+SSI6/z+ThzZ+PALjeFSXABfqIiOoT2evcKBQKrF69GrGxsXrH//jjDzz22GNQqVQmLdDUuM6NdTt6UY3hy/aioKQCA8L9MHNIa5zPL+ECfUREdZxZ17lxcnJCaGiowfHQ0FA4ODjIvR2RyWTlFWH08n9QUFKBLqFeWDSiI5zsbRHs5Wrp0oiIqAbJHnMzYcIEvP322ygtLdUdKy0txTvvvIOJEyeatDgiY+UUlGDkV3/jckEpWjV0x+ejo+Bkb2vpsoiIyAJkt9ykpKRgy5YtaNSoESIjIwEAhw4dQllZGfr374+hQ4fqrk1ISDBdpUS3oC4px+ivknA2rwiNvVzwzdNdoHC2t3RZRERkIbLDTYMGDfDwww/rHQsODjZZQUTGUqqKcSK7AAv/TMcxpRo+bo74dmwX+Hk4Wbo0IiKyINnhZvny5eaog0iWm1cfdrSzwddPd0aIN8fXEBHVd7LH3KSlpd3y3MaNG++qGCJjVLX6cLlGCy9XDmgnIqJqhJuoqCh88sknesdKS0sxceJEPPTQQyYrjOhWqlp9WCu4+jAREV0nO9ysXLkSs2fPRmxsLLKzs3Hw4EF06NABW7duxe7du81RI5GeoxfVBse4+jAREVWSHW6GDh2Kw4cPo6KiAm3btkV0dDT69OmD5ORkdOzY0Rw1EunsPpWLuX8cB3B99WGAqw8TEZE+2QOKAUCj0aCsrAwajQYajQYNGzaEo6OjqWsj0nMiuwDjv01GhVbg/shAvHpvS2RdKebqw0REpEd2y83q1asREREBhUKBkydP4vfff8eyZcvQq1cvnDlzxhw1EuGSugRPLf8HBaXXVx+e/2gEgjxdEN3Um8GGiIj0yA43Y8eOxbvvvotffvkFvr6+GDhwIFJTUxEUFIT27duboUSq7wpLK/D0iiRcVJWgia8rlo3qBEc7rj5MRERVk90tdeDAAbRs2VLvmKenJ3744Qd8++23JiuMCAAqNFpM/P4A0i6q4e3qgBVjuqCBC6d8ExHRrcluuWnZsiUqKirw559/YunSpSgoKAAAXLx4kVPByaSEEPjfL2nYduIynOxt8OWYzmjszRlRRER0e7Jbbs6ePYt7770XWVlZKC0txcCBA+Hu7o558+ahpKQES5YsMUedVM8oVcX46M90rE46B0kCPn6sA9oHN7B0WUREVAfIbrmZPHkyoqKikJ+fD2fn/wZyPvTQQ9iyZYtJi6P6aU1SFrrHb8XqpHMAgP+LCEBMm4YWroqIiOoK2eFm165deOONN+DgoD/uISQkBBcuXDBZYVQ/KVXFmJGQihsXIN5wOBtKVbHFaiIiorpFdrjRarXQaDQGx8+fPw93d3eTFEX11z9nrkDctLWCRghurUBEREaTHW4GDhyIhQsX6l5LkoRr165h5syZuO+++0xZG9UzBSXl+GhLusFxbq1ARERyyB5Q/OGHH6Jv375o3bo1SkpKMGLECKSnp8PHxwerVq0yR41UD2i0ApNXH8SZ3EK4O9qhsKwCWsGtFYiISD7Z4SYwMBAHDx7E6tWrkZycDK1Wi7Fjx+KJJ57QG2BMJEf8hmPYejwHjnY2+O6ZrvDzcERmbhG3ViAiItkkIW4e4WDd1Go1FAoFVCoVPDw8LF0OAVj9TxZmJKQCABaN6ID/iwi0cEVERFTbyPn9LXvMDZEp7T2dhzd+OgIAeGlACwYbIiK6aww3ZDGZuYV4fuX1Xb6HRAZiUv9mli6JiIisAMMNWYSquBxjv07C1aJyRAY3wPxHIiBJkqXLIiIiKyB7QDHR3Tp3pRAvrDyA05cLEaBwwucjO8HJnrt8ExGRaVSr5ebq1av44osvEBcXhytXrgC4vls4VyimO1mTlIV75m1H6gU1AODRTo3g5+Fk4aqIiMiayA43hw8fRosWLfDee+/h/fffx9WrVwEA69evR1xcnKnrIyuiVBVjxjr9rRU+3XaaWysQEZFJyQ43U6dOxZgxY5Ceng4np//+xR0bG4udO3eatDiyLhuPZOPmdQe4tQIREZma7HCTlJSEcePGGRwPCgpCdna2SYoi66NUFePjLacMjnNrBSIiMjXZ4cbJyQlqtdrg+IkTJ+Dr62uSosi6lJRrMP7bZOQXlaGhhyNs/p0Uxa0ViIjIHGTPlnrggQfw1ltv4YcffgBwfePMrKwszJgxAw8//LDJC6S6TQiBN346gkPnVWjgYo8fxnWHvZ3ErRWIiMhsZLfcvP/++7h8+TL8/PxQXFyM3r17o1mzZnB3d8c777xjjhqpDvtm71n8mHweNhKw6PGOaOx9PdBEN/VmsCEiIrOQ3XLj4eGBXbt2YevWrThw4AC0Wi06duyIAQMGmKM+qsP2ncnD278dBQDExYajZ3MfC1dERET1gexwk5mZidDQUPTr1w/9+vUzR01kBS5cLcaElQdQoRV4oH0gnukVZumSiIionpDdLdWkSRP07NkTS5cu1S3gR3SjygHEeYVlaB3ggblDubUCERHVHNnhZv/+/YiOjsacOXMQGBiIBx54AGvXrkVpaak56qM6RKkqxp5TuZiy+iBSL6jg6WKPpSM7wdmBWysQEVHNkYQQN6+rZhQhBLZv347vv/8e69atg0ajwcMPP4yvvvrK1DWalFqthkKhgEqlgoeHh6XLsRprkrIQl5AK7b8/TZIErBzbFd2bcZwNERHdPTm/v6u9K7gkSejbty8+//xz/Pnnn2jSpAm+/vrr6t6O6jClqlgv2FQK83W1TEFERFSvVTvcnDt3DvPmzUP79u3RuXNnuLq6YtGiRaasjeqIjNxCg2AjBLitAhERWYTs2VLLli3DypUrsXv3brRs2RJPPPEEfvrpJ4SGhpqhPKoLGjUwXK+G2yoQEZGlyA43b7/9Nh577DF89NFHaN++vRlKorrmq92Zeq+5rQIREVmS7HCTlZXFab2k8/PBC1ixJxMAMP+RCDTydOG2CkREZFFGhZvDhw+jbdu2sLGxQWpq6m2vjYiIMElhVPudvFSAGeuu/zxM7NsMj0YFW7giIiIiI8NN+/btkZ2dDT8/P7Rv3x6SJOHGGeSVryVJgkajMVuxVHsUlJRj/LfJKC7XoGczH7w0sIWlSyIiIgJgZLjJyMiAr6+v7s9UvwkhMG3tYZzJLUSgwgkfPdYetjbsqiQiotrBqHATEhKi+/PZs2fRvXt32Nnpv7WiogJ79uzRu5as0xd/ZWBjWjbsbSV8+kRHeLs5WrokIiIiHdnr3PTt27fKPaVUKhX69u1rkqKo9vr7TB7mbjwOAPjfkDbo0NjTwhURERHpkz1bqnJszc3y8vLg6soVaa2VUlWMlLP5eP2nNGi0Ag91CMKTXRtbuiwiIiIDRoeboUOHArg+eHjMmDFwdPyvK0Kj0eDw4cPo3r276Sski7t536iGHo5496F2XBKAiIhqJaPDjUKhAHC95cbd3R3Ozv+tY+Lg4IBu3brh2WefNX2FZFFV7RuVU1CKq8VlcHbgWjZERFT7GB1uli9fDgAIDQ3FK6+8wi6oeqKqfaO0/+4bxYX6iIioNpI95mbmzJnmqINqKUc7wzHn3DeKiIhqM9nhBgB+/PFH/PDDD8jKykJZWZneuQMHDpikMLK8sgot3v7tmN4x7htFRES1neyp4B9//DGeeuop+Pn5ISUlBV26dIG3tzfOnDmD2NhYc9RIFjJv43EcPHcVHk52SHg+Gque7YZdM/pieGfOkiIiotpLdrhZvHgxli1bhkWLFsHBwQHTp09HYmIiJk2aBJVKJbuAxYsXIywsDE5OTujUqRP++usvo963e/du2NnZcWdyM9mclo0vdl1fjfr9RyPRMcQL0U292WJDRES1nuxwk5WVpZvy7ezsjIKCAgDAyJEjsWrVKln3WrNmDaZMmYLXX38dKSkp6NWrF2JjY5GVlXXb96lUKowaNQr9+/eXWz4Z4Xx+EV5ZewgAMLZnGGLaNLRwRURERMaTHW4aNmyIvLw8ANe3Zdi3bx+A63tO3biZpjEWLFiAsWPH4plnnkF4eDgWLlyI4OBgfPbZZ7d937hx4zBixAhER0fLLZ/uoKxCi4nfp0BdUoHI4AZ49d5Wli6JiIhIFtnhpl+/fvj1118BAGPHjsVLL72EgQMHYvjw4XjooYeMvk9ZWRmSk5MRExOjdzwmJgZ79uy55fuWL1+O06dPGz1rq7S0FGq1Wu+Lbm3+pv/G2Sx6vAMcqpgtRUREVJvJni21bNkyaLVaAMD48ePh5eWFXbt2YciQIRg/frzR98nNzYVGo4G/v7/ecX9/f2RnZ1f5nvT0dMyYMQN//fWXwcadtxIfH4/Zs2cbXVd99ufRS/j8r+vjbOY/GolgL073JiKiukd2uLGxsYGNzX//mh82bBiGDRtW7QJuXsL/VntXaTQajBgxArNnz0aLFi2Mvn9cXBymTp2qe61WqxEcHFzteq3VhavFePnfcTZP9QjFII6zISKiOsqocHP48GGjbxgREWHUdT4+PrC1tTVopcnJyTFozQGAgoIC7N+/HykpKZg4cSIAQKvVQggBOzs7bN68Gf369TN4n6Ojo94+WGQo60ohnl6RBFVxOSIbKRAXG27pkoiIiKrNqHDTvn17SJJ0xwHDkiRBo9EY9cEODg7o1KkTEhMT9cbqJCYm4oEHHjC43sPDA6mpqXrHFi9ejK1bt+LHH39EWFiYUZ9L+tYkZWHGulRU/pe9t21DjrMhIqI6zahwk5GRYZYPnzp1KkaOHImoqChER0dj2bJlyMrK0o3diYuLw4ULF/DNN9/AxsYGbdu21Xu/n58fnJycDI6TcZSqYsxI+C/YAMD7m07iwQ5BXM+GiIjqLKPCTUhIiFk+fPjw4cjLy8Nbb70FpVKJtm3bYsOGDbrPUyqVd1zzhqrvyHkVbm6M0wjBTTGJiKhOk4TMxWm++eab254fNWrUXRVkbmq1GgqFAiqVCh4eHpYux6Ke+Xo//jx2Se+YrSRh14y+DDdERFSryPn9LXu21OTJk/Vel5eXo6ioCA4ODnBxcan14Yau+/ngBfx57BIkCZAAaAU3xSQiIusgO9zk5+cbHEtPT8fzzz+PadOmmaQoMq+LV4vxxk9HAABT+rfAsM6NkJlbhFAfFwYbIiKq82SHm6o0b94cc+fOxZNPPonjx4+b4pZkJlqtwCtrD6Hg3+0VJvRtCjtbG4YaIiKyGiab82tra4uLFy+a6nZkJsv3ZGLP6Tw429viw2GRsLPltG8iIrIusltufvnlF73XQggolUosWrQIPXr0MFlhZHonsgvw3sbrLWuvDw5HE183C1dERERkerLDzYMPPqj3WpIk+Pr6ol+/fvjggw9MVReZWGmFBlPWHERZhRZ9W/riia6NLV0SERGRWcgON5WbZlLdsvDPdBxTquHpYo/3Homocv8uIiIia8ABF/VAUuYVLNlxGgAQPzQCfu5OFq6IiIjIfGS33Agh8OOPP2Lbtm3IyckxaMlJSEgwWXF099IvFeD575IhBPBop0a4ty13+yYiIutWrUX8li1bhr59+8Lf35/dG7XYmqQsvLruv81G2wbV7xWZiYiofpAdbr777jskJCTgvvvuM0c9ZCKVm2Le6K1fjyGmTUOuaUNERFZN9pgbhUKBJk2amKMWMqG0i+pbbopJRERkzWSHm1mzZmH27NkoLi42Rz1kIr8dMlxQ0VaSEOrjYoFqiIiIao7sbqlHH30Uq1atgp+fH0JDQ2Fvb693/sCBAyYrjqpn7+k8/HTwerixkbgpJhER1S+yw82YMWOQnJyMJ598kgOKa6GScg3iEg4DAEZ0bYwX+zXjpphERFSvyA43v//+OzZt2oSePXuaox66Sx/+eRKZeUVo6OGEGbGt4OFkz1BDRET1iuwxN8HBwfDw4JTi2ujw+av4fOcZAMCcB9vCw8n+Du8gIiKyPrLDzQcffIDp06cjMzPTDOVQdZVrtJj+42FoBTAkMhADWvtbuiQiIiKLkN0t9eSTT6KoqAhNmzaFi4uLwYDiK1eumKw4Mt7SHadxPLsAni72mDmktaXLISIishjZ4WbhwoVmKIPuxqmca/h4yykAwMwhbeDj5mjhioiIiCxHdrgZPXq0OeqgatJqBV5ddxhlGi36tvTFA+0DLV0SERGRRckON1lZWbc937hx42oXQ/J9u+8sks/mw9XBFnMeasep+UREVO/JDjehoaG3/QWq0WjuqiAy3oGzV/DuhmMAgBmxrRDUgFO+iYiIZIeblJQUvdfl5eVISUnBggUL8M4775isMLq91f9k6W2MaWcre+IbERGRVZIdbiIjIw2ORUVFITAwEPPnz8fQoUNNUhjdmlJVjLibdvx+Y/0R9GnpywX7iIio3jPZP/dbtGiBpKQkU92ObuPIeTVu2vCbO34TERH9S3bLjVqt1nsthIBSqcSsWbPQvHlzkxVGt/Z7Knf8JiIiuhXZ4aZBgwYGA4qFEAgODsbq1atNVhhV7UBWPn4+xB2/iYiIbkV2uNm6dateuLGxsYGvry+aNWsGOzvZtyMZKjRavL7+CIQAHu7YCK8MasEdv4mIiG4iO4306dPHDGWQMb7eexbHlGoonO3x2n2t4O3myFBDRER0E9kDiuPj4/HVV18ZHP/qq6/w3nvvmaQoMqRUFWPB5hMArq9p480tFoiIiKokO9wsXboUrVq1Mjjepk0bLFmyxCRFkaG3fzuKwjINOjZugOFRwZYuh4iIqNaSHW6ys7MREBBgcNzX1xdKpdIkRZG+bSdysCE1G7Y2EuY82A42NtxigYiI6FZkh5vg4GDs3r3b4Pju3bsRGMhNG02tpFyDmT+nAQCe6h6K1oEeFq6IiIiodpM9oPiZZ57BlClTUF5ejn79+gEAtmzZgunTp+Pll182eYH13afbTiHrShECFE6YMrCFpcshIiKq9WSHm+nTp+PKlSt44YUXUFZWBgBwcnLCq6++iri4OJMXWJ+dyrmGJTtOAwBmDmkNN0dOtSciIroTSQhx80r+Rrl27RqOHTsGZ2dnNG/eHI6OdWP2jlqthkKhgEqlgodH7e3iEUJgxOd/Y++ZPPRr5YcvR0fddjd2IiIiaybn93e1mwLc3NzQuXPn6r6dbkOpKsa3e89i75k8ONnbYPb9bRhsiIiIjMR+jlpmTVIW4hJSof23Pa13C18Ee3HPKCIiImOZbFdwuntKVbFesAGAxKOXoFQVW64oIiKiOobhphbJyC3UCzbA9Y0xM3OLLFMQERFRHcRwU4uE+bgaHLOVJIT6sFuKiIjIWAw3tUj6pWt6r20lCe8ObcvNMYmIiGTggOJaQqMVeHfDMQDA8KhgPNghCKE+Lgw2REREMjHc1BJr95/D8ewCKJztEXdfKzRwcbB0SURERHUSu6VqgWulFXh/80kAwKT+zRlsiIiI7gLDTS2wZPtp5F4rRai3C0Z2C7F0OURERHUaw42FXbxajM//OgMAiLsvHA52/E9CRER0N/ib1MLmbzqB0gotuoR5Iaa1v6XLISIiqvMYbizo0LmrWJ9yAQDw5uDW3D+KiIjIBBhuLEQIgTm/HwUADO0YhHaNFBauiIiIyDow3FjIxiPZSMrMh5O9DaYNamnpcoiIiKwGw40FlFZoMHfjcQDAc72acKE+IiIiE+IifjVMqSrGp1tP4WxeEXzdHTGud1NLl0RERGRVGG5q0JqkLMQlpOp2/u7d3BeujvxPQEREZErslqohSlWxXrABgISU81Cqii1XFBERkRViuKkhGbmFesEGALQCyMwtskxBREREVorhpoaE+bji5mVsbCUJoT4ulimIiIjISjHc1JAAhTOGRATqXttKEt4d2pYzpYiIiEyMo1lrUGWv1KOdGmFqTAsGGyIiIjNgy00N2p95BQDwUMcgBhsiIiIzYbipIReuFkOpKoGtjYT2wQ0sXQ4REZHVYripIZWtNm0DPeDiwN5AIiIic2G4qSH7M/MBAJ1CvCxcCRERkXVjuKkhSf+23HQO9bRwJURERNaN4aYGqIrLceJSAQCgE8MNERGRWTHc1ICUrHwIAYR4u8DP3cnS5RAREVk1i4ebxYsXIywsDE5OTujUqRP++uuvW16bkJCAgQMHwtfXFx4eHoiOjsamTZtqsNrqqRxvE8XxNkRERGZn0XCzZs0aTJkyBa+//jpSUlLQq1cvxMbGIisrq8rrd+7ciYEDB2LDhg1ITk5G3759MWTIEKSkpNRw5fLsP3t9vE0Uu6SIiIjMThJCiDtfZh5du3ZFx44d8dlnn+mOhYeH48EHH0R8fLxR92jTpg2GDx+O//3vf0Zdr1aroVAooFKp4OHhUa265SjXaNFu1iaUlGvx59R70MzP3eyfSUREZG3k/P62WMtNWVkZkpOTERMTo3c8JiYGe/bsMeoeWq0WBQUF8PK6dXdPaWkp1Gq13ldNSruoRkm5Fg1c7NHEx61GP5uIiKg+sli4yc3NhUajgb+/v95xf39/ZGdnG3WPDz74AIWFhRg2bNgtr4mPj4dCodB9BQcH31XdclUu3hcV4gkbG+kOVxMREdHdsviAYknS/4UvhDA4VpVVq1Zh1qxZWLNmDfz8/G55XVxcHFQqle7r3Llzd12zHFy8j4iIqGZZbB8AHx8f2NraGrTS5OTkGLTm3GzNmjUYO3Ys1q5diwEDBtz2WkdHRzg6Ot51vdUhhNANJubifURERDXDYi03Dg4O6NSpExITE/WOJyYmonv37rd836pVqzBmzBh8//33GDx4sLnLvCtn84qQe60MDrY2aBuksHQ5RERE9YJFd3CcOnUqRo4ciaioKERHR2PZsmXIysrC+PHjAVzvUrpw4QK++eYbANeDzahRo/DRRx+hW7duulYfZ2dnKBS1LzxUbrkQ0UgBJ3tbC1dDRERUP1g03AwfPhx5eXl46623oFQq0bZtW2zYsAEhISEAAKVSqbfmzdKlS1FRUYEJEyZgwoQJuuOjR4/GihUrarr8O0o+++94G3ZJERER1RiLrnNjCTW5zk3/D7bj9OVCfDEqCgNa334cEREREd1anVjnxtpdKSzD6cuFAIBOIWy5ISIiqikMN2ZS2SXVzM8Nnq4OFq6GiIio/mC4MRNOASciIrIMhhsz4eJ9RERElsFwYwYl5RqknlcBYMsNERFRTWO4MYPUCyqUabTwcXNEYy8XS5dDRERUrzDcmEHl4n2dQz2N2ieLiIiITIfhxgySdeNt2CVFRERU0xhuTEyrFdj/7zTwzqEcTExERFTTGG5M7PTla1AVl8PZ3hatA827AjIREREZYrgxsaR/u6TaBzeAvS0fLxERUU3jb18Tq1y8L4pTwImIiCyC4cbEKhfvi+J4GyIiIotguDGhHHUJsq4UwUYCOjZuYOlyiIiI6iWGGxOqnCXVsqEH3J3sLVwNERFR/cRwY0I7TlwGALQOcLdwJURERPUXw42JrEnKwpr95wAACQcuYE1SloUrIiIiqp8YbkxAqSpGXEKq7rUA8FrCEShVxZYrioiIqJ5iuDGBjNxCaIX+MY0QyMwtskxBRERE9RjDjQmE+bjC5qb9MW0lCaE+3BGciIiopjHcmECAwhnxQ9vB9t8dwG0lCe8ObYsAhbOFKyMiIqp/7CxdgLUY3rkx7mnhi8zcIoT6uDDYEBERWQjDjQkFKJwZaoiIiCyM3VJERERkVRhuiIiIyKow3BAREZFVYbghIiIiq8JwQ0RERFaF4YaIiIisCsMNERERWRWGGyIiIrIqDDdERERkVRhuiIiIyKow3BAREZFVqXd7SwkhAABqtdrClRAREZGxKn9vV/4ev516F24KCgoAAMHBwRauhIiIiOQqKCiAQqG47TWSMCYCWRGtVouLFy/C3d0dkiSZ9N5qtRrBwcE4d+4cPDw8THpvMsTnXbP4vGsWn3fN4vOuWdV53kIIFBQUIDAwEDY2tx9VU+9abmxsbNCoUSOzfoaHhwf/56hBfN41i8+7ZvF51yw+75ol93nfqcWmEgcUExERkVVhuCEiIiKrwnBjQo6Ojpg5cyYcHR0tXUq9wOdds/i8axafd83i865Z5n7e9W5AMREREVk3ttwQERGRVWG4ISIiIqvCcENERERWheGGiIiIrArDjYksXrwYYWFhcHJyQqdOnfDXX39ZuiSrsXPnTgwZMgSBgYGQJAk//fST3nkhBGbNmoXAwEA4OzujT58+SEtLs0yxdVx8fDw6d+4Md3d3+Pn54cEHH8SJEyf0ruHzNp3PPvsMERERuoXMoqOj8ccff+jO81mbV3x8PCRJwpQpU3TH+MxNZ9asWZAkSe+rYcOGuvPmfNYMNyawZs0aTJkyBa+//jpSUlLQq1cvxMbGIisry9KlWYXCwkJERkZi0aJFVZ6fN28eFixYgEWLFiEpKQkNGzbEwIEDdfuIkfF27NiBCRMmYN++fUhMTERFRQViYmJQWFiou4bP23QaNWqEuXPnYv/+/di/fz/69euHBx54QPcXPJ+1+SQlJWHZsmWIiIjQO85nblpt2rSBUqnUfaWmpurOmfVZC7prXbp0EePHj9c71qpVKzFjxgwLVWS9AIj169frXmu1WtGwYUMxd+5c3bGSkhKhUCjEkiVLLFChdcnJyREAxI4dO4QQfN41wdPTU3zxxRd81mZUUFAgmjdvLhITE0Xv3r3F5MmThRD8+Ta1mTNnisjIyCrPmftZs+XmLpWVlSE5ORkxMTF6x2NiYrBnzx4LVVV/ZGRkIDs7W+/5Ozo6onfv3nz+JqBSqQAAXl5eAPi8zUmj0WD16tUoLCxEdHQ0n7UZTZgwAYMHD8aAAQP0jvOZm156ejoCAwMRFhaGxx57DGfOnAFg/mdd7zbONLXc3FxoNBr4+/vrHff390d2draFqqo/Kp9xVc//7NmzlijJagghMHXqVPTs2RNt27YFwOdtDqmpqYiOjkZJSQnc3Nywfv16tG7dWvcXPJ+1aa1evRoHDhxAUlKSwTn+fJtW165d8c0336BFixa4dOkS5syZg+7duyMtLc3sz5rhxkQkSdJ7LYQwOEbmw+dvehMnTsThw4exa9cug3N83qbTsmVLHDx4EFevXsW6deswevRo7NixQ3eez9p0zp07h8mTJ2Pz5s1wcnK65XV85qYRGxur+3O7du0QHR2Npk2b4uuvv0a3bt0AmO9Zs1vqLvn4+MDW1taglSYnJ8cgkZLpVY685/M3rRdffBG//PILtm3bhkaNGumO83mbnoODA5o1a4aoqCjEx8cjMjISH330EZ+1GSQnJyMnJwedOnWCnZ0d7OzssGPHDnz88cews7PTPVc+c/NwdXVFu3btkJ6ebvafb4abu+Tg4IBOnTohMTFR73hiYiK6d+9uoarqj7CwMDRs2FDv+ZeVlWHHjh18/tUghMDEiRORkJCArVu3IiwsTO88n7f5CSFQWlrKZ20G/fv3R2pqKg4ePKj7ioqKwhNPPIGDBw+iSZMmfOZmVFpaimPHjiEgIMD8P993PSSZxOrVq4W9vb348ssvxdGjR8WUKVOEq6uryMzMtHRpVqGgoECkpKSIlJQUAUAsWLBApKSkiLNnzwohhJg7d65QKBQiISFBpKamiscff1wEBAQItVpt4crrnueff14oFAqxfft2oVQqdV9FRUW6a/i8TScuLk7s3LlTZGRkiMOHD4vXXntN2NjYiM2bNwsh+Kxrwo2zpYTgMzell19+WWzfvl2cOXNG7Nu3T/zf//2fcHd31/1uNOezZrgxkU8//VSEhIQIBwcH0bFjR93UWbp727ZtEwAMvkaPHi2EuD6lcObMmaJhw4bC0dFR3HPPPSI1NdWyRddRVT1nAGL58uW6a/i8Tefpp5/W/b3h6+sr+vfvrws2QvBZ14Sbww2fuekMHz5cBAQECHt7exEYGCiGDh0q0tLSdOfN+awlIYS4+/YfIiIiotqBY26IiIjIqjDcEBERkVVhuCEiIiKrwnBDREREVoXhhoiIiKwKww0RERFZFYYbIiIisioMN0RERGRVGG6ISKdPnz6YMmWKpcvQEULgueeeg5eXFyRJwsGDBy1dEhHVAQw3RFRrbdy4EStWrMBvv/0GpVKJtm3bWrqkOmnFihVo0KCBpcsgqjF2li6AiKybRqOBJEmwsZH/b6nTp08jICCAOzITkSxsuSGqZfr06YNJkyZh+vTp8PLyQsOGDTFr1izd+czMTIMumqtXr0KSJGzfvh0AsH37dkiShE2bNqFDhw5wdnZGv379kJOTgz/++APh4eHw8PDA448/jqKiIr3Pr6iowMSJE9GgQQN4e3vjjTfewI1b0JWVlWH69OkICgqCq6srunbtqvtc4L9Wgt9++w2tW7eGo6Mjzp49W+X3umPHDnTp0gWOjo4ICAjAjBkzUFFRAQAYM2YMXnzxRWRlZUGSJISGht7yme3evRu9e/eGi4sLPD09MWjQIOTn5wMASktLMWnSJPj5+cHJyQk9e/ZEUlKS7r3VfVZ9+vTBxIkTb/us8vPzMWrUKHh6esLFxQWxsbFIT083eFabNm1CeHg43NzccO+990KpVOp9f8uXL0d4eDicnJzQqlUrLF68WHeu8uchISEBffv2hYuLCyIjI7F3717d9/fUU09BpVJBkiRIkqT7eVq8eDGaN28OJycn+Pv745FHHrnlMyaqU0yy/SYRmUzv3r2Fh4eHmDVrljh58qT4+uuvhSRJut2iMzIyBACRkpKie09+fr4AILZt2yaE+G8n9W7duoldu3aJAwcOiGbNmonevXuLmJgYceDAAbFz507h7e0t5s6dq/fZbm5uYvLkyeL48ePiu+++Ey4uLmLZsmW6a0aMGCG6d+8udu7cKU6dOiXmz58vHB0dxcmTJ4UQQixfvlzY29uL7t27i927d4vjx4+La9euGXyf58+fFy4uLuKFF14Qx44dE+vXrxc+Pj5i5syZQgghrl69Kt566y3RqFEjoVQqRU5OTpXPKyUlRTg6Oornn39eHDx4UBw5ckR88skn4vLly0IIISZNmiQCAwPFhg0bRFpamhg9erTw9PQUeXl5Zn9W999/vwgPDxc7d+4UBw8eFIMGDRLNmjUTZWVles9qwIABIikpSSQnJ4vw8HAxYsQI3T2WLVsmAgICxLp168SZM2fEunXrhJeXl1ixYoXez0OrVq3Eb7/9Jk6cOCEeeeQRERISIsrLy0VpaalYuHCh8PDwEEqlUiiVSlFQUCCSkpKEra2t+P7770VmZqY4cOCA+Oijj27zk0lUdzDcENUyvXv3Fj179tQ71rlzZ/Hqq68KIeSFmz///FN3TXx8vAAgTp8+rTs2btw4MWjQIL3PDg8PF1qtVnfs1VdfFeHh4UIIIU6dOiUkSRIXLlzQq69///4iLi5OCHH9FzYAcfDgwdt+n6+99ppo2bKl3md9+umnws3NTWg0GiGEEB9++KEICQm57X0ef/xx0aNHjyrPXbt2Tdjb24uVK1fqjpWVlYnAwEAxb948IYT5ntXJkycFALF7927d+dzcXOHs7Cx++OEHIcR/z+rUqVN6z8Df31/3Ojg4WHz//fd639fbb78toqOjhRD//Tx88cUXuvNpaWkCgDh27JjucxQKhd491q1bJzw8PIRara7y2RHVZeyWIqqFIiIi9F4HBAQgJyfnru7j7+8PFxcXNGnSRO/Yzfft1q0bJEnSvY6OjkZ6ejo0Gg0OHDgAIQRatGgBNzc33deOHTtw+vRp3XscHBwMvoebHTt2DNHR0Xqf1aNHD1y7dg3nz583+ns8ePAg+vfvX+W506dPo7y8HD169NAds7e3R5cuXXDs2DG9a039rI4dOwY7Ozt07dpVd97b2xstW7bU+2wXFxc0bdpU9/rG/9aXL1/GuXPnMHbsWL3nPWfOHL3nfXP9AQEBAHDbn5mBAwciJCQETZo0wciRI7Fy5UqDLkqiuooDiolqIXt7e73XkiRBq9UCgG5grrhhbEd5efkd7yNJ0m3vawytVgtbW1skJyfD1tZW75ybm5vuz87Oznq/9KsihDC4pvJ7utN7b+Ts7Hzbz6jqflV9tqmf1Y3/fW732VV9TuV7Kz/v888/1wtJAAye/8313/j+qri7u+PAgQPYvn07Nm/ejP/973+YNWsWkpKSOLOK6jy23BDVMb6+vgCgN+jUlOu/7Nu3z+B18+bNYWtriw4dOkCj0SAnJwfNmjXT+2rYsKGsz2ndujX27NmjFwL27NkDd3d3BAUFGX2fiIgIbNmypcpzzZo1g4ODA3bt2qU7Vl5ejv379yM8PFxWvVW53bNq3bo1Kioq8Pfff+vO5+Xl4eTJk0Z/tr+/P4KCgnDmzBmD5x0WFmZ0nQ4ODtBoNAbH7ezsMGDAAMybNw+HDx9GZmYmtm7davR9iWorttwQ1THOzs7o1q0b5s6di9DQUOTm5uKNN94w2f3PnTuHqVOnYty4cThw4AA++eQTfPDBBwCAFi1a4IknnsCoUaPwwQcfoEOHDsjNzcXWrVvRrl073HfffUZ/zgsvvICFCxfixRdfxMSJE3HixAnMnDkTU6dOlTVtPC4uDu3atcMLL7yA8ePHw8HBAdu2bcOjjz4KHx8fPP/885g2bRq8vLzQuHFjzJs3D0VFRRg7dqzsZ3Oz2z2r5s2b44EHHsCzzz6LpUuXwt3dHTNmzEBQUBAeeOABoz9j1qxZmDRpEjw8PBAbG4vS0lLs378f+fn5mDp1qlH3CA0NxbVr17BlyxZERkbCxcUFW7duxZkzZ3DPPffA09MTGzZsgFarRcuWLav1LIhqE4Ybojroq6++wtNPP42oqCi0bNkS8+bNQ0xMjEnuPWrUKBQXF6NLly6wtbXFiy++iOeee053fvny5ZgzZw5efvllXLhwAd7e3oiOjpYVbAAgKCgIGzZswLRp0xAZGQkvLy+MHTtWdlBr0aIFNm/ejNdeew1dunSBs7MzunbtiscffxwAMHfuXGi1WowcORIFBQWIiorCpk2b4OnpKetzqmLMs5o8eTL+7//+D2VlZbjnnnuwYcMGg66o23nmmWfg4uKC+fPnY/r06XB1dUW7du1krSTdvXt3jB8/HsOHD0deXh5mzpyJAQMGICEhAbNmzUJJSQmaN2+OVatWoU2bNnIeAVGtJIlbdQwTEdEt9enTB+3bt8fChQstXQoR3YRjboiIiMiqMNwQERGRVWG3FBEREVkVttwQERGRVWG4ISIiIqvCcENERERWheGGiIiIrArDDREREVkVhhsiIiKyKgw3REREZFUYboiIiMiq/D9nTOl88kk65wAAAABJRU5ErkJggg==",
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"plt.plot(np.cumsum(pca.explained_variance_ratio_),'.-')\n",
"plt.xlabel('number of components')\n",
"plt.ylabel('cumulative explained variance');"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## mini batch K-Means\n",
"\n",
"Given that it looks like our data may have three clusters, let's find these clusters using mini batch K-Means."
]
},
{
"cell_type": "code",
"execution_count": 18,
"metadata": {},
"outputs": [],
"source": [
"from sklearn.cluster import MiniBatchKMeans\n",
"from sklearn.metrics.pairwise import pairwise_distances_argmin"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Q3. Specifying *k*, the number of clusters\n",
"\n",
"As always, with a K-Means type algorithm, we must specify the number of clusters before running the algorithm. Use your thoughts from above and put this in the variable `n_clusters`."
]
},
{
"cell_type": "code",
"execution_count": 19,
"metadata": {
"nbgrader": {
"grade": false,
"grade_id": "cell-956d77de44aaa49b",
"locked": false,
"schema_version": 3,
"solution": true,
"task": false
}
},
"outputs": [],
"source": [
"# Type your answer here and then run this and the following cell.\n",
"n_clusters = 3"
]
},
{
"cell_type": "code",
"execution_count": 20,
"metadata": {
"nbgrader": {
"grade": true,
"grade_id": "cell-b05818d9386980f7",
"locked": true,
"points": 1,
"schema_version": 3,
"solution": false,
"task": false
}
},
"outputs": [],
"source": [
"# This is a test of the above, do not change this code.\n",
"assert type(n_clusters)==int\n",
"assert ads_hash(n_clusters)=='4e07408562'"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now we are going to actually run the algorithm from scikit learn."
]
},
{
"cell_type": "code",
"execution_count": 21,
"metadata": {},
"outputs": [],
"source": [
"mbk = MiniBatchKMeans(n_clusters=n_clusters, batch_size=6, random_state=0, n_init='auto').fit(X);"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## plotting the clustering results in the original \"number of reads\" space\n",
"\n",
"Let's first plot the our raw read data in a scatter plot like above, but colored according to our cluster label. We will also plot our cluster centers here."
]
},
{
"cell_type": "code",
"execution_count": 22,
"metadata": {},
"outputs": [],
"source": [
"mbk_means_cluster_centers = mbk.cluster_centers_\n",
"mbk_means_labels = pairwise_distances_argmin(X, mbk_means_cluster_centers)"
]
},
{
"cell_type": "code",
"execution_count": 23,
"metadata": {},
"outputs": [
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAkQAAAGwCAYAAABIC3rIAAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjkuMiwgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy8hTgPZAAAACXBIWXMAAA9hAAAPYQGoP6dpAAB9+klEQVR4nO3de3xT9f0/8Fd6S+ktpS290QqVm2AREJQW8YoW2BCZDlH37aowHE5hCMx9dajomKgTmV+dd0F0OvZzDicTuUzlJpQqUuQmghRpoXfa9AZpm57fHyWHJM3lJDkn5yR5PR8PHg+SnCSfc06a887n8/68PzpBEAQQERERhbAwtRtAREREpDYGRERERBTyGBARERFRyGNARERERCGPARERERGFPAZEREREFPIYEBEREVHIi1C7AYGiq6sLp0+fRnx8PHQ6ndrNISIiIgkEQUBzczMyMzMRFua8H4gBkUSnT59Gdna22s0gIiIiL5SXlyMrK8vp4wyIJIqPjwfQfUATEhJUbg0RERFJ0dTUhOzsbPE67gwDIoksw2QJCQkMiIiIiAKMu3QXJlUTERFRyGNARERERCGPARERERGFPAZEREREFPIYEBEREVHIY0BEREREIY8BEREREYU8BkREREQU8hgQERERUchjQEREREQhjwERERERhTwGRERERBTyuLgrUQhqa2rHZ6sPofpEE9L6J2BC0TDEJESp3SwiItWwh4goBH22+hDKD5+BqbUT5YfP4LPVh9RuEhGRqhgQEYWg6hNNELq6/y90ATUnmtVtEBGRyhgQEYWgtP4J0J3/69eFAan949VtEBGRyhgQEYWgCUXDkD00CdGxkcgemoQJRcPUbhIRkaqYVE0UgmISonDz3JFqN4OISDPYQ0REREQhjwERERERhTwGRERERBTyGBARERFRyGNARERERCGPARERERGFPAZEREREFPIYEBEREVHIY0BEREREIY8BEREREYU8BkREREQU8hgQERERUchjQEREREQhjwERERERhTwGRERERBTyVA2IXnnlFVx22WVISEhAQkIC8vPz8emnn4qP33333dDpdDb/8vLybF7DZDJh7ty5SElJQWxsLKZOnYqKigqbbRoaGlBYWAiDwQCDwYDCwkI0Njb6YxeJiIgoAKgaEGVlZeHpp5/G119/ja+//ho33HADbrnlFhw8eFDcZtKkSaisrBT/rV+/3uY15s+fj7Vr12LNmjXYsWMHWlpaMGXKFJjNZnGbu+66C6WlpdiwYQM2bNiA0tJSFBYW+m0/iYiISNt0giAIajfCWlJSEv785z9j1qxZuPvuu9HY2IiPPvrI4bZGoxF9+vTBu+++ixkzZgAATp8+jezsbKxfvx4TJ07E4cOHMWzYMBQXF2Ps2LEAgOLiYuTn5+O7777DkCFDHL62yWSCyWQSbzc1NSE7OxtGoxEJCQny7jQREREpoqmpCQaDwe31WzM5RGazGWvWrEFrayvy8/PF+7ds2YLU1FQMHjwYs2fPRk1NjfjYnj170NHRgYKCAvG+zMxM5ObmYufOnQCAXbt2wWAwiMEQAOTl5cFgMIjbOLJs2TJxiM1gMCA7O1vO3SUiIiINUT0g2r9/P+Li4qDX6zFnzhysXbsWw4YNAwBMnjwZ7733Hj7//HMsX74cX331FW644Qax56aqqgpRUVHo3bu3zWumpaWhqqpK3CY1NbXH+6amporbOPLwww/DaDSK/8rLy+XaZSIiItKYCLUbMGTIEJSWlqKxsREffvghioqKsHXrVgwbNkwcBgOA3NxcjBkzBv369cMnn3yCW2+91elrCoIAnU4n3rb+v7Nt7On1euj1ei/3ioiIiAKJ6j1EUVFRGDhwIMaMGYNly5ZhxIgReOGFFxxum5GRgX79+uHo0aMAgPT0dLS3t6OhocFmu5qaGqSlpYnbVFdX93it2tpacRsiIiIKbaoHRPYEQbBJZrZWX1+P8vJyZGRkAABGjx6NyMhIbN68WdymsrISBw4cwLhx4wAA+fn5MBqNKCkpEbfZvXs3jEajuA0RERGFNlWHzB555BFMnjwZ2dnZaG5uxpo1a7BlyxZs2LABLS0tWLJkCW677TZkZGTgxIkTeOSRR5CSkoKf/exnAACDwYBZs2Zh4cKFSE5ORlJSEhYtWoThw4fjxhtvBAAMHToUkyZNwuzZs/Haa68BAO69915MmTLF6QwzIiIiCi2qBkTV1dUoLCxEZWUlDAYDLrvsMmzYsAE33XQTzp49i/379+Odd95BY2MjMjIycP311+Mf//gH4uPjxddYsWIFIiIicPvtt+Ps2bOYMGEC3n77bYSHh4vbvPfee5g3b544G23q1Kl46aWX/L6/REREpE2aq0OkVVLrGBAREZF2BFwdIiIiIiK1MCAiIiKikMeAiIiIiEIeAyIiIiIKeQyIiIiIKOQxICIiIqKQp/paZqSctqZ2fLb6EKpPNCGtfwImFA1DTEKU2s0iIiLSHPYQBbHPVh9C+eEzMLV2ovzwGXy2+pDaTSIiItIkBkRBrPpEE4Su7v8LXUDNiWZ1G0RERKRRHDILYmn9E1B++AyELkAXBqT2j3f/JJlx2I6IiAIBe4iC2ISiYcgemoTo2EhkD03ChKJhfm8Dh+2IiCgQsIcoiMUkROHmuSNVbQOH7YiIKBAwICJFaWHYjkiLOJxMpC0cMiNFaWHYjkiLOJxMpC3sISJFaWHYjkiLOJxMpC3sISIiUkFa/wTozn8DcziZSH0MiIiIVMDhZCJt4ZAZEZEKOJxMpC3sISIiIqKQxx4iUgSnFBMRUSBhDxEpglOKiYgokDAgIkVwSjEREQUSBkSkCE4pDm21zSYUrSzByCc3oWhlCWqbTWo3iYjIJQZEpAhOKQ5tiz7Yhx3H6tDY1oEdx+qw6IN9ajeJiMglJlWTIjilOLTtq2iEuUsAAJi7BHxb0ahug4iI3GAPERHJbkRWIsLDdACA8DAdLstKVLdBRERuMCAiChJaytt5bvoIjB+Ygt4xkRg/MAXPTR+hWluIiKTQCYIgqN2IQNDU1ASDwQCj0YiEhARV28IaP+RI0coS7DhWB3OXgPAwHcYPTMHqmVeq3SwiIlVJvX6zhygAscZP8Glrase6F0vx5sJtWPdiKdqa2j1+DebtEBF5j0nVKvK2p4c1fryn1d41S5ArdEEMcj1NSh+RlWjTQ8S8HSIi6dhDpCJve3qCpcaPHL0intJq75ocQS7zdtSnpTwuIvIMAyIVeXsRlKPGjxrBiD01ghOt9q75EuRazuW/l+zGz1uj8OX867B65pXoE69XqLXkDOsvEQUuBkQq8vYiaKnxM2v51bh57kivhny00FOiRnCi1d41X4JcLZxL6sY8LqLAxRwiFU0oGobPVh9CzYlmpPaP92s1Zy30lKT1TxDzZvwVnPhyzJXMP/KlkKVS51Kr+VZaxjwuosClag/RK6+8gssuuwwJCQlISEhAfn4+Pv30U/FxQRCwZMkSZGZmolevXrjuuutw8OBBm9cwmUyYO3cuUlJSEBsbi6lTp6KiosJmm4aGBhQWFsJgMMBgMKCwsBCNjY3+2EWX5Ojp8ZYWekrUWN7Dl2Ou1Z4Ypc6lVvdXy5jHRRS4VA2IsrKy8PTTT+Prr7/G119/jRtuuAG33HKLGPQ8++yzeP755/HSSy/hq6++Qnp6Om666SY0N1/4BTx//nysXbsWa9aswY4dO9DS0oIpU6bAbDaL29x1110oLS3Fhg0bsGHDBpSWlqKwsNDv+6slWlhrTM2A0Bta6FVzRKlzqdX91bI+8Xqsnnkl9j5WwDwuogCjucKMSUlJ+POf/4yZM2ciMzMT8+fPx+9//3sA3b1BaWlpeOaZZ/DrX/8aRqMRffr0wbvvvosZM2YAAE6fPo3s7GysX78eEydOxOHDhzFs2DAUFxdj7NixAIDi4mLk5+fju+++w5AhQxy2w2QywWS6MEOkqakJ2dnZmijMSOpY92KpzRBf9tCkoF6vLdT2l4iCU8AVZjSbzVizZg1aW1uRn5+PsrIyVFVVoaCgQNxGr9fj2muvxc6dOwEAe/bsQUdHh802mZmZyM3NFbfZtWsXDAaDGAwBQF5eHgwGg7iNI8uWLROH2AwGA7Kzs+XeZQowWuhV86dg3F8tzK4kIm1SPal6//79yM/Px7lz5xAXF4e1a9di2LBhYrCSlpZms31aWhp+/PFHAEBVVRWioqLQu3fvHttUVVWJ26SmpvZ439TUVHEbRx5++GEsWLBAvG3pIaLQ5UvicyAKxv2VowAmEQUn1QOiIUOGoLS0FI2Njfjwww9RVFSErVu3io/rdDqb7QVB6HGfPfttHG3v7nX0ej30eo7/EwUT5kURkTOqD5lFRUVh4MCBGDNmDJYtW4YRI0bghRdeQHp6OgD06MWpqakRe43S09PR3t6OhoYGl9tUV1f3eN/a2toevU9EFNy0MLuSiLRJ9YDIniAIMJlMyMnJQXp6OjZv3iw+1t7ejq1bt2LcuHEAgNGjRyMyMtJmm8rKShw4cEDcJj8/H0ajESUlJeI2u3fvhtFoFLfRGuY5ECkjGPOivMHvGKKeVJ1l9sgjj2Dy5MnIzs5Gc3Mz1qxZg6effhobNmzATTfdhGeeeQbLli3DqlWrMGjQIDz11FPYsmULjhw5gvj47l929913H/7zn//g7bffRlJSEhYtWoT6+nrs2bMH4eHhAIDJkyfj9OnTeO211wAA9957L/r164d169ZJbqvULHU5cHYPESlJ6ncMi3NSMJB6/VY1h6i6uhqFhYWorKyEwWDAZZddJgZDAPDQQw/h7Nmz+M1vfoOGhgaMHTsWmzZtEoMhAFixYgUiIiJw++234+zZs5gwYQLefvttMRgCgPfeew/z5s0TZ6NNnToVL730kn931gP+ynPQypedVtpBVNtswqIP9mFfRSNGZCXiuekjgrKWkNTvGCahUyjRXB0irQrGHiKt9ERppR1ERStLbJbeGD8wBatnXql2s2Qn9W/uzYXbYGrtFG9Hx0Zi1vKr/dhSIt8FXB0iusBfeQ5amXGjlXYQ+bI4a22zCUUrSzDyyU0oWlmC2maT+yf5gaN2Sf2OYRI6hRLVp91TT/6q/6LG4qpabgeRL4uzLvpgn/jcHcfqsOiDfZroXXLWLinfMWouQE3kbwyIQphWvuy00g6i56aPwKIP9uHbikZcdj6HSCpfepeU5Eu7grE4J5EzDIhCmFa+7LTSDiLL4qze8KV3SUlabReR1jCHiIhClpz1eJ6bPgLjB6agd0wkxg9M8ah3SUlabReR1nCWmUT+nGVGRP7BGY5EwY+zzIiI3OAMRyKyYA4RUZBggUvPcYYjEVmwh4iCUiiu1WSpKmxq7RSrCpNrXNuMiCzYQ0RBKRSXHODwj+c4w5GILBgQUVCSKzgIpGEoDv9QKAiV9ebI/zhkRl7R+pCUXEsOeDMMpdax4fAPhQJL5e3Gtg6x8jaRHBgQkVe0nq8iV3DgTU+TWsfGMvwza/nVuHnuSM32ZBH5QqsVwSnwcciMvCJ3vorcQ1Ny5YZ4MwzFXB4i5bDyNimFAZGKAik/xZ7c+SrukqDVOlberLPGXB7vOTrPADT7d8J8Fv/zZb05IldYqVoiJSpVB3KVXMuFyzpQ8OUi9ebCbTC1doq3o2MjMWv51eLtQDpWch+bUOLoPAPQ7LkvWlli01sxfmCKJla4J6ILpF6/2UOkokAeWpF7urK7XpVAOlacyu09R+dZgKDZcx+I+Syh0KsVyL3vpB4mVatIrplQwcBdEjSPVWhwdJ61fO5HZCUiPEwHAAGTzxIKs7S0PumDtIk9RCryJj8lWLnrVQnUY8Vfqp5xdp61eu4DMZ8lEHu1PBVIPcqkHcwhkoir3ZM3AiH3iUFbaClaWYIdR2thPv/N3zsmEpsevDaohs0C4e+O/Ier3RNpQCD8UuXwQmh5bvoIJPSKFG8bz3YE3bAZi5SSNzhkRpoULL0WgTAFX4mgLRQSdwNVn3g9rIcFugQE3bAZJzaQN9hDpCKtL3+hpmDptQiEX6pKJC2HQuKuEmqbTShaWYKRT25C0coSlJ9uVuQ7QovJ4Pb7XttsUrtJFGKYQyQR6xD5l7u6RBbB0pOkJiXqJo18chMa2zrE271jIrH3sQJfmxr07OsazTTHonezWfbvCEsPnnUyuNo9eKzpREphHaIAEAj5JWqROtTkrsK1lmklmFNieIHLK3jHfgZYdFMnBKG7J0fO74g+8XrNBRuhMPuNtI1DZirScn0VtUkdavI1qFRz2DJYhgUdeW76CIwfmILeMZEYPzAlIKaja4H9UNa5hIiQ+Y7Q4jAehRb2EKkoUGvr+IPUXgtfk5bV7GHSWg+hdY9VSlYcAKCuosWr3ist9kAEAvu6Rr+cNBSlH/7Q4ztCK72LcrYlEGs6UXBhDpFErEOkHY4u3PUVrV7lv0jNVVKC1nLIrNtjTQtts6alYEAtWvrsaKktWsFZltrCOkSkCC3MjLMeajp9tBHhEWGYtfxq3Dx3pMcXRjWHLbU2A826x8qaFnqvrAXzUKNUWupd9HdbAmE2GmdZBiYGROQRLVyM7L+Aq8uavA7S1AxKLMOC3gZzcrMODq1pLXfF/vxXHG4IudIVWso/9HdbAiHYYIJ4YGJARB7Rwi9T+y9gXZjO6yBNraBECz1t9qyDw75DEtF3SKJmeq+s2QduXV1CyPUWaal30d9tCYRggwnigYlJ1eQRKUnMSud42CejV5UZVQ/SPKXFcgGBUt3X+vy3n+tE1/lFuQLl3MtBS+fK320JhJIOTBAPTAyIyCNSZsYpfbG3/wK2T+rU0vCOM1roaQtU1uc/0M49k219FwjBBmdZBiZVh8yWLVuGK664AvHx8UhNTcW0adNw5MgRm23uvvtu6HQ6m395eXk225hMJsydOxcpKSmIjY3F1KlTUVFRYbNNQ0MDCgsLYTAYYDAYUFhYiMbGRqV3MehIGWLy98VeC8MHng6B+SvvQotDc3LSwrn3RCDkv2idJdjY+1gBVs+8kgElyUbVafeTJk3CHXfcgSuuuAKdnZ34wx/+gP379+PQoUOIjY0F0B0QVVdXY9WqVeLzoqKikJSUJN6+7777sG7dOrz99ttITk7GwoULcebMGezZswfh4eEAgMmTJ6OiogKvv/46AODee+9F//79sW7dOklt5bR76UJxGq6n+6zEchlytMtb7PmQhkuaEPlfQCzdsWHDBpvbq1atQmpqKvbs2YNrrrlGvF+v1yM9Pd3haxiNRrz11lt49913ceONNwIA/va3vyE7Oxv//e9/MXHiRBw+fBgbNmxAcXExxo4dCwB44403kJ+fjyNHjmDIkCEK7WFo8nfBSS3UpfG0V8xfeRf+6q2z9HyYuwSx50PtIQMtBmmBkP9CFKo0NcvMaDQCgE3vDwBs2bIFqampGDx4MGbPno2amhrxsT179qCjowMFBRd+ZWVmZiI3Nxc7d+4EAOzatQsGg0EMhgAgLy8PBoNB3MaeyWRCU1OTzT+SxnKxv2XpUHxyyasoWH8D5myeg7qzdYq8nxZKAWhpGrQ1f7VLizN/tDg8xSVNiLRLM0nVgiBgwYIFGD9+PHJzc8X7J0+ejOnTp6Nfv34oKyvDo48+ihtuuAF79uyBXq9HVVUVoqKi0Lt3b5vXS0tLQ1VVFQCgqqoKqampPd4zNTVV3MbesmXL8MQTT8i4h/6hhd4Si8U7FqO4shhmwYziymIs3rEYr970quzvo4UEZWe9Yv46H87ex11vnVy9KFrs+dBikMZkWyLt0kxA9MADD+Dbb7/Fjh07bO6fMWOG+P/c3FyMGTMG/fr1wyeffIJbb73V6esJggCdTifetv6/s22sPfzww1iwYIF4u6mpCdnZ2ZL3Ry1ams59oP4AzIIZAGAWzDhYf1CR9/F1PTM5WA+B1TabcN8HpdhX0YjprXr0bjYrfj6cnXd3Q3NyDXV5O/NHyYBRi0EaEWmXJobM5s6di48//hhffPEFsrKyXG6bkZGBfv364ejRowCA9PR0tLe3o6GhwWa7mpoapKWlidtUV1f3eK3a2lpxG3t6vR4JCQk2/wKBFnpLLHKTcxGu605qD9eF49LkSxV5H63NNLIeqtE3dfrlfNjXYqoukzbEK1cvirczf5Qc7uTwFBF5QtUeIkEQMHfuXKxduxZbtmxBTk6O2+fU19ejvLwcGRkZAIDRo0cjMjISmzdvxu233w4AqKysxIEDB/Dss88CAPLz82E0GlFSUoIrr+z+9bt7924YjUaMGzdOob1ThxZ6SyyWjl+KxTsW42D9QVyafCmWjl+qyPtoqUgdYBtkVIZ3oX9nGMKgU/R8hIWFATCLt3Vhjns+7andi6JkAM/hKSLyhKoB0f3334/3338f//73vxEfHy/m8xgMBvTq1QstLS1YsmQJbrvtNmRkZODEiRN45JFHkJKSgp/97GfitrNmzcLChQuRnJyMpKQkLFq0CMOHDxdnnQ0dOhSTJk3C7Nmz8dprrwHonnY/ZcoUVWeYKTFc4O8ZXq6k9EpRJGdI66yDjE1xHbhDiEV6Z5ii50PoElzedsbVUJc/Zml5G8BrKVeOiIKDqnWInOXvrFq1CnfffTfOnj2LadOmYe/evWhsbERGRgauv/56/PGPf7TJ5zl37hx+97vf4f3338fZs2cxYcIEvPzyyzbbnDlzBvPmzcPHH38MAJg6dSpeeuklJCYmSmqrEnWIQrFeTyiwBBLWQYbS072V+CwVrSyx6T0aPzBF9h4Xb+sx8W8n9GixjAIFBqnXb1UDokCiRED05sJtMLV2irejYyMxa/nVsrw2hRYlCj1quYigv/526s7WYfGOxThQfwC5yblYOn4pUnqlyP4+5J4/AnQKTgFRmDHUaSnfh6TR6lCNEnlUaucXueKvvx3r0hG7Kotxyz/movXkPR71UHj7mWGPiC0tllGg4KKJWWahSmuzo8g9LRSB9Bctz9KS82+nttmEopUlGPnkJhStLEFts0l8zLp0RJdghtF83ONCj95+ZrRYWFJNI7ISEX5+soDWAnQKDuwhUpHWZkf5i1Z7WaTwZ1kDtYdrtDxLS86/HVe1mHKTc8UeIghhMJ/rLgviSQ+Ft5+ZYOoRkaO3KxBWuafAxh4i8rtA7mXx5xIdluEao8koVvom+bkKPJaOX4q8jDwk6hORgGFor+ou7eFJD4W3nxkle0Rc9YopwVFvl6dt4Cr3pDQGROR3Wioe6Sl/DnP6q9J3qHMVeFhKR2y/Yzs+uu1tjM/J8XgI0dvPjJJDlv4ejnMUdHJIkLSGQ2bkd4GcTO7PYU7r4RolK30rwZMhErWTh6UOxXg7hOjtZ8b6/eyP0cOTL8GyT7/z+ph5Ohzn6zlylKCv9SFBtT+X5H+cdi+REtPuQ5USU8SDkSWHyLrSt5I5RHLmdnkyRdqf06k92Uep2/oj18tyjPSdAn5yNgoZnWGojOjC+l7tMEV4fsw8Pea+niNHtbmsc7e0OI2e0/yDB+sQyYwBkWfUSpzWYsK2FtvkiJzFDj2pYWTZVhfejOjMDxDRqwJXZY9SJLDwZB+lbjtn8xybnry8jDzZK7RbjtFtLVHiUjBdEHAiogsfxrV7XCPK0+KhStSkUqOAqSe0XIeLPCP1+s0cIlKEWonTWkzY1mKbHJEzt8uThGDLttGZHyA89hgQ3qZYErkn++hqW+uE4OJTpYrnelmOUYa5OxgCgDDokG4O8yrh2tMEZSUSvLWeJM1p/qGHAREpQo6La1tTO9a9WIo3F27DuhdL0dbU7pf3lZsW2+SInDPoPEkItmwb0asCOl33gVIqsPBkH11ta50Q3N7aFxC6N1Qq18tyjOqiBFi69AUA9VGCX2pEabkmlVJCcZ9DHZOqyYZcwztyJE5belaELog9K+6GcLSYsK3FNjki18LAniajWnoK5mwepXgSuSf76Gpb64Tgs6enIy77n0hMrBZzveRmOUb2+XczJfx9yvE3rYWaVP5OctbCPpN/MYdIIi3nEMmZoyJXHokcidPerFflz4Rtqcc9mJLIpSQQe5uM6u8kcl8EUsJtsCyEG0jHPNgF2gw8JlXLTMsBkZxfeFpacNZ6vyx0YUDmoEQUzMr1KKhQIrHZ2+MeKEnWjkhJIHaVjBrI+w5cuBCUljciTAd0CQJGZvfW9AVBS3/TvmCSs3YEWnDKpOoA4E2OjCNy5qj4sxKzO5aCdmHnExuB7v07daTR48RkJRKbvTnutc0mrPjTLpw4WK/5JGtHpBSLdJWMGigJ5s5YcoeMZzvQdK4TI7N7+zUh2JLMnf/4Jvzp91vxxgL33x1a+pv2BZOctUPrNaS8xYBIRXJdHOT8wtPSgrOWgnaRvcJ7POZp0KdEYnNa/wRAZ3WHDm6D2kUf7IO+qVOcKaTlJGtHcpNzEa7rPh/O8nyemz4C1/VLwh1n9ZhrjMZUY4R4XAIlwdwZtS8EloBsXL0OCcZOtLe5/+7Q0t+0L5jkrB3BGpwyqVpFcl0c5EqGBbS54Gxa/wScPHjG5j5Pgz4lEpsnFA3D35/cjXMt3d34praOHonf9kNE39c1IiVcZ1NLxlVbtDbEtHT80h55Pvb6xOsxrT0a5R1tELqA6qON4nEJhATztqZ2fPrWAZQfa0RlRBfqhsXh6btGoU+83mHFZX+yBGTW0+/dfXdI+ZsOhJwQJjlrR7AutMuASEUpWXE4daRRvJ2cFevV62gxiJHThKJh2PTWAVQeMwICkDHI4DLocxREyBk0WsQkRME6Bc/Rhcl+ptyUeD3WxLWioCUSGeYwmBIiXLbF/vmb3jqA8IgwrwIkOYIry9pe7jgL9pU4D3L7bPUhVB5pRCSALLMO5gPNWPTBPqyeeaXqFwJLQFYZ3iUG1XIEltZVoy3rijH4IGeCNThlQESaF5MQhWkPXi55e2fT9ZUIGh31eFj/2r67OgKRVoFBotGMOwyx+CTZhEH94vHc9BGIiXcelNgHFpVHjRAgeFSKwMKbMgbectYTFAjBe/WJJnEkNAw6pHWG4bPzQ2NqXwgsAdmuHxuRdC4CqR06pOck+BxYqj0USKQFDIhUVFfRYnO7vqJVpZYEF3/mqTjq8bjvg1Lx13ZFmA79zeE2qUa9m814OCsVN88c6fb17QML6IDzOc0e75vaxyVQpPVPwI8Hz0AHoAsCqiO6NJMjoVRApvZQIJEWMCBSUSDkUwQK6+EgnU7XnewsKH9cHfV47KtohL5TwOS2KKR3huGcTkAvwXamXM2JZklDWPaBhbmzC6ePNnr1mfHn5y0QeoKcmVA0rDuH6IdGVIULaBgW73BoTGv5Xb5QeyiQSAtYh0giJeoQBVPBPrXZ1wTSx0QCAlQ5rkUrS9BnrxH9OrpzPAQAveIiYWrrsKlZBMDjOkbOPjNSkmJ9/bwFUwAgB1d1qLxJUubx9UwgJIKTNrAwo8y0XJiRtFV8rrbZhPf+90tEmi/cp4+JQFpOgk0w8v4TxbK12R+F0gKl4rGUatpycPWZ8+Z8BMrx1YpAKw5I6pF6/eaQGQUFLQ0/9onXY8AlSTbtSctJ6HFxk7PN/kiKdZaDpLVf6ot3LBaraRdXFmPxjsWSZsZ5ytX58+Z8BHqNJn9zd4ytP5dD07svgoermjTxGSVtYmFGCgpaKz4npT3etNlZdXN/FEpzVgDUeuV3y5RtNUmppi0HR+fPUkm65dyFniOp5yNYKkr7i7vPvPXnctfxeuw6Xq+ZzyhpE4fMJFIyh4g5A4FFzfPmbFjF8mvYOilW7l/AznKQtLbGlLv11uQcUrPvHWvv7ELJiTNiz0VEmA5Xna+qLDWHiDmF0rj7zNt/Lq2p/Rkl/2IOkcyUCIiYMxCY1Dxv/syVkho4aC2Xw9Ju62ra1u2WskCtVPb7rgPQ2XXhK5UXXvVYnxtrWviMkn8xhygAMGcgMKl53vyZKyU1F0drU7bdVdOWc0jNPo8lIkyH8DCdTT0fNXOstJbf5U/Wn8tLzucQfVfVpInPKGkTAyIVaSkRmKSTa8kVT1gubN/XNWJKvF62CsWuSA0c1K7e7Knc5FybHiJHC9RKZV/Q8Ir+SYiKCLMJDuVeFsOTIdtQXpIj0D6XpD7ZkqrLy8sxc+ZMuV4uJIy7dWB3vRx0180Zd+tAlVtEWmW5sFWaOrAyvBU7cqNx89yRiuaYSFnZPhAtHb8UeRl5SNQnIi8jz+ECtVLZr8D+f3eOwuqZV2LvYwVYPfNK9InXyz4D0LIEi6nV/Ur3XJKDSDrZeojOnDmD1atXY+XKlXK9ZNDb+a9jMLVdWCl957+OBXwOUSgkiqux5IoaFzZHK9tr6fx6OxwkdYFaKaT0Qsi9LIYnQ7ZckoNIOskB0ccff+zy8ePHj/vcmFATjDlE/lxAVC1qDHWOyErEN9/XoaAlEhnmMJiECLQ1tXscjHgS0DgKHNa9WaqZ8xsow0Fy51h58vnTWn4XkZZJDoimTZsGnU4HV5PSdDqd08eoJzVyUZQWjEGePTUWLn1u+gi8vrQYCZ2dCIMOMc1mr4IRXwNWLZ1fuXvNlOr9kjuXxZPPH/NoiKSTHBBlZGTgr3/9K6ZNm+bw8dLSUowePVqudlGAkqP3REvDMo7ItXCpJ0M+feL1SOvUwYTuHx3eBiO+BjRamggg93BQoPRuBvLCuURaJjmpevTo0fjmm2+cPu6u94h6UiMXRWlyVIz2JGnUX9qa2vHRim/wyv1f4OXffI6PVnwjVon2lrMKz86qUctRydjX19BSRXD7hGZfh4Pk6v2yVKse+eQmFK0sQW2zyad2BYJQ3GcKPpIDot/97ncYN26c08cHDhyIL774wqM3X7ZsGa644grEx8cjNTUV06ZNw5EjR2y2EQQBS5YsQWZmJnr16oXrrrsOBw/aTv81mUyYO3cuUlJSEBsbi6lTp6KiosJmm4aGBhQWFsJgMMBgMKCwsBCNjY0etVduwViq3/Lrddbyq72eBaWlYRmLz1YfwqkjjegyCxC6gFNHGn0O1JwN+TgLCOWYlehrQCPH+ZWLZTjIekaXL+T6e/R0KZO6s3WYs3kOxq8Zjzmb56DubJ1X76smrS3fQuQNyQHR1VdfjUmTJjl9PDY2Ftdee61Hb75161bcf//9KC4uxubNm9HZ2YmCggK0tl7oKXn22Wfx/PPP46WXXsJXX32F9PR03HTTTWhuvnCRnD9/PtauXYs1a9Zgx44daGlpwZQpU2A2X1hu/K677kJpaSk2bNiADRs2oLS0FIWFhR61V26Wi5M+JgL6mEhUlzXZ9AiEKn8Hio56ZOx/8VaVNfV43vGjlT5dvEZkJSK1S4f7G6OxqDEaRTURqD/V4jAg7O6h2otzLd2zEs+1ds9K9JSWAhqtkav3y9PcJksBTKPJKBbADDSc3k/BQFNLd9TW1iI1NRVbt27FNddcA0EQkJmZifnz5+P3v/89gO7eoLS0NDzzzDP49a9/DaPRiD59+uDdd9/FjBkzAACnT59GdnY21q9fj4kTJ+Lw4cMYNmwYiouLMXbsWABAcXEx8vPz8d1332HIkCFu26bE0h0WXMLDlr/XdHJ0/P8Z226TnzLTHItE44UAW4CA8sTvYJyw3+sp3LXNJrz38JeI6BSgO58bFB0XidR+8T3aAwAnD56xeb6Sy3Y4I+c6YMHK06VMxq8ZD6PJKN5O1Cdi+x3bfW6HP3PxtLZ8C5E1qddvTa12bzR2fykkJXVfAMrKylBVVYWCggtrAen1elx77bXYuXMnAGDPnj3o6Oiw2SYzMxO5ubniNrt27YLBYBCDIQDIy8uDwWAQt7FnMpnQ1NRk808pWhwiUpO/ezEcHX/7X7yfRJvQd0gizLpOmNGJU/Hf44sB72F/3X6v37dPvB6RnRCDIQA419LhsKei+kTPz58aQ6y+9maolWvizft621ZPc5uUKoDpz1w8ufO5iNSgmaU7BEHAggULMH78eOTm5gIAqqqqAABpaWk226alpeHHH38Ut4mKikLv3r17bGN5flVVFVJTU3u8Z2pqqriNvWXLluGJJ57wback0tLMnVDk6PiPiNXb/OId1C8R02ZejqvXXI1GU6P4XL0u0af3jo6LFIfBACAsvDs4su8htG6j5XlqJDT7ug6YWrWD3L2vo96URf/0rq2eTnV3VABTDu5+aMm5zhmn91Mw0ExA9MADD+Dbb7/Fjh07ejxmX99IEAS3NY/st3G0vavXefjhh7FgwQLxdlNTE7Kzs12+p7fUqGtDFzg6/nk6wWFBuy7LFeY8+9uemvbgKPy/p75Cl7m7N0roEhxO93bURjXyf0bGjkZs6WCktlyEmriTaL3qe4+er1auibv3dTTlfl+Df9oqZ+Vsa+5+aFmCRH2ngD57jXhvz5cYcEmS5spcEPmLJgKiuXPn4uOPP8a2bduQlZUl3p+eng6gu4cnIyNDvL+mpkbsNUpPT0d7ezsaGhpseolqamrEWXHp6emorq7u8b61tbU9ep8s9Ho99HplV4W2/1V65+Nj+UWkAkd1XWIAh794h6cMt1kYdHjKcJ/eO7lvHCKjw2Fq7QQACMKFJGr7Hgst5JVd/8P/oNJohE4IQ7ZxCDJ+8KxXQK2lJNy9r6PelBGXBvayF+5+aFmCxMltUejXGYYwaLv+EpHSvMohevfdd3HVVVchMzNTHLr6y1/+gn//+98evY4gCHjggQfwr3/9C59//jlycnJsHs/JyUF6ejo2b94s3tfe3o6tW7eKwc7o0aMRGRlps01lZSUOHDggbpOfnw+j0YiSkhJxm927d8NoNLosJaA0LdbbIdfkXBjUwtGsOq1+NhrKz0IndDdWJ4ShsfycR89XK9fE3fs6Ogf+aKuSOVXucvFGZCUiPEyHDHMYwnws+EkUDDzuIXrllVfw2GOPYf78+fjTn/4kTm1PTEzEX/7yF9xyyy2SX+v+++/H+++/j3//+9+Ij48X83kMBgN69eoFnU6H+fPn46mnnsKgQYMwaNAgPPXUU4iJicFdd90lbjtr1iwsXLgQycnJSEpKwqJFizB8+HDceOONAIChQ4di0qRJmD17Nl577TUAwL333ospU6ZImmGmlOoy21+l1Q6mdgczrVekdkSJ4Q1Hv+Tff6JY1kR7uY61r/lu3uaa+Jrv4u59HQ5Jxkcpnhej5npslnXO6vY1IcvUndrPHEYKZR5Pux82bBieeuopTJs2DfHx8di3bx8uvvhiHDhwANdddx3q6qTXZXGWv7Nq1SrcfffdALp7kZ544gm89tpraGhowNixY/HXv/5VTLwGgHPnzuF3v/sd3n//fZw9exYTJkzAyy+/bJPzc+bMGcybN09cpHbq1Kl46aWXkJiYKKmtSky7f3PBNpjaOsXb+pgI/Or5a2R57UDAcgPOyX1s5Ho9f5dEsAjWad0jn9yExrYLSfW9YyKx97ECF8+Qn1rnlMhfpF6/Pe4hKisrw6hRo3rcr9frbQoqSiElFtPpdFiyZAmWLFnidJvo6Gi8+OKLePHFF51uk5SUhL/97W8etU9p7ec6Xd4Odiw34Jyr/A9venvkOtb2+VZ1Z+uwYLM8dYlc1TgK1sJ/auVUWePaaETdPM4hysnJQWlpaY/7P/30UwwbxtlRnrHtIXM3cy7YBOPSJXJxlf/hTX6RUsdazirLrl7Lku8CICATnJ1h/Z7QxjXgtMXjHqLf/e53uP/++3Hu3DkIgoCSkhL8/e9/x7Jly/Dmm28q0cagFRUdbjNkFqkPV7E13vElNyUUyg0okSflTW+PUsfaXV0iTypbu3otS76LfRmEQOdr/R5XuVVy1hkiZaiZQ0Y9eRwQ3XPPPejs7MRDDz2EtrY23HXXXejbty9eeOEF3HHHHUq0MWgJ0MyqKV5zVL9Favd7KHTV+3J8nPEmsVmpY52bnGtThsC+yrKl18csmMVeH2dJ6Y5eyzqg/Hn/BLwy/zrN5LdoYRkTVxdUXmy1L1iHggOVV9PuZ8+ejR9//BE1NTWoqqpCeXk5Zs2aJXfbgl56jsFmGCMtR1qytqPFSNXCPCDXlDg+rhYh9edno62pHTcdnIV7vl6GqUcewPje1/YoQ2Dp9enVHo+JB3+Fwf+e4rRdD458DLFdQwFzDGK7huLBkY9ptvwAoI1FWZ1dUGubTfjyfDBk/xhph7OhYA6lqcOntcxSUlIcLolB0oyakQZjn0qci2iFsU8lRs1wXCTSnpYuEsGcB+TuS0nKl5YSx0fu/CJvfbb6EKq/b0ZEux59Gwdh4ol7evSQWNbpuv7YXcgyDoG+M8Zpu55aV4Gq7wvR/P1jqPq+EE+tq5AtoFQiUPR1GRM5OLugLvpgHzq7bHuggyXvKpg4yyGz9O41tnWIvXukPI+HzKqrq7Fo0SJ89tlnqKmp6TFTzFKXiNxbuu8JFA8ohvni7iGCH/dtl1TjRuleGU/yXoI5D8jdkIOUIYlLJl6EH46cQUSXgI4wHS6ZeJGibfbms+HofAPApyv3oeJ4HWrifoQx/zCW3PioTcAj5b0s63SllfRHGMJdbuuot+Pn/VNlWedPiaFLd8OF/uAst2qfXW9QRJhOk3lXoZ7n5CyHjENp6vA4ILr77rtx8uRJPProo8jIyAi5mVFysh5OuP7YXUgr6Y9135W6TbxVejFYTy4ewZwH5O5LScqX1v97az8SOgXooEN4p4AP3vgWwy9KVKwYpTefDUfnGwAqjxgRIeiRfmYAOr80Y3H0hfyftqZ22799neP3shSyXPddqdt2OZqCPuHn8gTcSvyIUGpRVk9YLqiWoPbfS3YjrX8CRqclYMuPZ8RjedXAFJ+SrZUKXLxZdFcrOWRK0kI5hlDkcUC0Y8cObN++HSNHjlSgOaHF8gvTMpwQhnBJv16V7pVhXlA3d19KUr60ops6xWURwqBDXLNZ9p4Ka958NhydbwGCuERHGMLRpyUbO+vXiM/5bPUhmKwKCkbHRrp8LyntctTbERPvOuCWmtisxI8IpRZl9YZ9UPuTQYnoHJjicFaeN8nWSiVoe7PobrD+ALMWrLMqtc7jgCg7O1tSQUVyz5PhBGtK98oo3QPlL77+unT3pSTlS+tcQgSijN1BURcE6HQ6r4NNKfvjzWfD2fn+8VAddEIYumBGbVy5zZCQdRDVvTNweWzdtautqR3Fqw/j6hPn8PP+qZjw8+6lM9yROovNn0O7agwD2Qe1jRWtWP3g1Q639WY4RqkhHG8W3Q0FvpZjIO94nFT9l7/8Bf/7v/+LEydOKNCc0GL5hTloSJamEpNdzWIKJL4mGFu+lPY+VoDVM6/scVFz9zgA/PK3l6PJEIFzOgFNhgikXex9krVSCdOOzveEomHIGGJAZ5QJVUnH0XrV9zZDQnIni3u7b1Jnsblb6FQqKcnZaiTEenI+vClyqVRhTG8W3SVSisdrmfXu3RttbW3o7OxETEwMIiMjbR4/c+aMrA3UCiXWMrP84q8qMyIsLAxCl4C0nNAZJ/eEN709by7cBlPrhcKX0bGRmLXc8a9mJVm3PSUrDgBQX9Hq8bpRvu6PnHVz5F7/ytt9m7N5DoorizHx4K/EYWcl18WTsiac/fpkOgDXDO6jaE+RJ+fD0oNl3bMpNYfI0XOU7BHjOmskB8XWMvvLX/7iS7vIivX4uC7MzMVNXfAml0ArQ3/WbT99tBHZQ5O8Csw83R/7IHJj/1UobpBWJNEduYdtvT1X3g47e0vKEI71MBAACIDihREdnQ9nPyK8GY5x9RwlC0AG86QN0h6PA6KioiIl2hGSQnV83BtaWq7CU3KdZ0/3xz6INFQOhXnI5wDUq5vjjLfnypNZbHKQErhZcsu2fV8r1qJXY+q0sx8RcvfocIo4BQuPAyIA+OGHH7Bq1Sr88MMPeOGFF5CamooNGzYgOzsbl17q/1ocgUorPRiBwNGxcjeMppVfl9ZtB4D2c51Y96L78gqOhrjc7Y8gCKivr0dLSwuOHT6JSHOsmMid2tIP4bpwVevmOOPrufJX8CvlfSy9KUUrS1SdOu0sEJe7R4dTxClYeJxDtHXrVkyePBlXXXUVtm3bhsOHD+Piiy/Gs88+i5KSEvzzn/9Uqq2qUjKHiOPj7jk6VrZDjsrljfjK0vaKww3oOv9LWkp7LfkxlgAmLyNPHOKy/5X/6E398Mm/1uCvf30ZR49+L75GWmI2xg+7GXmXTETO8AxsvvQtm7o5/l57K5R4k6sjJ2f5TvY5Tr1jIrH3sQKv30ft/SRyR+r12+OAKD8/H9OnT8eCBQsQHx+Pffv24eKLL8ZXX32FadOm4dSpUz43XouUCIjIN1pJmpbK0/aOXzMeRpNRvJ2oT8T2O7YDgE3vg+nENzjz72dgbjdh5MVXY0T/qxGjj0ObqQWlZdtQWrYd+sho/P39Nbjl1inK7aAXpCbLWweAw7J0iM78J75vPKjaoqpa4Wr4y9kPLvueq/EDUzjFm4KaYknV+/fvx/vvv9/j/j59+qC+vt7TlyMN03qVWK0MOUo9Tp6219XSEJa8jbPH96D2wycxNGsM/ufaRUiISbJ5jcsHXIumtjN4f9ty/Pz2n2HxvS+gb69cVc6noyHAXasrnCbLWx/X6ggB3+ha0QwBpWdXIrzqGKDr8jk53F+shzLj4uKQnJwsS5V/V8NfzoYhWfSPyDGP6xAlJiaisrKyx/179+5F3759ZWkUaYOWFpG1V3+qBdVlF3IkLOUK1CD1OHla32np+KXIy8hDoj4ReRl5NnWARmQlAu2tqP/3MxiaNQa/nvjHHsGQRUJMEmYXPIkhfUfj6bceQsOZRlXOp6PV4V0lnFsf1wRjJwpaukt86KIrAF33k7SWHG6vsbERLyz/K353+4t4a9F2PPubNbj4osEYNOQSvPDCC2hsbPTp9b1JaJZSP4soFHkcEN111134/e9/j6qqKuh0OnR1deHLL7/EokWL8Mtf/lKJNpJKtDwL7qMVe2FquzD81Fh9VrXeK6nHydPigJYZVNvv6F7013pY6LnpI5BaWQyh04T/uXYRwsPCXb5WeFg47rpmIdo7z6Hk+02qnE9Hq8O7KrxnfVzDoEOGuXtD4VwWcH5ZEa0lh1vbuHEjsi+6CEc+b8FFSUMRF23AJdlXYObtr6I6Ih0PLlyI7IsuwsaNG71+D6UKJgYSKcUyiaTwOCD605/+hIsuugh9+/ZFS0sLhg0bhmuuuQbjxo3D4sWLlWgjqURLVWLtv/TOtXTYPG5/29nzlPiy9PY4+dK2lLgoNO75BKMuvsZpz5A9Q2wyRva/GtsPfQzoBFnOpyf7kJuci3Bdd+BmCWRc9ZrZH1dTQgR6x0RiZK85uCLdcc+ZVmzcuBE/nTIFXWmX4OLs0Vb7rUPfXslInvoQ+s55G11pl+CnU6Z4HRS5q/QcCrTck02BxeOkaosffvgBe/fuRVdXF0aNGoVBgwbJ3TZNCcWkai3NgrOfMaPT6dBlvvDRjY6LxKzneiYoS6ks7Ctvj5MnbbPPUxoxJRX9Lu6LmTc+hssHXCu5rd/8sAUr//tH/G3ZF/jZb8b5fD492QdLDpHUWW5a+vx5orGxEdkXXYSutEuQ8rPF+HlbL/TvDBPXszsR0YUP47oDR6HLjLq1SxFW/R3KT55EYmKiLG1QYz01f7H/W6gua7LpLXY3WSGYjw05plhStcWAAQMwYMAAb59OAUArdXyAnsNSkb3CEBYehnMtHYiOi8S0B0c5fl6Z7fOqy5pkb5u3x8l+n344cgYjn9zk8Evavshedf3p7vfWx3n0nr3Ob3/VHf1lCS48GVb1dHV4LX3+PLF69Wq0trWh78R50IWF49OYdkxui0K6OQxV4V34NOZCL5ouLBy9J85F5av34J133sG8efNkaYOS1aPVZv+3oI+JhC4MkicrBPOxId94HBAtWLDA4f06nQ7R0dEYOHAgbrnlFiQlSevGp8Dlz1lo9jO00i82SLpY6sJ0Lm+ryXqfBAAVOrPNgqDWX9L2gUdLTXcuTpupxaP3PHt++/h4eYY/vZnpp/XZi85I6VkQBAEv/vVlxAy+CuFxvQEAbWEQe4QciYhLQq/B4/B/L/0Vc+fOlWX2mbfVowOh98T+b0HoEpA9NElyUU5W1iZnPM4h2rt3L9566y28/vrr2Lp1K7Zs2YI33ngDb731Fj777DMsWLAAAwcOxKFDHMcNdtZj9ycO1uKF5R+g7mydrO9hyVGpKjNCHxMJfUyEpBlaFl1dXTa3hS6vRogVYZ0/U67vwvpe3RdNR1/S9vk0F1+ShUGDBmPfie0evWdp2XYMGjRYth8sns6cAwI350PKKvb19fX44ej36DV4nEev3WvQOPxw9HuPFsd2lb/lbbK1lH30VG2zCUUrSzDyyU0oWlmC2maTT69n/7eQlpPg0WQFJqKTMx4HRLfccgtuvPFGnD59Gnv27ME333yDU6dO4aabbsKdd96JU6dO4ZprrsGDDz6oRHtJQ2xnAYUjqj4ei3fIm1hvuXi2t5lhausQv/yk9iik5xh6fHla89cMFUfvYz3rrGpEAkwRzr+k7QOPG+++FPff/xuUHt+OpjZpF1Fjaz1Ky7ajdeAE3L3qK/HC5MsFy9OZc4C2Zy+6IqVnoaWluwcuLNqzoUzL9s3N0o+Fq8DS22Tr0nLbfSwtb5S+E07IHWR5E4RbYyI6OePxkNmf//xnbN682SYxKSEhAUuWLEFBQQF++9vf4rHHHkNBgfel4CkwpPVPwImDtQhDOLpgRk3sSdlrwvh68XS39pSzBTDlZv8+n751AB8bOsWhiYcnX4Jln37ntFieo3yaoqIiPProY3h/23LMLnjS5dR7c5cZ729bDl2EHuGDr7UZlvN3ToWcBTXdDb85KgbpKpHb1ZCRlDW74uK6A5uuc54NZVq292Qo09XfhrsV7Z3tp/2IspQRZnfDbHIPUfmaW+bu2FDo8riHyGg0oqampsf9tbW1aGrqTlhNTExEeztrQQS7CUXD0JJWg3MRLagwHMG2QWtkrwnj69R/dz0Y/uqtsH+f8h8aL/xqLivDrI2/xg8xCzA2/19YfufFkvI2EhMT8cEH/w/fnfoab2x6DMZWx5Xija31eGPTYzhU8TWSp/0vwqLjbC5M/s6p8PUXvjV3w2/WxSC/PLUL16+e47IXzFVvhpSeheTkZAwYNBjnvt/p0X6cPboTAzwcyvTlb8PZfprtJh13SZiE7K4HiENUFCg87iG65ZZbMHPmTCxfvhxXXHEFdDodSkpKsGjRIkybNg0AUFJSgsGDB8vd1qATqMmlFjEJUZj9vxPFqdQjzv8Cl5PSq5j7a/kP+/epDO8Sg5Co9P+HJhwDTN1LUSz57x8x8cQ9kj4XEydOxH/+8x9Mn347Hnv/LozIGY+ROVejlz4OZ00tKC3bjn1lO9ArphdyfvFHmDMvA9D9y99yYfJ1tXJPe2Gc/cL35u/BXUBrXQwSui50RZa77AVzFRxK6VnQ6XSYe/9v8ODChUhsaRATq13pbDmDs9/vxLznn/coodqXvw1n+zkqu7fNZ2Fktvv2uwuouVQIBQqP6xC1tLTgwQcfxDvvvIPOzu7aDxERESgqKsKKFSsQGxuL0tJSAMDIkSPlbq9qlKhD9NGKb3DqSKN4u++QREx78HJZXlsNgRjg+VLrxpNAwP59Poo6hy0/noG5S0Dc4CehC28Tt5165AH0bRwkuXZSbbMJ81bvwLb1H6L1m09grD4pPjZo0GA88MD92BWWi5JTZ2Ep3dQ7JhKbHrwWfeL1Pq9WPmfzHJs11/Iy8iRNr7cfaplqjED10UaPaka5q4Nk3TZBCIO5dSDOls90usK7HAuf2tch0rkYyhS6zKhfuxQ6mesQueNsP735LHCxWNI6xVa7t2hpacHx48chCAIGDBggjp0HKyUCopd/87n46xYAwsJ0uO/l62V5bTX4owiilngbCACwufDEXLQKLWGH0XX+de75ehki2i9chNwVmitaWYJvvq9DQUsk0jt1aIxqw//MvgSpmclISkqCTqfDyCc3obHtQjVvZwGBN8avGQ+jySjeTtQnYvsd7me/2V9I5xqjEWm+8Liz/bYOpEanJeAnbVForGh1GNBagtbiU/vQ3pqJs6enI0xIcHrR9jU4tLBUqtb3H4XeE+ciIq7nUFhnyxk0bHwRprK9uH7ectQmXuLVVHdvpsrLtZ9yvxaREhQvzBgXF4fLLrvM26cTurvXBVjFoxJ7y7XaEyNHPo4/983X97IMx/Rqj8f1x+5CWkl/rPuu1OHrOOpNslyQ685eblPBOeviFFR/3yx5GG9fRSMKWiLFasjR7bE4tqUNQ+deGLb2dVjMldzkXJvAUGoemf1QS1VEFy4Swtzut3US+JYfz6BzYApWP+g4YLQUgxQv2nrXwzZyJdxOnDgRn/znP/j59OmofPUe9Bo8Dr0GjUNYdBy6zrXg7NGdOPv9TsTExOD6ectxPHogzE5qULnjTVK8nInFwZSk7OnwLwUXj5OqST4ZAw0ubzujZB0XX6ahy7H2mT9r1Dh6L2/W5rr+2F3IMg6BvjPGaZsdrfRuYb+I6+SZIzxKOh6RlYgMc3cwBHQvhGofjPoy1djdtPyl45ciL8PztcXsk21rh8VJ2m9vV3h/bvoIXJaViH0VjVj0wT6f6+G4M3HiRJSfPIkVzz+P9M5q1H38DGr+36Oo+/gZpHdWY8Xzz6OivBy1iZf4lNQe7IUGvS0L4c3zXP2dUvDzesgs1CgxZOZt/sqbC7fB1Cp97R5P+DLsJcfaU0rum5T3Su0f7/HaXIP/PQX6zhiXbfZ2WEmK2mYTXl9ajARjJ8Kgk324UqkcEW+HWrxtj5q5LoIg4MyZM2hubkZ8fLw4lClHu7x9fiBUpQb8e76V/Dsl9Sg+ZEa+87aehpIzo3wZ9pJj7Sl/zfpy9l72+19V1oSilSUOLxqWnp0PD36FyiNG6IQwCLouJGZH93gvb4eVpOgTr8eDf8hXZDZebbMJX56/qADy9kB4M9TS1tSOqcYIjDJGoyqiC7XD4vC0xN4uNXtSdDodkpOTkZyc3OMxX2dhefv8QFnTy9vz5s3zlPw7Je1Tdchs27ZtuPnmm5GZmQmdToePPvrI5vG7774bOp3O5l9eXp7NNiaTCXPnzkVKSgpiY2MxdepUVFRU2GzT0NCAwsJCGAwGGAwGFBYWorGxUeG9U46cdVzsyTHs5Qsl903Ke9nvf02k4LbK7hcD/oZywxGcjWhBueEIvhjwtx7beDus5Erd2TrM2TwH49eMx4Ld85D/qyyPKkZLseiDfei0W+5EzToyn60+hOqjjYg0Axd1hGFae7TkXg3rIbp46PDzVr3iFcrtORrGsQSGex8rwOqZV3rcS+Pt8wNlqM3bOkbePE+Jv1MKHKoOmX366af48ssvcfnll+O2227D2rVrxVpGQHdAVF1djVWrVon3RUVF2RQvu++++7Bu3Tq8/fbbSE5OxsKFC3HmzBns2bMH4eHd010nT56MiooKvP766wCAe++9F/3798e6deskt1WJITMLLSVJOxr2AiBb+/y9r54mSdrv/1N1Nag0uZ6dpVY3uy+z3KSyn50WEabDrocnqDa04suQqvUQ3c9b9ejdbPb7jEh/D9u5GhYLlOny3g6t+nP2W6AMP4Yqxafdy02n0zkMiBobG3v0HFkYjUb06dMH7777LmbMmAEAOH36NLKzs7F+/XpMnDgRhw8fxrBhw1BcXIyxY8cCAIqLi5Gfn4/vvvsOQ4YMkdQ+JQMirU9Xl7N9rl5LiWDJ16BBykXDH4GJI54GYu6Or6PH7/tnqaYumnJ9Fv2Zq2ZNyfIHQM8Lc3tnF0pOnHF4/jhdXj6BElyGKqnXb83PMtuyZQtSU1MxePBgzJ4922bZkD179qCjo8Nm3bTMzEzk5uZi587u0vm7du2CwWAQgyEAyMvLg8FgELdxxGQyoampyeafUrS+2KWc7XP1Wt7MMHM3K8y6UrFZMHu81pqU2VlydLN7M7vPMssNgKR8B3fH19HjWlsIU64hVSWHhpVYhV4q+2U0vjpxBvpOAbe1ROG+Bj0y9jWJ7fF1qI4uCJThR3JN00nVkydPxvTp09GvXz+UlZXh0UcfxQ033IA9e/ZAr9ejqqoKUVFR6N3btrx8WloaqqqqAABVVVVITU3t8dqpqaniNo4sW7YMTzzxhLw75IQ/E4m9IWf7XL2WN4GXu8VZfU2SlJL4a0mu9oU3i8wuHb/Upn6Ru0DM3fF19LhcNWbk6v2TI3EfsF32IjE7Ghv7r8Iza/YgNzkXi0c8jr3/qPa6ra7OpVLLWFh6e7Z9XytWNjN3CYgI0+EnZ6PQ73yNqiyTTrEFjEOZknW+yH80HRBZhsEAIDc3F2PGjEG/fv3wySef4NZbb3X6PEEQbNYEcrQ+kP029h5++GEsWLBAvN3U1ITs7GxPd0ESpdfr8pWc7XP1Wt4EXu4u8p4GDWrxJhj0NBBzd3yVDMy9CfiUZB1YWQ95FlcW490dn8NQm9Gjrc7yROzz1EaX3en1KvTesvQMWec/hIfpcEX/JGTtaxOHAnTQVg+0lvInfcH12oKDpgMiexkZGejXrx+OHj0KAEhPT0d7ezsaGhpseolqamowbtw4cZvq6uoer1VbW4u0tDSn76XX66HX+6cLWa5fvUqQ+wvL1b5aB0vJWbEwd3bhzYXbnL5vW1O7bVCr63kRl6P3xh/80UvoLrBVMjD3JODzd4Kq/bCqvt7gsK3OpqlbivlZAqp+8VfDcC7Drz2+1kM2QHfgYxniLDYd1mwPtNYCZW8FU7XuUBZQAVF9fT3Ky8uRkZEBABg9ejQiIyOxefNm3H777QCAyspKHDhwAM8++ywAID8/H0ajESUlJbjyyu4P7O7du2E0GsWgiZyz/8L6dOU+bL70LUVK21sHS9bJs86+KD9bfQgmqwTV6NhIzfWuSeWPXkJ3gbcngbmnQYsnAZ+S9XEcBfj2w6qmZCOia2N6tNVZnoh9QPXZgHfx25Sn/drjaz9kY53Uq6UeaPvjX1Vm1HT+JIUWVQOilpYWHDt2TLxdVlaG0tJSJCUlISkpCUuWLMFtt92GjIwMnDhxAo888ghSUlLws5/9DABgMBgwa9YsLFy4EMnJ3QtZLlq0CMOHD8eNN94IABg6dCgmTZqE2bNn47XXXgPQPe1+ypQpkmeYhTL7X/YVx+tQnHTh1/DiHYt97oFxdJGy/6KsLuuZ1G7dtu4NoUh3u7teMjl6NBwFI1oeTvA0aPHkoqxkgqqjHomlv7IdVi2cdAP2/qO6R1ud5YnYB1QDM/rj5l+OlK3NUrgasnEW6KoxVdz++EdF216CkrNiFX1/IldUDYi+/vprXH/9hdXdLTk7RUVFeOWVV7B//3688847aGxsREZGBq6//nr84x//QHz8hV+XK1asQEREBG6//XacPXsWEyZMwNtvvy3WIAKA9957D/PmzRNno02dOhUvvfSSn/YycDkakqqJ+9GnWVuOWH9Jnjx4Bn9/cjd0divd6s7PzLEOEnS67mUq3PU6OKpFFNORIDnYcNet7yw4kBLQuNpGy8MJngYtnvQ+KZmg6mjoztGwatbcjB7PdRZ0aCFPzZshG2964nwNouyPf/u5TtdPIPIjVQOi6667Dq7KIG3cuNHta0RHR+PFF1/Eiy++6HSbpKQk/O1vPasHk2uOhqSM+YcR3hAua2l7+56ecy0dYgBkIZy/+FoHCdAB+l4R6DhnBnSAubMLbU3tPYIO+xyPxTsW46ffzZEcbLjLf3EWHEgJaFxtI3c5Bjl7nJQMWpRMUPUlV8tZ0KFGnpoc59KbnjhfhzPtj79Op4NglQpeX9EKgIUOSR2ar0NE6nE0JLXkxkdlL22f1r9noSwdYFMnJi0noWebBKDjnBkCBHSZBZw+2uiwdpGjWkSeBBvuatY4qy0j5T1cbSN3rRxv6jw542t9IutlR+ZsnoO6s3XiY0rWx/Hn0jBKcncua5tNuPP1Ygx8ZD0GPrIed75e3GO1d29qIvk6nGl//DMGGhx+xu3rKTlaModIbgGVVE3+5ejXtBK/hicUDcPfn9yNcy3ne6N0QMYgA8Ijwnrkcdi3CTrgfKzjNOhwVIvIk54Cd/kvzno0pLxH76w4VB5phA6AACDRKodC7mRYOXucfJ1V46jXzh+9LFqe0ekJd+dy0Qf7sOt4vXh71/H6Hr053vTE+dozaH/8nS0VxEKHpAYGROS0+91fs1NiEqJw52Nje7yXoyEA+zaZO7tw+mijy6DDUY5HzNjuHKKqE0bUxVXgX4Zn8MnmHIez5txdRJ0FB1KO3/qYdvSONCOtMwzVEV3YG9OO2yS+r6e0VADU1wrioc7dudznIICwDyq8CWqdBVHeDnE5+4yz0CGpQTNrmWmdkmuZqU3ra6m54ugXpie5FGqtQ2ah9NpW1nw9VnKyP+6Xp46F+fQsSRdU6wC+d1Yc1se0Y091k8PnaXmmni/cncuilSXY+n2tzXOuHdxHsVo5cq/lxXXWSE4Bt7ir1gVzQKTWQpdaoNZK9RZFK0vwzfd1KGiJRIY5DKaECDz4h3ynF+1gucBbZv5Zeu2aym/D7mMdki6o1gG8AOBEpBn/jG13+DzrbaHr/mwLghDQx06K2mYT5v19L746cQYAcEX/JPzfnaMUCyr8GdgTeUrq9ZtDZqSpoRR/83atM7kCk+emj8DrS4uR0NmJMOgQ02x2OeNNy1PxPWGfizbyyU2Sc0aqyy7kz+gApHeGOX2efRK+JU8tkI+dM/bDVkoGQPY4xEXBgLPMKGhm3njD25Xq5Zqx1Sdej7ROHcLO111yl+ws91R8NVmvCj+9VY94SJvxZF2SQTj/z9nzrGfqWQv0Y+eImjOzfJ11qBW1zSYUrSzByCc3oWhlSY+ZeRTc2EOkIrWHP+zf/87HxwbtEIIz3s6akzMw8aSHLlh682qbTXj9T8VIMHb3jCXqgDsSYvHPWJPbGU9dXRdqQegARIbp0Dsm0uHzrBPboQNMbR0Bf+ycUXNmVrCs5aXksjGkfQyIVKT28Ifa7x/I5AxMPJnNp+a6VHIG8Is+2IfhTZ1izxiE7qEvKXkn6TkGm2M/4JIk7HXyubWexeRsinew4LCV7zjdP7QxIFKR2sMfvry/2r1bapMrMPH0OKpZR0fOAHpfRSNSwnXo3xmGMOjQBUFyUOntsQ+WGkTOKFnhO1QwqAxtDIhUpObwh6N1yjx5/1DvXZJ6cXVXn0WO4+ivZQ7kCuDbmtoxvVUPfWcnzgHQ6QSYEiIY2PgoWIat1MSgMrQxqVpFaiYzO1qnzJP39+bi6Gq5hkAjdV/cJbrKEWT4K5lWrqVEPlt9CL2bzegFHaIBmBIicO/iPM32MAbT5xZg4rArSi4bQ9rHgEhFll+6s5ZfjZvnjvTrBcHROmWevL83F0fLcg1Gk1FcriFQSd0XdzkJcgQZcuc9OAsArAP4zEGJMHd24c2F27DuxVK0NbVLfn3rz14YdEjvDFPkwmM9i83TNloLps8twHXCiJxhQBSifL0Qe9O7FUzLNUjdF3cLaE4oGoa0wfHojDLhVOL32Nh/lcc9EN4s0umKswDAOoAPjwjD6aONXpUdcPXZk7M3Rq7SCN58bqX0wsgVsHnaBiYOEznGgChE+Tpc503vVm5yLsJ14QAgFkFU+qJgT673c7QvjrirzxKTEIXNl76FVWMexsdD/oodDVs97oGQuwaMlADAl6E+V589OXtj5Mp5knqurUnphZErYJPShq3f1yJ/2WcoWlmCoekJsgbQRMGCSdUqkmOmlrevoUZiqqNFVj970/ukYm/2Xa5kcEf74oijRFf7dh8zlPnUcyZ3Mq2U6t2+TAhw9dmTsxdRrkkLUs+1NSm9ML4EbJalTw7UH0Bucq7DRYmt2wAAnedr61zZPwnjB6YwcZjIDgMiFclxcQ6k2V6OiiBWnzjk9UXBm32Xq9fA24KOQM92T+jzS/xjwJ89Xj5EKVICAKXqITkLxryZSedrG4/UnsbMTxaiqes4EsIuxsqf/gND+mRKao+U6du+BGyWnjSzYBZ70uw/j9ZtsDB3CfiuqonrjBE5wIBIRXJcnNWuZeQrXy4KjvbdXa+Rr70GcvTq2bc7pSULeRl5HvVAKElKsKdUD6OzYMybCsK+tnHmJwthxCHowrtgFA5h5icL8eXdf5fUHinTt30J2KT0pFna8OWxOnSeD4o4REbkHAMiFflycbZcmNvPXlilXslaRlK66L3hy0XB0fFz12vka6+BHD1y9u1O72/wurcp2DgLxvyRCGzf69OE49CFd0euOl0XmszHJbdHyjCmLwGblGFNSxss+8UhMiLXGBCpyJeLs/WFGQDCwnXIuqS3YrWM7Lvol/z3j5h44h6fK1V7c1GwBINVZUboYyIhdAlIy+luw/tPFLvsMfO118Bdj5yUHiQ1l9/wByUKRSpRQdg+yG8qvw27j3WIvT4xF2VDiD4Kna4LghAGQ9jFirbHE57kNfmzYKO/ioQSKUEnCILgfjNqamqCwWCA0WhEQkKC2s3Bmwu3wdR6oXcoOjYSs5Zfrdj7jV8zHkaTUbw99cgD6Ns4SOzlyB6a1GPNKKWW9Vj3YqlND4v1e7t6TOn39sf7B4KilSU2wcL4gSk+X5Ad9XL4eqGds3mOTS+LuW0gmk/cIz6eEHsO8dn/tMohWt4jh0jO9gQDJc69txickYXU6zd7iAKUv5f9sO+iT225yGlPidKJ3q56aZTufXH3+s7a5ixIDMY14ZQY3vK0l0PKxdA+Dyc8+hTCw3TixXxU32ysPp8z5Gt7lKSlC7+Wahxx5XryFOsQBSh/L/uxdPxS5GXkIVGfiLyMPGRdnOK0uJ7Sid6uCvspXf3b3es7a5uzmjNK16JRg9yFIr0hpQ6QfX2hy9Mvk7Wek79oqfK0Fs69hZaCMwoM7CEKUP6uI2Sf7No2tt1pT4nSvVdSe4HU6H1x1jZnQaIaswSVPi6eLpCpRMK+lIuhozwcOSYK+JsvF365e5e0tDiq2nleFHiYQySRv3KIAnUIxbrdKVlxAID6ilYxKFBjH7SUz2PflsxBiQiPCEPFdw3oMl/4E4yOi8Sdj41V9Hhp6bgAPXN58jLyfJ51JzWXRanZk3Jz9b3gS96OlnJ+5MY8L7KQev3mkJnGBOoQinW7Tx9tRHhEmCqL1lrTUo0m+yFOoDu/yjoYAgBTW4fi51xLxwXomctzrPKEz8urSF3OJFAWbnX1veDL0i2+9i65W6/NE3K/HleuJ09xyExj5JjWrQatXWQBZYbu5Foq5c2F28TjZc0fx87fCfnu2CfsT/ihEOW1viXl29fguWnFVodDQoGy4LD931dVWROKVpb4PNTly7CS3EnLTIImtbGHSGPcrUKv1R4kd+1Wg6eJ51IWfpXr+FsfL2v+OHZKJ+R7umK9fcJ+SnOWpOBayvu4Szj2ZuFWNdj/fdVECrIkUqvVu+SP1yPyFHuINMbbad1q02KxQU8Tz6WUC5Dr+Fsfr+SsWAC2OVdKUjohX8o6W9bsE/bXfVcqqQdLyvu4u8h6s3CrGuz/vt6tq4HZ5Hvw4Ev5ALmSli29eC3nLtRVYxI0qYEBkca4u1hpbbjDnoDAzdGXEuykZMXh1JFG8bYlmPGU9Xm2DMMpfez8Va/G12EoqcG1lPdxd9H2ZpFeNRKx7b8X/rmyBDUqz6CSa0aZ9VAZAESE6XBVAJU9oODBIbMA42i4Q8pQj9K0OpTnCbWG/T5bfQgnD3Ufu5MHz+DvT+5W5Bz6q15NbnIuwuzGA90Nm1mTWktKynCXL0NCzmghEVuJ/fKUXEnL1r14ABAfHRFwSdByJ4STOthDFGAc9SBZT6NWojK0FL4OJWkhWVxKz0RdRYvN7fqKVp/ft/pEE6w7h861dChyDv2Vo7F0/FL87N8/Q6Op+/WbTE1uh828fR93w13uhoS8+dxpIRFbS5WyfeXJ0JuWqnJbY0J4cGAPURDQQl6Rr70rWuhhktIzoUQvUlr/nnUxfEkkdsZZFWG5f92m9EqxGf7rQpciQYNluGv7Hdvx6k2vejVs5c3nTs1E7GDsibDu7bqyfxLaO7uc7p+WqnJbY0J4cGBAFAS0MMPL15lLcgR1vgQLUikxQ2tC0TBEx0WKt6UkEksdrrE+JuGZb2HswMgewyxKXGQCZfaWN587+1lxjnqmlApctBoQ+MJ66C0qIgwlJ8443T+tBh5aWrKEvKdqQLRt2zbcfPPNyMzMhE6nw0cffWTzuCAIWLJkCTIzM9GrVy9cd911OHjQ9pemyWTC3LlzkZKSgtjYWEydOhUVFRU22zQ0NKCwsBAGgwEGgwGFhYVobGxUeO/8x9/rmllY5y59tvoQJhQN87oYoxxBnT9yO5RYKy0mIQp3PjYWF13q/hx6OlxjfUy+qdmNhOwPe+R8KHGRkRI0aIE3nzspPVNKBS5aDQjk4m7/tBp4aCGni3ynag5Ra2srRowYgXvuuQe33XZbj8efffZZPP/883j77bcxePBgLF26FDfddBOOHDmC+PjuL6758+dj3bp1WLNmDZKTk7Fw4UJMmTIFe/bsQXh49y/Uu+66CxUVFdiwYQMA4N5770VhYSHWrVvnv51VkL/XNbOQc1V7OabtayG3w1tSz6F9EUN3PS9yzMTyhjezt9SgVLkIpQKXYF+fy93+aWmtNGvBlNMVyjSzlplOp8PatWsxbdo0AN29Q5mZmZg/fz5+//vfA+juDUpLS8MzzzyDX//61zAajejTpw/effddzJgxAwBw+vRpZGdnY/369Zg4cSIOHz6MYcOGobi4GGPHjgUAFBcXIz8/H9999x2GDBnisD0mkwkm04Vu7qamJmRnZyu+llkgeXPhNphaL9QOiY6NxKzlV6vWHiXWxNIay5RvqQuSSjkmobTmk7+ScpVaIyzYz1Ww7x+pQ+paZpoNiI4fP44BAwbgm2++wahRo8TtbrnlFiQmJmL16tX4/PPPMWHCBJw5cwa9e/cWtxkxYgSmTZuGJ554AitXrsSCBQt6DJElJiZixYoVuOeeexy2Z8mSJXjiiSd63M+A6AKtLRIqJViQczabFmbGueNpABUoi516y1+LmfLCTqQdUgMizU67r6qqAgCkpaXZ3J+WloYff/xR3CYqKsomGLJsY3l+VVUVUlNTe7x+amqquI0jDz/8MBYsWCDetvQQ0QVaq04tZZhGzmE+OV9LKZ4OXXlaZTrQeDKU5UtvEodQiAKPZgMiC51OZ3NbEIQe99mz38bR9u5eR6/XQ6/nLzpX1Mpd8oW3s9kc9ZxoodyB3AI5D0sKT3JwQq22TLD3DhK5o9lp9+np6QDQoxenpqZG7DVKT09He3s7GhoaXG5TXV3d4/Vra2t79D4FAi1UpQ5knswqsj7Wbzy9Eft+PGAzg00L5Q6syTHVO1Cmy3vLk9lAwT6jy54WKnATqUmzAVFOTg7S09OxefNm8b729nZs3boV48aNAwCMHj0akZGRNttUVlbiwIED4jb5+fkwGo0oKSkRt9m9ezeMRqO4TSDRQgHDQOZJiQLrYx1XnYprjt4B4ELPiVrlDpzxZaq3JZjatfsmxHYNRUKUQdPT5b3lbLkJRzWstDrFWynB3jsY7IKxaKe/qTpk1tLSgmPHjom3y8rKUFpaiqSkJFx00UWYP38+nnrqKQwaNAiDBg3CU089hZiYGNx1110AAIPBgFmzZmHhwoVITk5GUlISFi1ahOHDh+PGG28EAAwdOhSTJk3C7Nmz8dprrwHonnY/ZcoUpzPMtCwYh2nkZJ33MTotAT9pi0JDRYtN0rPUYT7rYx2GcKS2XgTgQs+J1oYMfenR+O0H21B69lXoMirQ0JqFkV2P49WbblKopa6pkazuKHfquekvqDbFW43hK09LOpC2hNoQrxJU7SH6+uuvMWrUKHEW2YIFCzBq1Cg89thjAICHHnoI8+fPx29+8xuMGTMGp06dwqZNm8QaRACwYsUKTJs2DbfffjuuuuoqxMTEYN26dWINIgB47733MHz4cBQUFKCgoACXXXYZ3n33Xf/urEy0NkyjNda9JL0PNKPySKPXvWn2x7o9uVmThQYtQ3t3V0fg561RiOnyvEdjf/trCIs9hrCINoTFHsP+9teUa7AbavSCOuodkWvxUm+oMXwVKMU0ybFQG+JVgmam3Wud1Gl7SrP8erae2aW1qd5qGvnkJjS2dQAAHjBGo5dwIXHeWZ0kZz0Sahxrb2Y2WZc/EABU6LtQOSLBo1lRI9/Og1l3YaHacCEOpXfv8mVXvOZLfStve5d8rWEld32j8WvGw2gyircT9YnYfsd2r1+Pgp+/SkoEIqnXb83mEJFjSiwdEUys8z6qIrrEJUZd9aY565FQ41h7kwdkPbSnAzAoQu9xj8bl6SMA4fzXgRCGy9Mv86L18nDWCyplQoG3vUu+9o7IvVRHsCe3k/wCefkQreQ/aX7aPXkmEIoFKqW22YT2zi7oAESE6VBzSRzy2/VorGh1WSepusw2L6u6rMl/jbbjTbd3Wv8EmwKZ3gyjPnvtn3oUcJRKEATU19ejpaUFcXFxSE5OdlsawxVn9a2k1H3yNsfO16VG5B6uWDp+qdfng0JTINe+0kr+EwOiIBMIxQKVsuiDfSg5cUbsMtb1Csdt91/u9nm6MJ3L2/7kzVpVchTI9CYgaGxsxOrVq/HSX1/CsaMXJkcMHDQQD9z/AIqKipCYmOhxW5wlq0sJduQIDr0h9xpjgbIWHJEctJL/xCGzIKOVWWhq1Evy9o+qq6vL5rbQpV5anTfd3moM7W3cuBHZF2VjwcIFqEuqQ/ZvstH/d/2R/Zts1CXVYcHCBci+KBsbN26U7T2lTChQqxRCIA9XEKlNKyUu2EMUZNT6hWxPjZ4qb3+lp+cYbI5ZWo56SfNqdXt7Ms1748aN+OmUnyL20lgMumcQIhMjbR43XGlAR2MHKldV4qdTfopP/vMJJk6c6HMbpfSEqVUKIZCHK4jU9tz0EaqVuLDGWWYSKTHLTIl8H7VmodnvS1WZEe1tZvFxT2YKecvbBTUDdeaenDObpM6yamxsRPZF2Qi7OAzZ87KhC3c+vCiYBZT/Xzm6jneh/GS5V8NnRES+CrjV7rVOiYBIa6vF+8J+X/QxkTC1dQTFvtnTSuK6nNNsHU3z3viTz3rs5xurXsGChQswaHnPniFHOho7cHThUax4fgXmzZvnVduCkaPPUKtOkHXqPhF147T7AKCVfB852O+L0CVoalkLOWll+RRfExGtp7oK57IRZjfN234///v2Ibz015eQMCZBUjAEAJGJkUgYnYAXX3oRUn57aWX6rdIcfYbknrovp1A5LxTaGBCpKJiqTtvvS1pOQtDWS9JKIOtrIqL1Bbjqh2mI6xpqU4fHfj+rTxhx7OgxxI/27HMaPyYex44ew5kzZzxqk9aCAjk5+gxpZaaNI6FyXii0MSBS0bhbB0If0/1LWx8TiXG3DlS5Rd7T2kKnStJKIOvrzCabC3BHHNpO3oPtd2zHqze9ipReKT3205DeHdSGx4Y7e0mHwmO6t29udh84ajkokJOjz5BWZto4EirnhUIbZ5mpaOe/jsF0fpkJU1sHdv7rWMDm2WhtoVMlyVH3Rw6+zmxyNyvPfj9H3ZwG/B4wt5odv6AT5vPJ9dZrEHrbJjnJvdyGJxx9hvLO5xCpPdPGEX+eFyK1MKlaIiWSqn1Zs4nIV57OyhMEAYOHDEZdUh2y7suS/D4VL1cgpSEF3x/53m0Fa29nCnrD26R0uQIpNQMyT/nzvBDJTer1mz1EKtJKzSAKTZ72MOl0Ojxw/wNYsHABOho7JM8ya9rThCeef0LSch7+rOfj7TCQXMsMaGW5AilYZ4lCAXOIVKSlvBs1KkuHgmA7rkVFRYiJiUHlqkoIZtedy4JZQNXbVYiJicEvf/lLP7VQOm9zduTKp2FeDpG2MCBSkZZWrpc6lbzubB3mbJ6D8WvGY87mOag7W+fnlgYWuaboayWwSkxMxD8/+CdaD7ai/P/K0dHY4XC7jsYOlP9fOVoOtODDf36oyaKMniSlW0871wGwLHfnSz6NlpOoiUIRc4gkUiKHSEuk5jNJrWhM3eTKE9NaEc+NGzfi59N/jra2NiSMTkD8mHiEx4TD3GZG89fNaNrThJiYGHz4zw9RUFCgWjvlYpNvpAMSenUPF/qST8O8HCL/YA4ReURqPtOB+gMwC92zhsyCGQfrD/qzmQFHrjwxrdQ+spg4cSLKT5bjnXfewYsvvYhjL9uudv/E80+gqKgIBoNBxVbKx2Z46/xPyL2P+RboMS+HSFs4ZEYApOcz5SbnItyuojE5J1eemFZqH1lLTEzEvHnz8P2R71FXV4eysjLU1dXh+yPfY968eUETDAHaG97i0DWR/DhkJlGwD5lJZVkV/WD9QVyafKnLVdFJPoG6AG2w0NrwFoeuiaTj4q4yY0BEwcoS5B6oP4Dc5FzNBLlabZcWOFqMd/sd21VskTYEUm0n8h8u7kpBgUMDylu8YzGKK4thNBlRXFmMxTsWe/waSiz+KUe7ghWHrh3jmmvkCwZEpGm8KCpPjkR5JS5ETOB3bun4pcjLyLNZjNdbwbSSPWs7kS8YEJGm8aKoPDl6G5S4ELEXxLmUXil49aZXbRbj9VYw9apoLfmdAgsDItK0YLgoaqWoojNy9DYocSGSsxeEnAumXhVPim0S2WNStURMqlZHMMxq01pRRSVobRYWSeftIrdEgYKFGSkoWIYGApnWiioqgUUGA9dz00f0CGaJQhEDIiKFyVWtmkgJDGaJujGHiEhhclWr1rJgmqlERKGJOUQSMYeIyDnmoRCRVrEwIxH5TTDNVCKi0MSAiIh8xvovRBToGBAFIS53Qf7G+i+2AvFv0Js8MOaOUTBhDpFEgZRDxJWwidQViH+D3uSBMXeMAgHrEIUwLncROtqa2vHZ6kOoPtGEtP4JmFA0DDEJUWo3K+QF4t+gN3lgzB2jYKLpIbMlS5ZAp9PZ/EtPTxcfFwQBS5YsQWZmJnr16oXrrrsOBw/afvGYTCbMnTsXKSkpiI2NxdSpU1FRUeHvXfErR8tdBGIXPrn32epDKD98BqbWTpQfPoPPVh9Su0mEwFxyxps8MOaOUTDRdEAEAJdeeikqKyvFf/v37xcfe/bZZ/H888/jpZdewldffYX09HTcdNNNaG6+UAl4/vz5WLt2LdasWYMdO3agpaUFU6ZMgdlsVmN3/MLRGlBcNT44hUIV7EAUiOuweZMHxtwxCiaaziFasmQJPvroI5SWlvZ4TBAEZGZmYv78+fj9738PoLs3KC0tDc888wx+/etfw2g0ok+fPnj33XcxY8YMAMDp06eRnZ2N9evXY+LEiU7f22QywWS6kCDY1NSE7OzsgMghcmT8mvEwmozi7UR9IrbfsV3FFpEcQmGdNCIiXwRNHaKjR48iMzMTOTk5uOOOO3D8+HEAQFlZGaqqqlBQUCBuq9frce2112Lnzp0AgD179qCjo8Nmm8zMTOTm5orbOLNs2TIYDAbxX3Z2tgJ75z+B2IVP7oVCFWwiIn/QdFL12LFj8c4772Dw4MGorq7G0qVLMW7cOBw8eBBVVVUAgLS0NJvnpKWl4ccffwQAVFVVISoqCr179+6xjeX5zjz88MNYsGCBeNvSQxSoLMNm1qvGU+CLSYhijxARkQw0HRBNnjxZ/P/w4cORn5+PAQMGYPXq1cjLywMA6HQ6m+cIgtDjPntSttHr9dDr9V62XHuCYdV4IpKuttmERR/sw76KRow4v4p9n/jg+U4jkpvmh8ysxcbGYvjw4Th69Kg428y+p6empkbsNUpPT0d7ezsaGhqcbkPKamtqx7oXS/Hmwm1Y92Ip2pra1W4SZ9xRSFj0wT7sOFaHxrYO7DhWh0Uf7FO7SUSaFlABkclkwuHDh5GRkYGcnBykp6dj8+bN4uPt7e3YunUrxo0bBwAYPXo0IiMjbbaprKzEgQMHxG1IWVqcFq7EjDsGWeQNJSs9s0YQkWc0HRAtWrQIW7duRVlZGXbv3o2f//znaGpqQlFREXQ6HebPn4+nnnoKa9euxYEDB3D33XcjJiYGd911FwDAYDBg1qxZWLhwIT777DPs3bsX//M//4Phw4fjxhtvVHnvQoMWp4UrUTSPZQ1c4xIPjinZi8MaQUSe0XRAVFFRgTvvvBNDhgzBrbfeiqioKBQXF6Nfv34AgIceegjz58/Hb37zG4wZMwanTp3Cpk2bEB8fL77GihUrMG3aNNx+++246qqrEBMTg3Xr1iE8PFyt3Qopaf0ToDv/KdOFAan9410/wQ/knHFnGRIc/O8pmHjwV+jVHh8wlYn9icM3jinZi8MaQUSe0XQdIi0JpLXMtMSytETNiWak9o/XxNISdWfresy4S+mV4tVrWdcB6oIZFYYj2HjpmwGxdpU/jXxyExrbOsTbvWMisfexAhfPCA1cC4xIeVzLjDRBi9PC5ZxxZz0kGIZwpLX2C5jKxP40IivR5sLP4Ztuz00fgUUf7MO3FY247PxMMCJSBwMiIh+k9U+wqRQ9aEg2FrBnSOyFO1B/ALnJuXjk5sfw1Drwwm+nT7yePUJEGsGAiMhD1hf7kf1H43rz/6Cx/Jw4JEgXkszNghnFlcVYgSexeiYDRQosrOUUWhgQEXnI+mK/o30rOi814dX5vNhbU2ImH5G/WSYDmLsEcTIAe/SCl6ZnmRFpES/27nHtPAoGrOUUWhgQEXmIF3v3lo5firyMPCTqEzWbZK6FYppaaAM5x1pOoYXT7iXitHuykHPaPnnHUs6h+kQT0voneFXOYc7mOeLQZ7guXJVSCVpoAzlnySGyngzAHKLAw2n3RB6wnxXlKsjhQrnSKJmQalkSRuiCuCSMp+UdtDD0qYU2kHOcBRhaOGRGBC69oQQlq1PLsSSMFoY+tdAGIurGgIgI/KWuBCUTUuVYEkYLeU5aaAMRdeOQGRG6f6lb53Lwl7p77vJ4lKxOPaFoWI8lYTylhaFPLbSBgoMnw/7kGJOqJWJSdXBjorQtKV+u1uu46cKA7KFJNnk8TEilUKVGQUcm6Dsn9frNgEgiBkQUSqR8ub65cBtMrZ3i7ejYSMxafrW/m0qkOWos2jt+zXgYTUbxdqI+Edvv2K7oewYKqddv5hARUQ9ScqrkyOMhCkZqFHRkgr7vGBARUQ9SvlwnFA1D9tAkRMdGIntoEtdxIzpPjYKOTND3HYfMJOKQGYUS5lT5HxcSDR7Mn9MW5hDJLJQDIjmqAhORa2rknRCFAuYQkWwsVYFNrZ1iVWAikhcXEiVSFwMickuOqsBE5BoXEiVSFwMicouziYiU99z0ERg/MAW9YyIxfmAKnps+Qu0mEYUU5hBJxBwi26rAzCEiIqJAwNXuSTYxCVEeryROREQUSBgQEZEmcNq5MnhciaRhDhERacKiD/Zhx7E6NLZ1YMexOiz6YJ+k59U2m1C0sgQjn9yEopUlqG02KdzSwOLtcSUKNQyIiEgTvJ12zgu+a5zOTyQNAyIicqitqR3rXizFmwu3Yd2LpWhralf0/bydds4Lvmuczk8kDQMiFdWdrcOczXMwfs14zNk8B3Vn69RuEpHI3wU5vZ12zgu+a5zOTyQNp91LpMS0+zmb56C4shhmwYxwXTjyMvLw6k2vyvLaRNa8WX7lzYXbYGrtFG9Hx0Zi1vKrlW6qx7huFBG5wmn3AeBA/QGYBTMAwCyYcbD+oMotomBl6e0RuiD29rgrpZDWP0F8jpYLcvaJ13PNLyLyGYfMVJSbnItwXTgAIFwXjkuTL1W5RRSsvFl+ZULRMGQPTUJ0bCSyhyZhQtEwhVtJRKQe9hCpaOn4pVi8YzEO1h/EpcmXYun4pWo3iYKUN709LMhJRKGEOUQShfLSHRT4uPwKEYUq5hARkYi9PUREroVUDtHLL7+MnJwcREdHY/To0di+fbvaTSIiIiINCJmA6B//+Afmz5+PP/zhD9i7dy+uvvpqTJ48GSdPnlS7aURERKSykMkhGjt2LC6//HK88sor4n1Dhw7FtGnTsGzZMrfPD8YcorqzdVi8YzEO1B9AbnIulo5fipReKQ639aaODVEo4OKpwYHnMXhJvX6HRA9Re3s79uzZg4KCApv7CwoKsHPnTofPMZlMaGpqsvkXbBbvWIziymIYTUYUVxZj8Y7FTrf1d9ViokDBtdSCA88jhURAVFdXB7PZjLS0NJv709LSUFVV5fA5y5Ytg8FgEP9lZ2f7o6l+5UlhSG/q2BCFAq6lFhx4HikkAiILnU5nc1sQhB73WTz88MMwGo3iv/Lycn800a88KQyZ1j8BuvOfFi1XLSbyN66lFhx4HikkAqKUlBSEh4f36A2qqanp0WtkodfrkZCQYPMv2CwdvxR5GXlI1CciLyPPZWFIVi0mcoyLpwYHnkcKqaTq0aNH4+WXXxbvGzZsGG655ZaQTaomIiIKdizMaGfBggUoLCzEmDFjkJ+fj9dffx0nT57EnDlz1G4aERERqSxkAqIZM2agvr4eTz75JCorK5Gbm4v169ejX79+ajeNiIiIVBYyQ2a+4pAZERFR4GEdIiIiIiKJGBARERFRyGNARERERCGPARERERGFPAZEREREFPIYEBEREVHIY0BEREREIY8BEREREYU8BkREREQU8kJm6Q5fWQp6NzU1qdwSIiIikspy3Xa3MAcDIomam5sBANnZ2Sq3hIiIiDzV3NwMg8Hg9HGuZSZRV1cXTp8+jfj4eOh0Otlet6mpCdnZ2SgvLw+JNdJCaX+5r8GJ+xq8Qml/Q2lfBUFAc3MzMjMzERbmPFOIPUQShYWFISsrS7HXT0hICPoPpbVQ2l/ua3DivgavUNrfUNlXVz1DFkyqJiIiopDHgIiIiIhCHgMilen1ejz++OPQ6/VqN8UvQml/ua/BifsavEJpf0NpX6ViUjURERGFPPYQERERUchjQEREREQhjwERERERhTwGRERERBTyGBCp7OWXX0ZOTg6io6MxevRobN++Xe0meWTJkiXQ6XQ2/9LT08XHBUHAkiVLkJmZiV69euG6667DwYMHbV7DZDJh7ty5SElJQWxsLKZOnYqKigp/74pD27Ztw80334zMzEzodDp89NFHNo/LtX8NDQ0oLCyEwWCAwWBAYWEhGhsbFd47W+729e677+5xrvPy8my2CYR9XbZsGa644grEx8cjNTUV06ZNw5EjR2y2CabzKmV/g+XcvvLKK7jsssvEYoP5+fn49NNPxceD6by629dgOad+JZBq1qxZI0RGRgpvvPGGcOjQIeG3v/2tEBsbK/z4449qN02yxx9/XLj00kuFyspK8V9NTY34+NNPPy3Ex8cLH374obB//35hxowZQkZGhtDU1CRuM2fOHKFv377C5s2bhW+++Ua4/vrrhREjRgidnZ1q7JKN9evXC3/4wx+EDz/8UAAgrF271uZxufZv0qRJQm5urrBz505h586dQm5urjBlyhR/7aYgCO73taioSJg0aZLNua6vr7fZJhD2deLEicKqVauEAwcOCKWlpcJPf/pT4aKLLhJaWlrEbYLpvErZ32A5tx9//LHwySefCEeOHBGOHDkiPPLII0JkZKRw4MABQRCC67y629dgOaf+xIBIRVdeeaUwZ84cm/suueQS4X//939VapHnHn/8cWHEiBEOH+vq6hLS09OFp59+Wrzv3LlzgsFgEF599VVBEAShsbFRiIyMFNasWSNuc+rUKSEsLEzYsGGDom33lH2QINf+HTp0SAAgFBcXi9vs2rVLACB89913Cu+VY84ColtuucXpcwJ1X2tqagQAwtatWwVBCO7zKgg991cQgvfcCoIg9O7dW3jzzTeD/rwKwoV9FYTgPqdK4ZCZStrb27Fnzx4UFBTY3F9QUICdO3eq1CrvHD16FJmZmcjJycEdd9yB48ePAwDKyspQVVVls496vR7XXnutuI979uxBR0eHzTaZmZnIzc3V/HGQa/927doFg8GAsWPHitvk5eXBYDBo7hhs2bIFqampGDx4MGbPno2amhrxsUDdV6PRCABISkoCEPzn1X5/LYLt3JrNZqxZswatra3Iz88P6vNqv68WwXZOlcbFXVVSV1cHs9mMtLQ0m/vT0tJQVVWlUqs8N3bsWLzzzjsYPHgwqqursXTpUowbNw4HDx4U98PRPv74448AgKqqKkRFRaF37949ttH6cZBr/6qqqpCamtrj9VNTUzV1DCZPnozp06ejX79+KCsrw6OPPoobbrgBe/bsgV6vD8h9FQQBCxYswPjx45GbmwsguM+ro/0Fguvc7t+/H/n5+Th37hzi4uKwdu1aDBs2TLyAB9N5dbavQHCdU39hQKQynU5nc1sQhB73adnkyZPF/w8fPhz5+fkYMGAAVq9eLSbwebOPgXQc5Ng/R9tr7RjMmDFD/H9ubi7GjBmDfv364ZNPPsGtt97q9Hla3tcHHngA3377LXbs2NHjsWA8r872N5jO7ZAhQ1BaWorGxkZ8+OGHKCoqwtatW522MZDPq7N9HTZsWFCdU3/hkJlKUlJSEB4e3iPKrqmp6fELJpDExsZi+PDhOHr0qDjbzNU+pqeno729HQ0NDU630Sq59i89PR3V1dU9Xr+2tlbTxyAjIwP9+vXD0aNHAQTevs6dOxcff/wxvvjiC2RlZYn3B+t5dba/jgTyuY2KisLAgQMxZswYLFu2DCNGjMALL7wQlOfV2b46Esjn1F8YEKkkKioKo0ePxubNm23u37x5M8aNG6dSq3xnMplw+PBhZGRkICcnB+np6Tb72N7ejq1bt4r7OHr0aERGRtpsU1lZiQMHDmj+OMi1f/n5+TAajSgpKRG32b17N4xGo6aPQX19PcrLy5GRkQEgcPZVEAQ88MAD+Ne//oXPP/8cOTk5No8H23l1t7+OBOq5dUQQBJhMpqA7r45Y9tWRYDqnivFf/jbZs0y7f+utt4RDhw4J8+fPF2JjY4UTJ06o3TTJFi5cKGzZskU4fvy4UFxcLEyZMkWIj48X9+Hpp58WDAaD8K9//UvYv3+/cOeddzqc5pqVlSX897//Fb755hvhhhtu0My0++bmZmHv3r3C3r17BQDC888/L+zdu1csjSDX/k2aNEm47LLLhF27dgm7du0Shg8f7vepra72tbm5WVi4cKGwc+dOoaysTPjiiy+E/Px8oW/fvgG3r/fdd59gMBiELVu22ExJbmtrE7cJpvPqbn+D6dw+/PDDwrZt24SysjLh22+/FR555BEhLCxM2LRpkyAIwXVeXe1rMJ1Tf2JApLK//vWvQr9+/YSoqCjh8ssvt5kKGwgsdTwiIyOFzMxM4dZbbxUOHjwoPt7V1SU8/vjjQnp6uqDX64VrrrlG2L9/v81rnD17VnjggQeEpKQkoVevXsKUKVOEkydP+ntXHPriiy8EAD3+FRUVCYIg3/7V19cLv/jFL4T4+HghPj5e+MUvfiE0NDT4aS+7udrXtrY2oaCgQOjTp48QGRkpXHTRRUJRUVGP/QiEfXW0jwCEVatWidsE03l1t7/BdG5nzpwpfp/26dNHmDBhghgMCUJwnVdX+xpM59SfdIIgCP7rjyIiIiLSHuYQERERUchjQEREREQhjwERERERhTwGRERERBTyGBARERFRyGNARERERCGPARERERGFPAZEREREFPIYEBEREVHIY0BERCSTl19+GTk5OYiOjsbo0aOxfft2tZtERBIxICIiksE//vEPzJ8/H3/4wx+wd+9eXH311Zg8eTJOnjypdtOISAIGREQUMJqbm/GLX/wCsbGxyMjIwIoVK3Dddddh/vz54jbt7e146KGH0LdvX8TGxmLs2LHYsmWL+Pjbb7+NxMREbNy4EUOHDkVcXBwmTZqEyspKm/datWoVhg4diujoaFxyySV4+eWXXbbt+eefx6xZs/CrX/0KQ4cOxV/+8hdkZ2fjlVdekfMQEJFCGBARUcBYsGABvvzyS3z88cfYvHkztm/fjm+++cZmm3vuuQdffvkl1qxZg2+//RbTp0/HpEmTcPToUXGbtrY2PPfcc3j33Xexbds2nDx5EosWLRIff+ONN/CHP/wBf/rTn3D48GE89dRTePTRR7F69WqH7Wpvb8eePXtQUFBgc39BQQF27twp4xEgIqVEqN0AIiIpmpubsXr1arz//vuYMGECgO5enMzMTHGbH374AX//+99RUVEh3r9o0SJs2LABq1atwlNPPQUA6OjowKuvvooBAwYAAB544AE8+eST4uv88Y9/xPLly3HrrbcCAHJycnDo0CG89tprKCoq6tG2uro6mM1mpKWl2dyflpaGqqoqGY8CESmFARERBYTjx4+jo6MDV155pXifwWDAkCFDxNvffPMNBEHA4MGDbZ5rMpmQnJws3o6JiRGDIQDIyMhATU0NAKC2thbl5eWYNWsWZs+eLW7T2dkJg8Hgso06nc7mtiAIPe4jIm1iQEREAUEQBACOgw6Lrq4uhIeHY8+ePQgPD7fZLi4uTvx/ZGSkzWM6nU58na6uLgDdw2Zjx4612c7+NS1SUlIQHh7eozeopqamR68REWkTc4iIKCAMGDAAkZGRKCkpEe9ramqyyQ0aNWoUzGYzampqMHDgQJt/6enpkt4nLS0Nffv2xfHjx3u8Rk5OjsPnREVFYfTo0di8ebPN/Zs3b8a4ceO82Fsi8jf2EBFRQIiPj0dRURF+97vfISkpCampqXj88ccRFhYm9hoNHjwYv/jFL/DLX/4Sy5cvx6hRo1BXV4fPP/8cw4cPx09+8hNJ77VkyRLMmzcPCQkJmDx5MkwmE77++ms0NDRgwYIFDp+zYMECFBYWYsyYMcjPz8frr7+OkydPYs6cObIdAyJSDgMiIgoYzz//PObMmYMpU6YgISEBDz30EMrLyxEdHS1us2rVKixduhQLFy7EqVOnkJycjPz8fMnBEAD86le/QkxMDP785z/joYceQmxsLIYPH24zvd/ejBkzUF9fjyeffBKVlZXIzc3F+vXr0a9fP192mYj8RCdYD8ATEQWQ1tZW9O3bF8uXL8esWbPUbg4RBTD2EBFRwNi7dy++++47XHnllTAajeJU+VtuuUXllhFRoGNAREQB5bnnnsORI0fERObt27cjJSVF7WYRUYDjkBkRERGFPE67JyIiopDHgIiIiIhCHgMiIiIiCnkMiIiIiCjkMSAiIiKikMeAiIiIiEIeAyIiIiIKeQyIiIiIKOT9f8D9d+0LSaysAAAAAElFTkSuQmCC",
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"fig, ax = plt.subplots(nrows=1, ncols=1)\n",
"\n",
"x_gene_idx = 0\n",
"y_gene_idx = 1\n",
"\n",
"for k in range(n_clusters):\n",
" my_members = mbk_means_labels == k\n",
" cluster_center = mbk_means_cluster_centers[k]\n",
" line, = ax.plot(X[my_members, x_gene_idx], X[my_members, 1], '.', markersize=5)\n",
" ax.plot(cluster_center[x_gene_idx], cluster_center[1], 'o', markersize=10, markeredgecolor='black', markerfacecolor=line.get_color())\n",
"ax.set_xlabel('gene %d' % x_gene_idx)\n",
"ax.set_ylabel('gene %d' % y_gene_idx);"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## plotting the clustering results in PCA space\n",
"\n",
"Hmm, the plot above was not too informative. It does not seem to show obvious clusters in the data, and the points look very interwoven with others, at least for these two genes.\n",
"\n",
"Let's re-plot our cluster assignments, but this time using the projection into PCA space."
]
},
{
"cell_type": "code",
"execution_count": 24,
"metadata": {},
"outputs": [
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAlAAAAGwCAYAAABmTltaAAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjkuMiwgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy8hTgPZAAAACXBIWXMAAA9hAAAPYQGoP6dpAABdUElEQVR4nO3de3wU1fk/8M8Sks2FZCEJ5ALhZgChUZFEISjloiYiaLFWsFRKvqXUiIAYLBb8/pRaLmoVL1C0VSpeqKAirSKXUBWUkggEUBAUUCCBJIRAsgmXXEjO7w++O81udrM7uzM7M7uf9+u1r5LdszPnTLDz8JznnDEJIQSIiIiIyGPttO4AERERkdEwgCIiIiKSiQEUERERkUwMoIiIiIhkYgBFREREJBMDKCIiIiKZGEARERERydRe6w4EoubmZpSWliI6Ohomk0nr7hAREZEHhBCora1FcnIy2rVrO8fEAEoFpaWlSElJ0bobRERE5IWSkhJ069atzTYMoFQQHR0N4MovICYmRuPeEBERkSdqamqQkpIi3cfbwgBKBbZpu5iYGAZQREREBuNJ+Q2LyImIiIhkYgBFREREJBMDKCIiIiKZGEARERERycQAioiIiEgmBlBEREREMjGAIiIiIpKJARQRERGRTAygiIiIiGRiAEVEREQkEwMoIiIiIpkYQBERERHJxACKiIiISCYGUEQ6cLSoAu8t2oWjRRVad4WIiDzAAIpIB/ZsPoEzxbXYs/mE1l0hIiIPMIAi0oFB2T3QuXs0BmX30LorRETkgfZad4AoGB0tqsCezScwKLsHUtO7SC8iIjIGZqDIsIxcN8QpOyIiYzNMAPXKK6/g2muvRUxMDGJiYpCZmYmNGzdKnwshMH/+fCQnJyMiIgIjRozAt99+a3eM+vp6zJgxA/Hx8YiKisJdd92FkydP2rWpqqrCpEmTYLFYYLFYMGnSJFRXV/tjiCSTkYMQTtkRERmbYQKobt264emnn8bu3buxe/dujBo1Cj/72c+kIOnZZ5/FkiVLsGzZMuzatQuJiYm47bbbUFtbKx1j1qxZWLduHVavXo3t27fj/PnzGDt2LJqamqQ2EydOxL59+7Bp0yZs2rQJ+/btw6RJk/w+XnJPD0GIJ1mwlm1sfwaA8fNu4LQdEZFBmYQQQutOeCs2NhZ//vOf8Zvf/AbJycmYNWsWHnvsMQBXsk0JCQl45pln8MADD8BqtaJz5854++23MWHCBABAaWkpUlJSsGHDBmRnZ+PQoUMYMGAACgsLMXjwYABAYWEhMjMz8d1336Ffv34e9aumpgYWiwVWqxUxMTHqDJ504b1Fu3CmuBadu0dj/Lwb3LYB4LY9ERFpQ8792zAZqJaampqwevVqXLhwAZmZmTh27BjKy8uRlZUltTGbzRg+fDh27NgBACgqKkJjY6Ndm+TkZKSlpUltCgoKYLFYpOAJAIYMGQKLxSK1caa+vh41NTV2LwoOnmTBWrbxd9bMyHViRER6ZqhVePv370dmZibq6urQoUMHrFu3DgMGDJCCm4SEBLv2CQkJOHHiSn1MeXk5wsLC0KlTp1ZtysvLpTZdurSeUunSpYvUxpnFixfjj3/8o09jI2PyZPWcYxt/Ttu1rBPjdCERkXIMlYHq168f9u3bh8LCQjz44IOYPHkyDh48KH1uMpns2gshWr3nyLGNs/bujjN37lxYrVbpVVJS4umQSEXMvuijTkxN/B0TkVYMlYEKCwtDamoqACAjIwO7du3CSy+9JNU9lZeXIykpSWpfUVEhZaUSExPR0NCAqqoquyxURUUFhg4dKrU5ffp0q/OeOXOmVXarJbPZDLPZ7PsASRG2PZbqLzaiprIu4LMvjntKtRTo+0sxw0ZEWjFUBsqREAL19fXo1asXEhMTsWXLFumzhoYGbNu2TQqO0tPTERoaatemrKwMBw4ckNpkZmbCarVi586dUpuvvvoKVqtVakPqUiKjYLupAgjo7IuNkbdz8FWgZ9iISL8Mk4GaN28eRo8ejZSUFNTW1mL16tXYunUrNm3aBJPJhFmzZmHRokXo06cP+vTpg0WLFiEyMhITJ04EAFgsFkyZMgWzZ89GXFwcYmNj8eijj+Kaa67BrbfeCgDo378/br/9dkydOhV//etfAQC/+93vMHbsWI9X4JFvlMgoDMru4TIjE4hajjfYBHqGjYj0yzAB1OnTpzFp0iSUlZXBYrHg2muvxaZNm3DbbbcBAObMmYNLly5h2rRpqKqqwuDBg5Gfn4/o6GjpGC+88ALat2+P8ePH49KlS7jllluwcuVKhISESG1WrVqFmTNnSqv17rrrLixbtsy/gw1iSgQDwXZTDbbxEhHpgaH3gdIr7gNFRERkPAG/DxQRERGRlhhAEREREcnEAIoMifv/EBGRlhhAkSEF89J9IiLSHgMoMqRA3f+HmTUiImMwzDYGpK62drPW4/kDdek+d9YmIjIGZqAIgPZTYlqfXy/0lFljNoyIyDUGUARA+xu31ufXi9T0Lhg/7wafs09KPhIn2INaIiJnOIVHALSfEvPn+bWervQHpR+JQ0RE9hhAUdAJhjojPhKHiEhdDKAo6ARDZoXBDxGRuhhAUdBhcEFERL5iETkRERGRTAygiIiIiGRiAEWkIO6dREQUHBhAESmIeycREQUHBlBkeEpkfZTKHHFDUCKi4MBVeGR4SuzrpNTeUFzhR0QUHJiBIsNTIuujxDHaymJ5muFiDRURkTEwA0WG5Pg4Fl+zPt4cw7EPbWWxPM1wBcMu6UREgYAZKDIkPRRrO/ahrSyWpxkutTNhRESkDGagyJD08DgWxz7YMka2gKplBsnTDJcS2TRmsYiI1McAigxJD8Xazvqgh+BFD8ElEVGgYwBFpCA9BC8tAzvHOi0iIlIGAyjStaNFFShYdxQAkHl3qu6DAD1kxlqSmxFjwEVE5BkWkZOu7dl8AjWVdaiprOPu3l6QW5TuWBjPgnQi49iwvwxjl36JDfvLtO5KUGAGinRtUHYPKQOl1bRYy6wMAEUyNI6ZHrUybXIzYo5TkHqo6SIizyzfehQHTtVg+dajuOOaJK27E/AYQJGuuQsA/DHl5JiVUSKgcAxMbJk222daBSuO11sPNV1E5JlpI1KxfOtRTBuRqnVXggIDKDI0f2RInGVlfA0oHI85KLsHvlj9PeovXkZyn46+dlkxeqvpIiLX7rgmiZknP2IARYbmjwyJYxChREDh7Jh7Np/ApdpalB6p9vn4RESkLgZQZGh6yJB4O43o+D1Pg0GulCMi0h5X4RH5yNvHyjh+LzW9C8bPu8FtzdenKw9q/hgbIqJgxwCKyEfePr/Om+/t2XwClxub0T60ndPvcdsBIiL/4BQeGZZeprK8nUb05nstp/mcfZfbDlAg2LC/TFpNxqJo0itmoMiwvJ0684Y/MjtKnMPbbJiafSKSq+V+RkR6xQCKWtHbTdNVf5QOFtrij2CtYN1RnCmulTbU9KYfzuqofPl9+jNIJbKZNiIVaV1juJ8R6ZphAqjFixfjhhtuQHR0NLp06YJx48bh+++/t2sjhMD8+fORnJyMiIgIjBgxAt9++61dm/r6esyYMQPx8fGIiorCXXfdhZMnT9q1qaqqwqRJk2CxWGCxWDBp0iRUV1erPUTd8NdN09Mbux5u4nKDNbWCUG/rpry9fv4MUols7rgmCetnDOP0HemaYQKobdu24aGHHkJhYSG2bNmCy5cvIysrCxcuXJDaPPvss1iyZAmWLVuGXbt2ITExEbfddhtqa2ulNrNmzcK6deuwevVqbN++HefPn8fYsWPR1NQktZk4cSL27duHTZs2YdOmTdi3bx8mTZrk1/FqSe2bpi24sGVc3N3YXfXHn4GVJyvkAPljaynz7lR07h6NzLv/+69ux0DM03605Mvv05vzERkdnylHnjAJIYTWnfDGmTNn0KVLF2zbtg0//elPIYRAcnIyZs2ahcceewzAlWxTQkICnnnmGTzwwAOwWq3o3Lkz3n77bUyYMAEAUFpaipSUFGzYsAHZ2dk4dOgQBgwYgMLCQgwePBgAUFhYiMzMTHz33Xfo169fq77U19ejvr5e+rmmpgYpKSmwWq2IiYnxw9UwlvcW7cKZ4lrExIfDHBnqVRG4Ws+Oc3UuT4vVlRibs+O1D22HW3IGMJAh8oOxS7/EgVM1SOsag/UzhmndHfKjmpoaWCwWj+7fhslAObJarQCA2NhYAMCxY8dQXl6OrKwsqY3ZbMbw4cOxY8cOAEBRUREaGxvt2iQnJyMtLU1qU1BQAIvFIgVPADBkyBBYLBapjaPFixdL030WiwUpKSnKDlYheqltsmVEMu9O9bpex/bsOHNkqNt9k3wds5xMV1tj88ag7B5oH9oOlxubWYdE5CeswSJPGDKAEkIgLy8PN998M9LS0gAA5eXlAICEhAS7tgkJCdJn5eXlCAsLQ6dOndps06VL65tely5dpDaO5s6dC6vVKr1KSkp8G6BK9FBLBLQ9LeRpHz2dlvLkeO6CLFfncvY9b6e8XPUhNb0LbskZwDokIj9iDRZ5wpD7QE2fPh3ffPMNtm/f3uozk8lk97MQotV7jhzbOGvf1nHMZjPMZrMnXdeUP54b5ytP++jpHkqeHM/d3kmuzqXknkttHUsPj6shIiJ7hgugZsyYgY8++ghffPEFunXrJr2fmJgI4EoGKSnpv/9qqKiokLJSiYmJaGhoQFVVlV0WqqKiAkOHDpXanD59utV5z5w50yq7ZTR6uhG7qitSuo+eHK+tIKut+ic5Aam7OiojBLdERPRfhpnCE0Jg+vTp+PDDD/HZZ5+hV69edp/36tULiYmJ2LJli/ReQ0MDtm3bJgVH6enpCA0NtWtTVlaGAwcOSG0yMzNhtVqxc+dOqc1XX30Fq9UqtSHf6WU6EfB+SlHOyjx3z69TY7WbXmreiIgCkWECqIceegjvvPMO/vGPfyA6Ohrl5eUoLy/HpUuXAFyZdps1axYWLVqEdevW4cCBA8jJyUFkZCQmTpwIALBYLJgyZQpmz56NTz/9FHv37sX999+Pa665BrfeeisAoH///rj99tsxdepUFBYWorCwEFOnTsXYsWOdrsCj/5Jzwx6U3QMx8eGov9io6xu8Els6uHt+nVr0FKQSEQUawwRQr7zyCqxWK0aMGIGkpCTptWbNGqnNnDlzMGvWLEybNg0ZGRk4deoU8vPzER0dLbV54YUXMG7cOIwfPx433XQTIiMj8fHHHyMkJERqs2rVKlxzzTXIyspCVlYWrr32Wrz99tt+Ha8Ryblhp6Z3gTkyFDWVdZre4N0FfUpkhmxBmL+3IVByPy9ms4iI7Bl2Hyg9k7OPRCCR+3BfPTwM2LbPUufu0Rg/7wZN+gDo41q0hftREVEwkHP/NlwROemX3AJwtYvaPQlKvCkET+7TEaVHqhUNdpRc0aeGQdk98OnKg9J+VHrsIxGRPzGAooDlSVAiJ4izHa+q7ILigYS7QE7rDJXtnM76qHXfiIi0YJgaKCK5lC5Ut9UU/eSnXRXf2NJdrZWaBeGe1je56iOL1SnQ8dl45AwDKApoF60NihWq2wKIm+/t4/cH7PpaEN5WkORrAKT2w6cpOOkpaFm+9SgOnKrB8q1Hte4K6QgDKApY7rYP0HplmZzz+7oasK0gydcASI09rIj0FLTw2XjkDAMo0hUlgxp32wdoPfXkz/M7C5Js1xoAAyDSHT0FLXw2HjnDInLSFSVXo7krENf68Sn+PL+za6H3lX8U3O64JokBC+kaAyjSFa2DCiV4uipN62cTah1AEpHvNuwvw/KtRzFtRCoDTj9jAEW6onRQ4Y8l9o7nMEpmR+sAjoh817JWjAGUf7EGigKaP+qMHM/hbVG21kXtRGQctlWKQ3rHaVYrpqeVklpgAEUBzR9L7B3P4e2qNK2L2olIvxyDFVvmqfDHs4oXuHsaGOlppaQWGECRYvSYQfHHEnulzuGPYE+PvyMics8xWFFzlaKngZGeVkpqgQEUKYYZFN/4I9jj74i0EOxTPc7IvSaOwYqaWyt4Ghh50odA/t0zgCLFcEdq/ePviLRgtKkef9z05V4Tf+5FpeS5jPa7l4MBFCnGlkEBEDTTRFpMiflyTu4aTlow2lSPP276Rrsm3grkcXIbA1Kc4zJ+f2wloBVftizw9roYZZsEIhujbYo5bUSqtLeSWtS6JnrbF8pov3s5mIEixTlOEwVy3Y0vU2LeXhdOw5ERuZoW00uNTMt+uJvC0kufnQnkKTO9YQBFinOcJjL6Db+tKTNfpsS8vS7+nIbjqj1Siqsbu15u+HL6oZc+OxPIU2Z6wwCKVGf0uhu1MmhGuC5Kj50BWfBydWN39b6/szxyAg+5QYo/x8IHH/uPSQghtO5EoKmpqYHFYoHVakVMTIzW3SEf6bWGS4vH1PjqvUW7cKa4Fp27R0sLDoicGbv0Sxw4VYO0rjFYP2OY1t3xSSCNJdDJuX8zA0XkhqeZIn9nV/xRW6Z0lszo07mkDE8yMoE0FRVIY6H/YgZKBcxA6ZtamRt/Z1f0mhkjcocZGdIrZqCI4DojpFbmxpvsCvd0omDEjAwFAgZQpGu+BBiuAiW1ppG8CWi8DeZYjE1GJqfQWQ9bBijVBz2MhZTDAIp0zZdskatASU+ZG2+DuUDeW4uoJT1sGaBUH/QwFlIOAyjSNV+yRXoKlFzxto8sxqZgofR0nzdZIKX6YDvOkN5xzEQFABaRq0BvReQsNjY2tX9//PtBwcSXAnZPH5Pirh2L6PWLReRBzrE+htM96rJd7+3vH1GlLknt3x//flAwsGWeEqLDER7aDkN6x8k+hqdTcO7auctosVbKGBhABSDHG6LepnsCrQDadr2//eKUblb36en4RHpgC2r+80Ml6hqbUfjjWdnH8HQqz107d0X0rJUyBk7hqUDrKTy9T8kE2m7Utuud3KcjSo9U+3Tdlfrd6fXvgF77RerydOrLH30Y0jsOhT+e1bQv7vh6vfRwvY1Kzv2bAZQKtA6glKb0TY830dZs16T+YiNqKut8Ci6PFlXg05UHcbmxWXdBqrvgmX83AhNrfvyL19t7rIEiRSldI2OE1XH+VrDuKM4U16Kxvsnn6bQ9m0/gcmMz2oe20920nLPpwpZTuqzHCkxKrGLToi7I3+dU6nzcqNQ/mIFSATNQxj6vFt7+3x2oqaxDTHw4Ji0Y6tOxjHbdWmalBmX3MFTfyX9sWZWU2AhYIkKl4MA2Lbf523IAwNzR/RWbtvJ3JoeZI+0xA0WK0ipj5Ek2Qq2CdDnHVaIPmXenonP3aGTe7fu/GL39fbkah9pF/y2zUsxOGpOczIm3WRZbVgWAVGBtK7Z+p/AESs5dQsm5S7ILr9vqj78zOXrPHHF1oD0GUKQINW6ynqwOU2vKR85xleiDHgIHV+NQe1pND2Mn37hbNdbyxuvtCjPbyrW5o/tLQYYt4Lh/SA+kxEYgJTaizeDDWQDQsj+On8t55IwS7rgmCdNGpEp9ccffAQ1XB9pjAEWKUOMm68mNVa0l+HKOGyjbALgaR6CMj9TjLnPS8sbra5alZVBj+/P/jhmAL+eMwpdzRrUZ7DgLAFr2Rw8Bgpw++Lu/es+Q+Z0wkG3btomxY8eKpKQkAUCsW7fO7vPm5mbx5JNPiqSkJBEeHi6GDx8uDhw4YNemrq5OTJ8+XcTFxYnIyEhx5513ipKSErs2586dE/fff7+IiYkRMTEx4v777xdVVVUe99NqtQoAwmq1ejtUwzmy+7RYs3CnOLL7tNZdISKd+eSbUjHm5S/EJ9+Uat6Pm5/5VNz8zKdSX1r2TQ/9lNMHPfQ30Mi5fxsqA3XhwgVcd911WLZsmdPPn332WSxZsgTLli3Drl27kJiYiNtuuw21tbVSm1mzZmHdunVYvXo1tm/fjvPnz2Ps2LFoamqS2kycOBH79u3Dpk2bsGnTJuzbtw+TJk1SfXxG5s9pmEDbiNOI+DsgOfw9FdZWPywRoXa1UrYsTt57+wDAaT/9OVUm51rZ2gJgbZIGDBVAjR49GgsWLMDPf/7zVp8JIfDiiy/i8ccfx89//nOkpaXhzTffxMWLF/GPf/wDAGC1WrFixQo8//zzuPXWW3H99dfjnXfewf79+/Hvf/8bAHDo0CFs2rQJr7/+OjIzM5GZmYnXXnsN69evx/fff++0X/X19aipqbF7qYU3Lv08ekTr34WW59fL74BILsdpqGkjUhEe2g51jc0up8L8MVXmS5Cmh6nHYGSoAKotx44dQ3l5ObKysqT3zGYzhg8fjh07dgAAioqK0NjYaNcmOTkZaWlpUpuCggJYLBYMHjxYajNkyBBYLBapjaPFixfDYrFIr5SUFDWGCIA3LkA/NTnOfhf+DGrU+Lvgaf/18jsgkht4OGZ47rgmCUvGD2yztmfaiFSkxEbAeqmx1XmUyk75EgSxNkkbARNAlZdf2QMkISHB7v2EhATps/LycoSFhaFTp05ttunSpfU0VJcuXaQ2jubOnQur1Sq9SkpKfB6PK7xx6WfVlrPfhT8DXDX+Lnjaf738DojkBh5yAx7bykEATrdJ8CbwcdYHX4KglkEhtxrwn4AJoGxMJpPdz0KIVu85cmzjrH1bxzGbzYiJibF7qSWQblxaT4H5ytnvwp8Bru38ABS7jgzQA0Mw3USdBR5tjd9ZwNNWEGT7DIDTAEdu4LNhfxny3tvX6nxK1YlxOs9/AiaASkxMBIBWWaKKigopK5WYmIiGhgZUVVW12eb06dOtjn/mzJlW2S3yjZZTUIFEyesYSAF6MDPqTdSbwM9Z4NHW+J0FPG0FQbbP5o7u7zTAkRv4LN96FHWNzQgPbafKlBun8/wnYAKoXr16ITExEVu2bJHea2howLZt2zB06JVHY6SnpyM0NNSuTVlZGQ4cOCC1yczMhNVqxc6dO6U2X331FaxWq9SGlKHlFJRatDg/s0bkyKg3UU8DP3eBVlvjdxbwtBUEKb2C0Na3JeMH+nxMZ9dBLyseg4GhnoV3/vx5HD165T+s66+/HkuWLMHIkSMRGxuL7t2745lnnsHixYvxxhtvoE+fPli0aBG2bt2K77//HtHR0QCABx98EOvXr8fKlSsRGxuLRx99FGfPnkVRURFCQkIAXFntV1pair/+9a8AgN/97nfo0aMHPv74Y4/6GWjPwnNHT89ek9MXNfrt6TH1dM2I9MJWbzRtRGqbAYDcZ8Z5elw1+qomPjtPeXLu3+391CdF7N69GyNHjpR+zsvLAwBMnjwZK1euxJw5c3Dp0iVMmzYNVVVVGDx4MPLz86XgCQBeeOEFtG/fHuPHj8elS5dwyy23YOXKlVLwBACrVq3CzJkzpdV6d911l8u9p8g+66JEMNAyuLAd39NAIzW9i8d9ULrfcs7vybmdBVmBFngF2njIN7bdxd2x7RruaYZt8cZDKDl3CYs3HlIs2GmZLdMqgJJ7HUhZhspAGUUwZaCOFlWgYN2VrGDm3amK3ATfW7QLZ4pr0bn7lcDX9mdbwbRStLx5e3LultehZbG4WtdDC4E2HtKnYc9+hpJzl5ASG4Ev54yS9V1Xmaa2MlBqZ6f0kP0KVHLu3wFTA0Xa2LP5BGoq62CODFUsCGlZ06NUfY+z4nJ/F0y37IO3z/lr+V4gFMyzfksbwbRKD4D0AOK5o/vL/q6ruqy2ao3ULuJXe+sG8gwzUCoItgyUEaZglMp0+DJepbMtzN6Qt1g747mW2R4Adpkfb7JTSvfJ2fEdP+fv23PMQJHfGGXZu1KZDl9W2SmdbUnu0xHtQ9shuU9Hn48VCNks8pxRV+lpoWWmyTHz4012Suk+OePYL/6+1WGoInIib8kpLm/LoOwedgXu7jhmrJQMNEuPVONyYzNKj1T7fCw1CupJvzwt1laanmp3vOnLg8OvwkufFKFfVB2yFn+MYdf0BgCPAhN/jt2xuFyr33egYwaKSAa5GTfHjJWSmR4lM1qsRSJ/0NMGn459aatOqLq6Gi+99BIe/sVIbJl3F5ZMycKWeXfh6SmjcVvzHgxNiZB9PjUp9WgX1k61jQEUkYocAxO5U4BtBVxKTp8aZSqWjE2pqaS2buye3vQd++IqwNm8eTNSunfHI7Nn43T7RMT/7A/oMmEB4n/2ByCuJ2blzUZStxRs3rxZ1vn8xZfATU8Brx6xiFwFwVREHuiULpKXezwWipM/6WmKrS2ORdEt+2276TsWTMstvAauBE9jxo6Fuef1iM2eiZAOnVp9r+l8Fc5uehkNJ/bik/XrkZ2drd7AveDL79Qofx+UJOf+zQBKBQygAofWAYxRVjlSYNBytZacm3Vbq8xa1v+0PI7csVVXVyOle3c0J1yN+Lv/F6Z2IS7biuYmVK5bgHanv0NJcTE6duzotK8Agi4gMRquwiNywpv6I61rg7yZWuOKOvKU43SXlqu15EwXOa5Ca9lvVyvU5I7tzTffxIWLFxGbPbPN4AkATO1C0Cl7Bi5evIi33nrL5bj0PiXGmid5mIFSATNQ+qR1NslfgmWc5DslMk6eZo68mULTihACffpdjfL2iYi/a47H36v86BkkXj6NI99/B5PJBEA/GShPri/3i2IGisgpf2ST9JD90TprRsbhKisjJxPhaVbFXTu5eyepmS05e/YsfjhyGBF9h8r6XkSfofjhyGGcO3dOeq/luDwZo21cCz45aPe/vo7Tk98T94uSh/tAkV/ooZZH6X2YnNHDfkr+GCcFBlf7A8l5UK6nD7RV+sG3aj7M9/z58wCAduEdZH3P1r62thZxcXFends2rqMV51HX2Cz9r6/jHNI7DkcrzmNIb9f94n5R8jADRX7hyw7eRsLsDwUCOZkITzNHSuzO3TLrpHS2pOWxO3S4Egg1152XdQxb++joaK/7MW1EKlJiI9A+pB1CQ0y46ap4RcZZ+ONZ1DU2o/DHs14fgzVS9hhAkV9oEVj4Op3mzff1tp+SHqYUyXjUfhSJtxyzTkr2seWx4+LicFWfvqg7vEPWMS4d2YGr+vRFbGys1/2445okWCJCcb7uMhqbBE7X1ikyTiUCTr0XwfsbAyjyCy0CC1+zXlpnzRyDH2+CIa3HQKQkNWt0Wh7bZDJhxkPTcOHwf9B0vsqj718+fw6XDu/AzOkPSQXkrrjL5NiyUCmxEYqNVYmAkzVS9rgKTwVchacPvtZdyfm+GjVejqvpvFldp4faMyI9c7U6Te4+UGfXLYDJyT5Qzs7jarNPOf0jdXAVHhF8z3rJ+b6cTI+nmSTHaU9vpkH1NqVI5IpW9TWupqU6duyID95/H/XH96Jy3QJcPn/O6fcvnz+HynULcOnYXgy4/0ks+0+p03G0PI+cTI4S02asXVIHM1AqYAYq+MjJ9HCfJtIjf2U6XJ1n2LOfoeTcJaTERuDLOaNUPZecNps3b8Yv7r0XFy9eRETfoYjoMxTtwjugue48Lh3ZgUuHdyAsPALxd/0BId0HIjy0Heoam2U/SsaXMbjD/Z08x0e5aIwBlHOcTrqC14H0yF83WVfnUSOAUmpM1dXVeOutt/Dysr/ghyOHpfev6tMXM6c/hE/q+uD7c80ID22H+4f0QOGPZ3U15RaI04BqjUnO/Zv7QJHfOO6RFEyBRMuxEumR0vs0yT3P3NH9FT+/UmPq2LEjZs6ciRkzZuDcuXOora1FdHQ0YmNjYTKZkKrzACUQ93dScx8wTzEDpQJmoJxzDJi0nspy7I+aAV3LsQKQ/jwou0fQBJFEehaIWZpApocMFIvIyW8cC5q13nTSsfBbzSX/Lcfa8s/cZoACjS8Fy1oWO3OPI+9p8XvTw15lnMIjzWj9yJGW2R9nPyvJcawt/8ypPQokvkytaDkt468pTE8ZKSOmh+k0LXAKTwWcwjMWJafugqmui8gZX278eg8a/Nk/I62c0/vvTQ5O4RHJoOQ0GqfkKNj5MrXi67SM2lNJrqb51DivkXb91sN0mhYYQFHQU7IWS+u6Ln/ic/ZIK64CFrXrmFwFNWqc1xaUAOAmmDrFGigKekrWYmld1+VPjttSEPmLq5obteuYXG0HoOZ5g7W+yAiYgSJV+JKdYGbDGPyRbePfBXLGVSZIiakkb6bj1JzCMtJUXrBhBopU4Ut2gpkNY/BHto1/F4Kbq+JkNTeG1FvGJxA3wQwUzECRKnzJTgRTHZFaAiVzw78LwU2LvZmG9I5DaIgJZdY6v9Qd8UG/xsVtDFTAbQxIa1rv8k6kBLWXxzs7vm37AAAebSHgax9t5wsNMSHREo65o/sz46QhbmNAhhcoGRStMHNDgUDt5fHOMlzTRqQiJTYCKbERHtUd+bq1wbQRqQgPbYfGJoGSc5e4E7qBsAaKFKPkJpKsffFNMK0GJH3wJhNj+86Q3nEo/PGs3zdidLZ6Tm7NkasVeJ7WUtk+W7zxkHQ8MgZO4akgWKfwlJw24o7eRMbizc7Ztu+Eh7ZDXWOz7nbdDuRd1ck5TuGRJpScNnJ88DAR6Zu75fbOprRs37l/SA9dLtX3pYg9WHfnDibMQLVh+fLl+POf/4yysjL85Cc/wYsvvohhw9z/6yhYM1BERK60zFC1nPbSW4DRMnMEwKN++jJ9qcdrEMyYgVLAmjVrMGvWLDz++OPYu3cvhg0bhtGjR6O4uFjrrhkai8ONSwiByspKHD9+HJWVleC/vYKHEkvtW2aovM3s+GPJv2PtkqssUsu+eDMeLbZoIGUxgHJhyZIlmDJlCn7729+if//+ePHFF5GSkoJXXnlF664ZGh+2azzV1dV46aWX0K/f1ejcuTN69eqFzp07o1+/q/HSSy+hurpa6y6SypS42bcMRrzdXdsfQYenfWvZF0+/0zLoGtI7DuGh7TCkd5yS3Sc/4hSeEw0NDYiMjMT777+Pu+++W3r/4Ycfxr59+7Bt2za79vX19aivr5d+rqmpQUpKCqfwnFC7OJzF58ravHkz7r13PC5euIiBvYfhup7DEGnugIv15/H18S+x78cvERkViffffw/Z2dlad5dUopfpJr30w9u+tJzGBCC76J7UJ2cKj9sYOFFZWYmmpiYkJCTYvZ+QkIDy8vJW7RcvXow//vGP/uqeoam9vF6r7Q8CMXDbvHkzxo4di6u7ZmDiuNmIiYy1+3zQVcNRk3kO//jieYwdOxbr169nEBWg9PI4Eb30A/CuL45bHqj54GNSH6fw2mAymex+FkK0eg8A5s6dC6vVKr1KSkr81UVyoNUGkoE2NVldXY177x2Pq7tmYGrWU62CJ5uYyFhMzXoKV3fNwL33jud0HgUlT2uzWk5jcpWe8TGAciI+Ph4hISGtsk0VFRWtslIAYDabERMTY/cibWi1/UGg7fz95ptv4uKFi5j409kIaRfSZtuQdiH45bA8XLxwEW+99ZafekhqCPTnsikxPmfH0FNBeKD/DvWEAZQTYWFhSE9Px5YtW+ze37JlC4YOHapRr0jP9LhvlbcrHoUQ+MtflmNg72EuM0+OLFFxuK7XzVi27C9cnWdgcgMBrW/Wcs+vRKDj6vEvtiJyd31S+5rpKZgLdAygXMjLy8Prr7+Ov//97zh06BAeeeQRFBcXIzc3V+uuEXnE22nFs2fP4siRw7iup7zC1oG9huHIkcM4d+6crO+RfshdHaf1zVru+b1d/efuGC2n49z1Se1rpsQYyTMsIndhwoQJOHv2LJ566imUlZUhLS0NGzZsQI8egTFFQ4FvUHYPqbBdjvPnzwMAIs0dZH0v4v/a19bWIi6OS7ONSKnnwNmovWpO7vmdjU9uH91dI3d9cvW5UtdKT4X2gY7bGKiAO5GTkVVWVqJz5874za1PYNBVwz3+3p4ftuLv//4TKisrGUAFGVc3f2+ej9fW8eTy5Pze9tFXjmPUqh9kjzuRE5HX4uLi0KdPX3x9/EtZ39t37Ev06dMXsbGe1U1R4HA1LeXN8/HaOp5cnkxnaTXl5ThGTr0Zj8cBVGNjI+bMmYPU1FTceOONeOONN+w+P336NEJC2l6tQxTMjPIYG5PJhIcemoZ9P36Jmoue1TNZL5zF18e2Y/r0h5xu9UGBzXbzH9I7zi4gcrdU39vAy1OebBWg1XYCjmPktgbG43EAtXDhQrz11lvIzc1FVlYWHnnkETzwwAN2bTgbSOSakfaKmjx5MiKjIvGPL55HU3NTm22bmpvw7pdLEBkViV//+teq980ogWgwsd38C388q0hRdzAEE2qPUesVksHA4wBq1apVeP311/Hoo49iwYIFKCoqwueff47/+Z//kQIn/suTyDUj7RXVsWNHvP/+e/ju1G68lv8ErBfOOm1nvXAWr+U/ge9O7cYHH7yPjh07qt43IwWivjBioCg3cxQMgZJWtF4hGQw8LiKPjIzEwYMH0bNnT+m90tJSjBo1ChkZGXj22WeRkpKCpqa2/7UaDFhEToGi5bPwrut1Mwb2GoYIcwdcqj+Pfce+xNfHtiMyKhIffPA+srKy/NKnQHxsjjPvLdqFM8W16Nw9GuPn3aB1d4KCnp6156tAGos/ybl/exxA9e7dG6+99hpuueUWu/dLS0sxcuRIdO/eHZ999hkDKDCAosBSXV2Nt956C8uW/QVHjhyW3u/Tpy+mT38IkydPhsVi0bCHgSnQAkUj3NC5Eo5UCaB++9vfQgiBFStWtPrs1KlTGDFiBH788UcGUGAARYFJCIFz586htrYW0dHRiI2N5bQ9ecwIwYkRgjxSl5z7t8cbaf6///f/8N133zn9rGvXrvjiiy+Qn58vr6dEZBgmkwlxcXHc44m84m6DST3wdRNKBmDBhRtpqoAZKCIiZRkhOBn27GcoOXcJKbER+HLOKK27Q17gRppERBRQuKqM9IYBFBER6Z4RduqeO7o/0rrGYO7o/lp3hfyAU3gq4BQeEZF22pruM8JUIGmHU3hERBS02pru41QgKcXjAKqqqgpLly5FTU1Nq8+sVqvLz4iIiPyprek+I0wFkjF4PIX3pz/9Cd988w3ef/99p5+PHz8e1113HR5//HFFO2hEnMIjIiIyHlWm8NauXYvc3FyXnz/wwAP44IMPPO8lERGRyvhQXVKLxwHUDz/8gD59+rj8vE+fPvjhhx8U6RQREZES9FLzxEAu8HgcQIWEhKC0tNTl56WlpWjXjjXpRESkH3qpedJLIEfK8Tjiuf766/HPf/7T5efr1q3D9ddfr0SfiIjIwPSUbbnjmiSsnzFM8y0L9BLIkXI8DqCmT5+O559/HsuWLbN7YHBTUxOWLl2KF154AQ899JAqnSQiIuNgtsUe954KTB4HUPfccw/mzJmDmTNnIjY2Ftdffz0GDRqE2NhYzJo1C3l5efjFL36hZl+JiMgAmG2xx4AyMMneiXznzp1YtWoVjh49CiEE+vbti4kTJ+LGG29Uq4+Gw20MSClHiyqwZ/MJDMrugdT0Llp3h4i8wAyUcci5f/NRLipgAEWOvA2E3lu0C2eKa9G5ezTGz7tBxR5SsOFNnag1VfaBunjxIh566CF07doVXbp0wcSJE1FZWelzZ4mCwZ7NJ3CmuBZ7Np+Q9b1B2T3QuXs0BmX3UKlnFKw4rUTkG48DqCeffBIrV67EmDFjcN9992HLli148MEH1ewbUcDwNhBKTe+C8fNu4PQdKY51SkS+8XgK76qrrsLChQtx3333AbhSC3XTTTehrq4OISEhqnbSaDiFR0REZDyqTOGVlJRg2LBh0s833ngj2rdv3+bmmkRERESByOMAqqmpCWFhYXbvtW/fHpcvX1a8U0RE5Ln84/mYsH4C8o/na90VoqDR3tOGQgjk5OTAbDZL79XV1SE3NxdRUVHSex9++KGyPSQiojatOLACB88exIoDK5DVM0vr7ugeVyCSEjwOoCZPntzqvfvvv1/RzhARkXxT0qZgxYEVmJI2ReuuGELLFYgMoMhb3AdKBSwiJ9IHtTci5UanxsQMFLmiShE5EZESjhZV4L1Fu3C0qEL1c3m7/5Zejk/q0MsDhsnYGEARkV/5M+hQeyNSrTc69WcwSkT2PK6BIiJSwqDsHtK0l9pS07uoOrWm9vHdaRmMcgqRyL8YQBGRX2kddLRk9BomfwajRGSPARQRuWX0QMMVo2dw9BSMEgUbw9RALVy4EEOHDkVkZCQ6duzotE1xcTHuvPNOREVFIT4+HjNnzkRDQ4Ndm/3792P48OGIiIhA165d8dRTT8FxIeK2bduQnp6O8PBw9O7dG6+++qpawyIyhEAtlta6homIjMswAVRDQwPuvfdelw8wbmpqwpgxY3DhwgVs374dq1evxtq1azF79mypTU1NDW677TYkJydj165dWLp0KZ577jksWbJEanPs2DHccccdGDZsGPbu3Yt58+Zh5syZWLt2repjJNIrvQUaSu28zYc1E5G3DLcP1MqVKzFr1ixUV1fbvb9x40aMHTsWJSUlSE5OBgCsXr0aOTk5qKioQExMDF555RXMnTsXp0+flnZUf/rpp7F06VKcPHkSJpMJjz32GD766CMcOnRIOnZubi6+/vprFBQUeNRH7gNFpK4J6yfg4NmDGBA3AGvGrtG6O0QUIIJyH6iCggKkpaVJwRMAZGdno76+HkVFRVKb4cOH2z2OJjs7G6WlpTh+/LjUJivL/lEI2dnZ2L17NxobG52eu76+HjU1NXYvIlLPlLQpGBA3gDtvE5FmAiaAKi8vR0JCgt17nTp1QlhYGMrLy122sf3srs3ly5dRWVnp9NyLFy+GxWKRXikpKYqMiYicy+qZhTVj1/C5b0SkGU0DqPnz58NkMrX52r17t8fHM5lMrd4TQti979jGNoMpt01Lc+fOhdVqlV4lJSUe95mIiIiMR9NtDKZPn4777ruvzTY9e/b06FiJiYn46quv7N6rqqpCY2OjlFFKTEyUMk02FRVXdvB116Z9+/aIi4tzem6z2Ww3LUhERESBTdMAKj4+HvHx8YocKzMzEwsXLkRZWRmSkq483yg/Px9msxnp6elSm3nz5qGhoQFhYWFSm+TkZClQy8zMxMcff2x37Pz8fGRkZCA0NFSRvhIREZGxGaYGqri4GPv27UNxcTGampqwb98+7Nu3D+fPnwcAZGVlYcCAAZg0aRL27t2LTz/9FI8++iimTp0qVdJPnDgRZrMZOTk5OHDgANatW4dFixYhLy9Pmp7Lzc3FiRMnkJeXh0OHDuHvf/87VqxYgUcffVSzsRMREZHOCIOYPHmyANDq9fnnn0ttTpw4IcaMGSMiIiJEbGysmD59uqirq7M7zjfffCOGDRsmzGazSExMFPPnzxfNzc12bbZu3Squv/56ERYWJnr27CleeeUVWX21Wq0CgLBarV6Pl4iIiPxLzv3bcPtAGQH3gSJqW6A+GobIZsP+MizfehTTRqTijmuStO4OeSgo94EiIu0cLarAe4t24WhRhUftA/XRMEqSe01JX5ZvPYoDp2qwfOtRrbtCKmEARUQ+kxsQ6e3RMHrEINPYpo1IRVrXGEwbkap1V0glnMJTAafwKNhwSk55vKZE/ifn/s0ASgUMoIjs+TMY0Hvgoff+EQUz1kARka74czpK71Nfeu8fEXmGARQRqc6fNU96r6/Se/+IyDOcwlMBp/CIjCf/eD5WHFiBKWlT+JBioiDFKTwiIplWHFiBg2cPYsWBFVp3hYgMgAEUEfksEPYsmpI2BQPiBmBK2hStu0JEBqDpw4SJKDC0LIw26sqyrJ5ZnLojIo8xA0XkB55kaPKP52PC+gnIP57v87H8jYXRRBRsGEAR+YEnS9c9rcHR4zL41PQuGD/vBsNmn4iI5GIAReQHnmRoPK3BkZvt2f7+Efx1xlZsf/+IrD4TEZFr3MZABdzGgPTkrzO24nJjM9qHtsMDS0do3R0iIt3iNgZEJPnJT7uifWg7/OSnXbXuSpv0WNtFROQKV+ERBbib7+2Dm+/t0+p9b57JptZz3I4WVeDTlQdxubFZsZV83vaVz6ojIk8wA0UUpLwpRlergH3P5hPSNKNSK/m87asei/SJSH8YQBEFKW+2HlBruwLbcW/JGaBY1sfbvrr7npGnGo3cdyK9YRG5ClhEToFG6WktIz937r1Fu3CmuBadu0dj/LwbtO6OLEbuO5E/sIiciBSl9LSWkZ87Z+RNQ43cdyK9YRE5Ebk1KLuHlIHyhLsM05S0KdLneuFpli01vYthi8uN3HciveEUngo4hUfBbsL6CTh49iAGxA3AwqSlhljV5sn0FlfoEQU2TuERkaZa7qrubvpPL4XNbU1v2fpYsO4oV+gREQAGUES64+lDhfUsq2cW1oxdg6yeWW7rbvy5bUD+8XyMXjsao9eObnV923qen62PAFhDREQAGEAR6Y6RC6ydcfegYX8WNv8r/zMM3jEBYSfiZF1fWx8z707lQ5OJCACLyIl0x1mBtZGX/bvjz8Lm60/dhvoLJtxYdgdu+Hm8x99j8TUROWIGikhnWk5/2WiZlVJ6SlHLmqcRd12Dzt2jMeG+WwMuECUi/2IARWQALYuy/c1d8CY3wHJW8+SvoMrddKIv9FIMT0T+wQCKyACcZaV8Zbvhb3//SJs3fnfBm9zsmLOaJz08f85VAORpgKiHMRCR/zCAIgpSthv+t1+cavPG7y54k5sdS03vgo4Tq/B42QwpKPFHIbm7QMhVAORpgMhdvomCCzfSVAE30iQjsG0KmdynI0qPVPt1c8iWG22uGbtGF+d0tUlmIBfwE5E9bqRJZFD+rKOx1QMl9rZI7/lrDyotarrcndNVfZQa06dAYOz3RRTMmIFSATNQ5C1PHiei5jnXXvucV5khZmnk0yILR0RtYwaKyKC0qKNpeU5vM0NqbrOgl9VtR4sq8Pb/7sBfH/sUD/3tDz5njrRcWUlEvmMGSgXMQAUGPjjWc2pmoLTIyjnz9v/uQE1lHQDgTFQxDo3cyMwRUYBhBopIAYG+LN3TzI4n7dSqEwJ0uLqtncCZft8xc0QU5AwRQB0/fhxTpkxBr169EBERgauuugpPPvkkGhoa7NoVFxfjzjvvRFRUFOLj4zFz5sxWbfbv34/hw4cjIiICXbt2xVNPPQXHJNy2bduQnp6O8PBw9O7dG6+++qrqYyT90d2NWyG2gKhg3VGPAkStA0m9bH6ZeXcqOnePRvaUa/CX3z0tO1jUy1QkESnDEM/C++6779Dc3Iy//vWvSE1NxYEDBzB16lRcuHABzz33HACgqakJY8aMQefOnbF9+3acPXsWkydPhhACS5cuBXAlNXfbbbdh5MiR2LVrFw4fPoycnBxERUVh9uzZAIBjx47hjjvuwNSpU/HOO+/gP//5D6ZNm4bOnTvjnnvu0ewakP8Z5flncqcabQFRTHy4RwHioOwe0vEDTcvg0N218/Xvg5xzEZEBCIN69tlnRa9evaSfN2zYINq1aydOnTolvffuu+8Ks9ksrFarEEKI5cuXC4vFIurq6qQ2ixcvFsnJyaK5uVkIIcScOXPE1VdfbXeuBx54QAwZMsTjvlmtVgFAOi+RmtYs3CmWPfCpWLNwp0ftj+w+LdYs3CmO7D6tcs/0T6lrsfnYZjH+4/Fi87HNip7Lk+MSkXLk3L8NMYXnjNVqRWxsrPRzQUEB0tLSkJycLL2XnZ2N+vp6FBUVSW2GDx8Os9ls16a0tBTHjx+X2mRl2afms7OzsXv3bjQ2NjrtS319PWpqauxeRP4id6pRzSkxo1HqWniyCtGbc2n5EGkiapshA6gffvgBS5cuRW5urvReeXk5EhIS7Np16tQJYWFhKC8vd9nG9rO7NpcvX0ZlZaXT/ixevBgWi0V6paSk+DZAYr2IDK5uzLyG/yWEQGVlJY4fP47KyspWdY+O5F47tbYk4FYHRPqlaQA1f/58mEymNl+7d++2+05paSluv/123Hvvvfjtb39r95nJZGp1DiGE3fuObWz/Ryq3TUtz586F1WqVXiUlJe6GTm5oXbgsh14DFU+voZL99/VYSl/L6upqvPTSS+jbry86d+6MXr16oXPnzujbry9eeuklVFdXO/2e3L9/LVchKrnDuJqrG4nIN5oGUNOnT8ehQ4fafKWlpUntS0tLMXLkSGRmZuJvf/ub3bESExOlLJJNVVUVGhsbpYySszYVFVf+j9pdm/bt2yMuLs7pOMxmM2JiYuxe5BsjrYDzV7AnN7jw9Bo667+3QYCv16Ll9131wdPrsHnzZqR0T0He7DxUxlYiZVoKev6+J1KmpaAythJ5s/OQ0j0FmzdvbvVdX/7+cdqNKDhougovPj4e8fHxHrU9deoURo4cifT0dLzxxhto184+9svMzMTChQtRVlaGpKQkAEB+fj7MZjPS09OlNvPmzUNDQwPCwsKkNsnJyejZs6fU5uOPP7Y7dn5+PjIyMhAaGurLcEkGo6yAA7xfpebt6jl3q7haHteTjSed9b9lEOBJ9qPlg4ltx/RGy748fuDKY2VeKHrBbpNOT67D5s2bMWbsGET9JAp9/qcPQjva/7drudGCxupGlL1RhjFjx+CT9Z8gOztb+tyXv39T0qZI/VULN3kl0p4hdiIvLS3F8OHD0b17d7z11lsICQmRPktMTARwZRuDgQMHIiEhAX/+859x7tw55OTkYNy4cdI2BlarFf369cOoUaMwb948HDlyBDk5OXjiiSfstjFIS0vDAw88gKlTp6KgoAC5ubl49913Pd7GgDuRkyfk7rDt6U1TiZ275e4s7u6c7o7n7HPbezX1NTh5/qT0zDh316G6uhop3VPQrnc7pMxMgSnE+dQ7AIgmgZKXS9D8YzNKikvQsWNHt2PVA73szk4UaAJuJ/L8/HwcPXoUn332Gbp164akpCTpZRMSEoJPPvkE4eHhuOmmmzB+/HiMGzdO2icKACwWC7Zs2YKTJ08iIyMD06ZNQ15eHvLy8qQ2vXr1woYNG7B161YMHDgQf/rTn/Dyyy9zDyhSnFqr55SY/szqmSVlUjyZxnN3zpYZLWdTc86mvWz1P4+kP2JXSO3uOrz55pu4ePEikv4nqc3gCQBMISYk/U8SLl68iLfeesvtOPXCSFPcRIHKEBkoo2EGioyqZXbn8bIZqDsciszTd+IX40f6NFXUMsNkC5ZsGaWWn49v/1s07eno9dSUEAJ9+/VFZWwluj3YzePvnVx+EvFV8Tj8/WGXi0WIKPAFXAaKKBhpsbqvZX3RlLQpyDx9J6KtnX0ukG+5mszZ0nzb5017OrotQm+rwP3s2bM4euQoMgaNxD3fzEbvs9d51L/ojGgcPXIU586dkz84hSi5eo+I1McAikintNjKoeXUUFbPLPxi/EjFp4raWprvydRUW6vczp8/DwAYgrHofKE7rj91q0d9Com8UldZW1vrtq1agY6nq/e0CLT0ulUHkZYYQBHplD/qXBxvxo71RanpXaSVcWrdPFv2wZM6r7Y2l+zQoQMAoBDrcSaqGKUxRz3KRDVdbAIAREdHu+2vWtsUeLppphbbJBhpXzYif2EARaRT/njkiic3Y09vnt5mRuQGBG1lsOLi4nD70PG44fxo7O36byTXpHqUiardXYvUPql2j4dyJv94Pmrqa9CtQzfFtynwdNNMLXYnZ9E6UWsMoIgMQo1pFE9uxp7ePL3NjLjrg5xxm0wmjLlhErpGXoXrim/B3q7/xpmoYuzt+m+X32msbkRNUQ1mTJ/htoB8xYEVOHn+JGLMMZrtDq7F7uR8fiJRa1yFpwKuwiM1+GPvH182aJS7d5Sn5I77my+P4d2Xt+CLsx/Cev9Jt/tAFb9cjMs/XEZpSanbfaA8HaNa14KI1MVVeEQByB/TKL7UurjKjPha9Cx33OUpR7DjmlUo/GILSl4uQWN1o9N2jdWNKH65GLUHanHD72/waBNNT7M/fJwLUeBjBkoFzECRUanxiJAJ6ye02vfJl/O5+47tfLEnYrHnuT24ePEiYtJjEJ0RjZDIEDRdbELt7lrUFNXAHGHGDb+/AY//+nFFM0W+ZqCYwSLSBjNQRAajRH2TEsfwptYl/3g+Rq8djdFrRzvNMmUkZCA8JBwZCRmtPvMm4+XsOy3HbqupevzXj6OkuAQvLHkB8VXxKFleguPPHUfJ8hLEV8XjhSUvoOxkGbY9sU3xIMXXOiWlM1jcY4pIeQygiHSgYN1RnCmuRcG6o14fQ6ul5rbC6pPnTzq94e8+vRt1TXXYfXp3q8+8mZZ09p2WY28ZvHTs2BEzZ87E4e8Po7KyEseOHUNlZSUOf38YM2fOhMVi8W7QKnMsrPc1AOKUIpHyGEARBQglaqTaulG7ynBNSZuCbh26uVza39YqO28yXs6+427sJpMJcXFx6NmzJ+Li4nT/uBbHDJavAZAWWx8QBTrWQKmANVAklxq1R95oq17JH6sAyTnWRBH5h5z7NwMoFTCAIqNq60atlyCPiEgtDKA0xgCK9IpBEBGRa1yFR6QhXwp+fVlJ5+67R4sq8OnKg34tNOdDaIkoUDGAIlKYLwW/vqykc/fdPZtP4HJjM9qHtmuz0FzJJe96fwgtAzwi8hYDKCKF+bLiyZeVdG1992hRBeovNiImPhy35Axoc/pOySXvau2e7irwkRsQOQZ4zr7PIIuInGmvdQeIAk1WzyyvV0qlpndxW5vkqo6pre/u2XwCNZV16Nw92u3xp6RNkQrJPT23L+PxRsvAp+XxXb3vyqDsHtJ4XH1f7jGJKDgwA0VkIN7WMcnJBDnbRduWhbFt+Cnn3M4yOEo/H892vJBB1bIyXo57Sjk77rb4tTAnCFWfQUhExsNVeCrgKjxyxddVcLa9mNqHtnM7Faek15/8FPWnTWhvEehkiUHIoGq8d/l1j/YlcrZ/1Oi1o3Hy/El069ANG+/Z6HP/HPevUmrfpLb2xSKiwMNVeEQKUrIGxteialuGxJ/BEwDs7boFZ6KK8c1VWzB+3g147/LrHtdJeZr98iUr5Vh3plQdF3fwJiJXmIFSATNQgUXJHbiNug9Ty4wOALxQ9AIA4JH0R7zK8DjLENmyPd06dEOMOcan7JFWO3dzx3AiY+NGmhpjABVYjBr0eEruTV+taS1bP2rqa3Dy/ElDTptxyo/I2DiFR/R/lJh+8+aBt0Yid7pL7WmtUd1HGXbajFN+RMGD2xhQQOMSdPfa2rbAGV+2aWiLLZADYNjsjVrXhoj0hxkoCmjuCpi5SeJ/ty3ofXagatfCkwJxZm+IyEgYQFFAczf9puSjRpR8BIoW1HzsiifThM72nyIi0isGUBTUlHzUiK9L57XOhqn12BXAeXbJ6AEnEQU3rsJTAVfhBSdfl7AruV2CEbhascatAIhIK1yFR+RnR4sqUP2PTliYtNTrm75SGSCtM1nOOOuTq5onJR9m7Ixj5ouZMCLyBgMoIgUoUT+k1HYJatYyectZn1zVPKldTO4YoKkdsBFRYGIARaQANeuHjNwXGzmPc1F7+s4xQOPqPyLyBmugVMAaKCJ5AmEXciIyPtZAERGAK7VHb//vDrz9vzt0VRPlqOUmmlplg7SqhWINFpExMYAiCmB7Np9ATWUdairrdFUT5cg2jfZI+iOa7QWlVS0Ua7CIjIkBFFELelzB5otB2T0QEx+OmPhwXdVEOVJiE01fMzla1UKxBovImAwTQN11113o3r07wsPDkZSUhEmTJqG0tNSuTXFxMe68805ERUUhPj4eM2fORENDg12b/fv3Y/jw4YiIiEDXrl3x1FNPwbEMbNu2bUhPT0d4eDh69+6NV199VfXxkT7ocQWbL1LTu2DSgqGYtGBowD8L0NdMjlY7oXMHdiJjMkwANXLkSLz33nv4/vvvsXbtWvzwww/4xS9+IX3e1NSEMWPG4MKFC9i+fTtWr16NtWvXYvbs2VKbmpoa3HbbbUhOTsauXbuwdOlSPPfcc1iyZInU5tixY7jjjjswbNgw7N27F/PmzcPMmTOxdu1av46XtKHHFWzkGWZyiMifDLsK76OPPsK4ceNQX1+P0NBQbNy4EWPHjkVJSQmSk5MBAKtXr0ZOTg4qKioQExODV155BXPnzsXp06dhNpsBAE8//TSWLl2KkydPwmQy4bHHHsNHH32EQ4cOSefKzc3F119/jYKCAqd9qa+vR319vfRzTU0NUlJSuAqPiIjIQAJ+Fd65c+ewatUqDB06FKGhoQCAgoICpKWlScETAGRnZ6O+vh5FRUVSm+HDh0vBk61NaWkpjh8/LrXJyrJPpWdnZ2P37t1obGx02p/FixfDYrFIr5SUFCWHSxT0uFKNiPTGUAHUY489hqioKMTFxaG4uBj/+te/pM/Ky8uRkJBg175Tp04ICwtDeXm5yza2n921uXz5MiorK532a+7cubBardKrpKTEt4ESkR2uVCMivdE0gJo/fz5MJlObr927d0vtf//732Pv3r3Iz89HSEgIfv3rX9sVgJtMplbnEELYve/YxvZ9uW1aMpvNiImJsXtR8GGWRD2sbyIivWmv5cmnT5+O++67r802PXv2lP4cHx+P+Ph49O3bF/3790dKSgoKCwuRmZmJxMREfPXVV3bfraqqQmNjo5RRSkxMlDJNNhUVV5aru2vTvn17xMXFeTVOCg4tsyRcUaWsrJ5ZvKZEpCuaBlC2gMgbtqyQrXg7MzMTCxcuRFlZGZKSkgAA+fn5MJvNSE9Pl9rMmzcPDQ0NCAsLk9okJydLgVpmZiY+/vhju3Pl5+cjIyNDqrcicmZK2hTpOW5ERBTYDLEKb+fOndi5cyduvvlmdOrUCT/++COeeOIJlJWV4dtvv4XZbEZTUxMGDhyIhIQE/PnPf8a5c+eQk5ODcePGYenSpQAAq9WKfv36YdSoUZg3bx6OHDmCnJwcPPHEE9J2B8eOHUNaWhoeeOABTJ06FQUFBcjNzcW7776Le+65x6P+8ll4RERExhNwq/AiIiLw4Ycf4pZbbkG/fv3wm9/8Bmlpadi2bZu0oi4kJASffPIJwsPDcdNNN2H8+PEYN24cnnvuOek4FosFW7ZswcmTJ5GRkYFp06YhLy8PeXl5UptevXphw4YN2Lp1KwYOHIg//elPePnllz0OnoiIiCjwGSIDZTTMQBERERlPwGWgiLTAVXVEROQKAygiF7j3EBERucIAisgF7j1ERESuaLqNAZGece8hIiJyhRkooiDVVo0X67+IiNrGAIooSLVV48X6L2NjAEykPgZQREGqrRov1n/Jo7eAhQEwkfq4D5QKuA8UeeJoUQX2bD6BQdk9kJreRbG25H8T1k/AwbMHMSBuANaMXaN1d5B/PF96rBDr+Ig8x32giAxgz+YTOFNciz2bTyjalvxPbxm7rJ5ZWDN2DYMnIhVxFR6RRgZl95CySkq2Jf/jik2i4MMpPBVwCo+IiMh4OIVHRLqmt6JrIiK5GEARkd9xlRgRGR0DKCLyO70VXRMRycUiciLyOxZdE5HRMQNFREREJBMDKCIiIiKZGEARERERycQAioiIiEgmBlBEREREMjGAIiIiIpKJARQRERGRTAygiIiIiGRiAEVEREQkEwMoIiIiIpkYQBERERHJxACKiIiISCYGUERu5B/Px4T1E5B/PF/rrhARkU4wgCJyY8WBFTh49iBWHFihdVeIiEgnGEARuTElbQoGxA3AlLQpWneFiIh0or3WHSDSu6yeWcjqmaV1N4iISEeYgSIiIiKSiQEUERERkUwMoIiIiIhkYgBFREREJBMDKCIiIiKZDBdA1dfXY+DAgTCZTNi3b5/dZ8XFxbjzzjsRFRWF+Ph4zJw5Ew0NDXZt9u/fj+HDhyMiIgJdu3bFU089BSGEXZtt27YhPT0d4eHh6N27N1599VW1h0VEREQGYrhtDObMmYPk5GR8/fXXdu83NTVhzJgx6Ny5M7Zv346zZ89i8uTJEEJg6dKlAICamhrcdtttGDlyJHbt2oXDhw8jJycHUVFRmD17NgDg2LFjuOOOOzB16lS88847+M9//oNp06ahc+fOuOeee/w+XiIiItIfQwVQGzduRH5+PtauXYuNGzfafZafn4+DBw+ipKQEycnJAIDnn38eOTk5WLhwIWJiYrBq1SrU1dVh5cqVMJvNSEtLw+HDh7FkyRLk5eXBZDLh1VdfRffu3fHiiy8CAPr374/du3fjueeecxlA1dfXo76+Xvq5pqZGnQtAREREumCYKbzTp09j6tSpePvttxEZGdnq84KCAqSlpUnBEwBkZ2ejvr4eRUVFUpvhw4fDbDbbtSktLcXx48elNllZ9psmZmdnY/fu3WhsbHTat8WLF8NisUivlJQUX4dLRP+HzyIkIj0yRAAlhEBOTg5yc3ORkZHhtE15eTkSEhLs3uvUqRPCwsJQXl7uso3tZ3dtLl++jMrKSqfnnjt3LqxWq/QqKSmRP0gicorPIiQiPdI0gJo/fz5MJlObr927d2Pp0qWoqanB3Llz2zyeyWRq9Z4Qwu59xza2AnK5bVoym82IiYmxexGRMvgsQiLSI01roKZPn4777ruvzTY9e/bEggULUFhYaDf1BgAZGRn41a9+hTfffBOJiYn46quv7D6vqqpCY2OjlFFKTEyUMk02FRUVAOC2Tfv27REXFyd/kETkEz6LkIj0SNMAKj4+HvHx8W7bvfzyy1iwYIH0c2lpKbKzs7FmzRoMHjwYAJCZmYmFCxeirKwMSUlJAK4UlpvNZqSnp0tt5s2bh4aGBoSFhUltkpOT0bNnT6nNxx9/bHf+/Px8ZGRkIDQ01OcxExERkfEZogaqe/fuSEtLk159+/YFAFx11VXo1q0bACArKwsDBgzApEmTsHfvXnz66ad49NFHMXXqVGlKbeLEiTCbzcjJycGBAwewbt06LFq0SFqBBwC5ubk4ceIE8vLycOjQIfz973/HihUr8Oijj2ozeCIiItIdQwRQnggJCcEnn3yC8PBw3HTTTRg/fjzGjRuH5557TmpjsViwZcsWnDx5EhkZGZg2bRry8vKQl5cntenVqxc2bNiArVu3YuDAgfjTn/6El19+mXtAERERkcQkHLfhJp/V1NTAYrHAarWyoJyIiMgg5Ny/AyYDRUREROQvDKCIiIiIZGIARURERCQTAygiIiIimRhAEREREcnEAIqIiIhIJgZQRERERDIxgCIiIiKSiQEUERERkUyaPkw4UNk2d6+pqdG4J0REROQp233bk4e0MIBSQW1tLQAgJSVF454QERGRXLW1tbBYLG224bPwVNDc3IzS0lJER0fDZDJJ79fU1CAlJQUlJSUB+Yw8js/YOD5j4/iMjePTByEEamtrkZycjHbt2q5yYgZKBe3atUO3bt1cfh4TE6Prv0C+4viMjeMzNo7P2Dg+7bnLPNmwiJyIiIhIJgZQRERERDIxgPIjs9mMJ598EmazWeuuqILjMzaOz9g4PmPj+IyHReREREREMjEDRURERCQTAygiIiIimRhAEREREcnEAIqIiIhIJgZQCqqvr8fAgQNhMpmwb98+u8+Ki4tx5513IioqCvHx8Zg5cyYaGhrs2uzfvx/Dhw9HREQEunbtiqeeeqrV83i2bduG9PR0hIeHo3fv3nj11VfVHhbuuusudO/eHeHh4UhKSsKkSZNQWloaEOM7fvw4pkyZgl69eiEiIgJXXXUVnnzyyVZ9N+r4AGDhwoUYOnQoIiMj0bFjR6dtjDw+Ty1fvhy9evVCeHg40tPT8eWXX2rdpVa++OIL3HnnnUhOTobJZMI///lPu8+FEJg/fz6Sk5MRERGBESNG4Ntvv7VrU19fjxkzZiA+Ph5RUVG46667cPLkSbs2VVVVmDRpEiwWCywWCyZNmoTq6mqVRwcsXrwYN9xwA6Kjo9GlSxeMGzcO33//vV0bI4/xlVdewbXXXittFpmZmYmNGzcGxNgcLV68GCaTCbNmzZLeC6TxeUSQYmbOnClGjx4tAIi9e/dK71++fFmkpaWJkSNHij179ogtW7aI5ORkMX36dKmN1WoVCQkJ4r777hP79+8Xa9euFdHR0eK5556T2vz4448iMjJSPPzww+LgwYPitddeE6GhoeKDDz5QdVxLliwRBQUF4vjx4+I///mPyMzMFJmZmQExvo0bN4qcnByxefNm8cMPP4h//etfokuXLmL27NkBMT4hhHjiiSfEkiVLRF5enrBYLK0+N/r4PLF69WoRGhoqXnvtNXHw4EHx8MMPi6ioKHHixAmtu2Znw4YN4vHHHxdr164VAMS6devsPn/66adFdHS0WLt2rdi/f7+YMGGCSEpKEjU1NVKb3Nxc0bVrV7FlyxaxZ88eMXLkSHHdddeJy5cvS21uv/12kZaWJnbs2CF27Ngh0tLSxNixY1UfX3Z2tnjjjTfEgQMHxL59+8SYMWNE9+7dxfnz5wNijB999JH45JNPxPfffy++//57MW/ePBEaGioOHDhg+LG1tHPnTtGzZ09x7bXXiocfflh6P1DG5ykGUArZsGGDuPrqq8W3337bKoDasGGDaNeunTh16pT03rvvvivMZrOwWq1CCCGWL18uLBaLqKurk9osXrxYJCcni+bmZiGEEHPmzBFXX3213XkfeOABMWTIEBVH1tq//vUvYTKZRENDgxAi8Mb37LPPil69ekk/B8r43njjDacBVKCMry033nijyM3NtXvv6quvFn/4wx806pF7jgFUc3OzSExMFE8//bT0Xl1dnbBYLOLVV18VQghRXV0tQkNDxerVq6U2p06dEu3atRObNm0SQghx8OBBAUAUFhZKbQoKCgQA8d1336k8KnsVFRUCgNi2bZsQIjDH2KlTJ/H6668HzNhqa2tFnz59xJYtW8Tw4cOlACpQxicHp/AUcPr0aUydOhVvv/02IiMjW31eUFCAtLQ0JCcnS+9lZ2ejvr4eRUVFUpvhw4fbbTKWnZ2N0tJSHD9+XGqTlZVld+zs7Gzs3r0bjY2NKoystXPnzmHVqlUYOnQoQkNDpX4FyvgAwGq1IjY2Vvo50MbnKNDH19DQgKKiolZ9y8rKwo4dOzTqlXzHjh1DeXm53TjMZjOGDx8ujaOoqAiNjY12bZKTk5GWlia1KSgogMViweDBg6U2Q4YMgcVi8fv1sFqtACD99xZIY2xqasLq1atx4cIFZGZmBszYHnroIYwZMwa33nqr3fuBMj45GED5SAiBnJwc5ObmIiMjw2mb8vJyJCQk2L3XqVMnhIWFoby83GUb28/u2ly+fBmVlZWKjMeVxx57DFFRUYiLi0NxcTH+9a9/SZ8FwvhsfvjhByxduhS5ubnSe4E0PmcCfXyVlZVoampy2jdb343A1te2xlFeXo6wsDB06tSpzTZdunRpdfwuXbr49XoIIZCXl4ebb74ZaWlpUt9s/W3JSGPcv38/OnToALPZjNzcXKxbtw4DBgwIiLGtXr0ae/bsweLFi1t9Fgjjk4sBlAvz58+HyWRq87V7924sXboUNTU1mDt3bpvHM5lMrd4TQti979hG/F+Brtw2So7P5ve//z327t2L/Px8hISE4Ne//rVdAbHRxwcApaWluP3223Hvvffit7/9rd1ngTC+tuhtfGpw1jc99Esub8bh7nfp6XGUNH36dHzzzTd49913W31m5DH269cP+/btQ2FhIR588EFMnjwZBw8edNkvo4ytpKQEDz/8MN555x2Eh4e7bGfU8XmjvdYd0Kvp06fjvvvua7NNz549sWDBAhQWFrZ6vk9GRgZ+9atf4c0330RiYiK++uoru8+rqqrQ2NgoReuJiYmtouuKigoAcNumffv2iIuLU2V8NvHx8YiPj0ffvn3Rv39/pKSkoLCwEJmZmQExvtLSUowcORKZmZn429/+ZtcuEMbXFj2OT0nx8fEICQlx2jfHfy3rWWJiIoAr/0JPSkqS3m85jsTERDQ0NKCqqsruX/kVFRUYOnSo1Ob06dOtjn/mzBm/XY8ZM2bgo48+whdffIFu3bpJ7wfCGMPCwpCamgrgyn1g165deOmll/DYY48BMO7YioqKUFFRgfT0dOm9pqYmfPHFF1i2bJm0mtKo4/OKf0qtAteJEyfE/v37pdfmzZsFAPHBBx+IkpISIcR/i3RLS0ul761evbpVkW7Hjh1FfX291Obpp59uVaTbv39/u/Pn5ub6vUi3uLhYABCff/65EML44zt58qTo06ePuO++++xWgtgYfXw27orIjT6+ttx4443iwQcftHuvf//+hiwif+aZZ6T36uvrnRbprlmzRmpTWlrqtEj3q6++ktoUFhb6pUi3ublZPPTQQyI5OVkcPnzY6edGH6OjUaNGicmTJxt+bDU1NXb3uv3794uMjAxx//33i/379xt+fN5gAKWwY8eOudzG4JZbbhF79uwR//73v0W3bt3slolXV1eLhIQE8ctf/lLs379ffPjhhyImJsbpMvFHHnlEHDx4UKxYsUL1ZeJfffWVWLp0qdi7d684fvy4+Oyzz8TNN98srrrqKmlFlpHHd+rUKZGamipGjRolTp48KcrKyqSXjZHHJ8SVIH/v3r3ij3/8o+jQoYPYu3ev2Lt3r6itrQ2I8XnCto3BihUrxMGDB8WsWbNEVFSUOH78uNZds1NbWyv9fgCIJUuWiL1790rbLTz99NPCYrGIDz/8UOzfv1/88pe/dLpMvFu3buLf//632LNnjxg1apTTZeLXXnutKCgoEAUFBeKaa67xyzLxBx98UFgsFrF161a7/9YuXrwotTHyGOfOnSu++OILcezYMfHNN9+IefPmiXbt2on8/HzDj82ZlqvwhAi88bnDAEphzgIoIa7cxMaMGSMiIiJEbGysmD59ut2ScCGE+Oabb8SwYcOE2WwWiYmJYv78+dK/7m22bt0qrr/+ehEWFiZ69uwpXnnlFVXH880334iRI0eK2NhYYTabRc+ePUVubq44efJkQIzvjTfeEACcvgJhfEIIMXnyZKfjs2UQjT4+T/3lL38RPXr0EGFhYWLQoEHS0nk9+fzzz53+riZPniyEuJKhefLJJ0ViYqIwm83ipz/9qdi/f7/dMS5duiSmT58uYmNjRUREhBg7dqwoLi62a3P27Fnxq1/9SkRHR4vo6Gjxq1/9SlRVVak+Plf/rb3xxhtSGyOP8Te/+Y30d6xz587illtukYIno4/NGccAKtDG545JCIethImIiIioTVyFR0RERCQTAygiIiIimRhAEREREcnEAIqIiIhIJgZQRERERDIxgCIiIiKSiQEUERERkUwMoIiIiIhkYgBFREREJBMDKCIKWjk5OTCZTDCZTAgNDUXv3r3x6KOP4sKFC3bt1q5dixEjRsBisaBDhw649tpr8dRTT+HcuXMuj71w4UIMHToUkZGR6Nixo8ojISJ/YwBFREHt9ttvR1lZGX788UcsWLAAy5cvx6OPPip9/vjjj2PChAm44YYbsHHjRhw4cADPP/88vv76a7z99tsuj9vQ0IB7770XDz74oD+GQUR+xmfhEVHQysnJQXV1Nf75z39K702dOhXr169HWVkZdu7cicGDB+PFF1/Eww8/3Or71dXVbrNLK1euxKxZs1BdXa1s54lIU8xAERG1EBERgcbGRgDAqlWr0KFDB0ybNs1pW07NEQUvBlBERP9n586d+Mc//oFbbrkFAHDkyBH07t0boaGhGveMiPSmvdYdICLS0vr169GhQwdcvnwZjY2N+NnPfoalS5cCAIQQMJlMGveQiPSIARQRBbWRI0filVdeQWhoKJKTk+2yTX379sX27dvR2NjILBQR2eEUHhEFtaioKKSmpqJHjx6tgqSJEyfi/PnzWL58udPvsjCcKHgxA0VE5MLgwYMxZ84czJ49G6dOncLdd9+N5ORkHD16FK+++ipuvvlmp6vzAKC4uBjnzp1DcXExmpqasG/fPgBAamoqOnTo4MdREJEaGEAREbXhmWeeQXp6Ov7yl7/g1VdfRXNzM6666ir84he/wOTJk11+74knnsCbb74p/Xz99dcDAD7//HOMGDFC7W4Tkcq4DxQRERGRTKyBIiIiIpKJARQRERGRTAygiIiIiGRiAEVEREQkEwMoIiIiIpkYQBERERHJxACKiIiISCYGUEREREQyMYAiIiIikokBFBEREZFMDKCIiIiIZPr/aBkafQWk2kkAAAAASUVORK5CYII=",
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"fig, ax = plt.subplots(nrows=1, ncols=1)\n",
"\n",
"projected_centers = pca.transform(mbk.cluster_centers_)\n",
"\n",
"for k in range(n_clusters):\n",
" my_members = mbk_means_labels == k\n",
" projected_cluster_center = projected_centers[k]\n",
" line, = ax.plot(projected[my_members, 0], projected[my_members, 1], '.',\n",
" markersize=1.8)\n",
" ax.plot(projected_cluster_center[0], projected_cluster_center[1], 'o',\n",
" markersize=10, markeredgecolor='black', markerfacecolor=line.get_color())\n",
"ax.set_xlabel('PC 1')\n",
"ax.set_ylabel('PC 2');"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## silhouette analysis with K-means\n",
"\n",
"OK, so that last plot (in PCA space) is looking better. The automatically detected clusters seem to agree with the idea we had from just looking at the data. Let's now use a silhouette analysis as one way to check whether this was a particularly good number of clusters for this data."
]
},
{
"cell_type": "code",
"execution_count": 25,
"metadata": {},
"outputs": [],
"source": [
"from sklearn.metrics import silhouette_samples, silhouette_score\n",
"from sklearn.cluster import KMeans\n",
"import matplotlib.cm as cm"
]
},
{
"cell_type": "code",
"execution_count": 26,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"For n_clusters = 2 The average silhouette_score is : 0.10616550010654774\n",
"For n_clusters = 3 The average silhouette_score is : 0.13476859870312252\n",
"For n_clusters = 4 The average silhouette_score is : 0.10793693499115094\n",
"For n_clusters = 5 The average silhouette_score is : 0.0668711029107827\n",
"For n_clusters = 6 The average silhouette_score is : 0.050878820272807025\n"
]
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAABZoAAAKgCAYAAAAS1si3AAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjkuMiwgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy8hTgPZAAAACXBIWXMAAA9hAAAPYQGoP6dpAAEAAElEQVR4nOzdd1gUV9sG8Hthd+kgvQtiwYLYRWyIYO89sZeYGH01tiSaxBqjSUyMpmjim8Qeu0aNSmJPjCVq7C3GXlBRpEtZ9nx/8DEvCwsssDCU+3ddXMzOnDnzzOzM7syzZ84ohBACRERERERERERERESFZCJ3AERERERERERERERUtjHRTERERERERERERERFwkQzERERERERERERERUJE81EREREREREREREVCRMNBMRERERERERERFRkTDRTERERERERERERERFwkQzERERERERERERERUJE81EREREREREREREVCRMNBMRERERERERERFRkTDRTESl1sqVK6FQKKS/rNq0aSONHz58uDT+zp07OvMcPny4ZIOmUufw4cM6+8SdO3dKbNmzZ8+Wluvr61tsy4mPj8dbb70FHx8fqFQqaZkrV64stmVS2SbncVEa8LuC9Cmpz+z8DB8+XIqjTZs2ssVRGhR1W5TnbcnPMSIiKo2YaCaiEiGEwE8//YT27dvDxcUFKpUKlSpVgp+fH9q2bYspU6bg999/lzvMUs2Qi6WKnjyqqMaMGYMvv/wS9+7dg0ajkTscADn3xexJ7+joaDRq1Eiabmpqih9//FHvvAqFAgMGDNC7nB9++CFH2dmzZxfz2pEx5LV/EJHxlJYEurGV5yRyWeHr68vv3nxERETgnXfeQcuWLeHr6wsLCwtYWVkhICAAU6dOxZMnT+QOkYjIqJRyB0BEFcOQIUOwbt06nXGxsbGIjY3F7du3cejQIcTGxqJ169bS9CZNmmDhwoUlHSqR0bRv3x7W1tYAADs7u2JZRlpaGjZv3iy9btWqFbp06QJTU1M0adKkWJZZVFFRUQgPD8eFCxcAAKampli1ahUGDRqU6zzbtm3Dw4cP4enpqTP+66+/LtZYqXxycHDQ+X6pWrWqjNEQUW5eeeUVBAQEAAC8vb1ljoao4Hr27ImUlJQc4y9fvozLly9j1apVOHTokLSfExGVdUw0E1Gx27t3r06SOSgoCOHh4TAzM8P9+/dx/fp1HD9+PMd8derUQZ06dUoyVCKjat68OZo3b16sy4iMjERaWpr0etasWQgLCyvWZSYnJ8PU1BQqlarA80ZGRiIsLAxXr14FAKhUKqxbtw79+vXLcz6NRoNvv/0WH374oTTu6NGjOHfuXIFjoIorc9+1tbXF1KlT5Q6HiPLRsWNHdOzYUe4wqBTRaDRIS0uDhYWF3KEYzNTUFG3atEFwcDCEENi2bZt0HvTs2TOMGTMGR48elTlKIiLjYNcZRFTs9u3bJw1Xr14dx44dw7x58zBjxgwsX74cR44cwZMnT/D666/rzJdXH80FsXnzZjRt2hQWFhZwcnLC8OHDER0drbfs/v370adPH3h6ekKtVsPOzg5BQUH4+OOPER8fr1M2v77x8rud8OzZsxgxYgT8/Pxgbm4OGxsbNGnSBIsWLUJycnKO7bBq1Spp3JEjR3IsW6FQIDQ0VGcZVapU0duXdUGWn5/k5GS8//776NixI/z8/GBnZweVSgUnJye0bt0aX3/9dY7uHPRtu7Vr16Jx48Z5vk9Pnz7F22+/jbZt28LHxwc2NjZQq9VwdXVF+/btsXbtWgghDIq7bdu20vKHDRuWY/qSJUuk6a6urlIy9+LFixg8eDB8fX1hZmYGCwsLVK5cGW3btsX06dPx8OFDqY68ble+e/cu3njjDVSvXh0WFhYwNzeHp6cnWrRogcmTJ0sXIHnx9fWFj4+Pzrjw8HC9Xadcv34dY8aMkZZnZWWFmjVrYsKECXq7WMneD/rZs2fRuXNn2Nvbw8LCQmc9DfXgwQOEhIRI66ZWq7F58+Z8k8wmJhmnK8uXL9dpFfTVV1/pTM/Lv//+i3HjxqFmzZqwtLSEpaUl6tati1mzZiE2NjZH+c2bN2PQoEEICAiAi4sL1Go1rK2tUadOHYwfP96gbXb9+nX069cPDg4OsLCwQHBwsN4+NAuyT+UnLS0N//3vfxEeHg5nZ2eo1Wq4uLigRYsWBt8hklsf+IBx9unM+rMaMWJErvVGRkZi2rRpCAwMhI2NDczNzVGjRg1MnjwZjx8/zjd+fftuXp/f2dcxJiYGkyZNgre3N8zMzODv749ly5bp3XYXL15Et27dYGtrC1tbW3To0AFnzpwpUtcFRT12Dd0P87Jz50507NgRrq6uUKlUsLW1RdWqVdGzZ08sWLAAWq1WKrt//36MHDkSDRo0gJubG8zMzGBpaYnq1atj5MiRuHjxYo76s3eB8M8//6BXr16ws7ODg4MDBg4cKN1efujQIbRq1QqWlpZwdnbGqFGj8OLFC536sp8/JCcnY9asWahatSrMzMxQtWpVzJs3T+dHOkPExMRg3rx5aNKkCezs7GBmZgZfX1+MHj0a//77b4HqAoDff/8dbdq0gZWVFRwcHNCvXz/cvHkzz3m+++479OvXDzVr1oSTk5P0fjRo0ADTpk3Ds2fPpLKZ5wZz5syRxt29e1dvtzX//vsv3nrrLbRs2RLe3t6wsrKCmZkZvLy80L17d/zyyy8Gr9fixYul+v39/XWmNWjQQJqW9fwwazdIrq6u0ne5vu4xDD0v0ufp06d444034ObmBnNzc9SrVw9bt241eN0Ke/5SEEIIbNy4EV27doW7uzvUajUcHR3RpEkTvPvuuwbVkVe3InmdXz979gxTp05FnTp1YGVlBbVaDTc3NzRt2hT/+c9/cOLECZ367969K807Z86cXOst6LGTPf5bt25hwIABcHJyglqtxsmTJwEY9/uzuIwYMQI3b97E/v378eGHH2LevHk4e/asTmOaP//8M8d1BhFRmSWIiIrZ+PHjBQABQDg6Oorr168bNN+KFSuk+bJ/XIWEhEjjhw0bJo2/ffu2zjzt27fXeZ3516JFixzLmzx5st6ymX/Vq1cXd+/ezXVZhw4d0qnPx8dHmjZr1iydaV999ZUwNTXNdVlNmjQRMTExereDvr9Dhw7lWybrdirI8vMTFRWV77LDw8OFRqPJddu1aNHCoPfp1KlT+S5rxIgROvNk3za3b98WQgixdetWaZyFhUWO9W3evLk0ffLkyUIIIS5fviwsLS3zXP7evXulOmbNmiWN9/HxkcY/efJEODs751nPsmXL8t32WfcxfX+Z67px40Zhbm6eazkbGxvx66+/6tSd9Rhr0KBBjvXOrDs32bf7rFmzRJUqVaTX5ubmYs+ePQbN26NHD2l49erVQgghHj58KJRKpQAgevbsmWNZWW3dulVYWFjkuv5Vq1bVObaFEKJLly55bltbW1tx4cKFXLdZYGCgsLa2zjGfWq0Wly5dkuYp6D6Vl6ioKNGoUaNc68m6D+Z2XGRfj6yfG0IYZ5/OWn9+cR49elQ4ODjkWtbFxUWcPXs21/cht303r8/vrOvo6OgoatasqXfZy5cv11nuqVOn9L7n5ubmIjw8XO/65aeox66h+2FeDPkOevnypVR+3LhxeZZVq9Vi3759OssYNmyYNL1KlSrC3t4+x3z+/v5i7dq1wsTEJMe01q1b5xlz27Zt9cbSq1cvnfly27+FEOLatWuicuXKua6XlZVVjvciL7/88ov0GZb1z8HBQQQHB0uvQ0JCdOarU6dOntvX09NTPHz4UAiR8zjX97dixQohhBCbN2/Ot+ycOXMMWrfz58/rzPf48WMhhBBxcXE65x4zZsyQ5sm6D/Tv31/v+MxtYeh5Ufb5/f399X5vKhQKg9+7wp6/GCopKUl07Ngxz3XLLZasn2P6tlum3M6vX758Kfz9/fNc9rvvvpuj/vziLMyxk7X+6tWrCxcXlxzraszvT0P2qax/2bdpYUyZMkWnzmfPnhW5TiKi0oBdZxBRsatfv740/Pz5c9SsWROBgYFo0qQJmjRpgvDwcPj5+RXLsn/77TcEBwcjLCwMv/zyi3Sb/Z9//onjx48jODgYALB69WosWrRImi8wMBDdu3fHnTt3sG7dOgghcOPGDfTv319qzVFYf/75JyZMmCC11mnZsiXCw8MRExODVatW4cWLFzh16hTefPNN/PTTT1Jf1Rs3bsTp06cBAH5+fnjzzTelOqtWrYqFCxfi5s2b+Pbbb6Xx7733Huzt7QFA6vutoMvPj0KhQLVq1RAUFAQPDw/Y29sjLS0N165dw+bNm6HRaLB//35s3boV/fv3z3WbGPI+mZiYoE6dOmjSpAlcXV1RqVIlJCcn4+zZs9i1axeEEFixYgXGjBmDpk2b5hl3jx49ULlyZdy7dw8vX77EunXrMHbsWADAw4cPdbpzyWzVuWrVKiQlJQEAvLy8MHjwYFhZWeHBgwe4dOmSwfvG1q1bERUVBQCwt7fHiBEj4OjoiEePHuHatWv4448/DKrn/fffx507dzB//nxp3JgxY6T+Zh0cHHDjxg0MHTpUagns7OyMYcOGQaPR4Mcff0RcXBzi4+PRr18//PPPP3B1dc2xnLNnz0KlUmH48OGoWrUqLl++XOBuM+bOnSvtc5aWlti5c6fBXXwMGjQIv//+O168eIGvv/4aQ4YMwbJly6SW8uPHj8fPP/+sd95bt25h0KBBUiv9wMBA9OzZE6mpqVizZg0ePnyImzdv4tVXX8Wff/4pzWdvb4+OHTvC398f9vb2UKvVePLkCbZt24b79+8jLi4O7777Lvbs2aN3uRcuXICTkxPGjBmDJ0+eYM2aNQCA1NRUfPnll/juu+8AGG+fAjL6wj9z5oz0uk6dOujUqROUSiVOnz6db0vJoijIPv3mm2+ia9euePvtt6VxAwYMQOPGjQH8rz/z2NhY9OrVS2oZ6Ofnh/79+0OlUmHTpk24fv06nj59it69e+Pq1aswMzPLEVdu+66hLVmfP3+OmJgYjBw5Eo6Ojvjmm2+k9+uzzz7D6NGjpbIjRoxAQkKC9PrVV1+Fn58fNm3ahP379xu0vKyMcewauh/mJWvr7SZNmqBr167QaDS4f/8+Tp48mePuC2tra4SGhqJOnTpSK+rnz59j9+7duHr1KlJTUzFhwgRcuXJF7/Ju374NR0dHvP3227h165bU2vT69etSy8WBAwfizz//xJEjRwBktAw+ceIEmjVrprfOQ4cOYciQIahcuTK2bt2Ka9euAQC2b9+OtWvXYvDgwXlug/T0dPTq1Qv37t0DALi6umLQoEGws7PDL7/8glOnTiExMRH9+/fHjRs34OzsnGd9SUlJGDlypPQZplKpMHLkSNjb22Pt2rV6uxPL5OrqimrVqsHPzw8ODg5QKBR4+PAhNm3ahOfPn+Phw4eYN28eli5dKp0b/Pbbb1LrYXt7e7z33ntSfZl9+atUKjRs2BCNGjWCs7MzbG1tkZCQgD///BOHDh0CAHz44YcYNWpUjr7ys6tbty6cnJyk1tVHjx5Fnz59cOzYMaSnp0vlsn4uZH0gdPa7s7Iz9Lwou+vXr8PS0hLjx4+HVqvFt99+i/T0dAgh8Pnnn6N9+/Z5LlcfQ89fDDV58mRERERIr319fdGjRw/Y2NjgwoUL2L17d4FjNNShQ4dw/fp1AIC5ubn0Xj9+/Bj//vuvdLwB/+s7e/78+dIdBe3atcuxDY1x7Ny4cQMKhQL9+vVD3bp1cefOHVhZWRn1+1MOmdsayLgD0dHRUcZoiIiMSM4sNxFVDKmpqaJevXp5tgwIDQ0V165d05nPGC2amzVrJtLS0oQQQjx//lynJc2XX34pzZc1vipVqui0zpo7d65OnUePHtW7LENbNPfq1Usa36FDB6HVaqVpEREROi1s7t+/L03Lq3VKprxaKRZ1+fl58uSJ2LFjh1i6dKn47LPPxMKFC0VAQIBU38iRI6WyhX2fMt29e1ds2bJFfP3119KyPD09pXnmzp1r0DaZP3++NL5BgwbS+C+++EIa37hxY2n8hAkTpPELFizIEVd0dLSIjo6WXufWOm7RokXS+DfeeCNHPQkJCVILsPzktx++9dZb0jQTExNx5coVadrvv/+uM++8efOkadlbnebW+jg3ebWk27RpU4Hm3bVrl5g6dar0+vfffxeurq4CgKhTp44QQuiUz3q8TZo0SRpft25dkZKSIk27du2aznx//vmnThypqani999/Fz/88IP44osvxMKFC8WIESOk8mZmZiI1NVXvNjMxMRHnz5+XpmVtdd2wYUNpfEH3qdxkb0HYrVs36ZjKdPPmzVy3cVFbNBdmn866/MxWlVktWbJEmu7i4qJz18GLFy90WvquW7dOb/y57buGtmgGIL7++mtp2uLFi3WmxcXFCSGEOHbsmM74zFZ/QmS8h1lb6BraotkYx66h+2FeAgMDpXmOHz+eY/rt27dFenq6zrj09HRx8uRJsXLlSrF48WKxcOHCHHcN3bt3TyqfvXVk5vesVqsV7u7u0niVSiXNFxMTI1Qqld7viuznDx999JE0LTY2Vjg5OUnTWrVqJU3Lbf/esWOHNF6tVos7d+5I01JSUnRaa2ZdVm7Wr1+vE9/333+vsz2zrpe+7/vExESxf/9+sXz5crFo0SKxcOFCnTs//Pz8dMrn1VI7u+vXr4sNGzaIr776Svp+zdpqNPOukvz06dNHmuett94SQgjxwQcfCCDjTgEg426ilJQU8eDBA53tkfXOt7zOfQw5L8q+b/3yyy/StIkTJ0rjHRwcDFqvop6/5OX58+c6rdwbNWokEhISdMpk/Rw3dovmbdu2SeM6dOiQI77k5GTx4MEDnXF53b0nROGPnezv29KlS3PUbazvTyGEuHTpkli4cKHBfxs2bDCo3txs2rRJZ/1+/PHHItVHRFSasEUzERU7lUqFI0eOYN68eVi5cqVO/4GZDh06hPbt2+PSpUuwsbEx2rJHjRoFpTLjo87BwQFOTk5SP4+ZLTASExNx/vx5aZ5+/frB3Nxcej1s2DDMnDlTen3s2DG0aNGi0DFlbTX566+/5tq/rBACJ06cQN++fQu9rJJY/suXLzF27FisXr1ap5/O7B48eJDrNEPeJyCjdeGwYcPybdGT17KyGj16NObOnSu1ij5z5gwaNWqEzZs3S2VGjBghDbdq1QpffvklAOCDDz7Arl274O/vD39/fwQFBaFVq1YwNTXNd7ktWrSAQqGAEALLly/HqVOnULt2bfj7+6Nx48YIDQ3V2zqxMI4dOyYNN27cGLVq1dJZnypVquD27ds5ymZVr149dOrUySjxABnbrkWLFvDw8DB4nrFjx2LRokXQarV49dVXpf1j/Pjxec6XdX+/ePGi3lavmY4dOyY9vHHdunWYOHGi3s+rTCkpKXj27Bnc3d1zTAsODkZgYKD0Oms/pVn3aWPtU1nXEwBmzJghHVOZiuvOEaB49ums6/T06VNUqlQp17LHjh3DwIEDc4wv6r5ramqKUaNGSa+z9zf74sUL2NjY6LQkB4ChQ4dKw/b29ujRo4fUF66hjHHsGrof5qVVq1a4cOECgIwWi8HBwahevTpq166N1q1bo27dujrl9+3bh9dee01qwZibBw8ewNvbO8d4Hx8f6TtWoVDAx8cHkZGRADL2s8x57Ozs4OLiIvXBmtf6DBkyRBq2tbVFt27dsGLFCgCQWsTmJeu+mJqammc/27m9F1llX2bWfdfX1xctW7aUWhFnt2jRIsyaNUun9Xx2hemX9s6dOxg0aFC+8Rv6/RoaGiq1Rs98yFnm/zFjxuDTTz/Fy5cvcebMGZ1+fj09PVGjRo0Cx28IT09PdOnSRXpdmOMhO0PPXwxx8uRJnWdavPvuu7CystIpU5yf402aNIGZmRlSUlLw66+/ok6dOggMDESNGjXQoEEDhIWF5duaPTtjHDsODg45nuMCGO/7EyjZB5CvWLFCZ30mTZqkc65JRFTWMdFMRCXCzs4OCxcuxCeffILLly/jxIkTOHToEH7++We8fPkSAHDv3j1s27ZN74PZCiv7g9KyJpkyk6IxMTE6ZVxcXHReZ0+O5HbhILI9hC7rQ8uyKsgDYjJvRTcmYy9/+vTpBiVQctsegGHvE5BxQWfIbaN5LSsrJycnDBgwQHqg0Pfffw9XV1fptmUzMzO8+uqrUvm+ffti6tSp+Oqrr5CSkoJjx47pXBj5+Phg9+7d+V6sNG3aFIsWLcKMGTOQkJCAv//+G3///bdOXJs3b87xAJ/CyLq/Zt+3gYz9OzNZldu+bYyLfj8/P9y6dQsA8M8//6B169Y4dOiQ3kSTPlWqVEGXLl2wa9cuKYlSqVKlfG95L8z+/vfff2Po0KF5/nCSKbd9zdB92lj7VPb1LOgD53Jj6OdacezTxvisKuq+6+rqqvPDY/YfKnL7HnFzc8vztSGMcewauh/mZf78+bh16xb27t2LhIQE7Nu3T+chbiEhIdizZw8sLS3x6NEj9OzZU7qdPS+57UvZE1lZY84+LeuPKXmtT17f6y9fvkRKSkqeP0IZ+3sz6/5iY2MDCwuLXOPL6ueff8aUKVPyrd/Q78CsevbsqfOje1Hrztr9xblz5xAdHY2//voLQMYPFgcOHMCJEydw9OhRaT/OPp+x5XU8ZP+sM0adhh5jmeT+HPfy8sLKlSsxfvx4PHv2DFeuXNHp4sba2hrff/89BgwYYPCyjXHsVK1aVW/C2FjfnwBw+fJl7N271+BYvb29C7QdMs2aNQtz586VXr/zzjv45JNPClwPEVFpxkQzEZUoExMT1K1bF3Xr1sXo0aNx9uxZNGzYUJpemKe25yV7P7LZn4INIEcruadPn+q8zmyZkimzz+PsLYEzE+YAEB8fn2O+rPNnnkyHhoaic+fOucZf0L79DGHs5W/cuFEaDg0NxfLly1GlShWYmpqif//+Oq2Dc2PI+5SYmKjz1PtXXnkFCxcuhIeHB0xMTNC0aVOcOnUq32VlN378eCnR/NNPP8HLy0u6KOvZs6f0fmdauHAhPvjgAxw7dgzXrl3DP//8g507d+LRo0e4e/cuxo0bl+vT7rOaOHEiXn/9dZw4cQKXL1/GjRs3EBERgRs3buDZs2cYPnw47ty5U+D1yS5r/Nn3bUB3/86+rpksLS2LHMcHH3yA06dPY+nSpQCAmzdvIiQkBAcPHjT4Ynr8+PHYtWuX9HrkyJE5Wntll3Wd6tWrl2diOrOv0s2bN0sJAisrK2zZsgUhISGwsLDAnj17dFrE5caQfTqTMfYpBwcHndd37tzJt5/Y3GT9bMv6uQZk9JWZG2Pv01nfu8qVK+fZej17S+NMRd13DX0f9X2PZH1PHj9+XOBlG+PYLch+mBtbW1vs2bMHDx48wIkTJ/DPP//gypUr2L59O5KSknDkyBF8+umnmD17Nnbt2iUlmRUKBdauXYtu3brBxsYGV65cMSjhk1f/79lb6Rvq6dOnOj9qZd125ubmeSaZAd3ta21tjVmzZuVa1pAfFbLuL/Hx8Xj58qVOsjm384es37ceHh7YunUrGjRoADMzMyxduhTjxo3Ld9n6XL9+XSfJPGnSJEybNg3Ozs5QKBRwcXEp8A/ftWvXhqurK548eYL09HR8/fXXSEpKgkqlQtOmTdGqVSucOHECf/zxR4klmo1xPBRnnfo+xzO/lwqqsJ/jr7zyCvr06YO//voLFy9exI0bN3Do0CGcPXsWCQkJGDVqFLp27Zrvd28mYxw7eX2OG+uc7NSpUzrPDchPSEhIgRLNaWlpeO2117B69WoAGe/P4sWL870ri4ioLGKimYiK3apVq5CcnIyBAwfm6BbD2tpa53Vet0YXFysrK9SrV0+6yNqyZQvmzJkjtWLLTEJmyry1PvOBVZlOnjwpJW0XLlyYa+uY5s2bY8eOHQAykg9vvvlmjhP2uLg47N27V+dBilkvZnJrLZb9gkdfucIuPzfPnz+Xhrt27Ypq1aoByLiwz+3W38KIjY3VeYhQv3794OXlBQC4evWqQS2x9GnUqBGaNWuGEydOIC4uDvPmzZOmZb+V8fbt27C3t0elSpXQqVMn6Zb89u3bo3fv3gCQ4xZ6fR49egRTU1O4urqibdu2aNu2LQDo/PBy9+5dPH/+vMgPh2nevLmUgD99+jSuXr0q3YKf/QI/c98uDgqFAt988w3UajUWL14MIGN7hoSE4NChQwbdDhweHo6aNWvi2rVrMDExMSipknX9IyMjMXjw4BwXs8nJydi8eTNCQkIA6O7Tfn5+6Nixo/R6w4YN+S6zIIy1T2Xvzuejjz7Cli1bdBJzd+/ezdH6Tp+sn8Nnz55Famoq1Go1rl69qpPoz6ow+7RSqZRuE8/tsyrzh6onT56gS5cuOt1HAIBGo8Evv/yCli1b5rtexSl7MmjDhg2YPXs2gIzWxpmfuQVRWo7dS5cuwd/fH15eXjpdKb311lvSbeuZ+2jWY8fOzg6vvPKKlPAy9rFTEGvWrJEegBcXF6ezH2c+hDIvWbdvQkICGjZsKO3jmYQQOHjwoEGfZdmX+dNPP0ldtNy5c0fqYiK7rNs387sLyGg5m9ePuvmdP2StFwAGDx4stQI/ePBgoe+uatOmjZQc/+qrrwBkrLuFhQVatWqFhQsX4vDhwzrdgGTfrnkx5LyoLAkKCtL5XFy4cCG6du2q8yNEYT7Hr1+/jtjYWNjZ2eHx48dSsjO76OhoxMfHS93XZH6vvHjxQkqCJyYm4tq1a2jUqBGA/N8DYx87WRnr+7O4xcbGonfv3jh48CCAjOuO9evXo1u3bjJHRkRUPJhoJqJid/v2bcyZMwcTJ05Eq1atUL9+fdjb2+Pp06c6rXMUCkWhnvhtDJMmTcLw4cMBALdu3UJQUBB69OiB27dvY926dVK5pk2bSifednZ2qF69utQyZN68ebhw4QJiY2PzTLBOmTIFO3fuhBACV69eRUBAAHr37g0nJydER0fj3Llz+OOPP+Dm5qbTWiLrLcNnzpzBW2+9BW9vb6jVakyYMCFHGSCjX9uOHTtCqVSie/fuqFGjRqGXnxt/f39cunRJ2gZPnjyBQqHAmjVr8uzftqBcXFxQqVIl6Zbjt956S2phs3LlSqSmpha67vHjx0tPJ09OTgaQcQtpu3btdMpt3LgRs2bNQps2bVC9enW4u7sjMTER69evl8oY8mPJ77//jkGDBqFly5aoVasWPDw8kJ6ejm3btkll1Gp1jtupC2Ps2LFYtmwZUlNTodVqERISgmHDhkGj0eDHH3+UytnY2OC1114r8vLy88UXX0ClUmHhwoUAMrrMad26NQ4ePJhvNwcKhQKbNm3CzZs3YWNjY9BF6fjx4/Htt98iJSUFT58+Rb169dC/f394eHggLi4OFy9exJEjR5CQkCD145q1dezFixcxYMAABAQE4PDhw9KForEYa58KDAxEhw4d8OuvvwIAduzYgYYNG6JTp05QqVQ4f/48rly5gps3b+ZbV+PGjbF9+3YAGXeZNGnSBDVr1sSvv/6a63FWmH3a09NT6pv1888/x/Pnz2FhYSH1BTp8+HDMmzcPz58/R0pKCpo1a4b+/fujSpUqePnyJa5cuYLDhw8jOjpaSjjIJSgoCIGBgVJfxnPnzsWtW7dQuXJlbNq0qVD9v5aWY3fq1Kn466+/EBYWBm9vbzg7O+PRo0dSH8fA//bRrMdOTEwMOnXqhFatWuHMmTP4+eefiy3G/HzwwQe4du0afHx8sGXLFp3vptGjR+c7f9euXeHv74/r168DALp06YI+ffqgZs2a0Gg0+Oeff3D48GFERkbi0KFDqFKlSp71de/eHc7OzlICd+zYsTh16hTs7e2xdu1apKWl6Z3P399f6rZk9+7dGD16NDw9PbF79+48+5rOem4QFRWFESNGoHbt2lAoFBg3bhyqVasGExMT6U6OwYMH45VXXkFkZGSB+xbPKjQ0VDrPy9zmmT8KtWzZEgqFAvHx8VJ5X1/fAnUXYch5UVni4OCAUaNG4bvvvgOQ0cq2Tp066NmzJ2xtbXHlyhXs2LHDoO5Lsv6YERcXh0aNGqFJkyY4fPhwrj8c/PPPPwgODkaTJk1Qr149eHh4QKlUIiIiQqdc1u8kT09P6W7ElStXwtzcHLa2tqhatSp69epl9GMnK2N9fwLA8OHDpesAY2vRogUuX74sve7evTuuX78ubZNMAwYMMLg7MSKiUk2OJxASUcWS9Wnnef29++67OvPl9lRsIYQICQmRxg8bNkwan9cTuIXI++nYWZ9ere/Pz89P3L59W2ee7777Tm/Z+vXrC2dn51yX9eWXX+o8mVzfX/Ynw589e1aYmJjkKGdlZaVTrmHDhnrr27x5c5GWn5v169frnd/d3V20a9dO71PPC/s+ffzxx3qXFRAQIBo1aqR3nzh06JBO2ezvoRBCpKamCjc3N51y7733Xo5yCxYsyHc/XrJkiVQ+676fdXvmts2y/k2ePNmg7Z/ftsxcnpmZWa7LsrKyEnv27NGZJ7djzFDZt/uKFSt0pr///vs59perV6/qnXfXrl35Li9r+ezH25YtW4SFhUW+2zzT8+fPhYeHh94yw4YNy3V/ymub5bYvFHSfyktUVJTOcZDXMZ3XcREZGSns7e1zzG9mZiZat25ttH160qRJesuNGzdOKvPHH38IBweHfOs29H3IlNdxk9t7ld92O3XqlLC2tta73dq2bSu9rlKlSn5vpc52Neaxm9e65aZDhw55bntzc3Nx8uRJIUTGZ2ndunUNOnaybvOs07J+V+S3Prl9V2Q/f+jSpYvemLp37y60Wq1B2+fq1auicuXK+e6L+j6D9dmxY4fe72EbGxud7/Gs2+PGjRvCxsYmxzxKpVIMGjRIZ1xWkZGRwtLSUm+8UVFRQgghxowZo3d6WFiY8PT01Lud83P9+vUc9e3YsUOaHhAQoDNt5MiROerIa98w5Lwor/nzOs/MTVHOMw2RlJSU7zFnSCxJSUmiatWqOeZVKBQiPDxcb33Hjx/Pd//u3bu3TrxLlizRW65Lly5SmcIcO3m9b5mM+f1ZnPKLsaCfHUREpZ1uB6NERMVg4sSJ2LJlC8aOHYumTZuicuXKsLCwgFqthre3N3r37o3du3fj448/ljXOJUuWICIiAj179oS7uzuUSiWsra3RuHFjzJs3D2fPns3R0ub111/H0qVLUaNGDahUKnh5eWHq1Kn4448/8uxTbvz48Th9+jRGjRqFatWqwdzcHFZWVqhevTo6duyIJUuW4Pfff9eZp379+li/fj0aNmyo83Cq7LZu3YpevXrBwcEh174CC7P83LzyyivYtGkT6tWrB5VKBUdHRwwYMAAnTpyAh4eHQXUY6t1338U333wjbW83NzeMHj0aR44cydENS0GoVKocTzTX9wTwnj17YubMmQgPD4evry8sLS2hVCrh7u6OLl26YOfOnQa1omrZsiU++ugjdOnSBVWrVoWNjQ2USiWcnZ0RFhaGlStX4rPPPiv0+mT3yiuv4OzZsxg9ejSqVq0Kc3NzmJubo0aNGhg3bhwuXLgg3XJaUubNmyd1LQBkdGvRpk0bnVY/xtKnTx9cvHgREyZMQO3atWFlZQVzc3P4+fkhNDQUCxYswLVr16TyDg4OOHr0KHr37g1bW1tYWFigSZMm2LZtm9FbPBlrnwIyHrh37NgxfPfdd2jbti0cHR2hVCrh4OCAoKAgjB071qB63NzccPjwYbRr1w6WlpawsbFB586dcfz48Vz7Ty3MPv3RRx9hwoQJ8PT01Pugp8x6L1++jOnTp6NBgwawsbGBWq1G5cqV0aJFC8yYMQNnzpwx2kOziqJx48Y4duwYunTpAmtra1hbWyMsLAy///47qlevLpUrSBdRpeHYffvtt/HWW2+hWbNm8PT0hFqthpmZGfz8/DBs2DD89ddfaNq0KYCMz9KDBw9i+PDhcHR0hJmZGQICArB8+XKd472kbdu2DXPnzkXVqlWhVqvh6+uLOXPmYPPmzQb3qVuzZk1cuHAB8+fPR1BQEOzs7KBSqeDp6YmgoCBMmTIFf/zxB1q3bm1Qfd27d8f+/fvRunVrWFhYoFKlSujRowdOnjyJunXr6p2nWrVq+P3339G+fXtYWlrC2toaISEhOHDgAMLDw3NdlpubG3bt2oUWLVrk2rfuV199hblz58LHxwcqlQqVK1fG22+/jV27dhW6b+waNWrotDpWKBQ63fy0atVKp3xB+2c29LyoLLGwsMDevXuxfv16dO7cGa6urlCpVLCzs0P9+vUNehhkZj0HDhyQvscsLS3RunVr7N+/H4MGDdI7j7+/Pz7//HP07t0bNWrUgJ2dHUxNTWFvb48WLVpgyZIlObrAGTduHGbPng0/P79c9xNjHzuZjPn9SURExqMQopCP2CUiIipH1q9fj4EDBwLIuPg1NNFORAQAqampUCqVOR4Um5CQgICAAKmbkNGjR2P58uVyhFhhrFy5UufHQl7uEBEREZUM9tFMREQVVkxMDM6dO4fHjx/j/fffl8Yb8pA5IqKsrly5gu7du2PQoEGoXbs27O3tcefOHSxbtkxKMhv6EEsiIiIiorKIiWYiIqqwzp07l+NW3RYtWqBfv34yRUREZdn9+/dz7QZKrVZj2bJlqFevXglHRURERERUMphoJiKiCk+hUMDNzQ09evTA/Pnzc9z6TkSUH29vb0yaNAmHDx/GvXv3EBsbC3Nzc1SpUgVt2rTB2LFjUbNmTbnDJKISZshx37RpU6xevboEoiEiIipe7KOZiIiIiIiIqBgY8sDJkJAQHD58uPiDISIiKmZs0UxERERERERUDNiui4iIKhLeG0xERERERERERERERcJEMxEREREREREREREVCRPNRERERERERERERFQkTDQTERERERERERERUZEw0UxERERERERERERERcJEMxEREREREREREREVCRPNRERERERERERERFQkTDQTERERERERERERUZEw0UxERERERERERERERcJEMxEREREREREREREVCRPNRERERERERERERFQkTDQTERERERERERERUZEw0UxERERERERERERERcJEMxEREREREREREREVCRPNRERERERERERERFQkTDQTERERERERERERUZEw0UxERERERERERERERcJEMxEREREREREREREVCRPNRERERERERERERFQkTDQTERERERERERERUZEw0UxERERERERERERERcJEMxEREREREREREREVCRPNRERERERERERERFQkTDQTERERERERERERUZEw0UxERERERERERERERcJEMxEREREREREREREVCRPNRERERERERERERFQkTDQTERERERERERERUZEw0UxERERERERERERERcJEM5VaCoXCoL/Dhw/j8OHDUCgU2LJli9xhY+XKlVAoFLhz5440bvjw4fD19dUpp1Ao8J///KdkgyugPXv2YPbs2XqnzZ8/Hz///HOJxpPVnTt3oFAosHLlygLPe+XKFcyePVvnPcrPxo0bUadOHVhYWEChUODcuXMFXq4x4mvTpg0CAgKKbdly0Hd8lCVF2RcN8ejRI8yePbtY9zkiIqKypKxeJwCQ4jl8+LDcoUChUOic6xd3bMeOHcPs2bMRExOTY1qbNm3Qpk2bYlmusdy5cwddunSBg4MDFAoFJk6cmGvZ3K6VMq8VT58+XXyBGqiin8MW9RrE19cXw4cPL/B8SUlJmD17dqn4DCAqDkw0U6l1/Phxnb/OnTvDwsIix/iGDRvKHaqOLl264Pjx43B3d5c7lCLbs2cP5syZo3ea3Inmorhy5QrmzJljcKI5KioKQ4YMQdWqVREREYHjx4+jRo0apSa+sm7GjBnYvn273GGUWo8ePcKcOXNK7Uk6ERFRSSur1wkA0LBhwwob27FjxzBnzhy9iealS5di6dKlxbJcY5k0aRJOnjyJH3/8EcePH8ekSZNyLVuWr5WMheew+iUlJWHOnDlMNFO5pZQ7AKLcNGvWTOe1s7MzTExMcowvbZydneHs7Cx3GGRE//zzD9LS0jB48GCEhIQYpc6kpCRYWloapa6yKnMbVK1aVe5QKqSXL1/C3NwcCoVC7lCIiIgKpKxeJwCAra1tqY1Tzthq164ty3IL4tKlS2jatCl69uwpdygVGs9hiUo3tmimciUtLQ3vv/8+PDw8YGtri/DwcFy/fj1Huf379yMsLAy2trawtLREixYtcODAgXzr12q1mDdvHvz9/WFhYYFKlSohMDAQS5Yskcro6zojL2vWrEGtWrVgaWmJevXq4ZdffslR5ujRowgLC4ONjQ0sLS3RvHlz7N69W6fM7Nmz9X7Z5hbPxo0bERwcDCsrK1hbW6NDhw44e/asNH348OH45ptvAOjenph5i1ViYiJWrVoljc96q9vjx4/xxhtvwMvLC2q1GlWqVMGcOXOg0Wjy3R6+vr7o2rUrtm/fjsDAQJibm8PPzw9ffvllvvMasq1WrlyJfv36AQBCQ0Ol+HO7ZWz48OFo2bIlAGDAgAE51nXnzp0IDg6GpaUlbGxs0K5dOxw/flynjsz35u+//0bfvn1hb2+fa3LV0PhOnTqFVq1awdLSEn5+fvj444+h1Wp1ysTFxWHq1KmoUqUK1Go1PD09MXHiRCQmJua5DSdOnAgrKyvExcXlmDZgwAC4uroiLS0NQMZ+1L59e7i7u8PCwgK1atXCtGnTcixj+PDhsLa2xsWLF9G+fXvY2NggLCxMmpb9trXk5GRMnz5dJ/Zx48blaAGT/ZbPTNlvZUtKSpK2hbm5ORwcHNC4cWOsX78+z20BAA8fPsTrr78Ob29vqNVqeHh4oG/fvnjy5Emu8+R2K56+43Tz5s0ICgqCnZ2d9H6OHDkSQMYtrE2aNAEAjBgxQtofsq7z6dOn0b17dzg4OMDc3BwNGjTApk2bdJaR+Tnw22+/YeTIkXB2doalpSVSUlIQFRUlrZ+ZmRmcnZ3RokUL7N+/P99tQ0REVFYU53VCVFQU1Go1ZsyYkWPatWvXoFAopHNZfd1T3Lp1C6+88go8PDxgZmYGV1dXhIWF6bQENfScJyoqCmPHjkXt2rVhbW0NFxcXtG3bFn/88UfeG0hPbJnn/bn9Zdq3bx969OgBLy8vmJubo1q1anjjjTfw7Nkzqczs2bPx9ttvAwCqVKmi070JoL/rjOjoaIwdOxaenp5Qq9Xw8/PD+++/j5SUFJ1ymV0SGnJdpc+9e/cwePBguLi4wMzMDLVq1cLnn38unVtnbpd///0Xe/fu1bku0ie/ayUAiI+Px5tvvgknJyc4Ojqid+/eePToUY668rtmy0t5P4ctyPZZuXIl/P39pfd39erVBm1DIOOz45133oGbmxssLS3RsmVL/PXXXznKGXLs3blzR2qUNmfOHGm7ZB7D//77L0aMGIHq1avD0tISnp6e6NatGy5evGhwvERyY6KZypX33nsPd+/exffff4/ly5fjxo0b6NatG9LT06Uya9euRfv27WFra4tVq1Zh06ZNcHBwQIcOHfI9ifz0008xe/ZsvPrqq9i9ezc2btyIUaNG6b39yxC7d+/G119/jblz52Lr1q1wcHBAr169cOvWLanMkSNH0LZtW8TGxuKHH37A+vXrYWNjg27dumHjxo2FWu78+fPx6quvonbt2ti0aRPWrFmD+Ph4tGrVCleuXAGQ0Z1B3759Aejenuju7o7jx4/DwsICnTt3lsZn3ur2+PFjNG3aFL/++itmzpyJvXv3YtSoUViwYAFGjx5tUHznzp3DxIkTMWnSJGzfvh3NmzfHW2+9hc8++yzP+QzZVl26dMH8+fMBAN98840Uf5cuXfTWOWPGDCnhPn/+fJ11/emnn9CjRw/Y2tpi/fr1+OGHH/DixQu0adMGR48ezVFX7969Ua1aNWzevBnffvut3uUZEt/jx48xaNAgDB48GDt37kSnTp0wffp0rF27ViqTlJSEkJAQrFq1ChMmTMDevXvx7rvvYuXKlejevTuEELlux5EjRyIpKSnHiV5MTAx27NiBwYMHQ6VSAQBu3LiBzp0744cffkBERAQmTpyITZs2oVu3bjnqTU1NRffu3dG2bVvs2LEj125ZhBDo2bMnPvvsMwwZMgS7d+/G5MmTsWrVKrRt2zbHxYUhJk+ejGXLlmHChAmIiIjAmjVr0K9fPzx//jzP+R4+fIgmTZpg+/btmDx5Mvbu3YvFixfDzs4OL168KHAc2R0/fhwDBgyAn58fNmzYgN27d2PmzJnSjzINGzbEihUrAAAffPCBtD+89tprAIBDhw6hRYsWiImJwbfffosdO3agfv36GDBggN4fT0aOHAmVSoU1a9Zgy5YtUKlUGDJkCH7++WfMnDkTv/32G77//nuEh4fnu22IiIjKkuK8TnB2dkbXrl2xatWqHD/8r1ixAmq1GoMGDcp1/s6dO+PMmTP49NNPsW/fPixbtgwNGjQo1DVGdHQ0AGDWrFnYvXs3VqxYAT8/P7Rp06bAt+pnnvdn/du5cydsbW1Rq1YtqdzNmzcRHByMZcuW4bfffsPMmTNx8uRJtGzZUmqc8Nprr2H8+PEAgG3btuXbvUlycjJCQ0OxevVqTJ48Gbt378bgwYPx6aefonfv3jnKG3JdpU9UVBSaN2+O3377DR9++CF27tyJ8PBwTJ06VXqeTmaXIm5ubmjRooXOdZE+eV0rZXrttdegUqnw008/4dNPP8Xhw4cxePBgnTKGXLPlpiKcwxq6fVauXIkRI0agVq1a2Lp1Kz744AN8+OGHOHjwoEHrOnr0aHz22WcYOnQoduzYgT59+qB37945tqMhx567uzsiIiIAAKNGjZK2S+aPVI8ePYKjoyM+/vhjRERE4JtvvoFSqURQUJDeH8aISiVBVEYMGzZMWFlZ6Z126NAhAUB07txZZ/ymTZsEAHH8+HEhhBCJiYnCwcFBdOvWTadcenq6qFevnmjatGmeMXTt2lXUr18/zzIrVqwQAMTt27d1Yvfx8dEpB0C4urqKuLg4adzjx4+FiYmJWLBggTSuWbNmwsXFRcTHx0vjNBqNCAgIEF5eXkKr1QohhJg1a5bQd0hnj+fevXtCqVSK8ePH65SLj48Xbm5uon///tK4cePG6a1TCCGsrKzEsGHDcox/4403hLW1tbh7967O+M8++0wAEJcvX9ZbXyYfHx+hUCjEuXPndMa3a9dO2NraisTERCGEELdv3xYAxIoVK6Qyhm6rzZs3CwDi0KFDecaSKXP/2rx5szQuPT1deHh4iLp164r09HRpfHx8vHBxcRHNmzeXxmW+NzNnzjRoeXnFFxISIgCIkydP6oyvXbu26NChg/R6wYIFwsTERJw6dUqn3JYtWwQAsWfPnjxjaNiwoc46CCHE0qVLBQBx8eJFvfNotVqRlpYmjhw5IgCI8+fPS9OGDRsmAIgff/wxx3zZj4+IiAgBQHz66ac65TZu3CgAiOXLl0vjAIhZs2blqNPHx0dn/wwICBA9e/bMa5X1GjlypFCpVOLKlSu5ltG3L+o75oXIeZxmHhcxMTG51n/q1Kkc9WeqWbOmaNCggUhLS9MZ37VrV+Hu7i7tm5mfA0OHDs1Rh7W1tZg4cWKuyyciIirtSsN1ws6dOwUA8dtvv0njNBqN8PDwEH369MkRT+Z53rNnzwQAsXjx4jzrN/ScJzuNRiPS0tJEWFiY6NWrV551Zo8tu8TERNG0aVPh7u4u7ty5o7dM5vng3bt3BQCxY8cOadrChQtzXCdlCgkJESEhIdLrb7/9VgAQmzZt0in3ySef5NjOhl5X6TNt2jS959ZvvvmmUCgU4vr169I4Hx8f0aVLlzzry5TbtVLmOdnYsWN1xn/66acCgIiMjBRCFOyaTZ/yfg5r6PbJvGZr2LChdC0ohBB37twRKpVK77pmdfXqVQFATJo0SWf8unXrBIBCHXtRUVG5Hs/66khNTRXVq1fPEQNRacUWzVSudO/eXed1YGAgAODu3bsAMh5AER0djWHDhkGj0Uh/Wq0WHTt2xKlTp/LsVqBp06Y4f/48xo4di19//VVv1wIFERoaChsbG+m1q6srXFxcpHgTExNx8uRJ9O3bF9bW1lI5U1NTDBkyBA8ePCjwL5u//vorNBoNhg4dqrMNzM3NERISUuSHEvzyyy8IDQ2Fh4eHTv2dOnUCkNHqOD916tRBvXr1dMYNHDgQcXFx+Pvvv/XOUxzbKi/Xr1/Ho0ePMGTIEJiY/O+j1NraGn369MGJEyeQlJSkM0+fPn2Msmw3Nzc0bdpUZ1xgYKC03wAZ70NAQADq16+v8z506NDBoKeJjxgxAseOHdPZZitWrECTJk0QEBAgjbt16xYGDhwINzc3mJqaQqVSSf1YX716NUe9hmyDzNYF2Z/i3K9fP1hZWRnUzU12TZs2xd69ezFt2jQcPnwYL1++NGi+vXv3IjQ0VKfVjjFl3lLYv39/bNq0CQ8fPjR43n///RfXrl2TWkhlfZ87d+6MyMjIHPu8vu3ftGlTrFy5EvPmzcOJEyeklkdERETlSXFfJ3Tq1Alubm5SK04g47z70aNHUncC+jg4OKBq1apYuHAhFi1ahLNnz+ZoFV1Q3377LRo2bAhzc3MolUqoVCocOHBA77mZodLT0zFgwABcvXoVe/bsgY+PjzTt6dOnGDNmDLy9vaXlZU4v7DIPHjwIKysr6Q7LTJnnh9nPB/O7rsprObVr185xbj18+HAIIQxu9VpQ+e2PRb1mK+/nsIZun8xrtoEDB+p0/eHj44PmzZvnG+uhQ4cAIMcdCf3794dSmfORZ0U99jQaDebPn4/atWtDrVZDqVRCrVbjxo0bRTp+iUoSE81Urjg6Ouq8NjMzAwApqZTZH1Xfvn2hUql0/j755BMIIaRbXvSZPn06PvvsM5w4cQKdOnWCo6MjwsLCcPr0aaPEmxlzZrwvXryAEELvbVkeHh4AUODb2zO3QZMmTXJsg40bN+r0pVYYT548wa5du3LUXadOHQAwqH43N7dcx+W2vsWxrfKSWVduy9NqtTlup8rt9rqCym+/ATLehwsXLuR4H2xsbCCEyPd9GDRoEMzMzKRb165cuYJTp05hxIgRUpmEhAS0atUKJ0+exLx583D48GGcOnUK27ZtA4AcyVxLS0vY2trmu37Pnz+HUqnM8VBNhUIBNze3Qr2PX375Jd599138/PPPCA0NhYODA3r27IkbN27kOV9UVBS8vLwKvDxDtW7dGj///LN0ouzl5YWAgACD+o7OPJanTp2a430eO3YsgJzHm759cOPGjRg2bBi+//57BAcHw8HBAUOHDsXjx4+NsIZERESlQ3FfJyiVSgwZMgTbt2+XurxYuXIl3N3d0aFDh1znUygUOHDgADp06IBPP/0UDRs2hLOzMyZMmID4+PgCr+eiRYvw5ptvIigoCFu3bsWJEydw6tQpdOzY0eAf2vUZM2YMIiIisGXLFtSvX18ar9Vq0b59e2zbtg3vvPMODhw4gL/++gsnTpwAkPN80FDPnz+Hm5tbjn6BXVxcoFQqc5wPGnJ+nNtySur6IStD98fCXrOV93NYQ7dP5vuX1/VlXnKbX6lU5ngPjXHsTZ48GTNmzEDPnj2xa9cunDx5EqdOnUK9evWKdPwSlaScP8EQlWNOTk4AgK+++irXJyq7urrmOr9SqcTkyZMxefJkxMTEYP/+/XjvvffQoUMH3L9/H5aWlkaN197eHiYmJoiMjMwxLfNhEZnrZG5uDgBISUmRTlSAnF/SmeW3bNmi0xLBWJycnBAYGIiPPvpI7/TMk7a86EtwZY7TdxIJFGxbGUNmHLktz8TEBPb29jrjS/LJyE5OTrCwsMCPP/6Y6/S82Nvbo0ePHli9ejXmzZuHFStWwNzcHK+++qpU5uDBg3j06BEOHz4stWIGkGt/goauv6OjIzQaDaKionSSzUIIPH78WGpBAWSclOvrszn7RYGVlRXmzJmDOXPm4MmTJ1Lr5m7duuHatWu5xuLs7IwHDx4YFHdW5ubmeuPSd1HQo0cP9OjRAykpKThx4gQWLFiAgQMHwtfXF8HBwbkuI/M9nD59ut6+CgHA399f57W+98DJyQmLFy/G4sWLce/ePezcuRPTpk3D06dPpT7kiIiIyruiXicAGXeELVy4EBs2bMCAAQOwc+dOTJw4EaampnnO5+Pjgx9++AEA8M8//2DTpk2YPXs2UlNTped6GHrOs3btWrRp0wbLli3TGV+YpHWm2bNn4/vvv8eKFSvQvn17nWmXLl3C+fPnsXLlSgwbNkwa/++//xZ6eUDG+eDJkychhNA5f3n69Ck0Go3RzusdHR1L7PqhIIp6zVbez2EN3T6Z12x5XV/mJev8np6e0niNRlMsx97atWsxdOhQ6Zk9mZ49e4ZKlSoZXA+RnJhopgqlRYsWqFSpEq5cuSI93KGwKlWqhL59++Lhw4eYOHEi7ty5g9q1axsp0gxWVlYICgrCtm3b8Nlnn8HCwgJARsuBtWvXwsvLCzVq1AAA6enAFy5c0EnE7dq1S6fODh06QKlU4ubNm/l2Y5D1l/XMZWedpu9X1a5du2LPnj2oWrVqjkSroS5fvozz58/rdJ/x008/wcbGJtcHhhRkW2VvMVAY/v7+8PT0xE8//YSpU6dKJz+JiYnYunUrgoODC/3DgzHi69q1K+bPnw9HR0dUqVKlUHWMGDECmzZtwp49e7B27Vr06tVL5wQnc52z/rABAN99912h4waAsLAwfPrpp1i7di0mTZokjd+6dSsSExMRFhYmjfP19cWFCxd05j948CASEhJyrd/V1RXDhw/H+fPnsXjxYiQlJeX6XnXq1Alr1qzB9evXc5zw5sXX1xdPnz7FkydPpIvS1NRU/Prrr7nOY2ZmhpCQEFSqVAm//vorzp49i+Dg4Fz3B39/f1SvXh3nz5/PcTJaWJUrV8Z//vMfHDhwAH/++adR6iQiIioLjHGdUKtWLQQFBWHFihVIT09HSkqKzt1ghqhRowY++OADbN26VafLOEPPeRQKRY5zswsXLuD48ePw9vYu4BoBP/zwA+bMmYO5c+fm6NYsc3mAYeeDBTnHDQsLw6ZNm/Dzzz+jV69e0vjVq1dL040hLCwMCxYswN9//61znbF69WooFAqEhoYWql5DWlPnpSDXbPqU93NYQ7ePv78/3N3dsX79ekyePFnaX+/evYtjx47l2wiqTZs2AIB169ahUaNG0vhNmzZJDz7MZOixl9dxoK+O3bt34+HDh6hWrVqesRKVFkw0U4VibW2Nr776CsOGDUN0dDT69u0LFxcXREVF4fz584iKisrxC2RW3bp1Q0BAABo3bgxnZ2fcvXsXixcvho+PD6pXr14sMS9YsADt2rVDaGgopk6dCrVajaVLl+LSpUtYv3699GXZuXNnODg4YNSoUZg7dy6USiVWrlyJ+/fv69Tn6+uLuXPn4v3338etW7fQsWNH2Nvb48mTJ/jrr7+klp8AULduXQDAJ598gk6dOsHU1BSBgYFQq9WoW7cuDh8+jF27dsHd3R02Njbw9/fH3LlzsW/fPjRv3hwTJkyAv78/kpOTcefOHezZswfffvttvrdxeXh4oHv37pg9ezbc3d2xdu1a7Nu3D5988kmeyVtDt1VmH8PLly+HjY0NzM3NUaVKlVxbS+tjYmKCTz/9FIMGDULXrl3xxhtvICUlBQsXLkRMTAw+/vhjg+vKzhjxTZw4EVu3bkXr1q0xadIkBAYGQqvV4t69e/jtt98wZcoUBAUF5VlH+/bt4eXlhbFjx+Lx48c5LpSaN28Oe3t7jBkzBrNmzYJKpcK6detw/vz5gq90Fu3atUOHDh3w7rvvIi4uDi1atMCFCxcwa9YsNGjQAEOGDJHKDhkyBDNmzMDMmTMREhKCK1eu4Ouvv4adnZ1OnUFBQejatSsCAwNhb2+Pq1evYs2aNfn+IDB37lzs3bsXrVu3xnvvvYe6desiJiYGERERmDx5MmrWrKl3vgEDBmDmzJl45ZVX8PbbbyM5ORlffvmlzpPtAWDmzJl48OABwsLC4OXlhZiYGCxZskSnr+uqVavCwsIC69atQ61atWBtbQ0PDw94eHjgu+++Q6dOndChQwcMHz4cnp6eiI6OxtWrV/H3339j8+bNeW7r2NhYhIaGYuDAgahZsyZsbGxw6tQpRERE6LQwmTt3LubOnYsDBw7otF4nIiIqL4p6nZBp5MiReOONN/Do0SM0b9483yTfhQsX8J///Af9+vVD9erVoVarcfDgQVy4cAHTpk2Tyhl6ztO1a1d8+OGHmDVrFkJCQnD9+nXMnTsXVapUyZEYy8/x48cxZswYtGjRAu3atZO6w8jUrFkz1KxZE1WrVsW0adMghICDgwN27dqFffv25agv89piyZIlGDZsGFQqFfz9/XX6Vs40dOhQfPPNNxg2bBju3LmDunXr4ujRo5g/fz46d+6M8PDwAq1LbiZNmoTVq1ejS5cumDt3Lnx8fLB7924sXboUb775ptRQpaByu1YyVEGu2fQp7+ewhm4fExMTfPjhh3jttdfQq1cvjB49GjExMZg9e7ZBXWfUqlULgwcPxuLFi6FSqRAeHo5Lly7hs88+y9EloKHHno2NDXx8fLBjxw6EhYXBwcEBTk5O8PX1RdeuXbFy5UrUrFkTgYGBOHPmDBYuXKj3+lmpVCIkJKRQz68hKlayPYaQqIAMeZr05s2bdcbre5KuEEIcOXJEdOnSRTg4OAiVSiU8PT1Fly5dcsyf3eeffy6aN28unJychFqtFpUrVxajRo3Seepy5pNxsz5NWd/TewGIcePG5ViGvidH//HHH6Jt27bCyspKWFhYiGbNmoldu3blmPevv/4SzZs3F1ZWVsLT01PMmjVLfP/993qf7vzzzz+L0NBQYWtrK8zMzISPj4/o27ev2L9/v1QmJSVFvPbaa8LZ2VkoFAqdes6dOydatGghLC0tBQCdp0RHRUWJCRMmiCpVqgiVSiUcHBxEo0aNxPvvvy8SEhLy3MaZT3PesmWLqFOnjlCr1cLX11csWrRIp1xu762h22rx4sWiSpUqwtTUNNenIWfKbf/K3I5BQUHC3NxcWFlZibCwMPHnn3/qlMl8SnNUVFSe625IfCEhIaJOnTo5yuvbxxISEsQHH3wg/P39hVqtFnZ2dqJu3bpi0qRJ4vHjxwbF8d577wkAwtvbW3r6c1bHjh0TwcHBwtLSUjg7O4vXXntN/P3333qfYJ3b8asv9pcvX4p3331X+Pj4CJVKJdzd3cWbb74pXrx4oVMuJSVFvPPOO8Lb21tYWFiIkJAQce7cuRzH0bRp00Tjxo2Fvb29MDMzE35+fmLSpEni2bNn+W6D+/fvi5EjRwo3NzehUqmEh4eH6N+/v3jy5IkQIvd9cc+ePaJ+/frCwsJC+Pn5ia+//jrHE7t/+eUX0alTJ+Hp6SnUarVwcXERnTt3Fn/88YdOXevXrxc1a9YUKpUqx1Oqz58/L/r37y9cXFyESqUSbm5uom3btuLbb7+VymR+Lp06dUqn3uTkZDFmzBgRGBgobG1thYWFhfD39xezZs0SiYmJUrnMuHN7Cj0REZGcSsN1QqbY2FhhYWEhAIj//ve/ucaT+Z365MkTMXz4cFGzZk1hZWUlrK2tRWBgoPjiiy+ERqOR5jP0nCclJUVMnTpVeHp6CnNzc9GwYUPx888/53o9kvWcIntsmecPuf1lunLlimjXrp2wsbER9vb2ol+/fuLevXs56hdCiOnTpwsPDw9hYmKis6yQkBCd6wkhhHj+/LkYM2aMcHd3F0qlUvj4+Ijp06eL5OTkHOth6HWVPnfv3hUDBw4Ujo6OQqVSCX9/f7Fw4cIc576Z1ymGyO1aKbdzsuzbPpMh12y5Kc/nsAXdPt9//72oXr26UKvVokaNGuLHH3/Ue0zok5KSIqZMmSJcXFyEubm5aNasmTh+/HiRjr39+/eLBg0aCDMzMwFAqufFixdi1KhRwsXFRVhaWoqWLVuKP/74Q+/xkf0anKi0UAghRPGksImICs7X1xcBAQH45Zdf5A6FiIiIiIiIiIgMZCJ3AERERERERERERERUtjHRTERERERERERERERFwq4ziIiIiIiIiIiIiKhI2KKZiIiIiIiIiIiIiIqEiWYiIiIiIiIiIiIiKhImmomIiIiIiIiIiIioSJRyLFSr1eLRo0ewsbGBQqGQIwQiIiIiKgZCCMTHx8PDwwMmJmzTUFHw/J6IiIio/DL0HF+WRPOjR4/g7e0tx6KJiIiIqATcv38fXl5ecodBJYTn90RERETlX37n+LIkmm1sbABkBGdraytHCGRsycnA4MEZw2vXAubm8sZDREREsoiLi4O3t7d0vkcVA8/viYiIiMovQ8/xZUk0Z95OZ2tryxPR8sLUFNi3L2PYyirjj4iIiCosdp9QsfD8noiIiKj8y+8cnx3nEREREREREREREVGRMNFMREREREREREREREXCRDMRERERERERERERFQkTzURERERERERERERUJEw0ExEREREREREREVGRKOUOoDxL06YhVaTKHUbJSE+E1f8PJqYnAumyRpOvdJEOG1ObfJ+WSURERERERERERPljorkYDb48GPeS78kdRsn5q1nG/+s95I0jD6YKU6hN1DBTmKG3S2+M9hwtd0hERERERERERERlHhPNxehRyiM8T3sOZ7Wz3KFUCAIC8Zp4xGnioBEaWCutYW1qDXOFOcxMzaBWqGFmYgZXtStc1a7o5dxL7pCJiIiIiIiIiIjKBSaai5m9yh4OKge5wyjXUrWpeJjyMCO5bGqNRraNEGQbhLrWdVHLqhbc1e4wNzWXO0wiIiIiIiIiIqJyi4lmMgpVSjomv38OALDoo/pIMzMtkeUKIXD35V3Utq6NXs690KJSC1Qxr8K+l4mIiIiIiIiIiEoQE81kFCZagZb7IwEAiz+sV2LLTUhPgKWpJWZWmYn6NvVLbLlERERERERERET0PyZyB0BUFDGaGNgp7RBoHSh3KERERERERERERBUWE81UZsVr4qERGoxwHwETBXdlIiIiIiIiIiIiuTA7R2XWk9QnaGzTGEPch8gdChERERERERERUYXGRDOVSSnaFJgqTDHUfSgf/EdERERERERERCQzJpqpTEpKT4KVqRUa2DSQOxQiIiIiIiIiIqIKj4lmKpNStCmwNrWGrdJW7lCIiIiIiIiIiIgqPKXcAVD5kGJuir7HO0rDxS0xPREtK7WEqaL4l0VERERERERERER5Y6KZjEOhQIpFye1OAgK1rGqV2PKIiIiIiIiIiIgod0w0U5mTrE2GicIEPuY+codCRERERERUakVHR2P9+vUwMTHBwIEDYWdnJ3dIRERUjjHRTEahTE3Hfz68CAD4ekZdaNTF06WFEAL3k++jnnU9tLFvUyzLICIiIiIiKg8WLlyIS5cuAQCePHmC2bNnyxsQERGVa3wYIBmFabpA2K4HCNv1AKbpotiWcyf5DpxUTnjH5x2YmZgV23KIiIiIiIjKuqdPn+odJiIiKg5MNFOZkaxNBgB8UOUDNLJtJHM0REREREREpdurr74KU1NTKJVKvPLKK3KHQ0RE5Ry7zqAy43nac3iZeSHUPlTuUIiIiIiIiEq98PBwNG/eHAqFAhYWFnKHQ0RE5RxbNFOZIIRAgiYBDWwasMsMIiIiIiIiA1laWjLJTEREJYKJZioTYtNjYWNqg34u/eQOhYiIiIiIiIiIiLJhopnKhNi0WPhb+aOBTQO5QyEiIiIiIiIiIqJsmGimMiFVpCLAKgAKhULuUIiIiIiIiIiIiCgbPgyQjCLF3BSDDraTho1NAQUsTS2NXi8REREREREREREVHRPNZBwKBeIciu8hfQoooFKoiq1+IiIiIiIiIiIiKjx2nUFlRiVVJblDICIiIiIiIiIiIj3YopmMQpmajtc+uwIA+H5qbWjUxus+Qyu00EILF5WL0eokIiIiIiIiIiIi42GLZjIK03SBLpvuosumuzBNF0atO1YTC2tTa/hY+Bi1XiIiIiIiIiIiIjIOJpqp1HuW9gyh9qGoYVlD7lCIiIiIiIiIiIhIDyaaqVRLF+kAgFD7UJkjISIiIiIiIiIiotww0Uyl2rPUZ3BRu6ChTUO5QyEiIiIiIiIiIqJcMNFMpZYQArGaWDS1bQo3Mze5wyEiIiIiIiIiIqJcMNFMpVaiNhEWphYY4DpA7lCIiIiIiIiIiIgoD0w0U6mVqk2FuYk5qlpUlTsUIiIiIiIiIiIiyoNS7gCofEg1M8Wo3W2lYWOISYtBU9umcFA5GKU+IiIiIiIiIiIiKh5MNJNRCBMFnnpaGq0+rdAiHeno6NTRaHUSERERERERERFR8WDXGVQqRadFw9bUFs1sm8kdChEREREREREREeWDiWYyCmWaFiMWXcGIRVegTNMWqS6NVoPotGj0cu4FHwsfI0VIRERERERERERExYWJZjIKU40WvVffQu/Vt2CqKVqi+bnmOdzN3DHWe6yRoiMiIiIiIiIiIqLixEQzlTrJ2mRUNq8MO6Wd3KEQERERERERERGRAZhoplInVZuKhjYN5Q6DiIiIiIiIiIiIDMREM5UqQggAQHXL6jJHQkRERERERERERIZioplKlYT0BFiZWKGaRTW5QyEiIiIiIiIiIiIDMdFMpUqKNgXmpuaoYlFF7lCIiIiIiIiIiIjIQEw0U6mSIlLgqHKE2kQtdyhERERERERERERkICaayShSzUwxbksIxm0JQaqZaaHrSU5PRmXzykaMjIiIiKhsWrZsGQIDA2FrawtbW1sEBwdj79690vThw4dDoVDo/DVr1kynjpSUFIwfPx5OTk6wsrJC9+7d8eDBA50yL168wJAhQ2BnZwc7OzsMGTIEMTExJbGKRERERFSOMNFMRiFMFLhXzQb3qtlAmCgKV4cQ0EKLQOtAI0dHREREVPZ4eXnh448/xunTp3H69Gm0bdsWPXr0wOXLl6UyHTt2RGRkpPS3Z88enTomTpyI7du3Y8OGDTh69CgSEhLQtWtXpKenS2UGDhyIc+fOISIiAhERETh37hyGDBlSYutJREREROWDUu4AiDLFaGJgZWqFRjaN5A6FiIiISHbdunXTef3RRx9h2bJlOHHiBOrUqQMAMDMzg5ubm975Y2Nj8cMPP2DNmjUIDw8HAKxduxbe3t7Yv38/OnTogKtXryIiIgInTpxAUFAQAOC///0vgoODcf36dfj7+xfjGhIRERFRecIWzWQUyjQtXl12Ha8uuw5lmrZA8woh8CLtBZ6kPkEdqzpoZMtEMxEREVFW6enp2LBhAxITExEcHCyNP3z4MFxcXFCjRg2MHj0aT58+laadOXMGaWlpaN++vTTOw8MDAQEBOHbsGADg+PHjsLOzk5LMANCsWTPY2dlJZfRJSUlBXFyczh8RERERVWxs0UxGYarRYuB3NwAA24ZXhUZl+G8YsZpYxGpi0c2pG97wfKO4QiQiIiIqcy5evIjg4GAkJyfD2toa27dvR+3atQEAnTp1Qr9+/eDj44Pbt29jxowZaNu2Lc6cOQMzMzM8fvwYarUa9vb2OnW6urri8ePHAIDHjx/DxcUlx3JdXFykMvosWLAAc+bMMeKaEhEREVFZx0Qzye552nPUta6LRTUWyR0KERERUani7++Pc+fOISYmBlu3bsWwYcNw5MgR1K5dGwMGDJDKBQQEoHHjxvDx8cHu3bvRu3fvXOsUQkCh+N8zNbIO51Ymu+nTp2Py5MnS67i4OHh7exd09YiIiIioHGGimWSVpk0DAIzwGCFzJERERESlj1qtRrVq1QAAjRs3xqlTp7BkyRJ89913Ocq6u7vDx8cHN25k3GXm5uaG1NRUvHjxQqdV89OnT9G8eXOpzJMnT3LUFRUVBVdX11zjMjMzg5mZWZHWjYiIiIjKF/bRTLJK1ibD0tQSdazqyB0KERERUaknhEBKSoreac+fP8f9+/fh7u4OAGjUqBFUKhX27dsnlYmMjMSlS5ekRHNwcDBiY2Px119/SWVOnjyJ2NhYqQwRERERkSHYoplklS7SYaIwgYWJhdyhEBEREZUq7733Hjp16gRvb2/Ex8djw4YNOHz4MCIiIpCQkIDZs2ejT58+cHd3x507d/Dee+/ByckJvXr1AgDY2dlh1KhRmDJlChwdHeHg4ICpU6eibt26CA8PBwDUqlULHTt2xOjRo6VW0q+//jq6du0Kf39/2dadiIiIiMoeJppJVgnpCfA294aDykHuUIiIiIhKlSdPnmDIkCGIjIyEnZ0dAgMDERERgXbt2uHly5e4ePEiVq9ejZiYGLi7uyM0NBQbN26EjY2NVMcXX3wBpVKJ/v374+XLlwgLC8PKlSthamoqlVm3bh0mTJiA9u3bAwC6d++Or7/+usTXl4iIiIjKNiaaSVYv01+ikU0jmCjYiwsRERFRVj/88EOu0ywsLPDrr7/mW4e5uTm++uorfPXVV7mWcXBwwNq1awsVIxERERFRJiaaySjS1KaYvLalNGwohUIBa1Pr4gqLiIiIiIiIiIiISgATzWQUWlMFbgRUKtA8QggICDipnYonKCIiIiIiIiIiIioR7K+AZPM49THslfYIsg2SOxQiIiIiIiIiIiIqAiaaySiUaVr0WnkTvVbehDJNm295IQTiNHHo5tQNNa1qlkCEREREREREREREVFzYdQYZhalGi5GLrwIA9gzwgUaV928YMZoY2Cpt0cWpS0mER0RERERERERERMWILZpJFqkiFdam1qhnU0/uUIiIiIiIiIiIiKiImGgmWaRp01BJWUnuMIiIiIiIiIiIiMgImGgmWbzUvkRtq9pyh0FERERERERERERGwEQzyUIBBXwtfOUOg4iIiIiIiIiIiIyAiWYqcVqhBQBUtagqcyRERERERERERERkDEw0U4l7qX0JcxNzeJh5yB0KERERERERERERGYFS7gCofEhTm2L6f5tJw3mJ18TDXmWPahbVSiI0IiIiIiIiIiIiKmZMNJNRaE0VuNTEyaCySdokNLJsBJWJqpijIiIiIiIiIiIiopLArjOoxGmFFrWtassdBhERERFRgR04cABr165FZGSk3KEQERERlSps0UxGYZqmRYet9wAAv/apjHRV3r9hWJlalURYRERERERGs2fPHixbtgwAsG/fPvz3v/+FWq2WOSoiIiKi0oGJZjIKpUaLNz++BAA40MMr10SzVmghIGBtal2S4RERERERFdnNmzel4ejoaMTExMDFxUXGiIiIiIhKD3adQSUqOi0a9kp7NLNtJncoREREREQFEhoaKrVgbtSoEZydnWWOiIiIiKj0YItmKlGpIhXuanf4WPjIHQoRERERUYEEBATgv//9L54/fw4/Pz8oFAq5Q8qVVqvFgQMHkJSUhPbt28PCwkLukIiIiKicY6KZSlS6SGe3GURERERUZjk4OMDBwUHuMPK1cuVKbN++HQBw8uRJzJ8/X+aIiIiIqLxj1xlUojRCg0qqSnKHQURERERUrl27dk0avn79uoyREBERUUXBRDOVmBRtCtJFOpraNJU7FCIiIiKici00NFTvMBEREVFxYdcZVGKS0pNgq7RFD5cecodCRERERFSuderUCbVq1UJSUhJq1aoldzhERERUATDRTEaRpjLBnC+bSMP6CAiYwARmCrOSDI2IiIiIqELy9fWVOwQiIiKqQJhoJqPQKk1wurVrnmXStGmwVlrDytSqhKIiIiIiIiIiqhiepj7F7FuzEZkaiX4u/TDQbaDcIRFRBcM+mqnEpIpUOCodoVAo5A6FiIiIiIiIqFzZ9nQb7qfch0ZosP7JekSnRcsdEhFVMGzRTEZhmqZFmz0PAQCHO3siXU/3GcnaZNS2ql3SoRERERERERGVe1nvHlYr1FAr1DJGQ0QVERPNZBRKjRYTZ50HABxt76430ayAAi5ql5IOjYiIiIiIiKjc6+/aH3GaODxKfYQeTj1grbSWOyQiqmCYaKYSZae0kzsEIiIiIiIionLHzMQM47zHyR0GEVVg7KOZSpSFqYXcIRAREREREREREZGRMdFMJUIIAQEBCxMmmomIiIiIiIiIiMobJpqpRCRrk6FSqOCgcpA7FCIiIiIiIiIiIjIyJpqpRMRqYuGidkFDm4Zyh0JERERERERERERGxocBUolISE9Aq0qtoDZRyx0KEREREVG5lJycjG3btiE5ORm9e/dGpUqV5A6JiIiIKhAmmsko0lQm+PjThtJwVlqhhYBAM7tmcoRGRERERFQhLFu2DAcPHgQAXL16FQsXLpQ5IiIiIqpImGgmo9AqTfBnew+905K1yTA3MUcdqzolHBURERERUcVx//59vcNEREREJYF9NFOxi9XEwlnljOqW1eUOhYiIiIio3OrevTtMTDIu8Xr16iVzNERERFTRsEUzGYWJRovgg48BAMfbukGrzDjB1Qot4jRx6ObUjf0zExEREREVozZt2iAwMBAajQYuLi5yh0MEIQQUCoXcYRARUQlhopmMQpWmxbR3/gYA9D3eESn/n2h+qX0Ja1Nr9HXpK2d4REREREQVgoODg9whEOFxymPMujULj1Mfo59LPwx2Hyx3SEREVALYdQYVq8T0RFiZWsHXwlfuUIiIiIiIiKgEbI/ajkepj6CFFhufbkR0WrTcIRERUQlgopmKjRACMWkxCLAOgJWpldzhEBERERERUQmwVdpKw2qFGmYmZjJGQ0REJYVdZ1CxeZr6FPYqewx3Hy53KERERERERFRC+rn0Q7wmHo9SHqGnc082PCIiqiCYaKZiE5ceh2FuwxBkFyR3KERERERERFRC1CZqjPEaI3cYRERUwth1BhULrdACAKpaVpU5EiIiIiIiIiIiIipubNFMxSIuPQ42pjZoYttE7lCIiIiIiIjKvCsJV3DoxSFUsaiCzk6d5Q6HiIgoByaaySg0ShMsnlNPGk5KT4KH2gO+5r7yBkZERERElIcLFy7g3r17aN68ORwcHOQOh0ivF2kvMPPWTKSIFACAmYkZwhzCZI6KiIhIFxPNZBTpKhMc6OEtvU57mQZHlSMUCoWMURERERER5e7YsWNYsGABAGD79u345ptvYG5uLnNURDk9T3suJZkB4FHKIxmjISIi0o99NFOxSBWpqGdTT+4wiIiIiKic0mg0iI+PL1Idly5dkoafPn2KqKioooZFFZxGo8GiRYvw+uuvY926dUar18/CD41sGgEAHJQOCHcIN1rdRERExsIWzWQUJhotGh7LODE/FmQDE5jAx9xH5qiIiIiIqDx6+PAh3nvvPURHRyM8PBxvvfVWoepp1qwZ9u7dC41GAz8/P7i5uRk5UiqMFy9eIDk5Ge7u7nKHUmD79+/HoUOHAAAbNmxA48aN4e/vX+R6TRQmmFVlFqLSomCntIOZiVmR6yQiIjI2JprJKFRpWsyacAoA0PRgbdR1qovOjnxABREREREZ3+7duxEdHQ0gI7HXv3//QiUlAwMD8dVXXyEyMhJ169aFSqUydqilmhAC+/btQ3R0NNq3b18q+qg+duwYFi5cCI1Ggz59+mD48OFyh1QgQog8XxeFQqGAi9rFaPVR6bbv+T7si96HapbVMMpjFEwVpnKHRESULyaayeg0QoOmtk1hbsr+7YiIiIjI+JydnaVhc3NzWFtbF7ouLy8veHl5GSOsMmfTpk1Yu3YtAODw4cNYtmyZ7M9Y+eWXX6DRaAAAO3bsKHOJ5vDwcFy+fBlXr15FmzZtULNmTblDojLoYfJDfPXgKwgIXE26Ck8zT3Rx6iJ3WERE+WKimYqFk9pJ7hCIiIiIqJzq3r07UlJScP/+fXTq1Ak2NjZyhySJiYnB6tWrodFoMHjwYLi4lN4WqP/++680/PDhQ6SkpMj+MERvb29cvHgRAMrkDwAqlQpTp041ap1CCGi1WpiaskVrRfFS+xIC/2sNn5ieKGM0RESGY6KZjE5AwE3N/u2IiIiIqHiYmprilVdekTsMvZYsWYLTp08DyEjefv755zJHlLvw8HCcPn0aGo0GrVu3lj3JDACjRo2Co6MjEhIS0KNHD7nDkd3Fixfx0UcfISUlBWPHjkW7du3kDolKQDXLaujm1A2/Pv8V1SyrsVtKIiozmGgmo1MpVHBSsUUzEREREVU8z58/1ztcGgUFBeG7775DTEwMqlevLnc4AAC1Wo3+/fsbrb7ExESYm5uX2dbAa9euRWJiRmvWH374gYnmCuR1z9fxuufrcodBRFQgJnIHQOWPSqGCrdJW7jCIiIiIiErcoEGDoFaroVQqMWzYMLnDyZeLiwtq1Kghe9/MxWHZsmV45ZVXMHLkSNy/f1/ucAqlUqVKeoeLS3x8PCIjI4t9OUREVD4x0UxG52Pug2oW1eQOg4iIiKhMW7ZsGQIDA2FrawtbW1sEBwdj79690nQhBGbPng0PDw9YWFigTZs2uHz5sk4dKSkpGD9+PJycnGBlZYXu3bvjwYMHOmVevHiBIUOGwM7ODnZ2dhgyZAhiYmJKYhXLpaCgIGzcuBEbN25EaGio3OFUWFFRUdizZw8AIDo6Grt27ZI5osIZO3YswsLC0Lx5c7z//vvFuqwLFy5gxIgReP3117Fs2bJiXRYREZVPTDSTUWiUJlg2LQBzp7igjn2DctkigoiIiKgkeXl54eOPP8bp06dx+vRptG3bFj169JCSyZ9++ikWLVqEr7/+GqdOnYKbmxvatWuH+Ph4qY6JEydi+/bt2LBhA44ePYqEhAR07doV6enpUpmBAwfi3LlziIiIQEREBM6dO4chQ4aU+PqWJ0qlEmq1Wu4wKjQrKytYWFhIr52cymbXfnZ2dpg4cSKmT58Ob2/vYl3WL7/8gpSUFADAnj17kJycXKzLIyKi8kchhBD5FzOuuLg42NnZITY2Fra25beLhVanWyFVpMJFXXqfNG1s/yb9i/d838MQd16cEBERVUQV5TxPLg4ODli4cCFGjhwJDw8PTJw4Ee+++y6AjNbLrq6u+OSTT/DGG28gNjYWzs7OWLNmDQYMGAAAePToEby9vbFnzx506NABV69eRe3atXHixAkEBQUBAE6cOIHg4GBcu3YN/v7+BsXF951KoytXrmDXrl3w9PTEK6+8AqWSjyjKy5o1a7Bp0yYAgLOzM3744Qc2ICIiIgCGn+vxm5aMJl2kQ0DA0tRS7lCIiIiIypX09HRs3rwZiYmJCA4Oxu3bt/H48WO0b99eKmNmZoaQkBAcO3YMb7zxBs6cOYO0tDSdMh4eHggICMCxY8fQoUMHHD9+HHZ2dlKSGQCaNWsGOzs7HDt2LNdEc0pKitTyEci4+CAqbWrXro3atWvLHUaZ8eqrr8LS0hLPnz9Ht27dmGQmIqICY6KZjMIkXcD95L/wN7VCy3rBcodDREREVC5cvHgRwcHBSE5OhrW1NbZv347atWvj2LFjAABXV1ed8q6urrh79y4A4PHjx1Cr1bC3t89R5vHjx1IZF5ecd9+5uLhIZfRZsGAB5syZU6R1I6LSRalUok+fPnKHUWoIIbB3717cu3cP4eHhqFaNzyEiIsoPE81kFKrUdCwfeyPjxSA7eYMhIiIiKif8/f1x7tw5xMTEYOvWrRg2bBiOHDkiTc/e4lAIkW8rxOxl9JXPr57p06dj8uTJ0uu4uLhi7z+WiKgk/frrr9JDEQ8fPoz//ve/sLGxkTkqIqLSjQ8DJCIiIiIqpdRqNapVq4bGjRtjwYIFqFevHpYsWQI3NzcAyNHq+OnTp1IrZzc3N6SmpuLFixd5lnny5EmO5UZFReVoLZ2VmZkZbG1tdf6IiMqTBw8eSMOJiYmIiYmRLxgiojKCiWYiIiIiojJCCIGUlBRUqVIFbm5u2LdvnzQtNTUVR44cQfPmzQEAjRo1gkql0ikTGRmJS5cuSWWCg4MRGxuLv/76Sypz8uRJxMbGSmWIiCqi8PBwqQVzkyZN4OXlJXNERESlH7vOIKMQQsgdAhEREVG58t5776FTp07w9vZGfHw8NmzYgMOHDyMiIgIKhQITJ07E/PnzUb16dVSvXh3z58+HpaUlBg4cCACws7PDqFGjMGXKFDg6OsLBwQFTp05F3bp1ER4eDgCoVasWOnbsiNGjR+O7774DALz++uvo2rVrrg8CJCKqCHx9ffH9998jJiYG7u7ufDgiEZEBmGgmo9BCK3cIREREROXKkydPMGTIEERGRsLOzg6BgYGIiIhAu3btAADvvPMOXr58ibFjx+LFixcICgrCb7/9ptOH6BdffAGlUon+/fvj5cuXCAsLw8qVK2FqaiqVWbduHSZMmID27dsDALp3746vv/66ZFeWiKgUsrS0hKWlpdxhEBGVGQohQ1PUuLg42NnZITY2tlz359bqdCukilS4qHM+ybu8USQmYWeLgxkvEhIAKyt5AyIiIiJZVJTzPNLF952IiPIjhMDZ+LMwNzFHbevacodDRAVg6LkeWzSTUSRrk+UOgYiIiIgIAPD777/jhx9+gJ2dHd599114enrKHRIRUYX35f0vsf/FfgDAMLdh6OvaV+aIiMjY+DBAMooUUy2+Hl8ZyR9/CKhUcodDRERERBWUEAJLlixBdHQ0bt++jVWrVskdEhERATgWe0zvcF4uxF/AjJsz8OX9L5GUnlRcoRGRkTDRTEaRrNRi49DKUL0zHVCr5Q6HiIiIiCowVZaGDyo2gsiXVmhx9+VdJGgS5A6FqEyK18Tj7su70Ao+uygvAdYBeodzk6pNxYd3PsS5hHPYF70P6x6vK87wiMgI2HUGGUWyNhl+ln4wVZjmX5iIiIiIqJgoFApMmzYNq1evhq2tLUaOHFniMQghsGzZMhw7dgx169bFlClToFSWzksvrdBi7u25OBN/BlYmVphfbT78LPzkDouozLiZdBPv33wfidpENLZpjBlVZsBEwTZ9+rzr8y4OvzgMcxNztKrUKt/yGqFBijZFeh2fHl+c4RGREZTOsx0qczRpKWh5wwxIPgU0bAiYMuFMRERERPKoX78+6tevL9vyz507h7179wIAjh49ikaNGiE8PFy2ePLyIOUBzsSfAQAkahNxMPog/DyZaCYy1IEXB5CoTQQAnI4/jUcpj+Bl7iVzVKWT2kSN9o7tDS5vaWqJYe7DsPbxWjirnDHAZUAxRkdExsBEMxWZRquBSUoqxvVZBWAVkJAAWFnJHRYRERERkSyyd9dRmrvvcFA6wNrUGgnpGd1m+Jj7yBwRUdlS2byyNGxjagN7lX2R63yS8gQmChM4q52LXFdZ18elD3o794ZCoZA7FCIyABPNVGRRaVHwNvcGcFvuUIiIiIiIZBcQEICBAwdKXWe0bt1a7pByZa20xoKqC3DgxQFUNquMdo7t5A6JqEzp6NgRpjDFvZR7CLMPg5Vp0RpdbX+6HT9G/ggFFBjrNRYdHTsaKdKSkZSehJ8e/4SE9AQMcB0AdzP3ItfJJDNR2cFEMxVZmkiDm8pN7jCIiIiIiEqNV199Fa+++qrcYRjE18IXoyxGyR0GUZllzB9odjzbAQAQENgZtbPMJZqXP1yOAy8OAACuJV3DtzW/lTkiIipJ7KGeiiwlPQU1rWrKHQYRERERERFRmVbZ7H9dcZTFrmyi0qL+N5walUdJIiqP2KKZiiRZmwyliRLN7JrJHQoRERERERFRmfaOzzvYHrUdpgpT9HLuJXc4BdbXpS/+SfoHKdoUDHIbJHc4RFTCmGimIolOi4anmSeC7ILkDoWIiIiIiIioTLNWWmOI+xC5wyi0BjYNsLbOWmiEpsj9VRNR2cNEMxVJsjYZ1S2rw8zETO5QiIiIiIiIiIrVw4cP8dNPP8HS0hJDhw6FjY2N3CGVOmYmZjADcwREFRETzVQkGqGBh9oDUKmAWbMyRqpU8gZFREREREREVAw+/PBDPHz4EACQlJSEt99+W+aIiIhKDyaaqdCEEFBAAVczV0CtBmbPljskIiIiIiIiomITHR2td5iIiAATuQOgsitZmwwzhRnqWdeTOxQiIiIiIiKiYjd8+HCYmJjAwsICr776qtzhEBGVKmzRTIX2UvsSlqaW8Lf0B7Ra4OrVjAm1agEm/A2DiIiIiIjIGDQaDWJiYuDg4AATXmvJqnPnzggPD4epqSlMTU3lDoeIqFRhopkKLSk9CZXNK8Pa1BpISgICAjImJCQAVny6LBERERERUVHFxcVh2rRpuH//PmrWrImPPvoIarVa7rAqNG5/IiL9+FMoFYoQAknaJHiZeUGhUMgdDhERERERlQH//vsvfvzxR/z+++9yh1JmHD16FPfv3wcAXLt2DWfPnpU5IiIiIv3YopkKJbN/5gGuA+QOhYiIiIiIyoAXL15g+vTpSE5OBgAolUo0b95c5qhKP3d3d2lYoVDA1dVVxmiIiIhyx0QzFUq6SIfKRIXK5pXlDoWIiIiIiMqAJ0+eSElmALhz547RE82JiYmwKmfd+DVo0ACTJk3CxYsX0axZM/j6+sodEhERkV5MNFOhpCMdpjCFpaml3KEQEREREVEZULVqVdSqVQtXr16FjY0NWrdubbS6k5OTMXPmTFy9ehW1atXChx9+CDMzM6PVL7e2bduibdu2codBRIWQLtJhquCDI6liYKKZCiUxPRGOSkfYK+3lDoWIiIiIqFxbt24d9u/fj+rVq2PKlCllNoGqUqkwf/583L9/H87OzrC2tjZa3SdPnsTVq1cBAFevXsWJEycQEhJSqLpOnTqF1NRUBAcHw8SEjzUiosK59fIWZt+ajVhNLIa7D0cvl15yh0RU7JhopkJJ1abCx8IHKhOV3KEQEREREZVbt27dwoYNGwAAz549w969e9GzZ095gyoCpVKJKlWqGL1eR0fHPF8bas2aNdi0aRMAIDQ0FJMnTy5ybERUMW18shEvNC8AACsiV6CrU1fmUKjcY6KZCkwIgRRtCrzMvP43UqUCpk793zARERERERVZ9ha1bGGrX0BAACZMmIDTp0+jcePGCAgIKFQ9p0+f1jtMRFRQdko7adja1BpKBVNwVP5xL6cCS9QmwsrUCj2ce/xvpFoNLFwoX1BEREREROWQr68vhg0bJnWd0alTp2JdXmxsLMzNzctk9xzt2rVDu3btilRHo0aNcOvWLWmYiKiwhrkPg1ZoEZ0WjQGuA6BQKOQOiajYMdFMBabRaqA2UcPb3FvuUIiIiIhKJY1Gg8OHD+PmzZsYOHAgbGxs8OjRI9ja2hq1X9qKTAiBlJQUmJubyx1Ksevbty/69u1b7MtZsWIFtm3bBisrK8yaNQu1atUq9mWWNkOHDkWtWrWQkpKC5s2byx0OVRAJmgQ8S3sGb3NvPjSuHLEytcJ/vP8jdxhEJYqJZiqwNJEGlUKFSspK/xup1QL37mUMV64M8JY+IiIiqqDu3r2Ljh074t69e0hJSUG7du1gY2ODTz/9FMnJyfj222/lDrHMi4yMxPvvv4+oqCh07NgR48aNkzukMi85ORnbtm0DACQmJuLnn3/ONdF8/fp13L59G02aNCl0X8ilWZMmTeQOgf7f3bt38cknnyAxMRGvv/46WrRooTP9edpz3E++jxqWNWBpailTlEVzL/kepv07DfHp8QiwCsCHfh9CacJUDRGVTcwGUoElpifC19xX95fWly+BKlUy/l6+lC84IiIiIpm99dZbaNy4MV68eAELCwtpfK9evXDgwAEZIys/du3ahaioKABAREQEIiMjZY6o7DMzM4O9vb302tXVVW+58+fP4+2338Y333yDKVOmIDExsaRCpApo5cqVuH//PqKjo7FkyRKdaXdf3sWb197EjFszMOXGFLxML5vXoYdfHEZ8ejwA4FLiJdxJviNvQERERcCfyajA0kQa/Cz85A6DiIiIqFQ6evQo/vzzT6jVap3xPj4+ePjwoUxRlS9ZW9GamZmxOxIjUCgU+PDDD7F9+3Y4OjpiwIABestduHABQggAwPPnz/HgwQP4+/uXZKhUgaiyPGg++2fqybiTeKnNSC4/SHmAf1/+i7rWdUs0PmPwNfeVhi1NLOGsdpYvGJJNqjYV5+LPwVntjCoWVeQOh6jQmGimAhMQfFoqERERUS60Wi3S09NzjH/w4AFsbGxkiKj86dGjB5KSkvDgwQN07tyZ29VIfHx8MHHixDzLNG7cGNu2bYNGo4G7uzsqV65cMsFRhfT6668jNTUV8fHxGDFihM40f0t/KKCAgICViRW8zLxkirJoWtu3RrpIx+3k22hj3wZ2Sju5QyoWJ2NPIjE9Ea0qtYLKRJX/DBWIEAIzbs3AlcQrUECBaT7T0LwS+4insonZQiowhVDwi4GIiIgoF+3atcPixYuxfPlyABktRRMSEjBr1ix07txZ5ujKB6VSiSFDhsgdRoVUq1YtfPnll7h37x4CAwN1uochMjYnJyfMnj1b77R6NvUwz28ebry8gSDbINir7PWWKwtCHUIRilC5wyg2Gx5vwLon6wAAf8T8gVl+s2SOqHR5oXmBK4lXAGQ07DsRd4KJZiqzmGimAlMoFLAytZI7DCIiIqJSadGiRWjbti1q166N5ORkDBw4EDdu3ICTkxPWr18vd3hERebt7Q1vb2+5wyBCoE0gAm0C5Q6D8nEu4ZzeYcpgp7SDt5k37qfcBwDUtSp7XcAQZWKimQpMAQUcVeXv6dJERERExuDp6Ylz585hw4YNOHPmDLRaLUaNGoVBgwax9SdRGfL06VNs2LABarUagwYNKjddtAghoFAo5A6DKpAg2yBcTrwsDZMuU4UpPqn2Cf6I+QOualc0sm0kd0hEhcZEMxWYgIC5ibncYRARERGVOmlpafD398cvv/yCESNG5OhTlIjKjvnz5+PmzZsAgJiYGEybNk3miIpuw+MN2PBkA1zULpjjNwfuZu5yh0QVQC+XXqhmWQ3P057DReWC5PRkmJsyp5CVjdIGnZ3YvRaVfUw0U4GkadNgqjCFuzrbCYlSCYwd+79hIiIiogpIpVIhJSWFrQWJyoGoqChp+OnTpzJGYhyxmlipn9zI1EhsfroZE7wnyBwVVRSeZp5YdG8RnqU9g7vaHZ9X/xw2yvJxlwAR/Y+J3AFQ2ZKiTYFaoYaz2ll3gpkZ8M03GX9mZvIER0RERFQKjB8/Hp988gk0Go3coRBREQwaNAgKhQJqtRoDBgyQO5wiM1OY6dyZaqe0kzEaqmhOxZ3Cs7RnADJ+6DifcF7miIioOLDpKRVIXHoc3NRu8LPwkzsUIiIiolLp5MmTOHDgAH777TfUrVsXVla6D1Hetm2bTJERFdzZs2eRlpaGJk2aVLiW+p07d0abNm1gamoKs3LQmMbc1Bzv+76PbU+3wc3MDQNcijd5HpUahUX3FuGF5gWGuQ9DsF1wsS6PSjdfc18ooICAgFKhhI+5j9whEVExYKKZCiRZm4yqllVhqjDVnSAE8Czj10k4OQEV7CSUiIiIKFOlSpXQp08fucMgKrJ169Zhw4YNAIDw8HC89dZbMkdU8iwtLeUOwajq29RHfZv6JbKsVZGrcCnxEgDgs7ufYXPdzTBR8Kbqisrfyh8f+n2ICwkX0Ni2MbzNveUOqUDSRToOvzgMAGhj3yZnToSIADDRTAWULtLhonLJOSEpCXD5//EJCUC2ljtEREREFcWKFSvkDqHc02q12LJlC+7fv49OnTqhdu3acodULp08eVIa/uuvv2SMhMoiAZHnaypZ6x6vw7n4c2hm1wx9XDJ+DI2IiMCBAwfg7++PkSNHwsSkeH8IqGdTD/Vs6hXrMorLV/e/woEXBwAAFxMuYmLlifIGRFRKMdFMBcanwxIRERGRnHbu3Ik1a9YAAE6cOIEVK1bA2tpa5qjKn/r16+P27dvSsKHOnz+PlJQUNG7cuNgTV1R6DXMfhudpz/EiLaPrDLYAlc+J2BPY8CTj7oRrSddQw7IG7KLtsHTpUgghcO3aNXh5eaFjx44yR1p6XU68LA1nttQnopwqXKL5999/x8KFC3HmzBlERkZi+/bt6Nmzp9xhlRkKKHiCQERERJSHKlWq5NmX7a1bt0owmvLp6dOn0nBycjLi4+OZaC4GI0aMQM2aNZGWloaWLVsaNM+GDRuwbt06AEBoaCgmT55cnCGWCjt27MCBAwdQvXp1vPnmm1AqK9xltl4uahd8XO1jucMgAEnpSTleq1+qIcT/Wpm/fPmypMMqU1rYtcDWqK3SMBHpV+G+ARMTE1GvXj2MGDGCfecVkpmi7D8Ig4iIiKi4TJw4Ued1Wloazp49i4iICLz99tvyBFXOdO7cGX/++Seio6MRFhYGd3d3uUMqlxQKBZo3b16gebJ2sWGs7jaio6Px22+/wdHREeHh4aXqoYR37tzB999/DwC4ffs2/Pz80KVLF5mjItLVqlIr/Bn7J87Hn0eQXRCa2DaBiZ0JOnfujAMHDqBGjRro0KGD3GGWasM9hqORbSMIIRBoEyh3OESlVoVLNHfq1AmdOnWSO4wyzVntLHcIRERERKVWbg9M++abb3D69OkSjqZ88vLywg8//IDExETY2dnJHQ5lUa9ePdy4cUMaLiohBN577z08fPgQAPDixQv079+/yPUaS1pams7r1NRUmSIhyp3KRIUZVWbkGP/mm2/izTfflCGisqmudV25QyAq9dhhFhksWZsMpUIJLzMvuUMhIiIiKnM6deqErVu3yh1GuaFUKplkLoWGDh2K6dOnY/LkyUZpwf/y5UspyQwAN2/eLHKdxlS9enX07t0btra2aNSoUZlp1BQZGYnx48dj4MCB+PXXX+UOh0oprdAiXaTLHYbBDhw4gIEDB2Ls2LF48OCB3OEQVUgVrkUzFV6CJgE2pjZoYNNA7lCIiIiIypwtW7bAwcFB7jCIjE6j0eCff/6Bk5MTXFxcCtzdRl4sLS3RsmVLHD16FEqlEmFhYUar21hGjBiBESNGyB1Ggaxbtw537twBACxduhRVq1bF7t274eDggAEDBkCtVssbYBFcvnwZT58+RVBQECwtLeUOp8w6HXcan9z9BFqhxUTviWhl30rukPKUnp6Or7/+GhqNBvHx8VizZg2mT58ud1hEFQ4TzWSwVJEKD7UHLEwtck5UKoFhw/43TERERFRBNWjQQKcPWSEEHj9+jKioKCxdulTGyIiMTwiBOXPm4Ny5c1CpVJg9ezYCA43bf+k777yDXr16oVKlSnBxcTFq3RWVubm5NKxSqTBnzhzExMQAyOgOZOTIkTJFVjSHDx/G559/DgCoWrUqFi1aBBMT3shdGKsiVyFZmwwAWBG5otQnmk1MTGBmZgaNRgNAdx8n4xBC4Ez8GagVavZTTbliRpAMphEaVFJW0j/RzAxYubIkwyEiIiIqlXr06KGTaDYxMYGzszPatGmDmjVryhgZlSWpqak4cuQILC0t0bx581L1ALysoqKicO7cOQAZCcojR44YPdGsUChQo0YNo9ZZ0Q0dOhTx8fF4/vw5+vbti48++kia9uTJExkjK5q///5bGr558yZiYmJ4J0khZb32zzUPUIooFAq89957WLNmDSpVqlRq7jJI1aYiKjUKrmpXKE3KdgruqwdfYV/0PgDAQNeBeNXtVZkjotKobO/lVKK0Qqu/NTMRERERSWbPni13CFQOLFiwQHp45IABAzB48GCZI9KvUqVKcHZ2RlRUFICMPoszRUdHw9raukx3w1Be2dra6nQr0KdPH2zduhWWlpbo2bOnfIEVUePGjXHo0CEAGftipUqV5A2oDJtYeSJWPloJjdBgqPtQucMxSGBgIBYuXCh3GJI4TRze+fcdPEx5CF9zX3xc7WNYmVrJHVahnYg9oTPMRDPpU+ESzQkJCfj333+l17dv38a5c+fg4OCAypUryxhZ6Zdni2YhgKSkjGFLS6CUtrggIiIiKm6mpqaIjIzMcYv/8+fP4eLigvT0svNgJZLPhQsX9A6XNmq1Gp988gkOHjwIDw8PtGqVcXv94sWLceDAAdja2uKjjz6Cr6+vvIFSnoYPH45evXrB3NwcZmZmcodTaK1bt4azs7PUR/OBAwewfPly2Nra4v3334efn5/cIZYZjipHTPGZIncYZdrJ2JN4mJLxMNM7yXdwNv4sWlZqKXNUhVfPuh6Oxh4FAHadQbmqcJ0VnT59Gg0aNECDBhkPtJs8eTIaNGiAmTNnyhxZ6SaEgIBAsF2w/gJJSYC1dcZfZsKZiIiIqAISQugdn5KSwpadZLDg4P+ddxvz4XrFwdnZGQMGDJCSzE+fPsWBAwcAAHFxcdi9e7ec4RWrx48fIz4+Xu4wjMLOzq5MJ5kz1apVCyEhITAzM8OyZcuQnJyMp0+fYu3atXKHRhWMp5knFMhohGcCE3iYecgcUdFMqTwFk7wn4V2fdzHSvWz2407Fr8K1aG7Tpk2uJ/+Uu1SRCpVCBW9zb7lDISIiIiqVvvzySwAZ/UR+//33sLa2lqalp6fj999/Zx/NZLApU6agTZs2sLS0RO3atfMtvytqF47FHkOAdQAGug6UtU9nGxsbWFlZITExEQDg5uYmWyzF6ZtvvkFERATMzc0xc+ZM1K1bV+6QKAuFQgFLS0vExsYCgM5nMlFJqG1dG9N9p+N8/Hk0tm0MP4uy3aJeaaJEW4e2codBpVyFSzRT4aSJNKgUKjio+CAFIiIiIn2++OILABktmr/99luYmppK09RqNXx9ffHtt9/KFR6VMQqFAo0bNzao7PXE61j+aDkA4FLiJfiY+8h6e7aFhQU+/PBD7NmzBx4eHujVq5dssRSXpKQkREREAACSk5OxZ88eJppLoRkzZmDNmjWwtbXFqFGj5A6HKqBgu+Dc7wwnKoeYaCaDaIUWJgoTKBXcZYiIiIj0uX37NgAgNDQU27Ztg729vcwRUUWRkJ6Q52s5VK9eHW+99ZbcYRQbc3NzODk54dmzZwAAT09PmSMiffz9/TFv3jy5wyh2mdfrRERyY9aQDBKjiUE1i2rwMvOSOxQiIiKiUu3QoUNyh0AVTEObhmhdqXVG1xlWAQi1D5U7pDIjNTUVJ06cgIODAwICAgyez8TEBB999BF++eUXODo6okePHsUYJZF+t1/exuxbsxGricUw92Ho5VL+7h4gorKFiWYySIo2BfWs6/FXUiIiIiIDPHjwADt37sS9e/eQmpqqM23RokUG1bFgwQJs27YN165dg4WFBZo3b45PPvkE/v7+Upnhw4dj1apVOvMFBQXhxIkT0uuUlBRMnToV69evx8uXLxEWFoalS5fCy+t/DQhevHiBCRMmYOfOnQCA7t2746uvvkKlSpUKuuokA4VCgbd93pY7jDJp1qxZuHTpEgDgP//5Dzp06GDwvB4eHnj99deLKzSDaDQaLF26FNeuXUPr1q3xyiuvyBoPlayNTzYiWhMNAFgRuQJdnLpAbcKHzhKRfJg1JIMooICPhY/cYRARERGVegcOHIC/vz+WLl2Kzz//HIcOHcKKFSvw448/4ty5cwbXc+TIEYwbNw4nTpzAvn37oNFo0L59e+kBa5k6duyIyMhI6W/Pnj060ydOnIjt27djw4YNOHr0KBISEtC1a1ekp6dLZQYOHIhz584hIiICEREROHfuHIYMGVKk7UBU2iUnJ0tJZgA4deqUjNEUzsGDB7Fv3z7cv38f69atw/Xr12WJ42riVYy+OhqjrozChfgLssRQEdkp/4+9+w5vqnz/OP7OTpvuvaClLJkyRGTIlCEyRNyIGxAFB4IbRRQQUJGvCk7APRBQceBAHMiQYRmCyKali+6ZpEnO74/+CFagpG3SdNyv6+K6TpJznvNJSyG9z3PuJ9C57afxQ6fSeTGNEELIjGbhAkVRUFAI0VayEKBGA1dffXpbCCGEEKKRevTRR3nwwQeZNWsW/v7+rFy5koiICMaOHcvQoUNdHufUQmOnLFu2jIiICLZv306fPn2czxsMBqKios46Rn5+Pm+//Tbvvfcel112GQDvv/8+TZo04ccff2TIkCHs27ePtWvXsnnzZrp37w7Am2++SY8ePdi/f3+FGdRCNCRGo5G2bduyd+9eAJcXX6xLbDZbhcf/voBUm15LeY10azoAi08s5rUL6tfCp2+deIuN+Rvp6NeRKU2moFHVj99pb46+GZtiI6csh+sjr0elUnk7khCikZNCszivMqUMrUpLuD783DsZjbBiRe2FEkIIIYSoo/bt28dHH30EgFarpbS0FD8/P2bNmsWoUaOYNGlStcbNz88HICSk4sX/n3/+mYiICIKCgujbty+zZ88mIiICgO3bt1NWVsbgwYOd+8fExNC+fXs2btzIkCFD2LRpE4GBgc4iM8All1xCYGAgGzdulEJzPeRQHPxZ+CcmjYkLTBfU+vkVReHb7G9JsaQwOGQwCT4JtZ7BVbNmzWLjxo2EhobSsWNHb8epsssuu4xdu3axb98++vbtS9u2bb2SQ6c+PZNWr6pfrRuSCpP4IusLANblrqOjX0cGhAzwcirXmDQmpjSZ4u0YQgjhJIVmcV4FtgL8Nf608m3l7ShCCCGEEHWeyWTCYrEA5UXdQ4cO0a5dOwCysrKqNaaiKEydOpXevXtXWLDs8ssv55prriE+Pp4jR44wY8YMBgwYwPbt2zEYDKSnp6PX6wkODq4wXmRkJOnp5bMP09PTnYXpf4uIiHDu818Wi8X5HgEKCgqq9b7qC0VR6tVMwReOv8Cveb8CMCFmAiPCR9Tq+b/J/obXTpTPaP0592feavMWvhrfWs3gKoPBQP/+9XfxRL1ezyOPPOLtGNzX5D4WpyzGgYO7Yu/ydpwqUf+no6iK+vOzLoQQdY0UmsV55dpyGRY6jBBdJa0zhBBCCCEEUD4b+Pfff6dt27ZcccUVPPjgg+zevZtVq1ZxySWXVGvMyZMns2vXLjZs2FDh+euuu8653b59ey666CLi4+P5+uuvueqqq8453n8Lp2crolZWXJ07dy5PP/10Vd9GvZOTk8NTTz3FsWPHuOKKK5g4caK3I7lkY/7GCtu1XWhONic7twvtheTZ8upsofl88m35rMgov3Pzusjr8Nf613qGv//+m++//574+HhGjhxZo4seJfYSALd/P5oYmzC3xVy3jllbOvp3ZEz4GDbmb6SDXwf6Bvf1diQhhKi3pNAszkuFiram89yCVVwMfn7l20VFYDJ5PpgQQgghRB304osvUlRUBMDMmTMpKirik08+oUWLFixcuLDK402ZMoUvv/ySX3/9lbi4uEr3jY6OJj4+ngMHDgAQFRWF1WolNze3wqzmzMxMevbs6dwnIyPjjLFOnjxJZGTkWc/z6KOPMnXqVOfjgoICmjRpUuX3Vtd9/fXXHD16FICvvvqKyy+/nKZNm3o3lAvam9qTVJRUvu3XvvKdPWBQyCB+zv2ZYkcx3QO6E62PrvUM7vL8seedX8sUSwozE2fW6vkLCgqYMWMGZrMZAJ1Ox7Bhw6o11s+5P7MoeRGKonBvk3vrTXuI2nBrzK3cGnOrt2MIIUS9J4VmUakyRxlqldorvd2EEEIIIeqjxMRE57avry+LFy+u1jiKojBlyhRWr17Nzz//TLNmzc57THZ2NsnJyURHlxf2unbtik6n44cffuDaa68FIC0tjT179jB//nwAevToQX5+Pn/88QcXX3wxAFu2bCE/P99ZjP4vg8GAwWCo1vuqTwICApzbWq0WX9/6MSv3iWZP8HPuz5g0JnoF9qr18zf3bc7bbd8mtyyXWENsvWo7UmovZd6xeRwsPciQkCHOBe4AUi2ptZ4nLy/PWWSG8p/f6vo442NsSvnigR9lfFTnCs12xc43Wd9QZC9iWNgwArWB3o4khBCiiqTQLCplUSwYVUZiDDHejiKEEEIIUW/k5eXx2WefcejQIaZPn05ISAg7duwgMjKS2NhYl8a45557+PDDD/niiy/w9/d39ksODAzEx8eHoqIiZs6cyZgxY4iOjubo0aM89thjhIWFMXr0aOe+d9xxBw8++CChoaGEhIQwbdo0OnTowGWXXQZAmzZtGDp0KOPHj+f1118HYMKECQwfPrzRLwR4xRVXkJ2dzdGjRxk6dChhYWHejuQSg9rAkNAhXs1g0pgwaerfXY5fZ33N9sLtAHya+Sljwsew6uQqVKi4JuKaWs/TpEkTevbsycaNGwkKCqqwsGdVRegiOGE5Ub6tP7Mvu7ctT1vO5yc/B+CPgj9Y2Krqd4AIIYTwLik0i0rZFTsalQaTuv59SBRCCCGE8IZdu3Zx2WWXERgYyNGjRxk/fjwhISGsXr2aY8eO8e6777o0zpIlSwDo169fheeXLVvGrbfeikajYffu3bz77rvk5eURHR1N//79+eSTT/D3P91HduHChWi1Wq699lpKS0sZOHAgy5cvR6PROPf54IMPuPfee51FrJEjR/LKK6/U8CtR/2m1Wm6//XZvxxC1SKfWVXg8MGQgoyNGo0JFgDbgHEd5jkqlYtq0abz22mtkZ2dz8uTJarepeTD+QT5M/xAFhRsib3Bz0po7XHrYuX2k9Ei9W4RTCCGEFJrFeZwqNNfXxTuEEEIIIWrb1KlTufXWW5k/f36Fgu/ll1/OjTfe6PI4iqJU+rqPjw/ffffdeccxGo28/PLLvPzyy+fcJyQkhPfff9/lbHWFFKKEuw0LHcbR0qMcLD3I4JDBNDF6v/f4V199xffffw/A7t27Wbp0KYGBVW8rEagNZFLcJHfHc5shIUPYU7QHBw6GhA6Rn20hhKiHpNAsKlXqKCVWH4ufxs/bUYQQQggh6oWtW7c6W1D8W2xsrLP9haiZrKwsnnzySU6cOMHo0aO59dZbvR1JNBA6tY77mt7n7RgVZGdnO7etVitFRUXVKjS7YlXmKnYU7qBbQDdGhY/yyDnOpU9wH1r7tqbYUUyiT+L5DziHjIwMXnzxRQoKCrj99tvp1q2bG1MKIYSojNrbAUTdZnFYSPRJlKvJQgghhBAuMhqNFBQUnPH8/v37CQ8P90Kihufzzz8nOTkZh8PBypUrycjI8HYkITxm5MiRREZGAuV3Rrja572qthdsZ1naMnYW7eSt1LfYVbjLI+epTKQhskZFZoClS5eyd+9eUlJSWLBgwXnvDhHCncx2M1sLtnLCfMLbUYTwCpnRLM7J5rBhV+x08Otw/p01Ghg27PS2EEIIIUQjNWrUKGbNmsWnn34KlPdYPX78OI888ghjxozxcrqG4d8tSbRaLUaj0YtphPCsiIgI3nzzTcrKytDr9R47T6G9sNLHQojKlTnKePjgwxw2H0ar0vJM4jO092vv7VhC1CopNItzKnWU4qfxY1DIoPPvbDTC1197PpQQQgghRB33/PPPM2zYMCIiIigtLaVv376kp6fTo0cPZs+e7e14DcLo0aPJy8sjJSWF4cOHe6yNgBB1hUql8miRGaBnYE9+8vuJpKIkLvK/iO4B3T16Pk+57bbbyM3NdbbO8NbduX/k/8Fx83H6BvclXC93szQGJywnOGwuX9TSptjYnL9ZCs2i0ZFCszgnm2JDq9ISpAvydhQhhBBCiHojICCADRs28NNPP7Fjxw4cDgddunThsssu83a0BkOv1zNx4kRvxxCiQdGr9cxqPqveL7IZFRXF/PnzvZrh59yfeeH4CwB8lf0Vr7V+DaOm5ndepKWl8cEHH6DX67nllltqdJHtaOlRPsn4hABtALdE34KvxrfG+Rq7KH0UYbowssqyAGhrauvlRELUPik0i3OyK3Y0aPBR+3g7ihBCCCFEnRYSEsI///xDWFgYt99+O4sWLWLAgAEMGDDA29GEaNSOHz/O888/T3FxMXfddZcsDOeC+lxkriv+Lv7buZ1dlk12WTZhqjA25m0kWBdMJ/9O1Rp37ty5HDlyBIDCwkIef/zxamd8+sjTzoKoTbExpcmUao8lyhk1Rha0WMCm/E00NTblQv8LvR1JiFoniwGKc7IpNgwaAzqV7vw7FxeDyVT+p7jY8+GEEEIIIeoQq9XqXADwnXfewWw2ezmREALgrbfe4siRI2RmZrJw4UJvxxGNRO+g3s7foy/wvYBIfSQzD8/kxeQXmXF4Bl9nVa/tZE5OjnM7Ozu72vkcioPcstzTY5VVfyxRUZg+jBHhI6TILBotmdEszsnisNDe2N71K9olJZ4NJIQQQghRR/Xo0YMrr7ySrl27oigK9957Lz4+Z78rbOnSpbWcToiK0tLSSE1NpV27dg1+IUWtVnvWbSFq4rvs73gn7R1CdaE8lvAY0YboCq+392vPktZLyLBmcIHpAhw42FO8x/n69oLtXBF2RZXPe8stt/Dqq6+i0+kYO3ZstfOrVWpuib6FZWnLMGlMXBd5XbXHEkKIf5P/acU5lSllxOhjvB1DCCGEEKLOe//991m4cCGHDh1CpVKRn58vs5pFnbRnzx5mzJiBzWajefPmLFiwAJ3OhTsY66nx48djNpspLi7mzjvv9GqWdTnr2Fm0k4sDLqZ3UG+vZhHVZ3VYWZyyGAcOCu2FfJD+AdPip52xX6QhkkhDpPNxR7+O7CraBUC3gOq1cBk0aBB9+/ZFrVbX+MLJ6IjRXBF2BRqVBo1KU6Ox6qNSeykLji3gsPkwQ0OGcn3U9d6OJESDIIVmcU4KiiwEKIQQQgjhgsjISJ577jkAmjVrxnvvvUdoaKiXUwlxps2bN2Oz2QA4dOgQqampxMfHezmV50RHRzNnzhxvxyCpMImXkl8CyheKi9JH0cK3hXdDiWpRo0av1mN2lF9MNKpduyvgqWZPsSV/C8G6YNr7ta/2+fV6fbWPPWMstfvGclVOWQ55tjyaGZt5tR/4mqw1bC3cCsAHGR/QM6gnTY1NgfIZ62+eeJNAbSBPNHuCZj7NvJZTiPpGejSLs1IUBYB4Y8P90CmEEEII4QlHjhyRIrOos9q0aePcDgsLIzIyspK9hbtkWDOc2woKmdZML6YRNaFVa3k0/lFa+7amZ2BPbo6+2aXj9Go9lwZfWqMic323q3AX4/eN575/7mPesXlezfLfWdwayh87FAevnXgNi2IhsyyT99Pf90Y8IeotmdEszqrAXoCv2pf2psb7n6AQQgghhBANTa9evXj66adJTk6mV69eDb5Hc13RK7AXa7LWcMx8jNa+reka0NXbkTzuuPk4B0sO0tGvI2H6MJePK7IVccx8jASfBEwakwcTVl+XgC50Ceji7Rj1zo+5P2JVrAD8nv87+bZ8ArWBLh1bYi9hS/4WogxRtDG1Of8B5zEibARHSo9wuPQwQ0OHEmuMBUCFCl+1LwX28gV+/TR+NT6Xt+WU5eCn8fPKDHbR+EihWZzVSetJ+gX3c8s/4EIIIYQQQoi6o0uXLnTpIkWy2uSn9WNRq0Xk2/IJ1gZ7tWVAbThQcoCHDj6ETbERpA3ildavuFRQzCnLYeqBqWSXZROuC2dhq4UuFyJF9X2U/hErMlcQa4jlqWZPEaYPw67Y2VG4Az+Nn9vqAgnGBOd2mC4Mk9q1Cwl2xc6jBx/lsPkwANObTqdPcJ8aZdGr9Wftra1SqZjRbAYfpH9AgDaAO2LuqNF5vO2FYy/wc97PBGoDmdt8Lk2MTbwdSTRwUmgWZ7ArdgD6B/d3/QOQWg19+57eFkIIIYQQQgjhpFFpCNGFeDuG08GDB3nzzTfR6/XcfffdREdHu23sXUW7sCnlvcDzbHkcLj1MZ//O5z1uR+EOssuyAThZdpKdhTtrXFCsiW0F29hdtJtuAd2q1PKiwFbAwZKDNPNpRrAu2KVjjpUe49PMTwnUBjIuahw+Gp/qxq6S7LJsPsz4EICj5qOszFzJxLiJPH/seTbkbwBgQswERoSPqPG5RoePxlfjS4Y1g6EhQ9GqXStJ5ZblOovMUP73xJN/Ly4wXcAzzZ/x2Pi1Jc2Sxs95PwOQb8vnm6xvmBg30buhRIMnhWZxhmJ7MSaNiUsCL3H9IB8f+Plnj2USQgghhBBCnN/BgwcxGAw0aSKz1kTlnn/+eU6cOAHAq6++yrPPPuu2sTv6dUSn0lGmlBGsDSbRJ9Gl4xJ9EtGgwY4drUpLgk+C2zJV1d6ivcw6MgsFhS+zvuR/rf7n0mzQvLI87j9wP9ll2fhr/Hmp1UtE6CPOe9zMIzPJKssCoMxRxj1N7qnxe3CFXqV3fq8ANBYNb7/9Nh8e/pCoQVHog/VszN/olkKzSqViaOjQKh8XrAsm0ZjIYfNhVKjo4i93ZLgiQBuAr9qXEkcJAFGGKC8nEo2BFJrFGWyKDZ1KR7DWtSuvQgghhBCNXUFBgcv7BgQEeDCJaMzeeustvvjiC1QqFXfffTdDh1a9oOMpiqKQlJSERqOhY8eO3o5TZRs3buTkyZP079+/wfwMWyyWs267Q0vflrzU6iUOlRyio39Hl9tfJPokMqf5HHYW7aSFTwuWpi7lpPUkN0TdQO+g3m7NeD7HzMdQUIDy35FTLCkuFZr3FO9xzsoutBeyo3DHeYurDsVBTlmO8/GpgnNt8Nf683D8w3x+8nNiDbFkfpjJpg2bKC0u5WDyQdo+2JYL/S6stTxno1FpmNtiLn8U/EGkPlJafLrIpDExK3EWa7PXEmuIZURYzS8WCHE+UmgWZzA7zITrwhtE03shhBBCiNoQFBTkcssxu93u4TSisfr++++B8qLuDz/8UKcKzW+++SZr1qwB4Nprr2XcuHFeTuS6NWvW8MYbbwDlX+NXXnmlQfRYnjx5Mv/73/8wGAyMHz/e7eM3NTalqbFplY9r69eWtn5teTX5VbYXbgfgheMvcJH/RRg1tbd4ZffA7nya+SlZZVk0MTSho59rF0gSfRLRq/RYFStalZZWvq3Out+ak2v4KfcnWvm2YkLsBMZFjePd9HfxVftyTcQ17nwr59U9sDvdA7sDMDVjKlB+saC0uJTHEh6jR2CPWs1zNr4aX/oF9/N2jHqntak1rU2tvR1DNCJSaBYVKIpCoa2QUWGjqvbhqbgYEhLKt48eBVPdXB1YCCGEEMIT1q9f79w+evQojzzyCLfeeis9epT/cr5p0ybeeecd5s6d662IohFo2bIlu3btAqBFixZeTlPRxo0bK2zXp0Lz3r17ndvHjx+nqKgIf39/LyZyj65du/LOO+94O8Y52Tl9UU5RlFo/f4guhMWtF5NqSSXOGIdBbXDpuBhDDM+3fJ6kwiTa+bU7a9uQo6VHeSO1/OLFwdKDJBgTuDryaoaHDUer0rrcu9gTrr76ahYsWIDdbuf+W+6vE0VmIUT9IYVmUUGpoxRfjS9XhF1R9YOzau/2HiGEEEKIuqTvqUWRgVmzZvHiiy9yww03OJ8bOXIkHTp04I033uCWW27xRkRRh1gsFlJTU4mOjsZodN8Mzccee4xvv/0WHx8fhgwZ4rZxd+7cyebNm2nXrh29e1evfUHHjh2dF2Q6dOjgtmy14dJLL+X3339HURQ6d+7cIIrM9cHYqLGcsJzgpPUkY6PG1ups5lN8ND40921e5eOa+TSjmU+zc75ucVRsVWJ2mAG88h7/q2fPnrz//vvY7fYG0yZGCFF7VIoXLg0WFBQQGBhIfn5+g/6H69Jtl2JVrC41/q8riuxFFJQV8FnHzyr9j/EMxcXg9/+tNoqKZEazEEII0Ug1ls95lfH19WXnzp20bNmywvP//PMPnTp1oqSkxEvJPEe+764rLCxk+vTpnDhxgqioKJ5//nkCA13rX+sNKSkpTJkyBZvNBsAzzzxDp06dqjyOzWbj119/Ra1W06dPH9RqtZuTetbx48fJzs6mQ4cOaLUyX8sVDsWBWlW/vs+16c0Tb7IuZx2tfFvxWMJjdaLI7C6N+Xv/U85PfJX1FfHGeCbFTUKv1ns7khBu4epnvcb5ky/Oya7Y0ag0+Kp9vR1FCCGEEKJeatKkCa+99toZz7/++us0aXL+haREw/bnn39y4sQJANLT09m6dauXE1UuLS3NWWQGSE5OrtY4Wq2WAQMG0K9fv3pXZAZo2rQpnTt3btRF5o/TP+axg4/xVdZXle533Hyc2/bexlW7ruKzjM9qKV39Mz52PB93+JhZzWc1qCLzqsxVXLXrKm7bexvHzce9HadWZVmzWJS8iAOlB/gx90c+P/m5tyOJWqQoCrlluTgUh7ejeFXj/V9SnFWZowytSuvyqsBCCCGEEKKihQsXMmbMGL777jsuueQSADZv3syhQ4dYuXKll9MJV2zYsIH8/Hz69++Pr697J2DExcWhVqtxOByoVKo6f/GhQ4cOtGjRgoMHDxIREUGvXr28HalGVq5cyV9//UWvXr0YOHCgt+PUGxvzNvJBxgcA7C7eTQufFlxguuCs+36S8QlZZeVtFd9Nf5fhYcMbVCFVnJvZbmZ52nIUFLLKsvgk4xOmx0/3dqxaU6aU4eB0kfFUSxTR8FkdVp449AT7SvYRb4znuebP4af183Ysr5BCs6jArtjx0/q5vNCBEEIIIYSoaNiwYRw4cIDFixfz999/oygKo0aN4q677qrzRUUBn3zyCe+//z4AP//8MwsWLHDr+ImJiTz99NNs376dTp060bp1a7eO725Go5EFCxaQnp5OeHg4BoOBH7J/YG3OWhKNiUyMneiWhctycnLQaDQebSPy+++/s3z5cgC2bdtGs2bNSEw8c6E2caYie1Glj//t35OWfNW+aFXn/vuRZc3CoDbgr208fa8VRUGlUnk7hkdoVVp81b4UO4oBGt0EtmhDNNdHXs+ak2toamzKqPBR3o4kasmOwh3sK9kHwDHzMTbkb2Bo6FAvp/IOKTSLCsyKmWa6Zg32Pz4hhBBCiNoQFxfHnDlzvB2jwVIUhc8//5yUlBSGDBlCq1at3Db2X3/95dzev38/drsdjUbjtvEBOnXqVK0+x96i1WqJi4sD4KOvPuKRpY9gCDOQeEsicca4GhdTVq9ezdKlS9FoNEydOpU+ffq4I/YZ8vLynNuKolR47KqcshzePPEmpfZStF9pObLrCF27dmXSpEkN+neovsF9+TXvV/YU7aFHYA+6+Hc5577josZhdVjJKsvi2ohrz3kh4oP0D/g442N0Kh2PxD/CxYEXeyp+nWC2m5l5ZCZ7i/fSI7AHD8c/XGf7GH+b9S0HSg/QL6gfHf07unycVq3lqcSn+CTjE8J0YdwUdZMHU9ZNY6PGMjZqrLdjiFoWrgtHhQqF8mXwIvWRXk7kPVJoFhWUOcroG9T3/Dv+l1oNF110elsIIYQQohHLy8vjjz/+IDMzE4ejYq++m2++2UupGo41a9awdOlSoHyW6ttvv43JTYtRX3rppfz5558A9OjRw+1F5vqsoKCAt5e8jbnIjDnbTNr3aZQ2L63xuCtWrADAbrezevVqjxWa+/Xrx7p16zhw4ADt27cnPDy8ymMsTlnMloIt5O7OJfnzZDr6deTbb7+lc+fO9OjRwwOp6waD2sCzzZ91aTauj8aHyU0mn3fMzzLL+zeXKWV8fvLzBl9oXp+7nr+Kyy9kbczfyJ+Ff9I1oKuXU53pl9xfWHxiMQAfrf6IiF8jiIuM44knniA6Ovq8x7cxtWFm4kzPhhSijmnu25yH4x9mc/5mOvp1pLN/Z29H8hopNIszhOur/oELHx+o4wuZCCGEEELUhjVr1jB27FiKi4vx9/evUJRRqVRSaHaD9PR053ZxcTH5+fluKzQPGjSI5s2bU1BQQMeOrs/kayxMWhPR+mgyrZnEGmIZHja8xmPGxsby999/AxATE1Pj8c7FZDLx4osvsm7dOv73v/9x9913c80111TpZ7LQXujctimnF0lsyLOZ/60q77OgoIAtW7YQFxdHmzZtzng9Rh/DcUv5YnGxhli3ZayrArQBlT6uK9IsaQDYzXaOrDqC0dfI8ePH+eSTT7j//vu9G06IOqxXUC96BdXvdQzcQQrNwklRFBQU/DSNs2G5EEIIIYQ7PPjgg9x+++3MmTPH7QvJiXJDhgzhl19+oaCggN69e7s0y64qpG/v2QUEBDB58mQ+++wzoqOjeXDKg25Z7Oixxx7js88+Q6/Xc80117ghaeW+++47550GX375ZZUKzbdG38rso7MxdDRwyahLKNhXQJcuXejevbtLx1utVpYuXcqJEycYMWIEF1/cMGfxWq1Wpk+fTmpqKiqViscee8y5OOopMxNnsipzFX5aP66OuNo7Qd3o19xf+SrrK5LNyTT3ac7Y6LG0MZ0usPcK6sVNlpvYU7SHXkG9aOnb0otpz21AyAC+y/mOzLJMgo3BmDTlF/F8fHy8nEwIUR+oFEVRavukBQUFBAYGkp+fT0BA3byK5w6XbrsUq2IlQh/h7SgusTgspFnSWNp2Kd0Cunk7jhBCCCHqocbyOa8yJpOJ3bt3N6pipTe+74cOHeLw4cP07t1bCiCiSl599VXWrl0LQMuWLXnxxRfPul9BQQGff/45er2e0aNHYzCcXjC9ugu6ffzxx3zwwQcA6HQ6li9fTkBAAFarFb1eX413UzelpKQwadIk5+Phw4czceJELybyrAxLBhP+nsDh0sNkWjOJN8bT3Lc5H7b7sF7Odrc6rOTb8jm26xgrVqwgPDycSZMmue3OkX/LsGTw7NFnybRmMjZqLCPDR7r9HEKImnP1s57MaBZOBbYCgrRBtPatxsrXJSXQtm359t69ILN3hBBCCNFIDRkyhG3btjWqQnNtS0pK4umnn8Zms/HNN9+wYMECtFr51aauUxSFTZs2YbPZ6N27N2ovre0yfvx4IiIiKCkpYdSocy9kOGfOHOfikGlpaTzwwAPO16pbPCwsPN16o6ysDLPZzLJly/jxxx+JiYlhzpw5hIaGVmtsKG978EnGJ/hp/Lgx6kZ8Nd75vSwyMpL4+HiOHTuGWq3molPr+TRQxY5iHDic7VRsio0Sewk2xYZOpfNyuqrTq/WE68MJvyjc49+7TzI/4aj5KABvpb7FwJCBzlnUQoj6Rz6NCadiezEXB1xcvV5RigLHjp3eFkIIIYRopK644gqmT5/O3r176dChAzpdxSLDyJEyW6umNm/ejM1WXtA5ePAgGRkZxMY2/B6v9d3bb7/NF198AcD27dsrFG5r07ladGRaM3nx+Ivk2fK4Lfo2jh8/7nwtOTnZLee+8sor+fPPP0lNTWX06NGUlJTw448/ApCamso333zDuHHjqj3+rCOzSLGkAFBkL+L+pve7I3aV6XQ65s2bx59//klMTEyDv/CW6JPIsNBhrLKvQoWKGEMMd8bciU5d/4rMtc1HffqOFJ1KhwZZgFWI+kwKzcKpTCmjqbGpt2MIIYQQQtRr48ePB2DWrFlnvKZSqbDb7bUdqcFp164dX3/9NQARERGEhYV5OZFwxY4dO5zbSUlJ3gtyDstSl/FXcfkM5uePP89VI67iww8/RK1W02lgJ9468RaJPokMCBlQ7XOEh4ezePFiZ+uNrKwstFqt88JJcHBwjd5DpjXTuZ1hzajRWDVlMpno3bu3VzPUpklxk7gr9i5UKlW1W6s0RjdG3Ui+LZ9MaybXRl6LUWP0diQhRA1IoVk4qVARrg/3dgwhhBBCiHrt1CJjwnMuvfRS/P39SU5OplevXhV654q6q3v37s6Zwd261f01Ya6//nr69etHqaqUR04+QmlWKQAalYa+wX1rNPapImRYWBiPPfYY3333Hc2aNWPYsGE1GvemqJtYlrYMg9rAtZHX1mgsUXWnvq9SZHadSWNiWvw0b8cQQriJFJpFBRG6+rFwoRBCCCGEaNw6depEp06dvB1DVOLkyZPs37+fCy64gLCwMG655Rbat2+P3W6vk4Xm22JuI8eWQ15ZHrfF3IZKpSI6OpoDJQcozSh17nfcfPyMY61WK3a7vVoLU3br1s1tX4/REaMZHDoYrUqLQS0XYIQQQtQulwrNBQUFLg/YWFcXr+/sih0FRXpICSGEEELUUEpKCkFBQfj5+VV4vqysjE2bNtGnTx8vJROi9mRkZHDfffdRXFyMn58fixYtIiIigq5du3o72jlF6COY12IeR44c4bmHnuPlopeZOHEiPXv3pIOpA7uLd+Ov8adfcL8Kx23bto25c+dSVlbGxIkTueKKKzySr8xR5tLva7KQWv3x3nvv8dVXX5GQkMATTzyBv7+/x85ldVjRq/UeG18IIQBcWuY3KCiI4ODgSv+c2kfUT+nWdGIMMXQLqHszC4QQQggh6oO0tDQuvvhi4uPjCQoK4pZbbqGoqMj5ek5ODv379/diQiFqz549eyguLgagqKiIv/76y8uJXPfOO++QmppKQUEBL7/8Mlq1lmeaP8MrrV7hzTZv0sTYpML+H3/8MVarFUVReO+999yeJ9OayYR9E7hq91UsSVni9vErY7Vaeffdd3nppZcqLI4oai4lJYVPP/2UkpIS9u7dy5dffnnW/bKsWewp2kOZo6xa5ymyFXH/P/czZvcY5h6di0OR9k7ekGXNYl3OOo6WHvV2FCE8yqUZzevXr/d0DuFlJfYSbo66mRhDTPUGUKmgbdvT20IIIYQQjcwjjzyCRqNhy5Yt5OXl8eijj9KvXz9++OEH54QMRVG8nFKI2nHBBRdgNBoxm80YjUZat27t7UguMxqNZ2xrVBrifeLPun94eDj79+8HyhendLc1WWtIs6YB8E32N4wMG0msMdbt5zmb9957j88//xyAP//8k+XLlzeY/sNljjK2FW4jRBtCa1Pt//3U6/XOhQOh4t+7U/4u/psnDj2BRbHQxrcNc5rPQauuWgfUdbnrOFR6CICN+RvZU7SHjv4da/4GhMvybfk8cOAB8mx5aFVa5reYT0vflt6OJYRHuPQvVN++NVvoQNRtp/5ja+XbqvqD+PpCPZqlIIQQQgjhbj/++COrV6/moosuAsoXrLvuuusYMGAA69atA2SBKNF4xMbGsnDhQvbs2UOHDh2IianmhBYvGD9+PGVlZRQVFXHrrbeed/+7776bwMBAzGYzN9xwg9vzBGmDnNt6lR4/rd+5d3azzMxM53ZOTg5Wq/Wsi2/aHDY0Kk29+jdu1pFZJBUlAXBv3L0MCh1Uq+ePiIjgvvvu49tvvyU+Pp4RI0acsc9veb9hUSwA7CvZR6o1labGplU6T7D29J3nKlQEagNrFlxU2eHSw+TZ8gCwKTZ2Fe1yudC8vWA73+d8T4Ixgesir0OtcqkxgRBeU63FAH/77Tdef/11Dh8+zIoVK4iNjeW9996jWbNm9O7d290ZhYfZFTsalabCBxghhBBCCFE1+fn5FVrJGQwGPvvsM6655hr69+/P+++/78V0QtS+uLg44uLivB2jykJDQ5kxY4bL+/v7+3PXXXfV6JyFtkJUqM5aRB4VNooiexHHzccZFjqsVguFV155JTt37qS4uJirr776rEXmTzM+5f309wnWBvN04tMk+CTUWr7qsjgsziIzwJaCLbVeaAYYOHAgAwcOPOfr/54MFqwNJlwXXuVz9AnuQ4Y1g33F++gT3OecM/OF5zT3aU6INoQcWw46lY5Ofp3OuW+GJYOfcn8ixhBDB78OzD46mzKljI35GwnQBnBFmGd6wAvhLlUuNK9cuZJx48YxduxYduzYgcVSfnWtsLCQOXPm8M0337g9pPAss2LGoDIQoXf/bV5CCCGEEI1FYmIiu3btomXL07OUtFotK1as4JprrmH48OFeTCeEqKvWZq9lccpi1Ki5v+n9Zyw2qFVruSX6Fq9ka9OmDe+++y5ms5mAgIAzXjfbzbyf/j4KCjm2HD7N/JSH4h/yQtKqMagNtPZtzf6S8pYnF/pd6OVEFeXb8nn68NMcMR+hvak9nf07c2nQpfhofKo13jWR17g5oaiKAG0AC1stZFfRLpr7ND+jz/spVoeVhw89THZZNgBXh19NmXK6N/ep54Woy6o85/7ZZ5/ltdde480330SnO73ibc+ePdmxY4dbw4naUWwrxqA2EKmPrP4gJSXQrl35n5IS94UTQgghhKgnLr/8ct54440znj9VbO7UqVPth2rAdhXu4pusb8gry/N2FFEPZGdnk51dN4s0n2R8goKCHTsrMlZ4O84Z9Hr9WYvMAFqVFpPG5Hxcn+6SfTbxWe6Nu5eZzWYyIvzMthWn2BU7SYVJHCs9VmvZvsr6igOlB7ApNvYU7+HigIuJNkTX2vmF+4XoQugX3O+cRWaA3LLcCsXkQnshA4IHABCtj2ZY6DBPxxSixqo8o3n//v306dPnjOcDAgLIy8tzRyZRi8ocZeTb85kYOxF/rX/1B1IU2Lv39LYQQgghRCMze/ZsSs5xwV2r1bJq1SpSUlJqOVXD9Hve7zx37DkAVp9czautX0Wv1ns5lair1q5dy+LFiwGYOHEiV1xRt249j9JHkVWWBVDviolatZanmj3FiswVhOnCuDnqZm9HcplRY3SpXcbsI7PZWrgVFSqmNZ1Gn+Az6yE1UWovZcGxBRwxH+Hy0Mu5NvJa/DSnW6ioUeOr8XXrOUXdFKGPoJNfJ5KKktCr9PQL7kd7v/bcFXsXRrWxXvVAF41XlQvN0dHRHDx4kISEhArPb9iwgcTERHflErWk1FFKgCaA6yKu83YUIYQQQoh6TavVnnPWH4BGoyE+XnpjusPuot3O7XRrOietJ4k1xnoxkajLVq1a5VwAffXq1XWu0PxQ/EN8mvEpGpWG6yK9+3vZhrwNfJj+IRH6CB5o+oBL/aAvMF3AjGau97SuT0rtpWwt3AqAgsKG/A1uLzSvyVrjPMd76e/RI7AHV4ReQaY1k8Olh7k89HJpc9lIqFQqnmr2FAdLDxKmCyNMHwZQ7ZYpQnhDlQvNEydO5L777mPp0qWoVCpSU1PZtGkT06ZN48knn/RERuFBFocFnUonK88KIYQQQoh64+KAi1mbvRY7dhKNiTVrAScavCZNmpCWlgZQJxcnDNYFMzFuordjYLabeeH4C9gUG8mWZN5Pe597mtzj7Vhe5aPxIcGYwFHzUQDa+LZx+znU/+loqkaNVq1lfOx4t59L1H1atZYLTBd4O4YQ1VblQvNDDz1Efn4+/fv3x2w206dPHwwGA9OmTWPy5MmeyCg8KN+Wz2Uhl511dWMhhBBCCCHqoi4BXVjUahFp1jQu9LsQrbrKv9aIRmTq1KmsXLkSRVEYM2aMt+PUacq/2iA6cHgxSd0xp/kcfsr9iVBdKL2Dert9/BHhIzhiPuKcvXy+uzNOmE/wdurbANwZeycxhhi3Z6qJ3UW7WZezjkSfREaEjZB2D0I0MtX6RDZ79mwef/xx9u7di8PhoG3btvj5SaGyvmrh08LbEYQQQgghhKiSeJ944n2kFYk4P5PJhK+vLx999BFbtmzhqaeeIjLS+7PgM62ZfHnySwK0AYwOH41OrfNqHqPGyJQmU/gw/UPC9eHcGHWjV/PUFf5af0aFj/LY+Aa1genx013ef2HyQvaX7Aeg6HgR81vOd3umb7K+YWnqUkJ0IcxoNqPSBez+Lacsh5mHZ2JVrKzLXYevxpfLQi5zez4hRN1V7Uv/vr6+REZGolKppMhcj6lQYVQbvR1DCCGEEEIIl+Xn5zNnzhySk5O56qqruPrqq70dSdRhBQUFvPvuuyiKQnJyMp9++ilTpkzxdixmHJpBqjUVgAJbAXfG3unlRDAwZCADQwZ6O4aoRJG96Kzb7lLmKOP1E6/jwEGaNY0P0z/k4YSHXTo2uywbq2J1Pk6zpLk9nxCiblOff5eKbDYbM2bMIDAwkISEBOLj4wkMDOSJJ56grKzMExmFBykohOpCaz6QSgXx8eV/5NYYIYQQQjRyv/32GzfddBM9evTgxIkTALz33nts2LDBy8kahpUrV7J3714KCwt55513OHnypLcjedXWrVvZtGlThbYH4jSdTodOd3q2sMlk8mKacnbFTpr1dBEuxZLixTSiPhkfMx5/jT/+Gn/ujHH/xQm1Sl1hMpqfxvWJhc19mtM9oDsAYbowBocMdns+IUTdVuUZzZMnT2b16tXMnz+fHj16ALBp0yZmzpxJVlYWr732mttDCs+wK3YA9ywE6OsLR4/WfBwhhBBCiHpu5cqVjBs3jrFjx/Lnn39isVgAKCwsZM6cOXzzzTdeTlj/GQwG57ZarUaj0XgxjXe98847fPbZZwAMHDiQ+++/37uB6iAfHx8ee+wxPvvsM6Kiorjhhhu8HQmNSsPIsJF8kfUFOpWOK8Ku8Hak80q3pAMQZYjychLXWRwWdCodalWV59jVWV0DuvJh+w89Nr5GpWFGsxl8mP4hIboQbo6+2eVj1So1jyc8To4thwBNgNfbwQghap9KqeJl78DAQD7++GMuv/zyCs9/++23XH/99eTn5593jIKCAgIDA8nPzycgIKBqieuRS7ddilWxEqGP8HaUs8ouy8au2Pm84+dEG6K9HUcIIYQQDUBj+ZxXmc6dO/PAAw9w88034+/vz86dO0lMTCQpKYmhQ4eSnp7u7YhuV9vfd7PZzCuvvEJKSgqjRo2if//+Hj9nXTVlyhSO/v+Ej8DAQN5//33vBhJVkm5Jx0fj457JP/+yZ88e3n33XQICArj77rsJCQmp0XhfnPyCt1LfQoWKO2PuZGT4SDcl9ZwP0j/g44yPCdQG8nSzp2nu29zbkYQQot5y9bNelS/rGY1GEhISzng+ISEBvV5f1eGEFxXYCujk10mKzEIIIYQQbrR//3769OlzxvMBAQHk5eXVfqAGyGg0cvvttzNp0iQuvfRSb8fxqs6dOzu3u3bt6sUkojrS96Wz/NXlrF271q3jzpkzh3379rFlyxbefvvtGo+3JmsNUN568ausr2o8nqeV2kv5OONjAPJt+aw8udLLiYQQonGocuuMe+65h2eeeYZly5Y5b1mzWCzMnj2byZMnuz2g8BybYiPWEOuewUpL4dQvVL/+Cj4+7hlXCCGEEKKeiY6O5uDBg2dMztiwYQOJiYneCdXA7Nu3jxkzZmCxWOjYsSPPPPMManXDuTW+Km677TbatWtHWVkZPXv29HYcUQXp6ek8/fTT2Gw2fvzxR/z9/enVq1eNx1UUxdmyB8rvAKipBGMCGdYMAOKN8TUez9N0Kh3+Gn8K7YUA7lmX6Bzybfnk2/JpYmiCStYrEkI0ci4Vmq+66qoKj3/88Ufi4uK48MILAdi5cydWq5WBA2V12vrCpthQoaKjf0f3DOhwwLZtp7eFEEIIIRqpiRMnct9997F06VJUKhWpqals2rSJadOm8eSTT3o7XoPwyy+/OAtpu3btIi0tjdhYN02gqGdUKhXdu3f3doxGrcxRxtfZX2O2mxkeNhw/rWuLp508eRKbzeZ8nJaWVsnerlOpVEyZMoU33niDgIAAbrnllhqPObXpVL44+QUqVIwKH+WGlJ6lVWt5OvFpVmauJEwXxk1RN3nkPH8V/cXMIzMxO8z0DuzNwwkPe+Q8QghRX7hUaA4MrNgvasyYMRUeN2nSxH2JRK0osZfgp/Gjm383b0cRQgghhGhQHnroIfLz8+nfvz9ms5k+ffpgMBiYNm2a3AHoJs2bn+61GhQURGio52YrNlZ2u52XX36Z3bt307NnT+644w5vR6qS/Px8Pv30U9RqNddeey3+/v4eO9cbJ95gbU5564udRTuZ22Ku87USewnbCrYRbYimpW/LCse1adOGjh07smvXLiIiItzaa7xfv37069fPbeP5any5Icr7iyhWRUvfljyS8IhHz/F9zveYHeUzxjfkb2B82XhCdDXrh/1vh0oOsb1wO+1M7Wjn185t4zZkxfZiPsn4BJti4+qIq936/RBCnJ9LheZly5Z5OoeoZTbFhlaldfuiE0IIIYQQAmbPns3jjz/O3r17cTgctG3bFj8/12Y5ivMbNGgQBoOB5ORk+vfvj9Fo9HakBufXX39l3bp1AHz++edcdNFFzjta64P58+ezdu1a0tLSeOutt1izZg1hYWEeOddh8+HT26Wnt20OG48efJTD5sOoUPFYwmNcEniJ83WtVsszzzzD7tTdxIXGEeojF0zqm3+3EQnRhuCvcd8FjTRLGg8dfAirYkWNmgUtF9DKt5Xbxm+oXk5+md/zfwfgYMlB5rec7+VEQjQuVe7RLBoGs8NMtD4ak8bk7ShCCCGEEA2Sr68vF110kbdjNFhnW3BReE596z179OhRUlJSgPKWFCtXrmTixIkeOdfQkKEcKDmAgsKwsGHO57PLsp1FaAWFrQVbKxSaARYcX8CG/A0Yc4083exp2vq19UhG4Rmjw0djVBtJt6YzNHQoOrXObWMfKT2CVbEC4MDBwZKDVS40m+1mCuwFhOvC693PcHWlWU63oEm1pnoxiRCNU7VWzPjss8+49tprueSSS+jSpUuFP6J+KLGX0NbUttH8ZyOEEEIIUVuKi4uZMWMGPXv2pEWLFiQmJlb446q5c+fSrVs3/P39iYiI4Morr2T//v0V9lEUhZkzZxITE4OPjw/9+vXjr7/+qrCPxWJhypQphIWFYTKZGDlypLMAd0pubi7jxo0jMDCQwMBAxo0bR15eXrW/BqL+69u3L4MGDSI6OpqrrrqKjh3dtLZLLbnqqqtQq9WoVCqio6Px9fX12LkGhQ7i9Qte5+VWL3NL9Ol+yKG6UJoamjofd/bvXOG47zZ8x1uz3+LYZ8cosZTwfc73HssoPEOlUjEsbBi3x9xOjCHGrWN38OtApD4SgEBtIBcFVO3C5bHSY9yx7w7u2HcH847NQ1EUt+arq8ZEjEGr0qJCxTUR13g7jhCNTpVnNP/vf//j8ccf55ZbbuGLL77gtttu49ChQ2zdupV77rnHExmFmymKgoJCB78O3o4ihBBCCNHg3Hnnnfzyyy+MGzeO6Ojoal/Y/+WXX7jnnnvo1q0bNpuNxx9/nMGDB7N3715MpvK70ubPn8+LL77I8uXLadWqFc8++yyDBg1i//79zp60999/P2vWrOHjjz8mNDSUBx98kOHDh7N9+3Y0Gg0AN954IykpKaxdW95ndsKECYwbN441a9a44SviOYqisGjRIn7//Xc6dOjAI488gl6v93asBkGtVnPvvfd6O0YF+/fv59dff6Vly5YV+g+vzV7L11lfE2+MZ0qTKRjUBsaMGUNAQAArvliBI8pB28s9O1M491AuTz/9NL6+vsydO5eoqCi0ai3zWsxjS8EWovXRFWYr5+bmsvj5xZjzzBT8U4AuUEf8zfGVnMH7Cm2F7CveR4JPAhH6CG/HafD8tf4sarWIw6WHaWpsWuW2l9/lfEeBvQCA3/N/J9WSSqyx4S+a2ie4D539O2NX7ATpgrwdR4hGp8qF5sWLF/PGG29www038M477/DQQw+RmJjIk08+SU5OjicyCjcrshfho/aho5+bZyV4qOeZEEIIIUR98u233/L111/Tq1evGo1zquh7yrJly4iIiGD79u306dMHRVF46aWXePzxx7nqqqsAeOedd4iMjOTDDz9k4sSJ5Ofn8/bbb/Pee+9x2WWXAfD+++/TpEkTfvzxR4YMGcK+fftYu3Ytmzdvpnv37gC8+eab9OjRg/3799O6desavQ9P+vPPP519hLdu3cr69esZMmSIl1MJT8jKyuLxxx/HYrEAoNfr6dmzJ5nWTBanLEZB4aj5KE2NTbk28loALul/Ce/GvEueLY+nTzzNTP1MugR45i7cG264gfT0dGfWUxdp/LR+DAwZeMb+ZrMZh93BBaYLyLRm0lvXmyvDr/RINncothcz9cBU0q3pGNVGFrRYQIJPgrdjNXgmjanaE8Si9dGnx1GbaqXoqihKnbhr2l/rucU/hRCVq3LrjOPHj9OzZ08AfHx8KCwsBGDcuHF89NFH7k0nPKLIXkSoLtS9M5pNJjh5svyPSfo+CyGEEKLxCg4OJiTE/avc5+fnAzjHPnLkCOnp6QwePNi5j8FgoG/fvmzcuBGA7du3U1ZWVmGfmJgY2rdv79xn06ZNBAYGOovMAJdccgmBgYHOff7LYrFQUFBQ4Y83+Pj4VPpYNByZmZnOIjOU/14KYFfsKJxuCVCmlDm3Uy2p5NnygPIeyXuL93okm9VqJTc31/k4IyPjvMdER0czevRoTDoTl7a+lCdverJOFOjO5UDJAdKt5YV0s8PMtoJtNR7ToTgosBU0uJYOOWU5vHHiDd5Ne5dSe6nXcgwPG86dMXcyNGQozzR/xqPrMxXZiph2YBpX7rqSl46/1OC+p0II11W50BwVFUV2djYA8fHxbN68GSj/oCv/mNQPRfYi+gT1Qa2qVotuIYQQQghRiWeeeYYnn3ySkpISt42pKApTp06ld+/etG/fHsA5ezIyMrLCvpGRkc7X0tPT0ev1BAcHV7pPRMSZt8FHREQ49/mvuXPnOvs5BwYG0qRJk5q9wWpq06YNt99+O61bt+bqq6/m0ksv9UoO4XktW7akTZs2AAQFBdG3b18Aog3RjIsaR5A2iAv9LmRU2CjnMfHGeOIMcZTaS8m2Zjv73bqbXq/n6quvRqVSoSgKo0ePdum422+/ndWrV/PKK68QGhrqkWzuEm+Mx19TPktUjZq2ppq1Iim0FTJl/xTG/jWWJw4/gc1hc0dMt/g191du3HMjE/ZN4EjpkSofP/vobNZkrWFF5goWpyz2QELXqFQqRoWP4p4m99DSt6VHz/V9zvfsL9mPAwfrctfxd8nfle6fac0ky5rl0UxCCO+ocuuMAQMGsGbNGrp06cIdd9zBAw88wGeffca2bduct+yJusvqsKJRaegTLKt0CyGEEEK4S+fOnSvMRjx48CCRkZEkJCSg0+kq7Ltjx44qjz958mR27drFhg0bznjtv7MgXbl1+b/7nG3/ysZ59NFHmTp1qvNxQUGB14rNo0ePdrmwJ+ovnU7HnDlzSE1NJSwsrMLiftdGXutsl+FwOJzPGzVGHop/iAn7JmDSmFh8YjGJPok0923u9nwvvvgiJpOJP/74g40bN/LVV18xfPjw8x5Xl2cx/1uwLpgXWr7AtoJttPRtyQWmC2o03i95v3DcUj4rfVfRLnYW7aRrQFd3RK2xl1NexuwwU2gv5J20d5iZOLPS/f/7b+UJ8wnndqo11UMp65ZTFyEAVKjw0/idc98vTn7BW6lvoULFXbF3MSxsWG1EFELUkioXmt944w3nf9533XUXISEhbNiwgREjRnDXXXe5PaBwr0xrJjH6GLoFdHPvwKWlcPnl5dvffgty26IQQgghGpErr7zSY2NPmTKFL7/8kl9//ZW4uDjn81FRUUD5jOTo6NO9ODMzM52znKOiopy39f97VnNmZqazHV5UVNRZb/U/efLkGbOlTzEYDBgMhpq/OSGqQKvV0rRp0wrP7dixg2XLlrFp0yb27NmDxWLBYDDQvn17evTowUVXX4QxyAiATbHxd8nfHik0A+zZs8e5GOVvv/3mUqG5vii0FbKlYAuBmkBa+9a8b3u4Lty5rUJFqK7uzOg2qo2YHWbndmVeTn6ZH3N+pIVvC2Y2m4m/1p9rIq9hedpytCoto8Mbx0Wwy0IuI82axv6S/QwIHkAT47kvPH5x8gugvJ3N5yc/dz4/KGQQOrXuHEcJIeqLKhea1Wo1avXplgvXXnst1157rVtDCc9QFIUSewlXx17t/v5MDgf88svpbSGEEEKIRuSpp55y+5iKojBlyhRWr17Nzz//TLNmzSq83qxZM6Kiovjhhx/o3LkzUN4r9pdffmHevHkAdO3aFZ1Oxw8//OD8zJ6WlsaePXuYP38+AD169CA/P58//viDiy++GIAtW7aQn5/vLEbXRSdOnCA9PZ327dtL0bsROnjwIBMmTGD9+vXExsZy2WWXcdNNNxEQEEBBQQFJSUnOthQx3WNo/XhrIhIi6OTXyWOZ2rdvT1JSknO7IZlxeAaHSg8BkGHN4Pqo62s0XvfA7kyKncRfxX/RM7BnnVpY8LGEx3gn7R38NH5MiJ1wzv3+KfmH73O+d25/l/0dV0dezZiIMfQP7o9OpWs0i9KpVCpujr7ZpX2bGptysuwkACmWFJacWALAnuI9PBT/kMcyCiFqh0uF5l27drk8YMeOHasdRniWHTsalYZ2fu28HUUIIYQQosFKTExk69atZ/RczcvLo0uXLhw+fNilce655x4+/PBDvvjiC/z9/Z39kgMDA/Hx8UGlUnH//fczZ84cWrZsScuWLZkzZw6+vr7ceOONzn3vuOMOHnzwQUJDQwkJCWHatGl06NCByy67DCjvczx06FDGjx/P66+/DsCECRMYPnw4rVvXfOaiJ+zcuZOZM2dis9lo2bIl8+fPR6ut8hwaUU99+OGH3HnnnURHR7Nq1SpGjBhx1u+/zWZjzZo1TJs2jU3XbWLR64uI7RDrsVyPP/44P/30E35+fhX6hVsdVl44/gJ/F/9N3+C+3B5zu8cyeILNYXMWmQH2l+x3y7jDwobVybYJbUxteK7Fc+fdz6Q2oULlXIzST3u6XUSIzv0LwjYU05pOY/XJ1ahVatblrHMWnfcXu+fvlRDCu1z6NNapUyfnwgaVUalU2O12twQT7me2mzGoDXXqtiQhhBBCiIbm6NGjZ/1MbLFYSElJcXmcJUvKZ3n169evwvPLli3j1ltvBeChhx6itLSUu+++m9zcXLp3787333+Pv//pWXQLFy5Eq9Vy7bXXUlpaysCBA1m+fDkajca5zwcffMC9997L4MGDARg5ciSvvPKKy1lr26ZNm7DZyhcPO3DgABkZGcTGeq6AKOqODz/8kJtuuombbrqJJUuWYDKd+05NrVbL6NGjGTx4MJMmTeKuW+7CT+PnvBDjbkajkWHDziyc/pDzAxvzNwKw+uRqegb2rHGP49qkVWvpHdibDfkbUKGib3Bfb0eqE2KNsdzf5H7W5a6jhU8LBocM9nYkAIrtxazIWIEDB1dHXE2ANsDbkSrw0/oxLnocABo0fJDxAQD9gvt5L5QQwm1cKjQfOVL1lVZF3ZNVlkVr39a08m3l7ShCCCGEEA3Ol19+6dz+7rvvCAwMdD622+2sW7fujPYXlTnfJA8on+gxc+ZMZs6cec59jEYjL7/8Mi+//PI59wkJCeH99993OZu3tW3bluWrl2N2mGkd25qwsDBvR6qXNudvZm/xXroHdK8Xdz0eOHCAO++8k5tuuonly5dXaOkI5TOYc3JyCAkJqTDD2WQysXz5cgDuvPNOLr74Ylq0aFFruTUqTaWP64OH4h/iiuIrCNAG0NTY9PwHNBIDQgYwIGSAt2NUsPD4QrYUbAHgSOkRnmn+jJcTndv1UdfTNaArDsVBa1PdvINGCFE1LhWa4+PjPZ1D1AKbYmNI6JB6+cFGCCGEEKKuO7UgoEql4pZbbqnwmk6nIyEhgRdeeMELyRqeknYl6G7VYc+0Y+9qx66VuyqrKqkwidlHZwPwVdZXvNr6VaIN0ec5yrsmTpxITEwMS5YsqVBkttvtvPDCC8yeM5eC/DwCAoN47NFHmDZtmnPmvlqtZsmSJfz+++9MmDCBn376qdZyXxZ8Gf+U/MPfxX/TL7gfLX1beuxcWdYsdhbtpIVPC+J93Pd7vEqlor1f3es7rSgK76e/z+6i3fQK6sWo8FHejuR1JywnzrpdV3ny50EIUfukkVkjYXFYUKvUblkhWAghhBBCnMnx/wsiN2vWjK1bt8osWw/6K/UvUr5MoTSjFFuRjdyLcvHV+Ho7Vr1yzHzMuV2mlJFqSa3Thebt27ezfv16Vq1adUa7jFmzZjFr1izn44L8PB555BFKSkp4+umnnc+bTCYWLFjAmDFj2LFjB126dKmV7Fq1lnub3Ovx8+Tb8nngwAPk2fLQqrTMbzG/wRfxfs//nU8zPwVgX8k+Wvu2rldtSTzhqvCreCXlFRQUxkSM8XYcIUQjoz7/LqIhyC7LJlofTbeAbp47ia9v+R8hhBBCiEbsyJEjUmT2MPNvZiypFhS7QslPJWjy5I69quoV2Mu5dkszYzPamep264zly5cTFxfHiBEjKjxvNpuZv+B5AGJi43jzzTeJiY0DYP6C5zGbzRX2HzlyJLGxsSxbtqx2gteiQyWHyLPlAeV3s+4u2u3xcx4uPczOwp04FIdHxlcUpdKxS+wlFR4X24s9kqM+GRQ6iHfavsPytsu5IuwKb8cRQjQyMqO5kSi2FzMkZAg+Gh/PnMBkgmL5T10IIYQQQnhe85DmXOh/IVaHFX+DPz4+HvqM24CF6cNY3HoxGdYMYg2x6NV6b0eq1KZNmxg4cGCF3ssA27Ztw1xaXmy8/757ufPOO8nLy2P69OmYS0vYvn07vXr1cu6v1WoZOHAgmzdvrtX8rkhLSyM/P5/WrVujUqmqfHxz3+YEa4PJteWiU+no6NfRAylP+yH7B15OeRkFhd6BvXk44WG3jp9UmMTco3MpU8qYEjeF/iH9z9inX3A/fs//nd1Fu+kZ2JMu/rUzS72uC9IFeTuCEKKRqtKMZrvdzi+//EJubq6n8ggPOHUFuLHfQiSEEEIIIRqGvn37UlpUSsqhFDp26Fhh4UXhOl+NL818mtX5IjPAnj176NSp0xnP79q1y7ndoUMHANq3P91LeOfOnWcc06lTJ3bv9vxs36rYvHkzkyZNYvr06cyfP79aYwRqA1nYaiFTm0xlUatFtPD17IKHv+X9hkL5oqW/5//u9lnN76W/R4mjhDKljKVpS8+6j16t5+nEp1nVcRXT4qdVq0AvhBDCfapUaNZoNAwZMoS8vDwPxRHuVuYo41DJISL1kfQPPvMKsBBCCCGEEPXNN998g7+/P61ateLPP/8kMzPT25FqTW5ZLlnWLG/HqFUOhwOLxUJAQMAZrxX/665Kf39/gAr7FZ/lrsvAwEAsFouzr3pdsG7dOuz28kUtN2zYcEbLD1eF6kLpH9KfJsYm7ox3Vm1NbZ3brXxboVadu7xQYCsg01q1n9NAzekLSEHaoCrnE+5jdVhZl7OOjXkbURTlnPvZFVmYVVR0uPQwjxx8hCcOPcEJc91fnFLUXJVbZ3To0IHDhw/TrFkzT+QRbpZZlklTY1Oeb/m8Zz9smM0w5v8XGli5EoxGz51LCCGEEKKOstlsfPDBBwwZMoSoqChvx2mw/r0YnFarxWAweDFN7fkp5ycWJS/CgYPbo29ndMRob0eqFWq1GoPBQEFBwRmv/fvvQmFhIUCF/f67cCBAfn4+BoMBtfr8864KCwvZtm0bTZo0oUULz80QbtmypbOdR1xcXL34O31d5HVEG6IpsBUwIGTAOffbWrDV2QLj6oiruSX6FpfGn9xkMstSl2FVrNwcdbO7YotqeO7oc2wt3ArAtRHXMi563Bn7vJbyGt9kf0OsIZZnEp8hTC9rFQh4/tjzJFuSAXgl5RXmtpjr5UTC06pcaJ49ezbTpk3jmWeeoWvXrmf8x322q8zCe0rtpXQO7kxHf8/258Juh2++Ob0thBBCCNEIabVaJk2axL59+7wdpUG76qqryM7OJiUlhREjRjSa1hmfn/wcB+WzcFedXNVoCs1Q3g4jKSnpjOc7djz9e87u3bsZOnQoe/bscT534YUXnnFMUlKSs81GZaxWK9OnT+fEiROoVCpmzpxJly6e6QF8zTXXEBoaSnZ2NoMHD64XLSBUKhV9g/ued78vT35JmVIGwKrMVdwcdbNL7y9EF8KD8Q+e9bVPMz5lb/Fe+gT1qbTIXR+kWdJQoSLKUHcvTu4qOt2iZmfRTsZRsdCcYk7h6+yvy7ctKXyV9RW3xtxamxFFHWVVrM5ti8PixSSitlS50Dx06FCgfLXef//noCgKKpXKebuP8D6H4kBBoZN/J29HEUIIIYRoNLp3705SUhLx8fHejtJg6fV67rnnnhqPU2wvptBWWKcLPP8WZ4zjiPlI+bYhzstpalePHj1YvXo1NputwoKAF110EQajDxZzKQtfWkRwcDALX1oEgNHHl65du1YYx2azsW7dOkaPPn+RPjU1lRMnym/1VhSFHTt2eKzQrFKpGDhw4Hn3s1gs/Pbbb/j7+9O9e3ePZHG3OEMcSUVJAETro0m3phOqC3WpN/iOgh38kPMDzXyacU3ENahUKn7L/Y330t8rf71wB4k+iST4JHjwHXjOysyVLE9bjgoVE2InMDxsuLcjnVWPwB78nPezc/u/fDW+aFVabIoNKO8XLgTAPXH3sCh5ETqVjgmxE854XVEU0q3pBGuDMWrkzviGoMqF5vXr13sih/AAs8OMXqWnlW8rb0cRQgghhGg07r77bqZOnUpycvJZ7wD89wxMUX3ZZdmctJ6khU8LtOoq/1rD/uL9PHn4SUocJfQP7s/UplM9kNK9psRNIVofTZlSxpiIMd6OU6tuu+02XnnlFdasWVOhSGw0Gnn4oenMmjWLtNQTjB8/3vnaQ9OnYfxPS78vv/ySEydOcNttt533nNHR0cTExJCamopKpaJz587ue0PV9MwzzzgXOBw3bhzXXnutV3Jsyd/CUfNRegf2JtYYW+m+t8XcRqA2kJyyHHYV7WLC3xOI1kczv8V8gnRB5zwuuyybZ48+S5lSxob8Dfhr/Lk87HLybHnOfRSUCo/rm6+yvgLK38fXWV/X2ULzA00foE9wH3zUPrT3a3/G675qX4aEDGF30W66BnRlRNgIL6QUdVFn/84sb7v8rK85FAfPHnmWrYVbCdQGMrf53FrpLy88q8qfyPr2Pf+tMaJuSLem097Unnamdt6OIoQQQgjRaFx33XUA3Hvvvc7nVCqV3AHoRvuK9zHj0AwsioUOpg482/zZShciO5u12WspcZQAsD53PbdG30qILsQTcd3GR+Nz1t6ojUGXLl3o378/06ZNY/DgwRUu4Dz55JP4+voyZ+5zFOTnERAYxOOPPcqDD1Zsu1BcXMyD0x8k8uJIVgWuoq29baUz6AwGA88//zzbtm0jLi6Oli1beuz9uUJRFHbtOt3CYNeuXV4pNG/I28C8Y/OA8rYYr1/wOn5av3Pur1fruT7qerbkb+HbnG8BSLOmsTF/I8PChp3zuHxbvrPlBkBWWfkimANCBrA+dz0HSg/QM7AnHf3cf/HuYMlBcm25dPbrXK0LWa6KN8Y731eCMcFj56kptUpNt4BuZ31NURQeP/w4/5T8A8DVxqs9+jUTDcdx83Fn7+98Wz4/5vzIbTHnvwgo6rZq/fT/9ttvvP766xw+fJgVK1YQGxvLe++9R7Nmzejdu7e7M4pqcigO+gX3k9sPhBBCCCFq0ZEjR7wdocH7JfcXLEp5r8fdxbtJs6Sdd1blf8UaTu8fqA3ET3PuQpmoG9544w06duzIpEmTWL58uXMxP41Gw8MPP8yDDz5Ibm4uwcHBFdprADgcDiZNmkRKagqXvnQpO4t2si53HVeEXVHpOf39/enfv7/H3lNVqFQqunfv7lw00BOtM7KsWWwv3E6iTyItfc9eWD9QcsC5XWAvILMss9JC8ynRhmg0aLBTfrHt3z+DZ9PM2Iw+QX34Ne9XIvWRDA0tb+Np0ph4sdWL2Bw2jxQ01+esZ2HyQhQUOvt1ZlbzWW4/xynT46fz5ckvUavUjAob5bHzeFKBvcBZZAbYVriN/iF142empo6WHuWXvF/K/y4G9/F2nAYnRBeCj9qHUkcpcP5/E0T9UOV/lVeuXMm4ceMYO3YsO3bswGIp/4BXWFjInDlz+ObUgnDCq/JseWhV2jp9VVQIIYQQoiGS3sye18K3BWSXb5tKTfgr/lUe46qIq9CqtaRZ0hgWOsylfrHudOjQIRYtWoTNZmPy5Mm0bdu2Vs9fH7Vo0YK3336bsWPHArBkyZIKM5u1Wi3h4eFnHFdcXMykSZN4//336TSnE6am5cf4qn0rPV9xaTHzPpuHQ+Pg4TEP42+o+t8zd3vkkUfYtm0bAQEBtGnTplpjfPHFF2zZsoXOnTtzzTXXOJ//ZdMvjF84HrvRTotxLXi+x/N08Dtz0cQuui6ssa6hTF9GK99WNDG4dqt7U2NTZjSbwZaCLbQ3tedC/zMXavw3lUrF9PjpTIqdhK/G94y7Fjw1a3Zj/kYUFAD+LPoTs93ssclbJo2JG6Ju8MjYnpJpzSTflk8LnxaoVCoCNAG09GnJgdLyCxBd/bue89i8sjz8NH71YsZzoa2QRw89SpG9yPncuYrNhbZCdCqdTPKrogBtAM8kPsNPuT8Rb4xnUMggb0cSblDln+5nn32W1157jZtvvpmPP/7Y+XzPnj2ZNctzV/pE1WRZsxgUMsh51VcIIYQQQtSeQ4cO8dJLL7Fv3z5UKhVt2rThvvvuo3nz5t6O1iBcFnIZBpWB95e/z+EfDzPBfwKzZs2iVSvX1yZRq9RcGX6l50Kex+LFi52z3//3v//x2muveS1LfXLDDTegKAp33nknv//+OwsWLGDkyJFnzGCG8oX/vvzyS6ZPn05aWhoffPAB/oP8+TX3V9qa2tIvuF+l57rusevYuqP8tu5tB7ax9qm1AGRlZbFx40aaNm1Kp06d3PwOK6fRaGo0k3n37t289dZbzu2EhAS6dStviTDvhXnkn8wH4OjnR9ndYfcZhea1a9eyZMkSbNi4/p7rue6y69CpdS6fv2tAV7oGnLsQeTauzJZ2pw5+HdhcUD5rvIVPCyke/suW/C3MPToXO3b6BPVhevx0VCoVs5vPZnP+ZsL14Wft4Qzw4vEXWZ+7nmBtMHOazyHOWPUFTQ+UHGB97nqaGZsxKNSzRcmTZScrFJkPlx4+a6H585OfszR1KTqVjkcTHuWigIs8mquhaW1qTWtTa2/HEG5U5ULz/v376dPnzB+ugIAA8vLy3JFJuElL35aoVKraOZnJBIpSO+cSQgghhKjDvvvuO0aOHEmnTp3o1asXiqKwceNG2rVrx5o1axg0SGbsuENXQ1fm/zQfo9pIcXExn3/+OQ899JC3Y7ns35/Ta+0zewNx4403cvHFFzNhwgTGjBlDbGwsAwcOpFOnTgQGBpKfn09SUhLr1q3jxIkTDBgwgO+++44WLVoAuLzg2sEDB53bhw4cAqC0tJTp06eTlVXeV/exxx6jR48ebn6HnlNUVHTOxyatCYPagMVhQaPSnHVm6kcffYTD4UCNmj/W/MG4wXW/Z7hDcZBpzSREF+LSnQsjw0cSpY8iuyxb2iX8x485Pzpbn/ya9ytT4qZg1Bjx0fhU2i4j1ZLK+tz1AOTacvkm+xsmxE6o0rnzbfk8fuhxZ5sFrUrr0RYdTQ1NaWdqx1/Ff2FSm+gbfPb1yj5I/wAFBatiZUXmCik0i0avyoXm6OhoDh48SEJCQoXnN2zYQGJiortyCTcI0gZ5O4IQQgghRKPzyCOP8MADD/Dcc8+d8fzDDz8shWY3MRgMzqIiQGRkpJcTVc0999zDyy+/jM1m45577vF2nFpntVo5cuQI0dHRBAQEVPn4Fi1a8NNPP7Fjxw6WLVvG5s2b+eSTT7BYLBgMBjp06MDo0aO57bbb6NKlS7UyDhk4hI8/L7+Ld/DAwQBkZGQ4i8wAe/furVeF5m7dunHJJZfwxx9/0LlzZ3r16uV87ZHpj7DkzSWU6EuY+sDUs84yjIyMJCcnx7ld19kcNp468hS7inYRpgtjXot5ROgjznvcxYEX10K688uyZrG3eC8tfVsSbYj2dhya+zR3zvaONcS6PNs7QBOAUW3E7DADEKmv+t+dLGuWs8gMcNxyvMpjVIVWreXZxGc5aj5KuD6cQG3gWfeL1EdyzHzMuS1EY6dSlKpNQ50/fz7vvPMOS5cuZdCgQXzzzTccO3aMBx54gCeffJLJkyefd4yCggLnh8LqfKioLy7ddilWxerSf2TuVGovJcOaweLWi7k0+NJaPbcQQgghGrfG8jmvMkajkd27d9OyZcWFtP755x86duyI2Wz2UjLP8db3/ejRo3z++eeEhoZy/fXXo9O5fgu/8B6z2cxDDz3EkSNH8Pf3Z8GCBcTGumcRKIfD4Vwk0B3W71qPQ+tgYNuBAJSVlTFt2jQOHz6MVqvlmWeeoX37s7cKOB+73c4HH3zA8ePHufzyy+natWotJWpCUZRqzaTPycnho48+QqvVcuONN+Lv77m+1fn5+fz6669ERUU523tU1Z6iPTx66FHn43FR47g28lp3RfSonLIcpuyfQoG9AKPayIstX6SJ0bV+2J6iKAo/5PxAdlk2Q0KHEKILcfnYfcX7+Db7W5oYmjAmYswZPbfPx67YmXl4JklFSQRoAniuxXNe/3oAZFgy+CTzE3zVvtwYdSO+msp7vwtRX7n6Wa/KM5ofeugh8vPz6d+/P2azmT59+mAwGJg2bZpLRWbheWnWNDqYOnBJ4CW1d1KzGcb9/21T770HRuljJYQQQojGKTw8nKSkpDMKzUlJSURE1O4EhIYuISGB+++/39sxRBX9888/zv7UhYWFbNy4scKidDXhziIzQP+OFW/N1+l0zJs3jz179hATE0NMTEy1x/7yyy9ZsWIFADt27GDp0qUEBQXVJK7LqtuuJSQkpFZm4NtsNh5++GFOnDgBwL333lutu0Ei9BHoVDrKlDJK00qxlFpQIqpXZHeHTGsmSYVJtPRtSTOfZpXu+3fx3xTYCwAwO8zsLtrt9cKqSqVicOjgah3bxtSGNqbqLWAJoFFpeDrxaVItqYToQupMQTfSEMm9Te71dgwh6oxqLfU5e/ZsHn/8cfbu3YvD4aBt27b4+dVug35xdiX2EgCujri6Sosy1JjdDp99Vr69fHntnVcIIYQQoo4ZP348EyZM4PDhw/Ts2ROVSsWGDRuYN28eDz74oLfjCeF1MTExGI1G5+z++taC0Wg0ctFFNe/Dmpub69wuKyujqKio1grNdV1eXp6zyAzw119/VbvQPLPZTN766i22vrOVT3WfcrL/SaZOnerOuC7JK8vjgX8eoMBegFalZX6L+bT0bXnO/Vv5tsJP40eRvQi9Sk87U7taTFs3qVXqai0iKISoPVUuNN9+++0sWrQIf3//Cv+5FhcXM2XKFJYuXerWgKJq8mx5NDE0YVT4KG9HEUIIIYRolGbMmIG/vz8vvPACjz5afst2TEwMM2fO5N57ZdaTOyiKwnfffUdKSgqXXXbZGevHCM/asmULP/zwA4mJidxwww1Vnh0aFhbGvHnz2LhxI61bt67VlhHVlWXNwqbYiDJEuW3M4cOHs3nzZtLS0hg6dChxce4poK3NXsu2gm1cFHARQ0OHumXM2hYaGkrbtm3Zu3cvarWanj17Vnusjv4dCfgrgDBdGAA///wzDzzwQK3Paj5cetg5Q9mm2NhTtKfSQnOYPoyFLReWz2Q2NOGrrK8oshdxQ9QNNDU2ra3YVWK1WtHrz7/goiedMJ8g1ZpKB1MHl3tICyHcp8o9mjUaDWlpaWfc9peVlUVUVBQ2m+28YzSW3n3e6NGcbE7mAt8L+LjDx7V2TgCKi+HUrPaiIjCZavf8QgghhKgTGsvnvP/68ssvufzyy8/oEVxYWAjg0T6mdUFtf9+//fZbFi9eDJR/bd966y18fevGbdQNXWZmJhMnTnT+3nf33Xdz+eWXezmVZ63LWcei5EUoKB7p8Vvd4pzNYeOt1Lc4VHqIwSGDGRQ6iN1Fu3ns0GPOfeY0n0MHvw7ujFtrrFYru3btIiIigqZNa1ZYfe+99/j0008BaN26Nc8//7w7IlZJga2AKfunkGPLQa/Ss6DlAhJ9XJvNv/D4Qn7K/QmACF0Eb7d925NRq6ygoIDHH3+co0eP0rt3bx566CGvtCfZVbiLp448hU2x0dynOc+3eB6tulo38gsh/sPtPZoLCgpQFAVFUSgsLMT4rx68drudb775RnrO1QEWh8XrfZuEEEIIIRqb0aNHk56eTnh4eIWJGQ29wOwtx48fd24XFhaSl5cnheZaUlhYWGFyUU5OjhfT1I4vT36JQvn8rC+zvnR7obm6M0C/zf6Wr7O/BmB/yX7a+bUjp6zi9+O/j+sTvV7vlhYlADfddBMxMTEUFBQweHD1egzXVIA2gJdavcSeoj0k+iQSa3R9Acx/fx9zbbmV7Okd33//PUePHgVgw4YNjBgxgrZt29Z6js0Fm7Ep5f8+HSo9RJo1TeojQtQyl1dKCAoKIiQkBJVKRatWrQgODnb+CQsL4/bbb6+VRQFE5RSUWp1BLYQQQgghyhcA3Lx5M1De1sFbC001FgMHDsT0/3fQdevWjejoaC8najwSExPp3798gbzY2NgGP5sZqNCmoImh7hStSh2lzm0FBbPDTI/AHrQ3tQegvak9PQJ7eCtenaJSqRg4cCCjR492/tvhDcG6YC4NvrRKRWaAGyJvwKQ2oUbNbdG3eShd9YWEhDi31Wo1gYGBFV7fWrCVcX+N47a9t7GveJ/HcrQ1nS5uR+gipDYihBe4PKN5/fr1KIrCgAEDWLlyZYV/SPR6PfHx8TVacVfUnENxAMgiAUIIIYQQteyuu+5i1KhRqFQqVCoVUVHn7uNqt9trMVnD1KJFC958803y8vKIi4uTwn4tUqlUTJ06lXvuuQeDwVDhtSJbEfOOzeO4+TjDw4ZzTeQ1XkrpXvfE3UOsIRarYuXK8CurfTEpuyybPwv/JNEn0eWWCZUZFjqMHYU7OFR6iCEhQ5xjzm0xF7PdLP1pG5C2fm35sP2H2BU7OrXu/AfUsv79+5OVlcU///xDv379iI2tWEhfkrKEPFseAG+eeJMXW73okRy9g3rjp/Ej2ZxMr6BeGNSG8x8khHArlwvNffv2BeDIkSM0bdpUPszVQaWOUnzUPiQYE7wdRQghhBCiUZk5cybXX389Bw8eZOTIkSxbtoygoCBvx2rQ/P39pTWJF/23yAzwRdYXJBUlAfBu+rv0DupNtKH+zzY3aoxcH3U9eXl5zHhwBseOHWPYsGFMmDDB5TEKbYVM/WcqObYctCotc5rPoY2pzVn3PVx6GH+NP+H68ErH9NP68VyL586ZWTQsapUatcrlm9JrlUql4tprz91Sxqg+/ffRR+Pj0Syd/DvRyb+TR88hhDi3KndF37dvH8nJyfTu3RuAV199lTfffJO2bdvy6quvEhwc7PaQwjVmhxmj2ki8T3ztn9zXt3wRwFPbQgghhBCNzAUXXMAFF1zAU089xTXXXCM9g0Wjo1Wd/vVShQqNSuPFNO63Zs0aDh8+7Ny+/PLLadLEtVYaR0qPkGMr77NrU2zsLtp91kLzy8kv833O92jQ8FD8Q/QM6um+N1AP7NmzB41GQ5s2Zy/Ci/ppevx03kp9C51Kx8TYid6OI4TwoCpfDps+fToFBQUA7N69m6lTpzJs2DAOHz7M1KlT3R5QuK7UXkq4PhxftRd+qVGpwGQq/yOz3YUQQgjRiD311FNSZBaN0qiwUfQJ6kO8MZ674+5ucP1R/fz8nNsajQYfH9dnZjbzaUaYLgwoL8ifbcalzWHjh5wfALBj5/uc72sWuJ55++23efTRR3nooYf46KOPXD4u3ZLO/5L/x9upb1NiL/FgwsbrQMkBFh5fyEfpH2Fz2M5/wH8082nG7OazmZk4s0Hc5SCEOLcqz2g+cuSIc/XQlStXMmLECObMmcOOHTsYNmyY2wMK15kdZlr4tJC2JkIIIYQQQohaZ9QYmR4/3dsxPGbEiBFkZWVx9OhRLr/8csLCwlw+1l/rz4stX2RX0S4SfRJpYjxzJrRWraWJoQnHLccB3NLHuT759ddfndu//fYbN9xww1n3KywsJCMjg4SEBLRaLc8cecb5NTteepxiRzEWh4UJsRPo4NehVrI3ZBaHhScPP0mRvfwOZrVKzXWR13k5lRCirqpyoVmv11NSUn6V8Mcff+Tmm28GylcZPTXTWdQ+u2JHQaGLfxfvBLBYYOL/3wLz+utwlp5tQgghhBBCiIqOHj3KTz/9RHx8PAMHDvR2nEbDYrHw6quvcuzYMUaOHOnS116r1TJ+/PhqnzNYF0zf4L6V7vNM82f4NvtbArWBDAut+kSuvXv3snTpUkwmE5MnTyY8vPI+z95gdVh5P/19Mq2ZjA4fTWtTawDatWvHb7/9BuCc3PZfycnJPPzwwxQWFtK6dWvmzp1LhjXD+foPuT8QqgsF4MXjL7Ks7TIPv5uGr9he7CwyAxW+3kII8V9VLjT37t2bqVOn0qtXL/744w8++eQTAP755x/i4uLcHlC4Jrcsl2BtMENDh3ongM0G77xTvv3qq1JoFkIIIYQQ4jyKi4t57LHHKCwsBEBRFC677DIvp6qedevWsXr1asLCwnjkkUcwGuv2YnSrV69m/fr1ACxatIgLL7ywSjOUPSVEF8LYqLHVPn7evHnk5JT3gn799dd54okn3BXNbT7K+IjVJ1cDkFSYxLvt3kWv1vPAAw9w4YUXotFo6N+//1mP/fXXX50/L/v37+fw4cPcGHUjy9OWo1PpuMD3Ak6WnQTAoThq5w3VoiOlR1iauhSD2sCE2Am10p4mRBfC0JChrM1ZS4AmgOFhwz1+TiFE/VXlQvMrr7zC3XffzWeffcaSJUuIjY0F4Ntvv2XoUC8VOQUWxUITQxPC9N7/cCSEEEIIIcqZzeY6X3AT3pOdne0smkH57Ob6KC0tjWeeeYb9+/fjcDjYt28fH3/8cZ1u6We1Wp3biqJQVlbmxTTuY7FYnNv/fo91SXZZtnP7VJsLvVqPTqdjyJAhlR7brFkz57avry8RERG0Dm7NoJBB6FQ6MssyefH4i5gdZu6Kvctj78Fb5h2bxwnLCaB8UcmZiTNr5bz3NLmHm6Jvwkftg16tr5VzCiHqpyoXmps2bcpXX311xvMLFy50SyBRdXbFTrGtmAtDL/R2FCGEEEKIRs/hcDB79mxee+01MjIy+Oeff0hMTGTGjBkkJCRwxx13eDuiqCPi4uLo1KkTSUlJmEwmBgwY4O1I1VJaWkpWVhYOR/kM0oMHD3Ly5EkiIs4/29Jms6HVVvnX0hq78sor2bdvH8ePH2fkyJFERzeMBcruu+8+XnvtNUwmE7fffrvHz3eqaHyqXYUrrgq/ih2FO8i35XN1xNX4a/1dPrZnz548/PDDHDp0iEsvvZTg4GAA5xhNNU15qdVLrr+BeqbUXurcLrYX1+q5A7WBtXq+hirZnMySlCUoKEyMnUiCT4K3IwnhVipFUZSqHHD8+PFKX2/atOl5xygoKCAwMJD8/HwCAgKqcvp65dJtl2JVrB6/naXYXkxeWR4ftf/I2d+q1hUXw6lVmIuKwGTyTg4hhBBCeFVj+ZxXmVmzZvHOO+8wa9Ysxo8fz549e0hMTOTTTz9l4cKFbNq0ydsR3U6+79Vnt9tJTk4mNDQUf3/XC27etGbNGg4dOsSAAQPo2LEjAPfeey8rVqzA19eXnj178vbbb6PXn3vmY3JyMk8++STZ2dnceOONXH/99bUV3yNKSkqw2WyN6u//11lf8/qJ1wG4O+7uKrVxdCgOrA4rRo3c8VEVG/M28r/k/2FQG3gk4RHamNp4O5KoomkHprG/ZD8AicZEFrVe5OVEQrjG1c96Vb50nJCQUOktUHa7vapDihoqc5ShU+uqdBVZCCGEEEJ4xrvvvssbb7zBwIEDueuu07dud+zYkb///tuLyURdpNFoSEhI8HYMl61bt4433ngDgN9++43XX3+dsLAw/ve//3HNNdeQmprKgAEDKi0yA6xYsYKsrCwAPvjgA0aMGIGpnk5W2bx5M/Pnz8dms3HHHXcwatQol46z2+0cO3aMsLCwelmgXpW5CoXyeWurM1dXqdCsVqmlyFwNPYN60jOop7djnCGvLI9VJ1dhUBsYEz5GvreVsDpOt7SxKJZK9jy79TnrWZG5gih9FPc3vZ8Abf37t0M0bFUuNP/5558VHpeVlfHnn3/y4osvMnv2bLcFE64rthcTqgslRBfi7ShCCCGEEI3eiRMnaNGixRnPOxyOBtMHVjRe6enpzm2r1Upubq5zEb1LL73U5XGCgoLIt+VjdViJDYxFp9O5PWtt+eyzz5w/2x999JFLhWaHw8HMmTNJSkrC19eX2bNnn/XfjbqsibEJmWWZAMQZ47ycRnjT7KOz+buk/EJqhjWDqU2nejlR3ZBvy+fl5JfJteVyU9RNdPbvzF2xd/Fi8os4FAd3x95dpfGKbEUsSl6EHTvJlmQ+zviYCbETPJReiOqpcqH5wgvP7AN80UUXERMTw4IFC7jqqqvcEky4rsRRwi1ht6BWqb0dRQghhBCi0WvXrh2//fYb8fHxFZ5fsWIFnTt39lIqIdxj0KBB/Pjjj2RlZXHxxRfTvHnzao0TPiSc3EO5WHOtNB/WvF4XmqOioti/v/xW+KCIID7N+JRQXSgDggec827gEydOkJSUBJS33Vi/fn29KzRPazqNlSdXokLFmIgx3o4jvCjFknJ625xSyZ6Ny7LUZWwp2ALA3KNz+bj9x7T1a8tbbd6q1ngKCg4czscOxVHJ3kJ4h9tWXWjVqhVbt25113DCRVnWLHzUPnTx7+LdIL6+kJl5elsIIYQQopF66qmnGDduHCdOnMDhcLBq1Sr279/Pu+++e9ZFtYVwhd1u5/jx44SFhXm1l3NERARvvvkmBQUFBAcHV9pWsTJ/2/4m4doEAAoooMBeUG8XG5s0aRIhISGUlJSwtetW3kt/D4A8W945C7AhISH4+/tTWFgIUK/ap5zip/XjluhbajTGgZID5JTl0NW/K1p17S8KWZsOlBxgScoS1Co1k+MmN6hF4K4Kv4p3099Fg4ZR4a61jjmbL05+wXfZ39HcpzlTmkxBr668BU9dZ1VOt8koU8pwKI4aTRD01/pzT9w9fJLxCdGGaK6LvM4dMYVwqyr/S15QUFDhsaIopKWlMXPmTFq2bOm2YMI1uWW5XBVxFb2Dens3iEoF4eHezSCEEEIIUQeMGDGCTz75hDlz5qBSqXjyySfp0qULa9asYdCgQd6OJ+ohu93ubLNgMpm468m7CGsaRjtTu2oXeqvj1DryWq2WkJCate3rHtCd3/J+Q0GhnakdAZr622fUZDJx++23U2wv5rs93zmfP1ByoNJjnnvuOX766SeaNGnCwIEDayNqnbI+Zz0LkxeioNDJrxPPNH/G25E8alHyIo6ZjwHwcsrLvNDyBS8ncp9rIq+hX3A/dCodQbqgao2RbE7mrdTymb7JlmQSfRIZHTHafSH/I6csh2PmY7T0aYmf1s8j57gp6iaSzcnk2nK5Lfo2t1xMGRI6hCGhQ9yQTgjPqPLf8qCgoDM+zCiKQpMmTfj444/dFky4RqVSEa4Pr9UPmEIIIYQQonJDhgxhyBD5RVC4R3JysrPNwpHcI9y34j6aXtmUy4Iv476m99VKhj179jBnzhwsFgv33HMPAwYMqNF4fYL7EGOIIassiy7+XerF7zNmu5kypQx/7dlnlJs0JnoE9mBT/iY0aOgf3L/S8Zo2bcqtt97qgaT1w6aCTc7FBJOKkii1l+Kj8fFyKs+xK/azbtd1hbZCthduJ84QRwvfc7d3CdfXbOLZf78mnvwapVnSmHpgKkX2IiJ0EbzU6qVz/lzXRIwhhpdbv+z2cYWoy6pcaF6/fn2Fx2q1mvDwcFq0aIFW27BvdalrFEVBQcFP45mrb1ViscDU/2/4/+KLYDB4N48QQgghhJds3boVh8NB9+7dKzy/ZcsWNBoNF110kZeSifoqLCwMPz8/ioqKyC7LJjy6vKDzc97PtVZofu+995xtHt56660aF5oBWvi2oAXn70tcWFjIzz//TGhoKD179qzxeatjR8EO5hydg0WxcEvULVwdefVZ93s0/lH+LvmbYG0wUYaoWk5Zzuaw4cBxzrYDDsWB1WHFqDHWcrKKOpg6sCl/EwAtfFo06CIzwJS4Kfwv5X+oUTMpdpK347jE6rDy0MGHSLGkoELFU82eomtAV4+cK84Qh4/ahy35W2jl24qhIUM9ch6AbQXbKLIXAZBZlsm+4n1cHHixx84nRGNS5cpw3759PZFDVEOxvRgftQ8XB9SBfxBtNli8uHx7/nwpNAshhBCi0brnnnt46KGHzig0nzhxgnnz5rFlyxYvJRP1lZ+fH3PnzuWnn36irX9b9rbaC0Ab3za1liEw8HT/5ICA2mtzoSgKjz32GEePHgXgzjvvZNSo6veAra6VJ1diUSwAfJjxYYVCs6IozhnZKpWKNqba+7781x/5fzDv2Dzsip0pTaYwMKRiS46jpUeZcXgGebY8ro64usY9lmtiRPgIogxRZJdlc2nQpR45h6IorFixgqNHjzJkyBAuvPBCj5zHFW392vLaBa957fzVkW5Ndy70p6CwvXB7jQvN5+pTvDF/I6WOUjr6dwRgZ/FOegX1qtLYZruZL7O+RIWKEWEjznkxpZVvK9SoceDAqDY2qH7ZQnibS4XmL7/80uUBR44cWe0womoK7AVE66Pp4NfB21GEEEIIIcT/27t3L126nLlQc+fOndm7d68XEomGICEhgdtvvx1FUfgp9yeK7cUMCqm9nt933303BoOB0tJSbr755lo7b2lpqbPIDOU/X94oNEfqI8/Y/rv4b549+iwl9hImxU5iUKj3e7B/kP6BcwGyd9PePaPQvPrkavJseQB8lvkZV4Vf5ZGWAa7qFtDNreM5HA7U6tNFzK+//pr33itfnHHLli28/fbbBAUFnfVYs93MHwV/EKmPpLWpdZXOe6T0CC8df4kypYy74+6mvV/7ar+HuiRKH0WsIZYTlhOoUNHZv3ONxvs4/WM+yviIcH04Tzd7mlhjrPM1X41vhX3/+9gVzx9/ni0F5RdzD5Ue4pGER866X2tTa55r8Rz7ivfRxb8LEfqIKp9LCHF2LhWar7zySpcGU6lU2O31p9dQfWd2mGnu27xGq5YKIYQQQgj3MhgMZGRkkJiYWOH5tLQ0aTUnakylUp1RPKwNQUFBPPjgg7V+Xl9fX7p27cr27dtRqVT06lW1GY7uMj5mPH4aP4rsRVwTcQ0A76e/T74tH4A3Ut9gUOggthZs5c/CP+ns39ntRVRXhOpCOWw+7Nz+rxDd6UUcTWoTBnX9vhN1x44dLFu2jE2bNrFnzx4sFgsGg4H27dvTo0cPQkNPfw2sViv5+flnLTQ7FAePHnqUg6UHsTls9A3uy6CQQS7P3l2SssT5dV+UvIg327zplvfnbXq1ngUtFrC1YCtxxjha+baq9liFtkI+yPgAgAxrBp9lflah9c9FARcxNnIsOwp3cFHARdUqah8pPeLcPlx6uNJ925jaePXuAyEaKpc+6TocDk/nEFVkV+zYHDZa+Jy/p5kQQgghhKg9gwYN4tFHH+WLL75wthvIy8vjscceY9Ag7894bCgyLBlkWDO4wHTBOXvRiobhiSeeYPfu3QQHB5OQkOCVDD4aH26Pub3CcwHa0y1EAjQBHCg5wDNHnkFB4ausr3ih5Qu09G1ZqzmvDL+SEkcJYdowxkWPO+P1GyJvwK7YybRmMjp8dI1/dmwOG2+kvsGh0kMMDhnMkFD3LYJaaCvk66yv8dH4cEXoFWjVp8sXBw8eZMKECaxfv57Y2Fguu+wybrrpJgICAigoKCApKYnVq1dz4sQJYmJiaN26NcOHD6dp06ZnPVeuLZeDpQdxKA7+Kv6L45bj/J7/O1ObTKV/SOWLOgIVJn+pqPsLW1aFv9afASE178muU+kwqo2YHWYAArWBZ+xzfdT1XB91fbXPMSxsGMvTlju3hRC1T6ZU1FNZ1iyCdcFcHXH2RSiEEEIIIYR3vPDCC/Tp04f4+Hg6dy6fkZWUlERkZKTzFm5RM3uK9vDk4ScpU8q4wPcC5jafW6EIJRoWrVbr/FmqKYfioNBeSIAmwNlXubomxk5Eq9JSZCtiXPQ4jpYeRUEByvvZpphTUKepee+99zCZTIwfP/6cbRvORVEUDpYeJFgbTJg+rNJ91+WsY1HyIhQU+gX1I9IQecY+erX+jIJ5TXyT/Q3fZn8LwIGSA7Q3ta/QDqEmnjnyDPtK9gGQakllUlz5Anoffvghd955J9HR0axatYoRI0ac9W4Rm83GmjVrmDZtGps3b2b8+PHn/J4Ha4NpZmzGvuJ9WBwW4rRxAOwt3utSoXlS7CT+l/I/rA5rvVnor7YZNUZmJMxg1clVROojuT6y+gXlcxkTMYbuAd1RoXLb30MhRNW4/Gnsp59+YvLkyWzevPmMxR/y8/Pp2bMnS5YsoU+fPm4PKSoqtZdSaC9kctxk+cdTCCGEEKKOiY2NZdeuXXzwwQfs3LkTHx8fbrvtNm644QZ0Op234zUIG/I2kLUvC3OGGWsnKxlNMhrl5+JMayZfZX1FsDaYEWEjpNh+HgW2Ah45+AjJlmQ6mDrwdOLT6NTV/5kM1AYytelU5+MwXRhxhjhSLCnEGeK4KOAi7n3wXrKysoDyO4UffvjhKp3juWPPsTF/IzqVjicSnqBLwJn930/5OfdnZ6H7l7xfmNp0ao2L6edzanYqlBfXTy2YWF0p5hT8NH4E6YIqtD44tf3hhx9y0003cdNNN7FkyRJMJtM5x9JqtYwePZrBgwczadIkxo4di6Io3HjjjWfsq1apmdtiLr/n/c6H6R+SbctGg4aeQT1dyh3vE88LLV+o4rttfDr6d3Qu9ucpccY4j44vhKicy59EXnrpJcaPH3/WFYYDAwOZOHEiCxculEJzLcguy6a5T3Mmxk70dhQhhBBCCHEWJpOJCRMmeDtGg2XZaWH/4v0A5P6Si997fl5O5B1PHHqCNGsaUL5Q+C3Rt3g5Ud32S+4vJFuSAdhdvJtdRbtc7sHrCn+tP4taLSLDmkGkPhK9Wk9RUZHz9X9vu6LAVsDG/I0AlCllrMtdV2mh+QLTBSQVJQHQyreVx4vMAFeEXcGfhX9yqPQQQ0OHkuiTeP6DzuHl5Jf5Pud79Co9jyU8xuVhl/P5yc9RoWJo6FAOHDjAnXfeyU033cTy5csrLPoHUFxcTF5eHkFBQRUK0CaTieXLlwNw5513cvHFF9OixZktKE0aE4NDB9MvuB+7i3YTqY+s90XLfcX7SDGn0D2we4VWL0II4SkuF5p37tzJvHnzzvn64MGDef75590SSlTO4rAQb4yvWzMWfHzgyJHT20IIIYQQjdzevXs5fvw4Vqu1wvMjR470UqKGw5BsoKVPS8wOMyHmEIpyiwj0PbPfZ0NW5ihzFpkBks3JXkxTP0ToI5zbKlSE6SpvRVEderWeJsYmzsd33XUXixcvxs/Pj3HjzuyZXBmTxkSkPpIT5hOcLDtJqb0URVHOWUC+MfJGovRRFNgKGBw6uEbvoyoZ57aYW+NxzHYz3+d8D4BVsbI2ey2PN3ucgcEDMaqNRBmiGHD1AGJiYliyZImzyGyz2ZgyeTK//vwT+/45iKIoJDRtwpFjxyuMr1arWbJkCb///jsTJkzgp59+OmcWvVrv1gsQ3rI5fzNzjs5BQSEmM4aXW79co57cG/I2sDZ7Lc18mnFL1C11qx4hhKgzXP6XISMjo9Jb/bRaLSdPnnRLKHFumdZMdCodl4Vc5u0oFanV4KWFOYQQQggh6pLDhw8zevRodu/ejUqlQlHKb2U/VRyy2+3ejNcgXHLJJXz33XfYbDZatGhBZOSZvWjPx2azsWTJEv755x/69+/PVVdd5YGknqNT6xgWOoxvsr9Br9JzeejlbhlXURSWLl1KUlIS3bp14+abb3bLuNX1xRdfsHv3bnr06MHAgQNrNFb3wO7cHXs3fxX/JFdx6gAAuGZJREFURc/AnsT7xGO321EU5aw9fv+r0FZIni2POEOcy7OFBw4cyIABA6o1u1ij0vBc8+cY+9dYtCotWwu28knGJ+dcLE2lUjEwpGZfI28xqA1E6iPJsGYA0NRYvmhfgk8CANu3b2f9+vWsWrWqwmzl1NRUXnv99QpjZWVnnfUcJpOJBQsWMGbMGHbs2EGXLueeHd4QJBUmOVuppFpTybRmVnuGdqY1kwXHFuDAwc6inYTpwhgVPsqdcYUbWR1WdCpdrdzVIMR/uVxojo2NZffu3We9xQRg165dREdHuy2YOLsCW/ktcVeGX+ntKEIIIYQQ4izuu+8+mjVrxo8//khiYiJ//PEH2dnZPPjgg3IHoJt06tSJl19+mfT0dNq3b+9SkfC/fvjhB77/vnwG5bJly+jUqROJidW/7b+qKpuZ6qpJcZMYGTYSP60fgVr3zOjetGkTn3/+OQBHjx6lffv2XivI/fHHH7z11lvO7aZNm9KyZUvn60W2IqyKlRBdiMtjXh52OZeHlRfld+zYwdy5c7HZbEyePLnSQvY/Jf8w49AMShwl9AjswaPxj7r8/avJ9zlIG4RerSdcHw7A/pL91R6rLlOpVMxpPoevsr4iVBfK8LDhFV5fvnw5cXFxjBgxosLzISEhNEtoSkhwMEePJ5OdnVPpeUaOHElsbCzLli2r9O+1oigsObGETfmb6OjXkQeaPFDvZvB2C+jGt9nf4sBBvDGeSH3VL8idUmIvwYHD+bjQVuiOiA3K73m/88XJL4g1xHJX3F0Y1IZqj1WT/x/eT3ufTzM/JVgbzKzEWcT7xFc7hxDVoT7/LuWGDRvGk08+idlsPuO10tJSnnrqKYYPH36WI4W7FNmL0Kg09AzsWfeuTFmtMH16+Z//3B4qhBBCCNGYbNq0iVmzZhEeHo5arUatVtO7d2/mzp3Lvffe6+14DUZcXBwXXXQRRqOxWseXlZVV+thT9uzZw9ixY7n22mvZsGFDjceLNca6rcgM5TO9/622vi5nk5NzumioKAq5ubnOx3/k/8HNe2/mlr238HH6x9Ua//3338dsNmOz2Vi2bFml+/6Q/QMljhIANuVv4mRZ7dzNq1Vr6RNUvg6SChX9g/vXynmTCpN48tCTLE5ZjMVRswX+XBWhj+D2mNsZFT4KjUpT4bVNmzYxcODAMy4q+fn5cfjIMbbtSKLtBa3Pew6tVsvAgQPZvHlzpfv9Wfgn32Z/S54tj1/zfuWXvF+q/oa8rGtAVxa2WsjD8Q8zr8W8Gi18meCTwLDQYahR08zY7IwLAY1dvi2f548/z76SffyY+yOfZX5WrXHMdjOPHnyUUbtGMe/oPByK4/wH/UuhrZBPMj9BQSHHlsPKkyurlUOImnD5ktwTTzzBqlWraNWqFZMnT6Z169aoVCr27dvHq6++it1u5/HHH/dk1kYv1ZzKoJBBXBJ4ibejnKmsDE7N0Jk5E/TV7/0khBBCCFGf2e12/PzKF6cLCwsjNTWV1q1bEx8fz/79DXM2Yn00ZMgQdu7c6Wyd0br1+YtU7rB8+XIKCgoAeOONN+jdu3etnNdVvXr1Ytu2bezYsYOLL76Yiy++2GtZ+vTpw/fff8+BAwfo0qVLhRmoq0+upkwpL4KvyFxxznYSlQkJOT0TOjg4uNJ9T7VyAAjUBhKgqb2F1aY1ncaw0GEEagNrZXG6Unspzx55FotigSLw0/hxc7R3W6js2bOHm266yS1jderUiU8++aTSfbSqiqUSnar6RVpvSvRJrNECjf82KW4Sd8XeVeNJb4qi8H3O96RYUrgs+LIGMeO2zFGGTTl9ka7UXlqtcX7K/Yk9xXsA2JC/gcFFg+ns39nl4w1qAya1iWJHMQAhWtfv9hDCXVwuNEdGRrJx40YmTZrEo48+WqHX3JAhQ1i8eHG1eqMJ16lUKoaEDqlRA38hhBBCCOFZ7du3Z9euXSQmJtK9e3fmz5+PXq/njTfeqNXWDKJyBoOBGTNm1Pp5/f39ndunLkjUJRqNhqlTp3o7BgC+vr68+OKLWCwWDIaKt6HHGGKcBZloQ3kLx3U563gv/T3CdGE8HP+ws93EuUyePBk/Pz+sVut5i5jDw4ajUWlItaQyOHQwRk31ZtJXh0qlop1fu1o7n8VhIdWaSqm9lFBdKAW2glo799k4HA4sFgsBAe4p7gcGBmKxWHA4HM5FBf+ro39Hro+83tk649KgS91y7vrOHXdWr81ey+ITi4Hyn9m32ryFr8a3xuN6U5g+jLGRY1l5ciVxhjiuiqhez/8AbcW/436aqv0foVfreSrxKVZlriJCH8ENUTdUK4cQNVGlJkPx8fF888035ObmcvBg+YquLVu2PO/VX1FzDsWBChUmjen8OwshhBBCCK954oknKC4un0307LPPMnz4cC699FJCQ0PPO4tONHz33HMPb7/9NhaLhVtvvdXbceqF/xaZAcbHjCdIG0SRvYirI67G4rDwcvLL2LGTXZbNB+kfcH/T+885pqIo/Fb2G7ox5YsqxvjGVJpBpVIxLGxYTd9KvbCjcAdmu5k0SxpF9iK3LTRZXWq1GoPB4LwToKby8/MxGAznLDKfMjZqLGOjxjofF9oK8dP41b02lvXMMfMx53ahvZDcstx6X2gGuD7q+mrdWfFvvQJ7cWPkjewp3kPvwN609G15/oP+o42pDY83k24Dwntc7tH8b8HBwXTr1o2LL75Yisy1xKbY0Kg0UmgWQgghhKjjhgwZwlVXlc9mSkxMZO/evWRlZZGZmcmAAQOqNNavv/7KiBEjiImJQaVSORdpO+XWW29FpVJV+HPJJRXbrFksFqZMmUJYWBgmk4mRI0eSkpJSYZ/c3FzGjRtHYGAggYGBjBs3jry8vCq/d3F+YWFhPPzwwzz55JM0bdr0/AeIszJqjIyLHsekuEmE68NRoarQ1/e/rQ/+a232Wt5IfYO1OWuZcWhGnVrcTFEUTphPeC3TodJDxBpj6RbQjQtMF9SJO2rbt29PUlKSW8ZKSkqiQ4cOLu9vc9iYcWgGN/51I1P+mVKn/q4ApFnSyCvL83YMlw0MGYhJXV7X6ObfjRhD5Rd5GhOVSsUNUTcwu/ls56KlQtQ31So0i9qXZkkjUh9JgjHB21GEEEIIIYSLkpOTSUlJISQkpFqz4IqLi7nwwgt55ZVXzrnP0KFDSUtLc/755ptvKrx+//33s3r1aj7++GM2bNhAUVERw4cPx263O/e58cYbSUpKYu3ataxdu5akpCTGjRtX5by1LS8vj0cffZRbb731jPddH5XYS9hTtId8W763o9QKs93M+pz17CrcVeOx9Go90+KnkWBM4CL/i7gpqvJWGCcsJ5zbJY4S8mx5Nc7gLs8ff5679t/FHfvu4O/iv2v9/H2D+2JUG0EF7U3t60QhsEePHvz4449nLFYJ8PPPP/P666+Tlp4BgLXMxuuvv85nn525IJvNZmPdunVnXJCrzM6inSQVJQHls3F/zv25Wu/BE5alLvs/9u47vKmyfwP4fbLbtE333qWFIrtAmQIiS0Vlg4rIi4K4XqaCOEBFFBVRVFyIoqg4cKAI4usWZU9lj5Yu0t2mzc75/dGfkUoLHUlP2t6f6+LyJDnnee5Ahfab53wfTD86HVOPTMWO0h1Sx6mTZO9kvJH6Bl5u+zIeSniIK8SJWph6tc4g6VhFK24MuRFhavbBJiIiIvJkNpsNS5YswYsvvgiDwQCgqhfvvffei0cffRRKZd03lRoxYgRGjLj0qia1Wo3w8PAaXystLcWaNWvw7rvv4uqrrwYAvPfee4iJicF3332HYcOG4ciRI9iyZQv++OMPpKenAwDeeOMN9O7dG8eOHWuyTfIa4qOPPsLhw1V9el999VX07dsXOp1O4lQNU2GvwJzjc5BjyYGv3BfPJT/n7D3sKmVlZVixYgXy8vIwbtw4DB48+KJzLBYLMjMzERERAa3WvXdTPnL6ERypPAIAuCvqrkav4Out643eut51Ondo0FD8WPIjSm2lSPdLR7Ta/Zvs1UWhtRA/l/wMADA6jNhauBXttO3qNYbFYcGe8j0IUgYhxTul3hlSvFPwWrvXkG/JR5JXUrWV4lKZOnUqXnrpJWzatAmjRo2q9tqEcWOhLyh0PrZYrLjzzjsBANnZ2YiM/KdQ/uWXXyI7OxtTp06t89zBymAIECCiap+qUFVoY96Ky4iiiM/zPwdQdQf0poJNSNelN+n8BrsBvop/+s7/UPQDXsl+Bd4ybzwY/yDaamv+98NX4VvtOvI820u244VzL0ApU2JB3AJ08OkgdSRqJriiuRkQRREiRI/55oeIiIiIanfPPffg9ddfx/Lly7Fv3z7s27cPy5cvx5o1a3Dvvfe6fL4ff/wRoaGhSElJwR133AG9Xu98bc+ePbBarRg6dKjzucjISHTo0AHbt28HAPz+++/Q6XTOIjMA9OrVCzqdznnOv5nNZpSVlVX7JQW5/J8CmEwmu2zPVU/2V8VfyLHkAKjqW7qzbKfL59iwYQP27NmD7OxsrFq1CuXl1VsAGI1GzJkzB7Nnz8Zdd91V7WupvmyOi1eeXshkNzmLzACwp3xPg+dqiFhNLN5s9ybebPcmFsUvcumqSpvNBlEUG3Str9wX/gp/5+NYTf3bqzx6+lE8efZJzDsxDz8U/VDreXv37sVbb71VY0uKQGUg2mrbQiHzjLVp3bp1w6BBgzBv3jxnD/y/+fv713iNSqWEl5eX83FFRQXmz5+PQYMGoVu3bnWeO84rDg/EPYD+/v0xI2pGkxZzAdS4ihuoarNwYY2gIV8rDVVhr8Cs47Nw05834cGTD8LqsAIAXs1+FSaHCYWWQryT+06T5SHXey37NVQ6KlFqK8VbOW9JHYeaEc/4V4MuqcRWAi+ZV5P+w1FvXl7A/68mwQX/mBMRERG1Nh988AE+/PDDaiuRO3XqhNjYWEycOBGvvvqqy+YaMWIExo0bh7i4OJw5cwYPP/wwrrrqKuzZswdqtRp5eXlQqVQX7asSFhaGvLw8AEBeXh5CQy9eoRcaGuo859+WLVuGJUuWuOx9NNSECROQl5eHnJwcjB07Fr6+zXeFXJwmDmpBDbNohgAByV713wTqci4sftZUCP3zzz+RkVG1UVdRURH++OMPXH/99fWa45zpHB45/QgKrYWYEDah2mZqF9LINeig7YDDFVU/Q/Tw61GveVxBI9dAI9e4dMwNGzZg/fr1CAgIwJIlSxAfH1+v61UyFZ5MehJbCrcgXBWO64Kvq9f1FfYK5++pCBE7ynZgUOCgi847ceIEFi9eDFEU8cUXX+D5559HYmJiveZqaq+//jo6deqEmTNn4u2333Z+sLTvwEEUFxdfdL6Pj4/zDgeHw4GZM2ciNzcXW7durffcff37oq9/38a9gXqy2WxYunQpdu/ejdTUVDz22GPQaKp/vS5JXIIvCr6Ar9wXo0JG1TKS6/1S8gtOm04DAA5VHMLe8r1I16XDR+6Dc7vO4cz7Z5ChysCYx8cgLS2tyXKR6/jIfVBkK3IeE9UVC80eThRF5FvycXP4zejmW/dPXZucTAZccYXUKYiIiIgkp9FoaiwuxcfHQ6Vy7aZaEyZMcB536NAB3bt3R1xcHL7++mvnhoQ1EUWx2grOmlZz/vucCy1cuBBz5sxxPi4rK0NMTExD3kKj+Pj4YNGiRU0+rzuEqkKxPHk5dpbuRHtte7T3ae/yOSZMmIDMzEzk5uZiwoQJFxXmo6KioFQqYbVWrU6sb5EUAD7Vf4oCawEA4MPzH+L64OtrvUV+SeIS7CjdgUBlIK7waf4/S5hMJrz33nsAqgr1H3/8MebPn1/vcWI0Mbgj6o4GZfCWeaONVxucNJ4EAHT26VzjeZmZmc4PGxwOB86dO9dkheZjFcdQYitBmm9avVZMt2nTBmvWrMHNN1d9eLF69WpotVp4e3vD29u71usqKiowc+ZMvPfee1i/fj3atGnT6PfQFPbu3Yvdu3cDAI4cOYKffvoJw4YNq3ZOsCoY0yKnNWkum8MGk8MEm8MGhUwBAQKClcEAgAfjH8SYR8bAX/RHlBCFdevWsdDcTD0Q/wDW5qyFUqbEHZEN+/uIWicWmj2cRbRAJVNhWNAwNsknIiIiagbuvvtuPP7441i7di3UajWAqlYTS5cuxT333OPWuSMiIhAXF4cTJ04AAMLDw2GxWFBcXFxtVbNer0efPn2c55w/f/6isfLz8xEWVvP+IGq12vneyHUSvRKR6OW+Yp9Op8MTTzxR6+sRERFYunQpdu7cifbt26NTp071nuPCtg9eMi+oZbV/nahkKvQP6F/vOTyVQqGAVqt1tnb4950ETUEQBCxNWorfSn5DkDII3fxqXqzUvXt3hIeHIy8vD5GRkfVqJdEYWwu34qWsqs1N03zTsDhxcb2unzRpEkRRxO23347ffvsNzzzzDK6//nooFBeXNmw2G7788kvMnz8fubm5WL9+PSZNmuSCd1G1cv+Q4RCu0F6BOK84AMCRiiM4YzyDnn49EawKvugah+jAIcMh6BQ6xHvFX3aOf/ebr61FSFOyOCx48NSDOFZ5DEaHEX18+2B40HAkeScBAJK8kzAoZhBOmqs+6PCEzNQwsZpYPJr4qNQxqBliodnDnTOdQ7J3coM2cWhSFgvw5JNVxw8+CLh4tQ4RERFRc7Fv3z7873//Q3R0NDp3rlpNeODAAVgsFgwePLjaSuONGze6dO7CwkKcO3cOERFVm8ilpaVBqVRi27ZtGD9+PAAgNzcXhw8fxvLlywEAvXv3RmlpKXbu3ImePXsCAHbs2IHS0lJnMZpaj9TUVKSmpjb4+knhk2B2mKG36jEqZBRUstbzc4FCocCjjz6KTz75BMHBwbjlllskyeEt98aQoCGXPEen02HVqlXIyclBVFRUk31w9EfpH87jPeV7YHVYoZTVfYNUALjpppvQs2dPTJ8+HWPGjEFUVBQGDx6MLl26QKfTobS0FPv378f//vc/ZGdn46qrrsLWrVtdtpI5x5yD2cdnwyyaoRJUWJmyEoXWQjxy+hGIELHh/Aa83PZl+CiqtxtYdnYZ/ij7AwIEzImdg4EBA52v7S/fj4/Of4RgVTBmRM2AVq5F27Ztce+99+L3339Hp06dqvXRl8op4ykcqzwGoGpDv44+HXFlwJXVzrn//vuxbt06KBSKem26SEQtAwvNHsxoN0IhKHB/3P0IUDb9p+H1YrUCf/fpmz+fhWYiIiJqtfz9/TFmzJhqzzW0rYTBYMDJkyedj8+cOYP9+/cjMDAQgYGBWLx4McaMGYOIiAicPXsWDz74IIKDgzFqVFWvTp1Oh2nTpmHu3LkICgpCYGAg5s2bh44dO+Lqq68GUFVYHD58OO644w689tprAIDp06fjuuuuQ9u2bRuUm1qniooKfP/992jn1w7Tr5zeKu/ITE1NxcMPPyx1jDrRaDRN3pe5s29n7C6vageR6p1aryJzhb0C3jJvCIKANm3a4Pvvv8fevXuxdu1a/PHHH9iwYQPMZjPUajU6duyIUaNGYerUqS5frX288jjMohlA1R3IxyuPI9ecCxFVrUiKbEXINmejreKfvz8tDgv+KKsqsosQ8UvJL85Cs8VhwdKzS2FymICKqn6406OmAwCGDh1abTNXqYWpwqCRaaqyAjWuzI6IiMADDzzQxMlczy7asTxjOXaW7URXn65YGL+w3h+KELVGLDR7sFxLLlK9UyXZGIOIiIiIGmbt2rUuG2v37t0YNOifjbz+7os8ZcoUrF69GocOHcK6detQUlKCiIgIDBo0CBs2bKjWe/f555+HQqHA+PHjYTQaMXjwYLz99tuQy+XOc9avX4/77rvPWdC4/vrr8dJLL7nsfdCliaKI3377DWazGQMGDKixDYAURFHEr7/+CqvViiuvvPKyuRYvXoyjR48CAHJyclzWpoA8i8FmwPHK44j3ikegMrBe194YciOi1FEosZagv3/d2qaIooinMp7C9tLtiFJH4cmkJ53zduvWrVoh2eFwODcJdJcO2g7wlfui3F4OH7kPOvp0RJQ6ChvzN8IqWhGpikScJq7aNSqZCkleSThlPAWgqsj+N7toh9lhdj422A1uzd8YgcpALEtahl9LfkUb7zborestdSS32VG6A9tLtwMAdpXvwq8lv9a4sSYRVecZ38HQRURRhE20YWLYxEv2NSMiIiIiz2I0GiGKonNzqoyMDHz22Wdo3759vVemDRw40LlhV022bt162TE0Gg1WrVqFVatW1XpOYGCgcxMzanpr167FZ599BqDqw4UHHngAeoseH5//GN5yb0wMmwgvuVeT53rrrbfw+eefAwB27dp1yVWKDocDx44dcz7+66+/3B2PJFBuK8es47Ogt+qhlWnxXPJziNJE1WuM+i6kOl553FnwyzZnY1vRNkwIm1Djua4uMh8sP4gSWwl66Xo528AEq4Kxqu0qHKs4hhTvFASrghGqCsWqlFXINGeio7YjNHLNRWM9kfgEvi/+HgGKgGq9yb3kXpgWOQ3rctchRBWCCaE1vzdP0ca7Ddp4N48NFeujzFaGPWV7EOcVh0SvRPjIq7c++XcrFCKqGQvNHsoOO+SQI1wdLnUUIiIiIqqHG264AaNHj8add96JkpIS9OzZEyqVCgUFBVixYgVmzpwpdUTyMAcOHLjo+PEzj+Os6SwAoNRWilmxs9w2/+nTp/Hyyy8DqNrM8u92ChfmOnjw4CXHkMlk6NevH3755RcIgoArr7zykue705bCLcgwZuCqwKuQ7J1c63nF1mKszV0Ls8OMW8NvrXfBtDU6WnkUeqseAFDhqMCe8j1u/33zV/hDIShgE20AgGDlxRvtucOm/E14Ped1AEAXny54POlx52tByiD08a/ewz5KE3XJ3wsfhQ+uD7m+xtduCLkBN4Tc4ILUnk9v0eOFcy+gzFaGqRFTa92wsimZ7CbMOzEPuZZcyCDDksQl6OLbBXE/xmH7ju1I65aG7nO7Sx2TqFlw7z0l1GB55jwEKAMQpeY3O0RERETNyd69e9G/f9VqtU8++QTh4eHIyMjAunXr8OKLL0qcjjzRhZt89erVCwCQa851PpdnyXPr/C+88AKOHz+O48eP44UXXnA+37t3b9hsNmRnZ0OtVsNsNl90bXFxMbZs2YIjR45g/vz5WLp0KV544QUMGXLpzejqIicnB1u2bMHZs2frfM22wm14OetlfFX4FR469RDKbeW1nvtS1kv4ofgHbC/djqcynrro9XPnzuHgwYNwOBwNiX+RY8eO4ZlnnsG6detgtVpdMmZTi9PEQSOrWq0rgwxtvd3fxz1MHYYFcQvQV9cXU8Kn4KqAq9w+J1C1WeHf9hv2w+awNcm8Ld2anDU4aDiIs6azWJ6xXOo4AIAcSw5yLVV/5zrgwN7yvdizZw8yvstAVHkU8n7Kw++//y5xSqLmgSuaPZBdtMPoMGJO7BwkeCVIHYeIiIiI6qGystLZI/nbb7/F6NGjIZPJ0KtXL2RkZEicjjxJeXk5Hn30UZw8eRIpKSmYNGkS0tLSAACTwifh7dy3oRJUGBM65jIjNY7dbkeprRQZpgycKzqHc6ZziNHEYNKkSfjpp59QUVGB/Px8rFq1CvPmzXNeZzKZMG/ePOj1egiCgIcffhg9etR/f5nDhsMoshZVa0+g1+sxe/ZsVFZWQqlUYsWKFYiPj7/sWOfM55zHlY5KFFoL4avwrfHcEluJ87jYVlzttZ9//hnPPvssRFFEeno6HnrooUvOazab8dFHH6GsrAyjR49GRETERa8/+uijqKioAADI5XLcfPPNl30/niZUFYrnkp/D7rLdSNWmoq22aTYMTdelI12XfvkTXSjNN81ZbO7s0xkKGcsnrmAX7f8cww5RFOu9cajJbsIbOW8gz5KH0SGjkeaX1qhMkapIRKginCuau/l2gyXLUj233V7L1UR0If5N6YGMDiO8Zd7o6ddT6ihEREREVE9t2rTB559/jlGjRmHr1q2YPXs2gKrCmZ+fn8TpyJN89913OHHiBADg+PHj8PLychZcxoSOwdWBV0MpKOEt93Zrjrvvvhs3LL4Bgq+AgDEBeCP7DTyW9BiAqg9OdDodAFy0sjg3Nxd6fVUbBVEUcejQIfTo0QN79uzB7t270aVLl2qrtWuytXArXsqq2njyCu0VeKpN1crikydPorKyEgBgtVpx5MiROhWarw68Gt8VfYdyeznSfNMQq4mt9dzJ4ZOx7OwyWEUrpkVMq/bazz//7OyPvmPHDphMJmg0F/fd/dtbb72FzZs3A6hqOfL6669Xe91oNDqLzABQUFBw2ffiqWI1sZf8fW0pRoaMRKwmFiW2kha96V1T+0/kf1BkLUKprRS3R91e7yIzAHx4/kN8W/QtAOBoxVG8d8V7jepjr5Fr8EzyM9hbthcxmhi08W4DsYeI4cOHY9euXejSpQv69u3b4PGJWhMWmj1QviUfSV5JSPRKlDpK3Wk0wM6d/xwTERERtVKPPPIIbrrpJsyePRuDBw9G795VBYpvv/0WXbt2lTgdeZILP3gQBOGiDyJ0Cl2T5EhNTUWvR3o5V/XKhH86LF5zzTVYv349BEHAiBEjql0XFRWFmJgYnDt3DnK5HN27d8eZM2fw2GOPweFw4Ouvv8bTTz+N1NTUWufeXbbbefxnxZ8w2o3wknuhXbt20Ol0KC0thZeXFzp16lSn9xKricWbqW+i2FqMSHXkJYtYXXy74MMOH8IBB+SCvNpr7dq1w44dOwAA8fHxlywyA1VF97+dP3/+olWa/v7+uOGGG/DFF184j91lfd567CnbgzS/NNwc7vmrps+ZzuGH4h8Qo47BoMBBUsepprNvZ6kjSKbMVoaXs15GkbUIk8Im1dpL2SE6sKVwCwqsBQhQBMBf4Y9+/v1q/X8vUh2JFSkrGpXNYDc4jy2iBRbRAi80bsNUnUJX7etPEATcfffdtZ5/ovIEPs//HKGqUEwKm+S8G4OotWOh2cPYRTtsog1TIqZAKVNKHafu5HKgAbfJEREREbU0Y8eORb9+/ZCbm4vOnf8pUgwePBijRo2SMBl5mquuugp5eXk4fvw4Bg4ciJiYGMmyzIudhzdy3oCXzAt3RN7hfH7ixIno168f5HL5Re0gVCoVnnnmGRw4cADR0dGIjY3Fr7/+6uxpLIoisrKyLlloTvNLwx9lfwAAUr1TnasSAwMD8eKLL+LIkSNITk5GaGhond+Lt9y7zqvABUGAHPKLnh87dizCwsJQWFiIwYMHX3acUaNG4a+//oLZbMb48eNrLLLdfvvtmDRpEjQaDeTyi+d0hd1lu/Hh+Q8BACeMJ9DOu12j2wq4U6W9EgtOLkCZvQxAVSuFqwOvljgVAcA7ue9ge+l2AMCyjGX44IoPamwf8sH5D/Dh+Q9xxngG5fZydPLphIOGg7g7pvYibWONDR2LPyv+RJ4lD5PCJjXZh3J/szqsePT0oyi3V/WAFyDg1ohbmzQDkadiodnDGB1GeMm8kKqt/ZsxIiIiIvJs4eHhCA8Pr/Zcz55si0bVCYLgMX16O/l2wqq2q2p8LTo6utbrtFot+vTp43zctWtXxMXFISMjAxEREZf9uh8eNByRqkgUWgvRx79PtdcCAwMlvV39700966Jr165Yt24dzGYzAgICaj1Pq9W6IlqtTA5TtcdGh9Gt8zVWobXQWWQGgNPG0xKmoQtd+LVkcVjgQM2bYp4xngFQtQLa7DDDLtpxwHDArdnC1eFY3W61W+e4FLPD7CwyA1V3pRNRFRaaPYjZYUa2KRtdfbsiyStJ6jj1Y7EAf+9Q/d//AireNkJERERE1NpotVo8//zzOH/+PEJDQ6Gqw88FnXzr1hbDk2WaMvF67usQIGCG1wxEa2ovzrtTb11v9Pfv72yd4em9haPUUejs0xkHDAfgJfPCoADPap3Rmt0cfjMyTBkoshbh1ohba20NMTRwKPaU74G/wh922CEX5Oil69XEaasrsBRgS+EWBKuCMSxwWIP6QF+Kj8IHo0NGY2P+RvjJ/TAqlHcrEf1NEP/e4aAJlZWVOfttteQNUfrv7g+LaEGo6tK3eTlEB4ptxci35KOnX0+8kPICglXBTZTSRSoqAB+fqmODAXDzJ/VERETkmVrL93lUHf/cL23Lli349NNPERUVhblz58LX11fqSM2GKIp4Lfs17CrbhTS/NMyMmunyopErzDo+C6eMpwAA7bzb4ZnkZyRO1HzYRTvOGM8gRBXS5C0Q/q3CXgE55NDIue9QfRRYClBqK0WxtRgyQVZrP+emIIoiZhydgVxLVd/0yeGTMT5svFvmqrBXQC2oa2wpQtTS1PV7PVmtr1CTcIgOnDSehE20YXTIaCxvs7z5FZmJiIiIiKhGJSUleOWVV5CXl4c9e/bg448/ljpSs7KzbCe+Lvwaeqse3xR+g99Lf5c6Uo0ubDPw7/YVdGlyQY423m0uKjJv1G/EuEPjcN+x++rVmsBut8NqtQIAbA4bNuo34q2ct6C36C953Rf5X2DS4Um4+c+bsatsV/3fSCsWrApGkncSuuu6S1pkBqraxfxdZAbg/ADIHbRyLYvMRP/CQrOE7KIdZ41nEaQIwlupb+Hp5KcRpYmSOhYREREREZFH8sTVzABwZ9Sd0Ml1qLBXIE4Th0p7ZZ2vLSwsxKpVq/DKK6+gtLTUjSmbj1JbKd7OfRsmhwlnTGfw0fmP6nTd/v37MWnSJIwbNw7btm3D+vPrsTZ3LT7L/wwPnXrokte+n/c+RIiwiBZ8fJ4fCDVX3nJvXOl/JQBAISgwJHCIxImIWhcWmiWUb8lHoDIQy9osQwefDlLHISIiIiIXeffdd9G3b19ERkYiIyMDALBy5Up88cUXEiejpubv74+7774bERER6N69O8aNGyd1pGalp19PjAweiXBVOK4Nuha9/KTt/VqbLr5dkOaXBq1ci59KfsLTGU/X+drly5fj22+/xTfffIOVK1e6L2QzohAUUApK52NvuXedrlu/fj2MRiPsdjveeustZJoyna/lWnJhdVhrvfbClpc+ch+8nv063sl9p14fGrQmeosepyrdt1q4MebFzsPK5JV4o90b6O7XXeo4RK0K1/hLyOgwopNPJwwIGCB1FCIiIiJykdWrV+ORRx7BrFmzsHTpUtjtdgBVBceVK1fihhtukDghNbVhw4Zh2LBhUsdolgRBwPSo6ZgeNb3RY/1Y/CNOVp5Ef//+aKtt64J01Z02nnYe1+d2fb1eX+Nxa6aVa/FA3AP4RP8JItQRmBg2sU7XBQQEoMxWBpkgQ2xgLK4Jugb7yvfBKlpxTdA1UMqUtV77UPxD2KDfAC+ZF/6s+BO7yqvaZ+gtesyPm++S99VS/FbyG57JeAZ22DEkcAjui7lP6kjVCIKAJO8kqWMQtUpc0SwRm2iDVbSir39fqaMQERERkQutWrUKb7zxBhYtWgS5XO58vnv37jh06JCEyYhar+0l2/Fc5nP4ouALLDq1CIXWQpfPMSxoGARUtfYYETSiztfdfPPNkMlkUCgUmDRpkstzNRd//fUX3n33XRw8eBAA0FPXE8uTl2N27Gx4yb3qNIbiBgUKOxUiLyUPnad3RppfGta2X4tX276KmdEzL3ltmDoM98Xchzui7qjWEzrbnN3wN9VCbSvaBjuqPkT9rug72EW7xInobxX2Cnx0/iN8kf/FJVfwE7kLVzRLwCbacLryNFK8U9gviIiIiKiFOXPmDLp27XrR82q1GhUVFRIkaplOnz6NnJwcdOvWDd7edbutvikVWYtQaC1EklcSZALX90jtwhYKZtEMvUWPIGWQS+e4Lvg6dPXpCptoQ5xXXJ2vu/rqq9G3b18IggCNRuPSTM1FRkYGFi1aBJvNhk8++QTPPvsskpOT6z3OXsdeJNyUAAA46nUUAKBT6C7aaPByxoeNx5qcNZALcowJGVPvHC1dolci9pTvAQDEaeIgF+SXuYKayrKzy3DAcAAAcM50DvfE3CNxImptWGiWQJYpC0neSXgt9TVEqiOljuMaGg3www//HBMRERG1UgkJCdi/fz/i4qoXmr755hu0b99eolQty+7du/H444/D4XAgPj4eK1asgFJZ+y3xTe2w4TAePf0oLKIFPXx74OGEhz12E7vWYkDAAHxV+BVKbaVI9U5FG682bpmnoZu7e3nVbcVuS2Sym7D1r60wWAzQyDRwOBw4e/ZsgwrN7bXtnS0v2msb/vftDSE34Er/K6EQFPBV+DZ4nJbqlvBbEKwMRomtBNcEXSN1HLrAhW176tPCh8hVWGhuYjbRBptow+2Rt7ecIjMAyOXAwIFSpyAiIiKS3Pz583H33XfDZDJBFEXs3LkTH3zwAZYtW4Y333xT6ngtwu7du+FwOAAAZ8+ehV6vR1RUwwp87vB98fewiBYAwK7yXSi0FiJYFSxxqtYtQh2B19u9jgJrASJVkVDI+KNwXf1W8hvOms7iSv8rEaOJcenYNocNC04twFG/ozihOYG4yjgkhiciLS2tQeMtiF+A74u/h0amwQD/xu2FFKAMaNT1LZlMkOGaYBaYPdHwoOH4RP8JBAgYFsS9Aajp8V/XJlJuK0e+NR920Y5IdSR663pLHYmIiIiI3GDq1Kmw2Wy4//77UVlZiZtuuglRUVF44YUXMHFi3Ta0okvr3LkzNm/eDFEUERkZiZCQEKkjVZOgSXAeBymD4KfwkzAN/c1b7o1YeazUMZqVX4p/wfLM5QCArwu+xmvtXnPpCt9cSy5OGU9B6aNE+/vbo5e5F+amzYVWq23QeCqZCsODhrssH1FzMyViCgb4D4BSUDb4DguixmChuQlkmbJgE23o6dsTVwddjSv9r0SEOkLqWK5ltQKvv151PH064EG3LhIRERE1FZvNhvXr12PkyJG44447UFBQAIfDgdDQUKmjtSi9e/fGU089hezsbKSnp0OlUkkdqZqRISPhJfdCrjkXVwdeDZWs4fnKy8vxxBNPICMjA9deey0mT57swqTkKnv37sV7770Hf39/3HvvvQgIaBmrYS+89b7cXrV4ypWF5hBlCEKUIci35kOukeOqtlc1uMhMRFXiveKljkCtmCCKotjUk5aVlUGn06G0tBR+fi330/3+u/vjvOU81DI1FsYvxKSwSS23N1tFBeDjU3VsMAD85oCIiKhVai3f512Kt7c3jhw5clGP5paMf+7us379enz44YfOx6tXr0Z0dLSEiVqXCnsFzhjPIE4TV2uB1eFwYMKECTCZTACAq666CrNnz27KmG5z2ngaC08uRKWjEu2822FZ0jKXtx0ptBbit5LfEKuJRRffLi4dm4iIXKOu3+txRbOL2Bw25FpykWXOQpYpC9nmbCgEBXzkPrgu+DpMCJvQcovMREREROSUnp6Offv2tapCM/2joKAAGzduhFarxdixY6FWqxs13oXXC4LQ4NXbfxn+Qrm9HN39ukMuyBuVqTkz2AzwlntDJsgue26ZrQyzj8+G3qqHv8IfzyU/h1DVxXcnOBwO2Gw252OLxeKyvCa7CZ/oP4HRYcSY0DEIVAa6bOy6SPRKxGvtXsN5y3kkeiW6tMh8znQOj515DEXWIkyJmNIii8xltjJ8X/w9gpXB6OffT+o4RERux0JzIxVZi/B+3vvYmL8R5bZyGB1G2EU7AMAhOjA5YjIWxS9ikZmIiIiolbjrrrswd+5cZGVlIS0t7aLbwDt16iRRMmoKS5YswdmzZwEAJSUluPvuuxs13vXXX4+cnBxkZGTgmmuuaVAblk35m/B6TlWbu15+vbAoYVGjMjVHoiji2cxn8XPJzwhVhmJZm2U1Fo0vdNhwGHqrHgBQYivBnrI9GBE84qLzFAoF7rvvPqxduxYBAQEubW/yavar+F/x/wAARyqOYEXKCpeNXVf+Sn/4K/1dPu6H5z9EniUPAPBmzpsYHjS8UW1mPI0oilh4ciEyzZkAqlZu3xByg8SppJNvyYdckDf5hyVE1LRYaG4AURSRYcrA1wVf4xP9J8i15EIr18JH7oNAZSCUghKCIOB4xXH08OvBIjMRERFRKzJhwgQAwH333ed8ThAEiKIIQRBgt9ulikZNIDs7u8bjhlKpVNW+lhrij7I/nMc7ynY4vxZbkwxTBn4u+RkAoLfq8U3hN5gSMeWS18Rp4qASVLCIFsggQ5J3Uq3nDho0CIMGDXJpZgDINv/zNZRlznL5+FLykfs4j71kXpKttLfb7SguLkZgYCBkssuvdK+rSkels8gMVH1Q0FoLzRv1G7E2dy1kkOG+mPswOHCw1JGIyE1YaL4Mh+hAobUQueZc5FhycMhwCNtLtyPLlIUyexl85D5I8EqAQuBvJREREREBZ86ckToCSWjMmDH48MMPoVAocP3110sdBwDQ2aczDhoOOo9bW5EZAPwUfs6iMVC1Cd3lRGmi8FSbp7C3fC+u0F6BFO8Ud8e8yI0hN+LZzGdhE20YEzrGbfN8mf8lNhduRrwmHrNiZkEj19R43onKE3jy7JMw2A24M+rORhUMb424FSaHCYXWQkwMm1hrofmM8Qxyzbno5tut1lwNVVFRgYULF+LMmTNISkrCsmXL4OXl5ZKxtXItevj2wK7yXZBBhiv9r3TJuJ6q2FqMElsJ4jXxF/0d81n+ZwAABxz4PP9zFpqJWjBWR/+l3FaOu4/djSJrEcwOc9Uv0QyTwwSzwwyD3QCrwwpvuTd85D6wiTbkmHOkjk1EREREHoK9mVu3m2++GUOHDoVarfaYjRHHh41HnCYO5fbyFl/sqk2gMhAPJzyMb4u+RbwmHiOCLm6BUZNk72QkeyfXeZ5SWylOVp5EG+820Cl0DY3r1Ne/Lzr4dIDVYUWwKrjR49Uk15yLN3LeAFC1gjrRKxHjw8bXeO663HUosBYAqGrr0ZiCoVauxezYS2+auKtsF5448wQccCDJKwnPtnnWpX2id+zY4fxw8NSpU9i1axeuvNJ1/48sSliEPw1/IkAZgBhNTIPGsDgsyLfkI0wVVqf3/tH5j/BZ/meIVkdjUfwit7Q9+bfDhsN49PSjsIgW9NH1wYK4BdWKzTHqGJTYSqqOG/j7QETNAwvN/1JuL0ehtRBWhxUAoJapoYYaOoUOwcrgeq1cVggKJHgluCsqEREREXmgdevWXfL1W2+9tYmSkFRCQi6/WrappevSa3x+3759+PjjjxESEoLp06df1FO8qR0sP4gN+g0IVARiRtQM+Ch8Ln9RHXXx7eLWDecKLAWYfWI2Smwl8Ff4Y2XKSgQpgxo9risK1pfiEB2XfHyhC9tdaOXu/1rZWboTDlTlOWU8hXxrPiLUES4bPzw83HksCALCwsJcNjYAyAU5Ovk2vC9/ibUE95+8H7mWXCRqEvFUm6fgJa99xXW+JR/v5r0LADhaeRQb8zfiP5H/afD8dbWtaJvzboHtpdtRbCuu1ot5QfwCbNRvhFKmxOiQ0W7PQ0TSYaH5XyLVkfi6y9dSx2h+1Grgq6/+OSYiIiJqpf773/9We2y1WlFZWQmVSgVvb28Wml1AFEV8Xfg1skxZGBo0FIleiVJHapYsFguefPJJmEwmAIBWq8X06dMly2Nz2LD07FJUOioBABqZBnfHNG4zRXcptZXiT8OfSPBKcBY+DxoOOldtlthKcLD8IAYFur5vs6tFaaIwJXyKs3XG9SG1t3yZHlX19WGwG3BrhPv/Luvk0wlbirZU5VRHIVjp2lXd7du3x/z587F37150794dbdu2den4jfV76e/IteQCAE6bTuOA4QB66XrVer5CUEAOOeyo2gtALWuan83jNfHOY4fowJ1H74RKpsIDcQ+go09H+Cn8cFvkbU2ShYikxUIzuYZCAVx7rdQpiIiIiCRXXFx80XMnTpzAzJkzMX/+fAkStTybCzfjtezXAAA/lfyEN1PfdMnqyh07dmDDhg0IDQ3F3XffDV9f30aP6cmsVivMZrPzcUVFRaPH/Ouvv5CZmYmePXsiMDDw8hdcwAEHjA7jP3kcjc/jDuW2csw6PgsF1gKoBTWWJy9Holcikr2ToRSUsIpWKAUl2ni3kTpqnY0NG4uxYWMve16AMgAPxD/QBImq9A/oD51ChxxLDnrrekMpU7p8jiuvvNKl7TIAoMJegTJbWaNXX0epo5zHMsgQobr0eAHKAMyOnY0v8r9AtCYaY0Ia3tf7M/1n+Fj/MaLUUXgw/kEEKANqPffGkBvhLfdGniUP3xR8gwpHBYwOI9bkrMHKlJUNzkBEzQ8LzUREREREbpacnIynnnoKt9xyC44ePSp1nGYvy5TlPDbYDSi1lTa60GwymbB8+XJYLBacOHECAQEBmDFjRmOjejStVoupU6fivffeQ0hICCZMmNCo8Xbt2oXHH38coiji448/xssvvwyNpu6bt6lkKkyPmo61OWsRpAzCTWE3NSqPu5wynnL2KTaLZuwr34dEr0TEaGLwTJtncNBwEJ18OrEXrYt08u2ETqi5/YQoithRtgMCBPT06+kRG13uK9uH6Uenw+QwYULYBDyU8FCN51XaK7GlcAs0Mg2GBQ2rcTPETr6dsCBuAQ4aDqKnX0/EeV1+D4ABAQMwIGBAo95DkbUIb+W+BaCqBcen+k9xe9TttZ4vCAKGBQ0DAOwu240KU9WHRE3RXoWIPAsLzeQaViuwfn3V8c03A0rXf9JMRERE1JzJ5XLk5HATaVcYEjQEP5b8CIPdgF5+vS67yq8u7HY7rFar8/GFK31bslGjRmHUqFEuGevgwYMQRREAoNfrkZeXh/j4eADAoUOHcPLkSfTq1QsREbX/eV0XfB2uC77OJXn+dsZ4BnqLHl18u7iklUCcJg6+cl+U28shhxxXaK9wvpbknYQk76RGz0F182r2q9hcuBkAMDJ4pLO1h5QePfMoMk2ZAIC3ct7CPdH31Lgh39KzS3HQcBAAcM50DjOia/5gq69/X/T17+u2vDWRC/JqLThUMlWdr50fNx9v5bwFhaDAHZF3uCsiEXkoFprJNSwWYOrUquNx41hoJiIiolbryy+/rPZYFEXk5ubipZdeQt++TVssaKkSvRLxZuqbKLWVIkIV4ZJVjFqtFjNmzMD69esRGhqKiRMnuiBp69KjRw989dVXsNlsiImJQWRkJABg//79eOSRR5wrnVevXg2dzr0b3P1tR+kOLD27FCJEtPVui+VtlkMmyBo1ZoAyACuSV2Bf+T608W6DZO9kF6Wl+tpdtrvasScUmv/+sAWo6ldc26re45XHnccnjCfcnqs+dAod5sTOwWf5nyFKHYVxoePqfG2sJhaLExe7LRsReTYWmomIiIiIXOjGG2+s9lgQBISEhOCqq67Cc889J02oFkgr17rstuyysjLs3bsXqampeP/9910yZkMdqTiCA+UH0NW3K9pqPWtjssvp1KkTXnjhBWRlZaFz585QqapWQR45csRZfCsvL0d2dnbTFZrLdkBE1dzHKo+h0FqIEFVIo8cNV4djhHpEo8ehxknzS8M3hd9UHfumSZLBaDfirOksYtQx8FH4YGH8Qsw5MQeV9krcF3NfrX2lhwQOwaaCTRAgYHDA4CZOfXlXBlyJKwNc27uaiFo+FpqJiIiIiFzI4XBIHYHqwWQyYd68ecjNzYVcLsdjjz2GTp1q7gfrbqeNp7Hw5ELYYccG/Qa8mPKis89vdnY2VCoVQkIaXyR1JVEU8csvv6CsrAyDBw9GbGwsYmNjq52Tnp6OjRs3wmQyITo6GomJiU2Wr6O2I7YVbQNQtbFagKL2Dc2o+ZkZNRNdfbtCgIB0v/Qmn7/cVo65J+Yi15KLQEUgnkt+Dn38++B/3f4Hu2iHn8Kv1munR03HoIBB0Mg07OftRka7EV5yL6ljELUaLDS7kcFgQHl5udQxmoRQWYnw/z/Oy8uD6O0taZ7mRBRFVFZWQiaTNek33UREROQejz32GObNmwfvf30/ZDQa8cwzz+CRRx6RKBnV5Ny5c8jNzQVQ1ad53759khWaT1WecvZEtYk2nDGeQYwmBuvXr8eHH34IQRDw3//+F4MHe87qxw0bNmD9/+/V8vPPP2P58uUXnZOYmIiXX34Z586dQ2pqar02CGysQYGDEKAMQI45B/38+0Ehq/1H4J+Kf8KanDXQKXRYELcAUZqoJsvZ0hwsP4h9hn3o6tMVnXzd9/+TIAjorevttvEvZLAZ8F7eezA6jJgYNhER6ggcNBxErqXq748iWxF2l+/G8KDhdb7bgm1X3MdkN+Gh0w/hWOUxdNR2xOLExfXqNU1EDcNCsxvdcsstyM7OljpGk9DY7fjl/4/HjRsHk/ziHXOpiiAIkMvlUCgUzl9/P16+fDnat28vdUQiIiJqhCVLluDOO++8qNBcWVmJJUuWsNDsYaKjoxEaGgq9Xg+ZTIYuXbpIlqWbXzcEKgJRZCtCiDIEnX07AwA2bdoEoGqBwtdff11joVkURezevRuiKKJHjx4u6VtdF3/++afz+OjRoxBFsca5Q0NDERoa2iSZ/q2Lbxd08e1yyXMcogMvnnsRFtGCYlsx1uWtw8L4hU0TsIU5bTyNh08/DAcc2KjfiOdTnkeiV/NfULM6ezV+LvkZAHDKeAovtX0JcZo4KAUlrKIVAgQkaBIkTkl/+630NxyrPAYAOFRxCLvLdqOPfx+JU12eXbTjZOVJBKuCEaQMkjoOUb2x0OxGhYWFqKio8Ljb29xBY7c7j729vSFrRYVms9mMoqIiGI1GiKIILy8vaDQaeHl5VSsm//3Lz88PPj4+8PX1df7X19cXcXFxSE1NlfrtEBERUSPVVmg7cOAAAgMDJUhEl+Ll5YXnnnsOe/bsQVxcHNq0aSNZliBlEF5q+xIyTBlI8EpwroqMj493FnTj4uJqvHbNmjX44osvAADXXHMNZs6c2SSZ+/fvj/379wMA+vbt22QFblcTIEAhKGARLQAAlcCVjw2VYcyAA1UthBxwIMOY4dGFZlEUYXaYoZFfeqV9viX/ouNoTTSeTHoSe8r3oKO2Y7Prq96SBSoDL/nYE4miiCWnl2CfYR9UggpLEpegg08HqWMR1QsLzW7m6+sLP7/a+zK1FGqbzXns6+sLlaLlf2k5HA5kZGRAFEUkJCSgXbt2SEpKQkxMDGJiYhAdHY2AgACoVKpm+w03ERER1V1AQAAEQYAgCEhJSan277/dbofBYMCdd94pYUKqjb+/v8e0o/BV+F5UWHjwwQfxxRdfQK1WX7TZ5N927tzpPN61a1eTFZqHDh2KpKQklJeXo3Pnzk0ypzsIgoCF8QuxLncd/BX+mBo5tdrr3333HbZs2YKEhATMmDEDin/9vHOw/CC2Fm1FnCYO40LHterv/7v5dUOYKgznLecRpgpDN79uUkeqVaG1EA+efBA5lhwMChiE2TGza/2zmxA2AcvOLoNFtGByxGTn8+207dBO266pIkum0l6J9XnrYbAbMD50vMe3lunq2xUzo2Ziv2E/evr1bBZ/RnqLHvsM+wAAFtGCn4p/YqGZmp2WXw2kJmGVyfBUt27O49agqKgI3t7eWLRoEUaMGOHcVZuIiIhap5UrV0IURfznP//BkiVLoNPpnK+pVCrEx8ejd++m6SVKLYufnx8mT558yXO6deuGr7/+2nnclJKSkpp0PneprcVGbm4uXnzxRYiiiGPHjiEqKqpawb/EWoIlZ5Y4V0Nr5VpcG3xtE6X2PDqFDqtSViHLnIVodbRHb8T2TcE3yLHkAAB+KP4BN4bcWOvq6zS/NLzf4X3YRbtHvyd3eTPnTefGmkcqjuD11NclTnR51wRfg2uCr5E6Rp35K/2d7ZMAePSdAES1YaGZXMIhk+G3yEipYzQZu92OoqIi3HLLLbjhhhukjkNEREQeYMqUKQCAhIQE9OnTB0qlUuJE1JrMmDEDnTp1giiK6NPH8/uQiqIIi8UCtVotdZTLslgsEEXR+dhkMlV7vdRW6iwyA1WrEj2J2WGGWta0v89ecq9msdHdhe0UFIICfvJL343cmjeTu/DrOt+af4kzqaHUMjWebvM0/lf8P0SpozAwYKDUkYjqjYVmogYoLS2Fr68vbrrpJqmjEBERkYcZMGCA89hoNMJqtVZ7vTW0VaOmJwhCsygwA4Ber8eiRYuQl5eH4cOH4+6775Y60iXFxcVhzJgx2Lx5MxITE3HttdVXK8dqYjHQfyB+LPkRIcoQXBPkGSsoS22lePDkg8g0Z6Kfrh/uj7u/WbT0+LbwW6zPW48QVQgWxC1AsCrYbXONCBqBUlspThtPY2jQULfO5clEUcSRiiPQyrWI86q5D/z40PE4VnkMZocZt4bf2ug5P8j7AHvK96C7b3dMDJ/Y6PFainB1OG4Ov1nqGEQNxkIzuYTM4UDvvDwAwO/h4XC04PYZdrsd+fn5mDRpEhITeSsLERERVVdZWYn7778fH330EQoLCy963X7BJsrkenv37oXNZkOPHj2aRVGtMc6ePQuVSoXIZnZn4VdffYW8///ZYcuWLbjhhhsQHR0tcapLu+2223Dbbbdd9PzO0p3YVLAJ0epovBz7MrZ9tg1f/vYlxo0bB39//ybPeaGthVuRac4EAPxa+iuur7weqVrP3nzcaDfi5ayX4YADRbYivH/+fdwXc5/b5hMEAZPCJ9X5/FxzLt7KeQuCIOA/Ef9BuDrcbdma0qqsVdhWtA0CBNwTfQ+GBg296JxOvp2w/or1sIpW50alDbW7bDfeP/8+AOBY5TEkeycjzS+tweOJoogyexl85b6QCe6rRVgcFlgcFvgofNw2B1Fzx0IzuYTS4cCCvXsBAGOHD4e5BRea9Xo9wsLCcNddd7X4H16IiIio/ubPn48ffvgBr7zyCm699Va8/PLLyM7OxmuvvYannnpK6ngt2rp16/Dxxx8DAIYNG4Z77rlH4kTu8/bbb+PTTz+FIAi45557MHToxYUhTxUY+E+7ApVKBR+f5lm0KbWVYlnGMthEG/Yb9uPH1T/CcNAAADh16pTk/78HKYOcxzLI4K/wly5MHckEGeSCHA7RAQBQCv+0ILI4LFAKSkl/BluRuQJHK48CqOrNvTx5uWRZXOmH4h8AACJE/FD8Q42FZqCqdYgKjW8fYrQbqz92GGs58/KsDisWn1mMg4aDiFXH4qk2T8FX4dvYiBc5bDiMx888jkpHJW4Ou5mrsIlq0XKrgURuYjAYMHr0aISFhUkdhYiIiDzQpk2b8Morr2Ds2LFQKBTo378/HnroITz55JNYv3691PFatB07djiPd+7cKWES99uyZQuAqpV8fx83FyNHjsT48ePRq1cvLFq0yO0rf8+cOYNt27ahoKDApeOa7CbYRJvz8fmc887j7Oxsl87VEFcFXIXJ4ZOR7peOB+IeQIQ6QupIl6WWqTE/bj4SNYlI90t3thBYn7ceYw+NxW1/3YYMY4Zb5rY5bNBb9LCLtd91Um4vr/G4uUvxTnEet/VuW+21C/uTu0pvXW/01fWFRqZBP10/9NY1fKPcg4aDOGg4CADINGfix+IfXZSyuo36jah0VAIA3j//PmwO22WuIGqduKKZqB5sNhtkMhm6dOkidRQiIiLyUEVFRUhISABQ1Y+5qKhq9/h+/fph5syZUkZr8bp27YrMzKpWAZf7fi3DmIFz5nPo7NPZLavf3C0xMRGHDh0CACQlJUmcpn7kcjkmT57cJHMdO3YMCxYsgM1mg06nw8svvwydTueSscPUYRgTMgaf5X+GKHUUht00DGtfXguHw4Fx48a5ZI7GEAQB48PGSx2j3nrrelcrPBpsBnx4/kMAQJGtCJ/mf4o5sXNcOmeZrQwPnHwAWeYsJHsl48mkJ6GRay46b1rkNDyb8SwECJgWOc2lGaT0SMIj+LbwW/jIfXB14NXO5z/Vf4r38t5DsDIYixMWI0oT5ZL5FDIFFsQvcMlYQcogCBAgoqogHqoKdcm4/xaiCqk2p0LGchpRTfh/BlE9lJeXw8fHB6mpnt3bjIiIiKSTmJiIs2fPIi4uDu3bt8dHH32Enj17YtOmTZL3bG3ppk2bhvbt28Nms6Fv3761nnfYcBgPnXoIdtgRpY7CyuSVNRaVPNmiRYvw1VdfQaPR4JprPGPzuaZSXl6Oo0ePIi4uDqGhly4qHTp0CDZb1crD0tJSnDlzxqWLRm6LvA1TIqZUtXNoBwxKHwS73Y6AgACXzdHcmOwmvJv3LgqsBRgTOqbaatmGUMlU0Mq0qHBUAAACFYGXuaL+tpduR5Y5CwBwwngCe8v3oo//xZtr9vDrgQ0dN7h8fqlp5VqMCh1V7blKeyXeyX0HIkTkWfKwQb/B5QV+V4j3iseCuAX4rfQ3XKG9Aum6dLfMMzViKtQyNUpsJRgXKv0HSUSeioVmonqwWCzw9vZm2wwiIiKq1dSpU3HgwAEMGDAACxcuxLXXXotVq1bBZrNhxYoVUsdr0QRBQJ8+FxeH/m132W7YUXV7fLY5G9nmbCR5N69VwVqtFhMmTJA6RpMzGAyYPXs2zp8/D41Gg2eeeQbx8fG1nt+1a1d88MEHsFgsCAoKcsvq7wt7Bvv5+bl8/Obmvbz38GXBlwCAQ4ZDWNd+XaNWf6pkKixOXIxP9Z8iVBVap837bA4b3sx5E6eNpzEsaBgGBw6+5PkRqn/aiggQWswmf42hEBTQyDTO/sm+cs+986OPf58aPxhwJY1cg/9E/setcxC1BCw0E9WDxWJBREQENwEkIiKiWs2ePdt5PGjQIBw9ehS7d+9GUlISOnfuLGEy+ltn387YmL8RIkSEKEMQqY6UOlKDWCwW2O12eHl5SR2lyZw8eRLnz1f1QjaZTNizZ88lC81JSUlYsXIFfjvyG/p06QNfX88tlrUUxbZi53G5vRxW0QpFI0sP7bTtsChhUZ3P31y4GV8Xfg0AOFp5FO217S/Zo7qzb2fMjZ2Lg4aDSPdLR6JXYqPytgQqmQoPxT+Ej/UfI0QV4uyX3dpU2Cvwif4TWB1WjAsbB53CNa13iFoqFpqJ6kAURRQVFcFisWDkyJFSxyEiIqJmwmQyITY2FrGxsVJHoQt09e2KZ9o8g0xTJrr7dYeXvPkVanfv3o1ly5bBarXizjvvbDXtM2JjY6HValFRUQFBEC7b0s4hOvCG5Q0cCDuAz85/hqU+SxvdyuFSrA4rlDKl28ZvDsaEjsEBwwGU2koxKWySJP9/VdorncciRJgcpsteMzBgIAYGDHRbpr9tLtiMrYVbkeSdhJlRMz3666WTbyd08u0kdQxJvXjuRWwv3Q4AOGM6g6VJSyVOROTZZFIHoJbBJpNhZefOWNm5M2yylvVlVVFRgRMnTsBisWDy5Mm47bbbpI5EREREHsxut+Pxxx9HVFQUfHx8cPr0aQDAww8/jDVr1kicjv7WVtsWQ4KGIEBZvZduqa0UT599Gg+efBB/Gf6SKN3lffjhh7BYLBBFEe+++67UcZpMYGAgnnvuOdx+++14+umn0b59+0uen2POwQHDAQCAyWHCj8U/uiVXpb0S807Mw+hDo/HY6cdgF+1umacu/lf0P0z9ayrmn5iPfEt+k8+f6JWId9u/i5dSXoIIEb8U/9LkGa4Nvhap3qlQC2rcEHwDErwSmjxDTbJN2Xg1+1WcNp3GtqJt2Fy4WepIdBnZ5mzncZYpS8IkRM0DVzSTS9hlMvwvJkbqGC7ncDiQnZ2NQYMG4Z577kGHDh2kjkREREQebunSpXjnnXewfPly3HHHHc7nO3bsiOeffx7Tpk2TMB1dzpqcNfi19FcAwBNnn8D7Hd6XOFHNQkJCcOzYMedxaxIVFYWoqKg6nRuoDISf3A9l9jIAQILGPQXHH4t/xLHKYzCeN+L9N99HQUgBHr37UQQFBbllvtqYHWasOrcKdthRYC3A+rz1mBU7q0kz/J3jodMPocRWAgCwiJbL9kl2JV+FL5YnL2+y+erKKlohQnQ+NjvMEqahuhgVMgovnnsRIkSMDR0rdZwmdaLyBL4r+g7R6mhcF3wdW4hSnbDQTFQLk8mEvLw8+Pn5Yfbs2Wjbtq3UkYiIiKgZWLduHV5//XUMHjwYd955p/P5Tp064ejRoxImo7q48JZ7k8MEh+iATPC8O/buuusu6HQ6mEwmTJp0+c3R6sJqteL8+fMIDQ2FSqVyyZhS85Z746k2T+GH4h8Qo47BoMBBbpnHX+EPADj19ikYs404rD2MVY5VWLx4sVvmq40AATJB5lxRLRfkTTr/3wqthc4iMwCcrDzZpIVmd7M5bA3a4DDeKx7jQ8djS+EWJHkl4brg69yQjlxpcOBgdPfrDrtoR6AysM7XFVgKsLNsJxK8EpCqvXSLH09ksBnw8KmHUeGoAFD1d8k1wa2jRRM1DgvN5BIyhwPd8qtuy9obEgJHM2+fYTAYkJubi+TkZEyePBkpKe7r40ZEREQtS3Z2Ntq0aXPR8w6HA1arVYJEVB+3hN+CDFMGSm2luCPyDo8sMgOAr69vtQ8yGquiogLz58/HuXPnEBUVhWeeeabFbJwXo4nBrRG3unWOPv59MNUyFY+bH0e4Vzi0ci1KS0vrfP2ximP4pvAbRKojMTZ0bIO/7lQyFebHzcf7ee8jSBmEyeGTLzqnwl6BM8YziNPEwVfhnj/jCHUEOmo74lDFIagFNQYEDHDLPE3NaDfikdOP4GjlUfTw7YEH4x+sd8F5csRkTI64+M+FPNeFGwCa7CZsLtwMuSDHiKARUMku/lCuwl6BuSfmoshWBAECFicsRje/bk0ZudFKbCXOIjNQvYUI0aWw0EwuoXQ48OiuXQCAscOHw9yMC812ux05OTno0aMH3nrrrRazmoOIiIiaxhVXXIFffvkFcXFx1Z7/+OOP0bVrV4lSUV3Fe8XjjdQ3pI7R5Hbv3o1z584BqPqwZOfOnRg8uOWsQG0Ko0NHI2RWCFauXAmlUokpU6bU6boKewUeOf0IKh1Vq+mVghKjQkc1OEdvXW/01vWu8bVSWynmHJ8DvVWPQEUgVqSsQJDS9e09ZIIMjyU+hpPGkwhRhbhlDin8VPITjlZW3Zmyq3wX9hn2oYdfD4lTuVamKRObCzYjTBWGG0Ju8NgP26TyTOYz2Fm2EwBwyngKc2LnXHROjjkHRbYiAFWbUR6uONzsCs1R6ij08uuFP8r+gK/cF0MCh0gdiZoJFpqJ/iU/Px8RERF49NFHWWQmIiKienv00UcxefJkZGdnw+FwYOPGjTh27BjWrVuHr776Sup4RDWKioqCIAgQRRGCICA6Otql4+eac+Er94WPwsel43qa/v37o1+/fgBQ536mBpvBWWQGgDxLXp3nK7IW4cmzTyLHnINxoeMuW6A+UH4Aequ+6lpbEfaW7cWQIPcUkBQyBdpp27llbKkEKKpvHnrhSld3OlF5AmaHGR183LtnkMVhwYOnHkSprWo1vl20Y2xY6+pLfDknK0/WeHyhGHUMotRRyDZnQyEomuWHEYIg4MH4B5FnyYO/wh9eci+pI1EzwY+miC5gtVpRVlaGPn36IDk5Weo4RERE1AyNHDkSGzZswObNmyEIAh555BEcOXIEmzZtwpAh9Svo/Pzzzxg5ciQiIyMhCAI+//zzaq+LoojFixcjMjISXl5eGDhwIP78889q55jNZtx7770IDg6GVqvF9ddfj6ysrGrnFBcXY/LkydDpdNDpdJg8eTJKSkoa8vbJTX4t+RXT/pqGeSfm4bz5vMvHb9OmDR5++GFce+21WLRokUv3J1mRuQLTj07Hf478B0crWn6fckEQ6rVpVpg6DIMDqlaP6xQ6XBNU9z6on+g/wbHKYyi3l2Nt7loUW4sveX6CVwIUQtV6MznkSPRKrPNcBKTr0jE1Yiq6+3bHvdH3IsXb/S0WN+o3Ys6JOVh4aiFezXrVrXMZ7AZnkRkAssxZlzi7dRoaNNR5XNsqX41cg+eSn8Oi+EV4KeWlZtmjGaj6uyxCHcEiM9ULVzQTXSArKwtt27bFnDkX3/5CREREdCmnT59GQkICBEHAsGHDMGzYsEaPWVFRgc6dO2Pq1KkYM2bMRa8vX74cK1aswNtvv42UlBQ88cQTGDJkCI4dO+bsrztr1ixs2rQJH374IYKCgjB37lxcd9112LNnD+Tyqo3CbrrpJmRlZWHLli0AgOnTp2Py5MnYtGlTo98DNZ5dtOP5zOdhES3QW/V4J+8d3B93v8vn6dGjB3r0cO3KuyJrEX4o/gEAYHQYsaVwS4tb5eoKs2JnYUrEFGjl2hp7vtZGLVM7j+WC3FlErk2MJgZPJT2FfeX70NGnI5K8kxqcubUaHToao0NHN9l8PxX/5Dz+ueRn3Bntut7s/xaoDMSggEH4ofgHeMu8MSJohNvmaq5uDr8ZvXW9oRAUiNXE1nqeVq5FL12vJkxG5BlYaCa6gMPhwKhRoxAcHCx1FCIiImpmkpOTkZubi9DQUADAhAkT8OKLLyIsLKzBY44YMQIjRtT8g74oili5ciUWLVqE0aOrih7vvPMOwsLC8P7772PGjBkoLS3FmjVr8O677+Lqq68GALz33nuIiYnBd999h2HDhuHIkSPYsmUL/vjjD6SnpwMA3njjDfTu3RvHjh1z6cpWahgBQlWfVLHqsawZ3ZjqI/eBv8IfJbYSAEC02rUtOVqSAGXA5U/6l3Gh45BvyUeOOQejQ0fXaXO/ttq2aKvl/9fNRXtte5w2nQaAJlkZOyd2DiaFTYKfwg9audbt8zVHvBOAqHYsNBP9P7vdDofDAS8v3hZCRERE9SeKYrXHmzdvxrJly9w235kzZ5CXl4ehQ/+5jVetVmPAgAHYvn07ZsyYgT179sBqtVY7JzIyEh06dMD27dsxbNgw/P7779DpdM4iMwD06tULOp0O27dvZ6HZA8gEGebHzsc7ue8gQBmA2yJukzpSnalkKjyZ9CQ2F2xGuDocI4NHSh2pRfGWe2Ne3DypY7RYJypPIMuUhe5+3etUxHeHO6LuQJJ3EiwOC64OvLpJ5oxQRzTJPETU8rDQTPT/9Ho9wsPDMXDgQKmjEBEREV1WXl7VhmH/XjEdFhaGjIwM5zkqlQoBAQEXnfP39Xl5ec5V2BcKDQ11nvNvZrMZZrPZ+bisrKzhb4TqpKeuJ3rqekodo0FiNDGYET1D6hhUA71Fjy/zv4ROocOokFFQyFgi+Nuesj1YcmYJRIiIUkfhxZQX69XWxFVkgqzJCsxERI3Ff0XIJWwyGVZ36OA8bm5EUUR5eTmuueYahIeHSx2HiIiImqGaNgCrz4ZgjZn3QqIoXnbef59T0/mXGmfZsmVYsmRJA9ISXV55eTnMZrPb2tm9k/sOthZuRZJXEhbGL4S33Nst8zQHj5x+BNnmbABAqa0Ut0fdLnEiz7G3fC/E/+9Xk23ORq45F3FecRKnIiLybCw0k0vYZTJsjo+XOkaDGQwGaLVajB07VuooRERE1EyJoojbbrsNanXV5lwmkwl33nkntNrqPS43btzokvn+/nA8Ly8PERH/3Oas1+udq5zDw8NhsVhQXFxcbVWzXq9Hnz59nOecP3/+ovHz8/Nr7S+9cOHCapsnl5WVISYmpvFvilq9HTt24Omnn4bVasX48eMxefJkl45/2ngan+g/AQDsN+zH5oLNGBvWOn8GsIt25JhznI+zzFkSpvE8XX27YlPBJueKZraTICK6vOa39JTIDUpLSxEaGooO/78qm4iIiKi+pkyZgtDQUOh0Ouh0Otxyyy2IjIx0Pv77l6skJCQgPDwc27Ztcz5nsVjw008/OYvIaWlpUCqV1c7Jzc3F4cOHnef07t0bpaWl2Llzp/OcHTt2oLS01HnOv6nVavj5+VX7ReQKX375JaxWKwDXfShzIZWggoB/VupL0QrBU8gFOa4Pvh4AoBSUuDb4WokTeZbuft3xXPJzmBMzB8+0eaZeXyu7ynbh3mP34uFTD6PQWujGlEREnoUrmsklZKKI9oVV/4D+FRQERxPcJuoqxcXFMJvNuPHGGyFrhm0/iIiIyDOsXbvW5WMaDAacPHnS+fjMmTPYv38/AgMDERsbi1mzZuHJJ59EcnIykpOT8eSTT8Lb2xs33XQTAECn02HatGmYO3cugoKCEBgYiHnz5qFjx464+uqqnp+pqakYPnw47rjjDrz22msAgOnTp+O6667jRoDU5KKionDw4EEAVRtXNsafhj+RZc5CL10v6BRVH/JEa6JxZ9Sd2Fq4FW2822BE0IhGZ27Obo+6HdcGXwtvubfz94j+keydjGTv5Hpd4xAdWJ6xHCaHCUBVq5Y5sXMuc1XrZrKb8EvJLwhUBiLNL03qOETUCCw0k0so7XYs++MPAMDY4cNhVjSPL62ysjIUFRXh5ptvxn/+8x+p4xARERFVs3v3bgwaNMj5+O92FVOmTMHbb7+N+++/H0ajEXfddReKi4uRnp6Ob7/9Fr6+vs5rnn/+eSgUCowfPx5GoxGDBw/G22+/Dblc7jxn/fr1uO+++zB06FAAwPXXX4+XXnqpid6lNGwOGyocFSyueZjbb78d/v7+MBgMGD16dJ2vO3v2LHbs2IF27dqhc+fO2F6yHcsylgEANuo3YlXbVc4VqdcEX4Nrgq9xS353yjZl47fS35DglYAefj1cNi5bQriWCBF20e58bBNtEqZpHh4+/TCOVh4FAEyPnI6RISMlTkREDSWIoig29aRlZWXQ6XQoLS1t0bfZ9e/fHxaLpcZdvFsatc2GT7ZsAdC8Cs2nTp3ClVdeidWrVzfJZj1EREQtXWv5Po+qa25/7ufN57Hg1AIUWAvQR9cHC+IW8HvBZqygoAAzZ86EyWSCIAh44okn8Fvgb9hcuNl5zqttX0WUJkrClI1TbivHnUfvRJm9DACwKH4Reul6SZyKsk3ZyDJnoaNPx2qbSv5S/AvW5q5FgDIA82PnI1zNDedrY3aYMfbQP33S0/3S8VDCQxImIqKa1PV7veZRDSRyA4PBAIfDgbS0NP5gQURERNSKbC3aigJrAQBge+l2nDGdQaJXosSpWh9RFF3yfXhmZiZMJpNzzJMnT6LH1T2wpXALHHAgXhOPMFXNG1s2F3mWPGeRGQCOVx5vcKHZLtqxuWAzyu3luDb4Wq7qb6A/DX/iodMPwSbaEKuOxfMpzztXzfcP6I/+Af0lTtg8qGVqdPHpgv2G/QCqCs1EdSWKIn4r/Q0O0YG+/n0hF+SXv4jcioVmarXy8/ORnp7u8p2siYiIiMizhar+ueNQJajgr/CXLkwrcaziGPKt+eju2x0auQbv572Pj85/hFBVKJYkLmlU+4Z27dohKioK2dnZ8PHxQXp6OqL8orAyZSVyzDno6tsVClnz/tE3ThOHNl5tcNJ4EhqZBn10NW/UWRfv5L6DtTlrkWfJw5s5b2JLly0evymiKIoos5fBR+7jMYWknWU7nW0xMs2ZyDJnNZsPrH4s/hEFlgIMCRriER80PJLwCHaX70aAIgDttO2kjkPNyBs5b2BTwSYAwJ7yPZgdO1viRNS8/7UlagSr1YqUlBRoNBqpoxARERFRExoWOAyV9kqcNZ3F1QFXI1AZKHWkFu2n4p/wbOazAIC23m3xUPxD+OD8BwCAXEsuPtF/gntj7m3w+N7e3nj++edx6tQpREdHw9/fHwCQ4JWABK+ERuf3BCqZCk+3eRrHK48jQh2BIGVQg8c6UnEEJ40n4RAd+MvwFz46/xFuibjFhWldyyE6sPTsUuws24lwVTiWJS1DsCpY6ljo4NMBn+V/BhEigpRBCFc1j/YYn+o/xdu5bwMA/lf8P7zS9hXJ7/BVypTorestaQZqnvaX76/xmKTDQjO1WjKZDGFhzfsWOiIiIiKqP0EQMDq07hvNUePsLNvpPD5WeQwmhwlqQQ2zaAYA+Cnq1tfbZDLh+PHjiIqKQlBQ9UKrl5cXOnTo4LrQHqCiogJPPfUUzp49i2uvvRYTJ05EB5/Gv8cr/a/Eu7nvAgBCVCGosFc0ekx3Ol553Pk1lGfJw3dF32Fi+MQGj1dhr8CpylOI84pr1GreHn498GTSk8gwZSDdL71aj2ZPdrzyuPM4y5yFSkcltHKthImIGi5dl45z+nPOY5IeC83UKomiCFEUERISInUUIiIiIqIWrZtvN/xc8jMAIMkrCWGqMDyU8BA26jciXB2OCaETLjuGyWTCvHnzkJGRAS8vLyxfvhzx8fFuTt54DtGBcns5/OR+9V41+uWXX2L//v0AgPXr16Nfv36Ijo5udKaRISPxiPkRfJb/Gdp4tcGo0FGNHtOdApWBUAgKZ5uKxvTbLreVY/aJ2ThvOQ8/uR+eS36uURv1dfDp4JLi/9/yzHk4Xnkc7bXt3bZqe2DAQPxR+gcccCDdL51FZmrWpkRMQSefTrCJNnT37S51HAILzeQidpkMb6WmOo89nd1uh1wuv2glBBERERERudbgwMEIUYYg35qP3rreEAQBXXy7oItvlzqPcerUKWRkZAAAjEYj/vjjD48vNJfbyrHg5AJkmjPRUdsRSxKXQClT1vl6pfKfcwVBgELhuh/f74q+CzOjZkreMqEuQlWheCj+IfxY/CPaeLfBoMBBF53z9ddfY8uWLUhMTMTdd98NlarmntN/VvyJ85bzAIAyexn2lO/Btepr3Zq/rrJN2Zh1YhZMDhP85H54se2LjWqRUpveut5Y3W41iq3FSNWmunx8oqbW1ber1BHoAiw0k0vYZDJ8lpQkdYw6y8nJgZ+fH6KioqSOQkRERETU4nXy7dSo66OiouDj4wODwQAASElJcUUst/q55GdkmjMBAIcqDuGA4QC6+9V9xd3IkSORmZmJM2fO4JprrkF4uGt7ADeHIvPf0vzSkOaXVuNr2dnZeO211yCKIs6ePYv4+HiMGlXzKu14TbyzbYsMMrTxauPO2PVy0HAQJocJQFUR/FjFMfTxb/imj5cSqY5EpDrSLWMTkXsdrTiKrwu+RpQ6CuPCxnnMBql/Y6GZWh1RFGEymTB37lwkJLSMzUGIiIiIyD0OHTqEn376CSkpKRg6dKjUcZqdnaU7sTZ3LXQKHebEzkGoKrRB4xSoCnDFrCtQdrgMk7pNQteunr+CLUT5T5s+AQKClfVrhaBWqzFnzhxXx2px7HY7RFF0PrZarbWeG64Ox/Lk5dhTtgftte3RVtu2KSLWSXtte6gEFSyiBVqZFsneyVJHIiIPU2mvxKOnH0WloxIAoBAUGBs2VuJU1bHQTC4hE0UklZYCAE7pdHB48KfjpaWl8PX1RY8ePaSOQkREREQeLD8/H48++iisViu2bt0KLy8v9O/fX+pYzYYoingm8xmYHCZkmbPwVs5bWBC/oN7jVNgr8NCph1ChqQC6A1mRWegKzy8099T1xF1Rd+FwxWH00fVBvFe81JFapNjYWEycOBHffPMNkpKScN11113y/ESvRCR6JTZRurqL84rDypSVOFpxFB18OiBExf2EiKg6g93gLDIDgN6qlzBNzVhoJpdQ2u1Y8euvAICxw4fD7ML+Ya5mMBiQlJSE1FT2oyIiIiKi2uXn51dbHZmTkyNhmrox2Aywww6dQid1lIuIEC9/Ug3KbGWocFQ4H2ebs10Vye1GBI/AiOARUsdo8W6++WbcfPPNUsdotBhNDGI0MVLHICIPFaoKxZDAIdhWtA3+Cn9cF3zpD9ak4Pm7thG5mMViYW9mIiIiIrqslJQUdOpU1Vs4ODgYgwZdvAmZJ/mt5DdM/msyJv85GZ/pP5M6DgRBwLzYeYhSRyHVOxVTI6Y2aJxwVTj66foBAHzlvhgeNNyVMYmIiJqN+2Luw/or1mNt6lrEamKljnMRz112SuQGRUVFsNvtaNeundRRiIiIiMjDKRQKPP7448jPz0dAQABUKpXUkS5pY/5G2EQbAOAj/UcYFVrzhmhNKV2XjnRdeqPGEAQB98fdj6nWqfCT+0Ej17goXet02ngar2a9Crkgx13Rd3EFLRFRM+On8JM6Qq24oplaDaPRiKKiIkyZMgVTpkyROg4RERERNQMymQxhYWEeX2QGqlb+/i1CFSFhEtcTBAGhqtBWUWQ22Az46PxH+KrgK9gcNpeP/3zm8zhSeQSHKw5j1blVLh+fiIhaL65oplZBFEWcO3cOPXv2xNy5c5vFDwpEREREVDNRFPHVV18hKysLQ4cORVJSktSRmtwvxb9gVdYqqGVqPBj/IFK1qbg7+m4EK4NhdpgxLmyc1BGpgZ44+wT+rPgTAJBtysaM6BkuHd/isDiPzQ6zS8cmIqLWjYVmahWKioqg0+mwaNEiFpmJiIiImrmvv/4ar7/+OgDgp59+wpo1a6DVaiVO1bRey3kNRocRRocRa3PWYnnycnjLvTE1smF9kFu6wsJCiKKI4OBgqaNc1snKk87jU8ZTLh//7ui78cK5FyAX5Lgz+s6LXtdb9FAICgQqA10+N7lPjjkHL2e9DKvDijui7kCyd7LzNYfogAABgiBImJCIWgO2zqBWoby8HB06dGBvZiIiIqIWIDs723lcUVGB0tJSCdNIw0fuU+MxXeybb77B1KlT8Z///AdfffWV1HEua2jQUACAAAFDAoe4fPxOvp2wpv0avJ76OlK1qdVe++T8J5h2ZBqm/jUVPxT94PK5G0IURWwr3IYN5zeg2FosdRyP9XLWyzhoOIgjlUfwXOZzzud/Lv4Z4w6Nw4TDE7C3bK+ECRvH5rBhU/4mfHL+E1TaK6WOQ0S14Ipmcgm7TIb3k5Odx55EFEVYLBZ069ZN6ihERERE5AJDhw7FTz/9hPLycvTp0wcRES2rH3FdLIhbgLdz34Zapsb0qOlSx/Fon332GURRBAB8/vnnuO666yROdGnTo6ZjcMBgaGQaRGmiXDJmqa0Un+o/hVJQYmzoWHjJvWo8b2P+RgCAAw58UfAFBgUOcsn8jfGR/iO8l/ceAODH4h+xut1qiRN5pgvboFzYHuWt3LdgES2ACKzLW4dufs3z5+JXs1/F1qKtAIADhgN4POlxiRMRUU1YaCaXsMlk+KBtW6lj1Eiv18PPzw8DBw6UOgoRERERuUBCQgLWrFmD0tJShIWFtcrbweO94rE4cbHUMZqFmJgY5ObmOo+bgyRv1/YdX3Z2mbPvc54lD/Pj5td4XowmBn9V/FV1rPaM36sLW4lkmbNgsptaxaaQ9TU9ajqezXgWVtGKu6Pvdj6vk+tQaC0EAPgr/CVK13gnje5tKUNErsFCM7V4paWluOuuu9ChQwepoxARERGRC1gsFrz11lvIysrCyJEj0adPH6kjkQebM2cOPv30U4iiiDFjxkgdRxJZ5qx/jk1ZtZ73YPyD2KjfCJVMhTEhnvF7NThwMHaV7YIddvT3788icy1SvFPweurrFz2/IH4B3sl9B0pB2ax7uA8JHIJT2aecx0TkmVhoJpcQRBExBgMA4JyPD0QPWVVisVigUCiQlpYmdRQiIiIicpGNGzdiy5YtAICjR4/i7bffhk6nkzgVeSqtVotbb71V6hiSGhMyBm/lvgUZZLgx5MZaz9MpdB5XjOyl64VX272KUlspUrxTpI7T7ESoI7AgfoHUMRrt2uBr0cmnEywOi8tX/BOR67DQTC6hstvx8k8/AQDGDh8Os8IzvrTy8vIQFRWFjh07Sh2FiIiIiFykoqLCeWyz2WA2my9xNhGNCh2F/v79oRAU8Ff6Sx2n3sLV4QhXh0uaocBSgGUZy5BnzsPEsIkYGTJS0jytUYzGM9q5EFHtPGvXNiIX+vuHjltvvZUrXIiIiIhakBtvvBEJCQlQKpUYP348QkNDpY5E5PGCVcHNssjsKT7Sf4TjlcdRZi/DGzlvoMxW1qBxSm2lWHRqEab9NQ1bCre4OCXwe+nvWHhyIV4+93K1TQGJiJqCZyw7JXKD7OxsxMfHY+RIftJMRERE1JIEBQXhxRdflDoGEbUiKkHlPJYLcsgFeYPG+ej8RzhoOAgAeCXrFfTW9YZO4ZqFUaW2UizPWA6baMPhisMIUgZhYvhEl4xNRFQXLDRTi1RZWQm73Y4ZM2ZwNTMRERERERE1yqTwSSi0FuK85TzGho6FVq5t0DgChGrHMhfeaG52mGETbc7HBrvBZWMTEdUFC83UIuXn56NDhw5czUxEREREHqGiogKZmZmIi4uDt7e31HGoHjKMGQCAOK84iZOQlLRyLR6If6DR40wIm4Accw5yLbkYGzoWvgpfF6SrEqoKxfjQ8diYvxHR6uhLbvxIROQOLDRTi2SxWNCnTx8oPGRTQiIiIiJqvYqKijB37lwUFBQgNDQUK1as4F13zcRH5z/Cu3nvAgCmhE/B2LCxEiei5s5X4YtHEh9x2/iTIyZjcsRkt41PRHQp3AyQWhxRFAEAbdq0kTgJERERERGwb98+FBQUAAD0ej32799fp+sKLAV4N/ddbC7Y7Pwel5rW1sKtzuNvi7516dgO0YGfi3/Gz8U/wyE6XDo2eRarw4pccy5sDtvlTyYiasa43JNcwi6TYWNiovNYSlarFXK5HL6+rrsFiYiIiIiooRISEiCXy2G326FQKBAXd/kWDKIo4sFTDyLXkgsAKLOVcVMvCbTxbgN9qR4AkOSV5NKxV2etxpaiLQCAA4YDuDfmXpeOT56h3FaO+SfnI9ucjURNIp5q8xS85F5SxyIicgsWmsklbDIZ1rZvL3UMAFWrROLi4tClSxepoxARERERITExEU888QQOHDiArl27Ij4+/rLXmBwmZ5EZAM6YzrgxIdVmTuwctCtoBwC4Nvhal46937DfeXzAcMClY5Pn+L30d2SbswEAp02nsbd8L/r695U4FRGRe7DQTC2O0WhEeno6/Pz8pI5CRERERAQA6NChAzp06FDn873kXhjgPwA/lfwEhaDAkMAhbkxHtVHL1BgVOsotY6f7peOLgi8AAL38erllDpJepDrSeSxAQIQ6QsI0RETuxUIzuYQgiggxGgEA+V5eEAVBkhx2ux2CILA/MxERERE1e3Nj52J06Gj4yf0QrAqWOg652O1Rt6ObbzeIEJHmlyZ1HHKTDj4d8EDcAzhQfgA9dT2R6JUodSQiIrdhoZlcQmW3Y8333wMAxg4fDrNCmi+t0tJS6HQ6DBnCFR9ERERE1LwJgsCiVAvXza+b1BGoCfTz74d+/v2kjlFvmws2Y0/5HvTw64HhQcOljkNEzQALzdSilJWVoUOHDggNDZU6ChERERERkUcSRRGCRHehNpbNYUOhtRBByiAoZCxpuMv+8v1Ynb0aALCzbCei1dHo4FP39j9E1Drxb2VqMSwWC2w2G0aOHCl1FCIiIiIiIo9jc9jwVMZT2Fm2E519OuPhhIehkqmkjlVnFfYKLDy5EGdMZxCnicNTSU/BR+EjdawWqdhaXO1xia1EmiCtwG8lvyHXnIuBAQPZJomaPZnUAYhcpaysDP7+/hg+nLf0EBERERG50pGKI3jy7JN4M/tNWBwWqeNQA+0s24kdZTsgQsR+w378WvKr1JHqZXfZbpwxnQEAZJgysLNsp8SJWq4+/n1whfYKAEAnn07o6ddT4kQt09bCrXgq4ym8k/cOHjj5AKwOq9SRiBqFK5qpxSgtLcVVV12FwMBAqaMQEREREbUYFocFS04vQYWjAgCglCkxJWKKxKmoIfwUftUe+yp8Gz3mOdM5LM9Yjgp7BWZEzUC6Lr3RY9YmQh0BAQJEiBAgIEId4ba5Wju1TI2n2jwFs8MMtUztljmKrcU4ZzqHZO9keMm93DKHpztWecx5rLfqUWIrQYgqRMJERI3DQjO1GA6HA1FRUVLHICIiIiJqUcwOs7PIDABF1iIJ01BjdPDpgDsi78DOsp3o4tMFPfx6NHrMNTlrcNZ0FgDwfObz+LDjh40eszYp3ilYELcAe8r3oKtvV6RqU902F1VxV5E525SNeSfnwWA3IEodhRXJK+At93bLXJ7sSv8r8UPxD7CJNnTy6YRgJVtnUPPGQjO1CA6HAwCQkpIicRIiIiIiopbFV+GL8aHj8ZH+IwQqAjE6ZLTUkagRrg+5HteHXO+y8RTCP2WFpticr49/H/Tx7+P2eci9/ij7Awa7AQCQbc7G8crj6OLbRdpQEuji2wWr265GvjUfqd6pzXaTTqK/sdBMLmEXBHwdF+c8bmqZmZmIjo5Gz57sG0VERERE5GqTIyZjQtgEKAUlCyFUzfSo6TA5TDDYDZgWOU3qONRMpHinONugeMm8EK2OljqSZMLV4QhXh0sdg8glWGgml7DJ5Xi1Y0dJ5jabzbDb7Zg1axZiYmIkyUBERERE1NKpZCqpI0jiQPkB/FryK9pp22Fw4GCp43icUFUonkh6QuoY1Mx09OmIJxKfwNHKo+jp1xPBKraMIGoJWGimZi8/Px+JiYkYMmSI1FGIiIiIiKgFyTXnYvGZxbCJNmwp2gIfuY9bN7sjak06+XZCJ99OUscgIheSSR2AWghRhJ/ZDD+zGRDFJp3aaDSiQ4cOUKvds0kBERERERG1TvmWfNhEm/NxljlLwjRERESejYVmcgm13Y7127Zh/bZtUNvtTTav3W6HIAjo3Llzk81JREREREStQ6o2Fe217QEAIcoQDPAfIHEiIiIiz8XWGdSslZWVwc/PD1dddZXUUYiIiIiIqIVRypR4MulJ5FvyEagMbLV9qomIiOqiVa5ofuWVV5CQkACNRoO0tDT88ssvUkeiBiovL0d0dDRCQ0OljkJERERERC2QXJAjXB3OIjMREdFltLpC84YNGzBr1iwsWrQI+/btQ//+/TFixAhkZmZKHY3qyWAwwGw24+qrr4YgCFLHISIiIiIiapVKrCWYdXwWRh0chTU5a6SOQ0REEml1heYVK1Zg2rRpuP3225GamoqVK1ciJiYGq1evljoa1YMoisjKysLVV1+Nm2++Weo4RERERERErdamgk04ZTwFm2jD5/mf45zpnNSRiIhIAq2q0GyxWLBnzx4MHTq02vNDhw7F9u3bJUpFDVFaWgofHx/cdttt8PPzkzoOERERERFRq6WVa53HcsjhJfOSMA0REUmlVW0GWFBQALvdjrCwsGrPh4WFIS8vT6JUVF8GgwH5+fmYOHEi0tLSpI5DRERERETUql0ffD3yLfk4azqLEUEjEKwKljoSERFJoFUVmv/2736+oiiyx28j2QUB/4uOdh67iyiKyMnJwdChQ7Fw4UL+uREREREREUlMIVNgRvQMqWMQEZHEWlWhOTg4GHK5/KLVy3q9/qJVzlQ/NrkcK7t0cfs8JSUl8PHxwfTp06FWq90+HxEREREREZFUvi/6HgcNB5GuS0dvXW+p47iFKIrYUbYDMsjQw68HF5QRNWOtqkezSqVCWloatm3bVu35bdu2oU+fPhKlorqy2+3Q6/W45ppr0KFDB6njEBEREVErIYoifi7+GZvyN6HSXil1HCJqJfaX78fz557H/4r/h2Vnl+G08bTUkdzi5ayXsfTsUjx+9nGsyVnToDGOVRzDbX/dhomHJuKX4l9cnJCI6qpVFZoBYM6cOXjzzTfx1ltv4ciRI5g9ezYyMzNx5513Sh2teRNFqG02qG02QBTdMkVJSQmCgoJw33338RNOIiIiImoyG85vwDOZz+D1nNfx6OlHpY5DRK1EnuWfu7FFiNBb9BKmcZ/d5btrPK6Pt3PfRqG1EBWOCqzOXu2qaERUT62qdQYATJgwAYWFhXjssceQm5uLDh06YPPmzYiLi5M6WrOmttvxyZYtAICxw4fDrHD9l1ZpaSmSkpIQEhLi8rGJiIiIiGrzZ8WfzuNjlcfgEB2QCa1uzQ5JoNxWDqWghEaukToKSaCvri++zP8S58zn0Na7Lbr6dpU6kluk+abh26JvnccN4S33dh5r5VqX5CKi+mt1hWYAuOuuu3DXXXdJHYPqweFwwG63Y+rUqVJHISIiIqJW5kr/K3HAcAAiRPTV9WWRmZrER+c/wrt570Ij02BR/CJ08e0idSRqYr4KX7yY8iJKbCUIVAa22L977om+B2m+aZAJMqT7pTdojJlRMyGDDEaHEVMjWDcgkkrL/FuKWpzi4mL4+fmha9eW+QkuERERUUMsXrwYgiBU+xUeHu58XRRFLF68GJGRkfDy8sLAgQPx559/VhvDbDbj3nvvRXBwMLRaLa6//npkZWU19VvxaEOChmBlyko8nvg47o+73/m8KIr4teRX/Fj8I+yiXcKE1NKIoogPzn8AADA5TPhU/6nEiUgqCpkCwargFltkBgBBENDHvw966Xo1uE1msCoYixIW4YmkJ5DkneTihERUVy33bypqUQwGA9q3b4/4+HipoxARERF5lCuuuAK5ubnOX4cOHXK+tnz5cqxYsQIvvfQSdu3ahfDwcAwZMgTl5eXOc2bNmoXPPvsMH374IX799VcYDAZcd911sNtZOL1Qolciuvh2qVYEWZOzBk9nPI3nMp/D85nPS5iOWhpBEBCqDHU+DlOFSZiGiIioblpl6wxqXhwOB0wmE1JSUqSOQkRERORxFApFtVXMfxNFEStXrsSiRYswevRoAMA777yDsLAwvP/++5gxYwZKS0uxZs0avPvuu7j66qsBAO+99x5iYmLw3XffYdiwYU36Xpqb/Yb9NR4TucLixMX4WP8xfOQ+uCnsJqnjEBERXRZXNJPHKygoQHBwMMaOHSt1FCIiIiKPc+LECURGRiIhIQETJ07E6dOnAQBnzpxBXl4ehg4d6jxXrVZjwIAB2L59OwBgz549sFqt1c6JjIxEhw4dnOfUxGw2o6ysrNqv1ujCXqK9/HpJmIRaogh1BO6LuQ//ifwPNwMkIqJmgSuayeOVlZXh2muv5YpmIiIion9JT0/HunXrkJKSgvPnz+OJJ55Anz598OeffyIvLw8AEBZW/Zb7sLAwZGRkAADy8vKgUqkQEBBw0Tl/X1+TZcuWYcmSJS5+N83P5IjJ6OjTEVbRiu6+3aWOQ0RERCQpFprJJRyCgF8jIpzHrlJZWQmZTIZBgwa5bEwiIiKilmLEiBHO444dO6J3795ISkrCO++8g169qlbY/ntjJVEUL7vZ0uXOWbhwIebMmeN8XFZWhpiYmIa8hWavi28XqSMQEREReQS2ziCXsMrleDotDU+npcEql7tkTIPBgOzsbPTp08fZM5CIiIiIaqfVatGxY0ecOHHC2bf53yuT9Xq9c5VzeHg4LBYLiouLaz2nJmq1Gn5+ftV+EREREVHrxkIzeaz8/Hz07NkTq1atglqtljoOERERkcczm804cuQIIiIikJCQgPDwcGzbts35usViwU8//YQ+ffoAANLS0qBUKqudk5ubi8OHDzvPISIiupxyWzk26jfi+6LvIYqi1HGISCJsnUEeSRRFWK1WdOvWDRoNN74gIiIiqsm8efMwcuRIxMbGQq/X44knnkBZWRmmTJkCQRAwa9YsPPnkk0hOTkZycjKefPJJeHt746abbgIA6HQ6TJs2DXPnzkVQUBACAwMxb948dOzYkXeUNXM7duxAYWEhBgwYAK1WK3WcejleeRzHKo6hm283RGmipI5DRHXw0KmHcNpUtRmt3qLHxPCJEiciIimw0EwuobbZ8MmWLQCAscOHw6xo3JeWyWSCWq1G7969XRGPiIiIqEXKysrCpEmTUFBQgJCQEPTq1Qt//PEH4uLiAAD3338/jEYj7rrrLhQXFyM9PR3ffvstfH19nWM8//zzUCgUGD9+PIxGIwYPHoy3334bche1Q6Omt2nTJrz++usAgK1bt2LlypWX7cvtKY5VHMMDJx+AHXZoZVq83O5lBCmDpI5FRJdgdVidRWag6sMiImqdWGgmj1RWVgatVuv8IYmIiIiILvbhhx9e8nVBELB48WIsXry41nM0Gg1WrVqFVatWuTgdSeXw4cPO49OnT8NoNMLb21vCRHV3pPII7LADACocFThrPOvWQrPVYcWusl0IVAainbad2+Yhaip6ix5rctZAhIipEVMRoY5w+5xKmRL9dP3wa+mvECBgQMAAt89JRJ6JhWbyOKIooqSkBJMnT3ZuYkNERERERHXTt29f/P777xBFEV27dm02RWYASPNNw/uy92F0GBGiDEGKd4pb51t8ZjEOGg4CAO6Lvg9Dgoa4db7WLsuUhX3l+9Be2x5J3klSx2mRVmauxKGKQwCAQmshnkt+rknmvT/uflxXcR38FH6I0cQ0yZxE5HlYaCaPc+bMGQQGBqJfv35SRyEiIiIianauvPJKREdHo6ioCF26dJE6Tr3EaGLwUtuXcNZ4Fu207eCr8L38RQ1gtVqRV5iHA+UHnG1FdpbtZKHZjfQWPeaemItKRyUUggLPtnmWxWY3KLOX/XNsK7vEma4lCAKu8LmiyeYjIs8kkzoA0YUMBgMUCgWWLl2KQYMGSR2HiIiIiKhZSkxMRPfu3aFo5N4pUghVhaKnrif8FH5uGb+wsBAzZ87EXXfchfxX8+GwOQAAXXy7uGU+qnLaeBqVjkoAgE204WjlUYkTtUxTI6ZCK9NCI9NgWuQ0qeMQUSvT/L7roBYtLy8PAwcOxMCBA6WOQkRERERELdCPP/6I8+fPAwCCs4JxQ+UN6NGlB7r6dpU4WcuWqk1FoCIQRbYieMu80cWni9SRWqQ0vzR80OEDAGg2m4ASUcvBQjN5jMrKqk+3BwwYwF3OiYiIiIjILSIi/tkcTaVUYWSbkYjwdf+Gaa2dTqHDi21fxNGKo0jySkKwKljqSC0WC8xEJBUWmsklHIKAXaGhzuOGyM3NRXp6OkaOHOnKaERERERERE59+vTBPffcg2PHjqF///7VCs/kXjqFDum6dKljEBGRm7DQTC5hlcvxWM+eDb6+uLgYANCvXz9otVpXxSIiIiIiIrrIsGHDMGzYMKljtHiHDYeRacpEL10vBCoDpY5DRERuxs0ASXIOhwO5ubkYPnw4pk6dKnUcIiIiIiJqYcpt5fjT8Ccq7BVSR2k1dpbuxIOnHsTq7NWYd2IeTHaT1JGIWrXTxtM4YzwjdQxq4biimSR35swZxMXFYeLEiezNTERERERELlVgKcDsE7NRYitBmCoMK5JXwE/hJ3WsFu9QxSGIEAEA+dZ85FnyEO8VL20oolbqg7wP8P759wEAt4bfinFh4yRORC0VVzSTS6htNnz8zTf4+JtvoLbZ6nyd1WqFKIq477770LMRrTeIiIiIiIhqsrt8N0psJQCA85bzOGw4LG2gVqKnX08ohKq1bbHqWESqIyVORNR6bSva5jz+rug7CZNQS8cVzeQyGru93tfk5OQgISEBAwcOdH0gIiIiIiJq9RK9EiGDDA44oBSUiNPESR2pVejo0xEvpryIbHM2Ovl0gkqmkjoSUauV7J2M/NJ8AEAb7zYSp6GWjIVmkpTFYsHYsWPh7+8vdRQiIiIiImqBUrxTsDRpKQ4bDqObXzdEaaKkjtRqxGhiEKOJkToGUas3N3Yu2he2hwABw4OGSx2HWjAWmklSgiAgKChI6hhERERERNSCdfDpgA4+HaSOQc3cR+c/wu+lv6OjT0dMjZgKQRCkjnSRc6Zz2HB+A/wUfrgl/BZ4y72ljkQeQCVT4YaQG6SOQa0AC80kGVEUIYoilEql1FGIiIiIiIiIanXYcBjv5r0LADhpPIkU7xT08+8ncaqLLT69GHqrHgBgcphwX8x9EiciotaEmwGSZMxmM1QqFcLCwqSOQkRERERERG5Saa9s8jn1Fj1yzDkuG8/kMFV7bHaYXTa2q4iiiCJbkfNxgaVAwjRE1Bqx0EySqayshFarRXJystRRiIiIiIiomXCIDqkjUB1ZHBY8ePJBTDg8AfNOzIPJbrr8RS6wpXALbj9yO2YcnYEN5ze4ZMw03zRcHXA1tDIt+uj6YID/AJeM60qCIGBy+GQIEOAt88b4sPFSRyKiVoatM8glREHAocBA53FdVFZWIi4uDn5+fu6MRkRERERELUC5rRyPnH4Ep4ynMDBgIGbHzPbIHrn0j91lu3Go4hAA4FjlMfxa+iuuDrza7fN+XfA1RIgAgK8KvsKEsAmNHlMQBPw39r/4L/7b6LHcaXToaFwTdA0UggIKGUs+RNS0+LcOuYRFLseDffrU6xqj0YjOnTu7KREREREREbUk3xZ9i5PGkwCAH4p/wIigEUjVpkqcii4lUBlY7XGQsmk2go/XxOOs6azzuLXRyDVSRyCiVoqFZpKEw1F1u1uvXr0kTkJERERERM2BTqFzHgsQ4Cv3lTAN1UU7bTvMipmFnWU70dmnM7r6dm2See+JuQcxmhhYRStuCL6hSeYkIiIWmkkiNpsNSqUSwcHBUkchIiIiIqJmYHDAYOSZ83C88jgGBQxCtCZa6kitltFoxIYNG2AymTB27NhL/lw3OHAwBgcObsJ0gFqmZn9iIiIJsNBMLqG22bDm++8BANOuugpmxaW/tCoqKuDt7Y2YmJimiEdERERERM2cIAi4JeIWqWMQgNWrV+OHH34AABw7dgzPP/+8xImIqDUqshbht5LfEKmORJpfmtRxCCw0kwvpLJY6n2swGJCSkoLw8HA3JiIiIiIiIqK6+LXkV3ye/zmi1FGYGTXzkn1+c3JyajwmopbtkOEQthRuQawmFuNCx0EmyCTLYnFY8MDJB5BnyQMAzI2di4EBAyXLQ1Wk+4qgVs1utyMwMPDyJxIREREREZFbldnK8FzmczhWeQzfF3+Pj/UfX/L8MWPGQKFQQBAETJgwoYlSEpGUymxlWHJ6CX4u+Rnv5b2Hrwq+kjRPobXQWWQGgD8Nf0qYhv7GFc0kCYvFwv7MREREREREHsAqWmETbc7HJofpkuf37t0b7777Lmw2G/z9/d2cjog8QZmtDGbR7Hyst+glTAOEqkLR1rstjlUegxxy9Nb1ljQPVWGhmZpcZWUl1Go1RowYIXUUIiIiIiKiVi9IGYRbw2/FJ/pPEKWOwpjQMZe9xsfHpwmSEZGniNZEY1DAIPxQ/AOClcG4NvhaSfPIBTmWJi3FIcMhhKvCuUGsh2ChmZpcYWEh4uLikJ6eLnUUIiIiIiIiAjAubBzGhY2TOgYRebA5sXNwR+Qd8JZ7Qy7IpY4DtUyN7n7dpY5BF2CPZmpSoiiioqICV1xxBRQKfs5BRERERERE5E56ix67ynah3FYudRRqAXwVvh5RZCbPxEofuYQoCDih0zmPa5Obm4vAwEDceOONTZSMiIiIiIiIqHXKNGVi7om5MDlMCFWG4oWUF+CjYNsTInIPFprJJSxyOeb073/Jc6xWKyoqKrBo0SL06tWriZIRERERERERtU67y3Y7N3fUW/U4Xnkc3fy6SZyKiFoqFpqpyRiNRvj4+GDQoEFSRyEiIiIi8jgHDx7E22+/DV9fX9x7770IDg6WOhIRNXOp2lTIIIMDDmhlWsR7xUsdiYhaMBaaqclYLBao1WqEhoZKHYWIiIiIyOM89dRTKC+v6qH6xhtvYOHChRInIqLmLlWbiuVtluNY5TGk+aYhUBkodSQiasFYaCaXUNvtePnHHwEAdw8cCLP84sbwJpMJCQkJUKlUTZyOiIiIiMiziaIIm83mfGy1WiVMQ0QtSVttW7TVtpU6BhG1AjKpA1ALIYoIMxoRZjQColjjKUajESkpKU0cjIiIiIjI8wmCgP/+978ICgpCfHw8pk6dKnUkIiIionrhimZqEqIoQhRFdOnSReooREREREQeqW/fvujbt6/UMYiIiIgahCuaqUmIogiZTIawsDCpoxAREREREREREZGLsdBMTUL8/3YaMhm/5IiIiIiIiIiIiFoaVv2oSej1evj7+yM6OlrqKERERERERERERORiLDSTW9lsNuj1ehQXF+PGG29EUlKS1JGIiIiIiIiIyE0sDgtOVZ5Cpb1S6ihE1MS4GSC5hiAg08fHeQwA5eXlyMnJQUhICMaNG4cJEyZIGJCIiIiIiIiai0p7JZadXYaTxpMYGjgUUyOnNngsURQhQoRM4Fo7dzPajZh/cj4yTBkIVATiueTnEKwKljoWETURFprJJcxyOe4eOLDacwaDAdHR0fj0008REBAgTTAiIiIiIiJqdjYXbMZ+w34AwMb8jRgQMACJXon1Hudg+UE8efZJWEQL7om+B1cFXuXipHShwxWHkWHKAAAU2Yrwe+nvGBkyUuJURNRU+HEeuY3BYMCAAQNYZCYiIiIiIqJ6UcvUzmMBAlSCqkHjvJv3LiocFbCKVryZ86ar4lEtotRRUApKAFV/bvFe8dIGIqImxRXN5BY2mw2CIKB9+/ZSRyEiIiIiIqI6OFl5Em/kvAGVoMJd0XchQh0hWZYRQSOQacrESeNJDAkcgmhNwzaW1yl0zmN/hb+L0lFtItWRWJq0FDtKd+AKnyvQ0aej1JGIqAmx0EwuobbbseKXXwAAs/v1w+nMTMTExGDw4MESJyMiIiIiIqK6eDbzWWSbswEAr2S9gseTHpcsi0KmwN0xdzd6nHui74F3rjdMDhNuDb/VBcnoclK1qUjVpkodg4gkwEIzuYYoItZgAABkZ2XB19cXCxYsQGBgoMTBiIiIiKilEUUR3xR+g3OmcxgSNKRBfVuJ6GImh6nG4+bMX+mPObFzpI5BRNQqsEczuZzZbMaMGTNw1VXcZIGIiIiIXO+bwm+wOns1vir8CotOLUKFvULqSEQeweFwNOr6u6PvRqAiEOGqcNwRdYeLUhERUWvBFc3kcl5eXuzNTERERERuc850znlssBtQYi2BVq6VMBGR9F599VVs3rwZ0dHReOKJJxp0d2kPvx5454p33JCOiIhaA65oJpebO3cuevToIXUMIiIiImqhhgQNgY/cBwCQ7peOSHWkxImIpHXu3Dl8/fXXEEUR586dw6ZNm6SORERErRBXNJPLjRkzBpDxMwwiIiIico9Er0S8mfomSqwliFRHQhAEqSMRSUqr1UKhUMBmswEAdDqdxImIiKg1YqGZXKKxvcCIiIiIiOpDK9eyXQbR/wsMDMQDDzyAb775BnFxcbjuuuukjkRERK0QC83UaBaLBZmnTyNPo0FQUBCUXFFCRERERETUpHr16oVevXpJHYOIiFox9jegRrFarThz5gxSunSBfscOKLOyAG9vqWMRERERERERERFRE+KKZmqU3NxcJCQk4M0332QfMCIiIiIiIiIiolaKK5qpwSwWC6xWK6ZNm8YiMxERERERERERUSvGQjM1iMPhwPnz5xEYGFi10YTRCPToUfXLaJQ6HhERERERERERETUhFpqpXoxGIzIzM3Hq1CmoVCoMHz4c3t7egMMB7N5d9cvhkDomERERETXAK6+8goSEBGg0GqSlpeGXX36ROhIRERERNRPs0Ux1lpmZCYfDgcTERFx//fUYMmQIYmNjpY5FRERERC6wYcMGzJo1C6+88gr69u2L1157DSNGjMBff/3F7/mIiIiI6LJYaKY6MZvNsFqtmDdvHiZPngylUil1JCIiIiJyoRUrVmDatGm4/fbbAQArV67E1q1bsXr1aixbtkzidM1PlikLn+g/gU6hw6SwSdDINXW67tSpU/jiiy8QGhqKCRMm8PtuolbgtPE0Ps//HCHKEEwMmwiljP/fU/2JooiN+Rtx1ngWQwKHoJNvJ6kjUSvEQjPVSVZWFjp37ozx48fzm10iIiKiFsZisWDPnj1YsGBBteeHDh2K7du3X3S+2WyG2Wx2Pi4rK3N7xubm0dOPQm/VAwBMDhNmRs+87DVWqxUPP/wwysvLAVQVDSZPnuzWnEQkLZvDhkdOP4JSWykAwAEHpkRMkTgVNUdbi7bi7dy3AQDbS7fjzdQ3EaAMkDYUtTrs0UyXZTAYIIoihgwZAh8fH6njEBHR/7V353FR1esfwD+DwDCMQArKoghuaIZiQhmamhuQG2YmLhnerJs/I716tSxToW6p3XK9ZmZeXNLUn9v1l1uoiBuuiZkQGuCWIIKKgCwCz+8PL0cGBphhTfi8X695yZz1Oc/3y/icL2fOISKqYikpKcjPz4e9vb3OdHt7eyQlJZVYfu7cubCxsVFezs7ONRXqE6FACpDyMEV5fyv3lkHrZWdnK4PMAHD79u0qj42I/lxyJEcZZAaA5NzkWoyGnmRF/6/JlVzcy7tXe8FQvcWBZipTWloaEhMT0b9/f4waNaq2wyEiIiKiaqRSqXTei0iJaQDw4YcfIi0tTXldv369pkJ8IpioTDDK/lHtrDHRYHjT4QatZ2VlBX9/f+XnIUOGVFuMRPTnoG2gxStNXgEAWDWwwtAmQ2s3IHpi+TX2g52ZHQDgRZsX4WrhWrsBUb3EW2dQqbKyspCcnIwRI0bgo48+goVFOfeVs7OrmcCIiIiIqErZ2dmhQYMGJa5eTk5OLnGVMwCo1Wqo1eqaCu+JNNJhJAbaDYTaRA1zE3OD13vrrbcwYsQIaDQa3rKOqJ540+lNDG86HBYmFkZ9XhAVZa+2x8r2K5FZkAkbU5vaDofqKV7RTKW6e/cuXF1dMXPmzPIHmbVa4PbtRy+ttmYCJCIiIqIqYW5uDk9PT4SFhelMDwsLQ7du3WopqieflalVhQaNrK2tOchMVM9Ym1pzkJkqzdTElIPMVKt4RTPpJSLIyMjA8OHDebUKERERUT0wdepUjB07Fl5eXvD29sa3336La9euYcKECbUdGhERERE9ATjQTHolJSXBysoKvr6+tR0KEREREdWAgIAApKam4pNPPkFiYiLc3d2xe/duuLi41HZoRERERPQE4EAz6RARpKWlISsrC9OnT8ezzz5r2IpZWcDLLz/6ec8eQKOpviCJiIiIqFpMnDgREydOrO0wiIiIiOgJxIFmAgA8fPgQ169fR35+PiwtLdG1a1eMGTNG71PG9SooACIiHv9MRERERERERERE9QYHmuu5wiuYb926haeffhqvvvoqnn/+ebi5ucHEhM+KJCIiIiIiIiIiovJxoLkey8jIwM2bN2FlZYX+/ftj2rRpaNmyZW2HRURERERERERERE8YDjTXQ7m5ubh58yYKCgrg4+ODd999F+3atTP8NhlERERERERERERERXCguR4QEWRmZuLevXvIysqCiYkJWrVqhfHjx2Pw4MEwNWU3ICIiIiIiIiIioorjCGMdVXRw+cGDB9BoNGjWrBl69eoFLy8vdO3aFVqttrbDJCIiIiIiIiIiojqAA811zIMHD5CUlIT8/HxoNBo4OjrCx8cHL730Ejp27IgGDRpU384tLatv20RERERERERERPSnxYHmJ9zDhw/x4MEDZGZmIjMzEw0aNICnpyf69+8PT09PtGvXrnoHlwtptUBmZvXvh4iIiIiIiIiIiP50ONBczUQEBQUFld5OTk4OcnJykJ2djezsbDx8+BAqlQomJiawtLSEnZ0devfujR49emDgwIG87zIRERERERERERHVGI5GViMzMzOkpKQgPT290tsyNzeHhYUFrK2t4eHhgVatWqFZs2Zo1aoVWrduDUdHR6hUqiqImoiIiIiIiIiIiMg4HGiuRkuWLMHt27erZFu2trZwcnKCra3tn3NAOTsbePXVRz9v3QpYWNRuPERERERERERERFRjONBcjdzd3Ws7hJqTnw/s3v34ZyIiIiIiIiIiIqo3TGo7ACIiIiIiIiIiIiJ6snGgmYiIiIiIiIiIiIgqhQPNRERERERERERERFQpHGgmIiIiIiIiIiIiokrhQDMRERERERERERERVYppbexURAAA9+/fr43dU3XIzHz88/37QH5+7cVCREREtaawvius96h+YH1PREREVHcZWuPXykBzamoqAMDZ2bk2dk/VzcmptiMgIiKiWpaamgobG5vaDoNqSHp6OgDW90RERER1WXp6epk1fq0MNDdu3BgAcO3atTp7AnL//n04Ozvj+vXrsLa2ru1wqBLYlnUL27PuYFvWHWzLuiUtLQ0tWrRQ6j2qH5ycnHD9+nVYWVlBpVLVyD752WEc5ss4zJfhmCvjMF/GYb4Mx1wZh/kyjoggPT0dTuVcXForA80mJo9uDW1jY1PnG9Pa2rrOH2N9wbasW9iedQfbsu5gW9YthfUe1Q8mJiZo3rx5reybnx3GYb6Mw3wZjrkyDvNlHObLcMyVcZgvwxlysTDPAIiIiIiIiIiIiIioUjjQTERERERERERERESVUisDzWq1GnPmzIFara6N3deI+nCM9QXbsm5he9YdbMu6g21Zt7A9qaawrxmH+TIO82U45so4zJdxmC/DMVfGYb6qh0pEpLaDICIiIiIiIiIiIqInF2+dQURERERERERERESVwoFmIiIiIiIiIiIiIqoUDjQTERERERERERERUaVwoJmIiIiIiIiIiIiIKqVGBprv3r2LsWPHwsbGBjY2Nhg7dizu3btX5jrbtm2Dr68v7OzsoFKpEBUVVROhGuXrr79Gy5YtYWFhAU9PTxw5cqTM5SMiIuDp6QkLCwu0atUK33zzTQ1FSuUxpi23bduG/v37o0mTJrC2toa3tzf27dtXg9FSeYz93Sx07NgxmJqaonPnztUbIBnM2LbMycnBzJkz4eLiArVajdatW+Pf//53DUVLZTG2LdevXw8PDw9YWlrC0dERf/nLX5CamlpD0VJpDh8+jMGDB8PJyQkqlQo7duwodx3WP1RdKvr/fV0SHBwMlUql83JwcFDmiwiCg4Ph5OQEjUaDl156CRcvXtTZRk5ODt577z3Y2dlBq9ViyJAhuHHjRk0fSpUr7/OqqnJTkXPdP6Py8jVu3LgSfe2FF17QWaa+5Gvu3Ll47rnnYGVlhaZNm2Lo0KGIjY3VWYb96zFD8sX+9djy5cvRqVMnWFtbK+MNe/bsUeazbz1WXq7Yr2qJ1AA/Pz9xd3eX48ePy/Hjx8Xd3V0GDRpU5jpr166VkJAQWblypQCQc+fO1USoBtu4caOYmZnJypUrJTo6WiZPnixarVauXr2qd/n4+HixtLSUyZMnS3R0tKxcuVLMzMxky5YtNRw5FWdsW06ePFnmz58vp06dkkuXLsmHH34oZmZm8vPPP9dw5KSPse1Z6N69e9KqVSvx8fERDw+PmgmWylSRthwyZIh07dpVwsLCJCEhQU6ePCnHjh2rwahJH2Pb8siRI2JiYiKLFy+W+Ph4OXLkiDzzzDMydOjQGo6citu9e7fMnDlTtm7dKgBk+/btZS7P+oeqS0X/v69r5syZI88884wkJiYqr+TkZGX+vHnzxMrKSrZu3SoXLlyQgIAAcXR0lPv37yvLTJgwQZo1ayZhYWHy888/S+/evcXDw0Py8vJq45CqTHmfV1WVm4qc6/4ZlZevwMBA8fPz0+lrqampOsvUl3z5+vpKaGio/PrrrxIVFSUDBw6UFi1aSEZGhrIM+9djhuSL/euxnTt3yq5duyQ2NlZiY2Plo48+EjMzM/n1119FhH2rqPJyxX5VO6p9oDk6OloAyIkTJ5RpkZGRAkB+++23ctdPSEj4Uw40P//88zJhwgSdae3bt5cZM2boXf7999+X9u3b60x755135IUXXqi2GMkwxralPh06dJCQkJCqDo0qoKLtGRAQIB9//LHMmTOHA81/Esa25Z49e8TGxqZE8UC1z9i2/Oc//ymtWrXSmbZkyRJp3rx5tcVIxjNkoJn1D1WXqqjf6oKy6paCggJxcHCQefPmKdOys7PFxsZGvvnmGxF59Id2MzMz2bhxo7LMH3/8ISYmJrJ3795qjb0mFf+8qqrcVPZc98+qtIFmf3//Utepz/lKTk4WABIRESEi7F/lKZ4vEfav8jRq1Ei+++479i0DFOZKhP2qtlT7rTMiIyNhY2ODrl27KtNeeOEF2NjY4Pjx49W9+2qRm5uLs2fPwsfHR2e6j49PqccUGRlZYnlfX1+cOXMGDx8+rLZYqWwVacviCgoKkJ6ejsaNG1dHiGSEirZnaGgo4uLiMGfOnOoOkQxUkbbcuXMnvLy88MUXX6BZs2Zwc3PDtGnTkJWVVRMhUykq0pbdunXDjRs3sHv3bogIbt26hS1btmDgwIE1ETJVIdY/VB2qon6rSy5fvgwnJye0bNkSI0eORHx8PAAgISEBSUlJOnlSq9Xo1auXkqezZ8/i4cOHOss4OTnB3d29TueyqnJTF891y3Lo0CE0bdoUbm5uePvtt5GcnKzMq8/5SktLAwDlfJD9q2zF81WI/auk/Px8bNy4EZmZmfD29mbfKkPxXBViv6p5ptW9g6SkJDRt2rTE9KZNmyIpKam6d18tUlJSkJ+fD3t7e53p9vb2pR5TUlKS3uXz8vKQkpICR0fHaouXSleRtizuq6++QmZmJkaMGFEdIZIRKtKely9fxowZM3DkyBGYmlb7RyIZqCJtGR8fj6NHj8LCwgLbt29HSkoKJk6ciDt37vA+zbWoIm3ZrVs3rF+/HgEBAcjOzkZeXh6GDBmCpUuX1kTIVIVY/1B1qIr6ra7o2rUr1q5dCzc3N9y6dQv/+Mc/0K1bN1y8eFHJhb48Xb16FcCj31Fzc3M0atSoxDJ1OZdVlZu6eK5bmpdffhmvvfYaXFxckJCQgFmzZqFPnz44e/Ys1Gp1vc2XiGDq1Kl48cUX4e7uDoD9qyz68gWwfxV34cIFeHt7Izs7Gw0bNsT27dvRoUMHZWCTfeux0nIFsF/VlgqPqgQHByMkJKTMZU6fPg0AUKlUJeaJiN7pT5Li8Zd3TPqW1zedap6xbVnohx9+QHBwMP7zn//o/fCh2mFoe+bn52P06NEICQmBm5tbTYVHRjDmd7OgoAAqlQrr16+HjY0NAGDBggUYPnw4li1bBo1GU+3xUumMacvo6GhMmjQJs2fPhq+vLxITEzF9+nRMmDABq1atqolwqQqx/qHqUtH6rS55+eWXlZ87duwIb29vtG7dGmvWrFEeeFSRPNWXXFZFburquW5xAQEBys/u7u7w8vKCi4sLdu3ahWHDhpW6Xl3PV1BQEH755RccPXq0xDz2r5JKyxf7l6527dohKioK9+7dw9atWxEYGIiIiAhlPvvWY6XlqkOHDuxXtaTCt84ICgpCTExMmS93d3c4ODjg1q1bJda/fft2ib/CPCns7OzQoEGDEn+9SE5OLvWYHBwc9C5vamoKW1vbaouVylaRtiy0adMmjB8/Hps3b0a/fv2qM0wykLHtmZ6ejjNnziAoKAimpqYwNTXFJ598gvPnz8PU1BQHDx6sqdCpmIr8bjo6OqJZs2bKIDMAPP300xCREk8OpppTkbacO3cuunfvjunTp6NTp07w9fXF119/jX//+99ITEysibCpirD+oepQmfqtrtNqtejYsSMuX74MBwcHACgzTw4ODsjNzcXdu3dLXaYuqqrc1MVzXUM5OjrCxcUFly9fBlA/8/Xee+9h586dCA8PR/PmzZXp7F/6lZYvfep7/zI3N0ebNm3g5eWFuXPnwsPDA4sXL2bf0qO0XOlT3/tVTanwQLOdnR3at29f5svCwgLe3t5IS0vDqVOnlHVPnjyJtLQ0dOvWrUoOoqaZm5vD09MTYWFhOtPDwsJKPSZvb+8Sy//000/w8vKCmZlZtcVKZatIWwKPrmQeN24cNmzYwHuG/okY257W1ta4cOECoqKilNeECROUv4oWvQ8T1ayK/G52794dN2/eREZGhjLt0qVLMDExKbeYpepTkbZ88OABTEx0S5QGDRoAeHw1LD0ZWP9Qdaho/VYf5OTkICYmBo6OjmjZsiUcHBx08pSbm4uIiAglT56enjAzM9NZJjExEb/++mudzmVV5aYunusaKjU1FdevX1dugVSf8iUiCAoKwrZt23Dw4EG0bNlSZz77l67y8qVPfe5f+ogIcnJy2LcMUJgrfdivakg1P2xQRET8/PykU6dOEhkZKZGRkdKxY0cZNGiQzjLt2rWTbdu2Ke9TU1Pl3LlzsmvXLgEgGzdulHPnzkliYmJNhFyujRs3ipmZmaxatUqio6Plb3/7m2i1Wrly5YqIiMyYMUPGjh2rLB8fHy+WlpYyZcoUiY6OllWrVomZmZls2bKltg6B/svYttywYYOYmprKsmXLJDExUXndu3evtg6BijC2PYsr6+ntVLOMbcv09HRp3ry5DB8+XC5evCgRERHStm1beeutt2rrEOi/jG3L0NBQMTU1la+//lri4uLk6NGj4uXlJc8//3xtHQL9V3p6upw7d07OnTsnAGTBggVy7tw5uXr1qoiw/qGaU97nSn3x97//XQ4dOiTx8fFy4sQJGTRokFhZWSl5mDdvntjY2Mi2bdvkwoULMmrUKHF0dJT79+8r25gwYYI0b95c9u/fLz///LP06dNHPDw8JC8vr7YOq0qU93lVVbkx5Fz3SVBWvtLT0+Xvf/+7HD9+XBISEiQ8PFy8vb2lWbNm9TJf//M//yM2NjZy6NAhnfPBBw8eKMuwfz1WXr7Yv3R9+OGHcvjwYUlISJBffvlFPvroIzExMZGffvpJRNi3iiorV+xXtadGBppTU1NlzJgxYmVlJVZWVjJmzBi5e/eubiCAhIaGKu9DQ0MFQInXnDlzaiJkgyxbtkxcXFzE3NxcunTpIhEREcq8wMBA6dWrl87yhw4dkmeffVbMzc3F1dVVli9fXsMRU2mMactevXrp7ZuBgYE1HzjpZezvZlEcaP5zMbYtY2JipF+/fqLRaKR58+YydepUnaKfao+xbblkyRLp0KGDaDQacXR0lDFjxsiNGzdqOGoqLjw8vMz/A1n/UE0q63OlvggICBBHR0cxMzMTJycnGTZsmFy8eFGZX1BQIHPmzBEHBwdRq9XSs2dPuXDhgs42srKyJCgoSBo3biwajUYGDRok165dq+lDqXLlfV5VVW4MOdd9EpSVrwcPHoiPj480adJEzMzMpEWLFhIYGFgiF/UlX/ryVHw8g/3rsfLyxf6l680331T+b2vSpIn07dtXGWQWYd8qqqxcsV/VHpUIv4NKRERERERERERERBVX4Xs0ExEREREREREREREBHGgmIiIiIiIiIiIiokriQDMRERERERERERERVQoHmomIiIiIiIiIiIioUjjQTERERERERERERESVwoFmIiIiIiIiIiIiIqoUDjQTERERERERERERUaVwoJmojrhy5QpUKhWioqJqbJ+rV6/GU089pbwPDg5G586dlffjxo3D0KFDayyeui44OBj29vZQqVTYsWOH3mnG5Lw2+kxVOnToEFQqFe7du1fboRARERFRHaGv5q7u/RU9h3rSJCUloX///tBqtTrnhkRUP3GgmegJoFKpynyNGzeuVuIKCAjApUuXamXfxihtQPVJGgiPiYlBSEgIVqxYgcTERLz88st6py1evBirV682aJvOzs5ITEyEu7t7lcZaU0U5ERER0ZNq3Lhxeuv633//vUq2X/yCEDKMvvq6KtVknbxt2zb4+vrCzs6uQheXuLq6YtGiReUut3DhQiQmJiIqKqpKzw0N3T8R/bmY1nYARFS+xMRE5edNmzZh9uzZiI2NVaZpNBrcvXu3xuPSaDTQaDQ1vt/6KC4uDgDg7+8PlUpV6jS1Wm3wNhs0aAAHB4cqjpSIiIiIDOHn54fQ0FCdaU2aNKmlaEr38OFDmJmZ1XYYNUJffV0Rf4acZWZmonv37njttdfw9ttvV9t+4uLi4OnpibZt21bbPiojNzcX5ubmtR0GUb3BK5qJngAODg7Ky8bGBiqVqsS0QvHx8ejduzcsLS3h4eGByMhInW0dP34cPXv2hEajgbOzMyZNmoTMzMxS933+/Hn07t0bVlZWsLa2hqenJ86cOQPA8CslvvzySzg6OsLW1hbvvvsuHj58qMy7e/cu3njjDTRq1AiWlpZ4+eWXcfnyZWW+vq+SLVq0CK6urjrTQkND8fTTT8PCwgLt27fH119/rcxr2bIlAODZZ5+FSqXCSy+9hODgYKxZswb/+c9/lCtIDh06BAD4448/EBAQgEaNGsHW1hb+/v64cuVKmcd48eJFDBw4ENbW1rCyskKPHj2UQrWgoACffPIJmjdvDrVajc6dO2Pv3r0665e1z+DgYAwePBgAYGJiApVKpXcaUPIq7YKCAsyfPx9t2rSBWq1GixYt8NlnnwHQf6V3dHQ0BgwYgIYNG8Le3h5jx45FSkqKMv+ll17CpEmT8P7776Nx48ZwcHBAcHCwMr+wXV555RWoVKoS7VTI29sbM2bM0Jl2+/ZtmJmZITw8HADw/fffw8vLC1ZWVnBwcMDo0aORnJxcahtURV/Jzc1FUFAQHB0dYWFhAVdXV8ydO7fUfRIRERFVlFqt1qnpHRwc0KBBAwDA//3f/8HT0xMWFhZo1aoVQkJCkJeXp6y7YMECdOzYEVqtFs7Ozpg4cSIyMjIAPLq92F/+8hekpaUpdW5hvabvitqnnnpK+UZcYX24efNmvPTSS7CwsMD3338PoOwaSp8tW7agY8eO0Gg0sLW1Rb9+/ZTzjsKaNSQkBE2bNoW1tTXeeecd5ObmKuvv3bsXL774Ip566inY2tpi0KBBSn1d6MaNGxg5ciQaN24MrVYLLy8vnDx5UplfXh6LKq2+Lq+WLytnRZVXJ69btw6urq6wsbHByJEjkZ6erswTEXzxxRdo1aoVNBoNPDw8sGXLljLzP3bsWMyePRv9+vUrdZng4GC0aNECarUaTk5OmDRpEoBHNf/Vq1cxZcoUpQ/p4+rqiq1bt2Lt2rU637RNS0vDX//6V6Vt+/Tpg/PnzyvrxcXFwd/fH/b29mjYsCGee+457N+/X5lf2v4NqfcL+9bcuXPh5OQENzc3ABU7xyMi43GgmaiOmTlzJqZNm4aoqCi4ublh1KhRSjF14cIF+Pr6YtiwYfjll1+wadMmHD16FEFBQaVub8yYMWjevDlOnz6Ns2fPYsaMGUb9dT48PBxxcXEIDw/HmjVrsHr1ap1bO4wbNw5nzpzBzp07ERkZCRHBgAEDdAajy7Ny5UrMnDkTn332GWJiYvD5559j1qxZWLNmDQDg1KlTAID9+/cjMTER27Ztw7Rp0zBixAj4+fkhMTERiYmJ6NatGx48eIDevXujYcOGOHz4MI4ePYqGDRvCz89Pp/At6o8//kDPnj1hYWGBgwcP4uzZs3jzzTeVvC9evBhfffUVvvzyS/zyyy/w9fXFkCFDlAH18vY5bdo05WqXwlj1TdPnww8/xPz58zFr1ixER0djw4YNsLe317tsYmIievXqhc6dO+PMmTPYu3cvbt26hREjRugst2bNGmi1Wpw8eRJffPEFPvnkE4SFhQEATp8+DeDRiUhiYqLyvrgxY8bghx9+gIgo0zZt2gR7e3v06tULwKNB308//RTnz5/Hjh07kJCQUOnbxJTXV5YsWYKdO3di8+bNiI2Nxffff1/qYDkRERFRddi3bx9ef/11TJo0CdHR0VixYgVWr16tXCwAPBoIXbJkCX799VesWbMGBw8exPvvvw8A6NatGxYtWgRra2ud2tEYH3zwASZNmoSYmBj4+vqWW0MVl5iYiFGjRuHNN99ETEwMDh06hGHDhunUfgcOHEBMTAzCw8Pxww8/YPv27QgJCVHmZ2ZmYurUqTh9+jQOHDgAExMTvPLKKygoKAAAZGRkoFevXrh58yZ27tyJ8+fP4/3331fmG5LHokqrr8ur5UvLWXFl1clxcXHYsWMHfvzxR/z444+IiIjAvHnzlPkff/wxQkNDsXz5cly8eBFTpkzB66+/joiIiFJasHxbtmzBwoULsWLFCly+fBk7duxAx44dATy67Ubz5s3xySeflHmucfr0afj5+WHEiBFITEzE4sWLISIYOHAgkpKSsHv3bpw9exZdunRB3759cefOHQCP2m7AgAHYv38/zp07B19fXwwePBjXrl0zav+lKexbYWFh+PHHHyt0jkdEFSRE9EQJDQ0VGxubEtMTEhIEgHz33XfKtIsXLwoAiYmJERGRsWPHyl//+led9Y4cOSImJiaSlZWld39WVlayevVqg2KZM2eOeHh4KO8DAwPFxcVF8vLylGmvvfaaBAQEiIjIpUuXBIAcO3ZMmZ+SkiIajUY2b96sd5siIgsXLhQXFxflvbOzs2zYsEFnmU8//VS8vb1F5HFuzp07p7NMYGCg+Pv760xbtWqVtGvXTgoKCpRpOTk5otFoZN++fXrz8OGHH0rLli0lNzdX73wnJyf57LPPdKY999xzMnHiRIP3uX37din+ka1vWtFjun//vqjValm5cqXeuIrnZdasWeLj46OzzPXr1wWAxMbGiohIr1695MUXXyxxLB988IHyHoBs375d7z4LJScni6mpqRw+fFiZ5u3tLdOnTy91nVOnTgkASU9PFxGR8PBwASB3794VkarpK++995706dNHpy2IiIiIqlpgYKA0aNBAtFqt8ho+fLiIiPTo0UM+//xzneXXrVsnjo6OpW5v8+bNYmtrq7wv7ZxBX51mY2MjoaGhIvK4Ply0aJHOMuXVUMWdPXtWAMiVK1f0zg8MDJTGjRtLZmamMm358uXSsGFDyc/P17tOcnKyAJALFy6IiMiKFSvEyspKUlNT9S5fkTzqq6/Lq+VLy5k++vI/Z84csbS0lPv37yvTpk+fLl27dhURkYyMDLGwsJDjx4/rrDd+/HgZNWpUufss7Vzoq6++Ejc3t1LPYVxcXGThwoXlbt/f318CAwOV9wcOHBBra2vJzs7WWa5169ayYsWKUrfToUMHWbp0aZn7N6TeDwwMFHt7e8nJyVGmVeQcj4gqhvdoJqpjOnXqpPzs6OgIAEhOTkb79u1x9uxZ/P7771i/fr2yjIigoKAACQkJePrpp0tsb+rUqXjrrbewbt069OvXD6+99hpat25tcDzPPPOM8hXAwpguXLgA4NHDNkxNTdG1a1dlvq2tLdq1a4eYmBiDtn/79m1cv34d48eP17n3WF5ens4tRQxVmCMrKyud6dnZ2SW+qlcoKioKPXr00Hul9/3793Hz5k10795dZ3r37t2Vr49VZJ+GiImJQU5ODvr27WvQ8mfPnkV4eDgaNmxYYl5cXJzytbOifQx41KZl3dJCnyZNmqB///5Yv349evTogYSEBERGRmL58uXKMufOnUNwcDCioqJw584d5eqUa9euoUOHDkbtDzCsr4wbNw79+/dHu3bt4Ofnh0GDBsHHx8fofRERERGVp3fv3jq1j1arBfCoJjt9+rTOlbf5+fnIzs7GgwcPYGlpifDwcHz++eeIjo7G/fv3kZeXh+zsbGRmZirbqQwvLy/l54rU2x4eHujbty86duwIX19f+Pj4YPjw4WjUqJHOMpaWlsp7b29vZGRk4Pr163BxcUFcXBxmzZqFEydOICUlRacWdHd3R1RUFJ599lk0btxYbwyG5LE8htTyhYrmzFiurq465wJF6+vo6GhkZ2ejf//+Ouvk5ubi2WefrfA+X3vtNSxatAitWrWCn58fBgwYgMGDB8PUtHLDRGfPnkVGRgZsbW11pmdlZSnnNpmZmQgJCcGPP/6ImzdvIi8vD1lZWcoVzZXVsWNHnfsyV9f5FhGVxIFmojqm6GBn0fuKFf77zjvvKPfeKqpFixZ6txccHIzRo0dj165d2LNnD+bMmYONGzfilVdeMTqewpgK45EiX50rSkSU2E1MTEosV/S2GoXbWrlypc6ANQCdAW5DFRQUwNPTU2cwvlBpD2cx5IGIxe9rVvQYK7JPQxj7oMaCggIMHjwY8+fPLzGv8I8WQNltaowxY8Zg8uTJWLp0KTZs2IBnnnkGHh4eAB4Vnz4+PvDx8cH333+PJk2a4Nq1a/D19S31621V0Ve6dOmChIQE7NmzB/v378eIESPQr1+/cu+BR0RERGQsrVaLNm3alJheUFCAkJAQDBs2rMQ8CwsLXL16FQMGDMCECRPw6aefonHjxjh69CjGjx9f7u3nVCpVmfVS0diKxgMYV283aNAAYWFhOH78OH766ScsXboUM2fOxMmTJ5Xnp5QVIwAMHjwYzs7OWLlyJZycnFBQUAB3d3elFiyv1i0vj8Yoq5YvVJkB/rLq68J/d+3ahWbNmuksZ8yDwItzdnZGbGwswsLCsH//fkycOBH//Oc/ERERUakHGRYUFMDR0VF5/k1Rhc/3mT59Ovbt24cvv/wSbdq0gUajwfDhw8u9jUV59X6h4m1RXedbRFQSB5qJ6pEuXbrg4sWLegvasri5ucHNzQ1TpkzBqFGjEBoaavBAc1k6dOiAvLw8nDx5Et26dQMApKam4tKlS8rV1U2aNEFSUpJOMVf04XX29vZo1qwZ4uPjMWbMGL37Kfxrdn5+fonpxad16dIFmzZtUh5cYYhOnTphzZo1ep8ubW1tDScnJxw9ehQ9e/ZUph8/fhzPP/98hfdpiLZt20Kj0eDAgQN46623yl2+S5cu2Lp1K1xdXSt1JYOZmVmJvOozdOhQvPPOO9i7dy82bNiAsWPHKvN+++03pKSkYN68eXB2dgYA5SGUpamKvgI8arOAgAAEBARg+PDh8PPzw507d0q9WoaIiIioKnXp0gWxsbGl1uxnzpxBXl4evvrqK5iYPHrs0ubNm3WW0VfnAo/qpaL3u718+TIePHhQZjyG1lDFqVQqdO/eHd27d8fs2bPh4uKC7du3Y+rUqQAePXQ8KytLGTA+ceIEGjZsiObNmyM1NRUxMTFYsWIFevToAQA4evSozvY7deqE7777rtQ6rbw8GsKQWt4YhtbJRXXo0AFqtRrXrl1TnmVSVTQaDYYMGYIhQ4bg3XffRfv27XHhwgV06dKl1D5Uni5duiApKQmmpqalPuvkyJEjGDdunHJOmZGRUeLBfPr2X169X1ZM1XG+RUQl8WGARPXIBx98gMjISLz77ruIiorC5cuXsXPnTrz33nt6l8/KykJQUBAOHTqEq1ev4tixYzh9+rTeW2xURNu2beHv74+3334bR48exfnz5/H666+jWbNm8Pf3B/DoicO3b9/GF198gbi4OCxbtgx79uzR2U5wcDDmzp2LxYsX49KlS7hw4QJCQ0OxYMECAEDTpk2h0WiUh9ulpaUBePQVtV9++QWxsbFISUnBw4cPMWbMGNjZ2cHf3x9HjhxBQkICIiIiMHnyZNy4cUPvcQQFBeH+/fsYOXIkzpw5g8uXL2PdunWIjY0F8Ogv9vPnz8emTZsQGxuLGTNmICoqCpMnTwaACu3TEBYWFvjggw/w/vvvY+3atYiLi8OJEyewatUqvcu/++67uHPnDkaNGoVTp04hPj4eP/30E958802jikxXV1ccOHAASUlJuHv3bqnLabVa+Pv7Y9asWYiJicHo0aOVeS1atIC5uTmWLl2K+Ph47Ny5E59++mmZ+62KvrJw4UJs3LgRv/32Gy5duoT//d//hYODg3L1BREREVF1mz17NtauXYvg4GBcvHgRMTEx2LRpEz7++GMAQOvWrZGXl6fUSevWrcM333yjsw1XV1dkZGTgwIEDSElJUQaT+/Tpg3/961/4+eefcebMGUyYMMGgq1fLq6GKO3nyJD7//HOcOXMG165dw7Zt23D79m2d84jc3FyMHz8e0dHRyjcng4KCYGJigkaNGsHW1hbffvstfv/9dxw8eFAZoC40atQoODg4YOjQoTh27Bji4+OxdetWREZGGpRHQ5VXyxvD0Dq5KCsrK0ybNg1TpkzBmjVrEBcXh3PnzmHZsmWlPowRAO7cuYOoqChER0cDAGJjYxEVFYWkpCQAwOrVq7Fq1Sr8+uuvSj/SaDRwcXFRYj18+DD++OMPpKSkGHyM/fr1g7e3N4YOHYp9+/bhypUrOH78OD7++GPlwpE2bdpg27ZtiIqKwvnz5zF69OgS35DUt39D6n19qut8i4j0qJ1bQxNRRZX3MMCiD3m4e/euAJDw8HBl2qlTp6R///7SsGFD0Wq10qlTpxIPtyiUk5MjI0eOFGdnZzE3NxcnJycJCgpSHhxoyMMAiz9sb/LkydKrVy/l/Z07d2Ts2LFiY2MjGo1GfH195dKlSzrrLF++XJydnUWr1cobb7whn332mc4DH0RE1q9fL507dxZzc3Np1KiR9OzZU7Zt26bMX7lypTg7O4uJiYmy/+TkZCUXRfOUmJgob7zxhtjZ2YlarZZWrVrJ22+/LWlpaXrzJCJy/vx58fHxEUtLS7GyspIePXpIXFyciIjk5+dLSEiINGvWTMzMzMTDw0P27Nmjs355+6zIwwAL9/2Pf/xDXFxcxMzMTFq0aKE8FEVfn7l06ZK88sor8tRTT4lGo5H27dvL3/72N+XBGb169ZLJkyfr7LP4A0B27twpbdq0EVNT0xLtVNyuXbsEgPTs2bPEvA0bNoirq6uo1Wrx9vaWnTt36sRb/GGAIpXvK99++6107txZtFqtWFtbS9++feXnn38u8xiIiIiIjKWvTi5q79690q1bN9FoNGJtbS3PP/+8fPvtt8r8BQsWiKOjo1I/r127tkRdNGHCBLG1tRUAMmfOHBER+eOPP8THx0e0Wq20bdtWdu/erfdhgMUfHCdSfr1dVHR0tPj6+kqTJk1ErVaLm5ubzoPeCo9/9uzZYmtrKw0bNpS33npL5wFyYWFh8vTTT4tarZZOnTrJoUOHSjxM78qVK/Lqq6+KtbW1WFpaipeXl5w8edLgPBanr74ur5YvK2fF6auTDXnAXUFBgSxevFjatWsnZmZm0qRJE/H19ZWIiIhS9xUaGioASrwK+8L27dula9euYm1tLVqtVl544QXZv3+/sn5kZKR06tRJ1Gp1iZwUVfxcQOTRQ8nfe+89cXJyEjMzM3F2dpYxY8bItWvXlJz17t1bNBqNODs7y7/+9a8S5xml7b+8er+0362KnOMRkfFUIqXcJJWIiIiIiIiIqIqNGzcO9+7dw44dO2o7FCIiqkK8dQYRERERERERERERVQoHmomIiIiIiIiIiIioUnjrDCIiIiIiIiIiIiKqFF7RTERERERERERERESVwoFmIiIiIiIiIiIiIqoUDjQTERERERERERERUaVwoJmIiIiIiIiIiIiIKoUDzURERERERERERERUKRxoJiIiIiIiIiIiIqJK4UAzEREREREREREREVUKB5qJiIiIiIiIiIiIqFI40ExERERERERERERElfL/7XhQAhBMU5gAAAAASUVORK5CYII=",
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAABZoAAAKgCAYAAAAS1si3AAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjkuMiwgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy8hTgPZAAAACXBIWXMAAA9hAAAPYQGoP6dpAAEAAElEQVR4nOzdd3gU1foH8O9sS2+bnhCS0EINvfdepYiAUqSJIlwQEK9YKSKoqNcK6k8vKCAdRKQoIKBIEZAqRaSXJIT0nuzu+f2RmzGbbJJNnU3y/TxPnuzOnDnzzuzM7sw7Z85IQggBIiIiIiIiIiIiIqISUikdABERERERERERERFVbkw0ExEREREREREREVGpMNFMRERERERERERERKXCRDMRERERERERERERlQoTzURERERERERERERUKkw0ExEREREREREREVGpMNFMRERERERERERERKXCRDMRERERERERERERlQoTzURERERERERERERUKkw0E5HNWrVqFSRJkv9y69atmzx8woQJ8vCbN2+aTXPw4MGKDZpszsGDB822iZs3b1bYvBcsWCDPNyQkpNzmk5SUhOeeew7BwcHQarXyPFetWlVu86TKTcn9whbwt4Isqajv7KJMmDBBjqNbt26KxWELSrsuqvK65PcYERHZIiaaiahCCCHw7bffok+fPvDx8YFWq4W7uztq1aqFHj164Pnnn8cvv/yidJg2zZqTpeqePKqupk6dio8++gi3b9+GwWBQOhwA+bfFvEnv2NhYtGzZUh6vVqvx3//+1+K0kiRh1KhRFufz1Vdf5Su7YMGCcl46KguFbR9EVHZsJYFe1qpyErmyCAkJ4W9vEfbt24cJEyagadOm8PX1hVarhaOjI+rUqYMxY8bw/IeIqhyN0gEQUfUwbtw4rF271mxYQkICEhIScOPGDRw4cAAJCQno0qWLPL5169ZYtmxZRYdKVGb69OkDZ2dnAICbm1u5zCMrKwubNm2S33fu3BkDBw6EWq1G69aty2WepRUdHY1evXrh3LlzAAC1Wo2vv/4aY8aMKXCarVu34t69ewgMDDQb/sknn5RrrFQ16fV6s9+X2rVrKxgNERXk8ccfR+PGjQEAQUFBCkdDVHzfffcdvv76a7NhBoMB165dw7Vr1/Dtt9/i448/xr/+9S+FIiQiKltMNBNRudu9e7dZkrlt27bo1asX7OzscOfOHVy5cgVHjx7NN12jRo3QqFGjigyVqEx16NABHTp0KNd5REREICsrS34/f/589OzZs1znmZ6eDrVaDa1WW+xpIyIi0LNnT1y6dAkAoNVqsXbtWowYMaLQ6QwGAz777DO88cYb8rDDhw/jzJkzxY6Bqq+cbdfV1RVz585VOhwiKkK/fv3Qr18/pcMgG2IwGJCVlQUHBwelQ7GKnZ0d2rVrh+bNm8PHxwcqlQpnzpzBd999ByEEAOCVV17BM888U6LjKiIiW8OuM4io3O3du1d+XbduXRw5cgSLFy/Ga6+9hi+++AKHDh1CVFQUnn76abPpCuujuTg2bdqENm3awMHBAV5eXpgwYQJiY2Mtlt23bx+GDx+OwMBA6HQ6uLm5oW3btnjrrbeQlJRkVraovvGKup3w9OnTmDhxImrVqgV7e3u4uLigdevWeP/995Genp5vPeRuDXHo0KF885YkCd27dzebR2hoqMW+rIsz/6Kkp6fjlVdeQb9+/VCrVi24ublBq9XCy8sLXbp0wSeffJKvOwdL627NmjVo1apVoZ/TgwcP8MILL6BHjx4IDg6Gi4sLdDodfH190adPH6xZs0Y+aC9Kjx495PmPHz8+3/gPP/xQHu/r6ysnc8+fP4+xY8ciJCQEdnZ2cHBwQM2aNdGjRw+89NJLuHfvnlxHYbcr37p1C8888wzq1q0LBwcH2NvbIzAwEB07dsScOXPkRGxhQkJCEBwcbDasV69eFrtOuXLlCqZOnSrPz8nJCfXr18fMmTMtdrGStx/006dPY8CAAfDw8ICDg4PZclrr7t276Nq1q7xsOp0OmzZtKjLJrFJlH6588cUXyMjIkId//PHHZuML8/fff2P69OmoX78+HB0d4ejoiCZNmmD+/PlISEjIV37Tpk0YM2YMGjduDB8fH+h0Ojg7O6NRo0aYMWOGVevsypUrGDFiBPR6PRwcHNC+fXuLfWgWZ5sqSlZWFv7v//4PvXr1gre3N3Q6HXx8fNCxY0er7xApqA98oGy26Zz6c5s4cWKB9UZERGDevHkIDw+Hi4sL7O3tUa9ePcyZMweRkZFFxm9p2y3s+zvvMsbHx2P27NkICgqCnZ0dwsLCsGLFCovr7vz583jkkUfg6uoKV1dX9O3bF6dOnSpV1wWl3Xet3Q4L8/3336Nfv37ybd+urq6oXbs2hg4diqVLl8JkMsll9+3bh0mTJqF58+bw8/ODnZ0dHB0dUbduXUyaNAnnz5/PV3/eLhD++usvDBs2DG5ubtDr9Rg9ejSioqIAAAcOHEDnzp3h6OgIb29vTJ48GXFxcWb15T1+SE9Px/z581G7dm3Y2dmhdu3aWLx4sdlFOmvEx8dj8eLFaN26Ndzc3GBnZ4eQkBBMmTIFf//9d7HqAoBffvkF3bp1g5OTE/R6PUaMGIFr164VOs3nn3+OESNGoH79+vDy8pI/j+bNm2PevHl4+PChXDbn2GDhwoXysFu3blnstubvv//Gc889h06dOiEoKAhOTk6ws7NDjRo1MHjwYPzwww9WL9cHH3wg1x8WFmY2rnnz5vK43MeHubtB8vX1lX/LLXWPYe1xkSUPHjzAM888Az8/P9jb26Np06bYsmWL1ctW0uOX4hBCYMOGDRg0aBD8/f2h0+ng6emJ1q1b48UXX7SqjsK6FSns+Prhw4eYO3cuGjVqBCcnJ+h0Ovj5+aFNmzb417/+hWPHjpnVf+vWLXnahQsXFlhvcfedvPFfv34do0aNgpeXF3Q6HY4fPw6gbH8/y8t7772Ho0ePYvny5ViwYAFef/11bN26FU899ZRcJjExsVTbDBGRTRFEROVsxowZAoAAIDw9PcWVK1esmm7lypXydHm/rrp27SoPHz9+vDz8xo0bZtP06dPH7H3OX8eOHfPNb86cORbL5vzVrVtX3Lp1q8B5HThwwKy+4OBgedz8+fPNxn388cdCrVYXOK/WrVuL+Ph4i+vB0t+BAweKLJN7PRVn/kWJjo4uct69evUSBoOhwHXXsWNHqz6nEydOFDmviRMnmk2Td93cuHFDCCHEli1b5GEODg75lrdDhw7y+Dlz5gghhPjzzz+Fo6NjofPfvXu3XMf8+fPl4cHBwfLwqKgo4e3tXWg9K1asKHLd597GLP3lLOuGDRuEvb19geVcXFzEjz/+aFZ37n2sefPm+ZY7p+6C5F3v8+fPF6GhofJ7e3t7sWvXLqumHTJkiPz6m2++EUIIce/ePaHRaAQAMXTo0Hzzym3Lli3CwcGhwOWvXbu22b4thBADBw4sdN26urqKc+fOFbjOwsPDhbOzc77pdDqduHDhgjxNcbepwkRHR4uWLVsWWE/ubbCg/SLvcuT+3hCibLbp3PUXFefhw4eFXq8vsKyPj484ffp0gZ9DQdtuYd/fuZfR09NT1K9f3+K8v/jiC7P5njhxwuJnbm9vL3r16mVx+YpS2n3X2u2wMNb8BqWlpcnlp0+fXmhZnU4n9u7dazaP8ePHy+NDQ0OFh4dHvunCwsLEmjVrhEqlyjeuS5cuhcbco0cPi7EMGzbMbLqCtm8hhLh8+bKoWbNmgcvl5OSU77MozA8//CB/h+X+0+v1on379vL7rl27mk3XqFGjQtdvYGCguHfvnhAi/35u6W/lypVCCCE2bdpUZNmFCxdatWxnz541my4yMlIIIURiYqLZscdrr70mT5N7Gxg5cqTF4TnrwtrjorzTh4WFWfzdlCTJ6s+upMcv1kpNTRX9+vUrdNkKiiX395il9ZajoOPrtLQ0ERYWVui8X3zxxXz1FxVnSfad3PXXrVtX+Pj45FvWsvz9tGabyv2Xd50WR3Jysvjtt99E3bp15fq8vb2FyWQqcZ1ERLaEXWcQUblr1qyZ/DomJgb169dHeHg4WrdujdatW6NXr16oVatWucz7p59+Qvv27dGzZ0/88MMP8m32v/32G44ePYr27dsDAL755hu8//778nTh4eEYPHgwbt68ibVr10IIgatXr2LkyJFya46S+u233zBz5ky5tU6nTp3Qq1cvxMfH4+uvv0ZcXBxOnDiBZ599Ft9++63cV/WGDRtw8uRJAECtWrXw7LPPynXWrl0by5Ytw7Vr1/DZZ5/Jw19++WV4eHgAgNzHYXHnXxRJklCnTh20bdsWAQEB8PDwQFZWFi5fvoxNmzbBYDBg37592LJlC0aOHFngOrHmc1KpVGjUqBFat24NX19fuLu7Iz09HadPn8aOHTsghMDKlSsxdepUtGnTptC4hwwZgpo1a+L27dtIS0vD2rVrMW3aNADAvXv3zLpzyWnV+fXXXyM1NRUAUKNGDYwdOxZOTk64e/cuLly4YPW2sWXLFkRHRwMAPDw8MHHiRHh6euL+/fu4fPkyfv31V6vqeeWVV3Dz5k0sWbJEHjZ16lS5v1m9Xo+rV6/iySeflFsCe3t7Y/z48TAYDPjvf/+LxMREJCUlYcSIEfjrr7/g6+ubbz6nT5+GVqvFhAkTULt2bfz555/Fvr1z0aJF8jbn6OiI77//3uouPnIelhMXF4dPPvkE48aNw4oVK+SW8jNmzMB3331ncdrr169jzJgxciv98PBwDB06FJmZmVi9ejXu3buHa9eu4YknnsBvv/0mT+fh4YF+/fohLCwMHh4e0Ol0iIqKwtatW3Hnzh0kJibixRdfxK5duyzO99y5c/Dy8sLUqVMRFRWF1atXAwAyMzPx0Ucf4fPPPwdQdtsUkN0X/qlTp+T3jRo1Qv/+/aHRaHDy5MkiW0qWRnG26WeffRaDBg3CCy+8IA8bNWoUWrVqBeCf/swTEhIwbNgwuZVXrVq1MHLkSGi1WmzcuBFXrlzBgwcP8Oijj+LSpUuws7PLF1dB2661LVljYmIQHx+PSZMmwdPTE59++qn8eb377ruYMmWKXHbixIlITk6W3z/xxBOoVasWNm7ciH379lk1v9zKYt+1djssTO7W261bt8agQYNgMBhw584dHD9+PN/dF87OzujevTsaNWokt6KOiYnBzp07cenSJWRmZmLmzJm4ePGixfnduHEDnp6eeOGFF3D9+nW5temVK1fkloujR4/Gb7/9hkOHDgHIbhl87NgxtGvXzmKdBw4cwLhx41CzZk1s2bIFly9fBgBs27YNa9aswdixYwtdB0ajEcOGDcPt27cBAL6+vhgzZgzc3Nzwww8/4MSJE0hJScHIkSNx9epVeHt7F1pfamoqJk2aJH+HabVaTJo0CR4eHlizZo3F7sRy+Pr6ok6dOqhVqxb0ej0kScK9e/ewceNGxMTE4N69e1i8eDGWL18uHxv89NNPcuthDw8PvPzyy3J9OX35a7VatGjRAi1btoS3tzdcXV2RnJyM3377DQcOHAAAvPHGG5g8eXK+vvLzatKkCby8vOTW1YcPH8bw4cNx5MgRGI1GuVzu74XcD0TLe3dWXtYeF+V15coVODo6YsaMGTCZTPjss89gNBohhMB7772HPn36FDpfS6w9frHWnDlzsGfPHvl9SEgIhgwZAhcXF5w7dw47d+4sdozWOnDgAK5cuQIAsLe3lz/ryMhI/P333/L+BvzTd/aSJUvkOwp69+6dbx2Wxb5z9epVSJKEESNGoEmTJrh58yacnJzK9PezInTr1s1sHeawt7fHihUrSnX3JhGRTVEyy01E1UNmZqZo2rRpoS0DunfvLi5fvmw2XVm0aG7Xrp3IysoSQggRExNj1pLmo48+kqfLHV9oaKhZ66xFixaZ1Xn48GGL87K2RfOwYcPk4X379jVrwbBnzx6zFjZ37tyRxxXWOiVHYa0USzv/okRFRYnt27eL5cuXi3fffVcsW7ZMNG7cWK5v0qRJctmSfk45bt26JTZv3iw++eQTeV6BgYHyNIsWLbJqnSxZskQe3rx5c3n4f/7zH3l4q1at5OEzZ86Uhy9dujRfXLGxsSI2NlZ+X1DruPfff18e/swzz+SrJzk5WW4BVpSitsPnnntOHqdSqcTFixflcb/88ovZtIsXL5bH5W11WlDr44IU1pJu48aNxZp2x44dYu7cufL7X375Rfj6+goAolGjRkIIYVY+9/42e/ZseXiTJk1ERkaGPO7y5ctm0/32229mcWRmZopffvlFfPXVV+I///mPWLZsmZg4caJc3s7OTmRmZlpcZyqVSpw9e1Yel7vVdYsWLeThxd2mCpK3BeEjjzwi71M5rl27VuA6Lm2L5pJs07nnn9OqMrcPP/xQHu/j42N210FcXJxZS9+1a9dajL+gbdfaFs0AxCeffCKP++CDD8zGJSYmCiGEOHLkiNnwnFZ/QmR/hrlb6Frborks9l1rt8PChIeHy9McPXo03/gbN24Io9FoNsxoNIrjx4+LVatWiQ8++EAsW7Ys311Dt2/flsvnbR2Z8ztrMpmEv7+/PFyr1crTxcfHC61Wa/G3Iu/xw5tvvimPS0hIEF5eXvK4zp07y+MK2r63b98uD9fpdOLmzZvyuIyMDLPWmrnnVZB169aZxffll1+arc/cy2Xp9z4lJUXs27dPfPHFF+L9998Xy5YtM7vzo1atWmblC2upndeVK1fE+vXrxccffyz/vuZuNZpzV0lRhg8fLk/z3HPPCSGEePXVVwWQfacAkH03UUZGhrh7967Z+sh951thxz7WHBfl3bZ++OEHedysWbPk4Xq93qrlKu3xS2FiYmLMWrm3bNlSJCcnm5XJ/T1e1i2at27dKg/r27dvvvjS09PF3bt3zYYVdveeECXfd/J+bsuXL89Xd1n9fgohxIULF8SyZcus/lu/fr1V9eZm6W4eb29vsWfPnmLXRURky9iimYjKnVarxaFDh7B48WKsWrXKrP/AHAcOHECfPn1w4cIFuLi4lNm8J0+eDI0m+6tOr9fDy8tL7ucxpwVGSkoKzp49K08zYsQI2Nvby+/Hjx+P119/XX5/5MgRdOzYscQx5W41+eOPPxbYv6wQAseOHcNjjz1W4nlVxPzT0tIwbdo0fPPNN2b9dOZ19+7dAsdZ8zkB2a0Lx48fX2SLnsLmlduUKVOwaNEiuVX0qVOn0LJlS2zatEkuM3HiRPl1586d8dFHHwEAXn31VezYsQNhYWEICwtD27Zt0blzZ6jV6iLn27FjR0iSBCEEvvjiC5w4cQINGzZEWFgYWrVqhe7du1tsnVgSR44ckV+3atUKDRo0MFue0NBQ3LhxI1/Z3Jo2bYr+/fuXSTxA9rrr2LEjAgICrJ5m2rRpeP/992EymfDEE0/I28eMGTMKnS739n7+/HmLrV5zHDlyRH5449q1azFr1iyL31c5MjIy8PDhQ/j7++cb1759e4SHh8vvc/dTmnubLqttKvdyAsBrr70m71M5yuvOEaB8tuncy/TgwQO4u7sXWPbIkSMYPXp0vuGl3XbVajUmT54sv8/b32xcXBxcXFzMWpIDwJNPPim/9vDwwJAhQ+S+cK1VFvuutdthYTp37oxz584ByG6x2L59e9StWxcNGzZEly5d0KRJE7Pye/fuxVNPPSW3YCzI3bt3ERQUlG94cHCw/BsrSRKCg4MREREBIHs7y5nGzc0NPj4+ch+shS3PuHHj5Neurq545JFHsHLlSgCQW8QWJve2mJmZWWg/2wV9FrnlnWfubTckJASdOnWSWxHn9f7772P+/PlmrefzKkm/tDdv3sSYMWOKjN/a39fu3bvLrdEPHz5s9n/q1Kl45513kJaWhlOnTpn18xsYGIh69eoVO35rBAYGYuDAgfL7kuwPeVl7/GKN48ePmz3T4sUXX4STk5NZmfL8Hm/dujXs7OyQkZGBH3/8EY0aNUJ4eDjq1auH5s2bo2fPnkW2Zs+rLPYdvV6f7zkuQNn9fgIV8wDynLt5YmJicPToURw6dAjR0dHo378/lixZgnnz5pXr/ImIKgoTzURUIdzc3LBs2TK8/fbb+PPPP3Hs2DEcOHAA3333HdLS0gAAt2/fxtatWy0+mK2k8j4oLXeSKScpGh8fb1bGx8fH7H3e5EhBJw4iz0Pocj+0LLfiPOwj51b0slTW83/ppZesSqAUtD4A6z4nIPuEzprbRgubV25eXl4YNWqU/EChL7/8Er6+vvJty3Z2dnjiiSfk8o899hjmzp2Ljz/+GBkZGThy5IjZiVFwcDB27txZ5MlKmzZt8P777+O1115DcnIy/vjjD/zxxx9mcW3atCnfA3xKIvf2mnfbBrK375xkVUHbdlmc9NeqVQvXr18HAPz111/o0qULDhw4YDHRZEloaCgGDhyIHTt2yEkUd3f3Im95L8n2/scff+DJJ58s9MJJjoK2NWu36bLapvIuZ3EfOFcQa7/XymObLovvqtJuu76+vmYXHvNeqCjod8TPz6/Q99Yoi33X2u2wMEuWLMH169exe/duJCcnY+/evWYPcevatSt27doFR0dH3L9/H0OHDpVvZy9MQdtS3kRW7pjzjst9MaWw5Snsdz0tLQ0ZGRmFXoQq69/N3NuLi4sLHBwcCowvt++++w7PP/98kfVb+xuY29ChQ80uupe27tzdX5w5cwaxsbH4/fffAWRfsNi/fz+OHTuGw4cPy9tx3unKWmH7Q97vurKo09p9LIfS3+M1atTAqlWrMGPGDDx8+BAXL1406+LG2dkZX375JUaNGmX1vMti36ldu7bFhHFZ/X4CwJ9//ondu3dbHWtQUFCx1gOAfOXfeOMNvP766xBC4OWXX0a/fv3MuhskIqqsmGgmogqlUqnQpEkTNGnSBFOmTMHp06fRokULeXxJntpemLz9yFrq/yxvK7kHDx6Yvc9pmZIjp8/jvC2BcxLmAJCUlJRvutzT5xxMd+/eHQMGDCgw/uL27WeNsp7/hg0b5Nfdu3fHF198gdDQUKjVaowcOdKsdXBBrPmcUlJSzJ56//jjj2PZsmUICAiASqVCmzZtcOLEiSLnldeMGTPkRPO3336LGjVqyCdlQ4cOlT/vHMuWLcOrr76KI0eO4PLly/jrr7/w/fff4/79+7h16xamT59e4NPuc5s1axaefvppHDt2DH/++SeuXr2KPXv24OrVq3j48CEmTJiAmzdvFnt58sodf95tGzDfvvMuaw5HR8dSx/Hqq6/i5MmTWL58OQDg2rVr6Nq1K37++WerT6ZnzJiBHTt2yO8nTZqUr7VXXrmXqWnTpoUmpnP6Kt20aZOcIHBycsLmzZvRtWtXODg4YNeuXWYt4gpizTadoyy2Kb1eb/b+5s2bRfYTW5Dc3225v9eA7L4yC1LW23Tuz65mzZqFtl7P29I4R2m3XWs/R0u/I7k/k8jIyGLPuyz23eJshwVxdXXFrl27cPfuXRw7dgx//fUXLl68iG3btiE1NRWHDh3CO++8gwULFmDHjh1yklmSJKxZswaPPPIIXFxccPHiRasSPoX1/563lb61Hjx4YHZRK/e6s7e3LzTJDJivX2dnZ8yfP7/AstZcVMi9vSQlJSEtLc0s2VzQ8UPu39uAgABs2bIFzZs3h52dHZYvX47p06cXOW9Lrly5YpZknj17NubNmwdvb29IkgQfH59iX/hu2LAhfH19ERUVBaPRiE8++QSpqanQarVo06YNOnfujGPHjuHXX3+tsERzWewP5Vmnpe/xnN+l4irp9/jjjz+O4cOH4/fff8f58+dx9epVHDhwAKdPn0ZycjImT56MQYMGFfnbm6Ms9p3CvsfL6pjsxIkTZs8NKErXrl2LnWjOa8iQIfIdk0IIHDp0iIlmIqoSmGgmonL39ddfIz09HaNHj87XLYazs7PZ+8JujS4vTk5OaNq0qXyStXnzZixcuFBuxZaThMyRc2t9zgOrchw/flxO2i5btqzA1jEdOnTA9u3bAWQnH5599tl8B+yJiYnYvXu32QFn7pOZglqL5T3hsVSupPMvSExMjPx60KBBqFOnDoDsE/uCbv0tiYSEBLOHCI0YMQI1atQAAFy6dMmqlliWtGzZEu3atcOxY8eQmJiIxYsXy+Nyd5sBZD+kysPDA+7u7ujfv798S36fPn3w6KOPAkC+W+gtuX//PtRqNXx9fdGjRw/06NEDAMwuvNy6dQsxMTHw9PQs0XLl6NChg5yAP3nyJC5duiTfgp/3BD9n2y4PkiTh008/hU6nwwcffAAge3127doVBw4csOp24F69eqF+/fq4fPkyVCqVVUmV3MsfERGBsWPH5juZTU9Px6ZNm9C1a1cA5tt0rVq10K9fP/n9+vXri5xncZTVNpW3O58333wTmzdvNkvM3bp1K1/rO0tyfw+fPn0amZmZ0Ol0uHTpklmiP7eSbNMajUa+Tbyg76qcC1VRUVEYOHCgWfcRAGAwGPDDDz+gU6dORS5XecqbDFq/fj0WLFgAILu1cc53bnHYyr574cIFhIWFoUaNGmZdKT333HPybes522jufcfNzQ2PP/64nPAq632nOFavXi0/AC8xMdFsO855CGVhcq/f5ORktGjRQt7Gcwgh8PPPP1v1XZZ3nt9++63cRcvNmzflLibyyr1+c367gOyWs4Vd1C3q+CF3vQAwduxYuRX4zz//XOK7q7p16yYnxz/++GMA2cvu4OCAzp07Y9myZTh48KBZNyB512thrDkuqkzatm1r9r24bNkyDBo0yOwiREm+x69cuYKEhAS4ubkhMjIS33zzjcVpYmNjkZSUJHdfk/O7EhcXJyfBU1JScPnyZbRs2RJA0Z9BWe87uZXV72d5ioqKwsWLF9GtW7d8FyHy3qHHhwESUVXBRDMRlbsbN25g4cKFmDVrFjp37oxmzZrBw8MDDx48MGudI0lSiZ74XRZmz56NCRMmAACuX7+Otm3bYsiQIbhx4wbWrl0rl2vTpo184O3m5oa6devKLUMWL16Mc+fOISEhodAE6/PPP4/vv/8eQghcunQJjRs3xqOPPgovLy/ExsbizJkz+PXXX+Hn52fWWiL3LcOnTp3Cc889h6CgIOh0OsycOTNfGSC7X9t+/fpBo9Fg8ODBqFevXonnX5CwsDBcuHBBXgdRUVGQJAmrV68utH/b4vLx8YG7u7t8y/Fzzz0nt7BZtWoVMjMzS1z3jBkz5KeTp6enA8i+hbR3795m5TZs2ID58+ejW7duqFu3Lvz9/ZGSkoJ169bJZay5WPLLL79gzJgx6NSpExo0aICAgAAYjUZs3bpVLqPT6fLdTl0S06ZNw4oVK5CZmQmTyYSuXbti/PjxMBgM+O9//yuXc3FxwVNPPVXq+RXlP//5D7RaLZYtWwYgu8ucLl264Oeffy6ymwNJkrBx40Zcu3YNLi4uVp2UzpgxA5999hkyMjLw4MEDNG3aFCNHjkRAQAASExNx/vx5HDp0CMnJyXI/rrlbx54/fx6jRo1C48aNcfDgQfz888+lWPr8ymqbCg8PR9++ffHjjz8CALZv344WLVqgf//+0Gq1OHv2LC5evIhr164VWVerVq2wbds2ANl3mbRu3Rr169fHjz/+WOB+VpJtOjAwUO6b9b333kNMTAwcHBzkvkAnTJiAxYsXIyYmBhkZGWjXrh1GjhyJ0NBQpKWl4eLFizh48CBiY2PlhINS2rZti/DwcLkv40WLFuH69euoWbMmNm7cWKL+X21l3507dy5+//139OzZE0FBQfD29sb9+/flPo6Bf7bR3PtOfHw8+vfvj86dO+PUqVP47rvvyi3Gorz66qu4fPkygoODsXnzZrPfpilTphQ5/aBBgxAWFoYrV64AAAYOHIjhw4ejfv36MBgM+Ouvv3Dw4EFERETgwIEDCA0NLbS+wYMHw9vbW07gTps2DSdOnICHhwfWrFmDrKwsi9OFhYXJ3Zbs3LkTU6ZMQWBgIHbu3FloX9O5jw2io6MxceJENGzYEJIkYfr06ahTpw5UKpV8J8fYsWPx+OOPIyIioth9i+fWvXt3+TgvZ53nXBTq1KkTJElCUlKSXD4kJKRY3UVYc1xUmej1ekyePBmff/45gOxWto0aNcLQoUPh6uqKixcvYvv27VZ1X5L7YkZiYiJatmyJ1q1b4+DBgwVeOPjrr7/Qvn17tG7dGk2bNkVAQAA0Gg327NljVi73b1JgYKB8N+KqVatgb28PV1dX1K5dG8OGDSvzfSe3svr9BIAJEybI5wFlKSIiAj169ECdOnXQq1cvBAUFITU1Fb///jv27dsnl1Or1WYXtYmIKrWKf/4gEVU3uZ92Xtjfiy++aDZdQU/FFsL8yc3jx4+Xhxf2BG4hCn86du6nV1v6q1Wrlrhx44bZNJ9//rnFss2aNRPe3t4Fzuujjz4yezK5pb+8T4Y/ffq0UKlU+co5OTmZlWvRooXF+jZt2lSq+Rdk3bp1Fqf39/cXvXv3lt/nfup5ST+nt956y+K8GjduLFq2bGlxmzhw4IBZ2byfoRBCZGZmCj8/P7NyL7/8cr5yS5cuLXI7/vDDD+Xyubf93OuzoHWW+2/OnDlWrf+i1mXO/Ozs7Aqcl5OTk9i1a5fZNAXtY9bKu95XrlxpNv6VV17Jt71cunTJ4rQ7duwocn65y+fd3zZv3iwcHByKXOc5YmJiREBAgMUy48ePL3B7KmydFbQtFHebKkx0dLTZflDYPl3YfhERESE8PDzyTW9nZye6dOlSZtv07NmzLZabPn26XObXX38Ver2+yLqt/RxyFLbfFPRZFbXeTpw4IZydnS2utx49esjvQ0NDi/oozdZrWe67hS1bQfr27Vvoure3txfHjx8XQmR/lzZp0sSqfSf3Os89LvdvRVHLU9BvRd7jh4EDB1qMafDgwcJkMlm1fi5duiRq1qxZ5LZo6TvYku3bt1v8HXZxcTH7Hc+9Pq5evSpcXFzyTaPRaMSYMWPMhuUWEREhHB0dLcYbHR0thBBi6tSpFsf37NlTBAYGWlzPRbly5Uq++rZv3y6Pb9y4sdm4SZMm5aujsG3DmuOiwqYv7DizIKU5zrRGampqkfucNbGkpqaK2rVr55tWkiTRq1cvi/UdPXq0yO370UcfNYv3ww8/tFhu4MCBcpmS7DuFfW45yvL3s7ycPn26yBjVarVYsWKFonESEZUl8w5GiYjKwaxZs7B582ZMmzYNbdq0Qc2aNeHg4ACdToegoCA8+uij2LlzJ9566y1F4/zwww+xZ88eDB06FP7+/tBoNHB2dkarVq2wePFinD59Ol9Lm6effhrLly9HvXr1oNVqUaNGDcydOxe//vproX3KzZgxAydPnsTkyZNRp04d2Nvbw8nJCXXr1kW/fv3w4Ycf4pdffjGbplmzZli3bh1atGhh9nCqvLZs2YJhw4ZBr9cXeBteSeZfkMcffxwbN25E06ZNodVq4enpiVGjRuHYsWMICAiwqg5rvfjii/j000/l9e3n54cpU6bg0KFD+bphKQ6tVpvvieZ5u80Asvtsfv3119GrVy+EhITA0dERGo0G/v7+GDhwIL7//nurWlF16tQJb775JgYOHIjatWvDxcUFGo0G3t7e6NmzJ1atWoV33323xMuT1+OPP47Tp09jypQpqF27Nuzt7WFvb4969eph+vTpOHfunHzLaUVZvHix3LUAkN3qp1u3bvjzzz/LfF7Dhw/H+fPnMXPmTDRs2BBOTk6wt7dHrVq10L17dyxduhSXL1+Wy+v1ehw+fBiPPvooXF1d4eDggNatW2Pr1q1l3uKprLYpIPuBe0eOHMHnn3+OHj16wNPTExqNBnq9Hm3btsW0adOsqsfPzw8HDx5E79694ejoCBcXFwwYMABHjx4tsP/UkmzTb775JmbOnInAwECLD3rKqffPP//ESy+9hObNm8PFxQU6nQ41a9ZEx44d8dprr+HUqVNl9tCs0mjVqhWOHDmCgQMHwtnZGc7OzujZsyd++eUX1K1bVy5XnC6ibGHffeGFF/Dcc8+hXbt2CAwMhE6ng52dHWrVqoXx48fj999/R5s2bQBkf5f+/PPPmDBhAjw9PWFnZ4fGjRvjiy++MNvfK9rWrVuxaNEi1K5dGzqdDiEhIVi4cCE2bdpk9e3q9evXx7lz57BkyRK0bdsWbm5u0Gq1CAwMRNu2bfH888/j119/RZcuXayqb/Dgwdi3bx+6dOkCBwcHuLu7Y8iQITh+/DiaNGlicZo6dergl19+QZ8+feDo6AhnZ2d07doV+/fvR69evQqcl5+fH3bs2IGOHTsW2Lfuxx9/jEWLFiE4OBharRY1a9bECy+8gB07dpS4b+x69eqZtTqWJMmsm5/OnTublS9u/8zWHhdVJg4ODti9ezfWrVuHAQMGwNfXF1qtFm5ubmjWrJlVD4PMqWf//v3y75ijoyO6dOmCffv2YcyYMRanCQsLw3vvvYdHH30U9erVg5ubG9RqNTw8PNCxY0d8+OGH+brAmT59OhYsWIBatWoVuJ2U9b6Toyx/P8tLSEgI3nzzTfTv3x8hISFwdnaGWq2Gu7s7WrZsidmzZ+PChQuYOnWqonESEZUlSYgSPmKXiIioClm3bh1Gjx4NIPvk19pEOxERAGRmZkKj0eR7UGxycjIaN24sdxMyZcoUfPHFF0qEWG2sWrXK7GIhT3eIiIiIKgb7aCYiomorPj4eZ86cQWRkJF555RV5uDUPmSMiyu3ixYsYPHgwxowZg4YNG8LDwwM3b97EihUr5CSztQ+xJCIiIiKqjJhoJiKiauvMmTP5btXt2LEjRowYoVBERFSZ3blzp8BuoHQ6HVasWIGmTZtWcFRERERERBWDiWYiIqr2JEmCn58fhgwZgiVLluS79Z2IqChBQUGYPXs2Dh48iNu3byMhIQH29vYIDQ1Ft27dMG3aNNSvX1/pMImoglmz37dp0wbffPNNBURDRERUvthHMxEREREREVE5sOaBk127dsXBgwfLPxgiIqJyxhbNREREREREROWA7bqIiKg64b3BRERERERERERERFQqTDQTERERERERERERUakw0UxEREREREREREREpcJEMxERERERERERERGVChPNRERERERERERERFQqTDQTERERERERERERUakw0UxEREREREREREREpcJEMxERERERERERERGVChPNRERERERERERERFQqTDQTERERERERERERUakw0UxEREREREREREREpcJEMxERERERERERERGVChPNRERERERERERERFQqTDQTERERERERERERUakw0UxEREREREREREREpcJEMxERERERERERERGVChPNRERERERERERERFQqTDQTERERERERERERUakw0UxEREREREREREREpcJEMxERERERERERERGVChPNRERERERERERERFQqTDQTERERERERERERUakw0UxEREREREREREREpcJEMxERERERERERERGVChPNRERERERERERERFQqTDQTERERERERERERUakw0UxEREREREREREREpcJEMxERERERERERERGVChPNRERERERERERERFQqTDSTzZIkyaq/gwcP4uDBg5AkCZs3b1Y6bKxatQqSJOHmzZvysAkTJiAkJMSsnCRJ+Ne//lWxwRXTrl27sGDBAovjlixZgu+++65C48nt5s2bkCQJq1atKva0Fy9exIIFC8w+o6Js2LABjRo1goODAyRJwpkzZ4o937KIr1u3bmjcuHG5zVsJlvaPyqQ026I17t+/jwULFpTrNkdERFSZVNbzBAByPAcPHlQ6FEiSZHasX96xHTlyBAsWLEB8fHy+cd26dUO3bt3KZb5l5ebNmxg4cCD0ej0kScKsWbMKLFvQuVLOueLJkyfLL1ArVfdj2NKeg4SEhGDChAnFni41NRULFiywie8AovLARDPZrKNHj5r9DRgwAA4ODvmGt2jRQulQzQwcOBBHjx6Fv7+/0qGU2q5du7Bw4UKL45RONJfGxYsXsXDhQqsTzdHR0Rg3bhxq166NPXv24OjRo6hXr57NxFfZvfbaa9i2bZvSYdis+/fvY+HChTZ7kE5ERFTRKut5AgC0aNGi2sZ25MgRLFy40GKiefny5Vi+fHm5zLeszJ49G8ePH8d///tfHD16FLNnzy6wbGU+VyorPIa1LDU1FQsXLmSimaosjdIBEBWkXbt2Zu+9vb2hUqnyDbc13t7e8Pb2VjoMKkN//fUXsrKyMHbsWHTt2rVM6kxNTYWjo2OZ1FVZ5ayD2rVrKx1KtZSWlgZ7e3tIkqR0KERERMVSWc8TAMDV1dVm41QytoYNGyoy3+K4cOEC2rRpg6FDhyodSrXGY1gi28YWzVSlZGVl4ZVXXkFAQABcXV3Rq1cvXLlyJV+5ffv2oWfPnnB1dYWjoyM6duyI/fv3F1m/yWTC4sWLERYWBgcHB7i7uyM8PBwffvihXMZS1xmFWb16NRo0aABHR0c0bdoUP/zwQ74yhw8fRs+ePeHi4gJHR0d06NABO3fuNCuzYMECiz+2BcWzYcMGtG/fHk5OTnB2dkbfvn1x+vRpefyECRPw6aefAjC/PTHnFquUlBR8/fXX8vDct7pFRkbimWeeQY0aNaDT6RAaGoqFCxfCYDAUuT5CQkIwaNAgbNu2DeHh4bC3t0etWrXw0UcfFTmtNetq1apVGDFiBACge/fucvwF3TI2YcIEdOrUCQAwatSofMv6/fffo3379nB0dISLiwt69+6No0ePmtWR89n88ccfeOyxx+Dh4VFgctXa+E6cOIHOnTvD0dERtWrVwltvvQWTyWRWJjExEXPnzkVoaCh0Oh0CAwMxa9YspKSkFLoOZ82aBScnJyQmJuYbN2rUKPj6+iIrKwtA9nbUp08f+Pv7w8HBAQ0aNMC8efPyzWPChAlwdnbG+fPn0adPH7i4uKBnz57yuLy3raWnp+Oll14yi3369On5WsDkveUzR95b2VJTU+V1YW9vD71ej1atWmHdunWFrgsAuHfvHp5++mkEBQVBp9MhICAAjz32GKKiogqcpqBb8Sztp5s2bULbtm3h5uYmf56TJk0CkH0La+vWrQEAEydOlLeH3Mt88uRJDB48GHq9Hvb29mjevDk2btxoNo+c74GffvoJkyZNgre3NxwdHZGRkYHo6Gh5+ezs7ODt7Y2OHTti3759Ra4bIiKiyqI8zxOio6Oh0+nw2muv5Rt3+fJlSJIkH8ta6p7i+vXrePzxxxEQEAA7Ozv4+vqiZ8+eZi1BrT3miY6OxrRp09CwYUM4OzvDx8cHPXr0wK+//lr4CrIQW85xf0F/Ofbu3YshQ4agRo0asLe3R506dfDMM8/g4cOHcpkFCxbghRdeAACEhoaadW8CWO46IzY2FtOmTUNgYCB0Oh1q1aqFV155BRkZGWblcroktOa8ypLbt29j7Nix8PHxgZ2dHRo0aID33ntPPrbOWS9///03du/ebXZeZElR50oAkJSUhGeffRZeXl7w9PTEo48+ivv37+erq6hztsJU9WPY4qyfVatWISwsTP58v/nmG6vWIZD93fHvf/8bfn5+cHR0RKdOnfD777/nK2fNvnfz5k25UdrChQvl9ZKzD//999+YOHEi6tatC0dHRwQGBuKRRx7B+fPnrY6XSGlMNFOV8vLLL+PWrVv48ssv8cUXX+Dq1at45JFHYDQa5TJr1qxBnz594Orqiq+//hobN26EXq9H3759izyIfOedd7BgwQI88cQT2LlzJzZs2IDJkydbvP3LGjt37sQnn3yCRYsWYcuWLdDr9Rg2bBiuX78ulzl06BB69OiBhIQEfPXVV1i3bh1cXFzwyCOPYMOGDSWa75IlS/DEE0+gYcOG2LhxI1avXo2kpCR07twZFy9eBJDdncFjjz0GwPz2RH9/fxw9ehQODg4YMGCAPDznVrfIyEi0adMGP/74I15//XXs3r0bkydPxtKlSzFlyhSr4jtz5gxmzZqF2bNnY9u2bejQoQOee+45vPvuu4VOZ826GjhwIJYsWQIA+PTTT+X4Bw4caLHO1157TU64L1myxGxZv/32WwwZMgSurq5Yt24dvvrqK8TFxaFbt244fPhwvroeffRR1KlTB5s2bcJnn31mcX7WxBcZGYkxY8Zg7Nix+P7779G/f3+89NJLWLNmjVwmNTUVXbt2xddff42ZM2di9+7dePHFF7Fq1SoMHjwYQogC1+OkSZOQmpqa70AvPj4e27dvx9ixY6HVagEAV69exYABA/DVV19hz549mDVrFjZu3IhHHnkkX72ZmZkYPHgwevToge3btxfYLYsQAkOHDsW7776LcePGYefOnZgzZw6+/vpr9OjRI9/JhTXmzJmDFStWYObMmdizZw9Wr16NESNGICYmptDp7t27h9atW2Pbtm2YM2cOdu/ejQ8++ABubm6Ii4srdhx5HT16FKNGjUKtWrWwfv167Ny5E6+//rp8UaZFixZYuXIlAODVV1+Vt4ennnoKAHDgwAF07NgR8fHx+Oyzz7B9+3Y0a9YMo0aNsnjxZNKkSdBqtVi9ejU2b94MrVaLcePG4bvvvsPrr7+On376CV9++SV69epV5LohIiKqTMrzPMHb2xuDBg3C119/ne/C/8qVK6HT6TBmzJgCpx8wYABOnTqFd955B3v37sWKFSvQvHnzEp1jxMbGAgDmz5+PnTt3YuXKlahVqxa6detW7Fv1c477c/99//33cHV1RYMGDeRy165dQ/v27bFixQr89NNPeP3113H8+HF06tRJbpzw1FNPYcaMGQCArVu3Ftm9SXp6Orp3745vvvkGc+bMwc6dOzF27Fi88847ePTRR/OVt+a8ypLo6Gh06NABP/30E9544w18//336NWrF+bOnSs/TyenSxE/Pz907NjR7LzIksLOlXI89dRT0Gq1+Pbbb/HOO+/g4MGDGDt2rFkZa87ZClIdjmGtXT+rVq3CxIkT0aBBA2zZsgWvvvoq3njjDfz8889WLeuUKVPw7rvv4sknn8T27dsxfPhwPProo/nWozX7nr+/P/bs2QMAmDx5srxeci5S3b9/H56ennjrrbewZ88efPrpp9BoNGjbtq3FC2NENkkQVRLjx48XTk5OFscdOHBAABADBgwwG75x40YBQBw9elQIIURKSorQ6/XikUceMStnNBpF06ZNRZs2bQqNYdCgQaJZs2aFllm5cqUAIG7cuGEWe3BwsFk5AMLX11ckJibKwyIjI4VKpRJLly6Vh7Vr1074+PiIpKQkeZjBYBCNGzcWNWrUECaTSQghxPz584WlXTpvPLdv3xYajUbMmDHDrFxSUpLw8/MTI0eOlIdNnz7dYp1CCOHk5CTGjx+fb/gzzzwjnJ2dxa1bt8yGv/vuuwKA+PPPPy3WlyM4OFhIkiTOnDljNrx3797C1dVVpKSkCCGEuHHjhgAgVq5cKZexdl1t2rRJABAHDhwoNJYcOdvXpk2b5GFGo1EEBASIJk2aCKPRKA9PSkoSPj4+okOHDvKwnM/m9ddft2p+hcXXtWtXAUAcP37cbHjDhg1F37595fdLly4VKpVKnDhxwqzc5s2bBQCxa9euQmNo0aKF2TIIIcTy5csFAHH+/HmL05hMJpGVlSUOHTokAIizZ8/K48aPHy8AiP/+97/5psu7f+zZs0cAEO+8845ZuQ0bNggA4osvvpCHARDz58/PV2dwcLDZ9tm4cWMxdOjQwhbZokmTJgmtVisuXrxYYBlL26KlfV6I/Ptpzn4RHx9fYP0nTpzIV3+O+vXri+bNm4usrCyz4YMGDRL+/v7ytpnzPfDkk0/mq8PZ2VnMmjWrwPkTERHZOls4T/j+++8FAPHTTz/JwwwGgwgICBDDhw/PF0/Ocd7Dhw8FAPHBBx8UWr+1xzx5GQwGkZWVJXr27CmGDRtWaJ15Y8srJSVFtGnTRvj7+4ubN29aLJNzPHjr1i0BQGzfvl0et2zZsnznSTm6du0qunbtKr//7LPPBACxceNGs3Jvv/12vvVs7XmVJfPmzbN4bP3ss88KSZLElStX5GHBwcFi4MCBhdaXo6BzpZxjsmnTppkNf+eddwQAERERIYQo3jmbJVX9GNba9ZNzztaiRQv5XFAIIW7evCm0Wq3FZc3t0qVLAoCYPXu22fC1a9cKACXa96Kjowvcny3VkZmZKerWrZsvBiJbxRbNVKUMHjzY7H14eDgA4NatWwCyH0ARGxuL8ePHw2AwyH8mkwn9+vXDiRMnCu1WoE2bNjh79iymTZuGH3/80WLXAsXRvXt3uLi4yO99fX3h4+Mjx5uSkoLjx4/jscceg7Ozs1xOrVZj3LhxuHv3brGvbP74448wGAx48sknzdaBvb09unbtWuqHEvzwww/o3r07AgICzOrv378/gOxWx0Vp1KgRmjZtajZs9OjRSExMxB9//GFxmvJYV4W5cuUK7t+/j3HjxkGl+uer1NnZGcOHD8exY8eQmppqNs3w4cPLZN5+fn5o06aN2bDw8HB5uwGyP4fGjRujWbNmZp9D3759rXqa+MSJE3HkyBGzdbZy5Uq0bt0ajRs3loddv34do0ePhp+fH9RqNbRardyP9aVLl/LVa806yGldkPcpziNGjICTk5NV3dzk1aZNG+zevRvz5s3DwYMHkZaWZtV0u3fvRvfu3c1a7ZSlnFsKR44ciY0bN+LevXtWT/v333/j8uXLcgup3J/zgAEDEBERkW+bt7T+27Rpg1WrVmHx4sU4duyY3PKIiIioKinv84T+/fvDz89PbsUJZB93379/X+5OwBK9Xo/atWtj2bJleP/993H69Ol8raKL67PPPkOLFi1gb28PjUYDrVaL/fv3Wzw2s5bRaMSoUaNw6dIl7Nq1C8HBwfK4Bw8eYOrUqQgKCpLnlzO+pPP8+eef4eTkJN9hmSPn+DDv8WBR51WFzadhw4b5jq0nTJgAIYTVrV6Lq6jtsbTnbFX9GNba9ZNzzjZ69Gizrj+Cg4PRoUOHImM9cOAAAOS7I2HkyJHQaPI/8qy0+57BYMCSJUvQsGFD6HQ6aDQa6HQ6XL16tVT7L1FFYqKZqhRPT0+z93Z2dgAgJ5Vy+qN67LHHoNVqzf7efvttCCHkW14seemll/Duu+/i2LFj6N+/Pzw9PdGzZ0+cPHmyTOLNiTkn3ri4OAghLN6WFRAQAADFvr09Zx20bt063zrYsGGDWV9qJREVFYUdO3bkq7tRo0YAYFX9fn5+BQ4raHnLY10VJqeuguZnMpny3U5V0O11xVXUdgNkfw7nzp3L9zm4uLhACFHk5zBmzBjY2dnJt65dvHgRJ06cwMSJE+UyycnJ6Ny5M44fP47Fixfj4MGDOHHiBLZu3QoA+ZK5jo6OcHV1LXL5YmJioNFo8j1UU5Ik+Pn5lehz/Oijj/Diiy/iu+++Q/fu3aHX6zF06FBcvXq10Omio6NRo0aNYs/PWl26dMF3330nHyjXqFEDjRs3tqrv6Jx9ee7cufk+52nTpgHIv79Z2gY3bNiA8ePH48svv0T79u2h1+vx5JNPIjIysgyWkIiIyDaU93mCRqPBuHHjsG3bNrnLi1WrVsHf3x99+/YtcDpJkrB//3707dsX77zzDlq0aAFvb2/MnDkTSUlJxV7O999/H88++yzatm2LLVu24NixYzhx4gT69etn9YV2S6ZOnYo9e/Zg8+bNaNasmTzcZDKhT58+2Lp1K/79739j//79+P3333Hs2DEA+Y8HrRUTEwM/P798/QL7+PhAo9HkOx605vi4oPlU1PlDbtZujyU9Z6vqx7DWrp+cz6+w88vCFDS9RqPJ9xmWxb43Z84cvPbaaxg6dCh27NiB48eP48SJE2jatGmp9l+iipT/EgxRFebl5QUA+Pjjjwt8orKvr2+B02s0GsyZMwdz5sxBfHw89u3bh5dffhl9+/bFnTt34OjoWKbxenh4QKVSISIiIt+4nIdF5CyTvb09ACAjI0M+UAHy/0jnlN+8ebNZS4Sy4uXlhfDwcLz55psWx+cctBXGUoIrZ5ilg0igeOuqLOTEUdD8VCoVPDw8zIZX5JORvby84ODggP/+978Fji+Mh4cHhgwZgm+++QaLFy/GypUrYW9vjyeeeEIu8/PPP+P+/fs4ePCg3IoZQIH9CVq7/J6enjAYDIiOjjZLNgshEBkZKbegALIPyi312Zz3pMDJyQkLFy7EwoULERUVJbdufuSRR3D58uUCY/H29sbdu3etijs3e3t7i3FZOikYMmQIhgwZgoyMDBw7dgxLly7F6NGjERISgvbt2xc4j5zP8KWXXrLYVyEAhIWFmb239Bl4eXnhgw8+wAcffIDbt2/j+++/x7x58/DgwQO5DzkiIqKqrrTnCUD2HWHLli3D+vXrMWrUKHz//feYNWsW1Gp1odMFBwfjq6++AgD89ddf2LhxIxYsWIDMzEz5uR7WHvOsWbMG3bp1w4oVK8yGlyRpnWPBggX48ssvsXLlSvTp08ds3IULF3D27FmsWrUK48ePl4f//fffJZ4fkH08ePz4cQghzI5fHjx4AIPBUGbH9Z6enhV2/lAcpT1nq+rHsNaun5xztsLOLwuTe/rAwEB5uMFgKJd9b82aNXjyySflZ/bkePjwIdzd3a2uh0hJTDRTtdKxY0e4u7vj4sWL8sMdSsrd3R2PPfYY7t27h1mzZuHmzZto2LBhGUWazcnJCW3btsXWrVvx7rvvwsHBAUB2y4E1a9agRo0aqFevHgDITwc+d+6cWSJux44dZnX27dsXGo0G165dK7Ibg9xX1nPmnXucpauqgwYNwq5du1C7du18iVZr/fnnnzh79qxZ9xnffvstXFxcCnxgSHHWVd4WAyURFhaGwMBAfPvtt5g7d6588JOSkoItW7agffv2Jb7wUBbxDRo0CEuWLIGnpydCQ0NLVMfEiROxceNG7Nq1C2vWrMGwYcPMDnByljn3hQ0A+Pzzz0scNwD07NkT77zzDtasWYPZs2fLw7ds2YKUlBT07NlTHhYSEoJz586ZTf/zzz8jOTm5wPp9fX0xYcIEnD17Fh988AFSU1ML/Kz69++P1atX48qVK/kOeAsTEhKCBw8eICoqSj4pzczMxI8//ljgNHZ2dujatSvc3d3x448/4vTp02jfvn2B20NYWBjq1q2Ls2fP5jsYLamaNWviX//6F/bv34/ffvutTOokIiKqDMriPKFBgwZo27YtVq5cCaPRiIyMDLO7waxRr149vPrqq9iyZYtZl3HWHvNIkpTv2OzcuXM4evQogoKCirlEwFdffYWFCxdi0aJF+bo1y5kfYN3xYHGOcXv27ImNGzfiu+++w7Bhw+Th33zzjTy+LPTs2RNLly7FH3/8YXae8c0330CSJHTv3r1E9VrTmrowxTlns6SqH8Nau37CwsLg7++PdevWYc6cOfL2euvWLRw5cqTIRlDdunUDAKxduxYtW7aUh2/cuFF+8GEOa/e9wvYDS3Xs3LkT9+7dQ506dQqNlchWMNFM1YqzszM+/vhjjB8/HrGxsXjsscfg4+OD6OhonD17FtHR0fmuQOb2yCOPoHHjxmjVqhW8vb1x69YtfPDBBwgODkbdunXLJealS5eid+/e6N69O+bOnQudTofly5fjwoULWLdunfxjOWDAAOj1ekyePBmLFi2CRqPBqlWrcOfOHbP6QkJCsGjRIrzyyiu4fv06+vXrBw8PD0RFReH333+XW34CQJMmTQAAb7/9Nvr37w+1Wo3w8HDodDo0adIEBw8exI4dO+Dv7w8XFxeEhYVh0aJF2Lt3Lzp06ICZM2ciLCwM6enpuHnzJnbt2oXPPvusyNu4AgICMHjwYCxYsAD+/v5Ys2YN9u7di7fffrvQ5K216yqnj+EvvvgCLi4usLe3R2hoaIGtpS1RqVR45513MGbMGAwaNAjPPPMMMjIysGzZMsTHx+Ott96yuq68yiK+WbNmYcuWLejSpQtmz56N8PBwmEwm3L59Gz/99BOef/55tG3bttA6+vTpgxo1amDatGmIjIzMd6LUoUMHeHh4YOrUqZg/fz60Wi3Wrl2Ls2fPFn+hc+nduzf69u2LF198EYmJiejYsSPOnTuH+fPno3nz5hg3bpxcdty4cXjttdfw+uuvo2vXrrh48SI++eQTuLm5mdXZtm1bDBo0COHh4fDw8MClS5ewevXqIi8ILFq0CLt370aXLl3w8ssvo0mTJoiPj8eePXswZ84c1K9f3+J0o0aNwuuvv47HH38cL7zwAtLT0/HRRx+ZPdkeAF5//XXcvXsXPXv2RI0aNRAfH48PP/zQrK/r2rVrw8HBAWvXrkWDBg3g7OyMgIAABAQE4PPPP0f//v3Rt29fTJgwAYGBgYiNjcWlS5fwxx9/YNOmTYWu64SEBHTv3h2jR49G/fr14eLighMnTmDPnj1mLUwWLVqERYsWYf/+/Wat14mIiKqK0p4n5Jg0aRKeeeYZ3L9/Hx06dCgyyXfu3Dn861//wogRI1C3bl3odDr8/PPPOHfuHObNmyeXs/aYZ9CgQXjjjTcwf/58dO3aFVeuXMGiRYsQGhqaLzFWlKNHj2Lq1Kno2LEjevfuLXeHkaNdu3aoX78+ateujXnz5kEIAb1ejx07dmDv3r356ss5t/jwww8xfvx4aLVahIWFmfWtnOPJJ5/Ep59+ivHjx+PmzZto0qQJDh8+jCVLlmDAgAHo1atXsZalILNnz8Y333yDgQMHYtGiRQgODsbOnTuxfPlyPPvss3JDleIq6FzJWsU5Z7Okqh/DWrt+VCoV3njjDTz11FMYNmwYpkyZgvj4eCxYsMCqrjMaNGiAsWPH4oMPPoBWq0WvXr1w4cIFvPvuu/m6BLR233NxcUFwcDC2b9+Onj17Qq/Xw8vLCyEhIRg0aBBWrVqF+vXrIzw8HKdOncKyZcssnj9rNBp07dq1RM+vISpXij2GkKiYrHma9KZNm8yGW3qSrhBCHDp0SAwcOFDo9Xqh1WpFYGCgGDhwYL7p83rvvfdEhw4dhJeXl9DpdKJmzZpi8uTJZk9dznkybu6nKVt6ei8AMX369HzzsPTk6F9//VX06NFDODk5CQcHB9GuXTuxY8eOfNP+/vvvokOHDsLJyUkEBgaK+fPniy+//NLi052/++470b17d+Hq6irs7OxEcHCweOyxx8S+ffvkMhkZGeKpp54S3t7eQpIks3rOnDkjOnbsKBwdHQUAs6dER0dHi5kzZ4rQ0FCh1WqFXq8XLVu2FK+88opITk4udB3nPM158+bNolGjRkKn04mQkBDx/vvvm5Ur6LO1dl198MEHIjQ0VKjV6gKfhpyjoO0rZz22bdtW2NvbCycnJ9GzZ0/x22+/mZXJeUpzdHR0octuTXxdu3YVjRo1ylfe0jaWnJwsXn31VREWFiZ0Op1wc3MTTZo0EbNnzxaRkZFWxfHyyy8LACIoKEh++nNuR44cEe3btxeOjo7C29tbPPXUU+KPP/6w+ATrgvZfS7GnpaWJF198UQQHBwutViv8/f3Fs88+K+Li4szKZWRkiH//+98iKChIODg4iK5du4ozZ87k24/mzZsnWrVqJTw8PISdnZ2oVauWmD17tnj48GGR6+DOnTti0qRJws/PT2i1WhEQECBGjhwpoqKihBAFb4u7du0SzZo1Ew4ODqJWrVrik08+yffE7h9++EH0799fBAYGCp1OJ3x8fMSAAQPEr7/+albXunXrRP369YVWq833lOqzZ8+KkSNHCh8fH6HVaoWfn5/o0aOH+Oyzz+QyOd9LJ06cMKs3PT1dTJ06VYSHhwtXV1fh4OAgwsLCxPz580VKSopcLifugp5CT0REpCRbOE/IkZCQIBwcHAQA8X//938FxpPzmxoVFSUmTJgg6tevL5ycnISzs7MIDw8X//nPf4TBYJCns/aYJyMjQ8ydO1cEBgYKe3t70aJFC/Hdd98VeD6S+5gib2w5xw8F/eW4ePGi6N27t3BxcREeHh5ixIgR4vbt2/nqF0KIl156SQQEBAiVSmU2r65du5qdTwghRExMjJg6darw9/cXGo1GBAcHi5deekmkp6fnWw5rz6ssuXXrlhg9erTw9PQUWq1WhIWFiWXLluU79s05T7FGQedKBR2T5V33Oaw5ZytIVT6GLe76+fLLL0XdunWFTqcT9erVE//9738t7hOWZGRkiOeff174+PgIe3t70a5dO3H06NFS7Xv79u0TzZs3F3Z2dgKAXE9cXJyYPHmy8PHxEY6OjqJTp07i119/tbh/5D0HJ7IVkhBClE8Km4io+EJCQtC4cWP88MMPSodCRERERERERERWUikdABERERERERERERFVbkw0ExEREREREREREVGpsOsMIiIiIiIiIiIiIioVtmgmIiIiIiIiIiIiolJhopmIiIiIiIiIiIiISoWJZiIiIiIiIiIiIiIqFY0SMzWZTLh//z5cXFwgSZISIRARERFRORBCICkpCQEBAVCp2KahuuDxPREREVHVZe0xviKJ5vv37yMoKEiJWRMRERFRBbhz5w5q1KihdBhUQXh8T0RERFT1FXWMr0ii2cXFBUB2cK6urkqEQLYoPR0YOzb79Zo1gL29svEQERFRsSUmJiIoKEg+3qPqgcf3RERERFWXtcf4iiSac26nc3V15YEo/UOtBvbuzX7t5JT9R0RERJUSu0+oXnh8T0RERFT1FXWMz47ziIiIiIiIiIiIiKhUmGgmIiIiIiIiIiIiolJhopmIiIiIiIiIiIiISoWJZiIiIiIiIiIiIiIqFSaaiYiIiIiIiIiIiKhUNEoHUJVliWgYEa90GJWHSIX9/16mi78B4ahoOBVNA09oJL3SYRARERERERERERUbE83l6KZhArLEfaXDqDx0ADKa/e/NBCBLuVCU4CA1Qqh2jdJhEBERERERERERFRsTzeXIiEQIGKGFt9KhkA0TMCALkXBV9VY6FCIiIiIiIiIiohJhormcqeAAlVS9uoAg6wghIJAGA2KgkfRwUw1WOiQiIiIiIiIiIqISYaKZbIaUboTvhDMAgKhVzSDs1coGVI5MIhOZuAkVHKCVAuChegwayUPpsIiIiIiIiIiIiEqEiWayHUYB560RAICor5oqHEz5MuAB7KRaCFQvgYPUGJKkVTokIiIiIiIiIiKiEmOimagCCWFEFu5DIAtu0hA4qporHRIREREREREREVGpMdFMVIEycRsayRteqqfgoXpM6XCIiIiIiIiIiIjKBBPNRBXEJNIBCPipX4CbaoDS4RAREREREREREZUZldIBEFUXmbgLB6kxXKQeSodCRERERERERERUpphoJqoAJpEJCRK81E9BJdkrHQ4REREREREREVGZYtcZROVICAEj4mBANOyk2nCSOigdEhERERERERERUZljoplshnBU41pcP/l1ZWcQD2FALNSSK9yl4fBST4ZaclI6LCIiIiIiIiIiojLHRDPZDkmCcKoam6RJZMCIeOhVT0CvfgL2UpjSIREREREREREREZWbqpHVI7IxRsRBI/nBT/0iVJKD0uEQEREREVE1FJuRhXU3I6GSJIwO8YObjikAIiIqP/yVIduRYYTPtPMAgAfLmwB2lbf7DBPS4SA1YpKZiIiIiIgUs+ziLVxISAYARKVnYEF4bYUjIiKiqkyldABEOSSDgOvqu3BdfReSQSgdTokJYYRAJpylrkqHQkRERERE1diDjMx/XqdnKRgJERFVB0w0E5UxE5KgllzhquqtdChERERERFSNPRHsC7UkQSNJeDzYV+lwiIioimPXGURlyCiSkIUHcJY6QotApcMhIiIiIqJqrJe/Jzp4u0MC4KCpvF0TEhFR5cBEM1EZMYkUZCECbqrBCFC/CkmSlA6JiIiIiIiqOUcmmImIqIIw0UxUSkIIGBABE9LgouoKf/UrUEtuSodFRERERERERERUYZhoJiolAyIBSQVf1Tx4qkZDkrhbERERERERERFR9cKHARKVkhHJcJeGw0v9JJPMRERERERERERULTErRjZDOKpx/V5v+XVlYBKpkKCCo6qJ0qEQEREREREREREpholmsh2SBJO3ndJRWEUIAzJxC4AKDlITOEtdlA6JiIiIiIiIiIhIMUw0E5WACWlQSY7wV78GN2kAJEmrdEhERERERERERESKYR/NZDsyjPCaeR5eM88DGUaloymUQCYk6OAi9WKSmYiIiIiIiIiIqj0mmslmSAYB989uwf2zW5AMQulwCiWQCTVcoJaclA6FiIiIiIiIiIhIcUw0ExVTloiCEUmwl+orHQoREREREREREZFNYB/NRMUghAFGJMJTNQk+6qlKh0NERERERERERGQT2KKZqBgMiIVacoVePRJqyU3pcIiIiIiIiIiIiGwCE81EVjKJNBiRCL30BOykUKXDISIiIiIiIiIishlMNBNZyYR0aCQ3eKonKB0KERERERERERGRTWGimcgKQmTBgBhoEQg13JUOh4iIiIiIiIiIyKbwYYBkM4SDGjf/6iG/tgVZIhpGxEOCClrJCz7q5yBJktJhERERERERERER2RQmmsl2qCQYQhyVjkImRBaMSICHajhcVN3hKLWARtIrHRYREREREREREZHNYaKZqAAmZEAFR3ipp8BOClE6HCIiIiIiIiIiIpvFPprJdmSa4DnvIjznXQQyTUpHA8AISVJDBdtpZU1ERERERERERGSLmGgmmyFlmeDx/nV4vH8dUpayiWYhBAyIgQrOUMNN0ViIiIiIiIiIiIhsHRPNRBYYEQOV5AB/9atQSXZKh0NERERERERERGTTmGgmysMoEmFEPNykoXBV9VA6HCIiIiIiIiIiIpvHRDNRHgbEwkFqAT/1v5UOhYiIiIiIiIiIqFJgopkoD4EsOEmtoJJ0SodCRERERERERERUKTDRTJSHBAk6VYjSYRAREREREREREVUaTDQT5SKEgICACg5Kh0JERERERERERFRpMNFMNkM4qHH7dFfcPt0VwkFd8fMXJmTgGjSSHjoEVfj8iYiIiHJbsWIFwsPD4erqCldXV7Rv3x67d++Wx0+YMAGSJJn9tWvXzqyOjIwMzJgxA15eXnBycsLgwYNx9+5dszJxcXEYN24c3Nzc4ObmhnHjxiE+Pr4iFpGIiIiIqhAmmsl2qCRkNnJBZiMXQCVV+OyNiIVGckOQ+iM4qBpV+PyJiIiIcqtRowbeeustnDx5EidPnkSPHj0wZMgQ/Pnnn3KZfv36ISIiQv7btWuXWR2zZs3Ctm3bsH79ehw+fBjJyckYNGgQjEajXGb06NE4c+YM9uzZgz179uDMmTMYN25chS0nEREREVUNGqUDILIVJqTDDvXgpGqldChEREREeOSRR8zev/nmm1ixYgWOHTuGRo2yL4rb2dnBz8/P4vQJCQn46quvsHr1avTq1QsAsGbNGgQFBWHfvn3o27cvLl26hD179uDYsWNo27YtAOD//u//0L59e1y5cgVhYWHluIREREREVJWwRTPZjkwT9IuuQL/oCpBpqvDZC2RCI3lU+HyJiIiIimI0GrF+/XqkpKSgffv28vCDBw/Cx8cH9erVw5QpU/DgwQN53KlTp5CVlYU+ffrIwwICAtC4cWMcOXIEAHD06FG4ubnJSWYAaNeuHdzc3OQylmRkZCAxMdHsj4iIiIiqNyaayWZIWSboF1+FfvFVSFkVm2gWIgsCRjhJ7YouTERERFRBzp8/D2dnZ9jZ2WHq1KnYtm0bGjZsCADo378/1q5di59//hnvvfceTpw4gR49eiAjIwMAEBkZCZ1OBw8P8wvpvr6+iIyMlMv4+Pjkm6+Pj49cxpKlS5fKfTq7ubkhKIjPtyAiIiKq7th1BhEAIxKgkTzhoRqmdChEREREsrCwMJw5cwbx8fHYsmULxo8fj0OHDqFhw4YYNWqUXK5x48Zo1aoVgoODsXPnTjz66KMF1imEgCT98zyM3K8LKpPXSy+9hDlz5sjvExMTmWwmIiIiquaYaCYCIGCECjqoJTelQyEiIiKS6XQ61KlTBwDQqlUrnDhxAh9++CE+//zzfGX9/f0RHByMq1evAgD8/PyQmZmJuLg4s1bNDx48QIcOHeQyUVFR+eqKjo6Gr69vgXHZ2dnBzs6uVMtGRERERFULu84gAiCQBTWYZCYiIiLbJoSQu8bIKyYmBnfu3IG/vz8AoGXLltBqtdi7d69cJiIiAhcuXJATze3bt0dCQgJ+//13uczx48eRkJAglyEiIiIisgZbNFO1J4QJJqTCWeqmdChEREREspdffhn9+/dHUFAQkpKSsH79ehw8eBB79uxBcnIyFixYgOHDh8Pf3x83b97Eyy+/DC8vLwwblt0VmJubGyZPnoznn38enp6e0Ov1mDt3Lpo0aYJevXoBABo0aIB+/fphypQpcivpp59+GoMGDUJYWJhiy05ERERElQ8TzVTtGREHteQGD/VQpUMhIiIikkVFRWHcuHGIiIiAm5sbwsPDsWfPHvTu3RtpaWk4f/48vvnmG8THx8Pf3x/du3fHhg0b4OLiItfxn//8BxqNBiNHjkRaWhp69uyJVatWQa1Wy2XWrl2LmTNnok+fPgCAwYMH45NPPqnw5SUiIiKiyk0SQoiKnmliYiLc3NyQkJAAV1fXip59hbmc1RlCZEIr5X+SN+UnpRhQ22MPAOBaXD8Ip4q5DpIursJdNQw1NEsrZH5ERERVWXU5ziNz/NyJiIiIqi5rj/XYoplshrBX486RTvLriiPBXqpXgfMjIiIiIiIiIiKqWphoJtuhlpDRyl2hWTsrMl8iIiIiIiIiIqKqQKV0AERKMolMSFBDi0ClQyEiIiIiIiIiIqq02KKZbEemCe4f3wAAxM8IBXTlfx3EiFhoJA84SE3KfV5ERERERERERERVFRPNZDOkLBO8XroEAEiYGgxRIYnmZLhLw6GWXIouTERERERERERERBax6wyq1iRI0EreSodBRERERERERERUqTHRTNWWEAICAio4KR0KERERERERERFRpcZEM1VbJiRCBUc4SI2VDoWIiIiIiIiIiKhSY6KZqi0DYuGgagx7qZHSoRAREREREREREVVqTDRTtSVggJPUEpIkKR0KERERERERERFRpcZEM1VLQhghQQUHqYnSoRAREREREREREVV6GqUDIMoh7NW4t7ed/Lo8GREHleQCnVSrXOdDRERERERERERUHTDRTLZDLSGtq1eFzMqAeLhLj8BOCq6Q+REREREREREREVVl7DqDqiUJgL3UUOkwiIiIiKiS2R8ZizU3IhCRlqF0KEREREQ2hS2ayXZkmeD25W0AQMJTNQFt+VwHMYpkACpoJb9yqZ+IiIiIqqZd9x5ixdW7AIC9EbH4v7YNoFOz7Q4RERERwEQz2RAp0wTv5y4AABKfrAFRTonmLETCRdUdLlL3cqmfiIiIiKqma8mp8uvYzCzEZxngo9YpGBERERGR7eDld6pWhBAABFykzlBJdkqHQ0RERESVSHdfPXQqCQDQUu8CbzutwhERERER2Q62aKZqRSADErSwk2orHQoRERERVTKN3Z3xf20bIiYjC7WcHSBJktIhFcgkBPZHxiLVYEQff084aNRKh0RERERVHBPNVK1kIQp2UggfBEhEREREJaK300JfCVoyr7p+H9vuRAMAjsckYkmzOgpHRERERFVdteo6Y+nSpWjdujVcXFzg4+ODoUOH4sqVK0qHRRVECAGBTLipBkItOSsdDhERERFRubmc8E9/0lcSUxSMhIiIiKqLapVoPnToEKZPn45jx45h7969MBgM6NOnD1JSeOBVHZiQBBUc4CS1VToUIiIiIqJy1d3XI9drvYKREBERUXVRrbrO2LNnj9n7lStXwsfHB6dOnUKXLl0UiooqghAmZCESbqoBcJCaKR0OEREREVG56h/ohQZuTkg1GtHA1UnpcIiIiKgaqFaJ5rwSEhIAAHo9r/DbAmGnwv3vWsuvy7RupEMFB3iqJtr0Q1uIiIiIiMpKiLOD0iEQERFRNVJtE81CCMyZMwedOnVC48aNlQ6HAECjQuoA33KpWiATkqSDViqf+omIiIiIiIiU9CA9EwvOXUdEWgZG1PTF6FA/pUMiomqmWvXRnNu//vUvnDt3DuvWrVM6FKoARiRDC39o4KN0KERERERERERlbuvtB7iTmg6DEFh3KxKxGVlKh0RE1Uy1bNE8Y8YMfP/99/jll19Qo0YNpcOhHFkmuKy7BwBIeiIQ0JbddRAT0uAoNWe3GURERERERFQlOWnU8mudSoJOxfNfIqpY1SrRLITAjBkzsG3bNhw8eBChoaFKh0S5SJkm+D51FgCQPNwfoowSzUaRDAkq2Em1y6Q+IiIiIiIiIlszMtgXiVkG3E/LwJAa3nDWVquUDxHZgGr1rTN9+nR8++232L59O1xcXBAZGQkAcHNzg4MDH5RRVRkQDUepFTxUo5QOhYiIiIiIiKhc2KlVmB4WpHQYRFSNVas+mlesWIGEhAR069YN/v7+8t+GDRuUDo3KkYABDlJjqCSd0qEQERERERERERFVSdWqRbMQQukQSAESVNBK/kqHQUREREREREREVGVVqxbNVP0IISBgglpyUToUIiIiIiIiIiKiKouJZqrSDIiGWnKFvdRQ6VCIiIiIiIiIiIiqrGrVdQZVP0YkwFOaCHupntKhEBERERGVq3SjEVtvRyPdZMSjQT5w12mVDomIiIiqESaayWYIOxUivm0hvy51ff/rk9tR1aTUdRERERER2boVf93Fz1FxAIBLCalY1qKuwhERERFRdcJEM9kOjQopjwWUWXUCmZCghQbeZVYnEREREZGtupOaket1uoKREBERUXXEPpqpyjIhCWrJBfZSfaVDISIiIiIqd4NreEElZb8eVoONLYiIiKhisUUz2Q6DCU7fRQIAUob6AZrSXQcRyIQGXlBLLmURHRERERGRTevmq0e4uwsMQsDHXqd0OEQQQkCSJKXDICKiCsJEM9kMKcME/9F/AACuxfWDKGWi2YQM6KQ6ZREaEREREVGloLfjAwBJeVkiEveN85ElIuGhGgFP9VilQyIiogrArjOoShLCAIEsOKCR0qEQERERERFVK/GmbcgS9wGYEGfaAIOIVTokIiKqAEw0U5VkwANopUDo1Y8rHQoREREREVG1ooKr/FqCDhLsFIyGiIgqCrvOoCrJiBS4SYOgkfRKh0JERERERFSteKhGwIQkZIn7cFcNhVpyUjokIiKqAEw0UxUlQSv5KR0EERERERFRtaOSdPBWT1U6DCIiqmDsOoOqHIOIhQp2sJfYPzMREREREREREVFFYItmqnIMiIFe9QScpc5Kh0JERERERFQm0sRFJJkOwE4KhZtqgNLhEBER5cNEM9kMoVMh6sum8usS1SEEAMBJ1RqSJJVZbERERERUNZ2LS8LtlHR08HaH3k6rdDhEFhlEHO4bXodABgBAgh1cVT0VjoqIiMgcE81kO7QqJD0ZVOLJhRAw4AFUsIcGvmUYGBERERFVRUei47H0z5sAgG13o/Fp6zDYq9XKBkVkgQExcpIZALLEfQWjISIisox9NFOVYUISTEiHp2oiHKVmSodDREREROXIYDIhKctQqjouxCfLrx+kZyI6Pau0YVE1ZzCZ8P6lW3j6+CWsvRFRZvXaoRYcpZYAALWkh6uqV5nVTUREVFbYoplsh8EEx5+iAQCpfbwBjfXXQYQwIQtRsJfqwUc9A5LEayhEREREVdW91HS8fOYaYjOz0MtPj+fq1yxRPe283LD7fgwMQqCWswP8HHRlHCmVRFxGFtJNJvg72CkdSrHti4zFgag4AMD6W1Fo5emKMFenUtcrSSr4q+fDgGio4QaVVPnWDRERVX1MNJPNkDJMCBh6AgBwLa4fRDESzSYkQi25IEC9iElmIiIioipu572HiM3Mbn28LzIWI4N9S5SUDPdwwcetwxCRloEm7s7QqqrXcaQQAnsjYxGbkYU+/p420Uf1keh4LLt4CwYhMDzIBxNqBygdUrH875ExBb4vDUmSoIVP2VVINi3RtBeJpr2wk+rASzUZksRufYjI9jHRTFWCCWlQwQUOUlOlQyEiIiKicuZt/0/LY3u1Cs6akidgajjao4ajfVmEVelsvBWFNTcjAQAHo+Kwok19xR+o/cO9hzD8Lzu7/W50pUs09/LX48+EFFxKTEE3Hw/Udyt9a2aqfjLFPTwwfgxAIF1cgk4KhJs0UOmwiIiKxEQzVXpCGGFEEjykEYofGBMRERFR+Rsc6I0Mowl3UtPRP8ALLlrbOa2Jz8zCN9cjYBACY0P94WNvu91x/J2cJr++l5aBDJNJ8YchBjna4/z/+s6u4Vj5uofQqlSY2zC4TOsUQsAkALWK5zrVhQlpAP5pDm8UKcoFQ0RUDLZzREZUQtmtmZ3hoR6hdChEREREVAHUKgmPh/gpHYZFH16+g5OxiQCAe6kZeK9lPYUjKlgvPz1OxiTCIAS6+LgrnmQGgMm1A+Bpp0WywYAhNbyVDkdx5+OS8eafN5BhNGFavRro7e+pdEhUAeylOnBTPYJE04+wk+rATTVA6ZCIiKzCRDNVAUZIkhoqOCsdCBERERFVczH/6zs672tb1NbLDZ+3bYD4zCzUdXFUOhwAgE6twshg3zKrL8VghL1KVWlbA6+5GYEUgxEA8NW1+0w0VyPe6qfhrX5a6TCIiIqlej3tgqokgSxI0EDNRDMRERERKWxMiB90KgkaScL4UH+lwymSj70O9VydqmQXdCv+uovHD5/HpGMXcSclXelwSsQ9V7cw7hXQRUxSlgERaRnlPh8iIqqamGimSs+EDGjgBZVkG60wiIiIiMrCihUrEB4eDldXV7i6uqJ9+/bYvXu3PF4IgQULFiAgIAAODg7o1q0b/vzzT7M6MjIyMGPGDHh5ecHJyQmDBw/G3bt3zcrExcVh3LhxcHNzg5ubG8aNG4f4+PiKWMQqqa2XGzZ0aoINnZqgu59e6XCqrej0TOy6/xAAEJuZhR33ohWOqGSm1QtCTz89Oni54ZXGoeU6r3NxSZh49CKePn4JK/66W/QEREREeTDRTDZD6FSI/rAxoj9sDKErzqZpYrcZREREVOXUqFEDb731Fk6ePImTJ0+iR48eGDJkiJxMfuedd/D+++/jk08+wYkTJ+Dn54fevXsjKSlJrmPWrFnYtm0b1q9fj8OHDyM5ORmDBg2C0WiUy4wePRpnzpzBnj17sGfPHpw5cwbjxo2r8OWtSjQqFXRqnmopyUmjhkOuz8DLznYfylgYN50Gs+rXxEuNQxHkZF+u8/rh3kNkmEwAgF33HyI91/cEERGRNSQhhCi6WNlKTEyEm5sbEhIS4OrqWtGzrzCXszpDiExoJR+lQ6nS0sXfcFcNQg3NMqVDISIiqvaqy3GeUvR6PZYtW4ZJkyYhICAAs2bNwosvvgggu/Wyr68v3n77bTzzzDNISEiAt7c3Vq9ejVGjRgEA7t+/j6CgIOzatQt9+/bFpUuX0LBhQxw7dgxt27YFABw7dgzt27fH5cuXERYWZlVc/NzJFl1MSMaOuw8R6GiHx4N9oVEx+V+Y1dcjsPF2FADA206Lr9o1rJJdqhARUfFZe6zHhwFSpSZE9lV2R6m1wpEQERERlR+j0YhNmzYhJSUF7du3x40bNxAZGYk+ffrIZezs7NC1a1ccOXIEzzzzDE6dOoWsrCyzMgEBAWjcuDGOHDmCvn374ujRo3Bzc5OTzADQrl07uLm54ciRIwUmmjMyMpCR8U8/romJieWw1ESl09DNGQ3deOejtZ4I8YWjRoWYjCw8UsObSWYiIio2JprJdhgFHA7HAADSOnkC6sIPbAwiDgZEQyfVhIuqa0VESERERFShzp8/j/bt2yM9PR3Ozs7Ytm0bGjZsiCNHjgAAfH19zcr7+vri1q1bAIDIyEjodDp4eHjkKxMZGSmX8fHJf/edj4+PXMaSpUuXYuHChaVaNiKyLRqVCsNr+hZdsJoQQmD3/RjcTklHL3896rjwmUBEREXhvUNkM6R0IwJ7H0Ng72OQ0gvvD0wIEwyIhofqMYRqVkMr8YCIiIiIqp6wsDCcOXMGx44dw7PPPovx48fj4sWL8vi8LQ6FEEW2QsxbxlL5oup56aWXkJCQIP/duXPH2kUiIqoUfoyIwYqrd7Hz/kO8evYakrIMSodERGTzmGimSsmAaGgkD3irp0Mr+SkdDhEREVG50Ol0qFOnDlq1aoWlS5eiadOm+PDDD+Hnl338k7fV8YMHD+RWzn5+fsjMzERcXFyhZaKiovLNNzo6Ol9r6dzs7Ozg6upq9kdEVJXcTf2ne6AUgxHxmUw0ExEVhYlmqlSEEMgSUTAhFXppHHRSgNIhEREREVUYIQQyMjIQGhoKPz8/7N27Vx6XmZmJQ4cOoUOHDgCAli1bQqvVmpWJiIjAhQsX5DLt27dHQkICfv/9d7nM8ePHkZCQIJchIqqOevnp4aJRAwBae7qihqOdwhEREdk+9tFMlYZJZCITt6GWXOCjmgEv1WSlQyIiIiIqNy+//DL69++PoKAgJCUlYf369Th48CD27NkDSZIwa9YsLFmyBHXr1kXdunWxZMkSODo6YvTo0QAANzc3TJ48Gc8//zw8PT2h1+sxd+5cNGnSBL169QIANGjQAP369cOUKVPw+eefAwCefvppDBo0qMAHARIRVQchzg74sl1DxGca4O+g48MRiYiswEQzVQpCCGTiFhykRvBTvwwnVUulQyIiIiIqV1FRURg3bhwiIiLg5uaG8PBw7NmzB7179wYA/Pvf/0ZaWhqmTZuGuLg4tG3bFj/99BNcXFzkOv7zn/9Ao9Fg5MiRSEtLQ8+ePbFq1Sqo1Wq5zNq1azFz5kz06dMHADB48GB88sknFbuwREQ2yFGjhqNGXXRBIiICAEhCCFHRM01MTISbmxsSEhKqdH9ul7M6Q4hMaKX8T/Km/KQUA2p77AEAXIvrB+H0z3UQk8hEFu6hpmYFXFSdlQqRiIiIilBdjvPIHD93IiIqihACp0+fhr29PRo2bKh0OERUDNYe67FFM1UKRjyERvKGoxSudChEREREZON+iYrDV9fuw02nwYsNgxHoaK90SERE1d5HH32Effv2AQDGjx+Pxx57TOGIiKis8WGAZDOEVoWHSxvg4dIGENp/Nk0hDDAiEW5Sf6glNwUjJCIiIiJbJ4TAh1duIzYzCzeS0/D19QilQyIiIgBHjhyx+Low586dw2uvvYaPPvoIqamp5RUaEZURtmgm26FTIf752vkGZ+I27KUG0KufUCAoIiIiIqpstCoVMk3G/73mA7yKYjKZcOfOHXh6esLZ2VnpcIgqHaNIggGx0CEIksT2fAVp3Lgxfv/9d/l1UTIzM/HGG28gPT0dAODg4IApU6aUa4xEVDpMNJNNE8IAARO81JOhk4KUDoeIiIiIbJwkSZjXMATf3IiAq1aNSbUDKjwGIQRWXL2LI9EJaOLujOcb1IRGZZvJJ5PJhEWLFuHUqVNwcnLCkiVLUKtWLaXDIqo0MsQ13DO+ApNIgaOqFfxVrzHZXIAXX3wRBw8ehL29PTp3LvrZSwaDARkZGfL7pKSk8gyPiMoAE81kO4wCdqcTAAAZzd0AtQQDYqGR3OAsdVQ4OCIiIiKqLJrpXdBM76LY/M/EJWH3/RgAwOHoeLTUu6CXv6di8RTm7t27OHXqFAAgJSUFP//8MxPNRMWQaNoPk0gBAKSaTiJLdR861FA4Ktuk0+nQp08fq8s7Ojpi/PjxWLNmDby9vTFq1KhyjI6IygITzWQzpHQjgjocBgBci+uHTMcHMCETHtJj0EheCkdHRERERGQdbZ7Wy3nf2xK9Xg9nZ2ckJycDAIKDgxWOiKhy0Uk15dcqyQVqeJS6ziwRBUAFreRd6roqu+HDh+PRRx+FJLEbJKLKgIlmskkmkQoTMuCn/jf0qnFKh0NEREREZLXG7s4YHeKHI9HxaOLujC4+7kqHVCBnZ2csXboU+/fvR82aNdG7d2+lQyKqVNxU/SBBjUxxGy6qnlBLTqWqL860DTHG/wKQ4K2eBjdVv7IJtIKYRCpiTd/CiGToVaOglfxLXSeTzESVBxPNZJOyu8zwgV41mj8qRERERFTpPBHihydC/JQOwyohISGYPHmy0mEQVVquqrK7QJNg2v6/VwIJpu8rXaI52vQFkkz7AQDp4jKCNZ8pHBERVSTbvYeLqjWBLHirnoEk8VoIERERERERVQ86/NMVh06qfF3ZGES0xddEVD0wi0c2SSP5wE01QOkwiIiIiIiIiCqMr/rfiDdtgwQ13FXDlA6n2DxUjyHd+BcEMqBXj1E6HCKqYEw0k01yk/pCLSn3pHAiIiIiIiKiiqaWnOGprrzPKXJUNUeotAYChlL3V01ElQ8TzWST7FUNlA6BiIiIiIiIyMy91HR8ezMSjmo1nqzlDxct0yp5qSQ7AHZKh0FECuA3ItmMLE08HrzqBXupAVx0fZQOh4iIiIiIiMjMG+dv4F5aBgAg1WjECw1DlA2IiMiGMNFMNsOgi0PW/GfhrV4ISZKUDoeIiIiIiIjITGxm1j+vMwwKRkJEZHtUSgdABAAmkQoJWrip+jDJTERERERERDZpQq0AqCTAQa3CEyG+SodDRGRT2KKZbIIB8dCJGnC66AJIfwINGgAqXgchIiIiIiIymEyIzzRAb6eFig1zFDUg0Au9/PRQSxLUKn4WRES5MdFMihNCwIRkOKf3g9SkWfbA5GTAiU+oJSIiIiKi6i0xy4B5p//GndR01Hd1wptNa0OnZqMcJXH9ExFZxm9HUpQQJmThHlRwhrtqsNLhEBERERFROfo7KRX/vXYPv0TFKR1KpXH4QTzupKYDAC4npuB0XJLCEREREVnGFs2kqEzchkbSw1M1AfZSI6XDISIiIiKichKXkYWXzvyNdKMJAKBRSejg7a5sUJWAv4NOfi0B8LXXFVyYiIhIQUw0k2KEMEIgEx6qkfBSTwSkFKVDIiIiIiKichKVniknmQHgZnI6OniX7TxSDEY4adRlW6nCmutdMbt+TZyPT0Y7LzeEODsoHRIREZFFTDRThRPCiEzcgUAWtJIvnKXOSodERERERETlrLaLAxq4OuFSYgpcNGp08XUvs7rTjUa8fvY6LiWmoIGrE95oWht2Vagf3R5+evTw0ysdBhGVgBBGSFLVugBGVBAmmqnCZeEeNJI3vFVPw1XVCxrJS+mQiIiIiIhs1tobEdgXGYu6Lo54vkFwpU2galUqLGlWG3dSM+Btp4WztuxOR48/TMSlxOw7JC8lpuDYwwR09fUoUV0nYhKQaRRo7+0GlSSVWYxEVL1kiOu4b1wAo0iAp3oCPFTDlA6JqNwx0UwVyiQyYEIGfFRPQq9+XOlwiIiIiIhs2vWkVKy/FQUAeJiRgN33H2JokI/CUZWcRqVCaDl0/eBppy30vbVWX4/AxtvZ67u7rwfmNAgudWxEVD3FmjbAKLIffBpjXAl3aRAkqWTfTUSVBRPNVGGMIglZiICT1BpuqgH5C2i1wNy5/7wmIiIiIqrm8raoZQtbyxq7O2NmWBBOxiSilacrGrs7l6iek7GJ/7yOSSykJBFR4dRwk1+rJGcwBUfVAbdyqhBGkYAsRMNdNQT+6lehllzzF9LpgGXLKj44IiIiIiIbFeLsgPG1/LEvIhZ1XR3RP8CzXOeXkGmAvVpVKbvn6O3vid7+pVs/LfUuuJ6clv3a08I5CxGRlTxV4wGYYEAs9KpRkHihkKoBJpqp3AlhQhai4K4ajkD1IkgSNzsiIiKq2gwGAw4ePIhr165h9OjRcHFxwf379+Hq6gpn55K1tCRzQghkmEywV1f9Byw9VtMXj9X0Lff5rLx2H1vvPICTRo35TWqhgZtTuc/T1jxZKwAN3JyQYRTo4O1W9AREZcAokmHAQ+gQxIfGVSFqyQk+6n8pHQZRhWLGj8pdFiKhlXzgo55eeJLZZAJu385+XbMmoKp8rSiIiIiIbt26hX79+uH27dvIyMhA79694eLignfeeQfp6en47LPPlA6x0otIy8ArZ/5GdEYW+vl7YnpYkNIhVXrpRiO23nkAAEgxGPHdnQdo4BZqseyVxBTcSE5Da09XeNrpKjLMCtHakwlmW3ErOQ1vX7yFFIMRT9cJREcfd7PxMTExuHPnDurVqwdHR0dlgiylTHEbd43zYBJJcJAaI0D9BhtnEVGlxUwelSshsmBCMvSqJ6GTAgsvnJYGhIZm/6WlVUyARERERGXsueeeQ6tWrRAXFwcHh38eejZs2DDs379fwciqjh13oxGdkQUA2BMRg4i0DIUjqvzsVCp46P5Jbvk6WE4gn41Lwgt/XMWnf93F839cRYrBWFEhUjW06noE7qSmIzYzCx9euW027tatW3j22Wfx2muv4fnnn0daJT2HTDIdhEkkAQDSxAVk4KayARERlQIvk1G5EUIgE3egk0KgV41SOhwiIiKiCnH48GH89ttv0OnME3XBwcG4d++eQlFVLZ52/zw42k6lgrOGt5qXliRJeCO8NrbdjYanTotRwZa76jgXlwzxv9cxGVm4m5qOMNfq18UGVQyt6p8+bXV57ng9fvy4nFy+e/cu/v77bzRp0qRC4ysLOilEfq2SHKGFt3LBkGIyMzNx5swZeHt7IzTU8t0kRJUBE81UbkxIgAQ7+KvnWX74HxEREVEVZDKZYDTmb+V59+5duLi4KBBR1TOkhjdSDSbcTU3HgEAvuGh5WlMWgp0dMKt+zULLtPJ0xdY7D2AQAv4OdqjpaF9B0VF19HSdQGSaTEjKMmJi7QCzcWFhYZAkCUIIODk5oUaNGgpFWTouqi4AjMgQN+Ci6ga1VDW7bkkxHYcRKXCROkOStEVPUI0IIfDaa6/h4sWLkCQJ8+bNQ4cOHZQOi6hEeERG5caEVGgkPZylrkqHQkRERFRhevfujQ8++ABffPEFgOyWosnJyZg/fz4GDBigcHRVg0alwrha/kqHUS01cHPCR63CcDslHeEeznBga3IqR172OiwIr21xXNOmTbF48WJcvXoVbdu2hYeHRwVHV3ZcVN3hgu5Kh1FuYo3rEWtaCwBIVv2KAPV8hSOyLXFxcbh48SKA7KTzsWPHmGimSouJZioXQhhgQDxcpf6QJHYFTkRERNXH+++/jx49eqBhw4ZIT0/H6NGjcfXqVXh5eWHdunVKh0dUakFO9ghyYktmUl54eDjCw8OVDoOKkCrOyK/TTGcAXp8y4+bmhqCgINy5cwcAKmUXMEQ5mGimMmcQD2FAPHRSMJxVvApHRERE1UtgYCDOnDmD9evX49SpUzCZTJg8eTLGjBlj9nBAIrJtD9Izsf5mJHQqFcaE+lWZLlqEEJAkqeiCRGXESdUW6cY/5ddkTq1W4+2338avv/4KX19ftGzZUumQiEqsavxSks3Ibsn8EB6qUfBTv1Bl+5ciIiIisiQrKwthYWH44YcfMHHiREycOFHpkIiohJZcuIFrydkPm4vPMmBeoxBlAyoD69evx/r16+Hj44OFCxfC359d0FD581ANgz3qIEvEQCv5wCTSoZJ4V0RuLi4u7F6LqgT2aUBlQggjssQDZOA67KVG8FY/Xfwks0YDTJuW/afhNRAiIiKqfLRaLTIyMthakKgKiM7Ikl8/SM9UMJKykZCQgLVr18JoNCIiIgKbNm1SOiSqRrRSIGLF17hnfBF3jDNhFElKh0RE5YCJZioxIQSyRBTSxVVk4AYkSQ0v1VMI1nwBnVT406otsrMDPv00+8/OruwDJiIiIqoAM2bMwNtvvw2DwaB0KERUCmNC/CAB0KkkjAr2VTqcUrOzs4O9/T+tSN3cePcpVZwUcQIG8RAAkCUikCbOKhwREZUHNhulEhNIhQlpcFF1h5tqAJyk1tBKfkqHRURERKSo48ePY//+/fjpp5/QpEkTODk5mY3funWrQpERFd/p2ERkmQRae7pWu5b6AwK90M3XA2pJgp268rfRsre3xyuvvIKtW7fCz88Po0aNKtf5ZYloPDC+DwPi4KkaD2dV+3KdH9k2OykEgARAQIIGOilY4YiIqDww0UwlZkQq1JIraqjfKpu+mIUAHmZf4YSXF1DNDmSJiIioanB3d8fw4cOVDoOo1NbeiMD6W1EAgF5+ejxXvwR3LVZyjhq10iGUqWbNmqFZs2YVMq8Y09dIExcAAFHGd+EkbYIkVf6EPZWMvRSGAPUbSBPn4KhqBZ0UpHRIxSKEEUniIADAReoGSapa3w1EZYWJZioxE1LgJLUtuwf+paYCPj7Zr5OTgTytf4iIiIgqg5UrVyodQpVnEgKbbz/AndR09A/wREM3Z6VDqpKOxyTKr3/P9ZrIOqKI91SRYoxrkSbOwEnVDh6q7Iuhe+4/xP7IOIS5OmJS7QCoyrmxl6OqKRzRtFznUV4emD5Gkmk/ACBNdR6+6lnKBkRko5hophIxiUyYkAYN9EqHQkRERETVzPd3o7H6RgQA4NjDBKxs1xDOWp7alLVmHs64kZwmv7bW2bgkZBhNaOXpWu6JK7JdnqrxMIgYGP/XdQZbgCon2XQMcab1AIB042XYox6i0+pi+V93IQBcTkxBDUc79AvwUjZQG5Yu/pRf57TUJ6L8eDRGxWISachCJAATHKWm8FJPVjokIiIiIpsSGhpaaF+2169fr8BoqqYH6Zny63SjCUkGIxPN5WBirQDUd3VClkmgk7e7VdOsvxmJtTcjAQDdfT0wp0HV74d1+50H2B8Vh7ouDni2bg1oVOweAgC0kg9qaN5SOgwCYEJqvvdpRqNZG/M0o6lig6pknKSOiBdbAADOUkeFoyGyXTwaI6sIIZCFexDIgL3UGHr1CLhK/aCWXJQOjYiIiMimzJo1y+x9VlYWTp8+jT179uCFF15QJqgqZkCgF36LTkBsZhZ6+unh72CndEhVkiRJ6GBlgjnH7+XQ3UZsRhZ+ioiBp50Wvfz0NvVQwpvJafjy2n0AwI3kNNRydsTAQLYKJdviInVGiuo3pJrOwknVFo5Sa4S5qjAgwAv7I2NRz9URff09lQ7TpnmpJ8BJagkBAUdVuNLhENksJprJKkbEAFDBT/0K9KqRkCSt0iERERER2aTnnnvO4vBPP/0UJ0+erOBoqqYajvb4ql0DpBhMcNPxlMaWNPVwxtWk7NaTTd1L33e2EAIvn/kb99IyAABxmQaMDPYtdb1lJctk3u9wpomtQsn2SJIW/urXgDy9lzxbrwaerVdDmaAqIQdVE6VDILJ5vKeHrGJAHNxVg+GpHsMkMxEREVEJ9O/fH1u2bFE6jCpDo1IxyWyDngz1x0uNQjCnfk280LD03WakGU1ykhkAriWlFlK64tV1dcSjQT5w1WrQUu+C/gGVo1VoREQEZsyYgdGjR+PHH39UOhyyUSaTCUajUekwrLY/MhajD5/HtN8v425qutLhEFVLPDKrJoQQAAwQyIKAEQJGQP5vgIAJAgZ5mAQVAAnZTwaWoJac4arqreASEBEREVVumzdvhl7PBylT1WMwmfBXUiq87HTwsdcVu7uNwjhq1Ojk7Y7D0fHQSBJ6+tnePjSxdgAm1g5QOoxiWbt2LW7evAkAWL58OWq3bY+dkfHQ67QYFewLnbrytkn7Mz4ZD9Iz0dbLDY4aPoCwpE6ePIm3334bJpMJs2bNQufOnZUOqVBGk8AnV+7AIASSDEasvh6BlxqHKh0WUbXDRHMVJIQBRsTDhHQIpP+vg38BCRpI0P7vab9qSFBDBXuo4AwVnKGWXKGGG9RwhVpyggqOUMEJKskRarjDSWpXvoFrNMD48f+8JiIiIqqEmjdvbtaHrBACkZGRiI6OxvLlyxWMjKjsCSGw8PwNnIlLglYlYUGTWgj3KNvnuPy7YTCGJXnDXaeFj72uTOuuruzt7eXXWp0OC/+8hfis7JarWcKESbUDlQqtVA5GxeK9S7cBALWdHfB+y3pQ2VCf3pXJ119/jfT07FbBK1eutPlEs0oC7NQqGAzZ27F9Jb5YYquEEEgVpyBBx36qqUDM5lUy2S2TTblaJJvwT8vk7OFGxEEjecEOobCTakEnBUMrBUCLAGgk/T8JZDhCgp3tPEzDzg5YtUrpKIiIiIhKZciQIWbHVyqVCt7e3ujWrRvq16+vYGRUmWQaTTj0IA6OajU6eLvZzjF7HtEZWTgTlwQgu7/iQw/iyjzRLEkS6rk6lWmd1d2TTz6JpKQkxMTE4LHHn8Cbyf90jxCVlqlgZKXzR2yS/PpachriMw3Q27Hrx5Jwd3e3+NpWSZKElxuFYPWNSLjrNDZzl4FJZMKAaGjhC0mq3Cm4aNPHSDTtBQDoxWjo1U8oHBHZosq9lVcCmbgNk0gpxhQCgPhf4lgCoIIkjzEhu2XyPy2SAdX/Wiir/tdC2Q5a1EeAegEcVS3KdFmIiIiIqGgLFixQOgSqApb+eRMnYxMBAKOCfTE21F/hiCxz12rgbadFdEYWAKCui6M8LjYjC84adaXuhqGqcnV1xUsvvSS/H37tPrbceQBHtRpDg3wUjKx0WuldcSAqDkD2tujOftxLbNasWVi1ahUMBgOefPJJpcOxSriHC5aV8YWu0jCKRNw1/htZ4h50UggC1W9BLVXei2bJ4pj8OkUcgx5MNFN+/NYtR+7SYGRKt4s9XXZ3Fi5QSY5QweGfP8kBUu73FobZVAvl4hICSP3fwz0cHYHKuhxERERUranVakRERMDHxzxZExMTAx8fn0r1YCVSzrn4f1pmnotLBmy0q1GdWoW3m9fFz5GxCHC0Q2cfDwDAB5dvY39kLFy1GrzZtDZCnB0UjpQKM6F2AIYF+cBerYJdJb4w0MXXA972uv/10eyK/ZGx+OLve3DVavBKoxDUynUhhArn6emJ559/XukwKrUUcRxZ4h4AIFPcRJo4DWepk8JRlZyj1BTJ4jAAwEFi1xlkGRPN5chP84LSIVQuqamAs3P26+RkwKnyXukjIiKi6iu7q7P8MjIyoNOxf1myTnsvdxx6kN0ys4O3m8LRFM7bXodRIX7y+wfpmdgfGQsASMwyYOe9h5geFqRUeOUqMi0DTho1XLSV/9TarYq0/m3g5oQGbk4QQmDF1bvIMgmkGzOx5mbk/7N33+FRVOsDx79ndrOb3nshIfQqIIogooACooDY7lXBLlas2Bs2uHb92b0qWPDaUbArYkEEEURAEOk1JKTXrXN+f0QXIi1lk015P8/Dw8zumTPvpu3sO+e8h7t6ZQc6PNGGBKk0qmeqa8AgSDWPch71lWTcQKg6AgMbYeroQIcjmqnW8U4ihBBCCCFEgP3f//0fUF0n8qWXXiL87xvogNfr5fvvv5cazaLWbujWjuOSYgi1GnSPCj9k+7lz57Jw4UJ69uzJ2WefHdBZjhFWC2FWCxV/LcqVHNI6b7A8s3Ybn+cUEGwxuKtnNr1iDv19Ek1HKUWoxUKJ6QEg3GoJcESirQlR3Um23EqV/o1Q1R+7atk3OpSyEqmGBToM0cxJolkIIYQQQgg/ePzxx4HqEc3PP/88FsuepIbNZiMrK4vnn38+UOGJFkYpRf+4yFq1Xbt2LS+++CIAq1atIjMzk8GDAzc9O8Rq4b7eHfh0Zz6pIXbGt+CavwdS6fHyeU4BAA6vyac78yXR3Azd2as9r2/MITLIykUd0gIdjmiDwo2BhDMw0GEI0WQk0SyEEEIIIYQfbNq0CYChQ4fywQcfEBMTE+CIRFtRXl5+0P1A6BQZyjWR7QIdRqMJthjE24PI/2sRxLRQe4AjEvvTJTKM+/t0DHQYjU5rE6Vabm1tIUTrIX+JhBBCCCGE8KP58+dLklk0qX79+jFkyBCsVit9+vRh6NChgQ6pxXB5Tb7PLWJVcd2S84ZSPHBYR8akxXN+dgr/zkxqpAiFODCn3sQmz3ls8JxKkTk70OEIIYSMaBZCCCGEEMLftm/fzpw5c9i6dSsul6vGc4899lit+pg+fToffPABf/zxByEhIQwaNIgHH3yQLl26+Nqcf/75vPrqqzWOGzBgAIsWLfLtO51OpkyZwv/+9z+qqqoYPnw4zz77LOnp6b42RUVFXH311cyZMweAsWPH8tRTTxEdHV3Xly4CQCnFjTfKQuT1cfeKjawqqU4yX9U5g5GpcbU+NjXUzqRO6Ydu2Ig8psmzf27nj9JKhiRG8++9FmUUrV+R+TZeXb3wZoF3BlHqJAzVOmuiCyFaBkk0CyGEEEII4Ufz5s1j7NixtG/fnrVr19KzZ082b96M1pp+/frVup/vvvuOK6+8kiOOOAKPx8Ptt9/OiBEjWL16NWFhYb52o0aNYsaMGb59m61mkuHaa69l7ty5vPXWW8TFxXHDDTdw8skns3TpUl8d6bPPPpvt27fz+eefAzBp0iQmTpzI3LlzG/KlEKJZc3i9viQzwJKCkjolmpuDb3KL+GpXdaJx1uZd9I2NoEtk2CGO8r8qvYY872NoTBKNawg1ejd5DG2RhSjftqHCUQQFMBohhJBEc6NaU1LBbofr0A0FAMrhoOvJYwH4I78UXd5yvnblHi/bKx10jQxjSJJMlRVCCCHasltvvZUbbriBe++9l4iICN5//30SExM555xzGDVqVK37+Tvp+7cZM2aQmJjI0qVLGTJkiO9xu91OcvL+RzGWlJTw8ssv8/rrr3P88ccD8MYbb5CRkcHXX3/NyJEjWbNmDZ9//jmLFi1iwIABAPz3v/9l4MCBrF27tsYIaiFak2CLhe5RYawuqQCo9eKLzYnH1DX2vVofoGXjyvc+j1vvAmC3+SyZRsta+DTf+xLleiEhqjeJxmSUshz6oGYg1jgXjQcPhcQa/0YpFeiQhBBtnCSaG9GVS/5gV5Uz0GG0LJNurv5/xabAxlFLFqUIthh//bNgNwyOSYyWN3ghhBCiDVuzZg3/+9//ALBarVRVVREeHs69997LuHHjuPzyy+vVb0lJCQCxsbE1Hv/2229JTEwkOjqaY489lgceeIDExEQAli5ditvtZsSIEb72qamp9OzZk4ULFzJy5Eh++uknoqKifElmgKOOOoqoqCgWLlwoieYWyDRNfv31V8LCwujatWuTn19rzWeffcb27dsZMWIEWVlZTR5Dbd3buwMLdxcTZw+id0xEoMOps+OTY1lRXM6akgqOTYqme1R4QOLYeyStomWVbqg0l1NsfgRAmZ5HiOpNpBoW4Khqx6LCSLRMDnQYQgjhI4nmRuQ2TcKsFhKCW9YbrTi0taWVdIoI4eiEaDJCg0kPtZMeGkxmWLAkmYUQQog2LiwsDKezerBBamoqGzZsoEePHgDk5+fXq0+tNddffz2DBw+mZ8+evsdPPPFEzjjjDDIzM9m0aRN33nknw4YNY+nSpdjtdnbt2oXNZttnccKkpCR27aoefbhr1y5fYnpviYmJvjb/5HQ6fa8RoLS0tF6vq6XQWreoa7xHH32U77//HqgugzJmzJgmPf+nn37K889Xj2j99ttveemllwgNDW3SGGrLbjEYmhx76IbNlM1icEuPrECHQaLlGnZ7n0VjkmC5LNDh1JFRY0/Rcn7XhRCiuZFEcyMzlMLSgi5KxaFtrXCQYA/i1h7tOVbKZAghhBDiH4466ih+/PFHunfvzkknncQNN9zAypUr+eCDDzjqqKPq1edVV13FihUrWLBgQY3H//Wvf/m2e/bsSf/+/cnMzOSTTz7h1FNPPWB//0yc7i+JerDk6vTp07nnnnvq+jJanEKnm7tXbGBLhYOT0uK5NMALv9XWwoULa2w3daJ527Ztvu2ysjKKi4ubbaL5UEpKSnj33XeB6t+3iIimH/X8R0kFX+YUkBkWzNj0hAbd9DB1JQCG8u/3w6YySLNO92ufTSXU6E20Po0KvZAQ1YtwdWygQxJCiBbLOHQTIZqGvaqKuUP7MndoX+xVVYEOZ78cXhOXaXJpp3RJMgshhBBivx577DFfGYqpU6dywgkn8Pbbb5OZmcnLL79c5/4mT57MnDlzmD9/PunpB090pqSkkJmZybp16wBITk7G5XJRVFRUo11eXh5JSUm+Nrm5ufv0tXv3bl+bf7r11lspKSnx/ds7sdiafLIjn80VDjTw8Y58tlY4Ah1Srew96n3v7aZywgkn+BasHDBgACkpKU0eg7888sgjfPTRR3z00Uc8+uijTX7+UreHO1ds4Ktdhby0YSef7Syod19l5rds8pzDRs/ZlJrf+DHKli/ecj6Z1hdJtExGKUmTCCFEfcmIZiHqYHulg/6xkYzPSAh0KEIIIYRoprKzs33boaGhPPvss/XqR2vN5MmTmT17Nt9++y3t27c/5DEFBQVs27bNl9g7/PDDCQoK4quvvuLMM88EICcnh1WrVvHQQw8BMHDgQEpKSvj555858sgjAVi8eDElJSUMGjRov+ex2+3Y7fZ6va6WJDJoz4JgVqUItbSMBNQdd9zBt99+S1hYGEcffXSTn79Dhw68/PLLFBUVkZaW1qLKjpi6il3eB3Gynkg1skb5mJ07dzZ5PMUuDw6v6dvPacAaQIXmW2g8ABSZ/yPSaF51iL1eL59++inl5eWMHj2aqKioQIckhBCijiTRLEQtVXm9aGBocgzRtqBDthdCCCFE21VcXMx7773Hhg0buPHGG4mNjWXZsmUkJSWRlpZWqz6uvPJK3nzzTT766CMiIiJ8Ca+oqChCQkIoLy9n6tSpnHbaaaSkpLB582Zuu+024uPjGT9+vK/tRRddxA033EBcXByxsbFMmTKFXr16cfzxxwPQrVs3Ro0axSWXXMILL7wAVNf1Pfnkk9v8QoAnpcVT4HKzudzBqNQ44lvI2it2u52RI0cGNIawsDDfqOaWpER/QqVeCkCRfodxp53Gi89+gFKKM844o8njyQi1Myg+ioX5JUQHWRmRElfvvoJIxM0OAKzsW5c90GbOnMmHH34IwM8//8zjjz8e2ICEEELUmSSahTgEr9ZsKXegFBwWHc4p6c3vokwIIYQQzceKFSs4/vjjiYqKYvPmzVxyySXExsYye/ZstmzZwmuvvVarfp577jkAjjvuuBqPz5gxg/PPPx+LxcLKlSt57bXXKC4uJiUlhaFDh/L222/XqCP7+OOPY7VaOfPMM6mqqmL48OHMnDkTi2XPaN1Zs2Zx9dVXM2LECADGjh3L008/3cCvRMtnNQwu7FC7GwOidVDUHFAyYuRwjhk4HqUUkZGRTR+PUkzp1o7n1++gwOlmt9NFRlhwvfpKstxAofkmGk2scZafI224jRs3+rY3bdrU4hbhFEIIIYlmIQ4pz+EiPjiI23q0Z2hSDLYWMmVSCCGEEIFx/fXXc/755/PQQw/VSPieeOKJnH322bXuR2t90OdDQkL44osvDtlPcHAwTz31FE899dQB28TGxvLGG2/UOrbmQhJRwt+i1Gicxmacej2RxghsKgNbgCs4fLyzgC9zCgFYWVzOK0f1IMpW94/yFhVFguVyf4fnNyNHjmTVqlWYpsnIkSPld1sIIVogSTQLsR9aa8o9Xgpdbtym5rz2KYxMrf80NSGEEEK0HUuWLPGVoNhbWlpajXqvov7yHS7uWrGRHVUOxqcncn6H1ECHJFoJpYJIslwT6DBqKHC6fdsuU1Pu8dQr0VwbReYHVJrLCDOOINoY1yjnOJAhQ4bQpUsXKioqatS6r6vcKieP/bGVUreHCzukckSc1HoWQoimIkMzhfgHl9dkfVkVJW4PXSLCuKFbJhd2lCmTQgghhKid4OBgSktL93l87dq1JCTIgsL+8OH23WyrdGBqeH9bHrkNWCBNiOZubHoCSX/VBz8xNY600PqVzjiUCnMpBd4ZVOnfyPe+RKW5olHOczBJSUkNSjIDvLJhJ6tLKthe6eTh1VsOOTtECH8ytYMKcwkuvSPQoQgREDKiWTQbpsVgyYDBvu1A8GrNlgoHvaLDublHFofHRsiULSGEEELUybhx47j33nt55513gOoaq1u3buWWW27htNNOC3B0rUOEdU99aatSBO9Vb1qI1iYx2MZ/B3TDbepGLeNnUnbQfSHEwWntZof3Zpx6IworqZb7CDF6BjosIZqUJJpFs+G22bn3PweuHdiYXF6TbZUONBBnD+Karu3oH9f0i30IIYQQouV75JFHGD16NImJiVRVVXHssceya9cuBg4cyAMPPBDo8FqF8RmJFLs9bK90cnJafKOVERCiuVBKYbM07gCYMDWIUPUNlXo5oUZ/wtSARj1fY7mgQypFLo+vdEagBg79/PPPbN26lWOPPVZms7QRLnbg1NWLWmo8VOhFhCCJZtG2yBWZaPO01mypdNAtMowJ7ZM5JjGGxL+mpgkhhBBC1FVkZCQLFizgm2++YdmyZZimSb9+/Tj++OMDHVqrYbMYXNopPdBhCNGqGMpGqvXeFr/IZnKInYf6dQpoDN9++y2PPvooAB9//DHPP/88wcENL3mSU+Vk1qZd2AzFedmpDbrJ5tSbKTLfxkIkccZ5GCq0wfG1dUEkY1XxeHQ+AMGqe4AjEqLpSaJZtGlaazaVVxFvC+KWHlkMiJeFIoQQQghRd7Gxsfz555/Ex8dz4YUX8uSTTzJs2DCGDRsW6NCEaNO2Vjh4ZM0WKjxeLuuUJgvD1UJLTjI3F3/88Ydvu6CggIKCAlJS46nQC7EQQ6jRp179Tv99M5vKqwAo83i5vWf7eseY473HlxDVeEi0TK53X6KaoYJJtzxMuf4JG+0INQ4LdEhCNDlZDFA0G/aqKt49cSDvnjgQe1VVk5wzz+kmIsjKf/p2kiSzEEIIIerN5XL5FgB89dVXcTgcAY5ICAHw0vodbCqvIs/h4vE1WwMdjmgjBg8eTFBQEABdu3YlKSmJHO9Ucr2PsdN7JyXmJ/Xqt9Dp9m0X7LVdV1qbeHSRb9+jC+rdl6jJquKJNsZIklm0WTKiWTQrwU38oazC42VYUgyDE6Ob9LxCCCGEaF0GDhzIKaecwuGHH47WmquvvpqQkJD9tn3llVeaODohasqpcrKz0kmP6LBWv5Ci1VD73RaiIUrMLygwX8VKHCmW2whSKTWe79mzJ8899xy5ubl07doVw2JS5Vnle75CLyWKk+p83vOyU3jmz+0EGYpzspLrHb9SBnGW8yjwzsBQYcRY/lXvvoQQYm+SaBZtltYat2mSFbb/D4FCCCGEELX1xhtv8Pjjj7NhwwaUUpSUlMioZtEsrSou587fNuDRmg7hITzcrxNBRuud6HpJxzQcXpMKj5eLO6QFNJZ58+bx22+/ceSRRzJ48OCAxiLqz9QudnufBUxclFFgziLZMmWfdklJSSQlJfn2Q1RvqvQKAMLUEfU69wkpcRybGIOhwNrA39sYYzxR6iQUFpRq3Tec9sfUVewyH8alNxKpRhFr+XegQxKiVZBEs2iz8p1uYmxBjM+QFYCFEEII0TBJSUn85z//AaB9+/a8/vrrxMXFBTgqIfa1KL8Ej9YAbCivYmelk8zw1jvwIiXEzrQ+HQMdBsuXL+eJJ54AqheKS05OpmPHwMcl6k5hoLChqb6ZaFC7Rf5SLHdToRdjJYYQo2e9z2+z+O/GkKFsfuurtjy6EC/F2Ggf0HrgxeZcKs0lABTqWYQbg7CpdkD1iPV873+xqChSLHdgV/WvhS1EW9N6b10LcRBerSlyeTglPYHsCFldVwghhBD+s2nTJkkyi2arW2SYbzveHkRSSNMnmtqi3Nxc37bWmry8vABGIxpCKSspllsJVl0IMwYRZ5xbq+MMZSPCOKZBSeaWrtJcwRbPJWzzXEOu+WBAY9l3FHf1vtYm+d7n0Tjx6DwKzTeaPjghWjAZ0SzapCKXmxiblfM7pAY6FCGEEEIIIZrM0YnR3GPNZluFg6MTolt9jebm4uijj2bu3Lls2bKFLl26cPjhhwc6pEbn0ltx6PWEqt5YVXytj/Pqclx6CzaVhUWFHfqAAAg1+hFq9At0GC1Omf4ajQuAcvNHvEYJFhVVq2NNXVk9IlwlE6K6NTiWKDUGp7GpunSGMQqb+ru0jsJQoXh19QK/BuENPlegeXQhBuEBGcEu2h5JNIs2qcjp4eT0eFJC7IEORQghhBBCiCbVLzaSfrGRgQ6jTQkPD+fJJ5+kpKSEmJiYgJYMaAoOvY4dnpvQeLCoaNpZnq5VQtGjC9nuvR6PLsCqEsiwPF7rRKSov0Lv/ygy3yVIpZFquRurikdrL5V6GYYK90tiF8CmsnzbVhWPQe1uJGjtZYf3Vpx6IwBJlhuJMIY0KBZD2fZbW1spRYrlTgq8s7CoSOKNixp0nkDL9T5KmfktFhVFmmU6NpUR6JBEKyeJZtFsaEOx8rDDfduNxWNqUHB8cmyjnUMIIYQQQggh9maxWIiNbT6fQdaXVfLf9TuwGQZXdE736yCcKr0CjQcAry7GqTcSqvoe8rhKvQyPLgDAo3dTqX8jQjUsodgQv/zyCytXruSII46gZ8/al7woLS1l/fr1tG/fnpiYmFods2XLFt555x2ioqKYOHEiISFNUzvdowsoNN8EwKU3U2S+T4LlUnLNRyg3FwAQb5lEtDGmweeKVuMxLKF4dC6RxiiUql1KykuRL8kM1T8nETTez0Ww6kqa9b5G67+puHUOZea3AHh1CSXmpyRYLg1sUKLVk0SzaDZc9mBue+KlRj2H02uypcJBWqidHlEtfwqMEEIIIYQQe1tfVondMMgIq90CZaLtemT1FnZUOQF4Zu027vfjookhqjeKIDRuLCoGu8qu1XHV7SyAF4UV+14jYJva6tWruffee9FaM2fOHP7v//6PjIxDjwYtLi7m2muvpaCggIiICJ544gkSExMPedzUqVPJz88HwO12c+WVVzb4NdSGwub7XgFUecJ5edMOtrvLODEjmFi7gwpzoV8SzUopotSoOh9nofpnqDrZrAhVUrakNgwiMVQopq4EIEglBzgi0RZIolm0KbudLjJC7cwc1IP0ULn4FkIIIYR/lJaW1rptZKSULBCN46X1O/ho+24UcEXndEal1r4ubmPTWrO8qAyLUvSOiQh0OHW2cHcxux0uhibHEhnUOj5GO01zr23t176DVScyrE/g1BsIUb1rXf7CrrJJs06jyvwNd1lHpj3xCrt37+ass85i8ODBfo3xULZs2YLW1V8Xj8fD9u3ba5VoXrVqFQUF1aOyy8rKWLZsGaNGHTy5apomhYWFvv2/E85NwaIiSLbcTLH5IUEqjRl/DmDB7t04dC+2lkdya58fCFGHNVk8+6OUhTTLdCr0z1hVkt9KebR2FhVGquVeSszPsak0olTDbxYIcSit4x1SiFqo8Hhxek3Gt0uUJLMQQggh/Co6OrrWNVe9Xm8jRyPaqi9zqpNbGvgqp7BZJZr/u34Hc3dUJ8/ObJfExOyUAEdUe3O37+bF9TsA+DKnkKeP6NIqaixf1TmD/1u7DbvF4JKO/l8k3abaYVPt6nxciOpOiKU7z8x6hqVLlwLw6KOP0r9/f4KDm+5z3IABA3jnnXfIz88nIyOD3r171+q47OxsbDYbLpcLq9VK586d99uu2JxLmfkNwaoz8cYkJk6cyGuvvUZoaChnnHGGP1/KIYUZAwgzBgCQ6/gTADudKHXGkmw5hnBjYJPGsz+GCiVCHRfoMFqcYNWFYEuXQIch2hBJNItmw15VxctnjQbgov99itPPNalKXB6Sgu1c2jHt0I2FEEIIIepg/vz5vu3Nmzdzyy23cP755zNwYPWH859++olXX32V6dOnBypE0QZ0ighlRXE5AB0jQgMcTU0L80v22i5uUYnm1SUVvu2tlQ7KPV4iWsGo5sPjInl1UI9Ah3FAe9+U+3tkcVOKjY3l2WefZefOnaSnp2O3166GdWpqKo888gjLly+nR48eZGfvWzbEqTeT733xr+312FQWp59+OieffDJWqxWrNXA/X6e3S+Th1VvwYjAxqw/hRkLAYhFCtDwt/91RtCpRJcWN1ne5x8v52SlYDaPRziGEEEKItunYY4/1bd9777089thjnHXWWb7Hxo4dS69evXjxxRc577zzAhGiaEacXpOdVU5SQmwEWyx+6/e2nu35bGc+IRYLI1P8t+jcb0VlLMovoUdUOIMTo+vVR+/ocObnFgHQK7plrZVyTGI0P+4uRgN9YyJaRZK5JTjnnHPYsWMHu3fv5pxzzmnS0cx/CwkJoUOHDnU+rn379rRv3/6Az2ucNfZNHAABeY3/NCghmjeOjsCrdaspEyOEaDryV0O0CbsdLsKtFo5KqF1tMCGEEEKI+vrpp594/vnn93m8f//+XHzxxQGISDQnZW4PNy5bx44qJ8nBNh7p15kom38+loVZLZzeLskvff1te6WDqSs24tGaj3fkE27tQJ/YutdYvrpLBn1iIjAUDEmM8WuMjW1QQjRPH9GVAqerxSXJA0lrE6XqP8gnLi6OBx980I8RNR/BqgtRxljK9DyC6UyUOjHQIdUQZm3YDTDTNDHa6ACvUvMbSsyPsalMEozLMZQt0CEJ0aTa5m++aFPcpkmxy8O52Sn0j5XFd4QQQgjRuDIyMvabaH7hhRdqtZCUaN1+LSxjR1X1aMZdDhdLCkoOcURg5VQ58exVtmBbpaNe/VgNg2HJsRyXFIvRAusbtwsLpm9sZJueHfnWW29x22238fHHHx+0nUtvZbPnAjZ4TqXIfK+Jomt5EiyXkG19i1TrvRgq8COZ/eWDDz7g1FNP5YILLmDr1q2BDqdJeXQ+ed4ncep1lJlfU2x+GOiQRBPSWuPRRWhtHrpxKyYjmkWrV+zyEGWzcmZmUqtYtEMIIYQQzdvjjz/OaaedxhdffMFRRx0FwKJFi9iwYQPvv/9+gKMTtbEgr5gSt4ehSTGENnBk3z+lh9oxFJgaFJAR1rwTTL2iw+kYEcL6sioSg20cnRAd6JAa5P2tufxeUsHRCdEMT/ZfeZHWbuHChcyaNQuAlStX0rFjR7p27brftoXm23h09cKPBd7XiFInt6pEqjgwh8PBzJkz0VqTn5/P22+/zY033hjosJqMxg2Ye+3X78acaHlM7WKn9w4ceg02lUma5T9YVNucASOJZtGq5TpcVLi9TGifTHKwTFkRQgghROMbPXo069at49lnn+WPP/5Aa824ceO47LLLZERzC/D25l28sXkXAN/mFvFwv05+7T87IpR7enVgaWEpfWIi6BIZ5tf+/S3YYuHhvp3Y5XCRYLdhtxh89dVXfP7552RnZ3PppZf6ZeGyQqcbi1J+KyOyPz/mFTNzYw4AvxSU0j4smOxmtmhic1VeXn7Q/b1Z2FOu0FChqIOkHfLz87Hb7URE1L0cS0ultW61A6CsViuhoaFUVFQvoBkV1bZKVwapFGKMf1Oi52KjHdHGuECHJJpIpV6GQ68BwKW3UK4XEKVGBTiqwJBEs2i1yt0eqjxeruqSzqSO6a32zVwIIYQQzU96ejrTpk0LdBitltaaD7fvZnulg5EpcXT2Y7L295IK3/ba0gq8psZi+Pc6sk9sRL3qHAeK1TBID60ekfq/Veu45affsdtjyf76G9LT0xk3rmHJlNnb8nhlw04sSnF913YMSWqcGs7Fbo9vW/9jv7Y8upB88794tYMPNp7C8sIgDo+N4PJOrfvzxrHHHsv333/PqlWrGDhwIP369Ttg2zhjIhoXHp1PjOVMlNp/2mHWrFm89dZbBAUFccstt3DkkUc2VvjNgqkd7PROxaFXE2YMJNm4uUE1rBtTifkZTr2OcHUcoUbvWh9ntVq5++67efvtt4mPj2fChAmNF2QzFWc5hzjOCXQYookFqQSq5ylVl5oKwr/rJbQkkmgWzYY2FOu6dPdtN1S5x0tSsI3LWvlFnxBCCCGan+LiYn7++Wfy8vIwzZq1+s4999wARdV6zN2RzysbdgLw4+4SXj6qe4MXr/rbMYnR/FpUBsDA+Ci/J5lbslK3h5e37sYRHIojOJScdp2oqqpqcL/vbskFwKs1s7fnNVqi+bikGObtKmRdWSU9o8JIsNV9xuNu81kqzMUsL0jiox2/EaJ689nOAvrGRDCwhZcVORi73c79999fq9G4hgoh0XLVIft8773q+s1ut5sPP/yw1Seay/R8HPp3ACrMhVSqXwlThwc4qn2Vmd+x2/ssALN3bOarbWeRZI/gjl7tSQmxH/L4bt26MXXq1EaOUojmxa46kGy5mQq9iBDVm1Cjb6BDChhJNItmw2UP5vrnZ/mtP4/WRAZZJckshBBCiCY1d+5czjnnHCoqKoiIiKhxLaKUkkSzH+z6azE9gAqPlxKXx2+J5hNS4ugQHkKp20vvmLZZX/FgwsJCSUlJIS8vj7S0NE4++eQG95kWGswfpdUjyVNrkciqrzCrhccO78y8nAL+789tXPHLH5zRLpFzs1Nr3YdXl/m2NXtGRLeVzxx1eZ2lbg+L80tIDw2mW9S+sw5SU1N9i8WlpaX5LcbmykLNhektqnkuVO/W1eVlHB4L72zqih0nW71BvL0ll2u7tgtwdEI0X+HG0YRzdKDDCDhJNItWyWOalLu99I6WDwdCCCGEaFo33HADF154IdOmTSM0VOq/NoaRKXF8l1dMqdvD4IRoUkL8uxaH1O3dv8ggK1d1zuC9YDsph3Xnhm6ZhAc1/CPlbT2yeG9bHjZDcUa7xp9u/EVOIWb17GbmbM+vU6I5znI+u7wP0Ce2hHFp7VlVZKdfTAQD4mqXNHR5TV7ZsJMdVU7GpMVzZHzrrGHr8prcuGwdO6ucKOC2nu056h+vderUqXzwwQeEh4dz+umnByZQP/r+++/5/IuPSWi/jdMndiDedg4hqpvv+XDjaGL1BKr0KsKNowlW/q3/7i8RxjBK9RcYqpBgIwLDrL5JEGJpnmU+hBDNi9Ja66Y+aWlpKVFRUZSUlBAZ2Tzv4vnDMV8uwWVqEmURuiZlas36siq6Roby+OGd5YOCEEII0YTaynXewYSFhbFy5Uqys7MDHUqTCcT3fUNZJRvLqhicGEWIHxajE23HM2u38XlOAQCdIkJ57PDO+21X6vbw4bY8bIbB+IxE7Hsl2uq7oNtbm3cx66/FJoMMxcyBPYgMsuLymthaUSJve6WDy3/+w7d/clo8l3ZKD2BEjSs3N5dJkyZR5d2IR+fxr4szOWFMB9pb3myRo91N7cJLCb8V2nh3ax4JdhuXd07328yRvbl1Ljne+/GQR6xxDtHGWL+fQwjRcLW91pMrMtFs2B1VPHP+aQBcOfN9nMEh9eon1+EiOcTG//XvQmZ4/foQQgghhKivkSNH8ssvv7SpRHNTW15Yxj0rN+LRmk9z8nm4byesRutJ0rVWWmt+yi/BY2oGJ0ZjBCgBd0nHNBKDbVR6vYxLTzhgu2mrNvkWh8ypcnJdt0zfc/VNHpZ5vL5tt6lxeE1mbNjK17sKSQ2xM61PB+Ls9R+olJOTw9tvv014eDhnn312wGZVJAXbyAwLZkuFA0NB/9jWfeOxoqIC0zR95VQqyjyYuhLwAEEBja0+DGXDIIH+cdA/rnFH3ReZb+PSmwHI975EhBqORflvgVchRNOSRLNoPjQk5eb4tuujwuOlzO3ltIxESTILIYQQIiBOOukkbrzxRlavXk2vXr0ICqqZZBg7VkZrNdSi/BI8f03MXF9WRa7DRVpocICjEofy8oadfLR9NwBLC0trJG6bks1icEbmviU63DqPXO9jeCkm3riArRV7krTbKp37tK+PU9IT+LWwjJ1VTsZnJFDp8fL1rkIAdlY5+XRHAROzU+rd/7333sv27dsBKC8v59prr/VH2HUWZBg82LcTvxaWkRpia/WzTLOzsxk9ejSffv4BCZmKYaNTibdcjFItL8nc1BQhe20HofD/qGkhRNORRLNoVXZWORmaFMPkLhmBDkUIIYQQbdQll1wCVCd8/kkphdfr3edxUTc9osP4ZGc+AInBNuIbMAJUNJ1lhXsW0lteVB7ASPavwJyBQ/8OwC7vI4xJ+z/e3JKLoaAPTl566SWys7MZNmxYvc+REGzj2SO7+kpv5DtcWJXy3TiJsTXsI3peXp5vOzc3t0F9NVSY1cLgxOiAxtCULr/8ci677DKUUvUurdIWxRpn46UEj84jxjgTQ8lNQyFaMkk0i1bD4TWxKMVp7RL9siiJEEIIIUR9mKYZ6BBavWMSY4iwWtlW6eDohOgatXNF8zUgPpJtWx0AHFHLxfMC6d9ZyRyXHEtVeRm3XHkFVVVVAFgsFo499tgG9f13EjI+2MZtPbP4YmcB7cNDGJ0W36B+J0yYwIwZM7Db7Zx55pkN6kvU3d/fV0ky155FhZFsmRLoMIQQfiLZONFqlLg9JNiDGJIYE+hQhBBCCCFEI+sTG0Gf2IhAhyEOYrfDxdrSSrpGhhIfbOO87FR6RoXj1bpZJprjjAvw6EK8FBNnXIBSipQQO+u2b/UlmQG2bt26z7Eur4lXa0LqsVjaEXFRHOGnOrjjx49nxIgRWK1W7Ha7X/oUQgghaqtWiebS0tJad9hWVxcXgec2TZLCgmVEixBCCCECavv27URHRxMeHl7jcbfbzU8//cSQIUMCFJkQTSe3ysk1S/+kwuMl3Grhyf5dSAy2cXgzTDD/LUglkm59kE3lVdzw+2bKPau4tGMag9q3p1evXqxcuZKIiAiOO+64Gsf9UlDK9N834TY1l3ZK56QGjko+EK3dtar5GxYmC6m1FK9vzOHjHflkhQdzR8/2RDTizFyXy4XNJmWGhBCNq1Z/xaKjow859ePvGkRSc04EisvUUp9PCCGEEAGTk5PDuHHjWLp0KUopzjnnHJ555hlfwrmwsJChQ4fK9bJoE1aVVFDhqf5ZL/d4+b24nMTk2ABHVTuvbtzJzqrqxf+e+nMbQ47pzX333cf27duJj4/fJ5H71pZduMzqGsuvb8rxe6LZrfPY6b0Dt84hyhhNguVyv/Z/MC6vyVtbdlHo8nBqRiLtwqR+rr9sr3TwztbqOtqrSyqYs30357TfdyFIj87HrXcRrLrUa3HB8vJy7rjjDjZs2MCgQYO4+eabMQwZnNXUPDqfSv0bdtUBu8oKdDhCNJpaJZrnz5/f2HEIAQq2Zmb7tuvK1JpuUXL3XgghhBCBccstt2CxWFi8eDHFxcXceuutHHfccXz11VfExFSX9tJ/LfglRGvXNTKUYIuBw2sSbDHoEtlyrtODLXvKXwT/lZCzWCxkZmbut32C3cZaKoHqxSn9rcSci1vn/LX9KVHGWGwqze/n2Z/XN+Xw4fbdAPxaWMbMgd1bTf1ht9vNL7/8QmxsLF26dGny89sMAwX8/a4QvJ+ZuQ79Bzs8d6BxEqy6kWaZhlJ1G/U8b948NmzYAMDChQtZtWoVvXv3bmD0oi68uoRt3uvw6mIUVtKsDxGsOgU6LCEaRa3+QjV0oQMhasMZHMKVM9+v17EOr4mBIlPusAshhBAiQL7++mtmz55N//79ATjmmGP417/+xbBhw5g3bx4gC0SJtiMtNJjHD+/MquJyekWHkxracuoFX9IxFbdpUu7xcn526iHbX9E5naggKw7T5KzMJL/HY1HRvm2FDQvhB27sZ3kOl2+70OXGZWrsln3/jmntASwt6m/cvffey/LlywG4+uqrOeGEE5r0/InBNq7p2o7PduaTGRbMmLSEfdqUmT+gqR5d79BrcLMTG+3qdJ6/b3RC9XtQVJR/6oGL2nPqjXh1MQAaD1V6Ra0TzRXmUkr1l9jJIsb4F0rJaHTRvNWrANAPP/zACy+8wMaNG3n33XdJS0vj9ddfp3379gwePNjfMQpxSPlOF5nhwYxMiQt0KEIIIYRoo0pKSmp8oLfb7bz33nucccYZDB06lDfeeCOA0QnR9NJDg0kPbXkDQeLsNu7slV3r9hFBVi7rnN6gc5aVlaGU2qe2O0C0GodplONiK5FqNBbVdInCUzIS+a24nAqPl9PbJe53PZxC7zsUmm9gUTGkWu5pEWUBnE6nL8kMsHjx4iZPNAMMT45l+EFKygSrzpT8tW1RMVjZNxl9KEOGDCE3N5c1a9YwZMiQA47MF43HrjpgUbF4dSGKIEJVnwO2detcysxvCFKphKhe7PI+gMZNBQuxqEii1ElNF7gQ9VDnRPP777/PxIkTOeecc1i2bBlOZ/XdtbKyMqZNm8ann37q9yCFOJhilxuH12R8egI2WQhQCCGEEAGSnZ3NihUr6NRpzyglq9XKu+++yxlnnMHJJ58cwOiEEM3V559/zrPPPothGFx77bX7LDaolJU4y3kBia1bVBivDeyBwzSJ3M9CdaZ2UGi+AWi8upAi8x2SLTc1faB1ZLfb6dKlC2vXrgXgsMMOC3BENXl1CTu99+DSmwhWPQlVfYkwjsFQIfXq74wzzvBzhKIuLCqSDMvjVOkV2FUHbCpjv+1M7WKH92Y8ugCAaON0NG7f838/LkRzVues3P3338/zzz/Pf//7X4KC9hSiHzRoEMuWLfNrcKJtsTuqeOb803jm/NOwO6pqdYzbNMlzuDkzM2m/CycIIYQQQjSVE088kRdffHGfx/9ONvfp06fpg2rFVqxYwaeffkpxcXGgQxEtQIHTRYHTdeiGAfD222+jtcbr9fLuu+8GOpx92CzGfpPMAAorhtpTf9tCdBNF1XD3338/V199NVOnTmXMmDEHbOf1elm+fDlbtmxpstiKzY9x6nVoPDj0KsKMIwlS8nm3JbOqWCKM4w6YZAbwUlQjmWzqMiKMYQAEqRSijNGNHqcQDVXnEc1r165lyJAh+zweGRkpF3miYTS027LRt10b5W4vUUFWLu6QRqjVcugDhBBCCCEayQMPPEBlZeV+n7NarXzwwQds3769iaNqnX788Uf+85//ADB79myeeeYZbDb/L8ImWofPd+bz7J/Vv3uXdkrnpLT4AEdUU3JyMvn5+QCkpLSsZKJSVlItd1NkvouVeOKMcwMdUq0FBwfXqlzGAw88wJIlS1BKMWXKlP3mQxrC1FXsMh/GpTcRqU4k1nImFrV3CRUDg1C/nlM0T1YSCVF9qNLLUdiIMI4jxOhJgnEZiuAWVQNdtF11TjSnpKSwfv16srKyajy+YMECsrNrX8dKCH8o9Xg5LDqcDFkEUAghhBABZrVaiYyMPODzFotFamP6ycqVK33bu3btYvfu3aSlpQUwItGcfbBtt28cy+xtec0u0XzTTTfxzjvvYLFY+Ne//hXQWBYsWMCbb75JYmIi1113Xa0WjgtWXUmx3NkE0TW9qqoqlixZAoDWmgULFvg90VxszqXSrD5HoX6dcGMgUeok3EYeLr2RSONEglSiX88pmielFKmWu3GyHivxWFX136r6lkwRIhDqXDrj0ksv5ZprrmHx4sUopdi5cyezZs1iypQpXHHFFY0RoxAH5NWaKFu91rQUQgghhBAt1JFHHonFUj2bLTs7m6SkpABHJJqzjFC7bzt9r+3mIiYmhksvvZSLL76YiIiIgMXhcDh49NFH2bZtG0uXLpUFTIGQkJAag+y6devm93Mo9c+0jIFSVhIsl5BmnU6E4d/EtmjelLISrLr6ksxCtDR1ztDddNNNlJSUMHToUBwOB0OGDMFutzNlyhSuuuqqxohRiP3ymCZerekbE7iLMSGEEEII0fT69evHk08+SU5ODocddhhWqww8EAd2fbdM3t+aiwZOy5CRoQej9Z4ahqZpBjCS5mPatGl88803xMXFMXjwYL/3H6XG4DQ24dQbiTJOxKYOPjvDpXeQb74MQLxxMTaV6veYGqLKXEmpnoddZROlxki5ByHamHpdkT3wwAPcfvvtrF69GtM06d69O+Hh4Yc+UAg/2lnlIjMsmFPlYlEIIYQQos3JzMyUUiSiVsKsFkKtFv63eReL80u5u1d7kkICP7LZrfMoMedgEEmMMR6lggIaT3BwMJMnT+bNN98kISGBs88+O6DxNBcRERGMGzeu0fo3lJ1ky421bp/nfRyHXlu9rctJtz7k95g+/fRTXnnlFWJjY7nzzjvJyDjwAnZ78+hCdnqnonFRxjwMSyiR6ni/xyeEaL7qfes/NDSUpKQklFKSZBYB4fSanN4uiRh7YC/IhBBCCCFE0ypxeZj2+ya2VTg4tV0ip7eT0hniwErdHl7bmIMGtlU6eGdrLpO7tAt0WOz03olb7wTApJR4y8UBjgiGDx/O8OHDAx2GOAgv5b5tc69tf3G73bzwwguYpklOTg5vvvkmN998c62O9VCAxrWnL53j9/iEEM1bnWs0ezwe7rzzTqKiosjKyiIzM5OoqCjuuOMO3G53Y8Qo2goFuUkp5CalwCFm17i8JhalyJRFAIUQQgjRDP3www9MmDCBgQMHsmPHDgBef/11FixYEODIWof3t+WyuqSCMo+XVzfmsNvhOvRBrdiSghJ+2l1co+yB2CNIKYKMPR8wwqyWAEZTTWtvjSScS28PYDSiJYk3LsFQERgqgnjD/zcnDMMgOHjP5+y6DCy004EwYwAAVhVPpDHC7/EJIZq3Oo9ovuqqq5g9ezYPPfQQAwcOBOCnn35i6tSp5Ofn8/zzz/s9SNE2OINDuPitT2vVttTtIdJmYWD8oVdBFkIIIYRoSu+//z4TJ07knHPO4ddff8XpdAJQVlbGtGnT+PTT2l3viAOzG3vGyxgKLG24BuirG3fy3tY8AIYnx3Jt18CP1G1uQqwWbuvRnve25pEcYuOszORAh4RSFqKNsRSbH6EIIso4KdAhHdKuXbsASE4O/NevtkztRBG0nwX3Wq4w43CyjTcbrX+LxcKdd97Jm2++SWxsLOeee26tj1XKINm4Ha9RiIXIgJeDEUI0PaXreNs7KiqKt956ixNPPLHG45999hn//ve/KSkpOWQfpaWlREVFUVJSQmRkZN0ibkGO+XIJLlOTGGwLdCititaadWVVjEmP55F+nQMdjhBCCCH20lau8w6mb9++XHfddZx77rlERETw22+/kZ2dzfLlyxk1apQvWdOaNPX33eH18vTa7WyvdDAuPYGhybGNfs7mavKSP9hc4QAgKsjKG0f3DHBEoi7cehcGIViUfwfQrCou57WNOUQGWbiicwaxDSw3+NFHH/HSSy+hlOLiiy9m7Nixfoq08RR4Z1FkvoVFRZFquQe76hDokIQQosWq7bVenW/rBQcHk5WVtc/jWVlZ2GySUBWNL8/hJiLIwvnZzWt1XSGEEEIIgLVr1zJkyJB9Ho+MjKS4uLjpA2qFgi0WLuyQyuWd0zkmMTrQ4QRU39gI3/bhe22LluH3ojCeXlvC5zvz/drvtFWbWFNaweKCUl7esKPB/c2dOxeoHvTz8ccfN7i/xmbqKorMtwDw6hKKzPcDHJEQQrQNdS6dceWVV3LfffcxY8YM7PbqlXqdTicPPPAAV111ld8DFG2HzengP9dcBMAtT76My75v/eUKj5dyj4drurajR1RYU4cohBBCCHFIKSkprF+/fp/BGQsWLCA7OzswQbUya0oquPO3DThNk97R4dx3WAeMNlo+44LsVHpEheM2NYMSpKxcS7Krysk9Kzfi0ZqvdxUSYbVytB9unGitcZqmb9/hNQ/SunaysrLIzc0FIDMzs8H9NTZFEIaKwNRlAFiJa7RzlZSUUFJSQkZGBqqN/h0SQoi/1SrRfOqpp9bY//rrr0lPT+ewww4D4LfffsPlcsnqtKJBlKnptHa1b3t/djtc9ImJ4OIOafImLoQQQohm6dJLL+Waa67hlVdeQSnFzp07+emnn5gyZQp33XVXoMNrFb7LLfIl0lYUl5NT5SQttG0uEq2UYoCsWxJQWrsp0Z9gagdRxslYVO0WT9vtcOPZq5JljsPpl3iUUkzuksGL63YQGWTlPD/MBL3++uv56KOPUEoxbtw4P0TZuJSykmq5h2LzfazEE2tMaJTz/P7770ydOhWHw8HgwYO5+eabG+U8QgjRUtQq0RwVVfPC5bTTTquxn5GR4b+IhDgAt2niNjVDk2KwGJJkFkIIIUTzdNNNN1FSUsLQoUNxOBwMGTIEu93OlClTZAagn3SICPFtRwdZiWtg/VmxL6+peerPbawsLmdQfBQXdUwLdEh1UuLy8M7WXAzgzMwkIoLqPJm31nabL1Jqfg5Alf6NNOt033OVlZX88ssvpKSk0KlTpxrHdYsKpXd0OCuKy0kMtjE0KcZvMR2XFMtxSf6rXR4aGspZZ53lt/6aQrDqRLLllkY9x5dffonDUV0jfcGCBVxyySXExvrv6+7UG6gwlxKiehBi9PBbv62ZV1dQZL6NxkOMcTpW1XZr+AsRCLV6t50xY0ZjxyHEIVV5TSKCLIxOiw90KEIIIYQQB/XAAw9w++23s3r1akzTpHv37oSH126Uozi0E1LisBsG2yodDE2KJdhiCXRIrc73eUXM21UIwIfbd9M/LpLDYlpODeiHVm/m850F5FQ5eWn9DuYe14f4Rlqk3ak37tlmz7bH4+HWW29l48aNKKW47bbbOOqoo3zPWw2D+3pns3LzFtJjY4izy5pHLc3eZURiY2OJiPDf74hb57DdcxMaF2CQrh4mWHX2W/+t1W7zKcrNHwFw6vWkWx8KcERCtC2Nd1tXCD/SWrPb4aJ9eAhJjXSBKIQQQgjhT6GhofTv3z/QYbRaQ/w4+lMcWkubT7i5wsH2quqRpjkOF+9vy+PSTumNcq4oYxR53nWAJkqN9j1eUFDAxo3ViWetNUuWLKmRaAZ4+OGHWbBgAcHBwdxzzz107969UWIUjWP8+PEEBweza9cuRo0aRVCQ/2ZXOPWmv5LMACZOvb7OiWaHw0FpaSkJCQltpvSkW+fs2WZnACMRom0y6nPQe++9x5lnnslRRx1Fv379avwTojEUuz2EWCzc1D0Lq1GvH1shhBBCiCZRUVHBnXfeyaBBg+jYsSPZ2dk1/tXW9OnTOeKII4iIiCAxMZFTTjmFtWvX1mijtWbq1KmkpqYSEhLCcccdx++//16jjdPpZPLkycTHxxMWFsbYsWPZvn17jTZFRUVMnDiRqKgooqKimDhxIsXFxfX+GoiW79ikGE5IjiUlxM6pGYn0bkGjmQFOzUjAQKFQpATbCG3EUe+RxglkWl8gw/oUcZbzfI/HxcXRrl07337fvn1rHPfFhm28VOJlS4eeVDpdfPnll40Wo2gcSilGjx7NhRdeSGpqw2th7y1E9cKqkgCwqChCVd1uXG7ZsoWLLrqIiy66iAcffBCt978OUmsTbZyGwgooYowzAh2OEG1OnUc0/9///R+333475513Hh999BEXXHABGzZsYMmSJVx55ZWNEaMQFLs8tAsLZnBCdKBDEUIIIYQ4qIsvvpjvvvuOiRMnkpKSUu9RZN999x1XXnklRxxxBB6Ph9tvv50RI0awevVqwsLCAHjooYd47LHHmDlzJp07d+b+++/nhBNOYO3atb4p3Ndeey1z587lrbfeIi4ujhtuuIGTTz6ZpUuXYvkr+Xb22Wezfft2Pv+8us7spEmTmDhxInPnzvXDV6TxaK15cu02ftxdTK/ocG7pnoXNIoMS/MFQiqu7tjt0wya0trSC7/OK6RQRUqP+cIn5OSXmJ9hUJonGZAxl57R2SURaLby7fhtmXg7dy0OAlEaLbV1JBPes3E2o9Xem9+lAckgwVquVBx98kMWLF5OSklJjtHKR082zW/NxJKZS6nIR5HTUKMPQHJWVlbFmzRqysrJITEwMdDitnkVFkGF5EpfeiE21w6LqtujnF198QWlpKQA//vgjO3fuJC2tZdVar48IYwihqi8aL1YVHehwhGhz6pxofvbZZ3nxxRc566yzePXVV7npppvIzs7mrrvuorCwsDFiFG1ISVT0Po9prfGYmrMyk2URQCGEEEI0e5999hmffPIJRx99dIP6+Tvp+7cZM2aQmJjI0qVLGTJkCFprnnjiCW6//XZOPfVUAF599VWSkpJ48803ufTSSykpKeHll1/m9ddf5/jjjwfgjTfeICMjg6+//pqRI0eyZs0aPv/8cxYtWsSAAQMA+O9//8vAgQNZu3YtXbp0adDraEy/FpX56ggvKShlfm4RI1PjAhyVaAz5Dhe3L9+A0zQBsBkGgxKices8dnufBTQuvRkb7Yi1nAnAURF2XvvvYxQXF3OPUkydOrXRZuGe9eMqdjmc1bE63cw9rg8A4eHhDB8+fJ/2DtPEVIquXbuSl5fH4I4ZnHLKqEaJzR8qKiq4/vrr2bVrF8HBwTz88MNkZWUFOqxWz6LCCFG96nVsSsqeGythYWFER0f7KaoD01o3ixIdFtWyZmAI0ZrU+Xb/1q1bGTRoEAAhISGUlZUBMHHiRP73v//5NzrRpjhDQpjw4XwmfDgfZ8ielcR3OVzE2K30jZU3CyGEEEI0fzExMcTG+n+V+5KSEgBf35s2bWLXrl2MGDHC18Zut3PssceycOFCAJYuXYrb7a7RJjU1lZ49e/ra/PTTT0RFRfmSzABHHXUUUVFRvjb/5HQ6KS0trfEvEEL+UQ4hREYzt1p5TpcvyQywtcLx15YX2FMSQOP2be/cudNXAkZrzerVqxslNpfXpMi157y5DtdBWldLCbEzPiOBsJAQjunWmbtOGt4sEnQHsm7dOnbt2gVU1/395ZdfGtyn1iZeXdrqSjp4dCG7vS9S4H0NU1cFLI6TTz6Ziy++mFGjRnHffff5ZsI0hvLycqZMmcIpp5zCE0880eq+p0KI2qvzlVhycjIFBQVA9QqrixYtAqovdOWPifC3Co+XYpeHsWkJ9IyWldqFEEII0fzdd9993HXXXVRWVvqtT601119/PYMHD6Znz54AvqRPUlJSjbZJSUm+53bt2oXNZiMmJuagbfY3DT4xMdHX5p+mT5/uq+ccFRVFRkZGw15gPXWLCuPCDql0iQzl9HaJHJMYHZA4ROPrFBFKt8jqRFl0kJVj/1oMMkilEGtMxKKiCVGHEW2Mw/wrIZ2ZmUl6ejpVVVUUFBTs87viLzaLwentElG6+nd1fFp8rY67sEMas4f05ukjuhJnb94LnmdmZvrK8RiG0eBFC726jG3eyWzynMNO7x1o7fFHmH5RZn7PRs/ZbPFMwqk31fn4HO8DlJhzKTLfZbf5bCNEWDtKKcaNG8eVV15Jp06dGvVcX375JWvXrsU0TebNm8cff/xx0PZunYdH5zdqTEKIwKhz6Yxhw4Yxd+5c+vXrx0UXXcR1113He++9xy+//OKbsieEP5S5PexyuDg+OZZzsxuvnpoQQgghREP17du3xmjE9evXk5SURFZWFkFBQTXaLlu2rM79X3XVVaxYsYIFCxbs89w/R0HWZuryP9vsr/3B+rn11lu5/vrrffulpaUBSzaPz0hkfIbUi23tggyDaX06sLPKRbw9iFDrntHsm3/ryIwZ0fz00+esWvUITqcTu91Oz5496dGjB2VlZURGRvLss8+SnZ1Nhw4d/B7fY4d3Icxi4eeCUhYWlPLx9t2cnJ5wyOOa8yjmvcXExPDoo4/yyy+/0KlTJ7p27dqg/sr0d7j0VgCq9Aoq9W+EqcP9EWqD5XmfQuPApIwC76ukWqcetP0//1a62eHbdumdjRVms/L3TQio/pkODz/wILFi8yPyvS8BigTLZUQZo5sgQiFEU6lzovnFF1/03SG+7LLLiI2NZcGCBYwZM4bLLrvM7wGKtsPmdDD15qsAmHL/E+SYBmPT45nepyNWQ6ZBCiGEEKL5OuWUUxqt78mTJzNnzhy+//570tPTfY8nJycD1SOS967FmZeX5xu5mZycjMvloqioqMao5ry8PF85vOTkZHJzc/c57+7duw84AtRut2O32xv+4oSoA6th0C4s2Le/fv16Jk2axPz580lLS+P4449nwoQJREZGUlpayvLly/nqq6/YuXMnCQkJ9OzZkz/++KNREs0Aq0oqfItR/rC7uFaJ5pairKyMxYsXExUV5Ze67UHs/bVRWFXzqa1uqGC82uHbPpinnnqKr7/+mo4dOzJ16lQiIiKIMc6gwDsThZUYY3xThBxwxx9/PDk5Oaxdu5Zhw4Yd9MZjsfnRX1uafNeH/PhN9d4JJ5ywz41ZIUTLU+dEs2EYGHsl/c4880zOPPNMvwYl2iZlanr9thSAvConI7PSuKd3B0kyCyGEEKLZu/vuu/3ep9aayZMnM3v2bL799lvat29f4/n27duTnJzMV199Rd++fQFwuVx89913PPjggwAcfvjhBAUF8dVXX/mu2XNycli1ahUPPfQQAAMHDqSkpISff/6ZI488EoDFixdTUlLiS0Y3RzsqHeyqctEzOhy71GZuc958800uvvhiUlJS+OCDDxgzZgxW674fbz0eD3PnzuW6665jwYIFnHbaaY0WU8/ocJYXVa9h1DOqdZX9u/POO9mwYQMAubm5/Pvf/25Qf2HGABK4nCr9O+FqEHaV5Yco/SPZchsF3lexqHDijUkHbPfnn3/y5Zdf+ra/+OILTj/9dGKM04hQQ1EEtZlF6ZRSnHvuubVqa6MdHnYD8PrT21n63XMArFq1iptuuqnRYhRCNI1aJZpXrFhR6w579+5d72CE8NFwQkpcjSlxQgghhBAtQXZ2NkuWLCEuruYIveLiYvr168fGjRtr1c+VV17Jm2++yUcffURERISvXnJUVBQhISEopbj22muZNm0anTp1olOnTkybNo3Q0FDOPvtsX9uLLrqIG264gbi4OGJjY5kyZQq9evXi+OOPB6Bbt26MGjWKSy65hBdeeAGASZMmcfLJJ/tl5GJj+K2ojKkrNuLRmk4RoTzUV2bAtSVvvvkmEyZMYMKECTz33HMHXeTMarUyfvx4RowYweWXX87kyZOJiYnx/Y740+09s/hmVxHhVkuNeuEul4tHH32UP/74g2OPPZYLL7zQ7+duTB6Px5dkBli7dq1f+o0yRhNF8yubEKK6kW79zyHbhYWFoZTyrVW1d7kIq/L/grCtRZJlCsXmbMBgx9p58FfS2V8/V0KIwKpVorlPnz41/oAeiFIKr9frl8BE22YoCJcksxBCCCFaoM2bN+/3mtjpdLJ9+/Za9/Pcc9WjvI477rgaj8+YMYPzzz8fgJtuuomqqiquuOIKioqKGDBgAF9++WWNepmPP/44VquVM888k6qqKoYPH87MmTOxWPZca82aNYurr76aESNGADB27FiefvrpWsfa1H7aXYLnr88m68oqyXW4SAs9+BR30TqsW7eOiy++mAkTJjBz5swas20BKioqKC4uJjo6ukYCOiwsjJkzZwJw8cUXc+SRR9KxY0e/xhZssTB6PwsBfvXVVyxcuBCA2bNnM2jQoAbXOG5KVquVwYMHs2DBApRSHHvssYEOqVlIS0vj2muvZd68eXTs2NH39zPQvLqCIvNdwCTGOB2Ligx0SDVYVDhxlokADB9uYdasWcC+73VCiJZJ6UNlj4EtW7bUusPMzMxDtiktLSUqKoqSkhIiI5vXHz1/OubLJbhMTWJw815BuLmwV1Xx3ujq6ZlXz/+FaUcfRnhQnau7CCGEECKA2sp13v7MmTMHqK7X/OqrrxIVFeV7zuv1Mm/ePL766qtWOWqrqb/v3+cWcdP3v+CoctAlNYnXhvaX8hn1sGjRIlavXs2AAQPo0aNHoMOplWHDhrF161Z+++03XyLZ4/Ew+aqr+P7bb1jz53q01mS1y2DTlq37HF9RUUHv3r3JzMzkm2++aZKYP//8c5555hnf/mOPPUanTp2a5Nz+orXm999/JzIyknbt2gU6HHEQOd77qTAXAxCi+pBmvS/AER3cunXrME2z2c6gEUJUq+21Xq2yeLVJHrcU33//PQ8//DBLly4lJyeH2bNnN+riLaJ+pvXpKElmIYQQQrQof19TKqU477zzajwXFBREVlYWjz76aAAia30qf11M0Nx38YaE4XWW4x30NISGBjqsFmX58uU88MADAHz88cc888wzNRaVbI6WLl3K/Pnz+eCDD2qMVt65cyfP/1X25W/5Bfn77SMsLIyHH36Y0047jWXLltGvX79GjRmqF0r7888/+eOPPzjuuOMaNcmcn5/Pb7/9RseOHf36OV4pRc+ePf3Wn79orSk036BKryTcOJpoY1ygQwo4l97h23az4yAtm4eWdtNFCHFwbS6TV1FRwWGHHcYFF1zQqAtBiLqrcO+ZYipJZiGEEEK0NKZpAtWL9C1ZsoT4+H2n0Av/+H3LNra370ZVaDie7RsoKioiVBLNdbL3rFW3283OnTubfaJ55syZpKenM2bMmBqPx8bG0j6rHbExMWzeuo2CgsKD9jN27FjS0tKYMWNGkySarVYrV199daOfp6SkhOuuu47i4mKsVisPPfRQq0/iVegfKTLfAcDhXUOw6kKwajllSRpDjHEqed6nAU2MITkPIUTTanPZvBNPPJETTzwx0GGI/ShwuXAGh2AzFCrQwQghhBBC1NOmTZsCHUKr5+h5OM7yX9FeL5U9j8ASE3fog0QNRx99NLNnz6agoID27du3iNIZP/30E8OHD8dqrfkxNjw8nI2bqhPnQwYP4ocffzpoP1arleHDh7No0aJGizUQNmzYQHFxMVBdTmTlypWNnmjeuHEjZWVl9OrVa5962f6gtUZrfcC+TSpr7Ht1BW39w2SkcQKh6gjAlEUJhRBNrs0lmkXzpLWm2GbnsSW/c2vP9oEORwghhBBCNGMd0lI57DATl8tFRFgoIVb5WFNX8fHxPPvss+Tm5pKWlobN1vzXlVm1ahUTJkzwS199+vTh7bff9ktf/pJT5aTE5aFLZChK1T1b2qFDB2JiYigqKiIoKIjevXs3QpR7fPXVVzz11FNorRk8eDA333yzX/tfvnw506dPx+12M3nyZIYOHbpPm3B1HOXqR6r0SsKMQYSqxh+h3hJYVXSgQxBCtFF1uiLzer0sWLCA3r17ExMT01gxiTaowOUm3Grl2CT5uRJCCCGEEAd3bFI0z6/bTo5H86/oCKJskmiuj9DQUNq3bxmDPEzTxOl0+m2xyaioKJxOJ6ZpNspI3LpalF/Cf37fjFdrBidEc3OPrDr3ERUVxeOPP86KFSvo2LEjGRkZ/g90Lz/88ANaawB+/PFHv38tX3/9dSorq0csv/LKK/tNNBvKRqr1Hr+dUwghRMPU6V3AYrEwcuRI33QcIfzBY2oKnW7OzkpmYHzUoQ8QQgghhBBt2qc7CogIstI5Moxfi8rIc7gCHVKTKSoqIj9//wvdtWaGYWC32yktLfVLfyUlJdjt9maRZAaYt6sQ719J2wW7i3F4vYc4Yv/i4uIYOnRooyeZAbp37+7b7ty580G/lqWlpeTl5dWp/6ioPZ8No6Oj6xyf8B9Tuyg151FuLvTdXNgfrev3cytaL6feyHbPLezw3FFjoUrRetX51n+vXr3YuHFji7nzLZq/EreHWFsQF6bFok4+ufrB99+H4ODABiaEEEIIUUcej4dZs2YxcuRIkpOTAx1OqxVmtfi2rUphbybJwsb2zTff8OSTT2KaJhdeeCHjx48PdEhNqmfPnixfvtwvfS1fvpxevXodsl2Z28MvBaVkhAXTMaLxFpzsFBHKovwSANJD7S3iZ/pf//oXKSkplJaWMmzYsAO2W7Jkia8Exumnn855551Xq/6vuuoqZsyYgcvl4txzz/VX2KIedpn/odJcAkCMcSZxlon7tNntfZ4S81OCVBpplvuwKlkQV0Cu9xFcehsAu71Pk2adHuCIRGOrc6L5gQceYMqUKdx3330cfvjhhIWF1XjeX1OZRNvh9JokhdiItRrw6afVD9bzDr4QQgghRCBZrVYuv/xy1qxZE+hQWrVTMxIpcLrZXulkTHp8mymd8eGHH2KaJgAffPBBm0s0Dxw4kNmzZ+PxePZZEPDbb79l7dq15OzKBcDl9vDCCy8QFxfH6aefXqOtx+Nh3rx5h/z6ubwmNy5bx44qJwqY2jubfrGN83n3jHaJxNmDKHC6GZESW68azU1NKcWxxx57yHZz5szB7XYD1T+35557bq1eX2xsLDfccMN+n3vnnXdYvXo1Q4YMOWiSuyXIyclBKdWsb05WmSv2bOvfgJqJZpfeTon5CQBuvZ1i82PiLec3YYSiuTJx7bXtDGAkoqnU+Yps1KhRAIwdO7bGm4PWGqUU3maeICwvL2f9+vW+/U2bNrF8+XJiY2Np165dACNrm7TWlHu8jI2TGxRCCCGEaB0GDBjA8uXLyczMDHQorZbNYnBll4aXBqioqKCsrKxZJ3j2lp6ezqZNm3zbbc0FF1zA008/zdy5c/dJEv/rjNPJyy/w7btcbi677DIAduzYQWpqqu+5OXPmsGPHDi644IKDnm9nlZMdVdWJEQ0sKyxrtESzUorhybGHbOf0mvyQV0REkJUBLaTsYHp6um8kekpKCrt27SIuLq5WC1BWmsso1V9hoz0xxhkopfjhhx94/fXXAVi2bBnZ2dlkZWU14itoPO+//z4zZ85EKcWkSZM4+e8Zvs1MuDGQMvNbAMKMgfs8bxCKworGA4BFtYyfTdH4Eo0ryTOfRBFEgmXSPs9rrfGwCwsxGEpmtbcGdU40z58/vzHiaDK//PJLjUUErr/+egDOO+88Zs6cGaCo2q4il4fIIAtnZbWMi3shhBBCiEO54ooruP7669m2bdt+ZwD27t07QJG1LgUFBezevZuOHTvuM7q1NtauXctdd91FZWUlQ4cO9X0uaM4mT55MSkoKbreb0047LdDhNLl+/foxdOhQpkyZwogRI2r8bkVHR9dINP/NZgsiJCTEt19RUcGNN97I0KFD6dev30HPlxJiJzXEzs6/RjT3jYnw22upr/tWbuS34nIAJrZP4czMpIDEsXjxYjZv3szgwYNJS0s7aNsLLriAqKgoCgsLWbFiBZMmTSIlJYWHHnrooLWXPbqAHO/9aNzAAiwqgih1Yo01o7TWLXoNqY8//hiofh2ffPJJs000JxrXEa6GYBBCiNFzn+cNQokwRlKlVxKmDidajQlAlKI5CjX6kmXM3O9zWpvkmPdTaS7BoqJIs0zHphq/vrxoXHW+IqvN1Jjm7Ljjjjto8XrRdEytyXe6GJoUS+fIMKioCHRIQgghhBAN9q9//QuAq6++2veYUqrFzABsCdasWcOdd96J0+mkV69e3H///XVe1O3zzz+nsrISqB5Mc/755xMbe+gRpYEUEhLCxIn71kZtS1588UV69+7N5ZdfzsyZM33f919/W0FRUdE+7cPDw32LypmmyeWXX8bOnK28+slITO046Ag6u8XgkX6d+KWglPTQYDpFNl6N5trQWrPiryQzwIqisoAkmhcsWMCDDz4IVI8Of+GFFwgPDz9ge5vNxr///W8WL17MZ599BlSXi1i4cCGjR48+4HFeSv5KMlfz6OpFMIcNG8b8+fNZt24dgwYNapSbd+vXr6eoqIi+ffvW60ZWbWVmZvoW92zOo7KVMghTR+z3Oa01O7y349R/AmA3TkeptlHOSDSMi62+2t9eXUKp+TXxloPPNBHNX71++3/44QdeeOEFNm7cyLvvvktaWhqvv/467du3Z/Dgwf6OUbRSxS4PUbYgrukqJUuEEEII0Xr8XdpANJ7vvvsOp7O6pMHKlSvJyck55KjKf9q7fVRU1EETZaL56NixIy+//DLnnHMOAM899xxhYWGEhoYSGnrgRHBFRQWXX345b7wxi0df7UNyh22U6XlEqZMOer6IICtDa1HSoikopRgQH+VbNLAxSmfk5+ezdOlSsrOz6dSp037brFu3zrddWlpKXl5erX5/UlJSsFgsvptth/qdtdGecGMI5eb3WFUSkUZ1Gc+wsDAee+yx/dbq9of58+fz+OOPo7Wmb9++3HvvvX4/x99uvPFG5syZg2EYjBs3rtHO05hMSn1JZoAK/QsRDD3IES2HU2+m3PwOm2pPhDEk0OG0OlZiMVQIpq4CwKbq9j4umqc6/1V+//33mThxIueccw7Lli3zXeCVlZUxbdo0Pv17MTchDsFlmoRZLXQJ8MgAIYQQQgh/ktrMja9jx46+7bCERCJiYurcx6mnnorVaiUnJ4fRo0fXql6sP20oq+TJtdvwmJqruqTTPUoS3bV11llnobXm4osv5scff+Thhx9m7Nix+006ejwe5syZw4033khOzk4efbUPY/5dncwwOPjnkCqPiw92zifIcHJKyvHYLIH/3HJL9yx+KSwlMshKt6iwQx+wHx9ty2NxQSl9YyI4Y68R0d9t28Ulsz7AW1FOx1de5ZE7bqVXr177HN9v4CDmfv4F7soKOnfuTEZG7aa6t2vXjjvvvJPFixfTs2dPDjvssIO2V0qRbLkRr3F5dQ1gVXPWQmONNF64cKFvFvSvv/6Kw+EgOLhxaseGhYVx1llnNUrfjSUvL4+SkhI6duyIUgqDSOyqE05dfQMiVB1+wGM9uhgL4S1ixLNXl7HDeyum3jOL4EDJ5rKyMoKCghrt56S1sqhIUi33UWZ+g01lEqFOCHRIwg/q/Nt9//338/zzz3Puuefy1ltv+R4fNGhQo97pE61LlddLmdvLSWnxGC1gRWUhhBBCiLrYsGEDTzzxBGvWrEEpRbdu3bjmmmvo0KFDoENrFY4//njsdjtvbMtnY2wKk5Zt4N7e2dXl2GrJMAxOOeWUxgvyEJ79czubyqtHcf3fH9t4fkC3gMXSEp199tkceeSRTJo0idNOO420tDSGDx9Onz59iIqKoqSkhOXLlzNv3jx27NjBsGHD+OKLL4jP/oNy83uCVXfC1XEHPcedqz5iWWF1OY71ZTO4rduVAOQ7XCzML6FdaDB9Ypu2brPFUA0aybyyqJyXNuys3i4uJys8mCPiqvt7cOUGSgwrRESzuX03Vq5cuU+i+fOd+TyXW4Xn4hv4d6SVf/XtQVBQUK3Pf/jhh3P44QdORO6PRTXtTZhevXqxaNEioPqmliQP91i8eDHTp0/H6/UyZMgQbrzxRpRSpFkeoEIvwkrCfms4A+R6H6PMnI9FxZBmmYZN1X1BU4deR5k5H7tqT6TRuElJD7trJJmdeiMR7Jto/vDDD3nllVcICgri1ltvpX///o0aV2sTrLoQbOkS6DCEH9U50bx27VqGDNn3lysyMrJFF+EXTavA6SY7IoRbemTteTAsDKR+thBCCCFauC+++IKxY8fSp08fjj76aLTWLFy4kB49ejB37lxOOEFG7PjD4QMH8ZB3JcFAhcfLh9t2c1OP+o3wDIS9x1rIuIv66dixI9988w3Lli1jxowZLFq0iLfffhun04ndbqdXr16MHz+eCy64YK+F/zoSbdRuwbV1ZY69tl0AVHm83PjrOvKd1bWDb+uRxcCEaH++rEZV7vHU3HfvqRkfFhaG3W7H6XRiUWq/CeH/bc7F1GAEBfGzEczEJp4JUB9am3jIw0Ishjp0vGPHjiU5OZmCgoL95j7asq+//tpX+uT7779n8uTJBAcHY6gQItSBy2W49E7KzPkAeHURJeanJFgm1encXl3CTu/tvjILCisRRuOV6LDRjmDVA4f+HUOFEWHsf72yWbNmobXG5XLx7rvvSqJZtHl1TjSnpKSwfv36fQrVL1iwgOzsbH/FJVoxU2sqPV5OTIkj2GIJdDhCCCGEEH51yy23cN111/Gf//xnn8dvvvlmSTT7id0wiAqyUuKuTpwlhTT/hNferuycwVNrt+HRmis7131kX0vn8ppsqqgiJcROZFDDptH369dvr0Ry9aJ/dV0ccn+OT05g9ratAAxPjgcg1+HyJZkBVpdUtKhE8xFxkRwVH8XPBSX0jYng6L1iv6VnNs9ZDSoLC7i+2wl06dh+n+OTgm0Uuty+7eZOaw87vXdTpVdgVfGkWR4kSCUe8rgjjzyyCaI7NI/Op0qvJlh1IkilBDocOnTo4BvtnZaWVuvR3hYiUQSjqb55E6Tqvoilh3xfkhnApbfWuY+6UMpKmuV+nGwmiAQsav8zCZKSktiyZYtvW4i2TmldtyGkDz30EK+++iqvvPIKJ5xwAp9++ilbtmzhuuuu46677uKqq646ZB+lpaW+6UyRkZH1Dr65O+bLJbhMTWILeANuSvlOF2j44NjDSAmxBzocIYQQQvhRW7nOO5jg4GBWrly5z0Jaf/75J71798bhcBzgyJYrUN/3zeVVfLh9N3G2IP6dlUSQH5KLovE5vF5u+nU9m8qriLBaeLhfJ9JCm2d5glUl6wgyXHSJ6AGA2zSZsmwdG8ursCrFfYd1oGd0/Uo7eE3NrM05bK1wcGJqPIfHNd3vjtYaVY+h9IVON//bvAuroTg7K5mIBt4kOJgSl4fv84pIDrH5ynvUVZW5ih3eW337scZEYi1n+ivERuXRhWzzTsarS1EEk2F9DJuqXT3sxqK15quvvqKgoICRI0cSG1v7hTKr9BpKzc+wqQyi1Wn71Nw+9Lm97PROpUovx6IiSbP8J+BfD4Dc3FzefvttQkNDOfvssw+6KKkQLVltr/Xq/K5w0003UVJSwtChQ3E4HAwZMgS73c6UKVNqlWQWospj0iUydN8ks8MBEydWb7/+OkgtLCGEEEK0QAkJCSxfvnyfRPPy5ctJTDz0SDpRe1nhIVzbtV2gwxB19Gdppa8+dZnHy8LdJZyR2Tyv/XtG1fw9DjIMHuzbkVXFFaSG2EkNrf/AmTk7dvPu1jwAlhWV8cpR3Ym21b7ecUPUJ8kMEGsP4soujZ/c85gmN/+6jh1VTgCu7pLBCSlxde7HqhJRBKFxs7MigmKdTEx0/ZLs/pCXl+d7f2jfft8R43tz6D/w6lIANA6q9MqAJ1aVUowYMaJex4aoboRY6l+LXikLqZZ7cLMTK7EYqnkkdJOSkrj66qsDHYYQzUa9bj8+8MAD3H777axevRrTNOnevTvh4bJKsjg0rTVO09z/9DivF957r3p75swmjUsIIYQQwl8uueQSJk2axMaNGxk0aBBKKRYsWMCDDz7IDTfcEOjwhAi41BA7wRYDh9cEIDs8JMAR1U2wxUJ/P4w+LnLtKcHhNjXlHm+TJZqbu2KXx5dkBvi9pKJeieYglUiKZSqf5izllXXpWIhkaNJWru+W6c9wa6W4uJjrrruO0tJSrFYrDz300D43JPcWrDpjqHBMXY7CRrDq0YTRNk9KGdhoe6WGhGhJ6pxovvDCC3nyySeJiIioUeS8oqKCyZMn88orr/g1QNF6OLwm2ysdRFitjEtPCHQ4QgghhBCN4s477yQiIoJHH32UW2+tnrKdmprK1KlTZdSTn2it+SKngO2VTo5PjiWrhSUqW7rF+SV8lVNAdngoZ2Ul1Xl0aHywjQf7dGRhfgldIkObtGREfeXn5+PxeEhOTvZbnyenJbAov5ScKiejUuJI91P5kM8//5xffvmF/v37M2rUKL/02dTi7EF0jwpjdUkFhoJB8fUrnQEQavRm+e5QLJQD8G1uEdd1bdfko5o3btxIaWn1CGWPx8OqVasOmmi2qngyLI9TpVcSRAYl5seYlBNrnIVNNc+ZHC6vic0S2BJGLr0Dt95JiOqFoZrnTAkhWrM612i2WCzk5OTsM+0vPz+f5ORkPP9YxXZ/2krtPqnRvIfHNNlQXkXfmAiu65bJUfu7UKiogL9HxpeXQ1jLWTVcCCGEENXaynXeP82ZM4cTTzyRoKCaoxHLysoAiIiICERYTaapv++f7cjn2XXbAYiwWnjpqO6EWmWR6aaQ53Bx6eI1eP76GHlFp3ROTIsPcFSNa968eTz55JNorZk4cSJnnunfGr/1Tc55PB5eeuklNmzYwIgRIzjhhBNYuXIlt912m6/NtGnT6NWrlz/DbTIur8mK4nISg220C2tYwvD1jTm8szUXgC6RoTzSr7M/QqyT0tJSJk+eTGFhITabjYcffpjs7OxaHZvrfZwy8xuguhxIlvXlxgy1zkrdHm5fvp7NFQ4GJ0RzU/fMgJQnqTRXkOO9G40Hu+pAuuURlGq8OuJCtCV+r9FcWlqK1hqtNWVlZTVWF/V6vXz66adSc04c0G6nm2hbENP7dCQ7onnUUhJCCCGE8Jfx48eza9cuEhISagzMaO0J5kDZWrlnQcUyj5dil0cSzU2kzO3xJZkBCvcq/9BazZkzh7/HZ82ZM8fvieb6jgD97LPP+OSTTwBYu3YtPXr0oLCwsEabf+63JDaL4ZcSJQAT2ieTGmqn1O1hRD1KcPhDZGQkTzzxBKtWrSI7O5u0tLRaH+vRe76PXl3UGOE1yJc5BWyuqP67vGB3MWNK4+ke1fTlVSv0IjTVgx+degNucrAR+AUDhWhLav2OFh0dTWxsLEopOnfuTExMjO9ffHw8F154IVdeeWVjxipaKFNrytxeLsxOob1MaxRCCCFEK5SQkMCiRYuA6rIOgVpoqq0YnhxL2F+J5SPiIkkJkRmETSU7PIShSTEApIXYOTG1dY9mBmjXbk+ZgoyM5pO0qqqq8m1rrXE4HAwcOJCePXsC0LNnTwYOHBio8JoVpRTDk2MZn5Ho+9sRCDExMRxzzDF1SjIDxFrOwlBhgEGc5YLGCa4BYveqLW4oiPrHmkwV5hI2eSay2XMBVXpNo8URorr7tq0qESsyGFKIplbrEc3z589Ha82wYcN4//33iY2N9T1ns9nIzMwkNTW1UYIULVuFx0uY1eDYpFj50CWEEEKIVumyyy5j3LhxKKVQSh20jqvX623CyFqnjhGh/HdAN4pdHtJD7XKN2YSUUlzfLZMrO2dg/8dI3PLych588EG2bt3KySefzBlnnBGgKP3ryiuvJC0tDZfLxSmnnFLvm0kFBQX8+uuvZGdn17pkwsGMHj2aZcuWsWHDBkaOHOnrc/r06TgcjhqzkEXLFqK6097yJuBFqea3YOTQpBjynW7+LK3guKRY0v5Rb3y3+RxeXQxAvve/ZFgfa5Q4wo3BpBKOi22Eq6MxlL1RziOEOLA612jesmUL7do1rHB+W6ndJzWaq20sq6JvbASvD+px8J8bqdEshBBCtHht5Tpvf/744w/Wr1/P2LFjmTFjBtHR0fttN27cuKYNrAm05e+72GPWrFm89dZbvv0XX3yRlJSUAEbkX8UuN3ev2MiWCgejU+OY1Cm91seWlZVx1VVXUVhYiNVqZdq0aXTr1m2/bZ16IwYRBClZQF20Dls9V+DS2wAIUb1Jsz4Q4IiEEHXl9xrNf1uzZg3btm1j8ODBADzzzDP897//pXv37jzzzDPExMTUP2rR6mitMbVmeHItRjOHhlYnmP/eFkIIIYRoQbp27UrXrl25++67OeOMMwiV6xnRxlitez5eKqWwWFpX3ey52/PZWF5drmLujnxOTI0no5aL1G3atMlXL9nj8bBy5cr9JprzvE9Ran4JWEi23ES4Mchv8bcEq4rLsShFtygZdNSaJFluJN/7EoogEiyXBjocIUQjqvOqAzfeeCOlpaUArFy5kuuvv57Ro0ezceNGrr/+er8HKFo2l6mxGorutblQUKp6FHNYWPW2EEIIIUQLdPfdd0uSWbRJ48aNY8iQIWRmZnLFFVe0usXiw4P2JM4tShFSh0X82rdvT3x8dT1rq9VKnz599mmjtYdS86u/9rx/JZzbjpfX7+DW5eu56dd1/G/zrlof59a7yPP+H/nelzF1ZSNG2HY59DpyvY9T6P0fWnvqfLxdtSfN+gCp1qkEqdYzy0EIsa86j2jetGkT3btXF1h///33GTNmDNOmTWPZsmWMHj3a7wGKlm1nlZN4exBdI+WOtBBCCCGEEK1ZcHAwN954Y6DDaDRj0uLJd7rZXF7FianxxNehRGJERASPPfYYK1asIDs7e7+LCiplxaYycOmtANhVw+s4tyTf5xX7tn/IK+asrP3Xui9ze8h1uMgKC8ZqGOR47/N9zbZt38qspypwOp1MmjSJXr16NUXorZqpnez03oWp/5p9jEGs5V8BjUkI0XzVOdFss9morKy+S/j1119z7rnnAhAbG+sb6SwEgNs00Rqu75ZJlK0WP2pOJ1z61zSaF14AuxTuF0IIIYQQrdvm8iq+yS0kMyyE4cmxhz5A+IXTa/LMn9vYUuFgbHpCrb72VsPgko5p9T5nTEwMxx577EHbpFruo8T8DIuKIkrVfSDX6pJyXtmwkzCrhas6Z5DQDNcLcrlcvPHGG+Tl5TF+/Hi6dOkCQI+oMH7YXQxwwBmx2yoc3PzrOso8XrpEhjK9T0fcOtf3/MwXv2Lj2jgAHnvsMWbMmNG4L6YNMKnYK8kMHnIP0loI0dbVOdE8ePBgrr/+eo4++mh+/vln3n77bQD+/PNP0tNrvxiCaP0KnW6ibVaOio+q3QEeD7z6avX2M89IolkIIYQQQrRqFR4vty1fT5nHC1Svb3J8SlyAo6qfebsKmb0tj3h7ELd0zyTYWuePmk1q9rY85ucWAfDkH1s5LDq8TiOUG4tVxRJnOafexz/4+xYKXW4AXli3nTt6Nb9R0f/73/+YPXs2AMuXL+e1117DZrNxXbd2HBYTgUXB0KT9J/6/zyvy/b6sLa1kY3kVieFnU+CdiSIIm+4K7AbANM0meT1NadOmTbzyyivY7XYmTZrUJOVprCqWSGMUpebnWFQkUcbJjX5OIUTLVed3/6effporrriC9957j+eee460tOo7up999hmjRo3ye4Ci5Spxe7i0UzqJzeCCTQghhBAiEBwOB8HBtVssTLQ9BU63L2kGsLnCEcBo6i+nysl9KzeytrQSE82akgreGtzr0IuBB5BrrySkBtxaBy4YP3Lu9bpcZvN8TQUFBb7tiorqMhc2m40gw2Bk6sFvtLQPD/Fth1osJNptxBinEqlOQBHE5MvyeOyxx3A4HFx22WWN9hoC5cEHH2THjh1A9aKSU6dObZLzJlquJM6YgCIEQ8nneyHEgdU50dyuXTs+/vjjfR5//PHH/RKQaB201iil6B0dHuhQhBBCCCGalGmaPPDAAzz//PPk5uby559/kp2dzZ133klWVhYXXXRRoEMUzUR6qJ0+MREsLyojzGphWFJMoEOqlyqPl3ynG5PqxOb6sip2O921GnDiMU2sRp3XqG+wUzISWVNSydZKB2PT4kkJaR2zKa/pksHz63YQZrVwYYfURj/f30njuLjaj8Q/9dRTWbZsGSUlJZx++ulERETU+thBCdHc3D2LDeWVHJMQTYw9CACLqu6jXbt2PPHEE7V/AS1MVVWVb7uioqJJz21RtZypLA5q27ZtPPfcc2itufTSS8nKygp0SEL4VZ0TzVu3bj3o8+3atat3MKL1cJkam1LE/vXGL4QQQgjRVtx///28+uqrPPTQQ1xyySW+x3v16sXjjz8uiWbhYyjF1F7ZbKt0EGcPIiKoeZeb+Nvc7bvZUF7FsKQYesdEkB0RyrCkGN7dmkeo1aB7VBjRh3gt2yoc3LViAwVON2dnJfPvAyz81lgig6xM79vRb/1Verx4tCYywN/DgQnRDEyIbpJzffLJJ7zwwgsAXHHFFbWe4ZyVlcVrr72Gy+Wq14yPwYnRDE6MrvNxrcGll17K//3f/2G327nwwgsDHY6ohyeffJK1a9cC1QM2n3zyyQBHJIR/1fldMCsr66BToLxe7wGfE22HV2sshiKimddmE0IIIYTwt9dee40XX3yR4cOH15i63bt3b/74448ARiaaI4uhyNqrHEBzN29XIS+ur566/0NeES8c2Y34YBv/d0RXzshMYmelk2HJsdgsBx+l/O7WXPKd1bWEZ23exZj0BMKslkaPvzEsyi/hodWb8ZiaizqkMi6jdnVzvaZmS0UV8cG2gCeo6+ODDz5A/1VyZPbs2XUqpWkYhpQVqiXTNDH+GvU/aNAgBg0aFOCI9uXRxRSbH6CwE2OchqHke3sgLpfLt+10Out8fJk5nyLzXawqmSTjWiwq0p/hCdFgdX43+/XXX2vsu91ufv31Vx577DEeeOABvwUmWrYqr4nNMIi2tbwLJiGEEEKIhtixYwcdO+47UtI0TdxudwAiEsJ/dlXtSYy4TE2Ry+NbRO+YxNqX/oi2WSkpKcHldJGWGE9QM67nfCjvbc3F/Vc95P9tya1VotnUmqkrN7K8qIxQi4UH+nSgY0RoY4fqVxkZGeTl5QGQnp4e4Ghaj2XLljFjxgx++uknVq1ahdPpxG6307NnTwYOHMgFF1xAv379Ah1mDbu8D+DQ1TdSPeSSZLk+wBE1DyUlJTz11FMUFRUxYcIE+vbty2WXXcZjjz2GaZpcccUVderPq8vJ9T4JeHHpbRTyFgmWSY0TvBD1VOcs4GGHHbbPY/379yc1NZWHH36YU0891S+BiZbL5TUpcLo5o10iCbIQoBBCCCHamB49evDDDz+QmZlZ4/F3332Xvn37BigqIfzjhJQ4vt5VSL7TzZFxkXSIqN9o7IR1qyj69jtc9hA6aAdBx/bxb6BNKDnYztrSSgASg00Kve9gVXFEqGEHnA28o9LJ8qIyACq9XubnFrW4RPOUKVN4//33UUpx2mmnBTqcFm/9+vVMmjSJ+fPnk5aWxvHHH8+ECROIjIyktLSU5cuXM3v2bJ5++mmGDh3Kiy++uN+bmoHgYvuebb39IC3blhkzZrB48WIApk+fzltvvUX37t156aWX6tmjBsy99s0DNRQiYPw23LRz584sWbLEX92JFizX4aJTZAi39mxftwNDQ+GvO+KEtqyLLCGEEEKIv919991MnDiRHTt2YJomH3zwAWvXruW1117b76LaQtSG19RsrXQQH+BazonBNv47oBulbi8xNutByyoezB8rV5C1fiUApUBpaSlRUS1zsbHLO6cTa7dS6fFydPojFJqbAPBaiolR+0/AxtqDiLBaKPNUl57MCmt5pQbCw8M577zzGtTHunXrKCws5PDDD8fayssuOvQ6dnufQ2GQYLkKu8ryPffmm29y8cUXk5KSwgcffMCYMWP2+/XweDzMnTuXKVOm0Lt3b15++WXOOuusJnwV+xdjnEqB9zXAQrQxrt79FJsfUWp+gV11IMGYjKFa9sC1vctkuN3uGmVQ6sOiIkiwXEmR+TZBpBBj/MsfYQrhV3X+S15aWlpjX2tNTk4OU6dOpVOnTn4LTLRcDq9J/9jIutdYUwoSEhonKCGEEEKIJjJmzBjefvttpk2bhlKKu+66i379+jF37lxOOOGEQIcnWiCvuafMQpjVwmWxNuJNNz169Kh3orc+/q7HazUMYu31T5YADBgwgB9++AGtNT169CAysuXWGQ2zWriwQxpeXcEmzybf40697qDH/KdvJ77ZVUhGWDDDk2ObItRmZf78+Tz++ONorenTpw/33XdfoENqVHneJ3HpLX9tP0WG9VGgOsk8YcIEJkyYwHPPPUdYWNgB+7BarYwfP54RI0Zw+eWXc84556C15uyzz26S13AgMcYZhKvjUARhVdH16sOlt5Hvfcm3bVPZxKjx/gvyHzy6EJfegl11wqLCG+UcEyZMYNu2bRQVFXHBBRf45WZKlDGSKGOkH6ITonHU+ac8Ojp6n4sZrTUZGRm89dZbfgtMtEx/X3x2j2qcP9RCCCGEEC3ByJEjGTlSPggK/9hW6fCVWdi0M4dr3plHu02rOf7447nmmmuaJIZVxeVMW7UJp2lyZecMhjUwMTpkyBBSU1PJz8+nX79+TZowry+Hw4Hb7SYiImK/z1tUGGHGQCrMnwALEWroQftrFxbM+R1SGyHSluGnn37yfX5cvnw5VVVVhIS0nIUx60rj3WuvenvdunVcfPHFTJgwgZkzZ+4z2rW8vBy3271PHiYsLIyZM2cCcPHFF3PkkUc2WhmNsrIyli5dSnp6+kHPEaQaNmis5tcH2Gfff9w6h23e6zF1OVaVSIblCSxq/7/XDZGamspTTz3l936FaM7qfBt6/vz5fPPNN75/3377LatXr2bDhg0MHDiwMWIULUi5x0uI1aBrZD1KXzidcOWV1f/qsfqqEEIIIURzsGTJEl9Nxr0tXryYX375JQARiZYu3h5E+F+zBQsKCgitrE46f/vtt00Ww+ubcijzeHGZmpfW7/BLnx07duSoo47CZjv49Pgyt4e523ezcHexX85bH8uWLWPChAmcffbZvPfeewdsl2zcSpr1ITKtzxNmDGjCCPfQ2oOpXQd53sTUjiaMaP969erl2+7YsWOrTjIDJFomE6TSsKkMEiyXA3DppZeSmprKc88950syu93u6hnjXToRERFBbGwsMXEx3HHHHVRVVfn6MwyD5557jpSUFCZNapwF4VwuFzfddBOPPvoo119/PUuXLm2U8wDYSMcghEq9AhMHkYxqtHNV6F8wdTkAHp2HQ69ptHMJ0dbUeUTzscce2xhxiFYiz+HiyLgoekXXY0SzxwPPPlu9/dBDYLf7NzghhBBCiCZw5ZVXctNNNzFgQM0k044dO3jwwQf3m4QW4mDCg6xM79ORb3IL6b51DatztwHQrVu3Joshaq+60JFNWCNaa81ty9ezuaI6MXpxh1TGZSQ22fn/9v777+P8azDMm2++yemnn14jxr9HmyqlCKHpvi//VGH+zC7vg2i8JFomE2kMr/G8U29mp/dOvLqYGON04iwNq7HcEGPGjCE5OZmCggKOOeaYRjmH1pp3t+axubyKkalxHBbj/1GrtRWiupNpfd63v3TpUubPn88HH3xQo1zG6tWrueeee2ocW1JUwgMPPMCWrVt4/bXXfY+HhYXx8MMPc9ppp7Fs2TL69evn15h37drF9u3Vi/tprVm6dCmHH354g/rU2kSpfcc8luuFmFQRqnoDUMVvhHN0nfo2tYNicw5KKaLUGAy1/9rnwaoz1eMuTRTB2Paqly2EaJhaXSHMmTOn1h2OHTu23sGIls1jmmjgzMykFjH1TQghhBCiMaxevXq/H/b79u3L6tWrAxCRaA2ywkO4MDwNnf1vvklLpKKioklrfl/ROR27xaDK4+Xc7KYr91DlNX1JZoDVJRWMy2iy0/skJSXts+3Qf5DjvR9TV5JguZxII/A12AvNWWiqRzMXmK/tk2guNmfj1cUAFJnvEW2c2iglA2rriCOOaNT+P9mRz+ubcgBYXFDCy0d1J9oWtN+2DoeDn3/+maSkJLp06VKn8zj1JvK8T6Bxk2BcQYjR85DHzJw5k/T0dMaMGVPj8b+TzjGxMVxz9TVEREQw7T/TKNhdwJuz3uTRRx4lMXHPzZaxY8eSlpbGjBkz/J5oTk5OJi0tjR07dqCUom/fvg3qr9D7FoXm/7CqBFIt92BTab7nDGrOiv7nfm3kmo9QYVbfzHUaG0i23LLfdsGqC2nW/+DQawhV/QhSTX/zSojWqlaJ5lNOOaVWnSml8Hobr46OaN7KPF4ig6wcGddyF/IQQgghhGgou91Obm4u2dnZNR7Pycnxy0JAom1TSjF8+PBDN/SzaFsQN3TLbPLzhlotHB4bwdLCMhRwdEJ0k8cAcMkllxAeHk55eTlnnHEGAAXeN/DqEgB2e18k0jiBJUuW8Ouvv9K3b99GT6Luj0XFgd4IgJW4fZ63sqe2tqHCULTuWaS7nW7ftsvUlLg8+000m6bJrbfeyvr160F5uGLKsQwZfAJhRu1G7+72Pofzr697nvkkmcZ/D3nMTz/9xPDhw/d5X+jYsSMbNmwgKyvLV05j27ZtPPHEE5imSU5OTo1Es9VqZfjw4SxatKhWsdaFzWbj4YcfZsmSJaSnp9O5c+d69+XVZRSaswDw6FyKzPdIsuypMR9m9CdWn0OlXkao6k+oUfektlPvvRjnxoO2DVHdCFGBm30gRGtVqytd0zQbOw7RwhU43RQ43fSICiPOvv87xEIIIYQQbcEJJ5zArbfeykcffURUVBQAxcXF3HbbbU06ArW1y83NJTc3l65dux6yxq9o2e7o2Z6VxeXE2ILICg9MHd+QkBAuvPDCGo9ZVCToPdvr1q3jvvvuQ2vNxx9/zKOPPkqnTp2aNM5odQqmqsRKPHGWifs8H2OchcaLhzyijfEYqmG/Ox6PhxdffJENGzYwYsQIvy6CWlZWxieffEJISAgnnXRSvW7UjU6N44e8InY73QxNiqFd2P5LKRQVFbF+/Xo0Jg7zdxb8vJVOA38kieuJMA6+qGO1vUtB1G5276pVq5gwYcJ+n9v7RmV+fj7/e/t/AASHBO/3Z6pPnz68/fbbtTpvXUVERDBs2LAG96MIQhGMpnqGgoWofdrEWv5NLP+u9zmijNEUeGf6toUQTU+GVIgGM7WmwOnmrKwkruicIWUzhBBCCNGmPfroowwZMoTMzEzfNOPly5eTlJTE66+/foijRW2sWrWKu+66C7fbTdeuXZk+fbqMFm/FrIZB31j/zJo0TZOysjIiIyMb/LklwbgUhRUv5cQZE1m4fTNaV2eetdZs374dIzmN1zflEGa1cEnHtAOWbTgQrTVO1mMlBquKP2jbUnMeed4nAU2EcRxBKmmfNoayEW+5cN+D6+nTTz/ls88+A2DdunX07NmTtLS0QxxVO/fddx9r1lQv0rZz504uv/zyOveRFGLnpaO6U+nxEn6Q2uIxMTG0b9+eDZvWYGon3fumA1ClVxPBoRPNCZbLyfP+HxqXb6G/gzFNE6fTSWTkwX+uKyoqOHnsyeTm5AJw2623ERq6b0mJqKgonE4npmn6RkE3N4YKJsVyJ8XmBwSpJGKN+ieUDyTGOI0wNQBQNcpyCCGaTq2vxr755huuuuoqFi1atM8fw5KSEgYNGsRzzz3HkCFD/B6kaL5MrcmpchIZZOH87FQSg2U0iRBCCCHatrS0NFasWMGsWbP47bffCAkJ4YILLuCss84iKEhmfvnDggULyA+LxhEajmvjJnJzc/2W3GpJ8vLy+Pjjj4mJiWHMmDGSbD+E0tJSbrnlFrZt20avXr245557GvQ7aVFRJFmu9+337x9Peno627dvJz09nf79+3P1qk3k/1W+wdRwc4+sOp1jl/kfKsyFKIJIsdxBqHHgGrxl5rf8PcS6zPyOROP6Rh8E5HDsqZ+ttfYtmFhfLr0dg3CsKpqNG/eUPth7u64MpQ6aZAYwDIPp06fz008/QvybZPUoACyEq0G1OoddZZJhfbT2MRkGdrud0tLSA7aprKxk9MmjWfxTdc3hMWPHcOutt+63bUlJCXa7vdkmmf8WavQm1OjdqOewqfRG7V8IcXC1vhJ54oknuOSSS/Z7xy0qKopLL72Uxx9/XBLNbYjLNNlUXkWi3cbZ7ZPJPMA0JCGEEEKItiYsLIxJkyYFOoxWy5nVmbWl1QmVog7dCY+OCXBEgXHHHXeQk1O90FlpaSnnnXdegCNq3r777ju2bdsGwMqVK1mxYgWHH167Gry1ERERwZNPPklubi5JSUnYbDbKPXvWMNp7uza8upQKcyEAGjeleh6hHDjRHKy6UqWX/7XduUlmmp500kn8+uuvbNiwgVGjRu1Tm74u8rxPUWp+icJGsuU2TjzxRD788EOUUowaNarW/Xh1GU69CbvKxKL2Lc9wIGFhYRx//AhMfRxVeiVBKqlRk5Y9e/Zk+fLl+32uqqqKk8eezPfffg/A8SOO59133j3gzaTly5fTq1evffvRa3Dr7YSpAdWlXoQQopHVOtH822+/8eCDDx7w+REjRvDII4/4JSjRMuysdNI9KpznjuxKSogfFpEICYFNm/ZsCyGEEEK0YKtXr2br1q24XK4aj48dOzZAEbUeIECbQQAAuTZJREFU9uzOdKpSOBwOYmNjKVfGfqp9tm5ut9uXZAZ8CVRxYHsvoKaUIj7+4KUo6sNms5GRkeHbv6xTOs/+uY1wq5WJ7ZPr1JdBGFaVRHHpDn78ejfpsVWMHa4PmECONc4mSCXjpZRINaJBr6O2wsLCmD59eoP7MbWDUvNLADQuSvXnXHTR7QwfPpzg4GCSk2v3tfPqErZ5r8Wj87GoKNItjxGkEg994F4MZSNM+e8GxIEMHDiQ2bNn4/F4aiSQ3W43p4w/hfnz5gMQGRnJKWNPYdasWYSGhnLaaafVGInv8XiYN28e48ePr9F/ubmIXd5pgCZIpZJheapBNbnLzQWUmJ9jV+2JM85DKZlBIYTYV63/MuTm5h50WpHVamX37t1+CUo0f16tcZma4ckx/kkyAxgGZGX5py8hhBBCiADZuHEj48ePZ+XKlSilfDVb/04Oeb11G9Uo9nVUfBRfxMbi0ZqOESEk1aN8m8c0eW7ddv4srWRoUiyntqtbMirQgoKCGD16NJ9++ik2m40TTzzRL/1qrXllw06WF5VxRFwk52an+qXf+vpoWx4ri8sZmBDN8OTYBvU1YMAArrjiCn7//XcGDRpEZmYmXlOj0VhrUXKgrKyM4uJi0tPTaz1aeHhyLMOSYuo1ulgpC+mW/zB96jls3WjFqpZQlf82//73/mvbKqWIVMPrfJ7mQGHHqpLw6OpaxDbaAZBVx8+HVXolHp0PVCedK/WvRCn/LVDoTxdccAFPP/00c+fOrZEkXrRoEV9+8aVvv7S0lKuuusq3//3333PMMcf49ufMmcOOHTu44IILavRfPbq9+v3HrXfiIQ8b9Ruh7dZ57PI+DJhU6d+wqnii1bh69SUan8vlIigoSNbPEgFR60RzWloaK1eupGPHjvt9fsWKFaSkpPgtMNG8lbg8RNusnJrRsi7IhRBCCCEa2zXXXEP79u35+uuvyc7O5ueff6agoIAbbrhBZgD6SZ/YCJ46ogu7qlz0jA6rVZLwn77KKeTLnEIAZmzcSZ+YcLIj9l1kq7FofeCRqbV1+eWXM3bsWMLDw4mK8s+Y7p/yS/hwe/UAos0VDnpGh9PPTwvx1dXP+SW8tGFn9XZBKe1Cg+kUued7VF5ejsvlIja29gnoE0880ZeUX1ZYyvTfN+MxNVd1yThoIvvPP//kzjvvpLKykoEDB3LrrbfW+vvXoO+zN5qdm2xYVQIAa9eurX9fe2lui8YppUizTKPE/BiriiNKnVyvfmyqPQobGhdgwa461KsfrTW7zeeo0D8RonqTZFzn9xG8/fr1Y+jQoUyZMoURI0YQFhYGcMgFAvd+vqKightvvJGhQ4fSr1/Nsiqh6ghK+AwwsalMgth3ccjaMqkETN++V5fVu6/Wqtz8kWLzI4JUGgnGZRiq/gPyGvL+8MYbb/DOO+8QExPDvffeS2ZmZr3jEKI+av3OMnr0aO66664axf7/VlVVxd13383JJ9fvzUC0POUeL6khdlL9NZoZwOWCG2+s/vePKaZCCCGEEC3FTz/9xL333ktCQgKGYWAYBoMHD2b69OlcffXVgQ6v1UgPDaZ/XCTBFku9jnf/NdL8QPuNZVVxOef8uIozF6xkQV5xg/tLS0vzW5IZwGP+4+tiNs3XZX8KXW7ftgaK9tr/+eefOffccznvvPN466236tX/G5t24fCaeLRmxl8J7QP56quvqKysBKp/x5tqNq/VavWtg6SUYujQofXqZ9myZUyePJn+/fsTHByMxWIhODiY/v37M3nyZJYtW1ajfaW5nJ2eu8jzPoupG7bAX20FqUTiLRcSbYxDqfr9XttUGmnWB4mznEuadTrBav8D5Q6lSv9KqfkZXl1Mufk9Zfq7evVzKC+++CI5OTn/z959h0dVpn0c/54zk5n03kMKoSO9ClYEERVxUVFRUVkVxbYWVBRFdG2Lq/KKvawVFQvuWrGsXVcRlKYUkZ5CSE8mmXqe94/IQIRAyiRnktyf68rFmZlznvMbCMnMPc+5H2bOnIlh1BVyBw4cSHFxMTt37tzvq7i4mIEDBwJ1HxbMnDmTgoICnnrqqf3GjtCHkml9iFTLTWRY/oGmNX/hS7uWQ4x+EqBj07oSo0vtZ18+VcEu3z9xqnVUGZ9SZrzZrHEM5STPezO/e0+l0PcPlDIOfdA+qqqqWLx4MUopSktLeeutt5qVQ4iWaPRHcrfeeitLliyhZ8+eXHnllfTq1QtN01i3bh2PPvooPp+POXPmtGZWESQMpXD6DE5KTwjspRgeD+yZ5TNvHtia3z9KCCGEEMIsPp+PyMhIABITE8nPz6dXr15kZ2cHbDaiaLkT0hJYVVZV1zojNY5e0RFtct7nN+dT6fEC8NSmnRyZHNsm522sI5JiWV5ayU+lVYxIiGZEgnkLiB2dHMfHBaX8VlXDkPgohsRH+R97++238XjqCs9vvPFGg+0kDibetvftcJzt4G+Ns7Ky/NsxMTGHnHUaSLNmzeKkk04iJiaGLl2a1vpg06ZNzJgxg88//5yMjAzGjRvHeeedR3R0NJWVlaxcuZK3336bRx55hDFjxvDUU0+R2y2DAt9dKFygwEIkCZbzW+nZBV6o1r3ZBea96n8/aDS/SHsw3bt359lnn+Xcc88F4PHHHyciIoKEhISDHudwOJg5cyYvv/wyixYtavDKc7uWi11r/gKN+0qyzCRRv6zFNQClFJXqYzxqJ1H6OOxa+59xq/Cg8O5zu7ZZ41Spz6hVa4G6ntjR2njCtcGNPt5utxMREYHD4QBo0tUeQgRKowvNKSkpfPfdd8ycOZObb765Xq+5E044gccee4yUlOZfiiHaD7ehsFs0hid0tiVXhBBCCCEOrV+/fqxevZrc3FxGjhzJ/PnzsdlsdQWc3MC84RctZ7fo3Na/7f89ovZZ9CvSGnyLaVl0jev6BEfhJ9xq4cGhPXH5DOyW+hfjpqens3ZtXUFmTwvHSuO/lBovYSWRFMtNhPzRbqIhV/bKJHJzAW6fwXldD94GcuLEiVgsFvLz8xk/fjyhoaEteGZNo2kahx12WJOPe+WVV7j44otJS0tjyZIlnHLKKfUWndvD6/Xy7rvvMmvWLAYMGMBTzzzMsDPyMajFSgI+KgPxNNqE1zAodXtJsIVg0ZtfEA3XBxCnzva3zojUjjr0Qc00depUlFJcfPHFfPvtt9x///1MmjSpwX+rd955hxtuuIGCggIWLVrE1KlTWy3bnwViolmlWspu32N/bP+XHMsz6FrbtS1qDVYtkXj9XMqMt7BpXYjVT2vWOBbqf4Cla5FNOt5ms3H77bezZMkSkpOT2/R7Q4g9NKWafo1YWVkZmzZtQilFjx49iIuLa9LxlZWVxMTEUFFR0aafBLe1oz7+EbehSG7G4iTBrNztweVT/PuYgaSHB7B1hsMBf8z+oboaItpmVokQQgghAqezvM47mI8++giHw8Fpp53G5s2bmThxIuvXrychIYHFixdz3HHHmR0x4OTfvfGKnW6e/T0fl2FwYW46WRFtV7DsSJxOJ2+88QbV1dWcccYZJCRGs9l7FlC32GaUPpYUyzUNHq+U4r333mP79u0cf/zx9OzZs22Ct5FXXnmF8847j/POO88/S/ZQ9p0le9/zWZxwthMLUfSwLsWuN6/XcVuq8niZ/fMmttc46R4Vxr2Duje7tc4Bx6+qIjIystUWWPvz7POxY8cyaNAg/8/WlStX8t///pe8vDyOO+44nnzyyQZnMgez3b4nqDDe99/Osj6BTcswMVHwUEpRZrxGrVpLpH4kMXpgFnkVIhAa+1qvWYXmluosL0Q7aqF5c1UNIxNjePbwvoH9JSuFZiGEEKLd6yyv85qqtLSUuLi4Jr92+uqrr7j//vtZsWIFBQUFvP322/zlL3/xP37hhRfywgsv1Dtm5MiRfP/99/7bLpeLWbNm8eqrr1JbW8vYsWN57LHH6l2CX1ZWxtVXX80777wDwKRJk1i4cCGxsbGNyin/7sJshnKzxTv1j0XgIFo/gWTLlQ3u/+GHH/LYY3WzKsPDw3nmmWeIiopqcP+2pJQiPz+f6OjoZmX67bffGDhwIGeccQbPP//8fov+eb1eSktLiY+P32/WrGEYXHjhBbzx5mu8u+IocrpHkGV9DJuW2aLn1BY+KSjh4Q07/Ldv6psTkNY0Xq+XO+64g5UrV5Kdnc29997bqt8rP/30E8899xzff/89a9asweVyYbfb6d+/P4cffjjTp0+vt/CfRxWgEYZVi221TIHkVL+R77sNQzkI14eTpt/WasV7IUTgNPa1XvAsMyvaDR9wTErT3ygJIYQQQnQ2O3bsYOfOncTHxzfrtZPD4WDgwIE88sgjDe4zYcIECgoK/F8ffPBBvcevueYa3n77bV577TW++eYbqqurmThxIj6fz7/POeecw8qVK1m6dClLly5l5cqVTJs2rcl521q528PNP2/iwv/9wgd5xWbHabGamhrWrl1LRUWF2VHahNPp5PPPP2f16tUtHkvXbKRYZmHTcgjXhxGvn3fQ/fPy8vzbNTU1lJeXtzhDoPzzn//ksssu46KLLmL9+vVNPv7SSy8lPT2dxx9/vF6R2efzMX/+fBISk0hJSSEhMYl//OMf9X4W6LrO448/QXpaBrddvpYwrR8hpAfkebW2tH0WqteA1LDATPhatWoVK1euBGDbtm188cUXARm3IUOGDGHhwoX8+OOPOJ1OfD4fTqeTH3/8kYULF9YrMhf7nmObdwbbvNNxGD+0aq5ACdV6kG15mizro6Tpt0pdQYgOJviagomgpZSixOXBruv0bqPFUoQQQggh2ps9s98efvhhqqurAYiMjOSqq67i9ttvJySk8YtKnXjiiZx44sEvnbXb7aSmph7wsYqKCp599lleeuklxo0bB8DLL79MZmYmn376KSeccALr1q1j6dKlfP/994wcORKAp59+mlGjRrFhwwZ69erV6Lxt7fVtu1hbUfd3/MRvOzkiKZaYQyzqFqwcDgfXXXcd+fn5REVF8cADD/h7DwdKpcfLg+u2UVjrZkp2CmNT918oyu0z2F7jJC3MToQ1cG0HDmTu3LmsW7cOgMsvv/yQ3+uHEqmPIlIf1ah9x48fzxdffEFFRQUjR45s8iJ7raWkpISvvvoKgNraWj766CN69+7d6ONXrFjB559/zpIlS/Zrl3HnnXdy5513+m9XVpQze/ZsampquOOOO/z3R0REcP/9D3L66adTuGoyGUNb9/sgUPrFRnJDn2xWllUxPCGa7lGB6fubmJiIpmn+daqSk5MDMm5j/XlG+h5KKcqNf9dt46XceJcIfWSb5VJKYVCNRds7u7vK+Jwi32PoWjhpllsI1Q78+8OiRWEhOK4gEAdWbXxHkfF/aISQqs8mTO9ndiTRTsiMZtFoBU43bkNxTk4KQ+Pll4IQQgghxIFceeWVPPXUU8yfP5+ff/6Zn3/+mfnz5/Pss89y1VVXBfx8X3zxBcnJyfTs2ZNLLrmEoqIi/2MrVqzA4/Ewfvx4/33p6en069eP7777DoD//e9/xMTE+IvMAIcffjgxMTH+ff7M5XJRWVlZ78sMln1mwumaRgvW/jLdr7/+Sn5+PlDXC3bZsmUBP8fibbtYUVpFXq2LhRt2UOXx1nu81uvjup82cu2KjVy+bD1FTnezz+X1eg/6uNPp9BeZoe57tS1lZWXxzDPP8MwzzzBnzpyAzqr0GgbN7VAZFRVVr2VNVlZWk45//vnnSU9P55RTTql3v9PpZP79/wQgPaMLTz/9NOkZdcX1+ff/E6fTWW//SZMmkZGRwfPPv9SMZ2Geo1PiuLp3FqOSYgM2ZnZ2NjfddBNHHXUUl156ab2flW3BaxgHvF/TNGza3g9IbFrTvldawqcc7PRdwxbvOeR5b0EpDwC7jSdQOPEYpRR7X2yzPCLwdhtPYqgafKqCYuNfZscR7Uj7/LhftDmlFNUeHxd1S+fGw3Ja5yRhYfDHytGEhbXOOYQQQgghWtmrr77Ka6+9Vm925oABA8jKyuLss8/miSeeCNi5TjzxRKZMmUJ2djZbtmzhtttu47jjjmPFihXY7XYKCwux2Wz7Ld6dkpJCYWEhAIWFhQecoZecnOzf58/uvffeejMgzXJWdgqFTjf5NS7OyEomKqT9vr3Jzs7GbrfjcrnQNI0ePXoE/Bz7Fj8V+xdCf6lwsM1RV3AsdXv4vriCSV2SmnSOHTt2MHfuXEpKSjjrrLM499xzD7hfaGgo/fr1Y+0fr/+HDx/epPMEQmhoKKGhgV2McfHWQhZtLSTOFsIdA3LJiWza+xqbzcY999zD0qVLSU1NZeLEiU06/ttvv+X444/fr/fy8uXLcdbWAHDN367m4osvpry8nBtuuAFnbQ0rVqzgiCOO8O9vtVoZO3ZsvX7vndkRRxxR7++nLXgNg7vXbmV5aSV9oiO4c2DufosbplvuoNz4DzpRxOmT2yxbtfoal9oMQK1aQ436iQhtJDqRfL87lhc2DsamxzPvsEqGJkjf/vbIQiQ+Sv3bQjRW+30lJtqU0zCw6xrHpMQdeufm0nU47LDWG18IIYQQog2EhoaSk5Oz3/05OTnYbIFdJPqss87yb/fr149hw4aRnZ3N+++/z2mnndbgcUqpejM4DzSb88/77Ovmm2/muuuu89+urKwkM7PtFwuLDLEyp1/XNj9va0hOTmb+/PksW7aMvn370rdv34Cf46zsVLY7nBQ43ZyVnbJfYT4j3E6IruEx6orQORFNL8K+9dZbFBfX9ct+7bXXmDRpUoMLp91xxx388MMPxMfHc1gHeB/g9Pl4eWvdhzOlbg9vbN/FDX1zmjxOZmYml1xySbMy/Prrr5x//vn73b9vH+z+/fsDdT8z9li1atV+hdRBgwaxePHiZuU4mA0bNlBeXs7QoUP3K4iLvX4qrWJ5ad3VIusqHXy5q5wT0hPq7WPVEkm0XNSmuZTyopQThRcNK6Bh1RIBSLPcwn+2/A+lQlG+LF7cUiCF5nYq1XITxcZzaISQqDfv55HonOSnumiUMpeXeHsI/WLlkywhhBBCiIO54oor+Pvf/85zzz2H3V63OJXL5eLuu+/myiuvbNVzp6WlkZ2dzW+//QZAamoqbrebsrKyerOai4qKGD16tH+fXbt27TfW7t27SUlJOeB57Ha7/7mJwMnNzSU3N7fVxo+xWblrUPcGH08Ls3P3wO4sK6mgb0wEA+Ka3i5v37YPYWFhB/0+sdlsHHXUUU0+R7CyahoRVgsOb93ienG2xvdjDwTDMHC5XERH71/Yczgc/u09hf9999v38T1iYmJwuVwYhtFgn+Cm+uijj/yLmw4dOpR58+YFZNy2tmPHDtasWcNhhx1GdnY2AOvWrWPLli2MGDGCxMTE/Y5RyqBWrcGixWDXcg55jj/3m48Ngv7zhnKT77sFp9qAQS2R2mii9QnYtW4A2LVupId6qfHUAsGRWTSPTcsi3XK72TFEOyT/68Uh7XK6cRsGU3MyWndBELcb7rmnbvuWWyDAM36EEEIIIdrCzz//zH//+1+6dOnCwIEDgbrZgm63m7Fjx9ababxkyZKAnrukpIQdO3b4F5EbOnQoISEhfPLJJ5x55pkAFBQUsHbtWubPnw/AqFGjqKioYNmyZYwYMQKAH374gYqKCn8xWnQefWIi6BPT/IW/p06disvloqioiMmTJwd8Fn8ws+o6t/fP5c3tu0i02ziv64EX6Wwtuq5jt9sP2DN934UBq6qqAOrt9+eFA6FuMVG73R6wIjNQrxXHnh7yTVkgNRjk5+dz7bXX4nK5sNlsLFiwgJKSEubOnYtSisWLF/Poo48SGVl/klahcS8O43tAI8VyHVH6sf7HVq5cyeuvv05iYiKXXnopERER9IqO4KpemfxvdwUD4iIZmRjTtk/0AFz8jlNtAMBCFGFaf6L0o+vtc2PfHF7cXIBV15iem25GTCGEiaTQLBqklGK3y4PD6+PqXpnM6J7Ruif0eGBPr78bbpBCsxBCCCHapdjYWE4//fR69zW3rUR1dTWbNm3y396yZQsrV64kPj6e+Ph45s2bx+mnn05aWhpbt27llltuITExkcmT63p1xsTEcNFFF3H99deTkJBAfHw8s2bNon///owbNw6APn36MGHCBC655BKefPJJAGbMmMHEiRPp1atXs3KLzsnh9fHZ7kp6/+VMZiTHBnSBvfaiT0wEt/VvvVnph9KvXz9Wrly53/0DBgzwb69Zs4YJEyb4+2MD/g/F9rVy5Up/m41AGThwIMuXLwfqfvY0pcjsUw50wk3/vtq4cSMulwsAt9vNxo0bKSgo8PdALy0tJS8vr97PT0O5/ygyAyiq1ddEcax/jLvvvtu/IGNkZCQzZswAYHxaAuPT6rfLMFMIKWiEoqjLajvAzOy0MDs3tda6Tm3I5/P52xkNHjyYm2++ud19KCKEGaTQLBpU5PLgNQxm9sjg4m4Zpv9CF0IIIYRoD5577rmAjbV8+XLGjBnjv72nL/IFF1zA448/zpo1a3jxxRcpLy8nLS2NMWPGsHjx4no9cR966CGsVitnnnkmtbW1jB07lueffx7LPotKLVq0iKuvvprx48cDMGnSJP/l7aL1KaX4dncFLsPgmORYrAGcQdoSSim+2V2Ox1Ac3Yhc81ZvZn1lXQuG/FoXU3PadkavqLtC4e2338br9dbrfzxs2DDsoWG4nLU8tOD/iIuL46EF/wdAaFg4Q4cOrTeO1+vlv//9r/9Dq335VDUutRGbloNVi29Svr/85S9kZGRQXl7e6LYpSikKjftwGN8RomWQYbmnyecNpH79+hEVFUVVVRWRkZH079+fjIwMlixZgsfjIT093d9OYw9ds2HXuuFSvwMQqvXxP+bz+fyFa6j7gDFYWbV4Mqz3Um18Q6jWnUh9lNmRWs0PP/zAd999B8CPP/7IN998U+/3sRDiwKTQLBpU6fby127pXNkry+woQgghhBDtRm1tLUopwsPDAdi2bRtvv/02ffv29RdyG+vYY4/1z5I7kI8++uiQY4SGhrJw4UIWLlzY4D7x8fG8/PLLTcomAue5zfm8vWM3AMtLKrnpsByKiop44403CA8P5+yzzyYsLKzNc/3r93z+vbMu149/5GqIoRQbKvf2+f21Yv+ev6L1TZ8+nUceeYR33323XpE4NDSUm268gTvvvJOC/Lx6iw3eeMMsQkPrL/z4zjvvkJeXx/Tp0+vd71NV7PBdg1cVoWsRdLE8gE1r2pWvw4cPb9L+LjbiMOoKfh6VR6XxCfGWsw5xVGCsXr2a8vJyDj/8cH8bmMTERBYuXMiGDRvo2bMniYmJJCcns3DhQrZv307//v33+/sESLfcRZX6DAtxROl7i+xhYWFcdNFFvPjiiyQlJdVb5DUYhWrdCbU03Ou9vaqsrGTFihVkZ2eTm5u7X+uTP98WQhyYFJrFAfmUQtOgbwv6swkhhBBCdEannnoqp512Gpdddhnl5eWMGDECm81GcXExDz74IDNnzjQ7oggyq8qq99mu65/797//na1btwJ1vXKvueaaVjv/5qoaHt24E4ArenYhN6ruQ5JV5XtzrS4/+CxLXdM4MimWr3eXowFHJ8e2VtxDWrp0Kdu2beO4446jR48eDe7nVWWUGM9h4CJBP7/JBdNgNGTIEMaMGcOsWbMYP358vd7Lc+fOJTw8nHvuvY/KinKiY2KZc8vNXH/99fXGcDgc3HDDDYwZM4YhQ4bUe8yp1uNVRQAYykGNWtHqf28WYtGwovACYNX2X2ivNbz77rs89dRTAAwaNIi///3v/scSEhL262GfkZFBRkbDfxcWLZJYbdIBHzv11FM59dRTA5A6+HlUEUW+/8NHJYn6dML1IYc+qJU5nU5mzZpFQUEBuq5zxx13MGjQILKnzeC7whKGJsUybNgws2MK0S4ExzVZIqgopdjmcJIWZmdowv4rFgshhBBCiIb99NNP/kvC33zzTVJTU9m2bRsvvvgiDz/8sMnpRDAauc9r7sP/WPCroKDAf19hYWGrnv//NuxgY1UNG6tq+L8NO/z3j0qMwWso8mpc2HUNl8/Y79iysjKWLl3KunXruKFvNncP7Mb/DevF8QHoK5tf42JpfjFbq2sbfcwnn3zCo48+ynvvvcett97qX/juQHYbj1BlfI7D+I5C3337Pb7D4WR1WRXGQa4qaIoNlQ7u/3UrL27Ox2Ps/3cZKE899RQFBQXMnDkTY5/zWCwWbrrpJkqKd1NUVERJ8W5uvPHGem10DMNg5syZFBQU+Ius+7Jp2Wjsma2rE6q1fh/3EC2FVMtsIvUjSLBcQJR2XKufE+oWK9xj5cqVeL3eNjlvR1dsPEutWo1bbaXQmG92HKBugcc9P3MNw+Cnn35iRUkl25IzyRgwiMK0HP5XXGFySiHaB5nRLOox/igyR1ot3N4/l7Qwu9mRhBBCCCHalZqaGn+P5I8//pjTTjsNXdc5/PDD2bZtm8npRDCp8ni5ffVmNlXV0DMqnKnZKf6JHlOnTuX555/HZrPtt7hkoPmUoqKigm3btrHD62ZHSjiZmZlMzUnly11lOLw+djs9LNywg1l99/ae3TMLsKioCE3TuO2225rcFgFg7dq1lJaW1mtPUOR0c+2KjdT4fIToGg8O6UlO5KHbh+zYsbdQXlNTQ0lJSb2e5fvyqvK9fweU1Xvsq11l/HPdNhR1HwTceogF/lw+g9e37aLS4+W0rOT93ke5fAa3r96Mw+sDwKJpnNs17ZDPpzm6d+/Os88+y7nnngvA448/Xm9ms9VqJSkpab/jHA4HM2fO5OWXX2bRokV0775/e4QQLZlM6wM41HJCtT5tUmgGiNBHEsHINjnXHkOHDvUXmwcOHFiv57VoCZ9/SykfSqkmrwdlKCfFxtN4VCGx+mlE6EMPfdBBpKenk5aW5p/RPGTIENx/+oDJF6APnITo6OQnpahnu8NJUmgIt/bL5ZiUOLPjCCGEEEK0O927d+ff//43kydP5qOPPuLaa68FoKioiOhouVpM7PVpYSm/VdUAsLGqhjCrxV9wOf300xk3bhwhISH+ft+t5YqemZz66adoLjdxG1fydPl27rzzTgBqfD5ibHVvG7c66s8sLigooKioro2CUoo1a9YwfPhwVpRUsry0kkFxUYz8Y4Z2Qz766CP/wpOHHXYY991XN7N4U1UNNb66gpTHUKyrcDSq0Dxu3Dg+/fRTqqqqGDp0KFlZDa83k6BPo9C4F6U8JOoX1Xvsq6Iy9pSVfiipxOnzEbrPzN8/+9fv+XyQXwzUtRx5amSfeo/X+nz+IjNAsctzyOfSElOnTkUpxcUXX8y3337L/fffz6RJkw5YLPV6vbzzzjvccMMNFBQUsGjRIqZOndrg2DYtC5vW8dfxOeWUU8jKyqK8vJxRozruondtLUH/K15Vio8KEvWLm1xkBig1XqPS+BgAp289XbWX0bXm97EPDQ3l/vvv56effiIzM5Pu3bujlGJCWgI//vGz7Iik2GaPL0RnIoVm4aeUwm0oTu2SzNhUE1bxDQ2FZcv2bgshhBBCtENz587lnHPO4dprr2Xs2LH+AsXHH3/M4MGDTU4ngkl0yN63Y9qfbgPExBy8SBsofWIiOHzdMsrK6mb16vre2bsnpSeyaGshGnBiev3euBkZGWRmZrJjxw4sFgvDhg1jS3Utd67djKHg/bxi/jG4B30Osu7L8uXL/du//PILtbW1hIWF0Ts6gpgQKxUeL2EWnQFxjVuIKysri2eeeYaysjLS09MPWsQK1wfRVXsNMNC0+kXk3jER/FBSCUBOROhBi8wABbUu//Yup2u/WZqxthBO7ZLEf3buJjbEyqld9p9RHCiLFi1ixYoVDB06lNWrVzNjxgxOP/10MjIyGDt2LIMGDSImJoaKigpWrlzJf//7X/Ly8jjuuOP46KOPDjiTuTXt2LGDzz//nMzMTMaMGdOm5z6UgQMHmh3BNJWVlTz66KOUlpYyderU/fp176GUQaVaikcVYyUOixZLpHZkg//3bFo6mdYHW5TNYG/PeIUbhRto2YKpMTEx9b7/NE3jil6ZDe7vVL9RbvybEJKJ06eia7YWnV+IjkIKzcKvzO0lKsTC8WYUmQEsFmjGpXZCCCGEEMHkjDPO4Mgjj6SgoKBekWLs2LFMnjzZxGQi2ByXEkdhrYuNVTUcmxxHZoR5ky1mzZrF008/TVhYGJdccon//rNzUjkyORaLpu3XDsJms3H//fezatUqunTpQlZWFt8UlWP8MRVYATtrnActNA8dOpTvv/8egD59+hAWVlcsireH8PCwXqyrcNAjOpzk0MYXccLDwxs9C7yuGLZ/EfmMrBRSQm2UuDyNmoQzOTOJXyscuAyDM7NSDlhku7h7BlNzUgnVdSx602dxNsby5ct57bXXAPjtt9/o3bs3n332GT/99BPPPfcc33//PYsXL8blcmG32+nfvz+TJ09m+vTpDRYSW1NNTQ2zZ8+msrKuqO/z+Rg3blyb5xD7e+GFF/juu+8AuPfee3n11VcPOCO+1HiVMuM1XGoLBlWEaQOo1VeTbLmi1bLF6WdQq37BqwqJ06di0drmQ7k9lPKQ77sdQ+3pAa+RYDm/TTMIEayk0Cz8StweJndJ4rDYxs0WEEIIIYQQB5aamkpqamq9+0aMGGFSGhGstFbs09tUAwYMYOHChQd8rEt4wwXwiIgIRo8e7b89OD6K7IhQ/+LiIxIOXgCaMGEC6enplJSU1BsH6orNRyTHNv5JBNhRyY1vJTg4PpoXRx+Gy2cQZw9pcL8I68FnRreU0+msd7u2tq7dyZAhQ+oVkg3DQNf1Vs3SGCUlJf4iM8DmzZtNTCP2te/3ktvtrrew5L7cbAHARyUKF0r5qFWrWjVbiJZKtvXxVj3HwRi49ikyg5fdpmURIthIoVkAexvbH36IHmqtyu2G//u/uu2//Q1scumJEEIIIYQQ7UmE1cJDQ3uyy+km2W7DZjl0MXPAgAFtkKx1udV2yngKLBoR6lJsWhdTcowaNYqjjjrK3zqjod7CwVBkhrr2KwMHDmTVqlWEhYUFXeuMzuzcc89l27ZtlJaWcv755/sX6vyzaG08NazAQizgQ9MsRGiHt2nWP/OqYiqMpVi1RKK1E5rVB/pgLFoksfpplBtLsGjRxOpytZIQe2hKtf3SmZWVlf6eUB15QZSjPv4Rt6GadJmXWfJrXMTYrCw+sj9JZuV1OCDyj9nU1dUQ0fAldkIIIYQITp3ldZ6oT/7dD25pfjFvbS8iI9zO9X2yiQqR+T6NpZTiySef5Mcff2To0KHMnDkz4EWjQNjhvQaX+h2AUK03Xaz3m5yo/fD5fGzZsoWkpKQ260veEIfDgcViIVTWDGoSryrGqyrwqjJ0TSdcb/s2LHsopdjuuxSPKgAgXp9GvOXMVjmXTznQsaNp8jNddHyNfa0XHB9jClMppajyeukXE2FekVkIIYQQQogOqNzt4bGNOyl0ullRWsUb23eZHaldWbZsGe+//z5FRUV8+OGH/O9//zM70gEZOA+4LQ7NYrHQvXv3/YrMZcYSfvdMYbv3ajyq8a0JfIbC80ebB6W8lBlLKPb9C48qOuhx//nPf5g6dSrnnnsuP/74Y9OfSCdm1RIJ1bsRaRlmapEZQFHrLzIDuPi91c5l0SKkyCzEn0ihWVDm9hIbEsLF3TPMjiKEEEIIIYQQDQrG2cwASfpl+Dwx/Pc/Dr56M5uamppGH1vicrNww3Ye27iDCre3FVO2Hz5VQYnveRRO3GoLZcbrjTpuZWkVU79dw5Sv1/BJQQmlxiJKfM9RbrxNvu/Wgx77yiuvoJTC7XbzxhtvBOJpCBPoWjiR+tEAaFiJ1o43OZEQnYsUmgVlbi+D4iIZEBdldhQhhBBCiA7hpZde4ogjjiA9PZ1t27YBsGDBAv7zn/+YnEy0tVhbCFf0zCQtzM6w+GimZKWYHaldGTFiBKeccgqpqamcfPLJHH64ub1fGxKuD+KDJ4fy3gsRLF70Jf/4xz8afez8X7fxcUEpH+aXsGD99lZM2Z5Y0di7qKJOeKOOWrS1kFqfgU8p/vV7Pm72/n16VAFKeRo8Njk52b8dGRnJU089xQsvvNCkDw06E48q8reLCTYp+iwyrQvItj5NhD7M7DhCdCoyx7+TM5TCUIrj0xLMjiKEEEII0SE8/vjjzJ07l2uuuYa7774bn88HQGxsLAsWLODUU081OaFoayekJ3BCurzebg5N05gxYwYzZsxo8VhffPEFmzZt4qijjqJXr14BSFff5s2b/du//974AlyR033A7c7MokWQarmJMuNNQrQ04vWzG3VcnM1KZUUFusVCVnIi0dpJ1PAzCg8x+kloWkiDx956660sXryYsLAwfvnlF3/7jKKiIm644YaAPK+Ootr4lkLf/YCPaP14ki1Xmx2pHk3TsNPN7BhCdEoyo7mTK3F5iLeHMCrJ3EUXhBBCCCE6ioULF/L0008zZ84cLBaL//5hw4axZs0aE5MJ0Xl99913PPDAA/znP/9hzpw5lJSUBPwcJ5xwgr+1x4knntjo487NSUXXwKppTM1JDXiu9uLXimpe2lzA6rIqACL0EXSxzifFci26FtaoMaxffEDJl59Q+OWnDNz+KxH6UHKsz5FlfYIky8yDHpuSksLVV1/NJZdcwu7de3tC5+XlNf9JdVCVxieA74/tT1HKZ24g4edTDkp9r1Nu/OegM/iFaC0yo7kTU0pR5fExJD6KLuGyqq4QQgghRCBs2bKFwYMH73e/3W7H4XCYkKhj2lxVQ36tmyHxUYRbLYc+oI2VlpZSUlJCt27d0HWZ32O27dv3tlBwuVwUFRWRkBDYWeYTJ05k8ODBeL1esrOzG33cuLQEjkiKRdMg1BJ838ttYVt1LXNW/o5XKd7csYt/Du5Jj+jGtcvY10/ffE3XP37OrvdVwhmnYdFisNC0iVVnnnkmzz77LBaLhdNPP73JOTo6u5ZLjVoBgE3LRtM65/dtMCr03UutWgWAW99BsuVKkxOJzkYKzZ1UsctNqctLVIiFM7KSD31AWwgNhc8/37sthBBCCNEOde3alZUrV+5XaPrwww/p27evSak6luUllfx97WYMBTkRoTw4tCchQVTMXbt2Lbfffjtut5vhw4dz2223Be0idp3FMcccw3vvvUdFRQV9+vShe/furXKejIzmLbAeFoQflrQVQzlZX70KtwG6FoqhYKujtlmF5r59+/pbXrTk5+2pp57K0UcfjdVqJSpK1jL6s3j9PKxaIj5VTrR+ktlxxD5c7G3bE6w9tEXHJoXmTqja66PC7WVKdjKnZSYzOFgWAbRY4NhjzU4hhBBCCNEiN9xwA1dccQVOpxOlFMuWLePVV1/l3nvv5ZlnnjE7XoewvKQSQ9Vtb3U4KXK6yQiiK/Q+++wz3O66Xrs//vgjJSUlJCYmmpyqc0tLS+Opp56iuLiY9PR0rFZ5K9xY3377LVu3buXoo48mMzMzoGMr5SXPN5vk6B1E2o+myjWYlNAEhsZHN2u82bNn89lnnxEaGsoxxxzTomxxcXEtOr4j0zSdGE0KzMEoRptAmXoT0IjWTzA7juiE5LdrJ5Nf48LpMxgUF8XNh3UlohN/ci6EEEII0RqmT5+O1+vlxhtvpKamhnPOOYeMjAz+7//+j7PPbtyCVuLgBsZF8kF+MQpID7OTZLeZHamerl27+rcTEhKIjm5e0UwEVnh4OFlZWWbHaFe+/vpr5s+fD8D777/Pk08+GdAZvh4KcKnfiQqB2wZ/TpUzmgFRRzT7farNZmPChAkByydEe5NguYBI/Rg0QrBpzbvCQoiWkEJzJ6GUosTlwWUYXNsni/O7pmGzBM/lhQB4PPDUU3XbM2ZASMMrAgshhBBCBCOv18uiRYs45ZRTuOSSSyguLsYwDJKTg6RVWQcxKimW+wZ3J6/GxcjEmKB7XXvKKacQFhZGQUEB48aNw2ZrfiG8yuPlrrVb2OZwcnJ6ItNy0wKYVATKT6WVvLylkFiblat6ZhJn7xjvZX7/fe+l91VVVezevTughWYrSVi1JLxqN6FWHzkxPYjQZTKUEC1h13LMjiA6MSk0d3AOr49Sl4dan0F0iIULc9O5IDctqHrY+bndcOUfjeovvFAKzUIIIYRod6xWKzNnzmTdunUA0i6hFfWNiaRvTKTZMRo0bty4gIzzzs7d/FpRt7jZ69t3MSY1ThbybkM+5cCttmDTsrFoBy6wGkpx7y9bcfoMAJ7fnM+1fRq/GGAwO/roo/nwww+pqamhd+/eAZ8RrmuhdLHcT7X6FhtZhOuDAjq+EEKItiWF5g5IKYXHUFR5fZS5PXSPCmdcajxjU+PpFxu8L8aFEEIIITqCkSNH8vPPP++3GKDoHIqdbpbsKCLCauGMrBTsLZxtve/xGmBr5oSRX3/9laqqKoYNG4bF0nlnjFZXVxMeHo7eiL9Hn6pkh+9avKoIixZLF8sDhGj7X51gKIV3T9NwwL3PdksZykmZ8SYGtcTpp2PV4gM2dmPk5uby5JNPsmvXLnJzcwPa23rHjh3ceeedlJaWcsEFFzBp0qCAjR0sKisr+eyzz0hMTOTII480O44QQrQ6KTR3AA6vr64ths9gz2LWVk3DbtE5MimWx0f0xhqMM5iFEEIIITqgyy+/nOuvv56dO3cydOhQIiIi6j0+YMAAk5KJtnDHms1sdTgBKHd7uaJXyxZPm5SRRH6Ni20OJydlJJIc2vQ2HO+++y5P/dGi7vDDD2fOnDktytQeKaX45z//yVdffUVycjL33nvvIVva1Kq1eFURAD5VTo1aQYx24n77WXWdq3tl8tzmfOJsIUzrGrj2JruNJ6gy/guAU60j0/pgwMZurNjYWGJjYwM+7muvvUZhYSEAzzzzDBMmTGhRm5lgo5Ti5ptvZvv27QCUlJRw6qmnmpzKPB61Gw1Lm39YIoRoW1JobudqvT7yalwMioukd3QEGeF2UsPspIXZSA2t+1OKzEIIIYQQbeess84C4Oqrr/bfp2kaSik0TcPn85kVTbSBvFrXAbeby2bRubp3y9oVfP/99/7tH374wf+92Jls27aNr776CoCioiI+/PBDLrjggoMeY9Oy0bChcAM6dq1bg/uOSY1nTGrgC2gelbd3m50BH99MkZF7r7YNCwszbaa9z1CUuT3E20PQA/j/oqamxl9kBli3bl2nLTSXGUso8T0H6CRbriZaH2t2JCFEK5FCczumlGJHjYtjUmL5v6G9CGvmyrxCCCGEECJwtmzZYnYEYaLTM5N5bdsurJrGpC5JZscBYODAgaxevdq/3dmKzADR0dHYbDbcbjcASUmH/rexaRlkWO+jxviJMO0wQrWerR1zP7H6X9jl+ycKL7Ha6a12nnfeeYcPPviAnJwcrrnmGkJDD9wH/LfffuOee+6hurqayy67jLFjm18wPP/883E6nZSUlHD22Wc3WGjesmULBQUFDBkypMFczeXw+rh55Sa2VNfSLTKMewd1D9j76oiICIYPH86PP/6IruscffTRARk3WHlVGT7KsZGz38+YcuPtP7YMyo1/S6FZiA5MCs3tlFKKYpcHu0Xjwtx0KTILIYQQQgQJ6c3cuZ3bNY3xaQnYLTrRIcHxduvMM88kOzubqqqqDl/sakh8fDy33XYbH3/8MTk5OZx44v4tMA4kVOtBqKVHo89TUVHBpk2b6N69OzExMc2N6xepH0GY1g+FB6vWOouLFhQU8PTTTwOQl5dHbm4uZ5555gH3ffHFFykuLgbgiSeeaFGhOSIigmuvvfag+/z444/cddddGIZBt27d+Oc//xnQPtE/FFewpboWgN+ra/mxpJKjU+ICNv6cOXP45ZdfiIuLIzOzeW10DOXGy25CSEHTDv3cX3/9dd5++226dOnCnDlzWqXtyZ/VGmvJ992Owk2EPppUfXa9YrONTGopr9vWWtZOSAgR3ILjlY9oFK+hKPd4qHT78KGIslqYlpPGsPhos6MJIYQQQog/vPjiiwd9/Pzzz2+jJMIsSc3oo9zaRo4cecD7fy6t5I3tRSTZQ5jRowsRJk9gWb16NYsXLyY+Pp5LL720XnuFlho0aBCDBg0K2Hh/VlxczLXXXkt5eTmxsbEsWLCAhISEFo9r0VpesD4YwzAOentf+/57/Ln/fGtYtmyZP8/vv//O7t27SUsLXA/s1LC9/1c1ICUssP93LRZLi/rye1U5eb4b8agC7FouGZb70LWwBvffvXs3L730EgDr169nyZIl/PWvf232+RurUn3yR4sZcBjf4dPLsLK3lUyqZTZlxhI0QojTT2v1PEII80ihuR2o9njZ5XSjgFiblSOTYxmdFMOIhBj6xLT+L/c2Y7fDe+/t3RZCCCGEaIf+9re/1bvt8XioqanBZrMRHh4uheYAUErx/vvvs3PnTsaPH09ubq7Zkdolt8/gnl+24vTVFfIirBZm9OhiWh6v18vdd99NTU0NAKGhoVxxxRWm5TmYiooKfvnlF7p27eovfK5evZry8nIAysvLWb16NWPGjDExZeNkZGRwwQUX+FtnTJo0qcF9Z8yYAUB1dXWb/CwbMGAAS5cu9edMTAzsrO6+MZHc0Cebn8qqGBYfTa/o4Hp/7VD/w6MKAHCpzdSoVURqhze4v9VqxWKx+NcCsLfR+2qbluPfVhhs916GptlI1W8iTO+PRYsm0XJhm2QRQphLCs1BzFCKMreXUpeHI5NjmZiRyNHJccTbQ8yO1jqsVjj5ZLNTCCGEEEK0SFlZ2X73/fbbb8ycOZMbbrjBhEQdzwcffMCTTz4JwJdffskzzzwTkNmVPxRXsHjbLpJDbVzRswtRQdL6orV4lMLl2zt71eFt+UKVv1ZUs93hZERCTJPftxiGQW1t7d48DkeL87SGqqoqrrnmGoqLi7Hb7cyfP5/c3Fx69OhBSEgIHo+HkJAQunfvbnbURjvjjDM444wzDrlfXFwcN910UxskqnPUUUcRExNDfn4+o0aNIiQk8O+Fj06JC2i7DKj73q2srGzx7OsQMva5pROiHXy8uLg4rr32Wv7zn//QpUsXTj+9+X293377bd544w0yMjK45ZZbiItr+O8oVvsLuiUcryqkwvgQAweoWoqNZ8nUFzQ7gxCi/enYr5xMpqGxw1FLpcfbrOOVghiblb9kJnF7/1zpwyyEEEII0U716NGD++67j/POO4/169ebHafd27lzp3+7urqaioqKFheanT4f83/dittQ/FZVQ5zNyqUmzu5tCxFWC9O7pfPylgKS7DbOyk5t0Xg/llTw9zVbUMAboUU8OrwXoQ0s8HYgNpuNGTNm8Nxzz5GQkMA555zTojyt5ffff/f3KXa5XPz888/k5uaSmZnJ/fffz+rVqxkwYECze/KK+gYMGNBg+wmlFA71Axoa4dqIoFjo8td1P3Pz3BnU1joZf9xZzLru1gPuZ6gaKtRSdEKJ1k5A0/b/vxKuDyCV2dSq1YRrI7Brh14D4JhjjuGYY45p0XMoLS3lX//6F1DXguOtt97i4osvbnB/TdOI0U4AwKGW41Z1HxLpBNcMcSFE65NCcyua2bMLBbWuZh+fGmpnTGocaWGdpI2ExwOLFtVtn3sutMKn1UIIIYQQZrFYLOTn55sdo0M4/vjj+eKLL6iurubwww8PSM9WnwKPofy3953p25FNzkxmcmZyQMZaXVbNnr/BIqebwlo3OZF1/WTXlFWzqbqGwxNjDvr+ZuLEiUycODEgefbYsmULRUVFDBo0KCCtBLKzs4mKiqKqqgqLxcJhhx3mf6xbt25069atxecQjVNsPEGF8QEAMfopJFlmmJwI3vjgdqpqtgOw9LN/cfFfrzzggnwFvrupVasBcOs7SLJcesDxIvUjiOSIVst7IBaLpV4LDput8b2rUy03UOz7F5pmJVG/pLUiCiGClBSaW9HUnJbNCOh03G6YPr1ue8oUKTQLIYQQol1655136t1WSlFQUMAjjzzCEUe0bbGgo8rNzeWZZ56hoqKCtLS0gMxijLBauLRHFxZtKSA51MbZ8lq+yYYnRPNeXjFepcgMDyX9j4LyytIq5q7+vW6m87ZdPD6iDzG2tnkr+sMPP3D33XejlKJXr17Mnz8fXddbNGZcXBwPPvggP//8M927d6dHjx4BSiuayqGW+7dr1HLA/EJzcvreD6yiYowGr7Zwqo3+bZf6rdVzNUVMTAzXXXcdb7/9NhkZGUyZMqXRx9q0LNKt81ovnBAiqEmhWQghhBBCiAD6y1/+Uu+2pmkkJSVx3HHH8cADD5gTqgOKiIgISF9mgEqPl59KK+kTHc4rR/YPyJjNtW7dOlatWsXgwYPp1auXqVmaakBcFP83rBc7a5wMjIvCZqkr6K6rdPhnOld5feTVOomxRbZJph9++AGl6s6+YcMGSkpKSEpKavG4qampnHjiiS0eR7RMuDaUSvWhf9sMhqrFxVZsZGLRIjl3ys1gvY7dRTWcNvHqBvtKR+vHU2G8C2hE6WPbNnQjHH300Rx99NFmxxBCtDNSaBZCCCGEECKADKNztFzoKJw+H7N++o2CWhcWTePOAbkMiIsyJcvmzZu5+eab8fl8LF68mIcfftjf5zevxolN10kKbfwl7G1BKcXXReVUeryMTY0nKyKUrIjQevuMTIhmyY4inD6DLuF2cv9op9EW+vfvzyeffAJARkbGQRc0E+1Pkj6TcG0woBGhjWzz8/tUFTt91+NRBVi0eDItDxBtHc2MM/4L+LBo0Q0em2SZQZQ+Bp1QbJr0824thqpF19ruZ44QnZ0UmoUQQgghhAigO++8k1mzZhEeHl7v/traWu6//37mzp1rUjJxIDscLv+6Kj6l+LmsyrRC8++//+7vier1etmyZQuZmZks2lLAa9t2oQF/653F2NR4U/IdyOJtu1i0tRCAr4rKmT9k/zYSuVHhPDq8NzscTvrERDRpgcCWGjNmDHFxceTn53PkkUditTb8FvjLL7/k2WefJSYmhtmzZ5ORkdFmOTuaGmM1tepnwrTBhOsHXsgvEDRNI1Ib1Wrj76u6upqXX36Z2tpazj77bNLS0qhVq/GoAgB8qhSHWk6MNgGL1rirLUI1abvSWgzlJN93K061gTCtP2mWeehacH1QJ0RH1LLmVEIIIYQQQoh67rjjDqqrq/e7v6amhjvuuMOEROJguoTbSf5jlrCuwSCTiswAQ4YMIT6+roiclJTEwIEDAXg3rxgABbz/x/afKaX4saSCZcUV/lYRbeGXCod/e32lo8FzJ4faGJoQTbi17YrMewwaNIiTTjqJ6OiGZ5cahsHDDz9MWVkZW7du5cUXX2zDhB2LS20m33cbZcab5Ptuw6U2mx0pIB5//HHef/99PvvsM+6++24AbFo2GntaY2jYta7mBRT1VKtvcaoNANSqNX/08A5+Svlwqg14VYnZUYRoFpnRLIQQQgghRAAppQ64ON2qVav8RUQRPMKsFh4Y0oMVpVVkR4TSPSr80Ae1koSEBB555BG2bdtG165d/T2ocyJC/QXd7D+1pdjj2d/z+c/O3QCclJ7IzJ5d2iTzUcmxrCyrAuCIpNiALMxoBk3TsFqtuN1uAGw2mfnYXG61DdjTQsjArbZh13LNjHRQSikULnTtwP+39ti9e/d+2zatCxnWe3AYKwjT+hOqta++6h2Zlfq/b61a8P/+VUpR4LuDGvUzGjbSLXcQpvczO5YQTSKFZiGEEEIIIQIgLi4OTdPQNI2ePXvWK7j5fD6qq6u57LLLTEwoGhJrCwmadhRRUVH061e/sHBLv678Z8du7Badv3Q58EJ2y0oq/ds/llQwk7YpNI9PS6BbZBhVHh8D49pmgb/WoGkaN998My+++CKxsbFMnz693uOfFpSwtKCErhFhXNojA6te/+Lg1atX89FHH5Gdnc2UKVPabcE9EMK1IVi1FLxqF1YthXBtiNmRGuRVJeT5bsGj8onSx5CsX9vgv91ZZ53Fvffei9vtZtq0af77Q7XehFp6t1Vk0xiqhhJjEQbVxOlnYtOCu7VMuD6YJGZSo1YSoY0gVAv+fyMvRdSonwFQuKlSXxKGFJpF+yKF5lb0xRdfUFhYaHaMdkPz+ejyt78BsPPf/0a1Ye+2pqipqaGystL/VVVVRWVlJRdffDFjxwbfasFCCCGEaBsLFixAKcVf//pX7rjjDmJiYvyP2Ww2cnJyGDWqbXqJio4lOsTKtNy0g+4zJC6K9//oNT0kvuEWEa2hm4mzwANp0KBBDBo0aL/7C2pdPLxhBwrYUFlDRridv2Qm+x8vLy/njjvu8M+GjoiI4OSTT26j1MHHosWQZVmIm53Y6BLUC7FVGB/iUfkAVBmfE6v/BTsHnn09dOhQXnnlFXw+H2FhwfucWkux8QyVRt3Cmk61jmzrUyYnOrQY/SRiOMnsGI1mIRaLFo9PlQIE9ZUAQjRECs2taN68eWzfvp3Q0INfgiMO4OOPTTmtUgqXy1XvPovFgtVq9X+FhIRgsVgICQmpd/+7774rhWYhhBCiE7vgggsA6Nq1K6NHjyYkJOQQRwgROJf2yGBAXCRKweikmEMfYDKlFG5DYbcE/7JBbp/Bvp2nnT6j3uMVFRX+IjNAUVFRGyVrHJfLhd1ub9Nz6loYoQT/Qnf7tlPQsGLh4B/SdOaWKh619/vaq3YfZE/RXLpmp4vlH1Qa/8WmZRClH2t2JCGaTArNrcjn85GUlERycvKhdxamcrvdbN++HaUU0dHRhIWFkZmZSffu3YmPjyc6OrreV1RUVL0/O/MLDiGEEELUd8wxx/i3a2tr8Xg89R4/2IJkQjSXpmmMToo1O0ajFDndzFm5iUKnmwlpCVzRK9PsSAeVHRnG6ZnJfJBfTG5kGCdnJNZ7PCsri2OPPZYvvviCpKQkTjopOGZQVlRUcMstt7B9+3aOPPJIbrzxxnbR0uPjjz9m0aJFJCUlMXv2bBITEw99UDNFayfi0ytwsZlobTxWrfXOFcyUUqxbt46IiAiys7MPuE+cfiZO3wYULuIt57f4nKW+V6lRKwjXhhFvObvF43UUIVoqCZZzzY4hRLNJoVkEDd0wGPVHq5H/paZi6G0zu0Epxfbt2+nXrx/nnXceubm55OTkEBVl3orjQgghhGi/ampquPHGG3n99dcpKdl/1Xifz2dCqs7jp9JKvIZieEJ0uyiqtcTW6lpsuk56eNvOVm2p9/J2U+ismwG8tKCEUzOT6BIe3FeBXtgtnQu7pe93/7Jly3j33Xfp0qULjz7zLJ9UunmnysuUOA+xNnOvavjoo4/Yvn07AN988w2TJk2iT58+pmY6lNraWh599FEMw6C0tJRXXnmFq6++utXOp2ka8Zapjd6/oKCAf/3rX2iaxl//+ldSU1NbLVtbWrhwIZ988gmapnHllVcyfvz4/fYJ1wfQVVuEwoNFi2jR+RzGckqNVwBwqg3YtR5E6EObPZ5SCoNKdKLQtNarIxjKjcKNRWu//eiFaG1SaBZBI8QwmP3TTwCcMWECrgAXmpVSVFVVUVtbi9PpxO12o2mafxbzlVdeWW8GkhBCCCFEc9xwww18/vnnPPbYY5x//vk8+uij5OXl8eSTT3LfffeZHa9De3FzPm9sr7u8+4S0BK4M8pmyLfH87/m8taMIDbiyVybj0xLMjtRo8fsUYG26RqQ1ONdmOZSKigruvfdevF4vK1eu5IvoVKrT6maD/l5Vw32DzW0dkZCw93tC13ViY2PNC9NIuq5jsVgwjLr2JPu2IHK73YSEhJj6AdKDDz7I+vXrgbre3PPnzzctSyB9/vnnQN175s8///yAhWYAXbMBLb+a16C23m31p9tNoZSHfN88atVqbFoWGZb7sGiBnzRWa6ylwPg7hqohXj9XZmEL0QApNItOwePxsG3bNsLDw4mOjqZPnz507dqV9PR00tLSSE9PP+DCH0IIIYQQTfXuu+/y4osvcuyxx/LXv/6Vo446iu7du5Odnc2iRYs491y5JLa1/FBc6d9eVlIBdNxC89KCutnyCliaX9KuCs2nZCRR5fGxvcbJiekJrT7zd0t1LZuqahgcF0ViaOBa3jmdTrxer//2LrePPfM882pcBz6oDR133HGUlJSwceNGjjvuONLSDr6gZDCw2+3ccMMNvPbaayQlJfl/Xi5atIjFixcTFxfHnXfe2WB7h5ZQyouXUqwkoGkH/vCjqqrqgNvtXc+ePfn1118B6NWrV73HlFIBL+5HaqNw6EfgMFYQoQ8jQmv+Qrk1ajW1ajUAbrWdKvUFsdopgYrqV6aWYKgaAEqNV4jTz0DTpKQmxJ/J/wrRoSmlKC0tpaSkhN69e3PrrbcydOhQ9DZqyyGEEEKIzqe0tJSuXbsCdf2YS0vrVo8/8sgjmTlzppnROrzB8VFsr3ECMCju4DPatm3bxo4dOxg4cGC7bJmWGxnGmvJqALpFhpmcpmksusa03LYpem6odDD75014lSImxMqjw3sTYwvM2+CUlBROP/103n77bTIyMjhh1GCeK6jEUIop2SkBOUdLaJrGmWeeaXaMJhs1ahSjRu0tPFZXV/Paa68BdT9f33rrLa677rqAntOnKtnpuwmP2old60GG5R50bf92LhdddBH//Oc/0TSNiy66KKAZzDR37lw+/vhjIiMjGTdunP/+MuMtSn0vY9USSbPMw6ZlBOR8mmYl1TIbAnAxg1VLADT4Y8nOEFpnjawQkuqdU4rMQhyY/M8QHZbX62Xz5s1ER0dzzjnncPXVVxMXF2d2LCGEEEJ0cLm5uWzdupXs7Gz69u3L66+/zogRI3j33XfbxaXr7dlF3dLpGxOB11AccZCF8dauXcutt96Kz+cjIyODBQsWEBoa3D2C/2xOv668t3M3oRadkzI61wJmVR4v6ysdZEeEkXyIGcpryqvxqroCVIXHy5bqWgbFB+6DhQsvvJALLrjAP+NzTFcvPkMRZze3P7OZnE4nL730EsXFxZx++un07NmzRePZbDYiIiJwOBwAxMfHByJmPdXqOzxqJwAu9Rs16icitdH77Td8+HAWL14c8PObLSIigsmTJ9e7z1A1lPheABQeVUiZsZgUS2AL/IFg13JItcymWn1LmHYYEfrIVjlPgj4dDTs+yonTp7TKOYToCKTQLDqskpISUlJSePLJJ4N+0QshhBBCdBzTp09n1apVHHPMMdx8882cfPLJLFy4EK/Xy4MPPmh2vA5N0zRGH6TAvMfy5cv9izLm5eWRl5dHt27dWjldYEVYLZyV0zEWImuKao+Xa1dsZJfTTahF5/7BPcg5yIzuwXFRvKoX4jYUCfYQukUFfvb3vm0FokPkLfbLL7/MO++8A8CaNWt48cUXsVqb//dis9mYN28eb731FsnJyUydeujF+7xeL8888wybN2/mhBNOYOzYsQfdP4R9Z9hrhGid7//W/qzoWiiGquufrBO8V35E6qOJZP8PBgJJ10JJtPy1Vc8hREcgvwVFh6SUwuFw0K1bNykyCyGEEKJNXXvttf7tMWPGsH79epYvX063bt0YOHCgicnEHgMHDmTJkiUopUhKSiI9Pd3sSM3i9hn4lCKsnS6m1xybqmrZ5XQD4PQZrCitPGihuVtUOA8O7s63v21hdGYKUVIIbnVlZWX+7aqqKjweT4sKzQC9e/dmzpw5jd7/gw8+4P333wdg/fr19O3b96A9qsP1gaRwPbVqNRHaSOxabovydgS6ZiNVv5Uy4w1CtCQS9M65voBPOSg33kThIU6fgkWLMTuSEEFNfsuKDsUwDAoKCnA4HERFRTFlilzSIoQQQgjzOJ1OsrKyyMrKMjuK2MfgwYO5//772b59O8OGDSMsrH31OAZYXlLJvb9swWMoLuvRpdO0z8iKCCXCasHh9aEBfWIiDrq/YRg8/Y97WbVqFW+HhnL33Xe3uJXDwXg8HkJCOm/bDIDTTz+dVatWUVFRwdSpU035/1VTU+PfVkrhdDoPeUyUfixRHNuKqep88MEHfPTRR3Tr1o2ZM2cG9fdLuD6AcH2A2TFMVWQ8jMP4DgCX2kKG9W6TEwkR3KTQLIKGV9dZ8McsH28zF+vLy8sjMjKSadOmMWbMGJk1JIQQQog25/P5uOeee3jiiSfYtWsXGzduJDc3l9tuu42cnJwOtYBUe9arVy969eq13/0VFRU88cQTVFRUcN5559G3b18T0h3aa9vq2kEAvLSloNMUmuPtITwwpAfLSyrpGR1xyEJzfn4+q1atAuo++Pniiy9apdBcU1PD3Llz2bBhA8OHD2fOnDlYLObMNK80/kup8TJWEkmx3EiIlnTogwIoNzeXl156ie3bt/PNN9/w9ddfc9RRR7VphpNPPpmffvqJzZs3M2HCBP8CrWbLy8vjiSeeQCnF5s2byc7O5tRTTzU7ljgIj8rzb7vZaWISIdoHKTSLoOHTdf6bmdns4wsKCgCYMWMG559/fqBiCSGEEEI0yd13380LL7zA/PnzueSSS/z39+/fn4ceekgKzUHu2Wef5ZtvvgHgrrvu4pVXXjE50YEl2W1soG7WZtIhFsTraDLCQ8kIb9zijfHx8URHR1NZWQnQagXHL774gg0bNlAbFsErDij+9H/cfuwIEuxt+29jKBdFvoWADy/FlBqLSLFc06YZAFwuF7feeivl5eUAuN3uQ/ZJDqSoqCjmz5/fZudrLI/Hg/pjcUqo+3sSwS1Wn0yR72FAEaefYXacNuVUv1FlfEqI1oUYbWK9fvRCNEQKzaLDcDgczJw5k2nTppkdRQghhBCd2IsvvshTTz3F2LFjueyyy/z3DxgwgPXr15uYTDTGvpfcO51ODMNAb+bVdq3p8p5diAmx4jQMpmanBGRMj2Gwy+km2W7DZgm+59wc4eHh3HfffXz++edkZmYyZsyYVjlPbGwsAL/3HkptZCxrvRoLN+xg3oC2XmRSQ0NH4fvjljmzqktKSvxFZoBNmza1aaG5tXm93mb1nc7JyeHMM89k6dKldOvWjYkTJ7ZCOhFI0fpYIrRhKHxYtfhGH+dVxTjUMmxaV8K09rdulE9Vk++7DUM5ANAsFmK0k0xOJdoDKTSLoKEbBkN27wbgp6QkjCa8oPd6vWiaRv/+/eVTNiGEEEKYKi8vj+7du+93v2EYeDweExKJpjjvvPPYtm0bFRUVXHLJJUFZZAaICrFyWc8uARvP4fVxw0+/saPGSUaYnfuH9OgwC+dlZma2+hWPo0ePZvr06fx9l5PUxGQiIiKo8HgbffyGDRv48MMPSU9P54wzzmj2952u2Uix3ECp8QpWEojX95+E41MO3GoLNi0bixbVrPMcSlpaGv3792fNmjXY7XaOOeaYVjlPW6utrWXu3LmsX7+e4cOHc8sttzS54Dxt2jSZHNXO7LsAoKGcVKgP0LAQrZ2Iru1/1YJPOdjhux6fKgU00i3zCNeHtGHilvNR7i8yA7j3aSEixMF0jFcOokMIMQxu//FHAM6YMAFXE15cFRcXExsby2GHHdZa8YQQQgghGuWwww7j66+/Jjs7u979b7zxBoMHDzYplWisnJwcnn76abNjtLnlJZXsqKlbMC2v1sWykkrGpjZ+9p6A0047jaSiMhas306IrnNB1/RGHedwOJg7d65/Nn1ISAiTJ09udo5IfRSR+qgDPuZTFezwXYdXFWHR4sm0PIhVS2j2uRqi6zp33nknmzZtIikpiYSEwJ/DDF9++aX/ypQff/yRn3/+meHDh5ucKrDcajsVxgdYtRRitVPRtOD8sM0su4z7cRjLAHDpv5NiuW6/fTzk/1FkBlDUqrWE074KzSFkEKEfjsP4Hl2LIlo/3uxIop2QQrNo93w+H5WVlVx99dUkJyebHUcIIYQQndztt9/OtGnTyMvLwzAMlixZwoYNG3jxxRd57733zI4nxAFlhNvRAAVoQJdwe0DHLygoICoqisjIyICOG2yOSo7jyKRYgEZfaVldXV2vZUthYWGjz1daWso999xDfn4+U6ZMOWSBukatwquKAPCpUmrUT0RrrVNAslqt9O7du1XGNktcXFy92zExMQ3sGVhO9RtKuQjT+7XqeQzlJs93Cz5VUXeHxUec1rn6Eh+KU23yb7v22d6XjUxCtAw8Kg8NK+F6+/swQtM0UvVb8OqFWIhF18LMjiTaCfloSrR7O3fuJDMzkzPPPNPsKEIIIYQQnHLKKSxevJgPPvgATdOYO3cu69at49133+X445tW0Pnqq6845ZRTSE9PR9M0/v3vf9d7XCnFvHnzSE9PJywsjGOPPZZffvml3j4ul4urrrqKxMREIiIimDRpEjt37qy3T1lZGdOmTSMmJoaYmBimTZtWr7+qMN8333zDRRddxKxZs9i1a1fAx+8eFc5t/btycnoic/p1pVd0RMDGfvDBB5kxYwZ//etfO0Wfck3TmtTOLyUlxd+/OCYmhpNOanwf1DfffJMNGzZQVVXFc889R1lZ2UH3t2td0fzzzSzYtdxGn0vAyJEjmT59OsOGDeOqq66iZ8+erX7OMmMJO73Xkee7md2+J1r1XAbVe4vMgFvtPMjenVO0Nt6/HdXALF9dC6WL5QFSLXPItD7SLns0Q93PshAtTYrMoklkRrNo1wzDwOVyMXXqVJKSksyOI4QQQohObPPmzXTt2hVN0zjhhBM44YQTWjymw+Fg4MCBTJ8+ndNPP32/x+fPn8+DDz7I888/T8+ePbnrrrs4/vjj2bBhA1FRdb1Xr7nmGt59911ee+01EhISuP7665k4cSIrVqzAYqlbKOycc85h586dLF26FIAZM2Ywbdo03n333RY/B9FyPp+Phx56CLfbTVFRES+88AI33nhjwM8zPCGG4QmBnaFZWlrK559/DtT1t126dGmHm+UaCNdccw0XXHABERER2Gz793xtiN2+d+a5xWI5ZL9gm5ZJhvU+aoyfCdP6Y9faerHC9u+0007jtNNOa7PzVRtf+rer1FckcdlB9m4ZqxZPlD6GKuNzdC2cGP3EVjtXe5VgOZdIfRQaVmxaVoP7WbQIIrXD2zCZEMFBCs2iXdszm7m1Vo8WQgghhGisHj16UFBQ4G/lddZZZ/Hwww+TkpLS7DFPPPFETjzxwG/0lVIsWLCAOXPm+IseL7zwAikpKbzyyitceumlVFRU8Oyzz/LSSy8xbtw4AF5++WUyMzP59NNPOeGEE1i3bh1Lly7l+++/Z+TIkQA8/fTTjBo1ig0bNtCrV69m5xeBoWlavcXhgnWBwgOJjIwkNjbWP0O+S5fALWDY0fy5LUNjTJkyhd27d5Ofn89pp53m/4DpYEK1XoRa5P91exGq9cWlNgO0yczYFMt1xOtT0YnGogXuyoaORK4EEKJh7ecVihB/YhgGNTU1HH300eTmyg96IYQQQphLKVXv9gcffIDD4Whg75bbsmULhYWFjB+/9zJeu93OMcccw3fffQfAihUr8Hg89fZJT0+nX79+/n3+97//ERMT4y8yAxx++OHExMT49xHm0nWdG264gaysLAYOHMiFF15odqRGs9ls3HPPPUycOJGLL764TWeCdgbh4eHMmjWLBx98kCOPPNLsOB2OU/1GlfE5PlVlWoZE/RKSLX8jyTKTFP2mNjlniJYmRWYhRLPIjGbRbpWVlZGQkMDUqVPNjiKEEEII0eb2LBj25xnTKSkpbNu2zb+PzWbbb6ZkSkqK//jCwsIDLqicnJzc4KJkLpcLl8vlv11ZWdn8JyIaZcSIEYwYMcLsGM2SmZnJpZdeanYMcQBFRUW88847xMTEMHny5EO23uhMHMYKCnx3AIoQLYNMy8PoWuPbmgSKpulEa+Pa/LxCCNEc8ltEBA2vrvN4v37+7UOpqKhgyJAh9OjRo7WjCSGEEEIc0oEWAGvKgmAtOe++lFKHPO+f9znQ/gcb59577+WOO+5oRlohDq3K48XlM0gMbZ2i3gsvvMBHH31Et27duPnmmwkPD2+V87QHc+fOJS8vD6h7f3XxxRebnCh41KifgLorVTwqDw8F2Mk2N5QQQgQ5KTSLoOHTdT7IyWnUvm63G5/Px8SJE1s3lBBCCCFEIymluPDCC/2LczmdTi677DIiIupffrxkyZKAnC81NRWom5Gclpbmv7+oqMg/yzk1NRW3201ZWVm9Wc1FRUWMHj3av8+uXbv2G3/37t0N9pe++eabue666/y3KysryczMbPmTEp3eD8UV/OPXrXgMxZlZKUzLTTv0QU2wefNm3nzzTQBWrlzJBx98wBlnnBHQc7QXPp+P/Px8/+2dO3eamCb4hGuDqeBd9sxoDiGw34tCCNERSY9m0e4opdi2bRsDBw5kwoQJZscRQgghhADgggsuIDk5mZiYGGJiYjjvvPNIT0/3397zFShdu3YlNTWVTz75xH+f2+3myy+/9BeRhw4dSkhISL19CgoKWLt2rX+fUaNGUVFRwbJly/z7/PDDD1RUVPj3+TO73U50dHS9LyEC4Z2du/EYdbNIl+woCvj4Nput3kx9m63tWyEEC4vFwqRJkwAICQnh5JNPNjlRcInQh9HF+gApluvoYrm/SW0zHMaPbPdeRZ73NryqpBVTCiFEcJEZzSJo6ErRt6Tul/CvCQkYDVyq6XK5sNlsXHfddQF9syaEEEII0RLPPfdcwMesrq5m06ZN/ttbtmxh5cqVxMfHk5WVxTXXXMM999xDjx496NGjB/fccw/h4eGcc845AMTExHDRRRdx/fXXk5CQQHx8PLNmzaJ///6MG1fX87NPnz5MmDCBSy65hCeffBKAGTNmMHHiRHr16hXw5yTEwWSE21ldXg1Aepi9RWP98ssv7Ny507+4JUCXLl247LLL+Oijj+jevTsnnnhiizO3ZxdffDEnn3wy4eHh8t7qAEK1HoRqTWvVqJRBoW8+CicAJcYLpFiuO8RRnZvT6eTrr78mPj6eoUOHmh1HCNECUmgWQSPE5+Pe778H4IwJE3D9aSEKpRRFRUVUVFSQkpJCVlaWGTGFEEIIIdrM8uXLGTNmjP/2nnYVF1xwAc8//zw33ngjtbW1XH755ZSVlTFy5Eg+/vhjoqKi/Mc89NBDWK1WzjzzTGpraxk7dizPP/88FovFv8+iRYu4+uqrGT9+PACTJk3ikUceaaNnaQ6v14vD4ZDiWpC5uFsGsSEhVHu9nJa5/yKVDdlaXcsPxRX0jolgYFwU3333Hffeey9Q165m4cKF/tnLJ510EieddFKr5G9NbpVHtfEtdq0rEfrwgI27b+sdEQgK8O1zy2telHbitttuY/369UDdB52nnHKKyYmEEM0lhWbRbpSUlOD1epk+fTqTJ0+WF0RCCCGE6PCOPfZYlFINPq5pGvPmzWPevHkN7hMaGsrChQtZuHBhg/vEx8fz8ssvtyRqu7Jr1y5mz55NcXExo0ePZvbs2W2ycKM4NJtF55yuqU06ptjp5oaff8PpM9CAuwZ2Y9WqVf7H8/Pz2b17NxkZGQFO23Z8qoo83434VCUAqcwhUj/c5FQiLy+PnTt30r9/f/+ikppmIdlyLSXGc1iII0E/3+SUwc3lcvmLzACrVq2SQrMQ7ZgUmkW7UVZWxpQpU5g9e7bZUYQQQgghRDv20UcfUVxcDMB3333Hli1byM3NNTlV56OUCkiBf3uNE6fPqBsT2FRVy/Dhw1m6dCmGYZCTk9PgwpbthYdCf5EZwKU2EknzCs1K+ahQH2CoKmL0k7FoMqu/OX755RduvfVWvF4vWVlZPPTQQ/5Z81H6UUTpR5mcsH2w2+0MGjSIlStXAjBy5EhzA4l2RSmFQ32LwiBSOwJNsxz6INGqpNAs2g1N0+jWrZvZMYQQQgghRDuXnLy3JYPNZiM2Nta8MJ2EU23Aq3YTrg1D10J55ZVXeP3110lOTuaOO+5o0dWKvaMjyAizk1frItJqYWRiNBlZw1iwYAH5+fkMHjwYq7V9v/W1kY1d645LbUIjlAj9wAt1NkaJ8QJfLXuOT98ppEvGM8yasTToF0VUSlFZWUlkZGS9tj9mWrZsGV5vXVuM7du3s3PnznbzgdUXX3xBcXExxx9/fFC0D5o7dy7Lly8nLi6O3r17mx1HtCPFxtNUGO8CUKOvIMVyrcmJRPv+bSs6DY/Hg67r5OTkmB1FCCGEEEK0cyeccAI1NTVs3bqVcePGER8fb3akDq3K+JJdvn8CEKr1IrL6Vl599VUACgoKePPNN7nqqquaPX641cJDQ3vye3UtXcLtxNpCAOjatStdu3Zt+RMIArpmI8PyD1xqIyFaGlYtodljlVSu48n5m/C4Ddav/pWs2Nc577zzApg2sAzD4O6772bZsmWkpqZy7733kpiYaHYs+vXrx9tvv41SioSEBFJTm9byxSxvvfUWzz//PAD//e9/eeyxx0xvHRQSEsKoUaNMzSDap1q10r9ds8+2MI8UmkW74HK5CA0NlQUAhRBCCCFEi2maxmmnnWZ2jE7DoZb5t51qA7E2J3a7HZfLBUB0dHSjxnH6fGysrCEj3E6Cvf4M3DCrhX6xkYELHQQcXh/3/bKVrdW1nJyRyNk5qYRp/Vo8rt1zNB73SwCEaEk4HI4Wj9maNm7cyLJldd9DhYWFfPrpp5x99tnNHs+nHLjU79i17Ba1DRk+fDj33HMP27ZtY+TIkf4ezcFu48aN/u2dO3dSU1NDRESEiYmEaL4IbSRutcO/LcwnhWbRLuz55Zeenm52FCGEEEIIIUQThGtDqOYrAOxaNyLCUrj11ltZsmQJqampnHXWWYccw+nzMeun39jmcBJm0Zk/uAc5kWGtHb3FlDIwqEInusmzRt/ZuZuVZVUALNpayJHJsXQJD21xppzkUzj/7LkseettMtK6M3ny5BaP2Zri4+OxWq3+NhUt6bftU1Xs8F2LV+3CokXTxfIAIVrzZyL369ePfv1aXvzfw6MKcaqNhGl9sWqtM2v72GOP5fvvv8cwDEaOHClFZtGuJVguIEwbgMJLuDbM7DgCKTSLIOLTdf7Vp49/ew/DMCgvL2fKlCmEhrb8hZUQQgghhBCi7UTrY7GShJfdRGqj0DSNQYMGMWjQoEaP8XtVLdscTgBqfQbfF1cEfaHZp6rI883GrbYTpvUn3XIHmhbS6OND9L2FaQ2wBrC9wYXTLueC82aa3jKhMZKTk7n11lv54osv6N69O2PGjNlvn/fzilmaX0xuZBhX9MzEZtEPMBLUql/wql0A+FQlNWoFMdrJrZq/sdwqjx3ea1A4sWjRZFoeblGLlIaMGjWKxx9/nLKyMvr88f5biPYsXB9sdgSxDyk0i6Dh1XXePsBif/n5+aSlpTFjxgwTUgkhhBBCCCFaKlwf0KLjM8LtRFotVHt9APSMDv42BdXqK9xqOwC1ag01ahURTZhxd0pGEtsdTrZU13JSeiKpYfaA5msPReY9hg4dytChQw/4WF6Nkyd/24kCtjqc5ESGMTkz+YD72rUcNOwoXICOXeveeqGbqFatRlH3YYpPVeJUG4jUmr/o48Gkp6fL1cJCtFNOtZ4K431CyCBOn4KmBccCqXtIoVkEvZqaGqZMmSL9mYUQQgghRJtbU1bNl0Vl9IwOZ3xa4GcXdnQOYxnFxnNYiCHFch0h2oELgIdSvH0bh63+jsqUDKaOOZrB8Y3r62wmK0n73NKa3ArBbtG5rk92YEN1QD4Fap/bHkM1uG+IlkoX63xq1ApC6Uuo1qv1AzZSqNYXDRsKN7oWgV3rYXYkIUSQMVQN+b7bMVQNAJpmJU47w+RU9UmhWQQNXSm6VVQA8HtMDIam4XK5ZAVaIYQQQghhit1ON7ev+R2PofiooIQwi85RyXFmx2o3lFIU+u5H4cTDTkqMf5Fqmd3kcRwOB7feeqt/0bqdNsXgU04JdNyAi9BHkMTl1Kq1RGqjsWs5ZkfqkLIiQjk7O4UP80voFhXGxIyDF/TtWi52LbeN0jWeXcsm07oAp1pPmNaPEC3p0AcJIToVH9X+IjOARxWZmObApNAsgkaIz8eD33wDwBkTJuCyWtm9ezexsbEMGNCyS+2EEEIIIYRoqt0ud73Zkfk1LhPTNE51dTU+n4+YmBizo+xH0fBM04OprKz0F5kB8vLyAhWp1cXoJxLDiWbH6PDO7ZrGuV3TzI7RYjYtE5uWaXYMIUSQCtGSidaPp9L4BIsWS6w+0exI+zlwh3whgoBhGNTW1nLppZeSkCCXKQohhBBCiLbVMyqcAbGRACTaQxiTGm9yooP79ttvmTZtGtOmTePtt982Ow6appFqmUWIlkGo1odEfXqzxklNTeXII48EICoqigkTJgQyphBCCNFuJFuupqt1ETmW57BpwddiVmY0i6BVXV1NREQERxxxhNlRhBBCCCFEJ2TVdf4+sBu7nW7ibCHYLME9T2fJkiV4vV4AXn/9dSZPnmxyIojQRxKhj2zRGJqmceONNzJ9+nSio6MJDQ0NULrOafPmzTzxxBNYLBYuv/xyMjNlBq0QQrQnFi141ykI7ldKolMrLi6mZ8+e5OTkmB1FCCGEEEJ0UrqmkRJmD/oiM9TN/N0jLa39txHYl6ZpJCcnd4ois09VU+p7nXLjPZTyBnz8hx56iHXr1rF27VoWLlwY8PGFEEJ0XjKjWQQlp9MJwLRp09D14H9RL4QQQggh2o5SivfyitlZ42J8WjzdosLNjtTmvv76axYuXIjdbueWW26hT58+XHHFFSQmJuJyuZgyZYrZEUUzFfjuwql+AcCj55FkuTSg47vdbv+2yxX8fceFEEK0H1LBE0GptLSU7Oxsxo0bZ3YUIYQQQggRZN7PK+apTXl8kF/MnFW/4/D6zI7U5p588klqa2spLy/nueeeAyA8PJzp06dz2WWXyRonf1LiclPsdB96xyDgUpv22f494ONfccUVJCcnk5aWxmWXXbbf40VFRZSWlgb8vKJ15efnM2fOHG688UZ+++23eo8pZaBU8xbjFEKIppAZzSIo+Xw+0tLSsNlsZkcRQgghhBBBJq927yxMh9dHhdtLhNViYqK2FxkZSUVFhX9bNOzDvGIe/20nADO6ZzCxS5LJiQ4uWh9PhfEuoBGtHx/w8QcMGMCzzz57wMfefPNNXnjhBXRd55prrmHMmDEBP39TKaWoUp/iVaVE6+OxanFmRwpKjz76KKtXrwbggQce4IknngCgyviKIt//oWkWUvXZhOtDzIzZbEp5qVAfonARo52ErnW+K1mEaA+k0CyChk/XeaVHDwCqXS66detmciIhhBBCCBGMxqcl8OWuMqq8PkYnxpAW1vkmJ8yePZvnn38eu93OjBkzzI4T1N7euZs9czn/vXN30BeakywziNbHohGKTcsIyJg+VUGZ8RYaIcTpZ6BrYQfcb8mSJQAYhsF//vOfoCg0lxmvU2q8DECV+oJs6+MmJwpO+7ZB2bc9SonxLxRulIIS48V2W2jebTxBpfERADXaKjKsfzc5kRDiQKTQLIKGV9d5tVcvqqursZWX85e//MXsSEIIIYQQIgh1jQzj2cP7UuHxkhJqQ9M0syO1uZycHObNm2d2jHYhM9xOwR+z4DPD28dignYtsJNuCnz37u37TCGplhsOuF9mZia//vqrfzsYuNjbSsSjdmIoJ7rWPv4d29KMGTP45z//icfj4YorrvDfbyEGLyV/bMealK7l6rWUIfAtZYQQgSGFZhFUDMOgsLCQrl270rNnT7PjCCGEEEKIIOT2Gfzr93x21rg4pUsio5NizY4kgth1fbJ5a/suFHB6ZrLZcUzhYefebbWzwf1uueUWlixZgs1m4/TTT2+LaIcUpY3FwY+Aj0j9KCkyN6Bnz5489dRT+92faplNifECGiEk6NNNSBYY0frx7PbVFZijtcC3lBFCBIYUmkXQ0JQiavt2BttsXHHzzVit8u0phBBCCCH2t2RHEUsL6mbora908PyoSGJs8tpRHFiE1cL5uelmxzBVrH46Jb5/ATqx+l8a3C8mJobp04OrGBmpH0629gQ+KrAjk5GaKkRLI9Uy2+wYLRajn0yYNgCFO+Az/oUQgSOvxkTQsPl8vLZ2bd2NIe2zb5QQQgghhGh9Dq/Pv+1VCpdhmJhGiOAXp08mSjsKsGLVYs2O02QhWiohpJqawauKKfDdi5dC4vSzidVPMTVPZ2TTgqOdixCiYbrZAYTYY98FC4QQQgghhGjIXzKT6BoZRoiucWZWCsmhnW8xQCGayqoltssic7AoNV7HpTbiU5UU+57GpyqbNY5PVZDnncNW70VUGEsDnBKqjf+R572ZIt+jGEreYwsh2pbMaBZBw+FwmB1BCCGEEEK0Awl2Gw8P62V2DCFEJ6Kz9wMtDQtgadY4pcbr1KrVAOz2PUakNgqLFhOIiPhUBbt881F4qVVrsZJAvOXsgIwthBCNIYVmETRcLpfZEYQQQgghhBBCiP3E6VPxUoJH7SJOPwOLFtGscTS0ercCeaG5gQuFd5/b1QEbWwghGkMKzSJoSOsMIYQQQgjRUTm8PrY7nGRHhBJubd5MSGGObdu2AZCdnW1yEmEmixZBquWmFo8Tp5+Fm3w8quCPgnVUANLVCdGSidPPpNxYQojW5aALPwohRGuQQrMICjU1NVJoFkIIIYQQHVKpy8P1P22k2OUhOdTGg0N6EmOTt2Ltweuvv85LL70EwAUXXMAZZ5xhciLR3lm0KNItc1tt/ATLNBIs01ptfCGEOBhZDFCYTinFzp07Oeqoo8yOIoQQQgghRMD9XFZFscsDQJHTzcqyqkYdV1xczEsvvcQHH3yAUqo1I4oGfPTRR/7tjz/+OKBjG4bBV199xVdffYVhGAEdWwQXpTx4VAFKeQ+9sxBCtGPyMbowncPhICwsjIsuuwwSEuruDAkxN5QQQgghhBAB0jUiFIum4VMKq6aRHRF6yGOUUtxyyy0UFBQAUFlZydlny6Jeba179+4UFRUB0K1bt4CO/fjjj7N06VIAVq1axVVXXRXQ8UVw8KkqdvpuwKPysGu5ZFjuQ9fCzI4lhBCtQgrNwnRFRUUMHDiQfkOGwIgRZscRQgghhBAioHKjwrlrYDdWlVUxOD6KnMhDF5mcTqe/yAywZcuW1owoGnDdddfRu3dvAE4++eSAjr1y5Ur/9qpVqwI6tggeDvU/PCoPAJfaTI36iUjtCJNTCSFE65DWGcJ0hmFwxBFHYLXK5x5CCCGEEKJj6hcbybld0+gbE9mo/cPCwjjmmGMAsFqtHH/88a0ZTzTAbrczefJkJk+ejM1mC+jYI0eO9G8ffvjhAR1bBI8Q0ve5pRGipZmWRQghWptU9kRQiIqKAsOA7dvr7sjKAl0+BxFCCCGEEJ3X9ddfz2mnnUZ0dDSJiYlmxxEBdvHFFzNkyBCUUgwdOtTsOKKVhOn9SOUmatQqIrQR2LVcsyMJIUSrkUKzMJXP50MpRVpaGtTWQteudQ9UV0NEhLnhhBBCCCGEMJGmaeTmSlGqIxsyZIjZEUQbiNSPJJIjzY7RZB988AErVqxg+PDhTJgwwew4Qoh2QArNwjRKKbZu3UpGRgZ9+vQxO44QQgghhBBCdApKKTRNMztGs3i9XkpKSkhISJD2i61o5cqVPP744wAsW7aMLl260K9fP5NTCSGCnfQmEKYpKSkhIiKC++67jy5dupgdRwghhBBCCCE6NK/Xy1133cWpp57KbbfdhtvtNjtSkzgcDq677jouvvhirrnmGqqrq82O1GGVlZXVu11eXm5OkE6g2viWMuNNvKrY7ChCtJgUmoVpysvLOfbYYxk+fLjZUYQQQgghhBAHsW7dOu655x6eeeaZdlecFHstW7aMH374AaUUK1eu5JtvvjE7UpMsX76cLVu2ALBt2zaWLVtmcqKOa/To0Rx22GEADBgwgBEjRpicqGOqMD6i0HcfJb4X2Om7CaU8ZkcSokXkOhNhil27dmGxWGTRCyGEEEIIIYKc2+3mjjvuwOFwABASEsIFF1xgcirRHNHR0fVuR0VFtXhMt9pBoW8+Bg6S9EuJ0Ee2eMyGpKWloWmav/VHWlpaq52rs7Pb7dx33324XC7sdnurnMOrynCrHYRqPdC1sFY5R7BzqQ3+ba8qwks5ISSZmEiIlpFCs2hz5eXlOJ1OZs6cyeTJk82OI4QQQgghhDgIl8vlLzIDlJaWmphGtES/fv245JJLWLZsGYMGDQrI1aXFvmdxq60A7DIeIld/rcVjNqRnz57Mnj2bFStWMHjwYFnrpw20VpHZrfLY6ZuFoaoJ0TLItDyIroW3yrmCWaR2NFV8jsJLmDYAK4lmRxKiRaTQLNpccXExRx99NJdffnm7XYBCCCGEEEKIziIqKoozzzyT119/nfj4eE477TSzI4kWmDRpEpMmTQrYeJpmBfXHdhuUGEaPHs3o0aNb/TyidTnU9xiqrse2R+XhVBsJ1waZG8oE4fogsrTH8ardhGp9pEYi2j0pNIs2VVZWRkhICOPHj9//B6jVCpdfvndbCCGEEEIIERSmTZvGWWedRUhIiBRCRD2J+gwM5cSgmkT9IrPjiHYilJ6ABih0LQyb1sXsSKYJ0VIJ0VLNjiFEQEg1T7Sp6upqevfufeBZEHY7PPpo24cSQgghhBBCHJLNZjM7gilWrVrFN998Q+/evRk7dqzZcYJOiJZMhvUus2OIdiZM7086d+FU64nQR2DVpGWEEB2BFJpFm/J4PCQnJ8ssCCGEEEIIIUTQKygoYN68eXi9XpYuXUpkZCQjR7beYndCdCbh+gDCGWB2DCFEAOlmBxCdi8/no0uXBi6JUQp27677UqptgwkhhBBCCCHEn+zevRuv1+u/vXPnThPTCCGEEMFNCs2iTWmaRlZW1oEfrKmB5OS6r5qatg0mhBBCCCGEEH/Sp08f+vbtC0BSUhLHHHOMyYmEEEKI4CWtM0SbUUqhlCIpKcnsKEIIIYQQQghxSCEhIdxzzz3s3r2b+Pj4TtunWgghhGgMKTSLNuN2uwkJCSEuLs7sKEIIIYQQQgjRKBaLhdTUVLNjCCGEEEFPWmeINlNVVUV0dDS9evUyO4oQQgghhBBCiADxqnJ2eK/hd89kin3Pmh1HCCGESTplofmxxx6ja9euhIaGMnToUL7++muzI3UKDoeD7t27ExUVZXYUIYQQQgghhBABUmG8i0v9jsJLufFv3GqH2ZGEEEKYoNMVmhcvXsw111zDnDlz+PnnnznqqKM48cQT2b59u9nROjSlFC6Xi27dupkdRQghhBBCCCFEAOlaxD63LOiEmZZFCCGEeTpdofnBBx/koosu4uKLL6ZPnz4sWLCAzMxMHn/8cbOjdWi7d+8mOjqaSZMmmR1FCCGEEEIIIUQAxWqTiNEnEqb1I8VyHVYt0exIQgghTNCpFgN0u92sWLGC2bNn17t//PjxfPfddyal6viUUpSXl3PRRRcxaNCghne0WuGCC/ZuCyGEEEIIIYQIeppmJclyqdkxhBBCmKxTVfOKi4vx+XykpKTUuz8lJYXCwkKTUnV8paWlxMTEMHny5IPvaLfD88+3SSYhhBBCCCGEECLYffbZZ6xevZqRI0cyatQos+O0CqUUDvUDGjrh2nA0TTM7khCimTpVoXmPP//QUkrJD7JWVFVVxfDhw+nRo4fZUYQQQgghhGgypRRff/01FRUVjB07lvDwcLMjCSE6gZUrV/LQQw8BdQXnBQsWkJuba3KqwNttPEql8REAsfqpJFoubvIYTrWBQt+9GDhJ0q8gSj8q0DGFEI3QqXo0JyYmYrFY9pu9XFRUtN8sZxEYSincbjddu3ZtzM7gcNR9KdX64YQQQgghhGiExYsXc//99/PUU09x++23mx1HCNFJ7Fu7UEpRVFRkYprWU6OW+7cd+2w3RYnvebyqBEM52G3IGlxCmKVTFZptNhtDhw7lk08+qXf/J598wujRo01K1bE5nU5CQ0OZMGHCoXeuqYHIyLqvmprWDyeEEEIIIUQj/PLLL/7tDRs2YBiGiWlEZ1JVVYXT6TQ7hjDJEUccQWZmJgC9evVi8ODBJidqHeHa0ANuN4Wu7b3SxEJEizMJIZqn07XOuO6665g2bRrDhg1j1KhRPPXUU2zfvp3LLrvM7Ggd0p5Cc6NmNAshhBBCCBGEjj76aFatWoVSiiOOOAJd71TzdYRJXn/9dV566SVCQ0OZM2fOwRdWFx1SVFQUDz/8MOXl5cTHx3fYnz1J+pV/FJh1IrSRzRxjJqBjqFoSLdMDmk8I0Xgd86fUQZx11lksWLCAO++8k0GDBvHVV1/xwQcfkJ2dbXa0DqmkpIQBAwaQkJBgdhQhhBBCiA5n3rx5aJpW7ys1NdX/uFKKefPmkZ6eTlhYGMcee2y92bkALpeLq666isTERCIiIpg0aRI7d+5s66cS1I4//ngWLFjA3//+d2688Ub//UopvvnmG7744gt8Pp+JCUVHo5Ti1VdfBeom77z11lsmJxJmsVqtJCYmdtgiM9StoxWpjyZSP7zZ62dZtUTSLHPIsN6FXesW4IRCiMbquD+pDuLyyy9n69atuFwuVqxYwdFHH212pA7J4XBgtVqZOnWqLLYohBBCCNFKDjvsMAoKCvxfa9as8T82f/58HnzwQR555BF+/PFHUlNTOf7446mqqvLvc8011/D222/z2muv8c0331BdXc3EiROlcPonubm5DBo0qN7r2meffZZ//OMfPPDAA/4Fu4QIBE3TSE5O9t+WNYWEEEK0B52udYZoO4WFhYwcOVIK+UIIIYQQrchqtdabxbyHUooFCxYwZ84cTjvtNABeeOEFUlJSeOWVV7j00kupqKjg2Wef5aWXXmLcuHEAvPzyy2RmZvLpp59ywgkntOlzaW9Wrlx5wG0hAmHevHm88cYbREZGcs4555gdRwghhDikTjmjWbQNwzDo06cPVqt8niGEEEII0Vp+++030tPT6dq1K2effTabN28GYMuWLRQWFjJ+/Hj/vna7nWOOOYbvvvsOgBUrVuDxeOrtk56eTr9+/fz7HIjL5aKysrLeV2c0cuTeXqKHH364iUlER5SWlsbVV1/NX//6V0JDQ82OI4QQQhySVABFq9izEnePHj1MTiKEEEII0XGNHDmSF198kZ49e7Jr1y7uuusuRo8ezS+//EJhYSGw/yX3KSkpbNu2Dai7As1msxEXF7ffPnuOP5B7772XO+64I8DPpv2ZNm0a/fv3x+PxMGzYMLPjCCGEEEKYSgrNolVUVlYSFRXF0KFDG3+QxQJnnLF3WwghhBBCHNSJJ57o3+7fvz+jRo2iW7duvPDCC/4Ztn9eK0Mpdcj1Mw61z80338x1113nv11ZWUlmZmZznkK7N2jQILMjCCGEEEIEBWmdIVpFcXExw4cPb9objtBQeOONui+5NEwIIYQQoskiIiLo378/v/32m79v859nJhcVFflnOaempuJ2uykrK2twnwOx2+1ER0fX+xJCCCGEEJ2bFJpFwJWVlWG32znnnHMOOVtGCCGEEEIEjsvlYt26daSlpdG1a1dSU1P55JNP/I+73W6+/PJLRo8eDcDQoUMJCQmpt09BQQFr16717yOEEEIcik9VUWYsodL4DKWU2XGEECaR1hki4IqLizn99NM54ogjzI4ihBBCCNGhzZo1i1NOOYWsrCyKioq46667qKys5IILLkDTNK655hruueceevToQY8ePbjnnnsIDw/nnHPOASAmJoaLLrqI66+/noSEBOLj45k1axb9+/dn3LhxJj870RI/FFdQ4vJwTEocEdb21ZZu48aNbNiwgSFDhpCRkWF2HCFEI+T7bsWl6haj9epFxFvONjmREMIMUmgWAbXnk8v+/fs3fTazwwGRkXXb1dUQERHgdEIIIYQQHcvOnTuZOnUqxcXFJCUlcfjhh/P999+TnZ0NwI033khtbS2XX345ZWVljBw5ko8//pioqCj/GA899BBWq5UzzzyT2tpaxo4dy/PPP49F1sxot97duZunNuUB8FFBCQuG9mw3Vxpu2LCBm266CZ/PR0REBI8++igJCQlmxxJCHIRSHn+RGcDJRhPTCCHMJIVmEVBerxeLxdJpF4MRQgghhGhLr7322kEf1zSNefPmMW/evAb3CQ0NZeHChSxcuDDA6YRZ1pZX+7c3V9dS6zMIbyezmtetW4fP5wPA4XCwdevWVi00ezwefvzxR+Lj4+ndu3ernUeItuJRRRQbzwKKRH06IVpaq59T00KI1I+k2vgG0IjSjmn1cwohgpMUmkVA1dTUEB4eTlZWltlRhBBCCCGE6JSOSIrlf8UVKGBwXFS7KTJDXd/wV155hdraWpKSkujZs2ernm/evHmsXr0agKuvvprjjz++Vc/X2bnVTmrUz4RpfbFr3cyO0yEV+RZQq9YA4FUlZFofaJPzpug3EqNNxKJFY9Nk4pkQnZUUmkVAlZWVkZyc7F/lXAghhBBCCNG2jk6Jo0u4nVK3l0FxkWbHaZLMzEweeeQRtm7dSu/eveu1eQkkj2FQWOVg1erV7GkqsmzZMik0tyKPKmKn73oMVYOGlS7Wf0qxuRX4qPRvG/tstzZN0wjTDmuz8wkhgpMUmkXAuFwulFJcffXVhISEmB1HCCGEEEKITis3Kpxcs0M0U3JyMsnJya02fonLzU0/b2KX083uYyeS+OX76EoxaNCgVjunAJfajKFqAFB4car1UmhuBQn6dHYZ96OUjwT9IrPjCCE6GSk0i4Cprq4mMjKSI4880uwoQgghhBBCCHFAX+wqY5fTDUDioGGc2rcbw1MTGDx4sMnJOrYwrQ8WLR6fKkXXwgnTBpkdqUOK0IfSVXsVoN0sAiqE6Dik0CwCpqysjLFjx8qq0EIIIYQQQoiglRZm92/brFZOGX1UvftE67BoMWRZHvbPZLZqiWZH6rCkwCyEMIsUmkVAuN1uNE1j0qRJzR/EYoGTTtq7LYQQQgghhBABNjoplit7ZrKh0sFRybFSZG5DFi2GCG2k2TGEEEK0Eik0i4Dwer3Y7Xays7ObP0hoKLz/fuBCCSGEEEIIIcQBnJCewAnpciVma1u7di3bt2/n8MMPJz4+3uw4QgghWpkUmkVA+Hw+dF0nNDTU7ChCCCGEEEIIUU9VVRXbt28nJyeHiIgIs+N0CsuWLeOuu+5CKcWbb77JY489Ju8XhTCRS20GNOxaV7OjiA5MCs0iIKqqqoiNjSU1NdXsKEIIIYQQQgjhV1xczLXXXkt5eTkpKSk8+OCDREdHmx2rw1uzZg1KKQB2795NYWEhOTk55oYSopMq9b1KqfEKAAmW84nTp5icSHRUutkBRPunlKK6uprx48djt7egv5nDARERdV8OR+ACCiGEEEIIITqt5cuXU15eDsCuXbtYu3atuYE6iREjRmC11s1ty8rKIj093eREQnReleqTvdvGpyYmER2dzGgWLVZeXk5UVBQTJkxo+WA1NS0fQwghhBBCCCH+kJubi67rGIZBSEhIy9aVEY3Wv39/Hn74YfLy8hgwYAA2m83sSEJ0WnatB161+4/t7ianER2ZFJpFi1VXV5Odnc3AgQPNjiKEEEIIIYQQ9fTs2ZO7776btWvXMmTIEDIyMsyO1GlkZmaSmZlpdgwhOr0U/Xoqtb6ARrQWgEmCQjRACs2ixWprawMzm1kIIYQQQgghWkG/fv3o16+f2TFEO/f666/zv//9j/79+zN9+nQ0TTM70n527NjB4sWLiY6O5rzzziM8PNzsSCII6JqNWO1Us2OITkAKzaJFnE4nISEhMptZCCGEEEIIIUSHtXbtWl566SUANm3aRM+ePTnyyCNNTrW/efPmUVRUBNS9X7/66qtNTiSE6ExkMUDRbD6fj+3bt9OrVy8pNAshhBBCCCGEOCBDtf1aPEVFReTn5wdsPKfTWe+2y+UK2NiBopSitLTUf7u4uNjENEKIzkgKzaLZampqiIyM5M477yQiIsLsOEIIIYQQQohOwDAMsyOIRjKUmzzvLWz2nsVO7ywM5Tz0QQGwdOlSLr74Yi699FIWL14ckDGHDh3KuHHjiIiIYPTo0RxzzDEBGTeQNE1j2rRpaJpGeHg4Z555ptmRhBCdjLTOEM22e/du+vXrR8+ePQMzoK7Dnl/WunwGIoQQQgghhNirqqqKuXPn8vvvv3Psscdy7bXXBmWPXLFXjVpOrVoDgFNtoFp9Q7Q2rtXP+/7776OUAuC9997jrLPOavGYmqbxt7/9jb/97W8tHqs1nXbaaZx00klYrVasVin5CCHallTzRLMZhsFJJ51ESEhIYAYMC4Mvvqj7CgsLzJhCCCGEEEKIDuHjjz9m06ZNKKX4/PPPWb9+vdmRxCFYtfj6t0lok/Pm5OQccLuzCA0NlSKzEMIU8pNHNIvP5wMgKyvL5CRCCCGEEEKIziAmJsa/rWkaUVFRJqYRjRGq9SbZcg0OtYxwbSDh+uA2Oe+VV15JZmYmHo+HU089tU3OKYQQQgrNopmqq6uJjIwkNzfX7ChCCCGEEEKITmDs2LEUFhayceNGxowZQ5cuXcyO1GnVen0s3rYLp8/gjKxkEkNtDe4brY8lmrFtmA7sdrv0JxZCCBNIoVk0S3V1Nenp6YGd0exwwJ7LmrZuBVlgUAghhBBCCPEHTdM477zzzI4hgMd/28nnu8oA2FDl4KGhvUxOJITojEpLS/n2229JT09n6NChZscRSKFZNJPX6yUpKSnwi28UFwd2PCGEEEIIIYQQh/TNN9/w73//m4yMDGbOnEloaGiD++bXuvZu17jbIp4QIgjUGmuoUEuxkUWcPgVNM2/pN7fbzU033URhYSEA119/Pccee6xpeUQdWQxQNIvb7aZbt25mxxBCCCGEEEII0UKVlZU88MADbNiwgc8++4w33njjoPufnpmMVdPQgLOyU9ompBDCVD5VSb7vDqqNryg1XqZCvWdqnpKSEn+RGeCXX34xMY3YQ2Y0iybxeDxs376diIgIRowYYXYcIYQQQgghhBAt5PF48Hq9/ttOp/Og+49KiuWl0ZF4lSLWFtLa8YQQQcBHJYq9VzN4VZGJaSA5OZlevXqxYcMGLBYLo0aNMjWPqCOFZtEk+fn55OTkcMMNN8glCUIIIYQQQgjRASQkJHD++efz5ptvkpGRwemnn37IYyJDpJwgRGdi07oQpY+hyvgcq5ZIjH6yqXksFgt33303a9asITU1VRaIDRLym0E0idvt5pRTTmHMmDFmRxFCCCGEEEIIESBTpkxhypQpZscQQgSxFMt1JOqXoBOOplnMjoPdbmfYsGFmxxD7kB7NotFcLhdWq5X+/fubHUUIIYQQQgghhBCN4FFFOIwf8akqs6OIDsCiRQVFkVkEJ5nRLBqtpKSE9PR0hgwZ0jon0HXY80mULp+BCCGEEEIIIYQQLeFW29nhvR6FE6uWTKbl/7BokWbHEkJ0UFJoFo3mcDiYNGkS4eHhrXOCsDD48cfWGVsIIYQQQgghhOhkHGo5irrFHb2qCJfaSLjWSpPHhBCdnhSaRZP06dPH7AhCCCGEEEJ0SKvLqnh+cwFRIRau6plJYqjN7EhCiHYuVOtDXddUA12LwKblmJxICNGRSaFZNIrP50PTNOLi4syOIoQQQgghRId03y9bqfL6AHh6Ux439+tqciIhRHsXpvWhi3U+TrWBcG0oVi3e7EhCiA5MCs2iUWprawkLCyMnJ6f1TlJTA3371m3/+iu0VosOIYQQQgghgoxSCq9S/tuefbaFEKIlQrVehGq9zI4hhOgEZMU10SglJSXk5ua2bqFZKdi2re5LXlgLIYQQQohORNM0/tYriwR7CDkRoUzPTTc7khBCCCFEk8iMZtEo/9/encdFVa9/AP8MMAzDCCioLIKguYeioimamqWgueY110xvtpiSlm12TcW8ZXXLtG6aqReXNPXndr25lJqSprklZkJogIoKIiirAsI8vz+IIwMDzLCNwOf9es2LmbPMec7z/TJ8z8OZc3JycuDr6wu1Wm3pUIiIiIiIaqWejeujZ+P6lg6DiIiIqFx4RjOVSa/XQ6/Xo379+pYOhYiIiIiIiIiIiB5ALDRTma5fv47GjRtjxIgRlg6FiIiIiIiIiIiIHkAsNFOpkpKSICKYNm0amjZtaulwiIiIiIiIiIiI6AHEQjMZJSJISUlBYmIiBg4ciDFjxlg6JCIiIiIiIiJ6wOklB9kSDb3csXQoRFTNeDNAKiY7OxtxcXGws7PD0KFD8fLLL0OlUlX9hlUqoF27+8+JiIiIiIioTtLLHcTnLUQ2/oSjKhANrf9e7vcSEQAClYrn2lU1vdzF1bw3kSOXYa1yhpf1p7BRNbR0WERUTVhopmLi4uLg6+uLmTNnonv37tVTZAYAe3vg/Pnq2RYRERERERE9sFJlN+5KOAAgRbbBwaoPNKrmZr/PHf1vSNB/AJEcNLIOhqPV45UcKRV2V35HjlwGAOTJLWTIMdRXDbFwVERUXfjvPDKQnZ0NKysrTJkyBQEBAdVXZCYiIiIiIiL6iwoag1cq2JbrfW7p10EvmRDcQ5J+ZeUERyVSq5pABfVfr1TQwMeS4RBRNeMZzWQgPT0d9evXR/fu3S0dChEREREREVWjP//8EytWrICtrS2mTp0Kd3d3i8XipBqIHKsryJY/4WjVH7Yqz3K9j7XKCZD85zaoX3kBklG2Kg942LyPTP1xaFUPQ2vV3tIhEVE1YqGZFCKCW7duoV+/ftDpdNUfwJ07QNeu+c9Pnsy/lAYRERERERFVi08++QTXrl0DACxduhQLFiywWCwqlQ0aW0+r8Ps0sgqGFeyhRxZcrJ6thMioLFpVW2it21o6DCKyABaaSREfHw8HBwc8+6yF/viKABER958TERERERkhItizZw/i4uLQv39/NG9u/nVbiai4rKwso89rMhtVfbhaz7R0GEREdQKv0UwAgLt37yI7OxszZsxAt27dLB0OEREREVGJ9uzZg2XLluG7777D7NmzkZmZaemQiB4I+gqesDNt2jQ4OzvDzc0NL7zwQiVFRUREdQXPaCYA+TcB1Ol0GDhwoKVDISIiIiIqVVxcnPI8IyMDKSkplrn0G9ED5KsLV7H7ehI87e3wT7+H4KxRl71SEV27dsWaNWuqIDoiIqoLeEYzAcgvNNvZ2aF+/fqWDoWIiIiIqFT9+/dHvXr1AADdunWDh4eHhSMisqy4zCzsup4EARB3Jwv/u3bT0iEREVEdxDOaCSKCzMxMNG3aFDY27BJERERE9GBr3rw5Vq5ciZSUFHh4eEClUlk6JCKL0tlYw0alQu5fl85wUvO4joiIqh//+hCSkpJgZ2eHcePGWToUIiIiIiKT6HQ6Xi6D6C/OGjXeftgHe64nwVtnh8FNGlo6JCIiqoNYaCakpqZiyJAhGDFihGUDUakAb+/7z4mIiIiIiMgk3Rs6oXtDJ0uHQUREdRgLzXVcUlISbGxs0KtXL0uHAtjbA5cuWToKIiIiIiIiIiIiMhMLzXXYjRs3kJWVhRdffBGDBw+2dDhERERERERERERUQ1lZOgCyDBFBSkoKRo0aheDgYN5AhYiIiIiIiIiIiMqNheY6KikpCQ0aNMDAgQMfnCLz3btA1675j7t3LR0NERERERERERERmYiF5jrqzp07aNu2Lfz9/S0dyn16PXDqVP5Dr7d0NERERER1ztKlS9GsWTPY2dnB398fhw8ftnRIRERERFRDsNBcB+Xm5iI7Oxt+fn6WDoWIiIiIHhCbNm3Cq6++itmzZ+PMmTPo1asXBg4ciCtXrlg6NCIiIiKqAVhoroNSU1Ph7OyM8ePHWzoUIiIiInpALFq0CJMnT8bzzz+Ptm3bYvHixfDy8sKyZcssHVqNdPXqVSxevBihoaHIysoyeb3o9DtYFHkZ38TG4x6/5UdUJ2RLDG7kLUJy3jqI3LN0OFRDiQhu67fiRt6nuKP/zdLhUB1lY+kAqPqlpKSga9euaNy4saVDISIiIqIHQE5ODk6fPo1Zs2YZTA8MDMTRo0eLLZ+dnY3s7GzldVpaWpXHWNPMmzcPiYmJAICsrCy8/PLLZa5zT6/HnLPRSM/NAwCIABOau1dpnERkWSK5uJ43F3mS+tcUPVysJ1o0JqqZ0uR7JOetBgBk4Ci8VStho2pg2aCozuEZzXVMdnY2VCoVJkyYYOlQiIiIiOgBkZSUhLy8PLi6uhpMd3V1RUJCQrHlFy5cCCcnJ+Xh5eVVXaHWCHq9HklJScrrGzdumLReVp5eKTIDwM3snEqPjYgeLHpkFyoyA/eQaMFoqCbLlft/awQ5yEOK5YKhOouF5jomLS0Njo6O6Ny5s6VDISIiIqIHjEqlMngtIsWmAcA777yD1NRU5REXF1ddIdYIVlZWGDt2LABAq9Vi5MiRJq3noLbBMM9G+c9trDH0r+dEVHtZq3Sob/UUAMBK5YD6VsMtGxDVWI5WA2CjaggAqGf1KGzhY9mAqE7ipTPqkKSkJKSkpGDChAlwdna2dDjGNWxo6QiIiIiI6pyGDRvC2tq62NnLiYmJxc5yBgCNRgONRlNd4dVIY8aMwaBBg6DRaGBra2vyes+3aIJR3q7QWltBbcXzgojqgobWz6GB1UioYAcrlemfF0SFqVWu8LZeAT0yYa1ysnQ4VEdx5FJHpKenIy0tDS+++CJef/11S4djnE4H3LyZ/9DpLB0NERERUZ1ha2sLf39/7Nu3z2D6vn370KNHDwtFVfM5ODiYVWQu4Ki2YZGZqI6xVjmyyEwVplLZsMhMFsUzmms5EUFGRgauXr2KwMBAvPrqq7DioJWIiIiIipg5cyYmTJiALl26ICAgAF9//TWuXLmCKVOmWDo0IiIiIqoBWGiuxfLy8hATEwOtVovu3btj+vTpLDITERERkVGjR49GcnIy3nvvPcTHx8PX1xe7d++Gt7e3pUMjIiIiohqAheZaSK/XIzk5Gbdu3YKPjw8WLlyIzp07G72RywPl7l1g4MD853v2AFqtZeMhIiIiqmOmTp2KqVOnWjoMIiIiIqqBWGiuZbKzs3H58mU4Oztj7NixGDt2LNq0aWPpsEyj1wNhYfefExERERERERERUY3AQnMNlZeXh9zcXNy7d0/5mZWVhaysLHTq1AkffPABmjdvbukwiYiIiIiIiIiIqA5gobkGuHbtGu7cuQOVSgWVSgW9Xg8rKyvY2NhArVYrPz09PfHUU09h7NixsLe3t3TYREREREREREREVEew0PyAS09PR05ODoYNG4YmTZqgfv36cHJygpOTE+rXrw9HR0flp40Nm5OIiIiIiIiIiIiqHyuTD6icnBwkJCTg3r17CAwMxIIFC2Bra2vpsIiIiIiIiIiIiIiKYaH5AZSdnY1Lly6hRYsWGDduHEaNGsUiMxERERERERERET2wWGh+gIgIsrKyEBcXh06dOmHlypVwcHCwdFjVi9eWJiIiIiIiIiIiqnFYaLawrKws3Lp1C5mZmQAAjUYDV1dXvPjii3WvyKzTAX/lgYiIiIiIiIiIiGoOFprLQa/XIzs7G9nZ2cjKyjL6PDs7GwCU6yzr9Xro9Xrk5eVBr9dDRAAAarUabm5uGDx4MNq1a4fWrVujZcuW0Ol0ltxFIiIiIiIiIiIiIpOx0Gyi6dOnIzo6WikYFy4al/Rap9OhWbNmcHZ2hr29PbRaLXQ6nfLc0dERXbt2hb+/PzQajaV3kYiIiIiIiIiIiKhcWGg20aBBg/D1119Do9FAo9HAzs7O6M+ij6CgIDg5OVk6/JohKwv429/yn2/dCtjZWTYeIiIiIiIiIiIiMgkLzSYKCgpCUFCQpcOo3fLygN277z8nIiIiIiIiIiKiGsHK0gEQERERERERERERUc3GQjMRERERERERERERVQgLzURERERERERERERUISw0ExEREREREREREVGFsNBMRERERERERERERBViY4mNiggAIC0tzRKbpwdVZub952lpQF6e5WIhIiKicikY3xWM96hu4PieiIiIqPYydYxvkUJzcnIyAMDLy8sSm6eawMPD0hEQERFRBSQnJ8PJycnSYVA1SU9PB8DxPREREVFtlp6eXuoY3yKFZmdnZwDAlStXau0BSFpaGry8vBAXFwdHR0dLh0MVwLasXdietQfbsvZgW9YuqampaNq0qTLeo7rBw8MDcXFxcHBwgEqlqpZt8rPDPMyXeZgv0zFX5mG+zMN8mY65Mg/zZR4RQXp6OjzKODHUIoVmK6v8S0M7OTnV+sZ0dHSs9ftYV7Ataxe2Z+3Btqw92Ja1S8F4j+oGKysreHp6WmTb/OwwD/NlHubLdMyVeZgv8zBfpmOuzMN8mc6Uk4V5BEBEREREREREREREFcJCMxERERERERERERFViEUKzRqNBvPmzYNGo7HE5qtFXdjHuoJtWbuwPWsPtmXtwbasXdieVF3Y18zDfJmH+TIdc2Ue5ss8zJfpmCvzMF9VQyUiYukgiIiIiIiIiIiIiKjm4qUziIiIiIiIiIiIiKhCWGgmIiIiIiIiIiIiogphoZmIiIiIiIiIiIiIKoSFZiIiIiIiIiIiIiKqkGopNN++fRsTJkyAk5MTnJycMGHCBKSkpJS6zrZt2xAUFISGDRtCpVIhPDy8OkI1y9KlS9GsWTPY2dnB398fhw8fLnX5sLAw+Pv7w87ODs2bN8dXX31VTZFSWcxpy23btqF///5o1KgRHB0dERAQgO+//74ao6WymPu7WeDnn3+GjY0NOnbsWLUBksnMbcvs7GzMnj0b3t7e0Gg0eOihh/Cf//ynmqKl0pjbluvXr4efnx/s7e3h7u6Ov//970hOTq6maKkkP/30E4YMGQIPDw+oVCrs2LGjzHU4/qGqUt6/97VJSEgIVCqVwcPNzU2ZLyIICQmBh4cHtFotHnvsMZw/f97gPbKzs/HKK6+gYcOG0Ol0GDp0KK5evVrdu1Lpyvq8qqzclOdY90FUVr4mTZpUrK91797dYJm6kq+FCxeia9eucHBwQOPGjTF8+HBERUUZLMP+dZ8p+WL/um/ZsmXo0KEDHB0dlXrDnj17lPnsW/eVlSv2KwuRajBgwADx9fWVo0ePytGjR8XX11cGDx5c6jpr166V+fPny4oVKwSAnDlzpjpCNdnGjRtFrVbLihUrJCIiQmbMmCE6nU4uX75sdPmYmBixt7eXGTNmSEREhKxYsULUarVs2bKlmiOnosxtyxkzZshHH30kJ06ckAsXLsg777wjarVafv3112qOnIwxtz0LpKSkSPPmzSUwMFD8/PyqJ1gqVXnacujQodKtWzfZt2+fxMbGyvHjx+Xnn3+uxqjJGHPb8vDhw2JlZSVLliyRmJgYOXz4sDz88MMyfPjwao6citq9e7fMnj1btm7dKgBk+/btpS7P8Q9VlfL+va9t5s2bJw8//LDEx8crj8TERGX+hx9+KA4ODrJ161Y5d+6cjB49Wtzd3SUtLU1ZZsqUKdKkSRPZt2+f/Prrr9K3b1/x8/OT3NxcS+xSpSnr86qyclOeY90HUVn5mjhxogwYMMCgryUnJxssU1fyFRQUJKGhofL7779LeHi4DBo0SJo2bSoZGRnKMuxf95mSL/av+3bu3Cm7du2SqKgoiYqKkn/84x+iVqvl999/FxH2rcLKyhX7lWVUeaE5IiJCAMgvv/yiTDt27JgAkD/++KPM9WNjYx/IQvMjjzwiU6ZMMZjWpk0bmTVrltHl33rrLWnTpo3BtJdeekm6d+9eZTGSacxtS2PatWsn8+fPr+zQqBzK256jR4+Wd999V+bNm8dC8wPC3Lbcs2ePODk5FRs8kOWZ25b/+te/pHnz5gbTPv/8c/H09KyyGMl8phSaOf6hqlIZ47faoLRxi16vFzc3N/nwww+VaVlZWeLk5CRfffWViOT/o12tVsvGjRuVZa5duyZWVlayd+/eKo29OhX9vKqs3FT0WPdBVVKhediwYSWuU5fzlZiYKAAkLCxMRNi/ylI0XyLsX2Vp0KCBrFy5kn3LBAW5EmG/spQqv3TGsWPH4OTkhG7duinTunfvDicnJxw9erSqN18lcnJycPr0aQQGBhpMDwwMLHGfjh07Vmz5oKAgnDp1Cvfu3auyWKl05WnLovR6PdLT0+Hs7FwVIZIZytueoaGhiI6Oxrx586o6RDJRedpy586d6NKlCz7++GM0adIErVq1whtvvIG7d+9WR8hUgvK0ZY8ePXD16lXs3r0bIoIbN25gy5YtGDRoUHWETJWI4x+qCpUxfqtNLl68CA8PDzRr1gxjxoxBTEwMACA2NhYJCQkGedJoNOjTp4+Sp9OnT+PevXsGy3h4eMDX17dW57KyclMbj3VLc+jQITRu3BitWrXCCy+8gMTERGVeXc5XamoqACjHg+xfpSuarwLsX8Xl5eVh48aNyMzMREBAAPtWKYrmqgD7VfWzqeoNJCQkoHHjxsWmN27cGAkJCVW9+SqRlJSEvLw8uLq6Gkx3dXUtcZ8SEhKMLp+bm4ukpCS4u7tXWbxUsvK0ZVGffvopMjMzMWrUqKoIkcxQnva8ePEiZs2ahcOHD8PGpso/EslE5WnLmJgYHDlyBHZ2dti+fTuSkpIwdepU3Lp1i9dptqDytGWPHj2wfv16jB49GllZWcjNzcXQoUPxxRdfVEfIVIk4/qGqUBnjt9qiW7duWLt2LVq1aoUbN27gn//8J3r06IHz588ruTCWp8uXLwPI/x21tbVFgwYNii1Tm3NZWbmpjce6JRk4cCCefvppeHt7IzY2FnPmzMHjjz+O06dPQ6PR1Nl8iQhmzpyJRx99FL6+vgDYv0pjLF8A+1dR586dQ0BAALKyslCvXj1s374d7dq1Uwqb7Fv3lZQrgP3KUspdVQkJCcH8+fNLXebkyZMAAJVKVWyeiBidXpMUjb+sfTK2vLHpVP3MbcsC3377LUJCQvDf//7X6IcPWYap7ZmXl4dx48Zh/vz5aNWqVXWFR2Yw53dTr9dDpVJh/fr1cHJyAgAsWrQII0eOxJdffgmtVlvl8VLJzGnLiIgITJ8+HXPnzkVQUBDi4+Px5ptvYsqUKVi1alV1hEuViOMfqirlHb/VJgMHDlSet2/fHgEBAXjooYewZs0a5YZH5clTXcllZeSmth7rFjV69Gjlua+vL7p06QJvb2/s2rULI0aMKHG92p6v4OBg/Pbbbzhy5EixeexfxZWUL/YvQ61bt0Z4eDhSUlKwdetWTJw4EWFhYcp89q37SspVu3bt2K8spNyXzggODkZkZGSpD19fX7i5ueHGjRvF1r9582ax/8LUFA0bNoS1tXWx/14kJiaWuE9ubm5Gl7exsYGLi0uVxUqlK09bFti0aRMmT56MzZs3o1+/flUZJpnI3PZMT0/HqVOnEBwcDBsbG9jY2OC9997D2bNnYWNjgx9//LG6QqciyvO76e7ujiZNmihFZgBo27YtRKTYnYOp+pSnLRcuXIiePXvizTffRIcOHRAUFISlS5fiP//5D+Lj46sjbKokHP9QVajI+K220+l0aN++PS5evAg3NzcAKDVPbm5uyMnJwe3bt0tcpjaqrNzUxmNdU7m7u8Pb2xsXL14EUDfz9corr2Dnzp04ePAgPD09lensX8aVlC9j6nr/srW1RYsWLdClSxcsXLgQfn5+WLJkCfuWESXlypi63q+qS7kLzQ0bNkSbNm1KfdjZ2SEgIACpqak4ceKEsu7x48eRmpqKHj16VMpOVDdbW1v4+/tj3759BtP37dtX4j4FBAQUW/6HH35Aly5doFarqyxWKl152hLIP5N50qRJ2LBhA68Z+gAxtz0dHR1x7tw5hIeHK48pU6Yo/xUtfB0mql7l+d3s2bMnrl+/joyMDGXahQsXYGVlVeZglqpOedryzp07sLIyHKJYW1sDuH82LNUMHP9QVSjv+K0uyM7ORmRkJNzd3dGsWTO4ubkZ5CknJwdhYWFKnvz9/aFWqw2WiY+Px++//16rc1lZuamNx7qmSk5ORlxcnHIJpLqULxFBcHAwtm3bhh9//BHNmjUzmM/+ZaisfBlTl/uXMSKC7Oxs9i0TFOTKGParalLFNxsUEZEBAwZIhw4d5NixY3Ls2DFp3769DB482GCZ1q1by7Zt25TXycnJcubMGdm1a5cAkI0bN8qZM2ckPj6+OkIu08aNG0WtVsuqVaskIiJCXn31VdHpdHLp0iUREZk1a5ZMmDBBWT4mJkbs7e3ltddek4iICFm1apWo1WrZsmWLpXaB/mJuW27YsEFsbGzkyy+/lPj4eOWRkpJiqV2gQsxtz6JKu3s7VS9z2zI9PV08PT1l5MiRcv78eQkLC5OWLVvK888/b6ldoL+Y25ahoaFiY2MjS5culejoaDly5Ih06dJFHnnkEUvtAv0lPT1dzpw5I2fOnBEAsmjRIjlz5oxcvnxZRDj+oepT1udKXfH666/LoUOHJCYmRn755RcZPHiwODg4KHn48MMPxcnJSbZt2ybnzp2TsWPHiru7u6SlpSnvMWXKFPH09JT9+/fLr7/+Ko8//rj4+flJbm6upXarUpT1eVVZuTHlWLcmKC1f6enp8vrrr8vRo0clNjZWDh48KAEBAdKkSZM6ma+XX35ZnJyc5NChQwbHg3fu3FGWYf+6r6x8sX8Zeuedd+Snn36S2NhY+e233+Qf//iHWFlZyQ8//CAi7FuFlZYr9ivLqZZCc3JysowfP14cHBzEwcFBxo8fL7dv3zYMBJDQ0FDldWhoqAAo9pg3b151hGySL7/8Ury9vcXW1lY6d+4sYWFhyryJEydKnz59DJY/dOiQdOrUSWxtbcXHx0eWLVtWzRFTScxpyz59+hjtmxMnTqz+wMkoc383C2Oh+cFibltGRkZKv379RKvViqenp8ycOdNg0E+WY25bfv7559KuXTvRarXi7u4u48ePl6tXr1Zz1FTUwYMHS/0byPEPVafSPlfqitGjR4u7u7uo1Wrx8PCQESNGyPnz55X5er1e5s2bJ25ubqLRaKR3795y7tw5g/e4e/euBAcHi7Ozs2i1Whk8eLBcuXKlunel0pX1eVVZuTHlWLcmKC1fd+7ckcDAQGnUqJGo1Wpp2rSpTJw4sVgu6kq+jOWpaD2D/eu+svLF/mXoueeeU/62NWrUSJ544gmlyCzCvlVYabliv7IclQi/g0pERERERERERERE5VfuazQTEREREREREREREQEsNBMRERERERERERFRBbHQTEREREREREREREQVwkIzEREREREREREREVUIC81EREREREREREREVCEsNBMRERERERERERFRhbDQTEREREREREREREQVwkIzUS1x6dIlqFQqhIeHV9s2V69ejfr16yuvQ0JC0LFjR+X1pEmTMHz48GqLp7YLCQmBq6srVCoVduzYYXSaOTm3RJ+pTIcOHYJKpUJKSoqlQyEiIiKiWsLYmLuqt1f4GKqmSUhIQP/+/aHT6QyODYmobmKhmagGUKlUpT4mTZpkkbhGjx6NCxcuWGTb5iipoFqTCuGRkZGYP38+li9fjvj4eAwcONDotCVLlmD16tUmvaeXlxfi4+Ph6+tbqbFW16CciIiIqKaaNGmS0XH9n3/+WSnvX/SEEDKNsfF1ZarOcfK2bdsQFBSEhg0bluvkEh8fHyxevLjM5T777DPEx8cjPDy8Uo8NTd0+ET1YbCwdABGVLT4+Xnm+adMmzJ07F1FRUco0rVaL27dvV3tcWq0WWq222rdbF0VHRwMAhg0bBpVKVeI0jUZj8ntaW1vDzc2tkiMlIiIiIlMMGDAAoaGhBtMaNWpkoWhKdu/ePajVakuHUS2Mja/L40HIWWZmJnr27Imnn34aL7zwQpVtJzo6Gv7+/mjZsmWVbaMicnJyYGtra+kwiOoMntFMVAO4ubkpDycnJ6hUqmLTCsTExKBv376wt7eHn58fjh07ZvBeR48eRe/evaHVauHl5YXp06cjMzOzxG2fPXsWffv2hYODAxwdHeHv749Tp04BMP1MiU8++QTu7u5wcXHBtGnTcO/ePWXe7du38eyzz6JBgwawt7fHwIEDcfHiRWW+sa+SLV68GD4+PgbTQkND0bZtW9jZ2aFNmzZYunSpMq9Zs2YAgE6dOkGlUuGxxx5DSEgI1qxZg//+97/KGSSHDh0CAFy7dg2jR49GgwYN4OLigmHDhuHSpUul7uP58+cxaNAgODo6wsHBAb169VIGqnq9Hu+99x48PT2h0WjQsWNH7N2712D90rYZEhKCIUOGAACsrKygUqmMTgOKn6Wt1+vx0UcfoUWLFtBoNGjatCnef/99AMbP9I6IiMCTTz6JevXqwdXVFRMmTEBSUpIy/7HHHsP06dPx1ltvwdnZGW5ubggJCVHmF7TLU089BZVKVaydCgQEBGDWrFkG027evAm1Wo2DBw8CAL755ht06dIFDg4OcHNzw7hx45CYmFhiG1RGX8nJyUFwcDDc3d1hZ2cHHx8fLFy4sMRtEhEREZWXRqMxGNO7ubnB2toaAPC///0P/v7+sLOzQ/PmzTF//nzk5uYq6y5atAjt27eHTqeDl5cXpk6dioyMDAD5lxf7+9//jtTUVGWcWzBeM3ZGbf369ZVvxBWMDzdv3ozHHnsMdnZ2+OabbwCUPoYyZsuWLWjfvj20Wi1cXFzQr18/5bijYMw6f/58NG7cGI6OjnjppZeQk5OjrL937148+uijqF+/PlxcXDB48GBlfF3g6tWrGDNmDJydnaHT6dClSxccP35cmV9WHgsraXxd1li+tJwVVtY4ed26dfDx8YGTkxPGjBmD9PR0ZZ6I4OOPP0bz5s2h1Wrh5+eHLVu2lJr/CRMmYO7cuejXr1+Jy4SEhKBp06bQaDTw8PDA9OnTAeSP+S9fvozXXntN6UPG+Pj4YOvWrVi7dq3BN21TU1Px4osvKm37+OOP4+zZs8p60dHRGDZsGFxdXVGvXj107doV+/fvV+aXtH1TxvsFfWvhwoXw8PBAq1atAJTvGI+IzMdCM1EtM3v2bLzxxhsIDw9Hq1atMHbsWGUwde7cOQQFBWHEiBH47bffsGnTJhw5cgTBwcElvt/48ePh6emJkydP4vTp05g1a5ZZ/50/ePAgoqOjcfDgQaxZswarV682uLTDpEmTcOrUKezcuRPHjh2DiODJJ580KEaXZcWKFZg9ezbef/99REZG4oMPPsCcOXOwZs0aAMCJEycAAPv370d8fDy2bduGN954A6NGjcKAAQMQHx+P+Ph49OjRA3fu3EHfvn1Rr149/PTTTzhy5Ajq1auHAQMGGAx8C7t27Rp69+4NOzs7/Pjjjzh9+jSee+45Je9LlizBp59+ik8++QS//fYbgoKCMHToUKWgXtY233jjDeVsl4JYjU0z5p133sFHH32EOXPmICIiAhs2bICrq6vRZePj49GnTx907NgRp06dwt69e3Hjxg2MGjXKYLk1a9ZAp9Ph+PHj+Pjjj/Hee+9h3759AICTJ08CyD8QiY+PV14XNX78eHz77bcQEWXapk2b4Orqij59+gDIL/ouWLAAZ8+exY4dOxAbG1vhy8SU1Vc+//xz7Ny5E5s3b0ZUVBS++eabEovlRERERFXh+++/xzPPPIPp06cjIiICy5cvx+rVq5WTBYD8Qujnn3+O33//HWvWrMGPP/6It956CwDQo0cPLF68GI6OjgZjR3O8/fbbmD59OiIjIxEUFFTmGKqo+Ph4jB07Fs899xwiIyNx6NAhjBgxwmDsd+DAAURGRuLgwYP49ttvsX37dsyfP1+Zn5mZiZkzZ+LkyZM4cOAArKys8NRTT0Gv1wMAMjIy0KdPH1y/fh07d+7E2bNn8dZbbynzTcljYSWNr8say5eUs6JKGydHR0djx44d+O677/Ddd98hLCwMH374oTL/3XffRWhoKJYtW4bz58/jtddewzPPPIOwsLASWrBsW7ZswWeffYbly5fj4sWL2LFjB9q3bw8g/7Ibnp6eeO+990o91jh58iQGDBiAUaNGIT4+HkuWLIGIYNCgQUhISMDu3btx+vRpdO7cGU888QRu3boFIL/tnnzySezfvx9nzpxBUFAQhgwZgitXrpi1/ZIU9K19+/bhu+++K9cxHhGVkxBRjRIaGipOTk7FpsfGxgoAWblypTLt/PnzAkAiIyNFRGTChAny4osvGqx3+PBhsbKykrt37xrdnoODg6xevdqkWObNmyd+fn7K64kTJ4q3t7fk5uYq055++mkZPXq0iIhcuHBBAMjPP/+szE9KShKtViubN282+p4iIp999pl4e3srr728vGTDhg0GyyxYsEACAgJE5H5uzpw5Y7DMxIkTZdiwYQbTVq1aJa1btxa9Xq9My87OFq1WK99//73RPLzzzjvSrFkzycnJMTrfw8ND3n//fYNpXbt2lalTp5q8ze3bt0vRj2xj0wrvU1pammg0GlmxYoXRuIrmZc6cORIYGGiwTFxcnACQqKgoERHp06ePPProo8X25e2331ZeA5Dt27cb3WaBxMREsbGxkZ9++kmZFhAQIG+++WaJ65w4cUIASHp6uoiIHDx4UADI7du3RaRy+sorr7wijz/+uEFbEBEREVW2iRMnirW1teh0OuUxcuRIERHp1auXfPDBBwbLr1u3Ttzd3Ut8v82bN4uLi4vyuqRjBmPjNCcnJwkNDRWR++PDxYsXGyxT1hiqqNOnTwsAuXTpktH5EydOFGdnZ8nMzFSmLVu2TOrVqyd5eXlG10lMTBQAcu7cORERWb58uTg4OEhycrLR5cuTR2Pj67LG8iXlzBhj+Z83b57Y29tLWlqaMu3NN9+Ubt26iYhIRkaG2NnZydGjRw3Wmzx5sowdO7bMbZZ0LPTpp59Kq1atSjyG8fb2ls8++6zM9x82bJhMnDhReX3gwAFxdHSUrKwsg+UeeughWb58eYnv065dO/niiy9K3b4p4/2JEyeKq6urZGdnK9PKc4xHROXDazQT1TIdOnRQnru7uwMAEhMT0aZNG5w+fRp//vkn1q9frywjItDr9YiNjUXbtm2Lvd/MmTPx/PPPY926dejXrx+efvppPPTQQybH8/DDDytfASyI6dy5cwDyb7ZhY2ODbt26KfNdXFzQunVrREZGmvT+N2/eRFxcHCZPnmxw7bHc3FyDS4qYqiBHDg4OBtOzsrKKfVWvQHh4OHr16mX0TO+0tDRcv34dPXv2NJjes2dP5etj5dmmKSIjI5GdnY0nnnjCpOVPnz6NgwcPol69esXmRUdHK187K9zHgPw2Le2SFsY0atQI/fv3x/r169GrVy/Exsbi2LFjWLZsmbLMmTNnEBISgvDwcNy6dUs5O+XKlSto166dWdsDTOsrkyZNQv/+/dG6dWsMGDAAgwcPRmBgoNnbIiIiIipL3759DcY+Op0OQP6Y7OTJkwZn3ubl5SErKwt37tyBvb09Dh48iA8++AARERFIS0tDbm4usrKykJmZqbxPRXTp0kV5Xp7xtp+fH5544gm0b98eQUFBCAwMxMiRI9GgQQODZezt7ZXXAQEByMjIQFxcHLy9vREdHY05c+bgl19+QVJSksFY0NfXF+Hh4ejUqROcnZ2NxmBKHstiyli+QOGcmcvHx8fgWKDw+DoiIgJZWVno37+/wTo5OTno1KlTubf59NNPY/HixWjevDkGDBiAJ598EkOGDIGNTcXKRKdPn0ZGRgZcXFwMpt+9e1c5tsnMzMT8+fPx3Xff4fr168jNzcXdu3eVM5orqn379gbXZa6q4y0iKo6FZqJapnCxs/B1xQp+vvTSS8q1twpr2rSp0fcLCQnBuHHjsGvXLuzZswfz5s3Dxo0b8dRTT5kdT0FMBfFIoa/OFSYiSuxWVlbFlit8WY2C91qxYoVBwRqAQYHbVHq9Hv7+/gbF+AIl3ZzFlBsiFr2uWeF9LM82TWHujRr1ej2GDBmCjz76qNi8gn9aAKW3qTnGjx+PGTNm4IsvvsCGDRvw8MMPw8/PD0D+4DMwMBCBgYH45ptv0KhRI1y5cgVBQUElfr2tMvpK586dERsbiz179mD//v0YNWoU+vXrV+Y18IiIiIjMpdPp0KJFi2LT9Xo95s+fjxEjRhSbZ2dnh8uXL+PJJ5/ElClTsGDBAjg7O+PIkSOYPHlymZefU6lUpY6XCsdWOB7AvPG2tbU19u3bh6NHj+KHH37AF198gdmzZ+P48ePK/VNKixEAhgwZAi8vL6xYsQIeHh7Q6/Xw9fVVxoJljXXLyqM5ShvLF6hIgb+08XXBz127dqFJkyYGy5lzI/CivLy8EBUVhX379mH//v2YOnUq/vWvfyEsLKxCNzLU6/Vwd3dX7n9TWMH9fd588018//33+OSTT9CiRQtotVqMHDmyzMtYlDXeL1C0LarqeIuIimOhmagO6dy5M86fP290QFuaVq1aoVWrVnjttdcwduxYhIaGmlxoLk27du2Qm5uL48ePo0ePHgCA5ORkXLhwQTm7ulGjRkhISDAYzBW+eZ2rqyuaNGmCmJgYjB8/3uh2Cv6bnZeXV2x60WmdO3fGpk2blBtXmKJDhw5Ys2aN0btLOzo6wsPDA0eOHEHv3r2V6UePHsUjjzxS7m2aomXLltBqtThw4ACef/75Mpfv3Lkztm7dCh8fnwqdyaBWq4vl1Zjhw4fjpZdewt69e7FhwwZMmDBBmffHH38gKSkJH374Iby8vABAuQllSSqjrwD5bTZ69GiMHj0aI0eOxIABA3Dr1q0Sz5YhIiIiqkydO3dGVFRUiWP2U6dOITc3F59++imsrPJvu7R582aDZYyNc4H88VLh691evHgRd+7cKTUeU8dQRalUKvTs2RM9e/bE3Llz4e3tje3bt2PmzJkA8m86fvfuXaVg/Msvv6BevXrw9PREcnIyIiMjsXz5cvTq1QsAcOTIEYP379ChA1auXFniOK2sPJrClLG8OUwdJxfWrl07aDQaXLlyRbmXSWXRarUYOnQohg4dimnTpqFNmzY4d+4cOnfuXGIfKkvnzp2RkJAAGxubEu91cvjwYUyaNEk5pszIyCh2Yz5j2y9rvF9aTFVxvEVExfFmgER1yNtvv41jx45h2rRpCA8Px8WLF7Fz50688sorRpe/e/cugoODcejQIVy+fBk///wzTp48afQSG+XRsmVLDBs2DC+88AKOHDmCs2fP4plnnkGTJk0wbNgwAPl3HL558yY+/vhjREdH48svv8SePXsM3ickJAQLFy7EkiVLcOHCBZw7dw6hoaFYtGgRAKBx48bQarXKze1SU1MB5H9F7bfffkNUVBSSkpJw7949jB8/Hg0bNsSwYcNw+PBhxMbGIiwsDDNmzMDVq1eN7kdwcDDS0tIwZswYnDp1ChcvXsS6desQFRUFIP8/9h999BE2bdqEqKgozJo1C+Hh4ZgxYwYAlGubprCzs8Pbb7+Nt956C2vXrkV0dDR++eUXrFq1yujy06ZNw61btzB27FicOHECMTEx+OGHH/Dcc8+ZNcj08fHBgQMHkJCQgNu3b5e4nE6nw7BhwzBnzhxERkZi3LhxyrymTZvC1tYWX3zxBWJiYrBz504sWLCg1O1WRl/57LPPsHHjRvzxxx+4cOEC/u///g9ubm7K2RdEREREVW3u3LlYu3YtQkJCcP78eURGRmLTpk149913AQAPPfQQcnNzlXHSunXr8NVXXxm8h4+PDzIyMnDgwAEkJSUpxeTHH38c//73v/Hrr7/i1KlTmDJliklnr5Y1hirq+PHj+OCDD3Dq1ClcuXIF27Ztw82bNw2OI3JycjB58mREREQo35wMDg6GlZUVGjRoABcXF3z99df4888/8eOPPyoF6gJjx46Fm5sbhg8fjp9//hkxMTHYunUrjh07ZlIeTVXWWN4cpo6TC3NwcMAbb7yB1157DWvWrEF0dDTOnDmDL7/8ssSbMQLArVu3EB4ejoiICABAVFQUwsPDkZCQAABYvXo1Vq1ahd9//13pR1qtFt7e3kqsP/30E65du4akpCST97Ffv34ICAjA8OHD8f333+PSpUs4evQo3n33XeXEkRYtWmDbtm0IDw/H2bNnMW7cuGLfkDS2fVPG+8ZU1fEWERlhmUtDE1F5lXUzwMI3ebh9+7YAkIMHDyrTTpw4If3795d69eqJTqeTDh06FLu5RYHs7GwZM2aMeHl5ia2trXh4eEhwcLBy40BTbgZY9GZ7M2bMkD59+iivb926JRMmTBAnJyfRarUSFBQkFy5cMFhn2bJl4uXlJTqdTp599ll5//33DW74ICKyfv166dixo9ja2kqDBg2kd+/esm3bNmX+ihUrxMvLS6ysrJTtJyYmKrkonKf4+Hh59tlnpWHDhqLRaKR58+bywgsvSGpqqtE8iYicPXtWAgMDxd7eXhwcHKRXr14SHR0tIiJ5eXkyf/58adKkiajVavHz85M9e/YYrF/WNstzM8CCbf/zn/8Ub29vUavV0rRpU+WmKMb6zIULF+Spp56S+vXri1arlTZt2sirr76q3DijT58+MmPGDINtFr0ByM6dO6VFixZiY2NTrJ2K2rVrlwCQ3r17F5u3YcMG8fHxEY1GIwEBAbJz506DeIveDFCk4n3l66+/lo4dO4pOpxNHR0d54okn5Ndffy11H4iIiIjMZWycXNjevXulR48eotVqxdHRUR555BH5+uuvlfmLFi0Sd3d3Zfy8du3aYuOiKVOmiIuLiwCQefPmiYjItWvXJDAwUHQ6nbRs2VJ2795t9GaARW8cJ1L2eLuwiIgICQoKkkaNGolGo5FWrVoZ3OitYP/nzp0rLi4uUq9ePXn++ecNbiC3b98+adu2rWg0GunQoYMcOnSo2M30Ll26JH/729/E0dFR7O3tpUuXLnL8+HGT81iUsfF1WWP50nJWlLFxsik3uNPr9bJkyRJp3bq1qNVqadSokQQFBUlYWFiJ2woNDRUAxR4FfWH79u3SrVs3cXR0FJ1OJ927d5f9+/cr6x87dkw6dOggGo2mWE4KK3osIJJ/U/JXXnlFPDw8RK1Wi5eXl4wfP16uXLmi5Kxv376i1WrFy8tL/v3vfxc7zihp+2WN90v63SrPMR4RmU8lUsJFUomIiIiIiIiIKtmkSZOQkpKCHTt2WDoUIiKqRLx0BhERERERERERERFVCAvNRERERERERERERFQhvHQGEREREREREREREVUIz2gmIiIiIiIiIiIiogphoZmIiIiIiIiIiIiIKoSFZiIiIiIiIiIiIiKqEBaaiYiIiIiIiIiIiKhCWGgmIiIiIiIiIiIiogphoZmIiIiIiIiIiIiIKoSFZiIiIiIiIiIiIiKqEBaaiYiIiIiIiIiIiKhCWGgmIiIiIiIiIiIiogr5fxmf9uwy1/uUAAAAAElFTkSuQmCC",
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAABZoAAAKgCAYAAAAS1si3AAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjkuMiwgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy8hTgPZAAAACXBIWXMAAA9hAAAPYQGoP6dpAAEAAElEQVR4nOzdd3gUVdsG8Hs3W7Kb3juBUEINvYTee0dAKdJEEV8QEF/FRhFBRVEsoH4qqCAdBASigIAiRUB6E+mdAOl9d8/3x74Zsskm2SSbTMr9u669MjtzZuaZ2ZnszLNnzlEIIQSIiIiIiIiIiIiIiApJKXcARERERERERERERFS2MdFMREREREREREREREXCRDMRERERERERERERFQkTzURERERERERERERUJEw0ExEREREREREREVGRMNFMREREREREREREREXCRDMRERERERERERERFQkTzURERERERERERERUJEw0ExEREREREREREVGRMNFMRKXWsmXLoFAopFdW7du3l8aPHj1aGn/16lWLefbs2VOyQVOps2fPHotj4urVqyW27lmzZknrrVy5crGtJyEhAS+++CJCQ0OhVquldS5btqzY1kllm5znRWnA7wqypqT+Z+dn9OjRUhzt27eXLY7SoKj7ojzvS/4fIyKi0oiJZiIqEUII/Pjjj+jatSt8fX2hVqvh7u6OsLAwdOzYES+99BJ+//13ucMs1Wy5WaroyaOKasKECfjkk09w/fp1GAwGucMBkPNYzJ70fvToERo3bixNd3BwwLfffmt1XoVCgaFDh1pdzzfffJOj7KxZs4p568ge8jo+iMh+SksC3d7KcxK5rKhcuTK/ewtow4YNOa5beL1OROWJSu4AiKhiGDlyJFasWGExLi4uDnFxcbhy5Qp2796NuLg4tG3bVpretGlTLFiwoKRDJbKbrl27wtnZGQDg5uZWLOvIyMjA2rVrpfdt2rRBr1694ODggKZNmxbLOosqOjoanTt3xsmTJwEADg4O+O677zB8+PBc59mwYQNu3bqFoKAgi/GfffZZscZK5ZOnp6fF90vVqlVljIaIcvPkk0+ibt26AICQkBCZoyEqmocPH+L555+XOwwiomLFRDMRFbvt27dbJJmbN2+Ozp07Q6vV4saNG7hw4QIOHDiQY746deqgTp06JRkqkV21bNkSLVu2LNZ13LlzBxkZGdL7mTNnolOnTsW6ztTUVDg4OECtVhd43jt37qBTp044d+4cAECtVmPFihUYPHhwnvMZDAZ88cUXePvtt6Vx+/btw/HjxwscA1Vcmceuq6srpk+fLnc4RJSP7t27o3v37nKHQaWIwWBARkYGdDqd3KEU2MSJE3H//n25wyAiKlZsOoOIit2OHTuk4erVq2P//v2YO3cu3nzzTXz11VfYu3cv7t27h2effdZivrzaaC6ItWvXolmzZtDpdPD29sbo0aPx6NEjq2V37tyJQYMGISgoCBqNBm5ubmjevDneffddJCQkWJTNr228/B4nPHbsGMaMGYOwsDA4OjrCxcUFTZs2xcKFC5GamppjP3z33XfSuL179+ZYt0KhQIcOHSzWUaVKFattWRdk/flJTU3F66+/ju7duyMsLAxubm5Qq9Xw9vZG27Zt8dlnn+VozsHavlu+fDmaNGmS5+d0//59vPzyy+jYsSNCQ0Ph4uICjUYDPz8/dO3aFcuXL4cQwqa4O3bsKK1/1KhROaYvWrRImu7n5yclc0+dOoURI0agcuXK0Gq10Ol0qFSpEjp27IgZM2bg1q1b0jLyelz52rVreO6551C9enXodDo4OjoiKCgIrVq1wrRp06REbF4qV66M0NBQi3GdO3e2+ijmhQsXMGHCBGl9Tk5OqFmzJiZPnmz1kc3s7aAfO3YMPXv2hIeHB3Q6ncV22urmzZto166dtG0ajQZr167NN8msVJovV7766iukpaVJ4z/99FOL6Xn5999/8cILL6BmzZrQ6/XQ6/WoV68eZs6cibi4uBzl165di+HDh6Nu3brw9fWFRqOBs7Mz6tSpg0mTJtm0zy5cuIDBgwfD09MTOp0OkZGRVtvQLMgxlZ+MjAz83//9Hzp37gwfHx9oNBr4+vqiVatWNj8hklsb+IB9junM5Wc1ZsyYXJd7584dvPrqq4iIiICLiwscHR1Ro0YNTJs2DXfv3s03fmvHbl7/v7NvY2xsLKZOnYqQkBBotVqEh4djyZIlVvfdqVOn0KdPH7i6usLV1RXdunXD0aNHi9R0QVHPXVuPw7xs3rwZ3bt3h5+fH9RqNVxdXVG1alX0798f8+fPh8lkksru3LkTY8eORcOGDeHv7w+tVgu9Xo/q1atj7NixOHXqVI7lZ28C4Z9//sGAAQPg5uYGT09PDBs2DPfu3QMA7N69G23atIFer4ePjw/GjRuHmJgYi+Vlv35ITU3FzJkzUbVqVWi1WlStWhVz5861+JHOFrGxsZg7dy6aNm0KNzc3aLVaVK5cGePHj8e///5boGUBwO+//4727dvDyckJnp6eGDx4MC5dupTnPF9++SUGDx6MmjVrwtvbW/o8GjZsiFdffRUPHjyQymZeG8yePVsad+3aNavN1vz777948cUX0bp1a4SEhMDJyQlarRbBwcHo27cvfv75Z5u36+OPP5aWHx4ebjGtYcOG0rSs14dZm0Hy8/OTvsutNY9h63WRNffv38dzzz0Hf39/ODo6on79+li/fr3N21bY65eCEEJg9erV6N27NwICAqDRaODl5YWmTZvilVdesWkZeTUrktf19YMHDzB9+nTUqVMHTk5O0Gg08Pf3R7NmzfCf//wHBw8etFj+tWvXpHlnz56d63ILeu5kj//y5csYOnQovL29odFocOjQIQD2/f4sbuvWrcOaNWsAAP3795c3GCKi4iSIiIrZpEmTBAABQHh5eYkLFy7YNN/SpUul+bL/u2rXrp00ftSoUdL4K1euWMzTtWtXi/eZr1atWuVY37Rp06yWzXxVr15dXLt2Ldd17d6922J5oaGh0rSZM2daTPv000+Fg4NDrutq2rSpiI2NtbofrL12796db5ms+6kg689PdHR0vuvu3LmzMBgMue67Vq1a2fQ5HT58ON91jRkzxmKe7PvmypUrQggh1q9fL43T6XQ5trdly5bS9GnTpgkhhDhz5ozQ6/V5rn/79u3SMmbOnCmNDw0Nlcbfu3dP+Pj45LmcJUuW5Lvvsx5j1l6Z27p69Wrh6OiYazkXFxfxyy+/WCw76znWsGHDHNuduezcZN/vM2fOFFWqVJHeOzo6im3bttk0b79+/aTh77//XgghxK1bt4RKpRIARP/+/XOsK6v169cLnU6X6/ZXrVrV4twWQohevXrluW9dXV3FyZMnc91nERERwtnZOcd8Go1GnD59WpqnoMdUXqKjo0Xjxo1zXU7WYzC38yL7dmT9vyGEfY7prMvPL859+/YJT0/PXMv6+vqKY8eO5fo55Hbs5vX/O+s2enl5iZo1a1pd91dffWWx3sOHD1v9zB0dHUXnzp2tbl9+inru2noc5sWW76CUlBSp/AsvvJBnWY1GI3bs2GGxjlGjRknTq1SpIjw8PHLMFx4eLpYvXy6USmWOaW3bts0z5o4dO1qNZcCAARbz5XZ8CyHE+fPnRaVKlXLdLicnpxyfRV5+/vln6X9Y1penp6eIjIyU3rdr185ivjp16uS5f4OCgsStW7eEEDnPc2uvpUuXCiGEWLt2bb5lZ8+ebdO2nThxwmK+u3fvCiGEiI+Pt7j2ePPNN6V5sh4DQ4YMsTo+c1/Yel2Uff7w8HCr35sKhcLmz66w1y+2Sk5OFt27d89z23KLJev/MWv7LVNu19cpKSkiPDw8z3W/8sorOZafX5yFOXeyLr969erC19c3x7ba8/vTlmMq6yv7Ps3P/fv3pe/IkSNH5lhfftdURERlCZvOIKJi16BBA2n44cOHqFmzJiIiItC0aVM0bdoUnTt3RlhYWLGs+9dff0VkZCQ6deqEn3/+WXrM/s8//8SBAwcQGRkJAPj++++xcOFCab6IiAj07dsXV69exYoVKyCEwMWLFzFkyBCpNkdh/fnnn5g8ebJUW6d169bo3LkzYmNj8d133yEmJgaHDx/G888/jx9//FFqq3r16tU4cuQIACAsLMyijbeqVatiwYIFuHTpEr744gtp/GuvvQYPDw8AkNo4LOj686NQKFCtWjU0b94cgYGB8PDwQEZGBs6fP4+1a9fCYDBg586dWL9+PYYMGZLrPrHlc1IqlahTpw6aNm0KPz8/uLu7IzU1FceOHcOWLVsghMDSpUsxYcIENGvWLM+4+/Xrh0qVKuH69etISUnBihUrMHHiRADArVu3LJpzyazV+d133yE5ORkAEBwcjBEjRsDJyQk3b97E6dOnbT421q9fj+joaACAh4cHxowZAy8vL9y+fRvnz5/HH3/8YdNyXn/9dVy9ehXz5s2Txk2YMEFqb9bT0xMXL17E008/LdUE9vHxwahRo2AwGPDtt98iPj4eCQkJGDx4MP755x/4+fnlWM+xY8egVqsxevRoVK1aFWfOnClwsxlz5syRjjm9Xo/Nmzfb3MTH8OHD8fvvvyMmJgafffYZRo4ciSVLlkg15SdNmoSffvrJ6ryXL1/G8OHDpVr6ERER6N+/P9LT0/HDDz/g1q1buHTpEp566in8+eef0nweHh7o3r07wsPD4eHhAY1Gg3v37mHDhg24ceMG4uPj8corr2Dbtm1W13vy5El4e3tjwoQJuHfvHn744QcAQHp6Oj755BN8+eWXAOx3TAHmtvCPHj0qva9Tpw569OgBlUqFI0eO5FtTsigKckw///zz6N27N15++WVp3NChQ9GkSRMAj9szj4uLw4ABA6SagWFhYRgyZAjUajXWrFmDCxcu4P79+xg4cCDOnTsHrVabI67cjl1ba7I+fPgQsbGxGDt2LLy8vPD5559Ln9cHH3yA8ePHS2XHjBmDxMRE6f1TTz2FsLAwrFmzBjt37rRpfVnZ49y19TjMS9ba202bNkXv3r1hMBhw48YNHDp0KMfTF87OzujQoQPq1Kkj1aJ++PAhtm7dinPnziE9PR2TJ0/G2bNnra7vypUr8PLywssvv4zLly9LtU0vXLgg1VwcNmwY/vzzT+zduxeAuWbwwYMH0aJFC6vL3L17N0aOHIlKlSph/fr1OH/+PABg48aNWL58OUaMGJHnPjAajRgwYACuX78OAPDz88Pw4cPh5uaGn3/+GYcPH0ZSUhKGDBmCixcvwsfHJ8/lJScnY+zYsdL/MLVajbFjx8LDwwPLly+32pxYJj8/P1SrVg1hYWHw9PSEQqHArVu3sGbNGjx8+BC3bt3C3LlzsXjxYuna4Ndff5VqD3t4eOC1116TlpfZlr9arUajRo3QuHFj+Pj4wNXVFYmJifjzzz+xe/duAMDbb7+NcePG5WgrP7t69erB29tbql29b98+DBo0CPv374fRaJTKZf2/kLVD6OxPZ2Vn63VRdhcuXIBer8ekSZNgMpnwxRdfwGg0QgiBDz/8EF27ds1zvdbYev1iq2nTpiEqKkp6X7lyZfTr1w8uLi44efIktm7dWuAYbbV7925cuHABAODo6Ch91nfv3sW///4rnW/A47az582bJz1R0KVLlxz70B7nzsWLF6FQKDB48GDUq1cPV69ehZOTk12/P4vbxIkTER0djcDAQCxatAibNm2SOyQiouIjZ5abiCqG9PR0Ub9+/TxrBnTo0EGcP3/eYj571Ghu0aKFyMjIEEII8fDhQ4uaNJ988ok0X9b4qlSpYlE7a86cORbL3Ldvn9V12VqjecCAAdL4bt26CZPJJE2LioqyqGFz48YNaVpetVMy5VVLsajrz8+9e/fEpk2bxOLFi8UHH3wgFixYIOrWrSstb+zYsVLZwn5Oma5duybWrVsnPvvsM2ldQUFB0jxz5syxaZ/MmzdPGt+wYUNp/EcffSSNb9KkiTR+8uTJ0vj58+fniOvRo0fi0aNH0vvcasctXLhQGv/cc8/lWE5iYqJUAyw/+R2HL774ojRNqVSKs2fPStN+//13i3nnzp0rTcte6zS32se5yasm3Zo1awo075YtW8T06dOl97///rvw8/MTAESdOnWEEMKifNbzberUqdL4evXqibS0NGna+fPnLeb7888/LeJIT08Xv//+u/jmm2/ERx99JBYsWCDGjBkjlddqtSI9Pd3qPlMqleLEiRPStKy1rhs1aiSNL+gxlZvsNQj79OkjnVOZLl26lOs+LmqN5sIc01nXn1mrMqtFixZJ0319fS2eOoiJibGo6btixQqr8ed27NpaoxmA+Oyzz6RpH3/8scW0+Ph4IYQQ+/fvtxifWetPCPNnmLWGrq01mu1x7tp6HOYlIiJCmufAgQM5pl+5ckUYjUaLcUajURw6dEgsW7ZMfPzxx2LBggU5nhq6fv26VD577cjM71mTySQCAgKk8Wq1WpovNjZWqNVqq98V2a8f3nnnHWlaXFyc8Pb2lqa1adNGmpbb8b1p0yZpvEajEVevXpWmpaWlWdTWzLqu3KxcudIivq+//tpif2bdLmvf90lJSWLnzp3iq6++EgsXLhQLFiywePIjLCzMonxeNbWzu3Dhgli1apX49NNPpe/XrLVGM58qyc+gQYOkeV588UUhhBBvvPGGAMxPCgDmp4nS0tLEzZs3LfZH1iff8rr2seW6KPux9fPPP0vTpkyZIo339PS0abuKev2Sl4cPH1rUcm/cuLFITEy0KJP1/7i9azRv2LBBGtetW7cc8aWmpoqbN29ajMvr6T0hCn/uZP/cFi9enGPZ9vr+FEKI06dPiwULFtj8WrVqlU3LFUKIVatWSXFu3bpVCJHzM2CNZiIqT1ijmYiKnVqtxt69ezF37lwsW7bMov3ATLt370bXrl1x+vRpuLi42G3d48aNg0pl/lfn6ekJb29vqZ3HzBoYSUlJOHHihDTP4MGD4ejoKL0fNWoU3nrrLen9/v370apVq0LHlLXW5C+//JJr+7JCCBw8eBBPPPFEoddVEutPSUnBxIkT8f3331u005ndzZs3c51my+cEmGsXjho1Kt8aPXmtK6vx48djzpw5Uq3oo0ePonHjxli7dq1UZsyYMdJwmzZt8MknnwAA3njjDWzZsgXh4eEIDw9H8+bN0aZNGzg4OOS73latWkGhUEAIga+++gqHDx9G7dq1ER4ejiZNmqBDhw5WaycWxv79+6XhJk2aoFatWhbbU6VKFVy5ciVH2azq16+PHj162CUewLzvWrVqhcDAQJvnmThxIhYuXAiTyYSnnnpKOj4mTZqU53xZj/dTp05ZrfWaaf/+/VLnjStWrMCUKVOs/r/KlJaWhgcPHiAgICDHtMjISEREREjvs7ZTmvWYttcxlXU7AeDNN9+UzqlMxfXkCFA8x3TWbbp//z7c3d1zLbt//34MGzYsx/iiHrsODg4YN26c9D57e7MxMTFwcXGxqEkOAE8//bQ07OHhgX79+klt4drKHueurcdhXtq0aYOTJ08CMNdYjIyMRPXq1VG7dm20bdsW9erVsyi/Y8cOPPPMM1INxtzcvHkTISEhOcaHhoZK37EKhQKhoaG4c+cOAPNxljmPm5sbfH19pTZY89qekSNHSsOurq7o06cPli5dCgBSjdi8ZD0W09PT82xnO7fPIqvs68x67FauXBmtW7eWahFnt3DhQsycOdOi9nx2hWmX9urVqxg+fHi+8dv6/dqhQwepNvq+ffss/k6YMAHvv/8+UlJScPToUYt2foOCglCjRo0Cx2+LoKAg9OrVS3pfmPMhO1uvX2xx6NAhiz4tXnnlFTg5OVmUKc7/402bNoVWq0VaWhp++eUX1KlTBxEREahRowYaNmyITp065VubPTt7nDuenp45+nEB7Pf9CRRfB+T379/Hf/7zHwDm68mePXvafR1ERKUNE81EVCLc3NywYMECvPfeezhz5gwOHjyI3bt346effkJKSgoA4Pr169iwYYPVjtkKK3tHaVmTTJlJ0djYWIsyvr6+Fu+zJ0dyu3EQ2Tqhy9ppWVYF6SAm81F0e7L3+mfMmGFTAiW3/QHY9jkB5hs6Wx4bzWtdWXl7e2Po0KFSh0Jff/01/Pz8pMeWtVotnnrqKan8E088genTp+PTTz9FWloa9u/fb3FjFBoaiq1bt+Z7s9KsWTMsXLgQb775JhITE/H333/j77//tohr7dq1OTrwKYysx2v2YxswH9+Zyarcjm173PSHhYXh8uXLAIB//vkHbdu2xe7du60mmqypUqUKevXqhS1btkhJFHd393wfeS/M8f7333/j6aefzvOHk0y5HWu2HtP2Oqayb2dBO5zLja3/14rjmLbH/6qiHrt+fn4WPzxm/6Eit+8Rf3//PN/bwh7nrq3HYV7mzZuHy5cvY/v27UhMTMSOHTssOnFr164dtm3bBr1ej9u3b6N///7S4+x5ye1Yyp7Iyhpz9mlZf0zJa3vy+l5PSUlBWlpanj9C2ft7M+vx4uLiAp1Ol2t8Wf3000946aWX8l2+rd+BWfXv39/iR/eiLjtr8xfHjx/Ho0eP8NdffwEw/2Cxa9cuHDx4EPv27ZOO4+zz2Vte50P2/3X2WKat51gmuf+PBwcHY9myZZg0aRIePHiAs2fPWjRx4+zsjK+//hpDhw61ed32OHeqVq1qNWFsr+9PADhz5gy2b99uc6whISE27Yc333wTDx48QHBwMD766CObl09EVJYx0UxEJUqpVKJevXqoV68exo8fj2PHjqFRo0bS9ML02p6X7O3IZu8FG0COWnL379+3eJ9ZMyVTZpvH2WsCZybMASAhISHHfFnnz7yY7tChQ561Gwratp8t7L3+1atXS8MdOnTAV199hSpVqsDBwQFDhgyxqB2cG1s+p6SkJIte75988kksWLAAgYGBUCqVaNasGQ4fPpzvurKbNGmSlGj+8ccfERwcLN2U9e/fX/q8My1YsABvvPEG9u/fj/Pnz+Off/7B5s2bcfv2bVy7dg0vvPBCrr3dZzVlyhQ8++yzOHjwIM6cOYOLFy8iKioKFy9exIMHDzB69GhcvXq1wNuTXdb4sx/bgOXxnX1bM+n1+iLH8cYbb+DIkSNYvHgxAODSpUto164dfvvtN5tvpidNmoQtW7ZI78eOHZujtld2Wbepfv36eSamM9sqXbt2rZQgcHJywrp169CuXTvodDps27bNokZcbmw5pjPZ45jy9PS0eH/16tV824nNTdb/bVn/rwHmtjJzY+9jOutnV6lSpTxrr2evaZypqMeurZ+jte+RrJ/J3bt3C7xue5y7BTkOc+Pq6opt27bh5s2bOHjwIP755x+cPXsWGzduRHJyMvbu3Yv3338fs2bNwpYtW6Qks0KhwPLly9GnTx+4uLjg7NmzNiV88mr/PXstfVvdv3/f4ketrPvO0dExzyQzYLl/nZ2dMXPmzFzL2vKjQtbjJSEhASkpKRbJ5tyuH7J+3wYGBmL9+vVo2LAhtFotFi9ejBdeeCHfdVtz4cIFiyTz1KlT8eqrr8LHxwcKhQK+vr4F/uG7du3a8PPzw71792A0GvHZZ58hOTkZarUazZo1Q5s2bXDw4EH88ccfJZZotsf5UJzLtPZ/PPN7qaAK+3/8ySefxKBBg/DXX3/h1KlTuHjxInbv3o1jx44hMTER48aNQ+/evfP97s1kj3Mnr//j9romO3z4sEW/Aflp166dTYnmzHP55s2beT6VU6VKFQDmNurt9QMDEZFcmGgmomL33XffITU1FcOGDcvRLIazs7PF+7wuwoqLk5MT6tevL91krVu3DrNnz5ZqsWUmITNlPlqf2WFVpkOHDklJ2wULFuRaO6Zly5ZSJyB3797F888/n+OCPT4+Htu3b7foSDHrzUxutcWy3/BYK1fY9efm4cOH0nDv3r1RrVo1AOYb+9we/S2MuLg4i06EBg8ejODgYADAuXPnbKqJZU3jxo3RokULHDx4EPHx8Zg7d640LWuzGYD5BsDDwwPu7u7o0aOH9Eh+165dMXDgQADI8Qi9Nbdv34aDgwP8/PzQsWNHdOzYEQAsfni5du0aHj58CC8vr0JtV6aWLVtKCfgjR47g3Llz0iP42W/wM4/t4qBQKPD5559Do9Hg448/BmDen+3atcPu3bttehy4c+fOqFmzJs6fPw+lUmlTUiXr9t+5cwcjRozIcTObmpqKtWvXol27dgAsj+mwsDB0795der9q1ap811kQ9jqmsjfn884772DdunUWiblr167lqH1nTdb/w8eOHUN6ejo0Gg3OnTtnkejPqjDHtEqlkh4Tz+1/VeYPVffu3UOvXr0smo8AAIPBgJ9//hmtW7fOd7uKU/Zk0KpVqzBr1iwA5trGhen4qbScu6dPn0Z4eDiCg4MtmlJ68cUXpcfWM4/RrOeOm5sbnnzySSnhZe9zpyB++OEHqQO8+Ph4i+M4sxPKvGTdv4mJiWjUqJF0jGcSQuC3336z6X9Z9nX++OOPUhMtV69elZqYyC7r/s387gLMNWfz+lE3v+uHrMsFgBEjRki1wH/77bdCP13Vvn17KTn+6aefAjBvu06nQ5s2bbBgwQLs2bPHohmQ7Ps1L7ZcF5UlzZs3t/i/uGDBAvTu3dviR4jC/B+/cOEC4uLi4Obmhrt37+L777+3Os+jR4+QkJAgNV+T+b0SExMjJcGTkpJw/vx5NG7cGED+n4G9z52s7PX9SURE9sVEMxEVuytXrmD27NmYMmUK2rRpgwYNGsDDwwP379+3qJ2jUCgK1eO3PUydOhWjR48GAFy+fBnNmzdHv379cOXKFaxYsUIq16xZM+nC283NDdWrV5dqhsydOxcnT55EXFxcngnWl156CZs3b4YQAufOnUPdunUxcOBAeHt749GjRzh+/Dj++OMP+Pv7W9SWyPrI8NGjR/Hiiy8iJCQEGo0GkydPzlEGMLdr2717d6hUKvTt2xc1atQo9PpzEx4ejtOnT0v74N69e1AoFPjhhx/ybN+2oHx9feHu7i49cvziiy9KNWyWLVuG9PT0Qi970qRJUu/kqampAMyPkHbp0sWi3OrVqzFz5ky0b98e1atXR0BAAJKSkrBy5UqpjC0/lvz+++8YPnw4WrdujVq1aiEwMBBGoxEbNmyQymg0mhyPUxfGxIkTsWTJEqSnp8NkMqFdu3YYNWoUDAYDvv32W6mci4sLnnnmmSKvLz8fffQR1Go1FixYAMDcZE7btm3x22+/5dvMgUKhwJo1a3Dp0iW4uLjYdFM6adIkfPHFF0hLS8P9+/dRv359DBkyBIGBgYiPj8epU6ewd+9eJCYmSu24Zq0de+rUKQwdOhR169bFnj178NtvvxVh63Oy1zEVERGBbt264ZdffgEAbNq0CY0aNUKPHj2gVqtx4sQJnD17FpcuXcp3WU2aNMHGjRsBmJ8yadq0KWrWrIlffvkl1/OsMMd0UFCQ1Dbrhx9+iIcPH0Kn00ltgY4ePRpz587Fw4cPkZaWhhYtWmDIkCGoUqUKUlJScPbsWezZswePHj2SEg5yad68OSIiIqS2jOfMmYPLly+jUqVKWLNmTaHafy0t5+706dPx119/oVOnTggJCYGPjw9u374ttXEMPD5Gs547sbGx6NGjB9q0aYOjR4/ip59+KrYY8/PGG2/g/PnzCA0Nxbp16yy+m8aPH5/v/L1790Z4eDguXLgAAOjVqxcGDRqEmjVrwmAw4J9//sGePXtw584d7N69W6qdmJu+ffvCx8dHSuBOnDgRhw8fhoeHB5YvX46MjAyr84WHh0vNlmzduhXjx49HUFAQtm7dmmdb01mvDaKjozFmzBjUrl0bCoUCL7zwAqpVqwalUik9yTFixAg8+eSTuHPnToHbFs+qQ4cO0nVe5j7P/FGodevWUCgUSEhIkMpXrly5QLU5bbkuKks8PT0xbtw4fPnllwDMtWzr1KmD/v37w9XVFWfPnsWmTZtsar4k648Z8fHxaNy4MZo2bYo9e/bk+sPBP//8g8jISDRt2hT169dHYGAgVCoVoqKiLMpl/U4KCgqSnkZctmwZHB0d4erqiqpVq2LAgAF2P3eystf3JwCMHj1aug+wp5YtW1p9EuPatWsW52yPHj2g1+ttrilORFSqydEDIRFVLFl7O8/r9corr1jMl1uv2EII0a5dO2n8qFGjpPF59cAtRN69Y2ftvdraKywsLEev0F9++aXVsg0aNBA+Pj65ruuTTz6x6Jnc2it7z/DHjh0TSqUyRzknJyeLco0aNbK6vLVr1xZp/blZuXKl1fkDAgJEly5dpPdZez0v7Of07rvvWl1X3bp1RePGja0eE7t37863Z+/09HTh7+9vUe61117LUW7+/Pn5HseLFi2Symc99rPuz9z2WdbXtGnTbNr/+e3LzPVptdpc1+Xk5CS2bdtmMU9u55itsu/3pUuXWkx//fXXcxwv586dszrvli1b8l1f1vLZz7d169YJnU6X7z7P9PDhQxEYGGi1zKhRo3I9nvLaZ7kdCwU9pvISHR1tcR7kdU7ndV7cuXNHeHh45Jhfq9WKtm3b2u2Ynjp1qtVyL7zwglTmjz/+EJ6envku29bPIVNe501un1V+++3w4cPC2dnZ6n7r2LGj9L5KlSr5fZQW+9We525e25abbt265bnvHR0dxaFDh4QQ5v+l9erVs+ncybrPs07L+l2R3/bk9l2R/fqhV69eVmPq27evMJlMNu2fc+fOiUqVKuV7LFr7H2zNpk2brH4Pu7i4WHyPZ90fFy9eFC4uLjnmUalUYvjw4Rbjsrpz547Q6/VW442OjhZCCDFhwgSr0zt16iSCgoKs7uf8XLhwIcfyNm3aJE2vW7euxbSxY8fmWEZex4Yt10V5zZ/XdWZuinKdaYvk5OR8zzlbYklOThZVq1bNMa9CoRCdO3e2urwDBw7ke3wPHDjQIt5FixZZLderVy+pTGHOnbw+t0z2/P4sadmPPWvXpkREZZVlA6NERMVgypQpWLduHSZOnIhmzZqhUqVK0Ol00Gg0CAkJwcCBA7F161a8++67ssa5aNEiREVFoX///ggICIBKpYKzszOaNGmCuXPn4tixYzlq2jz77LNYvHgxatSoAbVajeDgYEyfPh1//PFHnm3KTZo0CUeOHMG4ceNQrVo1ODo6wsnJCdWrV0f37t2xaNEi/P777xbzNGjQACtXrkSjRo0sOqfKbv369RgwYAA8PT1zbSuwMOvPzZNPPok1a9agfv36UKvV8PLywtChQ3Hw4EEEBgbatAxbvfLKK/j888+l/e3v74/x48dj7969OZphKQi1Wp2jR/PszWYA5jab33rrLXTu3BmVK1eGXq+HSqVCQEAAevXqhc2bN9tUi6p169Z455130KtXL1StWhUuLi5QqVTw8fFBp06dsGzZMnzwwQeF3p7snnzySRw7dgzjx49H1apV4ejoCEdHR9SoUQMvvPACTp48KT1yWlLmzp0rNS0AmJu1aN++Pc6cOWP3dQ0aNAinTp3C5MmTUbt2bTg5OcHR0RFhYWHo0KED5s+fj/Pnz0vlPT09sW/fPgwcOBCurq7Q6XRo2rQpNmzYYPcaT/Y6pgBzh3v79+/Hl19+iY4dO8LLywsqlQqenp5o3rw5Jk6caNNy/P39sWfPHnTp0gV6vR4uLi7o2bMnDhw4kGv7qYU5pt955x1MnjwZQUFBVjt6ylzumTNnMGPGDDRs2BAuLi7QaDSoVKkSWrVqhTfffBNHjx4tFW1aNmnSBPv370evXr3g7OwMZ2dndOrUCb///juqV68ulStIE1Gl4dx9+eWX8eKLL6JFixYICgqCRqOBVqtFWFgYRo0ahb/++gvNmjUDYP5f+ttvv2H06NHw8vKCVqtF3bp18dVXX1mc7yVtw4YNmDNnDqpWrQqNRoPKlStj9uzZWLt2rc1t6tasWRMnT57EvHnz0Lx5c7i5uUGtViMoKAjNmzfHSy+9hD/++ANt27a1aXl9+/bFzp070bZtW+h0Ori7u6Nfv344dOgQ6tWrZ3WeatWq4ffff0fXrl2h1+vh7OyMdu3aYdeuXejcuXOu6/L398eWLVvQqlWrXGtMfvrpp5gzZw5CQ0OhVqtRqVIlvPzyy9iyZUuh28auUaOGRa1jhUJh0cxPmzZtLMoXtH1mW6+LyhKdToft27dj5cqV6NmzJ/z8/KBWq+Hm5oYGDRrY1Blk5nJ27dolfY/p9Xq0bdsWO3fuxPDhw63OEx4ejg8//BADBw5EjRo14ObmBgcHB3h4eKBVq1ZYtGhRjiZwXnjhBcyaNQthYWG5Hif2Pncy2fP7k4iI7EchRCG72CUiIipHVq5ciWHDhgEw3/zammgnIgKA9PR0qFSqHB3FJiYmom7dulIzIePHj8dXX30lR4gVxrJlyyx+LOTtDhEREVHJYBvNRERUYcXGxuL48eO4e/cuXn/9dWm8LZ3MERFldfbsWfTt2xfDhw9H7dq14eHhgatXr2LJkiVSktnWTiyJiIiIiMoiJpqJiKjCOn78eI5HdVu1aoXBgwfLFBERlWU3btzItRkojUaDJUuWoH79+iUcFRERERFRyWCimYiIKjyFQgF/f3/069cP8+bNy/HoOxFRfkJCQjB16lTs2bMH169fR1xcHBwdHVGlShW0b98eEydORM2aNeUOk4hKmC3nfbNmzfD999+XQDRERETFi200ExERERERERUDWzqcbNeuHfbs2VP8wRARERUz1mgmIiIiIiIiKgas10VERBUJnw0mIiIiIiIiIiIioiJhopmIiIiIiIiIiIiIioSJZiIiIiIiIiIiIiIqEiaaiYiIiIiIiIiIiKhImGgmIiIiIiIiIiIioiJhopmIiIiIiIiIiIiIioSJZiIiIiIiIiIiIiIqEiaaiYiIiIiIiIiIiKhImGgmIiIiIiIiIiIioiJhopmIiIiIiIiIiIiIioSJZiIiIiIiIiIiIiIqEiaaiYiIiIiIiIiIiKhImGgmIiIiIiIiIiIioiJhopmIiIiIiIiIiIiIioSJZiIiIiIiIiIiIiIqEiaaiYiIiIiIiIiIiKhImGgmIiIiIiIiIiIioiJhopmIiIiIiIiIiIiIioSJZiIiIiIiIiIiIiIqEiaaiYiIiIiIiIiIiKhImGgmIiIiIiIiIiIioiJhopmIiIiIiIiIiIiIioSJZiIiIiIiIiIiIiIqEiaaiYiIiIiIiIiIiKhImGgmIiIiIiIiIiIioiJhopmIiIiIiIiIiIiIioSJZiIiIiIiIiIiIiIqEiaaiYiIiIiIiIiIiKhImGgmIiIiIiIiIiIioiJhoplKLYVCYdNrz5492LNnDxQKBdatWyd32Fi2bBkUCgWuXr0qjRs9ejQqV65sUU6hUOA///lPyQZXQNu2bcOsWbOsTps3bx5++umnEo0nq6tXr0KhUGDZsmUFnvfs2bOYNWuWxWeUn9WrV6NOnTrQ6XRQKBQ4fvx4gddrj/jat2+PunXrFtu65WDt/ChLinIs2uL27duYNWtWsR5zREREZUlZvU8AIMWzZ88euUOBQqGwuNYv7tj279+PWbNmITY2Nse09u3bo3379sWyXnu5evUqevXqBU9PTygUCkyZMiXXsrndK2XeKx45cqT4ArVRRb+GLeo9SOXKlTF69OgCz5ecnIxZs2aViv8BRMWBiWYqtQ4cOGDx6tmzJ3Q6XY7xjRo1kjtUC7169cKBAwcQEBAgdyhFtm3bNsyePdvqNLkTzUVx9uxZzJ492+ZEc3R0NEaOHImqVasiKioKBw4cQI0aNUpNfGXdm2++iY0bN8odRql1+/ZtzJ49u9RepBMREZW0snqfAACNGjWqsLHt378fs2fPtppoXrx4MRYvXlws67WXqVOn4tChQ/j2229x4MABTJ06NdeyZfleyV54DWtdcnIyZs+ezUQzlVsquQMgyk2LFi0s3vv4+ECpVOYYX9r4+PjAx8dH7jDIjv755x9kZGRgxIgRaNeunV2WmZycDL1eb5dllVWZ+6Bq1apyh1IhpaSkwNHREQqFQu5QiIiICqSs3icAgKura6mNU87YateuLct6C+L06dNo1qwZ+vfvL3coFRqvYYlKN9ZopnIlIyMDr7/+OgIDA+Hq6orOnTvjwoULOcrt3LkTnTp1gqurK/R6PVq1aoVdu3blu3yTyYS5c+ciPDwcOp0O7u7uiIiIwKJFi6Qy1prOyMsPP/yAWrVqQa/Xo379+vj5559zlNm3bx86deoEFxcX6PV6tGzZElu3brUoM2vWLKtftrnFs3r1akRGRsLJyQnOzs7o1q0bjh07Jk0fPXo0Pv/8cwCWjydmPmKVlJSE7777Thqf9VG3u3fv4rnnnkNwcDA0Gg2qVKmC2bNnw2Aw5Ls/KleujN69e2Pjxo2IiIiAo6MjwsLC8Mknn+Q7ry37atmyZRg8eDAAoEOHDlL8uT0yNnr0aLRu3RoAMHTo0BzbunnzZkRGRkKv18PFxQVdunTBgQMHLJaR+dn8/fffeOKJJ+Dh4ZFrctXW+A4fPow2bdpAr9cjLCwM7777Lkwmk0WZ+Ph4TJ8+HVWqVIFGo0FQUBCmTJmCpKSkPPfhlClT4OTkhPj4+BzThg4dCj8/P2RkZAAwH0ddu3ZFQEAAdDodatWqhVdffTXHOkaPHg1nZ2ecOnUKXbt2hYuLCzp16iRNy/7YWmpqKmbMmGER+wsvvJCjBkz2Rz4zZX+ULTk5WdoXjo6O8PT0RJMmTbBy5co89wUA3Lp1C88++yxCQkKg0WgQGBiIJ554Avfu3ct1ntwexbN2nq5duxbNmzeHm5ub9HmOHTsWgPkR1qZNmwIAxowZIx0PWbf5yJEj6Nu3Lzw9PeHo6IiGDRtizZo1FuvI/D/w66+/YuzYsfDx8YFer0daWhqio6Ol7dNqtfDx8UGrVq2wc+fOfPcNERFRWVGc9wnR0dHQaDR48803c0w7f/48FAqFdC1rrXmKy5cv48knn0RgYCC0Wi38/PzQqVMni5qgtl7zREdHY+LEiahduzacnZ3h6+uLjh074o8//sh7B1mJLfO6P7dXph07dqBfv34IDg6Go6MjqlWrhueeew4PHjyQysyaNQsvv/wyAKBKlSoWzZsA1pvOePToESZOnIigoCBoNBqEhYXh9ddfR1pamkW5zCYJbbmvsub69esYMWIEfH19odVqUatWLXz44YfStXXmfvn333+xfft2i/sia/K7VwKAhIQEPP/88/D29oaXlxcGDhyI27dv51hWfvdseSnv17AF2T/Lli1DeHi49Pl+//33Nu1DwPy/47///S/8/f2h1+vRunVr/PXXXznK2XLuXb16VaqUNnv2bGm/ZJ7D//77L8aMGYPq1atDr9cjKCgIffr0walTp2yOl0huTDRTufLaa6/h2rVr+Prrr/HVV1/h4sWL6NOnD4xGo1Rm+fLl6Nq1K1xdXfHdd99hzZo18PT0RLdu3fK9iHz//fcxa9YsPPXUU9i6dStWr16NcePGWX38yxZbt27FZ599hjlz5mD9+vXw9PTEgAEDcPnyZanM3r170bFjR8TFxeGbb77BypUr4eLigj59+mD16tWFWu+8efPw1FNPoXbt2lizZg1++OEHJCQkoE2bNjh79iwAc3MGTzzxBADLxxMDAgJw4MAB6HQ69OzZUxqf+ajb3bt30axZM/zyyy946623sH37dowbNw7z58/H+PHjbYrv+PHjmDJlCqZOnYqNGzeiZcuWePHFF/HBBx/kOZ8t+6pXr16YN28eAODzzz+X4u/Vq5fVZb755ptSwn3evHkW2/rjjz+iX79+cHV1xcqVK/HNN98gJiYG7du3x759+3Isa+DAgahWrRrWrl2LL774wur6bInv7t27GD58OEaMGIHNmzejR48emDFjBpYvXy6VSU5ORrt27fDdd99h8uTJ2L59O1555RUsW7YMffv2hRAi1/04duxYJCcn57jQi42NxaZNmzBixAio1WoAwMWLF9GzZ0988803iIqKwpQpU7BmzRr06dMnx3LT09PRt29fdOzYEZs2bcq1WRYhBPr3748PPvgAI0eOxNatWzFt2jR899136NixY46bC1tMmzYNS5YsweTJkxEVFYUffvgBgwcPxsOHD/Oc79atW2jatCk2btyIadOmYfv27fj444/h5uaGmJiYAseR3YEDBzB06FCEhYVh1apV2Lp1K9566y3pR5lGjRph6dKlAIA33nhDOh6eeeYZAMDu3bvRqlUrxMbG4osvvsCmTZvQoEEDDB061OqPJ2PHjoVarcYPP/yAdevWQa1WY+TIkfjpp5/w1ltv4ddff8XXX3+Nzp0757tviIiIypLivE/w8fFB79698d133+X44X/p0qXQaDQYPnx4rvP37NkTR48exfvvv48dO3ZgyZIlaNiwYaHuMR49egQAmDlzJrZu3YqlS5ciLCwM7du3L/Cj+pnX/VlfmzdvhqurK2rVqiWVu3TpEiIjI7FkyRL8+uuveOutt3Do0CG0bt1aqpzwzDPPYNKkSQCADRs25Nu8SWpqKjp06IDvv/8e06ZNw9atWzFixAi8//77GDhwYI7yttxXWRMdHY2WLVvi119/xdtvv43Nmzejc+fOmD59utSfTmaTIv7+/mjVqpXFfZE1ed0rZXrmmWegVqvx448/4v3338eePXswYsQIizK23LPlpiJcw9q6f5YtW4YxY8agVq1aWL9+Pd544w28/fbb+O2332za1vHjx+ODDz7A008/jU2bNmHQoEEYOHBgjv1oy7kXEBCAqKgoAMC4ceOk/ZL5I9Xt27fh5eWFd999F1FRUfj888+hUqnQvHlzqz+MEZVKgqiMGDVqlHBycrI6bffu3QKA6Nmzp8X4NWvWCADiwIEDQgghkpKShKenp+jTp49FOaPRKOrXry+aNWuWZwy9e/cWDRo0yLPM0qVLBQBx5coVi9hDQ0MtygEQfn5+Ij4+Xhp39+5doVQqxfz586VxLVq0EL6+viIhIUEaZzAYRN26dUVwcLAwmUxCCCFmzpwprJ3S2eO5fv26UKlUYtKkSRblEhIShL+/vxgyZIg07oUXXrC6TCGEcHJyEqNGjcox/rnnnhPOzs7i2rVrFuM/+OADAUCcOXPG6vIyhYaGCoVCIY4fP24xvkuXLsLV1VUkJSUJIYS4cuWKACCWLl0qlbF1X61du1YAELt3784zlkyZx9fatWulcUajUQQGBop69eoJo9EojU9ISBC+vr6iZcuW0rjMz+att96yaX15xdeuXTsBQBw6dMhifO3atUW3bt2k9/PnzxdKpVIcPnzYoty6desEALFt27Y8Y2jUqJHFNgghxOLFiwUAcerUKavzmEwmkZGRIfbu3SsAiBMnTkjTRo0aJQCIb7/9Nsd82c+PqKgoAUC8//77FuVWr14tAIivvvpKGgdAzJw5M8cyQ0NDLY7PunXriv79++e1yVaNHTtWqNVqcfbs2VzLWDsWrZ3zQuQ8TzPPi9jY2FyXf/jw4RzLz1SzZk3RsGFDkZGRYTG+d+/eIiAgQDo2M/8PPP300zmW4ezsLKZMmZLr+omIiEq70nCfsHnzZgFA/Prrr9I4g8EgAgMDxaBBg3LEk3md9+DBAwFAfPzxx3ku39ZrnuwMBoPIyMgQnTp1EgMGDMhzmdljyy4pKUk0a9ZMBAQEiKtXr1otk3k9eO3aNQFAbNq0SZq2YMGCHPdJmdq1ayfatWsnvf/iiy8EALFmzRqLcu+9916O/WzrfZU1r776qtVr6+eff14oFApx4cIFaVxoaKjo1atXnsvLlNu9UuY12cSJEy3Gv//++wKAuHPnjhCiYPds1pT3a1hb90/mPVujRo2ke0EhhLh69apQq9VWtzWrc+fOCQBi6tSpFuNXrFghABTq3IuOjs71fLa2jPT0dFG9evUcMRCVVqzRTOVK3759Ld5HREQAAK5duwbA3AHFo0ePMGrUKBgMBullMpnQvXt3HD58OM9mBZo1a4YTJ05g4sSJ+OWXX6w2LVAQHTp0gIuLi/Tez88Pvr6+UrxJSUk4dOgQnnjiCTg7O0vlHBwcMHLkSNy8ebPAv2z+8ssvMBgMePrppy32gaOjI9q1a1fkTgl+/vlndOjQAYGBgRbL79GjBwBzreP81KlTB/Xr17cYN2zYMMTHx+Pvv/+2Ok9x7Ku8XLhwAbdv38bIkSOhVD7+V+rs7IxBgwbh4MGDSE5Otphn0KBBdlm3v78/mjVrZjEuIiJCOm4A8+dQt25dNGjQwOJz6Natm029iY8ZMwb79++32GdLly5F06ZNUbduXWnc5cuXMWzYMPj7+8PBwQFqtVpqx/rcuXM5lmvLPsisXZC9F+fBgwfDycnJpmZusmvWrBm2b9+OV199FXv27EFKSopN823fvh0dOnSwqLVjT5mPFA4ZMgRr1qzBrVu3bJ7333//xfnz56UaUlk/5549e+LOnTs5jnlr+79Zs2ZYtmwZ5s6di4MHD0o1j4iIiMqT4r5P6NGjB/z9/aVanID5uvv27dtScwLWeHp6omrVqliwYAEWLlyIY8eO5agVXVBffPEFGjVqBEdHR6hUKqjVauzatcvqtZmtjEYjhg4dinPnzmHbtm0IDQ2Vpt2/fx8TJkxASEiItL7M6YVd52+//QYnJyfpCctMmdeH2a8H87uvyms9tWvXznFtPXr0aAghbK71WlD5HY9FvWcr79ewtu6fzHu2YcOGWTT9ERoaipYtW+Yb6+7duwEgxxMJQ4YMgUqVs8uzop57BoMB8+bNQ+3ataHRaKBSqaDRaHDx4sUinb9EJYmJZipXvLy8LN5rtVoAkJJKme1RPfHEE1Cr1Rav9957D0II6ZEXa2bMmIEPPvgABw8eRI8ePeDl5YVOnTrhyJEjdok3M+bMeGNiYiCEsPpYVmBgIAAU+PH2zH3QtGnTHPtg9erVFm2pFca9e/ewZcuWHMuuU6cOANi0fH9//1zH5ba9xbGv8pK5rNzWZzKZcjxOldvjdQWV33EDmD+HkydP5vgcXFxcIITI93MYPnw4tFqt9Oja2bNncfjwYYwZM0Yqk5iYiDZt2uDQoUOYO3cu9uzZg8OHD2PDhg0AkCOZq9fr4erqmu/2PXz4ECqVKkenmgqFAv7+/oX6HD/55BO88sor+Omnn9ChQwd4enqif//+uHjxYp7zRUdHIzg4uMDrs1Xbtm3x008/SRfKwcHBqFu3rk1tR2eey9OnT8/xOU+cOBFAzvPN2jG4evVqjBo1Cl9//TUiIyPh6emJp59+Gnfv3rXDFhIREZUOxX2foFKpMHLkSGzcuFFq8mLZsmUICAhAt27dcp1PoVBg165d6NatG95//300atQIPj4+mDx5MhISEgq8nQsXLsTzzz+P5s2bY/369Th48CAOHz6M7t272/xDuzUTJkxAVFQU1q1bhwYNGkjjTSYTunbtig0bNuC///0vdu3ahb/++gsHDx4EkPN60FYPHz6Ev79/jnaBfX19oVKpclwP2nJ9nNt6Sur+IStbj8fC3rOV92tYW/dP5ueX1/1lXnKbX6VS5fgM7XHuTZs2DW+++Sb69++PLVu24NChQzh8+DDq169fpPOXqCTl/AmGqBzz9vYGAHz66ae59qjs5+eX6/wqlQrTpk3DtGnTEBsbi507d+K1115Dt27dcOPGDej1ervG6+HhAaVSiTt37uSYltlZROY2OTo6AgDS0tKkCxUg55d0Zvl169ZZ1ESwF29vb0REROCdd96xOj3zoi0v1hJcmeOsXUQCBdtX9pAZR27rUyqV8PDwsBhfkj0je3t7Q6fT4dtvv811el48PDzQr18/fP/995g7dy6WLl0KR0dHPPXUU1KZ3377Dbdv38aePXukWswAcm1P0Nbt9/LygsFgQHR0tEWyWQiBu3fvSjUoAPNFubU2m7PfFDg5OWH27NmYPXs27t27J9Vu7tOnD86fP59rLD4+Prh586ZNcWfl6OhoNS5rNwX9+vVDv379kJaWhoMHD2L+/PkYNmwYKleujMjIyFzXkfkZzpgxw2pbhQAQHh5u8d7aZ+Dt7Y2PP/4YH3/8Ma5fv47Nmzfj1Vdfxf3796U25IiIiMq7ot4nAOYnwhYsWIBVq1Zh6NCh2Lx5M6ZMmQIHB4c85wsNDcU333wDAPjnn3+wZs0azJo1C+np6VK/HrZe8yxfvhzt27fHkiVLLMYXJmmdadasWfj666+xdOlSdO3a1WLa6dOnceLECSxbtgyjRo2Sxv/777+FXh9gvh48dOgQhBAW1y/379+HwWCw23W9l5dXid0/FERR79nK+zWsrfsn854tr/vLvGSdPygoSBpvMBiK5dxbvnw5nn76aanPnkwPHjyAu7u7zcshkhMTzVShtGrVCu7u7jh79qzUuUNhubu744knnsCtW7cwZcoUXL16FbVr17ZTpGZOTk5o3rw5NmzYgA8++AA6nQ6AuebA8uXLERwcjBo1agCA1DvwyZMnLRJxW7ZssVhmt27doFKpcOnSpXybMcj6y3rmurNOs/arau/evbFt2zZUrVo1R6LVVmfOnMGJEycsms/48ccf4eLikmuHIQXZV9lrDBRGeHg4goKC8OOPP2L69OnSxU9SUhLWr1+PyMjIQv/wYI/4evfujXnz5sHLywtVqlQp1DLGjBmDNWvWYNu2bVi+fDkGDBhgcYGTuc1Zf9gAgC+//LLQcQNAp06d8P7772P58uWYOnWqNH79+vVISkpCp06dpHGVK1fGyZMnLeb/7bffkJiYmOvy/fz8MHr0aJw4cQIff/wxkpOTc/2sevTogR9++AEXLlzIccGbl8qVK+P+/fu4d++edFOanp6OX375Jdd5tFot2rVrB3d3d/zyyy84duwYIiMjcz0ewsPDUb16dZw4cSLHxWhhVapUCf/5z3+wa9cu/Pnnn3ZZJhERUVlgj/uEWrVqoXnz5li6dCmMRiPS0tIsngazRY0aNfDGG29g/fr1Fk3G2XrNo1AoclybnTx5EgcOHEBISEgBtwj45ptvMHv2bMyZMydHs2aZ6wNsux4syDVup06dsGbNGvz0008YMGCANP7777+XpttDp06dMH/+fPz9998W9xnff/89FAoFOnToUKjl2lKbOi8FuWezprxfw9q6f8LDwxEQEICVK1di2rRp0vF67do17N+/P99KUO3btwcArFixAo0bN5bGr1mzRur4MJOt515e54G1ZWzduhW3bt1CtWrV8oyVqLRgopkqFGdnZ3z66acYNWoUHj16hCeeeAK+vr6Ijo7GiRMnEB0dneMXyKz69OmDunXrokmTJvDx8cG1a9fw8ccfIzQ0FNWrVy+WmOfPn48uXbqgQ4cOmD59OjQaDRYvXozTp09j5cqV0pdlz5494enpiXHjxmHOnDlQqVRYtmwZbty4YbG8ypUrY86cOXj99ddx+fJldO/eHR4eHrh37x7++usvqeYnANSrVw8A8N5776FHjx5wcHBAREQENBoN6tWrhz179mDLli0ICAiAi4sLwsPDMWfOHOzYsQMtW7bE5MmTER4ejtTUVFy9ehXbtm3DF198ke9jXIGBgejbty9mzZqFgIAALF++HDt27MB7772XZ/LW1n2V2cbwV199BRcXFzg6OqJKlSq51pa2RqlU4v3338fw4cPRu3dvPPfcc0hLS8OCBQsQGxuLd9991+ZlZWeP+KZMmYL169ejbdu2mDp1KiIiImAymXD9+nX8+uuveOmll9C8efM8l9G1a1cEBwdj4sSJuHv3bo4bpZYtW8LDwwMTJkzAzJkzoVarsWLFCpw4caLgG51Fly5d0K1bN7zyyiuIj49Hq1atcPLkScycORMNGzbEyJEjpbIjR47Em2++ibfeegvt2rXD2bNn8dlnn8HNzc1imc2bN0fv3r0REREBDw8PnDt3Dj/88EO+PwjMmTMH27dvR9u2bfHaa6+hXr16iI2NRVRUFKZNm4aaNWtanW/o0KF466238OSTT+Lll19GamoqPvnkE4ue7QHgrbfews2bN9GpUycEBwcjNjYWixYtsmjrumrVqtDpdFixYgVq1aoFZ2dnBAYGIjAwEF9++SV69OiBbt26YfTo0QgKCsKjR49w7tw5/P3331i7dm2e+zouLg4dOnTAsGHDULNmTbi4uODw4cOIioqyqGEyZ84czJkzB7t27bKovU5ERFReFPU+IdPYsWPx3HPP4fbt22jZsmW+Sb6TJ0/iP//5DwYPHozq1atDo9Hgt99+w8mTJ/Hqq69K5Wy95unduzfefvttzJw5E+3atcOFCxcwZ84cVKlSJUdiLD8HDhzAhAkT0KpVK3Tp0kVqDiNTixYtULNmTVStWhWvvvoqhBDw9PTEli1bsGPHjhzLy7y3WLRoEUaNGgW1Wo3w8HCLtpUzPf300/j8888xatQoXL16FfXq1cO+ffswb9489OzZE507dy7QtuRm6tSp+P7779GrVy/MmTMHoaGh2Lp1KxYvXoznn39eqqhSULndK9mqIPds1pT3a1hb949SqcTbb7+NZ555BgMGDMD48eMRGxuLWbNm2dR0Rq1atTBixAh8/PHHUKvV6Ny5M06fPo0PPvggR5OAtp57Li4uCA0NxaZNm9CpUyd4enrC29sblStXRu/evbFs2TLUrFkTEREROHr0KBYsWGD1/lmlUqFdu3aF6r+GqFjJ1g0hUQHZ0pv02rVrLcZb60lXCCH27t0revXqJTw9PYVarRZBQUGiV69eOebP7sMPPxQtW7YU3t7eQqPRiEqVKolx48ZZ9Lqc2TNu1t6UrfXeC0C88MILOdZhrefoP/74Q3Ts2FE4OTkJnU4nWrRoIbZs2ZJj3r/++ku0bNlSODk5iaCgIDFz5kzx9ddfW+3d+aeffhIdOnQQrq6uQqvVitDQUPHEE0+InTt3SmXS0tLEM888I3x8fIRCobBYzvHjx0WrVq2EXq8XACx6iY6OjhaTJ08WVapUEWq1Wnh6eorGjRuL119/XSQmJua5jzN7c163bp2oU6eO0Gg0onLlymLhwoUW5XL7bG3dVx9//LGoUqWKcHBwyLU35Ey5HV+Z+7F58+bC0dFRODk5iU6dOok///zTokxmL83R0dF5brst8bVr107UqVMnR3lrx1hiYqJ44403RHh4uNBoNMLNzU3Uq1dPTJ06Vdy9e9emOF577TUBQISEhEi9P2e1f/9+ERkZKfR6vfDx8RHPPPOM+Pvvv632YJ3b+Wst9pSUFPHKK6+I0NBQoVarRUBAgHj++edFTEyMRbm0tDTx3//+V4SEhAidTifatWsnjh8/nuM8evXVV0WTJk2Eh4eH0Gq1IiwsTEydOlU8ePAg331w48YNMXbsWOHv7y/UarUIDAwUQ4YMEffu3RNC5H4sbtu2TTRo0EDodDoRFhYmPvvssxw9dv/888+iR48eIigoSGg0GuHr6yt69uwp/vjjD4tlrVy5UtSsWVOo1eocvVSfOHFCDBkyRPj6+gq1Wi38/f1Fx44dxRdffCGVyfy/dPjwYYvlpqamigkTJoiIiAjh6uoqdDqdCA8PFzNnzhRJSUlSucy4c+uFnoiISE6l4T4hU1xcnNDpdAKA+L//+79c48n8Tr13754YPXq0qFmzpnBychLOzs4iIiJCfPTRR8JgMEjz2XrNk5aWJqZPny6CgoKEo6OjaNSokfjpp59yvR/Jek2RPbbM64fcXpnOnj0runTpIlxcXISHh4cYPHiwuH79eo7lCyHEjBkzRGBgoFAqlRbrateuncX9hBBCPHz4UEyYMEEEBAQIlUolQkNDxYwZM0RqamqO7bD1vsqaa9euiWHDhgkvLy+hVqtFeHi4WLBgQY5r38z7FFvkdq+U2zVZ9n2fyZZ7ttyU52vYgu6fr7/+WlSvXl1oNBpRo0YN8e2331o9J6xJS0sTL730kvD19RWOjo6iRYsW4sCBA0U693bu3CkaNmwotFqtACAtJyYmRowbN074+voKvV4vWrduLf744w+r50f2e3Ci0kIhhBDFk8ImIiq4ypUro27duvj555/lDoWIiIiIiIiIiGyklDsAIiIiIiIiIiIiIirbmGgmIiIiIiIiIiIioiJh0xlEREREREREREREVCSs0UxERERERERERERERcJEMxEREREREREREREVCRPNRERERERERERERFQkKjlWajKZcPv2bbi4uEChUMgRAhEREREVAyEEEhISEBgYCKWSdRoqCl7fExEREZVftl7jy5Jovn37NkJCQuRYNRERERGVgBs3biA4OFjuMKiE8PqeiIiIqPzL7xpflkSzi4sLAHNwrq6ucoRAxSE1FRgxwjy8fDng6ChvPERERFTi4uPjERISIl3vUcXA63siIiKi8svWa3xZEs2Zj9O5urryQrQ8cXAAduwwDzs5mV9ERERUIbH5hIqF1/dERERE5V9+1/hsOI+IiIiIiIiIiIiIioSJZiIiIiIiIiIiIiIqEiaaiYiIiIiIiIiIiKhImGgmIiIiIiIiIiIioiJhopmIiIiIiIiIiIiIikQldwDlWspZICNa7ihKTlLK4+H4PwCjTr5YyhqRBqi8AadGckdCRERERERERERUYEw0F6er/wEy7sodRck6Ucv8N3oaUIFy7EWmUAOaIKDGZkDB05KIiIiIiIiIiMoWZrSKk8gAHJwAlY/ckVBpY0oB0m8BCiXg4G6uyRzwXyaZiYiIiIiIiIioTGJWq9gpAYWD3EFQaWJKATLuAK7tAY/+gFNTQM0fI4iIiIiIiIiIqOxiopnsJ80IvHzcPLygAaBlgt2CEIAx3tycitofqPQh4OAid1RERERERERERERFppQ7ACpHjAL45Y75ZRRyR1N6CAFk3ANSLwKmJMC1AxDyDpPMRERERERERERUbrBGM1FxMqUDGbcApR7wGQW49wF0dQGFQu7IiIiIiIiIiIiI7IaJZqLiIASQfg0QRkATCPhPB9y7yx0VERERERERERFRsWCimag4GB4CSh0Q8Crg1g1wcJI7IiIiIiIiIiIiomLDNpqJ7E0YzIlmXR3AcyCTzEREREREREREVO4x0UxkT0IAaVcAxxqA/0tyR0NERERERERERFQimGgmsidjHKB0AoJnA/q6ckdDRERERERERERUIthGM9mPzgE41v3xcEVkjAd0tQF9I7kjISIiIiIiIiIiKjFMNJP9KBSAvgIfUiIDMKUATk3N+4KIiIiIiIiIiKiCqMBZQSI7EgJIu2auzez1lNzREBERERER4VGyEStPJEKpUGBYA2e4ObL1TCIiKj5MNJP9pBuBt06Zh+fUAzQVpPkMUxqQfh1w8ACC3gQ0AXJHREREREREhAW/x+H0vXQAwL1EA2Z19pQ5IiIiKs/4cybZj0EAG2+aXwYhdzQlJ+Mu4BgOVF4CODWWOxoiIiIiIiIAwP0k4+PhRJOMkRARUUXARDNRUZjSAVMq4NIacGogdzRERERERESSp+o7wUEJqJTAk/Wd5A6HiIjKOTadQVQYQgCGB4AxFtA3ADyflDsiIiIiIiIiC52r6dGykiMUCkCnZj0zIiIqXkw0ExVG+nVA6Qj4PAP4jAdUbnJHRERERERElINewwQzERGVDCaaiQrKlAYIAxAwA/AcIHc0REREREREREREsmOimaggDI8Aw0PAsRbg1lnuaIiIiIiIiIiIiEoFPkNDZCthNCeZvYYDVb8DHFzkjoiIiIiIiIiIiKhUYI1msh+dA3Cgy+Ph8kQIIP0W4OAO+IwDHFzljoiIiIiIiIiIiKjUYKKZ7EehADy1ckdRPNKvmWsw+00BNIFyR0NERERERERERFSqMNFMlBchgLQrgNLR3PmfRx+5IyIiIiIiIiIiIip1mGgm+0k3AvPPmodn1AY05aD5DFMioNQCwW8Dbj3kjoaIiIiIiIiIiKhUYmeAZD8GAfx4zfwyCLmjsY+Me4C2GuDa0dw0CBEREREREREREeXARDNRboTB/NdntLnpDCIiIiIiIiIiIrKKiWai3KTfBrSVAedIuSMhIiIiIiIiIiIq1ZhoJrLGlA6IdMBrJKDykDsaIiIiIiIiIiKiUo2JZiJrjPGAyhPw6Cd3JERERERERERERKUeE81E1piSAQc3wMFJ7kiIiIiIiIiIiIhKPSaaibIzJpg7AvR8Uu5IiIiIiIiIiIiIygSV3AFQOeLoAOzq+Hi4rMqIBpybAd4j5Y6EiIiIiIiIiIioTGCimexHqQCC9XJHYQdGQN8QUCjkDoSIiIiIiIiIiKhMYNMZRFkZ4wGFGtDXkzsSIiIiIiIiIiKiMoM1msl+0k3AR+fNw1NrApoy9juGyADS7wIe/QGX9nJHQ0REREREREREVGaUsUwglWoGE/DtZfPLYJI7moLLeABoAoDA19hsBhERERERERERUQEw0UwEAMYEwJQIuPcDVG5yR0NERERERERERFSmMNFMBJibzHDrBvg+J3ckREREREREREREZQ4TzURCAAqY22V20MsdDRERERERERERUZnDRDMRBAAF4OAqdyBERERERERERERlEhPNRMYYQOkMaEPljoSIiIiIiIiIiKhMYqKZKjZhBDIeAB79AW1VuaMhIiIiIiIiIiIqk5hoJvtxdAB+bmd+OTrIHY1tMu4Dan/A9xlAoZA7GiIiIiLJkiVLEBERAVdXV7i6uiIyMhLbt2+Xpo8ePRoKhcLi1aJFC4tlpKWlYdKkSfD29oaTkxP69u2LmzdvWpSJiYnByJEj4ebmBjc3N4wcORKxsbElsYlEREREVI4w0Uz2o1QA1V3ML2UZSdoaEwDXToDaT+5IiIiIiCwEBwfj3XffxZEjR3DkyBF07NgR/fr1w5kzZ6Qy3bt3x507d6TXtm3bLJYxZcoUbNy4EatWrcK+ffuQmJiI3r17w2g0SmWGDRuG48ePIyoqClFRUTh+/DhGjhxZYttJREREROWDSu4AiGSlUAIaf7mjICIiIsqhT58+Fu/feecdLFmyBAcPHkSdOnUAAFqtFv7+1q9l4uLi8M033+CHH35A586dAQDLly9HSEgIdu7ciW7duuHcuXOIiorCwYMH0bx5cwDA//3f/yEyMhIXLlxAeHh4MW4hEREREZUnrNFM9pNuAj69YH6lm+SOJn/CAEABONaQOxIiIiKiPBmNRqxatQpJSUmIjIyUxu/Zswe+vr6oUaMGxo8fj/v370vTjh49ioyMDHTt2lUaFxgYiLp162L//v0AgAMHDsDNzU1KMgNAixYt4ObmJpWxJi0tDfHx8RYvIiIiIqrYmGgm+zGYgM8uml+GMpBoNqUCSh2grSx3JERERERWnTp1Cs7OztBqtZgwYQI2btyI2rVrAwB69OiBFStW4LfffsOHH36Iw4cPo2PHjkhLSwMA3L17FxqNBh4eHhbL9PPzw927d6Uyvr6+Odbr6+srlbFm/vz5UpvObm5uCAkJsdcmExEREVEZxaYzqOISBkChAhzc5I6EiIiIyKrw8HAcP34csbGxWL9+PUaNGoW9e/eidu3aGDp0qFSubt26aNKkCUJDQ7F161YMHDgw12UKIaDI0gmywkqHyNnLZDdjxgxMmzZNeh8fH89kMxEREVEFx0QzVVzGOHNtZqWL3JEQERERWaXRaFCtWjUAQJMmTXD48GEsWrQIX375ZY6yAQEBCA0NxcWLFwEA/v7+SE9PR0xMjEWt5vv376Nly5ZSmXv37uVYVnR0NPz8cu8sWavVQqvVFmnbiIiIiKh8YdMZVDEJAYh0wL0voFTLHQ0RERGRTYQQUtMY2T18+BA3btxAQEAAAKBx48ZQq9XYsWOHVObOnTs4ffq0lGiOjIxEXFwc/vrrL6nMoUOHEBcXJ5UhIiIiIrIFazRTxWRKBhSOgFMTuSMhIiIisuq1115Djx49EBISgoSEBKxatQp79uxBVFQUEhMTMWvWLAwaNAgBAQG4evUqXnvtNXh7e2PAgAEAADc3N4wbNw4vvfQSvLy84OnpienTp6NevXro3LkzAKBWrVro3r07xo8fL9WSfvbZZ9G7d2+Eh4fLtu1EREREVPYw0UwVkykRUHkA+rpyR0JERERk1b179zBy5EjcuXMHbm5uiIiIQFRUFLp06YKUlBScOnUK33//PWJjYxEQEIAOHTpg9erVcHF53CzYRx99BJVKhSFDhiAlJQWdOnXCsmXL4ODgIJVZsWIFJk+ejK5duwIA+vbti88++6zEt5eIiIiIyjaFEEKU9Erj4+Ph5uaGuLg4uLq6lvTqS87ZNubmGdQ5e/Iul5INQMMo8/Cx7oC+lP6OIQSQdhFw7QRUXix3NEREROVKhbnOIwv83ImIiIjKL1uv9UppJpDKJK0DsLb14+HSypQIKJ0A3+fkjoSIiIiIiIiIiKhcYKKZ7MdBAUS4yx1F/oyxgMoP0EXIHQkREREREREREVG5oJQ7AKISZUoBTOmA13BAoZA7GiIiIiIiIiIionKBNZrJftJNwPdXzMNPVwE0pfB3jIx7gD4C8HpK7kiIiIiIiIiIiIjKDSaayX4MJmDBOfPwsNDSmWg2pQG6uoBSLXckRERERERERERE5UYpzAQSFRNTCqBQAbpwuSMhIiIiIiIiIiIqV5hopopBCHOzGZogwGOA3NEQERERERERERGVK0w0U8VgjAfgAPhNNtdqJiIiIiIiIiIiIrthopkqBmMsoKsJuPeWOxIiIiIiIiIiIqJyh4lmqhhEOqCrBygUckdCRERERERERERU7jDRTBWEAnBwlTsIIiIiIiIiIiKicomN1ZL9aB2A71s8Hi5VFIBSK3cQRERERERERERE5RITzWQ/DgqgubfcUeQkDABMgNJJ7kiIiIiIiIiIiIjKJSaaqfxLuw5oqwLuPeSOhIiIiIjKuF3/puBOggGdquoQ4MrbKSIiIqJMvDIi+8kwAWuum4eHVALUpaAJcMMjQKkB/KcBKk+5oyEiIiKiMmzb+WQsORQPANhxMQX/N9AHGhU7myYiIiICmGgme8owAXNOm4cHBJeSRPNDwGMA4NpR7kiIiIiIqIy79ChDGn6UYkJsqgm+zqWtbxIiIiIieZSCTCBRMRHC/Ne5OaBgTRMiIiIiKpoOYTpo/pdXbhykgY8Tb6eIiIiIMlWoK6MlS5YgIiICrq6ucHV1RWRkJLZv3y53WFRcRDqgUAPqALkjISIiIqJyoK6/Bv830AcLe3nhzY4eUJTiygwmk8COi8nYdDYJKRkmucMhIiKiCqBCNZ0RHByMd999F9WqVQMAfPfdd+jXrx+OHTuGOnXqyBwd2Z0xFnBwB3S15Y6EiIiIiMoJT70DPPWlv7mMZX8nYOOZZADAoRtpmNeN/ZUQERFR8apQieY+ffpYvH/nnXewZMkSHDx4kInm8sgYb26f2cFF7kiIiIiIiErU+ejH7UlfiE6XMRIiIiKqKCpU0xlZGY1GrFq1CklJSYiMjJQ7HCourM1MRERERBVQhzCd1WEiIiKi4lKhajQDwKlTpxAZGYnU1FQ4Oztj48aNqF2bychyR/yvHTqVt7xxEBERERHJoEe4HrV81UhOF6jlq5Y7HCIiIqoAKlyiOTw8HMePH0dsbCzWr1+PUaNGYe/evUw224NGCXzZ9PGwnEzJgNIJcKwmbxxERERERDKp7MEEMxEREZWcCpdo1mg0UmeATZo0weHDh7Fo0SJ8+eWXMkdWDqiUQHs/uaMwM6UCSkdAU0nuSIiIiIiIiIiK3f1EI2btjMGdBAMG13PGsAbOcodERBVMhW2jOZMQAmlpaXKHQfZmSgJUvoBSK3ckRERERERERMVuw5kk3IgzwGACVp5IxKNko9whEVEFU6FqNL/22mvo0aMHQkJCkJCQgFWrVmHPnj2IioqSO7TyIcMEbLllHu4TBKhl+h3DEGtuo9lzkDzrJyIiIiIiIiphTmqFNKxxADQOijxKExHZX4VKNN+7dw8jR47EnTt34ObmhoiICERFRaFLly5yh1Y+ZJiAGSfMw90DZEw03wc8hgBew+VZPxEREREREVEJGxLhjPg0E27HG9Gvth7O2gr/EDsRlbAKlWj+5ptv5A6BipsQABSAa1tAwV9viYiIiIiIqGLQqhR4IdJN7jCIqALjz1tUzpgAKAAFe9gmIiIiIiIiIiIqKUw0U/mSfhNQ+wHaKnJHQkREREREREREVGEw0UzlizAAXiMAbajckRAREREREREREVUYTDRT+SEEABOg8pI7EiIiIiIiIiIiogqlQnUGSOWcKQFQOLI2MxERERFVSKkZJmw4k4xUgwkD6zjBXecgd0hERERUgTDRTPajUQIfN3o8XNIy7gGunQF9w5JfNxERERGRzJYcisdvl1IBAOfuZ2BBTz7pR0RERCWHiWayH5US6BEoz7qFMP916w4oFPLEQEREREQkoxuxxsfDcQYZIyEiIqKKiG00U/lgjAeUekBbWe5IiIiIiIhk0be2Hsr/1bkYUMdJ3mCIiIiowmGNZrIfgwnYcdc83MXfXMO5xNZ9H3DtCujqlNw6iYiIiIhKkfZhOkT4a2AwAb7ObJ+ZSgEh+MQpEVEFwkQz2U+6CZjyt3n4WPeSSzQLEwAF4NKSFzFEREREVKF56plgplIg/S5wayaQcRfwHAx4j5A7IiIiKgFsOoPKPpEGKLSszUxERERERFQaxGwEMm4DMAGPVgOGR3JHREREJYCJZir7jPGAgxugqSR3JEREREREROTg+nhYoTFXDCIionKPTWdQ2WdKAZwiAJWb3JEQERERERGR52DAlACk3wY8+gMO7JySiKgiYKKZyj6RAWjD5I6CiIiIiIiIAECpAXwnyB0FERGVMDadQWWbEAAUgDZU7kiIiIiIiIiIiIgqLNZoprJLCHP7zFAy0UxEREREROVbylkgfjegrQK495Q7GiIiohyYaCb7USuB+fUfDxe39GsAHADnFoCubvGvj4iIiIjKnZN30nA91oCWoY7w1DvIHQ6RdYYY4OZbgEgzv1doAbdO8sZERESUDRPNZD9qJTAwpGTWZYwHhAkIeh3wHAooFCWzXiIiIiIqN/ZfS8X8PbEAgI1nk/F5Xy84lkSFCaKCMjx8nGQGgIzb8sVCRESUC15FUdkjBJB+B3DvZe7BmElmIiIiogrHYBRISDMVaRmn76VLw/cTjYhOKtryiAxGgYV/xOLZDdFYcSzBfgvWhgH6xuZhB0/AtbP9lk1ERGQnrNFM9mMwAfuizcOtfQBVcf2OYQQUKsCjL6B0LKZ1EBEREVFpdSvOgNd+eYRHKSZ0rqbDi63cCrWcFiFabL+QDIMJCPNUwd+FTWeUBjEpRqRmCAS4lr3b1Z3/pmD35VQAwKqTSWgSrEW4j6boC1YogaCZgCEacHADlNqiL5OIiMjOyt43N5Ve6SbgucPm4WPdiy/RbEwElHpAHVA8yyciIiKiUm3rhWQ8SjHXPt75bwqG1HMqVFIyIkCLT/t64068AfX8NVA7VKwn5YQQ2HExBY9STOhaXVcq2qjefy0VC36PhcEEDKrrhNGNXeQOqUBE9vfZRxSFQgGofe24QCrV4naYX47VAJ9xgEL+85OIKD9MNFPZY4gG3HqYHx8jIiIiogrHx+lxwsVRpYCztvAVHILdVAh2q5i3RWtOJWH5sUQAwJ7LKVjS3xsKmZul+/m8uYY5AGw6m1TmEs2dq+lw5l46zkVnoH0VR9T0tUNtZqp40m8B9z4FIIDUc4AmyNx0JBFRKVcxr6io7BJGAArArQvbZiYiIiKqoPrW0iPNIHAjzoAeNfRwKUKi2d5iU4z4/u9EGEwCIxq6wNe59NZC/PdhhjR8K96INIOAo1rea+wQNxVO3TW3nV0WfwBQOygwva27XZcphIBJAA5K3v9UGKYUWNSPNybJFgoRUUGUvW9uqtgMDwCVD+DUTO5IiIiIiEgmDkoFnqzvLHcYVi36Mx5HbqUBMCdvP+zlJXNEuetcVYcjN9NgMAFtqzjCUS1/wn5cExd46ZVITDehXy0nucOR3am76XhndwzSDAITW7iiS3W93CFRSXCsBrj3AeJ++d9wT7kjIiKyCRPNVHYII2CIA7z7AGpvuaMhIiIiIsrhYbLR6nBp1LySI74c4IPYFCOqe6vlDgcAoFEpMCTCfj8iJKWb4KhSlNnawMuPJSAp3Vyz9ZsjCUw0VyS+z5pfRERliPw/WRPZyhgLqDz5ZUtEREREpdbwBs7QOJj7xR7VqPS3L+zr7IAaPhrZ22YuDksOxuPJlfcxdl00bsQa5A6nUNx1j2/Z3R2L//Y9Ic2EO/Flc18REZH8mGimskGYAEMsoPIA1H5yR0NERERU7JYsWYKIiAi4urrC1dUVkZGR2L59uzRdCIFZs2YhMDAQOp0O7du3x5kzZyyWkZaWhkmTJsHb2xtOTk7o27cvbt68aVEmJiYGI0eOhJubG9zc3DBy5EjExsaWxCaWS80rOWL1U35Y/ZQfOlTVyR1OhRWdaMS2C8kAgEcpJmw5VzbbuJ3Ywg2dqurQMlSL1zt4FOu6Tt5Jw5h10Xh24wMsORhfrOsiIqLyiYlmsh+1Enirrvll7/bd0m8CKm/A7wX7LpeIiIiolAoODsa7776LI0eO4MiRI+jYsSP69esnJZPff/99LFy4EJ999hkOHz4Mf39/dOnSBQkJCdIypkyZgo0bN2LVqlXYt28fEhMT0bt3bxiNj5t0GDZsGI4fP46oqChERUXh+PHjGDlyZIlvb3miclBAoyp/NYTLEieNArosHRt6O5XeThnz4uaoxJTWbpjR3gMh7sXb8uXP55ORZjA307HtQjJSM0zFuj4iIip/FEIIkX8x+4qPj4ebmxvi4uLg6upa0qsvOWfbACIdUPvKHUnZl/IP4D0SCHpD7kiIiIgoDxXmOk8mnp6eWLBgAcaOHYvAwEBMmTIFr7zyCgBz7WU/Pz+89957eO655xAXFwcfHx/88MMPGDp0KADg9u3bCAkJwbZt29CtWzecO3cOtWvXxsGDB9G8eXMAwMGDBxEZGYnz588jPDzcprj4uVNpdPZeOracT0aQqwOejHCGyoHJ/7z88HcC1pwy1/z2cVLim0E+5bJJFSIiKjhbr/XYGSCVfsYkQKEENCFyR0JEREQkC6PRiLVr1yIpKQmRkZG4cuUK7t69i65du0pltFot2rVrh/379+O5557D0aNHkZGRYVEmMDAQdevWxf79+9GtWzccOHAAbm5uUpIZAFq0aAE3Nzfs378/10RzWloa0tLSpPfx8XzMnkqf2n4a1PbTyB1GmfFUfWfoNQo8TDahT009k8xERFRgTDST/RgFcOShebiJF2CvGgMZdwCnZoDXU/ZZHhEREVEZcerUKURGRiI1NRXOzs7YuHEjateujf379wMA/Pws+67w8/PDtWvXAAB3796FRqOBh4dHjjJ3796Vyvj65nz6ztfXVypjzfz58zF79uwibRsRlS4qBwUG1XWWO4xSQwiB7RdScD3OgM5VdajmrZY7JCKiUo9tNJP9pBmBpw+aX2nG/MvbwpgEKFSA11BAydoIREREVLGEh4fj+PHjOHjwIJ5//nmMGjUKZ8+elaZnr3EohMi3FmL2MtbK57ecGTNmIC4uTnrduHHD1k0iIioTfvknBUsOxWPr+WS8seMREtLYZjURUX6YaKbSzRgPqHwBt25yR0JERERU4jQaDapVq4YmTZpg/vz5qF+/PhYtWgR/f38AyFHr+P79+1ItZ39/f6SnpyMmJibPMvfu3cux3ujo6By1pbPSarVwdXW1eBERlSc34w3ScFK6QGwKE81ERPlhoplKLyEAUwLg2hFQlM1eoomIiIjsSQiBtLQ0VKlSBf7+/tixY4c0LT09HXv37kXLli0BAI0bN4ZarbYoc+fOHZw+fVoqExkZibi4OPz1119SmUOHDiEuLk4qQ0RUEXWupoOL1vxkR9NgLYLdeE9KRJQfttFMpZfhIaB0ATx6yx0JERERUYl77bXX0KNHD4SEhCAhIQGrVq3Cnj17EBUVBYVCgSlTpmDevHmoXr06qlevjnnz5kGv12PYsGEAADc3N4wbNw4vvfQSvLy84OnpienTp6NevXro3LkzAKBWrVro3r07xo8fjy+//BIA8Oyzz6J37965dgRIRFQRVPZQ4+uBPohNNSHAxYGdIxIR2YCJZiqdTKmAMQbweQ7Q15c7GiIiIqISd+/ePYwcORJ37tyBm5sbIiIiEBUVhS5dugAA/vvf/yIlJQUTJ05ETEwMmjdvjl9//RUuLi7SMj766COoVCoMGTIEKSkp6NSpE5YtWwYHh8c181asWIHJkyeja9euAIC+ffvis88+K9mNJSIqhfQaJfQaPghORGQrhRBClPRK4+Pj4ebmhri4uPLdntvZNoBIB9Q5e/Iul5INQMMo8/Cx7oC+CL9jpP4LODUFKn8BOOjtEx8REREVuwpznUcW+LkTEVF+hBA4lnAMjkpH1HauLXc4RFQAtl7rsUYzlT7pdwCFBvAZwyQzERERERXY71dS8M3hBLg5KvFKO3cEufG2h4hIbp/c+AQ7Y3YCAEb5j8ITfk/IHBER2RufASH7USmBl2uZX6pCHlrGJECkAX7/AVza2jc+IiIiIir3hBBY9GccHqWYcCXGgO/+TpA7JCIiArA/br/V4bycTDiJNy+9iU9ufIJkY3JxhUZEdsKf9sl+NErgmapFW4ZIA5TOgNdQQMFefYmIiIio4NQOCqQbhTRMeTMJE26k3oCX2gvOKme5wyEqe4wJgOERoAkBFKzPl5u6znXxV/xf0nB+0k3pePvq20g1pQIAdEodxgeNL9YYiahomGim0sWUCqi8AKVL/mWJiIiIiLJRKBR4tZ07vv87Ea6OCoxtXPLXlUIILDkYj/3X01DPX4OXWrtBVUoT3iZhwpwrc3A04SiclE6YV20ewnRhcodFVHakXgJuvg6YkgCnJkDgm0w25+KV0FewJ2YPHJWOaOPeJt/yBmFAmilNep9g5BMqRKUdE81kP0YBnIkzD9dxAwp6MW3KAIyJgOcQQFE6L8SJiIiIqPRrEKhFg0CtbOs/ficd2/9JAQDsu5qKxkEadK5WOvseuZl2E0cTjgIAkkxJ+O3RbwgLYqKZyGbxu8xJZgBIOgJk3AY0wfLGVEpplBp09epqc3m9gx6jAkZh+d3l8FH7YKjv0GKMjojsgYlmsp80IzB4n3n4WHdAX8DDK/0GoK8D+Iyzf2xERERERCVErVTk+b408VR5wtnBGYnGRABAqGOozBERlTGaSo+HlS6Ag0fRl5lxD4ASUPsUfVll3CDfQRjoMxAKVkYjKhOYaKbSQRgAmADPoYDaW+5oiIiIiIgKra6/BsPqO2P/9VTU89egbRVHuUPKlbPKGfOrzseumF2opK2ELl5d5A6JqGxx727uXyj9OuDaCXBwKtryHm0EHnwLQAH4TjQvvywxJgMPfwRMieb7e01AkRfJJDNR2cFEM5UOxnjAwc38xUxEREREVMY91cAZTzUoGx3rVdZVxjgdnyokKjQ3O/5AE7vpfwMCiN1c9hLN0V+ZmxMBgJTzQJUv5I2HiEoUW6in0sGYAKj9WZuZiIiIiIiIKq6sTXFoymBTNhnRj4cN0bmXI6JyiTWaSV5CABl3zMOeT8gbCxEREREREZGcAv4LxGwE4AB4DpA7moLzfAK4/Q8g0gCv4XJHQ0QljIlmklfGLUChAfxe5JcQERERERERVWwOzoD3SLmjKDynhkDV5eZ+mIraXjURlTlMNJN8hABMyUDAJMDnabmjISIiIiIiIsrTrTgDfjyRCL1agacbucBFyxZJc1BqAWjljoKIZMBEM9mPSgn8p/rj4fyIDABKQFulWMMiIiIiIiIisoe3f4vBrXgjACA5Q+Dltu7yBkREVIow0Uz2o1ECk8LzLiMyzB3/GeMBUzqgqwXoapdMfERERERERERF8CjF9Hg42ZRHSSKiiofPeFDJMSYAqZcAYQT0jYCAqUDYt4DaT+7IiIiIiIiIiPI1upELlApAp1bgqfpsg5iIKCvWaCb7MQngUqJ5uKozoFRkm54MqAOA6hsAtXfJx0dERERERFQGGYwCsakmeOqUUGa/z6IS1bOmHp2r6eCgBBz4WRARWWCimewn1Qj03msePtYd0Gc5vIQBMMYBrk2ZZCYiIiIiIrJRfKoJr0Y9wo04A2r6qPFOV09oVExwyon7n4jIOjadQcVLCCAjGki9DGgqA37/kTsiIiIiIiKSyb8PMvDtkXj8fiVF7lDKjH1XU3EjzgAAOB+dgWO302SOiIiIyDrWaKbiY0oB0m4AKjfA9xnAZxyg8pQ7KiIiIiIikkFMihEzfnmEVIMAAKiUCrQMdZQ5qtIvwNVBGlYoAD8XhzxKExERyYeJZioewgCkXQecWwKBrwC6WnJHREREREREMrqXYJSSzABwNcaAlqH2XUdSuglOmvL14G7DQC2mtnbDqbvpaBGiRWUPtdwhERERWcVEMxWPtGuAawBQ6X1A7St3NEREREREJLOqXmrU8lXj3P0MuGgVaFvFfrWZUzNMeGtnDM7dz0AtXzXe7uIJbTlqR7djVR06VtXJHQYRFYYwAgo+iUAVAxPNVDz0jYDKrzHJTERERERURCuOJWDnpRRU91LjpTbuZTaBqnZQYF5XT9yIM8DHyQHOWvvVPD50Iw3n7mcAAM7dz8DB66loF1a4xOzhG6lINwKRlbRQKsvmviaiUiD1MnBrFmCMA7xHA54D5I6IqNgx0Uz2Ix4/BgfPQYA+Qr5YiIiIiIjKgcuPMrDqZBIA4EFSGrZfSEb/Ok4yR1V4KgcFqnjav+kHL71Dnu9t9cPfCVhzyry/O4Q5Ylob96KGRkQV1aPVgDHGPPxgKeDeG1Cy6Rsq35hoJvsQAjBdBUb7AZpKgFdnuSMiIiIiIirzsleoZQVb6+r6azC5pSuO3EpDkyAt6vprCrWcI7fSrA4TERWYg9vjYaUzoGAKjso/HuVkH6YkQKsDPvkacGktdzREREREROVCZQ81RjVyxs5/U1DdW40e4fpiXV9cqgmOKkWZbJ6jS3U9ulQv2v5pHKTF5UcGaZiIqNC8RwEwAYZHgOdQQFH2/q8SFRQTzWQfpkTzr3XOLeSOhIiIiEh2BoMBe/bswaVLlzBs2DC4uLjg9u3bcHV1hbOzs9zhlQtCCKQZBBzV9mvnt7R6op4znqhX/MfN0iMJ2HAmCU4aBWZ28kAt38LVCi7Lnm7kglo+aqQZgZaVmGimEmJMBAwPAE0IO40rTxycAL//yB0FUYliopmKRhiAtGsAFICuGXDtpnl8pUqAsvxf9BMRERFld+3aNXTv3h3Xr19HWloaunTpAhcXF7z//vtITU3FF198IXeIZd6deANe//URopNM6F5Dhxci3fKfifKUmmHChjPmtomT0gV+OpuUa6L5QnQ6rjwyoGmwFl5O5S8p1jTEUe4Q6H+uxWTgvb1xSEo34dlmrmhV2fKzeZjxEDdSb6CGvgb0DsVb27/YpF0HbrwKmBIAXV0g+G02sUBEZRb/e1HhCQOQdhlwrAn4TgAcWgCunuZpiYmAU9ntpISIiIiosF588UU0adIEJ06cgJeXlzR+wIABeOaZZ2SMrPzYcj4Z0UkmAEDUPykYWMcJAa68tSkKrUoBD50SMSnm/ernbD2BfOJOGt7cEQMhAC+9Ep/384aThhVMqHgsO5qIG3HmpkwW7Y+zSDRfS7mGl/99GSmmFARrg7Gw+kLoHHRyhVp4CXvMSWYASDkNpF0FHKvJGBARUeHxaowKL+064BgOhH4GaEOApCS5IyIiIiKS3b59+/Dnn39Co7GsDRoaGopbt27JFFX54qV/nNjUqhRw1jLRWVQKhQJvd/HAxjPJ8NIrMTTCelMdJ++kQwjz8MNkE27GGRDuU/Ga2KCSoc7ye4fGwbJ920Pxh5BiSgEA3Ey7iX9T/kU953olGZ59aCo/HlbqAZWPbKGQfNJN6TiecBw+Gh9U0VWROxyiQmOimQrH9L8emP0mm5PMRERERAQAMJlMMBqNOcbfvHkTLi4uMkRU/vSr5YTkdIGb8Qb0DNfDhYlmuwj1UGNK67ybIWkSrMWGM0kwmIAAFwdUcuctJRWfZ5u5It0Yh4Q0gTGNLf9/huvDoYACAgJOSicEa4NlirKIXNsCMAJpVwCX9oCqnDYFlHgIMCUBzm0ApVruaEoVIQTevPwmziadhQIKvBr6Klq6t5Q7LKJC4VUBFY4xHlB5AM7850dERESUVZcuXfDxxx/jq6++AmCuKZqYmIiZM2eiZ8+eMkdXPqgcFBjZiEl7OdTy1eCTPt64HmtARIAGugrQGSPJx9vJAbM6e1qdVt+lPuaGzcXFlIto7tocHmqPEo7Ojlw7AOggdxTF5+Eq4OEK87DTH0DQTHnjKWViDDE4m3QWACAgcDD+IBPNVGYx0UwFZ0oFDPcBfQOgrHa4QERERFRMFi5ciI4dO6J27dpITU3FsGHDcPHiRXh7e2PlypVyh0dUZCHuKoSwJjOVAhEuEYhwiZA7DMpP8nHrwwQAcFO5IUQbghtpNwAA9ZzKYBMwRP/DqwOynSkNSL8OKNSAphLg2kXuiIiIiIhKnaCgIBw/fhyrVq3C0aNHYTKZMG7cOAwfPhw6XRnsqIqogrqfaMSqE4nQqBQY3sC53DTRIoSAQqHIvyCRvTg1B1LOPB4mCw4KB7xX7T38EfsH/DR+aOzaWO6QiAqNiWayjRBAxm1AGwYEvgE4NQSUvFEiIiIiyiojIwPh4eH4+eefMWbMGIwZM0bukIiokObtjsGlRwYAQGyKCa+2d5c3IDtYdXcVVt1bBV+NL2aHzUaANkDukKgi8BwAOFYDDA8Bla/5KWmlo9xRlSouKhf09GbzWlT2MdFMtjHGm2sy+00GXHJpK0ilAiZOfDxMREREVMGo1WqkpaWxtiBRORCdZJKG7yfm7OCzrIkzxGHFPXM7uXfS72Dt/bWYHDJZ5qiowtAEAXcXAoYHgDoAqPQh4MC29onKm/Lx7A8VP1MSoPYH3LrlXkarBT7/3PzSaksuNiIiIqJSZNKkSXjvvfdgMBjkDoWIimB4A2coFIDGARga4SR3OEWmVWjhmKUWqZvKTcZoqMJJPGxOMgNAxh0g+YS88RBRsWC1U8qbMALGOMCUCOi7A6ydQ0RERJSnQ4cOYdeuXfj1119Rr149ODlZJqg2bNggU2REBXfsdhoyjAJNg7UVrqZ+z5p6tA9zhINSAa2q7G+7o4MjXq/8Ojbc3wB/rT+G+g4t3hVmRP+vBmsM4D0KcIks3vVR6aatDEABQAAKFaAJlTkgIioOTDSTdaZ0IOMWIAyAgxvg1hXwn5L3PEIAD/73C6W3N5PSREREVCG5u7tj0KBBcodBVGQrjiVg1ckkAEDnajq82Kri1YDVa8rXQ8ANXBqggUuDklnZg++AlNPm4bsfAM5rAUX52p9UALpwIPhtIPkk4NQE0IbIHVHBCCMQv8c87NoeUDjIGQ1RqcVEM+VkSgPSrgK6moDXCMClLaDxz3++5GTA19c8nJgIOJX9x8uIiIiICmrp0qVyh1DumUwC604n4UacAT1q6FHbTyN3SOXSoRtp0vBfWYaJbCPyeU8l6sEKIPk44NwC8DT/GBp1IRm7LqUg3EeNsY1doFQWc2UxfX3zqyy69ykQv8s8nHIq/4p4RBUUE81kSRiAtGvmJHPVFWycn4iIiIhKnc3nkvHDsUQAwMHraVj6hA+ctawpaW8NAjW4EmOQhm114k4a0gwCTYK0xZ+4otLLexRgePi46QzWAJVP4kHg0SrzcOp5wLEGrqfXwuJD8RACOB+dgWBXFbqH6+WNszRLOZNl+LR8cRCVckw0k5kQ5g7/0m8BulpAyLtMMhMREREVQpUqVfJsy/by5cslGE35dD/JKA2nGgQS0kxMNBeDMY1dUNNHgwyjQOvKjvnPAGDViUSsOG7+EaBDmCOmtXEvxghLh01nk7Dr3xRU91bj+eauUDkwuQ4AUPua7ytJfqbkHO9TMkwQWSqZpxhY4zxPzq2AmPWPh4nIKiaaKxphAkS6+WVKtxxW6gDnZuaLAU2w3JESERERlUlTpkyxeJ+RkYFjx44hKioKL7/8sjxBlTM9w/X482oqHqWY0KmqDgGuvK0pDgqFAi1DbUswZ8raxMZfN+3T3MajZCN+vZgCL70SnavpSlWnhFdjMvD14QQAwJUYA8I81ehVk7VCqZRxbgM4/QkknwCcmwNOTRHurETPcD12XUpBDW81ulXXyR1l6eYzGnBqDEAA+gi5oyEqtXhFVp4IEyAyrCeSkeViTKEGFFrzX7U/oA4AHKsDbp0BfUN20EBERERUBC+++KLV8Z9//jmOHDlSwtGUT8FuKnwzyAdJGQJujrx2LU3qB2hw8WGGNFxUQgi89ssj3Io312KPSTFhSIRzkZdrLxlGy/fpRtYKpVJIqQaC3swx+vkWrni+hasMAZVR+npyR0BU6jHRXBYJAcBobk/ZlAoYEwCRap4mJZE1gMob0AQAmhDzY0sq78cvtQ+g8gKUBauhQERERESF06NHD8yYMYOdBdqJykEBNzZRUOo83cgZ1b3VSDMItLGxuY28pGQIKckMAJceZRR5mfZU3VuNgXWcsPPfFFT3VqFHjbJRK/TOnTuYN28eHj58iFGjRqFbt25yh0SlkMlkghACDg5lo33tXf+m4Jsj8XB3dMBrHdwR7MaUF1FJ41lX3AwxgMKG3SxMMCeP//fKTCQLASgUMNdIzvx1XABwMHemoHQEHKsCTs0BfR1zDWWVjzmZ7MBHtoiIiIhKi3Xr1sHT01PuMIjszmAU+OdBBrydHODr7FDg5jbyotco0bqyI/ZdTYVKCXSqWvoSuWOauGBMk7LVv82KFStw9epVAMDixYtRtWEbbL2YAU+dEkMjnKFRld0fcc7cS8f9RCOah2ih1/CJh8I6cuQI3nvvPZhMJkyZMgVt2rSRO6Q8GU0Cnx2Ig8EEJKQZ8MOxBMxo7yF3WEQVDhPNxUkT9L9ksSn/sgoloHAElM7mTvhUboDSFXBwBRyczOOV+v8N6wGlk3lY5WtOLpeGdspUKmDUqMfDRERERBVQw4YNLdqQFULg7t27iI6OxuLFi2WMjMj+hBCYvSsGx++kQ+0AzOrkgYgArV3X8d+2bhhQWw93nTmRTUXn6Pj4xwC1RoPZuxMQm2qu2JRhEhjbpGw2p7Dncgo+/CMOAFDVU4WFvbygVJaCe+Uy6LvvvkNqqvnJ6aVLl5b6RLNSAWhVChjSzcexYxn+saTUEgJIOgooNWynmnLFbGBxqrrc3E6yLRSq/zV7UYb/GWq1wLJlckdBREREJKt+/fpZJJqVSiV8fHzQvn171KxZU8bIqCxJNwjsvZICvVqJlqHaUtUBXlbRSSYcv2O+58kwAnuvpNo90axQKFDDp+jtPdNjTz/9NBISEvDw4UM8MXQY3jn7uG3pe4nGPOYs3f6+9bgDykuPDIhNNcFTzx8nCsPd3d3qcGmlUCjwWnt3/HAsEe46JcY0LiVPGZjSAUM0oPaz7Wn30uzep0D8DvOw1zDA6yl546FSqYwf5aWcQgU4cBcTERERVSSzZs2SOwQqB+bvicWR/yXNhkY4YUTDUpI0ycbdUQkfJyWik8xPcVb3UkvTHiUb4axRlulmGMorV1dXzJgxQ3o/SJmA9aeToFcr0L+2k4yRFU2TYC12XzbXwq3upYY7OwsttClTpmDZsmUwGAx4+umn5Q7HJhEBWiyw8w9dRWKMB67/F8i4BWgqAyHvmp9ML6sSD1oOM9FMVjALSvYjBJCcbB7W68t27WwiIiKiQnJwcMCdO3fg6+trMf7hw4fw9fWF0Vh2awtSyTl5Ny3LsI1PScpAo1Lgve5e+O1yCgJdHNCmirkN5Y/3xWHXpRS4apV4p5sHKnuo81kSyWl0YxcMqOMER5UC2jL8w0DbKjr4ODlIbTTvupSCr/5KgKujEq93cEeYJ49DW3l5eeGll16SO4yyLfGQOckMAOlXgeRjgEtrWUMqEn19IHHf/4bZdAZZx5/3yH6SkwFnZ/MrM+FMREREVMEIIayOT0tLg0bDx//JNpGVHreh27KS/TrXKw4+zg4YGuEsJZnvJxqx61IKACA+zYSt58vvvcHdBAMS0mzok6cMcHNUlukkc6Zavhq0C9NBq1JgyaF4pBoE7icasfxYotyhUUWjCQKQeU4pAXWgnNEUXcBLgP9UIOAVwHus3NFQKcUazUREREREdvDJJ58AMLcT+fXXX8PZ2VmaZjQa8fvvv7ONZrLZS23c0D5MB71agdp++f9AsSV6C/bH7Udd57oY5jdM1jadXbQKOGkUSPpfp1z+LuWzjdzPD8Qh6p8UOKoUeKuTB+r584ek0kShUECvViLOaP4hwFlT9pPoVMboagMBM4CUE4C+CeAYJndERaNQAa4d5Y6CSjkmmomIiIiI7OCjjz4CYK7R/MUXX8DB4XFyTaPRoHLlyvjiiy/kCo/KGIVCgSbBtrU1eiHpAr66/RUA4HTSaYQ6hqK1u3yPZ+vUSrzdxRPbLiQj0NUBA8pwm7+5SU43Ieofc63tVIPAtgvJTDSXQm92NHcO56pVYlxTV7nDoYrIJdL8IqogmGgmIiIiIrKDK1euAAA6dOiADRs2wMPDQ+aIqKJINCbm+V4O1b3VeNHbTe4wio2jSgFvJyUe/K8TxCDX8llru6wL99FgbldPucMofsIEKNgyKhHJj4nmYhSdHo0YQ4zcYZQYRXIyqv9v+GLyRQiF3mo5ozAiJiMGzVybQaXkIUhERETly+7du+UOgSqYRi6N0Na9rbnpDKe66ODRQe6Qyox0g8DBG6nw1DmgbgFqJCuVCrzT1RM/n0+Gl16JfrXKX61tKgPSrgA3ZwHGOMB7FOA5QO6IiKiCY5avGI06Owp30u7IHUaJcUwx4sD/hp8+8zRSdTl/1dcoNdApddApdRgXOA5P+D1RskESERERlYCbN29i8+bNuH79OtLT0y2mLVy40KZlzJ8/Hxs2bMD58+eh0+nQsmVLvPfeewgPD5fKjB49Gt99953FfM2bN8fBgwel92lpaZg+fTpWrlyJlJQUdOrUCYsXL0ZwcLBUJiYmBpMnT8bmzZsBAH379sWnn34Kd3f3gm46yUChUODl0JflDqNMmrkzBqfvmc/R/0S6olsN65VlrAl0VeHZZvI2x2AwCiw+GI/z0RloW8URT9Z3zn8mKj8ergaMj8zDD5YC7r0AJZtwISL5MNFcjBIMCTDCCB+1j9yhFDujMCLe9DipnmhIhEnooFVooVVq4ah0hLfaG1V0VRDqGIoquiro6tlVxoiJiIiIiseuXbvQt29fVKlSBRcuXEDdunVx9epVCCHQqFEjm5ezd+9evPDCC2jatCkMBgNef/11dO3aFWfPnoWT0+Pak927d8fSpUul9xqNZZJhypQp2LJlC1atWgUvLy+89NJL6N27N44ePSq1Iz1s2DDcvHkTUVFRAID/Z+++w6MotweOf2d7skk2vZCEhBAEadIEQQQpAiKg2AtYEcX6u4i9YUGuXa9eUa8KKnYFBbsiqAgogggIIr2lkbap2+f3x2BCJEDKbjblfJ4nD+/uzrxzNtmQ3TNnzjt16lQmT57M4sWLG/OtEKJZc7h9VUlmgNX7nPVKNDcH322v5JttWq/ot9aV0budic5xQUg0Vm6GnKe0Fg6JN0Noz6aPoS3SH9KeRhcGijF4sQghBJJoDrgQXQih+pb1ZqW+Kr2VZDuz6RCSxIYxCiG6EB7odCvxtvYkmBJINCUSpg8L6srXQgghhBBN5c477+SWW27hwQcfJDw8nI8++oj4+HguueQSxowZU+d5/k76/m3u3LnEx8ezZs0ahgwZUnW/2WwmMTGx1jnsdjuvvvoqb775JiNHjgRg/vz5pKam8u233zJ69Gg2b97Ml19+yapVqxgwYAAA//vf/xg4cCBbtmypUUEtRGtiMeroGm9kU54bgH7JdVt8sTnx+Gre9vpq3y7g8l4Ed442zn0BOrSwhU/zXoGyFVqCPOFGUFpIz+3YS0H1aFXN0ReCfOYWQgSZJJpFo3hVL3sde+lq7cpLx79E/BfxAGQGOS4hhBBCiGDZvHkz77zzDgAGg4HKykrCwsJ48MEHOfPMM5k2bVqD5rXb7QBER9dc2GrZsmXEx8cTGRnJ0KFDmTVrFvHx2nuyNWvW4Ha7GTWq+kqydu3a0b17d1asWMHo0aNZuXIlNputKskMcNJJJ2Gz2VixYoUkmlsgn8/Hb7/9htVqpUuXLk1+fFVV+aLgC/Y59zEqehTpIelNHkNdPXhaNCt2O4gJ1dEzqeUlmkdmhrA+x8XmPBdDMyx0TQhS24RDK2lbWuuG8nVQ/Ik2LlmiJZsjhgc1pDrTWyHxxmBHIYQQVSTRLBqs0F1IviufDiEduC39NuJN8cEOSQghhBAi6KxWK06nE9CSutu3b6dbt24A5OfnN2hOVVWZPn06gwcPpnv37lX3n3766Zx33nmkpaWxc+dO7r33XoYPH86aNWswm83k5ORgMpmIioqqMV9CQgI5OVr1YU5OTlVi+lDx8fFV2/yT0+mseo4AJSUlDXpeLYWqqi3q6rwnn3ySH374AdDaoIwfP75Jj/95wee8uF+raF1WtIxXjn+l2V7laTYoDOsYEuwwGsxkULjj1MhghwEJN0PeC4AP4q8NdjT1o+j+eUdQwhBCiNZAEs2iQQrdhZR4Srgw4UKuS7mOBHNCsEMSQgghhGgWTjrpJH766Se6du3KGWecwS233MKGDRtYsGABJ510UoPmvOGGG1i/fj3Lly+vcf8FF1xQNe7evTv9+vUjLS2Nzz77jLPPPvuI8/0zcVpbEvVoydXZs2fzwAMP1PdptDiFFV7u/7aI3cUezugcyjUDgrvwW12tWLGixripE817HXurxqXeUoo9xc020XwsdrudDz74ANB+38LDw5s8hj/zXHy9tZK0KAMTjg9t3EkPb4X2r79/HuZUSJ3t3zmbSmhPiDpHa50R0gPChwY7IiGEaLEk0SzqrcxTRoG7gEsSLuGeDvdUv9EpL4ewg6scl5XBIYvUCCGEEEK0FU899RRlZWUAzJw5k7KyMt577z0yMzN5+umn6z3fjTfeyKJFi/jhhx9ISUk56rZJSUmkpaWxdetWABITE3G5XBQVFdWoas7Ly2PQoEFV2+Tm5h4214EDB0hIqL2Y4M4772T69OlVt0tKSkhNTa33c2vuPvuzgl1FHgA+/bOC0zuH0j6y+X+E6t69O+vWrasaN7XTok9jWdEyyn3lDIgYQJIpqclj8Jcnnnii6nu5b98+Zs6c2aTHL3H4uPebIhweFQCjTmFslwYmiUuWQe6zoKqQeFPLaQ/RFOIu176EEEI0SvN/lySaFZfPRZYzizNiz+C29Nta1CWEQgghhBBNISMjo2ocGhrKCy+80KB5VFXlxhtvZOHChSxbtowOHTocc5+CggL27t1LUpKW2Ovbty9Go5FvvvmG888/H4Ds7Gw2btzIY489BsDAgQOx2+388ssv9O/fH4Cff/4Zu91elYz+J7PZjNnc8vrZ1leEpfqSeoMOQo0t473vPffcw7Jly7BarZx88slNfvyOoR15teurFLmLSDYnt6zPDL5KyHoUnNvANrpG+5isrKwmD6fY4atKMgNkl3oaPlnBu9rCcQAF7zS7RLNX9fJ5/ueUecsYGzsWm8EW7JCEEELUkySaRb0UugtJtiTzQMYDmHWt/8OFEEIIIURDFBcX8+GHH7J9+3ZuvfVWoqOjWbt2LQkJCSQnJ9dpjuuvv563336bTz75hPDw8KqEl81mIyQkhLKyMmbOnMk555xDUlISu3bt4q677iI2NpaJEydWbXvVVVdxyy23EBMTQ3R0NDNmzKBHjx6MHDkSgOOPP54xY8Zw9dVX89JLLwFaX99x48a1+YUAz+gcSkGFl11FHsYcF0qsVR/skOrEbDYzevTooMZg1Vux6lvgFY7Fn0HFGm1c+D7nTjiH//5vAYqicN555zV5OKk2PYPSzKzY7STSomNUp0a0vDDGg3u/NjY0v/V15mXP4+MDHwPwS8kvPH1c/a8AEUIIEVySaBZ1pqoqFb4KTrCcQLih6XuTCSGEEEK0BOvXr2fkyJHYbDZ27drF1VdfTXR0NAsXLmT37t288cYbdZpnzpw5AJx66qk17p87dy6XX345er2eDRs28MYbb1BcXExSUhLDhg3jvffeq9FH9umnn8ZgMHD++edTWVnJiBEjmDdvHnp9ddL0rbfe4qabbmLUqFEATJgwgeeff76R34mWz6BXuLJfy+jLLPxEMda4OXrUCE4aMhFFUYiIaPrXgqIozBhs40VTKQUVXg6Ue0ltaPuWxFug4G1AhZiL/BqnP+yo3FE13lm5s8UtwimEEEISzaIOnD4nua5cHD4HYfowRsWMCnZIQgghhBDN1vTp07n88st57LHHaiR8Tz/9dC6++OI6z6Oq6lEfDwkJ4auvvjrmPBaLheeee47nnnvuiNtER0czf/78OsfWXEgiSvidbSw4d4FjG9hGgTkVW5Av5Px0SyVfb60EYEOOi9fOjcd2SFuXOjPYIGGan6Pzn9HRo9lYthEfPkbHjJbfbSGEaIEk0SyOSFVVclw5lHvL6RTaidHRozkl8hR6hPUIdmhCCCGEEM3W6tWrq1pQHCo5OblGv1fRcPnlXu77poj9JR4mdrNyeV+52k74ic4IiTcHO4oaCiq8VWOXF8qcvoYlmuuicAFUrAXriRB1ZmCOcQRDoobQObQz5b5yMkIyjr3DEeSWenhquZ0Sp48r+4ZzYqrFj1EKIYQ4Gkk0i1pVeCvIdmYTog9hevvpTE6cjEUvf6CFEEIIIY7FYrFQUlJy2P1btmwhLi4uCBG1Ph9vKmevXVvU7KON5Zx+XAgJ4fLRRrROE463smqPk9wyL6cfF0KyLUCv9fI1kD9XG1f8DuYOENozMMc6ggRzQqPneG1NKZvy3AA8/qOd9y4yS3W0aDo+B1RsAFM7MNVtTQYhWhN5NyZqKPOWkePMwaAY6GrtytTkqXVvlaHXw9ix1WMhhBBCiDbozDPP5MEHH+T9998HtB6re/bs4Y477uCcc84JcnStQ7i5uprToAOLMUDVnUI0A/Fhev53dixuL5gMAUyYekuPflsIcXQ+N+y9HZw7QDFA8kMQ2j3YUQnRpCTRLKpUeivJdmYz0DaQSxMv5ZTIUzDo6vESsVjgs88CF6AQQgghRAvwxBNPMHbsWOLj46msrGTo0KHk5OQwcOBAZs2aFezwWoWJXa0UV/rYZ/cwrkto4NoICNFMKIqCKdCf3sMGQeh3ULEOrP0gbECADxgYV/QNp6jSR4nDx5X9woNWzfzLL7+wZ88ehg4dKleztBXu/VqSGUD1QNkqSTSLNkcSzaJKkaeIZHMyL3Z5EbMuyCteCCGEEEK0UBERESxfvpzvvvuOtWvX4vP56NOnDyNHjgx2aK2GyaBwzYCIYIchROuiM0HKg6Cq0IJbTSSGG3js9JigxrBs2TKefPJJAD799FNefPFFLJbGt6LMLvHw1royTHqFy/qGN+4km3MXFLwH+giIvQz0oY2Or80zJoIhFjz52u2QrsGNR4ggkESzALRq5jJPGZcmXipJZiGEEEKIeoqOjuavv/4iNjaWK6+8kmeffZbhw4czfPjwYIcmRJu2p9jDEz8UU+5Wuba/LAxXJy04ydxc/Pnnn1XjgoICCgoKSE6KhbIVoI8Ca68GzTt7WTE7i7T+9KUuH3cPi2p4kPsfqE6Iqh5IvLHhcwmNzgKpj0PZSjC3h9ATgh2REE1OrjETHHAdIMuZRd+IvlyYcGHDJyovB6tV+yov91+AQgghhBDNnMvlqloA8PXXX8fhcAQ5IiEEwCurS9hZ5CGvzMvTP9mDHY5oIwYPHozRaASgS5cuJCQkwP6ZkPMU7L8XihvWcrKw0lc1Lij3HWXLY1B94Cmqvu0paPhcoiZjLESNlySzaLOkollQ7CnmooSLuDP9Tkw6U+Mmq6jwT1BCCCGEEC3IwIEDOeuss+jbty+qqnLTTTcREhJS67avvfZaE0cnRE3ZJR6ySr10ize2+oUUDTql1rEQjVL8FeS/DoYYaHcXmJJqPNy9e3fmzJlDbm4uXbp0waDzQeXG6g3K10DkGfU+7GV9wvjvqhKMOoVLeoc1PH5Fp7XLyJ8LOivEXNDwuYQQ4hCSaG7DvKqX/c79WHVWTos+rfFJZiGEEEKINmr+/Pk8/fTTbN++HUVRsNvtUtUsmqWNOS7u/aYQjw86Rht4fGwMRn3rTcBefWI4Do9KucvHlBOD29d7SeESfi/7nf4R/RkcOTiosYhG8Lkg7wXAB65SKHgLkmYctllCQoJWyfy3kJ5QuV4bW09s0KFP6xTK0A4h6BQwNPb3NnqiluxW9NpXW+OrhOzHtcX7bGMgphFXdwshqkiiuY0q9ZSS5cwi1ZLKDSk3MNA2MNghCSGEEEK0WAkJCfz73/8GoEOHDrz55pvExAR3MSoharNqrwPPwSvutxd6yCrxkBZlDG5QAZQUYeCR0dHBDoN1pet4Zu8zACwrWkaiKZHM0MzgBiUaRtGBYgL14MlEXR37fiffD+U/az2aQ7s3+PAmgx9PDAWj2MxTCJ5iMHcIbj/wosVQvlobF7wFYYO0vsqgVawf+B/obZB8jxarEKJOWvd1UqJWld5K9jv3c1r0aczvNp+J8RNRZMEHIYQQQgi/2LlzpySZRbN1fFx1YinWqiMhrA1WMgZBriu3aqyikufKC2I0olEUA7S7EyydteRk7KV1209ngvBTGpVkbvEq1sPOq2HPzZD9aHBj+WcV99+3VR8ceBFUJ3jyIH9+08cmRAsmFc1tzD7HPtyqmxPCTuCm1JtIMicdeychhBBCCCFEq3ByuoUHjFHstXs4Oc3S6ns0Nxcn205mcf5idjt20zm0M30j+gY7pMBz7gHnNq1lhDG27vt5y8C5G8zpoLcGLLxGsfbRvkT92L8F1aWNy34Cjx0Mtrrt663QKsKNiRByfONjiRwPzp3VrTNMyQcfUEAXCl5tgV/0jeiF3Vx4CkEXFpwKdtHmSKK5DVFVlUpfJdcmX8sNKTdg0MmPXwghhBBCiLamT7KZPsnmYIfRpoQZwnj2uGexe+xEGaJa/xWljq2w9zZQPaCPhLTn65ZQ9BTCnungKQBDHLR/uu6JSNFwBe9A4QdgTNZafBhjQfVC+Vot0eqPxC5oJw9KD44NsXU/kaB6Yd+dWlIYIPFWiBjSuFh0plp7a6Mo0O5erZ2GPgLirmrccYIt+0koXaa1AUmZDebUYEckWjnJNLYh5d5yQnWhjI4ZHZgks04HQ4dWj4UQQgghhBBCAKBX9EQbg98v+m/b8t38b3UJJr3CdSdFkBThx8+IFeu1JDOAt1hLEBp6H3u/8rVakhnAcwAqfm98QrERfv31VzZs2MCJJ55I9+51b3lR4ilhW8U2OoR0IMoYVad9du/ezfvvv4/NZmPy5MmEhIQ0NOz6cRdAwdva2LULij6C+Gsg+wkoW67dHzcVosY3/lhRE7VqYXcuRI7R2pDUhaeoOskMULE2sK+LkC6Q8lDg5m8qrmwtyQzgtYP9c+1nK0QASaK5DfHgwaAzEFufy5bqIyQEli0LzNxCCCGEEEKIY9qW78ZsUEiNlI964uie+LGY/SVeAP67qoSHR/kxCR7aExQjqG5t8TtzRt32M2cAesCrJSHN6f6LqZ42bdrEgw8+iKqqLFq0iP/85z+kph67GrTYXcz/bf0/CtwFhOvDeea4Z4g3xR9zv5kzZ5Kfnw+A2+3m+uuvb/RzqBOdqfpnBZR7w3l3dQmubIXz0q3EWsqhbIV/Es2KoiWY68tw8DXk3AEoECptS+pEH6El9n0V2m1jYnDjEW2CvPtoI9w+N7nOXE4IOwGbXHokhBBCCOFXJSUldd42IiIigJGItuyV1SV8sqkCRYHrBkQwpnNosEOqoqoq67Jd6BXomdTy2nas2O3gQLmXYRkhRFhax9WbTq9aPfaoR9myASydoP0z4Nyu9Wiu62dQSwakPgIVv2M3ZfL0/tc44DrARYkXMThysH9jPIbdu3ejqtr3xePxsG/fvjolmjeWb6TArVVll3pLWVu6ljExR0+u+nw+CgsLq27/nXBuEvpwSLodij4GUzL/3TyKH3dXgKM/20pieLL/xxB6QtPFUxtFr7V9KP8FjAn+a+XR2umtkPwg2L/UelBH+uFkgRDHIInmNkBVVXY7dtPV2pXnOj+HSRrACyGEEEL4VWRkZJ17rnq93gBHI9qqr7dWAqCq8M22ymaVaP7f6lIWb9aq6s7vYWVyn/AgR1R3izeX8/IvWmPZr7dW8vyEmFbRY/mGgTb+85Mds0Hh6hMD8PMwt9e+6iukK4R0Zf7e/7KmdA0AT+55kn7h/bDoLX4O8sgGDBjA+++/T35+PqmpqfTs2bNO+2WEZGBSTLhUFwbFwHGhx9W+YdFiKPkOLMehi5/K5MmTeeONNwgNDeW8887z4zOpg7AB2heQs/pg6xLzcWSrUZDUFcIHNm08tdGHQsSpwY6i5QnprH0J0UQk0dwGlHpLCdGFcGf6nSSaA3ipRHk5pKdr4127wNpMVwgWQgghhPCzpUuXVo137drFHXfcweWXX87AgdqH85UrV/L6668ze/bsYIUo2oBOMUbW57gAyIwxBjmamlbsdlSP9zhaVKJ5U567aryn2EOZSyXc3PITzX2Tzbx+/rFbOgSLl+qTcn9XFjel6OhoXnjhBbKyskhJScFsrlslfjtzO57o9ATrStfRLawbGSG1tA1x7oIDLx8cbwNzOueeey7jxo3DYDBgMAQvVXNuDyuP/1CMV9VxYd9MCJfP9UKIupNEcxtQ4ikh0hBJn/Am6GPUlJf4CCGEEEI0E0P/XhAZePDBB3nqqae46KKLqu6bMGECPXr04OWXX+ayyy4LRoiiGXF6VLJKPCSF67EY/deG4a5hkXyxpYIQo47Rnfy3kNjv2U5W7XHSLcHE4PSGVZT2TDSxdIeWbO6R0LKusDwl3cJPux2oKvRuZyLc3DpaZzR3lyRewn7nfg64DnBJ4iVNWs38t5CQEDp27Fjv/TqEdKBDSIcjb+Bz/uO29rthsTT9c/ynQWkW5l8Qj9dHq2kTI4RoOpJobuVcPhcV3gquSb4Go655VTUIIYQQQrRGK1eu5MUXXzzs/n79+jFlypQgRCSak1Knj1s/L2B/iZfEcD1PjI3B5qdkjtWk49weYX6Z62/77B5mfluExwef/llBmCmKXu3q32P5pkE2erUzo1NgSAOT1cEyKM3C8xNiKajwtrgkeVCpPlAa/tqOMcbwaOajfgyoGQnpDJEToGQJWI6DyNODHVENVlPj/k/yqT50jfjZt2gl30HRp2BOg/hp2mKLQrQhbfQ3v/VTVZVdlbvY69hLx9COjI4ZHeyQhBBCCCHahNTU1FoTzS+99FKdFpISrdtvWU72l2gtAXJKvaze5zjGHsGVXeLB46u+vdfuadA8Br3C8I4hnJoRgk7X8tpOtI800LudGYO+5cXuL+/mvMtd2+7i0/xPj76hcw/suAK2ng2FHzZNcC1R/NWQ+S6kPAi6lnXy5WgW5C3g7PVnc8WmK9jj2BPscJqWOx9yngXnVij5VltgUbQdqgqeIu0kWxsmFc2tVLm3HINi4N4O9zI+djwhev9dOieEEEIIIY7s6aef5pxzzuGrr77ipJNOAmDVqlVs376djz76KMjRibpYvsuB3eFjWIaF0EZW9v1Tis2ATgGfCooCqbbm/ZGsR6KJzBgD2wo8xIfpOTmtZSfEPtpYxh+5bk5OszAiUz4j1dWK4hW8lfsWABvKN5AZkkkXa5faNy58DzwHWyrmvwGR41pVIlUcmcPrYF72PFRU8t35vJf7Hrem3RrssJqO6gYOSTKqzftEovAjnwv23QOOzWBKg9R/g96/Vxi1FM37XY1osEpfJaG6UMbFjpMksxBCCCFEExo7dixbt27lhRde4M8//0RVVc4880yuvfZaqWhuAd5bX8b838oAWLajksfHxvh1/oxoIw+MjGLNfie92pnpHNe8L6u2GHU8fnoMOWVe4qx6zAaFbwq+4cvCL8mwZHBN8jUYdI3/WFlY4UWvU/zWRqQ2P+1yMG+N9rP9db+TDtEGMqKlvWBdlHnLjnq7Br2teqwLBeXIr4/8/HzMZjPh4S1ncchGUw+eZWqFDIqBUF0o5b5yAGwG2zH2aGVMSRB9IRQvBlN7iDwz2BGJplKxVksyA7h2Q+lyiBwT3JiCRBLNrVCZp4widxHnJpxLqD402OEIIYQQQrQ5KSkpPPLII8EOo9VSVZWPN1Wwz+5hdKcQjvNjsvaPXFfVeEu+G69PRe/nVg+92pkb1Oc4WAx6hZSDldfv/LGPO1bkYbZkknH8ElIsKZwZ17hkysI/ynnt11L0Opg+2MaQDoEplCl2VFcaqioUVzbg8mZPIeT9D9Xn4MVdl/Jrbhh925mYdlIESitNHgIMjRrKD8U/sLFsIwNtA4++0HzsZFBdWhuBmPOPmGh+6623ePfddzEajdxxxx30798/QNE3Ez4H7J8JlZsgbCAk3d6oHtYBVfwFOLZCxKkQ2rPOuxl0Bu7PuJ/3ct8j1hjLpMRJgYuxuYq9RPsSbYshDlAAVbttTAhmNEElieZWKMeVw8jokdyRdkfTHling379qsdCCCGEEG1UcXExv/zyC3l5efh8NZNZl156aZCiaj0Wb67gtV9LAfhpt4NXz4lr9OJVfzsl3cJvWVqyeWB7s9+TzC1ZicPHq7+4cDjCcTjCyd7Tm8qUykbP+8EGrTrW69OSzoFKNJ+aYWHJtkq2FrjpHm8kztqA10zuC1D+M78cSOPzDVshtCdf/FVJ73ZmBrbwtiJHY9aZebjjw6iqeuyEui4EEm445pwffqj1b3a73Xz88cetP9FcshQq/9DGZSug4jew9g1uTLUp+R7yXgBg0R95zM+OJC48lHuGRZIUcewU0vHW45mZMTOwMQrR3Fg6aiePylZpJ2esvYMdUdBIormVUVUVFZWTI08m3NDElx+FhMDq1U17TCGEEEKIZmbx4sVccskllJeXEx4eXiMpoyiKJJr9IKfMWzUud6nYHT6/JZpP6xRKxxgjJQ4fPRObd1uLYLDqQ0kyJZHnyiPZnMy42HGNnjM5wsCfB9wAtKtDIquhrCYdT42LYcm2Cv6zooTrPingvB5WLu1Tj89NvtLqsVq9MGIrLmauoT5V2yUOHz/vdZBiM3B8/OG/S+3atWPPHm2xuOTkZL/F2GzpI45+u7lwZwNQ6THyypYTUS1O9hSbeG99Of83uI21whCiPsJP1r7aOEk0tzJl3jJCdCF0s3YLdihCCCGEEG3SLbfcwpVXXskjjzxCaKi0MQuE0Z1C+H6HgxKnj8HpFpLC9X6dX/r21i7CouOGgRF8uDGdpPCO3HJKJGGGxif47xoWyYcbyjHpFc7rYfVDpEf31dZKfAevbl60uaJ+iebYyyFrFv3jchnfLZ5fC/T0STYzILVurVBcHpXX1pSy3+5h/PGh9E9tnVXQLo/KrV8UkFXiRVHgrlMjOal9zec6c+ZMFixYQFhYGOeee26QIvWfH374ga+//JSMuL1cdnZH9PGXQMjx1RuEnwyuSVC5EcJOBkun4AV7NBHDwf4Vem8RJlM4zoMLmoUY28jZFCFEoyiqqqpNfdCSkhJsNht2u52IiKY7izd79mwWLFjAn3/+SUhICIMGDeLRRx+lc+fOATneKb+egkt1EW+KD8j8tdnn2EeiKZHPe33eqnuECSGEEKJ5Ctb7vObEarWyYcMGMjIygh1KkwnGz317gZsdhW4Gp5kJMfk30Sxat/+utPPlX1rLj04xRp4aV/uCjyUOHx9v0hLgE7tZMRsO+XzVwAXd3v29jLfWaa1CjHqYd248ERYdLo+KydB6Pr/ts3uY9nF+1e1xXUK5ZkDr/ZuQm5vL1KlT8VXuAE8eU89PY/zIjtDx7ZZZ7u5zgdfOmtxw3t9QTpxVz7STIvx25UgN7lzY/zB48iDmEoia4P9jCCEara7v9dpURfP333/P9ddfz4knnojH4+Huu+9m1KhRbNq0Cas18GfOm0Klr5IzYs8ITpK5ogK6dtXGmzaBVPAIIYQQog0aPXo0v/76a5tKNDe1dVlOHlhShMcHn28x8PjpMRj0LTCZ08aoqsrKPU48PpXBaRZ0Qep/ffWJEcSH6alwqZzZ9cifWR5ZVsQfuVpLj+xSD/8aHFn9YAM/b5U6q3u2u73g8KjM/cnOt9sqaReh55FR0cRYG37iJNuZzXu57xGmD+PixIuDtjh8QpietEgDu4s96BTol9JyFr9siPLycq0f/8F2KqXlHvBVaLeVFniFhM4Eujj6pkDflABX3Re8B65d2vjAKxAxAvStIz8jRFvUphLNX375ZY3bc+fOJT4+njVr1jBkyJAgReU/qqqioJBqSQ1WALB7d/VYCCGEEKINOuOMM7j11lvZtGkTPXr0wGismWSYMEGqtRpr1V4nnoP5um0FHnLLvCTb2tRHmxbp1V9L+WRTBQBrOjprJm6bkMmgcF6PsMMfcOdBzlPgKYa4K9hTnF710N5i7+HbN8BZXa38luUiq9TDxK5WKtw+vt2mVVdnlXj5fEsFk+vTyuMfHtz5IPuc+wCtreL/tf8/f4Rdb0a9wqOnR/Nblot2EfpW344mIyODsWPH8uXnC+gQq3DGsHYQNwV0rft5+4XukMU/FSMocoWKEC1Zm343ZrfbAYiOjg5yJP5xwH2ASEMkJ4SdEOxQhBBCCCHarKuvvhqABx988LDHFEXB6/VPwqot6xZv5LM/tXF8mJ7YRlSAiqazdr+rarwuy3WULYPkwFyo/EMbZz/BhC6v8dbv5egU6NWhiFf2LyQjJIPh0cMbfIi4MD0vnBWrFQkpCvnlXgw6qk6cRIU0rjVBniuvapzrym3UXI1lNekYnN46e1DXZtq0aVx77bXa1cUNbK3SJsVcDF67dqIn+nzQtZ3XjBCtUZtNNKuqyvTp0xk8eDDdu3cPdjiN5lW9FLgLODvubNJD0oMdjhBCCCFEm+Xz+Y69kWiUUzqEEG7Wsdfu4eQ0S83euaLZGpBqZq9day1wYgtopXDhCWEMzQihUi3ljj03UZmvVR7rFT1Do4Y2au6/Wx3GWvXcdWokX22tpEOUgbGdG9fqYlLiJOZmz8WsM3N+wvmNmkvUX1ULS0ky153eCkkzgh2FEMJP2myi+YYbbmD9+vUsX7482KH4RZYzizRLGpMSJwU7FCGEEEIIIQKuVzszvdo1/2RlW3agzMuWfDdd4ozEWvVc1jec7okmvD61eSaa464Ab2FV6wwUhaQIA1sr8qn0VVZttsex57BdXR4Vr6oSYqx/RfKJqRZOTPVPFefE+ImMihmFQTFg1jXD77EQQohWrU6J5pKSkjpP2BJWF7/xxhtZtGgRP/zwAykpKcEOxy+cPif9wvvRM7xnsEMRQgghhGjT9u3bR2RkJGFhNXvAut1uVq5c2SrWBhHiWHJLPdz8aQHlLpUwk8Kz42OJD9PTN7kZJz+N8ZD6KDsL3fz7m2LKnHlcMyCcQWkd6GHtwYbyDYTrwzk16tQau/26z8nsZUW4fXBN/wjO6BKgBfh87jr1/LXKQmotxptrS/n0zwrSowzcMzyKcHPjWqccjcvnwqQzBWx+IYSAOiaaIyMjqy8BOYK/e0w1555zqqpy4403snDhQpYtW0aHDh2CHZJflHnLUFHJCJGVzYUQQgghgiU7O5szzzyTNWvWoCgKl1xyCf/973+rEs6FhYUMGzasWb9fFsJfNua6KXdpC4SXuVT+yHURHxZyjL2ah9fXlpJVov2ePreihCEdEnio40Psc+wj1hR7WCL33fVluA7+Wr/5W6n/E83uPNh3D7izwTYWEqb5d/6jcHlU3l1fRmGFj7O7W2kf2WYviva7fXYP728oB2BTnptFm8q5pHctC0G688GdA5bODVpcsMxTxj077mF75XYG2QZxe9rt6JTAJbTFEbjzoeJ3sHQEc3qwoxEiYOr0V2Lp0qWBjqNJXH/99bz99tt88sknhIeHk5OTA4DNZiMkpGW86alNviuf/hH9uaLdFcENRFGga9fqsRBCCCFEG3LHHXeg1+v5+eefKS4u5s477+TUU0/lm2++ISoqCtAKH4RoC7rEGbEYFBweFYtBoXNc/RNkwWIx6A4Za59r9IqetJC0WrePs+rZcsANQHwgFqYsXqwlmQHsn0PUBDAl+/84tXjzt1I+3lQBwG9ZTuadF3fMIrSWwu1z82vpr0Qbouls7dzkxzfpFf5eNxDAYqzl+1r5p3aSQXWC5XhIfQSU+iX7lxQtYXvldgBW2FewsWyjXAnd1Dx22PMv8BZrP7/Ux8DSKdhRCREQdfofaujQxi100FzMmTMHgFNPPbXG/XPnzuXyyy9v+oD8xK26OSHshOBfBhMaCn/8EdwYhBBCCCGC5Ntvv2XhwoX069cPgFNOOYULLriA4cOHs2TJEoBWk6AR4liSbQaeHhfDxhwXPRJNtItoOZWwV58YjturUubycXnfWipM/+G6kyKwWXQ43CoXnRCAthX6yOqxYgJd2BE39be88uorMAorfbi8YK7tR6l6AH2LKjh6cOeDrCtbB8BNKTdxWsxpTXr8+DA9Nw+y8cVfFaRFGhjfpZbXTumPWpIZwLEZXFlgbl+v40QZoqrGCgo2g60xYYuGcO7Qksyg/a5UrK97orl8Ddi/1qqgoy8AqUYXzVyD/tr/+OOPvPTSS+zYsYMPPviA5ORk3nzzTTp06MDgwYP9HaPftMYKkhJPCXpFT2ZoZrBDEUIIIYRo0+x2e1XlMoDZbObDDz/kvPPOY9iwYcyfPz+I0QnR9FJsBlJsLSfB/LcYq557R0Qde8ODws06rh3QuLWKSj2lKCiEGWpJIkedCd4ycO2ByLHQhInCs7pa+T3bRblL5dzuVsyGWhLJBe9DwXzQR0HKAy2iLYDT56xKMgP8XPJzkyeaAUZkhjAi8yhXV1uOqx7ro8AYV+9jDIkaQq4rl83lmxkSNeSIlfkigCwdQR+tLTaqGCG015G3dedCyXdgbAehPSBrFqhuKFsB+giIPKPJwhaiIer9V/+jjz5i8uTJXHLJJaxduxanUzu7VlpayiOPPMLnn3/u9yDFkeW6cjkz9kzGxIwJdihCCCGEEG1aRkYG69evp1On6iolg8HABx98wHnnnce4ceOCGJ0Qorn6suBLXtj3Ajp0/F/7/ztssUEUA8RdFozQOD7exBvnxePwqERYaqmk9Dm0JDOqlkQrfB+SbmvyOOvLrDPTObQzWyq2AHBC2AlBjugfPHbY/wC4doKlO1h7Q/gpoGtYy8/zEs7zc4CiXvQRkPa0Vsls7gjm1Nq387lg7+3gKdBuR52rJZn/9vf9QjRj9a65f/jhh3nxxRf53//+h9FY3Wdr0KBBrF271q/BiaPzqB506BgTMwazrhms3lxRAd26aV8VFcGORgghhBCiSZ1++um8/PLLh93/d7K5V69eTR9UK7a+dD2f539Osbs42KGIFqCg3EtBefNciPO93PdQUfHi5YPcD4IdzmFMBqX2JDNoSXDdIS0fDm3z0cw9nPEwN6XcxMwOMxkfN/6I23lVL+tK17G7cnfTBVf8KTi3am0WHBshrD+Ykpru+ML/DNEQceqRk8wA3qKayWRvKUQM18bGJG0xUCGauXpXNG/ZsoUhQ4Ycdn9ERATFxcX+iEnUUb4rn1hjLN3CugU7FI2qwqZN1WMhhBBCiDZk1qxZVBzhZLvBYGDBggXs27eviaNqnX4q/ol/7/43AAsPLOS/nf8b/PVKRLP15ZYKXvi5BIBr+kdwRpfQIEdUU6IpkXx3PgBJ5haWTFQMkHw/FH4AhliIvTTYEdWZRW+pU7uMWTtnsbp0NQoKM9rPYEjU4fmQRvFVQvbj4NwJttMh5nzQH9pCRQe65vWaFQFiiNfaalSs0/qxR5wKod0h/lpQLC2qB7pou+qdaE5KSmLbtm2kp6fXuH/58uVkZGT4Ky5RB6XeUs6MO5N4U3ywQxFCCCGEaPMMBgMREUfu06rX60lLk96Y/rChbEPVOMeVwwHXAZItyUGMSDRnC/4or6qDWfhHebNLNN+Wdhvv576PXtFzQcIFQY1lefFy3s55m3hTPP9q/6+6LRwX0gWS7w18cEFQ6a1kdelqAFRUltuX+z/RXLQYyrVjUPAmhA3U+vC687RF5Gyng1E+87cJiqKduHFs007cGGO1+xvYMkWIYKh3ovmaa67h5ptv5rXXXkNRFLKysli5ciUzZszgvvvuC0SMohZe1YuC0vx6SQkhhBBCCBFg/SP682XBl3jxkmHJIMGUEOyQRDOWajOQXaq1zUix6YMczeGijFFck3JNsMPA4XXw5J4n8age9jr3Mj97PtenXh/ssIIqRB9CuiWdXY5dABwferz/D6LoDr+tGCD+av8fSzR/ikE7eSNEC1XvRPNtt92G3W5n2LBhOBwOhgwZgtlsZsaMGdxwww2BiFHUIt+dj81go1d4r2CHIoQQQgghRJPqE9GHZ497lmxXNieEnYBBV++PNaINmX6KjY82alXN53S3HnuHNkw9pAWiD18QI2k+Hun4CN8VfUeMMYbBkYP9f4DI8VrbjL+rl03HuDrDtR8OvKqN46aAqZ3/Y2qMig1QsgTMGdpzk3YPQrQpDXpHNmvWLO6++242bdqEz+eja9euhIWFHXtH4Rde1YvdY+fa5GtJtRylkbwQQgghhBCtVFpIGmkh0opEHJvVpCPUqPDO72X8vNfJ/SMiSQhvBicn3HlQtAj0ERA1EXTGoIZj0Vu4MfVG3s55mzhTHBcnXhzUeJqLcEM4Z8adGbgD6MyQdGvdt895GhxbtLG3DNo/5veQPs//nNeyXiPaGM29He6te97BUwj7Z4LqApZovaVtI/0enxCi+WrwX9fQ0FASEhJQFEWSzE0s35VPnDGOixIuCnYoQgghhBBCNDm7w8cjS4vYa/dwdjcr5/aQzyPiyEocPt74rQxVhb12D+9vKOfGQXXoPRxo++4Fd5Y29pZA/JTgxgOMiB7BiOgRwQ5DHI23rHrsKzvydg3k9rl5af9L+PCR7crm7Zy3uT399rrt7Ck4mGT+e7Jsv8cnhGjedMfepCaPx8O9996LzWYjPT2dtLQ0bDYb99xzD263OxAxioN8qo9cZy52j53xseNJNCcGO6SaFAXS0rQvuTxGCCGEEG3Yjz/+yKRJkxg4cCD79+8H4M0332T58uVBjqx1+GhjGZvy3JQ6VV5fW8aBMm+wQwqq1XsdrNztqNH2QFQz6sF4yCdfq6kZfFZRvTWTcK59wYtFtCzxV4MuXPuK8//JCZ2iw6KzVN0O09fjRJ65I1gHaGNDLNhG+Tk6IURzV++K5htuuIGFCxfy2GOPMXDgQABWrlzJzJkzyc/P58UXX/R7kEJrl7GjcgexxliuTbmWK5KuCHZIhwsNhV27gh2FEEIIIURQffTRR0yePJlLLrmE3377DafTCUBpaSmPPPIIn3/+eZAjbPnM+upEoU4Bfb3LZ1qP19eU8uHGcgBGdAzh/wY3g0rdZibEqOOuYVF8uKGcxHA9F53QDCrgFT1EToDiT0AxQuQZwY7omHKcOQDNr+DpaHxO7fv7zwX3WjJrX8h8O2DT6xU993a4l7dz3ibaGM2lSZfWfWdFB+3u1lpo6COC3g5GCNH0FLWep71tNhvvvvsup59+eo37v/jiCy688ELsdvsx5ygpKcFms2G324mIiKhfxC3IKb+egkt1EW+Kb/AcqqqS48qh1FNKiiWFZ497lu5h3f0YpRBCCCGE/7SV93lH07t3b/71r39x6aWXEh4ezu+//05GRgbr1q1jzJgx5OTkBDtEv2vqn7vD7eP5lSXss3s4s6uVYR1DAn7M5urGRfnsKvIAYLPomH9Bwz97iCBw5YAuBAz+PUGwMcfFG7+VEmHWcd1JEUSH6hs13ycHPuGVrFdQUJjSbgoT4ib4KdIAyn8LCt8FvQ2SHwBLx2BHJIQQLVZd3+vV+7SexWIhPT39sPvT09MxmUz1nU4chaqq7HLsQq/ouSn1Jt7t/q4kmYUQQgghmrktW7YwZMiQw+6PiIiguLi46QNqhSxGHVf2C2faSRGckm459g6tWO921Z/B+ibL57GWZl1+FM/+DF9uqfDrvI8sK2Jznpuf9zp59dfSRs+3OH8xACoqn+Z/2uj5As5XqSWZAbx2KPoouPEIIUQbUe/WGddffz0PPfQQc+fOxWw2A+B0Opk1axY33HCD3wNsywo9hVh0Fh7LfIyhUUODHc6xVVbC3x+qfvgBQtpuZYkQQggh2q6kpCS2bdt2WHHG8uXLycjICE5QrczmPBf3flOE06PSM9HEQ6dFodM1g767QXBF33C6xZtw+2BQe3OwwxH1kFPq4YElRXh88O22SsLNOk72w4kTVVVxeqovXHa4G9+7O92STq4rF4A0S1qj5ws4xaj1MPYdTLIbYgJ2KLvHjt1jJ9WciiJrFQkh2rg6JZrPPvvsGre//fZbUlJSOOGEEwD4/fffcblcjBghq9P6i0/1UeAq4MKEC1tGkhnA54Nff60eCyGEEEK0Qddccw0333wzr732GoqikJWVxcqVK5kxYwb33XdfsMNrFb7f6ahKpK3PcZFd6iXZVu8amlZBURQGtG/bVd1B53OD/TPwOSByHNRx8bQD5T48h3xsyi71+CUcRVG4cZCNl38pIcKs47K+4Y2ec3r76Xxy4BMUFM6MO9MPUQaYYoCUB6DwI21RuphJATnMH2V/MHPnTBw+B4Ntg7k9/faAHEcIIVqKOr0bs9lq9os655xzatxOTU31X0QCn+pjZ+VO2pnbMSXZ/6vICiGEEEKIwLntttuw2+0MGzYMh8PBkCFDMJvNzJgxQ64A9JOO0dUfYyItOmJCW9FCX82E16fy3IoSNuS6GNTezFUntqye63aHj/fXl6FT4PyeYYSbA/gaOfAy2L/UxhW/Q+rsqocqvBX8WvIrSeYkOoV2qrHb8XFGeiaaWJ/jIj5Mz7AM/10RempGCKf6cb5QfSgXJV7kt/mahKUTtLsjoIf4uvBrHD4HAMvty7nafTXRxmj/HcCxHcrXQEg3CO3mv3lbM285FL4HqgeizwWDH38eQohjqlOiee7cuYGOQxyi2FNMqD6URzIfIdUiSXwhhBBCiJZm1qxZ3H333WzatAmfz0fXrl0JC6tblaM4ttM6hWI2KOwt9jCsYwgWoySa/e2HnQ6WbK8E4ONNFfRLMXNCUstpzfHY98V8+VcF2aVeXlldyuLLEom1Nm5BvCNy7qh17PF5uHPbnexw7EBB4a70uzjJdlLV4wa9wkOnRbJh2z5S4mzEBCo+ETCHthGJNkQTrm989XgVVzbsvQ1UF6CD1Mch5Dj/zd9a5T4HZT9pY8c2aP9YcOMRoo1pm9eXNWN2j50CdwFDI4dyUsRJx95BCCGEEEI0S6GhofTr1y/YYbRaQzrIeiBNqaV1nt1V5GafXWtFkV3q5aON5VwzIEBV2bYx4NgKqGAbW3V3gbuAHQ4t8ayisrpkdY1EM8Djjz/O8uXLsVgsPPDAA3Tt2jUwMYqAmBg3EYvOQo4rhzExYzDqjP6b3LnzYJIZwAfObfVONDscDkpKSoiLi2s7/aPd2YeMs4IXhxBtVINO/X/44Yecf/75nHTSSfTp06fGl2gYr+ol35XPPsc+hkUN49njnm07fwiEEEIIIVqR8vJy7r33XgYNGkRmZiYZGRk1vupq9uzZnHjiiYSHhxMfH89ZZ53Fli1bamyjqiozZ86kXbt2hISEcOqpp/LHH3/U2MbpdHLjjTcSGxuL1WplwoQJ7Nu3r8Y2RUVFTJ48GZvNhs1mY/LkyRQXFzf4eyBavqEdLJyWGUJSuJ6zu1np2YKqmQHO7m5FpygoikJSuJ5QYwA/W9lOg/SXIO05iLus6u4YYwztze2rbvcO711jt6825vHKXxHsjhpIhcPF119/HbgYRUAoisLY2LFc2e5K2pnb+Xfy0B5gTNDGehtY63ficvfu3Vx11VVcddVVPProo6hq4xeFbBGiztF6dKNA9HnBjkaINqfeFc3/+c9/uPvuu7nsssv45JNPuOKKK9i+fTurV6/m+uuvD0SMrV6hu5B8Vz4xxhjOiz+Pq5KvwqKXBT2EEEIIIVqiKVOm8P333zN58mSSkpIaXDzw/fffc/3113PiiSfi8Xi4++67GTVqFJs2bcJqtQLw2GOP8dRTTzFv3jyOO+44Hn74YU477TS2bNlCeLh2Cff//d//sXjxYt59911iYmK45ZZbGDduHGvWrEGv1y7Vv/jii9m3bx9ffqn1mZ06dSqTJ09m8eLFfviOBI6qqjz7Uwk/7XbQI9HEHUMjMRmkWMMfdDqFm062HXvDJrTlgIsfdjroFGus2X+4+Eso/gzMaZBwI+jMnNM9jAiTjg825eML2UXXDBvQPWCxbSqK4YElhYQa85g9OprECAMGnYFHMx/l55KfSTIl0TWsulq5qNLLC2s8OCLSKXElY/RWkJaWdpQjBF9paSmbN28mPT2d+Pj4YIfT+unDof2zWjsWU3sw1O/38auvvqKkpASAn376iaysLJKTkwMRafMSMQSsvUH1giEy2NEI0ebUO9H8wgsv8PLLL3PRRRfx+uuvc9ttt5GRkcF9991HYWFhIGJs1bKd2bh8Li5NupSpyVOJM8UFO6TGiY0NdgRCCCGEEEH1xRdf8Nlnn3HyySc3ap6/k75/mzt3LvHx8axZs4YhQ4agqirPPPMMd999N2effTYAr7/+OgkJCbz99ttcc8012O12Xn31Vd58801GjhwJwPz580lNTeXbb79l9OjRbN68mS+//JJVq1YxYMAAAP73v/8xcOBAtmzZQufOnRv1PALptyxXVR/h1fucLN1RyejjQoMclQiE/HIvd39dhNOjVWWa9AqD0izgzoO8FwAVXLu0hFzM+QCclOHlDffdFHuKeWC3wkzdTPpEBOYq3IvezSWn1KvFWuFj8WWJAIQZwhgRPeKw7R1uFR86unQ5nry8PAb3GcNZZzXu/4xAKi8vZ/r06eTk5GCxWHj88cdJT08Pdlitn96qVTY3QFJSUtXYarUSGRnpp6COTFXV5nFltj97ZQsh6qXerTP27NnDoEGDAAgJCaG0tBSAyZMn88477/g3ulbO7XNT7i3nptSbuCv9rpafZLZa4cAB7etglY0QQgghRFsTFRVFdLT/V7m32+0AVXPv3LmTnJwcRo0aVbWN2Wxm6NChrFixAoA1a9bgdrtrbNOuXTu6d+9etc3KlSux2WxVSWaAk046CZvNVrXNPzmdTkpKSmp8BUPIP9oh/PO2aD3yyrxVSWaAPcVa/2VUL3BISwDVXTXMcmZR7CnW7kZlU/mmgMTm8qgUVfqqbueWeY+5T1KEgYndQrGGWjilZwb3XTiweSTojmDr1q3k5OQAWt/fX3/9tfGTqj7wlkBra+ngKYS8lyH/DfBVBi2McePGMWXKFMaMGcNDDz1UdSVMIJSVlTFjxgzOOussnnnmmbbTpkMIcZh6J5oTExMpKCgAIC0tjVWrVgHaG135z6R+yrxlRBgiOCvurGb9pkIIIYQQQtTdQw89xH333UdFRYXf5lRVlenTpzN48GC6d9cu//876ZOQkFBj24SEhKrHcnJyMJlMREVFHXWb2i6Dj4+Pr9rmn2bPnl3Vz9lms5Gamtq4J9hAx8ebuLJfOJ3jjJzb3cop6dJ+rrXqFGvk+HhtobVIi46hHQ7+rE1JEDMZ9JEQegI+2/iqfdIsaaSYU6j0VlLgKiDBlFDLzI1nMiic292KgpYzndi1blX1V/aLYOGkBJ4/M5YYqz4gsflLWlpaVTsenU7X+EULvaWw+0bYfgnsuwdUjx+i9JOSH2DbxbBzqrYgX31lzYLixVD4AeS+4P/46khRFM4880yuv/56OnXqFNBjff3112zZsgWfz8eSJUv4888/j76DOw/c+QGNSQgRHPVunTF8+HAWL15Mnz59uOqqq/jXv/7Fhx9+yK+//lp1yZ6oG5fqwqKzEGOMCXYoQgghhBCiEXr37l2jcGDbtm0kJCSQnp6O0Wisse3atWvrPf8NN9zA+vXrWb58+WGP/bNgoS6XLv9zm9q2P9o8d955J9OnT6+6XVJSErRk88RuViZ2k6vpWjujXuGRUdFklXqJDdURatJqptauXcvcuT+ycuVmNm78AKdzFmazme7duzNw4EDGXjSW/1j+g1Vv5YX9L5ARkkHH0I5+j++pcbFYTTp+2edgxR4nn24uZ9zxx35dtpSCo6ioKJ588kl+/fVXOnXqRJcuXRo3Ycn34NqjjSvXQ8XvYO3b+ED9Ifc5UB3gK4UDr0PKzKNuftj/la791WN3VmBibGb+PgkB2ms6LCzsyBsXfQIHXgEUiL8WIscGPkAhRJOpd6L55ZdfxufTLgu69tpriY6OZvny5YwfP55rr73W7wG2ZuWecnrYerSYNxfHVFkJp5+ujb/4AkJCjr69EEIIIUQrcdZZZwVs7htvvJFFixbxww8/kJKSUnV/YqLWAzYnJ6dGL868vLyqKufExERcLhdFRUU1qprz8vKq2uElJiaSm5t72HEPHDhwWLX038xmM2azufFPToh6MOgV2kdqH2G3bdvG1KlTWbp0KcnJyYwcOZJJkyYRERFBSUkJ69atY+HChTz//PPEnRhH93u742nv4c+KPwOSaAbYmOvCpNcS4D/uctQp0dxSlHpK+dnwM7aTbXSO8kPfduOhbSMVMDSj4iudBbyO6vFRPLf3Ob4t/JbM0ExmdphJuCEcos+D/HmgGCBqYuDjbQZGjhxJdnY2W7ZsYfjw4Uc/8Vj0ycGBiufAx3x9sEPTaaeddtiJWSFEy1PvRLNOp0Onq+64cf7553P++ef7Nai2INeVi0Fn4Ky4s4Idiv/4fPD999VjIYQQQog24v777/f7nKqqcuONN7Jw4UKWLVtGhw4dajzeoUMHEhMT+eabb+jduzcALpeL77//nkcffRSAvn37YjQa+eabb6res2dnZ7Nx40Yee+wxAAYOHIjdbueXX36hf//+APz888/Y7faqZHRztN/uIafMS/cEE2ZDKyncEHXy9ttvM2XKFJKSkliwYAHjx4/HYDj8o63H42Hx4sVMv2U6P57/I/1m9qPXzb0CFlf3BBPrsl1V49bk3h33sr1yO6B9lr0w8cLGTRg2AOKnQeUfEDYIzOmND9Jf2t0F+a+DLgzipx5xs78q/uLrwq+rxl8VfMW5CedC9DkQMQwUY5tZlE5RFC699NK6bWxqD54DAPxn/j6Wrp0DwMaNG7ntttsCFaIQoonUKdG8fv36Ok/Ys2fPBgfTVqiqSrG7mGkp0xgXOy7Y4QghhBBCCD/KyMhg9erVxMTUrNArLi6mT58+7Nixo07zXH/99bz99tt88sknhIeHV/VLttlshISEoCgK//d//8cjjzxCp06d6NSpE4888gihoaFcfPHFVdteddVV3HLLLcTExBAdHc2MGTPo0aMHI0eOBOD4449nzJgxXH311bz00ksATJ06lXHjxtG5sx8qFwPg92wnM78twuODTjFGHjs9GoNeks1twdtvv82kSZOYNGkSc+bMOeoCZwaDgYkTJzJq1CimTZvG/Dvn833q91W/H/5297BIvtvuIMys1OgX7vK5eHLPk/xZ/idDo4ZyZbsrA3L8QPH4PFVJZoAtFVv8M3Hk2ObZNiHkeEj99zE3s+qsKCioBxejDDMc0i7C4P8FYVuNpBlQtBDQ8WfWEkBLOm/Z4qfXlRAiqOqUaO7VqxeKohxzsT9FUfB6j73CblvnUl0YdUYGRAxoPW0zhBBCCCEEALt27ar1PbHT6WTfvn11nmfOHK3K69RTT61x/9y5c7n88ssBuO2226isrOS6666jqKiIAQMG8PXXX9fol/n0009jMBg4//zzqaysZMSIEcybNw+9vnrxsbfeeoubbrqJUaNGATBhwgSef/75Osfa1FbuceI5eAHd1gI3uWVekm31vlhTtDBbt25lypQpTJo0iXnz5tW40hagvLyc4uJiIiMjaySgrVYr8+bNA2DKlCn079+fzMxMv8dnMeoY2+XwhQC/KfyGFXatP8DCAwsZZBtEF2sjexw3IYPOwGDbYJbbl6OgMDRqaLBDahaSLcn8X+r/saRoCZkhmYyKHhXskDTecm0hQnwQfS7oI4IdUU36MIidDMDwEXreeust4PC/dUKIlklRj5U9Bnbv3l3nCdPS0o65TUlJCTabDbvdTkREM/tPz49O+fUUXKqLeFP1Kt5On5PdlbvpHtadeV3naT2cWovycvi76X9ZGRylukAIIYQQrVNbeZ9Xm0WLFgFav+bXX38dm81W9ZjX62XJkiV88803rbJqq6l/7j/srOS2b7fh8FXSOTKON85Jl/YZDbDKvopN5ZsYEDGAbmHdgh3OMQ0fPpw9e/bw+++/VyWSPR4PN95wAz8s+47Nf21DVVXS26eyc/eew/YvLy+nZ8+epKWl8d133zVZ3F8WfMl/9/236vZTnZ6iU2inJju+P6iqyh/lfxBhiKC9pX2wwxFHs/9hKP9ZG4f2gpSHghrOsWzduhWfz9dsr6ARQmjq+l6vTqf965I8FnWzx7GH3uG9ebjjw60rySyEEEII0cb9vSCgoihcdtllNR4zGo2kp6fz5JNPBiGy1qci4nuMmZ/grYzEm3AAr/If4PBKUnFk60rXMWvXLAA+zf+U/3b+L0nmpGPsFTxr1qxh6dKlLFiwoEa1clZWFi8ebPnyt/yC/FrnsFqtPP7445xzzjmsXbuWPn36BDTmv42MGslfFX/xZ/mfnBp1akCTzPn5+fz+++9kZmb69XO8oih0D+vut/n8RlWhYD5UbIDwkyHqzGBHFHzu/dVj1/4jb9dMdOrUsk66CCGOTq4va0I+1YeCwuSkyWSG+v9SLSGEEEIIETy+g4shd+jQgdWrVxMbGxvkiFqvP4qy2LdzAJUVkXhcv1PUrYhQvSSa62O3o/qqVbfqJsuZ1awTzfPmzSMlJYXx48fXuD86OpoO6e2Jjopi1569FBQUHnWeCRMmkJyczNy5c5ss0WzQGbgp9aaAH8dut/Ovf/2L4uJiDAYDjz32WOtP4pX9BIXva2PHZrB0hpCW05YkIKLOhtznAVVbmFAIIZqQ7tibCH/wqT52VO4gwZRAz7BWvGBiaKj2JYQQQgjRRu3cuVOSzAHmyB2CszwOVdVRkX0qeldCsENqcU62nUyMUVuwsoOlA92szbt1xsqVKxkxYgQGQ81aqbCwMHbs3M2va9fRtcuxL703GAyMGDGCVatWBSrUoNm+fTvFxcWA1lJkw4YNAT/mjsod/F76Oz7VF5D5VVU9+ty+in/cLg9IHC2K7TTIeB0y5kHkGcGORgjRxkhFcxPZ69hLgimBJzs9SaolNdjhBIbVqvVpFkIIIYQQIoA6hiVyQrgZl89NuDGUEJPUz9RXrCmWFzq/QK4rl2RzMiadKdghHdXGjRuZNGmSX+bq1asX7733nl/m8qfsEg92h4/OccYGLRrfsWNHoqKiKCoqwmg00rNnYAucvin4huf2PYeKymDbYG5Pv92v868rXcfsXbNxq25uTLmRYdHDDt8o/FQo/QkqN0DYIAhtmir1Zs8QGewIhBBtVL0SzV6vl+XLl9OzZ0+ioqICFVOr41N9uFQX16VcR9+IvsEORwghhBBCiBZtaAcLL/6sJ7tU5YKeJmwWSTQ3RKg+lA4hHYIdxjH5fD6cTqffFpq02Ww4nU58Ph86XfN47aza4+Df3xfj9cHgdAu3D42s9xw2m42nn36a9evXk5mZSWpqYAucfiz+ERUVgJ/sP+FTfegU/30/38x5k4qDFcuvZb9We6JZZ4KUB/x2TCGEEI1Tr78Cer2e0aNHV12OI+qmyFNEuD6cPuFydlUIIYQQQojG+nxLBeFmHcfFmvgty0VemTfYITWZIncR+a7aF7trrXQ6HWazmZKSEr/MZ7fbMZvNzSbJDLBkeyXegx0ilu9y4HA3rBVFTEwMw4YNC3iSGaCrtWvV+LjQ446aZC4pKSEvL69e89v0tqpxpFToBpfPBfYlULpCW4DxSNS283+xqCPHDth7B+y7p0UsTikar96tM3r06MGOHTvo0KH5n/luDlRUClwFXJp0KR1DOgY7nMByOOCcg4sNfPQRWCzBjUcIIYQQool5PB7eeustRo8eTWJiYrDDabWsh7TKMOjAbKh/m4GW6LvC73h277P48HFl0pVMjJ8Y7JCaTPfu3Vm3bp1f5lq3bh09evSo07alTh+/7nOSajOQGWv0y/Fr0ynGyKo9TgBSbPoW8Zq+IOECksxJlHhKGB49/IjbrV69mtmzZ+N2uzn33HO57LLL6jT/Dak3MDdrLi7VxaWJl/orbNEQ2f+G8tXaOPp8iJ18+DZ5L0Lx52BKhuSHwChrFQgg5wlw7dXGuc9D6uzgxiMCrt6J5lmzZjFjxgweeugh+vbti9VqrfG4vy5nai1KPaWEG8K5IOGCBvXZalG8Xvj88+qxEEIIIUQbYzAYmDZtGps3bw52KK3a2d2sFFR42Wf3Mv740DbTOuPjAx/jQ6t0XXBgQZtKNA8cOJCFCxfi8XgOWxBw2bJlbNmyheycXABcbg8vvfQSMTExnHvuuTW29Xg8LFmyhIkTj/29c3lUbv28gP0lXhQFZo6Iok+y2X9P6hDn9bASE6qnoMLLqE4hLeKzo6IoDI0aesztFi1ahNvtBmDBggVceumldXp+0cZobkm7pdbH3n//fTZt2sSQIUMYPvzISe6WIDs7G0VRmvfJyYr1h4x/B/6RaHbtg+LPDhl/CnGXN1V0ojlTXdVjnzN4cYgmU+9E85gxYwCYMGFCjT8OqqqiKApeSTDWUOgupH9E/9ZfzSyEEEIIIQAYMGAA69atIy0tLdihtFomg8L1A23H3vAYysvLKS0tbd4JnkOkWFLY6dipjc0pQY6maV1xxRU8//zzLF68+LAk8QXnnUtefkHVbZfLzbXXXgvA/v37adeuXdVjixYtYv/+/VxxxRXHPGZWqYf9JdrnW1WFtVnOgCWaFUVhRGbIMbdzelR+3FVJuEnHgPYt4wrSlJSUqmr0pJQkclw5xBhj6rYAZflasH8D5g4QfR4oCj/++CNvvvkmAGvXriUjI4P09PTAPYEA+uijj5g3bx6KojB16lTGjRsX7JBqFzYQSpdVj/9JFwqKAVSPdlvf+P+fRSsRfz3kPguKEeKnHv64qoI7BwxRoGsZ/6eJo6t3onnp0qWBiKPVMulM9Anv0yLOSAshhBBCiMa77rrrmD59Onv37q31CsCePXsGKbLWpcBdwAHXATJDMjHo6v2xhi1btnDfffdRUVHBsGHDmD59egCi9K8bU24kyZSEW3VzTvw5wQ6nSfXp04dhw4YxY8YMRo0aVeP3KjIyskai+W8mk5GQkOrkbXl5ObfeeivDhg2jT59jr5+TFG6gXYSerIMVzb3bBSbJXB8PfVfE79laheDk3mGc3zMsKHH8/PPP7Nq1i8GDB5OcnHzUba+44gpsNhuFZYWsP3E9U/+cSpIpiccyHyPSGHnkHd0FkPUwqG4oWw76cIg8vcaaUaqqtug1pD799FNAex6fffZZ8000J/4LwoeALgRCux/+uC4UIkZD5Qaw9oWo8U0fo2ierL0hY17tj6k+7Xe8fLV2ciJlNpgD319eBFa935ENHXrsS2OERlEUOod2blOXtAkhhBBCtHUXXHABADfddFPVfYqiyBWAfrS5fDP3br8Xp+qkh7UHD3d8+KgLkdXmyy+/pKKiAtCKaS6//HKio6MDEa7fhOhDmJxUS2/UNuLll1+mZ8+eTJs2jXnz5lUt5vfb7+spKio6bPuwsDBsNq2y0ufzMW3aNLKz9/HVS5nawlTt7jlqBZ3ZoPDE2Bh+3eckxWagUwB7NNeFqqqsz6m+DH19jovzg3Deavny5Tz66KOAViH+0ksvERZ25IS3yWTiwgsv5Gf7z3yx6wsAsl3ZrLCvYGzs2CMfyGvXksx/82iLYA4fPpylS5eydetWBg0aFJCTd9u2baOoqIjevXsf1qrFn9LS0sjP155Xs67KVnQQdmLtj6kq7LsbHH9pt6PP1aqbhTgW157q3t9eO5R8C3HHvtpENG8N+u3/8ccfeemll9ixYwcffPABycnJvPnmm3To0IHBgwf7O8YWqdBdSLg+nERTIu0t7YMdjhBCCCGEaCI7d+4Mdgit3vdF3+NUtV6PG8o3kO3MJtly9KrKfzq0CtNmsx01USaah8zMTF599VUuueQSAObMmYPVaiU0NJTQ0NAj7ldeXs60adOYP38+bz3Ri8z2Jq3PbMkSiDzjqMcMN+sY1vHYLS2agqIoDEg1Vy0aOCDV/xXW+a581pSuISMkg06hnWrdZuvWrVXjkpIS8vLy6vT7k2ROQo8eL9rJtmTzMX5nzR20KtrSH8CYADatjafVauWpp56qtV+3PyxdupSnn34aVVXp3bs3Dz74oN+P8bdbb72VRYsWodPpOPPMMwN2nIDyllQnmQHKf4WIYcGLx5+cu6Dke+21GDEk2NG0PoZorUreV6ndNtXv77honur9v/JHH33E5MmTueSSS1i7di1Op/ZHrrS0lEceeYTP/14Mro1y+Vz8WPwjL+1/if3O/VyRJGdjhBBCCCHaEunNHHiZoZlwsFOC1ZdIuFL/SuSzzz4bg8FAdnY2Y8eOxWSqQ79YP9pe4ObZn+x4fHDDwAi6JjTt8Vuqiy66CFVVmTJlCj/99BOPP/44EyZMqDXh6PF4WLRoEbfeeivZ2dm8NfdJLhr4XfUGuiMnpwEcLg9frluJSedk1AmDMBiPvn1TuGNoJL/ucxJh0XF8fMNeM59sKufnvU56tzNxXo/qBPH3u4q4eslSvPoSMrvM54nut9EjrMdh+/cZMJjFX3yNu7KM4447jtTUul3q3t7Snns73MvPJT/T3dqdE8JPOPoOigJJt0L8tIM9gGtetRCoSuMVK1agqioAv/32Gw6HA4slML1jrVYrF110UUDmDpQ8Vx52j53MkEytRag+AsydwHnwBIS175F39hSDPqxlVDx7S2HvneArq77vCMnmUk8pRsWIRS89hutFHwHJD0HJd2BOg4jTgh2R8IN6/3Y//PDDvPjii1x66aW8++67VfcPGjQooGf6WoLN5Zu5fdvt7KjcgU/14VW9hBvCgx2WEEIIIYRoYtu3b+eZZ55h8+bNKIrC8ccfz80330zHjrJAtD+MjB6JWTEzf62THXsymfpnCQ+O1HNcXN0TbzqdjrPOOitwQR7DC6tK2FmkLZz1nxV2XpwYF7RYWpqLL76Y/v37M3XqVM455xySk5MZMWIEvXr1wmazYbfbWbduHUuWLGH//v0MHz6cr776iszMTCjqpFXIhnSF8FOPepzZny9jbZbWXmXXgQVcd/okAPLLvazY7aB9pIFeTdy3Wa9TGrUI4IYcF6+sLq0ap0caODFVm+/RH/OxV5iBOHZt78+G9A2HJZq/3FLBnF/D8Yx+lAszyrng5I4YjXVvKdI3oi99I46SiKyNvmmvNujRowerVq0CtCr6QCWZW6Kf7T8ze9dsvHgZEjmEW9Nu1U4IpM6CslVgiKu9hzNA9lNQuhT0UZD6CJgasKCpYyuULNUqjG0BTkq6D9RMMjt3AIcnmj8+8DGvZb2GUTFyZ/qd9IvoF9i4WpuQztqXaDXqnWjesmULQ4Yc/ssVERHRopvwN5bT5+TpPU/zZ/mfpIWkYdFZ+Kv8r2Pv2JpYrVp/JiGEEEKINuyrr75iwoQJ9OrVi5NPPhlVVVmxYgXdunVj8eLFnHaaVOz4Q1/ryTy2Lw+LDspdKh9vquC2oS2nKvjQtcJl3fD6y8zM5LvvvmPt2rXMnTuXVatW8d577+F0OjGbzfTo0YOJEydyxRVX1Fz4L2qc9lUHfxVU91P/K98HQKXbx61fFJBfrt2+69RIBqa1nERkmdNX87ar+vObVW/FrDPj9DnRKzr6hh+eEH7n9zJ8KugMJn4pDWVyE18J0BA+1UeeK49oYzQm3bHjnTBhAomJiRQUFNSa+2jLvi38tqr1yQ/FP3Bjyo1aFa8u5OjtMlxZWpIZwFsExZ9D/NT6Hdxj13pB/91mQTEEtkWHuT2EdIPKP0BnhYja1yt7K+ctVFRcqosP8j6QRLNo8+qdaE5KSmLbtm2HNapfvnw5GRkZ/oqrRSl0F/LQzof4ofgHUi2pWI6yoIQQQgghhGjd7rjjDv71r3/x73//+7D7b7/9dkk0+4nZoGCz6LA7tMRZQpg+yBHVz/UnRfDcihI8PpXrB0YEO5wm5/Ko7CxykxRuIMJSv4UcD9WnT58aiWSfz1e1SGBjjcgM55M/nAfHVgByy7xVSWaATXmuFpVoPjHFzEntzfxysHXGyYfEfsfQGOb80oMK8pk+uBedrYevNZQQrqewsuX8znl8Hu7feT/ry9YTa4zl0cxHiTfFH3O//v37N0F0deDOh8pNYOkEpqRgR0PHkI6sKtGqvZPNyXVvFaGPAMUCqkO7bUyo/8E9+dVJZgDnnvrPUR+KAVIe1vo0G+LAYKt1swRTArsdu6vGQrR19U40X3PNNdx888289tprKIpCVlYWK1euZMaMGdx3332BiLFZU1WVB3c+yBf5X9DO3I5QffD7dgkhhBBCiODZvHkz77///mH3X3nllTzzzDNNH1ArpdcpPDwqio//qCAmVMeFJ7Ssxfw6RBt5alxMsMMICofbx21fFLKzyEO4WeHx02NItvmnZ6u/kswAU4YOYkjmLkw6J+lJ2qXdyREGMqIN7Cj0YNDBgNSGJ5m9PpW31pWxp9jD6Z1D6Zsc+DYcBr3C3cOiUFVV6697iL7JZl6Z2A5od8T97xgayTu/l2HQKVzcK7C/c3aHjx92VpIYpq9q71Fff1b8yfqy9QDku/NZVrSM8xPO92eYgeMphD03a4vtKRZo/xSY69YPO1AuSLiAaGM0Be4CRseMrvuO+jBIeRCKv9CeQ+T4+h/cnA6hvaBinZa4jhhe/znqSzGAJfOom9ybfi/v5b1HqC6UixMvDnxMQjRz9f5rftttt2G32xk2bBgOh4MhQ4ZgNpuZMWMGN9xwQyBibNZ2OnayvHg58aZ4wgwt682t3zkcMHmyNn7zTZBeVkIIIYRog+Li4li3bh2dOnWqcf+6deuIjz92JZ2ou/QoI/83uPYqM9F8/ZXvrupPXepUWbHHUWNRuubkuOT0GreNeoVHx0SzMddNuwg97SIaniBftLmCDzaUA7A2y8lr58QRGdI0VcL/TDLXVXSonusHBv53zuNVuf2LAvaXaG0abhoUwWmd6l/UFW+Kx6gYcatuKsujcJa2R40/PMneZNx5WqLU0knrM3w0lX9qSWbQKoErNwQ90awoCqNiRjVs55Djta8GH1wPyQ+AOwv00dBMivwSzAnclHpTsMMQotlo0F/FWbNmcffdd7Np0yZ8Ph9du3YlLKx5vjEIpHJvOXP2zaHUWyqXSAB4vfDhh9p43ryghiKEEEIIESxXX301U6dOZceOHQwaNAhFUVi+fDmPPvoot9xyS7DDEyLo2kUYsBgUHB6tP3BGdN0Xk2sOLEYd/VIaX31cVFndA9rt1folR4Y0etpWodjhq0oyA/yR6+a0TkfZ4QjiTfHM7DCTVzZuYvWmbry/NY4D2XamnxLpv2DrylMMe/51sELZAKmPaQnnI7EcB7owbUE6xaT1C27rFF3DFhEUQjSZeiear7zySp599lnCw8Pp16+6yXl5eTk33ngjr732ml8DbK5UVeWazdewwr6CWGMslYf2ChJCCCGEEG3WvffeS3h4OE8++SR33nknAO3atWPmzJncdJNUPfmDqqp89Vcl+0o8jMwMIT2qZSUqW7qf9zj4ZlslGdFGLjrBWu/q0FirnkdPj2bFbgedY41N0jKisfJd+XhUD4nmRL/NOa6LlVV7nGSXehlzXAgpfmof8mXBl/xa8iv9IvoxJmaMX+ZsajGhOrrGG9mU50anwKC0hr9Geob3JKI0hVijC4BlOx38a3AQqpqdOw6pUPZAxcajJ5qNsdD+aa2S2ZQKxZ+CtwxiLtIWqmuGXB4VkyHIq5u69muLD4b2AFk/S4gmp6iqqh57s2p6vZ7s7OzDLvvLz88nMTERj8dzzDlKSkqw2WzY7XYiIlrmwhf7HfuZ9Mck7B77Ebex6Cz8O/PfDIlqIyvVlpfD35XtZWVgtQY3HiGEEEI0udbwPq8hFi1axOmnn47RWDPhWVpaCkB4eHgwwmoyTf1z/2JLBS+s0hI24WaFV86OI9Tkv9684sjyyrxcs/AAnoPr4V13UgSnd24el7AHypLCJTy791lUVCYnTvZ7j9+GJuc8Pg+vZL3C9srtjIoexWkxp7GhbAN3bb+raptHOj5Cj7Ae/gy3ybg8KutzXMSH6Wkf2bgk/JtrS3n/YJuSznFGnhgbhP7o3hLYdSN4C7UK5dTHwZJRt31znoaS77SxIR4yXg1cnA1Q4vBx99eF7CryMDjdwm1DbMFpT1KxHvbfryXyzR2h/RNa9bgQotHq+l6vzr9xJSUlqKqKqqqUlpZiOaT/rtfr5fPPP29TPeeSLcnM7zYfh89xxG30ip40S1oTRiWEEEIIIYJh4sSJ5OTkEBcXV6Mwo7UnmINlT3F1cUupU6XY4ZNEcxMpdfqqkswAhRXeI2/cSiw6sAgVrT5rUf4ivyeaG1oB+kXBF3xW8BkAWyq20C2sG4Xuwhrb/PN2S2IyKH5pUQIwqXcY7SIMlDh9jOoUpP4k+ghIewYqN4I5A0zJdd/Xc8jP0Vvk99Aa6+utFew62Hd9+S4H47uE0jXB1PSBlK3SkswAzu3gyg56X2sh2po6J5ojIyNRFAVFUTjuuOMOe1xRFB544AG/BtfcJVvq8YdBCCGEEEK0WnFxcaxatYrx48ejqkFcaKqNGNExhKU7Kil3qZyYYiYpvGkWUBOQEW1gWIaFpTscJEfoW301M0B7S3t2OHYAkNqMklaHtm9UUXH4HAy0DaS7tTsbyzfS3dqdgbaBQYyw+VAUhRGZzaABtiEKwk+p/34xF4FjK/gqIfYK/8fVSNGh1f8H6xSwWf5x4q9sNeT+R6suTrqtcYsCHk1IVyherI0N8WBsO8WQQjQXdW6d8f3336OqKsOHD+ejjz4iOjq66jGTyURaWhrt2rWr00Hb6iWVrZ60zhBCCCHavLb6Pm/mzJk8+OCDdUowe72trwI0GD/3UqeP4kofKTa9JPaDwOlRMf+jEresrIxHH32UPXv2MG7cOM4777wgRedfDq+Djw98jEt1cVbcWYTrwxv0mitwF/Bb6W9khGSQEVLHlglHUeYp4+FdD7O9cjujo0czJXlKjZgteulP26qoPlC9oGt+PelVVeWDDeX8le/m1IwQBqf/47W340rwHNDG5k6Q9lTggilfB669EH4yGKKPubkQom7q+l6v3j2ad+/eTfv27Rv1Zq6tfgBp9STRLIQQQrR5bfl93p9//sm2bduYMGECc+fOJTIystbtzjzzzKYNrAm05Z+7qPbWW2/x7rvvVt1++eWXSUpKCmJE/lVc6eX+b4vYXexhbOdQpvav+2u91FPKDVtuoNBTiEEx8EjHRzjeeoSqTscO0IeDMc5PkQsRZLuu05K/ACE9IXVWcOMRQtSb33s0/23z5s3s3buXwYMHA/Df//6X//3vf3Tt2pX//ve/REVFNTxq0bKFhmoJ5r/HQgghhBBtSJcuXejSpQv3338/5513HqHyfki0MQZD9cdLRVHQ61tXS5PFmyvYUeipGp9+XCipdVykbmflTgoP9tn1qB42lG2oPdGc8xyUfA3otRYD4YP8FX6LsDHHhV4Hx8cHob+vCJykWyHvFVCMEH9NsKMRQgRQvVfMuPXWWykp0VZ43rBhA9OnT2fs2LHs2LGD6dOn+z1A0YIoilbFbLVqYyGEEEKINuj++++XJLNok84880yGDBlCWloa1113XatbLD7MXP3xWa+DEGPdP/N0COlArDEWAINioFd4r8M3Uj1Q8s3BG16wf92IaFueV1eXcOdXhdz2RSHvrCur+46uHMj5Dxx4FbwVgQuwLXNshZynoeCd6sX26sPcQatiTpkJptZzlYMQ4nD1rmjeuXMnXbt2BeCjjz5i/PjxPPLII6xdu5axY8f6PUAhhBBCCCGEEM2fxWLh1ltvDXYYATO+Syj55V52FXk4vXMosda6V2yHG8J5qtNTrC9bT0ZIBqmWWhYVVAxgSgXXHu22pfF9nFuSH3Y6qsY/7nJwUa+wWrcrdfrILfWSHmXAoFcg66Gq79k+xx6ecZTj9DmZmjyVHmE9miT2Vs3nhH33ge/v5L8OYi4IakhCiOar3olmk8lERYV2lvDbb7/l0ksvBSA6Orqq0llo3F4Vh6deLbBbNqcTy/XXAuD474tgNgc5IP8z6sBirPeFAEIIIYQQQtRqV5Gb77ZXkhZpZERmSLDDaTOcHpX/rrSzu9jDhOOtdfreG/QKV9ejL/M/RRmjGBo19OgbpTwExV+A3gaR9S/k2pTr4rU1pViNCjcMtBEX1vzal7h8LubnzCfPlcfEuIl0tnYGoFuCiR93acnmrvG1L3i3t9jD7V8WUOpU6RxnZPboaIzu3KrHX8r/hi26GACe2vMUc7vODfCzaQN85YckmYFDvt9CCPFP9U40Dx48mOnTp3PyySfzyy+/8N577wHw119/kZKS4vcAW7JJ7+Wxp7gBl5W0UBZnBUvnvwHAqD734DC3rktG9TqIMOuYe24cCeH1/tURQgghhBCihnKXj7u+KqTUqRWnqKiMzGyZ76GXbKtk4R9lxFr13DEkEoupeRdnLPyjnKU7tKTmsyvsnJBkqleFcsAYoiH2kgbv/uj3xRRW+gB46ZcS7hne/NZQeif3HRYeWAjAutJ1vNHtDUw6E/8abOOEJBN6HQzLqD3x/8POyqrfly0H3OwodNM55mLInweKEZ+lC7gOAOBTfU3yfJrSzp07ee211zCbzUydOrVp2tMYosE2Buxfgj4CIscF/phCiBar3tmy559/nuuuu44PP/yQOXPmkJycDMAXX3zBmDFj/B5gS5ZV4qGgwkt8MzyLHAh6Xc2xvnm/tzymUqdKbpmH6BA9sVY9EWaFC3qGtZmfpxBCCCEaz+FwYLFYgh2GaKYKKnxVSTOAXUUts0glu8TDQ98VseWAG5+qsjnPzbsXxaM043VbXN7q77uqalejtgbOQ56Hq5k+pwJ3QdW43Ke1uTDpTBj1CqOPO/qJlg7R1ZXOoUZF+2wWcjbYTgPFyDWuPJ7a8xQOn4Nrk68N2HMIlkcffZT9+/cD4PF4mDlzZtMcOOF6iJkEuhDQyUKNQogjq3eiuX379nz66aeH3f/000/7JaDWJipET1RI20hMmnXVzzMyRI/T3HKfd1aJB5+qcmZXKxO7WhmaYSFEWmYIIYQQog58Ph+zZs3ixRdfJDc3l7/++ouMjAzuvfde0tPTueqqq4IdomgmUiL09EoysS7bhdWkMLxjy2ydUelRyS/34lO1xOa2AjcHyn11KtDweFWtz24TO6urlc15bvYUe5jQNZSkiNZxxeLNg2y8+HMJVpOOK/uFB/x4BQVa0jgmJqbO+5wddzZrS9di99g5N/5cwg11j3NQmoXbh0ayvcDNKR0s1Z+19doc7S3teea4Z+o8X0tTWVlZNS4vL2/agxtsTXu8Vmrv3r3MmTMHVVW55pprSE9PD3ZIQvhVvf+a7tmz56iPt2/fvsHBCBFszoNvkl0+lVtPieTSPmHNuhJDCCGEEM3Pww8/zOuvv85jjz3G1VdfXXV/jx49ePrppyXRLKrodAozR0ax1+4hJlRPuLllFDYs3lzO9gIPwzta6JlkJiPayPDMED5YX0aoSUfXeBORlqM/l73FHu77tpCCCh8XnxDGhSfUvvBboERYdMweE+23+SpcPjw+bd5gGphmYWBa01xF8dlnn/HSSy8BcN1119X5Cuf0kHTe6PoGLp8Li77+sQ5OtzA4vW1eKXLNNdfwn//8B7PZzJVXXhnscEQDPPvss2zZsgXQCjafffbZIEckhH/VO9Gcnp5+1MSb1+ttVEBCNDVVVbE7fBwo96LXKSRH6Dmrq5XJvSXJLIQQQoj6e+ONN3j55ZcZMWIE115bfel2z549+fPPP4MYmWiO9DqF9KjaFz5rjpZsq+TlX0oB+HFXJS9NjCPWquc/42M5r7uVrFIvwzNCMBmO/j76gw1l5JdrPXTfWlfG+ONDsTbzvs5HsmqPg8d+KMbjg6v6hXNmV2ud9vP6VHYXe4gN1Qc9Qd0QCxYsQD1Yxb5w4cJ6tdLUKboGJZnbIp/Ph06nvT4GDRrEoEGDghxRLTzFULQAFDNEnwM6+dkeicvlqho7nc76T1CyFAo/AGMiJP6f1jdbiGak3onm3377rcZtt9vNb7/9xlNPPcWsWbP8FpgQTSWn1ItXhZGZoZzd3cqg9mYs0iZDCCGEEA20f/9+MjMzD7vf5/PhdruDEJEQ/pNTWt1H2uWFokpf1SJ6p3Soe+uPyBAddo8dl89JcmgMRl3LLfD4cGM57oP1Vu/8XlanRLPPpzLz2yLWZbsINSrMGhVNZmzLOeEAkJqaSl5eHgApKSlBjqb1WLt2LXPnzmXlypVs3LgRp9OJ2Wyme/fuDBw4kCuuuII+ffoEO8yasmaB4+CJVHcuJE0PbjzNhN1u57nnnqOoqIhJkybRu3dvrr32Wp566il8Ph/XXXdd/Sb0lkHOs4AXXHuh4F2InxqQ2IVoqHonmk844YTD7uvXrx/t2rXj8ccf5+yzz/ZLYEI0BbdXpdSlMrV/ONMH26SCWQghhBCN1q1bN3788UfS0tJq3P/BBx/Qu3fvIEUlhH+c1imUb7dXkl/uo3+KmY7RDettHJe6iqJda3E5w+jYMR+j/n4/R9p0EsP0bDmgnURKtLqh4H0wxEDEcDjC54v9JV7WZWuVjRVulaU7KltconnGjBl89NFHKIrCOeecE+xwWrxt27YxdepUli5dSnJyMiNHjmTSpElERERQUlLCunXrWLhwIc8//zzDhg3j5ZdfrvWkZlC49tU+buPmzp3Lzz//DMDs2bN599136dq1K6+88koDZ1QB3yG3fUfaUIig8duKB8cddxyrV6/213SiBXKaQrjkPxuqxs2dx6uys8hDlzgjV/QNlySzEEIIIfzi/vvvZ/Lkyezfvx+fz8eCBQvYsmULb7zxRq2LagtRF16fyp5iD7HW4PZyjg/T87+JcZQ4fUSF6Br8HvpPx++kd/oJgBKgxFuCrYUuNjbtpAiiQ3VUulQuiJoJBdu0B7zFWhuBWkSH6gg3K5Q6tdYT6VEtbzHCsLAwLrvsskbNsXXrVgoLC+nbty8GQ8v7HtSLYyvkzgFFBwk3gDm96qG3336bKVOmkJSUxIIFCxg/fnyt3w+Px8PixYuZMWMGPXv25NVXX+Wiiy5qwidxBNFnQ/4bgB6izmz4PEWfgP0rMHeEhBtBZ/JbiMFwaJsMt9tdow1Kg+jDIf56KHwPjEkQfYEfohTCv+r9P3lJSUmN26qqkp2dzcyZM+nUqZPfAhMtkKJQEhEb7CjqxOtT2V7opkucicdPjyY69NgrYgshhBBC1MX48eN57733eOSRR1AUhfvuu48+ffqwePFiTjvttGCHJ1og7yFtFqwmhWuPLyfWUEG3bt2atFji7368Br3S6PfPAyIG8GPxj6iodLN2I6IF9xm1mnRc2S8CvOWwfVv1A46tR93n32Ni+G57Jak2AyMym3+hjr8tXbqUp59+GlVV6dWrFw899FCwQwqsnGfBtVsb5z4H7Z8EtCTzpEmTmDRpEnPmzMFqPXLrFYPBwMSJExk1ahTTpk3jkksuQVVVLr744qZ4BkcWfR6EnwqKEQyRDZvDuRcOHKz0de0FcwZET/RXhIfzFIJzN1g6gT4wi5FOmjSJvXv3UlRUxBVXXOGfkymRo7UvIZqper/KIyMjD3szo6oqqampvPvuu34LTIhAKnH6sFl0PHlGDJ1a2CVqQgghhGj+Ro8ezejR8kFQ+Mdeu6eqzcLOfbnc/Pki2hf/zMiRI7n55pubJIaNOS4eWVaE06Ny/UAbwzs2LjE6JGoI7cztyHfn0ye8T4u4utDhcOB2uwkPD699A70VwgZC2UpADxHDjjpf+0gDl/c9wlxtwMqVK6tOXqxbt47KykpCQlpzwt1bPVS18datW5kyZQqTJk1i3rx5NapdVVXFbrfj9XqJjo6u8TtitVqZN28eAFOmTKF///4Ba6NR6illTekaUswpZIYe5RjGuEYeyXuM237kyoY908FXBoZ4SHtGqxb2s3bt2vHcc8/5fV4hmrN61+wvXbqU7777rupr2bJlbNq0ie3btzNw4MBAxChaCIPbybVv3Mm1b9yJwd2A1VObUH65l8HpFjJjWvnlWUIIIYRocqtXr67qyXion3/+mV9//TUIEYmWLjZUT5hJSzIVFBQQ6i4CYNmyZU0Ww5u/lVLqVHF54ZXVJcfeoQ4yQzM5yXYSpmNcHl/q9LF4czkrdjv8ctyGWLt2LZMmTeLiiy/mww8/PPKGSXdC6mOQ/iKEDWi6AA+lesDnOsrjPvAF73v5tx49elSNMzMzW3mSGa0VhDEZTKkQPw2Aa665hnbt2jFnzpyqJLOqqlxx+eUkxMQQFRVFbGwsURERzJgxg8rKyqrpdDodc+bMISkpialTA7MgnMvn4rZtt/HknieZvnU6a0rWBOQ4AJhSQAmBivXa69M2JnDHKv9VSzIDePKgcnPgjiVEG1PvLNvQoUMDEYdoBfQ+L2d8Nw+AuRfci+fomwdNQYUXi0HhrK7WFlE5IYQQQoiW5frrr+e2225jwICaSab9+/fz6KOP1pqEFuJowsw6Zo+J5rvtlXQtt7Ppj78AOP7445ssBpulukYpogl7RKuqyl1fFbKrSPt0MeXEcM7seuTWAoHy0Ucf4XRqxTRvv/0255577qFBVi/6pygQ0nQ/l8OU/QLZj2oVswk3gm1Ezcedu2DfvVr/6KhzIa5xPZYbY/z48SQmJlJQUMApp5wSkGOoqsoHG8rZVeRh9HEhnJBkDshx6iSkK3R4sermmjVrWLp0KQsWLKjRLsPlcjHv9ddr7GovK+PJJ5+kID+fuQcrmUGrbH788cc555xzWLt2LX369PFryDmuHPY5tcX9VFTWlK6hb0Tfxk2q+rQ+1f9UugLUSgjtqd2u+B3CT67f3D4HFC3Sfg8jx4POUvt2luPQ6i59oFhq9MsWQjROnRLNixYtqvOEEyZMaHAwQgSax6uSX+Hlst7hDOlwhD86QgghhBCNsGnTplo/7Pfu3ZtNmzYFISLRGqRHGbmynxG175l81zmc8vLyJu35fd1JEZgNpVS6VS7t03TtHirdalWSGWBTnisoieaEhITDx5V/QtbD4KvQKlRtwe3B7vP50BW8BerBaub8Nw5PNBct1JLMAEUfaou4BaBlQF2deOKJAZ3/sz8rePM3rXL1570OXj0njsiQ2vuLOxwOfvnlFxISEujcuXP9DuTcCTnPgOqG+OsgtPsxd5k3bx4pKSmMHz++xv1Go5GJZ51FWHg4AwYMQFVVZj/8MFm5ubzzzju89PLLmEzVVwFMmDCB5ORk5s6d6/dEc6IpkWRzMvud+1FQ6B3eu3ETFrwLBe9obTaSHwBTcvVjutCa2/7zdl1kPwHlB0/mOrZDuztq3y6kM6T+W6tktvYBY3z9jyWEqFWdEs1nnXVWnSZTFAWvN4B9dIRoBLdXZUehm06xRi48IUyqmYUQQggREGazmdzcXDIyMmrcn52d7Z+FgESbpigKI0aMOPaGfhYZoueWUyKb/LihJh19k02s2e9CUeDktOAUi1x99dWEhYVRVlbGeeedp91ZMB+8dm2c9zLYTmP16tX89ttv9O7dO+BJ1LVr1zJ37lxWrlzJxo0bcTqdmM1GuncKZ2CvCK64cBB9Ov5jJ3109VhnBSWIFb5N4EC5r2rs8oLd4as10ezz+bjzzjvZtm0bCh5uu24og4ecBtY6Vu/mzgHnjoPjZ6HD/465y8qVKxkxYsRhfxd0Oh0LFi5EVVVKS0spLS3l3XfeISs3F5fbfVjOxWAwMGLECFatWlW3WOvBpDPxeObjrC5ZTYolheNCj2v4ZN5SKHhLG7tzofBDSDykx3xYP4i5BMrXgrUfWBuQ1HbuPGS84+jbhhwf3KsPhGil6vRO1+fzHXsjIZq5MpePqBA9L54VR2qkfMgTQgghRGCcdtpp3HnnnXzyySfYbDYAiouLueuuu5q0ArW1y83NJTc3ly5dutSo7hOtzz3DotiQ6yIqREd6VHAW8g4JCeHKK6+seac+osZ469atPPTQQ6iqyqeffsqTTz5Jp06d/B7Ltm3bmDp1KkuXLiU5OZmRI0cyadIkIiIiKCkpYd26dSz89muen/82w4Zl8/LLL1cvFBdzEeAFdx5ETYRj9Mc+Fo/Pw8tZL7O9cjujokcxOsZ/i6CWlpby2WefERISwhlnnNGgE3VjO4fw465KDpT7GJZhof0RPgcWFRWxbds2UH2olX+w+sc9DO74EyROP+aijsA/WkHUraBp48aNTJo06YiP33zzzYctJHf+uefW2su6V69evPfee3U6bn2FG8IZHj288RMpRq1NhXqwP7jedvg2MRdqXw0VORby51WPhRBNTrJtos0oc6pkxBhIsdV+qZQQQgghhD88+eSTDBkyhLS0NHr31iqy1q1bR0JCAm+++WaQo2sdNm7cyH333Yfb7aZLly7Mnj1bqsVbMYNeoXc7/1Te+lQfpd5SIvQRjb/CMe4awKAtKhY7mX0rdqGqKqD1Bt63bx+66HTe/K0Uq0nH1SeGH7FtwxGpKji3gT4KjLG8/fbbTJkyhaSkJBYsWMD48eNrfe17PB4WL17MjBkz6NmzJ6+++ioXXXSRlliOu7KWAzXM5wWf80XBFwBsrdhKd2t3ki3Jx9irbh566CE2b9YWacvKymLatGn1niMh3MArZ8dR4VYJO0pv8aioKDp06MDO7ZtBddKna4r2QOWmuiWa46dB7n+0RRgTjh2nz+fD6XQSERFxxG1yc3MPuy8iMrLWbW02G06nU2ufomu6Hur1orNA8r1QuACMCY1LKB9J9DkHF+FUarblEEI0mTq/G/vuu++44YYbWLVq1WH/GdrtdgYNGsScOXMYMmSI34MUorFcXpVKj8rQDhZpmSGEEEKIgEpOTmb9+vW89dZb/P7774SEhHDFFVdw0UUXYTQGpxqztVm+fDn5+ngclkhcW3eSm5tLcnLbSyrkufL4NP9TogxRjI8dj0EnyfajKfGUcMe2O9jr3EsPaw8eyHgAo64Rv5MGGyRNr7rZr18sKSkp7Nu3j5SUFPr168dNXxWRf7B9g0+F24dG1u8Y2f+GshWgGHl7eV8mXXUvkyZNYs6cOTUWkDssNIOBiRMnMmrUKKZNm8Yll1yCqqpcfPHFDXmmR+TwOarGKipO1dm4CV37QBcGhkh27KhufXDouL50OoUw89E/A+p0OmbPns2qlT+RoL5N97QCQA9hg+p2EHMatH+yHjHpMJvNlJSUHHGbWbNmMWrUKOx2O//9z3/YsXs3//vf/7j99tvp2LFmTxS73Y7ZbG6+Sea/hfasXuwvUEwpgZ1fCHFUdX4n8swzz3D11VfXesbNZrNxzTXX8PTTT0uiWTQ7bq+2gEiXOCOX9z3yGWMhhBBCCH+xWq1MnTo12GG0Ws74nmyJbwdAUdyJhNmij7FH63TP9nvIdmUDUOIt4bKky4IcUfP2fdH37HXuBWBD+QbWl62nb0Qde/DWQXh4OM8++yy5ubkkJCRgMpkoc1ZUPV7mrGdLSm+JlmQGtu4sYsr1DzJp0iTmzZt3WEKxrKwMt9tNZGRkjcIaq9XKvHnzAJgyZQr9+/evbqPhB2fEnsFvpb+xvXI7Y2LGkBGSceydjiTnOSj5GhQTtLuL008/nY8//hhFURgzZkzd5/GWar16TWnayYA6slqtjBg5CnynQuUGreo2gEnL7t27s27duiM+npmZWfWzMhqN3HTTTQD89ddfhyWa161bR48ePQ6fpHKzlrwPG1Cz1YsQQgRInRPNv//+O48++ugRHx81ahRPPPGEX4ISLZPLaOGqx3+pGjcHxZVeDpR76RBl5NYhkdgszfwMrxBCCCFajU2bNrFnzx5cLleN+ydMmBCkiFoPc3J3OnXaj8PhIDo6mjKvkbqnk1oHt89dlWQG2OvYG8RoWoZ4U3zVWEEh1hjr92OYTCZSU1Orbl87IIIXVtkJM+mY3DusfpPprGBMoNS5n3Pu+Y2kdsnMmTOnKsnsdruZNWsWb73zFtv+2gaALcrGDdfdwN13313Vy1en0zFnzhx++uknpk6dynfffeefJwtY9VZmZ85u/EQ+h5ZkBlBdYP+Sq666mxEjRmCxWEhMTKzbPB477Pk/8ORrPYDbPwXG+GPuVoPOVPdFABth4MCBLFy4EI/HU6P9yfr16xlyyimce955DBgwgJKSEp5/9tmqx//Z99vj8bBkyRImTpxY8wBlqyDrEUCFwnaQ9lzjenKXLgf7l2DuALGXgSJXUAghDlfn/xlyc3OPeqmfwWDgwIEDfglKtEyqTkdeXOqxN2wiXp9KXpmPC3qGcevQSMKP0pNLCCGEEMJfduzYwcSJE9mwYQOKolT1bP27ytDr9QYzvFbhpFQzX/0VhccHmTEGEsLqvwaHx6sy5+cS/sp3MywjhLO7H7kNQXNk1BkZGzOWzws+x6SYOD3mdL/Mq6oqr/1ayrpsFyemmLm0T7hf5m2oTzaVsyHHxcD2FkZkHr4IWn0MsA3guuTr+KP8DwbZBpEWkobXp6KqWh/oYyn1lFLsKSbFnFLndnwjMkMY3rGB7fsUPaT8m6kfjmfDajsLFsyt0S5j06ZNPPDAAzV2sRfZmTVrFrv37ObNN6p7wlutVh5//HHOOecc1q5dS58+feofTyApZq2C2H2wL7GpPQDp6en1m6dyg5ZkBvDaofw3iPTfAoX+dMUVV/D888+zePHiGkninTt3Yi8p4dVXX+XVV1+tsc85Z599WEX6okWL2L9/P1dccUXNA1SsA7S/P7izwJPX8Aptdx5kPw74oOJ3MMRC1JkNm0sEnMvlwmg0SttQERR1zrwlJyezYcOGIz6+fv16kpKS/BKUEP5QVOkjKlTHtJMiJMkshBBCiCZz880306FDB3JzcwkNDeWPP/7ghx9+oF+/fixbtizY4bUKvdqZeW5CLPePiGL26Og6JQn/6ZttlXy9tZJdRR7mrillR6E7AJEe2d8nIBpjWso0Xuz8Iq91fc1vLSBW7nHy8aYKdhV5+GBDOWv3N7LnbiP8stfBK6tL+Xmvk2dXOr1XzwAAtXpJREFU2NmaX/NnVOYpo9BdWK85T489nRlpMxgUOYi1+51c+E4e572dy5JtlUfd76+Kv5iyeQrXbbmO2btn1+vn15hkj0cfyapFOSQlJzF+/Pgaj/2ddI6KjmLmzJk8+eSTxMTFAPD2W2+Tl5dXY/sJEyaQnJzM3LlzGxxPwCgKpDwCURMhbgrENLCXtLmD1noDAD1YOh518yNSVch9AbZP1hKsqqdh8xxFnz59GDZsGDNmzKC8vLzq/gEDBjDujDMICw2tui8pPp4HHniAN/6xoGx5eTm33norw4YNO/zkgfVEqlI+pjQwJDQ8WF8FcEjrF29pw+dqrUp/gj23Qc6z4Gvk/5uN+Pswf/58zj33XC6//HJ2797duDiEaIA6VzSPHTuW++67j9NPPx2LpWZbhMrKSu6//37GjRvn9wBFy2HwuJj84b8BePPcO/AYGnFZjh+Uunz0SzaTFCGX9AghhBCi6axcuZLvvvuOuLg4dDodOp2OwYMHM3v2bG666SZ+++23YIfYKqTYDKTYGv4+z+1Vj3o7UDbmuJi9rBiXV+Xmk20MTm9cy7lki38XQfT4gvN9qU1hRXViS1WhqNILaFfZ/mL/hX/v/jdu1c0lCZdwYeKF9Z5//m9lODza85u7pvSoFdPfFHxDhU/rt7zSvpID7gM1WnEEikFnwPuHl1EjR9VorwBaD9/t27eTnp5e1U5j7969PPPMM/h8PrKzs4mPr47RYDAwYsQIVq1adewDl6+DogVgTIS4q0Bn9ufTqp0xHuKubNwcpmRIfRQqfoOQ7mBpYD/qit/A/oU2Lv0BQvuAbUTjYqvFyy+/TM+ePZk2bVpV7+3ExEQWf/opPp+P/Px8rFZrrQs/+nw+pk2bRnZ2Nl999dXhk1v7QvuntWrm0N7QmIUvzelgG3uwdUYaRErupwaPHXKe0E5IODZrFd+xl9R/Hp8D9j8AlX9A2MmQdCsodS+aKy0t5b333gOgsLCQjz76iOnTpx9jLyH8q86v2HvuuYfCwkKOO+44HnvsMT755BMWLVrEo48+SufOnSksLOTuu+8OZKyimdN7PZz95RzO/nIOeq//z/jWxz67B50Cfdo1wRsiIYQQQohDeL1ewsK0XqyxsbFkZWUBkJaWxpYtW4IZmjjE6ONC6Z9iJtKiY2K3UDrHNU2RxLy1pZQ4fTg8Ki//UtIkx6yPk9MsDMuwYLPoOC0zhP6pwXs/PaSDhU4xWnKsTztTjff2Cw8sxK1qFc4f5H3QoPmjQ6s/DkeFHP2jcXtL+6qxzWAjogkXVsv7K49evXrV+lhGRkZVkjk/P5933nsHAEuI5bBevgC9evU66pXKAPgqIevh6mRr4XuNir/JWTIh+jwIOb7hc/yz/7DSiCTtUWRmZvLqq68yf/58Lr/88hqVzTqdjvj4+FqTzOXl5Vx++eXMnz+fV1999cgLPFoyIHww6P3QGihhGnT6GNL+A4bIhs+jqlD8FRx4FZytpOJWddesevcd/QqJIyr5Dio3AiqULdfalNSD2Wyu8XqJjm6bC+WK4KpzCUBCQgIrVqxg2rRp3HnnnTV6zY0ePZoXXniBhIRGXIohhJ+oqkqlW+Vfg21M7R/cnnJCCCGEaHu6d+/O+vXrycjIYMCAATz22GOYTCZefvllMjIygh2eOMhsULh3RFSTHzfcVJ3QDDM1v/Zuep3C9FMigx0GAKEmHU+Ni8HpUTEbarafaGdux8byjQAkmQ+2cLQvgYI3tWrCpNvBGHfU+W8YGEGYqQyXV2XSMRbqGxc7Dr2iJ8uZxaiYUVj0TbP4uc/nw+l0EhFx9MR2eXk54yaMIzdb63F81513EXpI64W/2Ww2nE4nPp+vKkF9+EGdWhWsrxIMMeBtfidEjsTjVSms9BETqkOva0R/2tCeEH0hlK3UxuGn+C/If7joootQVZUpU6bw008/8fjjjzNhwoTDKthBW/hv0aJF3HrrrWRnZ/PWW29x0UUXBSy2w/ij56/9S8h74eB4CXR4BfSHv1ZbFGMsxFwChR9pfbCjz27YPP88gaWv3wKiJpOJ+++/nwULFhAfH9+0rw0hDqrXtWZpaWl8/vnnFBUVsW3bNlRVpVOnTkRFNf0bNCGOxOMDgw5OSDJJ83shhBBCNLl77rmnqirt4YcfZty4cZxyyinExMRUXdIq2q7rB0bw6q+lOD0ql/eVooi6+GeSGeDqdlcTaYikzFvGufHnasnR3OcAL3gKoOAtSPy/I86pqio/ln2OMW0PY2NOo11o5FFjUBSFsbFjG/dEGkCn02E2mykpOXKyt6KigrHjxvLzyp8BGD9hPHfeeWet29rtdsxm85GTzAAVa7VL+F3Z4C0Dm38Wmgy0UqePO74sZE+xh8wYA7NHR2MxNuJkTuwlNdoflHpKCdOHBeQz5sUXX0z//v2ZOnUq55xzDsnJyYwYMYJevXphs9mw2+2sW7eOJUuWsH//foYPH85XX3115Erm5sx1SBWzrxS8RS0/0QwQc6H21RhhJ2v9ySs2apXolsOvSjiW448/XroNiKBqUFOzqKgoTjzxRH/HIoRfeHwqBr2CzdL8KkSEEEII0fqNHj26apyRkcGmTZsoLCwkKiqq3gmKH374gccff5w1a9aQnZ3NwoULOeuss6oev/zyy3n99ddr7DNgwIAaPVidTiczZszgnXfeobKykhEjRvDCCy+QkpJStU1RURE33XQTixYtArRFw5577jkiIyPrFa84tlirntuHRgY7jBbPorcwOWly9R0+Fyh6UL3a7X+2PviHLwu+5OWslwH4ofgHXjn+FcINzSPxr6oqWVlZREREEB4eTvfu3Vm3bl2t21ZWVjJuwjh+WPYDACNHjfx/9u47PKoyfeP4d/qk95BCCB1BOkqzIIIoiihiw7L+WBXFthawi2BfXcuKrq5lrbi21V11FextLQiKiCIWekgI6X3q+f0xGIgQCMlMTsr9ua65fGfmzHvuSAiZZ97zvLz04ku7XQ0LsGLFCgYNGrTnAHW/hnodO7LBwk6b67VtX2ysY2NZqH3BL8V+luV5W9wDHcAf9LNg3QJWVK0g153L7b1uj8j3Su/evXn//ff5+uuveeKJJ/jiiy944YUX8Hg8uFwuBg0axLRp05g5c2bDjf+8+WCNalk7i9YUPwEqPoRgdWjDQkeW2YnaDosFUmZAitlBRJpPu6RJh+MPgs0CUQ6tZhYRERFzbdq0CYvF0qCouy+qq6sZMmQIM2fOZPr06bs95qijjuKJJ56ov+90NiwKXXrppbz++us8//zzpKSkcMUVVzBlyhSWL1+OzWYDQqvpNm/ezOLFiwGYNWsWZ555Jq+//nqzcreWstoAf/6onPxKPycPiuXo/dr3qriaQA1ra9eS484hwZ5gdpyIqwvU8Xn556Q4UhgcN7hlk1mdkDEHip/bfhn7GXs8PM+TVz+uCdZQ5i9rM4Xmv/zlL3z88cdERUVx0003MWbMGF599VX8fn+DArLP5+P4acfzwXsfABAfH8/xU49n0aJFREdHM336dByOHb2F/X4/7733HtOmTdtzgLhxUP42UBfaUM/ZPgqBmXE7/t9YLJARawvLvN9WfcuKqhUAbKjbwIelH3Js2rFhmXt3hg8f3qCQvMc2J9ueCG3aaLFD5tUQOypiucLG3Qd6PAr+0lCbCV2FLNKhqNAsHU5xTYAeyQ6y4/XtLSIiIq3P7/ezYMEC7r//fqqqqgCIjY3l4osv5sYbb2xQ+NmbyZMnM3nyni9bd7lcZGRk7Pa58vJyHn/8cZ555hkmTpwIwLPPPktOTg7vvvsuRx55JKtXr2bx4sV88cUXjBoVKlI8+uijjBkzhjVr1tCvX78m521tL35XzaqtXgAeXlrBQd3d7faqtupANZf/dDlbvFuIs8Vxd5+7d/QeDpOKuiD3fFpGQWWAkwbFMqF31C7HeP0GG8v8ZMbbiIlwD+l5a+exumY1ABdkX8Dk1Ba2aIgbE7o1waSUSXxY9iHl/nJGxY+iq6t5HwaFW3FxMR9/HFqdXFtby5IlS5g5cyYPPPAAr7/+eoMi8RdffMHbS96uv19RUcFFF11Uf//jjz/mkEN29BZ+7bXXyMvLY+bMmXsOEdUXevwdfNvA3Su0UrwdGJjhZO6hCazY4uXAri56p4ZnA79URyoWLBiE9qlKd6aHZd6marTIbBhQ+u/tYz+Uvd66hWbDgGAV2Hb6gKbiA9j6N7BGQ9a1ENXIvx+2uIavk7an8jPY+tfQRpiZV0P0QLMTSTvRPn8LE2mEP2jgD8LpQ2Nx2PTJqIiIiLS+iy66iEceeYQ777yTb775hm+++YY777yTxx9/nIsvvjjs5/vwww9JT0+nb9++nHvuuRQWFtY/t3z5cnw+H5MmTap/LCsri4EDB/LZZ58B8Pnnn5OQkFBfZAYYPXo0CQkJ9cf8nsfjoaKiosHNDDv/ume1hG7t1Q/VP7DFuwWAykAlSyuWhv0cL6ysYnmel7yKAAs/L6fSE2zwfK0vyOX/Leay/xZzwb+LKKwKNPtc/qB/j8/XBerqi8wAyyuXN/tczdHN3Y3H9nuMx/Z7jOu6XxfWvrv+gIFhGM16bVxcXIOWNd26dWP48OGMHz+eOXPm1Pd/B/a6QeDOz1dXVzN37lzGjx9fv1r26zwP/1hWwYotnl1fbE8OFQn30oKkrTm0RxSXHJTAmNzwbdaYG5XLVblXcUjiIZyXfR6jElp31bA/0Mj3ksUSWhH8G2e31gkEEKiGjZfCr6fBpmsh6As9XvgwGHUE/aUY255uvTwSfoV/h2ANBMph2z/MTiPtSPv6V0PaNK/DzYW3flg/bm2GYbCpzE9GnI1JfXZdnSEiIiLSGv75z3/y/PPPN1iJPHjwYLp168app57Kww8/HLZzTZ48mZNOOonc3FzWrVvHDTfcwOGHH87y5ctxuVwUFBTgdDp32by7S5cuFBQUAFBQUEB6+q4r9NLT0+uP+b3bb7+dBQsWhO3raK5TBsdSUBVgS0WAEwfGEOdqv+toct25uCwuPIYHCxb6RO37JlB7s3O5and10O+3+tiwvcdtSW2QLzbWMXVAzD6dY1PdJuatnUexr5hTupzC6Rmn7/Y4t83NwJiBrKpeBcCB8a2/B5Db5sZtC+/7lhdWVrFoRRVJbisLjkiie9K+rap1Op3cdtttLF68mIyMDKZMmQLAI488wuDBg5k9ezZPPvkkVquVIUOGUFRURF1d3S7zuN1uUlJCjV6DwSCzZ88mPz+fJUuWAPBzkY/575ViGPCfH2q4d0oKPZPDswK4Izoo8SAOSjyoVc/pDxjc+kEZy/I89E93cNPEpF03N8xeAGX/AWscJO2lJUo4VX4CnrWhce13oQ0kY0eBNZaPt2Ty1x/GYXUkc/VRHkZku1ovl4SPLRYCJTvGIk2kQrOEjWG1sjHbvEsrt1QGiHVZuX58EklR7ePyLhEREel43G433bt33+Xx7t2779I/uaVOOeWU+vHAgQM54IADyM3N5b///S8nnHBCo68zDKPBCs7dreb8/TE7u+aaa7j88svr71dUVJCTk9OcL6FFYl1WrhuftPcD24F0Zzp39rmTpeVLGRAzgAGxA8J+jlMGx7KxzE9+ZYBTBu1amM+Ot+GwgW/7QubuSfv+dvFfhf+iyFcEwPNbn2dq6tRGex8v6LmAL8u/JNmRzP6x++/zudqaOl+QZ78JtcspqQ3y0nfVzD00cZ/nycnJ4dxzz23wWO/evXn88cc5/fRQ4f6hhx4iJiamvpjcmOrqambPns2zzz7LokWL6N27NwAby/z1HzYEDdhU5m+1QvOaNWsoKytjxIgRjW5aKPD1Fg/L8kKrzVcX+vhoXR1H9v1dH3pHKqSd3brBDD8E60L/tdgBC9hTQ89lXcsTn/yK1xINtm48/XWlCs3tVeZVUPREqHVG2rl7P15kO/1Ulw6h0hPE4ze44uCE3faaExEREWktF154ITfffDNPPPEELlfoDbbH4+HWW29t0D81EjIzM8nNzeXnn38GICMjA6/XS2lpaYNVzYWFhYwdO7b+mK1bt+4y17Zt2+jSpctuz+Nyueq/NgmfnlE96RnVM2LzJ7it3DIpudHnM+Pt3DopmaWbPAxIdzA4c9//jBPtifXjKGsULmvjczitTg5JOqTR59sbu9VCjNNCtTdUwU2KCu8K+xkzZmAYBueccw7/+9//uOuuu5g6depui7V+v5/XXnuNuXPnkp+fz6JFi5gxY0b98wd0dZERZ6OgMkBWvI3hrVQMXLJkCQ888AAAI0aMYP78+a1y3nDbtGkT3333Hfvvvz+5ubkArF69mnXr1jFy5EhSU1N3fZERDK3+tSWAq/tez/H7fvOJbaH/fNALm6+FujUQqIW4sZBwVKiXN4C7F4kpCRQVh66MaBOZpXlc3SD7RrNTSDukQrOEjd3v5aTX7wfgpWMvwW8P74qdPSmuCTA8y8WMIbqkQ0RERMz1zTff8N5779G1a1eGDBkCwLfffovX62XChAkNVhq/8sorYT13cXExmzZtIjMztInciBEjcDgcvPPOO5x88skA5Ofns2rVKu68804AxowZQ3l5OUuXLmXkyJEAfPnll5SXl9cXo6Xz6J/upH9683+Pn5ExA0/QQ6GvkGlp03BaW+89gdnsNgs3Tkji5e+qSY2xccbQ8L83Oe200xg5ciSzZs1i+vTpZGdnM2HCBIYOHUpCQgLl5eWsWLGC9957j7y8PA4//HCWLFlSv5L5NwluKwuPTWFLZYDseDsue+s0OP/iiy/qx7/1kN+XDVLbgi1btnDZZZfh8XhwOp3cd999FBcXM2/ePAzD4IUXXuDBBx8kNvZ3f/75t0PVF4AFMi6H+MPqn1qxYgUvvvgiqampnHfeecTExNAvzcnFY+L5fKOHwZlORnVr/faUu/D8GioyA9jjIHoQxB/a4JArD03k6W+qsFth5ght+CfS2ajQLGFjC/g57T93A/DK0Re0aqHZGzDonWLH2p53gBEREZEOITExkenTpzd4rLltJaqqqvjll1/q769bt44VK1aQnJxMcnIy8+fPZ/r06WRmZrJ+/XquvfZaUlNTmTYt1KszISGBs88+myuuuIKUlBSSk5OZM2cOgwYNYuLEiQD079+fo446inPPPZe///3vAMyaNYspU6bQr595bdGk/an2Bnn/Vz/7uf7ArB7usG6w1170T3dyw4TIvg/q3bs377//Pl9//TVPPPEEX3zxBS+88AIejweXy8WgQYOYNm0aM2fOrN/4b3fcDis9k/d9xWkwGMRqbd5K1SFDhrBs2TIg9LNnn4rMgWqwRoc2wTPRTz/9hMcTamnh9Xr56aefyM/Pr98AsqSkhLy8vIY/P4Pe7UVmACPU43h7odnr9XLrrbfW99qOjY1l1qxZAEzqG82k37fLMJOjC1jcYGzvC+7svsshmfF2rhqX2KqxIiEQCHDnnXeydOlShg0bxjXXXNPuPhQRMYMKzdKuVXuDFFQGiHFYGRvGnYVFREREmuuJJ54I21zLli1j/Pjx9fd/64t81lln8dBDD/Hdd9/x9NNPU1ZWRmZmJuPHj+eFF14gLm7HKrJ7770Xu93OySefTG1tLRMmTODJJ5/EZtuxp8WiRYu45JJLmDRpEgBTp06tv7xdIs8wDP63wYPHbzCuhxu7rW0UaA3D4NP1dfiCcGj3veea/24pP27zAbClIsCMCKzolR2GDx/eoJDckgLwnvxW0P78889ZtWrV9oK2k4H7D2DM2IP3WtDe2fHHH092djZlZWUcckgT26YYBuTfAVWfgSMbcm4De+MtYCJt4MCBxMXFUVlZSWxsLIMGDSI7O5tXXnkFn89HVlZWfTuNelYnuHqFVgQDRPWvfyoQCNQXriH0AWObZU+GnNuh8lNw94a4MWYnipgvv/ySzz77DICvvvqKTz/9tMG/xyKyeyo0S7sVCBpsLvczOsfNaUNjmajezCIiItIG1NbWYhgG0dGhVWgbNmzg1VdfZcCAAfWF3KY67LDD6lfJ7c6SJUv2Oofb7WbhwoUsXLiw0WOSk5N59tln9ymbhM8Tyyt59fsaAJblebhqXCKFhYW89NJLREdHc+qppxIV1fq/6/5jWSX//iGU66vNnj2uUgwGDdYU+erv/1DojXQ8+Z1wF5l/+eUXZs2axQcffEB2djYTJ07kjDPOID4+noqKClasWMGrr77KAw88wPjx43nkkUd2adGxOwceeOC+Ban7KVRkBvDlQfk7kHLKnl8TJisrV1LmL2N0wuj6NjCpqaksXLiQNWvW0LdvX1JTU0lPT2fhwoVs3LiRQYMG4XbvZhFU11ug4n2wJ0HcjiJ7VFQUZ599Nk8//TRpaWkNNnltk9y9Q7cOpqKiguXLl5Obm0vPnj13aX2ySysUEdktFZql3SqpDZISbePOo5PJiNO3soiIiLQNxx13HCeccALnn38+ZWVljBw5EqfTSVFREffccw+zZ882O6K0Md/me3cah1Y23nzzzaxfvx6A8vJyLr300oidf22Jjwc/rwDgwjHx9Ex27JJrZf6eC8dWq4WDc918sr4OiwUO7WHe1YaLixezoXYDhycfTp/oPo0f6C+FbU+A4YHUP4Azu/VCtnHPPfcc55xzDpmZmbzyyisce+yxjW46+PrrrzNnzhwGDx7M448/3mDTwbCwJ4LFDoZ/+/3dbLQXAa9ve51HtjwCwNDYodzc6+b651JSUnbpYZ+dnU129h6+h2yxkDR1t08dd9xxHHfccS0P3R74CqHgrxCogLSZENO01fCRVFdXx5w5c8jPz8dqtbJgwQKGDh1K7pQr+Gx9FSO6RnPAAQeYHVOkXdAWoNIuBQ2DouoAh/Rwq8gsIiIibcrXX39df0n4yy+/TEZGBhs2bODpp5/m/vvvNzmdtEWjurrqx6NzQgXa/Pz8+scKCgoiev6//q+cn4p8/FTk46//K69/fEw3N/6gQV6FH5cdPP5dV9eXlpayePFiVq9ezdxDE7h1UhJ/nZLCEX1a3ld2S4WfxWtqWF/q2/vB271T/A4Pbn6QN4rf4Ppfr6fSX9n4wVsfgMoPQqtlt9yxy9ObyvyszPcQDDZ+VcG+WLPNy10fl/H015X4AuGZMxKee+45zjjjDE488URWrlzJtGnTdltkBrDb7UybNo2VK1dy4okncvrpp/Pcc8+FN5CjC2ReDbEHQepZEH94eOdvxPLK5fXjFVUr8Af9rXLeDm/b41C7ErzrIf9Os9MAoQ0ef/uZGwwG+frrr1me52GDez+y9zuAgtgBfL7Rs5dZRAS0olnaqQ2lfnIS7EzfP8bsKCIiIiIN1NTU1PdIfvvttznhhBOwWq2MHj2aDRs2mJxO2pJKT5Ab3ynllxIffVPtzBgSy4jsUNF5xowZPPnkkzidzl02lwy3QBDK/eVsqNvAJks1m+oOIMedw4yhsXy0rpZqr8G26gALPytnzqGJ9a/7bRVgYWEhFouFG264Yd/bIgCrqlZR4itp0J6gsCrAZW8UU+MzcNjgnmNS6J609424Nnk21Y9rgjUU+4qJs8ft/uBA2U7j0gZPfbyulr98Uo5hwKgcF9cfnrTH83r8Bi+urKLCE+SE/WPIjLfv8vyN75ZS7Q0VmG0WOH1YI7lM9PPPP3POOedwxhln8OSTT+7SjsPv91NSUkJycnKD4nNMTAxPPvkkAOeccw4jR45sUhuNJosdFbq1ohFxI+qLzUNih2C3qnwSFkag4dgw9n2Dx2AdFD4KvgJIPgFiRrQoUlZWFpmZmfUrmocPH473dx8wBcL0gZNIR6cVzdLuBIIGAQMuPySBUd20AaCIiIi0Lb179+bf//43mzZtYsmSJfV9mQsLC4mPjzc5nbQl7/5Sy8/FPgwDfiryE+WwYtlecJk+fTrPPvsszzzzTLOKt/viwjHxFFi+weIuIKnHGzya92j9czU+gwS3FbCwvrThis78/HwKCwuB0MaB3333HQDL8zz8/csKvtxYt9dzLylewjW/XsNdG+9i3tp59Y//Uuyjxhcq7PgCsLqwaauaJyZPJM4WKuCOiBtBN3e3xg9OOROs0WBxQNrZDZ76eF0dv7VH/3KThzpfcI/n/ceySl78rprFP9Vy47uluzxf6wvWF5kBimr2PJ9ZzjvvPLKysnjooYcaFJkDgQB33nknKalpdOnShZTUNP785z8TCOwoGlqtVh566CEyMzOZNWuWGfHD6ti0Y7ml5y3M6TaHeT3m7f0F0jRpfwRXH7CnQ8bl+15kBih+HireDq2M3nIbBGtbFMntdnPXXXdx+eWXc/fddzN06FAO7OriqL5RpERbmdArioNyVXsQaQp9JCdh43O4uHzeW/XjSKjxBdlc7icjzs4B2ZE5h4iIiEhLzJs3j9NOO43LLruMCRMmMGbMGCC0unnYsGEmp5O2JN61o5BnsTS8D5CQkNAqOfqnOxk96k1K/aECqdWSU//c0f2iWbSiCosFJvdr2A4jOzubnJwcNm3ahM1m44ADDmBdiY+b3islaMB/19Tw56OS6Z/ubPTcyyqW1Y+/r/6e2kAtUbYo9ktzkOC2Ul4XJMphYXBG43PsrJu7G4/1f4xSXylZrqz6wv1uxQyFXs8DQbDYGjy1X5qDLzeFLpXvnmTH7djzGq38yh1F+K1VAQzDaHDuxCgbxw2I5j8/1JDotnLcgJa3FmnMokWLWL58OSNGjOD0009v8uuWL1/OBx98wCuvvEJMTMMrR2+66SZuuumm+vsV5WVcffXV1NTUsGDBgvrHY2JiuOuuu5g+fTpff/01w4fvvf/uprpNfFD6ATmuHMYnj29y3tYwJG6I2RFMU1FRwYMPPkhJSQkzZsxo/M/SCEL5YvAVhTY6tCdC7MGNF5CdWZB7T8vCBat2Or8Xgl6wtmzD1ISEBMaP3/H9Z7FYuHDMHn4G1/0Mpf8OFcxTZoC1aT+jRDo6i7GnbawjpKKigoSEBMrLyzv0qo5DHs7DG4D0WNveD5Ym+bnIx/BsJzdOSKJfmn6Qi4iItDWd5fe8vSkoKCA/P58hQ4bUrwpcunQp8fHx7LfffianCz/9uTePYRg8t6KKn4p8HNYzivG9WlYoaYmVlSt5dMujRFmj+FPOn8h279jUbHO5H5uFXdpBAFRXV/Ptt9/StWtXunXrxqfr6/jzR2X1z18yNn6P/ZoXFy/mwc0PAtA/uj939tnRs7WkJsDqQh99Uh2mvKf6ZF0txTVBJvSOIs6150LzN1s83PpBGR6/wamDYxpti1HtDeK2W7BZm7GKswmWLVvWoPA7f/58RoxoWluBiy++mH//+9+sW7euQVuMuro6kpJTqKutISu7Kwvm38iN8xewJW8z7qhoSkuKcbt3rPb0+/10796dadOmsXDhwj2esyZQw7mrz6UiENqM8k85f2Ji8sR9+ZIlQhYuXMjbb78NhFb8/vOf/9x9r+6iRVDyPNStg2AlRA+GhKOgy4WRC+ctgC0LtrfOmAEpJ0fuXLsT9MHas0JfL0DySaENRUU6sKb+rqcVzdIuGIbB5ooAUQ4L0/ePUZFZRERE2rSMjAwyMjIaPDZy5EiT0khbZbFY2kyf3sFxg1nYb/dFwa4Jjb9tjImJYezYsfX3h2U5yU20s6HMT2acjZE5e77c/KiUo8hyZlHsK2Zs4tgGzyVH2ziou3mLdg7p0fTC/7AsF0+flIYnYJAU1XjmGGdku1fW1TVsV1Jb2/SWAp9//jkTJkzYpZi4bNky6mprALj0T5dwzjnnUFZWxty5c6mrrWH58uUcdNBB9cfb7XYmTJjAF198sddzFvuK64vMAGtr1zY5r0TWzt9LXq+XYLCRdi+edaH/BirA8IT6Ltd8G9lwzgzo/lBkz7EnhmdHkRnAt828LCJtjHo0S9jY/V6mvfk3pr35N+x+b1jnLq0NYgVunJDE9EGxYZ1bRERERETCI8Zp5d4pKTx0fCoPTE3d3t95zwbHDWZ88nhc1nbcGs+zkejCeSQVzwfvZtNijBkzhkMOOYTo6GgOOeSQ+tY9TbFq1SqGDh26y+MrV66sHw8aNAiAgQMH1j/27be7FhWHDh1a37N7T7Jd2QyJDbWniLJGMT6pbbXO6MxOP/10cnNziYuLY/bs2TidjSz2SpgEFnuoZYY9NdSGJnZ0q2bdha8Iip6FssUQiYv4bbGQdML2cTwkTQv/OUTaKa1olrCxBfz88cWbAXhzwv/ht4dv1XF5XZCxuW6O3z9m7weLiIiIiLQhi9fU8K/vq8mOt3HFIYl7bcPQ3jlslj2ugt4XhmHw97y/81XFV4yIH8Hs7Nl77rtsloJ7wPPr9vFfodtdpsSw2WxceeWV+/y6YDCIx+PZ7eXQ1dXV9eO4uNAK/J2P2/n53yQkJODxeAgGgw02Ffw9q8XKgp4LWFe7jjRnGgn21ulL3pjq6mpsNluDViCdVVZWFg888MDeD4wdCd0fBX85BErBYoWYvffmjhjDgM3Xgi8/dD9QEZnWGmkzIflksLpChXYRAbSiWdoJfxB6JuuHt4iIiIi0L2W1Af72ZQUFlQGW53l56buqvb9I6i2tWMp/i/9Loa+Qt4rf4vPyz82OtHvBut2P2wmr1YrL5aKiomKX53beGLCyMtQuYOfjfr9xIEB5eTkul2uPRebf2Cw2ekf33rXIXPIK/HwSbLhkn1oTBIIGvsD2VayGPzTPtn+Ar3CPr/vPf/7DjBkzOP300/nqq6+afD4BHKkQ1QtiDzC3yAwQrN1RZIYdHwBFgi1GRWaR31GhWdq8Ol8QmxX2U19mEREREZFOrU2uZgZIPx+vNYFXPdW8aM2lJlDT5JcWVwdY+Fk5f/u8nPK6RvrgtoKBAweyYsWKXR4fPHhw/fi3dhirVq2qf2zIkCG7vGbFihX1bTaaxV8ORU+CURfqAVzyYpNetmKLhxnPF3LSc1t55+ea0EZ1RU9A6auw+fo9vva5557DMAy8Xi8vvfRS87OLuWzREHdoaGyxQ/wR5uYR6WRUaJY2r7g2SNcEO0f3a3y3ahEREZG25JlnnuGggw4iKyuLDRs2AHDffffxn//8x+Rk0toSo2xcODqezDgbB2S7OEn7jeyTkfEjOTb1WDKcGRyTcgyj403u/dqYmKE86BzBP4IxPFP6EX/e8Ocmv/TOj8t4++da3vqplvs+LY9gyD0bM2YM7777Ln6/v8HjBxxwAC53aGPEe+/7K4899hj33vdXANxR0YwYMaLB8X6/n/fee4/Ro1vwZ2Wxg8Wx4761ae8FF62ootZnEAjCP5ZVgnfjjid9+RD0Nfra9PT0+nFsbCyPPPIITz31FDU1Tf/QoFPxFUJdBFcLt0TGHOh2X6ilR+wBZqcR6VRUaJY2zTAMqr1BjuoThdPeRlcviIiIiOzkoYce4vLLL+foo4+mrKyMQCAAQGJiIvfdd5+54cQUR/aN5pET0rhxYlKH788cbhaLhVnZs3i0/6Oc3/X8Fq1o/vDDD3nsscdYs2ZNGBPusLZ2bf3419qmF+AKqwO7Hbe2mTNnkpeXx+uvv97gcbfbzVVXzgUgf0se5557LlvyQhseXjl3zi79jF977TXy8vKYOXNm88PYYiDzKnD3h/jDIeXUJr0sKcpKRUU5VVVVJEfbIPHoHQXrhKPB6mj0tddffz1HHHEEU6dOpaSkhNdff52XX36ZBx98sPlfR0dV+T9YNws2XgoF95udZlcWC7h7hVp6iEir0m850qZV+wzcdguH9owyO4qIiIhIkyxcuJBHH32U6667DpvNVv/4AQccUH/ZuYi0rs8++4y7776b//znP1x33XUUFxeH/RxHphyJhVAhfHLK5Ca/7vShsVgtYLfCjCHmrXgfPnw448ePZ86cObts8Ddv3jzuuOMO4hMSAYhPSOTPf/4z8+bNa3BcdXU1c+fOZfz48Qwfvm+9en/Y6uWZrytZme8JPRA7ErrdCRmXgbVp7wftK5+neNlrFCx7nSE1n0HMCOjxBHR/GLrM3uNru3TpwiWXXMK5557Ltm07ekLn5eXt09fRKZS/A2z/UKTiXTDM+4BEfidQDcUvQul/9riCXyRS1LVc2izDMMivDDA6x8XQTPVnFhERkfZh3bp1DBs2bJfHXS7XLsUbab61JT62VAQYnuUk2tn21s+U+Eoo9hXTK6oXVkvby9fZbNy4o4WCx+OhsLCQlJSUsJ5jSuoUhsUOw2/4yY3KbfLrJvaO5qBcNxbA7TD3e+WRRx5h8ODBzJ49myeffLJ+Mz+bzcZVV13FFVdcQWlpKUlJSdjtDcsJwWCQ2bNnk5+fz5IlS/bpvBtKfVz3dgn+ILy8qpq/HJ1Cn9TGVx835uvPP6LH9p+zP361CWZMBXsCkLDnF/7OySefzOOPP47NZmP69On7nKPDc/eEmuWhsTMXLLY9Hy+tJ/92qPk2NPZugi4XmZtHOh0VmiVsfA4X11z1r/pxSxXXBIl1Wrh4bAI2q9pmiIiISPvQo0cPVqxYQW5uw0LTW2+9xYABA0xK1bEs2+zh5vdLCRrQPcnOPcek4LC1nd8XV1Wt4sa1N+I1vBwYdyA39Lih7W5i10mMGzeON954g/Lycvr370/v3r0jcp5sd3azXhdlcoH5N7179+bxxx/n9NNPB0KtgGJiYuqft9vtpKWl7fK66upqZs+ezbPPPsuiRYv27f9vsI4N+T/i9yeC1U3QgPWlvmYVmgcMGMBXX31VP26u4447jkMPPRS73U5cXFyz5+mwUs4Aeyr4y0LtSaTt2LlvdlvtoS0dmgrNEjZBq41V/ceGbb6S2gBnDI1jRHbLi9YiIiIirWXu3LlceOGF1NXVYRgGS5cu5Z///Ce33347jz32mNnxOoRleR6CRmi8vtRPYVWA7IS289bm/dL38RpeAL6q/IpiXzGpTvUKNVNmZiaPPPIIRUVFZGVl7bIaV3aYMWMGhmFwzjnn8L///Y+77rqLqVOn7vb/md/v57XXXmPu3Lnk5+ezaNEiZsyY0fSTGX7YdDVDg5vJ4AQKAgeQGp/Y7PeAV199Ne+//z5ut5tx48Y1a47fJCUltej1HZrFqgJzW5VwFJS+DFgg4Uiz00gnpH9dpU3y+A2cNgsTe6s3s4iIiLQvM2fOxO/3c+WVV1JTU8Npp51GdnY2f/3rXzn11KZtaCV7NiTDyZtrajAMyIq3kRbTti7b7uHuUT9OcaQQb483MY38Jjo6mm7dupkdo1047bTTGDlyJKf88RSmT59ORlYGkyZOYujQoSQkJFBeXs6KFSt47733yMvL4/DDD2fJkiX7vlLcmw+eX4l3wv2jXmajNUjXnqcR08x2OE6nk6OOOqpZrxXpENLOgvhxoU0wnc27wkKkJVRolrCx+X0c+eGzACw57AwC9n2/1Ok3FZ4g8S4rQ9SbWURERNoRv9/PokWLOPbYYzn33HMpKioiGAySnp5udrQOZUyumzuOTCavws+oHDdOe9tqS3Fs2rFE2aLI9+QzMXkiTmvzf6et9AS55f1SNpT5OaZfNGcO12X8bdHXeR6e/aaKxCgrF4+NJymqbX340Ry9e/fm4ucv5h8f/4NN/9nEG8vf4IUXXsDj8eByuRg0aBDTpk1j5syZ+7zxXz1HGtjTwL+NKLuPfpndoQ32XBdpV1zdzU4gnZgKzRI29oCP2c9eC8B7h5zSokJzIGgQ57a2yY1dRERERBpjt9uZPXs2q1evBiA1Ve0SImVAFycDurTdRQkTkyeGZZ7Xfqjmh0IfAC9+V834XlF0bUNtQjq8QDV41oErF2y7L/IHgwa3f1hGnT/Uz+XJ5ZVcdnBiK4aMnEOTDuWt/d8ioX8C+0Xvx+29bseKtX6TwBazuiHnLqj6Hzi7QczQ8MwrIiKm0G8o0iZV+wxG5rTdNw4iIiIijRk1ahTffPPNLpsBSudQVB3gle+riXFYOHFQLK4Wrrbe+fUWCzibuenhDz/8QGVlJQcccAA2W/tfbdtcVVVVREdHN61QGqiADZeBvxBsidDtbnDsenVC0AD/b03DAW8gjIGDdVDyMgRrIXk62JPDOPne9Yzqyd/3+ztbvVvpGdUTuzV8JYRNdZu4ad1NlPhKOCvzLKYmDQ3b3G1Fhb+C90vfJ9WRysGJB5sdR0Qk4lRoljbJMGBYlgrNIiIi0v5ccMEFXHHFFWzevJkRI0YQExPT4PnBgweblExaw4L3Sllf6gegrC7IhWMSWjTf1P4xbKkIsKHMz9H9okmP3fci8euvv84jjzwCwOjRo7nuuutalKk9MgyDv/zlL3z88cekp6dz++23772lTc2qUJEZIFAG1cshcfIuh9ltFi4Zm8ATyytJirJy5rDY8AUvfBgq3guNa1dD7j3hm7uJEh2JJDoSwz7v81ufp8BbAMBjWx7jqJSjWtRmpq0xDINrfrmGjZ6NABT7ijku7TiTU5nItw0stlb/sEREWpcKzdLm1PqCOKwwqA1fCikiIiLSmFNOOQWASy65pP4xi8WCYRhYLBYCgXAud5S2Jq/Cv9O45X/WTruFSw5qWbH6iy++qB9/+eWX9d+LncmGDRv4+OOPASgsLOStt97irLPO2vOLXLlgcYLhBazg6tXooeN7RTG+VwQ2Mvfm7Rj7Nod/fhPF2nYU5KOsUdgs5qy0DwQNSmuDJEdZsVrD9/eiJlhTX2QGWF29uvMWmktegaInACt0uQQSJpidSEQiRIVmaXOKqoN0TbAzPNtldhQRERGRfbZu3TqzI4iJpu8fw/Mrq7FbYWr/aLPjADBkyBBWrlxZP+5sRWaA+Ph4nE4nXq8XgLS0tL2/yJkNOXdA9dcQtT9E9Y1wyt1IOh4K/gKGH5KmR+w0r217jTeL36S7uzuX5lyK2+be7XE///wzt912G1VVVZx//vlMmND8guEfMv9AXbCOYl8xp3Y5tdFC87radeR78hkeN7zRXM1V7Q1yzeIS1pX66ZVs5/ajkolyhKf/dIwthgPjDuSryq+wYuXQxEPDMm+b5S8Nrfx3dg/1+dlZ6avbB0Eo/bcKzSIdmArN0qZUe4N4AwYzhsTiaGb/OREREREzqTdz53b6sDgm9YnGZbcQ724bG1uffPLJ5ObmUllZyaGHdvBiVyOSk5O54YYbePvtt+nevTuTJ+/aAmO33H1CtyYq95fzS80v9I7uTYK9ZSvRAYg7CKIGguEDR2Q2F8335PPolkcByPPk0TOqJyd3OXm3xz799NMUFRUB8PDDD7eo0Bxji+Gybpft8ZivKr7ilnW3ECRIr6he/KX3X8LaJ/rLTR7WbW9182uJn682ezi0R/hWpl/X4zq+r/qeJEcSOe6c5k0S9IJ/Gzi6gGXvX/uLW1/k1W2v0tXVleu6XxeRtie7qFkFeTeGVv/HjoXMqxsWm505UFsWGrua+f9BRNoFFZqlzaj0BCmoDHBYTzcnDw5jXzMRERGRVvT000/v8fk//OEPrZREzJLWjD7KkTZq1KjdPv7NFg8vfVdNWoyVWSPjiXGaWxxfuXIlL7zwAsnJyZx33nnExobvfcHQoUMZOnRo2Ob7vSJvEZf9fBll/jIS7Ync1/c+UhwpLZ84HAXrPQgawT3e39nOfx6/7z8fCUvLlxIklOfX2l/Z5ttGpiszbPNn7PR31WKBLmH+u2uz2Bgc14K+/P4y2HQl+PLB1TO0wt7aeCF8m3cbzxQ8A8CPNT/yyrZX+GPWH5t//qaqeGd7ixmg6jMIlDbsxZx1dah9hsUBySdEPo+ImEaFZgkbn93JgkufqR/vq/K6IPulObhvSkqLd+cWERERMcuf/vSnBvd9Ph81NTU4nU6io6NVaA4DwzD4b/F/2Vy3mUkpk+gZ1dPsSO2S129w2wdl1PkNAGKcoWKzWfx+P7feeis1NTUAuN1uLrzwQtPy7Em5v5zvq76nR1SP+sLnyqqVlPnLACjzl7GyciXjk8ebmLJpst3ZnJVxVn3rjKlpUxs9dtasWQBUVVW1ys+ywbGDWVyyOJTTlU1qmFd1D+jiZO6hCXyd5+WAri76pbWxfYKqPg8VmQE8a6HmW4gd3ejhdosdGzYChPrDu6yt1I7S2X3H2AjCuvPB6oTMqyB6ENjiIe3/WieLiJhKhWYJm6DNzrKhE5v9+jq/QbdEO+4w9cQSERERMUNpaekuj/3888/Mnj2buXPnmpCo43mz+E3+nvd3AD4q+4jH+j9GjK3lqyu/3FjHCyurSY+1ceGYeOJcHfv3Ul/QwBMw6u9XextfydpUP2z1srHMz8gcF8nR+7Y6NBgMUltbuyNPdXWL80RCpb+SS3+6lCJfES6Lizv73EnPqJ70ie6Dw+LAZ/hwWBz0ju5tdtQmO7HLiZzY5cS9HpeUlMRVV13VColCDkk6hAR7Alu8WxiTMAaH1RH2cxzaIyqs7TIAqgPVVPgrWr762pm90x0rOPY8X5Ijicu6XcZ/tv2Hru6uTE9rfl/vVwtf5aXCl8h2ZXNt92tJciTt4cTHgzUafAVQ/hYEqyFQC9seh9z7mp1BRNofFZqlTaj1BbFb4bgBkb/8SkRERKS19enThzvuuIMzzjiDH3/80ew47d7mus3146pAFeX+8hYXmut8Qe78uAxvAH4u9pEUZeW8Ueat7m0NMU4rM0fE8ew3laTF2Dilhe3rvtpUx80flGEY8NIqGw9OTdmnRSROp5NZs2bxxBNPkJKSwmmnndaiPJHya+2vFPlCfYo9hodvKr+hZ1RPctw53NX7LlZWrWRw7ODm9+SVBgbHDWYwjbSfMAyo/hKwQMzIXTehM8GPFd8w76dZ1AbrODztFC7rcf3uDwzUQPlisLoh4UjY3WaI0YND/Y5rVkLsSHDtfQ+AcUnjGJc0rkVfQ4mvhH/k/wMIteD4V+G/OCf7nMZfYLFA4pGhcfUy8G7/kMiq9/cinY0KzRI2Nr+Pwz5/BYAPx5xAwN70T5trfAaxTiuju7XSpT0iIiIircxms7FlyxazY3QIR6QcwYdlH1IVqGJ0/GgynS3v2RowwLfTgl6P32j84A5k2v4xTNs/PMWglQVejO3/2wqrAhRUBeieFCo0f1fg5ZdiH6NzXGTGN/42dMqUKUyZMiUseX6zrnYdhd5ChsYNDUsrgVx3LnG2OCoDldiwsX/M/vXP9YruRa/oXi0+hzRR4cNQ/mZonHgspM8yNw/w1sYbqfVsBOD9gn8ws+tFu9+Qb8utULsyNPZugvTzdj9h3EGhWyuyWWwNWnA4rfvQUiRzLmz7R2jjwvRzI5RQRNoqFZolbOwBH5c+fikAn448dp8KzWW1QYZnu4h2mP8JtIiIiEhLvPbaaw3uG4ZBfn4+DzzwAAcd1LrFgo6qZ1RPHuv/GOX+cjKdmVjCsIoxxmnlvJHxLFpRSXqMjVOHaHPqfXVgVxdv/FiDPwg5CXay4kJvN1ds8TDv3dLQSufvqnjo+DQS3K3TluTL8i+5df2tGBj0i+7Hnb3vxGpp2bmTHEnc0+cevqn8ht7RvekT3SdMaWWfVS/73dj8QnO2ZceHVImWYONXW9T9tNP45win2jcJ9gQu73Y5r257lWxXNieln9T0F7u6Qdf5EcsmIm2bCs1iulpfEJsVzj4gLixvEkRERETMdPzxxze4b7FYSEtL4/DDD+fuu+82J1QHFGOLCUtfZoCKuiBfb/HQP93Bc6d2CcuczbV69Wq+/fZbhg0bRr9+/UzNsq8GZ7r467GpbC73MyTTiXP7Bt+rC331K50rPQZ55X4S3K2z6dqXFV9iEDr5mpo1FPuKSXOmtXjeDFcGk12TWzyPtFDMiFBP4N/GZgjWgmc9OHPAFsuJ3a7B4b+crYEajsm+pPG+0glHQNnrgAXiJ7Rm4iY5NOlQDk061OwYItLOqNAspttaFaBXsoODu7vNjiIiIiLSYsFgyzdUk9ZT5wsy581i8isD2Kxw08QkBmea085t7dq1XHPNNQQCAV544QXuv/9+cnJCfX7zyv04bRbSYvdtg71IMwyDT9bXUVEXZELvKLol2umW2PBt5qhuLl75vpo6v0HXBBs9k1vvbeigmEG8U/IOANmubJLse9jQTNqf9NkQPSzUIzhmVOufP1AJG68AXz7YkqHb3VjjxjJt4HtAAGx76POePgvix4PFDS71846YYC1Yw7vZo4g0ToVmMZ0vYDBt/xgcNq1mFhERkfbvpptuYs6cOURHRzd4vLa2lrvuuot58+aZlEx2Z1N5gPzKUB/SQBC+2eI1rdD866+/EgiEsvj9ftatW0dOTg6Lvqnk+ZXVWCzwp7EJTOjddoomL6ysZtGKKgA+Xl/HnZNTdjmmZ7KDB49LZVO5n/5pjn3aILClxiePJ8mRxBbPFg5OPBi7tfG3wB999BGPP/44CQkJXH311WRnZ7dazg6nZiVUfwMxw0Ib2kWKxQJxYyI3/06q/FU8W/AstcFaTu1yKpmuzNDX6csPHRAoCbXvSDwKmnq1hVttVyImWAebr4e6NRA1CLLnw770mhaRZmm9f+FFdiMQNLBYLGTFt62VGSIiIiLNtWDBAqqqqnZ5vKamhgULFpiQSPaka4KN9O2rhK0WGJplXiFi+PDhJCcnA5CWlsaQIUMAeP3HGgAMA/67ffx7hmHw1aY6lm6qwzBabyPD77d668c/bvM1eu70WBsjsl1EO1v/LejQuKEcnXo08fbGV5cGg0Huv/9+SktLWb9+PU8//XQrJuxg6tbC5hug9OXQf+vWmp0oLB7Ke4j/Fv+X90vf59b1t4YedOWC5bfWGBZw9TAtn/xO5f9CRWaA2u8a9vNuy4wA1K4BX7HZSUSaRSuaxVS+IDht0KWNXQIoIiIi0lyGYex234lvv/22vogobUeUw8rdRyezPM9LbqKd3qlN39A63FJSUnjggQfYsGEDPXr0ICYmtCqye5Kd77f6AMhN2v1buMeXVfKfH0JF6KP7RTN79B4u2Q+jQ7q7WZEfKjYflOtut3uuWCwW7HY7Xm/oa3E6tfKx2bwbgN9aCAVD9909zUy0Z4YBhgese27luM27bdexsyt0vQ2ql0P0IIhqX33VOzR78p7vt0WGAXkLoOYbsDghewFEDzQ7lcg+6XSF5o8//pi77rqL5cuXk5+fz6uvvrrLhi3SevxBA5vFQlQrXj4nIiIiEglJSUlYLBYsFgt9+/ZtUHALBAJUVVVx/vnnm5hQGpMYZWsz7Sji4uIYOLBhYeHaw5L4zw/VuOwWjh+w+0vyl27y1I+/2lzHbFqn0DypbzS9UhxUeoIMyWy/xVmLxcI111zD008/TWJiIjNnzmzw/Lu/1LD4p1p6JNk5b2Q89t+1/VtZuZIlJUvIdedyUvpJ7bbgHhbRw8HRBXxbQ/+NHm52osb5imHzteDbAnHjIeOyUDuO3Tilyyncvv52vIaXMzPP3PFE1H6hW0cXqIHiRRCsguSTwdnGW8vEDAv18K5ZATEj28efkb8wVGQGMLxQ+ZEKzdLudLpCc3V1NUOGDGHmzJlMnz7d7Dgdis/u5I4LHqkfN0WVJ0hilJXcxE73rSgiIiIdzH333YdhGPzxj39kwYIFJCQk1D/ndDrp3r07Y8a0Ti9R6Vji3VbOHB63x2OGZ7vq22oMz2rdHtO9UsxbBR5OQ4cOZejQobs8nl/h5/7PKjAMWLPNR3a8neP331HwL/OVsWDdArxGaDV0jC2GY1KPaa3YbY89AXIXgndzaMVvW96IrfytUJEZoPIDSDq+0dXXI+JH8NzA5wgYAaJsbfhripRtj0FFaGNNaldDj0fMzdMUiUeHbu2FLTG0qWSgJHTf1YavBBBpRKer7k2ePJnJkyebHaNDCtrs/G/ksfv0mhqfwf5d7DjtnfgTfxEREekQzjrrLAB69OjB2LFjcTg6RvFN2ofzRsYxOMOJYcDYXHM2M9wXhmHgDYCrHbwP8AYMdm49Xedv2Ie63F9eX2QGKPQWtla0JvF4PLhcrfw9YY1qHxvd7dxOwWIH256vBHB25s3k/Dt9X/u3NX6cNJ/VBTl/hor3QivG4w8zO5HIPut0hWZpO8pqA9gscNKgWLOjiIiIiITNuHHj6se1tbX4fL4Gz8fHt05LA+lcLBYLY3P33GO2rSisCnDd2yUUVAY4qm8UF45J2PuLTJSb5GD6wBjeXFNDz2Q7x+wX3eD5bu5uHJZ4GB+WfUiaI42jU9rGCsry8nKuvfZaNm7cyMEHH8yVV17ZLlp6vF38NosKFpHmTOPq3KtJdaZG7mQJkyFQDp61ED8JHBE8VxtmGAarV68mJiaG3Nzc3R+UfHJokzrDAyl/aPlJi/8Z6m0dcwCknNry+ToKZwaknm52CpFmU6FZwsYa8DNm+VsAfD5iMkHbnr+9CqsDHNU3mqP7dcLLjkRERKTDqqmp4corr+TFF1+kuHjXXeMDgYAJqTqPr/M8+IMGB3Z1tYuiWkusL/XhtFnIim9fb+ve+LGagsrQ34PFP9Vy3IAYuia07a/h/0bE8X8jdm1fsrR8Ka8XvU5XV1ce7PUE7/zo4LVvLZw0KEBilLkbni9ZsoSNGzcC8OmnnzJ16lT69+9vaqa9qQ3U8uDmBwkSpMRfwnNbn+OSnEsid0KLBVJmNPnwfE8+/9jyDywWC3/M/CMZrozIZWtFCxcu5J133sFisXDRRRcxadKkXQ+KHgy9FoHhA9vue8U3WdUyKH4uNK5bE1r9HjOi+fMZBgQqwBYHlgju/xT0hnon27RYTqQxbftfc2lXHH4vV/9tFgAn/v1XPHsoNJfVBoh2WDl+QEyHfwMgIiIincvcuXP54IMP+Nvf/sYf/vAHHnzwQfLy8vj73//OHXfcYXa8Du3pryt56btqAI7sE8VFY9v2StmWeHJ5Jf9aVY3FAheNjmdS3+i9v6iNSN6pAOu0Qayzfb4fKPeXc/uG2/EbflZUreDDb/pTVdIXgF9LfNxxVIqp+VJSdpzfarWSmJhoXpgmslqs2Cw2gkYQAIdlRwsib9CLw+Iw9f3jPRvv4ceaH4FQb+47+9xpWpZw+uCDD4DQyuYPPvhg94VmAKsTCEP7EKO24f1g7e6Pa4qgD/LmQ+1KcHaDnDtCBedwq1kFW26GYA2knK5V2CKNUKFZWp1hGBTVBBmU4WR8L61mFhERkY7l9ddf5+mnn+awww7jj3/8I4cccgi9e/cmNzeXRYsWcfrpuiQ2Ur7c5KkfL93s2cOR7d/in0Ib/xlGaFVweyo0H9s/mkpPkI3lfib3jY74yt91JT5+KfYxLMtFakz4zlUXqMNv+Ovvb600+G2dZ165+VcuHH744RQXF/PTTz9x+OGHk5mZaXakvXJZXczNncvzBc+T5kzj9IzQz8tFBYt4YesLJNmTuKnnTeRGNdLeoSUMP/hLwJ4Clt1/n1QGKnc7bu/69u3LDz/8AEC/fv0aPmkYoZXf4RQ7BmIP2tE6I7YFG+XWrgzdALwboeJDSNq3vaOapPSVUJEZQquxk08M9fUWkQb0t0JaXX5lgES3lTmHdNwVJiIiItJ5lZSU0KNHDyDUj7mkJLR7/MEHH8zs2bPNjNbhDctysrEsVPgbmrnnVXcbajewybOJIbFDiLNHYPVbhPVMdvBdQWgDul4p7ettnc1q4czhrfP/fM02L1cvLsEfhAS3lQePSyXBHZ5L67u4ujA9bTqvbnuVbFc2R47oxxNLIWjASYNa2FogDCwWCyeffLLZMfbZmIQxjEnYUXis8lfx/NbnASjxl/Cvbf/i8m6Xh/ekgQrYdBV4N4OrD+TcBtZde56fnXU2f9nwFyxYODvr7PBmMNG8efN4++23iY2NZeLEiTueKPkXFD8L9lTInh/aoC4cLHbIujo8c9lTAAuwfZNOR3p45t3lPGkNz6kis8hudbq/GVVVVfzyyy/199etW8eKFStITk6mW7duJibrHIKGQZU3yCVjExiZ0z42KxERERHZFz179mT9+vXk5uYyYMAAXnzxRUaOHMnrr7/eLi5db8/OPiCOAelO/EGDg/awMd6qqlVc/+v1BAiQ7crmvj734ba1r99NrxufyBs/1uC2Wzi6X/tZzRwOlZ4gPxZ6yU1ykB675xXK3xV48Ye6MFBeF2RdiY+hWa6wZfm/rP/jrMyz6ts5jM8NEjAMkkzuz2ymukAdzxQ8Q5GviOnp0+kb3bdF8zmtTmKsMVQHQ21xku3J4YjZUOVnoSIzgOdnqP4a4sbuctiB8QfywqAXwn9+k8XExDBt2rSGDwZqoOgpwABfARS/AJlhLvCHg6s7ZF4NVf+DqP0hdlRkzpM2E6wu8JdB8kmROYdIB9DpCs3Lli1j/Pjx9fcvvzz0g/Kss87iySefNClV5xAIGvxa4qNrgp2JvdUyQ0RERDqmmTNn8u233zJu3DiuueYajjnmGBYuXIjf7+eee+4xO16HZrFYGLuHAvNvllUsI0CotUGeJ488Tx69ontFOl5YxTitnDK4821IVeUJctkbxWytCuC2W7jr6GS6JzkaPX5Ylot/fluFNwAp0VZ6pTR+bHPt3DM4PkyrpduzZwue5bWi1wD4ruo7nh7wNHZr80sPTquT+T3n86/Cf5HuTGdGxt437/MH/Ty25THW1q7lyJQjmZA8YS8n2bmtiAUcHWOTvxax2EOrun/rnxyJvsfhEjd2tx8MhJXVDWl/jOw5RDqATldoPuywwzAMw+wYndLGcj85CXYeOj6NPqnh/wVPREREpC247LLL6sfjx4/nxx9/ZNmyZfTq1YshQ4aYmEx+MyRuCK9sewUDgzRHGlmuLLMjNYvXbxAwDKIcnae4+Uuxj61VoQ8J6vwGy/M8eyw090pxcM+UJP6Xv4mx2cnEuTrP/yuzlPpL68eVgUp8hg97C0sP+8Xsx3U9rmvy8W8Wv8l/i/8LwI81PzIgZgCZrj30qI4eAhlXQM3K0IpYd88W5e0QrE7Iuh5KXgq1jUjppPsLBKqh5GUwfKGVzHa1ABXZk05XaBZzVHuDWC1w1bhEFZlFRESk06irq6Nbt25q0dbGDIsbxl2972Jj3UYOiD+AKFv7u9pu2WYPt39Yii8I54+M5+j9Okf7jG6JdmKcFqq9BhYL9E/bcy/uoBHk0eKb+db7La9ucHNrr1tb3MphT3w+Hw5H536/Mz19Ot9WfUu5v5wZXWaY8verJlBTPzYwqAvW7f1F8YeFbhH2ZtGbLCleQq/oXszOno3D2oa/X6IHh26d2db7oeqz0NizDnJuNTePSBunj3MlbPw2B/edfR/3nX0fflvDfyyrvAYJbhuHdG9fve9ERERE9lUgEODmm28mOzub2NhY1q5dC8ANN9zA448/bnI6+U2/mH4ckXIESY6kBo+X+8v58/o/c+0v1/JD1Q8mpdu751eG2kEYBjzzTaXZcVpNcrSNu49O4ZwD4/jzUckM6LLnQvMWzxa+rfoWgLpgHR+WfhiRXDU1NcyZM4cTTjiBm266iUAgEJHzNEn5e7B2JmycC75trX76nlE9eWbAMzzQ9wEMDD4p/aTVMxyTegz9o/vjsrg4LvU4ekT1aPUMu5NXl8fDeQ+ztm4t75S8w5vFb5odSfbGm7fTeLN5OUTaCa1olrAJ2B28d8gpu32u1hdkSKYbdye6rE9EREQ6p1tvvZWnnnqKO++8k3PPPbf+8UGDBnHvvfdy9tlnm5hO9ubxLY/zafmnANyy/haeG/icyYl2Ly3GxpptvvpxZ5KdYCc7oWlvZZMdycTb4qkIVADQwx2ZguOHH37ImjVrqLUn8Nz6RIqeX82Nx/cnpbX/bIIe2LoQCIC/CIoXQcalrZsB8AQ9XL/2esr8ZQB4De/e+ySHUZw9jjv73Nlq52sqn+HDYEcrT0/QY2IaaZKkaaFVzRiQfKLZaVpX3c9Q/i44u0LiFNipH71IY1RologzDIM6v0F6J/sFWERERDqnp59+mkceeYQJEyZw/vnn1z8+ePBgfvzxRxOTSVPsfMl9XbCOoBHEaml7iyUuGB1PgttKnc9gxpCYsMzpCxhsrQqQHmPDae8YBYVoWzR39L6DD0o/IMeVw/jk8Xt/UTMkJiYC8GvqBGpdKawqj2Lh5+XMn5gckfM1zgIWKxi/rag25z1Ysa+4vsgM8EvNL61aaI40f9DfrA0Ou0d15+T0k1lcvJheUb2YkjolAukkrBImQMwBQADs+/D32VcE1UvB1QOi+kcsXsQEqmDzDRCsDt232CDxaHMzSbugQrOEjTXgZ/h3HwLw9aDDCNpC317FNUES3VamdJK+cSIiItK55eXl0bt3710eDwaD+Hw+ExLJvjgj4ww21G2g3F/OuVnntskiM0Ccy8r5o+LDNl+1N8jcN0vYVO4nO97GXUendJiN83LcOfwh8w8RPcfYsWOZOXMmN38dR0ZSBjExMZTXBZv8+jXVa3ir+C2yXFmcmH5i87/vrE7ImAvFz4E9BVLP3PWYQHWo16wrF2xxzTvPXmS6MhkUM4jvqr/DZXExLmlcRM7T2moDtcxbO48fa37kwLgDubb7tftccD4z80zOzNzNn4u0XTtvABisg7I3Q4XXhMmhv3O/F6iGjVdAoASwQPZ8iBneWmnDI1C2o8gMDVuIiOyBCs0SNg6/lxvvC/2DeeLff8WzvdBc7TMYnulkTK76M4uIiEjHt//++/PJJ5+Qm5vb4PGXXnqJYcOGmZRKmqp7VHce7f+o2TFa3bLNHjaV+wHIqwiwdJOHCb3b3yaJZjrhhBNIG1bLff8rx2GzcNbwphVxqwPVzFs7j5pgaDW9w+JgWvq05geJGxO67Y6/HDZeDv5CsCVDt3vAkdL8czXCarFyU8+b+KX2F9KcaaRE4Bxm+KjsI36sCV2Z8lXlV3xT9Q0Hxh9ocqow82yE8jfB3gWSjgutkJcd8u8KrVQGqPsVMi/f9Rjflu1FZgADale1v0KzIxtiR0PVF2CNg4QjzE4k7YQKzRJRhmHg8Qfp2sQeaiIiIiLt3Y033siZZ55JXl4ewWCQV155hTVr1vD000/zxhtvmB1PZLey4+1YLKHNBS0W6JoQ3pYL+fn5xMXFERsbG9Z525pDekRx8PYN0C1N7Gda5a+qLzIDFHgLmny+El8Jt62/jS2eLZyUftLeC9Q134aKzBAqhNV8HbECkt1qZ7+Y/SIyt1mS7A03D03YeaVrJNX9HOq/HT0wsucJemHztRAo3/5AoPP1Jd6bul92jD2/7P4YZ06oUOvLA4sdYtrhhxEWC2ReC74CsCeCVR88StPooymJqA1lfhLcNib20Q8lERER6RyOPfZYXnjhBd58800sFgvz5s1j9erVvP766xxxxL4VdD7++GOOPfZYsrKysFgs/Pvf/27wvGEYzJ8/n6ysLKKiojjssMP4/vvvGxzj8Xi4+OKLSU1NJSYmhqlTp7J58+YGx5SWlnLmmWeSkJBAQkICZ555JmVlZc358iVCPv30U84++2zmzJnD1q1bwz5/71QHN4xP5Jj9ornusET6pe3mcvBmuueee5g1axZ//OMfO0WfcovF0uQiM0AXVxcmJIX6FyfYEzg6pel9UF8ufJk1NWuoDFTyRP4TlPpK9/wCV49Q4QsAG7h6NvlcAqMSRjEzcyYHxB3AxV0vpm9038iftOSV0Cr0zddA4cORPVewaqciM+Dd3PixnVXCpB3j+Eb+Tbe6odvdkHUd5D7QPns0Q6jY7MxUkVn2iQrNEjG+gEEgCNcclshhPfWDSURERDq2tWvXYhgGAEceeSQfffQRVVVV1NTU8OmnnzJp0qS9zLCr6upqhgwZwgMPPLDb5++8807uueceHnjgAb766isyMjI44ogjqKysrD/m0ksv5dVXX+X555/n008/paqqiilTphAIBOqPOe2001ixYgWLFy9m8eLFrFixgjPPVA/RtiIQCHDvvfdSWFjImjVreOqppyJyngNz3Jw/Kp5R3cLX8q6kpIQPPvgAgNraWhYvXhy2uTuSS7tdytMDnuYf/f9BblTu3l+wncvqqh/bLDbslr1cSerKga53QMrp0PVWcPdqbuRO64T0E7ix541MStn3n+nNUvnRjnHFx5E9lz0Z4rZvmGmNDvUgloZST4duf4XcByF5D1cQ2GJCrSec2a2XTaQNUD8DiZgKT5AEt5VxPdSbWURERDq+Pn36kJ+fT3p6OgCnnHIK999/P126dGn2nJMnT2by5N2/0TcMg/vuu4/rrruOE044AYCnnnqKLl268Nxzz3HeeedRXl7O448/zjPPPMPEiRMBePbZZ8nJyeHdd9/lyCOPZPXq1SxevJgvvviCUaNGAfDoo48yZswY1qxZQ79+/ZqdX8LDYrFgte5YI7TzuK2LjY0lMTGxfoV8165dzQ3UhiU5kvZ+0O+clH4S27zb2OLZwgnpJxBnb0Jf6Kh+oZu0D1EDwLN2+7gVVsZmXg4pM8AWHyqWyq7cuhJApDHt5zcUaXfK64L0T3eQHB3e/m4iIiIibdFvq5l/8+abb1JdXd3I0S23bt06CgoKGqyUdrlcjBs3js8++wyA5cuX4/P5GhyTlZXFwIED64/5/PPPSUhIqC8yA4wePZqEhIT6Y8RcVquVuXPn0q1bN4YMGcL//d//mR2pyZxOJ7fddhtTpkzhnHPOqf9QRMIj2hbNnNw53NP3Hg5OPNjsOB1P3c9Q8QEEKvd+bKSknQtd/gTpsyHzqtY5pzNTRWYRaRataJaICBqhthlH9Y02O4qIiIhIh1RQENow7Pcrprt06cKGDRvqj3E6nSQlJe1yzG+vLygoqF+FvbP09PT6Y37P4/Hg8Xjq71dUVDT/C5EmGTlyJCNHjjQ7RrPk5ORw3nnnmR1DdqPQW8hr214jwZ7AtLRp2K0qEdSrXg55CwAjtLFb7v1gDV/v8iazWCFhYuufV0SkGfSviISN3+bgoTNuA6AiaCfKYWFIpgn/EIuIiIiYYHcbgO3LhmAtOe/ODMPY63l/f8zujt/TPLfffjsLFixoRlqRvav0BPH4DVJjInNl5FNPPcWSJUvo1asX11xzDdHRnXdxzLy188jz5AFQ7i/nnOxzTE7UhlR/DWy/UsWXB758cDW9f7aISGekQrOETcDu4M2JMzEMg7wSPwPS7eQm6ltMREREOgfDMPi///s/XK7Q5lx1dXWcf/75xMQ0vPz4lVdeCcv5MjIygNCK5MzMzPrHCwsL61c5Z2Rk4PV6KS0tbbCqubCwkLFjx9Yfs3Xr1l3m37ZtW6P9pa+55houv/zy+vsVFRXk5OS0/IuSTu/LjXX8+eMyfAE4eVAMZw5vQs/hfbB27VpefvllAFasWMGbb77JiSeeGNZztBcBI8AWz5b6+5s9m01M0wZFD4Oy16lf0ezI3OtLREQ6O/VolrAyDINN5QHiXVauGpeI26FvMREREekczjrrLNLT00lISCAhIYEzzjiDrKys+vu/3cKlR48eZGRk8M4779Q/5vV6+eijj+qLyCNGjMDhcDQ4Jj8/n1WrVtUfM2bMGMrLy1m6dGn9MV9++SXl5eX1x/yey+UiPj6+wU0kHF5bXYMvEBq/8n34e5w7nc4GK/Wdzs57BabNYmNq6lQAHBYHx6QeY3KiNib2AOh2N2RcDt3u2re2GVVfwfqLYfMN4CuOXEYRkTZGy00lbKzBAN2/+5wMn8Fx5x3JyBy32ZFEREREWs0TTzwR9jmrqqr45Zdf6u+vW7eOFStWkJycTLdu3bj00ku57bbb6NOnD3369OG2224jOjqa0047DYCEhATOPvtsrrjiClJSUkhOTmbOnDkMGjSIiRNDPT/79+/PUUcdxbnnnsvf//53AGbNmsWUKVPo169f2L8mkT3Jjrexcntr8Kz4lr1d/f7779m8eXP95pYAXbt25fzzz2fJkiX07t2byZMntzRyu3ZO9jkck3oM0bZoEuzh+yCsw3D3Cd32hRGE/DvBqAMvUPQUZF6+15d1ZnV1dXzyySckJyczYsQIs+OISAuo0Cxh4/B5+Ou9JwEQvM3EXXlFREREOohly5Yxfvz4+vu/tas466yzePLJJ7nyyiupra3lggsuoLS0lFGjRvH2228TF7ej3cC9996L3W7n5JNPpra2lgkTJvDkk09is+3of7to0SIuueQSJk2aBMDUqVN54IEHWumrNIff76e6ujqsq8yl5c45MJ7EKBtV3iAn7B+z9xdst77Ux5ebPOyX5mBIpovPPvuM22+/HQi1q1m4cGH96uWjjz6ao48+OiL5I8qbB5X/A1cPiD0wbNNmutQSIrwMILDTfb9ZQdqNG264gR9//BEIfdB57LHHmpxIRJrLYhiG0donraioICEhgfLy8g59md0hD+fhDUB6bGQ2sWhrXJ4aXj6vV+hOVRXENP0XQxEREekYOsvvedJQe/tz37p1K1dffTVFRUWMHTuWq6++ulU2bpTIKKoOMPvfRdT5DSwWuOWIJP7373/w5ptv1h/z8MMPk52dbWLKFgpUwvrzIVARup91HcSONjeTkFeXx2bPZgbFDiLattOmkpWfwLYnwJ4EGXPBmWFeyDbO4/E06JM+atQorr/+ehMTicjuNPV3PTXQlbAJtv5nFiIiIiIi+2zJkiUUFRUB8Nlnn7Fu3TqTE3VO4VrztLHMT53f2D4n/FLs58ADD8RqDb3d7d69e6MbW7YbvoIdRWaAup+aP5cRgNLXoeg58Je3PFsn9X3V91z000Xcsv4W5v48F2/Qu+PJuEOg5z9CPZ5VZN4jl8vF0KFD6++PGjXKvDDS/hgGVH4KFR+HfraJ6dQ6Q8LCMAzyyvWXWkRERETavvT09Pqx0+kkMTHRvDCdRe0a8G+DmAPA6ua5gud4ceuLpDvTWdBzQYvaN+yX5iA73kZeRYBYp4VROS6yEw7gvvvuY8uWLQwbNgy7vZ2/9XXmgqs3eH4Bixtid79RZ5MUPcVXHz3Bf94rIDv7Mc6+cnGb3xTRMAwqKiqIjY1t0PbHTEsrluI3Qm0xNno2stmzmZ5RPU1O1TQfln5IkbeII1KOaBO9uefNm8eyZctISkpiv/32MzuOtCfbHoWy10PjmuWQcZm5eUSFZgmP/MoAUVofLyIiIiLtwJFHHklNTQ3r169n4sSJJCcnmx2pY6v4CAr+Ehq7+1GeeT3/3PpPAPK9+bxc+DIX51zc7OmjnVbunZLCr8V+uibYSIwKFSJ79OhBjx49Why/TbA6IefPoZXMjkxwpDR7qsri1dzx6C94fUG+XfMD8d1f5PQzzghj2PAKBoPceuutLF26lIyMDG6//XZSU1PNjsXA2IG8uu1VDAxSHClktJOVy/8q/BdP5j8JwHul7/G3fn8zvXWQw+FgzJgxpmaQdqpmxY5x9YrGjpJWpEKztJg/aFDtDXLpqLi9HywiIiIiYjKLxcIJJ5xgdozOo3rpjnHdGpzBOlwWFx7DA0C8vWl9vet8QX4q8pEdbyclpuGq1iiHlYEZbXtV7r6qrq7mjjvuYP369RxzzDGceuqpED2wxfN63Ifi9T0TumNPo6q6usVzRtJPP/3E0qWh76GCggLefffd0P+L5gpUg+fX0CrxFqzmPTD+QG7rdRsb6jYwKn5Uwx7NbdhPNTvarmz2bKYmWEOMTfsrSTsVMwq8m0LjWLVdaQtUaJYWy68MkBlnZ0p//eMkIiIiIiK/Ez0cKj8OjV29iHJ24foe1/NK4StkuDI4Jf2UvU5R5wsy580SNpT5iXJYuHNyMt2THBEOHgZGMLSRny0e9nHV6GuvvcaKFSsAWLRoEQcffDBdu3ZtcaTU7sdyyh/m8fK/XiWza2+mTZvW4jkjKTk5Gbvdjt8falPRon7bgUrYeBn4tob+THJa1kN5YOxABsa2vPhfz1sQWrUeNQAckVm1fVjSYXxR/gVBgoyKH6Uis7RvaWdB9GAw/KHWTGI6FZqlRcpqAxiGwezR8STFO+HOO0NPONrBL30iIiIiIhJ5CRPAkQa+bRA7BiwWhsYNZWjc0CZP8WuJnw1loUJjrc/gi42etl9oDlTCpqvBuxGiBkH2ArA2PbNjp/dUFoslrH2mz/i/Czj9rNmmt0xoivT0dK6//no+/PBDevfuzfjx43c55r8/1rD4pxp6Jtu5cHQCTnsjX1ft96EiM4Q2V6xZDs5jIph+H3jzYMOlYNSFiuDd7m9Ri5TGjEkYw0P7PUSpr5T+Mf3DPr9Iq4sZZnYC2YkKzdIi1T6D7kkOThoUE/qEfu5csyOJiIiIiEhbEz24RS/PjrcR67RQ5TUA6JvaxovMEFrF7d0YGtd+BzXfQmzTV9wde+yxbNy4kXXr1nH00UeTkRHeHsDtocj8mxEjRjBixIjdPpdX7ufvSyswDFhf6qd7koNp+zeyStfZHSwuMDyANbTBYltRszJUZIZQEbxuDThasOnjHmS5sshyZUVkbhGJsNofoey/4MyG5JPA0jY2SP2NCs3SbGW1Aao9BrmJ9nb1S4qIiIiISFN9V+Dlo7W19E11MKlv++jB2qZULYWiJ8CWABmXgyO9WdMU5a1j/8KPqIjryYwjxzAs2xXmoBFgT9vpjmWfWyG4XC4uv/zy8GbqgAIGGMaO+76A0fjBzgzIuTO0ktk9AKL6RT5gU0UNAIsTDC9YY8Ddx+xEItLWBGog70YI1oTuW+yQfKK5mX5HhWZplkpPkOKaIKcOieFPB23fQCEQgK+/Do2HDwdb2/pURURERERkX2yrCnDjuyX4ArDk51qiHBYO6RFldqz2wzAg/67tqzQ3w7Z/QNbV+zxNdXU1119/PdXbN63bnDaLYdnHhjlsBMSOhPQLoHYVxI4FV3ezE3VI3RLtnDo4hrd+qqVXsp0p++3lAyF3z9CtrXHlQrf7oO5HiBoYajcjIrKzYNWOIjOAr9C8LI1QoVmapagmwMgcFzccnoTdtn01c10djBwZGldVQYw2FRARERGR9mtbdQBfYMf9LZWBxg9uI6r8VQQIkGBPMDvKbuxhpekeVFRU1BeZAfLy8sIVKPISJ4duElGnD4vj9GFxZsdoOVdO6CYisjuOdIg/AireAVsiJE4xO9EurGYHkPbHMAy8foMB6Y4dRWYRERERkQ6mb6qDwRlOAFJjrIzv2bZXM/+v7H+c+cOZnPn9mbxa+KrZcUJ7uGTOAUc2uPtD6sxmTZORkcHBBx8MQFxcHEcddVQ4U4qIiLQfGZdAr0XQ8wlwdTM7zS60oln22daqAAluK5P6qEediIiIiHRcdpuFm49IYlt1gKQoG057215k8cq2V/AbfgBeLHyRaenTTE4ExI4K3VrAYrFw5ZVXMnPmTOLj43G73WEK1zmtrV3Lw5sfxmaxcUHXC8hxawWtiEi7Yos3O0GjtKJZ9klZXZBan8GFY+IZmtUONuAQEREREWkBq9VClzh7my8yA2Q4M+rHmc5ME5OEn8ViIT09vXMUmQNVUPwilL4B2z84CKd7N97L6prVrKpexcJNC8M+v4iIdF5a0SxNFjQMCqv8nDwolrOGd4D+VyIiIiLSLhmGwRs/1rC5PMCkPlH0SnGYHanVffLJJyxcuBCXy8W1115L//79ubDrhaQ6UvEEPZzU5SSzI0pzbbkFar8PjX15kH5eWKf3Br31Y0/QE9a5RUSkc9OKZmmyouogsU4rfxgeh8XS9ld0iIiIiEjH9N8fa3hkaSVvrqnhurdLqPYGzY7U6v7+979TW1tLWVkZTzzxBADRtmhmZs3k/K7nk+JIMTlh21JcHaCouu1v5ghA3S87jX8N+/QXdr2QdEc6mc5Mzu96/i7PF3oLKfGVhP28Ellbtmzhuuuu48orr+Tnn39u+KQRBKN5m3GKiOwLrWiWvQoEDTaW+3FYLZw8KIZeyfq2ERERERHz5FXsKBhWew3K64LEODvXGprY2FjKy8vrx9K4t9bU8NCXFQDMOjCOKf1jTE60FwmToOx1wAIJR4R9+sFxg3l8wOO7fe7lrS/zVMFTWLFyac6ljE8eH/bz7zPDgIp3wV8S+n9jTzI7UZv04IMPsnLlSgDuvvtuHn744dATFR/D1r+CxQaZV0PMcBNTtoDhh7K3wPBAwtFg055RIm2RKoayR76AwbpSH90S7Fx9WBKH93I3vprZ4YAbb9wxFhERERGJgEl9ovhoXS2VHoOxuS4y42xmR2p1V199NU8++SQul4tZs2aZHadNe/X76vrFnP/+oabtF5rTZ0H8BLC6wZkdnjn95VD6L7A4IPlEsEbt9rBXtr0CQJAg/yn6T9soNJe8CMXPhsaVH0L3h8xM02Z5PDvaoHi9O9qjUPQPMLxgAEVPt99Cc+HDUL4kNK75FrrebG4eEdktFZqlUYZhsLnCT99UJwunptA9aS/FY6cT5s9vlWwiIiIi0nn1SHbw+PQ0yuuCdIm1dcq2bt27d2e+fvdukpwEO/mVgfpxu+DuFd758m/fqe9zAWTO3e1hOe4cfqj+ITR25YQ3Q3N5dmol4t0MwbpQEV4amDVrFn/5y1/w+XxceOGFO56wJYC/ePs40ZRsYRHhljIiEh7t5F9ZaW3+oMH6Uj/RDgvTB0bvvcgsIiIiItJKvH6DfyyrZHN5gGP7RzM2V0UnadzlhyTwr1WhVc3TB7bx1cyR4t28+/HvXNv9Wl4pfAWn1cn0tOmtEKwJ4idA1VdAAOIOUZG5EX379uWRRx7Z9YnMq6HoqdBq9rSZrR8sXBKOgMJfd4xFpE1SoVl2ETRCReaeyXbmT0jigK6uJr4wCKtXh8b9+4O1c/XJExEREZHW8cr31Sz+qRaAH7d5efKkdBLc+t1Tdi9m+4bmnVrS9FALBayQdHyjhyXYE5iZ1caKkbGjofvDECgHd1+z07Q/zkzIutrsFC2XeAxEDQ61AQn3in8RCRsVmmUXBZUBUqKt3HREMiOym1hkBqithYEDQ+OqKojppKsFRERERCSiqr3B+rE/CB6/YWIakXYgeVpoNbDFDvZEs9PsO2cGkGFuBl9RqAWJrwCST4WkY83N0xm1lXYuItIofewvu6j2BpnUO2rfiswiIiIiIq3k+AEx9Eiy47DByYNiSI/tfJsBiuwzR2r7LDK3FSUvQt1PEKiAbY+G/tsc/nLYdB2sPRvKFoc3I0Dl57DpGtj6IAS9ez9eRCSMtKJZGvAHDMDC/hlOs6OIiIiIiOxWSoyN+6emmh1DRDoTy07vkS02oJkfcJW8CLUrQ+PCv0HsGLAntDgeECpiF9wJhh9qV4E9BVJODc/cIiJNoEKz1CutDVBUHSQ3ya7VzCIiIiIiIiK/SZkB/mLwbYXkE8HW3FaRloZjSxgvNDc8oSLzbwJV4ZtbRKQJVGgWAAzDoLAqyLT9o7l2fJI2UxERERERCaNqb5CNZX5yE+1EO/W7dnuyoXYDALlRuSYnEVPZYiDrqpbPk3IK+LaALx+STgRbGDeqdKRD8slQ+go4uu5x40cRkUhQoVkAKKkNkhhl4azhcSoyi4iIiIiEUUlNgCveLKaoOkh6rI17jknR79ztxItbX+SZgmcAOCvjLE7scqLJiaTds8VB9rzIzZ96ZugmImIC/XYjANR4DXokORjQRb2ZRURERETC6ZstXoqqgwAUVgVYscXTpNcVeYt4Jv8Z3ix6E8MwIhlRGrGkeEn9+O2St8M6dzAY5OOPP+bjjz8mGAyGdW5pY4I+8OY3bGshItIBaUWzAOANGHRLbOG3g8MBc+bsGIuIiIiICD2S7disEAiC3Qq5SXv/vdswDK799VryvfkAVPgrODVDm3q1tt7RvSksLwSgV1SvsM790EMPsXjxYgC+/fZbLr744rDOL21EoBI2zgVfHrh6Qs4dYI0yO5WISESo0CwABAyDeJdl7wfuidMJd90VnkAiIiIiIh1Ez2QHtxyRzLf5HoZlueietPdFGXXBuvoiM8C6unWRjCiNuLzb5exXtB8Ax6QeE9a5V6xYUT/+9ttvwzq3tCFVn4eKzACetVD9NcQdZG4mEZEIUesMAcBqsZAao88dREREREQiYWCGk9OHxTW5VV2ULYpxieMAsFvsHJF8RCTjSSNcVhfT0qcxLX0aTmt42wyOGjWqfjx69Oiwzi1tiCNrpzsWcGSaFkVEJNJUWRQMw8AwIK6lK5qDQdi4MTTu1g2s+hxDRERERKS5ruh2BSekn0C8LZ5UZ6rZcSTMzjnnHIYPH45hGIwYMcLsOBIp0QMh8yqo+RZiRoK7p9mJREQiRoVmobwuSKzTwgHZrpZNVFsLPXqExlVVEBPT8nAiIiIiIp2UxWKhZ5SKUh3Z8OHDzY4grSHu4NCtnXnzzTdZvnw5Bx54IEcddZTZcUSkHVChWSivCzIk00W/NG3gJyIiIiIi0tEZhoHF0sIrWk3i9/spLi4mJSUFu10ljUhZsWIFDz30EABLly6la9euDBw40ORUItLW6adyJxc0DDwBg4FdHO32Fw0RERERERHZO3/Qzx0b7mBpxVKGxA7hhh43hL33dCRVV1dzzTXXsG7dOnJzc7njjjuIjY01O1aHVFpa2uB+WVmZOUE6g8r/gS8f4g4Dh9okSfumJrqdXHFNkJRoG38YHmd2FBERERERaaNWV6/mtvW38VjeY3iDXrPjSDMtrVjKlxVfYmCwomoFn5Z9anakfbJs2TLWrVsHwIYNG1i6dKnJiTqusWPHsv/++wMwePBgRo4caXKiDqpsCeTfAUVPwaarIOgzO5FIi2hFcyfm9RuU1AQYm+smM17fCiIiIiIisitv0MuCtQuoDlYD4LA6OCvzLJNTSXPE2+Mb3I+zh2HBkWcT5N8JwWpIPw9iR7V8zkZkZmZisVjqW39kZmZG7Fydncvl4o477sDj8eBytXA/p8b4S8G7Cdx9wBoVmXO0dXVrdoz9hRAoA2uaaXFEWkrVxU7KHzBYV+pjWJaLq8Ylmh1HRERERETaKE/QU19kBijxlZiYRlpiYOxAzs06l6UVSxkaO5QD4w9s+aTbHgfv+tC44F7o/XzL52xE3759ufrqq1m+fDnDhg2jf//+ETuXhESsyOzNg41zIFgFjmzodg/YoiNzrrYs7lCo/AAMP0QNBrtaZ0j7pkJzJ1VaFyQ91sbCqamkx9rMjiMiIiIiIm1UnD2Ok9NP5sXCF0m2J3NC2glmR5IWmJo2lalpU8M3ocW++3GEjB07lrFjx0b8PBJhVV+EiswAvjyo+wlihpoayRQxQyH3IfBvg6j+oL2zpJ1TobmT8gUMkqJs4S0y2+1wwQU7xiIiIiIi0iGcmXkmp3Q5BYdFm4jL76TPgq11EKiCtLPNTiPthbsvYAGMUNsMZ1ezE5nHmRG6iXQAqgZ2UrU+g/5pjvBO6nLBgw+Gd04REREREWkTnFan2RFM8e233/Lpp5+y3377MWHCBLPjtD2OdOh6i9kppL2JHhT6vqn9EWJHgkMtI0Q6AhWaO7E+qZ3zF0UREREREZGmyM/PZ/78+fj9fhYvXkxsbCyjRkVuszuRTiV6cOgmIh2G1ewA0rp8AYNfS3xEOSz0Tgnz5wyGAdu2hW6GEd65RUREREREWtm2bdvw+/319zdv3mxiGhERkbZNheZOZlO5n17JDv5ydAoTe0eFd/KaGkhPD91qasI7t4iIiIiISCvr378/AwYMACAtLY1x48aZnEhERKTtUuuMTqTOH1plfNGYeMb3CnORWUREREREpINxOBzcdtttbNu2jeTkZJxOtR8UERFpjArNnUhZbYAusTbG9XCbHUVERERERKRdsNlsZGRkmB1DRESkzVPrjE7EE4BuiXbcDv2xi4iIiIiISJj4y2DDpfDzNNj2uNlpRETEJKo4dhJbK/34AgZDMnSpl4iIiIiIiIRR2evg+RUMP5T+GzybzE4kIiImUOuMTqCiLkit3+BPY+OZeUC82XFERERERESkI7HG7HTHBlbtCSQi0hmp0NwJlHuC9EtzcN6oeCwWi9lxREREREREpCNJmgr+beBZDwmTwZFqdiIRETGBCs0dXHldkEpPkJRoW+SLzHY7nHXWjrGIiIiIiIh0fBY7pJ9ndgoRETGZqoEdWKUnSHFNgGP6RTN7dCu0zHC54MknI38eERERERERkU7g/ZL3WVm1klEJoxiTMMbsOJFhGFD9JWCFmANBV2KLtFsqNHdQhmFQ6QmSFGXlnmNSsNv0g1pEREREpDkMw+CTsk8o95czIXkC0bZosyOJSCewonIF9266F4D3S9/nvr730TOqp8mpIqDwQShfEhonHgfp5+z7HLVrIP92CNZBlwsh7pDwZhSRJrGaHUDCr9ob5OdiP0EDDsp1t16R2TCgujp0M4zWOaeIiIiISIS9sPUF7tp4F49seYQb195odhwR6SQKvAX1YwODQm+hiWkiqHrZ7sf7ouhJ8BdDsBq2PhSWWCKy71Ro7oDyKwMc2t3NkyelccdRya134poaiI0N3WpqWu+8IiIiIiIR9H319/XjNTVrCBpBE9NIZ1Lpr6QuUGd2DDHJQQkHkePKAaBfdD+GxQ0zOVGERI/YMY4Z0fhxe2Ld6UoTW0zL8ohIs6l1RgcSNAwKqwJYLTClfzRDMl1mRxIRERERafcOTTyUb6u+xcDgoISDsFq0Xkci78WtL/JMwTO4rW6u634dQ+OGmh1JWlmcPY77+95Pmb+MZEdyx/3Z0+WiUIHZYoWYUc2bI302bLNCsBZSZ4Y3n4g0WQf9KdX5+IMGvxb7cdktzB4VzxG9o8yOJCIiIiIRNn/+fCwWS4NbRkZG/fOGYTB//nyysrKIiorisMMO4/vvv28wh8fj4eKLLyY1NZWYmBimTp3K5s2bW/tLadOOSDmC+/rex809b+bK3CvrHzcMg0/LPuXD0g8JGAETE0pHYxgG/9z6TwDqgnX8q/BfJicSs9itdlKdqR23yAyhzf/ixkLs6OZvBOhIhazroOst4O4V3nwi0mQd+CdV57G10s/aEj89ku08ekIaF41NINqpP1oRERGRzmD//fcnPz+//vbdd9/VP3fnnXdyzz338MADD/DVV1+RkZHBEUccQWVlZf0xl156Ka+++irPP/88n376KVVVVUyZMoVAQIXTnfWM6snQuKFYdiqCPL7lcf684c/cvfFu7t14r4nppKOxWCykO9Lr73dxdjExjYiISNOodUY7YRgGvgB4gwa+gIE3AL6AQZ3fwGW3cPGYeE4bGktytM3sqCIiIiLSiux2e4NVzL8xDIP77ruP6667jhNOOAGAp556ii5duvDcc89x3nnnUV5ezuOPP84zzzzDxIkTAXj22WfJycnh3Xff5cgjj2zVr6W9WVG1YrdjkXCY33M+LxW+RKwtltO6nGZ2HBERkb3Sstc2zDAMNpf7+bnYxy/FfrZU+qmoC+IPQozTQt9UB5P6RHHVoQlcOCZeRWYRERGRTujnn38mKyuLHj16cOqpp7J27VoA1q1bR0FBAZMmTao/1uVyMW7cOD777DMAli9fjs/na3BMVlYWAwcOrD9mdzweDxUVFQ1undGo+B29REfHjzYxiXREma5MLsm5hD9m/RG3zW12HBERkb3SiuY2yDAMSmqDFNcESYm2Mnt0PN0S7KREW0mJsZESbSPeZWlw2Z6IiIiIdD6jRo3i6aefpm/fvmzdupVbbrmFsWPH8v3331NQUABAly4NL7nv0qULGzZsAKCgoACn00lSUtIux/z2+t25/fbbWbBgQZi/mvbnzMwzGRQ7CJ/h44C4A8yOIyIiImIqFZrboOKaILV+g5MHxXDGsFj6pTnNjtQ0NhuceOKOsYiIiIhE1OTJk+vHgwYNYsyYMfTq1YunnnqK0aNDK2x/vzjBMIy9LljY2zHXXHMNl19+ef39iooKcnJymvMltHtD44aaHUFERESkTVChuY0IGgbVXoPS2iC+gMHkftHcPCnZ7Fj7xu2Gl14yO4WIiIhIpxUTE8OgQYP4+eefOf7444HQquXMzMz6YwoLC+tXOWdkZOD1eiktLW2wqrmwsJCxY8c2eh6Xy4XL5YrMFyEiIiIi7ZJ6NLciwzDw+g0qPUGKawJsqfCzvtTHT0Ve1pb4qfQE6ZZo59rxidw6KWnvE4qIiIiI7MTj8bB69WoyMzPp0aMHGRkZvPPOO/XPe71ePvroo/oi8ogRI3A4HA2Oyc/PZ9WqVXssNIuIiDQQqISSV6DifTAMs9OIiEm0ojmCbFYLhRWhArJB6GetwwYumwWn3UJGnI2seDvdEmz0T3cyNNNFz2Q7Vqt6L4uIiIjI3s2ZM4djjz2Wbt26UVhYyC233EJFRQVnnXUWFouFSy+9lNtuu40+ffrQp08fbrvtNqKjoznttNMASEhI4Oyzz+aKK64gJSWF5ORk5syZw6BBg5g4caLJX520xJcb6yiuCTKup5sYZ/taX/TTTz+xZs0ahg8fTnZ2ttlxRKQpNl8PntBmtPgKIeVUc/OIiClUaI6gGw5PoqDSD4R64yVHWUmLtZEeYyM1xkqUo339wrdX1dUQGxsaV1VBTIy5eUREREQ6uM2bNzNjxgyKiopIS0tj9OjRfPHFF+Tm5gJw5ZVXUltbywUXXEBpaSmjRo3i7bffJi4urn6Oe++9F7vdzsknn0xtbS0TJkzgySefxKY9N9qt11dX88jSSgCW/FzDfVNS2s1G4mvWrOGqq64iEAgQExPDgw8+SEpKitmxRGRPgr4dRWaAup/MyyIiplKhOYIm9I4yO4KIiIiIdGDPP//8Hp+3WCzMnz+f+fPnN3qM2+1m4cKFLFy4MMzpxCyrtnrrx2tL/NT6DKKd7aPQvHr1agKBAADV1dWsX78+ooVmX9DHVxVfkexIZr+Y/SJ2HpFW4yuEbY8DBqTOBGfmXl/SYlYHxB4MVZ8CFogbF/lzikibpEKziIiIiIhIB3JQrpvPN3owDBiW5SS6HbXOGDFiBM899xy1tbWkpaXRt2/fiJ5v/rr5rKxaCcAlXS/hiJQjInq+Ts+7Gaq/gagB4O5ldpqOqeA+qP0uNPYXQ7e7W+e8mVdC7RSwxYMrp3XOKSJtjgrNIiIiIiIiHcihPaLommCnpCbI0Eyn2XH2SU5ODg888ADr169nv/32a9DmJZx8AYOC6hq+rVzJb11FllYsVaE5knyFsPEKCNaAxQ45f1GxORICFbsfR5rFAtH7t975RKRNUqFZRERERESkg+mZ7KBnstkpmic9PZ309PSIzV9cHeCqxSVsrQqwzfkHUvd7Fqs1yNC4oRE7pxDq4RusCY0NP9T9qEJzJKTNhPy7wAhA2tlmpxGRTkaFZhEREREREek0PlxXy9aqUB/oVM9YjovqwoHZcQyLG2Zysg7O3R9syRAoAWs0RA81O1HHFDMCev0zNG4nm4CKSMehQrOIiIiIiIh0GplxO94GO202js0a2+AxiRB7AuTeH1rJ7OoFjlSzE3VcKjCLiEn0r6mEj80GRx+9YywiIiIiItLGjM11c9GYeNZs83FIDzeZ8Xpb3GrsCRA7yuwUIiISIfoXNYLuueceNm7ciKUzfZr4267Q11zT6CGGYVBTU0NVVRVVVVX4fL7dHmexWMjMzOTxxx+PRFIREREREemkjuwbzZF9zU7R8a1atYqNGzcyevRokpPbadNwERFpMhWaI+jVV1/l559/JiUlxewobUIwGKSyspKYmBjsdnv9zWazNbi/8+PZ2dlmxxYRERERkXausrKSjRs30r17d2JiYsyO0yksXbqUW265BcMwePnll/nb3/6G2+02O5ZI51W3NtRWxdXD7CTSganQHGG5ubkR3TG5PSkqKiI+Pp6rr76a9PR04uLi6m+xsbG4XK7OtfpbREREREQirqioiMsuu4yysjK6dOnCPffcQ3x8vNmxOrzvvvsOwzAA2LZtGwUFBXTv3t3cUCKdVfE/ofi50Dj1D5B8krl5pMNSoVnCxuX38+w77wBwxhFH4LGHvr2qq6vJz8/HarVy0kknMW3aNDNjioiIiIhIJ7Js2TLKysoA2Lp1K6tWrWLs2LHmhuoERo4cyRtvvIHf76dbt25kZWWZHUmk8yp/Z6fxuyo0S8So0Cxh5Q4E6sder5eKigpKSko45JBDmDFjBocccoiJ6UREREREpLPp2bMnVquVYDCIw+EgNzfX7EidwqBBg7j//vvJy8tj8ODBOJ1OsyOJdF7uPlC1bfu4t7lZpENToVnC5rfLogB+/fVXvA4HiYmJTJ48mXnz5mnzBxERERERaXV9+/bl1ltvZdWqVQwfPlz7wLSinJwccnJyzI4hIhlXQPkAwAIJR5mdRjowFZolLAKBAOvWrau//8c//pGhBx3EkCFD1P9MRERERERMNXDgQAYOHGh2DGnnXtz6Ip+Xf86g2EHMzJzZJvcY2rRpEy+88ALx8fGcccYZREdHmx1J2gKrE5KOMzuFdAIqNEuLBYNB1q1bR5+uXeGnnwC4+OKLQbs5i4iIiIiISAewqmoVzxQ8A8Avtb/QN7ovBycebHKqXc2fP5/CwkIA6urquOSSS0xOJCKdidXsANJ++f1+8vPz+eWXX8jMzOSWW24xO5KIiIiIiIi0NYGaVj9lobeQLZ4tYZuvLljX4L4n6Anb3OFiGAYlJSX194uKikxMIyKdkQrNss8Mw2D9+vWsX7+e6Ohozj//fBYtWsTgwYPNjiYiIiIiIh1cMBg0O4I0VdALm66FX0+BjXPgd8XaSFlcvJhzVp/DeT+exwtbXwjLnCPiRjAxaSIx1hjGJoxlXOK4sMwbThaLhTPPPBOLxUJ0dDQnn3yy2ZFEpJNR6wzZZ+Xl5TidTq655hqOPvpoEhMTQ0/U1sK47f/YWvUZhoiIiIiIhE9lZSXz5s3j119/5bDDDuOyyy5rkz1yZSfVy6D2u9C4bg1UfgoJEyN+2v8W/ReD0Gb1bxS9wSldTmnxnBaLhT91+xN/4k8tniuSTjjhBI4++mjsdjt2u0o+ItK6VA2UfeLxeNi6dSsHHXQQM2bM2FFkBoiKgg8/DN2iokxKKCIiIiIiHdHbb7/NL7/8gmEYfPDBB/z4449mR5K9sSf/7n5Kq5y2u7v7bsedhdvtVpFZREyhnzzSZMXFxRQXF3PggQdy1VVXafWAiIiIiIi0moSEhPqxxWIhLi7OxDTSJFH7QZdLoXopRA+BmGGtctqLci4ix52Dz/BxXOpxrXJOERFRoVmaqLq6mrKyMmbOnMmFF16oX+pERERERKRVTZgwgYKCAn766SfGjx9P165dzY7UadX6grywspo6v8GJA2NIjbE1fnDChNCtFbmsLk7uov7EIiKtTYVm2SvDMNi6dSsDBw5k7ty52GyN/BJRXQ3du4fG69dDTExrRRQRERERkQ7OYrFwxhlnmB1DgIe+qOCDtaGN/dZs83LvlFSTE4lIZ1RSUsL//vc/srKyGDFihNlxBBWapQny8vKIjo7mjDPOaLzI/JuiotYJJSIiIiIiImHz6aef8u9//5vs7Gxmz56N2+1u9NgtlYEd44pAo8eJSAdT8x2ULwZnN0g+CSzmbf3m9Xq56qqrKCgoAOCKK67gsMMOMy2PhGgzQNkjwzCoqanhvPPOY+rUqWbHERERERERkTCrqKjg7rvvZs2aNbz//vu89NJLezx++v4x2K1gscApg2NbKaWImCpQAXkLoPJjKH4Wyt4wNU5xcXF9kRng+++/NzGN/EYrmmUXPp+P8vJyKioqCAQCJCcnM3LkSLNjiYiIiIiISAT4fD78fn/9/bq6uj0ePybXzTMnp+MPGiRG7eWqVxHpGAIVYHh23PcVmpcFSE9Pp1+/fqxZswabzcaYMWNMzSMhKjQLhmFQVVVFWVkZdXV1WK1WEhISOPjggxk7dizDhw9n4MCBZscUERERERGRCEhJSeEPf/gDL7/8MtnZ2UyfPn2vr4l16QJpkU7F2RXixkPlB2BPhcRjTI1js9m49dZb+e6778jIyNAGsW2ECs2dXH5+PlVVVURHR5Obm8uhhx7K8OHDGTp0KElJSWbHExERERERkVZw0kkncdJJJ5kdQ0TasszLIf1csEaDxfyrGVwuFwcccIDZMWQnKjR3YsFgkKqqKv7v//6P448/nr59+2K16lNpERERERERkQ7DVwieDRC1H9jizE4j7Z2+h2QPVGjuxAoKCkhISODUU0+le/fuLZ/QaoXfPklSwVpERERERETEXJ6NsPEKMOrAng65fwWbNnAUkchQobmTKi8vx+fz8ac//Sk8RWaAqCj46qvwzCUiIiIiIiIiLVO9LFRkBvAXQt1PEDPc3Ewi0mGp0NzJ+P1+NmzYgMViYcyYMZx55plmRxIREREREWBlvocnl1cR57Jw8dgEUmPM738pIu1cVH/ACgTBGgOu7iYHEpGOrFP2N/jb3/5Gjx49cLvdjBgxgk8++cTsSK2mqKiI9PR0/vKXv/Dggw9isVjMjiQiIiIiIsAdH5Xxc7GPr7d4efSrCrPjiEhHENUfcu6EtHOh291gTzY7kYh0YJ2u0PzCCy9w6aWXct111/HNN99wyCGHMHnyZDZu3Gh2tFZRV1dHz549mTx5Mi6XK7yT19RA9+6hW01NeOcWEREREenADMPAH9xx3xcwL4uIdDBR/SBpKjizzU4iIh1cpys033PPPZx99tmcc8459O/fn/vuu4+cnBweeughs6NFXF1dHX6/n0MPPTQyJzAM2LAhdDOMyJxDRERERKQDslgs/GlsAinRVron2Zk5Is7sSCIiIiL7pFP1aPZ6vSxfvpyrr766weOTJk3is88+MylV68nPz2fw4MGccsopZkcREREREZHfOai7m4O6u82OISIiItIsnWpFc1FREYFAgC5dujR4vEuXLhQUFJiUqvX4/X569+5NVFSU2VFERERERERERESkA+lUhebf/H4DPMMwOvymeIWFhTgcDgYNGmR2FBEREREREREREelgOlWhOTU1FZvNtsvq5cLCwl1WOXcklZWVVFVVcdFFF6lthoiIiIiIiIiIiIRdpyo0O51ORowYwTvvvNPg8XfeeYexY8ealCqy/H4/+fn5HHjggcyaNavDr9wWERERERERERMFvVD3KwRqzE4iIq2sU20GCHD55Zdz5plncsABBzBmzBgeeeQRNm7cyPnnn292tLCrrq5m8+bN7Lffflx33XWRLzJbLDBgwI6xiIiIiIiISHMEaiD/dqj7BRImQdrM5s9lGIABlk611s4cwVrYOBe8G8CWDN3uBkeq2alEpJV0ukLzKaecQnFxMTfddBP5+fkMHDiQN998k9zcXLOjhd2WLVsYN24ct956K+np6ZE/YXQ0fP995M8jIiIiIiIiHVv5m1CzIjQufQXixoG7577PU7MSttwGhhe6XATxh4c1pvxOzapQkRkgUAJVn0PSseZmEpFW0+kKzQAXXHABF1xwgdkxIqqmpgar1crUqVNbp8gsIiIiIiIiEi4W1853wOps3jxFz0CwOjQufEyF5khzZoPFAYYPsICru9mJRKQVdcpCc0dXXFxMSUkJ48ePZ+LEiWbHERERERERkXbgl19+4dFHH8XpdHLBBReQmZlpXpjEyeDduL11xhHg7Nq8eWwJO8b2xLBEkz1wZkHXW6HqS4jaH6IHmZ1IRFqRCs0dSF1dHZs3byYqKoqZM2fypz/9Cbfb3XoBamrgwAND46++CrXSEBERERERkXbhL3/5C3l5eQD87W9/4+abbzYvjMUOXS5s+TxdLoJt0WDUQeofWj6f7F1U/9BNRDodFZo7CMMw2LhxI8OHD+fCCy/koIMOivzmf7uGgB9+2DEWEREREYkAwzB4q/gtNtVt4oiUI+gZ1Yy+rSKyi7q6ut2O2zV7ImRebnYKEZFOQVuudhBerxen08lll13GwQcf3PpFZhERERGRVvJW8Vs8lPcQbxS/wXW/Xkd1oNrsSCJtQjDYsgU/F154IcnJyWRkZHDuueeGKZWIiHQWWtHcQRiGgdVqbd1WGSIiIiIiJthUt6l+XBWoosxXRowtxsREIuZ7+MsK3lxTQ9d4O7dMSiI52rbPcxx44IE89dRTEUgnIiKdgVY0dxAejwebzYbL5dr7wSIiIiIi7dgRKUcQa4sFYFT8KLJcWSYnEjHXpjI///2xBsOATeV+Xl9dY3YkERHphLSiuQOoqqpi69atHHXUUfTq1cvsOCIiIiIiEdUzqieP9X+MMl8ZWa4stY2TTi/GacFuBX8wdD/BrTVlIiLS+lRo7gDy8/OZOHEiN998M3a7/khFREREpOOLscWoXYbIdsnRNq4al8hba2rITbIzZb9osyOJiEgnpKpkOxcMhj6ynjJlCvHx8eaGsVggN3fHWERERERERFrF6G5uRnfTnj0iImIeFZrbOb/fj8PhIDU11ewoEB0N69ebnUJERERERERERERamRo3tXN+vx+73W7+amYRERERERERERHptFRobud8Ph8Oh4OkpCSzo4iIiIiIiIiIiEgnpUJzOxcIBLDZbMTEtIGNUGpr4cADQ7faWrPTiIiIiIiIiIiISCtRobkdCwaDFBcX0717d6Kj28CuwsEgLFsWum3fpFBERERE2o+//e1v9OjRA7fbzYgRI/jkk0/MjiQiIiIi7YQKze3Ypk2b6NKlC/Pnz8disZgdR0RERETasRdeeIFLL72U6667jm+++YZDDjmEyZMns3HjRrOjiYiIiEg7oEJzO1VSUgLAnDlz6Nevn8lpRERERKS9u+eeezj77LM555z/b+/O46Kq1z+Af0BgGNYUlU0El9xCMbQUTU1ToFywrolmhtlmhnrzltktBeqW2S1zuWVmXlzS1Ot2/eUWGpIGuRCoCaEBitoQggqIAgLP7w8uRwYGmGEbgc/79ZqXM+d8z5xnnu8XfM6XM+e8iJ49e2Lp0qVwc3PDypUrjR1ak3T58mUsXboU4eHhyM/P13u75Kw7WHLkBr6Jy8WdYmnACInonpGfAmiWAJkbgJI7xo6GmioR4Np2QPMpcOu0saOhFsrM2AGQ4fLz85GVlYXnn38eY8aMMXY4RERERNTEFRYWIjY2FvPnz9da7uvri+jo6ErtCwoKUFBQoLzOyclp8BibmpCQEGRkZAAord9fffXVGre5UyxYEHENuQWlE8wiwFRv2waNk4iMTIqAKwuB4uz/vS4B2gUZNyZqmrIPAJlrS5/fjAY6fQ2YtTZqSNTy8IzmJqakpARpaWl4+OGHMWfOHF4yg4iIiIjqLDMzE8XFxXB0dNRa7ujoiPT09ErtFy1aBHt7e+Xh5ubWWKE2CSUlJcjMzFRe//nnn3ptl18kyiQzAFzNK6732IjoHlNScHeSGQCKMowXCzVtd8r9XyOFQPENo4VCLRcnmpuYixcvwtXVFQsXLoSlpaWxwyEiIiKiZqTiSQwiovPEhrfffhvZ2dnK49KlS40VYpNgamqKyZMnAwDUajUmTJig13a2KlME9LL633MTjOtp3WAxEtE9opU10PrJ0uemtkDr8UYNh5qw+/wBs7alz20eASw8jBoOtUy8dEYTUlhYiJKSEgQHB6Nr167GDke3tm2NHQERERERGaht27Zo1apVpbOXMzIyKp3lDAAqlQoqlaqxwmuSJk2ahNGjR0OlUsHCwkLv7V58yA4Te9tAbW4C81b89iJRi9BuOtBmAmBiCZjq//uCSIu5I9BpNVCcB5jZGzsaaqF4RnMTkZubiwsXLsDT0xMjR440dji6WVsDV6+WPqx59gURERFRU2FhYYF+/fohIiJCa3lERAQGDRpkpKiaPltbW4MmmcvYWZpykpmopWllx0lmqjsTM04yk1HxjOYmID8/HxqNBv7+/pg3bx7s7OyMHRIRERERNTNz587F1KlT0b9/f/j4+OCrr75CWloaZsyYYezQiIiIiKgJ4ETzPS4jIwPZ2dno27cvFi9ezOsyExEREVGDCAwMRFZWFt577z1oNBp4enpi7969cHd3N3ZoRERERNQEcKL5HiUiyMzMRF5eHl599VVMnz793p9kvn0bePzx0uf79gFqtXHjISIiIiKDzJw5EzNnzjR2GERERETUBHGi+R6VlpYGlUqFoKAgzJo1C6amTeBy2iUlQFTU3edERERERERERETUInCi+R51584dBAcH4+WXXzZ2KERERERERERERETVagKnybY8165dg5mZGTp16mTsUIiIiIiIiIiIiIhqxDOa7wEigqKiIuTn5yM/Px9XrlzB888/jxEjRhg7NCIiIiIiIiIiIqIacaLZiHJzc5Geng4AMDMzg6WlJSwtLeHj44PRo0ejVatWRo6QiIiIiIiIiIiIqGacaDYijUaDkSNHYvjw4XB1dYWrqyucnJxgYWFh7NCIiIiIiIiIiIiI9MaJZiPJzc2FhYUFJk+ejEceecTY4dQfKytjR0BERERERERERESNjBPNjejOnTtIT09Hfn4+zM3NMWzYMAwcONDYYdUfa2sgL8/YURAREREREREREVEj40RzI7lz5w5SU1PRpUsXjBo1CgMHDoS3tzfMzNgFRERERERERERE1LRxlrMBmZiY4PLly8jJyUFxcTEeeOABLF++HG5ubsYOjYiIiIiIiIiIiKjecKK5Ab322mvQaDQAAAsLC0yYMAHt27c3clQNKD8f+MtfSp9v3w5YWho3HiIiIiIiIiIiImoUnGhuQIGBgcYOoXEVFwN79959TkRERERERERERC2CqbEDICIiIiIiIiIiIqKmjRPNRERERERERERERFQnnGgmIiIiIiIiIiIiojrhRDMRERERERERERER1QknmomIiIiIiIiIiIioTsyMsVMRAQDk5OQYY/fUUPLy7j7PyQGKi40XCxERERlFWX1XVu9Ry8D6noiIiKj50rfGN8pEc1ZWFgDAzc3NGLunxuDiYuwIiIiIyIiysrJgb29v7DCokeTm5gJgfU9ERETUnOXm5lZb4xtlorlNmzYAgLS0tGZ7AJKTkwM3NzdcunQJdnZ2xg6H6oB92bywP5sP9mXzwb5sXrKzs9GxY0el3qOWwcXFBZcuXYKtrS1MTEwaZZ/83WEY5sswzJf+mCvDMF+GYb70x1wZhvkyjIggNzcXLjWcWGqUiWZT09JLQ9vb2zf7zrSzs2v2n7GlYF82L+zP5oN92XywL5uXsnqPWgZTU1N06NDBKPvm7w7DMF+GYb70x1wZhvkyDPOlP+bKMMyX/vQ5WZhHAERERERERERERERUJ5xoJiIiIiIiIiIiIqI6McpEs0qlQkhICFQqlTF23yhawmdsKdiXzQv7s/lgXzYf7Mvmhf1JjYVjzTDMl2GYL/0xV4ZhvgzDfOmPuTIM89UwTEREjB0EERERERERERERETVdvHQGEREREREREREREdUJJ5qJiIiIiIiIiIiIqE440UxEREREREREREREdcKJZiIiIiIiIiIiIiKqk0aZaL5+/TqmTp0Ke3t72NvbY+rUqbhx40a12+zYsQN+fn5o27YtTExMEB8f3xihGuSLL75Ap06dYGlpiX79+uHIkSPVto+KikK/fv1gaWmJzp0748svv2ykSKkmhvTljh07MGrUKLRr1w52dnbw8fHBgQMHGjFaqomhP5tlfvrpJ5iZmaFv374NGyDpzdC+LCgowDvvvAN3d3eoVCp06dIF//73vxspWqqOoX25ceNGeHl5wcrKCs7Oznj++eeRlZXVSNFSVX788UeMHTsWLi4uMDExwa5du2rchvUPNZTa/n/fnISGhsLExETr4eTkpKwXEYSGhsLFxQVqtRqPPvoozp49q/UeBQUFmDVrFtq2bQtra2uMGzcOly9fbuyPUu9q+n1VX7mpzbHuvaimfE2bNq3SWBs4cKBWm5aSr0WLFuGhhx6Cra0t2rdvj/HjxyMpKUmrDcfXXfrki+PrrpUrV6JPnz6ws7NT5hv27dunrOfYuqumXHFcGYk0An9/f/H09JTo6GiJjo4WT09PGTNmTLXbrF+/XsLCwmT16tUCQOLi4hojVL1t3rxZzM3NZfXq1ZKQkCBz5swRa2truXjxos72KSkpYmVlJXPmzJGEhARZvXq1mJuby7Zt2xo5cqrI0L6cM2eOLF68WI4fPy7nzp2Tt99+W8zNzeWXX35p5MhJF0P7s8yNGzekc+fO4uvrK15eXo0TLFWrNn05btw4GTBggEREREhqaqocO3ZMfvrpp0aMmnQxtC+PHDkipqamsmzZMklJSZEjR47IAw88IOPHj2/kyKmivXv3yjvvvCPbt28XALJz585q27P+oYZS2//vm5uQkBB54IEHRKPRKI+MjAxl/UcffSS2trayfft2OXPmjAQGBoqzs7Pk5OQobWbMmCGurq4SEREhv/zyiwwfPly8vLykqKjIGB+p3tT0+6q+clObY917UU35CgoKEn9/f62xlpWVpdWmpeTLz89PwsPD5ddff5X4+HgZPXq0dOzYUW7evKm04fi6S598cXzdtXv3btmzZ48kJSVJUlKS/P3vfxdzc3P59ddfRYRjq7yacsVxZRwNPtGckJAgAOTnn39WlsXExAgA+e2332rcPjU19Z6caH744YdlxowZWst69Ogh8+fP19l+3rx50qNHD61lr7zyigwcOLDBYiT9GNqXuvTq1UvCwsLqOzSqhdr2Z2BgoLz77rsSEhLCieZ7hKF9uW/fPrG3t69UPJDxGdqX//znP6Vz585ay5YvXy4dOnRosBjJcPpMNLP+oYZSH/Vbc1Bd3VJSUiJOTk7y0UcfKcvy8/PF3t5evvzySxEp/UO7ubm5bN68WWlz5coVMTU1lf379zdo7I2p4u+r+spNXY9171VVTTQHBARUuU1LzldGRoYAkKioKBHh+KpJxXyJcHzVpHXr1vL1119zbOmhLFciHFfG0uCXzoiJiYG9vT0GDBigLBs4cCDs7e0RHR3d0LtvEIWFhYiNjYWvr6/Wcl9f3yo/U0xMTKX2fn5+OHnyJO7cudNgsVL1atOXFZWUlCA3Nxdt2rRpiBDJALXtz/DwcCQnJyMkJKShQyQ91aYvd+/ejf79++Pjjz+Gq6srunXrhjfeeAO3b99ujJCpCrXpy0GDBuHy5cvYu3cvRAR//vkntm3bhtGjRzdGyFSPWP9QQ6iP+q05OX/+PFxcXNCpUydMmjQJKSkpAIDU1FSkp6dr5UmlUmHYsGFKnmJjY3Hnzh2tNi4uLvD09GzWuayv3DTHY93qHD58GO3bt0e3bt3w0ksvISMjQ1nXkvOVnZ0NAMrxIMdX9SrmqwzHV2XFxcXYvHkz8vLy4OPjw7FVjYq5KsNx1fjMGnoH6enpaN++faXl7du3R3p6ekPvvkFkZmaiuLgYjo6OWssdHR2r/Ezp6ek62xcVFSEzMxPOzs4NFi9VrTZ9WdGnn36KvLw8TJw4sSFCJAPUpj/Pnz+P+fPn48iRIzAza/BfiaSn2vRlSkoKjh49CktLS+zcuROZmZmYOXMmrl27xus0G1Ft+nLQoEHYuHEjAgMDkZ+fj6KiIowbNw4rVqxojJCpHrH+oYZQH/VbczFgwACsX78e3bp1w59//ol//OMfGDRoEM6ePavkQleeLl68CKD0Z9TCwgKtW7eu1KY557K+ctMcj3Wr8vjjj+Ppp5+Gu7s7UlNTsWDBAowYMQKxsbFQqVQtNl8igrlz5+KRRx6Bp6cnAI6v6ujKF8DxVdGZM2fg4+OD/Px82NjYYOfOnejVq5cyscmxdVdVuQI4royl1rMqoaGhCAsLq7bNiRMnAAAmJiaV1omIzuVNScX4a/pMutrrWk6Nz9C+LPPtt98iNDQU//3vf3X+8iHj0Lc/i4uL8cwzzyAsLAzdunVrrPDIAIb8bJaUlMDExAQbN26Evb09AGDJkiWYMGECPv/8c6jV6gaPl6pmSF8mJCRg9uzZWLhwIfz8/KDRaPDmm29ixowZWLNmTWOES/WI9Q81lNrWb83J448/rjzv3bs3fHx80KVLF6xbt0654VFt8tRSclkfuWmux7oVBQYGKs89PT3Rv39/uLu7Y8+ePXjqqaeq3K655ys4OBinT5/G0aNHK63j+KqsqnxxfGnr3r074uPjcePGDWzfvh1BQUGIiopS1nNs3VVVrnr16sVxZSS1vnRGcHAwEhMTq314enrCyckJf/75Z6Xtr169WumvME1F27Zt0apVq0p/vcjIyKjyMzk5Oelsb2ZmBgcHhwaLlapXm74ss2XLFrzwwgvYunUrRo4c2ZBhkp4M7c/c3FycPHkSwcHBMDMzg5mZGd577z2cOnUKZmZm+OGHHxordKqgNj+bzs7OcHV1VSaZAaBnz54QkUp3DqbGU5u+XLRoEQYPHow333wTffr0gZ+fH7744gv8+9//hkajaYywqZ6w/qGGUJf6rbmztrZG7969cf78eTg5OQFAtXlycnJCYWEhrl+/XmWb5qi+ctMcj3X15ezsDHd3d5w/fx5Ay8zXrFmzsHv3bkRGRqJDhw7Kco4v3arKly4tfXxZWFiga9eu6N+/PxYtWgQvLy8sW7aMY0uHqnKlS0sfV42l1hPNbdu2RY8ePap9WFpawsfHB9nZ2Th+/Liy7bFjx5CdnY1BgwbVy4dobBYWFujXrx8iIiK0lkdERFT5mXx8fCq1//7779G/f3+Ym5s3WKxUvdr0JVB6JvO0adOwadMmXjP0HmJof9rZ2eHMmTOIj49XHjNmzFD+Klr+OkzUuGrzszl48GD88ccfuHnzprLs3LlzMDU1rbGYpYZTm768desWTE21S5RWrVoBuHs2LDUNrH+oIdS2fmsJCgoKkJiYCGdnZ3Tq1AlOTk5aeSosLERUVJSSp379+sHc3FyrjUajwa+//tqsc1lfuWmOx7r6ysrKwqVLl5RLILWkfIkIgoODsWPHDvzwww/o1KmT1nqOL2015UuXljy+dBERFBQUcGzpoSxXunBcNZIGvtmgiIj4+/tLnz59JCYmRmJiYqR3794yZswYrTbdu3eXHTt2KK+zsrIkLi5O9uzZIwBk8+bNEhcXJxqNpjFCrtHmzZvF3Nxc1qxZIwkJCfLXv/5VrK2t5cKFCyIiMn/+fJk6darSPiUlRaysrOT111+XhIQEWbNmjZibm8u2bduM9RHofwzty02bNomZmZl8/vnnotFolMeNGzeM9RGoHEP7s6Lq7t5OjcvQvszNzZUOHTrIhAkT5OzZsxIVFSX333+/vPjii8b6CPQ/hvZleHi4mJmZyRdffCHJycly9OhR6d+/vzz88MPG+gj0P7m5uRIXFydxcXECQJYsWSJxcXFy8eJFEWH9Q42npt8rLcXf/vY3OXz4sKSkpMjPP/8sY8aMEVtbWyUPH330kdjb28uOHTvkzJkzMnnyZHF2dpacnBzlPWbMmCEdOnSQgwcPyi+//CIjRowQLy8vKSoqMtbHqhc1/b6qr9zoc6zbFFSXr9zcXPnb3/4m0dHRkpqaKpGRkeLj4yOurq4tMl+vvvqq2Nvby+HDh7WOB2/duqW04fi6q6Z8cXxpe/vtt+XHH3+U1NRUOX36tPz9738XU1NT+f7770WEY6u86nLFcWU8jTLRnJWVJVOmTBFbW1uxtbWVKVOmyPXr17UDASQ8PFx5HR4eLgAqPUJCQhojZL18/vnn4u7uLhYWFuLt7S1RUVHKuqCgIBk2bJhW+8OHD8uDDz4oFhYW4uHhIStXrmzkiKkqhvTlsGHDdI7NoKCgxg+cdDL0Z7M8TjTfWwzty8TERBk5cqSo1Wrp0KGDzJ07V6voJ+MxtC+XL18uvXr1ErVaLc7OzjJlyhS5fPlyI0dNFUVGRlb7fyDrH2pM1f1eaSkCAwPF2dlZzM3NxcXFRZ566ik5e/assr6kpERCQkLEyclJVCqVDB06VM6cOaP1Hrdv35bg4GBp06aNqNVqGTNmjKSlpTX2R6l3Nf2+qq/c6HOs2xRUl69bt26Jr6+vtGvXTszNzaVjx44SFBRUKRctJV+68lRxPoPj666a8sXxpW369OnK/23t2rWTxx57TJlkFuHYKq+6XHFcGY+JCL+DSkRERERERERERES1V+trNBMRERERERERERERAZxoJiIiIiIiIiIiIqI64kQzEREREREREREREdUJJ5qJiIiIiIiIiIiIqE440UxEREREREREREREdcKJZiIiIiIiIiIiIiKqE040ExEREREREREREVGdcKKZqJm4cOECTExMEB8f32j7XLt2Le677z7ldWhoKPr27au8njZtGsaPH99o8TR3oaGhcHR0hImJCXbt2qVzmSE5N8aYqU+HDx+GiYkJbty4YexQiIiIiKiZ0FVzN/T+yh9DNTXp6ekYNWoUrK2ttY4Niahl4kQzURNgYmJS7WPatGlGiSswMBDnzp0zyr4NUdWEalOaCE9MTERYWBhWrVoFjUaDxx9/XOeyZcuWYe3atXq9p5ubGzQaDTw9Pes11sYqyomIiIiaqmnTpums63///fd6ef+KJ4SQfnTV1/WpMevkHTt2wM/PD23btq3VySUeHh5YunRpje0+++wzaDQaxMfH1+uxob77J6J7i5mxAyCimmk0GuX5li1bsHDhQiQlJSnL1Go1rl+/3uhxqdVqqNXqRt9vS5ScnAwACAgIgImJSZXLVCqV3u/ZqlUrODk51XOkRERERKQPf39/hIeHay1r166dkaKp2p07d2Bubm7sMBqFrvq6Nu6FnOXl5WHw4MF4+umn8dJLLzXYfpKTk9GvXz/cf//9DbaPuigsLISFhYWxwyBqMXhGM1ET4OTkpDzs7e1hYmJSaVmZlJQUDB8+HFZWVvDy8kJMTIzWe0VHR2Po0KFQq9Vwc3PD7NmzkZeXV+W+T506heHDh8PW1hZ2dnbo168fTp48CUD/MyU++eQTODs7w8HBAa+99hru3LmjrLt+/Tqee+45tG7dGlZWVnj88cdx/vx5Zb2ur5ItXboUHh4eWsvCw8PRs2dPWFpaokePHvjiiy+UdZ06dQIAPPjggzAxMcGjjz6K0NBQrFu3Dv/973+VM0gOHz4MALhy5QoCAwPRunVrODg4ICAgABcuXKj2M549exajR4+GnZ0dbG1tMWTIEKVQLSkpwXvvvYcOHTpApVKhb9++2L9/v9b21e0zNDQUY8eOBQCYmprCxMRE5zKg8lnaJSUlWLx4Mbp27QqVSoWOHTvigw8+AKD7TO+EhAQ88cQTsLGxgaOjI6ZOnYrMzExl/aOPPorZs2dj3rx5aNOmDZycnBAaGqqsL+uXJ598EiYmJpX6qYyPjw/mz5+vtezq1aswNzdHZGQkAOCbb75B//79YWtrCycnJzzzzDPIyMiosg/qY6wUFhYiODgYzs7OsLS0hIeHBxYtWlTlPomIiIhqS6VSadX0Tk5OaNWqFQDg//7v/9CvXz9YWlqic+fOCAsLQ1FRkbLtkiVL0Lt3b1hbW8PNzQ0zZ87EzZs3AZReXuz5559Hdna2UueW1Wu6zqi97777lG/EldWHW7duxaOPPgpLS0t88803AKqvoXTZtm0bevfuDbVaDQcHB4wcOVI57iirWcPCwtC+fXvY2dnhlVdeQWFhobL9/v378cgjj+C+++6Dg4MDxowZo9TXZS5fvoxJkyahTZs2sLa2Rv/+/XHs2DFlfU15LK+q+rqmWr66nJVXU528YcMGeHh4wN7eHpMmTUJubq6yTkTw8ccfo3PnzlCr1fDy8sK2bduqzf/UqVOxcOFCjBw5sso2oaGh6NixI1QqFVxcXDB79mwApTX/xYsX8frrrytjSBcPDw9s374d69ev1/qmbXZ2Nl5++WWlb0eMGIFTp04p2yUnJyMgIACOjo6wsbHBQw89hIMHDyrrq9q/PvV+2dhatGgRXFxc0K1bNwC1O8YjIsNxopmomXnnnXfwxhtvID4+Ht26dcPkyZOVYurMmTPw8/PDU089hdOnT2PLli04evQogoODq3y/KVOmoEOHDjhx4gRiY2Mxf/58g/46HxkZieTkZERGRmLdunVYu3at1qUdpk2bhpMnT2L37t2IiYmBiOCJJ57QmoyuyerVq/HOO+/ggw8+QGJiIj788EMsWLAA69atAwAcP34cAHDw4EFoNBrs2LEDb7zxBiZOnAh/f39oNBpoNBoMGjQIt27dwvDhw2FjY4Mff/wRR48ehY2NDfz9/bUK3/KuXLmCoUOHwtLSEj/88ANiY2Mxffp0Je/Lli3Dp59+ik8++QSnT5+Gn58fxo0bp0yo17TPN954QznbpSxWXct0efvtt7F48WIsWLAACQkJ2LRpExwdHXW21Wg0GDZsGPr27YuTJ09i//79+PPPPzFx4kStduvWrYO1tTWOHTuGjz/+GO+99x4iIiIAACdOnABQeiCi0WiU1xVNmTIF3377LUREWbZlyxY4Ojpi2LBhAEonfd9//32cOnUKu3btQmpqap0vE1PTWFm+fDl2796NrVu3IikpCd98802Vk+VEREREDeHAgQN49tlnMXv2bCQkJGDVqlVYu3atcrIAUDoRunz5cvz6669Yt24dfvjhB8ybNw8AMGjQICxduhR2dnZataMh3nrrLcyePRuJiYnw8/OrsYaqSKPRYPLkyZg+fToSExNx+PBhPPXUU1q136FDh5CYmIjIyEh8++232LlzJ8LCwpT1eXl5mDt3Lk6cOIFDhw7B1NQUTz75JEpKSgAAN2/exLBhw/DHH39g9+7dOHXqFObNm6es1yeP5VVVX9dUy1eVs4qqq5OTk5Oxa9cufPfdd/juu+8QFRWFjz76SFn/7rvvIjw8HCtXrsTZs2fx+uuv49lnn0VUVFQVPVizbdu24bPPPsOqVatw/vx57Nq1C7179wZQetmNDh064L333qv2WOPEiRPw9/fHxIkTodFosGzZMogIRo8ejfT0dOzduxexsbHw9vbGY489hmvXrgEo7bsnnngCBw8eRFxcHPz8/DB27FikpaUZtP+qlI2tiIgIfPfdd7U6xiOiWhIialLCw8PF3t6+0vLU1FQBIF9//bWy7OzZswJAEhMTRURk6tSp8vLLL2ttd+TIETE1NZXbt2/r3J+tra2sXbtWr1hCQkLEy8tLeR0UFCTu7u5SVFSkLHv66aclMDBQRETOnTsnAOSnn35S1mdmZoparZatW7fqfE8Rkc8++0zc3d2V125ubrJp0yatNu+//774+PiIyN3cxMXFabUJCgqSgIAArWVr1qyR7t27S0lJibKsoKBA1Gq1HDhwQGce3n77benUqZMUFhbqXO/i4iIffPCB1rKHHnpIZs6cqfc+d+7cKRV/ZetaVv4z5eTkiEqlktWrV+uMq2JeFixYIL6+vlptLl26JAAkKSlJRESGDRsmjzzySKXP8tZbbymvAcjOnTt17rNMRkaGmJmZyY8//qgs8/HxkTfffLPKbY4fPy4AJDc3V0REIiMjBYBcv35dROpnrMyaNUtGjBih1RdERERE9S0oKEhatWol1tbWymPChAkiIjJkyBD58MMPtdpv2LBBnJ2dq3y/rVu3ioODg/K6qmMGXXWavb29hIeHi8jd+nDp0qVabWqqoSqKjY0VAHLhwgWd64OCgqRNmzaSl5enLFu5cqXY2NhIcXGxzm0yMjIEgJw5c0ZERFatWiW2traSlZWls31t8qirvq6plq8qZ7royn9ISIhYWVlJTk6OsuzNN9+UAQMGiIjIzZs3xdLSUqKjo7W2e+GFF2Ty5Mk17rOqY6FPP/1UunXrVuUxjLu7u3z22Wc1vn9AQIAEBQUprw8dOiR2dnaSn5+v1a5Lly6yatWqKt+nV69esmLFimr3r0+9HxQUJI6OjlJQUKAsq80xHhHVDq/RTNTM9OnTR3nu7OwMAMjIyECPHj0QGxuL33//HRs3blTaiAhKSkqQmpqKnj17Vnq/uXPn4sUXX8SGDRswcuRIPP300+jSpYve8TzwwAPKVwDLYjpz5gyA0pttmJmZYcCAAcp6BwcHdO/eHYmJiXq9/9WrV3Hp0iW88MILWtceKyoq0rqkiL7KcmRra6u1PD8/v9JX9crEx8djyJAhOs/0zsnJwR9//IHBgwdrLR88eLDy9bHa7FMfiYmJKCgowGOPPaZX+9jYWERGRsLGxqbSuuTkZOVrZ+XHGFDap9Vd0kKXdu3aYdSoUdi4cSOGDBmC1NRUxMTEYOXKlUqbuLg4hIaGIj4+HteuXVPOTklLS0OvXr0M2h+g31iZNm0aRo0ahe7du8Pf3x9jxoyBr6+vwfsiIiIiqsnw4cO1ah9ra2sApTXZiRMntM68LS4uRn5+Pm7dugUrKytERkbiww8/REJCAnJyclBUVIT8/Hzk5eUp71MX/fv3V57Xpt728vLCY489ht69e8PPzw++vr6YMGECWrdurdXGyspKee3j44ObN2/i0qVLcHd3R3JyMhYsWICff/4ZmZmZWrWgp6cn4uPj8eCDD6JNmzY6Y9AnjzXRp5YvUz5nhvLw8NA6FihfXyckJCA/Px+jRo3S2qawsBAPPvhgrff59NNPY+nSpejcuTP8/f3xxBNPYOzYsTAzq9s0UWxsLG7evAkHBwet5bdv31aObfLy8hAWFobvvvsOf/zxB4qKinD79m3ljOa66t27t9Z1mRvqeIuIKuNEM1EzU36ys/x1xcr+feWVV5Rrb5XXsWNHne8XGhqKZ555Bnv27MG+ffsQEhKCzZs348knnzQ4nrKYyuKRcl+dK09ElNhNTU0rtSt/WY2y91q9erXWhDUArQlufZWUlKBfv35ak/Flqro5iz43RKx4XbPyn7E2+9SHoTdqLCkpwdixY7F48eJK68r+aAFU36eGmDJlCubMmYMVK1Zg06ZNeOCBB+Dl5QWgtPj09fWFr68vvvnmG7Rr1w5paWnw8/Or8utt9TFWvL29kZqain379uHgwYOYOHEiRo4cWeM18IiIiIgMZW1tja5du1ZaXlJSgrCwMDz11FOV1llaWuLixYt44oknMGPGDLz//vto06YNjh49ihdeeKHGy8+ZmJhUWy+Vj618PIBh9XarVq0QERGB6OhofP/991ixYgXeeecdHDt2TLl/SnUxAsDYsWPh5uaG1atXw8XFBSUlJfD09FRqwZpq3ZryaIjqavkydZngr66+Lvt3z549cHV11WpnyI3AK3Jzc0NSUhIiIiJw8OBBzJw5E//85z8RFRVVpxsZlpSUwNnZWbn/TXll9/d58803ceDAAXzyySfo2rUr1Go1JkyYUONlLGqq98tU7IuGOt4ioso40UzUgnh7e+Ps2bM6C9rqdOvWDd26dcPrr7+OyZMnIzw8XO+J5ur06tULRUVFOHbsGAYNGgQAyMrKwrlz55Szq9u1a4f09HStYq78zescHR3h6uqKlJQUTJkyRed+yv6aXVxcXGl5xWXe3t7YsmWLcuMKffTp0wfr1q3TeXdpOzs7uLi44OjRoxg6dKiyPDo6Gg8//HCt96mP+++/H2q1GocOHcKLL75YY3tvb29s374dHh4edTqTwdzcvFJedRk/fjxeeeUV7N+/H5s2bcLUqVOVdb/99hsyMzPx0Ucfwc3NDQCUm1BWpT7GClDaZ4GBgQgMDMSECRPg7++Pa9euVXm2DBEREVF98vb2RlJSUpU1+8mTJ1FUVIRPP/0Upqalt13aunWrVhtddS5QWi+Vv97t+fPncevWrWrj0beGqsjExASDBw/G4MGDsXDhQri7u2Pnzp2YO3cugNKbjt++fVuZMP75559hY2ODDh06ICsrC4mJiVi1ahWGDBkCADh69KjW+/fp0wdff/11lXVaTXnUhz61vCH0rZPL69WrF1QqFdLS0pR7mdQXtVqNcePGYdy4cXjttdfQo0cPnDlzBt7e3lWOoZp4e3sjPT0dZmZmVd7r5MiRI5g2bZpyTHnz5s1KN+bTtf+a6v3qYmqI4y0iqow3AyRqQd566y3ExMTgtddeQ3x8PM6fP4/du3dj1qxZOtvfvn0bwcHBOHz4MC5evIiffvoJJ06c0HmJjdq4//77ERAQgJdeeglHjx7FqVOn8Oyzz8LV1RUBAQEASu84fPXqVXz88cdITk7G559/jn379mm9T2hoKBYtWoRly5bh3LlzOHPmDMLDw7FkyRIAQPv27aFWq5Wb22VnZwMo/Yra6dOnkZSUhMzMTNy5cwdTpkxB27ZtERAQgCNHjiA1NRVRUVGYM2cOLl++rPNzBAcHIycnB5MmTcLJkydx/vx5bNiwAUlJSQBK/2K/ePFibNmyBUlJSZg/fz7i4+MxZ84cAKjVPvVhaWmJt956C/PmzcP69euRnJyMn3/+GWvWrNHZ/rXXXsO1a9cwefJkHD9+HCkpKfj+++8xffp0g4pMDw8PHDp0COnp6bh+/XqV7aytrREQEIAFCxYgMTERzzzzjLKuY8eOsLCwwIoVK5CSkoLdu3fj/fffr3a/9TFWPvvsM2zevBm//fYbzp07h//85z9wcnJSzr4gIiIiamgLFy7E+vXrERoairNnzyIxMRFbtmzBu+++CwDo0qULioqKlDppw4YN+PLLL7Xew8PDAzdv3sShQ4eQmZmpTCaPGDEC//rXv/DLL7/g5MmTmDFjhl5nr9ZUQ1V07NgxfPjhhzh58iTS0tKwY8cOXL16Ves4orCwEC+88AISEhKUb04GBwfD1NQUrVu3hoODA7766iv8/vvv+OGHH5QJ6jKTJ0+Gk5MTxo8fj59++gkpKSnYvn07YmJi9Mqjvmqq5Q2hb51cnq2tLd544w28/vrrWLduHZKTkxEXF4fPP/+8ypsxAsC1a9cQHx+PhIQEAEBSUhLi4+ORnp4OAFi7di3WrFmDX3/9VRlHarUa7u7uSqw//vgjrly5gszMTL0/48iRI+Hj44Px48fjwIEDuHDhAqKjo/Huu+8qJ4507doVO3bsQHx8PE6dOoVnnnmm0jckde1fn3pfl4Y63iIiHYxzaWgiqq2abgZY/iYP169fFwASGRmpLDt+/LiMGjVKbGxsxNraWvr06VPp5hZlCgoKZNKkSeLm5iYWFhbi4uIiwcHByo0D9bkZYMWb7c2ZM0eGDRumvL527ZpMnTpV7O3tRa1Wi5+fn5w7d05rm5UrV4qbm5tYW1vLc889Jx988IHWDR9ERDZu3Ch9+/YVCwsLad26tQwdOlR27NihrF+9erW4ubmJqampsv+MjAwlF+XzpNFo5LnnnpO2bduKSqWSzp07y0svvSTZ2dk68yQicurUKfH19RUrKyuxtbWVIUOGSHJysoiIFBcXS1hYmLi6uoq5ubl4eXnJvn37tLavaZ+1uRlg2b7/8Y9/iLu7u5ibm0vHjh2Vm6LoGjPnzp2TJ598Uu677z5Rq9XSo0cP+etf/6rcOGPYsGEyZ84crX1WvAHI7t27pWvXrmJmZlapnyras2ePAJChQ4dWWrdp0ybx8PAQlUolPj4+snv3bq14K94MUKTuY+Wrr76Svn37irW1tdjZ2cljjz0mv/zyS7WfgYiIiMhQuurk8vbv3y+DBg0StVotdnZ28vDDD8tXX32lrF+yZIk4Ozsr9fP69esr1UUzZswQBwcHASAhISEiInLlyhXx9fUVa2truf/++2Xv3r06bwZY8cZxIjXX2+UlJCSIn5+ftGvXTlQqlXTr1k3rRm9ln3/hwoXi4OAgNjY28uKLL2rdQC4iIkJ69uwpKpVK+vTpI4cPH650M70LFy7IX/7yF7GzsxMrKyvp37+/HDt2TO88VqSrvq6plq8uZxXpqpP1ucFdSUmJLFu2TLp37y7m5ubSrl078fPzk6ioqCr3FR4eLgAqPcrGws6dO2XAgAFiZ2cn1tbWMnDgQDl48KCyfUxMjPTp00dUKlWlnJRX8VhApPSm5LNmzRIXFxcxNzcXNzc3mTJliqSlpSk5Gz58uKjVanFzc5N//etflY4zqtp/TfV+VT9btTnGIyLDmYhUcZFUIiIiIiIiIqJ6Nm3aNNy4cQO7du0ydihERFSPeOkMIiIiIiIiIiIiIqoTTjQTERERERERERERUZ3w0hlEREREREREREREVCc8o5mIiIiIiIiIiIiI6oQTzURERERERERERERUJ5xoJiIiIiIiIiIiIqI64UQzEREREREREREREdUJJ5qJiIiIiIiIiIiIqE440UxEREREREREREREdcKJZiIiIiIiIiIiIiKqE040ExEREREREREREVGdcKKZiIiIiIiIiIiIiOrk/wEsS4uDYoUC7wAAAABJRU5ErkJggg==",
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAABZoAAAKgCAYAAAAS1si3AAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjkuMiwgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy8hTgPZAAAACXBIWXMAAA9hAAAPYQGoP6dpAAEAAElEQVR4nOzdd3gUVdsG8HuT3U3vvZEQSighdEJoARJ6BylSpIkifHQUsFFEUFFeUQTlVUEB6SAgEKUFRIqA9CbSO4GQXjd7vj/2zZhNNsmmTsr949qL2Zkzc56ZncnOPHvmjEIIIUBEREREREREREREVEgmcgdAREREREREREREROUbE81EREREREREREREVCRMNBMRERERERERERFRkTDRTERERERERERERERFwkQzERERERERERERERUJE81EREREREREREREVCRMNBMRERERERERERFRkTDRTERERERERERERERFwkQzERERERERERERERUJE81EVGatWrUKCoVCemXVtm1bafyIESOk8bdv39abJzIysnSDpjInMjJSb5+4fft2qdU9Z84cqV4/P78Sqyc+Ph6TJk2Cr68vVCqVVOeqVatKrE4q3+Q8LsoCfleQIaX1Nzs/I0aMkOJo27atbHGUBUXdFhV5W/LvGBERlUVMNBNRqRBC4KeffkLHjh3h6uoKlUoFe3t7+Pv7o3379pg2bRoOHz4sd5hlmjEXS5U9eVRZjR07Fl988QXu3r0LjUYjdzgAcu6L2ZPe0dHRaNy4sTTd1NQU33//vcF5FQoFBg4caLCe7777LkfZOXPmlPDaUXHIa/8gouJTVhLoxa0iJ5HLCz8/P3735iPr8Zfb69VXX5U7TCKiYqOUOwAiqhyGDRuGtWvX6o2LjY1FbGwsbt26hYMHDyI2NhZt2rSRpjdt2hSLFi0q7VCJik3Hjh1hbW0NALCzsyuROtLT07Fp0ybpfevWrdGtWzeYmpqiadOmJVJnUUVFRSE8PBznz58HAJiamuKHH37AkCFDcp1n69atePDgAby8vPTGL126tERjpYrJ0dFR7/ulWrVqMkZDRLkZNGgQAgMDAQA+Pj4yR0NERET5YaKZiErcnj179JLMwcHBCA8Ph5mZGe7du4dr167h2LFjOearW7cu6tatW5qhEhWrFi1aoEWLFiVax6NHj5Ceni69nz17NsLCwkq0zpSUFJiamkKlUhV43kePHiEsLAxXrlwBAKhUKqxduxb9+/fPcz6NRoOvv/4aH3zwgTTuyJEjOHv2bIFjoMorc9+1tbXF9OnT5Q6HiPLRuXNndO7cWe4wqAzRaDRIT0+HhYWF3KEU2MCBA9GkSZMc44OCgmSIhoioZLDrDCIqcXv37pWGa9SogaNHj2L+/Pl47733sGLFChw6dAhPnjzBa6+9pjdfXn00F8SmTZvQrFkzWFhYwNnZGSNGjEB0dLTBsvv27UO/fv3g5eUFtVoNOzs7BAcH46OPPkJ8fLxe2fz6xsvvdsIzZ85g5MiR8Pf3h7m5OWxsbNC0aVMsXrwYKSkpObbDDz/8II07dOhQjroVCgXatWunV0fVqlUN9mVdkPrzk5KSgnfeeQedO3eGv78/7OzsoFKp4OzsjDZt2mDp0qU5unMwtO3WrFmDJk2a5Pk5PX36FG+++Sbat28PX19f2NjYQK1Ww83NDR07dsSaNWsghDAq7vbt20v1Dx8+PMf0JUuWSNPd3NykZO6FCxcwdOhQ+Pn5wczMDBYWFqhSpQrat2+PWbNm4cGDB9Iy8rpd+c6dO3j99ddRo0YNWFhYwNzcHF5eXmjZsiWmTp0qJWLz4ufnB19fX71x4eHhBrtOuXbtGsaOHSvVZ2VlhVq1amHixIkGu1jJ3g/6mTNn0LVrVzg4OMDCwkJvPY11//59hIaGSuumVquxadOmfJPMJia605UVK1YgNTVVGv/ll1/qTc/LP//8g/Hjx6NWrVqwtLSEpaUl6tWrh9mzZyM2NjZH+U2bNmHIkCEIDAyEq6sr1Go1rK2tUbduXUyYMMGobXbt2jX0798fjo6OsLCwQEhIiME+NAuyT+UnPT0d//3vfxEeHg4XFxeo1Wq4urqiZcuWRt8hklsf+EDx7NOZy89q5MiRuS730aNHmDlzJoKCgmBjYwNzc3PUrFkTU6dOxePHj/ON39C+m9ff7+zrGBMTgylTpsDHxwdmZmYICAjA8uXLDW67CxcuoEePHrC1tYWtrS06deqE06dPF6nrgqIeu8buh3nZsWMHOnfuDDc3N6hUKtja2qJatWro3bs3Fi5cCK1WK5Xdt28fRo0ahYYNG8Ld3R1mZmawtLREjRo1MGrUKFy4cCHH8rN3gfD333+jT58+sLOzg6OjIwYPHownT54AAA4ePIjWrVvD0tISLi4uGD16NF68eKG3vOznDykpKZg9ezaqVasGMzMzVKtWDfPnz9f7kc4YMTExmD9/Ppo2bQo7OzuYmZnBz88PY8aMwT///FOgZQHA4cOH0bZtW1hZWcHR0RH9+/fHjRs38pznm2++Qf/+/VGrVi04OztLn0fDhg0xc+ZMPHv2TCqbeW4wd+5cadydO3cMdlvzzz//YNKkSWjVqhV8fHxgZWUFMzMzeHt7o2fPnvjll1+MXq/PP/9cWn5AQIDetIYNG0rTsp4fZu0Gyc3NTfouN9Q9hrHnRYY8ffoUr7/+Otzd3WFubo769etjy5YtRq9bYc9fCkIIgQ0bNqB79+7w8PCAWq2Gk5MTmjZtihkzZhi1jLy6Fcnr/PrZs2eYPn066tatCysrK6jVari7u6NZs2b4v//7Pxw/flxv+Xfu3JHmnTt3bq7LLeixkz3+mzdvYuDAgXB2doZarcaJEycAFO/3Z2no3Lkzpk+fnuPVsWNHuUMjIio+goiohE2YMEEAEACEk5OTuHbtmlHzrVy5Upov+5+r0NBQafzw4cOl8bdu3dKbp2PHjnrvM18tW7bMUd/UqVMNls181ahRQ9y5cyfXug4ePKi3PF9fX2na7Nmz9aZ9+eWXwtTUNNe6mjZtKmJiYgxuB0OvgwcP5lsm63YqSP35iYqKyrfu8PBwodFoct12LVu2NOpzOnnyZL51jRw5Um+e7Nvm1q1bQgghtmzZIo2zsLDIsb4tWrSQpk+dOlUIIcSlS5eEpaVlnvXv2bNHWsbs2bOl8b6+vtL4J0+eCBcXlzyXs3z58ny3fdZ9zNArc103bNggzM3Ncy1nY2Mjfv31V71lZz3GGjZsmGO9M5edm+zbffbs2aJq1arSe3Nzc7F7926j5u3Vq5c0/OOPPwohhHjw4IFQKpUCgOjdu3eOurLasmWLsLCwyHX9q1WrpndsCyFEt27d8ty2tra24vz587lus6CgIGFtbZ1jPrVaLS5evCjNU9B9Ki9RUVGicePGuS4n6z6Y23GRfT2y/t0Qonj26azLzy/OI0eOCEdHx1zLurq6ijNnzuT6OeS27+b19zvrOjo5OYlatWoZrHvFihV69Z48edLgZ25ubi7Cw8MNrl9+inrsGrsf5sWY76Dk5GSp/Pjx4/Msq1arxd69e/XqGD58uDS9atWqwsHBIcd8AQEBYs2aNcLExCTHtDZt2uQZc/v27Q3G0qdPH735ctu/hRDi6tWrokqVKrmul5WVVY7PIi+//PKL9Dcs68vR0VGEhIRI70NDQ/Xmq1u3bp7b18vLSzx48EAIkfM4N/RauXKlEEKITZs25Vt27ty5Rq3buXPn9OZ7/PixEEKIuLg4vXOP9957T5on6z4wYMAAg+Mzt4Wx50XZ5w8ICDD4valQKIz+7Ap7/mKspKQk0blz5zzXLbdYsv4dM7TdMuV2fp2cnCwCAgLyrHvGjBk5lp9fnIU5drIuv0aNGsLV1TXHuhbn96cx+1TWV/Ztmpesf1e8vLyElZWVMDMzE1WrVhWjRo0Sly5dMnpZRETlAbvOIKIS16BBA2n4+fPnqFWrFoKCgtC0aVM0bdoU4eHh8Pf3L5G6f/vtN4SEhCAsLAy//PKLdJv9H3/8gWPHjiEkJAQA8OOPP2Lx4sXSfEFBQejZsydu376NtWvXQgiB69evY8CAAVJrjsL6448/MHHiRKm1TqtWrRAeHo6YmBj88MMPePHiBU6ePIk33ngDP/30k9RX9YYNG3Dq1CkAgL+/P9544w1pmdWqVcOiRYtw48YNfP3119L4t99+Gw4ODgAg9XFY0Przo1AoUL16dQQHB8PT0xMODg5IT0/H1atXsWnTJmg0Guzbtw9btmzBgAEDct0mxnxOJiYmqFu3Lpo2bQo3NzfY29sjJSUFZ86cwc6dOyGEwMqVKzF27Fg0a9Ysz7h79eqFKlWq4O7du0hOTsbatWsxbtw4AMCDBw/0unPJbNX5ww8/ICkpCQDg7e2NoUOHwsrKCvfv38fFixeN3je2bNmCqKgoAICDgwNGjhwJJycnPHz4EFevXsXvv/9u1HLeeecd3L59GwsWLJDGjR07Vupv1tHREdevX8crr7witQR2cXHB8OHDodFo8P333yMuLg7x8fHo378//v77b7i5ueWo58yZM1CpVBgxYgSqVauGS5cuFbjbjHnz5kn7nKWlJXbs2GF0Fx9DhgzB4cOH8eLFCyxduhTDhg3D8uXLpZbyEyZMwM8//2xw3ps3b2LIkCFSK/2goCD07t0baWlpWL16NR48eIAbN27g5Zdfxh9//CHN5+DggM6dOyMgIAAODg5Qq9V48uQJtm7dinv37iEuLg4zZszA7t27DdZ7/vx5ODs7Y+zYsXjy5AlWr14NAEhLS8MXX3yBb775BkDx7VOAri/806dPS+/r1q2LLl26QKlU4tSpU/m2lCyKguzTb7zxBrp3744333xTGpf1duLM/sxjY2PRp08fqWWgv78/BgwYAJVKhY0bN+LatWt4+vQp+vbtiytXrsDMzCxHXLntu8a2ZH3+/DliYmIwatQoODk54auvvpI+r08//RRjxoyRyo4cORIJCQnS+5dffhn+/v7YuHEj9u3bZ1R9WRXHsWvsfpiXrK23mzZtiu7du0Oj0eDevXs4ceJEjrsvrK2t0a5dO9StW1dqRf38+XPs2rULV65cQVpaGiZOnIjLly8brO/WrVtwcnLCm2++iZs3b0qtTa9duya1XBw8eDD++OMPHDp0CICuZfDx48fRvHlzg8s8ePAghg0bhipVqmDLli24evUqAGDbtm1Ys2YNhg4dmuc2yMjIQJ8+fXD37l0AgJubG4YMGQI7Ozv88ssvOHnyJBITEzFgwABcv34dLi4ueS4vKSkJo0aNkv6GqVQqjBo1Cg4ODlizZo3B7sQyubm5oXr16vD394ejoyMUCgUePHiAjRs34vnz53jw4AHmz5+PZcuWSecGv/32m9R62MHBAW+//ba0vMy+/FUqFRo1aoTGjRvDxcUFtra2SEhIwB9//IGDBw8CAD744AOMHj06R1/52dWrVw/Ozs5S6+ojR46gX79+OHr0KDIyMqRyWf8uZH0gdPa7s7Iz9rwou2vXrsHS0hITJkyAVqvF119/jYyMDAgh8NlnnxWqVamx5y/Gmjp1KiIiIqT3fn5+6NWrF2xsbHD+/Hns2rWrwDEa6+DBg7h27RoAwNzcXPqsHz9+jH/++Uc63oB/+85esGCBdEdBhw4dcmzD4jh2rl+/DoVCgf79+6NevXq4ffs2rKysivX7s7RkbWF969Yt3Lp1C2vXrsVPP/2Evn37yhgZEVExkjPLTUSVQ1pamqhfv36eLQPatWsnrl69qjdfcbRobt68uUhPTxdCCPH8+XO9ljRffPGFNF/W+KpWrarXOmvevHl6yzxy5IjBuoxt0dynTx9pfKdOnYRWq5WmRURE6LWwuXfvnjQtr9YpmfJqpVjU+vPz5MkTsX37drFs2TLx6aefikWLFonAwEBpeaNGjZLKFvZzynTnzh2xefNmsXTpUqkuLy8vaZ558+YZtU0WLFggjW/YsKE0/j//+Y80vkmTJtL4iRMnSuMXLlyYI67o6GgRHR0tvc+tddzixYul8a+//nqO5SQkJEgtwPKT3344adIkaZqJiYm4fPmyNO3w4cN6886fP1+alr3VaW6tj3OTV0u6jRs3FmjenTt3iunTp0vvDx8+LNzc3AQAUbduXSGE0Cuf9XibMmWKNL5evXoiNTVVmnb16lW9+f744w+9ONLS0sThw4fFd999J/7zn/+IRYsWiZEjR0rlzczMRFpamsFtZmJiIs6dOydNy9rqulGjRtL4gu5TucnegrBHjx7SMZXpxo0buW7jorZoLsw+nbX+zFaVWS1ZskSa7urqqnfXwYsXL/Ra+q5du9Zg/Lntu8a2aAYgli5dKk37/PPP9abFxcUJIYQ4evSo3vjMVn9C6D7DrC10jW3RXBzHrrH7YV6CgoKkeY4dO5Zj+q1bt0RGRobeuIyMDHHixAmxatUq8fnnn4tFixbluGvo7t27UvnsrSMzv2e1Wq3w8PCQxqtUKmm+mJgYoVKpDH5XZD9/+PDDD6VpsbGxwtnZWZrWunVraVpu+/f27dul8Wq1Wty+fVualpqaqtdaM2tduVm3bp1efN9++63e9sy6Xoa+7xMTE8W+ffvEihUrxOLFi8WiRYv07vzw9/fXK59XS+3srl27JtavXy++/PJL6fs1a6vRzLtK8tOvXz9pnkmTJgkhhHj33XcFoLtTANDdTZSamiru37+vtz2y3vmW17mPMedF2fetX375RZo2efJkabyjo6NR61XU85e8PH/+XK+Ve+PGjUVCQoJemax/x4u7RfPWrVulcZ06dcoRX0pKirh//77euLzu3hOi8MdO9s9t2bJlOZZdXN+fQghx8eJFsWjRIqNf69evN2q5QuiOP2tra9GnTx/x1ltviffee0+0bdtWb/2sra3FkydPjF4mEVFZxhbNRFTiVCoVDh06hPnz52PVqlV6/QdmOnjwIDp27IiLFy/Cxsam2OoePXo0lErdnzpHR0c4OztL/TxmtsBITEzEuXPnpHn69+8Pc3Nz6f3w4cPx/vvvS++PHj2Kli1bFjqmrK0mf/3111z7lxVC4Pjx43jppZcKXVdp1J+cnIxx48bhxx9/1OunM7v79+/nOs2YzwnQtS4cPnx4vi168qorqzFjxmDevHlSq+jTp0+jcePG2LRpk1Rm5MiR0nDr1q3xxRdfAADeffdd7Ny5EwEBAQgICEBwcDBat24NU1PTfOtt2bIlFAoFhBBYsWIFTp48iTp16iAgIABNmjRBu3btDLZOLIyjR49Kw02aNEHt2rX11qdq1aq4detWjrJZ1a9fH126dCmWeADdtmvZsiU8PT2NnmfcuHFYvHgxtFotXn75ZWn/mDBhQp7zZd3fL1y4YLDVa6ajR49KD29cu3YtJk+ebPDvVabU1FQ8e/YMHh4eOaaFhIToPdwnaz+lWffp4tqnsq4nALz33nvSMZWppO4cAUpmn866Tk+fPoW9vX2uZY8ePYrBgwfnGF/UfdfU1BSjR4+W3mfvb/bFixewsbHRa0kOAK+88oo07ODggF69ekl94RqrOI5dY/fDvLRu3Rrnz58HoGuxGBISgho1aqBOnTpo06YN6tWrp1d+7969ePXVV6UWjLm5f/8+fHx8coz39fWVvmMVCgV8fX3x6NEjALr9LHMeOzs7uLq6Si0E81qfYcOGScO2trbo0aMHVq5cCQBSi9i8ZN0X09LS8uxnO7fPIqvsdWbdd/38/NCqVSupFXF2ixcvxuzZs/Vaz2dXmH5pb9++jSFDhuQbv7Hfr+3atZNaox85ckTv/7Fjx+KTTz5BcnIyTp8+rdfPr5eXF2rWrFng+I3h5eWFbt26Se8LczxkZ+z5izFOnDih90yLGTNmwMrKSq9MSf4db9q0KczMzJCamopff/0VdevWRVBQEGrWrImGDRsiLCws39bs2RXHsePo6JjjOS5A8X1/AiX7APKRI0dixowZOR5e+M4770h3pCUkJGDTpk0YP358icRARFSamGgmolJhZ2eHRYsW4eOPP8alS5dw/PhxHDx4ED///DOSk5MBAHfv3sXWrVsNPpitsLI/KC1rkikzKRoTE6NXxtXVVe999uRIbhcOIttD6LI+tCyrgjwgJvNW9OJU3PXPmjXLqARKbtsDMO5zAnQXdMbcNppXXVk5Oztj4MCB0gOFvv32W7i5uUm3LZuZmeHll1+Wyr/00kuYPn06vvzyS6SmpuLo0aN6F0a+vr7YtWtXvhcrzZo1w+LFi/Hee+8hISEBf/31F/766y+9uDZt2pTjAT6FkXV/zb5vA7r9OzNZldu+XRwX/f7+/rh58yYA4O+//0abNm1w8OBBg4kmQ6pWrYpu3bph586dUhLF3t4+31veC7O///XXX3jllVfy/OEkU277mrH7dHHtU9nXs6APnMuNsX/XSmKfLo6/VUXdd93c3PR+eMz+Q0Vu3yPu7u55vjdGcRy7xu6HeVmwYAFu3ryJPXv2ICEhAXv37tV7iFtoaCh2794NS0tLPHz4EL1795ZuZ89LbvtS9kRW1pizT8v6Y0pe65PX93pycjJSU1Pz/BGquL83s+4vNjY2ORJQuf0o8/PPP2PatGn5Lt/Y78Csevfurfeje1GXnbX7i7NnzyI6Ohp//vknAN0PFvv378fx48dx5MgRaT/OPl9xy+t4yP63rjiWaewxlknuv+Pe3t5YtWoVJkyYgGfPnuHy5ct6XdxYW1vj22+/xcCBA42uuziOnWrVqhlMGBfX9ycAXLp0CXv27DE6Vh8fH6O3Q/Z9JNPEiRP1uj7LrTshIqLyholmIipVJiYmqFevHurVq4cxY8bgzJkzaNSokTS9ME9tz0v2fmSzPwUbQI5Wck+fPtV7n9kyJVNmn8fZWwJnJswBID4+Psd8WefPPJlu164dunbtmmv8Be3bzxjFXf+GDRuk4Xbt2mHFihWoWrUqTE1NMWDAAL3Wwbkx5nNKTEzUe+r9oEGDsGjRInh6esLExATNmjXDyZMn860ruwkTJkiJ5p9++gne3t7SRVnv3r2lzzvTokWL8O677+Lo0aO4evUq/v77b+zYsQMPHz7EnTt3MH78+Fyfdp/V5MmT8dprr+H48eO4dOkSrl+/joiICFy/fh3Pnj3DiBEjcPv27QKvT3ZZ48++bwP6+3f2dc1kaWlZ5DjeffddnDp1CsuWLQMA3LhxA6GhoThw4IDRF9MTJkzAzp07pfejRo3K0doru6zrVL9+/TwT05l9lW7atElKEFhZWWHz5s0IDQ2FhYUFdu/erdciLjfG7NOZimOfcnR01Ht/+/btfPuJzU3Wv21Z/64Bur4yc1Pc+3TWz65KlSp5tl7P3tI4U1H3XWM/R0PfI1k/k8ePHxe47uI4dguyH+bG1tYWu3fvxv3793H8+HH8/fffuHz5MrZt24akpCQcOnQIn3zyCebMmYOdO3dKSWaFQoE1a9agR48esLGxweXLl41K+OTV/3v2VvrGevr0qd6PWlm3nbm5eZ5JZkB/+1pbW2P27Nm5ljXmR4Ws+0t8fDySk5P1ks25nT9k/b719PTEli1b0LBhQ5iZmWHZsmWFbg157do1vSTzlClTMHPmTLi4uEChUMDV1bXAP3zXqVMHbm5uePLkCTIyMrB06VIkJSVBpVKhWbNmaN26NY4fP47ff/+91BLNxXE8lOQyDf0dz/xeKqjC/h0fNGgQ+vXrhz///BMXLlzA9evXcfDgQZw5cwYJCQkYPXo0unfvnu93b6biOHby+jteXOdkJ0+e1HtuQH5CQ0MLlHA3Rm53GBIRlTdMNBNRifvhhx+QkpKCwYMH5+gWw9raWu99XrdGlxQrKyvUr19fusjavHkz5s6dK7Viy0xCZsq8tT7zgVWZTpw4ISVtFy1alGvrmBYtWmD79u0AdMmHN954I8cJe1xcHPbs2aP3IMWsFzO5tRbLfsFjqFxh68/N8+fPpeHu3bujevXqAHQX9rnd+lsYsbGxeg8R6t+/P7y9vQEAV65cMaolliGNGzdG8+bNcfz4ccTFxWH+/PnStKzdZgC6B7c4ODjA3t4eXbp0kW7J79ixo/QQl+y30Bvy8OFDmJqaws3NDe3bt0f79u0BQO+Hlzt37uD58+dwcnIq1HplatGihZSAP3XqFK5cuSLdgp/9Aj9z3y4JCoUCX331FdRqNT7//HMAuu0ZGhqKgwcPGnU7cHh4OGrVqoWrV6/CxMTEqKRK1vV/9OgRhg4dmuNiNiUlBZs2bUJoaCgA/X3a398fnTt3lt6vX78+3zoLorj2qezd+Xz44YfYvHmzXmLuzp07ubasyirr3+EzZ84gLS0NarUaV65c0Uv0Z1WYfVqpVEq3ief2tyrzh6onT56gW7duet1HAIBGo8Evv/yCVq1a5bteJSl7Mmj9+vWYM2cOAF1r48y/uQVRVo7dixcvIiAgAN7e3npdKU2aNEm6bT1zH8167NjZ2WHQoEFS8qS4j52CWL16tfQAvLi4OL39OPMhlHnJun0TEhLQqFEjaR/PJITAgQMHjPpblr3On376Seqi5fbt21IXE9ll3b6Z312AruVsXj/q5nf+kHW5ADB06FCpFfiBAwcKfXdV27ZtpeT4l19+CUC37hYWFmjdujUWLVqEyMhIvW5Asm/XvBhzXlSeBAcH6/1dXLRoEbp37673I0Rh/o5fu3YNsbGxsLOzw+PHj/Hjjz8anCc6Ohrx8fFS9zWZ3ysvXryQkuCJiYm4evUqGjduDCD/z6C4j52siuv7syTFx8djzpw5eOutt3LcqZD59zNT5kO7iYjKOyaaiajE3bp1C3PnzsXkyZPRunVrNGjQAA4ODnj69Kle6xyFQlGoJ34XhylTpmDEiBEAgJs3byI4OBi9evWSngadqVmzZtKJt52dHWrUqCG1DJk/fz7Onz+P2NjYPBOs06ZNw44dOyCEwJUrVxAYGIi+ffvC2dkZ0dHROHv2LH7//Xe4u7vrtZbIesvw6dOnMWnSJPj4+ECtVmPixIk5ygC6fm07d+4MpVKJnj17ombNmoWuPzcBAQG4ePGitA2ePHkChUKB1atX59m/bUG5urrC3t5euuV40qRJUgubVatWIS0trdDLnjBhgvR08pSUFAC6W0g7dOigV27Dhg2YPXs22rZtixo1asDDwwOJiYlYt26dVMaYH0sOHz6MIUOGoFWrVqhduzY8PT2RkZGBrVu3SmXUanWO26kLY9y4cVi+fDnS0tKg1WoRGhqK4cOHQ6PR4Pvvv5fK2djY4NVXXy1yffn5z3/+A5VKhUWLFgHQdZnTpk0bHDhwIN9uDhQKBTZu3IgbN27AxsbGqIvSCRMm4Ouvv0ZqaiqePn2K+vXrY8CAAfD09ERcXBwuXLiAQ4cOISEhQerHNWvr2AsXLmDgwIEIDAxEZGQkDhw4UIS1z6m49qmgoCB06tQJv/76KwBg+/btaNSoEbp06QKVSoVz587h8uXLuHHjRr7LatKkCbZt2wZAd5dJ06ZNUatWLfz666+5HmeF2ae9vLykvlk/++wzPH/+HBYWFlJfoCNGjMD8+fPx/PlzpKamonnz5hgwYACqVq2K5ORkXL58GZGRkYiOjpYSDnIJDg5GUFCQ1JfxvHnzcPPmTVSpUgUbN24sVP+vZeXYnT59Ov7880+EhYXBx8cHLi4uePjwodTHMfDvPpr12ImJiUGXLl3QunVrnD59Gj///HOJxZifd999F1evXoWvry82b96s9900ZsyYfOfv3r07AgICcO3aNQBAt27d0K9fP9SqVQsajQZ///03IiMj8ejRIxw8eBBVq1bNc3k9e/aEi4uLlMAdN24cTp48CQcHB6xZswbp6ekG5wsICJC6Ldm1axfGjBkDLy8v7Nq1K8++prOeG0RFRWHkyJGoU6cOFAoFxo8fj+rVq8PExES6k2Po0KEYNGgQHj16VOC+xbNq166ddJ6Xuc0zfxRq1aoVFAoF4uPjpfJ+fn4F6i7CmPOi8sTR0RGjR4/GN998A0DXyrZu3bro3bs3bG1tcfnyZWzfvt2o7kuy/pgRFxeHxo0bo2nTpoiMjMz1h4O///4bISEhaNq0KerXrw9PT08olUpERETolcv6neTl5SXdjbhq1SqYm5vD1tYW1apVQ58+fYr92MmquL4/AWDEiBHSdUBxysjIwOLFi7F06VKEhYVJn8vvv/+u19LayckJAwYMKPb6iYhkIccTCImocsn6tPO8XjNmzNCbL7enYgshRGhoqDR++PDh0vi8nsAtRN5Px8769GpDL39/f3Hr1i29eb755huDZRs0aCBcXFxyreuLL77QezK5oVf2J8OfOXNGmJiY5ChnZWWlV65Ro0YGl7dp06Yi1Z+bdevWGZzfw8NDdOjQQXqf9annhf2cPvroI4N1BQYGisaNGxvcJw4ePKhXNvtnKIQQaWlpwt3dXa/c22+/naPcwoUL892PlyxZIpXPuu9n3Z65bbOsr6lTpxq1/fPblpn1mZmZ5VqXlZWV2L17t948uR1jxsq+3VeuXKk3/Z133smxv1y5csXgvDt37sy3vqzlsx9vmzdvFhYWFvlu80zPnz8Xnp6eBssMHz481/0pr22W275Q0H0qL1FRUXrHQV7HdF7HxaNHj4SDg0OO+c3MzESbNm2KbZ+eMmWKwXLjx4+Xyvz+++/C0dEx32Ub+zlkyuu4ye2zym+7nTx5UlhbWxvcbu3bt5feV61aNb+PUm+7Fuexm9e65aZTp055bntzc3Nx4sQJIYTub2m9evWMOnaybvOs07J+V+S3Prl9V2Q/f+jWrZvBmHr27Cm0Wq1R2+fKlSuiSpUq+e6Lhv4GG7J9+3aD38M2NjZ63+NZt8f169eFjY1NjnmUSqUYMmSI3risHj16JCwtLQ3GGxUVJYQQYuzYsQanh4WFCS8vL4PbOT/Xrl3Lsbzt27dL0wMDA/WmjRo1Kscy8to3jDkvymv+vM4zc1OU80xjJCUl5XvMGRNLUlKSqFatWo55FQqFCA8PN7i8Y8eO5bt/9+3bVy/eJUuWGCzXrVs3qUxhjp28PrdMxfn9WVJevHiRb4z29vbi0KFDssZJRFSc2BEQEZW4yZMnY/PmzRg3bhyaNWuGKlWqwMLCAmq1Gj4+Pujbty927dqFjz76SNY4lyxZgoiICPTu3RseHh5QKpWwtrZGkyZNMH/+fJw5cyZHS5vXXnsNy5YtQ82aNaFSqeDt7Y3p06fj999/z7NPuQkTJuDUqVMYPXo0qlevDnNzc1hZWaFGjRro3LkzlixZgsOHD+vN06BBA6xbtw6NGjXSezhVdlu2bEGfPn3g6OiYa1+Bhak/N4MGDcLGjRtRv359qFQqODk5YeDAgTh+/Dg8PT2NWoaxZsyYga+++kra3u7u7hgzZgwOHTqUoxuWglCpVDmeaJ692wxA12fz+++/j/DwcPj5+cHS0hJKpRIeHh7o1q0bduzYYVQrqlatWuHDDz9Et27dUK1aNdjY2ECpVMLFxQVhYWFYtWoVPv3000KvT3aDBg3CmTNnMGbMGFSrVg3m5uYwNzdHzZo1MX78eJw/f1665bS0zJ8/X+paANB1a9G2bVtcunSp2Ovq168fLly4gIkTJ6JOnTqwsrKCubk5/P390a5dOyxcuBBXr16Vyjs6OuLIkSPo27cvbG1tYWFhgaZNm2Lr1q3F3uKpuPYpQPfAvaNHj+Kbb75B+/bt4eTkBKVSCUdHRwQHB2PcuHFGLcfd3R2RkZHo0KEDLC0tYWNjg65du+LYsWO59p9amH36ww8/xMSJE+Hl5WXwQU+Zy7106RJmzZqFhg0bwsbGBmq1GlWqVEHLli3x3nvv4fTp08X20KyiaNKkCY4ePYpu3brB2toa1tbWCAsLw+HDh1GjRg2pXEG6iCoLx+6bb76JSZMmoXnz5vDy8oJarYaZmRn8/f0xfPhw/Pnnn2jWrBkA3d/SAwcOYMSIEXBycoKZmRkCAwOxYsUKveO9tG3duhXz5s1DtWrVoFar4efnh7lz52LTpk1G96lbq1YtnD9/HgsWLEBwcDDs7OygUqng5eWF4OBgTJs2Db///jvatGlj1PJ69uyJffv2oU2bNrCwsIC9vT169eqFEydOoF69egbnqV69Og4fPoyOHTvC0tIS1tbWCA0Nxf79+xEeHp5rXe7u7ti5cydatmyZa9+6X375JebNmwdfX1+oVCpUqVIFb775Jnbu3FnovrFr1qyp1+pYoVDodfPTunVrvfIF7Z/Z2POi8sTCwgJ79uzBunXr0LVrV7i5uUGlUsHOzg4NGjQw6mGQmcvZv3+/9D1maWmJNm3aYN++fRgyZIjBeQICAvDZZ5+hb9++qFmzJuzs7GBqagoHBwe0bNkSS5YsydEFzvjx4zFnzhz4+/vnup8U97GTqTi/P0uKnZ0dIiMjMW3aNDRt2lT6G5rZbd+MGTNw6dKlAq87EVFZphCikI/YJSIiqkDWrVuHwYMHA9Bd/BqbaCciAoC0tDQolcocD3RKSEhAYGCg1E3ImDFjsGLFCjlCrDRWrVql92MhL3eIiIiISgf7aCYiokorJiYGZ8+exePHj/HOO+9I4415yBwRUVaXL19Gz549MWTIENSpUwcODg64ffs2li9fLiWZjX2IJRERERFRecREMxERVVpnz57Ncatuy5Yt0b9/f5kiIqLy7N69e7l2A6VWq7F8+XLUr1+/lKMiIiIiIiodTDQTEVGlp1Ao4O7ujl69emHBggU5bn0nIsqPj48PpkyZgsjISNy9exexsbEwNzdH1apV0bZtW4wbNw61atWSO0wiKmXGHPfNmjXDjz/+WArREBERlSz20UxERERERERUAox54GRoaCgiIyNLPhgiIqISxhbNRERERERERCWA7bqIiKgy4b3BRERERERERERERFQkTDQTERERERERERERUZEw0UxERERERERERERERcJEMxEREREREREREREVCRPNRERERERERERERFQkTDQTERERERERERERUZEw0UxERERERERERERERcJEMxEREREREREREREVCRPNRERERERERERERFQkTDQTERERERERERERUZEw0UxERERERERERERERcJEMxEREREREREREREVCRPNRERERERERERERFQkTDQTERERERERERERUZEw0UxERERERERERERERcJEMxEREREREREREREVCRPNRERERERERERERFQkTDQTERERERERERERUZEw0UxERERERERERERERcJEMxEREREREREREREVCRPNRERERERERERERFQkTDQTERERERERERERUZEw0UxERERERERERERERcJEMxEREREREREREREVCRPNRERERERERERERFQkTDQTERERERERERERUZEw0UxERERERERERERERcJEMxEREREREREREREVCRPNRERERERERERERFQkTDRTmaVQKIx6RUZGIjIyEgqFAps3b5Y7bKxatQoKhQK3b9+Wxo0YMQJ+fn565RQKBf7v//6vdIMroN27d2POnDkGpy1YsAA///xzqcaT1e3bt6FQKLBq1aoCz3v58mXMmTNH7zPKz4YNG1C3bl1YWFhAoVDg7NmzBa63OOJr27YtAgMDS6xuORg6PsqTouyLxnj48CHmzJlTovscERFReVJerxMASPFERkbKHQoUCoXeuX5Jx3b06FHMmTMHMTExOaa1bdsWbdu2LZF6i8vt27fRrVs3ODo6QqFQYPLkybmWze1aKfNa8dSpUyUXqJEq+zlsUa9B/Pz8MGLEiALPl5SUhDlz5pSJvwFEJYGJZiqzjh07pvfq2rUrLCwscoxv1KiR3KHq6datG44dOwYPDw+5Qymy3bt3Y+7cuQanyZ1oLorLly9j7ty5Rieao6KiMGzYMFSrVg0RERE4duwYatasWWbiK+/ee+89bNu2Te4wyqyHDx9i7ty5ZfYknYiIqLSV1+sEAGjUqFGlje3o0aOYO3euwUTzsmXLsGzZshKpt7hMmTIFJ06cwPfff49jx45hypQpuZYtz9dKxYXnsIYlJSVh7ty5TDRThaWUOwCi3DRv3lzvvYuLC0xMTHKML2tcXFzg4uIidxhUjP7++2+kp6dj6NChCA0NLZZlJiUlwdLSsliWVV5lboNq1arJHUqllJycDHNzcygUCrlDISIiKpDyep0AALa2tmU2Tjljq1Onjiz1FsTFixfRrFkz9O7dW+5QKjWewxKVbWzRTBVKeno63nnnHXh6esLW1hbh4eG4du1ajnL79u1DWFgYbG1tYWlpiZYtW2L//v35Ll+r1WL+/PkICAiAhYUF7O3tERQUhCVLlkhlDHWdkZfVq1ejdu3asLS0RP369fHLL7/kKHPkyBGEhYXBxsYGlpaWaNGiBXbt2qVXZs6cOQa/bHOLZ8OGDQgJCYGVlRWsra3RqVMnnDlzRpo+YsQIfPXVVwD0b0/MvMUqMTERP/zwgzQ+661ujx8/xuuvvw5vb2+o1WpUrVoVc+fOhUajyXd7+Pn5oXv37ti2bRuCgoJgbm4Of39/fPHFF/nOa8y2WrVqFfr37w8AaNeunRR/breMjRgxAq1atQIADBw4MMe67tixAyEhIbC0tISNjQ06dOiAY8eO6S0j87P566+/8NJLL8HBwSHX5Kqx8Z08eRKtW7eGpaUl/P398dFHH0Gr1eqViYuLw/Tp01G1alWo1Wp4eXlh8uTJSExMzHMbTp48GVZWVoiLi8sxbeDAgXBzc0N6ejoA3X7UsWNHeHh4wMLCArVr18bMmTNz1DFixAhYW1vjwoUL6NixI2xsbBAWFiZNy37bWkpKCmbNmqUX+/jx43O0gMl+y2em7LeyJSUlSdvC3Nwcjo6OaNKkCdatW5fntgCABw8e4LXXXoOPjw/UajU8PT3x0ksv4cmTJ7nOk9uteIaO002bNiE4OBh2dnbS5zlq1CgAultYmzZtCgAYOXKktD9kXedTp06hZ8+ecHR0hLm5ORo2bIiNGzfq1ZH5d+C3337DqFGj4OLiAktLS6SmpiIqKkpaPzMzM7i4uKBly5bYt29fvtuGiIiovCjJ64SoqCio1Wq89957OaZdvXoVCoVCOpc11D3FzZs3MWjQIHh6esLMzAxubm4ICwvTawlq7DlPVFQUxo0bhzp16sDa2hqurq5o3749fv/997w3kIHYMs/7c3tl2rt3L3r16gVvb2+Ym5ujevXqeP311/Hs2TOpzJw5c/Dmm28CAKpWrarXvQlguOuM6OhojBs3Dl5eXlCr1fD398c777yD1NRUvXKZXRIac11lyN27dzF06FC4urrCzMwMtWvXxmeffSadW2dul3/++Qd79uzRuy4yJL9rJQCIj4/HG2+8AWdnZzg5OaFv3754+PBhjmXld82Wl4p+DluQ7bNq1SoEBARIn++PP/5o1DYEdH873nrrLbi7u8PS0hKtWrXCn3/+maOcMcfe7du3pUZpc+fOlbZL5jH8zz//YOTIkahRowYsLS3h5eWFHj164MKFC0bHSyQ3JpqpQnn77bdx584dfPvtt1ixYgWuX7+OHj16ICMjQyqzZs0adOzYEba2tvjhhx+wceNGODo6olOnTvmeRH7yySeYM2cOXn75ZezatQsbNmzA6NGjDd7+ZYxdu3Zh6dKlmDdvHrZs2QJHR0f06dMHN2/elMocOnQI7du3R2xsLL777jusW7cONjY26NGjBzZs2FCoehcsWICXX34ZderUwcaNG7F69WrEx8ejdevWuHz5MgBddwYvvfQSAP3bEz08PHDs2DFYWFiga9eu0vjMW90eP36MZs2a4ddff8X777+PPXv2YPTo0Vi4cCHGjBljVHxnz57F5MmTMWXKFGzbtg0tWrTApEmT8Omnn+Y5nzHbqlu3bliwYAEA4KuvvpLi79atm8Flvvfee1LCfcGCBXrr+tNPP6FXr16wtbXFunXr8N133+HFixdo27Ytjhw5kmNZffv2RfXq1bFp0yZ8/fXXBuszJr7Hjx9jyJAhGDp0KHbs2IEuXbpg1qxZWLNmjVQmKSkJoaGh+OGHHzBx4kTs2bMHM2bMwKpVq9CzZ08IIXLdjqNGjUJSUlKOE72YmBhs374dQ4cOhUqlAgBcv34dXbt2xXfffYeIiAhMnjwZGzduRI8ePXIsNy0tDT179kT79u2xffv2XLtlEUKgd+/e+PTTTzFs2DDs2rULU6dOxQ8//ID27dvnuLgwxtSpU7F8+XJMnDgRERERWL16Nfr374/nz5/nOd+DBw/QtGlTbNu2DVOnTsWePXvw+eefw87ODi9evChwHNkdO3YMAwcOhL+/P9avX49du3bh/fffl36UadSoEVauXAkAePfdd6X94dVXXwUAHDx4EC1btkRMTAy+/vprbN++HQ0aNMDAgQMN/ngyatQoqFQqrF69Gps3b4ZKpcKwYcPw888/4/3338dvv/2Gb7/9FuHh4fluGyIiovKkJK8TXFxc0L17d/zwww85fvhfuXIl1Go1hgwZkuv8Xbt2xenTp/HJJ59g7969WL58ORo2bFioa4zo6GgAwOzZs7Fr1y6sXLkS/v7+aNu2bYFv1c8878/62rFjB2xtbVG7dm2p3I0bNxASEoLly5fjt99+w/vvv48TJ06gVatWUuOEV199FRMmTAAAbN26Nd/uTVJSUtCuXTv8+OOPmDp1Knbt2oWhQ4fik08+Qd++fXOUN+a6ypCoqCi0aNECv/32Gz744APs2LED4eHhmD59uvQ8ncwuRdzd3dGyZUu96yJD8rpWyvTqq69CpVLhp59+wieffILIyEgMHTpUr4wx12y5qQznsMZun1WrVmHkyJGoXbs2tmzZgnfffRcffPABDhw4YNS6jhkzBp9++ileeeUVbN++Hf369UPfvn1zbEdjjj0PDw9EREQAAEaPHi1tl8wfqR4+fAgnJyd89NFHiIiIwFdffQWlUong4GCDP4wRlUmCqJwYPny4sLKyMjjt4MGDAoDo2rWr3viNGzcKAOLYsWNCCCESExOFo6Oj6NGjh165jIwMUb9+fdGsWbM8Y+jevbto0KBBnmVWrlwpAIhbt27pxe7r66tXDoBwc3MTcXFx0rjHjx8LExMTsXDhQmlc8+bNhaurq4iPj5fGaTQaERgYKLy9vYVWqxVCCDF79mxh6JDOHs/du3eFUqkUEyZM0CsXHx8v3N3dxYABA6Rx48ePN7hMIYSwsrISw4cPzzH+9ddfF9bW1uLOnTt64z/99FMBQFy6dMng8jL5+voKhUIhzp49qze+Q4cOwtbWViQmJgohhLh165YAIFauXCmVMXZbbdq0SQAQBw8ezDOWTJn716ZNm6RxGRkZwtPTU9SrV09kZGRI4+Pj44Wrq6to0aKFNC7zs3n//feNqi+v+EJDQwUAceLECb3xderUEZ06dZLeL1y4UJiYmIiTJ0/qldu8ebMAIHbv3p1nDI0aNdJbByGEWLZsmQAgLly4YHAerVYr0tPTxaFDhwQAce7cOWna8OHDBQDx/fff55gv+/EREREhAIhPPvlEr9yGDRsEALFixQppHAAxe/bsHMv09fXV2z8DAwNF796981plg0aNGiVUKpW4fPlyrmUM7YuGjnkhch6nmcdFTExMrss/efJkjuVnqlWrlmjYsKFIT0/XG9+9e3fh4eEh7ZuZfwdeeeWVHMuwtrYWkydPzrV+IiKisq4sXCfs2LFDABC//fabNE6j0QhPT0/Rr1+/HPFknuc9e/ZMABCff/55nss39pwnO41GI9LT00VYWJjo06dPnsvMHlt2iYmJolmzZsLDw0Pcvn3bYJnM88E7d+4IAGL79u3StEWLFuW4TsoUGhoqQkNDpfdff/21ACA2btyoV+7jjz/OsZ2Nva4yZObMmQbPrd944w2hUCjEtWvXpHG+vr6iW7dueS4vU27XSpnnZOPGjdMb/8knnwgA4tGjR0KIgl2zGVLRz2GN3T6Z12yNGjWSrgWFEOL27dtCpVIZXNesrly5IgCIKVOm6I1fu3atAFCoYy8qKirX49nQMtLS0kSNGjVyxEBUVrFFM1UoPXv21HsfFBQEALhz5w4A3QMooqOjMXz4cGg0Guml1WrRuXNnnDx5Ms9uBZo1a4Zz585h3Lhx+PXXXw12LVAQ7dq1g42NjfTezc0Nrq6uUryJiYk4ceIEXnrpJVhbW0vlTE1NMWzYMNy/f7/Av2z++uuv0Gg0eOWVV/S2gbm5OUJDQ4v8UIJffvkF7dq1g6enp97yu3TpAkDX6jg/devWRf369fXGDR48GHFxcfjrr78MzlMS2yov165dw8OHDzFs2DCYmPz7p9Ta2hr9+vXD8ePHkZSUpDdPv379iqVud3d3NGvWTG9cUFCQtN8Aus8hMDAQDRo00PscOnXqZNTTxEeOHImjR4/qbbOVK1eiadOmCAwMlMbdvHkTgwcPhru7O0xNTaFSqaR+rK9cuZJjucZsg8zWBdmf4ty/f39YWVkZ1c1Nds2aNcOePXswc+ZMREZGIjk52aj59uzZg3bt2um12ilOmbcUDhgwABs3bsSDBw+Mnveff/7B1atXpRZSWT/nrl274tGjRzn2eUPbv1mzZli1ahXmz5+P48ePSy2PiIiIKpKSvk7o0qUL3N3dpVacgO68++HDh1J3AoY4OjqiWrVqWLRoERYvXowzZ87kaBVdUF9//TUaNWoEc3NzKJVKqFQq7N+/3+C5mbEyMjIwcOBAXLlyBbt374avr6807enTpxg7dix8fHyk+jKnF7bOAwcOwMrKSrrDMlPm+WH288H8rqvyqqdOnTo5zq1HjBgBIYTRrV4LKr/9sajXbBX9HNbY7ZN5zTZ48GC9rj98fX3RokWLfGM9ePAgAOS4I2HAgAFQKnM+8qyox55Go8GCBQtQp04dqNVqKJVKqNVqXL9+vUjHL1FpYqKZKhQnJye992ZmZgAgJZUy+6N66aWXoFKp9F4ff/wxhBDSLS+GzJo1C59++imOHz+OLl26wMnJCWFhYTh16lSxxJsZc2a8L168gBDC4G1Znp6eAFDg29szt0HTpk1zbIMNGzbo9aVWGE+ePMHOnTtzLLtu3boAYNTy3d3dcx2X2/qWxLbKS+aycqtPq9XmuJ0qt9vrCiq//QbQfQ7nz5/P8TnY2NhACJHv5zBkyBCYmZlJt65dvnwZJ0+exMiRI6UyCQkJaN26NU6cOIH58+cjMjISJ0+exNatWwEgRzLX0tIStra2+a7f8+fPoVQqczxUU6FQwN3dvVCf4xdffIEZM2bg559/Rrt27eDo6IjevXvj+vXrec4XFRUFb2/vAtdnrDZt2uDnn3+WTpS9vb0RGBhoVN/Rmcfy9OnTc3zO48aNA5DzeDO0D27YsAHDhw/Ht99+i5CQEDg6OuKVV17B48ePi2ENiYiIyoaSvk5QKpUYNmwYtm3bJnV5sWrVKnh4eKBTp065zqdQKLB//3506tQJn3zyCRo1agQXFxdMnDgR8fHxBV7PxYsX44033kBwcDC2bNmC48eP4+TJk+jcubPRP7QbMnbsWERERGDz5s1o0KCBNF6r1aJjx47YunUr3nrrLezfvx9//vknjh8/DiDn+aCxnj9/Dnd39xz9Aru6ukKpVOY4HzTm/Di3ekrr+iErY/fHwl6zVfRzWGO3T+bnl9f1ZV5ym1+pVOb4DIvj2Js6dSree+899O7dGzt37sSJEydw8uRJ1K9fv0jHL1FpyvkTDFEF5uzsDAD48ssvc32ispubW67zK5VKTJ06FVOnTkVMTAz27duHt99+G506dcK9e/dgaWlZrPE6ODjAxMQEjx49yjEt82ERmetkbm4OAEhNTZVOVICcX9KZ5Tdv3qzXEqG4ODs7IygoCB9++KHB6ZknbXkxlODKHGfoJBIo2LYqDplx5FafiYkJHBwc9MaX5pORnZ2dYWFhge+//z7X6XlxcHBAr1698OOPP2L+/PlYuXIlzM3N8fLLL0tlDhw4gIcPHyIyMlJqxQwg1/4EjV1/JycnaDQaREVF6SWbhRB4/Pix1IIC0J2UG+qzOftFgZWVFebOnYu5c+fiyZMnUuvmHj164OrVq7nG4uLigvv37xsVd1bm5uYG4zJ0UdCrVy/06tULqampOH78OBYuXIjBgwfDz88PISEhudaR+RnOmjXLYF+FABAQEKD33tBn4OzsjM8//xyff/457t69ix07dmDmzJl4+vSp1IccERFRRVfU6wRAd0fYokWLsH79egwcOBA7duzA5MmTYWpqmud8vr6++O677wAAf//9NzZu3Ig5c+YgLS1Neq6Hsec8a9asQdu2bbF8+XK98YVJWmeaM2cOvv32W6xcuRIdO3bUm3bx4kWcO3cOq1atwvDhw6Xx//zzT6HrA3TngydOnIAQQu/85enTp9BoNMV2Xu/k5FRq1w8FUdRrtop+Dmvs9sm8Zsvr+jIvWef38vKSxms0mhI59tasWYNXXnlFemZPpmfPnsHe3t7o5RDJiYlmqlRatmwJe3t7XL58WXq4Q2HZ29vjpZdewoMHDzB58mTcvn0bderUKaZIdaysrBAcHIytW7fi008/hYWFBQBdy4E1a9bA29sbNWvWBADp6cDnz5/XS8Tt3LlTb5mdOnWCUqnEjRs38u3GIOsv65l1Z51m6FfV7t27Y/fu3ahWrVqORKuxLl26hHPnzul1n/HTTz/BxsYm1weGFGRbZW8xUBgBAQHw8vLCTz/9hOnTp0snP4mJidiyZQtCQkIK/cNDccTXvXt3LFiwAE5OTqhatWqhljFy5Ehs3LgRu3fvxpo1a9CnTx+9E5zMdc76wwYAfPPNN4WOGwDCwsLwySefYM2aNZgyZYo0fsuWLUhMTERYWJg0zs/PD+fPn9eb/8CBA0hISMh1+W5ubhgxYgTOnTuHzz//HElJSbl+Vl26dMHq1atx7dq1HCe8efHz88PTp0/x5MkT6aI0LS0Nv/76a67zmJmZITQ0FPb29vj1119x5swZhISE5Lo/BAQEoEaNGjh37lyOk9HCqlKlCv7v//4P+/fvxx9//FEsyyQiIioPiuM6oXbt2ggODsbKlSuRkZGB1NRUvbvBjFGzZk28++672LJli16Xccae8ygUihznZufPn8exY8fg4+NTwDUCvvvuO8ydOxfz5s3L0a1ZZn2AceeDBTnHDQsLw8aNG/Hzzz+jT58+0vgff/xRml4cwsLCsHDhQvz111961xk//vgjFAoF2rVrV6jlGtOaOi8FuWYzpKKfwxq7fQICAuDh4YF169Zh6tSp0v56584dHD16NN9GUG3btgUArF27Fo0bN5bGb9y4UXrwYSZjj728jgNDy9i1axcePHiA6tWr5xkrUVnBRDNVKtbW1vjyyy8xfPhwREdH46WXXoKrqyuioqJw7tw5REVF5fgFMqsePXogMDAQTZo0gYuLC+7cuYPPP/8cvr6+qFGjRonEvHDhQnTo0AHt2rXD9OnToVarsWzZMly8eBHr1q2Tviy7du0KR0dHjB49GvPmzYNSqcSqVatw7949veX5+flh3rx5eOedd3Dz5k107twZDg4OePLkCf7880+p5ScA1KtXDwDw8ccfo0uXLjA1NUVQUBDUajXq1auHyMhI7Ny5Ex4eHrCxsUFAQADmzZuHvXv3okWLFpg4cSICAgKQkpKC27dvY/fu3fj666/zvY3L09MTPXv2xJw5c+Dh4YE1a9Zg7969+Pjjj/NM3hq7rTL7GF6xYgVsbGxgbm6OqlWr5tpa2hATExN88sknGDJkCLp3747XX38dqampWLRoEWJiYvDRRx8ZvazsiiO+yZMnY8uWLWjTpg2mTJmCoKAgaLVa3L17F7/99humTZuG4ODgPJfRsWNHeHt7Y9y4cXj8+HGOC6UWLVrAwcEBY8eOxezZs6FSqbB27VqcO3eu4CudRYcOHdCpUyfMmDEDcXFxaNmyJc6fP4/Zs2ejYcOGGDZsmFR22LBheO+99/D+++8jNDQUly9fxtKlS2FnZ6e3zODgYHTv3h1BQUFwcHDAlStXsHr16nx/EJg3bx727NmDNm3a4O2330a9evUQExODiIgITJ06FbVq1TI438CBA/H+++9j0KBBePPNN5GSkoIvvvhC78n2APD+++/j/v37CAsLg7e3N2JiYrBkyRK9vq6rVasGCwsLrF27FrVr14a1tTU8PT3h6emJb775Bl26dEGnTp0wYsQIeHl5ITo6GleuXMFff/2FTZs25bmtY2Nj0a5dOwwePBi1atWCjY0NTp48iYiICL0WJvPmzcO8efOwf/9+vdbrREREFUVRrxMyjRo1Cq+//joePnyIFi1a5JvkO3/+PP7v//4P/fv3R40aNaBWq3HgwAGcP38eM2fOlMoZe87TvXt3fPDBB5g9ezZCQ0Nx7do1zJs3D1WrVs2RGMvPsWPHMHbsWLRs2RIdOnSQusPI1Lx5c9SqVQvVqlXDzJkzIYSAo6Mjdu7cib179+ZYXua1xZIlSzB8+HCoVCoEBATo9a2c6ZVXXsFXX32F4cOH4/bt26hXrx6OHDmCBQsWoGvXrggPDy/QuuRmypQp+PHHH9GtWzfMmzcPvr6+2LVrF5YtW4Y33nhDaqhSULldKxmrINdshlT0c1hjt4+JiQk++OADvPrqq+jTpw/GjBmDmJgYzJkzx6iuM2rXro2hQ4fi888/h0qlQnh4OC5evIhPP/00R5eAxh57NjY28PX1xfbt2xEWFgZHR0c4OzvDz88P3bt3x6pVq1CrVi0EBQXh9OnTWLRokcHrZ6VSidDQ0EI9v4aoRMn2GEKiAjLmadKbNm3SG2/oSbpCCHHo0CHRrVs34ejoKFQqlfDy8hLdunXLMX92n332mWjRooVwdnYWarVaVKlSRYwePVrvqcuZT8bN+jRlQ0/vBSDGjx+fow5DT47+/fffRfv27YWVlZWwsLAQzZs3Fzt37swx759//ilatGghrKyshJeXl5g9e7b49ttvDT7d+eeffxbt2rUTtra2wszMTPj6+oqXXnpJ7Nu3TyqTmpoqXn31VeHi4iIUCoXecs6ePStatmwpLC0tBQC9p0RHRUWJiRMniqpVqwqVSiUcHR1F48aNxTvvvCMSEhLy3MaZT3PevHmzqFu3rlCr1cLPz08sXrxYr1xun62x2+rzzz8XVatWFaamprk+DTlTbvtX5nYMDg4W5ubmwsrKSoSFhYk//vhDr0zmU5qjoqLyXHdj4gsNDRV169bNUd7QPpaQkCDeffddERAQINRqtbCzsxP16tUTU6ZMEY8fPzYqjrffflsAED4+PtLTn7M6evSoCAkJEZaWlsLFxUW8+uqr4q+//jL4BOvcjl9DsScnJ4sZM2YIX19foVKphIeHh3jjjTfEixcv9MqlpqaKt956S/j4+AgLCwsRGhoqzp49m+M4mjlzpmjSpIlwcHAQZmZmwt/fX0yZMkU8e/Ys321w7949MWrUKOHu7i5UKpXw9PQUAwYMEE+ePBFC5L4v7t69WzRo0EBYWFgIf39/sXTp0hxP7P7ll19Ely5dhJeXl1Cr1cLV1VV07dpV/P7773rLWrdunahVq5ZQqVQ5nlJ97tw5MWDAAOHq6ipUKpVwd3cX7du3F19//bVUJvPv0smTJ/WWm5KSIsaOHSuCgoKEra2tsLCwEAEBAWL27NkiMTFRKpcZd25PoSciIpJTWbhOyBQbGyssLCwEAPHf//4313gyv1OfPHkiRowYIWrVqiWsrKyEtbW1CAoKEv/5z3+ERqOR5jP2nCc1NVVMnz5deHl5CXNzc9GoUSPx888/53o9kvWcIntsmecPub0yXb58WXTo0EHY2NgIBwcH0b9/f3H37t0cyxdCiFmzZglPT09hYmKiV1doaKje9YQQQjx//lyMHTtWeHh4CKVSKXx9fcWsWbNESkpKjvUw9rrKkDt37ojBgwcLJycnoVKpREBAgFi0aFGOc9/M6xRj5HatlNs5WfZtn8mYa7bcVORz2IJun2+//VbUqFFDqNVqUbNmTfH9998bPCYMSU1NFdOmTROurq7C3NxcNG/eXBw7dqxIx96+fftEw4YNhZmZmQAgLefFixdi9OjRwtXVVVhaWopWrVqJ33//3eDxkf0anKisUAghRMmksImICs7Pzw+BgYH45Zdf5A6FiIiIiIiIiIiMZCJ3AERERERERERERERUvjHRTERERERERERERERFwq4ziIiIiIiIiIiIiKhI2KKZiIiIiIiIiIiIiIqEiWYiIiIiIiIiIiIiKhImmomIiIiIiIiIiIioSJRyVKrVavHw4UPY2NhAoVDIEQIRERERlQAhBOLj4+Hp6QkTE7ZpqCx4fk9ERERUcRl7ji9Lovnhw4fw8fGRo2oiIiIiKgX37t2Dt7e33GFQKeH5PREREVHFl985viyJZhsbGwC64GxtbeUIofJKSQGGDtUNr1kDmJvLGw8RERFVKHFxcfDx8ZHO96hy4Pk9ERERUcVl7Dm+LInmzNvpbG1teSJa2kxNgb17dcNWVroXERERUTFj9wmVC8/viYiIiCq+/M7x2XEeERERERERERERERUJE81EREREREREREREVCRMNBMRERERERERERFRkTDRTERERERERERERERFwkQzERERERERERERERWJUu4AKrSHkUDSY7mj0JeU8u/wjU2Apbl8sZQ3IgNIjwNSY4DUF0DaC0BlAzR6HzCzlzs6IiIiIiIiIiIi2TDRXJJOzwES7gKmZSyZu6G27v+rn8gbh+wEkJGm+z9XJoCJCjBRAibq/w2rANP//a9QAkkPmWgmIiIiIiIiIqJKjYnmkqTNAMxdAAtXuSOp3IQW0CQDmgQgPRGA9n+5ZQEoLXRJZEVmMlkFqO0Bc0fAzAkwdwLMHAEzB91L7aBLKps5AGo7XXkiIiIiIiIiIqJKjolmqti0GUD8DUBpqUsMuwYDDoGAuTOgttW9VFn+V1kDCoXcURMREREREREREZUrTDRXNmkZwKKzuuE3GwBqUzmjKRlCAClPgbQ4XdLYugoQ/LEuwWyqljs6IiIiIiIiIiKiCoeJ5spGK4Ajj3TD0+rLG0txEwLISAGSnwIKAH69APdWulbM7L6EiIiIiIiIiIioxDDRTOWfEEDSA10/zKZmuj6UXYOBph/q+l0mIiIiIiIiIiKiEsUsHJV/SQ90D/MLGge4NAXsawFKc7mjIiIiIiIiIiIiqjSYaKbyLT0B0GqAxu8A/i/JHQ0REREREREREVGlZCJ3AESFpknWtWZ2qANU7St3NERERERERERERJUWE81UfqVEAQ6BQMsvAQV3ZSIiIiIiIiIiIrkwO0flV0Yq4NQAsHCVOxIiIiIiIiIiIqJKjX00VzZmpsC2zv8Ol0cZaUDyI8BEBTgFyR0NERERERERERFRpcdEc2WjUADm5fhjF1og4TZgVxOoNgjw6Sp3RERERERERERERJVeOc44UqWTkQLE3wWsPIGQxYBdDbkjIiIiIiIiKrOio6Oxbt06mJiYYPDgwbCzs5M7JCIiqsCYaK5s0jKALy/ohifUA9TlqPuMhHuAW3OgyTzAxlfuaIiIiIiIiMq0RYsW4eLFiwCAJ0+eYM6cOfIGREREFRofBljZaAWw777upRVyR2McIYDkp4DCFKgxlElmIiIiIiIiIzx9+tTgMBERUUlgopnKvpRngFYDBIwE3FvLHQ0REREREVG58PLLL8PU1BRKpRKDBg2SOxwiIqrg2HUGlW1aDZD6AvDpCNSfLnc0RERERERE5UZ4eDhatGgBhUIBCwsLucMhIqIKjolmKtsS7uke+tfwbbkjISIiIiIiKncsLS3lDoGIiCoJdp1BZVdaHKBQAIH/B1h6yB0NERERERERERER5YKJZiqbhBZIfgx4dwK8O8odDREREREREREREeWBiWYqm9ITAJUNUPcNQMHdlIiIiIiIiIiIqCxjH82VjZkpsK7Dv8NlVUYKoLQArHzkjoSIiIiIiIiIiIjywURzZaNQAPZmckeRP00yYF8LMFXLHQkRERERERERERHlg30SUNkjBKBNBRyD5I6EiIiIiIiIiIiIjMAWzZVNWgbw38u64TF1AHUZ7D4jIxkwNQc82sgdCRERERERERERERmBLZorG60Afrmje2mF3NEYlhoDmDkAjnXljoSIiIiIiIiIiIiMwEQzlS1pMYA2Bag+GFBayh0NERERERERERERGYGJZipb0uIAh7pArVfljoSIiIiIiIiIiIiMxEQzlS0iAzBzBhTcNYmIiIiIiIiIiMoLZvOo7BAC0KYDlu5yR0JEREREREREREQFwEQzlR3aNMBEDXiFyR0JERERERERERERFQATzVR2pEYDalvAMUjuSIiIiIiIiIiIiKgAlHIHQKVMbQqsav/vcFmhSQY0iUDASEBtI3c0REREREREREREVABMNFc2JgrAzVLuKPQJASQ9BCy9gFqvyh0NERERERERERERFRC7ziD5pb0AlBZA4/cBUzO5oyEiIiIiIiIiIqICYovmyiZdC/xwVTc8vBagKgO/NaTFA84NAY82ckdCREREREREREREhVAGsoxUqjK0wJabuleGVu5odLRpgH0tuaMgIiIiIiIiIiKiQmKimeSlSQZMlIBbC7kjISIiIiIiIiIiokJiopnklfocsPED3JloJiIiIiIiIiIiKq+YaCb5CC2QngjYVgdMVHJHQ0RERERERERERIXEhwGSPLTpQPwtwMIF8OkidzRERERERERERERUBEw0kzwS7gCO9YDgTwBbf7mjISIiIiIiIiIioiJgoplKl9ACCXcBpTUQNI1JZiIiIiIiIiIiogqAfTRXNmpT4OtQ3UttWvr1p8UCpuZAk7mAa/PSr5+IiIionFi+fDmCgoJga2sLW1tbhISEYM+ePdL0ESNGQKFQ6L2aN9c/v0pNTcWECRPg7OwMKysr9OzZE/fv39cr8+LFCwwbNgx2dnaws7PDsGHDEBMTUxqrSEREREQVCBPNlY2JAvC10b1MFKVff3oCYO2t65dZIUP9REREROWEt7c3PvroI5w6dQqnTp1C+/bt0atXL1y6dEkq07lzZzx69Eh67d69W28ZkydPxrZt27B+/XocOXIECQkJ6N69OzIyMqQygwcPxtmzZxEREYGIiAicPXsWw4YNK7X1JCIiIqKKgV1nUOkRAshIBjzDmGQmIiIiykePHj303n/44YdYvnw5jh8/jrp16wIAzMzM4O7ubnD+2NhYfPfdd1i9ejXCw8MBAGvWrIGPjw/27duHTp064cqVK4iIiMDx48cRHBwMAPjvf/+LkJAQXLt2DQEBASW4hkRERERUkbBFc2WTrgXWXNO90rWlW3daDKCyBap0Kd16iYiIiMq5jIwMrF+/HomJiQgJCZHGR0ZGwtXVFTVr1sSYMWPw9OlTadrp06eRnp6Ojh07SuM8PT0RGBiIo0ePAgCOHTsGOzs7KckMAM2bN4ednZ1UxpDU1FTExcXpvYiIiIiocmOiubLJ0AJrr+teGaWcaE6NBlwaA7bVSrdeIiIionLqwoULsLa2hpmZGcaOHYtt27ahTp06AIAuXbpg7dq1OHDgAD777DOcPHkS7du3R2pqKgDg8ePHUKvVcHBw0Fumm5sbHj9+LJVxdXXNUa+rq6tUxpCFCxdKfTrb2dnBx8enuFaZiIiIiMopdp1BpUcIwDU4/3JEREREBAAICAjA2bNnERMTgy1btmD48OE4dOgQ6tSpg4EDB0rlAgMD0aRJE/j6+mLXrl3o27dvrssUQkCRpRszhYEuzbKXyW7WrFmYOnWq9D4uLo7JZiIiIqJKjolmKh3adF2/zFa8ACEiIiIyllqtRvXq1QEATZo0wcmTJ7FkyRJ88803Ocp6eHjA19cX169fBwC4u7sjLS0NL1680GvV/PTpU7Ro0UIq8+TJkxzLioqKgpubW65xmZmZwczMrEjrRkREREQVC7vOoNKRFgOYOQCuTeWOhIiIiKjcEkJIXWNk9/z5c9y7dw8eHh4AgMaNG0OlUmHv3r1SmUePHuHixYtSojkkJASxsbH4888/pTInTpxAbGysVIaIiIiIyBhs0UylQ5MC2NUE1HZyR0JERERULrz99tvo0qULfHx8EB8fj/Xr1yMyMhIRERFISEjAnDlz0K9fP3h4eOD27dt4++234ezsjD59+gAA7OzsMHr0aEybNg1OTk5wdHTE9OnTUa9ePYSHhwMAateujc6dO2PMmDFSK+nXXnsN3bt3R0BAgGzrTkRERETlDxPNVPKEADRJ7J+ZiIiIqACePHmCYcOG4dGjR7Czs0NQUBAiIiLQoUMHJCcn48KFC/jxxx8RExMDDw8PtGvXDhs2bICNjY20jP/85z9QKpUYMGAAkpOTERYWhlWrVsHU1FQqs3btWkycOBEdO3YEAPTs2RNLly4t9fUlIiIiovJNIYQQpV1pXFwc7OzsEBsbC1tb29KuvvRsbw1o0wCLnE/ylk2KBugToRve1hkwL4XfGjTJQMozoO0qwLlByddHREREsqk053mkh587ERERUcVl7LkeWzRXNipT4PNW/w6XBk0yoLQAbKuWTn1ERERERERERERUqphormxMFUCAfenWqUkCbP3YPzMREREREREREVEFZSJ3AFQJZCQBzo3ljoKIiIiIiIiIiIhKCFs0VzbpWmD7Ld1wr6qAqoR/a9CmATABrH1Lth4iIiIiIiIiIiKSDRPNlU2GFvjuim64u2/JJ5rTEwAzO6BKt5Kth4iIiIiIiIiIiGTDrjOoZGWkAiZqwMxe7kiIiIiIiIiIiIiohDDRTCVHaIH0eMCnC6DgrkZERERERERERFRRMftHJSc9HlDZANUGyh0JERERERERERERlSAmmqnkZKQCSgvAxk/uSIiIiIiIiIiIiKgEMdFMJScjFbBwZ7cZREREREREREREFRwzgFRyMlIB6ypyR0FEREREREREREQlTCl3AFTKVKbAx83/HS4pGWm6/91alFwdREREREREREREVCYw0VzZmCqAIOeSrUNogYTbgEMg4N2xZOsiIiIiIiIiIiIi2bHrDCp+Kc8AlQ3QZB6gtpE7GiIiIiKiYrN/fzLWrInHo0cauUMhIiIiKlPYormy0WiBPXd1w12qAMpi/q1BkwykxwG1xgAOdYp32UREREREMtq9OwnLl8cBAPbuTcZ//+sCtVohc1REREREZUOlbtG8cOFCKBQKTJ48We5QSo9GCyy7qHtptMW7bCGAlCjA3BmoNRpQ8KSbiIiIiCqOGzfSpeHoaC1iYor5fJqIiIioHKu0ieaTJ09ixYoVCAoKkjuUiiPxPmCiAoKmA2o7uaMhIiIiIipW7dpZQK3WDTdurIaLS6W9nCIiIiLKoVJ2nZGQkIAhQ4bgv//9L+bPny93OBVDRiqQkQwEvgn49ZI7GiIiIiKiYhcYqMZ//+uC58+18PdXQlGG7+DTarXYv38/kpKS0LFjR1hYWMgdEhEREVVwlfIn+PHjx6Nbt24IDw+XO5SKQQgg/jbg3Bio0kPuaIiIiIiISoyjoylq1FDB1LTsJpkBYNWqVfjiiy/w7bff4oMPPpA7HCIiIqoEKl2L5vXr1+Ovv/7CyZMn5Q6l4shIAUzNgHqTAUs3uaMhIiIiIqr0rl69Kg1fu3ZNxkiIiIiosqhULZrv3buHSZMmYc2aNTA3N5c7nIojLQ4wdwGcGsgdCRERERERAWjXrp3BYSIiIqKSUqlaNJ8+fRpPnz5F48aNpXEZGRk4fPgwli5ditTUVJiamsoYYTmVkQQ41AJM1XJHQkREREREALp06YLatWsjKSkJtWvXljscIiIiqgQqVaI5LCwMFy5c0Bs3cuRI1KpVCzNmzKgcSWaVCTC36b/DRZWRCmgzAJ/ORV8WEREREREVGz8/P7lDICIiokqkUiWabWxsEBgYqDfOysoKTk5OOcZXWKYmQLNi7Ec58QHgFAT49S2+ZRIRERERERFRgTx9moE5c17g0SMN+ve3xuDB1nKHRESVTKXqo5lKghbwCgeU7POaiIiIiIiISC5btybi3j0NNBpg3boEREdnyB0SEVUylapFsyGRkZFyh1C6NFrg4APdcDsvQFmE3xqEAIQWsPYpntiIiIiIiIiIqFCsrBTSsFoNqNWKPEoTERW/Sp9ornQ0WmDxOd1wa48iJprTAYUpoLQsntiIiIiIiIiIqFAGDLBGXJwWDx9moFcvS1hb8yZ2IipdTDRT4SU+BGyrAQ6VpH9rIiIiIiIiojLKzEyB8ePt5A6DiCox/rxFhSc0gGd7wNxR7kiIiIiIiIiIiIhIRkw0U+GkxQEwAay85I6EiIiIiIiIiIiIZMZEMxVcRhqQ/Bjw6wlU7St3NERERERERERERCQzJpqp4JIeAva1gAazABN2801ERERERERERFTZMUtIBafVAD6dAbWt3JEQEREREdH/pKSkYOvWrUhJSUHfvn1hb28vd0hERERUiTDRXNmoTIC3G/07XFBaDaAAYO1brGEREREREVHRLF++HAcOHAAAXLlyBYsWLZI5IiIiIqpMmGiubExNgNaehZ8/5Slg4Qa4Ni++mIiIiIiIqMju3btncJiIiIioNLCPZiqY9ATAoy1g7ih3JERERERElEXPnj1hYqK7xOvTp4/M0RAREVFlwxbNlU2GFjj6WDfcwl3XwrkgFCaAuXPxx0VEREREREXStm1bBAUFQaPRwNXVVe5wiCCEgEKhkDsMIiIqJUw0VzbpWmDBX7rhbZ0LlmgWWkAIwIb9MxMRERERlUWOjrzzkOT3OCUBsy8dweOURPT3roWhvnXlDomIiEoBu84g4yU/BswcAIdAuSMhIiIiIiKiMmrbg+t4mJwArRDYcO8KotOS5Q6JiIhKARPNZBwhgPREoNogwLaq3NEQERERERFRGWWrVEvDahNTmJmYyhgNERGVFnadQcbRJAKm5oBbC7kjISIiIiIiojKsv08txGvS8DA5Ab29asAqS+KZiIgqLiaayTjJUYCtP+DSWO5IiIiIiIiIqAxTm5hibLWGcodBRESljF1nUP60aQC0QO0xgIK7DBEREREREREREelji2bKX0aartsM+9pyR0JERERERFQpXY57hoNP76KqlR26elSTOxwiIqIcmGiubJQmwNT6/w4bQ5MMKC0BK6+Si4uIiIiISAbnz6fi7l0NWrQwh6MjH1hGZdOLtBS8f/F3pGozAABmJqYIc/OTNygiIqJsmGiubJQmQAefgs2TkQzY1AKUFiUTExERERGRDI4eTcHChTEAgG3bkvDVV04wN2dXcVT2PE9LlpLMAPAwJUHGaIiIiAzjWRTlTZsOZKQArs3ljoSIiIiISKLRaBAfH1+kZVy8mCYNP32agagobVHDokpOo9Fg8eLFeO2117B27dpiW66/lT0aO7gDABzVFgh39Su2ZRMRERUXtmiubDK0wOko3XBjF8A0n98aUqMBC3cgYESJh0ZEREREZIwHDx7g7bffRnR0NMLDwzFp0qRCLad5czPs2ZMEjQbw91fC3Z1dZ5QFL168QEpKCjw8POQOpcD27duHgwcPAgDWr1+PJk2aICAgoMjLNVEoMLtOS0SlJsFOZQYzU17KExFR2cNvp8omXQvMPqkb3tY5/0SzJhmwqwmYOZR8bERERERERti1axeio6MB6BJ7AwYMKFRSMijIDF9+6YxHjzSoV08NlUpR3KGWaUII7N2bjOhoLTp2tCgTfVQfPXoUixYtgkajQb9+/TBixAi5QyoQIUSe74tCoVDA1dyq2JZHZdve//2rjuoYjdEwhfzHJxFRfphoptylxen6Z3ZuJHckREREREQSFxcXadjc3BzW1taFXpa3txLe3pXzsmjjxkSsWaPr6zcyMhnLlztDoZA32f7LL79Ao9EAALZv317uEs3h4eG4dOkSrly5grZt26JWrVpyh0Tl0AM8wJf4EgICV3AFXvBCN3STOywionxVzjMqyp8mGUh+Avh0A6oNkjsaIiIiIiJJz549kZqainv37qFLly6wsbGROyRJTEwGfvwxARqNwNChNnB1LbutEP/5J10afvAgA6mpAubm8iaafXx8cOHCBQCAt7e3rLEUhkqlwvTp04t1mUIIaLVamJqW3X2JilcykiHwb2v4RCTKGA0RkfGYaCbDNAmAuTPQfBFgqpY7GiIiIiIiiampKQYNKpuNIZYsicOpU6kAdMnbzz5zkjmi3IWHW+DUqVRoNECbNuYwN5f/WfGjR4+Gk5MTEhIS0KtXL7nDkd2FCxfw4YcfIjU1FePGjUOHDh3kDolKQXVURw/0wK/4FdVRHV3RVe6QiIiMwkQz5SQEkBoDuDRjkpmIiIiIqACeP88wOFwWBQeb45tvXBATk4EaNVRyhwMAUKvVGDBgQLEtLzFRC3NzBUxNy2f/22vWrEFioq4163fffcdEcyXy2v/+ERGVJ/L/ZE1lT3o8oLQAAifIHQkRERERUbkyZIg11GpAqQSGDy87XXrkxtXVFDVrqmXvm7kkLF8eh0GDnmLUqCjcu6eRO5xCsbe3NzhcUuLjtXj0qHxuKyIikh8TzZRTajTgEAi4NJE7EiIiIqJKa/ny5QgKCoKtrS1sbW0REhKCPXv2SNOFEJgzZw48PT1hYWGBtm3b4tKlS3rLSE1NxYQJE+Ds7AwrKyv07NkT9+/f1yvz4sULDBs2DHZ2drCzs8OwYcMQExNTGqtYIQUHm2PDBjds2OCGdu0s5A6n0oqKysDu3UkAgOhoLXbuLJ993I4bNw5hYWFo0aIF3nnnnRKt6/z5VIwcGYXXXnuG5cvjSrQuIiKqmJhormyUJsC4QN1LaeDjFwLISAWcGgAVsFUDERERUXnh7e2Njz76CKdOncKpU6fQvn179OrVS0omf/LJJ1i8eDGWLl2KkydPwt3dHR06dEB8fLy0jMmTJ2Pbtm1Yv349jhw5goSEBHTv3h0ZGf926TB48GCcPXsWERERiIiIwNmzZzFs2LBSX9+KRKlUQK3mubScrKwUsLD49zNwdi6fD9Kzs7PD5MmTMWvWLPj4+JRoXb/8koTUVN0D6HbvTkJKirZE6yMioopHIYQQ+RcrXnFxcbCzs0NsbCxsbW1Lu/rSs701oE0DLFzljsR46fFAWhzQfi3gUFvuaIiIiKicqTTneTJxdHTEokWLMGrUKHh6emLy5MmYMWMGAF3rZTc3N3z88cd4/fXXERsbCxcXF6xevRoDBw4EADx8+BA+Pj7YvXs3OnXqhCtXrqBOnTo4fvw4goODAQDHjx9HSEgIrl69ioCAAKPi4udOZdHly2nYuTMJXl6mGDTIGkolk/95Wb06Hhs36lp+u7iY4LvvXCpklypERFRwxp7r8WGApC/5KeBQF7CrLnckRERERPQ/GRkZ2LRpExITExESEoJbt27h8ePH6Nixo1TGzMwMoaGhOHr0KF5//XWcPn0a6enpemU8PT0RGBiIo0ePolOnTjh27Bjs7OykJDMANG/eHHZ2djh69GiuiebU1FSkpqZK7+PieJs9lT116qhRpw4fbm6sl1+2hqWlAs+fa9GjhyWTzEREVGBMNFc2GQK49Fw3XNcJyPr05dQXgIla9xBAk7Lx1GkiIiKiyuzChQsICQlBSkoKrK2tsW3bNtSpUwdHjx4FALi5uemVd3Nzw507dwAAjx8/hlqthoODQ44yjx8/lsq4uua8+87V1VUqY8jChQsxd+7cIq0bEZUtSqUC/fpZyx1GmSGEwJ49ybh7V4PwcAtUr85rZCKi/LCP5somPQOYcVz3Sv+3bz6kxQMpzwD//oB7a/niIyIiIiJJQEAAzp49i+PHj+ONN97A8OHDcfnyZWl69haHQoh8WyFmL2OofH7LmTVrFmJjY6XXvXv3jF0lIqJy4ddfk7F8eRx27UrCu+9GIz6efVYTEeWHiWbSSX4CeHcE6r/JhwASERERlRFqtRrVq1dHkyZNsHDhQtSvXx9LliyBu7s7AORodfz06VOplbO7uzvS0tLw4sWLPMs8efIkR71RUVE5WktnZWZmBltbW70XEVFFcv++RhpOTBSIiWGimYgoP0w0k44Cun6ZTdmHGREREVFZJYRAamoqqlatCnd3d+zdu1ealpaWhkOHDqFFixYAgMaNG0OlUumVefToES5evCiVCQkJQWxsLP7880+pzIkTJxAbGyuVISKqjMLDLWBjo2uE1bSpGby9TWWOiIio7GMfzQQIoXupbOSOhIiIiIj+5+2330aXLl3g4+OD+Ph4rF+/HpGRkYiIiIBCocDkyZOxYMEC1KhRAzVq1MCCBQtgaWmJwYMHAwDs7OwwevRoTJs2DU5OTnB0dMT06dNRr149hIeHAwBq166Nzp07Y8yYMfjmm28AAK+99hq6d++e64MAiYgqAz8/Fb791gUxMVp4eJjy4YhEREZgopmA9ARAaQk4N5Y7EiIiIiL6nydPnmDYsGF49OgR7OzsEBQUhIiICHTo0AEA8NZbbyE5ORnjxo3DixcvEBwcjN9++w02Nv82HvjPf/4DpVKJAQMGIDk5GWFhYVi1ahVMTf9tmbd27VpMnDgRHTt2BAD07NkTS5cuLd2VJSIqgywtTWBpyRvBiYiMpRBCiNKuNC4uDnZ2doiNja3Y/bltbw1o0wCLnE/ylk2KBugToRve1hkwVwKJDwArT6DTTvbPTEREREVSac7zSA8/dyIiypcQwPMzgKk54FBH7miIqACMPddji2YChBZQWjPJTEREREQVwuHDh/Hdd9/Bzs4OM2bMgJeXl9whERHRxS+AB/t0wzWHA/4vyRsPERU73gNS2ZiaAKNr616m//v4hQZQ28kbFxERERFRMRBCYMmSJYiOjsatW7fwww8/yB0SEREBwJOjhofz8vw8cPI9XZJak1QycRFRsWGL5spGZQK8VO3f91oNoE0HXJrIFxMRERERUTFSqVRIS0uThikfQgsk3APMnQCVtdzREJU78empiE5LgY+lLUx4p3DuHAOBp3/qhh0C8y+fkQb89QGQkaJ7b2oB1B5TcvERUZEx0VzZpTwFrLyAqn3ljoSIiIiIqMgUCgVmzpyJH3/8Eba2thg1alSpxyCEwPLly3H06FHUq1cP06ZNg1JZRi+9hBY4PQ94dhpQWgHNFgC2/nJHRVRu3Eh4gXcuHkaiJh1NHNzxXp2WTDbnpv4M4FGkro9m99b5lxcaICP13/fp8SUWGhEVjzJ6tkMlJkMA/8Tqhv2tdH+oq/TUtV4gIiIiIqoAGjRogAYNGshW/9mzZ7Fnzx4AwJEjR9C4cWOEh4fLFk+eEu/rkswAoEkEHh5gopmoAPY/vYNETToA4NSLx3iYHA9vSz4U1SBTNeDd0fjySktdX87/rAHMXYBqA0suNiIqFkw0VzbpGcDkI7rhVTUAl2pA3TfkjYmIiIiIqALJ3l1Hme6+w8xR111GeoLuvbWvvPEQlTNVsiSVbZRqOKjNi7zMJ3gCE5jABS5FXla5599Pdwc2W4kTlQtMNFdm1j5Ao3cAC1e5IyEiIiIiqjACAwMxePBgqeuMNm3ayB1S7lTWQLOFwIP9gHUVwLuD3BERlSud3f1hqlDgblIcwlz9YKVUF2l527AN3+N7KKDAOIxDZ3QupkhLR5ImHT/dvYwETRoG+tSGh0Ux9PvOJDNRucFEc2XWbCHg3kzuKIiIiIiIKpyXX34ZL7/8stxhGMfGD6g1Wu4oiMqtDm5Vi21Z27EdACAgsAM7yl2iecXNs9j/9A4A4Gp8NL5u3EnmiIioNJnIHQDJyLb4vgyJiIiIiIiIqGiqoIo07Ivy15VNVGpyluEkGSMhIjmwRXNlk5H277DSUr44iIiIiIiIiEjPW3gL27ANpjBFH/SRO5wCe8k7AH8nRCM1IwNDqtSROxwiKmVMNFc2aTFyR0BEREREREREBljDGsMwTO4wCq2hgxvWNOsOjdAWub9qIip/mGiuTLTpQGqM3FEQERERERERlUsPHmjw008JsLRU4JVXbGBjwx5JszMzVcJM7iCISBZMNFcmCXcB57rAjK6AuROgUskdEREREREREVG58cEHL/DgQQYAIClJ4M037eUNiIioDGGiubLQpgNCALUGA90HyR0NERERERERUbkTHa01OExERADv8agsEu8D9jWBKt3kjoSIiIiIiIioXBoxwgYmJoCFhQIvv2wldzhERGUKWzRXFiIDqDYQUFoBly7pxtWuDZjwtwYiIiIiIqKyTKMRiInRwtHRBCYmCrnDqdS6drVEeLgFTE0BU1N+FkREWTHRXBkIra7bDLU9kJwMBAbqxickAFb8BZaIiIiIiKisiovTYubMaNy7p0GtWip8+KEj1GomOOXE7U9EZBibs1YG6fGAygZwrCd3JEREREREVIn98086vv8+DocPJ8sdSrlx5EgK7t3TAACuXk3HmTOpMkdERERkGFs0VwYZaYCpGWDlBSTxhI6IiIiIiErfixcZmDUrGikpAgCgVCrQooW5zFGVfR4eptKwQgG4uZnmUZqIiEg+TDRXBtp0wNwJULABOxERERERyePJkwwpyQwAt29r0KJF8daRmJgIqwrWPWDDhmaYMsUOFy6koXlzM/j5qeQOiYiIyCAmmiuDjGTArqbcURARERERUSVWrZoKtWurcOVKOmxsFGjTpvhaM6ekpOD999/HlStXULt2bXzwwQcwMzMrtuXLrX17C7RvbyF3GERUCBlCC1M2/KNKgonmik4I3cMAXZrIHQkRERERERXC2rVrsW/fPtSoUQPTpk0rtwlUlUqBBQscce+eBi4uprC2Lr7Ey4kTJ3DlyhUAwJUrV3D8+HGEhoYWalknT55EWloaQkJCYGLC5BARFc7NhBjMuXwEsempGOFXD3282ACQKj4mmisyIYCEO4DaFnCoLXc0RERERERUQDdv3sT69esBAM+ePcOePXvQu3dveYMqAqVSgapVi7/rBycnpzzfG2v16tXYuHEjAKBdu3aYOnVqkWMjosppw70reJGWAgBYeesCuntUg8qEfaxTxcZEc0WWEgWYmgNN5wPOjXTjVCpg+vR/h4mIiIiIqMzK3qKWLWwNCwwMxMSJE3Hq1Ck0adIEgYGBhVrOqVOnDA4TERWUnerfu0+slSoo2X0GVQJMNFdU2nQgNRqoMQzw7vjveLUaWLRIvriIiIiIiMhofn5+GD58uNR1RpcuXUq0vthYLczNFTAzU5RoPSWhQ4cO6NChQ5GW0bhxY9y8eVMaJiIqrOF+gdBCIDotBQN9akGhKH9/V4kKSiGEEPkXK15xcXGws7NDbGwsbG1tS7v60rO9NaBNAyxcS6c+bbquFXN6IqBQAPa1gZD/ADa+pVM/ERERVXqV5jwvHxqNBpGRkbhx4wYGDx4MGxsbPHz4ELa2trC2tpY7vGInx+cuhEBqairMzYvvgXKV3cqV8di6NRFWVgrMnu2A2rXVcocki5MnTyI1NRUtWrRgC3IqFQlIwDM8gw98YAp2rUBEZY+x53ps0VxRaDOA+FuAlQ9Qpbvu4X/urQAzh2zltMDdu7rhKlUAnjgRERERFas7d+6gc+fOuHv3LlJTU9GhQwfY2Njgk08+QUpKCr7++mu5Qyz3Hj16hHfeeQdRUVHo3Lkzxo8fL3dI5V5KihZbtyYCABITBX7+OTHXRPO1a9dw69YtNG3atNB9IZdlTZs2lTsE+p87d+7g448/RmJiIl577TW0bNlSv0DKcyDhHmBfE1BayhNkEd3FXczETMQjHoEIxAf4AEqmaoionGKWsSJIfADE39S1nG70HtBkLuDbI2eSGQCSk4GqVXWv5OTSj5WIiIiogps0aRKaNGmCFy9ewMLCQhrfp08f7N+/X8bIKo6dO3ciKioKABAREYFHjx7JHFH5Z2amgIPDv5eHbm6GW1WeO3cOb775Jr766itMmzYNiYmJpRUiVUKrVq3CvXv3EB0djSVLluhPjL8DHHkDOPUecGwaoCmf17eRiEQ84gEAF3ERt3Fb3oCIiIqAP5OVd2lxgNAC9acDfr0Bc2e5IyIiIiKq1I4cOYI//vgDarV+a1BfX188ePBApqgqlqytaM3MzCpkdySlTaFQ4IMPHLBtWxKcnEwwcKDhbXr+/Hlk9r74/Plz3L9/HwEBAaUZKlUiqiwPsM/+NxVPT/ybXE68D8T9AzjWK8Xoiocf/KRhS1jCBS7yBUPyyUgDnp8FzF0A26pyR0NUaEw0l3fp8YCVJxAwWtcvMxERERHJSqvVIiMjI8f4+/fvw8bGRoaIKp5evXohKSkJ9+/fR9euXbldi4mvrwqTJ9vlWaZJkybYunUrNBoNPDw8UKVKlVKKjiqj1157DWlpaYiPj8fIkSP1J9oHAFAAEIDSCrDyliPEImuDNshABm7hFtqiLeyQ9zFYXp3ACSQiEa3RGiqo8p+hMhFC1zL/xWUACqDBTMC9hdxRERUKHwZYkkrqYYCaZCDlqe4XLxMVUGMo0GCGcfMmJgKZLT4SEgArq+KNjYiIiCq1SnOel4eBAwfCzs4OK1asgI2NDc6fPw8XFxf06tULVapUwcqVK+UOsdjxc69c7t27h7t37yIoKIhJfpLX8/NA7HXANRiwLp+J5spgPdZjLdYCAJqgCWZjtswRlTEp0UDk8H/fe7YDgqbKFw+RAXwYYEWVFgckP9bdEuQRCjg3Blwayx0VEREREf3P4sWL0b59e9SpUwcpKSkYPHgwrl+/DmdnZ6xbt07u8IiKzMfHBz4+PnKHQQQ4BeleVKadxVmDw/Q/ajvA2kf3YEugXHYBQ5SJiebyQpMEpDwDtOlA1X5Ao/cBpbncURERERFRNl5eXjh79izWr1+P06dPQ6vVYvTo0RgyZIjewwGJqGx7+jQD69cnQK1WYMgQa9jYmOQ/U3kgBLtdpFIVjGBcwiVpmLIxMQWafQw8/h2wcGNjQirXmGgu64QAEm4DChPAxh+o2heoPhgw4UdHREREVNakp6cjICAAv/zyC0aOHJmzT1EiKjcWLHiBGzc0AICYGC1mzrSXN6Di8M964MZ6XfeOTeYClh5yR0SVQB/0QXVUx3M8hytckYIUmIMN5/SobYAqXeWOgqjImK0sy7QaXTcZpuZAs4W6fnqKmmBWKoFx4/4dJiIiIqJio1KpkJqaCgVbCxKVe1FRWmn46dOcD/gsd9JigX90/eQi6RFwcxMQOFHemKjS8IIXFmMxnuEZPOCBz/AZbMA+3okqmgpy708FIISuA/j4W0DsP7pXwl1dS2bnRoB3h+JpxWxmBnz1le5lZlb05RERERGRngkTJuDjjz+GRqOROxQiKoIhQ6yhUABqNTBwYAV4iLqJma4RUya1nXyxUKVzEifxDM8AAI/wCOdwTuaIiKgksElrWaBJ0v2ibGoBuLcEbGsAVt66p+ZaeQNWXnJHSERERERGOnHiBPbv34/ffvsN9erVg5WVfoJq69atMkVGVHBnzqQiPV2gaVOzStdSv2tXS7Rtaw5TUwXMzCrAuivNgYbvALe3AhbugP/AEq0uClFYjMV4gRcYjuEIQUiJ1kdlmx/8oIACAgJKKOELX7lDIqISwESznIQWiL+ta7XsUBeoO07XPUaJ1imAZ7pfEeHszIdAEBERERUze3t79OvXT+4wiIps7dp4rF+fCAAID7fApEmVrwWspWUFuwnYuYHuVQp+wA+4iIsAgE/xKTZhE0x4U3WlFYAAfIAPcB7n0QRN4AMfuUMqkAxkIBKRAIC2aAtTmMobEFEZxURzaclIAzKSAE2y7iW0AISutXKDWYBn29J5wF9SEuDqqhtOSACsKsAtYERERERlyMqVK+UOocLTagU2b07EvXsadOliiTp11HKHVCGdOJEqDf/5Z2oeJYlyEhB5vqfStRZrcRZn0RzN0Q+6H0MjIpKwf38yAgJUGDXKBiYmJdsQrf7//pVHX+JL7Md+AMAFXMBkTJY3IKIyionmkpL0SPd/wh3dQxdMlIDSEjBzBNxqAnY1AWtfXf/L1uXrlzwiIiIiIjnt2JGE1asTAADHj6di5UoXWFuzpWRxa9BAjVu3NNKwsc6dS0VqqkCTJmYlnriisms4huM5nktdZ7AFqHyO4zjWYz0A4CquoiZqwu5ubSxbFgchgKtX0+HtrUTnzpYyR1p2XcIlaTizpT4R5cREc0l5ehIwswfcWgBV+wI2/oCtP2Dhxu4qiIiIiCqwqlWr5tmX7c2bN0sxmorp6dMMaTglRSA+XstEcwkYOdIGtWqpkZ4u0KqVef4zAFi/PgFr1+p+BGjXzhxTp9qXYIRlw/bt27F//37UqFEDb7zxBpRKXmYDgCtc8RE+kjsMApCEpBzv1claiCyNzJOT2eI8Ly3REluwRRomIsP4DVhS/HrqXkRERERUqUyePFnvfXp6Os6cOYOIiAi8+eab8gRVwXTtaok//khBdLQWYWEW8PDgZU1JUCgUaNHCuARzpqxdbBRXdxvR0Rn47bdkODmZIDzcokw9lPD27dv49ttvAQC3bt2Cv78/unXrJnNURPpaozX+wB84h3MIRjCaoilMAkzQtasl9u9PRs2aKnTqZCF3mGXaCIxAYzSGgEAQguQOh6jM4hkZEREREVExmjRpksHxX331FU6dOlXK0VRM3t5KfPedCxITBezs2JK5LKlfX43r19Ol4aISQuDtt6Px4IGuFfuLF1oMGGBd5OUWl/T0dL33aWlpMkVClDsVVHgP7+UY/8YbtnjjDVsZIiqf6qGe3CEQlXk8KyMiIiIiKgVdunTBli1b5A6jwlAqFUwyl0GvvGKNWbPsMXWqHd58077Iy0tOFlKSGQBu3EjPo3Tpq1GjBvr27QtbW1s0btwYXbp0kTskozx6pMGECc8wePAT/PprUv4zUOUktIA2I/9yZcT+/ckYPPgJxo17hvv3NXKHQ1QpsUUzEREREVEp2Lx5MxwdHeUOg6jYaTQCf/+dDmdnU7i6mha4u428WFqaoFUrcxw5kgKlEggLK3u3948cORIjR46UO4wCWbs2Abdv6xJxy5bFoVo1FXbtSoKjowkGDrSGWl12uicpqEuXLuHp06cIDg6GpSUfbldoUaeAsx/rks31JgMereWOKE8ZGQJLl8ZCowHi4zVYvToes2Y5yB0WUaXDRHNlo1QCw4f/O0xERERExaphw4Z6fcgKIfD48WNERUVh2bJlMkZGVPyEEJg79wXOnk2DSgXMmeOAoCCzYq3jrbfs0KePJeztdYlsKjpz83//RqlUwNy5LxATowUApKcLjBpVPrtTiIyMxGeffQYAqFatGhYvXgwTE975UCh//wBkpOiGr60s84lmExPAzEwBjUb3UMOs+zgVDwGB0zgNNdTsp5pyxUxjZWNmBqxaJXcURERERBVWr1699BLNJiYmcHFxQdu2bVGrVi0ZI6PyJC0tDYcOHYKlpSVatGhRph6Al1VUlBZnz+r6JU5PBw4dSin2RLNCoUDNmkXv75n+9corNoiP1+L5cy1eeskKH34YI0178qT8dJWQ3V9//SUN37hxAzExMbyTpLDU9v8Om9nnVqrMUCgUePtte6xenQB7exOMHGkjd0gAgDRtBqJSk+BmZgVlOf/R40t8ib3YCwAYjMF4GS/LHBGVRUw0ExEREREVozlz5sgdAlUACxculB4eOXDgQAwdOlTmiAyztzeBi4sJoqJ0rWFr1FBJ06Kjo2FtbQ21mknissbW1kSvW4F+/aywZUsiLC0V6N3bSsbIiqZJkyY4ePAgAF3/2fb29vIGVJ7Vmwz8vQrQaoCar8gdjVGCgsywaFHx/tBVFHHpqXjrfCQeJMfDz8oOH9ULhZWy/P49PI7jesNMNJMhTDSXoBM4gcd4LHcY+oSAaVIqACDD0gwo5ZYRaUjDdVzHYAyGH/xKtW4iIiKi0mBqaopHjx7B1dVVb/zz58/h6uqKjIzy21qQSs/58+cNDpc1arUCH3/shAMHkuHpaYrWrXV9KH/++efYv38/bG1t8eGHH8LPz0/eQClPI0bYoE8fK5ibK2BmVjZbzxujTZs2cHFxkfpo3r8/BStWxMPW1gTvvGMPf39V/gshHXMnIGia3FGUayeiH+JBcjwA4HZiLM7EPEUrZ2+Zoyq8+qiPIzgCAOw6g3LFRHMJmomZuI/7UJahzWyRpMVf1n8DABol1ESyVencuqGBBgooYAMbOMABnvDECIwolbqJiIiISpMQwuD41NRUtuwko4WEhODQoUMAgBYtWsgcTd5cXEwxcKC19P7p06fYv38/ACAuLg67du3C+PHj5QqvRD1+rIGVlQlsbMr3LfEAYGdX/tcBAGrXro3atWtDCIHly58gPR1IScnAmjUJeP99PhyOSo+XhQ0UUEBAwEShgKe5df4zlWHTMA1N0RRqqNESLeUOh8qospMBrYA00MARjnCFa/6FS4kZNAB0iWZ/+CO1hHYBLbRIRCISkIAkJEEFFZqiKXqgB0IQAi94lUi9RERERHL54osvAOj6ifz2229hbf3vBWVGRgYOHz7MPprJaNOmTUPbtm1haWmJOnXq5D/DnZ3Ak6OAQyBQfXCp37mYlY2NDaysrJCYmAgAcHd3ly2WkvTVV7GIiEiGubkC77/vgHr1+ENSWaJQKGBpaYLYWF23LtbW5belNpVPdWydMat2c5yLeYomDu7wt7aXO6QiUUKJ9mgvdxhUxjHRTEWSjnQkIQkp//uXhjQooPsCt4Ql7GGPUISiKZqiL/pCDZ58ERERUcX0n//8B4CuRfPXX38NU1NTaZparYafnx++/vprucKjckahUKBJkybGFY65BlxZoRuOvgjY+ALurUouuHxYWFjggw8+wO7du+Hp6Yk+ffrIFktJSUrSIiIiGQCQkiKwe3cSE81l0Hvv6R4OZ2trgtGjbeUOhyqhECcvhDixoR1VHkw0U6HFIQ6P8Rh2sIMVrFAHdeAPf3jDG57wRE3URBVUKVNdhxARERGVlFu3bgEA2rVrh61bt8LBgbdoUylJT8j7vQxq1KiBSZMmyR1GiTE3V8DZ2QTPnulay3p5meYzB8khIECN+fMd5Q6jxGmhhQkqRtcnRFS+MQNIhfYET9Ad3fEm3oQrXPnFRkRERATg4MGDcodAlY1zI8Cjzb9dZ3i2kzuiciMtTeD48RQ4OpoiMND4FskmJgp8+KEjfvklCU5OJujVy6oEoyQy7BZuYQ7mIBaxGI7h6IOKd/cAEZUvTDRTgWihRcL//mmhRShC4Y6K2ecaERERUWHdv38fO3bswN27d5GWlqY3bfHixUYtY+HChdi6dSuuXr0KCwsLtGjRAh9//DECAgKkMiNGjMAPP/ygN19wcDCOHz8uvU9NTcX06dOxbt06JCcnIywsDMuWLYO3t7dU5sWLF5g4cSJ27NgBAOjZsye+/PJL2NvbF3TVSQ4KBVD/TbmjKJdmz36Bixd1x+j//Z8tOnWyNHpeT08lXntN3u4YNBqBZcvicPVqOtq0McegQeX7YWP0/+zdd3gU1dfA8e+W7CbZ9IR0SAgdQqQjRXpXUMSGgopSRMGCYC+IAioqP8sriiKoYENBwYIFsCBFBEIRRHpNISHZ9K3z/rGYEBNgk+xmU84nTx7uzs7cOSGbZOfMvedWzKd8ylnOArCYxVzJlVKuUgjhUZJoFk47wxmyycaAgTDCGMpQutDF02EJIYQQQtQoa9euZcSIETRu3Jj9+/eTmJjI0aNHURSFDh06ON3PL7/8wj333EPnzp2xWq08/vjjDBo0iL1792IwlIyeHDJkCIsXLy5+rNOVTjLcf//9rF69mk8++YTQ0FAefPBBrrrqKrZt21ZcR/rmm2/m5MmTrFmzBoCJEycyduxYVq9eXZX/CiFqtKIie3GSGWDrVlOFEs01wbp1hfz4o6NW9LJlebRvr6NFi+pPNO7LyeCVf7ZiVxTua9aJpKDwao+hPgoksLjthx9eeHkwGiGEkERzvWPXqNhwXVRx21kKCllkcSM3cju3E0+8lMoQQgghhCjHo48+yoMPPsisWbPw9/fniy++IDw8nFtuuYUhQ4Y43c+/Sd9/LV68mPDwcLZt20avXr2Kt+v1eiIjy59hZjQaWbRoER9++CEDBgwAYOnSpTRs2JCffvqJwYMHs2/fPtasWcPmzZvp2rUrAO+88w7dunVj//79pUZQC1GXeHurad3ai717LQB06qT3cEQVZ7WWfmyzeSaOtw4lk1qUD8Cbh3bwVsfBngmkkt7lXTaykSSSmMpUNNSOmtu3citWrJzlLDdxEyqcv8YXQgh3kERzPWPx1vDC8o4VPi6XXLzx5mquJoEEN0QmhBBCCFE37Nu3j48//hgArVZLYWEhfn5+zJo1i6uvvprJkydXql+j0QhASEjpha1+/vlnwsPDCQoKonfv3syePZvwcMdowm3btmGxWBg0aFDx/tHR0SQmJrJx40YGDx7Mpk2bCAwMLE4yA1x++eUEBgayceNGSTTXRoodMnaAlwGCWnrg/Aqc+A7yT0LsIPCPr/4YnDRrVggbNxYRGqomKan2JZoHDPBh1y4z+/aZ6d3bm9atPVM2wUtdMghJp64dSdp/JZPMV3wFwFrWkkQS/ejn4aicY8DAVKZ6OgwhhCgmiWZxUXnkcZrT6NFzGZeRSKKnQxJCCCGEqNEMBgMmkwlwJHUPHTpEmzZtAMjIyKhUn4qiMG3aNHr27EliYsn7saFDh3L99dcTFxfHkSNHePLJJ+nXrx/btm1Dr9eTmpqKTqcjODi4VH8RERGkpqYCkJqaWpyYPl94eHjxPv9lMpmKv0aAnJycSn1dtYWiKKhUtWik4K6XIeVXR7vVRIgbXr3nP/Et7H3L0T79M/R+F7Q1sySFXq+ib18fT4dRaTqdikceCfJ0GNzXrBNvHtqBXVG4q0k7T4dTIf+dqSujgoUQovIk0SwuqIACUkhhCEO4kRvpQhe08pIRQgghhLioyy+/nN9//53WrVtz5ZVX8uCDD7J7925WrFjB5ZdfXqk+p0yZwq5du9iwYUOp7TfeeGNxOzExkU6dOhEXF8c333zDtddee8H+/ps4LS+JerHk6ty5c3nmmWcq+mXUOmfP2nj66SyOHbNy5ZW+TJrk2YXfnJa2sXS7uhPNeSdK2pZcMGXX2ETzJZmNcHi5o51wI+j8qz2Ev/8288MPhcTFaRkxwrdKNz0KKADAF9d+Pxr6BjC3bW+X9lldkkhiFKPYyEba0pbe1M6vQwghagLJGtYz+nwrn/s56v1dlzcEk6H8l4AVKyc5SSKJzGOerFwrhBBCCOGkV155hby8PABmzpxJXl4en376KU2bNmX+/PkV7m/q1KmsWrWKX3/9ldjY2IvuGxUVRVxcHAcOHAAgMjISs9lMVlZWqVHN6enpdO/evXiftLS0Mn2dOXOGiIiIcs/z6KOPMm3atOLHOTk5NGzYsMJfW033zTcFHD3qKIL79dcFDB3qS6NGteASKjgRMpNL2tUtdqBjJLM1H8K7gm9U9cfgKjtfKvm/zDsJnWZW6+lzcuw8+WQWRUUKAF5eKoYNq1yS+Gd+5lVeRUHhXu6tNeUhqsPt5z6EEEJUTS14lySqixkzZzhDAQWoUNGEJjzBE5JkFkIIIYSogISEkvUsfH19efPNNyvVj6IoTJ06lZUrV/Lzzz/TuHHjSx6TmZnJiRMniIpyJPY6duyIl5cXP/74IzfccAMAKSkp7NmzhxdffBGAbt26YTQa+eOPP+jSpQsAW7ZswWg0Fiej/0uv16PX1756thUVEFAypV6rBV/fWjKlvsMTjkSvlwEielT/+QOaQO9FYMoCQwzUorIjhTYLL/y9hYN5WQyObMzYwvPKxxScrvZ4srPtxUlmgJQU60X2vrhP+AQrjuM/5uOal2i22xxlVyx50GgY6AI9HZEQQogKkkSzAMCGjaMcpQlN6ElPOtKRznQmhJBLHyyEEEIIIUrJzs7m888/59ChQ8yYMYOQkBC2b99OREQEMTExTvVxzz338NFHH/HVV1/h7+9fXC85MDAQHx8f8vLymDlzJqNGjSIqKoqjR4/y2GOPERYWxsiRI4v3vfPOO3nwwQcJDQ0lJCSE6dOn07ZtWwYMGABAq1atGDJkCBMmTODtt98GYOLEiVx11VX1fiHAK6/0JTPTxtGjVoYM8SUsrJYscqbRQ8PBno3By+D4rGW+STnEtizHz9pnJ/5mQOQQog6/70iWJ1xf7fE0bKihe3c9GzeaCApSM2hQ5UtehBPOKU4Vt2ucf5bA0S8d7fQ/oHvFZ4AIIYTwLEk0CxQUTnOaSCJZxCKiqMVT24QQQgghPGzXrl0MGDCAwMBAjh49yoQJEwgJCWHlypUcO3aMDz74wKl+FixYAECfPn1KbV+8eDG33347Go2G3bt388EHH5CdnU1UVBR9+/bl008/xd+/pI7s/Pnz0Wq13HDDDRQWFtK/f3+WLFmCRlOSNF22bBn33nsvgwYNAmDEiBG88cYbVfyfqP20WhV33FFL6jILl/BSlb6ZYI0dCPEDABXoqv+1oFKpmD49kLfeyiUz08aZMzYaNqzcZfyDPMhHfISCwmhGuzhSF8g5XNLOPQKKUqtGwwshhJBEc71mxUo6Z8kmmwACuJu7JckshBBCCFFF06ZN4/bbb+fFF18slfAdOnQoN998s9P9KIpy0ed9fHz4/vvvL9mPt7c3r7/+Oq+//voF9wkJCWHp0qVOx1ZTXGzBQiEqY1hUAkcLjBzMy2JQRGMa+nr+RsPXXxfyww+FAOzebea998IJDFRf4qiyAglkMpNdHZ7rNBwMWXtAsTva8rMthBC1jiSa65lccovbxzmOD2Fcy7VcwzV0pasHIxNCCCGEqBu2bt1aXILifDExMcXlL0TVZGRk8NRTT3Hq1ClGjhzJ7bff7umQRB3hpdZwX7NOng6jlMxMW3HbbIa8PHulEs3OWHFyP9uz0+gcHMXVMc3cco4LiuoFgS0ci0gGJFx6/wtIS7PyyitGcnLs3HGHP507e7swSCGEEBcjieZ6xIiRfDKKH89jHu3pKXWYhRBCCCFcyNvbm5ycnDLb9+/fT4MGDTwQUd3z5ZdfcuLECQC++OILhg4dSkREhIejEsI9RowwsHmzibQ0G0OH+hAT457L+G1ZqSw+uhuAndnpNDYEkhRUzbWcfav+c/zee7ns3WsBYN48I59+qpeZD6LaFFHEbnYTTTQxOLcmgxB1iSSa6wkrVtJI4xrNEJRhTVAB/TWDALm7K4QQQgjhSldffTWzZs3is88+Axw1Vo8fP84jjzzCqFGjPBxd3XB+SRKtVou3t7ynFXVXeLiGd94Jw2IBnc59CdNci7n0Y6v5AnsKIcpjwcLDPMxhDqNFy7M8SyKJng5LiGolieZ6QEHhMIdpRSvu9X4I1TdyV00IIYQQwl1eeuklhg0bRnh4OIWFhfTu3ZvU1FS6devG7NmzPR1enTBy5Eiys7M5efIkV111FYGBgZ4OSQi3UqlU6HTuPUf3sBjWpUeQnJ1Op5BIuoZEu/eEbjJunD9ZWfbi0hkeG82c/gfkHYeo3uAjs1nqg1Oc4jCORS2tWNnMZkk0i3pHEs31QC65+OHHszwrUzeEEEIIIdwsICCADRs2sG7dOrZv347dbqdDhw4MGDDA06HVGTqdjkmTJnk6DCHqFJ1aw6zEK2r9IpuRkVpefDHUs0Gc/hl2vexoH/8aer4F2qrPvEhJsbJsWR46nYrbbvOvUq3uoxzlUz4lgABu4zZ88a1yfPVdJJGEEUbGuZKlrWnt4YiEqH6SaK4HMsjgci6XO2lCCCGEEG4SEhLCP//8Q1hYGHfccQevvvoq/fr1o1+/fp4OTYh67fhxKy+9lE1+vsJdd8nCcM6ozUnmGiP775J2USaYMjFpw9jIRoIJph3tKtXt3LnZHDliBSA3187jjwdXOsRneKY4IWrFylSmVrov4eCNN/OYxyY20YhGXMZlng5JiGrnnqVqRY1hw4YVK0kkoUIF+flgMDg+8/M9HZ4QQgghRJ1gNpuLFwB8//33KSoq8nBEQgiAd9/N4cgRK+npNubPN3o6HFFfRPYEtZejHdQSfCKYyUxe4RWe5Em+4ZtKdXv2rL24nZlpv8ieF2fHThZZJX2RWem+RGlhhDGc4ZJkFvWWjGiu47LIIpRQbuCGko0FBZ4LSAghhBCiDurWrRvXXHMNHTt2RFEU7r33Xnx8fMrd97333qvm6IQoLSXFyunTNtq08cLbu26PPdJqVeW2haiK7/me93mfUEJ5jMeIIqr0DiGJ0HMBFKZBUEvMajt72FP89Da2cSVXVvi8t93mx//9Xw5eXipuucWv0vGrUXMbt7GYxRgwcCM3VrovIYQ4nySa67h88mlP+7J/+IQQQgghhMssXbqU+fPnc+jQIVQqFUajUUY1ixppzx4zTz55FqsVmjTRMm9eKF5edTcBO2GCP0VFCvn5dsaPD/BsMKfWQuZOCO/iGPEqaiUzZt7kTezYySWXZSxjOtPL7ugb4fgEdEASSexiFwCd6Vypcw8c6Evv3j6o1VW/cTKSkVzJlWjOfdQ3hTYL8/b/weG8bIZENuamRlJPWQhXkERzHWfBQhhhng5DCCGEEKJOi4iI4PnnnwegcePGfPjhh4SGengxKiHKsXlzEVZHiVcOHbJy+rSVuDgvzwblRlFRWubMCfF0GJCRDLv/52if/hm6RUJgUw8GJCpLjRodOopw3Ez0xrm630/zNFvYQjDBVVo/Sadz3Y0hHTqX9eWss5wlm2wa09hR3tNDVp8+yNazKQAsO76X7mGxNPJ13Iz6nu95h3cIJJAneILGNPZYnELUNnV7ntR/LFiwgKSkJAICAggICKBbt2589913ng7Lbaw43kF2o5uHIxFCCCGEqD+OHDkiSWZRY7VqVZJYCgtTExFR/0YyekRh2nkPFChM91goomq0aHmUR2lBC7rTnVu51anjdOi4giuqlGSu7XaxiwlM4D7u4wVe8GgsGpX6P48dSW87dt7iLUyYSCedpSz1RHhC1Fr1akRzbGwszz//PE2bOu4cv//++1x99dXs2LGDNm3aeDg618smmxBC6E9/T4cihBBCCCGEqAF69PDmmWeCOXHCSo8e3nW+RnONEdkDjq2GvGMQ1AIadPR0RG53nOMc5CBJJFVolm0eeRzjGPHEY8Dgxggrr8O5D1ExP/ETZswA/M7vGDESSKBTxxZQwBa2EEkkrWhV5ViGRzflSH42h/ONDIlsTIyPPwAqVPjiSw6OBX79qHwt7JrirLkQP60OnVpuLAr3q1eJ5uHDh5d6PHv2bBYsWMDmzZvrbKJ5IAMJJtjToQghhBBCCCFqiA4d9HTooPd0GPWLlx90fxXMRtAHg6ru1sUGOMABHuIhrFgJIog3eMOphOJZzjKNaWSSSQMaMJ/5TiciReV9zMcsZzkxxPA0TxNGGDZsbGc7fvi5JLELEE98cTuMMKdvJNiw8SiPcpjDAMxgBr3oVaVYdGoN01t0LbNdhYoneZJlLCOAAO7kziqdx9Ne3v8HP585TqCXnrlte9PQ18O16kWdV68Szeez2WwsX76c/Px8unWre6UlznIWL7zKrmSrVkPv3iVtIYQQQgghhBDup9aAdw2oF33OwYMHeeedd9DpdNx9991ERbluAfld7Cou5ZhNNoc5THvaX/K47Wwnk0wAznCGneysckKxSs78CWd3Q4POEFKBkhfmHMg5CP6NHTcWnJF7DA5/BrpAaDYWtD6Vi7mCMsnkIz4C4ChH+YIvmMQkXuIlNrABgIlMZDjDL9aNU0YyEl98SSONIQxB62RKKous4iQzOF4n7nxdtKQlz/Ks2/qvLimFefx85jgARouJb1MOM6lJO88GJeq8epdo3r17N926daOoqAg/Pz9WrlxJ69Z1a3VRO3bOcIbbuZ0BDCj9pI8P/PyzR+ISQgghhBBCuNfBgwfR6/U0bNjQ06GIGu6ll17i1KlTAPzf//0fzz33nMv6TiIJL7ywYCGYYBJIcOq4BBLQoMGGDS3aUiNgq13WXtg2C1Dg2Cro/hr4OfFzZcqGTfdDUSZ4+UP3/4FP+KWP2zYTijIcbbsF2txT6dArQoeu+HsFoMn3Z9EnOXxkVhF5vQFdWD4b2eiSRLMKFUMYUuHj/n0NHeYwKlRStsRJAV46fDVeFNgc39tI75pZikbULfUu0dyiRQuSk5PJzs7miy++4LbbbuOXX36pU8nmfPLxx58buAENUoNHCCGEEMLdcnJynN43IECmrQr3ePfdd/nqq69QqVTcfffdDBlS8YSOuyiKQnKyGY0GkpJqX9mOjRuLOHPGRt++PgQE1I2ZoSaTqdy2KzSjGf/jfxziEEkkOV3+IoEE5jCHneyko7kpjXa9B0VnoOloiOzp0hgvKfcYoDjadivkn3Qu0Zy1x5FkBrDkQsZ2aHiJn0XFDqazJY//TThXA3/8eZiH+ZIviSGG9P8bxKbfCiikCwcPhtL65S+5jMuqLZ7yaNAwl7n8wR9EEOGyUh51nUGrY1ZiT9akHiHGx4/h0U09HZKoB+pdolmn0xUvBtipUye2bt3Kq6++yttvv+3hyFwnjzyCCPLs3V8hhBBCiHokKCgIlZM1V202m5ujEfXVDz/8ADiSuj/++GONSjS/804uq1cXAHDDDQbGjvX3cETOW706n4ULcwH44YdC3ngj1Omf95psypQpvPbaa+j1eiZMmODy/hud+6io1uc+OPB/kLHNsXHXyxDWCbTeLo7yIsK7OkpZFGU4EswhSc4d558Aah3YzaDWQmDzcndbzWrWsY7mNGeiaiKaZmPhnw9A6wsJ17vwC7m0ruc+AKalOpLkzWhOYUowj9Gabni+3KgvvvShj6fDqHVa+IfSwj/U02GIeqTeJZr/S1EUl9+99bQ88hjO8PLrHeXnQ3y8o330KBhk6oQQQgghRFWtX7++uH306FEeeeQRbr/99uK1QDZt2sT777/P3LlzPRWiqAeaNWvGrl27AIoH19QUGzcWlWrXpkTz3r2W4vbx41by8hT8/Wt/orljx468//77ng7jwpTzbsopSvWf3zsEer4JBafBEAsaJ0fiG6Lh8pcgMxmC20BA2bIhRznKQhYCcJCDxBPP0ITroNFVjuS02nOpmuuuMzBvXjY2m5r7b2pKNycX7BNCCKhniebHHnuMoUOH0rBhQ3Jzc/nkk0/4+eefWbNmjadDcxnl3NSei05tyai+aThCCCGEEPVB738XWwZmzZrFK6+8wujRo4u3jRgxgrZt27Jw4UJuu+02T4QoahCTycTp06eJiorC29t1IzQfe+wxvvvuO3x8fBg8eLDL+t2508TmzSbatNHRs2fl4k1K0rF+vSPZ3LatzmWxVYcrrvDm99+LUBRo316Hv3/dKJ1R4zW9BfJPQeEZaHZL9Y5m/pfWBwKaVPy4gMaOzwswUXqwWxHnbsR44mv8j+7dvVm6NBybjTpTJkYIUX3qVaI5LS2NsWPHkpKSQmBgIElJSaxZs4aBAwd6OjSXyCGHFFIII4ym1KwRDEIIIYQQ9cWmTZt46623ymzv1KkT48eP90BEoibJzc1lxowZnDp1isjISF566SUCA52rX3spBoOB6667ziV9/evkSSszZ2ZhtcLXXxfg5xdMu3YVr7F8772BtGunR62GXr08n0yriO7dvXnjjTAyM221LknuSXZFQV2VEiPeodD1BdcFVIO0oAUjGMFa1tKc5gxlqKdDKsVgqGKCWbGDqn4mqdexjq/5mjjimMxkdMjvDFG/1KtE86JFizwdgtuYMZNGGsMZznjGS3F8IYQQQggPadiwIW+99RYvv/xyqe1vv/02DRs6sZCUqNN27NjBqVOnAEhNTWXr1q0MGDDAw1FdWEqKFau15PGJE9ZKJZq1WhX9+vm4MLLq1aiRlkaN6tXlc1kHP4GzuyCiO8RddcHdjhfk8PRfv5FlNjEmrjXXxbasxiBrjwnnPuqcIysctab1wdDpGfCreJ3u2iqDDF7lVezYOcABoojiBm7wdFiimiiKQrbFRKCXvmo32Wq5ev6Xsm4ooohjHKMtbXmGZ/DDz9MhCSGEEELUW/Pnz2fUqFF8//33XH755QBs3ryZQ4cO8cUXX3g4OuGMDRuKMBrt9O3rja+va0flxcbGolarsdvtqFSqGn/zoW1bHU2bajl40Ep4uIYePWrXaOT/+uKLPP76y0KPHt707197E9/VLnUjHFzmaJ/dDYFNIaj8BPKnJ/aRYSoE4IOjf3FVVFO8NZJ6qBesRbB/CaA4FlE89ClcNsPTUVUbCxbs2IsfF5dEEXWe2W7jiT2/si8nkzjfQJ5P6o2ftn6OZpff9rWYHTsppFBIIZ3oxBM8IUlmIYQQQggPGzZsGAcOHODNN9/k77//RlEUrr76au66664an1QU8OmneSxdmgfAzz8XMm9eqEv7T0hI4JlnnmHbtm20a9eOFi1auLR/V/P2VjNvXiipqTYaNNCg16vg5I9wYo1jkbNWk1yycNnZszY0GhWBge6bbv/770UsWeL43v75p4nGjbUkJHi57Xx1ijWv9GNLXvn7AYFeJSPefbVatBcpoZCRYUOvV9WruteKoqCqq6Md1VrQ+oI13/FY55qyQLVFFFHcxE2sZjWNaMTVXO3pkEQ12Z6Vyr6cTACOFRjZkHGSIZFlFwKtDyTRXIulk44OHfdxHzdxE3oqPoVNCCGEEEK4XmxsLHPmzPF0GHWWoih8+eWXnDx5ksGDB9O8eXOX9f3XX+bi9v79Fmw2BY3GtUmhdu3a0a5dO5f26U5arYrYWMel4w+rPmb5gkeIDNYzY1QCAYZYiK9aMmXlynzeey8XjQamTQukVy/3jDTOzi4ZaagopR876yxneYd3KFSK0L51K0f+9KNjRx2TJwfU3eQhQFRvSPkVzu6BiG4Q1uGCu46Na4PZbiPDVMgNDVuiVZefRF62LJdPPsnHywseeSSILl1q92j5SymyWZn51wb25mTSLTSah1teXmOn13+XcogDeVn0adCIpKBw5w9Ua6Hj046RzN5h0GyM+4KsoW459yHqlwZ6X1SoUFAAiNAbPByR50iiuRayYyeXXLLJZixjuY0KrFyuVkOnTiVtIYQQQgjhctnZ2fzxxx+kp6djt5dOZt16660eiqruWL16Ne+99x4Av//+O4sWLcJgcM1F3RVXeLNjhyPZ3K2b3uVJ5tosJyeHN95ahHK2iNSzRXz2WwrjLyuscr/LlztGx9psjqSzuxLNffp4s3ZtIQcOWEhM9KJBg4pfD73Jm2xhC1l/xHHi2wMkkcR33xXSvr2ebt3qcKJUo4fOzzky9JdIjvpovJjStOMlu/z8c8eoV4sFvvyyoM4nmtenH+OvnAwANmaeYkd2Gh2DIz0cVVm/nDnOm4d2APDxCiPhW1sRG6HjiSeCiIpyIoUU3Ao6zXRvkELUME38gnm4ZVc2Z54mKagB7YMjPB2Sx0iiuZZJJx0jRvzwoxOdGM3oinXg4wNbt7onOCGEEEIIwerVq7nlllvIz8/H39+/1ChHlUoliWYXSE1NLW7n5+djNBpdlmgeONCXJk28yMmxk5RUP+srXozKy4DiGwVF6WCIueiicM6KidHy998WAKKj3XeJajCoeeWVUNauLeC113K4++5Mrr/ewK23+jvdRy65xW0rJask1tCBqa5XgS80JyeHLVu2EBsbS6tWZRerj47Wcvy44/8wJkbjshBrqgCv0jOQA2po/daUwnM3fkwqjqwOxtvfyvHjaj79NJ/7769fpTCEqIgeYbH0CIv1dBgeJ4nmWqSQQowYuYVbGMtY4ohDRX15RyOEEEIIUTs8+OCD3HHHHcyZMwdfX19Ph1MnDR48mF9++YWcnBx69uxJVFSUS/uXur3lCwgIYMqUKXz++edERUVx44MPglfV14h57LEgPv88H51OxfXXu3+68fffF/LvRINVqwoqlGi+nduZzWz0XdK4fHg4OX9q6NBBT9euzpUxNJsV3nsvl1OnrAwf7ltnR/GazWZmzJjB6dOnUalUPPbYY8WLo/5r5sxgVqzIx89PxXXX1YG1hlJ+xXzya372P8HvzZtwk/oWWlGSYO8RFsuYuDbsMZ6hR1gszfxDPBjshfULj+P7tCOkW4oI9tVh0Dp+H/r4SO5BCHFpKkVRlOo+aU5ODoGBgRiNRgICAqr79NXmCq7AjJlwKlDT6AJyySWFFK7gCuYxj2CCXRChEEIIIYRr1Zf3eRdjMBjYvXs3CQn1ZxEYT3zfDx06xOHDh+nZsyc+Pu4ptSDqpv/7PyNr1jhKfjRr5sUrr5S/4GNOTg5ffvklOp2OkSNHoteXJJMVlEoN+vnkkzyWLXOMGPXygiVLwgkIUGM2K+h0dSeRd/LkSSZPnlz8+KqrrmLSpEkejMjNCtLgt4kcUQ5zhnTWtIpjX1wTPuKjWjk4zGy3YbSYOLZbzfLl+TRooGHy5AAMBteX30wjjed4jnTSuYVbGMEIl59DCFF1zr7XkxHNtYANGymkcBVX8QzP4EcV7vYWFEDr1o723r0go2yEEEIIIVxq8ODB/Pnnn/Uq0VzdkpOTeeaZZ7BarXz77bfMmzcPrVYubWo6RVHYtMmE1arQs6c3arVnEnATJgQQHq6hoEDh6qsvfD00Z84c/vrrLwBSUlJ44IEHip+rbPIwN7ekZrvFAkVFCosXG/npp0KiozXMmRNCaGgVykgUpDgWYvPyg6Y3g9Yz13sRERHExcVx7Ngx1Go1nf5dJ6iusuaDYi8up+JrsVJAAVaseFH7Zkjo1Boa6H1p0Ak6dXLvqPtP+ZSjHAXgXd6lP/0xUH8XUhOitpN3Y7XAMY4RRxwP83DVkszgWLzh2LGSthBCCCGEcKkrr7ySGTNmsHfvXtq2bYuXV+kkw4gRMlqrqjZv3ozV6kjoHDx4kLS0NGJiYjwclbiURYty+eqrAgC2bTPxwANBHonDUaKj7HVVelE+r/yzlWyLiXHxbTl+/HjxcydOnHDJua+5xsCOHWZOn7YycqSBggI7P/3kGF19+rSNb78tYOxY50t5lLFtFuSfdLQtedD2/qoHXQleXl688MIL7Nixg+jo6Lp/4y0gARoNI+bECo74q9jRKJrxjK+VSebq5kPJjBQvvNBQ9+t1C1GXSaK5hiuiCBUqpjPdJSU4hBBCCCGEe02YMAGAWbNmlXlOpVJhs9mqO6Q6p02bNnzzzTcAhIeHExYW5uGIhDO2bzcXt5OTzRfZ0zMWH93NXzkZALz0zx9cO3w4H330EWq1miv7tIO/3wX/BIjpV+lzNGig4c03w1AUBZVKRUaGDa0Wzt03ITi4iqUJCtPPa6dVra8qMhgM9OzZ06MxVKvWk/FtdReDVCoGVrK0Sn10MzdjxEg66dzADXhTN+uWC1FfSKK5hssii0gi6UMfT4cihBBCCCGcYLfbL72TqJIrrrgCf39/Tpw4QY8ePUrVzhU1V9euek6ccGRUO3eu+d+zm266iT59+uClFBK29xE46hh5jEoD0b2r1LdK5UhChoVpeOyxIL7/vpDGjbUMG1bFUhfNxsD+xaDRQ8INVetLVNy576skmZ1nwMB0pns6DCGEi0iiuYYroojmNEeHztOhCCGEEEIIUWO0a9eOdu3aeToMcRFnzpxh//79tGzZkrCwMG67zZ/ERB02m1IjE83j4tty1lxEtqWIcfFtUalUREVFgfEAWAtLdsw7XuZYs9mMzWar1MKUnTt707mzi0ZxNh4JsYNArXUkm4UQQohq5FSiOScnx+kO6+vq4u5gxYoZM01o4ulQhBBCCCGEk06ePElQUBB+fqVrwFosFjZt2kSvXr08FJkQ1SctLY377ruP/Px8/Pz8ePXVVwkPD6djx5qb/Az3NvBCUh+OHLHw/GPZvJ6XzqRJ/vTq2RhC2sLZ3eDlD9F9Sh33559/MnfuXCwWC5MmTeLKK690S3wWLM7V/PWShdRqiw8/zOXrrwuIj9fyxBPB+PtXsXTKxdjMoJEBbEII93Lqt1hQUBDBwcEX/fx3H+EaFiwc5jAtacm1XOvpcIQQQgghxCWkpKTQpUsX4uLiCAoK4rbbbiMvL6/4+bNnz9K3b18PRihE9dmzZw/5+fkA5OXl8ddff3k4Iue9/34up0/byMmx8/rrOY7RwZ2ehR5vQK93wK9hqf0/+eQTzGYziqLw4YcfujyedNKZyESu5VoWsMDl/V+M2azwwQe5/O9/Ro4ft1brueu6kyetfPZZPgUFCnv3Wli1Kr/c/TJMBewxnsFir2R9f0sebLwffhwFO+aCIuWdPCHDVMDatKMczTd6OhQh3MqpEc3r1693dxziP4wYCSWUd3nXtYsAqlTQunVJWwghhBBCuMQjjzyCRqNhy5YtZGdn8+ijj9KnTx9+/PHH4gEZiqJ4OEohqkfLli3x9vamqKgIb29vWrRo4emQnObtrT6vfe6aSa0B/7hy92/QoAH79+8HHItTutpqVpNCCgDf8i0jGEEMMS4/T3k+/DCXL78sAGDHDhNLljQori9d69ktcOZP0IdAUPW/PnU6FSoV/Ptnofi1dp6/czJ5Ys+vmOw2WgWEMiexN1p1BUc9n1oLOYcc7bSNcHYPhCZVMXpREUaLiQeS15FtKUKrUvNiUh+a+Yd4Oiwh3MKpRHPv3lVb6EBUTAEFZJLJEIa4NskM4OsLtWg0gRBCCCFEbfHTTz+xcuVKOnXqBDgWrLvxxhvp168fa9euBag7CRohLiEmJob58+ezZ88e2rZtS3R0tKdDctqECf5YLAp5eXZuv93/kvvffffdBAYGUlRUxOjRo10eTxBBxW0dOvzwu/DOLpaeXjKK9uxZO2YzlLf2ptVuR6NS1a7fcdtmQWayo514L8QOrNbTh4druO++QL77roC4OC3Dh5ctefJbxglM50Yy78vJ5HRRHo18K1iuVH/+zHMV6AKrELWojMN52WRbigCwKnZ2Gc84nWjelpXKD6lHiDcEcmPDVqhr08+YqJcqtRjgb7/9xttvv83hw4dZvnw5MTExfPjhhzRu3JiePXu6OsZ6xY6dE5ygL315nMc9HY4QQgghhHCS0WgsVUpOr9fz+eefc/3119O3b1+WLl3qweiEqH6xsbHExsZ6OowKCw3V8OSTzpeF9Pf356677qraSc25jhmnXmWTyFdzNXnkcZzjDGMYgVRfovCaawzs3GkmP1/huusM6PVlk1yfndjH0mN7CdZ580ybnsQbakEi02YqSTIDpG+p9kQzQP/+PvTvf+EFJJufl4wM1nnTQF/xxSaJ6gWFaZC1z9G+wMh84T5N/III0flw1lyIl1pDu6ALDyhMI411rCOaaNqauzB73yYsdhsbM08R4KXnyihZw0vUbBVONH/xxReMHTuWW265he3bt2MymQDIzc1lzpw5fPvtty4Psr4wY+Y0pwkhhCd4gggiPB2SEEIIIYRwUkJCArt27aJZs2bF27RaLcuXL+f666/nqquu8mB0Qoga68Qa+OtNUKmh7f1lFhvUouU2bvNIaK1a6fjgg3CKihQCAsqWbCiyWVl6bC8KCmfNhXx24m8eatnVA5FWkEbvKJeR7Sh5Quhlno3nP4wWE8/8tYEj+UYSA8JoHxzBFWEN8dE4sRhkeRKud22AokICvPTMb9ePXdlnaOIXRMMLjEo3Y+ZhHiaTTACus9+OxV5ScivTVFgt8QpRFRVe0vS5557jrbfe4p133sHLq+SXXPfu3dm+fbtLg6tPssnmGMeIJJJ7uZeGNLz0QZVRUABt2jg+Cwrccw4hhBBCiHpo6NChLFy4sMz2f5PN7dq1q/6g6rLMXXD8WzBlezoSUQtkZmaSmZnp6TDKd+hTQAHFBoeXezqaMnQ6VblJZgCtSo1BW5IXCNKVU1ejpur0nKNkRseZEDf8wvvZbZCRDLnHqisyvj59kAN5WVgVO3tyMugSEk2UT/WVTBGuF6LzoU94owsmmQGyyCpOMgPk6lPoF+4YgR7l7cewqAS3xylEVVV4RPP+/fvp1atXme0BAQFkZ2e7IqZ6R0HhDGfoQx9e5mUMlK3N5LqTKbB3b0lbCCGEEEK4xOzZsym4wI18rVbLihUrOHnyZDVHVUel/g7JzzvaR1dCj/8Djc6zMYkaa82aNbz55psATJo0iSuvvNLDEf2HbyQUZZxrR3k2lgrSqtU83boHy0/+TZjel1vjEj0dkvO03s6Vy9gxG85sBVRw2XRH+QkXKrRZmLf/D47kZzM0MoEbGrbCT1vy+0ytUuGrqVTVU1HLhBNOO9qRTDI6dPRR9SGxeSJ3NWmHt1pbu2qgi3qrwr+toqKiOHjwIPHx8aW2b9iwgYQEubtSGemk448/4xnv3iSzEEIIIYRwG61WS0DAhUcqaTQa4uKkNqZLnN1d0i5IhaIzYIjxXDzCKXa7HbW6wpNqq2zFihUo5wbZrFy5suYlmi97CA59BmoNJNzo2VhSN8DBj8A7HJIecGrhuJYBoTzZukc1BOcB1sJzSWYAxfH/4+JE8+rTB9l6NgWAD4/9RbfQGK6MakK6KZ/D+UaGRiYQ7i15gvpAhYqneZqDHCTs3AdQ+ZIpQnhAhf/KT5o0ifvuu48tW7agUqk4ffo0y5YtY/r06dx9993uiLFOU1AwYmQ0o+lEJ0+HI4QQQgghRM0X3gVUGkc7IAF8ZG2Tmmj79u1MnTqVTp064e3tjUajwdvbm06dOjF16tRqK73YsGFJWcIauTihPhhaT4KW40Hn77k4rEWw62XIOwEZ2+CALGCK1gf840seB7Vy+SnU/xmlqlap0KrVTEhox9y2venVwE1lNUWNpEVLS1oWJ5mFqG0qPKL5oYcewmg00rdvX4qKiujVqxd6vZ7p06czZcoUd8RYp2WSSSCBDGawp0MRQgghhBCidgjrAN1fhYIUxyJeaplWXpMcPHiQiRMnsn79emJiYhgwYABjxowhICCAnJwckpOTWblyJW+88QZ9+/Zl4cKFNG3a1G3xTJs2jS+++AJFURg1apTbzlMnnF9eUbF7Lo6apPMcOL0OvEMhsqfLux8e1ZQj+UYO52UzNCqBGJ+L32w4xSkWsQiA8YwnmmiXx1QVu41nWJt2lAS/IIZHNZVyD0LUM5V6RzZ79mwef/xx9u7di91up3Xr1vj5SWH6ilJQOMtZxjCGNrTxdDhCCCGEEELUHv5xjk9Ro3z00UeMHz+eqKgoVqxYwfDhw9Fqy152Wq1WVq9ezfTp00lKSmLRokWMHj3aLTEZDAZ8fa/l44/z2LKliKef9iYiwvM3J9JJZxWrCCCAkYzECw9Pj9d6Q+LUc6UzGkDTmz0bT02h84f4q93WvV6jZUaLrk7vP5/57Gc/AHnk8SIvuj6o49/C/vdAHwIdngQ/50ZVnzUXMvOvDZjtNtamH8NX48WAiHjXxyeEqLEq/dfV19eXiIgIVCqVJJkrKZNM/PDjeq73dChCCCGEEELUGkajkTlz5nDixAmuvfZarrvuOk+HJHAkmceMGcOYMWNYsGABBsOF68pqtVpGjhzJoEGDmDx5MrfccguKonDzza5Pbubk2PnggzwUBU6csPLZZ/lMnXrp2sPu9iRPcprTAOSQw3jGezgiIKa/41PUWHnkldt2GbsF9r3tGNFekOK48dDuYacOzTQVYrbbih+nFLkhPiFEjVbhGs1Wq5Unn3ySwMBA4uPjiYuLIzAwkCeeeAKLxeKOGOucfPI5wAFyyCGeeJrivmliZahUEBfn+JQpLEIIIYQQbvHbb78xZswYunXrxqlTpwD48MMP2bBhg4cjqxu++OIL9u7dS25uLu+//z5nzpzxdEgetXXrVjZt2lS84J0nHDhwgPHjxzNmzBiWLFlSJslstVpJT0/HarWW2m4wGFiyZAljxoxh/PjxHDx40OWxeXk5PkvO6fnrIBs2UkgpfnySkx6MRtQmE5iA/7kP99ycUIPGu+Shl/MDC5v4BdM1xFHKI0zvw6CIxq4OTghRw1U40TxlyhQWLlzIiy++yI4dO9ixYwcvvvgiixYtYurUqe6Isc5JJZVGNOI1XmMZy9BWfmB5xfn6wtGjjk9f3+o7rxBCCCFEPfHFF18wePBgfHx82LFjByaTCYDc3FzmzJnj4ejqBr1eX9xWq9VoNBoPRuNZ77//PrNmzWLOnDm8+uqrHotj0qRJREdHs2DBAtTqkstMm83Giy++SGhYAyIiIggNa8ALL7yAzVYy6lGtVrNgwQKioqKYOHGiy2Pz8VHz2GPBJCbqGDDAh9GjPT8jV4OGEYwAwAsvruRKD0fkhIJUx2ctYrJZsXvwBow7dKQjH5376EAH159ArXGUywhpC1G9odmtzh+qUvF4q24s6XwlCzsOIcL7wrMahBB1k0qp4G3vwMBAPvnkE4YOHVpq+3fffcdNN92E0Wi8ZB85OTkEBgZiNBoJCAioWMS1yBVcgRkz4YQXb8siizzyeJInGYUsRCGEEEKIuqW+vM+7mPbt2/PAAw9w66234u/vz86dO0lISCA5OZkhQ4aQmlq7EjXOqO7ve1FREW+88QYnT57k6quvpm/fvm4/Z001depUjh49Cjiu1ZYuXVrtMWzbto1OnTqxYsUKRo4cWeq5p59+mlmzZpU55qmnnuKZZ54ptW3FihWMGjWKbdu20aGDGxJoNVAqqfjgQyCuLeWxZ4+ZDz7IJSBAzd13BxASUsWbMUe/gr/fBVTQcjzEj3BJnO607NhffHJiH4Feep5p05MmfsGeDkkIIWotZ9/rVXhEs7e3N/Hx8WW2x8fHo9PpKtpdvWLBQjrptKCFJJmFEEIIIeqo/fv306tXrzLbAwICyM7Orv6A6iBvb2/uuOMOJk+ezBVXXOHpcDyqffv2xe2OHTt6JIYlS5YQGxvL8OHDS20vKirixXkvARAdE8s777xDdEwsAC/Oe4mioqJS+48YMYKYmBgWL15cPYHXAKnJwSx5FdasKXBpv3PmZLFvn4UtW0wsWpRb9Q6PrT7XUOD411Xvz80KbRY+ObEPAKPFxBcn//FwREIIUT9UuGbDPffcw7PPPsvixYuLp6yZTCZmz57NlClTXB5gXWHHzhGOkEgiT/CE5wIpLIR/L3x+/RV8fDwXixBCCCFEHRQVFcXBgwfLDM7YsGEDCQkJngmqjtm3bx9PPvkkJpOJpKQknn322VLlGuqTcePG0aZNGywWC927d/dIDJs2baJ///5otaUvL//880+KCh0J1Pvvu5fx48eTnZ3NjBkzKCosYNu2bfTo0aN4f61WS//+/dm8eXO1xu8pqalWnnkmC6sVfvqpEH9/NT16eF/6wEtQFAWTqWTiclGRC0pH+MdDYZqj7RdX9f7czEulwV+rI9dqBiBUX/X/1wsyGx2fhoayDpIQot5zKtF87bXXlnr8008/ERsby2WXXQbAzp07MZvN9O8vq9NeyGlO04AGPM/zNKe55wKx2+HPP0vaQgghhBDCpSZNmsR9993He++9h0ql4vTp02zatInp06fz1FNPeTq8OuGXX34prn29a9cuUlJSiImJ8XBUnqFSqejatatHY9izZw9jxowps33Xrl3F7bZt2wKQmJhYvG3nzp2lEs0A7dq149NPP3VTpO5hwcI3fEMRRVzFVfjhXA3oM2fsnL82YkqK9cI7V4BKpWLq1EAWLswhIEDNbbf5V73TpGmO8hmoIP7qqvfnZlq1mmfa9OSLU/8QpvNhTKM27jnR2b9g20ywFUFkT2j3sHvOI4QQtYRTiebAwNL1okaNKl32oWHDhq6LqI5RUDjJSRQUpjLVs0lmIYQQQgjhdg899BBGo5G+fftSVFREr1690Ov1TJ8+XWYAukiTJk2K20FBQYSGhnowmrrJZlN4/fUcdu820727njvvLL8eo91ux2QylVuvMT8/v7jt7+9Idp6/3/nP/yswMBCTyYTdbq/SKHWj0c5nn+WhVsMNN/jh7+++Ee8LWcga1gCwk53MZW7Jk9YCOPMn+EZBYLNSx7Vq5UVSko5du8yEh2vo29d1s0379PGhTx8Xzl7V+kLT0a7rrxo08w/hkZaXu/ckJ39wJJkBUjdA0QTwDnFZ94fystiWlUqbgDDaBDZwWb91Wb7VzKcn/saq2LkutgUhOpnFLUR1cirRXJ9qZLnacY6TQAL3cz/Xc72nwxFCCCGEENVg9uzZPP744+zduxe73U7r1q3x83NulKO4tIEDB6LX6zlx4gR9+/bF29uN0+LrqV9/LWLt2kIAvvyygE6d9Fx2mb7Mfmq1Gr1eT05OTpnnDAZDcTs311En+Pz9zn/+X0ajEb1eX+VSKC++mM2aNQWkpNh4991cVq+OJCysigviXcBhDpfbxm6FPx6FnMOACto/BhEliU+tVsVzzwaRefwkgQ0C8TK4Jz7hRv7nlRHRh4DOBaPHz0kpzOOhXT9jtttQq1TMS+pLc3/XJbHrqtcPbuf3jJMAHMzL4sWk+rtYrBCeUOEazcI5RoyoUdOUpsxnPp3p7OmQhBBCCCFENfL19aVTp06eDqPOKm/BReE+Fys9m5iYSHJycpntSUlJxe3du3czZMgQ9uzZU7zt31KM50tOTi4us1EVR49aOHnSUYoiJcXGF1/kM2lS+aOyq2oIQzjAARQUhjGs5ImizHNJZgAFzmwtlWgGUO2aR1jqBjjgDZ2egeDWbolRuEn8SNB4Q0EqNBwCai+XdX0kPxuz3QaAXVE4mJdV8USztQgsOeDdoN7Uj04pzCtunz6vLYSoHpW6Tfz5559zww03cPnll9OhQ4dSn8JhAQvIIYdruEaSzEIIIYQQ9Uh+fj5PPvkk3bt3p2nTpiQkJJT6dNbcuXPp3Lkz/v7+hIeHc80117B///5S+yiKwsyZM4mOjsbHx4c+ffrw119/ldrHZDIxdepUwsLCMBgMjBgxgpMnT5baJysri7FjxxIYGEhgYCBjx44lOzu70v8Hovbr3dubgQN9iIrScO21BpKSyo5m/le3bt346aefsFpL1xju1KkTem/HtPX5/3uVd999l/n/exUAbx9fOnbsWGp/q9XK2rVrufzyqpc7uPZaA2q1CpVKRVSUBl9f9yXZBjKQt3mb13md27it5AnvUPBrVPI4rH2p4zb/ks4TLwSw8NtuWExmRxkGUbuoVNBoGLS8AwzRLu26bWADIrwdo/4DvfR0Co6sWAe5x+DXO+GXO2HnC6C4YFHIWmBUbAu0KjUqVFwf29LT4QhR71R4RPNrr73G448/zm233cZXX33FuHHjOHToEFu3buWee+5xR4y1Th55fMd3FFBAW6p+N14IIYQQQtQe48eP55dffmHs2LFERUWhquQosl9++YV77rmHzp07Y7Vaefzxxxk0aBB79+4tLjnw4osv8sorr7BkyRKaN2/Oc889x8CBA9m/f39xTdz777+f1atX88knnxAaGsqDDz7IVVddxbZt29BoHFP1b775Zk6ePMmaNY46sxMnTmTs2LGsXr3aBf8j7qMoCq++msPvvxfRtq2ORx4JQqerH6P23E2tVnHvvYGX3hEYN24cb7zxBqtXr2bkyJHF2729vXn4oRnMmjWLlNOnmDBhQvFzD82YXqbkyapVqzh16hTjxo0r9zz795v59dcimjXzKlV/eE3qYb5JOUScbwBTm3ZEr9EyapQfAQFqvv4yg8ahR7m+fyCQWG6/rpC1N5RnnjmLr286c+eGEBmpBbUWur4A6VscNZrPG62clWXjhflWrGnx7DwcQ4h/Ade1ibvIGWoAcy5k7wP/ePAJ93Q0dZ6/l55X2/XncL6RRr4BBHpd+GZPuU5+D+ZzpWpSf4dmp8FQ9xdN7dWgIe2DwrEpCkE6KaskRHVTKUrFbmu1bNmSp59+mtGjR+Pv78/OnTtJSEjgqaee4uzZs7zxxhuX7CMnJ4fAwECMRmO5i0bUdutYxwxmYMfOi7zIQAZ6OqQS+fkQH+9oHz0K5dRFE0IIIYSorLr+Ps8ZQUFBfPPNN/To0cOl/Z45c4bw8HB++eUXevXqhaIoREdHc//99/Pwww8DjtHLERERvPDCC0yaNAmj0UiDBg348MMPufHGGwE4ffo0DRs25Ntvv2Xw4MHs27eP1q1bs3nzZrp27QrA5s2b6datG3///TctWrS4ZGye+r5v327i6aezih9PmRLA4MG+1XZ+UaJfv34cO3aMXbt2laq9bLPZeOmll5gz93lyjNkEBAbx+GOP8uCDDxbf6ADHTICkpCTi4uJYt25dmf4zMmzcdVcGJpPj8vXRR4Po3t2b9KJ8xv+5BgXH9rFxbbihYSvHQeZc2HA3mLMBFXSaCWHumYV72WUnSE11lDno0sWb1asvPvo0JcXKxIkZjoXkCtMZOczMHdN71NzyBpZ82HS/o0SExhsun+dIOIua69hq2LfQ0dYaoPci8HLz9b+i1NzXsBCiSpx9r1fh0hnHjx+ne/fuAPj4+BQv6jB27Fg+/vjjSoZbt3SgA0/xFM/wDJfj5lVuK8pggDNnHJ+SZBZCCCGEcLng4GBCQly/YJPRaAQo7vvIkSOkpqYyaNCg4n30ej29e/dm48aNAGzbtg2LxVJqn+joaBITE4v32bRpE4GBgcVJZoDLL7+cwMDA4n3+y2QykZOTU+rTE3x8VBd9LKrPwoULSUlJYfLkydjt9uLtGo2Ghx9+mMyMM6Snp5OZcYaHHnqoVJLZbrczefJkUlJSWLhwYbn9p6fbipPMAMePO8p02BSlOMkMYDnv3BScPpdkBlAga2/Vv9BymM0KWVkl501Ls13ymKgoLSNH+qLReRPXJoGr7+hWsxN0xgOOJDM4kuNn/qxyl3ZFIcdiooJj32q8s+ZCFh5O5oOjeyi0WTwXSKOroOV4R+3ozs+6N8lsyYPN0+GHa2D3/+pNmQ4hRFkVTjRHRkaSmZkJQFxcHJs3bwYcb3Tr2h+IygoiiKu5mhGMwB/XrTorhBBCCCFqvmeffZannnqKgoICl/WpKArTpk2jZ8+eJCY6pv+npjqSPhEREaX2jYiIKH4uNTUVnU5HcHDwRfcJDy87DT48PLx4n/+aO3ducT3nwMBAGjZsWLUvsJJatdJxxx3+tGjhxXXXGbjiCpkm7SlNmzZl0aJFLF26lNtvv538/PxSz2u1Who0aIBWW7p6Y35+PrfffjtLly5l0aJFNG3atNz+mzXzolUrx0JrQUFqevd2fK+jfPwYG9eGIC9vLgsK5+qYZiUH+cWBIRashY6F+Xwiyuu6ynQ6FdddZ0ClcuTXRo50blT9HXcEsHJlBG+8EUZoqObSB3iSfxx4nbu2VamrvGhhrsXE1B0/csuW1Tyx5zes598g8LBfz5zg5s2rmPjnGo7kZ1f4+Nn7NrH69EGWn/ybNw/ucH2AzlKpIP5qaHMPBDa79P5VcfIHyN4Pih1OrYXsvy+6e3pRPhkm1/2NFELUHBWu0dyvXz9Wr15Nhw4duPPOO3nggQf4/PPP+fPPP7n22mvdEaMQQgghhBA1Wvv27UvVYj548CARERHEx8fj5eVVat/t27dXuP8pU6awa9cuNmzYUOa5/9aAVhTlknWh/7tPeftfrJ9HH32UadOmFT/OycnxWLJ55EgDI0fKTL2aYPTo0SiKwvjx4/n999+ZN28eI0aMKJNcBsfCf6tWrWLGjBmkpKSwbNkyRo8efcG+vbxUzJkTwunTNsLC1Pj6loyZuqFhq5JyGefTesNlD8FvEx2jOfe+CQEJENDEJV/v+V55JQyDQc0ffxSxcaOJr7/O56qrLv26rGwN92qnD4ZuLztGMgc2g6CqLbL2y5kTHC9wzITYZUxnpzGdjhVd7M5NXj+4jSKblVyrmfeP7mFmm54XP+A/5SJOFeYWt08X5bkrzJrF6/wBdirw8rvgrl+dOsC7R3aiQsVdTdoxLMr1P49CCM+pcKJ54cKFxVOh7rrrLkJCQtiwYQPDhw/nrrvucnmAwsUKC2HoUEf7u+/Ax+fi+wshhBBCiEu65ppr3Nb31KlTWbVqFb/++iuxsbHF2yMjHUmZ1NRUoqKiirenp6cXj3KOjIzEbDaTlZVValRzenp6cTm8yMhI0tLSypz3zJkzZUZL/0uv16PXV3BhKlEv3HzzzXTp0oWJEycyatQoYmJi6N+/P+3atSuu7ZicnMzatWs5deoU/fr14/vvv7/gSObzabUqGjWq4CVsYZqjpjCA3eoYaemGRDPAnj1mdDpHAvy334qcSjTXGuZcx6KGukAIvHTd9ktpoC8Z9a1CRaiu5lyXequ1FNkcpVm8NZd4ve15HU79BAFNoeNM0PlzfWxLlhzdjValZmRMc/cHXBPEDICCFMeo5ph+4HfhG49fnT4AgILC16f2M8yy3/FE7EBQe13wOCFE7VDhRLNarUatPu/u8Q03cMMNN7g0KOFGdjv88ktJWwghhBBCVNnTTz/t8j4VRWHq1KmsXLmSn3/+mcaNG5d6vnHjxkRGRvLjjz/Svn17AMxmM7/88gsvvPACAB07dsTLy4sff/yx+D17SkoKe/bs4cUXXwSgW7duGI1G/vjjD7p06QLAli1bMBqNxcnomujUqVOkpqaSmJgoSe8apmnTpqxbt47t27ezePFiNm/ezKefforJZEKv19O2bVtGjhzJuHHj6NDBPYvzFQtuBfoQMJ11LIgW2s5tp0pM1JGcbC5u1yl/Pgk5hxztgjRoelOVuusaGs3kJu35KyeD7qExxBsCXRCkazzW6nLeP7oHP62OiQmXXXjH7H8cJSMAjP/Aye8h4TpGxbagb3gjvFRq/L3qye8mlQqa3+rUro18AzhzrmzGtVlrIOOI44mze6DdQ+6KUAhRTZxKNO/atcvpDpOSkiodjBBCCCGEELVdQkICW7duJTQ0tNT27OxsOnTowOHDh53q55577uGjjz7iq6++wt/fv7hecmBgID4+PqhUKu6//37mzJlDs2bNaNasGXPmzMHX15ebb765eN8777yTBx98kNDQUEJCQpg+fTpt27ZlwIABALRq1YohQ4YwYcIE3n77bQAmTpzIVVddRYsWVR+56A47d+5k5syZWK1WmjVrxosvvlhueQbhWR06dCiVSLbb7aUGLVULXSD0eK1kJLN3mNtO9fjjQaxbV4Sfn6p0vXCbGXa97Ighqje0vMNtMbiF3VqSZAYw7ndJt8OimtTIsgmtAsJ4PqnPpXf0MgAq+HcxyvPKRYTUoBHaNc30Fl1Yeeof1Kjoc2QN/Lt2poteV0IIz3Lq3Vi7du1QqVSXXOxPpVJhs116hV0hhBBCCCHqqqNHj5b7nthkMnHy5Emn+1mwYAEAffr0KbV98eLF3H777QA89NBDFBYWcvfdd5OVlUXXrl354Ycf8PcvqZc5f/58tFotN9xwA4WFhfTv358lS5ag0ZQsPrZs2TLuvfdeBg0aBMCIESN44403nI61um3atAmr1TG1/cCBA6SlpRETE+PhqMSlVHuS+V+6QAjv6vbTeHurGTasnIUAT/0IaRsd7aMrIbJ7lWscVyu1FiJ7QuoGQOVIlgswxEDb+x2L3wU2hdhBno4IgHzyWc5y7Ni5jusIIMDTIZXip9UxNs6xqC2WAXBwmaMd1cdjMQkhXMepRPORI0fcHYcQQgghhBC12qpVq4rb33//PYGBJVPBbTYba9euLVP+4mIuNcgDHAM9Zs6cycyZMy+4j7e3N6+//jqvv/76BfcJCQlh6dKlTsfmaa1bt+abL5aAtYjwhi0IC3PfKNU6LW0zZO11JGFD2ng6mrpLpbn449rgsoeg0ZWgCwC/Rp6OpuaI6ef4rEHmM58tbAHgCEd4lmc9HNFFNL0JGnQExQ5BNXMGjRCiYpxKNMfFxbk7jjpp0rbv2Z+TiZen7tyXw7uwiNXn2sN/W06Rj/dF968q87k60CrAV+vF2x0H09C3Zt1RFUIIIYRwhX8XBFSpVNx2222lnvPy8iI+Pp6XX37ZA5HVPb0aF2AY4cWpTBs9LrOh18isygrLSIYdsx3t419Dz/8D36iLHiIqKWaAo4Zv9t+OUZuBzdx3rqIMyNzpWJzO34XX8SoVhCS6rj8XURSFpcf/YrfxDD1CY7k6xo3/t7XEKU6V266x3PnzIISodlLIzI325pzhZEEuYfpypk95iLfFXNzOtpgp0qrcdq7UojwMWh1hOh8CvHR0CI4g0rsOrbwshBBCCHEe+7kb7I0bN2br1q0yytaNMk/8xZIfT3IyoxBjvpWxg7JAW3Pec9cKecdK2nYL5J+WRLO7qLWQeK/7z2M2wsYHwJztOGfXF+t8Eu/3zFN8duJvAPblZNLCP4SWAaGXOKpuu5ZreYM3UFAYxShPhyOEqGck0exm4d4GwmtQolmvaCjydqx8G+Hti8nbPSOa86xmgry8mda8Mzc2bIWv1sst5xFCCCGEqGmk7Jz7rdxWxNEzJrArfLa5gEG5GiJkPEPFRPZw1AsuygT/xhAspTM8slihK+UcciSZwbGA39nd7k805xwGSy6EtAWVG/7vFAVQLth3gdVS6nG+zVLufvXJQAbSmc7YsRNCiKfDEULUM5JormdMPt5c/6P76+/lWS2E6w3cGp+Ixh1vOIQQQgghRL3l16AJhFwGdjNab3+8fXw8HVLt4x0GPd+EgjTHomYanacjqnbbt29n8eLFbNq0iT179mAymdDr9SQmJtKtWzfGjRtHhw4dqi2elJQUjEYjLVq0QKWqxMzTgCagDwZTFqi9ICTJ9UGe7+SPsOd1QHEsFtjuYdf2n5EMyXMdI+4Tp0J03zK79AlvxO+ZJ9ltzKB7aDQdgiJcG0MtFUSQp0MQQtRTFUo022w2NmzYQFJSEsHBwe6KSdQBBTYLLfxDJMkshBBCCCFcrnfv3rz11lukpKRw4403llp4UVSA1hcCnF+gsq44ePAgEydOZP369cTExDBgwADGjBlDQEAAOTk5JCcns3LlSt544w369u3LwoULadq0qVtj2rx5M88//zw2m42ePXvy8MOVSNrqAqHbfDi7y1Gj2a+h6wM9X+pvwLlFS1N/dyzo5srrvwMfgrXA0f77vXITzTq1hmfaXOG6cwohhKiSCiWaNRoNgwcPZt++fZJoFqUoikKu1Uy2xYTJbsOg8eLamOaeDksIIYQQQtRB3377Lf7+/vj7+7Njxw7S09MJDw/3dFjVw5QFis0xIllU2EcffcT48eOJiopixYoVDB8+HK227GWx1Wpl9erVTJ8+naSkJBYtWsTo0aPdFtfatWux2RyLWm7YsIH77rsP78qUOfQOLTch6xZBrSFjx7l284snmc05YCsCnwr8nOrOu4GkD6pUiMI1zHYbv505gY9GS7fQmAuOuLcpdhlsJko5zGEWshAtWiYzmRhiPB2ScLMKl85o27Ythw8fpnHj+nfnuy7wMpl59ImXAJj73HQs+qpNkVMUhTyrhTRTPt4aLU39gukZFkvXkCi6hcovECGEEELUL1arlWXLljF48GAiIyM9HU6dZTCUFGTWarXo9XoPRlONTq2DPa86Ro62uAMaj/R0RLXKRx99xJgxYxgzZgwLFiwo9Tr6L61Wy8iRIxk0aBCTJ0/mlltuQVEUbr75ZrfE1qxZMzZv3gxAbGxs7XhNN7nRsYCkJQei+114v/StJSUwEq6D5rc513+bKfDPYrCZofmtrolZVMrzf29m69kUAG5o2JKxcYll9nnr0A6+TTlMjI8fzyZeQVgNWqtKeM5LvMQJTgDwBm8wl7kejki4W4UTzbNnz2b69Ok8++yzdOzYscwf54CAAJcFJ1xPbbfTefOO4nZlFdmsnCrMxQ74arxoHRDGjBZd6BoSXbl6YkIIIYQQdYBWq2Xy5Mns27fP06HUaddeey2ZmZmcPHmS4cOH15/SGUe/dCSZAY6skERzBRw4cIDx48czZswYlixZUmbRv/z8fLKzswkKCip1jWswGFiyZAmKAnfeOZ4uXbq4pYzG9ddfT2hoKJmZmQwaNKh2XFOpVBDd+9L7HVvlSDKD43Xb7FbHsZfiHQJJD5b/3KHPIGsvRPWCmIskuWuDghRABb419+bkruz04vbO7HTGxpV+/mRBDt+kHHK0C3P5OuUQt8e3rc4QRQ1lxlzcNmHyYCSiulQ40TxkyBAARowYUeqPn6IoqFSq4uk+om5SFIUsi4n0ogI6h0QyIrop7YMjaOYXgro2vBkSQgghhHCzrl27kpycTFxc3KV3FpWi0+m45557qt6RJR8suTU6wVOKIRZyjzjafrGejaWWmTRpEtHR0SxYsKA4yWy1Wpk6ZQq//ryOff8cRFEU4hs15Mix46WOVavVvPXWAjZs+J2JEyeybt06l8enUqno37//JfczmRR++60Qf381XbtWorSGJxhiITPZ0faNgsJU0Ic6tQDl9qxUfkw7SmNDINfHtnTkIFJ+c9RvBsjYDgEJ4B/vtvDd6vAX8M8SQAWtJkLcVZ6OqFzdQmP4+czx4vZ/+Wq90KrUWM/dCAv0qgUj8kW1uId7eJVX8cKLiUws87yiKKQW5ROs88ZbU+EUpaiBKvxdXL9+vTviELVAjsVEalE+AV56RkQ3ZVqLzsT4+Hs6LCGEEEKIGuXuu+9m2rRpnDhxotwZgElJSR6KrI4pyoSiM45Fz9SVuDjN3g9/PuVYbCy6LyRNc32MrpY41ZGos1sgYZSno6k1tm3bxvr161mxYkWpn8fTp0/z1ttvl9o3IzOj3D4MBgMvvzyPUaNGsX37djp06ODWmC/k2Wez2LnTMUJw7Fg/brjBzyNxkL4Fco9CZE8wXKJkYotxjnrLprOQuQt+neh4HXd98aK1lzNNhTy3bxMWu40NGSfx1+oYGtUEzNnn7aWAKRtq62Xp8a/PNRQ4/k2NTTQ/0LwzvRo0xEejJTGwQZnnfTVeDI5szG7jGToGRzI8yr2LZ4raoz3tWcKScp+zKwrP7dvI1rMpBHrpmdu2Nw19pUpCbVfhd2S9ezsxNUbUKWa7jRMFuWjVaoZFJTC5SQea+4d4OiwhhBBCiBrpxhtvBODee+8t3qZSqWQGoCtl7YM/nwSbCULaQufnLr4QWXlOrHEkmQFOr4fmtzum6tdkWh9oPtbTUdRI2eYi/nfgTzLNhdzcqHWpUZdLliwhNjaW4cOHlzomJCSExvGNCAkO5ujxE2Rmnr3oOUaMGEFMTAyLFy/2SKJZURR27SqZhr5rl5kbbqj2MCB1AyS/4GgfWwVXvA1eF0l4a3TQ9CZHcvrEd45tBSmQthEaDbvgYUaLCYu95PdlhrnQ0Yju5/iZNR6AiO4Q6oabd8aDjoU3w9pX7kaWs/zioOjczY0aPCpbrVLROSSq3OcUReHxPb/yT67j5+e62BZo1bIgoLi04wU5xbW/jRYTP6UdZVxjuRlf21XqN+Zvv/3G22+/zeHDh1m+fDkxMTF8+OGHNG7cmJ49e7o6RuFhxwtyaB0QxpSmHejToFHtqBcmhBBCCOEhR44c8XQIdV/KL44kM8DZ3Y6k1aVGVf7X+fvrAi+eKBM13gfH9rAtKxWAefv/4JPLR6BTawDYtGkT/fv3R6stffnr5+fH4SPHAOjVszu//b7poufQarX079+/eNG+6qZSqejaVc/mzY7XfteubihPUJQBZ7Y5ylEENit/H+OBkrY5BwrTnfv58Y0ClQaUc8njS/zMNjYE0qtBQ349c4IIbwNDIhMcT3gZoNsrYLe6Jwl8ej3smg8ojkRzp1muP8e/LpvhSNar1BB3tfvO40Y5VnNxkhngz6xU+obXjdJRR/ON/HLmOI0NQfRq0NDT4dQ5ITpvfDRaCm1WAJkxX0dU+LfyF198wdixY7nlllvYvn07JpPjj1xubi5z5szh22+/dXmQwnOKbFZUqBjfOKnO/LEQQgghhHAnqc1cDQJKpmUbLQZ8VP5cutrrfzS+1pGkKkiBhsOcqhfrSocOWXj1VSNWK0yZEkDr1tV7/rrGriil2sp5j/fs2cOYMWNccp527drx6aefuqSvynjkkSD+/NNEQICaVq0q95r56qt8tmwx0b69juuvL0kQb92Uxbtz1uOny+HBUUuJHvKQY8bAf+T790Rt/QEfbR4ENgc/JxNwfo2gw5OOkc0hiRB62UV3V6lUzGjRlclN2uOr8Sq7JpC7RhqnbgTOvX4ydoC1CLRuqoftZYCmo93Tt7sUpoPZ6Pg9rFIRoNXRzC+YA3lZAHQMvnDN+2xzEX5aXa0Y8ZxrMfHo7l/Is5bMIrhgstmcC2ov971O6qgALz3PJl7BuvTjxPkGMDAi3tMhCReo8G/m5557jrfeeotbb72VTz75pHh79+7dmTXLjXf6RLUqsFo4ayki32qhU3AkvRs08nRIQgghhBC1xqFDh/jf//7Hvn37UKlUtGrVivvuu48mTZp4OrS6IXYAaPS8t2QpK387jGHZRGbNmkXz5s2d70Olhvhr3Bbipbz5Zg5HjjhGcb32mpG33ipb91Q475a4NpwqzCPDXMDYuET05xaVstvtmEwmAgJcU/czMDAQk8nEl1/mEh+vo1276l30TKNRVWkRwN27zbz7bm5xOz5eS+fOjv5enpdBfroeaMCiNV14ssvuMonmNWsKWLDAH7XyAg/elU/PLk0cCTZnNejo+KwAP20134QJaQvp50atBzSV5OH50rfAjrmOUelRveCyGahUKma37cXmzNM00PuWW8MZ4JV//mB9+nGCdd7MSexFbCVq8R7gAOtZT2MaM5CBVf1qLuqMqbBUkvlwfnb5ieajX8Lf7zl+Dto/Cg06uTWuuqaFfygt/EM9HYZwoQonmvfv30+vXr3KbA8ICCA7O9sVMQk3Mvl4M/y35Rfd56y5iCxzEfGGAAaEx3NTo1b4aivw5kEIIYQQoh77/vvvGTFiBO3ataNHjx4oisLGjRtp06YNq1evZuBA914c1xcFgR1ZufFF0HiTn5/Pl19+yUMPPeTpsJx2/uBMqUxXdQ30vsy7rG+Z7Wq1Gr1eT05OjkvOYzQa0Wr1LFqUD+Tz2GNBdOtWexKReXn2/zwuGfmt0hlAowebCZVaDWFlE8Iff5yH3Q52dHz6nS89h9X8kfh27KSTTggh6JyZ+xA/AnwjHQuORpXNfdRrJ38qKX2S8iu0mQpab3w0XhedAX26MJf16ccByDIX8W3qYSYmtKvQqY0YeZzHKcRRq1uLlr6U/Zl3lUa+AbQJCOOvnAwMWi96X2g084FlgAJ2MxxeLolmUe9VONEcFRXFwYMHiY+PL7V9w4YNJCQkuCou4SEZpgLOmotoExjGZ5dfUyumtAghhBBC1CSPPPIIDzzwAM8//3yZ7Q8//LAkml1Er9cTGBiI0WgEICIiwsMRVcw99wTw+us5WK0K99zjmtG2tYnZrHDkiIWoKC0BAe695khMTCQ5OdklfSUnJxMQ0LL48d695lqVaO7cWc/ll+v54w9H6YwePUpinz4jlEUL2+KnzeDOB9pBUNlZrRERGs6etRe3azorVp7maXaxizDCeIEXCCf80geGd3F/cE7IMBWwNyeTZn7BRPnUgDryAU1KRnsbYpwe7R3gpcdbo6XoXC3eCL2hwqfOIKM4yQxwnOMV7qMitGo1zyX24miBkQZ6XwK9LjB7wScC8o6VtIWo5yqcaJ40aRL33Xcf7733HiqVitOnT7Np0yamT5/OU0895Y4YRTUw221kW0zkWEzcHt+W8QmXSZJZCCGEEKIS9u3bx2effVZm+x133MH//ve/6g+ojtJoNDz33HN8+eWXhIaGctNNN3k6pApp3NiLV16pn9OFi4rsPPTQWY4cseLvr2LevFBiYtxUbxfo1q0bK1euxGq1llkQ8Oeff2b//v2kpKYBYLZYefvttwkNDeW6664rta/VamXt2rXExg4BQKulSmUsbDaFZcvyOH7cytChvnTs6P4yHFqtiscfD0ZRlDKLvHfsqKfj29FA9AWPf+SRID7+OA+tVsXNN7s38Wk0Gvn111+JjIykc+fOlerjb/5mF7sAR6LyZ37mBm5wZZhuc9ZcyH3Ja8mxmPDWaHnlsn40rES5CZdqciN4hzhGe8cOdvowP62OWW168l3qYRr6BDA8uumlD/qPeOJpRzuSSSaAAPrRr8J9VJRWraapX/DFd+rwJBz+FLS+0PRmt8ckRE1X4b/mDz30EEajkb59+1JUVESvXr3Q6/VMnz6dKVOmuCNG4UJeJjPTnnsdgFeemEquVs3JwlzUKhVBXt6MiG7GA807461x3xs9IYQQQoi6rEGDBiQnJ9OsWbNS25OTkwkPd2IknXBafHw8999/v6fDEBX0zz+W4vrUubkKGzcWlVqUztXGjRvHG2+8werVqxk5cmSp5268/jrSMzKLH5vNFu666y4ATp06RXR0SdJ11apVnDp1iuXL78LLK5joaA3R0ZW/blq1qoDly/MB2L7dxHvvNSAoqHpGCf83yeyskBAN99wT6OJoyrJarTz88MOcOnUKgHvvvbdSs0HCCccLLyxYKDxeiCnPhNKqbJK9uqQX5ZOcnU4z/2AaG4Iuuu/fOZnkWEwAFNms7Dae8XyiWaWC2EGVOrRVQBitAsIqfWoNGp7hGU5zmhBC8MW30n25lG8EJN7r6SiEqDEq9Vdx9uzZPP744+zduxe73U7r1q3x86sB0zjEJantdnr+7Jjq8ti0caRpVVweGsXt8W3pGBxJwIWmgwghhBBCCKdMmDCBiRMncvjwYbp3745KpWLDhg288MILPPjgg54OTwiPi47W4u2toqjIUR84IcG968F06NCBvn37Mn36dAYNGoTBUDJtPygoqFSi+V86nRc+Pj7Fj/Pz85kxYwZ9+/alWzfX1GDNyrIVty0WR73koCCXdF3rZWdnFyeZAf76669KJ5pnMpN3177L1le38pnyGWf6nmHatGmuDNcp2eYiHti5jhyLCa1KzYtJfWjmH3LB/Zv7h+Cn1ZFnNaNTa2hThSRtXaFGTSyxng5DCHERFU4033HHHbz66qv4+/vTqVPJH9j8/HymTp3Ke++959IAhevYFDsphfnFj9UqFZObtOPOxkn4S4JZCCGEEMIlnnzySfz9/Xn55Zd59NFHAYiOjmbmzJnce6+MenIFRVH4/vtCTp60MmCAD/HxsnB1ddqyZQs//vgjCQkJjB49usKjQ8PCNLzwQggbNxbRooVXtZSMWLhwIUlJSUyePJklS5agPlcmcMfOXWRlZZXZ38/Pj8BAx8hdu93O5MmTSUlJ4fvvv3dZTFddZWDzZhMpKTaGDPEhNtZFs0pPrIEzfzoWJWs4xDV9VrPQ0FBat27N3r17UavVdO/evdJ9JZFEwPoAwhRHovbnn3/mgQceqPZRzYfzs4tHKFsVO3tyMi6aaA7T+zK/XT/HSGZ/b772XUoeeYxmNI0oWz+7JjCbFXQ6z65ueopTnOY0bWmLN7WnfroQdYVKURTl0ruV0Gg0pKSklJn2l5GRQWRkJFar9ZJ95OTkFC/cERBQdxe+uGL9Usx2O+H6mjGl41hBDtE2WDPsTgBOpZ8mpkGUh6MSQgghRF1SX97n/deqVasYOnQoXl6lE565ubkA+Pv7eyKsalPd3/fvvivgzTdzAPD3V/Huuw3w9ZX1RapDeno6kyZNKr7uu/vuuxk6dKiHo3LOxx9/zC233MKYMWNYsGBBqZHNF5Kfn8/kyZNZunQpyx5qx+gJj0AT19b4rXRyzm6Fv9+FnEOOcgaxA+HsbvjjsZJ9usyBkLauC7Yamc1mdu3aRXh4OI0aVS2x+uGHHxbXzm/RogUvvfSSK0KskByLiak7fuKsuRCdWsO8pL4k+AU5dex85rOOdYBjlPYiFrkx0orLybHz+ONnOXrUSs+e3jz0UKBHypPsYhdP8zRWrDShCS/xEtrKTeQXQvyHs+/1nP6Jy8nJQVEUFEUhNzcXb++SO0M2m41vv/1Was7VYFa7nUKrhWFRJSskx3i6vpMQQgghRB0xcuRIUlNTadCgQamBGXU9wewpx4+XDG7JzVXIzrZLorma5ObmlhpcdPbsWQ9GUzGjR49GURTGjx/P77//zrx58xgxYkSZBQLBUSN41apVzJgxg5TTJxxJ5j4xcGyVyxPNlR4BeuI7OP6No529H4LbQNF/vh//fVyL6HS6UrOoq2LMmDFER0eTk5PDoEGVqzFcVQFeev7Xrj97jGdI8Asixsf5vw9nKfk+ZlF2BL6n/fBDAUePOn4vbNhQxPDhvrRurav2ODazGSuOOA5xiBRSaEjDao9DiPrM6URzUFAQKpUKlUpF8+bNyzyvUql45plnXBqccA2r3c6h/Gya+4cwICLO0+EIIYQQQtQ5DRo0YPPmzQwfPhxF8dxCU/VF//4+rF9fSH6+QufOeqKiqmcBNQEJCQn07duX9evXExMTU2tGM//r5ptvpkuXLkycOJFRo0YRExND//79adeuXfFIreTkZNauXcupU6fo168f3796A021exwd+NWgpJW18LwHCtiKIKIbhCTC2T2OfyO6eSy8mkSlUtG/f39Ph0GwzpsrGlT8NTSa0RzgAIUUMo5xboisakJCSn4Hq9UQGFj6xt/Wsym8dmAbWrWKh1p0rdKigBfTmtasZjXgGPkdjgyGFKK6OV0645dffkFRFPr168cXX3xBSEhJLSGdTkdcXFypFXkvpr5MqawppTOOF+QQ4+PPks7DCLcB/y7cmJcHTkwXE0IIIYRwVn15n/dfM2fOZNasWU4lmG022yX3qW088X3PzbWTnW0nNlYjiX0PMJlM6PX/qa1syYPkFyDvOMRdBQnXeyY4J23fvp3FixezefNmdu/eXfw1tW3blssvv5xx48bRoUMHsBbB0S/Bbob4a1C8/Cv3mivKhIwdEJDg+KwqSx5sf85ROqPhYGg5vuQ5axFopT5tXWLHjg0bXtS8mvSKorB8eT7//GOhTx8fevYs/dq7Y+u3nDEVANDML5hX2rkv6Z9MMic4QQ96EMKFa2ALISrG5aUzevfuDcCRI0do1KiRvJmrRUx2G9fENCPc2wD5+Zc+QAghhBBCVMjMmTO56aabOHjwICNGjGDx4sUEBQV5Oqw6zd9fjb+/lMvwlDJJZoCjX0FmsqP9zwcQ2RN8a+6aMB06dHAkks+x2+3FiwSWovWGpjeRnW3j6RlZHDuWxrBhvkycWIGbKuZc2DQNTGdBrYXOcyC4Vbm7Hs7Lxt9LR4NLDVjy8oOuz5f/nCSZ6xz1uY8Lvk49SKVSccMNfhd83ltTknry0bg3Ud7u3IcQwjMqXBV93759nDhxgp49ewLwf//3f7zzzju0bt2a//u//yM4ONjlQYrKs9rtAMT7OlZMxtfXMZL537YQQgghhHCJli1b0rJlS55++mmuv/56fOW9lqhv1OdfXqpAVbtKmlwqebd6dQGHD1uL20OH+tKwoZOX1LlHHElmcCzid3Z3uYnm1w9s44e0I2hUah5q0YXuYbEV+hpquz17zGg00KpV9df3ran+HXm/adMm9uzZUzzyPjExkW7dupWMvK/BZrTowruHd+GlVjMpoZ2nwxFCuFGFb4PNmDGDnBzHCs+7d+9m2rRpDBs2jMOHDzNt2jSXBygqT1EUjhbk0NgQSFJQA8dGlcpRLsNgcLSFEEIIIYRLPf3005JkFvVT3NUQ1Qv84qDN3eBTt+qj+vmVXD5rNODjU4HrKf/G4H2uLq1aC6Htyuxitdv5Me0oADbFzg/n2vXFokU5PProWR566Cwff5zn9HGppPIar7GIRRRQ4MYIq9fBgwfp168fHTt2ZOXKlSQmJvL888+zaNEinn/+eRITE1m5ciUdO3akX79+HDx40G2xHMg9y/x/tvLx8b3Fg9kqorEhiNltezGzTU+ifC488lkIUftVeETzkSNHaN26NQBffPEFw4cPZ86cOWzfvp1hw4a5PEBRefk2C3q1mpmtexLpLb/MhRBCCCGEEG6k9YbLZng6CrcZPtyXjAwbR49aGTrUl7CwCozY1vlDt1cgc5ejPnM5iwpq1Woa+vpzvMAxsCvBEOSiyGuHX38tKm7/9lsRo0eXfw2bm2snLc1GfLwWrVbFszzLcY4DYM87zoQ9+WAzQauJENK2WmJ3tY8++ojx48cTFRXFihUrGD58OFpt2fSN1Wpl9erVTJ8+naSkJBYtWsTo0aNdGovJZuWpvzaQZzUDoFapuLFh+WVfhBCiwolmnU5HQYHjLuFPP/3ErbfeCkBISEjxSGdRM+RbLQTrvOkYHFmy0WSCSZMc7bffhvJqqwkhhBBCCCGqxdGjR1m3bh1xcXH07+++BbJEaSaTwv/9n5Fjx6yMGGGgf3+fSx6j1aqYMKEKi13qgyG690V3eTbxCr5LOUygl55hUU0qfIq9e/fy3nvvYTAYmDJlCg0aNKhstO5jM8OBpVCUDvEjIagFAG3a6PjtN0eyuXXr8uv4njhh5eGHM8nNVWjRwou5c0NI80orfj5h34+QHep4sOsV6LPYvV+LG3z00UeMGTOGMWPGsGDBAgwGwwX31Wq1jBw5kkGDBjF58mRuueUWFEXh5ptvdlk8+TZLcZIZIK1I1n0SQlxYhRPNPXv2ZNq0afTo0YM//viDTz/9FIB//vmH2Nj6VT+qJlIUhSK7lbPmIgqsVi4PjUF7fq0xqxXef9/R/r//k0SzEEIIIYQQHpKfn89jjz1Gbm4u4HgvP2DAAA9HVTlr165l5cqVhIWF8cgjj+DtXbMXo1u5Mp/16x1JzVdfNXLZZbqKjVB2kxCdD7fEtan08S+88AJnzzpqQb/99ts88cQTrgrNdQ59DEdXOtoZydD3A9DoeOCBQC67TIdGA337lp/4//XXQnJzFQD277dw+LCFm1vczBKW4IUXrZWWwBnHzkrFSzx42oEDBxg/fjxjxoxhyZIlpeqGK4qC0WjEZrMREhKC6rxSmAaDgSVLlgAwfvx4unTpQtOmTV0SU4jOhyGRCaxJPUyAl56rolzTrxCibqpwovmNN97g7rvv5vPPP2fBggXExMQA8N133zFkyBCXByicl2MxkVqUj16jJVzvy/jGzbktPtHTYQkhhBBC1FtFRUU1PuEmPCczM7M4yQyO0c21UUpKCs8++yz79+/Hbrezb98+Pvnkk1KJsJrGbFaK24oCFotykb1rD5PJVNw2m80X2dODijJL2tZzZS40Ory8VAwefPH69o0bl4x09vVVER6uoQXXMpCBeOGFd+t0x0hmWxG0ustdX4HbTJo0iejoaBYsWFCcZFYUhTvGjeObVas4k5UFQKCfH+MnTeLZZ5/Fx8eRlFer1SxYsIDff/+diRMnsm7dOpfFdU/TDoyJa4OPRotO7fkbMkKImqvCieZGjRrx9ddfl9k+f/58lwQkKsem2EktymdoVAJjGrUhKShc/gAIIYQQQniA3W5n9uzZvPXWW6SlpfHPP/+QkJDAk08+SXx8PHfeeaenQxQ1RGxsLO3atSM5ORmDwUC/fv08HVKlFBYWkpGRgf3cImEHDx7kzJkzhIdfejFAq1VBq63+hPQ11xjYt8/C8eNWRozwJSqqwpfGNdJ9993HW2+9hcFg4I477nD/Cf9NGnuHOn9M42shYzuYjZBwnaN+tZO6d/fm4YeDOHTIwhVXeBMc7Ljm9edcH36NoPv/nI+lBtm2bRvr169nxYoVpcplmM1mlvw7K/kcY14eL7/8MpkZGSw+N5IZHCOb582bx6hRo9i+fTsdOnRwWXyBXjIb2iXyTsDeBYACrSaBf7ynIxLCpVSKolTo1u3x48cv+nyjRo0u2UdOTg6BgYEYjUYCAqpQ46qGu2L9Usx2O+F69646blcUDudnE+vjz3udh9HQ9yL/p/n54HduUYW8PLhIvSchhBBCiIqqL+/zLmbWrFm8//77zJo1iwkTJrBnzx4SEhL47LPPmD9/Pps2bfJ0iC4n3/fKs9lsnDhxgtDQUPz9nU+4edLq1fkcOmSlXz9vkpIcyad7772X5cuX4+vrS/fu3Vm0aBE6ne6CfZw4YeWpp86SmWnn5pv9uOmm2r14eUFBAVartX69/o9/A3vfdrTb3A0NKzDDWbE7ajVrZcbHv6ZOncqXX37JkSNHSi38Z7fbuW7UKPz8/enatSuKojD3uec4nZaGXqcjJze31M+a1WolPj6ekSNH8vrrr3viSxEXs3k6ZO93tAMSoPurno1HCCc5+16vwrdt4+PjLzoFymazVbRLUUWpRfmE6X15PqnPxZPMQgghhBDC7T744AMWLlxI//79ueuukqnbSUlJ/P333x6MTNREGo2G+Ph4T4fhtLVrC1m40FHu47ffCnn77QaEhWl47bXXuP766zl9+jT9+vW7aJIZYPnyPDIyHCOgly3LY/hwXwwG9UWPqak2b97Miy++iNVq5c477+Tqq6926jibTeHYMSthYRoCAmrh135kBXBu3NqRlRVLNKvUkmT+j02bNtG/f/9SSWZwlMRYsXIliqKQm5tLbm4un3z8MafT0jBbLGVyMFqtlv79+7N58+Zqiz2bbFawAj16RjEKb+R7e0G280ra2EwX3u8C1qcfY/nJ/UR6G7i/WScCZKS5qGEqnGjesWNHqccWi4UdO3bwyiuvMHv2bJcFJpyTb7VQYLMwMeEyOgZHejocIYQQQoh679SpU+UuwmS327FYLB6ISAjXSU21FrfNZsjKshcvonfFFVc43U9QkNpROsFmwjc4FC+vmlvP+VI+//zz4p/tjz/+2KlEs92uMHNmFsnJZnx9VcyeHULTpl6XPK5GMTSEwnRH2y/Ws7HUAXv27GHMmDEXfP6+++4rM0L5huuuK67RfL527drx6aefujzGC5nNbP7GcSM1jTSmMa3azl2jmY2w53UwZUGzMRDWHlrf5agjrtih9d0V6i7PaubVA9uwKXZOFOTwyYl9TExo557YhaikCieaL7vssjLbOnXqRHR0NPPmzePaa691SWDuMHfuXFasWMHff/+Nj48P3bt354UXXqBFixaeDq1SFEXhVGEu/cPjGNc4ydPhCCGEEEIIoE2bNvz222/ExcWV2r58+XLat2/voaiEcI2BA3356adCMjLsdOmip0mTytU2vvmKzZi2b+eM0Y9RgzLQeT3t4kirT2RkJPv3O6bCB0UG8RmfEUoo/eiHivIT6KdO2UhOdoxsLChQWL++sPYlmi+bDke+AFTQeJSno6nV7HY7JpPpotPR09LSymwLCAoqd9/AwEBMJhN2u714UUF3OsnJctv13v7FkL7F0U6eC/0/geDW0PvdSnWnKAr286rf2itWCVeIauGyFQ+aN2/O1q1bXdWdW/zyyy/cc889dO7cGavVyuOPP86gQYPYu3dvqWL7tYVVsaNVq7klro3zC//5+kJ6eklbCCGEEEK41NNPP83YsWM5deoUdrudFStWsH//fj744INyF9UWwhk2m8Lx444yC/7+niuzEB6u4Z13GpCTYyc4WH3RsooX412wk8lX/V6ywZIDukAXRVm9Jk+eTEhICAWFBWy9cSsf8iHgKCcwivITsCEhavz9VeTmOhJF8fG1cDFCLz9oflvV+jAeANNZCOsI6lr4f1ABB3LPsuDQDtQqFVOadiTeUPJ6V6vV6PV6cnJyLnj87NmzGTRoEEajkf977TUOHzvGO++8w8MPP0yTJk1K7Ws0GtHr9dWSZAa4lmv5gA/QoOFqnCsdU56v+Irv+Z4mNGEqU9Fx8RI8Nd75ZTLsFscoZlXlvyf+XnruadqeT0/8TZS3Hzc2bOWCIIVwrQr/Jv/vLz5FUUhJSWHmzJk0a9bMZYG5w5o1a0o9Xrx4MeHh4Wzbto1evXp5KKrKK7RZ8dFoaVSRuswqFTRo4L6ghBBCCCHqueHDh/Ppp58yZ84cVCoVTz31FB06dGD16tUMHDjQ0+GJWshmKymzYDComPNoPgkNCyC4jeP9fTX5dx15rVZFSIiTA10uJLwrpPwGKI6vw6v2rjVjMBi44447yCef7/m+ePsBDlzkGDXPPx/KunWFNGyopX//suUP6rzT62HXfECB0HbQ+VlPR+RWrx7YxrECIwCvH9zGy5f1K/V8YmIiycnJFzy+adOmxWWZvLy8uPfeewH4559/yiSak5OTadu2rQujv7jruZ4+9MELL4IIqlQfJzjBu7xb3E4ggZGMdGGUpZ01F3IsP4dm/sH4ad2U0G42BvJPOEpntBjnkpspgyMTGByZ4ILghHCPCr/Kg4KCyty1VhSFhg0b8sknn7gssOpgNDp+yYeEhHg4koqzKwpnTIU08Qsiyrt2r9AshBBCCFHXDB48mMGDB3s6DFFHnDhhLS6zkJ+Rxs9LVpEweAvEDIC291VLDHv2mJkzJwuTSeGeewLp16+KidGoXuAbDUUZENahWhPmlWYtcoxK1PmX+7QBA93oxiY2oUFDX/petLtGjbTcfnv5fdULaZsoXkwwMxmshaCtuwl3m2Ivt/2vbt26sXLlSqxWa6kFAXft2kWvK67guuuvp2vXruTk5PDGq68WP//fAX9Wq5W1a9cycqSLkrTmXMjYBoZYCCy7/sC/GlC1AW02bBd97EophXlM27mOPKuZcL0v/2vXH393LKpniIYer196PyHqkAonmtevX1/qsVqtpkGDBjRt2rTM6qg1maIoTJs2jZ49e5KYmOjpcCrEardzOD+bKB8/ZrToirYi02FMJph2rjD/K6+AXlYoFUIIIYRwpa1bt2K32+natWup7Vu2bEGj0dCpUycPRSZqq7AwDX5+KvLyFCjKJC48y/FEys/Vlmj+8MPc4jIP776bU/VEMziSVhdJXP0rN9fOzz8XEhqqoXt376qftzIytsOOOWAzOcpFJFxX7m6P8ih/8zfBBBOJZxZrt2LFjv2CZQfsioLZbsNb4+Hr95C255LNQEDTOp1kBpjarCOvHdiGWqVicpOy9frHjRvHG2+8werVq0sliY8cOYIxJ4dFixaxaNGiUseMuvbaMovPrlq1ilOnTjFu3LiqB20zw5aHIP8koIKOT0ODjlXvtxyxxOKDD1vYQnOaM4QhbjkPwJ9ZqeRZHTfv0k0F7MvNpEtItNvOJ0R9UuG/LL1793ZHHNVuypQp7Nq1iw0bNng6lAorsFkI8NLzZodBtA4Iq9jBViu8+aaj/eKLkmgWQgghhHCxe+65h4ceeqhMovnUqVO88MILbNmyxUORidrKz0/N3LkhrFtXSLzGSL+IfxxPBFVffc7AwJLBLQEB1VcjWlEUHnvsLEePWgEYP96fq6/2wPo6h79wJJkBDn5UKtGsoBQv+qdCRSs8Vzf1D/7gBV7Aho2pTKU//Us9fzTfyJN7fiPbUsR1sS24Lb76yiuUETccfCLBlAmRV7jlFIqisHx5PkePWhk82IfLLvPc9W/rgDDe6njhmS4dOnSgb9++TJ8+nUGDBhWvI9W1a1euuvJKfl6/nryCAgCiwsO56557mD59eqk+8vPzmTFjBn379qVDhw5VD7ow9VySGUBxjGyuYqLZriioy5nBsJGNFFJIEkkA7GQnPehRob6LKGIVq1ChYjjD8ab8G1PN/YNRq1TYFQVvjZZ439pZH16ImsipRPOqVauc7nDEiBGVDqa6TJ06lVWrVvHrr78SGxvr6XAqRFEUssxFBHjpiZaSGUIIIYQQNc7evXvLvcBv3749e/fu9UBEoi6Ij/fijju8QLkaTvuDJR9iq6/m9913B6DX51JYqHDrrdVX7qGwUClOMgPs3Wv2TKLZNwLOnmv7RADwN3/zHM9RQAGTmcxAPF+DfRnLMOMYqfkBH5RJNK889Q/ZliIAPj+5n2tjmrunZICzwju7tftvvingww/zANiypYhFixoQFHSB+uLWIjjzh+P7G9SiQuc5kp/N//75E4ti5+4m7UkMrFwZiYULF5KUlMTkyZNZsmQJarWayMhIVn/9NXa7nYyMDAwGQ3ES+nx2u53JkyeTkpLC999/X07vleATCYYYyD8FqCC07Ejsivjk+F4+PrGPBnpfnmnTkxifkt8lvviW2ve/j53xEi+xBcfN3EMc4hEeKXe/Fv6hPN+2N/tyMukQHEm4twd+pwhRRzmVaL7mmmuc6kylUmGzua+OTlUpisLUqVNZuXIlP//8M40bN/Z0SBVWYLOCSsUDzTsTpPPQtDEhhBBCCHFBer2etLQ0EhJKL9aTkpJSq0rNiRpKpYKY/pfez8WCgjQ8+GBQtZ/X11dNx446tm0zo1JBjx4eugZqOQG0fmDNg4TrAVjKUow41v1ZyEJHojl9K2TucCTk3JxELU8ooRzmcHH7v0LOu4Y0aL3Qe7p8hpudOVNSC9lsBqPRXn6iWbHDH49CzkHMWPmjXW98IgfSEedG7y44tIPD+dkAvHrgT97pNNTpGLdv387ixYvZtGkTe/bswWQy8eGHH6IoCm+99VZxUlmtVhMeHl5uH/n5+UyePJmlS5eybNmyMuU0Kk2jg67z4MxWR43moOaV7irXYmLZccfN1rSifD4/uZ/7mpWUkupEJ27hFraznU50oj0VT2of4Uhx+9+fgwtpFRBGq4rOEBdCXJJTf1Xs9rKF6muje+65h48++oivvvoKf39/UlNTAQgMDMTHp3bUg8q2FNFA78uQyNqXJBdCCCGEqA8GDhzIo48+yldffUVgoGM6bnZ2No899hgDB3p+xGOdUZAGhWkQ1NKRDBF11hNPBLN7t5ngYDXx8V6eCULrAy3vKLUpgIDSbeMB2P4soMCxr6HbyxDYjOp0Tf44CqwBhAVYGasaW+b50Y1aY1MU0k0FjIxphk59gdG9zrJbYd9CyDkEsYOgoQsXQTXnwvFvHP/3ja4EdcWT4sOG+fDbb4WcOWOnb19vGjW6QB+mLMg5iB07+/iLv9OP81Xk70xj2iUXdQRQU1IKQoVzC1sePHiQiRMnsn79emJiYhgwYABjxowhICCA9evX8+mnn/Lrr78yf/58RowYUe6NSqvVyqpVq5gxYwYpKSksW7aM0aNHO3V+p+n8IaZflbvxUmvw1mgpsjlmKASWM5L+pnMflTWMYSxhSXFbCFH96vbty/9YsGABAH369Cm1ffHixdx+++3VH1AlFFgtXBfbEoNW3kwLIYQQQtREL7/8Mr169SIuLo727R0jspKTk4mIiODDDz/0cHR1xNk98OdTYLc4Es1d5lYqCSVqB61WRfv2LirvoNjBkgteAY7R4VUwiUlo0ZJHHmMZC/lHAeXfE0H+SQ5lxPPhh7kYDGomTPC/cNmGC4WrKBzMyyJY502Y/uKlBNamHeXVA9tQiKVPg0ZEtIgos49OreGOxkkViuGijn8LJ75ztI0HICTRUWrBFbY/C9n7HO2C09B6coW7iIjQ8u67DSgoUPDzu0htcX0w+DfGnLsPEyYOhTlKbO5lr1OJ5slN2vPawW2Y7bZyF/r7r48++ojx48cTFRXFihUrGD58eKlE8h133MHTTz/NhAkTGDVqFBEREQwePJh27doRGBiI0WgkOTmZtWvXcurUKfr168f333/vupHMbuCt0fJkq+6sOPUPEd4Gbmro+lrmoxhFV7qiQkUMLnodCiEqxOl3Y+vWrWPKlCls3ryZgICAUs8ZjUa6d+/OggUL6NWrl8uDdBVFUS69Uw2mKI5lJloFlJ0CJYQQQgghaoaYmBh27drFsmXL2LlzJz4+PowbN47Ro0fj5eWh0Zh1TeoGdvyTwcmMInq0MRPSNs11ya3apDDdMXJWH+xYWE2S7RdnJzskEQAAt0hJREFUzoE/HoG8ExDSFjo9A+rK/0wGEsg0ppVsCAtzlBfIP+n4N6wTz03KIiPDMUPYboeHHw6q0Dme/3szGzNP4aXW8ESrbnQIjrzgvj+fOY5yLtH9y5kTTGveGVUVk+mXZCs674FSsmBiJZ3kJH74EUQQ5J5X+iDn4mUQLkatVuHnd4n/B5UauszFK/13fvX5iD0hmWjQ0J3uTp0jzhDIy5c5N+r3o48+YsyYMYwZM4YFCxaUW28ZoGnTpqxfv57t27ezcOFCVqxYwdKlS7Hb7ej1etq2bcvIkSMZN26caxb+qwZJQeEkBZVf/sNVYqld63AJUdc4/U7kf//7HxMmTCiTZAZH6YlJkyYxf/78Gp1oru1SivLx03oR61N9i28IIYQQQoiKMxgMTJw40dNh1Fm/7Tfx4of7AfjyjyzeHOaHB5cz85ytT0BBiqNtyYHmt3k2npou5RdHkhng7G7I3AUNnKvB6xSdP3R/1VHSxScCNDry8gqKn87Lq1hJyhyLiY2ZpwCw2G2sTT920URzS/9QkrPTAWjuH+z+JDM4Slpk7jhXOmMIBCRc+pgLeJ3X+YEf0KHjMR6jY8OhcPRLQAUNhzjdTy65HOEIccQRSKDzAXgZ0MQM4l760JfdRBDh8qTlgQMHGD9+PGPGjCle7O98eXl5WCwWgoKCir9/HTp04K233uLNN9/k9ttvZ/ny5ezevdup0cv7cjI4WZhL15BoAjy56KMQot5wOtG8c+dOXnjhhQs+P2jQIF566SWXBCXKyrGYsCh2pjfvQqeLvLm4JB8fOHKkpC2EEEIIIdxi7969HD9+HLPZXGr7iBEjPBRR3fFXmt5R+9ZWRDohZGTnEWOoQEKpLrBbSpLMUJJAFRfmc/5IShV4u2EhMI0O/BoWP7zrrgDefNOIn5+asWP9KtSVQetFhLeBnPwM2uXv4nL/fFC6XLDkx82NWhPpbSDHamZQRHxVvgrneRkcpWuqqIgifuAHAMyYWcMaOrZ83LHwpcYbfJ27BjZi5H7uJ4MMAgnkFV4hnIqNoNWhc3oRwIqaNGkS0dHRLFiwoDjJbLFYmD17Nss+XsbBfw4CEBgcyJS7p/D4448XryelVqtZsGABv//+OxMnTmTdunUXPdfmzFPM2bcZBYVon/283n5glWpyb2ADa1hDYxpzG7ehrV+VWIUQTnL6N0NaWtpFp/pptVrOnDnjkqBEWUaLiaZ+wYyNa1O1O9NqNcTHuywuIYQQQghR2uHDhxk5ciS7d+9GpVIVl2/79z2czWbzZHh1wuWXX87333+P1WqladOmRESUrUV7KVarwoIFOfzzj4W+fX249tryp6/XWGovaDTMUSNXrYOGQ13SraIovPdeLsnJZjp31nPrrZ6dTfnVV/ns3m2mWzdv+vev4kCZ8K7Q+m7I+gsiuoN/HDabgqI46kBfkjkXzNmOshhOXpP17+9Dv37elbqG06jUPN+2NxnrJxJqSSEs5W8w6KFp+YulqVQq+ldXgtnF9OiJIII00gBoRCPHE/7xFepnN7vJIANwJJ13sIPBuHCBwirYtm0b69evZ8WKFaXKZezdu5dnnnmm1L7GLCOzZ8/m2PFjfPhBSW1/g8HAvHnzGDVqFNu3b79oyYzk7PTiUiqnC/NIL8on1rfsDHVnpJPOPOZhx85OdhJGGFdzdaX6EtXAZnb8jaiOWQ1C/IfTieaYmJiLTs/YtWsXUVFRLgtMlLArCoU2K73DGlbP9CchhBBCCFFp9913H40bN+ann34iISGBP/74g8zMTB588EGZAegi7dq14/XXXyc1NZXExMRSi2g568cfC/nhh0IAFi/OpV07HQkJ1VdDW1GUqr+3bz0Z4kaAlx/oXDOie9MmE19+6Sj3cPSolcREHR06eGbK/R9/FPHuu7nn2iYaNdLSrNl53yNLniOh4h3ifKeNhjo+ge3bTcydm43VqjBlSuDFE9nZ/8CfT4K1ACK6QbtHnU7iVOX7HOalIwwj/LsQoHF/pfuqyVSomMMcvuZrQgnlKq6qVD+NaYwOHWbMaNDQhCaV6kdRFBYc2sGmzNMkBTXggWad0aovspigE5YsWUJsbCzDhw8vtf3fpHNwSDD33Xsf/v7+zHl+DplnMvlo2Ue8/NLLhIeXjMoeMWIEMf/P3n3HR1VmDRz/3enJpPdGEkJHCL0XRRBEBRuK2LGzllUE61pwVXxxLWtfXQUL9sW1LvauiCBFkE4oCQkhvU6/7x8XEwJJCMlMbsr55jMfnsnc+9wzpM2ce+55kpNZvHhxo4nmYVGJ/C9vJz5VJS04nHhb80+mVVGFj9rWL+WUN3uujurHgmze37eN5KBQrskYiNXY/IpvbXWuZv7e2PYa7Hhb690/9D4ITWt2HEI0R5O/80855RTuvvtupk6dis1mq/NYdXU199xzD6ed1rw/BqJxZW4noWYLpyU1749kHS4X3HmnNn7gAbBYWj6nEEIIIYSo8fPPP/PVV18RGxuLwWDAYDAwduxYFi5cyA033MCaNWv0DrFDSElJISWl+f1T3W610fuBsmGDi4ULS3C5VP7613DGjrUdfafG+HkRRI9Hn/+X+hQV1Sa2VBWKi73AwURz/kpY+5DWQqT7BQ1W+TbmtdcqcDi057d4cXnjieacz7UkM8D+n8Fx4LBWHAFiMEHieMj9DlAgaULgjwmsLdnPsuytJNjsXN41s0VJs6aKI47LuKxFcySTzP/xf6xhDf3oR3eO3se4PmtK9vO/PG0Bwu8O7GVwRHyLq8V//vlnJk6ceMSJse7du7Njxw7S09Nr2mns3buXxx9/HJ/PR25ubp1Es8lkYuLEiaxYsaLR4w2JTOCxARPZ56hgUEQc5ha0zUgnnVM4heUsJ420Zp8I6KhK3U7+sWUlHtXHprJCYixBXJB23DHP48DBAhawkY2MYQzzmY+BYzjB4SqHHW9pY2cRZP0HMuc2vo8QftbkvxZ/+9vfWLZsGT179uS6666jV69eKIrCpk2bePrpp/F6vdz5ZwJT+NUBZzUnJ3Qlwx7R8sncbvizkubeeyXRLIQQQgjhZ16vl5AQrRdrTEwM+/bto1evXqSlpbFlS8esRmyPpkwJZt0618HWGTZ69Wqd18VLlpRTVqYlUJ9/vqzliWY/GzPGxqpVTn77zcXw4VaGD9dvAbHx42189lk127a5GTz4sMrqXe9pSWaAne80K9EcFVWbwImMPEoyJyS1dmwJB3PzWhA0S+Y86HKKdtyQli9O5/P5jliE7lDVXjf3//ETTp/W5ifEZOHi9H4tPm5r6X7woyVMSt3/n5Ykaf+0YcMGLrzwwnofy8ioXUSxoKCAN956AwBbkI0ePXocsf3AgQN56623jnrMjJAIMkIimhfwYeYwh2u4pvmVtgepqspn+7PIri5nUlw6aR2gv77b58Wj1p4Yq/Z6mjXPV3zFBjYAWk/syUxmEIOaPoHRCiY7eCq1+9ZjuNpDCD9pcqI5Pj6en376iTlz5nD77bfX6TU3ZcoUnnnmmWb1RhONU1UVFZVJ8enSNkMIIYQQoh3o168f69evJyMjgxEjRrBo0SIsFgvPP/98nWSC0JfVqnDXXZGtftzQ0NoEVkhIyy7FDwSjUWHu3Ai9wwAgONjAo49G43SqWK2HvRcKToKiDQfHWgvHL/fv4tXdG4mxBnFr75HE/tluogHXXRdGSEgFLpfKhRceZaG+1NNAMULVPkiZDKZWPEGgKBB17NWRf/rtt99YvHgxP//8Mxs2bMDpdGK1WunXrx+jRo1i9uzZdVowOL1e9jkqqPZ6iLYEUeZx+uNZtAqPR6WoyEd0tAGjsfnvnzMj4jivS5+a1hnjYlqW4Pf5fDidTsLCGj9BUVlZyWnTT2N/rtar+o7b7yA4+Mjv4/DwcJxO51FPGvhbS5PMAMvzdvLMDu3Kni/37+bfQ6cSbGq9tkWBEGMN5oLUvvwnZyspQaGcldKzWfOEUff7I4RjW0AUowWG3ANZy7QrLrrPalYcQrTEMV3/kpaWxieffEJxcTHbt29HVVV69OhBZGTrv0DrLKq8HoKMJro0s2m/EEIIIYRoXX/729+orNSqie6//35OO+00xo0bR3R0dJMq0ETHdu21Ybz4YjlOp8qll+q70F57cUSSGaD3lWCJAE8FdJ2B0+vhye2/4VV9FLqqWbp7Izf2HNbwpKpKROkn3HjSHkg+CSIiGg9CUbTFF9uR7du3c9VVV/H111+TnJzMpEmTuPDCCwkLC6OsrIy1a9fy3nvv8dRTTzFhwgSef/55unfvzm8l+3F4veRWV1LhdjE1oX2cICsv93HbbUXs2eOhe3cTCxdGYbM1Pwl7QdpxddsfuMq1fujNKAAzGAxYrVbKysoa3KaqqopTTjuFX37+BYBp06dx++2317ttaWkpVqu1VZPM/rK7qvb/oNzjotjtaPeJZoDzUvtyXmrfFs0xhjGcz/lsYANjGUsPjqxmP6rIPhAp3QaEfprVaCkyMpJhwxr5oy38psztJM5q57iwGL1DEUIIIYQQTTBlypSacUZGBn/88QdFRUVERkYe8xVq3333HQ8//DCrV68mNzeX9957jzPOOKPm8UsvvZSXX365zj4jRoyo07vT6XQyb9483njjDaqrq5k4cSLPPPNMnf7GxcXF3HDDDXzwwQeAttjUk08+ScTRkm/imMXEGLn11gi9w2j/TDboeVHNXcXnxagoeA+2lD7qwm17l8Om57Vx7ncw/t9gaSOJf1XVKqfNYc2O6fXXX+eKK64gMTGRZcuWMW3atHoXzfR4PHz44YfMmzePzMxMXnzxRSpG9CE5KITkIK2a0uKHthGtYcUKB3v2aC0Ltm/3sGqVyz+taXweWL0ACtdCSBoMX9isr0u/fv1Yu3ZtvY9VV1dz2vTT+O6b7wCYNHkS77z9ToMLna5du5b+/fsDkEsuQQQRQcQxx6SHiXFpfHNgD5UeN8OiEkmyHWPVbgemoDALqUIW7Vv7O/3VyVR43PQIjWzxCrdCCCGEEKL17d27l+zsbKKioprVBq2yspIBAwbw1FNPNbjNySefTG5ubs3tk08+qfP4jTfeyHvvvcebb77JDz/8QEVFBaeddhper7dmm/PPP5+1a9eyfPlyli9fztq1a7nooosOP1SbU1JSwu23386ll156xPNulzxVWjsIV6nekbQOjwP2fQ2F61s8lcVgZF6v4aTbwxkamcCFqUdpNVGVc0gcVeAqaXEMfrP+H/D9NfDd5VCy+Zh3f/3117nwwguZMWMG69ev58wzz2wwYWkymTjzzDNZv349M2bM4IILLqDs65XYDi7+1y88lqSg9pEITEysfY6KAgkJfkqQF67TkswAFbsh95tmTTNq1Ci++OILPJ66/XvdbjdnnHkGX3/5NQBhYWGcMf0Mli5dyptvvonb7a6zvcfj4csvv2TkyJEsZjFXcRWzmc0v/NKsuFpbj9AoXhhyMk8Pnszf+oyWFqFCdDCBXzpWNJvT68VkMHB2Si+9QxFCCCGEEE3k8XhYsGABTzzxBBUVFQCEhIRw/fXXc88992A2N/0S4alTpzJ16tRGt7FarSQkJNT7WGlpKS+++CKvvvoqkyZNAuC1116jS5cufPHFF0yZMoVNmzaxfPlyVqxYwYgRIwB44YUXGDVqFFu2bKFXr7b7WvTtt99mwwatT+9zzz3HmDFjCA9vpwtLuSvh57kHK1lDYdQjNb2H/aWsrIxHH32UvLw8zjnnHCZOnHjENi6Xyp49HhITjdjtAS52WXU3lGzSxn3/AqmNf68fzajoZEZFJzdt45TJsO8bLakfNwLsLV9kzy8chVqFNYCnGvZ+ChG9m7z7tm3buOKKK7jwwgtZsmRJva0VvF4veXl5mM1m4uLiALDb7SxZsgSAu66/ke9WrSS0SyLd7JEYlfZR9NSvn4X588NZu9bFsGFWunf3UzsGWwygAAfL5YPimjXN7Nmzeeqpp/jwww8588wzaz6/YsUKPvv0s5r7ZWVlXHfddTX3v/vuO8aNG1dz/4MPPiAnJ4dLZ1/KfdwHgAcPH/IhIxjRrNiaQ0WlggpCqa3u/jp/N8/sWEOw0cwdfUbSKzS63n1DzVZCzfotNCqO7qeCbP65bTVmg4Hbeo+kX3is3iGJdqJ9/MXopPY7K+kSHMqwyPrfOAghhBBCiLbnuuuu4/nnn2fRokWsWbOGNWvWsGjRIl588UWuv/56vx/vm2++IS4ujp49e3LllVeSn59f89jq1atxu91Mnjy55nNJSUn069ePn376CYCff/6Z8PDwmiQzwMiRIwkPD6/Z5nBOp5OysrI6Nz0YjbUViwaDoV32K61R/IeWZAZwl0P+Sr8f4q233mL16tXk5OTw5JNPUl5eXufx6mofc+cWctNNhfzlLwXk53sbmKkJfJ7GH/c4apPMAAWrm3+s5ghJ1dpljP83DLqzWX13G+LxeFBVtXk7m0O13tN/Ckk9pt2vvvpqkhITePbZZ+v9efD5fEyadBIpKSnEx8fz8ccf1zxmMBh49tlnSUxM5JbrbqBXaHS7u7J2/PggbrghnFGj/LhYY2gaDLwVEsZBn6u1ExPNMHjwYCZMmMC8efNq+vgDR10g8NDHKysrmT9/PhMmTGDI4CGkUHuCJJVj+15piUoquZEbOZ/zuYM7cKNVXT+3Yy0Or4dCRyUvZ21otXiE//1r5zqqvG5K3U5eymr5VSei85CK5jZKVVUcXg+T4tL9e6YvKAgOVn0QFOS/eYUQQgghBABvvPEGb775Zp1K5MzMTFJTUznvvPN47rnn/HasqVOncs4555CWlkZWVhZ33XUXJ554IqtXr8ZqtZKXl4fFYjli8e74+Hjy8vIAyMvLq6lqPFRcXFzNNodbuHAhCxYs8NvzaK6ZM2eSl5fHvn37mDFjBqGhbaTHbnOEpoHRCl4noEB4MxaBOopDk5/1JUI3bnSze7eWIC4q8rFihYPp0+3HdpCKvVqlsqMQus2EHhfUv53JBlH9tFYhALE6rAFksmk3P3rrrbdYunQpkZGRLFiwgPT09GObwGiB4Q9qPaSDEyD1tCbvunr1ar7++muWLVuG3V7/1+3pp5/mm2++rrlfUFBQ53G73c7DDz/M2WefzW+//cbgwYOPLf6OKmGMdmuh559/nszMTObMmVNTcT5gwAAKCgpwOBxHbG+z2YiO1qqCfT4fc+bMITc3l08//RSABSzgfd4nlFDO5Mwj9g+U7/menewE4Hd+5zd+YwQjCDGZ2bt6HVnvfsJuazBnP/gwQ4YMabW4hP+EmMwUuaoPji06RyPaE0k0t0Een489VWWEm62MjfHzJVwGAxx3lH5lQgghhBCi2Ww2W73JpfT0dCwW/75ZmzlzZs24X79+DB06lLS0ND7++GPOOuusBvdTVbVOX8z6emQevs2hbr/9dubOnVtzv6ysjC5dujTnKbRISEgId955Z6sfNyCC4mDEIq2SObKvdvOzmTNnsmfPHnJzc5k5c+YRifnkZCNmM/zZEjY9vRlvF7P+A46Dycsdb0La9IYXThuyAPJ/AWsURLX/9ygOh4PXXnsNgKKiIt555x3mz59/7BOFdIE+Vx7zbkuWLCElJYVp06bV+3hWVhY33HDDUeeZPn06ycnJLF68ODCJ5pItWk/smCFg6Fwpie7du/Piiy9ywQXaCZhnn30Wu91ek0xuSGVlJXPmzOG1115j6dKldO/eHYAYYricywMe96E8Ph8OhxWPzYfJYEBBIYYYAO7oM4qzH3yKCMVEssnGK6+8IonmdurW3iNZnLUes8HIlRkD9A5HtCOd67d6O5FTXU5SUCi39xnJiOgkvcMRQgghhBDH4Nprr+Xvf/87ixcvxmrVrkxzOp088MADdfpuBkJiYiJpaWls27YNgISEBFwuF8XFxXWqmvPz8xk9enTNNvv37z9irgMHDhAfH1/vcaxWa81zE34UlqHdAiQ8PJz777+/wccTE0088EAUK1c66dvXTGZmM77Gh7Z9MAVpVdoNMVogcVzDj7czJpMJu91e0xbh8CsJAu3nn39m4sSJ9S78p6oql1/WtISkyWRi4sSJrFixwt8haj2nNx5c3DRmCAy91//HaA0Ve6Hod4g8TrsaAaB4E5RnQdzwg32d6/Lh43d+Z9SsUbymvsYVV1zBjz/+yMMPP8z06dPr/bp5PB4++OAD5s6dz/79uSxdupRZs2YF+tk1yOXzcsfv37KlvIjqmCGMzjBysmUC3egGQLeQSCak92L79u0ARERE6BaraJnU4DDuOW6s3mGIdkgSzW1MgbMaFbgyI5MT49L8fwCXCx58UBvfcQf4uapGCCGEEKKzW7NmDV9++SUpKSkMGKBVAa1btw6Xy8XEiRPrVBovW7bMr8cuLCxk7969JCZqi8gNGTIEs9nM559/zrnnngtAbm4uGzZsYNGiRQCMGjWK0tJSVq5cyfDhwwH45ZdfKC0trUlGi86jTx8Lffq04D1C91la+w9HPqSfqSWTOwmTycQ999zDu+++S0xMDBdeeGGrHn/Dhg0NHvPf//43Xx9smTF+/Hi+++67RucaOHAgb731lt9jJP+Q5HXBavC5weCnRftaS+U++Pkm7fvcYIHRj2utYlbdDaiw4y0Y+zSYQ+rstpCFrGAFCgpzz5/L+uHrueqqqzj77LNJTk5i4sRJDBw4kPDwcEpLS1m7di1ffPEl+/blkJl5PF988WlNJbNedlQUs6W8CIDQgkz6B/dlfGrdqy9uueUWXnnlFUwmE7Nnz9YjTCGEjiTR3IaoqkqRq5oL047jnJSmryx8TNxu+LOf3vz5kmgWQgghhPCziIgIzj777Dqfa25biYqKiprKMNAufV+7di1RUVFERUVx7733cvbZZ5OYmMiuXbu44447iImJ4cwztV6d4eHhXH755dx8881ER0cTFRXFvHnz6N+/P5MmTQKgT58+nHzyyVx55ZX861//AuCqq67itNNOo1evXs2KW3ROlZWVfPXVV4SF9Wb8+KsabL3SkfXp04e77rqr1Y/r8/lwOp31Liy3d+9errtWu5pi5IiRXHPNNUdNNIeHh+N0OvH5fP5dZDN6ABxYpY0j+hxTkrnS4yLYaNb/+6p068Fe6oDPpd2vygUO9j13FkFlDkTU/v504WIFWpJdReV7vueu7nfx1Vdf8duvv7D4gQtYseIj3npzKU6XF6vVSv/+/TnrrDOZPXt2m+mVHW+zYzOacHi1Xu7p9vAjtklMTOTWW29t7dD8z+eFdYvgwEqIHgSDbm9/J0WE0IEkmtuQSq+bIKOJqQkZ+v/xFEIIIYQQzbJ48WK/zbVq1SomTJhQc//PvsiXXHIJzz77LL///juvvPIKJSUlJCYmMmHCBN566606vXcfe+wxTCYT5557LtXV1UycOJElS5ZgNBprtlm6dCk33HADkydPBrQerU899ZTfnodonKqq/PijE6dT5fjjbZhMbeO9gKqq/PDDD7jdbsaPH1/vpf2Huvfee9m8eTMA+/bt0/US/87GYDBgtVopKys74rFbb70Vl9sFQLWjmocffrjmsUcffZSqqirmzJlTZ5/S0lKsVmu9SeYKKtjKVtJJJ4qoYws0/QwITtZ6NCc0rW2Kqqo8tHkFPxXmkBwUyoP9xxNl0XFh+6h+YA4Fd7lWtRzVH+zJkLVMq9AOToKQulcnW7DQjW7sYAcAfehT89jgQZkMvqYvfyaqfQnHYxg4r9WezrGIsgSxsP/x/FCQTfeQSEZFJ+sdUuDk/wL7f9LGB36FvB8gaULj+wghJNHclhS5HHS1hzMosv5eeEIIIYQQou2rrq5GVVWCg4MB2L17N++99x59+/atSeQ21QknnICqqg0+/umnnx51DpvNxpNPPsmTTz7Z4DZRUVE1i5iJ1rd4cTnvvVcFwKpVTm69NQKq82HnO2AKhm7naf2OW9lLL73Ef//7XwB+/fXXRqsUfT4fW7Zsqbn/xx9/BDo8cZh+/fqxdu3aIz6/c0dWzXjdunV1Hlu/fj0vL3nliETz2rVr6d+//xFzlVPOjdxIPvnYsfMIj5DMMSYb44Yd0+ZbK4r4qTAH0NYz+nz/LmZ26XOUvfykcL2WFI8bWdsGxhYDY57UFjWM6KndD4rTPlexR0s8m2xHTHU/9/MVXxFJJOM4JMluCoLel8PWVyAoFkOPtn2CpntIJN1DWrf/eKtwlWntXELStF75h7U+wRRS/35CiDok0dxGVHhcuHxepiZkYFT8eGmSEEIIIYRoVaeffjpnnXUW11xzDSUlJQwfPhyLxUJBQQGPPvroEQkdIdatcx0yPnhJ/m9/h/Jd2thVCv1vDNjxd+508/TTWiXstdeGkZFhPhhLbVJy/fr1jc5hMBgYO3Ys33//PYqiMH78+IDFe1R7l0P5bkg+EcJ7NLhZMcUsZjFOnFzMxceeMG1jRo0axXvvvYfH46lTfT799Gl4PJ6a+0VFhWTt0pLPaalpTD99Wp15PB4PX375ZU0LnkNtZjP55ANQSSWrWR3w/7cIsw2TYsCj+gCIaa1q5t0fwqbntXH0QBj299rHbNGQcFgPe3uydmtACCFMZ3r9D6afrt06gXxHJf/ctpoyj5PZ6f0ZHJmgd0jgccCKeVoLFMUAQxZAzEAWr7+Zlb9UMGhwMFdOGUrbuNZEiLZNMpptRKGzmt6h0VzWNVPvUIQQQgghRAv89ttvjBunVau9++67JCQksHv3bl555RWeeOIJnaMTbdGIEbV9P0eOPFgJWZVbu0FVXkCP/89/lrJ1q5utW93885+lNZ8fNWoUHo+HnJwcrFYrTqfzyJ2dxVpit3gT8+fP54EHHuCf//wnJ510Uovj2rdvH8uXL2fXrl1N3yn7c9j4NOz5CH79G7jKG9z0KZ7ia77mJ37iIR464vG9ez2sX+/E52v4qoJjsWXLFh5++GFeeeUV3G63X+Y81OzZs8nJyeHDDz+s8/k77riDVat/rbktfGhhzWML7lvAHXfcUWf7Dz74gJycnHoXcksjDRva96gBA70IfB/3eJud23qPZExMCpek9+PEuLSj7+QPB1bXjgvXgs/T4Kai6V7MWs/60nx2VZayaMsveoejqdpX+ztX9UHBb6xe7WTZ973Jdg3lwxV9+fnnen7/CSGOIBXNbYDT68Gt+piW1B2zwXj0HYQQQgghRJtVVVVV0yP5s88+46yzzsJgMDBy5Eh2796tc3SiLSkvL+eee+5h+/bt9Ow5mlmzbmTIEKv2YLdZsHUJGCzQ9exG52kprxetarp8Nz5rJVQMhZAuzJo1i2+//ZbKykoOHDjAk08+ybx5h/SO/bMKsDofUFAG30Vm5rG1RQCgaIO2gNoh7Qny8/O56aabqKqqwmw28+ijj5Kenn70uSr2HhJfFTgLwRJa76YllNSMiymu89h331Xzj3+UoqowYoSVv/2t8VYBTqfK229XUFbm46yz7CQmmg573Mk999xDZWUlAEajkQsuuODoz+cYDB48mAkTJjBv3jwmT56M3W6vd7uYmJh6x6At6Dh//nwmTJhQ7wJ0ccTxCI+wilX0oU+rJJoBRkQnMSI6qVWOVSN2iNZKAbRFDA2SPvEH7yHtoLyqiqqqx7xGlcPr4YWd68hzVHJWSk+GtLQqOjgJghNrK5pjBuMtq3uCyev1zwknITo6+U3ZBlR5PYSZrZye1PBlXUIIIYQQon3o3r07//3vfznzzDP59NNPuemmmwAtcRYWFqZzdKIt+eKLL9i2bRsAW7f+SFDQNBTlOO3BjLMhZRIYzFqf5gC69townrj1CzC5uHbKt7B5DQy9D9BOnISHhwMcWVlclXswyQygQtHvEDeM1audrFrlZOBACyNGHNmrto69n8LGgwtPRh4HI7TK4u3bt1NVpfWtdrvdbNq0qWmJ5pRJkPOFtlBbzBAISW1w04u4iIUsxI2by7m8zmPffefgz3zYL784cTh82GwNXxD80kvlfPKJFu+6dS6efz62zuPV1dU1SWaAgoKCoz+XZnj++efJzMxkzpw5LFmypN7F/CZOnEh+fj6qqhIXF1fzeZ/Px5w5c8jNzW20/3vqwY8OL22a9v3jLIH4UXpH02Fc1rU/Ra5qSt1OrsgYcMxJZoA3927is/1a+5fN5YW8NuI0gozmo+zVCJMNRj4MBb+BvQuEd2dYtMrJJwfx669OBg60MmbMUX6XCSEASTS3CeUeFxn2CKIsrfCLy2aDlStrx0IIIYQQwq/uvvtuzj//fG666SYmTpzIqFFaguKzzz5j0KBBOkcn2pJDTzwoinLkiQhLeKvE0aePhWdv+kRrgwFAl5rHTjnlFJYuXYqiKEydOrXujvZkCOmiVRErRogdSlaWm/vuK8bng48/ruL//i+KPn0sDR/8wKracfFG8FSDKYjevXsTHh5OaWkpQUFBZGY2scVgSCoc/2/tuQQnQSNJrIEM5E3exIcPI3WvLO3d28wvv2iXyqenmxpNMgPk5ta2Vdi/33tElWZERASnn34677//fs04ELp3786LD8zmgpufBVSeffa5eiubY2PrJsIrKyuZM2cOr732GkuXLqV79+4Bia9eFXth39fa91LShNY7blNED9A7Av24yrQ2NM4i6D4LYo6scAfw4WM5yylQC4ksHECEGsnYmJQGE8hJQaE8OnBii0Kr8NT2tXf5vLh8PoJaenG4JbzO95+iKFx7bcO/g7eVF/HffduIswYzK7UvFrk6XQhAEs268/h8OLxeTknMaNaZvGNmNMKwZlzOJoQQQgghmmTGjBmMHTuW3NxcBgyoTVJMnDix3sW1ROd14oknkpeXx9atWznhhBPo0qXL0XcKlMx5sPkFMAZBnytrPn3eeecxduxYjEYjiYmJdfcxWmDEw1C4DkJSICSVnE0OfNqabagqZGd7Gk80xw6B/BXaOKIPmLSF3qKionjiiSfYtGkTPXr0qFN5e1Sm4CZXgSsoRySZAWbMCCE+3khhoY+JE4+++NyZZ9r54w83TqfKuefa631vd8UVVzBr1ixsNhtGY4CSUgdWMavPHtT5A7nin2/y448/8vDD/2D69Ol1Fgj8k8fj4YMPPmD+/Pnk5uaydOlSZs2aFZjY6uOpgpW3aUlNAJ9Xq0oX+tv6Muz/SRuvWQgT36i3fcgbvMGbvElWZQnl7iAyd1zF+tIDXNu9/sS0P8xI6cXG0gLyHJXMSu1DuNkasGPVx+3zcs/GHyg/mPBWULg4vV+rxiBEWyWJZp1lV5fTPSSCs5Jbp7eVEEIIIYQIvISEBBIS6vaMHD58uE7RiLZKURS/9+lttuhMGPNkvQ+lpKQ0vJ/ZDgmja+4OGmQhLc3E7t0eEhONDB9+lKsou5ysVR47CyF+dJ2HoqKiGDNmTJOfgr+NG3f0BPOfBg2y8sorsTidKpGRDSeRG+qb7DdeBwDnT0hmeK8IrnqplLPPPpvk5GQmTpzIwIEDayrF165dy5dffklOTg4nnngin376aetWMgM4CmuTzADlO1v3+KJhB7+XAPC5tEXy6pGF1sKizOPCaa3Gq7hZV5Jf77b+kmAL4dkhUwJ6jMY4fd6aJDPAAWeVbrEI0dZIollHqqriVn2cn9qXaGvTX8S0iMsF//ynNv7rX8HSSHWBEEIIIYQQQhwDu93AY49Fs3+/l7g4IxZLE67ajG5iW4w2bE9VGc/vXIsCXG0dSEqwTv3Y40ZBwjgoWE33weP46tKb+W3tOhYvXsyKFSt46623cDqdWK1W+vfvz5lnnsns2bPrXfivVdiTtfYUheu0ava21jqjM+t+AZTv1lpn9Ly4ZqHOw01mMqtZTYTZhnd/V4yqmZGtvXDjYQqcVSzPyyLGGsSU+K5+v3o8xGThrOSeLMvZSpjZypnJPf06vxDtmaKqaqsvnVlWVlZzFrUjL4gy7uvXcPl8xFnrv2xrv6MSFXhp2Cn0D4+tdxu/q6yEkBBtXFEBgT6jLoQQQohOpbO8zhN1yde9ccuXV/Gf/1SSnGzk5psjCA1tvN+vOISqwqZ/wYFftcX9+s5ptO+yXm5c+wU7KkoA6B0azcMD2m7C1Ofz1btIoG58XijPgqDYVutL3iB3pdZv3CTrGR2LAgooVUspLgnGgMLgyISj7xQgqqpy9epPyXVUAHBR2nGc26VPQI5V6XFhNZgwtaWfJyECpKmv9eSnQSdun5cyt4vL0vvTLyxG73CEEEIIIYQQAVBS4uWZZ8rIy/OyerWLd96p0Duk9uXAStjzMVTnw97/wf6f9Y6oXg6vt3bs8zSypf7aVJIZwGCE8O5HJJmXsYxzOIcbuIEDHGjydF6vF7fbDWhrIi3L3sJLWevJd1Q2vuOu9+HLWfDVBZD/6zE/jc4shhi6Kd0YGpmoa5IZoNrrqUkyAzUngALBbrJIklmIw8hPhA5UVWVXZRl9wqKZmdqndRYBFEIIIYQQQoj2ro2+d7qm20BiTSYmV69hvmm3tshdExUWennyyVKeeaaU0tL6++B2NqWUsoQlOHCQRRZv83aT9lu7di2zZs3inHPO4fPPP2fpno0s3vU77+Vs5W8bvm985+2vA6rWj3jnOy1/EkIXwSYz42O1hVVNioGT4tP1DUiITkYSzTrY76wixGxmwXFjibK0Um9mIYQQQgjRal599VXGjBlDUlISu3fvBuDxxx/n/fff1zky0doiIoxce20YiYlGhg61cs45IXqH1L7EDoe0aRCcAKmnQtxIvSOq18CIeF4KzuJ673pSc96Htf/X5H0XLSrhs8+q+d//qnn88dIARtl+mDBhxlxzP5j621EebunSpVRXV+P1ennppZfYU1W70GCuowK3z9vwzkFxtWNzCGx6Hra+fEwnDTqTfEclOyqK9Q6jXvN6DufxgRN5YejJDI1K1DscIToVWQywlZW6nTi8Hm7oMaT1+jILIYQQQohW8+yzz3L33Xdz44038sADD+A9eEl9REQEjz/+OKeffrrOEYrWNmVKMFOmNC1RJg6jKNDnKu3WUvu+gbLt2mJ5Eb1aPt/hynfWjst2NHm3/HxvvePOzI6dW7mVd3mXRBI5j/OatF9UZCS4ykAxEBWVyimJ3VhTko/b5+WUxG6YDcaGdx70N9j5FhiDoHij1hcctLYtA+b74Vl1HD8WZPPwlpV4VR8nxadzQ4+heodUh6IodAuJ1DsMITolqWhuZQecVUyIS+WKrgOkZYYQQgghRAf05JNP8sILL3DnnXdiNNYmNYYOHcrvv/+uY2RCdGJ5P8H6R7Q+vL/eCY5C/x8jZQpw8D1el6lN3u2CC0IwGMBkglmzOm/F+x9/uHj11XLWr3cCMJzhLGIRN3ETQTTtSuC/TDBxUkYh45LzuOOCAQyJTGDxsFN4bsgU5nQb1PjOwfHQ7wbocyU4DukJXZnT3KfUYX2+fxdeVWvz8sX+3TVjob9KKnmbt3mf93Hj1jsc0QlJRXMr8qkqKjA6OlmSzEIIIYQQHVRWVhaDBh2Z0LBarVRWHmUxKtFkO3fuZN++fQwePJjg4DZYLewoAmchhHUDRep7dFexp3bsdWpVqrZo/x4j7TSIGQQ+D4SmNXm3SZOCGTPGhqKAzdY5v1d273Zz551FeDzw7ruV/OMf0fToYT76jocJr/yNG07vqt1RNmufM1sJN1uPbaKMc2Hzi9pChV3PPuY4OroMewSri/MASLOHYZTfcW3GQhayjnUA7GUv13GdzhGJzkYSza0oz1FJrDWY4VFJ+gVhs8HXX9eOhRBCCCGEX3Xt2pW1a9eSllY30fS///2Pvn376hRVx7Jq1Sr+/ve/4/P5SE9P59FHH8VsPvakVMAUbYBV92iLisUOg8F3tdlF7DqNpONhz0fgKoWIPhDePTDHsSc3a7egoM6bqHPg4NPdm6nwRGDDhs8Hu3a5m5VoJrJvbcuLyBb8vk0/HRLHg2ICS2jz5+mgLkw7jhhrECVuJ6ckZOgdjjjEDnbUOxaitUiiuRVVet3MSOlFRkiEfkEYjXDCCfodXwghhBCig5s/fz7XXnstDocDVVVZuXIlb7zxBgsXLuTf//633uF1CKtWrcLn0y7V3rVrF/n5+SQnNy/BFxD7vtKSzKAlvZyFYIvRN6bOLjgRxj8PjgIITgKDvBVusrwfoXyXlngN6eLXqT14uI3b2Dwwm20JZ5GWN5SMmAiGDDnGCuQ/DbxN+/kz2iDx+JYFZ5Uevw0xKAqnJHbTOwxRj5M5mXd5FwWFKUzROxzRCclf11bi8fkwAN2lIb0QQgghRIc2e/ZsPB4Pt9xyC1VVVZx//vkkJyfzz3/+k/POa9qCVqJxAwYM4JNPPkFVVZKSkoiNbWOLbId2rR3bosEcpl8sopYpGEJS9Y6ifcn9HtYt0sZ7PoZx//JrhW8uuexgB+Yw6PvEu4zc4+PmlPOx25tZ4W20QJeT/RafEO3NJVzC8RyPGTPJtKETsKLTkERzKyl0VRNutnFSfLq+gbjd8Pzz2viqq6AtXWIohBBCCNHOeTweli5dyrRp07jyyispKCjA5/MRFxend2gdyqhRo3jooYfIyclhxIgRWCwWvUOqK20aGIOgKhdSJmnJr2YqL/dx//3F7N7t4dRTg7noIrmMvy367Tcnr71WQUSEgeuvDyMy0nj0ndqDskMuvXeXa4vk+THRHHvw4wAHMAa5ObFXOnY6bxsRIfwhnXS9QxCdmKKqqtraBy0rKyM8PJzS0lLCwjru2f1xX79GtceDW/XhUX3MTOnD3ceN0TeoykoIObiScUUF2O36xiOEEEKIDqWzvM5rTHBwMJs2bTqiR3NHJl/3wFm6tJw336xdRPLZZ2NISZF6odZS6XGRVVlKWnAYoQ0sKOfzqcycmY/Dob21PvFEGzfdFNGKUQZQ2U5YeTt4qiCiNwxf6Pe2I4UU8iM/kkoqAxno17mFEEL4R1Nf68krlADLc1TSJyyaKzMGMCOlt97hCCGEEEKIABsxYgRr1qzpVIlmUaugwMuyZZXY7QozZoRgtbZsEcBD91cUsFiaOV/xH1pFasxQMHSQatvmcFdoLTSUo1fNlrmd3LT2S/KdVUSYbTwyYAJxtiMLdXw+8Hhq67dcLv+F6/B6eDd7C9VeN2en9CLKEuS/yZsiLENrl1G9Xxv7M8lcsRd+u49oRxHTe14C6QP9N3db4SrTekbbYiBhrN7RCCFEwEmiOcBCzBZu7jWck2UlViGEEEKITuEvf/kLN998M9nZ2QwZMgT7YVeQZWZm6hSZaA0LFhSza5cHgJISH9deG96i+aZPt7Nvn5fduz2cckowcXHNSBLv/hA2HWyfFzcSBt/ZopjaJVWF9f+A3O8gKE6rzA1qvKXNhtID5DurAChxO1hdnMfUehZAM5kUbrghnMWLy4mMNHDRRSF+C/u5HWv4Mn83AJvKCnl04ES/zd1k1gjt5m873oSqPG28+d9ab+UWtJlpc1RVqwav2KPd710I6afrG5OODjirMCpK658sEUK0Kkk0B1iYyUJmeBtbnEQIIYQQQgTMzJkzAbjhhhtqPqcoCqqqoigKXq9Xr9BEK8jJ8RwybvnX2mLRkpgtsn9F7Tj/Fy0BprSs0rrdqditJZkBqvNh7/+g5yWN7pJmD8diMOLyeTEoCt0aWdh9woQgJkzwfwItp7qiZpxdXe73+XVlPiQhbwoCRZ9Ke69XpbjYR1SUAYPBjz8XnqraJDNAySagcyaal2VvYfGu3zEoCjd0H8JEvdeuEkIEjCSaA0RVVUyKgSCLmQSb/85oCyGEEEKIti0rK0vvEISOzj7bzptvVmIywfTpwXqHo4keAEXra8edLckMYA4DgwV8B/ta2I5eDJQcFMpD/Y/nt5L9HBcWQ8/QqAAHeaQzknvwjy3FeFQfZ6f0CtyBdn0Aez+B0HTodyOYbPVvV7oN1jyotSDpew0kt6DCusfF4HGAsxC6nddwS5eyLG1hzZjBDcfVTJWVPm6/vYisLA/duplYuDCKoCA/LUZotkPsMDjwq9aqJWG8f+Zto4pdDkrcDtKDw1EO+x3zXs42AHyqyn/3bZNEsxAdmCSaA6TK6ybYaObEuDQMnfGFnBBCCCFEJyW9mTu3Cy4IZfLkYKxWhbAwPyWsWqrbuRCaBq5ySOzYya4G2aJg8F2Q/ZmWTO0ytUm79QiNosexJJhdpVC6HcK7g6WFlejAmJgU+oXH4vZ5ibEG6MRFVS5sfkEbV+ZAaIb2PVOfra+Ao0Ab//FcyxLNZjtk3tT4Nvm/wpr7QfVBWDcY+Q+/9on+5RcnWVnaVQg7dnj49Vcn48f7sTJ90J1QvBGskRDSpVlTuHxeDjiriLfaMRma8Dtlx9uw6z2wp2jHD0Tbk8NsKD3APRt/wOXzMjo6mdt6j6yTbO4SHEpJqUMbB8mCsUJ0ZJJoDpBgo5lbeo9gcES83qEIIYQQQohW9MorrzT6+MUXX9xKkQi9xMa2wcX24kbU++k1a5y8804lsbEGrroqDLtd5+R44XrY8ZaWGO5zdd32Ci0VM1C7BYqjAH66CVwlYImA0Y+DLbrF04abrS2eo1Gqr/H7hzr062E+cmFEvzuwsjaesh3gOADBiX6bPiGh9mdVUSA+3s8/uwYjRDe/L3+Jy8Et678h11FBhj2ChzKPJ8hobniH6gOw7dWDO2+GrGXQ+7JmH7+pPt+/C5dPaxX0U2EOxW5HnV7Mt/UeybKcrZgVA2el9Ax4PEII/UiiOUAUReH42FS9wziS1QoffVQ7FkIIIYQQfvXXv/61zn23201VVRUWi4Xg4GBJNPuDqsKej6EyG1ImQ5gsvN0cLpfKgw+W4HCoANjtWrJZNz4PrHlA620LYLTBcdfqF09jXKVQtBHCutYmPgvXa0lm0P4tWg9JE/SKsOnsyVq/6j0HW2ekT2942z5Xaf+6K6BnK/wui8qEvcu1sT0ZbDF+nb5vXwvz54fz228uhg610qtX21qM8OfCHHIdWp/unZUlrCvJZ2R0csM7GExar2v1YH94Y+u850+311bv+yL3cI35UiyYuZVb6U9/wsxWLk3v3yqxCCH0JYnmzsZkglNP1TsKIYQQQogOq7i4+IjPbdu2jTlz5jB//nwdIuqA9n4Cm/6ljXO/hfH/9kt15S+/OHjrrUri4oxce20YoaFtpPVFgLjdKk6nWnO/srKRStYm+uOPP9izZw/Dhw8nKuoYexqrPvBUHxJgZYvjCQhXOfx0o1bBbLTCiEXayY7wHmAwg8+t/RvWXe9Imy5jhnY7GmskDLw18PH8KXGc1oKkah/Ej9L+X/1s/Pgg/7bLAO17113W4urr5KDQmrFBUUg82vpP1kjofxPsfl9rndH17OYfPOs92PmOluAfdIc2dwPOSOpBsNFEnqOS/6W8T6VSRTXwIi/yOI83PwYhRLsjiWYhhBBCCCECrEePHjz00ENceOGFbN68We9w2r+K7Nqxu0KrLm1hotnh8LFoUQkuF2zb5iYy0sDVV3fsXqJ2u4HZs0N57bVyYmONzJzZsjYVv/76K3//+99RVZV33nmHp59+GpvtGBZvM1q0itkti7WWE93Pb1E8AVO2o7ZPsdcJBWu0RHNIFxj5sFbZHJ3Z7J684jDRmQ22n1BVlV+K9qGgMDwq8YhF6PRQXbKGvFVXoXgcxCTNJCTzb/VuV+VxszxvJzajiSkJXTEqR57YyoyI47beI1lfeoDhUYmk2ZvQ9zvpeO3WEo4i2PKSNi7ZDFn/gd5XNLi5oihMSdCuLFlFBJWUAGCnFdqrCCHaFEk0dzZuNyxdqo0vuADM/j8jLIQQQgghjmQ0Gtm3b5/eYXQMKSdB7jdakjlupF96tnq92kvlPx1a6duRnXmmnTPP9E8yaP369aiq9v+Wn59PXl4e6enpAPz+u4vt292MHGklMbGRt6Fpp2k3fyrLAkc+RA/0TyuB0DQwh4K7XGtTEHVc7WNh3bSbaBXP7VzLJ7k7AJiW1J2rMgbqGxCwYs892D17AKjc9xLH9bqu3gX5Htj0M+tL8wHYW1XO1d0G1jvfmJgUxsSkBCrc+hmMdVtwGJreUmQ+83mJlzBh4kquDFCAQoi2ShLNnY3LBbNna+NzzpFEsxBCCCGEn33wwQd17quqSm5uLk899RRjxozRKaoOJixDa5fhKtWSzH6oYrTbtQrmpUvLiYszct55flyErpMYNmwYH330ER6Phy5dupCUlATA2rVO7r67GFWFd96p4NlnYwkPb6W2JPm/wG8PACpE9NLaXNRTOXpMrJEw6lGtkjm8u9YyQ+hiVVHuIeM8rmoD7dqz7Sq9Do6LLL4Gr7bYWlFUM952yLhNsIRD5lytfYY9GTLOafKuqaRyL/cGLjYhRJsmiWYhhBBCCCH86IwzzqhzX1EUYmNjOfHEE3nkkUf0CaojMtv90pcZoKzMx2+/OenTx8zrr8f7Zc5mK94EhesgZpCWGG1HMjMz+ec//0l2djYDBgzAYtGqIDdtcnOw0JnycpWcHA/h4a206Fr+L8DBg5dsAUchBMW2fN7gBEid2vJ5RIsMiUzgf3k7a8Z6qKaaXeyiC10IIYQeGbfztWEuodVVdEu9ocG+0ifFp/Phvu0oKEyMS2vlqJsgcbx2E0KIYyCJZiGEEEIIIfzI52v5gmqi9TgcPubNKyQ314vRCPfdF0lmph/aKzRH2U5Yebt2ufrOt2D0EzV9fnNycrBYLMTG+iFJ6keqqvL99w7KynxMnBhEamoqqampdbYZMcLKsmWVOBwqKSlGMjJa8W1oVH/I/lwb25MbXdBMtD9zug1iUGQ8CjAiKqnVj19OOTdzM7nkEkUUj/AII5XR9O/6JV68hNFwn/erMgYyITYVm9FEl+CO3Q9eT9VeN0FGuZJbiNYiieYAuvrqA2zZ4m5T3Sls3io+PDieNi0XhzFY13iayuWqHZvNMGaMjQULjnEVayGEEEKIVnDfffcxb948goPrvs6qrq7m4Ycf5u6779YpMlGfvXu95OZqfUi9XlizxqVjonlHbU9UnwfKsyCkC0uXLuXNN99EURT++te/MnHiRH3iq8dbb1WydGkFAN9952DRougjtsnIMPP00zHs3euhTx8zNlsrtc0ASJoAlkio2gcJY8HQyFvgfd/Clhe1tgEDb9MS06JZ1rOeNaxhEIPIpP6F/PxBURRGRbfS18ldAdteA081dD8PghNZz3py0dp3FFHEKlZxMic3eRG8HqHynjZQHF4Pf9vwHVvKi+gfHsu9x43FYjDqHZYQHZ4kmgPojz9cZGd7iYlpxRdSR2Hz1lbYlJT4cBjbZsWNzwdVVSplZVp8YWGGgzcFm03h5JPbR4JcCCGEEJ3PggULuOaaa45INFdVVbFgwQJJNLcxKSlG4uKM5Od7MRhg4MBWaulQn5jBYI0CZxHYYiF6AAAffqiViqiqyscff1xvollVVVatcqKqMGyYFcUPfaubYuPG2oqQzZvdqKpa77Hj4rT/Z13EDAQGNr6N6oMNT4DPBc5i2PoKDLq9FYLreHayk7u4Cx8+lrGMx3iMDNpA8+SW+uNZyP1OG5ftgLFPkUYaZsy4caOg0JWu+sYoavxYkM2Wcq339e+lB1hVlMvo1l5UsRm8eNnOdmKIIZojT9wJ0dZJojnAdH1BVQ+rp/ZLHh9vwmlqG98CHo9KSYmP8nIf3oNFHMHBCunpFsaOtTF8uJUBA6xt6v9SCCGEEKI+DSXa1q1bR1SUVK+1NUFBBh55JIrVq12kpZno3l3HyxFt0TDmKajYDaFda3pQp6ens3HjRgDS0urv5frii+W8/34VAKecEsycOa1zKf64cTbWrtWSzWPG2Fotwe1/ilbt7DuYODfqeMKhndvNbnxoBUM+fOxmd5tONKuoOHFiw9b4htUHascObZxCCg/yIKtZTX/604v21Ve9I4uyBDV6vy1SUVnAAtawBgsWFrCAfvTTOywhjknbyDKKTsvlUtmzx4OiQHi4gdGjbWRmWujRw0yPHmbS0kwYje31xaoQQgghOpPIyEgURUFRFHr27Fkn4eb1eqmoqOCaa67RMULRkIgIIxMntpEkhCUUouomFu644w7ef/99rFbrEYtN/mnlSmfN+NdfHa2WaJ48OZhu3cyUl/sYMKAdJ2cVBQbeDtteAUsE9Jxd5+Evvqhi+fJqunY1cfXVYZhMh71HKVwP2Z9CSBpknKPN10kNZjDxxLOf/cQTz2AG6x1Sgwop5A7uYB/7mMAEbuImFBr42nWbCWsXgtcFPS6q+XTvgx8dXRVVLGUpFVRwLueSTNtuLTMoMp453QaxtiSf4VGJ9A5r+9XB+eSzhjUAuHDxLd9Kolm0O5Jo7mTcBgsPDX6+ZqwHr1elvNxHWZlKVZWPgQOtXH55KMOHW4mKkoplIYQQQrRPjz/+OKqqctlll7FgwQLCw8NrHrNYLKSnpzNq1CgdIxTtVVhYGBdddFGj2wwebOXjj6tqxq2pW7c2tChNS8QMPNhmo67cXA9PPFGGqsKWLW6Sk02cccYhPXidJbB6QW01tNkOqae2RsRtUjjhPMmTZJNNCikE0UZO4tTjf/yPfewD4Gu+5gzOaLj6OnYInPi61kfd1HafU6D8m3/zOdrCmpvYxPM8r3NER3dKYjdOSeymdxhNFkEEUURRhNbyoy1fCSBEQyTR3Mn4DCZ+TJqm2/HdbpUdO9xERhro3t3EqFE2zjrLTkZGB3lxKoQQQohO65JLLgGga9eujB49GnNbWhFadHhXXx1KZqYFVYXRo3VazPAYqKqKy+XCam37sbpcKqpae9/hUA/boLQ2yQxQnd86gTWV1wnG1v1/DiKIHvRo1WM2RxS17YxMmAjjKFcCdOKWKvnUfl8f4EAjW4rmsmLl//g/vuRLkknmBE7QOyQhjpkkmkWrcbtVsrLc9Oxp5plnYkhNNbXjHm5CCCGEEPU7/vjja8bV1dW43e46j4eFtU5LA9G5KIrC6NFH6THbRuTn53PnnXeSl5fHySefzLXXXqt3SI1KSzNz9tl2PvmkiowME6eeetjC5CGpkHQC7PtGW8Sxyyl6hHkkVymsvAMq9kDCWBhwS/to6ZH9GWxbCkGxMPA2sMUE7FBTmUoppexkJ5OZTAyBO1abpqpQsglMdgitvw/8uZzLFrbgxMnFXNziQ77BG6xmNUMZynmc1+L5OooEEriAC/QOQ4hmk0RzJ2PweRiV9z8Afk6Yis/Qet8COTkeeva08Nhj0aSlSYWPEEIIITqmqqoqbrnlFt5++20KCwuPeNz758rHIiB+++03PB4Pw4YN6/BFDbt2ubFYFJKS2tfbuo8++oi8vDwAli9fzumnn05KSorOUTXu0ktDufTS0CMfyF8Juz8EewqVQxfz9vtmPNsUzjnHS0SEzm0B936qJZkB8n6AtOkQ2UffmI7GUw0bnwbVB84i2P469LshYIdTUJjFrKbvUJULm1/SEva9LoPghIDF1qo2PgnZnwMK9LsOUiYfsUkmmSxlKW7c2LEfOccxWMUqXud1ALawhR70YAhDmj2fikoZZYQSigFDi2JrjOvgRwghATuGEO1d+3pFIlrM7HNx229XATDj5B04WynRXFbmw+OB888P0XclbyGEEEKIAJs/fz5ff/01zzzzDBdffDFPP/00OTk5/Otf/+Khhx7SO7wO7ZVXXuGdd94BYMqUKVx33XU6RxQ4S5aU85//VKIocN11YUyeHHz0ndqIqKjadgUWi4WQkHaatHGVaovD+TxQuJYnXurDT1t6ArBjh5uHHtJ58THbIcdXDGCN0C2UJlMMoBi1RDOA4ZD3jl6Xdl/PE0jrH4WSzdrYWQIjF+kXiz/t+/rgQNXG9SSaASwHP1qqmupG7x8LN27u5V7Ws55UUnmIhwilnpNCLbSBDfydv1NFFRdwgVRhC9EASTSLgPJ6Vfbu9aAocMopQUyb1n5eAAshhBBCNMeHH37IK6+8wgknnMBll13GuHHj6N69O2lpaSxdupQLLpBLYgPll19+qRmvXLlSx0gCb/lybeE/VYXly6vbVaJ52rRplJeXs2fPHqZOnUpERERAj5eV5Wb7djeDBlmJifFjlbHHoSWZD9qXV9u7OSenDVy5kHQiOAqhdKs2Dk7UO6KjM1phwHzY8abWhqT7wd+X25bCjrfAGglD72uwvUNLeHw+ilzVRFuDMCoNVMW6y+sft3fhPaH4j4PjXnUeUlFR8G9yfxSjGMOYmtYZo2j+QrnrD34A7GEP3/AN0/D/ulTLWEYV2u/d13mdGczAJCk1IY4gPxUioHbv9pCQYOTmmyOYOjWow1++KIQQQghRVFRE165dAa0fc1GRtnr82LFjmTNnjp6hdXiDBg1izx6tVcDAgQMb37h8N1TuhagBYPF/9VugZWSY+f13bQG6bt3a19s6o9HIRRdd1CrH2rLFxW23FeHxQHi4gaefjiE83E+X1gfHQ9ezYdd7YE/m7It78fgz4PPBOee0rLWAXygKdDtX7yiOXfwo7fYnd4WWeAatnUbWfyBzrl8PWeZ2cuv6b8iuLqdHSCQP9j8em7Gen6tel8P6fwAK9L7crzHoavDdWm9scwgkT6r59H/4D6/xGjHEcC/3kkyyXw5nwsRt3OaXuaKJRkFBRTvRE0ecX+Y9XCyxdY4pSWYh6ic/GSJgKip8KArMnRvBKae0nwoLIYQQQoiWyMjIYNeuXaSlpdG3b1/efvtthg8fzocffhjwys3O7vLLL6dv3754PB7GjBnT8IZFG+DXv4HqBXsyjHocTO1jIb0/3XlnBB99VIXNpnS619rl5T42b3aRlmYmLq7xCuXff3fhOVh0XFrqIyvLzcCBVv8F0+tS6HkJKAonAINH+vB6VSIjde7PrCePA7a9Co4CLREf0bNl8xks2iJ1nkrtvjWq8e2b4afCHLKrtQrlbRXF/Facx+iYevqGxw2DSW/5/fi6M9uh65l1PlVFFS/zMioqeeTxFm8xF/8m+P0hnXRu4zZ+5EeO4zhGMCIgx5nNbKxYKaGEczgnIMcQoiOQRLMImLw8L6NHWzn55CC9QxFCCCGEaDWzZ89m3bp1HH/88dx+++2ceuqpPPnkk3g8Hh599FG9w+vQFEVh9OjRR9/wwCotyQxQmQNVORDWLbDB+ZndbmDmzHba27gFKip83HRTIfv3e7HZFB5+OIr09IbXgBk0yMobb1TgckF0tIFu3QKwXswhV22GhQVuIbJ2Y/trsPsDbVz0O0x4BVqyNpDRAkPvhZ3/gaA46N6Exft8Htj8byjbCV2mQPLERjdPtNX+LCkoJNg638/W4UyYsGGr6Z8ciL7H/jL64Ecg2bBxGZcF9BhCdASSaBYBUVrqw2SCc84JwWiUdhlCCCGE6DxuuummmvGECRPYvHkzq1atolu3bgwYMEDHyESN6AGQtQxQtT6wwUl6R9QsLpeK16sSFNR5kpvbt7vZv187SeBwqKxe7Ww00dytm5l/PhbJzg176T84itDQzvN/pRtnce3YXQ4+d8sSzQARvWHwnU3ffs8nsOdjbVyyGSL7NtqjekBEHDf3HM760nxGRCWRERLRsng7AAsW/sbfeId3iCWWC+ic6wtUely8m70Ft8/HOV16E2724xURQnRAkmgWfuXzqeTkePF4VM46y86kSVLNLIQQQojOy+FwkJqaSmpqqt6hiEPFDIKRD0PFHogdCqb295p11SonCxcW43bDNdeEdZr2GampJux2hcpKFUWBPn0sje+g+kjZ/3dSDOvgdxvYHmh5K4fG+NxgCEDVdHvS9WwoXAeuUq36WI+fL0/VIXdUrZ3HUZwQl8oJca3wu3rPJ5D9qXYVRd85bfr7JfPgR2f2xLbV/FSYA0BWZSkP9B+vc0RCtG2SaO5kPAYzjw94vGbs17k9KtnZHiIiDPzlLxGcc44dk0mqmYUQQgjRuXi9Xh588EGee+459u/fz9atW8nIyOCuu+4iPT2dyy/vQAtItWcRvbTb4Vyl8Mdz2r89LtQqIdugN9/U2kEAvPpqeadJNEdFGXnkkWhWrXLSs6f56Inmyn1a0hPA64DcbwKTaPZUwaq7oWQLxA6DQXeCQZ8+zV/yZc0CbrdwS51FzFpFWAZMeFU7kZP3A+R+D4njWjeG1FOh4Dco3wldToawrq17/IZU5mi/X1C1th4haZB+ut5RiUbkVFfUjP/s4y2EaJhcN9TJeA1mvuwyky+7zMTrh0SzqqocOOBl2zYXu3d7sNsNXHppKLNmhUiSWQghhBCd0gMPPMCSJUtYtGgRFkttEqx///78+9//1jEy0SSbX9SSY0W/w2/36x1Ng2JjjfWOO4PkZBOnn24/epIZwBYFlrDa+6EBSjju+wZKtpBTEM6DT0aw6N5NFBZ6A3OsRjhx8iRPUkABm9nMUpa2egwAeJ3agps73oR1iyDny9Y9viUURi6Ck96F3le07rEb43MDau19r1O3UETTnJncA4OioKAwI6Wek5Md2LbyIp7dsYYP921HVdWj7yAEUtEsWmjvXi9mM1xwQQgjR9oYONDa6V7oCiGEEEIc6pVXXuH5559n4sSJXHPNNTWfz8zMZPPmzTpGJprk0EvuvQ5QfaC0vfqcv/wljPBwAw6HyqxZdr/M6Xar7N/vJS7OiMXSQYpGTMEw/CHY9zWEdIGkCYE5jiUCgEXvTmRnbjTkBVH1ZCn33hsVmOM1QEHBgAEvWpLbiE7vzZyF4CqpvV+6/agL8rUrPk/z+k6HpkPGuZC9XGudkXaa30MT/jUxPp2hUYl4VR9Rlqa3gSmggJWspCtd6UOfAEYYGBUeF3dt/J5KjxsAo6JwSmL7WjRX6EMSzZ2Mwedh8IFvAPgt9gR8LViUwedTcTpV5s2L4KKL2u4KtEIIIYQQrSknJ4fu3bsf8Xmfz4fb7dYhInFMelwIFbu11hm9r2yTSWaA0FAD11wTdvQNm6iy0sf8+UXs3eshOdnIww9Hd5yF80K6QM+LA3uMhNHQazal3lAISwCzndJSX9P3L9kCe/+nLUyZMaPZ33cWLMxnPq/zOtFEcxEXHbFNpcdFVmUpacFhhAZqYbPgRIjqr10ZYLRC0vGBOU5r81QfbJGy+WCLlDuOPeHc8yLtJtqNQxcAdODgEz7BiJGpTMXCkVdWVFLJzdxMEUUoKNzLvQxmcGuG3GIlLkdNkhkgR9qGiCaSRHMnY/a5uOdX7Y/ajJN34GxBormqSiU4WGHECFl1VQghhBDiT8cddxzff/89aWlpdT7/zjvvMGjQIJ2iEk0Wmg7jX9A7ila3apWTvXs9AOTkeFm50snEie1vkURddT2Ly2+p5vHHSzGbFS65pInFOO5KLXn5ZzW9wQxdz2x2GKMOftSn1O1k7tovyXdWEWUJ4tEBJxJtDcDXWTHA0PugbDvYYsEW7f9j6CH3Wy3JDHDgVyhYA3HD9I3Jz/ZUlfFJ7g7ibXZOT9LaRohaD/MwK1kJwA52MJe5R2yzj30UUQSAisoGNrS7RHNyUCgjo5NYUbiPUJOFk+LbSJ9z0eZJolk0W0WFj7AwA6mp8m0khBBCCPGne+65h4suuoicnBx8Ph/Lli1jy5YtvPLKK3z00Ud6hydEvZKTTSgKqCooCqSk+LnlQlUumEPBHOLfeduYceOCGDvWBoDS1ASdu6Juy5bqvKYf0FEEax/UFj3MOOeoCep1JfnkO7VjFbmq+a0kL3AJJIMJInoHZm69WCPr3reEt8pht5UX4fR56Rce2IUdXT4vd/z+LaVurXe0V/UxI6WDfQ1baDvb6x0fqgtdSCaZHHIwYWIY7e9khKIo3NF7FHmOSiIsVoKMLV/jS3QOHeRaKKGHigqVYcOs2GzybSSEEEII8adp06bx1ltv8cknn6AoCnfffTebNm3iww8/5KSTTjqmub777jumTZtGUlISiqLw3//+t87jqqpy7733kpSURFBQECeccAIbN26ss43T6eT6668nJiYGu93O9OnTyc7OrrNNcXExF110EeHh4YSHh3PRRRdRUlLSnKcvAiXvB/j2clgxD6r2+3367t3N3HVXBKeeGsydd0bQq1cTFtprqvWPwndXwbeX1VaDdmCKojQ9yQwQHF/bv9gSDl1Oafq+We9qbTfc5bBlMTiLG928qz0c08G2HEbFQIY9ounHEhA3AnrNhtih0O96iOgZ8EMuy97C3HVfcfvv3/LcjjUBPVaFx1WTZAbIrpJ2CYebzOSa8UnU/zfdho1HeIQ7uZOneKpd9mgG7XdZYlCIJJnFMZFSVHHMXC6VggIvXq9Kerp8CwkhhBBCAOzcuZOuXbuiKApTpkxhypQpLZ6zsrKSAQMGMHv2bM4+++wjHl+0aBGPPvooS5YsoWfPntx///2cdNJJbNmyhdBQ7bL9G2+8kQ8//JA333yT6Ohobr75Zk477TRWr16N0ahVrZ5//vlkZ2ezfPlyAK666iouuugiPvzwwxY/B+EHPi+sfwx8LqjOh60vw8Bb/H6YYcNsDBtm8++kjiJtIT7Q+tvuXd7xqlz9of+N0PMSMNnBeAxJfuMhbQwNRlAaf3/WJTiMhzKPZ03xfvqHx9ItJLLR7UU9up6l3VrJtwf21oy/O7CXa7oFrgVTlCWICXGpfJ2/h2CjmamJGQE7Vnt1ARcwilGYMJFKaoPb2bEzkpGtGJkQbYNkCcUxcbtVsrLcdOliYuZMOzNnduxL34QQQgghmqpHjx7k5uYSFxcHwMyZM3niiSeIj49v9pxTp05l6tSp9T6mqiqPP/44d955J2edpSU9Xn75ZeLj43n99de5+uqrKS0t5cUXX+TVV19l0qRJALz22mt06dKFL774gilTprBp0yaWL1/OihUrGDFiBAAvvPACo0aNYsuWLfTq1avZ8Qs/UZS6i8O10QUK62UOAUsEuEq0+/YUPaNp2w5vy9AUGedA9QGo2qclPy1H7wvdKzSaXqEdpGdyJ9A3LIadlSUA9AkL/Ndtbs/hzOrSlzCzBbvJj1c2dCAZSAJeiIZIolkck5ISH3FxRt55J56oKD/3bRNCCCGEaMdUVa1z/5NPPmHhwoUBO15WVhZ5eXlMnlx7Ga/VauX444/np59+4uqrr2b16tW43e462yQlJdGvXz9++uknpkyZws8//0x4eHhNkhlg5MiRhIeH89NPP0miuS1QDDBgvlbJbI2EXpfqHVHTGS0w/EHY8wkEJ0DaNL0j6lhMwTBgnt5RdFjbyovIri5naGQCoWbr0XcIgCszBtAtJAKXz8uk+PRWOWZikBSUCSGaRxLN4piUlPg4+eQgSTILIYQQQugsL09bMOzwiun4+Hh2795ds43FYiEyMvKIbf7cPy8vr6YK+1BxcXE12xzO6XTidNb28SwrK2v+ExFNEzdcu7VHIV2g79V6RyHqU50Puz/QekOnn6kt4CcAWF2cx4KNP6KikhwUyhODJmExtP77YIOitFqCWQghWkr+inQyHoOZZ/s9WDM+FtXVPiwWOPdcObsphBBCCHG4+hYAO6YFwVpw3EOpqnrU4x6+TX3bNzbPwoULWbBgQTOiFeLoyst9OJ0qMTEBSuptfRn2fgph3WDQ7VpVcGe16m6ozNHGrlLofYW+8bQhvxXnoaJdqZJTXU5udQVp9nCdoxJCiLZNEs2djNdg5pP02c3at6zMR0yMkaFD9blkSAghhBCiLVNVlUsvvRSrVXut5HA4uOaaa7Db7XW2W7ZsmV+Ol5CQAGgVyYmJiTWfz8/Pr6lyTkhIwOVyUVxcXKeqOT8/n9GjR9dss3///iPmP3DgQIP9pW+//Xbmzp1bc7+srIwuXbq0/EmJTu+XXxz83/+V4HbDuefaueiio/ccPiZlO2Hnu9q4cK3W0iNjhn+P0V74vFC5r/Z+RbZ+sbRBgyLi+XDfjpqKZmknIYQQR9eOVpEQejpwwEtpqcpxx1mwWAJfmSOEEEII0d5ccsklxMXFER4eTnh4OBdeeCFJSUk19/+8+UvXrl1JSEjg888/r/mcy+Xi22+/rUkiDxkyBLPZXGeb3NxcNmzYULPNqFGjKC0tZeXKlTXb/PLLL5SWltZsczir1UpYWFidmxD+8MEHVbjd2njZskr/H8BgAZTD7ndSBiOkTz84NkPqqfrG08YMjUrkkQETmNtzGA9nnnBMbTN+Lcrl+jWfc9eG7yh0VgcwSiGEaFukormTMahe+hb+AsAf0SPwKUf/Y1la6qOy0sdll4Vw+eXyJkIIIYQQoj6LFy/2+5wVFRVs37695n5WVhZr164lKiqK1NRUbrzxRh588EF69OhBjx49ePDBBwkODub8888HIDw8nMsvv5ybb76Z6OhooqKimDdvHv3792fSpEkA9OnTh5NPPpkrr7ySf/3rXwBcddVVnHbaabIQoGh1yclG1q/XxklJLXy7WrQRKrMhfqTWgxggJAX6XgPZn0JYd0id2rJjtHe9r9ASzKbg2v8jUaNHaBQ9QqOOaR+fqrJoyy84vB4AXt79O3N7ttP+6q3F44C878EaBbFD9I5GCNECkmjuZMxeJwtXnA3AjJN34DxKP7Lqah85OR5OOMHGLbdEtEqfQSGEEEIIoVm1ahUTJkyouf9nu4pLLrmEJUuWcMstt1BdXc1f/vIXiouLGTFiBJ999hmhobXtBh577DFMJhPnnnsu1dXVTJw4kSVLlmA01hYcLF26lBtuuIHJkycDMH36dJ566qlWepY68XnAUynJtTbmiivCiIgwUlHh46yz7Eff4aBdu9z88ouT3r3NDBhghbyfYO1C7cGsZTDmSTAerF5OPUW7tTM51eX8WJBNV3sEw6ISj75DUwX7cS6BiopXVWvue3xqI1sLAFbdBSWbtXGfqyBtmr7xCCGaTVFVtdV/65WVlREeHk5paWmHvsxu3LgcXC6Ii2v9lWkbYvVU8e7ybsDRE80HDngpL/fRo4eZefMiGDvW1lphCiGEEKKd6iyv80Rd7e7rXrUfVt4GjgKIHw0DbwMpqGi3Cgq8zJlTgMOhoihw//2RZJpe0vov/2ncc2BP1i/IFip3O7nmt88oczsBuLPPKEZGt9/n02FU5mhV81H96ywq+f2BvSze9TuRFhvzew0nwSb9nRvkdcLnh/RJjxsBg/+mXzxCiHo19bWeVDSLBhUXexk92sbzz8diNssLbyGEEEII0UFkf6olmQH2/wTlWRCWoW9MnZGq+iXBv2ePB4dDrZly+3YPmeOGwd7loPogNB2C6l/Ysr3Ic1TWJJkBtpYXNzvR7FV9fJK7k3KPi1MTuxFulsXem6VoI6z6m3Z1REgqjHqspmp+XGwXxsXKAqlNYrRC9EBtcU7QEs1CNJGKyo/8iA8fYxiDkbZT6NlZSaJZ1MvlUjGbFS68MFSSzEIIIYQQomMJiqsdGyxgidAtlM5iS3khB5zVDI1MwGY0wfbXYcfb2tdi6IIWtW/o3dtMcrKRnBwvISEKI0ZYIXYojHocqvZBzCAwtO+3vmn2cLqHRLK9ohib0cTomOZXM7+8awMbtn/CiPJf+cyewjmTHq5tK9JWqSq4y8AUoi1i2BYcWKklmQEq9miVze3lhNW+b7STbSkntY32QUPuhgOrwBoJEb31jka0Iy/wAh/yIQCrWc1N3KRzRKJ9/7UVAeN2a4nm1FT5FhFCCCGEEB1MyhTwVEH5LkieBLZjW+xLHJtvD+zhH1tWAtArNIqHew9G2f6G9mBVLux8F/pd3+z5g4MNPPZYNDt2eEhJMRIRcTARGdZVu3UAFoOR/8s8ga3lRSTaQoi2BjV7ruyyfcwo+C8m1QOO3ag730bpcaEfo/Uz1QdrHoD8lRCcAMMXgi1G76ggsh9kvQeoYIvWYmsPdv4Hti7Rxjlfwthn9G8dZDBD/Ch9YxDt0lrW1jsW+pEsojiCqqoUF/uw2ZQ21V9aCCGEEEIIv1AU6HqW3lF0GiuLcmvGW8qLKPNBuNGq9WYFsDStr7fD4WDr1q0kJycTHR1d57GgIAP9+rXxqtxjVFlZyUMPPcSuXbs49dRTOe+88+gXHtvieU+KTsSoapW4cbZgFHdli+cMqNKtWpIZoCoPsr+A7uc1e7pKKtnBDtJII5wWVPPGDYPhD0LFbq3dQyPrH7UppVtrx5XZ2kk3c9MX3hSiLRnBCPayt2Ys9CeJZlGHz6eSleUhJEThiitCCQ836B2SEEIIIYQQoh0bHBHPdwe0REC3kAjCbOEw6G+waxkEJUDGzKPO4XA4mDdvHrt37yYoKIhFixaRnp4e4MhbzqeqlHtchJksKMdYNfrBBx+wdu1aAJYuXcrYsWNJSUlpcUyjUgZQOnAOpl3LsIemQtczWzxnQFmjtNYnf7apCG5+v+1yyrmJm9jPfsII4xEeIYEWVCJH9dNufpLnqGBreTF9w6KJsQYocZ10AuSv0CrF40ZIklm0a5dwCZlk4sHDUIbqHY5AEs2djtdg4qU+d9WMD5eT4yU+3sjChVGMHGlr7fCEEEIIIYQQHczE+HRircEccFYxKjpZS7jGDNRuTbRjxw52794NQHV1NStWrGjzieZyt5Pbfv+WPVVl9A+PZcFxYzEfQ39hs9lcM1YUBZPJf2/fw/teDn0u079lQlMExWknJnK/gbDukDThiE0+/riK5curyMgwce214Vgs9T+vjWxkP/sBKKOM1azmVE4NZPRNllNdzo1rv8Th9RBmtvLEwEktapHSoPhRMPZZcBZDZB//zy9EKxvEIL1DEIeQRHMn4zFYeK/bX474vKpqlcwmE1x8cYgkmYUQQgghhBB+kxkRd/SNGpGcnExISAgVFRUA9OzZ0x9hBdR3BdnsqSoD4PfSA6wryWdoVNMXPZw2bRp79uwhKyuLU045hYQEP/cAbg9J5j/FDtFu9cjJ8fCvf5WhqrBrl4f0dDNnnll/lW466Vix4sSJAQPd6R7IqI/J+pJ8HF6tarvM7WRLeSGjrS2vYK+XPUm7CSHanc1s5mM+JplkzuEcjLStlreSaBYAFBb6sNsV7r8/ipNOCsBZUyGEEEIIIdqh33938e231fTsaWby5HbSg7UNWclKFrOYcMKZy1ziaF7COUIpYNHlx7FiSxk9Rs9i4KC2X8EWe0g1qoJyzK0QrFYrc+fO9XdYHY7XC6pae9/tVhvcNoEEFrGI1aymL33pRa9WiLBp+obFYDEYcfm82E1meoTKIqVCiLqqqOIe7qGKKgBMmJjBDJ2jqksSzZ2MQfXSrfR3AHaE98enGPF4VIqKfMyeHSIvnoUQQgghhDjowAEv99xThNsNn35aTVCQwrhxUpTRVCoqD/MwDhxkk81LvMRt3HbsE7kr4de/0cVTSZduQFQ2tINLpYdHJfGXboPYUFbA6Ohk0u0tWHhONCg11cR559n53/+q6dbNxGmnNf6eNuPgR1uTZg/n8YET2VxeSL+wWGID1aNZCNFuVVBRk2QGyCdfx2jqJ4nmTsbsdfLoD1MBmHHyDpymYMrLfUREGLjssqat9iyEEEIIIURncOCAF7e79v6+fV79gmkqdwWoXrC0vaSmSsOVpo1yl4GnsvZ+ZY5/AmoFUxO7MTWxm95hdHgXXBDKBReE6h1Gi3UJDqNLsLwvF0LUL444TuIkPudzIojgNE7TO6QjGPQOQOivokIlLs5IbKx8OwghhBBCCPGnnj3NZGZaAIiJMTBhQhuvZs77Eb6+CL66CLLe0zsaFBTmMY9kkulDH2Yzu3kTBSVAwlhtbA6FLif7L0ghhBCiHbmBG1jKUhazmFRS9Q7nCFLRLHA4fEyaZNNWfxZCCCGEEEIAYDIp/P3vkRw44CUy0ojF0sZfL2ctA5+2mBg734auZ+obDzDi4EeLKAoMuAV6zQZzGJhk4fIWKdsJfzwHBiP0/QuEdNE7IiGEEMcgjLZ75UOnK2H97rvvmDZtGklJSSiKwn//+1+9Q9JVRYUPo1Fh0CCr3qEIIYQQQgjR5hgMCvHxprafZAYITjhknKhfHIGgKBAU1ymSzBUeF2/v3cRH+7bj8fn8f4DfH4OSTVC0ATY86f/5hRBCdFqdrqK5srKSAQMGMHv2bM4++2y9w9GVx6OSk+Ph1FODGT5cEs1CCCGEEKJ9UFWVjz6qIjvby+TJQXTrZtY7pNaX+z1sfBIMVhh0B0T2geOuBVsMeJ2QcY7eEYpmuv+Pn9hYVgBATnUFV3cb6N8DeF21Y5/Tv3MLIYTo1Dpdonnq1KlMnTpV7zDahH37PMTG2rj11ghstk5X3C6EEEIIIdqpjz+u4vnnywH49ttqXnwxFru9k72e3fQv8FQD1bBlMYxcBKZgrb2EOEJhYSGqqhITE6N3KEe1vaK4ZryjsriRLZvpuGthwz9BMUKfa458vDofFBPYovx/bBE4lftg49Pgc0OfKyG8R81DPlVFAWmXKYQIuE72akwcympVuOeeSBISOt35BiGEEEII0Y7l5HhrxpWVKqWlAWgv0NaZQ+ofiyP873//Y/bs2Vx22WV89NFHeodzVJMTugLaYoonxaf7/wDRmXD8izD+ea0S/lA734VvL4dvZ8O+r/1/7GZQUfmcz3mLtygmAIn3jmLj01C0XmuLsv6Rmk9/d2Av5/z8X2aueJ/fivN0DLBlPD4fH+7bzrvZm6nyuPUORwjRAMkwdjJeg4mX0+dSUeHj4ssjmTw5WO+QhBBCCCGEOCaTJwfx7bfVlJerjB5tJTHRqHdIrW/gbbBlCRit0OcqvaNp09577z1UVQXgv//9L6eddprOETXuqoyBTIxLw2Y0kRwU6pc5S91O/pO9BbPBwIyUXgQZG2g3k7VM+1f1wa73IWmCX47fEm/zNq/xGgDf8A3P8qzOEbVRh7ZBOaQ9yktZ63H5tJNzr+zewODIhMP3bBee27mGT/OyAFhXks/f+43XOSIhRH0k0dzJeAwWnoy+ibCuBj67uu1fNiaEEEIIIcThunY18+KLsZSW+oiPN3bOy8FD02HovXpH0S506dKF3NzcmnF70C0k0q/zLdz0c03f5zxHJfN7jah/w5AuUPxH7bgN2M72mnE22ThwYKPjLwp5zHpfBev/obXOOO7amk+Hm60UuqoBiDC33/+3Oi1lKkr0C0QI0ShJNHcyLpdKWZmPadOCMZk64QtyIYQQQgjR7rlcKi+9VE52tpdp04IZPbr9Jk9E4M2dO5f//Oc/qKraaReEz64urx1XlTe84aA7tKpmgwW6to3/q4lM5Fd+xYuXcYyTJHNDInpq7VAOc1vvkby8ewNmxcDsrv11CMw/Torvyo6KNQfH6foGI4RokCSaOxG3W2XXThenZezihomR4IsAg7TpFkIIIYQQ7cuyZZUsX65V6G3e7GLJkjjCw+V1raif3W7n4osv1jsMXZ2d0ouXstZjUBTOSO7R8IaW8Da3oORIRvIcz1FKKT3pqXc47U5iUAi39R6pdxgtdmpiNzLDY3H5vH6v+BdC+E+nSzRXVFSwfXvtpTdZWVmsXbuWqKgoUlNTdYwssLxelawsN4P7eHn0wxPgM6CiAux2vUMTQgghhBDimFRW1i7+5/GA06nqGI0Qbd+ZyT0ZF5OCSTEQYWl/FcEJBz/0VOCsYuHmFeQ5KjmvSx+mJXXXNZ7OqEtwmN4hCCGOotOd9l+1ahWDBg1i0KBBgHYZ1aBBg7j77rt1jiywKipUwsIM/P3vUXqHIoQQQgghRIuccYadrl1NmM1w7rl24uI64WKAQhyjGGtwu0wytxVv793M1vIiytxOXti5jjK38+g71aOUUu7kTi7ncpaz3M9Rws/8zO3cztM8jQvX0XcQQgg/6nQVzSeccELNisOdSUGBl8GDrWRkdLovuRBCCCGE6GCio4088YQsbC2EaD0WQ+0JLaOiYGzmIqRv8zbrWQ/AMzzDKEYRTrhfYiyllEUswoOHDWwgmmjO4zy/zC2EEE0hWcdOwOtV8fngnHPs0pJZCCGEEEIIIYQ4RrNS+1Doqma/o5IZKb2wmyzNmkdBqTM2+PFCcydOPHhq7ldQ4be5hRCiKSTR3Ank5nqJijIwYIAF5NIZIYQQQgghWl1lpY89ezykpZkIDpbqj3alfLf2b2iavnEIXdlNFm71w6J6M5nJPvaRSy4zmEEooX6IThNHHOdyLstYRgopnMEZfptbCCGaQhLNHZiqqhQW+nC5VG6/PYL0dDNUSqJZCCGEEEKI1lRU5OXmmwspKPARF2fk0UejCQ+XZHO7sONt2PaqNu55CWTM0Dce0e6FEsrdBG6NqIsOfgghhB7k1U0HtmuXB69X5eKLQzjrLLve4QghhBBCCNEprVnjoqDAB0B+vpe1a5u4iJijALa+Cns+gU64zkybkP3pIePP/Du36oPc77Sb6vPv3KJNcfu85FZX4PHJ11kI0bFJRXMHVV3tQ1HgvvuiOPnk4NoHzGaYN692LIQQQgghhAiorl1NGI3g9YLJBGlpTXgbpqqw8g6oytXuu8qguyzq1erCukN1/sFxN//O/cezsHe5Ni5cB/2u9+/8ok0odzuZv/4bcqrLybBH8FDm8QQZ5b24EKJjkkRzB1VU5CMx0cjEiUF1H7BY4OGH9QlKCCGEEEKITigjw8z990exbp2TQYOsWku7o/E6apPMAOVZgQtQNCxzLuzprY1TT/Xv3IVrDxmv8+/cos34uXAfOdXlAOysLOG34v2MiUnROSohhAgMSTR3QMXFXhwOlVNOCcZsVo6+gxBCCCGEECKg+vWz0K+fpek7mIIg8XjI/RYMJkg5KXDBiYYZrdD1zMDMHTcCdr2vjeNbvsicaJuSgkJqxgoKibaQRrYWQoj2TRLNHYzLpVJQ4OOii0K47rrwIzfw+WDPHm2cmgoGadMthBBCCCFEm5R5M3Q9CyxhYIvROxrhb72vgJjBWpuU2CF6RyMCpF94LLf2Hsm6knyGRyWSERKhd0hCCBEwkmjuYCoqfISHG7jyyjBMpnqqmauroWvXPzcGuywSKIQQQgghRJukKBCWoXcUIpBiBusdgWgFY2NSGNse22Xs+QQKVkPsMOhyst7RCCHaAUk0dzBFRT4mTw4iNlYqlYUQQgghhBBC1ENVtRMZ7ZHPA45CsEVrbWVEYBSs1RasBMhfCfYUiOqna0hCiLZPfit3IKWlPoxGGD/ehtJeXzQIIYQQQgghhAgMnwfWPqQlDqMHwOC7wHgMvcP15q6Elbdri2OGpMGIh8AsPY8DwlV82P0SXcLoDH7kR3LJ5QROIAZpkyTaNyl77UDy8z1MmhTEmWdKOwwhhBBCCCGEHxVvgjUPwuZ/g9eldzSiufJXQv4vgAqFayHvB70jOjYHVmlJZoCK3drzEYERPxoij9PGUZkQO1zfeDqoT/mUh3iIl3mZW7kVN269QxKiRaSiuYPwelUURWHixCAMBqlmFkIIIYQQQviJ1wWrF4CnUrtvMEPPS/SNSTSPJazufXNoi6fcW1XGoi2/UOlxc3XGQEZEJ7V4zgYFJwIKoGr/BicG7lidndGqVYx7ndo4AIpdDvZWldEjNJIgozkgx2jrtrClZpxPPiWUEEusjhEJ0TKSaO4gvF4wmSAxUb6kQgghhBBCCD/yOmuTzACOIv1iES0T1Q96XwkHVkL0QIgb1uIpX8xaz67KUgAe2/Yrb0af3uI5GxTREwbepi1QFzMIIvsE7lhCE6Akc051OfPWfU2Fx0VyUCiPDjiRYFPnSzaPZzxf8zUePGSSKa0zRLsnWckOoqDAi91uIDpauqEIIYQQQggh/MgSChnnws63wRoFXc/SOyLREunTtZufmBRDveOASRit3US7tqJwHxUerQ1PTnU5WyuKGBgRr3NUrW8gA3mWZznAAfrQBwW5Ql20b5Jo7gCKiry43So33xxO165HOQNoMsFf/lI7FkIIIYQQQoij6XkRdJuptc2QhcfFIa7KGIDD56HC4+LyrgP0Dke0Ez1Do1BQUFEJMppICWp5G5f2KuHghxAdgWQaO4DCQh8nnRTErFlNWG3XaoWnnw58UEIIIYQQQoiOxWjROwJ9FK7TFs2L6A3JE/WOps2Js9m5v994vcMQ7Uz/8Fju7zeOzeWFDI9KIsYarHdIQgg/kERzO+b1qmRnewgOVpg+PRhFKguEEEIIIYQQwn+qcmH1veDzwN7lYA6BuBF6RyVEh5AZEUdmRJzeYQgh/Ega+rZTPp/Kzp0e4uKMLFgQyaRJQU3bUVXhwAHtpqqBDVIIIYQQQggh2rPqA1qS+U8V2frFIoQQQrRxUtHcTpWV+QgNVXjkkWgGDDiGVWCrqiDu4BnDigqw2wMToBBCCCGEEEK0d5F9ILIvFP8BtlhIOl7viIQQQog2SxLN7ZCqquTneznppGAyMztpnzQhhBBCCCGECDSDGYY9CI4DYI3qvH2qhRBCiCaQRHM75HCo2GwKV1wRKn2ZhRBCCCGEECKQDEYITtA7CiGEEKLNkx7N7ZDWNsNARoZZ71CEEEIIIYQQQnRyJZRwIzdyJmfyIi/qHY4QQgidSKK5HSorU5kyJYiwMPnyCSGEEEIIIYTQ14d8yA524MHDf/kve9mrd0hCCCF0IJnKdkZVVVRVJTZWup4IIYQQQgghhNCfndpF5o0YCSJIx2iEEELoRbKV7UxenpeICCNDh1r1DkUIIYQQQgghhGA60znAAXaxi6lMJYYYvUMSQgihA0k0tyM+n0p5uY+bbgpvfqLZZIJLLqkdCyGEEEIIIYQQLWDCxNVcrXcYQgghdCaZxnakqMhHRISRqVODmz+J1QpLlvgtJiGEEEIIIYQQQgRIzldQtB7iRkD8KL2jCQhVVfmlaB8GRWFYZCKKougdkhCimSTR3I4UF/s491w7aWlmvUMRQgghhBCi81BVyPseXKWQPBFMLSj8EEKIpipYC78/po1zvoLRj0NYhp4RBcTTO37j07wsAE5P6sEVGQOOeY4t5YUs3LQCh8/Dtd0GMy62i7/DFEI0gSwG2I4oCnTr1sIks6pCZaV2U1X/BCaEEEIIIURHtuMtWPcwbHoeVt2jdzRCiM6iOu+QOypU5+sWSiCtKqp9nquK8xrZsmFLdm2g0FVNpcfNszvW+Cs0IcQxkkRzO+FyqSgKpKS0sAi9qgpCQrRbVZV/ghNCCCGEEKIjK95YOy7ZAqpPv1hE5+IqB49D7yiEXuLHQMjBytyIXhAzSN94AmRIZMIh4/hmzRFsrM2V2E1yFbgQepHWGW2cz6eyb5+XqiofffpYGD26mYsACiGEEEIIIZoncTwUrgNUSBgDitTriFaw423Y9ioYbTDoTogZqHdEorVZQmH0E+AqAWtUh/3dc133wQyJjMegKIyISmrWHHO6DcKgKFR7PcxO7+/nCIUQTdUxf0t1IAcO+LBYFG6+OZznn48lKEi+ZEIIIYQQQnPvvfeiKEqdW0JCbWWYqqrce++9JCUlERQUxAknnMDGjRvrzOF0Orn++uuJiYnBbrczffp0srOzW/uptG0pJ2m9UYf+HQbcUvt5VYW8H2DfN+Dz6hWd6IhUFXa8oY29Dsj6j77xCP0YTGCL6bBJZgBFURgdk8LI6ORmLwQYYw3mzj6jub/feLqFRPo5QiFEU3Xc31QdQFWVj7IyH6edFsxVV4UTF2fUOyQhhBBCCNHGHHfcceTm5tbcfv/995rHFi1axKOPPspTTz3Fr7/+SkJCAieddBLl5eU129x444289957vPnmm/zwww9UVFRw2mmn4fVK4rSOsAytovTQJMiWF2Ht/8H6R2oX7BLCHxQFbHG194Oa105ACCGEaE3SOqMNKyjwcdxxZm65JULvUIQQQgghRBtlMpnqVDH/SVVVHn/8ce68807OOussAF5++WXi4+N5/fXXufrqqyktLeXFF1/k1VdfZdKkSQC89tprdOnShS+++IIpU6a06nNpdwrW1o4L1za0lRDNM/Re2PkOmEKg+/l6RyOEEEIclVQ0t2EOh4/x421Yrc27dEQIIYQQQnR827ZtIykpia5du3Leeeexc+dOALKyssjLy2Py5Mk121qtVo4//nh++uknAFavXo3b7a6zTVJSEv369avZpj5Op5OysrI6t04pbsQh45H6xSE6puBE6HcD9L4MTDa9oxFCCCGOSiqa2yivV8VoVMjMlMX/hBBCCCFE/UaMGMErr7xCz5492b9/P/fffz+jR49m48aN5OXlARAfX/eS+/j4eHbv3g1AXl4eFouFyMjII7b5c//6LFy4kAULFvj52bRDPS+CqP7gc0PsUL2jEUIIIYTQlSSa2yi3G0wmiIz0c9G50QgzZtSOhRBCCCFEuzV16tSacf/+/Rk1ahTdunXj5ZdfZuRIrcL28IWVVFU96mJLR9vm9ttvZ+7cuTX3y8rK6NKlS3OeQvsXM1DvCIQQQggh2gRpndFGHTjgJSHBRLduZv9ObLPBO+9oN5tcfiWEEEII0ZHY7Xb69+/Ptm3bavo2H16ZnJ+fX1PlnJCQgMvlori4uMFt6mO1WgkLC6tzE0IIIYQQnZskmtsoh0Nlxgw7oaHyJRJCCCGEEE3jdDrZtGkTiYmJdO3alYSEBD7//POax10uF99++y2jR48GYMiQIZjN5jrb5ObmsmHDhppthBBCiKMpdztZlr2Fr/J3o6qq3uEIIXQirTPaIKdTxWiEnj39XM0shBBCCCE6lHnz5jFt2jRSU1PJz8/n/vvvp6ysjEsuuQRFUbjxxht58MEH6dGjBz169ODBBx8kODiY888/H4Dw8HAuv/xybr75ZqKjo4mKimLevHn079+fSZMm6fzsREv88ouDwkIfxx9vw25vZ8UrJVuhdAvEDAZ7st7RCCGa4G8bvmdnZQkA+Y5Kzkvtq29AQghdSKK5jfH5VPbt85CebmLUqAC0tqishJAQbVxRAXa7/48hhBBCCCFaRXZ2NrNmzaKgoIDY2FhGjhzJihUrSEtLA+CWW26hurqav/zlLxQXFzNixAg+++wzQkNDa+Z47LHHMJlMnHvuuVRXVzNx4kSWLFmCUdbzaLc+/LCS558vB+DTT6t4/PHoo/blbjNKtsAvt4LqBZMdxj4Ntmi9oxJCNMLt89YkmQG2VhQ3vLEQokOTRHMb4nSq7N7tJjrayGWXhWK1tpMXg0IIIYQQQhdvvvlmo48risK9997Lvffe2+A2NpuNJ598kieffNLP0Qm9bNjgqhnv3OmhulolOLidvLco2aQlmQE8lVC+K7CJZp8b8n8FWxRE9A7ccYRoJfmOSl7MWo8KzE7vT2JQSMCPaTYYGRuTwg8F2SgoHB/bSReHFUJIorkt2bvXw7BhNu6/P5L0dGmbIYQQQgghhDh2Y8bY+PlnJ6oKgwZZCA5uR60zYoaA6XXwVIMtFsJ7BvZ4q+6FovXauN8NkHJSYI/XyWVXlbGmJJ++YdF0C4nUO5wO6fFtq/i99AAAha5qHhlwYqsc95ZeIzgtsRthZitdgmWBWCE6K0k0txEVFT4MBpg50y5JZiGEEEIIIUSzjR8fREqKiaIiHwMHWvQO59iEdIExT2mVzBG9wRJ61F2aw+1WKSmoIqZwPTVdRfJXSqI5gPIdldy87muqvG5MioF/DJggyeYAKHO7Dhk7W+24iqJwXHhsqx1PCNE2taNT2x2Xqmp9mcePtzF5crDe4QghhBBCCCHauYwMM0OHWjGZ2knLjEMFxUHccLAEpiqysNDLnDkFXHZVOXe+eTEe78G3xTEDA3I8odlZWUKV1w2AR/WxubxI54g6ptld+2M3mbEZTVzeNVPvcIQQnYxUNOvM41HJyvIQEWHkzDPt0pdZCCGEEEIIIQLom2+q2b9f6wP9e+Fo/rDEkzkoFGIG6RxZx9YnLIYoSxBFrmqCjWYGRsTpHVKHNCQygTdGTAdoP4uACiE6DEk062zXLg+9e5u5775IMjOteocjhBBCCCGEEB1aYmLt22CT2Uhsv9EQI2+NAy3cbOWJQZPYXFZIt5AIYqxyNW+gSIJZCKEX+WuqE59PJS/Pi9kM118f3npJZqMRTjmldiyEEEIIIYQQncjo0Tauuy6MLVvcjBtnq5N4FoEVbrYyIjpJ7zCEEEIEiPxF1Ul2tpeQEIVrrw3j+ONtrXdgmw0+/rj1jieEEEIIIYQQbcyUKcFMmaJ3FJ1A0Qao2ANxI8EWpXc0QgghAkwWA9SBqqo4nSpXXRXGZZeFtc8FOoQQQgghhBCivXCVQ9FGcFfqHUnnkb8SVt4BfzwLK+aBx6F3REJ0ajvZSRZZeochOjipaNZBUZGPkBCFkSOlJ7MQQgghhBBCBJSjAH66CVwlEBQPox4FS5jeUXV8Rb8DqjZ2HIDqPAhN1zMiITqtN3iD13kdgIu5mHM4R+eIREclFc0B5nCoVFf7qKrysX+/l+3b3ZSW+jjrLDu9ellaP6DKSrDbtVulnM0XQgghhBBCdHAHVmlJZoDq/Vo7BxF4ccPBcLC2LSQVgqU3sxB6+ZzPa8Zf8IWOkYiOTiqaAyg01EB5uZeCAh8A4eEGxo8PZuRIK6edpuMKu1VV+h1bCCGEEEIIIVpTaAYoBlB9YDBDaJreEXUOUf1h9BNQmQPRmWDUodBKCAFAD3pwgAMAdKe7ztGIjkwSzQH04ouxFBdrSWZFgbQ0E8HBUkQuhBBCCCGEEK0moicMe0CrZI4ZDPZkvSPqPEK6aDchhK5u5mb60hcFhZM5We9wRAcmieYASkw0kZiodxRCCCGEEEII0clF9dNuQrTEjrdh/89atXav2VpFWVtTsRd2vKX1Ie9xIZh0vJpatBkWLJzO6XqHIToBSTQLIYQQQgghhBBCNKZoA2x7VRuXbdcq5RPG6htTfVbfC9X52tjrgH436BqOEKJzkT4OQgghhBBCCCGECJgqj7v1D1qdD5X7/Def13HYfaf/5vYXVQVnUe19R4F+sQghOiVJNAshhBBCCCGEaD9Un94RiCZy+bzc8fu3zFzxPvPWfYXD62mdA+9dDt9eAd9frbWR8IeYIZA8CUx2iB8Nicf7Z15/UhTocRGgaC0zMs7VOyIhRCcjrTM6G4MBjj++diyEEEIIIYQQ7YGrHFbdDWU7IOkE6H9T2+yRK2qsKsrl99IDAGwpL+KHgmwmxacH/sB7PgZUbbz7I+g2s+VzKgr0/6t2a8u6ngVdTgGDSbsJIUQrkt86nU1QEHzzjd5RCCGEEEIIIcSxyf5M640LsO9r6DIVIvvoG5NoVJQlqM796MPuB0xoOpTvqh13Niab3hEIITopSTQHUElJCaWlpXqH0W6oqkpaWhqKVCUIIYQQQgghDmcJP+SOAuZQ3UIRTdM7LJobewxlZVEuAyLiGBQZ3zoHPu46sHcBnxvST2+dYwohhJBEcyBdfPHF5OTk6B1Gu2A0GomKimLBggWMGDFC73CEEEIIIYQQbU3yRKjOg9KtkDQBQlL0jqjTqq728dZblTgcKjNm2ImJMTa47cT4dCa2RruMQxmt0E36EwshRGuTRHMAFRcX43Q6iY2N1TuUGjavlzdWrABg1siROIwNvyAIFJfLRXZ2NoqiEBoaSnh4OMnJyUyfPp1hw4a1ejxCCCGEEEKIdkBRoMeFekchgGefLePrrx0AbNni4rHHYnSOSAjRKTmKYP+PEJwEsUP0jkYgieaAs9vthISE6B1GDavHQ4TbDWixmUz++RZQVRWv14vH48Hr9TY6LioqYsiQIZxxxhlkZmZy3HHHYbfb/RKHEEIIIYQQQohmyPsBdv0XgpOh75xG+/zu2+etdyyE6Nh+Lz3A8rydpAaHcU5Kbwx6tj71umDlrVCVp93PvFlbKFboShLNollcLhcFBQVUVlaiKAqqqmI0GjGZTEf8Gx4eXlO5HB4eTkREBOPHj+eEE07Q+2kIIYQQQgghhHCVwfpHwOeBki1gi4GeFzW4+dln21m0qASvF2bObDuFVUKIwClzO1mw8QecPu3kUpDRxPSkHvoF5CysTTIDFG+URHMbIIlmccyqq6vZs2cPXbp0YdasWfTo0QO73V5zCwkJwW63ExwcTHBwMEYd2nMIIYQQQgghhGgin1tLMv/J62h081GjbLz6ahwej0pEhLzfE6IzKHM7a5LMAPmOKh2jAWxxENFLOzmmGCF+lL7xCEASzaIJvF4v1dXVVFZWUlZWhsFgYPDgwbz44ovS8kIIIYQQQggh2jtbNPS8GHa+C/Zk6Hr2UXcJCTG0QmBCiLYiJTiMCXGpfJ2/hxhrEKcmdtM3IIMRhj0ARb9DUIIsENtGSKJZ1Mvr9bJnzx68Xu1sVXBwMCEhIZx44olMmDCB0aNHS5JZCCGEEEIIITqKjHO0mxBCNGBuz+Fc2XUAwSYzRqUNnGwyWiF2qN5RiENIolkcwev1snv3bmJiYjj//PPJyMggIyOD1NRUzGaz3uEJIYQQQgghhBCiifLJZze76U1vQgnVOxzRzoWarXqHINowSTR3MqqisC08vGZ8uOLiYvLz80lJSWH+/PlMnTq1tUMUQgghhBBCCCGEH+xhDzdzMw4cxBHHP/knIcgCjkKIwJBEcyfjMhqZO25cvY+VlZVRXFzMzJkzmTNnDklJSa0cnRBCCCGEEEIIIfxlFatwoC3umE8+W9nKYAbrHJUQoqOSRLPA4/Gwe/duFEVh+PDh3HfffSj1VDsLIYQQQgghAmf9eidLllQQGqpw/fXhxMQY9Q5JCNHO9aEPBgz48GHHTjrpeockhOjAJNEsyMvLIyUlhblz5zJhwgRJMgshhBBCCKGDhx4qobxcBeCFF8q4/fZInSMSQrR3fejDIhaxhS0MYQhRROkdkhCiA5NEcydj9Xp5+ptvALj2hBNwGAxUVVUxffp0Tj75ZH2DE0IIIYQQopNSVRWPp/a+261fLEKIjqXXwQ8hhAg0g94BiFamqsRXVxNfXY3q81FWVobVamXo0KF6RyaEEEIIIUSnpSgKf/1rONHRBtLTTcyeHap3SEIIIYQQx0QqmjsRr9dLVVVVzf0dO3agBgczceJESTQLIYQQQgihszFjbIwZY9M7DCGEEEKIZpFEcwdXXFxMQUFBTd/lCLO55rGrr76aYSecwMCBAzGZ5FtBCCGEEEIIIYQQQgjRPJJd7OAKCgqYMGECo0ePJjk5mZTISBg8GIA5c+aA3a5zhEIIIYQQQgghhBBCiPZOEs0dmMvlAmDChAmce+652icrK3WMSAghhBBCCCGEEEII0RF1ysUAn3nmGbp27YrNZmPIkCF8//33eofkV6qqUlxczK5duxgwYAATJ07UOyQhhBBCCCGEEEJ0Ai6flx0VxVR53HqHIoRoZZ0u0fzWW29x4403cuedd7JmzRrGjRvH1KlT2bNnj96h+UVFRQXbt2+nqqqKc889l2eeeYbo6OjaDRQF+vbVbgf7NgshhBBCCCGEEG1JFVXcxV3MYhaLWdyiuVRUfPj8FJloTLXXzdy1X3Hj2i+Z89tnFDir9A5JCNGKOl2i+dFHH+Xyyy/niiuuoE+fPjz++ON06dKFZ599Vu/QWiw7O5vCwkLGjx/PCy+8wH333Vc3yQwQHAwbN2q34GB9AhVCCCGEEEIIIRrxCZ+wlrVUUMEylrGTnc2aZz3rmcUsZjCDr/jKz1GKw20oLWB3VSkARa5qfi7cp3NEQojW1KkSzS6Xi9WrVzN58uQ6n588eTI//fSTTlH5R1VVFdXV1Vx11VU899xzDBkyBEUqloUQQgghhBBCtENWrDVjBQULlmbN8yqvUkklbtz8m3/7KzzRgOSgEMwGI6B93dLt4TpHJIRoTZ1qMcCCggK8Xi/x8fF1Ph8fH09eXp5OUbWcqqrs3buXE044gfPOOw+DoVOdPxBCCCGEEEII4Q+l22HzC2CwwHF/geBE3UKZylT2sIftbOckTiKFlGbNE05tojOCCD9FJxqSFBTKA/3G8UtRLseFxdA/PFbvkIQQrahTJZr/dHilr6qq7bb61+fzsXv3bqKjo7nllluIiYlpfIeqKhj2/+3deVxU9foH8A/INgyL4sIiCC65peJWBqbmBlhudVU0M7xqV6+SprfMrimoma2mdcvMDJc09ed2LbfQFDV3EjUhNEBRG0VARUBA4Pn9weXIwAAzLDMKn/frNS9nzjLnmef7BZ/z5cz5PlXw/NQp3j6DiIiIiIiICpz7BMi4XvD8wlfAUwtMFooFLDAFUyr9PsEIhi1skYUsvIpXqyAyKk8bhwZo41DO2AQR1Ui1aqC5QYMGqFOnTomrl5OSkkpc5fw4yM3NRXx8PFxdXRESEoIWLVqUv5MIEB398DkRERER0eNGBLi6G0i/Crj3BxyamToiopohL0v388dYXdTFDMwwdRhERLVCrbrHgpWVFbp06YLw8HCt5eHh4fD19TVRVBWn0WjQtGlTfPfdd+jdu7epwyEiIiIiMo6ru4HoZUDiT8Cp2cCDDFNHRPRIyM+v5MVEbacA1k6ArQvQ+rWqCYqIiGqNWnVFMwDMmDEDY8aMQdeuXeHj44NvvvkGiYmJmDRpkqlDM9j9+/fx7LPPolkzXsFBRERERLVI+tWHzx+kAzl3AEu1ycIhehR8/XUadu3KhLu7Bd57rx6cnOoY/iaNngIara764IiIqFaodQPNgYGBSElJwfz586HRaNCuXTvs2rULnp6epg5NbyKC9PR0AECjRo1MHA0RERERkZG59wc0BwsGmRt1A2zdTB0RkUldvZqLnTszlec//piJoCB7E0dFRES1Ta0baAaAyZMnY/LkyaYOo0JSUlKQkpIClUqFZ599FiNHjjR1SERERERExuXQDOj5bcGVzLZuwGM6sTdRVVGrzWBhAeTmFrx2dKxVd8kkIqJHRK0caH5c5eTkIDU1FSNHjsTQoUPh7e0Nc3MWEERERERUC1mqebsMov9xcqqDt9+ui927M+HpaYGBA21NHRIREdVCHGh+TIgIrl27Bnd3d8ycORNqdQWLajMzoPA2Ibzyg4iIiIiIqEZ45hkbPPOMjanDICKiWowDzY+JW7duwc7ODrNmzar4IDMA2NoCly9XWVxEREREREREREREvO/CIy4/Px83b97E3bt30bdvX/Tr18/UIRERERERERERERFp4RXNj6AHDx4gPT0d6enpuH//PpycnDBlyhSMHz/e1KERERERERERERERlcCB5kdIfn4+EhISAAD29vZo1qwZfH19MXz4cHgW3le5su7fB3r2LHh+6BCgUlXN+xIREREREREREVGtxYHmR0Rubi4SExPh6OiIkJAQdOrUCY0aNYJZVU/Yl58PnD798DkRERER0f989dVX+Pjjj6HRaPDkk09iyZIl6NGjh6nDIiIiIqLHAO/R/AgQEVy+fBkeHh5YuHAhAgIC4OzsXPWDzEREREREpdi4cSPeeOMNzJ49G2fOnEGPHj0wYMAAJCYmmjo0IiIiInoMcKDZxB48eIDr169DrVZjwYIF6NOnj6lDIiIiIqJaaPHixRg/fjwmTJiANm3aYMmSJfDw8MCyZctMHdrjKf0acH4JEBsG5GbpvVtc3AMsXnwH339/Dw8eSPXFR0SPjHjEYzEWYy3W4gEemDocekyJCLZci8WnsSdx7k6SqcOhWoq3zjCh69evIysrC40aNcKrr76Kp556ytQhEREREVEtlJOTg8jISMyaNUtruZ+fH44ePVpi++zsbGRnZyuv09LSqj3Gx05kCHD/fyf6eVlA23+Wu8uDB4I5c1Jx717BALMIMGaMfXVGSUQmlotczMVc3MVdAEA+8hGEIBNHRY+jvTcTsOryeQDA0ZTr+LbrANSzsjFxVFTb8IpmE8rMzMSECRPw448/Yty4caYOh4iIiIhqqeTkZOTl5cHZ2VlrubOzM27cuFFi+0WLFsHR0VF5eHh4GCvUx4PkA1nJD19n3tRrt6wsUQaZAeDWrbyqjoyIHjHZyFYGmQEgCbwSlSrmZlaG8jwnPw93Huj/bRqiqsKBZhPIy8vDtWvXYGtrC19fX9jb8yoFIiIiIjK94nOEiIjOeUPeeecd3L17V3lcvXrVWCE+HszMgeajCp5bqIBmw/Tazd7eHEOG2P7vuRkGD1ZXV4RE9IhQQ40X8SIAwB72GIqhpg2IHlsBLs3QwFoFAHi2gTu8bB1NHBHVRrx1hhGJCDQaDTIyMuDs7IwpU6bg6aefNn4gDRoY/5hERERE9Mhq0KAB6tSpU+Lq5aSkpBJXOQOAtbU1rK2tjRXe46nFSKDJC0Ada6COld67TZjggBEj7KBSmcHSkpODE9UG4zAOwzAMNrCBFfT/fUFUlLONGiu6DEBG3gM4WvL/aDINXtFsRBkZGcjOzsY///lPbN68GSNGjIC5uZGbQK0Gbt0qeKh5hQQRERERAVZWVujSpQvCw8O1loeHh8PX19dEUdUAVvYGDTIXcnAw5yAzUS3jAAcOMlOlWZibc5CZTIpXNBtJbm4url+/jl69emHixImwseEN2YmIiIjo0TFjxgyMGTMGXbt2hY+PD7755hskJiZi0qRJpg6NiIiIiB4DHGg2kjt37sDJyQkLFizgIDMRERERPXICAwORkpKC+fPnQ6PRoF27dti1axc8PT1NHRoRERERPQY40GwEIoLU1FQMHz4cLi4upg3m/n1gwICC57t3AyqVaeMhIiIiokfG5MmTMXnyZFOHQURERESPIQ40G8Fff/2FunXr4m9/+5upQwHy84GIiIfPiYiIiIiIiIiIiCqJkwFWs+zsbGRmZmLixIno1KmTqcMhIiIiIiIiIiIiqnIcaK5mqamp6NatG4YOHWrqUIiIiIiIiIiIiIiqBQeaq1ndunUxffp0ODk5mToUIiIiIiIiIiIiomrBezRXg7i4OISFhcHBwQFWVlZo3ry5qUMiIiIiIiIiIiIiqjYcaK4Ge/fuxdq1a2FjY4OFCxfC3t7e1CERERERERERERERVRsONFexpKQkHD9+HGq1Gnl5eY/mILOtrakjICIiIiIiIiIiohqE92iuQqmpqZgyZQpOnDgBNzc3U4ejm1oNZGQUPNRqU0dDRERERERERERENQCvaK4EEcHNmzcRHx+PEydO4Mcff8S1a9fQtGlTWFlZmTo8IiIiIiIiIiIiIqPgQHMFREZGYu7cucjMzERGRgYyMzORlpaG7OxsODo64urVq6YOkYiIiIiIiIiIiMhoONBcARkZGQAAlUoFlUoFNzc31K1bt8R2lpaWaNWqlZGjK0dWFvC3vxU837IFsLExbTxERERERERERET02ONAcwX07NkTPXv2NHUYFZOXB+za9fA5ERERERERERERUSVxMkAiIiIiIiIiIiIiqhQONBMRERERERERERFRpXCgmYiIiIiIiIiIiIgqhQPNRERERERERERERFQpHGgmIiIiIiIiIiIiokqxMMVBRQQAkJaWZorD124ZGQ+fp6UBeXmmi4WIiIhqnML6rrDeo9qB9T0RERFRzaVvjW+SgeaUlBQAgIeHhykOT4Xc3EwdAREREdVQKSkpcHR0NHUYZCT37t0DwPqeiIiIqCa7d+9emTW+SQaanZycAACJiYk19gQkLS0NHh4euHr1KhwcHEwdDlUC27JmYXvWHGzLmoNtWbPcvXsXTZo0Ueo9qh3c3Nxw9epV2Nvbw8zMzCjH5O8OwzBfhmG+9MdcGYb5MgzzpT/myjDMl2FEBPfu3YNbORetmmSg2dy84NbQjo6ONb4xHRwcavxnrC3YljUL27PmYFvWHGzLmqWw3qPawdzcHO7u7iY5Nn93GIb5MgzzpT/myjDMl2GYL/0xV4ZhvvSnz8XCPAMgIiIiIiIiIiIiokrhQDMRERERERERERERVYpJBpqtra0REhICa2trUxzeKGrDZ6wt2JY1C9uz5mBb1hxsy5qF7UnGwr5mGObLMMyX/pgrwzBfhmG+9MdcGYb5qh5mIiKmDoKIiIiIiIiIiIiIHl+8dQYRERERERERERERVQoHmomIiIiIiIiIiIioUjjQTERERERERERERESVwoFmIiIiIiIiIiIiIqoUoww03759G2PGjIGjoyMcHR0xZswY3Llzp8x9tm7dCn9/fzRo0ABmZmaIiooyRqgG+eqrr9C0aVPY2NigS5cuOHz4cJnbR0REoEuXLrCxsUGzZs3w9ddfGylSKo8hbbl161b0798fDRs2hIODA3x8fLB3714jRkvlMfRns9Cvv/4KCwsLdOzYsXoDJL0Z2pbZ2dmYPXs2PD09YW1tjebNm+O7774zUrRUFkPbct26dfD29oatrS1cXV3x97//HSkpKUaKlkpz6NAhDBo0CG5ubjAzM8P27dvL3Yf1D1WXiv5/X5OEhobCzMxM6+Hi4qKsFxGEhobCzc0NKpUKzz33HC5cuKD1HtnZ2Xj99dfRoEEDqNVqDB48GNeuXTP2R6ly5f2+qqrcVORc91FUXr7Gjh1boq8988wzWtvUlnwtWrQITz31FOzt7dGoUSMMHToUsbGxWtuwfz2kT77Yvx5atmwZOnToAAcHB2W8Yffu3cp69q2HyssV+5WJiBEEBARIu3bt5OjRo3L06FFp166dDBw4sMx91qxZI/PmzZMVK1YIADlz5owxQtXbhg0bxNLSUlasWCHR0dEybdo0UavVcuXKFZ3bx8fHi62trUybNk2io6NlxYoVYmlpKZs3bzZy5FScoW05bdo0+fDDD+XkyZNy8eJFeeedd8TS0lJ+++03I0dOuhjanoXu3LkjzZo1Ez8/P/H29jZOsFSmirTl4MGDpVu3bhIeHi4JCQly4sQJ+fXXX40YNeliaFsePnxYzM3NZenSpRIfHy+HDx+WJ598UoYOHWrkyKm4Xbt2yezZs2XLli0CQLZt21bm9qx/qLpU9P/7miYkJESefPJJ0Wg0yiMpKUlZ/8EHH4i9vb1s2bJFzp8/L4GBgeLq6ippaWnKNpMmTZLGjRtLeHi4/Pbbb9K7d2/x9vaW3NxcU3ykKlPe76uqyk1FznUfReXlKygoSAICArT6WkpKitY2tSVf/v7+EhYWJr///rtERUXJCy+8IE2aNJH09HRlG/avh/TJF/vXQzt27JCdO3dKbGysxMbGyr///W+xtLSU33//XUTYt4oqL1fsV6ZR7QPN0dHRAkCOHz+uLDt27JgAkD/++KPc/RMSEh7Jgeann35aJk2apLWsdevWMmvWLJ3bz5w5U1q3bq21bOLEifLMM89UW4ykH0PbUpe2bdvKvHnzqjo0qoCKtmdgYKC8++67EhISwoHmR4Shbbl7925xdHQsUTyQ6Rnalh9//LE0a9ZMa9nnn38u7u7u1RYjGU6fgWbWP1RdqqJ+qwnKqlvy8/PFxcVFPvjgA2VZVlaWODo6ytdffy0iBX9ot7S0lA0bNijbXL9+XczNzWXPnj3VGrsxFf99VVW5qey57qOqtIHmIUOGlLpPbc5XUlKSAJCIiAgRYf8qT/F8ibB/ladevXry7bffsm/poTBXIuxXplLtt844duwYHB0d0a1bN2XZM888A0dHRxw9erS6D18tcnJyEBkZCT8/P63lfn5+pX6mY8eOldje398fp0+fxoMHD6otVipbRdqyuPz8fNy7dw9OTk7VESIZoKLtGRYWhri4OISEhFR3iKSnirTljh070LVrV3z00Udo3LgxWrZsiTfffBP37983RshUioq0pa+vL65du4Zdu3ZBRHDz5k1s3rwZL7zwgjFCpirE+oeqQ1XUbzXJpUuX4ObmhqZNm2LkyJGIj48HACQkJODGjRtaebK2tkavXr2UPEVGRuLBgwda27i5uaFdu3Y1OpdVlZuaeK5bloMHD6JRo0Zo2bIlXnvtNSQlJSnranO+7t69CwDK+SD7V9mK56sQ+1dJeXl52LBhAzIyMuDj48O+VYbiuSrEfmV8FtV9gBs3bqBRo0Ylljdq1Ag3btyo7sNXi+TkZOTl5cHZ2VlrubOzc6mf6caNGzq3z83NRXJyMlxdXastXipdRdqyuE8//RQZGRkYMWJEdYRIBqhIe166dAmzZs3C4cOHYWFR7b8SSU8Vacv4+HgcOXIENjY22LZtG5KTkzF58mSkpqbyPs0mVJG29PX1xbp16xAYGIisrCzk5uZi8ODB+OKLL4wRMlUh1j9UHaqifqspunXrhjVr1qBly5a4efMm3nvvPfj6+uLChQtKLnTl6cqVKwAKfkatrKxQr169EtvU5FxWVW5q4rluaQYMGIDhw4fD09MTCQkJmDNnDvr06YPIyEhYW1vX2nyJCGbMmIFnn30W7dq1A8D+VRZd+QLYv4o7f/48fHx8kJWVBTs7O2zbtg1t27ZVBjbZtx4qLVcA+5WpVHhUJTQ0FPPmzStzm1OnTgEAzMzMSqwTEZ3LHyfF4y/vM+naXtdyMj5D27LQDz/8gNDQUPz3v//V+cuHTEPf9szLy8PLL7+MefPmoWXLlsYKjwxgyM9mfn4+zMzMsG7dOjg6OgIAFi9ejGHDhuHLL7+ESqWq9nipdIa0ZXR0NKZOnYq5c+fC398fGo0Gb731FiZNmoSVK1caI1yqQqx/qLpUtH6rSQYMGKA8b9++PXx8fNC8eXOsXr1amfCoInmqLbmsitzU1HPd4gIDA5Xn7dq1Q9euXeHp6YmdO3fipZdeKnW/mp6v4OBgnDt3DkeOHCmxjv2rpNLyxf6lrVWrVoiKisKdO3ewZcsWBAUFISIiQlnPvvVQablq27Yt+5WJVPjWGcHBwYiJiSnz0a5dO7i4uODmzZsl9r9161aJv8I8Lho0aIA6deqU+OtFUlJSqZ/JxcVF5/YWFhaoX79+tcVKZatIWxbauHEjxo8fj02bNqFfv37VGSbpydD2vHfvHk6fPo3g4GBYWFjAwsIC8+fPx9mzZ2FhYYFffvnFWKFTMRX52XR1dUXjxo2VQWYAaNOmDUSkxMzBZDwVactFixahe/fueOutt9ChQwf4+/vjq6++wnfffQeNRmOMsKmKsP6h6lCZ+q2mU6vVaN++PS5dugQXFxcAKDNPLi4uyMnJwe3bt0vdpiaqqtzUxHNdfbm6usLT0xOXLl0CUDvz9frrr2PHjh04cOAA3N3dleXsX7qVli9danv/srKyQosWLdC1a1csWrQI3t7eWLp0KfuWDqXlSpfa3q+MpcIDzQ0aNEDr1q3LfNjY2MDHxwd3797FyZMnlX1PnDiBu3fvwtfXt0o+hLFZWVmhS5cuCA8P11oeHh5e6mfy8fEpsf3PP/+Mrl27wtLSstpipbJVpC2BgiuZx44di/Xr1/OeoY8QQ9vTwcEB58+fR1RUlPKYNGmS8lfRovdhIuOqyM9m9+7d8ddffyE9PV1ZdvHiRZibm5dbzFL1qUhbZmZmwtxcu0SpU6cOgIdXw9LjgfUPVYeK1m+1QXZ2NmJiYuDq6oqmTZvCxcVFK085OTmIiIhQ8tSlSxdYWlpqbaPRaPD777/X6FxWVW5q4rmuvlJSUnD16lXlFki1KV8iguDgYGzduhW//PILmjZtqrWe/UtbefnSpTb3L11EBNnZ2exbeijMlS7sV0ZSzZMNiohIQECAdOjQQY4dOybHjh2T9u3by8CBA7W2adWqlWzdulV5nZKSImfOnJGdO3cKANmwYYOcOXNGNBqNMUIu14YNG8TS0lJWrlwp0dHR8sYbb4harZbLly+LiMisWbNkzJgxyvbx8fFia2sr06dPl+joaFm5cqVYWlrK5s2bTfUR6H8Mbcv169eLhYWFfPnll6LRaJTHnTt3TPURqAhD27O4smZvJ+MytC3v3bsn7u7uMmzYMLlw4YJERETIE088IRMmTDDVR6D/MbQtw8LCxMLCQr766iuJi4uTI0eOSNeuXeXpp5821Ueg/7l3756cOXNGzpw5IwBk8eLFcubMGbly5YqIsP4h4ynv90pt8a9//UsOHjwo8fHxcvz4cRk4cKDY29srefjggw/E0dFRtm7dKufPn5dRo0aJq6urpKWlKe8xadIkcXd3l3379slvv/0mffr0EW9vb8nNzTXVx6oS5f2+qqrc6HOu+zgoK1/37t2Tf/3rX3L06FFJSEiQAwcOiI+PjzRu3LhW5uuf//ynODo6ysGDB7XOBzMzM5Vt2L8eKi9f7F/a3nnnHTl06JAkJCTIuXPn5N///reYm5vLzz//LCLsW0WVlSv2K9MxykBzSkqKjB49Wuzt7cXe3l5Gjx4tt2/f1g4EkLCwMOV1WFiYACjxCAkJMUbIevnyyy/F09NTrKyspHPnzhIREaGsCwoKkl69emltf/DgQenUqZNYWVmJl5eXLFu2zMgRU2kMactevXrp7JtBQUHGD5x0MvRnsygOND9aDG3LmJgY6devn6hUKnF3d5cZM2ZoFf1kOoa25eeffy5t27YVlUolrq6uMnr0aLl27ZqRo6biDhw4UOb/gax/yJjK+r1SWwQGBoqrq6tYWlqKm5ubvPTSS3LhwgVlfX5+voSEhIiLi4tYW1tLz5495fz581rvcf/+fQkODhYnJydRqVQycOBASUxMNPZHqXLl/b6qqtzoc677OCgrX5mZmeLn5ycNGzYUS0tLadKkiQQFBZXIRW3Jl648FR/PYP96qLx8sX9pGzdunPJ/W8OGDaVv377KILMI+1ZRZeWK/cp0zET4HVQiIiIiIiIiIiIiqrgK36OZiIiIiIiIiIiIiAjgQDMRERERERERERERVRIHmomIiIiIiIiIiIioUjjQTERERERERERERESVwoFmIiIiIiIiIiIiIqoUDjQTERERERERERERUaVwoJmIiIiIiIiIiIiIKoUDzUQ1xOXLl2FmZoaoqCijHXPVqlWoW7eu8jo0NBQdO3ZUXo8dOxZDhw41Wjw1XWhoKJydnWFmZobt27frXGZIzk3RZ6rSwYMHYWZmhjt37pg6FCIiIiKqIXTV3NV9vKLnUI+bGzduoH///lCr1VrnhkRUO3GgmegxYGZmVuZj7NixJokrMDAQFy9eNMmxDVHagOrjNBAeExODefPmYfny5dBoNBgwYIDOZUuXLsWqVav0ek8PDw9oNBq0a9euSmM1VlFORERE9LgaO3aszrr+zz//rJL3L35BCOlHV31dlYxZJ2/duhX+/v5o0KBBhS4u8fLywpIlS8rd7rPPPoNGo0FUVFSVnhvqe3wierRYmDoAIiqfRqNRnm/cuBFz585FbGysskylUuH27dtGj0ulUkGlUhn9uLVRXFwcAGDIkCEwMzMrdZm1tbXe71mnTh24uLhUcaREREREpI+AgACEhYVpLWvYsKGJoindgwcPYGlpaeowjEJXfV0Rj0LOMjIy0L17dwwfPhyvvfZatR0nLi4OXbp0wRNPPFFtx6iMnJwcWFlZmToMolqDVzQTPQZcXFyUh6OjI8zMzEosKxQfH4/evXvD1tYW3t7eOHbsmNZ7HT16FD179oRKpYKHhwemTp2KjIyMUo999uxZ9O7dG/b29nBwcECXLl1w+vRpAPpfKfHJJ5/A1dUV9evXx5QpU/DgwQNl3e3bt/Hqq6+iXr16sLW1xYABA3Dp0iVlva6vki1ZsgReXl5ay8LCwtCmTRvY2NigdevW+Oqrr5R1TZs2BQB06tQJZmZmeO655xAaGorVq1fjv//9r3IFycGDBwEA169fR2BgIOrVq4f69etjyJAhuHz5cpmf8cKFC3jhhRfg4OAAe3t79OjRQylU8/PzMX/+fLi7u8Pa2hodO3bEnj17tPYv65ihoaEYNGgQAMDc3BxmZmY6lwElr9LOz8/Hhx9+iBYtWsDa2hpNmjTBwoULAei+0js6OhrPP/887Ozs4OzsjDFjxiA5OVlZ/9xzz2Hq1KmYOXMmnJyc4OLigtDQUGV9Ybu8+OKLMDMzK9FOhXx8fDBr1iytZbdu3YKlpSUOHDgAAPj+++/RtWtX2Nvbw8XFBS+//DKSkpJKbYOq6Cs5OTkIDg6Gq6srbGxs4OXlhUWLFpV6TCIiIqKKsra21qrpXVxcUKdOHQDAjz/+iC5dusDGxgbNmjXDvHnzkJubq+y7ePFitG/fHmq1Gh4eHpg8eTLS09MBFNxe7O9//zvu3r2r1LmF9ZquK2rr1q2rfCOusD7ctGkTnnvuOdjY2OD7778HUHYNpcvmzZvRvn17qFQq1K9fH/369VPOOwpr1nnz5qFRo0ZwcHDAxIkTkZOTo+y/Z88ePPvss6hbty7q16+PgQMHKvV1oWvXrmHkyJFwcnKCWq1G165dceLECWV9eXksqrT6urxavqycFVVenbx27Vp4eXnB0dERI0eOxL1795R1IoKPPvoIzZo1g0qlgre3NzZv3lxm/seMGYO5c+eiX79+pW4TGhqKJk2awNraGm5ubpg6dSqAgpr/ypUrmD59utKHdPHy8sKWLVuwZs0arW/a3r17F//4xz+Utu3Tpw/Onj2r7BcXF4chQ4bA2dkZdnZ2eOqpp7Bv3z5lfWnH16feL+xbixYtgpubG1q2bAmgYud4RGQ4DjQT1TCzZ8/Gm2++iaioKLRs2RKjRo1Siqnz58/D398fL730Es6dO4eNGzfiyJEjCA4OLvX9Ro8eDXd3d5w6dQqRkZGYNWuWQX+dP3DgAOLi4nDgwAGsXr0aq1at0rq1w9ixY3H69Gns2LEDx44dg4jg+eef1xqMLs+KFSswe/ZsLFy4EDExMXj//fcxZ84crF69GgBw8uRJAMC+ffug0WiwdetWvPnmmxgxYgQCAgKg0Wig0Wjg6+uLzMxM9O7dG3Z2djh06BCOHDkCOzs7BAQEaBW+RV2/fh09e/aEjY0NfvnlF0RGRmLcuHFK3pcuXYpPP/0Un3zyCc6dOwd/f38MHjxYGVAv75hvvvmmcrVLYay6lunyzjvv4MMPP8ScOXMQHR2N9evXw9nZWee2Go0GvXr1QseOHXH69Gns2bMHN2/exIgRI7S2W716NdRqNU6cOIGPPvoI8+fPR3h4OADg1KlTAApORDQajfK6uNGjR+OHH36AiCjLNm7cCGdnZ/Tq1QtAwaDvggULcPbsWWzfvh0JCQmVvk1MeX3l888/x44dO7Bp0ybExsbi+++/L3WwnIiIiKg67N27F6+88gqmTp2K6OhoLF++HKtWrVIuFgAKBkI///xz/P7771i9ejV++eUXzJw5EwDg6+uLJUuWwMHBQat2NMTbb7+NqVOnIiYmBv7+/uXWUMVpNBqMGjUK48aNQ0xMDA4ePIiXXnpJq/bbv38/YmJicODAAfzwww/Ytm0b5s2bp6zPyMjAjBkzcOrUKezfvx/m5uZ48cUXkZ+fDwBIT09Hr1698Ndff2HHjh04e/YsZs6cqazXJ49FlVZfl1fLl5az4sqqk+Pi4rB9+3b89NNP+OmnnxAREYEPPvhAWf/uu+8iLCwMy5Ytw4ULFzB9+nS88soriIiIKKUFy7d582Z89tlnWL58OS5duoTt27ejffv2AApuu+Hu7o758+eXea5x6tQpBAQEYMSIEdBoNFi6dClEBC+88AJu3LiBXbt2ITIyEp07d0bfvn2RmpoKoKDtnn/+eezbtw9nzpyBv78/Bg0ahMTERIOOX5rCvhUeHo6ffvqpQud4RFRBQkSPlbCwMHF0dCyxPCEhQQDIt99+qyy7cOGCAJCYmBgRERkzZoz84x//0Nrv8OHDYm5uLvfv39d5PHt7e1m1apVesYSEhIi3t7fyOigoSDw9PSU3N1dZNnz4cAkMDBQRkYsXLwoA+fXXX5X1ycnJolKpZNOmTTrfU0Tks88+E09PT+W1h4eHrF+/XmubBQsWiI+Pj4g8zM2ZM2e0tgkKCpIhQ4ZoLVu5cqW0atVK8vPzlWXZ2dmiUqlk7969OvPwzjvvSNOmTSUnJ0fnejc3N1m4cKHWsqeeekomT56s9zG3bdsmxX9l61pW9DOlpaWJtbW1rFixQmdcxfMyZ84c8fPz09rm6tWrAkBiY2NFRKRXr17y7LPPlvgsb7/9tvIagGzbtk3nMQslJSWJhYWFHDp0SFnm4+Mjb731Vqn7nDx5UgDIvXv3RETkwIEDAkBu374tIlXTV15//XXp06ePVlsQERERVbWgoCCpU6eOqNVq5TFs2DAREenRo4e8//77WtuvXbtWXF1dS32/TZs2Sf369ZXXpZ0z6KrTHB0dJSwsTEQe1odLlizR2qa8Gqq4yMhIASCXL1/WuT4oKEicnJwkIyNDWbZs2TKxs7OTvLw8nfskJSUJADl//ryIiCxfvlzs7e0lJSVF5/YVyaOu+rq8Wr60nOmiK/8hISFia2sraWlpyrK33npLunXrJiIi6enpYmNjI0ePHtXab/z48TJq1Khyj1naudCnn34qLVu2LPUcxtPTUz777LNy33/IkCESFBSkvN6/f784ODhIVlaW1nbNmzeX5cuXl/o+bdu2lS+++KLM4+tT7wcFBYmzs7NkZ2cryypyjkdEFcN7NBPVMB06dFCeu7q6AgCSkpLQunVrREZG4s8//8S6deuUbUQE+fn5SEhIQJs2bUq834wZMzBhwgSsXbsW/fr1w/Dhw9G8eXO943nyySeVrwAWxnT+/HkABZNtWFhYoFu3bsr6+vXro1WrVoiJidHr/W/duoWrV69i/PjxWvcey83N1bqliL4Kc2Rvb6+1PCsrq8RX9QpFRUWhR48eOq/0TktLw19//YXu3btrLe/evbvy9bGKHFMfMTExyM7ORt++ffXaPjIyEgcOHICdnV2JdXFxccrXzor2MaCgTcu6pYUuDRs2RP/+/bFu3Tr06NEDCQkJOHbsGJYtW6Zsc+bMGYSGhiIqKgqpqanK1SmJiYlo27atQccD9OsrY8eORf/+/dGqVSsEBARg4MCB8PPzM/hYREREROXp3bu3Vu2jVqsBFNRkp06d0rryNi8vD1lZWcjMzIStrS0OHDiA999/H9HR0UhLS0Nubi6ysrKQkZGhvE9ldO3aVXlekXrb29sbffv2Rfv27eHv7w8/Pz8MGzYM9erV09rG1tZWee3j44P09HRcvXoVnp6eiIuLw5w5c3D8+HEkJydr1YLt2rVDVFQUOnXqBCcnJ50x6JPH8uhTyxcqmjNDeXl5aZ0LFK2vo6OjkZWVhf79+2vtk5OTg06dOlX4mMOHD8eSJUvQrFkzBAQE4Pnnn8egQYNgYVG5YaLIyEikp6ejfv36Wsvv37+vnNtkZGRg3rx5+Omnn/DXX38hNzcX9+/fV65orqz27dtr3Ze5us63iKgkDjQT1TBFBzuL3les8N+JEycq994qqkmTJjrfLzQ0FC+//DJ27tyJ3bt3IyQkBBs2bMCLL75ocDyFMRXGI0W+OleUiCixm5ubl9iu6G01Ct9rxYoVWgPWALQGuPWVn5+PLl26aA3GFyptchZ9JkQsfl+zop+xIsfUh6ETNebn52PQoEH48MMPS6wr/KMFUHabGmL06NGYNm0avvjiC6xfvx5PPvkkvL29ARQUn35+fvDz88P333+Phg0bIjExEf7+/qV+va0q+krnzp2RkJCA3bt3Y9++fRgxYgT69etX7j3wiIiIiAylVqvRokWLEsvz8/Mxb948vPTSSyXW2djY4MqVK3j++ecxadIkLFiwAE5OTjhy5AjGjx9f7u3nzMzMyqyXisZWNB7AsHq7Tp06CA8Px9GjR/Hzzz/jiy++wOzZs3HixAll/pSyYgSAQYMGwcPDAytWrICbmxvy8/PRrl07pRYsr9YtL4+GKKuWL1SZAf6y6uvCf3fu3InGjRtrbWfIRODFeXh4IDY2FuHh4di3bx8mT56Mjz/+GBEREZWayDA/Px+urq7K/DdFFc7v89Zbb2Hv3r345JNP0KJFC6hUKgwbNqzc21iUV+8XKt4W1XW+RUQlcaCZqBbp3LkzLly4oLOgLUvLli3RsmVLTJ8+HaNGjUJYWJjeA81ladu2LXJzc3HixAn4+voCAFJSUnDx4kXl6uqGDRvixo0bWsVc0cnrnJ2d0bhxY8THx2P06NE6j1P41+y8vLwSy4sv69y5MzZu3KhMXKGPDh06YPXq1Tpnl3ZwcICbmxuOHDmCnj17KsuPHj2Kp59+usLH1McTTzwBlUqF/fv3Y8KECeVu37lzZ2zZsgVeXl6VupLB0tKyRF51GTp0KCZOnIg9e/Zg/fr1GDNmjLLujz/+QHJyMj744AN4eHgAgDIJZWmqoq8ABW0WGBiIwMBADBs2DAEBAUhNTS31ahkiIiKiqtS5c2fExsaWWrOfPn0aubm5+PTTT2FuXjDt0qZNm7S20VXnAgX1UtH73V66dAmZmZllxqNvDVWcmZkZunfvju7du2Pu3Lnw9PTEtm3bMGPGDAAFk47fv39fGTA+fvw47Ozs4O7ujpSUFMTExGD58uXo0aMHAODIkSNa79+hQwd8++23pdZp5eVRH/rU8obQt04uqm3btrC2tkZiYqIyl0lVUalUGDx4MAYPHowpU6agdevWOH/+PDp37lxqHypP586dcePGDVhYWJQ618nhw4cxduxY5ZwyPT29xMR8uo5fXr1fVkzVcb5FRCVxMkCiWuTtt9/GsWPHMGXKFERFReHSpUvYsWMHXn/9dZ3b379/H8HBwTh48CCuXLmCX3/9FadOndJ5i42KeOKJJzBkyBC89tprOHLkCM6ePYtXXnkFjRs3xpAhQwAUzDh869YtfPTRR4iLi8OXX36J3bt3a71PaGgoFi1ahKVLl+LixYs4f/48wsLCsHjxYgBAo0aNoFKplMnt7t69C6DgK2rnzp1DbGwskpOT8eDBA4wePRoNGjTAkCFDcPjwYSQkJCAiIgLTpk3DtWvXdH6O4OBgpKWlYeTIkTh9+jQuXbqEtWvXIjY2FkDBX+w//PBDbNy4EbGxsZg1axaioqIwbdo0AKjQMfVhY2ODt99+GzNnzsSaNWsQFxeH48ePY+XKlTq3nzJlClJTUzFq1CicPHkS8fHx+PnnnzFu3DiDikwvLy/s378fN27cwO3bt0vdTq1WY8iQIZgzZw5iYmLw8ssvK+uaNGkCKysrfPHFF4iPj8eOHTuwYMGCMo9bFX3ls88+w4YNG/DHH3/g4sWL+L//+z+4uLgoV18QERERVbe5c+dizZo1CA0NxYULFxATE4ONGzfi3XffBQA0b94cubm5Sp20du1afP3111rv4eXlhfT0dOzfvx/JycnKYHKfPn3wn//8B7/99htOnz6NSZMm6XX1ank1VHEnTpzA+++/j9OnTyMxMRFbt27FrVu3tM4jcnJyMH78eERHRyvfnAwODoa5uTnq1auH+vXr45tvvsGff/6JX375RRmgLjRq1Ci4uLhg6NCh+PXXXxEfH48tW7bg2LFjeuVRX+XV8obQt04uyt7eHm+++SamT5+O1atXIy4uDmfOnMGXX35Z6mSMAJCamoqoqChER0cDAGJjYxEVFYUbN24AAFatWoWVK1fi999/V/qRSqWCp6enEuuhQ4dw/fp1JCcn6/0Z+/XrBx8fHwwdOhR79+7F5cuXcfToUbz77rvKhSMtWrTA1q1bERUVhbNnz+Lll18u8Q1JXcfXp97XpbrOt4hIB9PcGpqIKqq8yQCLTvJw+/ZtASAHDhxQlp08eVL69+8vdnZ2olarpUOHDiUmtyiUnZ0tI0eOFA8PD7GyshI3NzcJDg5WJg7UZzLA4pPtTZs2TXr16qW8Tk1NlTFjxoijo6OoVCrx9/eXixcvau2zbNky8fDwELVaLa+++qosXLhQa8IHEZF169ZJx44dxcrKSurVqyc9e/aUrVu3KutXrFghHh4eYm5urhw/KSlJyUXRPGk0Gnn11VelQYMGYm1tLc2aNZPXXntN7t69qzNPIiJnz54VPz8/sbW1FXt7e+nRo4fExcWJiEheXp7MmzdPGjduLJaWluLt7S27d+/W2r+8Y1ZkMsDCY7/33nvi6ekplpaW0qRJE2VSFF195uLFi/Liiy9K3bp1RaVSSevWreWNN95QJs7o1auXTJs2TeuYxScA2bFjh7Ro0UIsLCxKtFNxO3fuFADSs2fPEuvWr18vXl5eYm1tLT4+PrJjxw6teItPBihS+b7yzTffSMeOHUWtVouDg4P07dtXfvvttzI/AxEREZGhdNXJRe3Zs0d8fX1FpVKJg4ODPP300/LNN98o6xcvXiyurq5K/bxmzZoSddGkSZOkfv36AkBCQkJEROT69evi5+cnarVannjiCdm1a5fOyQCLTxwnUn69XVR0dLT4+/tLw4YNxdraWlq2bKk10Vvh5587d67Ur19f7OzsZMKECVoTyIWHh0ubNm3E2tpaOnToIAcPHiwxmd7ly5flb3/7mzg4OIitra107dpVTpw4oXcei9NVX5dXy5eVs+J01cn6THCXn58vS5culVatWomlpaU0bNhQ/P39JSIiotRjhYWFCYASj8K+sG3bNunWrZs4ODiIWq2WZ555Rvbt26fsf+zYMenQoYNYW1uXyElRxc8FRAomJX/99dfFzc1NLC0txcPDQ0aPHi2JiYlKznr37i0qlUo8PDzkP//5T4nzjNKOX169X9rPVkXO8YjIcGYipdwklYiIiIiIiIioio0dOxZ37tzB9u3bTR0KERFVId46g4iIiIiIiIiIiIgqhQPNRERERERERERERFQpvHUGEREREREREREREVUKr2gmIiIiIiIiIiIiokrhQDMRERERERERERERVQoHmomIiIiIiIiIiIioUjjQTERERERERERERESVwoFmIiIiIiIiIiIiIqoUDjQTERERERERERERUaVwoJmIiIiIiIiIiIiIKoUDzURERERERERERERUKRxoJiIiIiIiIiIiIqJK+X+yOEhP23qXCgAAAABJRU5ErkJggg==",
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAABZoAAAKgCAYAAAAS1si3AAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjkuMiwgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy8hTgPZAAAACXBIWXMAAA9hAAAPYQGoP6dpAAEAAElEQVR4nOzdd3gUVdsG8Ht2s5uekN4ICaGEEkIvASFAQkeqFCmGIirwUsVXsVFEUFEUC6ivCgpIBxEpCggoUgSkN5FekhDS6yabPd8f+TJmk02ySTbZlPt3XbkyO3Nm5pnZmd2ZZ8+cIwkhBIiIiIiIiIiIiIiISklh7gCIiIiIiIiIiIiIqGpjopmIiIiIiIiIiIiIyoSJZiIiIiIiIiIiIiIqEyaaiYiIiIiIiIiIiKhMmGgmIiIiIiIiIiIiojJhopmIiIiIiIiIiIiIyoSJZiIiIiIiIiIiIiIqEyaaiYiIiIiIiIiIiKhMmGgmIiIiIiIiIiIiojJhopmIKq3Vq1dDkiT5L6+uXbvK48eNGyePv337tt48hw4dqtigqdI5dOiQ3jFx+/btClv3/Pnz5fX6+/uX23qSk5MxY8YM+Pn5QaVSyetcvXp1ua2TqjZznheVAb8ryJCK+swuzrhx4+Q4unbtarY4KoOy7ovqvC/5OUZERJURE81EVCGEEPj+++/Rs2dPuLu7Q6VSoVatWggICED37t3x4osv4rfffjN3mJWaMTdLNT15VFO98MIL+Pjjj3H37l1otVpzhwOg4LGYP+kdFxeH1q1by9OVSiW++eYbg/NKkoQRI0YYXM/XX39doOz8+fPLeevIFIo6PojIdCpLAt3UqnMSuarw9/fnd6+RMjIysHz5cnTp0gWurq5Qq9Xw9PRESEgI5s6di7S0NHOHSERkEhbmDoCIaoaxY8di3bp1euMSExORmJiIW7du4eDBg0hMTESXLl3k6W3btsXSpUsrOlQik+nZsyfs7OwAAI6OjuWyjqysLGzevFl+3blzZ/Tr1w9KpRJt27Ytl3WWVUxMDMLDw3H+/HkAgFKpxLfffovRo0cXOs+2bdvw4MED+Pj46I3/9NNPyzVWqp6cnZ31vl/q1atnxmiIqDAjR45EUFAQAMDX19fM0RCVzj///IN+/frh77//1hsfHR2N6OhoHD9+HFOnToWNjY2ZIiQiMh0mmomo3O3Zs0cvydy+fXuEh4fD0tIS9+7dw7Vr13Ds2LEC8zVt2hRNmzatyFCJTKpjx47o2LFjua4jMjISWVlZ8ut58+YhLCysXNeZkZEBpVIJlUpV4nkjIyMRFhaGK1euAABUKhXWrVuHYcOGFTmfVqvF559/jrfeeksed+TIEZw9e7bEMVDNlXvsOjg4YM6cOeYOh4iK0bt3b/Tu3dvcYVAlotVqkZWVBWtra3OHYpTk5GT06dMH//zzDwDAwcEBQ4YMQd26daHVavHw4UOcOnUKSqXSzJESEZkGm84gonK3b98+ebhBgwY4evQoFi1ahDfeeANffvklDh8+jOjoaDz33HN68xXVRnNJbN68Ge3atYO1tTVcXV0xbtw4xMXFGSy7f/9+DB06FD4+PlCr1XB0dET79u3xzjvvIDk5Wa9scW3jFfc44ZkzZzB+/HgEBATAysoK9vb2aNu2LZYtW4aMjIwC++Hbb7+Vxx0+fLjAuiVJQrdu3fTWUbduXYNtWZdk/cXJyMjAa6+9ht69eyMgIACOjo5QqVRwdXVFly5d8OmnnxZozsHQvlu7di3atGlT5Pv06NEjvPTSS+jevTv8/Pxgb28PtVoNDw8P9OzZE2vXroUQwqi4u3fvLq8/IiKiwPTly5fL0z08PORk7oULFzBmzBj4+/vD0tIS1tbWqFOnDrp37465c+fiwYMH8jKKelz5zp07eP7559GgQQNYW1vDysoKPj4+6NSpE2bPni0nYovi7+8PPz8/vXHh4eEGm065du0aXnjhBXl9tra2aNSoEaZPn26wiZX87aCfOXMGffv2hZOTE6ytrfW201j3799HaGiovG1qtRqbN28uNsmsUORcrnz55ZfQaDTy+E8++URvelH++ecfTJ06FY0aNYKNjQ1sbGzQrFkzzJs3D4mJiQXKb968GaNHj0ZQUBDc3d2hVqthZ2eHpk2bYtq0aUbts2vXrmHYsGFwdnaGtbU1QkJCDLahWZJjqjhZWVn43//+h/DwcLi5uUGtVsPd3R2dOnUy+gmRwtrAB0xzTOcuP6/x48cXutzIyEi88sorCA4Ohr29PaysrNCwYUPMnj0bUVFRxcZv6Ngt6vM7/zYmJCRg1qxZ8PX1haWlJQIDA7Fy5UqD++7ChQt48skn4eDgAAcHB/Tq1QunT58uU9MFZT13jT0Oi/Ljjz+id+/e8PDwgEqlgoODA+rVq4dBgwZhyZIl0Ol0ctn9+/djwoQJaNmyJTw9PWFpaQkbGxs0aNAAEyZMwIULFwosP38TCH///TcGDx4MR0dHODs7Y9SoUYiOjgYAHDx4EJ07d4aNjQ3c3NwwceJExMfH6y0v//VDRkYG5s2bh3r16sHS0hL16tXDokWL9H6kM0ZCQgIWLVqEtm3bwtHREZaWlvD398ekSZPkJFJJ/Pbbb+jatStsbW3h7OyMYcOG4caNG0XO88UXX2DYsGFo1KgRXF1d5fejZcuWeOWVV/D48WO5bO61wYIFC+Rxd+7cMdhszT///IMZM2bgiSeegK+vL2xtbWFpaYnatWtjwIAB+Omnn4zero8++khefmBgoN60li1bytPyXh/mbQbJw8ND/i431DyGsddFhjx69AjPP/88PD09YWVlhebNm2Pr1q1Gb1tpr19KQgiBjRs3on///vDy8oJarYaLiwvatm2Ll19+2ahlFNWsSFHX148fP8acOXPQtGlT2Nrays07tGvXDv/5z39w/PhxveXfuXNHnnfBggWFLrek507++G/evIkRI0bITU6cOHECgGm/P8vLBx98IG9j06ZNcevWLaxatQpvvvkmFi5ciK+++gpnz56Fl5eXmSMlIjIRQURUzqZNmyYACADCxcVFXLt2zaj5Vq1aJc+X/+MqNDRUHh8RESGPv3Xrlt48PXv21Hud+9epU6cC65s9e7bBsrl/DRo0EHfu3Cl0XQcPHtRbnp+fnzxt3rx5etM++eQToVQqC11X27ZtRUJCgsH9YOjv4MGDxZbJu59Ksv7ixMTEFLvu8PBwodVqC913nTp1Mup9OnnyZLHrGj9+vN48+ffNrVu3hBBCbN26VR5nbW1dYHs7duwoT589e7YQQohLly4JGxubIte/Z88eeRnz5s2Tx/v5+cnjo6OjhZubW5HLWblyZbH7Pu8xZugvd1s3btworKysCi1nb28vfv75Z71l5z3HWrZsWWC7c5ddmPz7fd68eaJu3bryaysrK7F7926j5h04cKA8/N133wkhhHjw4IGwsLAQAMSgQYMKrCuvrVu3Cmtr60K3v169enrnthBC9OvXr8h96+DgIM6fP1/oPgsODhZ2dnYF5lOr1eLixYvyPCU9pooSExMjWrduXehy8h6DhZ0X+bcj7+eGEKY5pvMuv7g4jxw5IpydnQst6+7uLs6cOVPo+1DYsVvU53febXRxcRGNGjUyuO4vv/xSb70nT540+J5bWVmJ8PBwg9tXnLKeu8Yeh0Ux5jsoPT1dLj916tQiy6rVarFv3z69dURERMjT69atK5ycnArMFxgYKNauXSsUCkWBaV26dCky5u7duxuMZfDgwXrzFXZ8CyHE1atXRZ06dQrdLltb2wLvRVF++ukn+TMs75+zs7MICQmRX4eGhurN17Rp0yL3r4+Pj3jw4IEQouB5buhv1apVQgghNm/eXGzZBQsWGLVt586d05svKipKCCFEUlKS3rXHG2+8Ic+T9xgYPny4wfG5+8LY66L88wcGBhr83pQkyej3rrTXL8ZKS0sTvXv3LnLbCosl7+eYof2Wq7Dr6/T0dBEYGFjkul9++eUCyy8uztKcO3mX36BBA+Hu7l5gW035/WnMMZX3L/8+LUrebX/ppZfE4MGDhbe3t7CyshJNmjQRb731lt5nKBFRVcemM4io3LVo0UIejo2NRaNGjRAcHIy2bduibdu2CA8PR0BAQLms+5dffkFISAjCwsLw008/yY/Z//HHHzh27BhCQkIAAN999x2WLVsmzxccHIwBAwbg9u3bWLduHYQQuH79OoYPHy7X5iitP/74A9OnT5dr6zzxxBMIDw9HQkICvv32W8THx+PkyZOYPHkyvv/+e7mt6o0bN+LUqVMAgICAAEyePFleZr169bB06VLcuHEDn3/+uTz+1VdfhZOTEwDIbRyWdP3FkSQJ9evXR/v27eHt7Q0nJydkZWXh6tWr2Lx5M7RaLfbv34+tW7di+PDhhe4TY94nhUKBpk2bom3btvDw8ECtWrWQkZGBM2fOYOfOnRBCYNWqVXjhhRfQrl27IuMeOHAg6tSpg7t37yI9PR3r1q3DlClTAAAPHjzQa84lt1bnt99+K3fWUrt2bYwZMwa2tra4f/8+Ll68aPSxsXXrVsTExAAAnJycMH78eLi4uODhw4e4evUqfv/9d6OW89prr+H27dtYvHixPO6FF16Q25t1dnbG9evX8cwzz8g1gd3c3BAREQGtVotvvvkGSUlJSE5OxrBhw/D333/Dw8OjwHrOnDkDlUqFcePGoV69erh06VKJm81YuHChfMzZ2Njgxx9/NLqJj9GjR+O3335DfHw8Pv30U4wdOxYrV66Ua8pPmzYNP/zwg8F5b968idGjR8u19IODgzFo0CBkZmZizZo1ePDgAW7cuIGnn34af/zxhzyfk5MTevfujcDAQDg5OUGtViM6Ohrbtm3DvXv3kJSUhJdffhm7d+82uN7z58/D1dUVL7zwAqKjo7FmzRoAQGZmJj7++GN88cUXAEx3TAE5beGfPn1aft20aVP06dMHFhYWOHXqVLE1JcuiJMf05MmT0b9/f7z00kvyuBEjRqBNmzYA/m3PPDExEYMHD5ZrBgYEBGD48OFQqVTYtGkTrl27hkePHmHIkCG4cuUKLC0tC8RV2LFrbE3W2NhYJCQkYMKECXBxccFnn30mv1/vv/8+Jk2aJJcdP348UlJS5NdPP/00AgICsGnTJuzfv9+o9eVlinPX2OOwKHlrb7dt2xb9+/eHVqvFvXv3cOLEiQJPX9jZ2aFbt25o2rSpXIs6NjYWu3btwpUrV5CZmYnp06fj8uXLBtd369YtuLi44KWXXsLNmzfl2qbXrl2Tay6OGjUKf/zxBw4fPgwgp2bw8ePH0aFDB4PLPHjwIMaOHYs6depg69atuHr1KgBg+/btWLt2LcaMGVPkPsjOzsbgwYNx9+5dAICHhwdGjx4NR0dH/PTTTzh58iRSU1MxfPhwXL9+HW5ubkUuLy0tDRMmTJA/w1QqFSZMmAAnJyesXbvWYHNiuTw8PFC/fn0EBATA2dkZkiThwYMH2LRpE2JjY/HgwQMsWrQIK1askK8NfvnlF7n2sJOTE1599VV5eblt+atUKrRq1QqtW7eGm5sbHBwckJKSgj/++AMHDx4EALz11luYOHFigbby82vWrBlcXV3l2tVHjhzB0KFDcfToUWRnZ8vl8n4u5O0QOv/TWfkZe12U37Vr12BjY4Np06ZBp9Ph888/R3Z2NoQQ+OCDD9CzZ88i12uIsdcvxpo9ezb27t0rv/b398fAgQNhb2+P8+fPY9euXSWO0VgHDx7EtWvXAABWVlbyex0VFYV//vlHPt+Af9vOXrx4sfxEQY8ePQrsQ1OcO9evX4ckSRg2bBiaNWuG27dvw9bW1qTfn+XlwYMH8rYDKPBk0eXLl/HGG29g165dOHDgANtoJqLqwZxZbiKqGTIzM0Xz5s2LrBnQrVs3cfXqVb35TFGjuUOHDiIrK0sIIURsbKxeTZqPP/5Yni9vfHXr1tWrWbBw4UK9ZR45csTguoyt0Tx48GB5fK9evYROp5On7d27V6+Gzb179+RpRdVOyVVULcWyrr840dHRYseOHWLFihXi/fffF0uXLhVBQUHy8iZMmCCXLe37lOvOnTtiy5Yt4tNPP5XX5ePjI8+zcOFCo/bJ4sWL5fEtW7aUx3/44Yfy+DZt2sjjp0+fLo9fsmRJgbji4uJEXFyc/Lqw2nHLli2Txz///PMFlpOSkiLXACtOccfhjBkz5GkKhUJcvnxZnvbbb7/pzbto0SJ5Wv5ap4XVPi5MUTXpNm3aVKJ5d+7cKebMmSO//u2334SHh4cAIJo2bSqEEHrl855vs2bNksc3a9ZMaDQaedrVq1f15vvjjz/04sjMzBS//fab+Prrr8WHH34oli5dKsaPHy+Xt7S0FJmZmQb3mUKhEOfOnZOn5a113apVK3l8SY+pwuSvQfjkk0/K51SuGzduFLqPy1qjuTTHdN7159aqzGv58uXydHd3d72nDuLj4/Vq+q5bt85g/IUdu8bWaAYgPv30U3naRx99pDctKSlJCCHE0aNH9cbn1voTIuc9zFtD19gazaY4d409DosSHBwsz3Ps2LEC02/duiWys7P1xmVnZ4sTJ06I1atXi48++kgsXbq0wFNDd+/elcvnrx2Z+z2r0+mEl5eXPF6lUsnzJSQkCJVKZfC7Iv/1w9tvvy1PS0xMFK6urvK0zp07y9MKO7537Nghj1er1eL27dvyNI1Go1djMe+6CrN+/Xq9+L766iu9/Zl3uwx936empor9+/eLL7/8UixbtkwsXbpU78mPgIAAvfJF1dTO79q1a2LDhg3ik08+kb9f89YazX2qpDhDhw6V55kxY4YQQojXX39dADlPCgA5TxNpNBpx//59vf2R98m3oq59jLkuyn9s/fTTT/K0mTNnyuOdnZ2N2q6yXr8UJTY2Vq+We+vWrUVKSopembyf46au0bxt2zZ5XK9evQrEl5GRIe7fv683rqin94Qo/bmT/31bsWJFgWWb6vtTCCEuXrwoli5davTfhg0bjFquoSfx2rVrJ+bNm6f3pAsAMXfuXKOWSURU2bFGMxGVO5VKhcOHD2PRokVYvXq1XvuBuQ4ePIiePXvi4sWLsLe3N9m6J06cCAuLnI86Z2dnuLq6yu085tbASE1Nxblz5+R5hg0bBisrK/l1REQE3nzzTfn10aNH0alTp1LHlLfW5M8//1xo+7JCCBw/fhxPPfVUqddVEetPT0/HlClT8N133+m105nf/fv3C51mzPsE5NQujIiIKLZGT1HrymvSpElYuHChXCv69OnTaN26NTZv3iyXGT9+vDzcuXNnfPzxxwCA119/HTt37kRgYCACAwPRvn17dO7c2ajOXDp16gRJkiCEwJdffomTJ0+iSZMmCAwMRJs2bdCtWzeDtRNL4+jRo/JwmzZt0LhxY73tqVu3Lm7dulWgbF7NmzdHnz59TBIPkLPvOnXqBG9vb6PnmTJlCpYtWwadToenn35aPj6mTZtW5Hx5j/cLFy4YrPWa6+jRo3LnjevWrcPMmTMNfl7l0mg0ePz4scF2FUNCQhAcHCy/zttOad5j2lTHVN7tBIA33nhDPqdyldeTI0D5HNN5t+nRo0eoVatWoWWPHj2KUaNGFRhf1mNXqVRi4sSJ8uv87c3Gx8fD3t5eryY5ADzzzDPysJOTEwYOHCi3hWssU5y7xh6HRencuTPOnz8PIKfGYkhICBo0aIAmTZqgS5cuaNasmV75ffv24dlnn9WrxWfI/fv34evrW2C8n5+f/B0rSRL8/PwQGRkJIOc4y53H0dER7u7uchusRW3P2LFj5WEHBwc8+eSTWLVqFQDINWKLkvdYzMzMLLKd7cLei7zyrzPvsevv748nnnhCrkWc37JlyzBv3jy92vP5laZd2tu3b2P06NHFxm/s92u3bt3k2uhHjhzR+//CCy/gvffeQ3p6Ok6fPq3Xzq+Pjw8aNmxY4viN4ePjg379+smvS3M+5Gfs9YsxTpw4odenxcsvvwxbW1u9MuX5Od62bVtYWlpCo9Hg559/RtOmTREcHIyGDRuiZcuWCAsLK7Y2e36mOHecnZ0L9OMCmO77Eyi/DsgzMzP1Xnt5eeG3336DpaUlhBBo27at/P2xbt06vSfUiIiqKiaaiahCODo6YunSpXj33Xdx6dIlHD9+HAcPHsQPP/yA9PR0AMDdu3exbds2gx2zlVb+jtLyJplyk6IJCQl6Zdzd3fVe50+OFHbjIPJ1Qpe307K8StJBTO6j6KZk6vXPnTvXqARKYfsDMO59AnJu6Ix5bLSodeXl6uqKESNGyB0KffXVV/Dw8JAfW7a0tMTTTz8tl3/qqacwZ84cfPLJJ9BoNDh69KjejZGfnx927dpV7M1Ku3btsGzZMrzxxhtISUnBX3/9hb/++ksvrs2bNxfowKc08h6v+Y9tIOf4zk1WFXZsm+KmPyAgADdv3gQA/P333+jSpQsOHjxoMNFkSN26ddGvXz/s3LlTTqLUqlWr2EfeS3O8//XXX3jmmWeK/OEkV2HHmrHHtKmOqfzbWdIO5wpj7OdaeRzTpvisKuux6+HhoffDY/4fKgr7HvH09CzytTFMce4aexwWZfHixbh58yb27NmDlJQU7Nu3T68Tt9DQUOzevRs2NjZ4+PAhBg0aJD/OXpTCjqX8iay8MeeflvfHlKK2p6jv9fT0dGg0miJ/hDL192be48Xe3h7W1taFxpfXDz/8gBdffLHY5Rv7HZjXoEGD9H50L+uy8zZ/cfbsWcTFxeHPP/8EkPODxYEDB3D8+HEcOXJEPo7zz2dqRZ0P+T/rTLFMY8+xXOb+HK9duzZWr16NadOm4fHjx7h8+bJeEzd2dnb46quvMGLECKPXbYpzp169egYTxqb6/gSAS5cuYc+ePUbH6uvra9R+yP8DaUhIiHyMSJKELl26yInmu3fvIisrq8RNkxERVTZMNBNRhVIoFGjWrBmaNWuGSZMm4cyZM2jVqpU8vTS9thcl/8Va/l6wgYIXgY8ePdJ7nVszJVdum8f5awLnJswBIDk5ucB8eefPvZju1q0b+vbtW2j8JW3bzximXv/GjRvl4W7duuHLL79E3bp1oVQqMXz4cL3awYUx5n1KTU3V6/V+5MiRWLp0Kby9vaFQKNCuXTucPHmy2HXlN23aNDnR/P3336N27dryTdmgQYPk9zvX0qVL8frrr+Po0aO4evUq/v77b/z44494+PAh7ty5g6lTpxba231eM2fOxHPPPYfjx4/j0qVLuH79Ovbu3Yvr16/j8ePHGDduHG7fvl3i7ckvb/z5j21A//jOv625TNFm4Ouvv45Tp05hxYoVAIAbN24gNDQUv/76q9E309OmTcPOnTvl1xMmTChQ2yu/vNvUvHnzIhPTuW2Vbt68WU4Q2NraYsuWLQgNDYW1tTV2796tVyOuMMYc07lMcUw5Ozvrvb59+3ax7cQWJu9nW97PNSCnrczCmPqYzvve1alTp8ja6/lrGucq67Fr7Pto6Hsk73sSFRVV4nWb4twtyXFYGAcHB+zevRv379/H8ePH8ffff+Py5cvYvn070tLScPjwYbz33nuYP38+du7cKSeZJUnC2rVr8eSTT8Le3h6XL182KuFTVJIlfy19Yz169EjvR628+87KyqrIJDOgv3/t7Owwb968Qssa86NC3uMlOTkZ6enpesnmwq4f8n7fent7Y+vWrWjZsiUsLS2xYsUKTJ06tdh1G3Lt2jW9JPOsWbPwyiuvwM3NDZIkwd3dvcQ/fDdp0gQeHh6Ijo5GdnY2Pv30U6SlpUGlUqFdu3bo3Lkzjh8/jt9//73CEs2mOB/Kc5mGPsdzv5dKqrSf4yNHjsTQoUPx559/4sKFC7h+/ToOHjyIM2fOICUlBRMnTkT//v2L/e7NZYpzp6jPcVNdk508eVKv34DihIaGGpVobtCggVxL3JC8x4uFhUWpP+OIiCoTfpIRUbn79ttvkZGRgVGjRhVoFsPOzk7vdVGPRpcXW1tbNG/eXL7J2rJlCxYsWCDXYstNQubKfbQ+t8OqXCdOnJCTtkuXLi20dkzHjh2xY8cOADnJh8mTJxe4YE9KSsKePXv0OlLMezNTWG2x/Dc8hsqVdv2FiY2NlYf79++P+vXrA8i5sS/s0d/SSExM1OtEaNiwYahduzYA4MqVK0bVxDKkdevW6NChA44fP46kpCQsWrRInpa32Qwgp5MqJycn1KpVC3369JEfye/ZsyeGDBkCAAUeoTfk4cOHUCqV8PDwQPfu3dG9e3cA0Pvh5c6dO4iNjYWLi0uptitXx44d5QT8qVOncOXKFfkR/Pw3+LnHdnmQJAmfffYZ1Go1PvroIwA5+zM0NBQHDx406nHg8PBwNGrUCFevXoVCoTAqqZJ3+yMjIzFmzJgCN7MZGRnYvHkzQkNDAegf0wEBAejdu7f8esOGDcWusyRMdUzlb87n7bffxpYtW/RuWu/cuVOg9p0heT+Hz5w5g8zMTKjValy5ckUv0Z9XaY5pCwsL+THxwj6rcn+oio6ORr9+/fSajwAArVaLn376CU888USx21We8ieDNmzYgPnz5wPIqW2c+5lbEpXl3L148SICAwNRu3ZtvaaUZsyYIT+2nnuM5j13HB0dMXLkSDnhZepzpyTWrFkjd4CXlJSkdxzndkJZlLz7NyUlBa1atZKP8VxCCPz6669GfZblX+f3338vN9Fy+/ZtuYmJ/PLu39zvLiCn5mxRP+oWd/2Qd7kAMGbMGLkW+K+//lrqp6u6du0qJ8c/+eQTADnbbm1tjc6dO2Pp0qU4dOiQXjMg+fdrUYy5LqpK2rdvr/e5uHTpUvTv31/vR4jSfI5fu3YNiYmJcHR0RFRUFL777juD88TFxSE5OVluvib3eyU+Pl5OgqempuLq1ato3bo1gOLfA1OfO3mZ6vuzPKlUKvTs2VP+zDl+/Lj8nQrod4LZunVrk/z4QURkbkw0E1G5u3XrFhYsWICZM2eic+fOaNGiBZycnPDo0SO92jmSJJWqx29TmDVrFsaNGwcAuHnzJtq3b4+BAwfi1q1bWLdunVyuXbt28oW3o6MjGjRoINcMWbRoEc6fP4/ExMQiE6wvvvgifvzxRwghcOXKFQQFBWHIkCFwdXVFXFwczp49i99//x2enp56tSXyPjJ8+vRpzJgxA76+vlCr1Zg+fXqBMkBOu7a9e/eGhYUFBgwYgIYNG5Z6/YUJDAzExYsX5X0QHR0NSZKwZs2aItu3LSl3d3fUqlVLfuR4xowZcg2b1atXF2gHrySmTZsm906ekZEBIOcR0h49euiV27hxI+bNm4euXbuiQYMG8PLyQmpqKtavXy+XMebHkt9++w2jR4/GE088gcaNG8Pb2xvZ2dnYtm2bXEatVhd4nLo0pkyZgpUrVyIzMxM6nQ6hoaGIiIiAVqvFN998I5ezt7fHs88+W+b1FefDDz+ESqWSe16/e/cuunTpgl9//bXYZg4kScKmTZtw48YN2NvbG3VTOm3aNHz++efQaDR49OgRmjdvjuHDh8Pb2xtJSUm4cOECDh8+jJSUFLkd17y1Yy9cuIARI0YgKCgIhw4dwq+//lqGrS/IVMdUcHAwevXqhZ9//hkAsGPHDrRq1Qp9+vSBSqXCuXPncPnyZdy4caPYZbVp0wbbt28HkPOUSdu2bdGoUSP8/PPPhZ5npTmmfXx85LZZP/jgA8TGxsLa2lpuC3TcuHFYtGgRYmNjodFo0KFDBwwfPhx169ZFeno6Ll++jEOHDiEuLk5OOJhL+/btERwcLLdlvHDhQty8eRN16tTBpk2bStX+a2U5d+fMmYM///wTYWFh8PX1hZubGx4+fCi3cQz8e4zmPXcSEhLQp08fdO7cGadPn8YPP/xQbjEW5/XXX8fVq1fh5+eHLVu26H03TZo0qdj5+/fvj8DAQFy7dg0A0K9fPwwdOhSNGjWCVqvF33//jUOHDiEyMhIHDx5E3bp1i1zegAED4ObmJidwp0yZgpMnT8LJyQlr165FVlaWwfkCAwPlZkt27dqFSZMmwcfHB7t27Sqyrem81wYxMTEYP348mjRpAkmSMHXqVNSvXx8KhUJ+kmPMmDEYOXIkIiMjS9y2eF7dunWTr/Ny93nuj0JPPPEEJElCcnKyXN7f379EzUUYc11UlTg7O2PixIn44osvAOTUsm3atCkGDRoEBwcHXL58GTt27DCq+ZK8P2YkJSWhdevWaNu2LQ4dOlToDwd///03QkJC0LZtWzRv3hze3t6wsLDA3r179crl/U7y8fGRn0ZcvXo1rKys4ODggHr16mHw4MEmP3fyMtX3JwCMGzdOvg8wtblz52LXrl3Q6XR4+PAhunTpgj59+uDo0aN6521VPGaJiAwyQweERFTD5O3tvKi/l19+WW++wnrFFkKI0NBQeXxERIQ8vqgeuIUounfsvL1XG/oLCAgQt27d0pvniy++MFi2RYsWws3NrdB1ffzxx3o9kxv6y98z/JkzZ4RCoShQztbWVq9cq1atDC5v8+bNZVp/YdavX29wfi8vL9GjRw/5dd5ez0v7Pr3zzjsG1xUUFCRat25t8Jg4ePCgXtn876EQQmRmZgpPT0+9cq+++mqBckuWLCn2OF6+fLlcPu+xn3d/FrbP8v7Nnj3bqP1f3L7MXZ+lpWWh67K1tRW7d+/Wm6ewc8xY+ff7qlWr9Ka/9tprBY6XK1euGJx3586dxa4vb/n859uWLVuEtbV1sfs8V2xsrPD29jZYJiIiotDjqah9VtixUNJjqigxMTF650FR53RR50VkZKRwcnIqML+lpaXo0qWLyY7pWbNmGSw3depUuczvv/8unJ2di122se9DrqLOm8Leq+L228mTJ4WdnZ3B/da9e3f5dd26dYt7K/X2qynP3aK2rTC9evUqct9bWVmJEydOCCFyPkubNWtm1LmTd5/nnZb3u6K47SnsuyL/9UO/fv0MxjRgwACh0+mM2j9XrlwRderUKfZYNPQZbMiOHTsMfg/b29vrfY/n3R/Xr18X9vb2BeaxsLAQo0eP1huXV2RkpLCxsTEYb0xMjBBCiBdeeMHg9LCwMOHj42NwPxfn2rVrBZa3Y8cOeXpQUJDetAkTJhRYRlHHhjHXRUXNX9R1ZmHKcp1pjLS0tGLPOWNiSUtLE/Xq1SswryRJIjw83ODyjh07VuzxPWTIEL14ly9fbrBcv3795DKlOXeKet9ymfL7s7x9/PHHQpKkQuOcNm2auUMkIjIZ/QZGiYjKwcyZM7FlyxZMmTIF7dq1Q506dWBtbQ21Wg1fX18MGTIEu3btwjvvvGPWOJcvX469e/di0KBB8PLygoWFBezs7NCmTRssWrQIZ86cKVDT5rnnnsOKFSvQsGFDqFQq1K5dG3PmzMHvv/9eZJty06ZNw6lTpzBx4kTUr18fVlZWsLW1RYMGDdC7d28sX75c73E6AGjRogXWr1+PVq1a6XVOld/WrVsxePBgODs7F/oIXmnWX5iRI0di06ZNaN68OVQqFVxcXDBixAgcP34c3t7eRi3DWC+//DI+++wzeX97enpi0qRJOHz4cIFmWEpCpVIV6NE8f7MZQE6bzW+++SbCw8Ph7+8PGxsbWFhYwMvLC/369cOPP/5oVI2UJ554Am+//Tb69euHevXqwd7eHhYWFnBzc0NYWBhWr16N999/v9Tbk9/IkSNx5swZTJo0CfXq1YOVlRWsrKzQsGFDTJ06FefPn5cfOa0oixYtkpsWAHKatejatSsuXbpk8nUNHToUFy5cwPTp09GkSRPY2trCysoKAQEB6NatG5YsWYKrV6/K5Z2dnXHkyBEMGTIEDg4OsLa2Rtu2bbFt2zaT13gy1TEF5HS4d/ToUXzxxRfo3r07XFxcYGFhAWdnZ7Rv3x5Tpkwxajmenp44dOgQevToARsbG9jb26Nv3744duxYoe2nluaYfvvttzF9+nT4+PgY7Ogpd7mXLl3C3Llz0bJlS9jb20OtVqNOnTro1KkT3njjDZw+fdpknWaVRZs2bXD06FH069cPdnZ2sLOzQ1hYGH777Tc0aNBALleSJqIqw7n70ksvYcaMGejQoQN8fHygVqthaWmJgIAARERE4M8//0S7du0A5HyW/vrrrxg3bhxcXFxgaWmJoKAgfPnll3rne0Xbtm0bFi5ciHr16kGtVsPf3x8LFizA5s2bjX5UvVGjRjh//jwWL16M9u3bw9HRESqVCj4+Pmjfvj1efPFF/P777+jSpYtRyxswYAD279+PLl26wNraGrVq1cLAgQNx4sQJNGvWzOA89evXx2+//YaePXvCxsYGdnZ2CA0NxYEDBxAeHl7oujw9PbFz50506tSp0LZ1P/nkEyxcuBB+fn5QqVSoU6cOXnrpJezcubPU7cY2bNhQr9axJEl6zfx07txZr3xJ22c29rqoKrG2tsaePXuwfv169O3bFx4eHlCpVHB0dESLFi2M6gwydzkHDhyQv8dsbGzQpUsX7N+/H6NHjzY4T2BgID744AMMGTIEDRs2hKOjI5RKJZycnNCpUycsX768QBM4U6dOxfz58xEQEFDocWLqcyeXKb8/y9u0adNw5MgRDB06FB4eHvJ3c69evbBjxw65GSIioupAEqKUXewSERFVI+vXr8eoUaMA5Nz8GptoJyICgMzMTFhYWBToKDYlJQVBQUFyMyGTJk3Cl19+aY4Qa4zVq1fr/VjI2x0iIiKiisE2momIqMZKSEjA2bNnERUVhddee00eb0wnc0REeV2+fBkDBgzA6NGj0aRJEzg5OeH27dtYuXKlnGQ2thNLIiIiIqKqiIlmIiKqsc6ePVvgUd1OnTph2LBhZoqIiKqye/fuFdoMlFqtxsqVK9G8efMKjoqIiIiIqGIw0UxERDWeJEnw9PTEwIEDsXjx4gKPvhMRFcfX1xezZs3CoUOHcPfuXSQmJsLKygp169ZF165dMWXKFDRq1MjcYRJRBTPmvG/Xrh2+++67CoiGiIiofLGNZiIiIiIiIqJyYEyHk6GhoTh06FD5B0NERFTOWKOZiIiIiIiIqBywXhcREdUkfDaYiIiIiIiIiIiIiMqEiWYiIiIiIiIiIiIiKhMmmomIiIiIiIiIiIioTJhoJiIiIiIiIiIiIqIyYaKZiIiIiIiIiIiIiMqEiWYiIiIiIiIiIiIiKhMmmomIiIiIiIiIiIioTJhoJiIiIiIiIiIiIqIyYaKZiIiIiIiIiIiIiMqEiWYiIiIiIiIiIiIiKhMmmomIiIiIiIiIiIioTJhoJiIiIiIiIiIiIqIyYaKZiIiIiIiIiIiIiMqEiWYiIiIiIiIiIiIiKhMmmomIiIiIiIiIiIioTJhoJiIiIiIiIiIiIqIyYaKZiIiIiIiIiIiIiMqEiWYiIiIiIiIiIiIiKhMmmomIiIiIiIiIiIioTJhoJiIiIiIiIiIiIqIyYaKZiIiIiIiIiIiIiMqEiWYiIiIiIiIiIiIiKhMmmomIiIiIiIiIiIioTJhoJiIiIiIiIiIiIqIyYaKZiIiIiIiIiIiIiMqEiWYiIiIiIiIiIiIiKhMmmomIiIiIiIiIiIioTJhoJiIiIiIiIiIiIqIyYaKZiIiIiIiIiIiIiMqEiWaqtCRJMurv0KFDOHToECRJwpYtW8wdNlavXg1JknD79m153Lhx4+Dv769XTpIk/Oc//6nY4Epo9+7dmD9/vsFpixcvxg8//FCh8eR1+/ZtSJKE1atXl3jey5cvY/78+XrvUXE2btyIpk2bwtraGpIk4ezZsyVeryni69q1K4KCgspt3eZg6PyoSspyLBrj4cOHmD9/frkec0RERFVJVb1PACDHc+jQIXOHAkmS9K71yzu2o0ePYv78+UhISCgwrWvXrujatWu5rNdUbt++jX79+sHZ2RmSJGHmzJmFli3sXin3XvHUqVPlF6iRavo1bFnvQfz9/TFu3LgSz5eWlob58+dXis8AovLARDNVWseOHdP769u3L6ytrQuMb9WqlblD1dOvXz8cO3YMXl5e5g6lzHbv3o0FCxYYnGbuRHNZXL58GQsWLDA60RwTE4OxY8eiXr162Lt3L44dO4aGDRtWmviqujfeeAPbt283dxiV1sOHD7FgwYJKe5FORERU0arqfQIAtGrVqsbGdvToUSxYsMBgonnFihVYsWJFuazXVGbNmoUTJ07gm2++wbFjxzBr1qxCy1bleyVT4TWsYWlpaViwYAETzVRtWZg7AKLCdOjQQe+1m5sbFApFgfGVjZubG9zc3MwdBpnQ33//jaysLIwZMwahoaEmWWZaWhpsbGxMsqyqKncf1KtXz9yh1Ejp6emwsrKCJEnmDoWIiKhEqup9AgA4ODhU2jjNGVuTJk3Mst6SuHjxItq1a4dBgwaZO5QajdewRJUbazRTtZKVlYXXXnsN3t7ecHBwQHh4OK5du1ag3P79+xEWFgYHBwfY2NigU6dOOHDgQLHL1+l0WLRoEQIDA2FtbY1atWohODgYy5cvl8sYajqjKGvWrEHjxo1hY2OD5s2b46effipQ5siRIwgLC4O9vT1sbGzQsWNH7Nq1S6/M/PnzDX7ZFhbPxo0bERISAltbW9jZ2aFXr144c+aMPH3cuHH47LPPAOg/npj7iFVqaiq+/fZbeXzeR92ioqLw/PPPo3bt2lCr1ahbty4WLFgArVZb7P7w9/dH//79sX37dgQHB8PKygoBAQH4+OOPi53XmH21evVqDBs2DADQrVs3Of7CHhkbN24cnnjiCQDAiBEjCmzrjz/+iJCQENjY2MDe3h49evTAsWPH9JaR+9789ddfeOqpp+Dk5FRoctXY+E6ePInOnTvDxsYGAQEBeOedd6DT6fTKJCUlYc6cOahbty7UajV8fHwwc+ZMpKamFrkPZ86cCVtbWyQlJRWYNmLECHh4eCArKwtAznHUs2dPeHl5wdraGo0bN8Yrr7xSYB3jxo2DnZ0dLly4gJ49e8Le3h5hYWHytPyPrWVkZGDu3Ll6sU+dOrVADZj8j3zmyv8oW1pamrwvrKys4OzsjDZt2mD9+vVF7gsAePDgAZ577jn4+vpCrVbD29sbTz31FKKjowudp7BH8Qydp5s3b0b79u3h6Ogov58TJkwAkPMIa9u2bQEA48ePl4+HvNt86tQpDBgwAM7OzrCyskLLli2xadMmvXXkfg788ssvmDBhAtzc3GBjYwONRoOYmBh5+ywtLeHm5oZOnTph//79xe4bIiKiqqI87xNiYmKgVqvxxhtvFJh29epVSJIkX8saap7i5s2bGDlyJLy9vWFpaQkPDw+EhYXp1QQ19ponJiYGU6ZMQZMmTWBnZwd3d3d0794dv//+e9E7yEBsudf9hf3l2rdvHwYOHIjatWvDysoK9evXx/PPP4/Hjx/LZebPn4+XXnoJAFC3bl295k0Aw01nxMXFYcqUKfDx8YFarUZAQABee+01aDQavXK5TRIac19lyN27dzFmzBi4u7vD0tISjRs3xgcffCBfW+ful3/++Qd79uzRuy8ypLh7JQBITk7G5MmT4erqChcXFwwZMgQPHz4ssKzi7tmKUt2vYUuyf1avXo3AwED5/f3uu++M2odAzmfHf//7X3h6esLGxgZPPPEE/vzzzwLljDn3bt++LVdKW7Bggbxfcs/hf/75B+PHj0eDBg1gY2MDHx8fPPnkk7hw4YLR8RKZGxPNVK28+uqruHPnDr766it8+eWXuH79Op588klkZ2fLZdauXYuePXvCwcEB3377LTZt2gRnZ2f06tWr2IvI9957D/Pnz8fTTz+NXbt2YePGjZg4caLBx7+MsWvXLnz66adYuHAhtm7dCmdnZwwePBg3b96Uyxw+fBjdu3dHYmIivv76a6xfvx729vZ48sknsXHjxlKtd/HixXj66afRpEkTbNq0CWvWrEFycjI6d+6My5cvA8hpzuCpp54CoP94opeXF44dOwZra2v07dtXHp/7qFtUVBTatWuHn3/+GW+++Sb27NmDiRMnYsmSJZg0aZJR8Z09exYzZ87ErFmzsH37dnTs2BEzZszA+++/X+R8xuyrfv36YfHixQCAzz77TI6/X79+Bpf5xhtvyAn3xYsX623r999/j4EDB8LBwQHr16/H119/jfj4eHTt2hVHjhwpsKwhQ4agfv362Lx5Mz7//HOD6zMmvqioKIwePRpjxozBjz/+iD59+mDu3LlYu3atXCYtLQ2hoaH49ttvMX36dOzZswcvv/wyVq9ejQEDBkAIUeh+nDBhAtLS0gpc6CUkJGDHjh0YM2YMVCoVAOD69evo27cvvv76a+zduxczZ87Epk2b8OSTTxZYbmZmJgYMGIDu3btjx44dhTbLIoTAoEGD8P7772Ps2LHYtWsXZs+ejW+//Rbdu3cvcHNhjNmzZ2PlypWYPn069u7dizVr1mDYsGGIjY0tcr4HDx6gbdu22L59O2bPno09e/bgo48+gqOjI+Lj40scR37Hjh3DiBEjEBAQgA0bNmDXrl1488035R9lWrVqhVWrVgEAXn/9dfl4ePbZZwEABw8eRKdOnZCQkIDPP/8cO3bsQIsWLTBixAiDP55MmDABKpUKa9aswZYtW6BSqTB27Fj88MMPePPNN/HLL7/gq6++Qnh4eLH7hoiIqCopz/sENzc39O/fH99++22BH/5XrVoFtVqN0aNHFzp/3759cfr0abz33nvYt28fVq5ciZYtW5bqHiMuLg4AMG/ePOzatQurVq1CQEAAunbtWuJH9XOv+/P+/fjjj3BwcEDjxo3lcjdu3EBISAhWrlyJX375BW+++SZOnDiBJ554Qq6c8Oyzz2LatGkAgG3bthXbvElGRga6deuG7777DrNnz8auXbswZswYvPfeexgyZEiB8sbcVxkSExODjh074pdffsFbb72FH3/8EeHh4ZgzZ47cn05ukyKenp7o1KmT3n2RIUXdK+V69tlnoVKp8P333+O9997DoUOHMGbMGL0yxtyzFaYmXMMau39Wr16N8ePHo3Hjxti6dStef/11vPXWW/j111+N2tZJkybh/fffxzPPPIMdO3Zg6NChGDJkSIH9aMy55+Xlhb179wIAJk6cKO+X3B+pHj58CBcXF7zzzjvYu3cvPvvsM1hYWKB9+/YGfxgjqpQEURUREREhbG1tDU47ePCgACD69u2rN37Tpk0CgDh27JgQQojU1FTh7OwsnnzySb1y2dnZonnz5qJdu3ZFxtC/f3/RokWLIsusWrVKABC3bt3Si93Pz0+vHADh4eEhkpKS5HFRUVFCoVCIJUuWyOM6dOgg3N3dRXJysjxOq9WKoKAgUbt2baHT6YQQQsybN08YOqXzx3P37l1hYWEhpk2bplcuOTlZeHp6iuHDh8vjpk6danCZQghha2srIiIiCox//vnnhZ2dnbhz547e+Pfff18AEJcuXTK4vFx+fn5CkiRx9uxZvfE9evQQDg4OIjU1VQghxK1btwQAsWrVKrmMsftq8+bNAoA4ePBgkbHkyj2+Nm/eLI/Lzs4W3t7eolmzZiI7O1sen5ycLNzd3UXHjh3lcbnvzZtvvmnU+oqKLzQ0VAAQJ06c0BvfpEkT0atXL/n1kiVLhEKhECdPntQrt2XLFgFA7N69u8gYWrVqpbcNQgixYsUKAUBcuHDB4Dw6nU5kZWWJw4cPCwDi3Llz8rSIiAgBQHzzzTcF5st/fuzdu1cAEO+9955euY0bNwoA4ssvv5THARDz5s0rsEw/Pz+94zMoKEgMGjSoqE02aMKECUKlUonLly8XWsbQsWjonBei4Hmae14kJCQUuvyTJ08WWH6uRo0aiZYtW4qsrCy98f379xdeXl7ysZn7OfDMM88UWIadnZ2YOXNmoesnIiKq7CrDfcKPP/4oAIhffvlFHqfVaoW3t7cYOnRogXhyr/MeP34sAIiPPvqoyOUbe82Tn1arFVlZWSIsLEwMHjy4yGXmjy2/1NRU0a5dO+Hl5SVu375tsEzu9eCdO3cEALFjxw552tKlSwvcJ+UKDQ0VoaGh8uvPP/9cABCbNm3SK/fuu+8W2M/G3lcZ8sorrxi8tp48ebKQJElcu3ZNHufn5yf69etX5PJyFXavlHtNNmXKFL3x7733ngAgIiMjhRAlu2czpLpfwxq7f3Lv2Vq1aiXfCwohxO3bt4VKpTK4rXlduXJFABCzZs3SG79u3ToBoFTnXkxMTKHns6FlZGZmigYNGhSIgaiyYo1mqlYGDBig9zo4OBgAcOfOHQA5HVDExcUhIiICWq1W/tPpdOjduzdOnjxZZLMC7dq1w7lz5zBlyhT8/PPPBpsWKIlu3brB3t5efu3h4QF3d3c53tTUVJw4cQJPPfUU7Ozs5HJKpRJjx47F/fv3S/zL5s8//wytVotnnnlGbx9YWVkhNDS0zJ0S/PTTT+jWrRu8vb31lt+nTx8AObWOi9O0aVM0b95cb9yoUaOQlJSEv/76y+A85bGvinLt2jU8fPgQY8eOhULx70epnZ0dhg4diuPHjyMtLU1vnqFDh5pk3Z6enmjXrp3euODgYPm4AXLeh6CgILRo0ULvfejVq5dRvYmPHz8eR48e1dtnq1atQtu2bREUFCSPu3nzJkaNGgVPT08olUqoVCq5HesrV64UWK4x+yC3dkH+XpyHDRsGW1tbo5q5ya9du3bYs2cPXnnlFRw6dAjp6elGzbdnzx5069ZNr9aOKeU+Ujh8+HBs2rQJDx48MHref/75B1evXpVrSOV9n/v27YvIyMgCx7yh/d+uXTusXr0aixYtwvHjx+WaR0RERNVJed8n9OnTB56ennItTiDnuvvhw4dycwKGODs7o169eli6dCmWLVuGM2fOFKgVXVKff/45WrVqBSsrK1hYWEClUuHAgQMGr82MlZ2djREjRuDKlSvYvXs3/Pz85GmPHj3CCy+8AF9fX3l9udNLu85ff/0Vtra28hOWuXKvD/NfDxZ3X1XUepo0aVLg2nrcuHEQQhhd67Wkijsey3rPVt2vYY3dP7n3bKNGjdJr+sPPzw8dO3YsNtaDBw8CQIEnEoYPHw4Li4JdnpX13NNqtVi8eDGaNGkCtVoNCwsLqNVqXL9+vUznL1FFYqKZqhUXFxe915aWlgAgJ5Vy26N66qmnoFKp9P7effddCCHkR14MmTt3Lt5//30cP34cffr0gYuLC8LCwnDq1CmTxJsbc2688fHxEEIYfCzL29sbAEr8eHvuPmjbtm2BfbBx40a9ttRKIzo6Gjt37iyw7KZNmwKAUcv39PQsdFxh21se+6ooucsqbH06na7A41SFPV5XUsUdN0DO+3D+/PkC74O9vT2EEMW+D6NHj4alpaX86Nrly5dx8uRJjB8/Xi6TkpKCzp0748SJE1i0aBEOHTqEkydPYtu2bQBQIJlrY2MDBweHYrcvNjYWFhYWBTrVlCQJnp6epXofP/74Y7z88sv44Ycf0K1bNzg7O2PQoEG4fv16kfPFxMSgdu3aJV6fsbp06YIffvhBvlCuXbs2goKCjGo7OvdcnjNnToH3ecqUKQAKnm+GjsGNGzciIiICX331FUJCQuDs7IxnnnkGUVFRJthCIiKiyqG87xMsLCwwduxYbN++XW7yYvXq1fDy8kKvXr0KnU+SJBw4cAC9evXCe++9h1atWsHNzQ3Tp09HcnJyibdz2bJlmDx5Mtq3b4+tW7fi+PHjOHnyJHr37m30D+2GvPDCC9i7dy+2bNmCFi1ayON1Oh169uyJbdu24b///S8OHDiAP//8E8ePHwdQ8HrQWLGxsfD09CzQLrC7uzssLCwKXA8ac31c2Hoq6v4hL2OPx9Les1X3a1hj90/u+1fU/WVRCpvfwsKiwHtoinNv9uzZeOONNzBo0CDs3LkTJ06cwMmTJ9G8efMynb9EFangTzBE1ZirqysA4JNPPim0R2UPD49C57ewsMDs2bMxe/ZsJCQkYP/+/Xj11VfRq1cv3Lt3DzY2NiaN18nJCQqFApGRkQWm5XYWkbtNVlZWAACNRiNfqAAFv6Rzy2/ZskWvJoKpuLq6Ijg4GG+//bbB6bkXbUUxlODKHWfoIhIo2b4yhdw4ClufQqGAk5OT3viK7BnZ1dUV1tbW+OabbwqdXhQnJycMHDgQ3333HRYtWoRVq1bBysoKTz/9tFzm119/xcOHD3Ho0CG5FjOAQtsTNHb7XVxcoNVqERMTo5dsFkIgKipKrkEB5FyUG2qzOf9Nga2tLRYsWIAFCxYgOjpart385JNP4urVq4XG4ubmhvv37xsVd15WVlYG4zJ0UzBw4EAMHDgQGo0Gx48fx5IlSzBq1Cj4+/sjJCSk0HXkvodz58412FYhAAQGBuq9NvQeuLq64qOPPsJHH32Eu3fv4scff8Qrr7yCR48eyW3IERERVXdlvU8Acp4IW7p0KTZs2IARI0bgxx9/xMyZM6FUKoucz8/PD19//TUA4O+//8amTZswf/58ZGZmyv16GHvNs3btWnTt2hUrV67UG1+apHWu+fPn46uvvsKqVavQs2dPvWkXL17EuXPnsHr1akRERMjj//nnn1KvD8i5Hjxx4gSEEHrXL48ePYJWqzXZdb2Li0uF3T+URFnv2ar7Nayx+yf3nq2o+8ui5J3fx8dHHq/Vasvl3Fu7di2eeeYZuc+eXI8fP0atWrWMXg6ROTHRTDVKp06dUKtWLVy+fFnu3KG0atWqhaeeegoPHjzAzJkzcfv2bTRp0sREkeawtbVF+/btsW3bNrz//vuwtrYGkFNzYO3atahduzYaNmwIAHLvwOfPn9dLxO3cuVNvmb169YKFhQVu3LhRbDMGeX9Zz1133mmGflXt378/du/ejXr16hVItBrr0qVLOHfunF7zGd9//z3s7e0L7TCkJPsqf42B0ggMDISPjw++//57zJkzR774SU1NxdatWxESElLqHx5MEV///v2xePFiuLi4oG7duqVaxvjx47Fp0ybs3r0ba9euxeDBg/UucHK3Oe8PGwDwxRdflDpuAAgLC8N7772HtWvXYtasWfL4rVu3IjU1FWFhYfI4f39/nD9/Xm/+X3/9FSkpKYUu38PDA+PGjcO5c+fw0UcfIS0trdD3qk+fPlizZg2uXbtW4IK3KP7+/nj06BGio6Plm9LMzEz8/PPPhc5jaWmJ0NBQ1KpVCz///DPOnDmDkJCQQo+HwMBANGjQAOfOnStwMVpaderUwX/+8x8cOHAAf/zxh0mWSUREVBWY4j6hcePGaN++PVatWoXs7GxoNBq9p8GM0bBhQ7z++uvYunWrXpNxxl7zSJJU4Nrs/PnzOHbsGHx9fUu4RcDXX3+NBQsWYOHChQWaNctdH2Dc9WBJrnHDwsKwadMm/PDDDxg8eLA8/rvvvpOnm0JYWBiWLFmCv/76S+8+47vvvoMkSejWrVuplmtMbeqilOSezZDqfg1r7P4JDAyEl5cX1q9fj9mzZ8vH6507d3D06NFiK0F17doVALBu3Tq0bt1aHr9p0ya548Ncxp57RZ0Hhpaxa9cuPHjwAPXr1y8yVqLKgolmqlHs7OzwySefICIiAnFxcXjqqafg7u6OmJgYnDt3DjExMQV+gczrySefRFBQENq0aQM3NzfcuXMHH330Efz8/NCgQYNyiXnJkiXo0aMHunXrhjlz5kCtVmPFihW4ePEi1q9fL39Z9u3bF87Ozpg4cSIWLlwICwsLrF69Gvfu3dNbnr+/PxYuXIjXXnsNN2/eRO/eveHk5ITo6Gj8+eefcs1PAGjWrBkA4N1330WfPn2gVCoRHBwMtVqNZs2a4dChQ9i5cye8vLxgb2+PwMBALFy4EPv27UPHjh0xffp0BAYGIiMjA7dv38bu3bvx+eefF/sYl7e3NwYMGID58+fDy8sLa9euxb59+/Duu+8Wmbw1dl/ltjH85Zdfwt7eHlZWVqhbt26htaUNUSgUeO+99zB69Gj0798fzz//PDQaDZYuXYqEhAS88847Ri8rP1PEN3PmTGzduhVdunTBrFmzEBwcDJ1Oh7t37+KXX37Biy++iPbt2xe5jJ49e6J27dqYMmUKoqKiCtwodezYEU5OTnjhhRcwb948qFQqrFu3DufOnSv5RufRo0cP9OrVCy+//DKSkpLQqVMnnD9/HvPmzUPLli0xduxYuezYsWPxxhtv4M0330RoaCguX76MTz/9FI6OjnrLbN++Pfr374/g4GA4OTnhypUrWLNmTbE/CCxcuBB79uxBly5d8Oqrr6JZs2ZISEjA3r17MXv2bDRq1MjgfCNGjMCbb76JkSNH4qWXXkJGRgY+/vhjvZ7tAeDNN9/E/fv3ERYWhtq1ayMhIQHLly/Xa+u6Xr16sLa2xrp169C4cWPY2dnB29sb3t7e+OKLL9CnTx/06tUL48aNg4+PD+Li4nDlyhX89ddf2Lx5c5H7OjExEd26dcOoUaPQqFEj2Nvb4+TJk9i7d69eDZOFCxdi4cKFOHDggF7tdSIiouqirPcJuSZMmIDnn38eDx8+RMeOHYtN8p0/fx7/+c9/MGzYMDRo0ABqtRq//vorzp8/j1deeUUuZ+w1T//+/fHWW29h3rx5CA0NxbVr17Bw4ULUrVu3QGKsOMeOHcMLL7yATp06oUePHnJzGLk6dOiARo0aoV69enjllVcghICzszN27tyJffv2FVhe7r3F8uXLERERAZVKhcDAQL22lXM988wz+OyzzxAREYHbt2+jWbNmOHLkCBYvXoy+ffsiPDy8RNtSmFmzZuG7775Dv379sHDhQvj5+WHXrl1YsWIFJk+eLFdUKanC7pWMVZJ7NkOq+zWssftHoVDgrbfewrPPPovBgwdj0qRJSEhIwPz5841qOqNx48YYM2YMPvroI6hUKoSHh+PixYt4//33CzQJaOy5Z29vDz8/P+zYsQNhYWFwdnaGq6sr/P390b9/f6xevRqNGjVCcHAwTp8+jaVLlxq8f7awsEBoaGip+q8hKldm64aQqISM6U168+bNeuMN9aQrhBCHDx8W/fr1E87OzkKlUgkfHx/Rr1+/AvPn98EHH4iOHTsKV1dXoVarRZ06dcTEiRP1el3O7Rk3b2/KhnrvBSCmTp1aYB2Geo7+/fffRffu3YWtra2wtrYWHTp0EDt37iww759//ik6duwobG1thY+Pj5g3b5746quvDPbu/MMPP4hu3boJBwcHYWlpKfz8/MRTTz0l9u/fL5fRaDTi2WefFW5ubkKSJL3lnD17VnTq1EnY2NgIAHq9RMfExIjp06eLunXrCpVKJZydnUXr1q3Fa6+9JlJSUorcx7m9OW/ZskU0bdpUqNVq4e/vL5YtW6ZXrrD31th99dFHH4m6desKpVJZaG/IuQo7vnL3Y/v27YWVlZWwtbUVYWFh4o8//tArk9tLc0xMTJHbbkx8oaGhomnTpgXKGzrGUlJSxOuvvy4CAwOFWq0Wjo6OolmzZmLWrFkiKirKqDheffVVAUD4+vrKvT/ndfToURESEiJsbGyEm5ubePbZZ8Vff/1lsAfrws5fQ7Gnp6eLl19+Wfj5+QmVSiW8vLzE5MmTRXx8vF45jUYj/vvf/wpfX19hbW0tQkNDxdmzZwucR6+88opo06aNcHJyEpaWliIgIEDMmjVLPH78uNh9cO/ePTFhwgTh6ekpVCqV8Pb2FsOHDxfR0dFCiMKPxd27d4sWLVoIa2trERAQID799NMCPXb/9NNPok+fPsLHx0eo1Wrh7u4u+vbtK37//Xe9Za1fv140atRIqFSqAr1Unzt3TgwfPly4u7sLlUolPD09Rffu3cXnn38ul8n9XDp58qTecjMyMsQLL7wggoODhYODg7C2thaBgYFi3rx5IjU1VS6XG3dhvdATERGZU2W4T8iVmJgorK2tBQDxv//9r9B4cr9To6Ojxbhx40SjRo2Era2tsLOzE8HBweLDDz8UWq1Wns/Yax6NRiPmzJkjfHx8hJWVlWjVqpX44YcfCr0fyXtNkT+23OuHwv5yXb58WfTo0UPY29sLJycnMWzYMHH37t0CyxdCiLlz5wpvb2+hUCj01hUaGqp3PyGEELGxseKFF14QXl5ewsLCQvj5+Ym5c+eKjIyMAtth7H2VIXfu3BGjRo0SLi4uQqVSicDAQLF06dIC17659ynGKOxeqbBrsvz7Ppcx92yFqc7XsCXdP1999ZVo0KCBUKvVomHDhuKbb74xeE4YotFoxIsvvijc3d2FlZWV6NChgzh27FiZzr39+/eLli1bCktLSwFAXk58fLyYOHGicHd3FzY2NuKJJ54Qv//+u8HzI/89OFFlIQkhRPmksImISs7f3x9BQUH46aefzB0KEREREREREREZSWHuAIiIiIiIiIiIiIioamOimYiIiIiIiIiIiIjKhE1nEBEREREREREREVGZsEYzEREREREREREREZUJE81EREREREREREREVCZMNBMRERERERERERFRmViYY6U6nQ4PHz6Evb09JEkyRwhEREREVA6EEEhOToa3tzcUCtZpqCl4fU9ERERUfRl7jW+WRPPDhw/h6+trjlUTERERUQW4d+8eateube4wqILw+p6IiIio+ivuGt8siWZ7e3sAOcE5ODiYI4TqKSMDGDMmZ3jtWsDKyrzxEBERUY2TlJQEX19f+XqPagZe3xMRERFVX8Ze45sl0Zz7OJ2DgwMvRE1JqQT27csZtrXN+SMiIiIyAzafULPw+p6IiIio+ivuGp8N5xERERERERERERFRmTDRTERERERERERERERlwkQzEREREREREREREZUJE81EREREREREREREVCZMNBMRERERERERERFRmViYO4Bq7edNwKOHFbc+jebf4fWfApaWFbfussjWApkZQEY6oEnP+Z+Z8e+wTldwnrmfAD7+FR4qERERERERERERFcREc3la/ylw7wZg51Bx6xzQKOf/ztUVt05jaLNyksYAoFIDSiWg+P8/pRJQKP7/dZ7/ecvkn56WYt7tISIiIiIiIiIiIhkTzeVJCMCjNuDsbu5IzCs1GXgcCXjVAeo2Bpq2BmwdAEtrwMoaUFvl/Nd7bfPvsEpl7i0gIiIiIiIiIiKiIjDRTOVLCCA2CmgeAry0DHB0NndEREREREREREREZGJMNFcn2mxg/9mc4fAWgIXSnNHkyEjLqZU8fDKTzERERERERERERNWUwtwBkAkJAdyIzPkTwryxZGUC8Y+B6HuAsxvQqIV54yEiIiIiIiIiIqJywxrNZFrZ2TnJ5exswKEWENIT6DkMUFuaOzIiIiIiIiIiIiIqJ0w0U9npdEDcIyAtGZAkwM0bGDMTaN0FsHc0d3RERERERERERERUzphoprJ7HAlYWgG9hgNB7YDgDoCTq7mjIiIiIiIiIiIiogrCRDOVXXoqEDYYeP4Nc0dCREREREREREREZsDOAKlssrNzmsvwqWvuSIiIiIiIiIiIiMhMWKOZSi9TA0TdBTxqA516mzsaIiIiIiIiIiIiMhMmmqsTCyXwXO9/h8uT0AGRd4BGLYDJ89kmMxERERERERERUQ3GRHN1IkmAqhzfUiGAjDQgNQlISQTcfYDn3wQCGpffOomIiIiIiIiIiKjSY6KZjJOtBe7fBKysAUcXIKQH0G8MUL+puSMjIiIiIiIiA+Li4rB+/XooFAqMGjUKjo6O5g6JiIiqMSaaq5PsbODQhZzhrs0ApQmbz0iIBVw9gZeXA/WaAiqV6ZZNREREREREJrd06VJcvHgRABAdHY358+ebNyAiIqrWFOYOgExIJ4Cr93P+dMK0y87UAJ51ctpkZpKZiIiIiIio0nv06JHBYSIiovLARDMZJzMD8PE3dxRERERERERkpKeffhpKpRIWFhYYOXKkucMhIqJqjk1nUPHSUgClBRDUztyREBERERERkZHCw8PRsWNHSJIEa2trc4dDRETVHBPNVDRtFhDzAHiiH9Cpl7mjISIiIiIiohKwsbExdwhERFRDMNFMBQkdEBMJZKQBCgXg5QdEvAio1OaOjIiIiIiIiIiIiCohJpqpoMdRgKUV0HcU0KQ10Kgl4FDL3FERERERERERERFRJcVEM+nL1ADpacDwF4Chk8wdDREREREREREREVUBTDRXJxZKYEKPf4dLSpMBRN0FmrYBerNHYiIiIiIiIiIiIjIOE83ViSQB1palm1cIIPoe0KIjMPMdwNbetLERERERERERERFRtaUwdwBUSSTFA9a2wIgpgIuHuaMhIiIiIiIiIiKiKoSJ5uokOxs4fCHnLzu7ZPMmJwANmwNBbcslNCIiIiIiIiIiIqq+mGiuTnQCuHgn508njJ9Pk57zP7R/+cRFRERERERERERE1RoTzZRTm9nVEwh90tyREBERERERERERURXERHNNlxQPpKfmNJmhUpk7GiIiIiIiIiIiIqqCmGiu6RIeA537AVMXmjsSIiIiIiIiIiIiqqKYaK7JtFmAQgG0CQVUanNHQ0RERERERERERFWUhbkDIDNJSQRio4A6DYC2Xc0dDREREREREREREVVhTDTXREIAsdFA1wHAmFmArb25IyIiIiIiIiIiIqIqjInm6sRCCYzt/u9wYdKSAbUV0GcU4OFTMbERERERERERERFRtVWj2mieP38+JEnS+/P09DR3WKYjSYCDTc6fJBkuo9UCMZFAu25Ag6CKjY+IiIiIiIiIiIiqpRpXo7lp06bYv3+//FqpLKLmb3WUEAO4eQOT57MDQCIiIiIiIiIiIjKJGpdotrCwqF61mPPK1gHHr+YMd2gEKPNVWM/WAqnJQP+xgEOtCg+PiIiIiIiIiIiIqqca1XQGAFy/fh3e3t6oW7cuRo4ciZs3b5o7JNPR6YCzN3P+dLqC06PuAnXqA/1GV3xsREREREREREREVG3VqERz+/bt8d133+Hnn3/G//73P0RFRaFjx46IjY01d2jlSwgg4XFO8rnfGMDJ1dwRERERERERERERUTVSo5rO6NOnjzzcrFkzhISEoF69evj2228xe/ZsM0ZWjnQ64MEtwMo6p8mM0P7mjoiIiIiIiIiIiIiqmRqVaM7P1tYWzZo1w/Xr180dSvlJSQRsbIEXPwDadDF3NERERERERERERFQN1aimM/LTaDS4cuUKvLy8zB1K+UlNAtx9gJadzB0JERERERERERERVVM1KtE8Z84cHD58GLdu3cKJEyfw1FNPISkpCREREeYOrXwkJwBZmUCX/oBSae5oiIiIiIiIiIiIqJqqUU1n3L9/H08//TQeP34MNzc3dOjQAcePH4efn5+5QzO92GhAlwX0HJbzR0RERERERERERFROalSN5g0bNuDhw4fIzMzEgwcPsHXrVjRp0sTcYZmOhRIYGQoMaAlkZwIRLwJTFwL2juaOjIiIiIhKaOXKlQgODoaDgwMcHBwQEhKCPXv2yNPHjRsHSZL0/jp06KC3DI1Gg2nTpsHV1RW2trYYMGAA7t+/r1cmPj4eY8eOhaOjIxwdHTF27FgkJCRUxCYSERERUTVSoxLN1Z4kAY5WgC4VCB8CDIjIGUdEREREVU7t2rXxzjvv4NSpUzh16hS6d++OgQMH4tKlS3KZ3r17IzIyUv7bvXu33jJmzpyJ7du3Y8OGDThy5AhSUlLQv39/ZGdny2VGjRqFs2fPYu/evdi7dy/Onj2LsWPHVth2EhEREVH1UKOazqgRMtIAO0dg+GQmmYmIiIiqsCeffFLv9dtvv42VK1fi+PHjaNq0KQDA0tISnp6eBudPTEzE119/jTVr1iA8PBwAsHbtWvj6+mL//v3o1asXrly5gr179+L48eNo3749AOB///sfQkJCcO3aNQQGBpbjFhIRERFRdcIazdVJtg746xZw6SGgsjR3NERERERkItnZ2diwYQNSU1MREhIijz906BDc3d3RsGFDTJo0CY8ePZKnnT59GllZWejZs6c8ztvbG0FBQTh69CgA4NixY3B0dJSTzADQoUMHODo6ymUM0Wg0SEpK0vsjIiIiopqNNZqrE50OuPD/be5ZqM0bCxERERGV2YULFxASEoKMjAzY2dlh+/btch8jffr0wbBhw+Dn54dbt27hjTfeQPfu3XH69GlYWloiKioKarUaTk5Oesv08PBAVFQUACAqKgru7u4F1uvu7i6XMWTJkiVYsGCBCbeUiIiIiKo6Jpqrk6SEf4fZbAYRERFRlRcYGIizZ88iISEBW7duRUREBA4fPowmTZpgxIgRcrmgoCC0adMGfn5+2LVrF4YMGVLoMoUQkPJcK0oGrhvzl8lv7ty5mD17tvw6KSkJvr6+Jd08IiIiIqpGmGiuThIemzsCIiIiIjIhtVqN+vXrAwDatGmDkydPYvny5fjiiy8KlPXy8oKfnx+uX78OAPD09ERmZibi4+P1ajU/evQIHTt2lMtER0cXWFZMTAw8PDwKjcvS0hKWlmyqjYiIiIj+xTaaqwttFqBQmjsKIiIiIipHQghoNBqD02JjY3Hv3j14eXkBAFq3bg2VSoV9+/bJZSIjI3Hx4kU50RwSEoLExET8+eefcpkTJ04gMTFRLkNEREREZAzWaK4uHkcBHj4Arpk7EiIiIiIygVdffRV9+vSBr68vkpOTsWHDBhw6dAh79+5FSkoK5s+fj6FDh8LLywu3b9/Gq6++CldXVwwePBgA4OjoiIkTJ+LFF1+Ei4sLnJ2dMWfOHDRr1gzh4eEAgMaNG6N3796YNGmSXEv6ueeeQ//+/REYGGi2bSciIiKiqoeJ5uogWwto0oGwIcCqX80dDRERERGZQHR0NMaOHYvIyEg4OjoiODgYe/fuRY8ePZCeno4LFy7gu+++Q0JCAry8vNCtWzds3LgR9vb28jI+/PBDWFhYYPjw4UhPT0dYWBhWr14NpfLfJ+HWrVuH6dOno2fPngCAAQMG4NNPP63w7SUiIiKiqk0SQoiKXmlSUhIcHR2RmJgIBweHil59xYnoDGRlAs4Fe/I2GSGA+zeA2gHAi8uAeo1yxqekALa25bdeIiIiIgNqzHUe6eH7TkRERFR9GXutxxrNVV1KImBpBUyeD/jVB3Lb17OyMmtYREREREREREREVHMw0VzVxccAT/QFmrYBJAlo29bcEREREREREREREVENozB3AFQGOh0ACWjXLSfJTERERERERERERGQGrNFclSXGAo5OObWZASAzE1i+PGd4xgxArTZfbERERERERERERFRjsEZzVZaWAjRoBrh55bzOygL++9+cv6ws88ZGRERERERERERENQYTzVVZthao28jcURAREREREREREVENx0RzVZWSBKitgGbtzR0JERERERERERER1XBMNFdV8TFA85CcPyIiIiIiIiIiIiIzYqK5KkpLASQA7cMASTJ3NERERERERERERFTDMdFc1WRqgJiHQEhPoHNfc0dDRERERERERERExERzlRPzEGgQDPznLcDaxtzREBEREREREREREcHC3AGQkYQOSIwDsrVA2GDA1r5gGSsr4ODBf4eJiIiIiIiIiIiIKgATzVXFwzuAtS3QawTQpZ/hMkol0LVrhYZFRERERERERERExERzVaDLBrKzgbGzgD4jzR0NEREREVGNdeBALCIjNQgLc4GXl6W5wyEiIiKqNJhoruyEACLvAK4eQNuuRZfNygK+/DJn+LnnAJWq3MMjIiIiIqopdu+OwcqV9wAA+/bF4n//awq1mt3eEBEREQHsDLByEwJ4cBOwdwKefxNw9Sy6fGYm8J//5PxlZlZMjERERERENcSNG+nycFxcFhISsswYDREREVHlwkRzZZacAKitgNnvAe27mzsaIiIiIqIarVs3J7kGc+vWDnBzU5s5IiIiIqLKg01nVGaJscATfYDmIeaOhIiIiIioxgsKssf//tcUsbGZCAiwgSRJ5g6pUDqdDgcOHEBaWhp69uwJa2trc4dERERE1RwTzZVVUjwgKYAmrYFKfAFLRERERFSTODur4Oxc+ftCWb16NbZv3w4AOHHiBBYvXmzmiIiIiKi6Y9MZlZFOB8THAD2eAnqPNHc0RERERERUxVy9elUevnbtmhkjISIiopqCiebKKCkecHAChj4LKJXmjoaIiIiIiKqYbt26GRwmIiIiKi9sOqMySksGfOsBnr7mjoSIiIiIiKqgPn36oHHjxkhLS0Pjxo3NHQ4RERHVAEw0VzYJsTn/+40p+byWlsBPP/07TERERERENZa/v7+5QyAiIqIahInmyiYxFggbDPQYWvJ5LSyAfv1MHxMRERERERERVWqPHmkwf/4NREZmYtgwD4wa5WXukIiohmEbzZVFViYQfR9QKIC6jQBJMndERERERERERFRFbNv2CPfuZUCr1WH9+kjExWWZOyQiqmFYo7kySIoH4mMAbz+g+yAgvBS1mQEgKwtYty5nePRoQKUyWYhEREREREREVHnZ2irlYbVaAbWaFdiIqGIx0WxuWZlAwmOg32jgmdmAjV3pl5WZCYwfnzM8bBgTzUREREREREQ1xPDhnkhK0uLhQw0GDnSHnR1TPkRUsfipY046HRATCTi5ARFzAGsbc0dERERERERERFWQpaUCU6fWMXcYRFSDsY1mc3pwE7BzAIZOYpKZiIiIiIiIiIiIqizWaK5oOh0Q/whITQasbYHnXgee6G3uqIiIiIiIiIiIiIhKjYnmihZ9H7CxBfqOAtp0BVp2MndERERERERERERERGXCRHNFinsEKBTAuJeAsMHmjoaIiIiIiIiIiIjIJJhorkgpicCTY5lkJiIiIiIik8vIyMC2bduQkZGBIUOGoFatWuYOiYiIiGoQJprLW1I8oPz/3azLBuoHld+6LC2BTZv+HSYiIiIiohpj5cqV+PXXXwEAV65cwdKlS80cEREREdUkTDSXJ3dvIFsLCN3/v/YB6jQov/VZWADDhpXf8omIiIiIqNK6d++ewWEiIiKiisBEc3lavBbIyvz3tVIJWFqZLx4iIiIiIqq2BgwYgA8//BA6nQ6DB7O5PiIiIqpYTDSXJ5Uq56+iaLXA9u05w4MH59RwJiIiIiKiGqFr164IDg6GVquFu7u7ucMhghACkiSZOwwiIqogzERWJxoNMHx4znBKChPNREREREQ1jLOzs7lDIEJUugbzzt9EVIYGw+p4YExdL3OHREREFUBh7gCIiIiIiIiIqPrYfi8GD9M10Alg451oxGmyzB0SERFVACaaiYiIiIiIiMhkHFRKeVitkGCpZOqBiKgmYNsKRERERERERGQyw+p4IDkrGw/TNRjk6wZbC2XxMxERUZXHRDMRERERERERmYxaqcALDWubOwwiIqpgTDSXo2Tdb8gSURW3wuwM5Hb9EZe9Fci2qrh1F0Et+cJOEWLuMIiIiIiIiIiIiKicMNFcjh5mv4lMcQ8KWFbI+qRsnZxojspeDJFdXu1gCQhkQUAYVdpWasdEMxERERERURlcTkzBwah41LWzRl8fV3OHQ0REVAATzeVIIBsWcIVKcq+YFVrqEP1VTi1mtaUPIJku0awVcdDiMQAJgIAES0hQ5vxJSiB3GJZQwBZKOEApOUAJRzgpnjJZHEREREREpnT+fDLu3s1Ax4614OysMnc4RAbFa7Lw5rmb0Oh0AABLpQJhns7FzEVERFSxmGiuTlQKJD/ja5JFCSGgQxp0SEI2UgEIOCh6wkERBgVsoYBNzn/JRu+1BBUkSTJJDERERERE5eno0QQsWXITALB9+yN89lkjWFmx0zKqfGIzs+QkMwA8TNOYMRoiIiLDmGgmPTqRiSw8hEAWFLCCheQGB6kPbBQt4SCFQSk5mjtEIiIiIiJotVqkp6fD3t6+1Mu4eDFFHn70SIOYmCz4+jLRTKWn1Wrx8ccf4+rVqwgNDcXo0aNNstwAO2u0drbH6bhkOKtVCPdibWYiIqp8mGiuTrQ62PwSAwBI6+kGWJS86YxM3IWVFIhaiv6wkdrBWmoCSeJhQkRERESVx4MHD/Dqq68iLi4O4eHhmDFjRqmW06GDI/bseQytVoeAABt4eqpNHCmVRnx8PDIyMuDl5WXuUEps//79OHjwIABgw4YNaNOmDQIDA8u8XIUkYV6zAMRosuCosoClsrz64yEiIio9ZhCrEUmjg/egkwCAG/G9IUqYaNaJNEhQwl05BQ6KnuURIhERERFRme3atQtxcXEAchJ7w4cPL1VSMjjYHp980giRkRo0a2YHlapmJe+EENi3LxZxcVno2dO1UrRRffToUSxduhRarRZDhw7FuHHjzB1SiQghinxdFpIkwd2KP4bUFPti92Ff3D7Ut6mPid4ToZT4tAURVX5MNBN0Ih1aPIYO6bCWgmEvdTd3SEREREREhXJzc5OHraysYGdnV+pl1a5thdq1rUwRVpWzaVM01q59CAA4dCgeK1c2Nnt/Kz/99BO0Wi0AYMeOHVUu0RweHo5Lly7hypUr6Nq1Kxo1amTukKgKepDxAJ/c/wQCAlfSrsDH0gf9XPuZOywiomIx0VzDaUU8tIiFlVQfDlIv1FIOYFMZRERERFSpDRgwABqNBvfu3UOfPn3K1E6zqSUkZOG77x5CqxUYM8YL7u6W5g6pUP/8kyYPP3iQAY1GZ/bOEH19fXHhwgUAQO3atc0aS2moVCrMmTPHpMsUQkCn00GpZI3WmiJdlw6Bf2vDp2anmjEaIiLjMaNYgwkhoEUMnBUj4aV8HZJk/kfliIiIiIiKo1QqMXLkSHOHYdDy5Xdx6lQiAODBAw0++KDs7fOWl/BwZ5w6lQStVocuXZzMnmQGgIkTJ8LFxQUpKSkYOHCgucMxuwsXLuDtt9+GRqPBlClT0KNHD3OHRBWgvk19POn6JH6O/Rn1beqjr0tfc4dERGQUJpprMB1SoIA1aikGMslMRERERGQCsbFZBocro/bta+GLLxojIUGLBg1szB0OAECtVmP48OEmW15qaiqsrKyqbG3gtWvXIjU1pzbr119/zURzDfKcz3N4zuc5c4dBRFQiNau3C9KjxWNYSY1gLbU0dyhERERERNXC6NGeUKsVsLBQICLC29zhFMvd3RING9qavW3m8rBy5UqMHDkSEyZMwL1798wdTqnUqlXL4HB5SU7WIjJSU+7rISKi6omJ5hpKK+IBALUUQ6rlRSURERFRVbdy5UoEBwfDwcEBDg4OCAkJwZ49e+TpQgjMnz8f3t7esLa2RteuXXHp0iW9ZWg0GkybNg2urq6wtbXFgAEDcP/+fb0y8fHxGDt2LBwdHeHo6IixY8ciISGhIjaxWmrfvhY2bgzGxo3B6NbN2dzh1FgxMTHYvXs3ACAuLg47d+40c0SlM2XKFISFhaFjx4547bXXynVd588nY/z4i3juuUtYubJqJuaJiMi8mGiuRoRagZjlQYhZHgShLvyt1Yo4ZCMOzopRcFIMqcAIiYiIiMhYtWvXxjvvvINTp07h1KlT6N69OwYOHCgnk9977z0sW7YMn376KU6ePAlPT0/06NEDycnJ8jJmzpyJ7du3Y8OGDThy5AhSUlLQv39/ZGdny2VGjRqFs2fPYu/evdi7dy/Onj2LsWPHVvj2VicWFgqoi7gep/Jna2sLa2tr+bWrq6sZoyk9R0dHzJw5E3PnzoWvr2+5ruunn2Kg0egAALt3xyAjI7uYOYiIiPRJQghRfDHTSkpKgqOjIxITE+Hg4FDRq68wV7M6Q4hMqCR3c4ciyxJR0CEDLopn4KGcDUmqmm2VERERUeVUU67zzMXZ2RlLly7FhAkT4O3tjZkzZ+Lll18GkFN72cPDA++++y6ef/55JCYmws3NDWvWrMGIESMAAA8fPoSvry92796NXr164cqVK2jSpAmOHz+O9u3bAwCOHz+OkJAQXL16FYGBxnVkx/edKqPLly9j586d8PHxwciRI2FhwS6KirJmzUNs2hQFAHBzU+Prr5vy6VciIgJg/LUev2lrkGyRBB008FDOgotiPC8aiIiIiKqI7OxsbN68GampqQgJCcGtW7cQFRWFnj17ymUsLS0RGhqKo0eP4vnnn8fp06eRlZWlV8bb2xtBQUE4evQoevXqhWPHjsHR0VFOMgNAhw4d4OjoiKNHjxaaaNZoNNBo/m3HNSkpqRy2mqhsmjRpgiZNmpg7jCrj6ac9YWOjRGxsFp580o33i0REVGJMNFcn2QLWR2IBAOlPuABK/QsDAQ2UkgNcFON40UBERERUBVy4cAEhISHIyMiAnZ0dtm/fjiZNmuDo0aMAAA8PD73yHh4euHPnDgAgKioKarUaTk5OBcpERUXJZdzdCz595+7uLpcxZMmSJViwYEGZto2IKhcLCwWGDvUovmANIYTAnj2PcfduBsLDXVC/vo25QyIiqvTYcFg1ImVkw6fHcfj0OA4pX3taQgjokA4FbCBJfNuJiIiIqoLAwECcPXsWx48fx+TJkxEREYHLly/L0/NXHhBCFFuhIH8ZQ+WLW87cuXORmJgo/927x47DiKh6+fnnWKxceQ+7dsXg9df/QXKy1twhERFVesw41gA6kQ4N/oEkqVBLGmDucIiIiIjISGq1GvXr10ebNm2wZMkSNG/eHMuXL4enpycAFKh1/OjRI7mWs6enJzIzMxEfH19kmejo6ALrjYmJKVBbOi9LS0s4ODjo/RERVSf372fIw6mpWiQkMNFMRFQcJpqrOZ3IQCbuwk7RAX7Kb+Bu8R9zh0REREREpSSEgEajQd26deHp6Yl9+/bJ0zIzM3H48GF07NgRANC6dWuoVCq9MpGRkbh48aJcJiQkBImJifjzzz/lMidOnEBiYqJchoioJgoPd4G9fU5ro23bOqJ2bUszR0REVPmxjeZqTotoWEoNUEe5EgrJ2tzhEBEREZGRXn31VfTp0we+vr5ITk7Ghg0bcOjQIezduxeSJGHmzJlYvHgxGjRogAYNGmDx4sWwsbHBqFGjAACOjo6YOHEiXnzxRbi4uMDZ2Rlz5sxBs2bNEB4eDgBo3LgxevfujUmTJuGLL74AADz33HPo379/oR0BEhHVBP7+1vjqq6ZISMiCl5cl+zkiIjICE83VmE6kQiAbrspxTDITERERVTHR0dEYO3YsIiMj4ejoiODgYOzduxc9evQAAPz3v/9Feno6pkyZgvj4eLRv3x6//PIL7O3t5WV8+OGHsLCwwPDhw5Geno6wsDCsXr0aSqVSLrNu3TpMnz4dPXv2BAAMGDAAn376acVuLBFRJWRjo4SNjbL4gkREBACQhBCiolealJQER0dHJCYmVuv23K5mdYYQmVBJBXvyLg9Sqhb1nPYCAG7E90aGzQOoJV/Ut9gBSeJvCkRERFT+asp1Hunj+05ERMURQiBdnIEkWcFaamLucIioBIy91mP2sZrSiLuQoIaTYhiTzERERERUo/z222/4+uuv4ejoiJdffhk+Pj7mDomIqMZ7pPsYybr9AAAXZQScFE+ZOSIiMrUa3RngkiVL5PbtqgOhUuDR4gBELXaFhdodPhbvwFU5ztxhERERERFVGCEEli9fjri4ONy6dQvffvutuUMiIiIAqeKoPJyiO1pEyX+l6c7jgfYNPMr+GDqRVl6hEZGJ1NiqridPnsSXX36J4OBgc4diMkIl4dGLFnBQjIS/8hWoJdbcICIiIqKaR6VSITMzUx6mogmhQybuwQIuUEp25g6HqMpJztIiTpMFX1srKNhpYKGspSCkij/l4eLoRCYis9+CQAbSBSDBGm7KSeUdJhGVQY2s0ZySkoLRo0fjf//7H5ycnMwdjskIZEKCCi6KMUwyExEREVGNJEkSXnnlFTRo0ACtW7fGhAkTKjwGIQRWrFiBMWPG4N1334VWq63wGIwlhA6R2QtxT/sf3Ml+Fhpx09whEVUpN5LTMOnEFfzn1DW8deEWdBXfDVaV4aF4Ge7KafBQvgQXxXgj5tBCQCO/0iG5/IIjIpOokTWap06din79+iE8PByLFi0ydzgmIUQ2MrPvwPGsJ6yUaUDrbEDJ3nGJiIiIqOZp0aIFWrRoYbb1nz17Fnv27AEAHDlyBK1bt0Z4eLjZ4ilKFu4jTZwGAOhEKpJ1v8JSGWDmqIiqjgNRcUjVZgMATsUl4WG6BrVtrMwcVeWkkNRwkHqWoLwNXJQRiMteCwvJDU6KEeUYHRGZQo1LNG/YsAF//fUXTp48ae5QTCoTd2ClqQPfjvsBdAdSUgBbW3OHRURERERU4+RvrqMyN9+hhDMUkh10IgUAoJb8zBwRUdVSx/bfpLK9hRJO6rKf79HpGigkCW5W6jIvq6pzUgxFLWkIJDZJQlQl1KhE87179zBjxgz88ssvsLKqPr8wZolISLCCh3IWgP3mDoeIiIiIqEYLCgrCqFGjcPToUTRr1gxdunQxd0iFUkp28FEuQbLuANRSHTgoepg7JKIqpbe3K5SShLupGQjzdIatRdmeLN5+7xG+ufEQEoApDWujt7eraQKtIGnabHx/Owop2myM8POAl7VlmZfJJDNR1SEJUfENCCUlJcHR0RGJiYlwcHCosPX+8MMPGDx4MJR5mpTIzs6GJElQKBTQaDR608rqalZnCJEJleRusmXmJ0QWNLgJN8VUeGieBez+v/MO1mgmIiIiMzDXdR6ZF993IiLTGHfsEmI1WQAAXxsrrGjXyMwRlcxHV+/iQFQcAMDH2hKft29s5oiIyBSMvdarUTWaw8LCcOHCBb1x48ePR6NGjfDyyy+bNMlc3oQQyEYstIiDldQItZQDzB0SEREREREREZVBHRsrOdHsZ1v1nsSOycj8d1iTWURJIqqOalSi2d7eHkFBQXrjbG1t4eLiUmB8ZadFNAR0cFGMg5vyeVhIzgBSzR0WEREREREREZXSf5v4Yfu9GCglCYN93cwdTok9VccdfyenQZOtw2h/L3OHQ0QVrEYlmqsDIbKRibsABFwUz8DT4mVzh0REREREREREJmCnssDYgKqboG3p7IC1HYOgFaLM7VUTUdVT4xPNhw4dMncIJZKJO1BLteGmnAIHqY+5wyEiIiIiIiKqMR48yMD330fCxkaJZ57xhr19jU+rFGCpVKDsXQASUVXET8QqRAgBgWy4KaeilsJAm8wqFTBv3r/DRERERERERGQyb711Ew8eZAAA0tKy8dJLdc0cERFR5cFEcxUikAUJKqjgabiAWg3Mn1+hMRERERERERHVFHFxWXmGtWaMhIio8lGYOwAyng6pUEg2UEv8xZSIiIiIiIiooo0b5w2FQoK1tRJPP11IJTAiohqKNZqrkGwkwAqNYAFXwwV0OuDKlZzhxo0BBX9HICIiIiIiquq0Wh0SErRwdlZBoZDMHU6N1revG8LDXaBUSlAq+V4QEeXFRHMVIIQOWjyGgA7OypGQpEK+zNLTgaCgnOGUFMDWtuKCJCIiIiIiIpNLStLilVf+xr17GWjUyBZvv90AajUrFZkT9z8RkWH8dKzktCIBGlyHJCnhqoiAo9TX3CERERERERGVyj//pOGbbx7gt9/izB1KlXHkSDzu3cvpfO7q1VScOZNk5oiIiIgMY43mSixbJCEbsailGAp35WSopTrmDomIiIiIiKhU4uOzMHfudWRkZAMALCwU6NixlnmDqgK8vCzlYUmS4OFhWURpIiIi82GiuRLLwiPYK7rDR7m48OYyiIiIiIiIqoDo6Ew5yQwAt2+nmzzRnJqaCttq1oRgy5YOmDXLDxcupKBDB0f4+1ubOyQiIiKDmGiuhIQQyEYcAAF7qROTzEREREREVOXVq2eNxo3tcOVKCuztLdCli5PJlp2RkYE333wTV65cQePGjfHWW2/B0rL61Pzt3t0F3bu7mDsMIiqFbJ2Akp14Ug3BRHMllInbUEjWcJKGwkHBNpmJiIiIiGqydevWYf/+/WjQoAFefPHFKptAVakUWLy4Pu7dy4Cbmxp2dqa7HT1x4gSuXLkCALhy5QqOHz+O0NDQUi3r5MmTyMzMREhICBQKdmtERKVzMzkN8y/cRGKWFuMCvDHY193cIRGVOyaaKxmdyAQg4K1cAEcmmYmIiIiIarSbN29iw4YNAIDHjx9jz549GDRokHmDKgMLCwXq1rUx+XJdXFyKfG2sNWvWYNOmTQCAbt26Yfbs2WWOjYhqpo13ohGfqQUArLrxEP19XKHij1dUzTHRXMlk4QFUkhdspY4ln1mlAubM+XeYiIiIiIiqtPw1alnD1rCgoCBMnz4dp06dQps2bRAUFFSq5Zw6dcrgMBFRSTmq/0252VkoYcFmUakGYKK5EsmpzayDh3I2LKRaJV+AWg0sXWrqsIiIiIiIyEz8/f0REREhN53Rp0+fcl1fYmIWrKyUsLSsegntHj16oEePHmVaRuvWrXHz5k15mIiotCICvKETQFxmFkb4ebD/LaoRJCGEqOiVJiUlwdHREYmJiXBwcKjo1VeYq1mdIUQmVJJx7fBkioewkJxRz+IHKKXq1VMyERER1Qw15TqvOFqtFocOHcKNGzcwatQo2Nvb4+HDh3BwcICdnZ25wzM5c7zvQghoNBpYWVlVyPpqglWrHmDbtmjY2lpg3rwANG5c/Y5VY5w8eRIajQYdO3ZkDXKqECnaFDzOegxfK18oJaW5wyEiKsDYaz3WaK4kdEIDHZJhLXUufZJZpwPu3s0ZrlMH4EURERERUYW7c+cOevfujbt370Kj0aBHjx6wt7fHe++9h4yMDHz++efmDrHKi4yMxGuvvYaYmBj07t0bU6dONXdIVV5GRja2bYsGAKSmavHDD48KTTRfu5aKW7fS0batA1xc1BUZZoVo27atuUOg/3fnzh28++67SE1NxXPPPYdOnTrpTdeKWGSKe7CSGkIhmb7t74pwN+MuXvnnFSRnJyPINghvBbwFCwVTNURUNTETWQkIIZCJu7CRWsFD+VLpF5SeDtStm/OXnm66AImIiIjIaDNmzECbNm0QHx8Pa2trefzgwYNx4MABM0ZWfezcuRMxMTEAgL179yIyMtLMEVV9lpYKODn928+Lh4elwXLnziXjpZf+xmef3cWLL/6N1FRtRYVINdDq1atx7949xMXFYfny5XrTNOIO7mZPxsPsN3Av+0XoRNW8Bz4UfwjJ2ckAgIupF3E747Z5AyIiKgP+TGYGQggIaKBDGnRIgQ7pUEke8FDOglryMXd4RERERFQGR44cwR9//AG1Wr+mp5+fHx48eGCmqKoXFxcXedjS0rJaNkdS0SRJwltv1cf27Y/g4qLCiBGeBsudP5+M3NYXY2Mzcf++BoGBvK2k8qHK08l9/s/UVN0JObmcJe5DI/6BtdSsQuMzBX8rf3nYRmEDN7Wb+YIhs9GJTKSLs7CQ3GAp1TV3OESlxisCM8jELQBKKCVbWKERrKXmqKUYAGtF6XpGJiIiIqLKQ6fTITs7u8D4+/fvw97e3gwRVT8DBw5EWloa7t+/j759+3K/moifnzVmzvQrskybNg7Ytu0RtFodvLwsUacO28im8vPcc88hMzMTycnJGD9+vN40KykQgARAQCHZQiXVNkuMZdXFqQuyRTZuZdxCV6eucLRwNHdI5eJE4gmkZqeic63OUClUxc9Qgwgh8DD7DWSIywAkeCpfgZ2io7nDIioVdgZYjgx1BiiEDpm4CVflJLgqJkIpmfBLJDUVyK3NkZIC2LJDQSIiIqpYNeU6rygjRoyAo6MjvvzyS9jb2+P8+fNwc3PDwIEDUadOHaxatcrcIZoc3/ea5d69DNy9m47gYHvY27PuEplPmu48NLgOW6k91FU00VwTbIjagHXR6wAAbezbYF7APDNHVLloRRxuayPk1/aKbvBQzjZjREQFsTPASiobCVBI9nBSjDBtkpmIiIiIKoVly5ahe/fuaNKkCTIyMjBq1Chcv34drq6uWL9+vbnDIyozX18r+PqyJjOZn40iGDYINncYVIyzKWcNDlMOJRyhlnyRKe4BQJVsAoYoFxPNFUgIHbSIQS1pMNtiJiIiIqqmfHx8cPbsWWzYsAGnT5+GTqfDxIkTMXr0aL3OAYmocnv0SIMNG6KgViswerRXtam9LYSAJEnmDoNqkPYO7XEp9ZI8TPokSQkf5btIEb/DAh6wVbQ2d0hEpVY9vimrAJ3IQCbuQyV5wl053dzhEBEREVE5yMrKQmBgIH766SeMHz++QJuiRFR1LF58CzdupAEAEhK0eOWVqt9BV1z2BsTpNkAlucNbuQAqycvcIVENMNh9MOrb1EdsVizcVe7IyM6AlZJPReSllOzhKPU1dxhEZcZEcznTIQUakQRAAWupGTyUM8qvNrOFBTBlyr/DRERERFShVCoVNBoNawsSVQMxMZny8KNHmUWUrBqyRSLidDnt5GaJSMTrNrMSFFUYH0sfLLu7DI+zHsNL7YUPGnwAewt25EpU3SjMHUB1p0M67BSdUdtiGepafAc7RafyW5mlJfDZZzl/lpbltx4iIiIiKtS0adPw7rvvQqvVmjsUIiqD0aO9IEkS1GoFRozwMHc4ZSbBEhL+rUWqBPsMoopzMukkHmc9BgBEZkbiXMo5M0dEROWB1V7LSaruNJSwgyT5w0v5OtRSHXOHREREREQV4MSJEzhw4AB++eUXNGvWDLa2tnrTt23bZqbIiEruzJkkZGUJtG3rUONq6vft64auXZ2hVEqwtKz6dbQUkhW8lK8hQbcNFpInnBQjynV9MZkxWHZ3GeK18YjwikCIY0i5ro8qN38rf0iQICBgIVnAz8rP3CERUTlgormcxOhWQiNuw8diYcUlmYUAHuf8QghXV6CGXQgSERERVQa1atXC0KFDzR0GUZmtWxeJDRsiAQDh4S6YMaPmJYZsbJTmDsGkbBQtYKNoUSHr+jbyW1xMvQgAeP/O+9jcbDMUUtVP2FPpBNoG4q2At3A+5TzaOLSBr5WvuUMqkWyRjUPxhwAAXZ26QilVr88GIlNhorkcZItkZIirAHRQwKHiVpyWBri75wynpAD5as8QERERUflbtWqVuUOo9nQ6gS1bonHvXgb69HFFkyZ25g6pWjpxIlEe/vPPxCJKEhUkIIp8TRVrXdQ6nE0+iw6OHTDUPefH0L17H+PAgVgEBtpiwgQfKBTlW1mtuX1zNLdvXq7rKC+f3PsEB+IPAAAupFzAzDozzRsQUSXFRLOJZYqHeJj9GrTiEQDWKCYiIiIiMrUff4zBmjUPAQDHjydi1aqmsLPjrY2ptWhhj1u30uRhY507lwyNRoc2bRzKPXFFlVeEVwRis2IRn5XTdAZrgJrP8cTj2BC9AQBwNe0qGto0hGNcfaxYcQ9CCFy9morata3Qu7ermSOtvC6lXpKHc2vqE1FBvBozsUTdT0jRHYUadZCJe+YOh4iIiIgqWN26dYtsy/bmzZsVGE319OhRpjyckZGN5ORsJprLwfjx3mjUyBZZWTo88YSTUfNs2BCJdetymtvo1s0Zs2f7l2OElcOOHTtw4MABNGjQAJMnT4aFBY9FAHBXu+Od+u+YOwwCkJadVuC1Ol0HIf6tZZ6enl3RYVUpnRw7YWvMVnmYiAzjN6AJ6YQGqeIEJCihkKzBJ4OIiIiIap6ZM2fqvc7KysKZM2ewd+9evPTSS+YJqprp29cVf/wRj7i4LISFucDLy9LcIVVLkiShY8daJZrnzz+TDA6XRVxcFn755TFcXNQID3euVJ0S3r59G1999RUA4NatWwgICEC/fv3MHBWRvs61OuOPxD9wLvkc2ju2R1uHtlA4KtC3rxsOHIhFw4a26NWLtZmLMs57HFo7tIYQAsH2weYOh6jSYqLZhBJ025GqOwYLeJg7FCIiIiIykxkzZhgc/9lnn+HUqVMVHE31VLu2Fb7+uilSU7Ph6KgydziUR/Pmdrh+PVUeLishBF599ToePMgAAMTHZ2H4cM8yL9dUsrKy9F5nZmYWUpLIfFQKFd6o+0aB8ZMn+2Ly5KrVKZ85NbNrZu4QiCo9dvlqIlrxGPG6nMcolBI7IyEiIiIifX369MHWrVvNHUa1YWGhYJK5EnrmGW/MnRuA2bP98dJL/mVeXnq6Tk4yA8CNG2lFlK54DRo0wJAhQ+Dg4IDWrVujT58+5g7JKJGRGkybdgWjRp3Hzz8/Nnc4VFnpdEB21WlS48CBWIwadR5TplzG/fsZxc9ARCbHGs0mkiwOIl1cgBp+5g6FiIiIiCqhLVu2wNnZ2dxhEJmcVqvD33+nwdVVBXd3yxI3t1EUGxslnnjCCUeOxMPCQoGwMBeTLdtUxo8fj/Hjx5s7jBJZty4St2+nAwBWrLiHevVssGtXDJydVRgxwhNqddWtk3bp0iU8evQI7du3h42NjbnDqbounQK+eTcn2TxmJtC6s7kjKlJ2tsCnn96DVqtDcrIWa9Y8xNy5AeYOi6jGYaLZRLJFMgAJWbgnt82sgBWkiqw0bmEBRET8O0xEREREFa5ly5Z6bcgKIRAVFYWYmBisWLHCjJERmZ4QAgsW3MTZs0lQqRSYP78egoPtTbqO//7XH4MHu6NWLQu4u7M9blOwsvr3PlWlkrBgwQ0kJOQ0A5KVJTBhgo+5QiuTQ4cO4YMPPgAA1KtXD8uWLYNCUXWT5mb147eA5v9rBe9YVekTzQoFYGmpgFarAwBYWSnNHFH1I4TA6eTTUEtqtlNNhWI20kQcFL2hgC3y9gAoSUrYSu0qLghLS2D16opbHxEREREVMHDgQL1Es0KhgJubG7p27YpGjRqZMTKqSjIzM3H48GHY2NigY8eOlaoDvLxiYjJx9mxOp39ZWTocPhxv8kSzJElo2NDWpMus6Z55xhvJyVrExmbhqac88PbbN+Vp0dEaM0ZWNn/99Zc8fOPGDSQkJPBJktKyr2V4uJKSJAmvvloXa9Y8RK1aKowf723ukAAAmdk6xGgy4WGlhkUV/9Hjk/ufYF/cPgDAKI9ReNrzaTNHRJURE80mopa84awcYe4wiIiIiMjM5s+fb+4QqBpYsmSJ3HnkiBEjMGbMGDNHZFitWiq4uakRE5PTCV6DBv82VRAXFwc7Ozuo1WpzhUeFcHCw0GtWYOhQD2zdGg0bGyUGDXI3Y2Rl06ZNGxw8eBBATvvZtWrVMm9AVdmYmcCO1UC2FnjyGXNHY5TgYHssXRpo7jBkSVla/Pev63iQroG/rRXeadkAthZVt6b18cTjesNMNJMhTDRXJ0IAaf/fOYaNDVBJaz0QERERVWdKpRKRkZFwd9dP1sTGxsLd3R3ZVahjJTKf8+fPGxyubNRqBd59tyF+/TUO3t6W6NzZCQDw0Ucf4cCBA3BwcMDbb78Nf39/8wZKRRo3zgeDB7vDykoJS8uqW+uyS5cucHNzk9toPnAgHl9+eR8ODhZ47bW6CAhgm81Gq+UCRLxo7iiqtBOPE/EgPecJgdupGTgTl4wn3GuZN6gyaG7XHEcSjwAAm86gQlXdbxAqKC0NsLPL+UurXL0xExEREdUUQgiD4zUaDWt2ktFCQkLk4Y4d/4+9+w6PovoaOP6drem9FxJCkxZpiiDSmygoggUBEUUQBQtib9hAxZ++VhRFQBTFAgoWLIgFBUQQAUGkJ4QU0uv2ef9YXIgJkLLJppzP8/Awu3PnzknfPXPm3N4ejOTswsMNXH11lCvJnJWVxbp16wAoLCzkiy++8GR4dSojw0xRkc3TYbhFYKC+USeZ/9W+fXv69euH0WhkwYJUTCY7WVlm3n033dOhiWYm1sfIv+V/GgVivBv3a4C7WtzFnfF3cm/CvdwQfYOnwxENlFQ0CyGEEEII4QYvvfQS4OwT+dZbb+Hn5+faZ7fb+emnn6RHs6iyu+66i/79++Pj40OHDh3OOj7fsYYSx694KZ0I0Vzr0Z7O/v7++Pr6UlJSAkBUVJTHYqlLr76awtq12Xh5aXnkkSQ6d3Zvb2pRO4qi4OOjpaDAuTicn1/jbVkgGqcOgX7c3zGRP/OK6REaQJJ/466o12l0DAwZ6OkwRAMniWYhhBBCCCHc4IUXXgCcFc2vv/46Wu3JpIbBYCAxMZHXX3/dU+GJRkZRFHr06FGlsSZ1L9n2hQCUqbswKgn4KX3qMrwz8vb25oknnuDLL78kJiaG0aNHeyyWulJaamft2mwATCY7X36ZLYnmBujhh5NYtuwYAQE6brwx1tPhiGaoV3gQvcKDPB2GEPVGEs1CCCGEEEK4waFDhwAYMGAAK1euJDg42MMRiebCrhaXf0zxaUbWnzZt2nD77bd7Oow64+WlISzMQHa2cxHE2FijhyMSlWnXzpcnn2zj6TDqnEN1oFEaf9sTIUTjJ4nmOmRz2LCq1vo7ob0M7xObZfYysDfMPzQGjQGtIrctCSGEEKJpWr9+vadDEM2Mj9INP01fV+sMf2WAp0NqNCwWB5s25RMSoqdTp6pXJGs0Ck891ZrPP88mNFTPZZeF12GUQlTuUNkh5hycQ4GtgEnRkxgd0fTuHhBCNC6SaK5DE3dP5EjZkXo7n1eZne9PbF+y/RJM3g0zmds3qC9Pt3na02EIIYQQQtSZo0ePsnr1alJSUrBYLOX2Pf/881WaY968eaxcuZK///4bb29vevfuzTPPPEO7du1cY66//nqWLl1a7riePXuyadMm12Oz2czs2bN5//33KSsrY9CgQbz22mvExcW5xuTl5XHbbbexevVqAEaNGsXLL79MUFBQdT904QGKohClvRsa5sv/Bu3RRw+wa1cRADNmtGDYsLAqHxsT48XUqXFnH1iHbDYHr72Wyt9/l9C3bzDXXBPt0XhE/VqRuYJcWy4Ai9MXc0nYJRg0jXvBOSFE4yaJ5jp01HSUbGs24Yb6ubp96oIfiqJ4dAGQ/zI5TORac/HSeBHvFe/pcIQQQggh6sy6desYNWoULVu2ZO/evXTq1InDhw+jqirdunWr8jw//vgjt956K+eddx42m40HH3yQoUOHsnv3bnx9fV3jhg8fzuLFi12PDYbySYY77riDNWvW8MEHHxAaGspdd93FpZdeytatW119pK+99lqOHj3K2rVrAZg6dSoTJ05kzZo1tflUCNGgmUx2V5IZYMuWwmolmhuC77/P5dtvcwB47710unYNoF0737Mc5X57Ckp4fs8RHMDt7eJJDpZ+1fUhUBfo2vbT+qFX9B6MRgghJNFc54L1wYToQ+rlXHqHnQ2DnVewA40h+Og9U9JgV+2U2kspc5RRai/FqlrRK3paeLXguqjruC76Oo/EJYQQQghRH+6//37uuusuHn/8cfz9/fnkk0+IiIhg/PjxDB8+vMrz/Jv0/dfixYuJiIhg69at9O3b1/W80WgkKiqq0jkKCgpYtGgRy5YtY/DgwQC8++67xMfH89133zFs2DD27NnD2rVr2bRpEz179gTgzTffpFevXuzdu7dcBbUQTYmXl5YOHfzYvdvZ07pHjwAPR1R9Npta7rHdrp5mZN16fd9RMkzOuzde++cor/ds75E4auqttLf4teBXkv2SmRk/s9G0erwu+jpsqo1cay7XRF7ToIrNhBDNkySamxCrUcszz3X3yLntqp1MSyYl9hIUFHy0Pvhp/ejo25Gu/l3pEdCDZL9kfLX1f3VdCCGEEKI+7dmzh/fffx8AnU5HWVkZfn5+PP7441x22WVMnz69RvMWFBQAEBJSvojhhx9+ICIigqCgIPr168dTTz1FREQEAFu3bsVqtTJ06FDX+JiYGDp16sSvv/7KsGHD2LhxI4GBga4kM8AFF1xAYGAgv/76qySaGyOHA/7+A7x9oeU59X56VVUpVL/Coh4lQDMUo5JY7zFU1eOPt+bXX/MJDdWTnNz4qnAHDw5lx45i9uwppl+/EDp08PNIHHrNyQSnQdsw1wo6ne1F2/ks+zMA1uWtI9kvmYEhAz0cVdX4an2ZGT/T02EIIYSLJJpFramqyoGyA0Qborku6jo6+3Um0TuReGM8eo3cuiOEEEKI5sXX1xez2Qw4k7oHDhygY8eOAGRnZ9doTlVVmTVrFn369KFTp06u5y+++GKuvPJKEhISOHToEA8//DADBw5k69atGI1GMjIyMBgMBAcHl5svMjKSjIwMADIyMlyJ6VNFRES4xvyX2Wx2fYwAhYWFNfq4GgtVVRtXpeDS/8HWn5zbY6dC/5H1evpC9UuO218HoEj9gUTtW2gUn3qNoaqMRg0DBtTPHah1wWDQcN99LT0dBre3a8Fr/xzFgcrNbTzbt7q6NJRPjCs0op91IYRoYCTRLGoty5JFoDaQ19q9Rge/Dp4ORwghhBDCoy644AJ++eUXOnTowCWXXMJdd93Fzp07WblyJRdccEGN5pwxYwY7duxgw4YN5Z6/+uqrXdudOnWiR48eJCQk8MUXX3DFFVecdr7/Jk4rS6KeKbk6b948Hnvssep+GI1Obq6VRx/dz5EjJi65JIxp0xrJWiN//lp+u54TzRY11bXtUIuwkY+BhploPquiAvjmI+f28KvBt/6rnv/+u4RvvskmIcGbUaPCa3XRo9ReCoCP1r1fj3hfL+Z1be3WOetLsn8yY8LH8GvBr3T260y/4H6eDkkIIRotSTQ3IcYyGx/3cvbyG7txOGbvuv3ymhwm8q35lNhLuLPFnZJkFkIIIYQAnn/+eYqLnT1f58yZQ3FxMStWrKB169a88MIL1Z5v5syZrF69mp9++om4uDNXCkZHR5OQkMC+ffsAiIqKwmKxkJeXV66qOSsri969e7vGZGZmVpjr+PHjREZGVnqe+++/n1mzZrkeFxYWEh/fSJKw1fDFF8c5fLgMgM8/P87FF4fRooW3h6Oqgtad4O/tJ7frWYBmCEXqDzjUEnw1PdETXe8xuM3S505+LjOPwi1z6vX0hYU2Hn54PyaTHQC9XmHEiJotNv9D3g+8mPoiqqpyW/xtjaY9RH24PuZ6ro+53tNhCCFEoyeJZlFtNoeNw6bD6BQdofpQRoePZnL0ZE+HJYQQQgjRICQlJbm2fXx8eO2112o0j6qqzJw5k1WrVvHDDz/QsuXZb4/PyckhNTWV6GhnYq979+7o9Xq+/fZbrrrqKgDS09PZtWsXzz77LAC9evWioKCA3377jfPPPx+AzZs3U1BQ4EpG/5fRaMRoNNbo42pMAgJOvl3S6TT4+DSOBcKY+hBs+cHZo7nrhfV+eqPSigTtIuzkoSe2UbUdKbPZeWb3YfYXlTEsOpSJ2ae0jzl+rN7jyc+3upLMAOnp5jOMPrMPMj/AptoAeD/z/QaXaFZVOwXqlzjUYgI1I9AqgZ4OSQghRDVJollUi6qqZFgyCNWH8nTrp+nu3x1vbSOo6hBCCCGEqEf5+fl8/PHHHDhwgLvvvpuQkBC2bdtGZGQksbGxVZrj1ltvZfny5Xz22Wf4+/u7+iUHBgbi7e1NcXExc+bMYcyYMURHR3P48GEeeOABwsLCGD16tGvsjTfeyF133UVoaCghISHMnj2bzp07M3jwYADat2/P8OHDuemmm3jjjTcAmDp1KpdeemmzXwjwkkvCyMmxcvhwGcOHhxEWZvB0SFVjMMKFwzwaglbxRUvjWwj8i2PZbM0tAuDDlEwG97mU6M8WgaLA0CvrPZ74eC969w7i11/zCQrSM3RoWI3nitBHkGZOc24bKvZl97QcxxLyHZ8CUKL+Rryu+neACCGE8CxJNIuzUlWVEnsJ+bZ8Sh2l+Gv9uTn2ZvoE9fF0aEIIIYQQDc6OHTsYPHgwgYGBHD58mJtuuomQkBBWrVrFkSNHeOedd6o0z4IFCwDo379/uecXL17M9ddfj1arZefOnbzzzjvk5+cTHR3NgAEDWLFiBf7+J/vIvvDCC+h0Oq666irKysoYNGgQS5YsQas9WZ373nvvcdtttzF06FAARo0axSuvvFLLz0Tjp9NpuOGGql0YEE2D/j/V17Zew6Bnf2ei2S+g3uNRFIXZsxN4/XUdOTkWjh+3EB/vVaO57kq4i+UZy1FRGRc5zs2R1p5ZPXjK9qHGtwinEEIISTSL0yu0FZJlyUJFxUfjQ6wxlmGhw+gX1I/Ofp09HZ4QQgghRIM0a9Ysrr/+ep599tlyCd+LL76Ya6+9tsrzqKp6xv3e3t58/fXXZ53Hy8uLl19+mZdffvm0Y0JCQnj33XerHFtDIYko4W4jYsM4XGJif1EpQ6NDiff1AmqW2HWXzz/P5ptvsgHYubOYt9/uSGCgvtrzBOoCmR433d3huU2AZhhl9l2Ag0DNMPnZFkKIRkgSzaIcVVUptDsTzF4aL/oH96dvUF+6+neljU8btEoj6UsnhBBCCOEhW7ZscbWgOFVsbKyr/YWonezsbB555BHS0tIYPXo0119/vadDEk2EXqPh9nNaeDqMcnJyrK5ti8VBcbG9RonmqliZksW23ELOCw3gsvj6ba/hr+mLl9IOByUYlaSzH3AamZlmnn/+CIWFNm64IZbzzpNez0IIUV8k0SxcLA4LR0xH8NX40j+4P9dFXUevwF5yJVkIIYQQohq8vLwoLCys8PzevXsJDw/3QERNz6effkpqaioAn3zyCRdffDGRkZEejkqIujFqVDibNhWQmWnm4ovDiI2tmwrrrTmFLD7oXPDwz/xiWvp5kxzsf5aj3Euv1P7n+O2309i9uxiA+fMPs2JFsrynFfXGZDexs2QnMYYYYr2k9ZJofiTR3IQ4NApb+kS4tqujxF5CmimNTn6deKjlQ3Tx6yJ/jIUQQgghauCyyy7j8ccf58MPPwScPVZTUlK47777GDNmjIejaxpObUmi0+nw8vJsawMh6lJEhJE33+yA1apiMGjq7DxFNlv5x1Z7nZ1LiKbI6rBy7/57OWg6iE7R8UTSE3Ty6+TpsISoV5JobkKsRi2Pv3J+tY5xqA4K7YVkmjMZEjKEJ1o9QYg+pI4iFEIIIYRo+p577jlGjBhBREQEZWVl9OvXj4yMDHr16sVTTz3l6fCahNGjR5Ofn8/Ro0e59NJLCQyUW+NF06YoCgZD3RYC9Q4L4vvgPLbnFdEjNICeYfW/+KE7TJ4cS16ezdU6w2MFVDt/g/QU6NEPQuRuluYgzZzGQZNzUUubamNTwSZJNItmRxLNzViqKRWTw4S/1p/uAd25J+EeSTILIYQQQtRSQEAAGzZs4Pvvv2fbtm04HA66devG4MGDPR1ak2EwGJg2bZqnwxCiSTFoNTx+bqtGv8hmVJSRZ59t69kgtvwAS//n3P7pc3j4dTDW/s6L9HQz772XjsGgMGlSTK16dR8uO8yKzBUE6AKYFD0JH61PreNr7qIMUYTpw8i2Ohfv7ODbwcMRCVH/JNHcTJXZy7Crdma3mM3Q0KHEG+Mb9YsJIYQQQghPCgkJ4Z9//iEsLIwbbriBF198kYEDBzJw4EBPhyZEs5aSUsZzzx2hpMTOzTfHycJwVSDvC93g0N8nt/NzID8Hc3gYv+b/SrA+mC7+XWo07bx5hzh0qBSAoiI7Dz5Y80UTHzv0mCshalNtzIyfWeO5hJOX1ov5reezsWAjLbxacK7/uZ4OSYh6V3cNnkS9M5bZ+OiCr/jogq8wltlOOy7PmkeqKZVwQzhXR15NC68W8mJCCCGEEKIWLBaLawHApUuXYjKZPByREALgrbfSOHSolKwsMy+8cMTT4Yjmomsf0J+oNm55DoRGMufgHJ5PfZ6HDz7MF9lf1Gja3Fyrazsnx3qGkWfmUB3kWfNOzmXNqfFcorwwQxgjw0dKklk0W1LR3MR4mc68YEOONYdCWyGjI0ZzXdR1+OvqdxVhIYQQQoimqFevXlx++eV0794dVVW57bbb8Pb2rnTs22+/Xc/RCVFeerqZY8fMdOzoi5eX1tPh1CmdTql0W4ja+Drna5amLyVUH8oDiQ8QbYwuP6BNJ3hoAeRkQstzsGgc7CrZ5dq9tXArl4RdUu3zTpoUw6uvpqDXaxg/PvrsB5yGRtEwKXoSi9MX46v15erIq2s8lxBCnEoSzc2EqqqkmdOwq3YmRU1idsJsqWIWQgghhHCTd999lxdeeIEDBw6gKAoFBQVS1SwapF27inj44QPYbA5atfJh/vy26PVN90bXm26Kw2RyUFJiZ8qUWI/GUuhYR5n6J77K+fhp+ng0FlFzFoeF146+hgMHRfYi3st4j9kJsysODI10/gMMQLJfMjuKdwBwXsB5NTr3kCGh9OsXjEYDOl3tfm5HR4zmkrBL0CpatErTvuBUmTKbnfl7jnCwuIzh0aFckxjl6ZCEaBIk0dxM5Fhz0CgaHkx8kDERYyTJLIQQQgjhRpGRkTz99NMAtGzZkmXLlhEaGurhqISoaNOmAmw2BwAHDpRy7JiZhITKq++bguhoI3PntvF0GJQ6tpNl/z8AiviBOCUKL6W1Z4MSNaJBg0FjwORwXkz00lRtkb9HWz7K5oLNBOuD6eTXqcbnNxjcd2HIoDG4ba6qyrXmkm/Lp6VXS4/mJdakZbMlx9ny6r3DGfQOD6KFr/Nr+XXO17yZ9iaBukAeavkQLb1beixOIRqbpnvpWrhYHVZyrDmc63cuYyPHSpJZCCGEEKIOHTp0SJLMosFq397XtR0WZiAysv4TTc2RlcxTHqnY1CyPxSJqR6fRcX/C/bTzaUfvwN5cF31dlY4zaAxcFHxRrZLMjd2Ooh3ctOcmbv/ndp458oxHY9EqlT92qA5eT3sds2omy5rFuxnv1n9wQjRiUtHcxNlUG4dMh+jg24F7E+71dDhCCCGEEEIID7rwwmAee0xLaqqJCy8MavI9mhsKP+VCCpQ1WNQjeCnt8FG6ezqkOpdiSmF/6X6S/ZIJM4RV+bhiq40jJSYS/bzx1TXM789uAd3oFtDN02E0Ot/lfYdFtQDwS8EvFNgKCNQFVunYUnspmws2E2WMor1v+1rHMjI2nEPFJmfrjJhQYn2c1cwKCj4aHwrtzmpnP61frc/lablmK346LQat1JqKuieJ5ibM6rBysOwgrbxb8UzrZ2jn287TIQkhhBBCCCE8rFu3ALp1C/B0GM2KVvEjXvsidgrQEtzk7zLdV7qPe/bfg021EaQL4pV2r1QpoZhrtjJr2z/kmK2EG/W80L0dgQZJW9S19zPe56Osj4g1xvJoy0cJM4RhV+1sK9qGn9bPLYldgESvRNd2mD4MX43v6Qefwq7auX///Rw0HQTg7hZ30ze4b61iMWg1zO6QUOF5RVF4uOXDvJfxHgG6AG6MubFW5/G0/+05wg+ZeQTqdczr0pp436q1ehGipuQ3dhOiKgo7u4cAYFItHDEdI8IQwVvt3yLWy7MLXwghhBBCCCFEc6YoWnSEeDoMl/379/Pmm29iMBi45ZZbiI6OdtvcO4p3YFNtAOTb8jlYdpCu/l3Pety23EJyzFYAjput/JlXRN/IYLfFVW1//Q77dkLH86BN1Vte2NVCzOp+DEpLdEoV4z92BL7+EPwD4dKJ4FU/vdNzrDksz1wOwGHTYT7J+oRpcdN47shzbCjYAMDUmKmMDB9Z63ONDh+Nj9aHTEsmw0OGo9NULSWVZ81zJZkBthVtq3Wi+UzO8T2HJ1o9UWfz15f0MjM/ZOYBUGC18eWxbKa1ifNwVKKpk0RzE2Lx0vLAot5YHBYOlR2ivW97bo69WZLMQgghhBBCNBP79+/HaDQSHx/v6VBEA/fcc8+RlpYGwKuvvsqTTz7ptrmT/ZLRK3qsqpVgXTBJ3klVOi7JzxutomBXVXSKQqKfBxeqPLAbXn8cVBV+WA33vQRRZ/+5sqn5HLXfgU3NQaP4E6/9P/RKxNnPt2AO5GWfmMQK19xau/iryKAYXF8rAK3Zl0WLjrL8YCFRQ7wwBJv4teBXtySaFUVheOjwah8XrA8mySuJg6aDKCh085e2JVURoNfho9VSarcDEOUlPflF3WtWieYFCxawYMECDh8+DEDHjh155JFHuPjiiz0bmBupqkqKKYVOfp14p8M7+Okafz8hIYQQQoiGrrCwsMpjAwKkZYGoG2+99RafffYZiqJwyy23MHx49RM6dUVVVbZvL0KrVUhO9vd0ONX266/5HD9uYcCAEAICmsbbaLPZXOm2O7TxacP/tf0/DpQeINk/ucp9eJP8fZjbpRV/5hXTJdiBzvg0KbbjhGjG4afp49YYz+rYEWeSGcBmg8yjVUo0m9Rd2NQcABxqEaXqNgKVs/wsOhxQkHvy8b8J53rgr/Pn3oR7+fT4p8QaY8la3pONG7IoK+nE/tQAOty1gXP9zq23eCqjVbTMaz2P3wp/I9IQ6bZWHk2dr07L4+cmsfZYDrE+RkbGhXs6JNEMNI2/kFUUFxfH008/TevWrQFYunQpl112GX/88QcdO3b0cHTukWXNwlfry70J90qSWQghhBCingQFBVW556r9RGWREO72zTffAM6k7rffftugEs1vvpnGmjVZAFx1VRQTJ8Z4OKKqW7Mmi4ULjwLwzTc5vPLKOU2ix/KMGTN46aWXMBqN3HTTTW6fv4VXC1p4taj2cR0C/egQ6EeW/VUKHVsByLT/Dx+lBxqlHvvLJveEbz50Jn2j4qFNcpUOMyhJKBhQsaCgw0tpW+m4NcfX8H3e97T1acvU2KloL50Ia94Bbx8YeqU7P5Kz6hnYk56BPQGYlbkXgDY+bSkrCeWBxL70CuxVr/FUxkfrQ//g/p4Oo9FpF+BLu4Cq9cIWwh2aVaJ55Mjyt3o89dRTLFiwgE2bNjWJRLO9uJC1l27DW+ONd0rV+0cJIYQQQojaWb9+vWv78OHD3HfffVx//fX06uV8c75x40aWLl3KvHnzPBWiaAbatGnDjh07AFzFNQ3Fr7/ml9tuTInm3btLXNspKWUUF9vx92/8b6W7d+/O0qVLPR3GGZy8KKei1v/pA0Pgwdfg+DGIjAODsUqHGZQY4nTPUapux1vpiFGp2DbkcNlhFh5bCMD+sv0keiVy8dCx0O9S0OpA57nvr7FjI5k//zB2u8odk7rQK7AKbT+EEOKExv/XsYbsdjsfffQRJSUlrjcAjV2uNZeQfDtQ7OlQhBBCCCGalX79+rm2H3/8cZ5//nnGjRvnem7UqFF07tyZhQsXMmnSJE+EKBoQs9nMsWPHiI6OxsvLfRWaDzzwAF999RXe3t4MGzbMbfP++WcRmzbl07GjH3361GxhtuRkP9avd7YG6Ny5cd15edFFwfzySz6qqtK1a0CTSDI3BiGa8VjUNGwcJ0Qzvn6rmf/l5Q3xrap9mFFpiVFpedr9Zkf5ViUmh+nEgR74GP+jd+8g3n23E3Y7TaZNjBCi/jS73xo7d+6kV69emEwm/Pz8WLVqFR06dPB0WG5hsps8HYIQQgghRLO3ceNGXn/99QrP9+jRgylTpnggItGQFBUVcffdd5OWlkZUVBTPPfccgYFV6197Nr6+vowdO9Ytc/3r6FETc+YcwGZz8Pnnx/Hz09KlS/X7jN92Wwu6dPFHo1Ho27dmyWpP6d07iFdeOYecHGujS5J7kkNV0dSixYhOCSVO94wbI2o42vm2Y1TYKNblrqOtT1suDm1Y60b5+tYuVaSqDhRF46ZoGpfvc7/n8+zPSfBKYHrcdAwaWYBPNC/N7ie/Xbt2bN++nU2bNjF9+nQmTZrE7t27PR1WrZXZy+QXmBBCCCFEAxAfH19povmNN94gPv7sC0mJpu2PP/4gLS0NgIyMDLZs2eLhiM4sPd2MzeZwPU5NrVlxi06nYeDAUPr3D0GjaXz9jVu08KZr1wB0umb3Ftol1/4BabYHyHd8fsZxKSUmJm/8iyt+2sHHKZn1FF3jc1PsTXzQ+QMeb/U4XlrPVzK7S55jJQdsV3DYNhmLmuLpcOpVtiWbF1NfZF/ZPr7L+45Pj3/q6ZBEPVJVlTyzFYfqgVY/DUizq2g2GAyufmU9evRgy5YtvPjii7zxxhsejqx2cqw5xBkigcafNBdCCCGEaMxeeOEFxowZw9dff80FF1wAwKZNmzhw4ACffPKJh6MTVbFhQx4FBTYGDAjBx0fr1rnj4uLQaDQ4HA4URWnwFx86d/ajdWsf9u8vJSLCyIUXNq5q5P/65JNM/vqrmAsvDGLQoFBPh9NoFDt+JdfxHgBl9p14Ka3xUs6pdOyKIxlkm60AvHMwnUtjw/DSuvfnSDRMDtVEjn0JoGJTs8l1rCBKe7enw6o3VtWKg5MX5lwtUUSTZ7E7eOjPA+wpLCHB14unu7TGT9/sUq5AM0w0/5eqqpjN5rMPbMCyLdlYVAtjI8YC6886XgghhBBC1J0RI0awb98+XnvtNf7++29UVeWyyy7j5ptvbvBJRQErVmTw7rvHAPjhh1zmz2/n1vmTkpJ47LHH2Lp1K126dKFdO/fO725eXlrmz29LRoaF8HADRqOGQse3FDjWYlSSCNdMQ1Fq/7YyN9eKVguBgXo3RF25X37JY8kSZzX5778X0rKlN0lJPnV2vqbE8Z91gOxqMZymMD3wlOSKj06L7gztM7KzLRiNmmbV91pVVZRatBRpyBR0aBQfHKpzAU0t7mkL1FhEG6O5JvIa1hxfQwuvFlwWfpmnQxL1ZFteEXsKnd/3R0pMbDiez/CYMA9H5RnN57c5zsUxLr74YuLj4ykqKuKDDz7ghx9+YO3atZ4OrcaOW45TYi9hSswUxgePB271dEhCCCGEEM1eXFwcc+fO9XQYTZaqqnz66accPXqUYcOG0bZtW7fN/ddfJxNqe/eWYreraLXuTQp16dKFLl26uHXOuqTTaYiLc97a/+XX77P0w/sIizQy5a4kDMFxBCm1S6asWpXJ22+nodUqzJqVQN++Ie4Iu4L8fJtrW1XVco+rKteay5tpb1JmN6H7/DIO7dDTvbs/06fHN9nkIYCf0o8i5SfK1F34aXrho3Q77diJLaOxOFSyzRauSohEp6m83ch776XzwQfp6PUa7ruvJeef37STkia7nTk7DrK7oIReYYHc2zGxVj2s69JXadnsKyqlf2QwycH+VT5OUXREax8lz74CnRJGqGZCHUbZMI2PGs/4qPGeDkPUs3CjHgX4t2lGpFfzbW3brBLNmZmZTJw4kfT0dAIDA0lOTmbt2rUMGTLE06HVSJm9jEJbIdPjpjMjbgaKyQQ9ejh3nuaPuRBCCCGEqHv5+fn89ttvZGVl4XA4yu277rrrPBRV07FmzRrefvttAH755RcWLVqEr6+vW+a+6KJg/vijEIBevQLdnmRuzAoLC3nt1UWU2k0czzDx1cfp3DylrNbzfvSRs4+v3a6yalVWnSWa+/cPZt26XPbtK6FTJz/Cw6tfPf3a0dfYXLiZvJ2RpH76J8l+nfnqKzNduwbQq1eQ+4NuIDSKkVjdk1WqxvXWaZnR7ux3b3z8sfPrbrU6+PTTrCafaF6fkcdfBc6Kx1+zC/gjt4juodVfWLOu/ZiZx2v7jgLw/qp0In43EBflxUMPJREdbTzr8d5Ke7x1c+o4SiEallb+PtzbIZFNOQUkB/nRNaTh/WzXl2aVaF60aJGnQ3CrXFsuUcYobo692fnH3tsbGvhiIkIIIYQQTd2aNWsYP348JSUl+Pv7l0vKKIoiiWY3yMjIcG2XlJRQUFDgtkTzkCGhtGrlTWGhjeTkqlfyNRdaxRe9Eo2NLPTEEqi5tNZzxsYa+ftvZ3VxTMzZE1k15eur4/nn27FuXQ4vvZTCLbfs4coro7juupgqz1FkL3Jt29STFdENtDDV7apTtV1YWMjmzZuJi4ujffv2FfbHxBhJSXFeqIiNrbuve0MR8J9+rf993FCklzlbi9rNKoc+L8PLX0NKShkrVmRwxx0JHo5OiIbrwoggLowI8nQYHtcwf7OJs7I4LJTaS7kx+kb0mrrrYyaEEEIIIarnrrvu4oYbbmDu3Ln4+Ej/17owbNgwfvzxRwoLC+nTpw/R0dFunV/69lYuICCAGTNm8PHHHxMdHc3N196FVvGr9bwPPJDExx9nYjAoXHlllBsiPbOvv87B4XDe4Lx6dVa1Es3XR1/PU4efwphcwAWXtaRwj5Fu3QLo2bNq1bgWi4O3304jLc3MyJHhTbaK12KxcPfdd3Ps2DEUReGBBx5wLY76rzlzWrFyZSZ+fjrGjo30UKRu9PtPWH75nB98U/mlbyuuiR1Pe9+TCfYLI4KYUBrFroISLgwPpE1Aw/w9MzAqhK/Tc8iyWgj20eOrcy7k6O0td00LIc5OUVVVPfsw9yosLCQwMJCCggICAppuOflFv1+ERbUQYYhw+9wpphRC9aF8lvwZ/jqptBBCCCFEw9BcXuedia+vLzt37iQpKcnTodQbT3zdDxw4wMGDB+nTpw/e3t71ck7RNLz6agpr12YD0KaNL88/X/mCjIWFhXz66acYDAZGjx6N0Xiy6ramC7p98EE6772XDoBer2HJkk4EBOiwWBwYDE0nkXf06FGmT5/uenzppZcybdo0D0ZUx3Iy4bGpHCo9yHFLFmsHJLDnvFYs77i8UfbuttgdFFhtHNlVxkcfZRIebmD69Dh8fd1fq5hpzuTJw0+SZclifNR4RoWPcvs5hBC1V9XXelLR3AjZHDbMDjPTY6eXTzKXlkKHDs7t3btBKmiEEEIIIerdsGHD+P3335tVorm+bd++ncceewybzcaXX37J/Pnz0enkrU1Dp6oqGzcWYLM56NMnGI3GMwm4m26KIyLCQGmpncsuO31R0Ny5c/nrr78ASE9P584773Ttq2nysKjI7tq2Wh2YTHYWL07ju+9yiInxYu7c1oSG1nwRKauaTq5jBVr8CNFci0bxzHvCyMhIEhISOHLkCBqNhh7/riXUVJWVgMPhaqfiY7JRai/FptrQK43vDmSDVkO41kB4DwM9etRt1f2KrBUcNh0G4K1jbzEoZBC+Wve0QhJC1D95NdbIOFQHKeYUYo2xDA4ZXH6nqsKRIye3hRBCCCFEvbvkkku4++672b17N507d0avL59kGDVKqrVqa9OmTdhszoTO/v37yczMJDY21sNRibNZtCiNzz7LAmDr1iLuvNMz/V4NBk2lLTqyTBae33OEfIuNya1iSElJce1LTU11y7kvvzyCP/4o5NgxM6NHR1Ba6uC773IAOHbMxJdfZjNxYtVbefzXMfvjWFXnQm52ionU3uGOsKtNr9fzzDPP8McffxATE9P0L7zFJcFFI4j9aSWHwhT+6BrDlJgp0uayCrw1J+9I0St6tGg9GI0QorYk0dzIpJnTCNGF8EDiAwTrgz0djhBCCCGE+I+bbroJgMcff7zCPkVRsNvtFZ4X1dOxY0e++OILACIiIggLC/NwRKIqtm0rdG1v3154hpGesfjAMf4qKAHguT1HuGLkSJYvX45Go2HIiC5k29/CoCQRoBlY43OEhxt47bUOrtYb2dkWdDoNNpsDgODg2iUmbWrWKduZtZqrtnx9fenTp49HY6hXV0/H56qbGaooDKlha5Xm6NqoaymwFZBlyeKqyKvw0np5OiQhRC1IormRMTlMXB1xNYNCBnk6FCGEEEIIUQmHw+HpEJq8iy66CH9/f1JTU7nwwgvL9c4VDVfPnoGkppoAOO+8hr8I3jXXXEP//v3R6MooCb6PfEcZAApa/DX9ajX3v0nIsDADDzzQkq+/zqFlS29GjKjdRZMQ7QRy7ItRMBKsuapWc4kaOPF1lSRz1flqfZmdMNvTYQgh3EQSzY2I1WFFg4Zz/c/1dChCCCGEEEJ4VJcuXejSpYunwxBncPz4cfbu3cs555xDWFgYkybF0qmTP3a7ynnnNbzFQie3iiHXYnW1zlAUhejoaEzqPopsZa5xFjWlwrEWiwW73V6jhSnPOy/QbYn3YM1oApShKOjQKHIBRgghRP2qUqK5sLDqtzU119XF60OaOY2W3i25KOgiT4cihBBCCCFO4+jRowQFBeHn51fueavVysaNG+nbt6+HIhOi/mRmZnL77bdTUlKCn58fL774IhEREXTv3nDfL0Z4GXimaxsOHSrl6QcP83LxEaZNi+Oii1rirXSmTN2JRvHHX9O/3HG///478+bNw2q1Mm3aNC655JI6ic/qsFap569WkYXUGotly47x+efHSUz05qGHkvD3r7taQIdqQaPUfKFJIYSoCk1VBgUFBREcHHzGf/+OEXUj25INwLTYafjr/D0cjRBCCCGE+K/09HTOP/98EhISCAoKYtKkSRQXF7v25+bmMmDAAA9GKET92bVrFyUlzn7HxcXF/PXXXx6OqOqWLj3GsWMmCgttvPxyKoqiI0b7BPG6V0jQvolBiS83/oMPPsBisaCqKsuWLXN7PFmWLKbumcoVO69gwdEFbp//TCwWB++8c4z/+78jpKSUnf0AUWVHj5r48MMMSkvt7N5dzOrVxysdl22ysCu/GGsN2zLZ1WJSbXdw0DaGdPs8VFXaO3lCtsnCuoxcDhfLz5Fo2qp0uWz9+vV1HYc4gwxzBlbVypSYKYwIHXH6gYoCHTqc3BZCCCGEEPXmvvvuQ6vVsnnzZvLz87n//vvp378/3377rasgQ1VVD0cpRP0455xz8PLywmQy4eXlRbt27TwdUpV5eWlP2XbWZimKFiMJlY4PDw9n7969gHNxSndbk72GdEs6AF/mfMmosFHEesW6/TyVWbbsGJ9+6lxg8I8/ClmypFOT6T+sqlZK1N/RKSF4KfX//WkwKCiK4vq78O/32qn+LijhoT8PYHY4aB/gy9wurdBpqlQv6FKkrsOsHgCgxPErZcoufJTk2n8AosoKLDbu3PoP+VYbOkXh2a5taBPg4+mwhKgTVUo09+tXu4UORM2ZHCaK7EXMbjGbKbFTzjzYxwcaUaWAEEIIIURT8t1337Fq1Sp69OgBOBesu/rqqxk4cCDr1q0DZIEo0XzExsbywgsvsGvXLjp37kxMTIynQ6qym26KxWp1UFxs5/rrzx73LbfcQmBgICaTiXHjxrk9niBdkGvboBjw0/mdfrCbZWVZXNu5uVYsFhWjseLvMZvDgVZRGtXvuGP2xylTtwMQob2NAM2Qej1/RISR229vwVdfZZOQ4M3IkeEVxvx8PB/ziUrmPYUlHCuz0MLXq1rn0XLqnecKWqXhL8TZ1BwsLiXfagPApqrsyC+qcqJ5a04h36TnkOjnzdUJkWga0c+YaJ5q1ADo559/5o033uDgwYN89NFHxMbGsmzZMlq2bEmfPn3cHWOzVWYvI9WUSveA7lwdebWnwxFCCCGEEGdQUFBQrpWc0Wjk448/5sorr2TAgAG8++67HoxOiPoXFxdHXFycp8OottBQAw8/3KrK4/39/bn55ptrdU67WoQzCVgxiXxZ2GUU24tJMaUwInQEgbr6SxRefnkEf/5ZTEmJjbFjIzEaK1bTfngkk3cPpRNs0PNYchKJftVfELG+OVSzK8kMUKJuJoD6TTQDDBoUyqBBoafd39b/ZDIy2KAj3Hj2Ht3/5a/pi41MytQ9+Ct9MSqVV+aLutPK34cQg55cixW9RqFL8OnboWaaM/k+73tijDF09unNU38dwupQ+TW7gAC9jktiw+oxciGqr9qJ5k8++YSJEycyfvx4tm3bhtlsBqCoqIi5c+fy5Zdfuj3I5khVVdLN6bT3bc8b57whfZmFEEIIIRq4pKQkduzYQZs2bVzP6XQ6PvroI6688kouvfRSD0YnhGioChxrOW5/DdAQqb2jwmKDOo2OSdGTPBJb+/Z+vPNOJ0wmBwEBFdMHJruddw+lowK5FisfHsnkno6J9R5ndWkUI15KO0yqs+WJt3KuhyMqr8Bi47GdBzlUXEanQD+6hvhzUUQQ3jrt2Q+uRLDmSmRFLc8J0Ot4oXtbduQX0crPh/jTVKVbHBbuPXAvOdYcAMaGTsHqOHlhIMdsqfQ4IRqS6jX3AZ588klef/113nzzTfT6k1fTevfuzbZt29waXHNWaC/EoDFwW/xtVU8yl5ZCx47Of6WldRugEEIIIYQo5+KLL2bhwoUVnv832dylS5f6D6oJK3XsoMDxJTY139OhiEYgJyeHnJwcT4dRqTzHCkAF7OQ5PvJ0OBUYDJpKk8wAOkXB95TkZ5ChRjdNe0SM9kkitLcRrZ1DkGbk6Qfa7fD3djh2pN5i+zztOPuKSrGpKrsKijk/NIBob2O9nV+4X4hRT//IkNMmmQHyrHmuJDNAkZrKwEjnJYJobyMjYqSaWTR81f4rsHfvXvr27Vvh+YCAAPLz890RkwByrDn08O/BgOBqrEyuqrB798ltIYQQQghRb5566ilKT3OxX6fTsXLlSo4ePVrPUTVNxY5fyLA/DUC+sop47atoFIOHoxIN1dq1a3nttdcAmDZtGpdccomHIypPTxQ2sp3bSrSHo6kenUbDo52T+CglkzCjgeuSGk/8GsWLAKUK7TLefAp2bQFFgUmzoUfFfEhtlNnszN9zhEPFZVwcE8ZVCZH4nZK81yjgU8NKZtG4RBgi6OLXhe3F2zEoBvoH96dTfAI3t4nDS6tpVD3QRfNV7URzdHQ0+/fvJzExsdzzGzZsICkpyV1xNWvZlmw0aBgbMVZ+kQghhBBCNBI6nY6AgIDT7tdqtSQkSG9MdyhTd7q2rWoGNo5jINaDEYmGbOXKlagnCnFWrVrV4BLNkdp7yHN8iIKWYI1n1+Ypdmwg17EcHRFEau+s0sJx5wT68nDnJpoLMJU5k8zgLOb6Y4PbE81r0rLZklMIwLJD6fQKC+SS2DCyzFYOFpVxcUwoEV5yIa05UBSFR1s+yv6y/YTpwwgzOCuYa9oyRQhPqHaiedq0adx+++28/fbbKIrCsWPH2LhxI7Nnz+aRRx6pixibDYvDwjHzMQCmxEzh0jDp4yeEEEIIIcR/+SrnU8BawI5RSUJPpKdDEg1YfHw86enpAA1ycUKdEky4dpqnw8Chmsi0/w8VGxZSyXG8S4T2Vk+H5Vle3hCbCGmHnY+T2rv9FBql4mOdRsNNreXiWXOk0+g4x/ccT4chRI1VO9F8zz33UFBQwIABAzCZTPTt2xej0cjs2bOZMWNGXcTYbBwxHaGtT1smR0/m8vDLpZpZCCGEEEKISvhouhGvvIhVTcdHORdFaTx9YZszh8OBRlPtZYJqbdasWXzyySeoqsqYMWPq/fyNicqpLRgdHoujQbltLvz2PQSGQrc+bp9+ZGw4h4rLOHiidUasz+l7+AKkmdJYdGwRAFNipxBjjHF7TLWxM6+YdZm5JPl5MzI2TPIaQjQziqrWrJlvaWkpu3fvxuFw0KFDB/z8/Kp8bGFhIYGBgRQUFJzx9sLG7qLfL8KiWogwRJx17FHTUbSKllfbvUrPwJ41O2FJCfz7dSguBl/fms0jhBBCCFFDzeV1nihPvu6iMtu2bWPx4sVs3LiRXbt2YTabMRqNdOrUiV69ejF58mS6detWL7F8/HEG77+fQWSkgUcfbUVkpOcXVsuyZLH6+GoCdAGMDh+NXqP3dEgUOtadaJ0RTpT2bnRKqKdDEv8xe99s9pbuBaC9T3uebfOs+0/y85ew6m0IDIFpD0NUfJUOyzVbuWnzbiwOZ5rp9nbxDI6W7yEhmoKqvtar8aV/Hx8fIiMjURSlWklmUVGhrRC7aufBxAdrnmQWQgghhBCimSgoKGDu3LmkpqZyxRVXMHbsWE+HJE6xf/9+pk6dyvr164mNjWXw4MFMmDCBgIAACgsL2b59O6tWreKVV15hwIABLFy4kNatW9dZPIWFNt55Jx1VVUlNNfHhh5nMnNmizs5XVQ8feJhjFmfrxEJbIVNip3g4IgjQDCJAM8jTYYgzKLYXV7rtNlYrfPQGOBxwPB2+XA433FulQ3PMVleSGSC9zOL++IQQDVq171uy2Ww8/PDDBAYGkpiYSEJCAoGBgTz00ENYrda6iLFJc6gO0s3pDA8dzpiIWt7GpSiQkOD8J7enCCGEEEJ4zM8//8yECRPo1asXaWlpACxbtowNGzZ4OLKm4ZNPPmH37t0UFRWxdOlSjh8/7umQPGrLli1s3LiRGt6s6lbLly8nOTmZI0eOsHLlSg4fPsySJUu44447uOGGG7jjjjtYsmQJhw8fZuXKlRw5coTk5GTef//9OotJr1fQ60++P/L19fzCWnbVTrol3fX4qPmoB6MRjclNMTfhr/XHX+vPlJg6uDih0YDxlPYdPlUvLGzl703PUGelY5hRz9DoEHdHJ4Ro4Kpd0TxjxgxWrVrFs88+S69evQDYuHEjc+bMITs7m9dff93tQTZlxfZi/HX+TIudVvveRT4+cPiwW+ISQgghhBA188knnzBx4kTGjx/PH3/8gdlsBqCoqIi5c+fy5ZdfejjCxs9oPNn2QKPRoNV6PnHoKUuXLuXjjz8GYNCgQdxxxx0ei2X58uVMmDCBCRMmsGDBAnzP0MpPp9MxevRohg4dyvTp0xk/fjyqqnLttde6PS5vby0PPJDExx9nEhVlYNy4KLefo7q0ipZRYaP4LPsz9IqeS8Iu8XRIZ2VVMwDQK57//FWV2e5Ar1HQNKFCrO4B3VneaXndnUCrhakPOyuZA0Ng5HVVPlSjKDzYqSW5FisBeh16D/RkF0J4VrV7NAcGBvLBBx9w8cUXl3v+q6++4pprrqGgoOCsczSXHm5n6tFsdpg5anJete7o25H3O72PTiOLmAghhBCicWsur/POpGvXrtx5551cd911+Pv78+eff5KUlMT27dsZPnw4GRkZng7R7er7624ymXjllVc4evQol112GQMGDKjzczZUM2fO5PCJYpPAwEDeffddj8Sxb98+zj33XMaOHcuSJUsqLPpns9nIzc0lJCQEna78+x6Hw8H111/Pxx9/zI4dO+q0jUZDk2HOwFvrTaAu0K3z7tpVxDvvpBMQoOOWW+IJCald/+d8x2dk298CFMK0UwjSjHJPoHXovUPpfHAkk0C9jseSk2jl7+PpkIQQotGq6mu9al9e8vLyIjExscLziYmJGAyG6k7XLNlUG4fLDtPZrzNzW89lUYdFkmQWQgghhGgi9u7dS9++fSs8HxAQQH5+fv0H1AR5eXlxww03MH36dC666CJPh+NRXbt2dW13797dY3FMmzaNmJgYFixYUC7JbLfbefbZZwkNCycyMpLQsHCeeeYZ7Ha7a4xGo2HBggVER0czdepUT4TvMRl7fFjyaj5r12a7dd65cw+xZ08xmzfns2hR7dty5DvWnNhSKXB8Xuv56lqZzc4HRzIBKLDa+CQly8MRCSFE81Dt7Oatt97KE088weLFi123rJnNZp566ilmzJjh9gCboixLFvFe8bzc7uVKq51rrKwM/n1T89NP4O3tvrmFEEIIIUSVREdHs3///grFGRs2bCApKckzQTUxe/bs4eGHH8ZsNpOcnMwTTzxRoYK2uZg8eTIdO3bEarXSu3dvj8SwdetW1q9fz8qVKyu0y3j88cd5/PHHXY8LC/K57777KC0t5bHHHnM97+vry/z58xkzZgzbtm2jW7du9Ra/p2RkmHnssYPYbA6++y4Hf38tF14YXOt5VVXFbHa4HptMjjOMrhqjkohNdSZuDUpCreera3qNgr9OS5HNeUEj1Fi7iu4zKiqA4gKIipe1koQQzV6VEs1XXHFFucffffcdcXFxnHvuuQD8+eefWCwWBg2S1WnPpshWRKGtkJFhI92bZAbnqrC//35yWwghhBBC1Ltp06Zx++238/bbb6MoCseOHWPjxo3Mnj2bRx55xNPhNQk//vijq/f1jh07SE9PJzY21sNReYaiKPTs2dOjMSxZsoS4uDhGjhxZ7nmTycSz858DICY2jsfmPMqjcx7jWNpRnp3/HPfffz9eXicXHRs1ahSxsbEsXry4USWarQ4rX+R8gclu4tKwS/HTVW3xtOPHLdhsJ9+3paeb3RKPoijMnNmChQuPEhCgY9KkmFrPGamZRT6fAQpBmstqH2Qd02k0PJbcik9Sswgz6pnQMrpuTrT/L1gwB8wm6NYHbri3bs4jhBCNRJUSzYGB5ftFjRkzptzj+Ph490XUhKmqyjHzMUaEjuCWuFs8HY4QQgghhKgD99xzDwUFBQwYMACTyUTfvn0xGo3Mnj1b7gB0k1atWrm2g4KCCA0N9WA0TZPdrvLyyyns3FlM796B3Hhj3GnHbty4kUGDBlXovfz7779jKisF4I7bb2PKlCnk5+dz9913YyorZevWrVx44YWu8TqdjkGDBrFp06Zax19QYOXDDzPRaOCqq6Lw96+7VoUL0xayNnctAH8W/8m81vNc+xxqKSXq7+iVaLyUNuWOa9/el+Rkf3bsKCIiwsiAASFui6l//xD693fffBrFhxDtOLfNVx/aBPhwX8fEuj3Jxm+cSWaAbRtgzE3OBfTc5EBRKVtzi+gY6EvHoKpdwGjuSmx2VhzJwOZQGdsikpC6rGYXQlRQpb+2ixcvrus4moU8Wx4BugCmx013fzWzEEIIIYRoMJ566ikefPBBdu/ejcPhoEOHDvj5SZLAXYYMGYLRaCQ1NZUBAwaUq4oV7vHTT3msW5cDwKefZtGjRyDnnutf6dhdu3YxYcKECs/v2LHDtd25c2cAOnXq5Hruzz//LJdoBujSpQsrVqyodfzPPnuYtWuzSU8389ZbaaxZ05WwsLpZU+ig6eDJ7bKT26pqI81+P2b1IKAQpX0AP80Frv06nYYnn2hFzp4jBMYEow+WNY8anehT2ogEhoBP5T8jNZFeZuaeP/ZhcahoFJjftQ1tA3zPfmAz9/LeVH45ng/A/qIynu3W5swHCCHcSlagqycO1cFxy3HGRY7jHN9zPB2OEEIIIYSoYz4+PvTo0cPTYTRZlS24KOrO6VrPOhwOzGZzpSvQl5SUuLb9/Z0JuFPHnbr/X4GBgZjNZhwOR636bh8+XMbRo85K0/R0M598ksm0aXVzJ+7wkOHsK92HisqIsBGu523knEgyA6iUqlvw44JyxypL5hO2bQMYveCWx6BVhzqJUdSRQaOdX7vsDLhwOOjdVz17qLgMi0MFwKE6k6bVTjSbTVBcCCHhzaZ/dHrZyRY0x8rc045GCFF1NfrL/fHHH3PVVVdxwQUX0K1bt3L/ROWsqhUvjReXR1zu6VCEEEIIIUQdKikp4eGHH6Z37960bt2apKSkcv+qat68eZx33nn4+/sTERHB5Zdfzt69e8uNUVWVOXPmEBMTg7e3N/379+evv/4qN8ZsNjNz5kzCwsLw9fVl1KhRHD16tNyYvLw8Jk6cSGBgIIGBgUycOJH8/Pwafw5E49evXzBDhoQSHW3kiisiSU6uvFJTo9FgNBopLCyssO/UhQGLiooAyo3778KBAAUFBRiNxlov7njFFZFoNAqKohAdbcDHR1ur+c5kSOgQ3jjnDV5u+zKToie5ntcRikFp4Xrso3Qtd9ym71J46DUbC//qiLXUAr9+U2cxijqiKHDRCBh9A0TUvhf2qToH+RHp5axyD9Tr6BFa8WLOGR07Ao/e6Pz39jOgqm6Nr6EaEx+BTlFQgCtbyJ3kQtS3alc0v/TSSzz44INMmjSJzz77jMmTJ3PgwAG2bNnCrbfeWhcxNgl21Y5W0eKt8fZ0KEIIIYQQog5NmTKFH3/8kYkTJxIdHY1SwyqyH3/8kVtvvZXzzjsPm83Ggw8+yNChQ9m9e7crQffss8/y/PPPs2TJEtq2bcuTTz7JkCFD2Lt3r6uC9I477mDNmjV88MEHhIaGctddd3HppZeydetWtFpn8u3aa6/l6NGjrF3r7DM7depUJk6cyJo1a9zwGak7qqry4osp/PJLPp07+3HffS0xGGqXoBROGo3CbbclnH0gznYY27dvr/B8cnKya3vnzp0MHz6cXbt2uZ77d3H5U23fvt3VZuO/9u4t4aef8mjTxqdc/+G1x7L5Ii2bBF9vZraLx6jVMGZMJAEBWj7/OIWW+gyu7OoLuDcReKq8A/489lgWPj67mDevNVFRXiiKjljtM5Som9Er0XgrJ6uV8/KsPPNyNraCaP7MCSPEaGLs2Kp9vj2mpAgO7oGYRAiVBF5d89freLFHOw4WldHC14tAQzXTN79+7axmBvjjF8g6BpFNf9HUvpHBdA3xx66qBBmkP7MQ9a3aiebXXnuNhQsXMm7cOJYuXco999xDUlISjzzyCLm5uXURY5NQai/FW+NNrLGOf7GHhdXt/EIIIYQQ4oy++uorvvjiiwq9Z6vr36TvvxYvXkxERARbt26lb9++qKrK//3f//Hggw9yxRVXALB06VIiIyNZvnw506ZNo6CggEWLFrFs2TIGDx4MwLvvvkt8fDzfffcdw4YNY8+ePaxdu5ZNmzbRs2dPAN5880169erF3r17adeuXa0+jrr0xx9Frj7CW7YUsH59LsOGyevh+tarVy9WrVqFzWYrtyBgjx49MHp5YzaV8cL/vUhwcDAv/N+LAHh5+9C9e/dy89hsNtatW8fo0aMrnCM728KDD+7DbHYAYDBo6N07iCyThdf+OYoKHC4x0cLXi6sSIgEY0tvIkPUvQGE+vKHA9DnQoW7uwh03bgcZGWZXrGvWOM+jVfwIUAZVGG8yObA5gJbnQO5xCs+Nh4EX10lsblFaAvNnOVtEGL1g1nyITfR0VE2er05L5+Aa9vcPiz657eML/kFuiemMVLVBtOjw10uXWCE8pdqX+1NSUujduzcA3t7erlugJk6cyPvvv+/e6JqIMnsZ2dZs+gT1wV/nvsUBKvD1hePHnf8quQ1NCCGEEELUveDgYEJCQs4+sJoKCgoAXHMfOnSIjIwMhg4d6hpjNBrp168fv/76KwBbt27FarWWGxMTE0OnTp1cYzZu3EhgYKAryQxwwQUXEBgY6BrzX2azmcLCwnL/PMHbW3PGx6J+TJ48mbS0tAoV8F5eXtx7z90ApB9L46abbuJYmrNtyz13z66wiOPq1atJS0tj8uTJFc6RlWVxJZkBUlLKALCrKqc2BLA6HKccdMyZZAZnAuzg7hp+hGdmsTjIy7O6HmdmWs56THS0kdGjI9H6eJNwQVsuu2dwg0jQnVbKPmeSGZx9f//6vdZTOlSVQqsNtYm1dMg1W1m47yjvHDxGmc3uuUD6XQpjpkCf4XDrE85kc10pLYbnZsPtl8Oy/2s2bTqEEBVV+5VYVFQUOTnOqoGEhAQ2bdoEOF/oNrU/EDV1sOwgnx3/DIAMcwYZlgwuCrqI2+Jv83BkQgghhBCirj3xxBM88sgjlJaWum1OVVWZNWsWffr0oVOnTgBkZDiTPpGRkeXGRkZGuvZlZGRgMBgIDg4+45iIiIq3wUdERLjG/Ne8efNc/ZwDAwOJj6+bRdbOpn17P264IZZ27XwZOzaSiy4KPvtBwu26devGgAEDmD17doUF/h555BGefvppAgKDAAgIDOKZZ57hkUceKTeupKSEu+++mwEDBlS69k+bNj60b++s7AwK0tOvn/OCS7S3kYktownS6zg3yI/L4sJPHhSTAJFxWALLyE/OwZwcWWFedzAYNIwdG4miOPNro0dXra3EDTfEsmpVF155pT2hoYY6ic1tYhLA90TRlEZT60ULi6w2Zm7Zy/hfdvHQnwewnXqBwMN+yszj2g07mbp5D4eKy6p9/FO7DrEmLZuPUrJ4bd/Rsx9QVxQFBlwG19wKCW3q9ly/fgOH94LDAZvXwaG/zzg8y2Qh23T2CzJCiMan2vcTDBw4kDVr1tCtWzduvPFG7rzzTj7++GN+//131y17zVmJvYQbd99ImjkNvUZPj4AezIibwYVBF2LQNPAXD0IIIYQQoka6du1arhfz/v37iYyMJDExEb2+fI/Ibdu2VXv+GTNmsGPHDjZs2FBh3397QKuqeta+0P8dU9n4M81z//33M2vWLNfjwsJCjyWbR4+OZPToukkgiqpbuHAhycnJTJ8+nSVLlrgW89Nqtdx7773cdddd5OXlERwcXK69BoDD4WD69Omkp6fz9ddfVzq/Xq9h7tzWHDtmJiys/OJ+VyVEutpllGP0wnrXPRwtm4rDyxfF8BpxahJGpZX7PvATnn/+HHx9tfz2WwG//prP558f59JLw896XE17uNe7gGCY/T9nJXNCG2fLj1r4MTOPlFITADvyi/kzr5ju1V3sro68/E8qJruDIpudpQePMSf5zN8v//1dmVZmdm0fKzVXdkjT43vKnduKAj6nb/fxWWoWbx04hgLc3CaOEbHS7kiIpqTaieaFCxfiOHG18eabbyYkJIQNGzYwcuRIbr75ZrcH2NjYVBsRhghUVHy1vsxJmkNnv8oXs3C7sjK4+ERfr6++Am9ZeFAIIYQQoj5cfvnldTb3zJkzWb16NT/99BNxcXGu56OiogBnRXJ09MlenFlZWa4q56ioKCwWiyvBd+qYf9vhRUVFkZmZWeG8x48fr1At/S+j0YjRaKz9ByeajNatW7No0SLGjx8PwIIFC1yLVgLodDrCwysmXktKSpg+fTrvvvsu7733Hq1btz7tOXQ6DS1aVO89jtkrE4fe2aJDxYZJ/btOEs0Au3aVuBaj/PnnvColmhsLu1pEUehmtH0D8VPaUdv0eLjXySIsBQg1NpxF27w0Gkx2Z87DS6s949gs+8sUOr7DqLQmRjsHreLPlS0iWHIwHZ2iMDq+mSyaeMFgOJ7urGo+fyBEnf7C42dHjwOgAp8fSWfEwd9OzDEE9A3n+0AIUTPVTjRrNBrX1WmAq666iquuusqtQTVmgbpAVnRe4ZmTOxzw448nt4UQQgghRL149NFH3T6nqqrMnDmTVatW8cMPP9CyZcty+1u2bElUVBTffvstXbt2BcBisfDjjz/yzDPPANC9e3f0ej3ffvut6zV7eno6u3bt4tlnnwWcC7kVFBTw22+/cf755wOwefNmCgoKXMnohigtLY2MjAw6deokSe8GYty4caiqypQpU/jll1+YP38+o0aNqlDBDM6F/1avXs3dd99Neno67733HuPGjXN7TN5Ke7RKCHY1F43ii7fSxe3n+FenTn5s317o2m5KjtkfxqweAMCqySREe02t5usZFsj0NnH8VVBM77AgEv0aTpHUA51asvTgMfx0Wqa2jj3tOJP6D4WObwAwq/9QqH5NsDKWMS0iGRAZgl6jNJ9F6RQFRl1XpaEtfL04bnb2NL/i5w8gdYdzx75dcMM9dRWhEKKeVOm33o4dO6o8YXJyco2DEUIIIYQQorFLSkpiy5YthIaGlns+Pz+fbt26cfDgwSrNc+utt7J8+XI+++wz/P39Xf2SAwMD8fb2RlEU7rjjDubOnUubNm1o06YNc+fOxcfHh2uvvdY19sYbb+Suu+4iNDSUkJAQZs+eTefOnRk8eDAA7du3Z/jw4dx000288cYbAEydOpVLL72Udu3auevT4lZ//vknc+bMwWaz0aZNG5599tlKk5mi/l177bWcf/75TJ06lTFjxhAbG8ugQYPo0qULgYGBFBQUsH37dtatW0daWhoDBw7k66+/PmMlc21olUBaaF9yVTLrlLq7Tf/BB1vy/fe5+Plpy/ULd6gWMh3/w6T+jb/SjzDtDXUWQ11QVZsryQxgYq9b5h0RG9Yg2ya0D/Tl6a5n72mswRdnPbZ64vHJiwshDahCu6GZ3T6BVanH0SjQf33WyR1H3PN9JYTwrCq9GuvSpQuKopx1sT9FUbDbPbiqqhBCCCGEEB52+PDhSl8Tm81mjh6t+sJQCxYsAKB///7lnl+8eDHXX389APfccw9lZWXccsst5OXl0bNnT7755hv8/U/2y3zhhRfQ6XRcddVVlJWVMWjQIJYsWYL2lFvC33vvPW677TaGDh0KwKhRo3jllVeqHGt927hxIzabDYB9+/aRmZlJbOzpKw9F/WrdujXff/8927ZtY/HixWzatIkVK1ZgNpsxGo107tyZ0aNHM3ny5EoX/nM3rRKIr9Kzzs/j5aVlxIiK7TKK1G8pcfwKQL66Cj9Nb7yU2vU4rk+KosNP04dixwZAwV/p5+mQGgSDEkuE9g6KHOswKq0JUIZ6OiTAuW7UR5kf4cDB2IixBOgaRu/rf/npdUxMOtHu6YJB8MV7zu0e/T0WkxDCfRT1bNlj4MiRI1WeMCEh4axjCgsLXVezAwIa1i+9Rq2kBPxOXEUtLoZTeqIJIYQQQtSH5vw6b/Xq1YCzX/PSpUsJDAx07bPb7axbt45vv/2WvXubXtVWfX/df/rpJ+Y9ew8OTMREtOP1Be9I+4waKHZswqTuxlfpibemY52fz+FwlGvD2FwUONZy3P6q63Gc7nm8lLNXzDYkqqpiUv9CqwRgUFp4OhxxBk8eepLNhZsB6OLXhSdaPeHhiM7iyD5n68+WDfMOGiGEU1Vf61WporkqyWMhhBBCCCGas38XBFQUhUmTJpXbp9frSUxM5H//+58HImt6zu1TyjSjnsw0O+ddaEdvkLsqq6vUsZ0M+1MAFPA5LZRX0SvRZzmqdppjkhkgQBmMWfMPJvVv/JT+dZtkzsuGvX9Ci9YQ47738Yqi4K10ctt87qKqKu8eymBnfjEXhgdyWXNZfO8M0sxplW43WAmN66KLEOLMpJGZEEIIIYQQbuA4sRhzy5Yt2bJlC2FhDa/3aFORkf0XK985SsbRMooKbHS6Pg8DPp4Oq1GxcPKuVRUrFvVYnSeaG4O6qLpWFB0R2tvcOmeligpg/p1QmA86Hdz5bJNP4v1yvIAPUzIB2FNYQrsAX84JbN539l4RfgWvHH0FFZUxEWM8HY4QoplpnpeUmzIfH+c/IYQQQgjhEYcOHZIkcx37/jMTaUfM2GwqX39SSm6m9uwHiXL8lAvRKc4FKw1KS7yVum+d0RBt27aNmTNn0qNHD7y8vNBqtXh5edGjRw9mzpzJtm3bPB1i1aUecCaZAWw22Lezzk9pVg9S6vgTVXXUyfyqqp5x7tL/9MMvscndDUNCh7C0w1KWdFjCJWGXeDocIUQzIxXNdejjlEzSy8z1e9Jte5z/H80Bcur33GfhUEGvUZjQMpoAvXzrCSGEEEKImgn2b4W3ci6qYsGg88fb29vTITU6OiWMFtrXsJKJnlg0isHTIdWr/fv3M3XqVNavX09sbCyDBw9mwoQJBAQEUFhYyPbt21m1ahWvvPIKAwYMYOHChbRu3bpOY0pPT6egoIB27dqhKEr1J4hvBQHBUJgHej20TXZ/kKcodHxLlv1lQMVP04co7b1unb/UsZ0MxzxU1UqEdib+mgEVxvSPCOaX4/nszC+md1gQ3UL8K5mp+QnSB3k6BCFEM1WtbJ/dbmfDhg0kJycTHBxcVzE1GS/9ncrB4jL89VJhAVBktRPva2RkbLgkmoUQQgghRI3169eP119/nfT0dK6++upyCy+KqtMoPhhp6ekw6t3y5cuZMmUK0dHRrFy5kpEjR6LTVXx/YrPZWLNmDbNnzyY5OZlFixYxbty4Oolp06ZNPP3009jtdvr06cO999YgaesfCPe8AP/scPZojop3f6CnKHb8DKgntn9B1ThQFPfdNJ3jWIZDLQUg2/F2pYlmg1bDY8mt3HZOIYQQtVOtbJ9Wq2XYsGHs2bNHEs1VoKIS62Mkwqt5VQecyupwUGCxkW+1EWzQMT4xinhfL0+HJYQQQgghGrEvv/wSf39//P39+eOPP8jKyiIionksAmZT8wA7OkXas9TE8uXLmTBhAhMmTGDBggX4+p6+n69Op2P06NEMHTqU6dOnM378eFRV5dprr3V7XOvWrcN+og3Ehg0buP322/HyqsH7pqBQOL9iQrYueCkdKFX/OLHd9sxJ5uJCMJsgtOo/p1ol8N88NlqCahGpqC2L3cHPx/Px1mroFRZ42op7u0NFq6lBNb5osg6WHWRh2kJ0io7psdOJ9Yr1dEiijlW7rLRz584cPHiQli2b35Xvhk5vMXP/I7MBmPf4c1gNxnqPwa6q5JmtFNrsOFQVDQqBBh0Xx4QxKCqE4dGh9R6TEEIIIUR9sdlsvPfeewwbNoyoqChPh9NknZoc1Ol0GI31/7rXEwod35NlfxFwEKq9gWDNaE+H1Kjs27ePKVOmMGHCBJYsWVJh0b+SkhLy8/MJCgoq9z3m6+vLkiVLAJgyZQrnn3++29totGnThk2bNgEQFxfXKL6ngzVXo1eisVOIvzLw9AN3bYFF88BqhSFj4bJJVZo/QjODHBbjwEKo5jo3RS1q4undh9mSUwjAVS0imZhUceHQ1/85ypfHson1MfJEcivCmnHBnTjpuSPPkWpOBeCVo68wr/U8D0ck6lq1E81PPfUUs2fP5oknnqB79+4VrgAHBAS4LThRPRq7g/M2b3Bt17csk4V8i41Qo54+4UF0DfanQ6AvnYL8CDHq6z0eIYQQQoj6ptPpmD59Onv27PF0KE3aFVdcQU5ODkePHmXkyJHNpnVGvuNTwHFie6Ukmqtp2rRpxMTEsGDBAleS2WazMXPGDH764Xv2/LMfVVVJbBHPoSMp5Y7VaDQsWLCAX375halTp/L999+7NbYrr7yS0NBQcnJyGDp0aM16NNczRVHwV/qdfeAPq51JZoB1K2HUdVCFj0+nhBCpvavynV9/CAd2Q/e+0PMMSe7G4Hi68/MR1nAvTu7IK3Zt/5lfxETKJ5qPlpr44lj2iW0zn6dlc32rmHqNUTRMFtXi2jY76nkNM+ER1U40Dx8+HIBRo0aV++OnqiqKorhu9xHNh0NVSS+zYFMdTGsTy7WJUUR5N/wr8EIIIYQQdaFnz55s376dhIQET4fSZBkMBm699dbaT1RaAqVFDTrBcyqDEodFPeTcJs7D0TQuW7duZf369axcubJcsdSxY8d4/Y03yo3NzsmudA5fX1/mz5/PmDFj2LZtG926dXNbfIqiMGjQoLOOM5sd/PxzHv7+Wnr2DHLb+etUZBz8vd25HRYN2RnOFh/6s1e8bsst5Nv0XFr6eXNliwhnDmLrz7BmmXPAnm0QlwSxiXUWfp369hP4bIkz0Tx2KvS71NMRVapXeCA/ZOY5t8MqXtjz0WrRKQo21dnrJNAgazIJp1vjbuXF1BfRK3qmxk6tsF9VVTJMFoINOry0sr5ZU1Dtn/7169fXRRyiETtUXEaIUc9NreK5Lim6UVx9F0IIIYSoK7fccguzZs0iNTW10jsAk5OTPRRZ02JTc7BxHCOtUZQaJDUO7YXXHoGyUmdP2+tmuT9IN4vQzERPNCpWgjVjPB1Oo7JkyRLi4uIYOXJkuedDQkJomdiCkOBgDqekkpOTe8Z5Ro0aRWxsLIsXL3ZrormqnnjiAH/+WQTAxIkxXHWVhy6S7NgMxw5D1z4QeZaeq5dPBr9AKMh1LlT42FQIj4Y7n4WAoNMelmO28OSuQ1gdKhuO5+Ov03JxbBgU5Z8cpKrlHzc2P33u/F9V4acvGmyi+c5zWtA3IghvrZZOQX4V9vvoNAyLDmVnfjHdQ/0ZGSs95IVTV/+uLOmwpNJ9DlXlyV2H2JJTSKBex7wurWVNryag2q/I+vWrwq0xoslzqCr5Fhu5FiveWg0Pdmzp/KMvhBBCCNHMXX311QDcdtttrucURZE7AN2oTN3DMdvDqJjxVjoTo33yzAuRVeaXtc4kM8Bv6+Gy6yEwxO2xupNG8SZUO9HTYTRI+RYr//d3CjlmK9cmRtErPKjc/o0bNzJo0CB0uvJvgf38/Dh46AgAffv05udfNp7xPDqdjkGDBrn6KdcnVVXZseNkC4MdO4o8k2jetgHefsa5/cNqeOQN8KmYfHTRG+Dia5zJ6Q1fOZ87ng5//goXjTjtYQUWG1aH6nqcbT7RfuP8gbBlPRzZB116Q9s6uHiXsh8K8+CcrqCrw+rc6ATIO1FB34CrsjWKwnmhlbcoUlWVB7cf4J8i5+/TsS0i0Gmq+ftYNEspJSZX7+8Cq43vMnKZLC1XGr0a/cb8+eefeeONNzh48CAfffQRsbGxLFu2jJYtW9KnTx93xygaEKvDQWqpGbtDJUCvY3BUCKPjI+gfGezp0IQQQgghGoRDhw55OoQmr9jxIyrOXo9l6k6spGOgmivZR5wy3j/wzIky0eC9czCdrbnOSt/5e47wQUgABu3JZNeuXbuYMGGCW87VpUsXVqxY4Za5qkNRFHr2DGTTpnwAevZ0f29ym5pNiboVo5KEl9Km8kEp+05uFxdCblbVfn7Co0GrhX8vtkWc+We2pZ83fSOC+Ckrn0gvA8NjTiws7+MLdz8PNlvdJIF/Ww/LXnBWGbfvCrc+7v5z/Ov6u53Jeo0GBlxWd+epQ4VWuyvJDPB7biEDohr2RbuqOlxcxo9ZebT09aav5DzcLsSox1uroezEGmOxPtKCtSmo9m/lTz75hIkTJzJ+/Hi2bduG2ex8gVdUVMTcuXP58ssv3R6kaBjsqsqhYhPtA325qkUkF0UEyW0NQgghhBD/Ib2Z655Rae3aLin0xeHnD9V9fzr4CmeS6ni6s6qyCv1i3enAgVJefDEFm83BjBkt6NBBEt21cepS6A4V1FMfOxyYzWa3LVwfGBiI2WzG4XC4FhWsL/fd15Lffy8gIEBH+/Y1+5757LMsNm8uoGtXf6688mRF9Kbf0nnpzZV4+xVzwx1L6Bb/AN6azhWOL2nXG833X+PtKIHEthAZX7UTR7eAaQ87K5tbd4J2555xuKIo3N0hkeltbPjotGj+26KxriqNt//qTDID7PkDzCYw1tH7Xh9fGDGubuauI1Y1CzsFJ9oWKQTotbTx92HfiWRz95DT/5zlW6z46bSNouK5yGrj/u37KbadvAvptMnmkiLQ6evu+6SJCtDreOLcVnyfkUeCrxdDmsgFiuau2r+Zn3zySV5//XWuu+46PvjgA9fzvXv35vHH6/BKn/C4AouNIIOO/+velkQ/b0+HI4QQQgjRYB04cID/+7//Y8+ePSiKQvv27bn99ttp1aqVp0NrEgI0g1EwsuTtd1n72UH8fafy+OOP07Zt26pPotHAwMvrLMazee21VA4dciZmXnophddf7+CxWJqC8YlRpJWayTZbmNgyGuMp1cwajQaj0UhhYaFbzlVQUIDBYGTHjmK6dHFP8rqqtFqlVosA7txZxFtvHXVtJyZ6c955zsro/z2/n5wiHRDER4vb0/7hnXhTPtG8dm02CxaUorHP4q4JOvqM6QR6fdUD6NDd+a8a/PT1vLBcm86w40RrlBatJXl4ihLHZtLt8wA7fpq+RGnvRlEUnjq3FZuyCwj3MlTawxng+T1HWJ+ZR7BBx9wurYnzqf7ndV/pPtbnraelV0uGhA6p5UdzZsdNlnJJ5oPFZZUnmr//FFa97Uw0T7kfOvao07iamnYBvrQL8D37QNFoVPsy0t69e+nbt2+F5wMCAsjPz3dHTKKGzN7ejFz/ByPX/4HZ232JYIeqkmmykG220jciSJLMQgghhBBn8PXXX9OhQwd+++03kpOT6dSpE5s3b6Zjx458++23ng6vydCauvPNZ8fQ4EVJSQmffvqpp0OqllOLM2Ut7doL9zIwv1sbFvfqyMBKquI6derE9u3b3XKu7du34+fXiocf3s/GjflumbO+FBfbT/tYq/iiUZy3BmgUBR9NxYTw+++n43Co2BQdK37xrvc7AWrCoTrIMGdgcViqdsCAUc7K66tvgRlP1m1wjUyh+h3g/J4pdvyEQzUB4K3TMiAq5LRJ5mOlZtZn5gGQZ7HxZVp2tc9dYCvgwQMPsiZ7DS8dfYn1uetr9kFUUQtfLzoGOhOgvjot/U5XzfzFe84KeKsFvvmoTmMSojGo9qXB6Oho9u/fT2JiYrnnN2zYQFJSkrviEg2AXVU5WmrG4nAQbNBxc5tYbmhVzd53QgghhBDNzH333cedd97J008/XeH5e++9lyFD6rYKq7kwGo0EBgZSUFAAQGRkpIcjqp5bb43n5ZdTsdlUbr21iq0HmhCLxcGhQ2VERxsJCKj7itVevXqxatUqbDZbhQUBf/jhB/bu3Ut6RqYzNquNN954g9DQUMaOHVturM1m45tvviMg4CIAdu8uplevoDqP313OOy+ACy4I4rffnK0zLrwwyLXv7tmteestLUa/HG6/aQheSsX395GRRnJzra7ths7msPHooUfZUbyDMH0Yz7R+hghDxNkP7Hx+3QdXBdkmC7sLSmgT4EO0t+c/30ZaUYKz2luvxKJRqlaVHKDX4qXVYDrRizfSq/oXKLIt2ZQ5ylyPU8wp1Z6jOnQaDU+e24rDJSbCjQYCDaf5PRUaCceOnNwWoplTVFVVzz7spGeffZalS5fy9ttvM2TIEL788kuOHDnCnXfeySOPPMKMGTPOOkdhYaHrRaG7+mQ1RBd9swWLQyWiBr9EPa3Mbie1xESinzfXJkYxNDq0QfxhE0IIIUTD1lxe552Jl5cXO3fupE2b8gtp/fPPPyQnJ2MymTwUWd3x1Nf98OHDfPrpp4SGhnLNNdegr84t/MJjTCY799yzj0OHSvH31zF/fltiY+u2PcG2bdvo3r07K1euZPTo0eX2RYaHkZWdU+lxaWlpxMTEuB6vXLmSMWPGcNFF7xIa2pEnnmhFp07+NYrJbld57710UlJMXHxxGN2719/PjqqqKDUopc/NtfL+++nodArXXhuNv3/dXSQoKCjgp59+IioqivPOO69Gc+wq3sX9B+53PZ4YNZGrIq9yV4h1KtdsZebveym02vDSani+W1uPr5GkqipF6rfY1BwCNMPQKVXvqbunoISvjmUT7+PFmBYRFXtun4VdtTPn4By2F28nQBvA062fJt6rAVyky8mEtSvAywdGXAvePp6OSIg6UdXXetX+q3DPPfdQUFDAgAEDMJlM9O3bF6PRyOzZs6uUZBZ1R28xM2vuQwA8/8CTWA3VTwxbHQ7SyyxYHQ56hQUxJzlJWmUIIYQQQlRDeHg427dvr5Bo3r59OxERVaikE1WWmJjIHXfc4ekwRDX980+pqz91UZGNX3/NL7coXV3o1q0bAwYMYPbs2QwdOhRf35M9QYOCgipNNBsMerxPaUlYUlLC3XffTb9+/XnuuUuJiTESE1PzxN/q1Vl89FEGANu2FfL22x0JCqqfiyU1STIDhIToufXWFm6OpiKbzca9995LWloaALfddluN7gaJMESgV/RYVStl6WWYy8yoETVLsrtDlsnC9rwi2vj70PIs77P/Liyh0GoDwGR3sDO/2OOJZkVRCFCG1ujY9oG+tA+seS9eraLlsaTHOGY+Rog+BB9tA0nohkbC+Ns8HYUQDUaNLj8+9dRTPPjgg+zevRuHw0GHDh3w85NVkj1NY3fQ58fvAPi/e6u/MKNdVTlYbCLJz4uJLaO5skUkBm3DXw1WCCGEEKIhuemmm5g6dSoHDx6kd+/eKIrChg0beOaZZ7jrrrs8HZ4QHhcTY8TLS4vJ5Oz1mpRUPwmjhQsXkpyczPTp01myZAkajfO9zh9/7iAvL6/CeD8/PwIDnQvlORwOpk+fTnp6Ol9//TWtWwfWOp68PJtr22p1UFxsr7dEc0OXn5/vSjID/PXXXzVONM9pOYe3Pn+LLUu38KH+Q44POM6sWbPcGW6V5Fus3Ln1HwqtNnSKwrNd29Am4PTf+239ffDTaSm22TFoFFe/4OZMo2iI84rzdBhCiDOodqL5hhtu4MUXX8Tf358ePU6upllSUsLMmTN5++233RqgqB+lNjtHS00k+Hqz6IIOxNZgBVghhBBCCAEPP/ww/v7+/O9//+P++523bMfExDBnzhxuu02qntxBVVW+/jqHo0dNDB4cSmKi3IFXnzZv3sy3335LUlIS48aNq3Z1aFiYgWeeacOvv+bTrp1vvbWMaN26NYsWLWL8+PEALFiwAF9fX3x8fPDxOX3Cr6SkhOnTp/Puu+/y3nvv0bp1a7fEc+mlYWzalE96upnhw8OIi3PPe7ACx1pK1d/xUXoQqBnuljnrW2hoKB06dGD37t1oNBp69+5d47mS/ZMJ+CuAMH0Y4OzJfeedd9Z7VfPB4jJXhbJNVdlVUHzGRHOYl4EXurc9UckMn+e9TXF2MeOixtHCq+6rymvCYnFgMHi2WC2t1MSxMjOdg/zw0mo9GosQzVG1ezRrtVrS09Mr3PaXnZ1NVFQUNpvtNEee1Fx699V3j2ZjWRkfj3D+AR775a+Yvav2gtvZj9nMgMhgHujUkhYevh1HCCGEEI1Xc3md91+rV6/m4osvrtAjuKioCAB//5r1cG0s6vvr/tVXx3nttVQA/P11vPVWR3x8JKFQH7Kyspg2bZrrfd8tt9zCxRdf7OGoqmf58uVMmTKF6Oho5s+fz6hRoyosEAjO9g2rV6/m7rtncyw9lblvdGbStfcRonVvj9+aJudU1Ua24y3M6gECNEMJ0AyhzLGTNPsDrjGx2rl4azq7M9x6Y7FY2LFjBxEREbRoUbvE6rJly/jwww8BaNeuHc8995w7QqyWQquNmVv2kmuxYtAozO/ahiT/qlXzv5DyAt/nfQ9AhD6CRR0W1WWo1VZYaOPBB/dx+HAZffoEc889iR5pT7Ijr4hHdxzEpqq08vPmuW5t0GnkLm0h3MHtPZoLCwtRVdXZ/L2oCC+vk8lIu93Ol19+KT3nGqFiq7OS+bzQAP7XvS2+OnmBLoQQQghRXaNHjyYjI4Pw8PByhRlNPcHsKSkpJxdULCqykZ9vlURzPSkqKipXXJSbm+vBaGrm2muv5fzzz2fq1KmMGTOG2NhYBg0aRJcuXVxvordv3866detIS0vjwgEtWPj5RSS09qVAXU0I7k0017QCtED9igLHFwCY7HvxUjpio/zX47+PGxODwVDuLuramDBhAjExMRQWFjJ0aM16DNdWgF7H/3Vvy66CYpL8vKt1F3Gu9eTXMc9Wsc2Lp33zTTaHD5cBsGFDHiNHhtOhQ/23V92UXYDtRC3lgeIy0sssHu9rLURzU+VEc1BQEIqioCgKbdu2rbBfURQee+wxtwYn6la+xUaO2UL/yGBmd0iQJLMQQgghRA2Fh4ezadMmRo4ciap6bqGp5mLQoFDWr8+jpMTGeecFEh1d/UWwRc0kJSUxYMAA1q9fT2xsbKOrZv5X69at+f7779m2bRuLFy9m06ZNrFixArPZjNFopHPnzowePZrJkycTe+56ihw/AGAg3rOBn8Khlp3ySEXFhK/SC2+lE2XqLryVTvgqvTwWX0OiKAqDBg3ydBgEG/VcFBFc7ePGRY5jX+k+yhxlTI6eXAeR1U5IyMm7eTQahcDA8qmmLTkFvPR3KjqNwj0dEmu1KOCZdAj0Y01aNgARXoZ6u7tcCHFSlVtn/Pjjj6iqysCBA/nkk08ICQlx7TMYDCQkJBATE1OlkzaXWyobcuuMEpudtFITY1tE8sS5rdDImyEhhBBCuEFzeZ33X3PmzOHxxx+vUoLZbrfXQ0T1yxNfd2cls424OKMk9j3g34RsOaXF8PYzkJ4C/S6FoVd6JrhacDgcrkUCXc+pJvIdn6JiIUhzORr8a/Y9l58Df/8BcUnOf7VkV4tJtz+JWT1AoGYYYdop5WLWKFLJ2ZQ4VAd21Y5e0/AWjFRVlY8+yuSff0rp3z+YPn3KJ9Nv2PgXx81WANr4+/B894rFi+6yPbeI1FITF4YHEWJseJ8rIRort7fO6NevHwCHDh2iRYsW8mKukXKoKiklJlSgX0Qw93VMlCSzEEIIIUQtzZkzh2uuuYb9+/czatQoFi9eTFBQkKfDatL8/XX4+1d7bXPhJhWSzADrP4O/tzu3V78DXftAeHS9xlVb/00yA2gUL0K015Cfb2XWowc4cqSMESPCmTo1ruoTlxTB/FlQkAs6Hdw2F5LaVzr0YFEp/nod4WcpWNIqfsTpnq7845Akc5OjUTRolIbZb1hRFK66Kuq0+52L8jkTzd7auv0YuoT40yVE2lYJ4SnVfmW2Z88eUlNT6dOnDwCvvvoqb775Jh06dODVV18lOLj6t4EI9zB7eTH2y19d25VJLTURbNBzT4cEhseESmN8IYQQQgg3OeecczjnnHN49NFHufLKK/HxqdoiT0I0GdpT3l4qCmiaVmu+NWuOc/Bg6YntLC6+OIz4+ComdNMOOZPMADYb7NtZaaL55b0pfJOei1ZRuKdDAr3Dg9wUfeOwa1cRWq1C+/b1399X1J27OyTw1v409BqFaW2qcYFGCNHoVDvLePfdd1NYWAjAzp07mTVrFiNGjODgwYPMmjXL7QGKalAUzN7ezpYZ/6lSVlWVY6VmQGFW+xZcGhcuSWYhhBBCiDrw6KOPSpJZNE8DLoPufSEmAa6+BUKb1mLxfn4nE+darYK3dzXeT8W2hOAw57ZOB+26VBhiczj4Nt2ZjLarKt+k59Qm3EZn0aKj3H//Pu655x/efz+9ysdlmDN4KfUlFh1bRKm9tA4jbL72FZbywp4jvH84A5vDUe3jW/p581SX1sxJbkW0t/TUF6Ipq3ZF86FDh+jQoQMAn3zyCSNHjmTu3Lls27aNESNGuD1AUXuqqpJusqAocFe7FoyMDfd0SEIIIYQQQoimxugFk+/2dBR1ZuTIcLKzrRw+XMbFF4cRFlaNtXh8/eHu5+GfHc7+zFEVFxXUaTTE+3iRUmoCIMnv9GvuNEU//ZTn2v755zzGjau87UpRkY3MTAuJiV7odBqeOPQEKeYUABwZKdz0fQlYzTBmKrTtXC+xN2Vmu4NHdhyg2OZcX0ADXJ14+jYZQojmrdqJZoPBQGmp8yrhd999x3XXXQdASEiIq9JZeIbOYmHG808C8Mqsh7Dq9eRYrOSabfjrtdyQFMOkVlVbsFEIIYQQQghR9w4fPsz3339PQkICgwYN8nQ4zYbZ7ODVV1M4csTEqFHhDBoUetZjdDoNN91Ui9v+A4KhR78zDnni3FZ8dSybQL2OEbFh1T7F7t27efvtt/H19WXGjBmEhze8IiOHaiHX8S42sgjSjMZLaQdAx45+/PyzM9ncoUPlrTNSU03ce+8/FBXZaNfOl3nz2pBpyXTtT/r8W8g68bVc9jw8sbhuP5hmoMRmdyWZATJNFg9GI4Ro6KqdaO7Tpw+zZs3iwgsv5LfffmPFihUA/PPPP8TFSa8dT9La7Qz6eg0AL864l30mK4F6PdcmRnJ1QhTnBPp6OEIhhBBCCCHEv0pKSnjggQcoKioCnHciDh482MNR1cy6detYtWoVYWFh3HfffXidZs2YhmLVqkzWr3e2qXjxxRTOPde/ehXKdSTEqGd8y6ovoOhwOMotYPjMM8+Qm+v8uN544w0eeught8dYW3mO98l3rAKgVN1OovYdNIqBO+9M4Nxz/dFqFQYMCKn02J9+yqOoyAbA3r0lHDxYxrVR17IkfQl6RU8H73OA487BNWjx0OAdPQSfvg0Go7Niux7a04QY9QyPDmVteg4Beh2X1uACiBCi+ah2ovmVV17hlltu4eOPP2bBggXExsYC8NVXXzF8+HC3ByhqJrXURPeYCB5NTqJdgCSYhRBCCCE8wWQyNfiEm/CcnJwcV5IZnNXNjVF6ejpPPPEEe/fuxeFwsGfPHj744AOU/6wb05BYLKprW1VVrFb1DKMbjm3btrF48WI2btzIrl27MJvNGI1GOnXqRK9evUhPT8dodPbAtVgaZuWpjZO9px1qCSpmwIBer2HYsDMnMVu2PNlOxMdHS0SEgXbBVzAkZAh6RY9XeBa88zxYTHDlzXX1IXjO4mcgM825bbPBLXPq5bS3totnQstovLUaDFpZ60kIcXrVTjS3aNGCzz//vMLzL7zwglsCEu7hp9dy+zktJMkshBBCCFHPHA4HTz31FK+//jqZmZn8888/JCUl8fDDD5OYmMiNN97o6RBFAxEXF0eXLl3Yvn07vr6+DBw40NMh1UhZWRnZ2dk4TlSQ7t+/n+PHjxMRcfZqS5vNgU5X/4mryy+PYM+eElJSyhg1KoLo6Ia9QNn+/fuZOnUq69evJzY2lsGDBzNhwgQCAgIoLCxk+/btrFq1irS0NGJiYujfvz833HBD3QeWfyJpHHT21iP/CtJcQam6DbtaQLBmLFrFv8rH9u4dxL33tuTAgVIuuiiY4GA9AP66E3NEt4B7/6/K8zUWrsp1U9nJJ8tK6jWGQEO100eiMhmpsGIBoMLYaRCb6OmIhHCrav+mSElJOeP+Fi1a1DgY4T6Pdk7i/NAAT4chhBBCCNHsPPnkkyxdupRnn32Wm266yfV8586deeGFFyTRLFw0Gg1z5swhNTWV0NBQ/P2rnnDzpDVrsjhwoIyBA0NITvYnKSmJgQMH8tFHH+Hj40OHDh0ICgo64xypqSYeeWQ/OTlWrr02imuuqXq7CHcICNAxb14bt81XWlqKzWYjIMD978GWL1/OlClTiI6OZuXKlYwcORKdruJbeZvNxpo1a5g9ezarVq3i0ksvJTEx0e3xuPz0BXz0hnP76lugT9XucDYqiSRq30HFgkap/h0fffoE06dPcLWPa0xOW7neqiW9jDYmd21Ht9H1cCFBuN+7L8Lhvc7tZS/AfS96Nh4h3KzaiebExMQz3gJlt9tPu0/Un/6RwQ36VjUhhBBCiKbqnXfeYeHChQwaNIibbz5563ZycjJ///23ByMTDZFWq63bZKCbrVuXw8KFRwH4+ec83nijA2FhBl566SWuvPJKjh07xsCBAzEYztzv+KOPMsjOdrZ2eO+9dEaODMfXt3FWTG7atIlnn30Wm83GjTfeyGWXXVal4+x2lSNHyggLMxAQUPnHvnz5ciZMmMCECRNYsGABvr6nv2NVp9MxevRohg4dyvTp0xk/fjyqqnLttdfW6OM6q3UrQT3RcuT7VVVONAMoigYFaSv0X1WqXP/uO155+wsGHCpl4cKFtG7d2tNhk2/NZ+XxlRg1RsaEj8FLK1/b07Kd0tLGaq724eszcvkoJYsobwN3nNOCAH3j/L0pmq5qf0f+8ccf5R5brVb++OMPnn/+eZ566im3BSaqz6Ge7Cum00jfJCGEEEIIT0hLS6v0jb/D4cBqtXogIiHcJyPjZJLEYnGQl2d1LaJ30UUXVXmeoCA9drUABxYCfMPQ6xvv+5ePP/7Y9bP9/vvvVynR7HCozJlzgO3bC/Hx0fLUU21o3dqn3Jh9+/YxZcoUJkyYwJIlS8ot+vcvu91ORkYGer3e1arE19eXJUuWADBlyhTOP//8uklGRsZDTtaJ7Tj3z9/M1KRyPTk5mUWLFjFu3DgPRHzSU4ef4u9S54XUTEsms1rM8mg8DUZRAbz/MhTmwSUToH1XZ+/wd54H1eG8E6Aaiq02Xtybil1VSS018cHhDKa2kZ890bBUO9F87rnnVniuR48exMTEMH/+fK644gq3BCaqR1VVjpSUnX2gEEIIIYSoUx07duTnn38mISGh3PMfffQRXbt29VBUQrjHkCEhfPddDtnZFs4/P5BWrXzOflAlLrlmF6mlP5B73JuRV5jQ67u5OdL6ExUVxd69zlvhgyKC+DDzQ0L1oQwMHnjau0zT0sxs314IQGmpnfXrcyskmqdNm0ZMTAwLFiyoNMnscDgYPHgIP/ywHoDPP/+cSy65BHC2ZVmwYAG//PILU6dO5fvvv3fbx+ty/Wz49hNQFBg8xv3zNyP/Vq6PHz+e119/vWFVrlfBUfPRk9umo2cY2cx8uhh2bHZuL5oHz34ArTrAY2/VaDqV8gWGjsaxhqloZtxWY9+2bVu2bNnirulENZXY7Kg+Pmz66x8uCA8Cn5q94BNCCCGEELXz6KOPMnHiRNLS0nA4HKxcuZK9e/fyzjvvVLqothBVYberpKQ42yz4+3vuVumICCNvvtmBwkI7wcG6GrfrU407GD9tl+uxg0K0BLorzHo1ffp0QkJCKC0tZUv3LSzLWAZAvi2fMRGVJ2BDQnT4++soKrIBkJjoXW7/1q1bWb9+PStXrjxt0vHVV191JZkBsrOzy+339fVl/vz5jBkzhm3bttGtm5uT+T5+cNmk2s1xZB8U5EKH7lBJ9W5Tsq+wlAX7jqJRYEbbeBL9nF/z7777jkmTJjF+/HiWLl1a7qKCqqoUFBRgt9sJCQkp9/NWb5XrVXBF+BW8k/EOWrRcFl611jGV+ez4Z3yd8zWtvFsxM34mBs2ZW/A0eNZT2mTYrOBwQC3uPvfX67i1bTwrjmQQ7W3k6oRINwQphHtV+zd5YWFhuceqqpKens6cOXNo08Z9iymI6rGroNNoSWzZArwb9orJQgghhBBN2ciRI1mxYgVz585FURQeeeQRunXrxpo1axgyZIinwxONkN1+ss2Cr6+OuTONJEVYoXVHZzVpPVFPVNLpdBpCQmrX6sJX6UkxPwMqXkpHNDTehcx9fX254YYbKLGX8PWur13P7yvdd4ZjdDz9dBu+/z6X+HgvBg0KLbd/yZIlxMXFMXLkyEqPP3ToELfddttZYxs1ahSxsbEsXrzY/Ynm2vptvXMxNFWFc7rAjCc8HVGdenFvCkdKTAC8vDeV/3Vvy/Lly7n++uuJjY3l9ddfdyWZVVXlhsmT+WL1ao7n5QEQ6OfHlGnTeOKJJ/D2diap66VyvQqujLyS/sH90St6gvRBNZoj1ZTKW8eclb6p5lSSvJMYHTHafUH+R67ZypGSMtr4++BXV32OL50AmanO1hmXTXbLxZRhMaEMiwk9+0AhPKTa3+VBQUEVrlqrqkp8fDwffPCB2wKrC/PmzWPlypX8/fffeHt707t3b5555hnatWvn6dBqJc9iJavMQpcQf8KMek+HI4QQQgjR7A0bNoxhw4Z5OgzRRKSmmlxtFkpS0/nh4XUkddgDFwyGCbfXSwy7dhUxd+4hzGYHt94az8CBtUt0+Gv6oldisKnZ+CjdGsdC5maTsyrR17/S3b5aX3oF9mJjwUa0aBkQPOCM07Vo4c3118dWum/jxo0MGjSo0h69qqpy4w03VilknU7HoEGD2LRpU5XG16s/N55cTPDv7WAqAy/vMx7SmNlPaXlgV1WWL1/O+PHjAXjhhRfKVa5bLBaWLF1a7viC4mL+97//kZOdzeITlcxQD5XrJUWwe6uzD3eL01dMhxvCa3Uau2o/42N3Si8zM2vrPxTb7ER4Gfi/7m3xr4tkc0QM3P+y++cVogGr9k/S+vXryz3WaDSEh4fTunXrSv8INiQ//vgjt956K+eddx42m40HH3yQoUOHsnv37jP2QGrIcsxWiqw2LosPZ1qLcHQzZzp3PP88GKWyWQghhBCivm3ZsgWHw0HPnj3LPb9582a0Wi09evTwUGSisQoL0+Pnp6O42Ab5OSS0LnLu+P2Heks0L1uW7mrz8NZbabVONAN4Ka1BOfut/kVFNn74IZfQUAO9ewfV+rw1snsbvDUXLGYYNQmGjq102P0J9/N36d8E64KJMkbV+HS7du1iwoQJle576623WH+iZUbfvn356aefzjhXly5dWLFiheuxQ1WxOBx4abU1js8t2nR2JpvBmcBswklmgJnt4nnp71Q0isLFWhOjp0yhXbt2lJSUVKhcN5vNXDpiBEEhIVxwwQWoqsq8J5/kWGYm77//Pm8sXIjBcLKtRJ1Vrlst8Pw9kHnUeffE9EedbU7qQJwxDm+NN5sLNtPWpy3DQ4bXyXkAfs8ppNjmTGRnmSzsKSjh/LDG2bpHiIam2pnhfv361UUc9WLt2rXlHi9evJiIiAi2bt1K3759PRRV7eRarFybEMkjya2gpARee82549lnJdEshBBCCOEBt956K/fcc0+FRHNaWhrPPPMMmzdv9lBkorHy89Mxb56zzUJi2l4GZp5YbKtl+3qLITDw5FvHgID6KzBSVZUHHtjH4cPOhc+nTInjsssi6u38Lt994kwyA3y1vFyiWVVVV0W2oii0963d18XhcGA2mwkIqNhOJDU1lRm3zgDggp4XcPPNN5810RwYGIjZ6+1ZcwAAw/NJREFUbMbhcJBSaubhPw+Qb7UxtkUEk5JiahVrrfQfCWFRkJ8D3S6qk1OoqspHH2Vy+HAZw4aFce65lVej14cOgX683tP5vTFw4EBiYmLw8fHhggsuQKfTYbVaeeqpp3jv/ffY/89+AAKCAoiKimLatGl88P77HMvMxGK1YreXr/ats8r17Axnkhmc1ee7t9Y60exQVTSV3MHwa8GvlDnKSPZPBuDPkj+5MOjCas1tsptYnb0aBYWRYSPx0npVOq5tgA8axbmYnpdW4+qXLYSovSq9Qli9enWVJxw1alSNg6lvBQUFAISEhHg4kppxqCqoOBf/E0IIIYQQDcLu3bsrrSjr2rUru3fv9kBEoilITPTmhhtiQb0GNkdAWQn0qr+e37fcEo/RqKGszMF110XX23nLyhyuJDPA7t3Fnkk0h56y6FaIc/vvkr958vCTlNpLmR47nSGh7vl6aDQajEZjhfWRAO69914sJxYYKzOVMX/+fNe+559/ntLSUqZPn17umIKCAoxGIxqNhlWpWeRbnZXpH6dkcUV8RN20DKiqTufV6fRffJHNsmXHANi8uYBFizoSFHSadpNmE+z8zfm1blm99pqHisv4v79TsDpUbmkbR6cgv9OOPXWhx3HjxnHdddcBzr8djz32WLmxhfmFPPfcczz33HOu564aO9bVo/lU/61cd4uwKIiMhcw0Z0XzOV1rNd0HhzN4/0gG4UYDjyUnEetzMhHso/UpN/a/j6viuZTn2FzovJh7oOwA9yXeV+m4dgG+PN2lDXsKSugW4k+EVyNfdFCIBqRKf1Euv/zyKk2mKEqFK2sNlaqqzJo1iz59+tCpUydPh1MjdlVFp1EI9OQLAyGEEEIIUY7RaCQzM5OkpKRyz6enpzf4VnOiEVAUuGBQvZ82KEjPXXcl1vt5fXy0dO8ewNathSiKwoUXBtV7DACMuQl8/KC0GIZeCcC7Ge9SYHMWLy08ttCZaN61Bf7+w5mQq0UStVOnTmzfvr3C8wcPHHJt//nnn+X27dixg6VL3qmQaN6+fTudO3cGIOSUNX18dVqMmtot6tjQHT9ucW1bLA4KCmyVJ5odDnjxfkjZjwUbv13RD+8eQ+geULXq3QX/HOVgsfOCyIt/p/DmBR1OO/bfhR4vueSScpXr/7bzDA4J5vbbbsff35/7H7gfi9lS7viAoKBK5z21cl3jrq+r3gCz5ju/ryPjILFtjacqstp473AGAJkmCx+nZHH7OS1c+3sE9GB85Hi2FW2jR0APuvpXP6l9qOzkz8fBsoNnHNs+0Jf2gY2zhaoQDVmVXuk6HI66jqPezZgxgx07drBhwwZPh1JjZoeKXqMQIIlmIYQQQogGY8iQIdx///189tlnBAY6ez7m5+fzwAMPMGRI/VWgNnk5mc5/Lc9xJkNEk/XQQ0ns3FlMcLCexEQP3eLu5Q2jbyj3VIDuZGuLAG0AHNkHbzzhbDHw4+cw+3+Q0KZGp+vVqxerVq3CZrOVu0A16rKR2Gw21+Pc3BwOHXYm1xJaJDDqsvK9fm02G+vWrWP06NEAjEuIwq6qZJmsjI4Px6CtZULSZoOPF8LRA9BrKFzoxkVQS4rgpy+cn/uLLoEaXKgbMSKMn3/O4/hxCwMGhNCiReWtFCjMg5T9OHCwp/gv/v4thc9Cf2FW/CwGhJx5UUcAzSmdIM62sOW/Cz0aDIZyleutW7fmwIEDJCYmuhLFO3fuZMmJhf/ioqM5mp7Om2++yb333kurVq3KzXtq5bpb+fpDz4G1nkavUfDSajDZnfmlygrmrom6hmuirqnxOUaEjWBJ+hLXthCi/jXLDOXMmTNZvXo1P/30E3FxcZ4Op8ZyzVYSfL1o4y/9hIQQQgghGor//e9/9O3bl4SEBLp2dVZkbd++ncjISJYtW+bh6JqIfbvgtUfAanUmmm+fV6MklGgcdDoNXbtW7FdcE6rqwEERGgLOmhA8m2mx09ApOoptxUyMngg7DzuTzM4TQeZRDtg0LFu2DF9fX2666SaCTlON+l+TJ0/mlVdeYc2aNa4kMcADDzzAAw884Hq8YsUKrrnGmZh77PHHmDRpUrl5Vq9eTVpaGpMnTwbAoNVwQ6vYmn/Q//Xzl7DhK+f2kX3QupOz1YI7vPEEHNzj3M46BldPP/P4SkRGGnnrrY6Ultrx8zvD74iAYIhriSVlD2aHmQOJzjzB7pLdVUo0T28Tx0t7U7E4HExve+Ycw6kLPf63cv3UO2Gys7P56mvn59bL24s77rqL2bNnA/DPP/9USDSfWrneEHlptTzcqSUrU7OI9DJyTWLk2Q+qpjERY+gZ0BMFhVgvN36fCyGqrMqvxr7//ntmzJjBpk2bKixKUFBQQO/evVmwYEGDXlRPVVVmzpzJqlWr+OGHH2jZsqWnQ6qxYqsNm0NlbIsIdE38dichhBBCiMYkNjaWHTt28N577/Hnn3/i7e3N5MmTGTduHHr9aXqDiur5YwN/HMvmaLGJC00WQnIy3ZfcakSsahYFjs/RKsEEKSNRFEm2n4ldLSTNfh8WNRVvpTMx2sdQlJr/TP4/e/cdHlWZPXD8e6emT3pvhN6rdFQEQVBRBAsiKquiqOsqgr3groqrPysqrrsKFlzbYkFdsOuqIALSlN5JIaQnk0y99/fHQCCSQEhmclPO53nm4b2Ze997hiSTmTPnntdmsjErfdbRL3SP9bUXOHjA92/3ATx88y0UFBQAviuF77zzznrN3a9fP0aOHMms22czZsyY6rYKfxQbG1vrGMButzNnzhxGjhxZa994v3A5jo41DdzORk13oNJBmMlIpMUMB45pfXDgxG0QTsRgUE6cZPbtBLfMw7zhR763v8Wm2EKMGBkaObRe58gIC+bJ/idvK/HHhR7rqlz/+eefGT5sGJ7DrUnPOP0Mnn/22er7O3asWSn/x8r15qpXVDi9ogK7IGNqUMstJhSiNaj3K5FnnnmG6667rtaVb202G9dffz1PP/10s04033TTTbz11lt89NFHhIeHk5fn6w9ks9lqbabfnBW5PKSEWLmiXdMtxCGEEEIIIeonNDSUGTNm6B1Gq/W/YiePr9oKwIfZxbwYHIZV55j0kOO9D7eWC4BqKCPGeNVJjmjbyrXvcGn7AajSNlKpbSBUqV8P3noJDYe7nvW1dIlJALOFioqK6ruPHdfHky+8yMB+fblh5kxeW7So1pYIo0aNIj8/H03TiI8/ukiiqqrMnDmT3Nxcli9f3vDHdDIjzvX1pN6/E4adA6lZJz+mDvO37uPz3CIsBoV7urej//Bx8PWHvr7kw86p9zzlnnJ2V+0mIzgDm8lW/wBCQjEOHsMt6pmMrNhIgiXB70nLPy70WFvlemVlJX+69k/VSWagxvdw0kUX0aFDhxrz/rFy/YjNpXYOVDoYFGuTlptCiCZR72ea9evX8/e//73O+8eMGVNjJdTmaMGCBQCceeaZNb6+cOFCrr766qYPqIFcqorTq3J5ZiKGYy/3Cg6G3buPjoUQQgghhG5+//139u3bh8tVcyGnCRMm6BRR6/GbZoX0juB0kG+LpqC8gpSIU0gotQKa5q5OMgO42K9jNC2DmfhjthRMSmyd+zb8JBZITKvevOGGG3jxxRcJCwtj2rRppzRVr86dGX73X1k8905A46UFL9Va2RwXF1dj2263M3PmTN58800WL158XFLSr0JCfa1rGsnh9fJ5bhEALlVjWW4h/S+6BgaNAmsQxCbWa55STym3bruVAncBNpONpzo+Rbwl/uQHHsNisNR7EcCGOLZdxpHK9dmzfZXrBoOB8yacx++bfkcBTEYj7sMJ56T4eG646abq9hlH1FW5vrKglEc37UYDkvflM39A50b15P6h5AeWFS6jXXA7rkq8CpNBEtdCiOPV+5nh4MGDJ7zUz2QycejQIb8EFSjakX5ZLZimaRywO0kNsTIx7Q9/MA0GyMzUJS4hhBBCCOGza9cuJk6cyMaNG1EUpfo16JF+sN5jqtREwwwePJjly5fj8Xjo0KEDCQmn3uvT41FZsOAA27bZGTkymosu8n+/0EBSFDM2w3hK1c9QsBChjPPLvJqm8eqr2axbV85pp9m48spkv8zbUB99lM/GjRUMGWJj1KiYRs0VahhEHDdSpf1GmDIUq5KB16uhaRom08kTcF6tHC8lmEmtd3/nUaNGcdZZZzWoH7TRoPDeHX/hycTPeObWt/npx//xxBNPMWHChBptFo7weDx8/PHHzJkzh9zcXBYvXsyUKVNO+bx6sBoMJARZOOjwfTCXHnJ40b6UzFOaZ2PFRgrcvlYlpZ5Sfi3/lbExflyg0A/+2C7j5ZdfplevXlx//fXkH8rnm6++ASA8IoKHH34Yr9dLZGQkU6dOPS4no6oqN9xwQ62V6+uKyjmSAcmpcpLvdJEaUsdiiCeR78rnib1PoKKyvmI9seZYLoi7oEFziSbgdoHJ7LsaQIgmVu9Ec0pKChs3bqzz09ANGzaQlCRtHALNrWkoCszuloHNIp8gCiGEEEI0N3/5y19o164dX375JVlZWaxatYrCwkJuv/32Zn8FYEvRp08f5s+fT15eHj169Kg16XYyX3xRyOef+xJSCxdm06dPOFlZIf4OtU6apjV6Mbo440xshgkYCcOo+Keie8WKUj78MB+APXuq6NEjjH79/LMQ36lataqUf/3rQPU4PT2Ijh2PVvR6tQo0XJiU6HrPaTOMw4YvKb92bRnz5u3G49G4+ea0EyayHdo2crz3o2qVhBqGkGi4u97fv8Z8n2OsBq6ZHsboESO478ZNTJo0iZSUFEaNGkWfPn2w2WyUlpaybt06vvrqK7KzsznrrLNYvnx5YCuZ/UxRFB7t04FPsg8RYzFzXkrcyQ+qRbugdlgUCy7NhREj7YPbn/ygWmiaxoLtB1hxqJReUWHc1iXdb2sj/bFdRocOHXjllVe4/PLLa+xXVlbGLbfcUr3dvn17RowYUb1tt9u54YYbWLx4ca2V66fFRPDf3AJUDTJCg0gIsjQ45kpvJSpq9Xa5p7zBc7VWP+aX8NGBQ6SEWLmhYyrWRlSPN+rvwydvwvJ3fQtc3vRXSM5ocBxCNES9X5GNHz+eBx54gHHjxhEUVPNTsKqqKh588EHOO+88vwcoaipzebCZTQyMqeWFpMsF997rGz/yCFga/odECCGEEEI0zIoVK/j666+Ji4vDYDBgMBgYPnw48+bN45ZbbuHXX3/VO8RWITU1ldTUhvdPdbu1E24HyqZN5cybtxuXS+Mvf0ln+PCoRs1nUfy7CKLHo9bYdrvVOvYMvKIid/VY0zSKiz3V23Z1FXnex9BwE22YSrTxslOe/803c3E4fFcYLFyYc8JEc5n6BapWefjcK/AYDv2hFUdgKIqJMMPpZHT4njc+H0zu+gm8+9p6Vq5cyTvvvIPT6cRqtdKzZ08mTpzI9OnT/bLw37qicpbszycx2MI17VMalTSrr/ggC39q37if55SgFP7e4e/8Wv4rPcJ60CGkYcn2X4vL+W9OIQDf55fQLzqCUYn1/0DjRP7YLiM0NJQpU6awZ88e7rnnnjqPO7Je1pHK9VmzZpGdnV1n5Xr/mAie7teJnCoXfaPDMTciUZ4ZnMn4mPEsK1xGRlAG58VK7udYpS4P/7d5Lx5NY3OZnVirmakNWE/L4XXw0O6H+M3+G8Nsw5iTMQeDcgrfN3s5LHvncFBF8OV/4MpZJz5GCD+rd6L5vvvuY8mSJXTq1Imbb76Zzp07oygKmzdv5oUXXsDr9XLvkSSnCIgqj5dCl5shsZFEW2tpY+J2w5EqmblzJdEshBBCCKEDr9dLWFgYALGxseTk5NC5c2cyMjLYunWrztGJI8aOjWX9+nK2batk5MhoOnc+vvdtICxalENZmS9h+vLLBxqdaPa3YcOiWL26jLVryxk4MIKBA/XrfX366VF8/nkh27fb6dcvgn79wqvvK1E/QMOXiC5W32tQojk6+uh7qqioE781tijp1WOjYsNI01V5JxhmY1PGY1RsdBiQyogBR+9TVbXWRQIbo8rj5eFNu3GqKhRDmMnIlVn6tlA5FR1COjQ4wXyE6Q/VpGY/tyA40i5j5syZLDq80OPdd9/N6NGjufXWW/npp59ITExk+PDhdOvWjZiYGL7++mueeuqp6sp1s9nMsmXLGDVqVJ3nyQoPISvcP1dqzEydyQ0pNzT6SgxN0/g8t4gDlQ5GJ0aTEdby15dyqyqeY1q1Vnkb9gHd18Vfs8m+CYAfSn9gTMUY+ob3rf8EFquvb3ql3bdt88+HI0KcinonmhMSEvjpp5+YOXMmd999d41ec2PHjuXFF19sUG80UT9eTWNfpYMRcVHc2yNT73CEEEIIIUQdevTowYYNG8jKymLQoEE8/vjjWCwWXn75ZbKysvQOTxxmtRq4//6GXVbfGOHhR9+ChYUZm/z8J2M0Ksyalal3GACEhBh56qnOOJ0qVmvNZKpZSaZK23R47Ksc/CqviDd25xJrNXNnt0ziTtIq4Oab0wgLM+JyqVxxxYmrD23KeShGI24thwjDGAxKw3rdNoSiKAQr3Wu9z99JZgCnqpJT5aTK6yXGaqbM3XL6yns8KkVFbmJiLBiNDU+I9ooK57KMBFYUlNIrMowR8ZH+CxKq22VMnToVgAULFhAaGsppp53Gjz/+yNq1a1m4cCErV65k6dKl1ZXr3bt3r/4g87XXXjthkjkQGptkBliWU8iL230tcb7KK+Jfg7sRYmp+z4WnIjbIwtTMRP6zP5/UECsX/XE9rXqKMNX8ACvMGHZqE5gtcMOD8OUSiI6HcS2jR7toXRStASvkFRcXs2PHDjRNo2PHjkRFndqn8GVlZdW9pI5c/tEajfj8F1yqRnwjeiEdUeryUOX18t6IXmTW9Ymf3Q6H/+hQUQG1rEgshBBCCBFIbeV13oksX74cu93ORRddxK5duzjvvPPYsmULMTExvPPOO5x11ll6h+h38n2vv4ICF6+8ko3TqXL11cmkp7f8aj49qJqDYvU9VCqINExGVWO49IeNeA+/vR2VGM2tXdLrnkDT4LtPIG8fDD4bMjs1UeTN39d5Rcxeu52cKifhJiPLzupLez9VxQZSebmHu+7azr59VXToEMK8eR0JCvJfAtOrlWMgzC/J1iPeeustrr32WpKSknjiiSfqXOjR5XLxySefVC/0+Morr7SYhR7/6KVtB/g0p+Do9sAupDRwkcLWRtM03j74NpvsmxhuG864WP8s8iqEP9T3tV6DVpOLioritNNOa3Bw4tQVOF10jwwjNcSqdyhCCCGEEOIExo4dWz3Oysri999/p6ioiKioqFNOUHz//fc88cQTrFmzhtzcXD744AMuvPDC6vuvvvpqXnvttRrHDBo0iJUrV1ZvO51OZs+ezb///W+qqqoYNWoUL774Yo3+xsXFxdxyyy18/PHHAEyYMIH58+cTGRl5SvGKk4uNtXDnne30DqPFMyhBxBinVW+7UDEq4D1cRvXH1gfH+WEZvP+yb7zme5j7LwgNP/ExTUXTID8HwiJ0iWlnRRUpIVZSgq2ggCUAVdOBsHJlKfv2VQGwY0clq1eX+aU1jaZ5yPE+RJW2DouSQYpxHkbFP9+Xyy+/nIEDBzJjxowGL/SY68wl2BBMpDnSLzEF2qjEaL7NL8bu8XJaTATJwZLjOEJRFKYktswPEIQ4okGJZtG0Kj1eTIrCDR1T/bbSrRBCCCGECLz9+/ejKEqDF62z2+307t2b6dOnM2nSpFr3Oeecc1i4cGH1tuUP63TceuutLF26lLfffpuYmBhuv/12zjvvPNasWYPR6Kv2u/zyyzlw4ADLli0DYMaMGUybNo2lS5c2KO6mUlJSwt///ndyc3O55JJLGD9+vN4hNYqqVeLUdmFR0jAq+vVGbiqq5sCurcBIDCGGXo2ay2I0MLtrBm/tySPWauGKdoknPiA/++i4qhLKS5pPonnR//mS30HBcNNfoV2XJj39GfGRfJ5biMOr0sMW1mISgUlJR5/7FEUhMdE/cVdq66nS1gHg0vZSrn1LpHK+X+YGXxuNr7/+uka7jPou9LgwZyFLDi3BpJi4K+MuBtkG+S2uQOkYEcI/B3Wl2OUhNcTq1wpxIYT+JNHcApS7PURZzQyLa/0vNoUQQgghWjqPx8NDDz3Ec889R0VFBQBhYWH8+c9/5sEHH8RsrmVR5zqMGzeOceNOfOms1WolMbH2pFppaSmvvPIKb7zxBqNHjwbgzTffJC0tjS+//JKxY8eyefNmli1bxsqVKxk0yJek+Oc//8mQIUPYunUrnTt3rne8Te3dd99l0yZfn96XXnqJYcOGYbO1zNfMXs3OAe8s3FoOBiWcNOOT1b2H/aWsrIynnnqKvLw8Lr744lr7u7pcKvv2OUhKshAaGti3izneB3BomwGI40ZshsZdJj4kLpIhcZH123noGFj9LZSXQq9BkNCwD4P8rqTQl2QGcFTBj8tPPdHsdsHva8AW06CWIJ0iQvnHwK4ccrpoHxaM0dAyEoE9eoQzZ04m69aVc9ppNjp08E+7D5MSCyiAr1zeTMP6755Mv379aiSST7bQo6ZpfHjoQwA8moelBUubNNGsaRoV3grCTUc/oPkmr4gXtx8gxGjknh6ZdI6ovZ1nuNlEuFnSUc3ZT4dKeHbLfswGhbu6Z9Ij8hT7RYs2S36zmzmvplHi9jA+JZYgY8tukC+EEEII0RbcfPPNfPDBBzz++OMMGTIEgBUrVjB37lwKCgp46aWX/Hq+b7/9lvj4eCIjIznjjDN45JFHiI/3JULWrFmD2+1mzJgx1fsnJyfTo0cPfvrpJ8aOHcuKFSuw2WzVSWaAwYMHY7PZ+Omnn2pNNDudTpxOZ/V2WVmZXx9TfRmPeX1sMBgCsjBaU3Fov+PWcgBQtXLs2ioilQv8eo533nmHNWvWADB//nwGDhxIePjRJFFVlZc5c7axd28V0dFmnniiE/HxDawK9Xigll6zR6iaozrJDFCprcFGE/YjTUr3tcuoKPUtmuXHqkqPx4PRaGxYpWZoOEREQlnJ0ThP1YsPwvZNvsc07TYYOLLW3dauXcu6devo168fffr0qXFftNVMtLX+H4o1F6efHs3pp0f7dU6rkkGi8U4qtB8JUroRamiaZO6R5zOPR8VkOv65TVEUUq2p7HPuAyA9qAE/Kw1k99q5Z8c97HLsomdoTx7KegizwcxL27NxeFWq3B5e25nDo307NllMwr/+sT2bSq8XvPDqzhye6i997EX9SKK5mdtrd5ARGsSUzJNc+gUQHAyHKzoIlkVFhBBCCCH08O9//5u33367RiVyr169SE9P57LLLvNronncuHFcfPHFZGRksHv3bu6//37OOuss1qxZg9VqJS8vD4vFctzi3QkJCeTl5QGQl5dXnZg+Vnx8fPU+fzRv3jweeughvz2Ohrr00kvJy8sjJyeHyZMn10iatjQWJQMFKxpOQMGq+D9Bc+w68LWtCf/bbxXs3evrcVtU5GblylImTDjF6s28/fDCA77K3HMuhXOn1rqbQQkiWOlBleZ7/xKi6LAGkDXId/Ojd955h8WLFxMVFcVDDz1EZmbmqU1gtsAtj/p6SMcmwhnnndrxlXZfkhl8vZ43/lxronn79u3MnTsXTdP46KOPePrpp8nKyjq1c7UhYYZhhDGsSc/p8ag88shuVq8upWvXMP761/bHLW74UNZDfFTwEeHGcCbGTWyy2P5X8j92OXYBsNG+kbXlaxlkG0SY2cj+tavY/Z+32BtkZdK8v9G/f/8mi0v4T5jJSJHLXT0Wor4k0dzMeVWNGzqm1nnJSQ0GA3TvHvighBBCCCFEnYKCgmpNLmVmZh7XP7mxLr300upxjx49GDBgABkZGXz66adcdNFFdR6naVqNasvaKi//uM+x7r77bmbNmlW9XVZWRlpaWkMeQqOEhYVx7733Nvl5A8GsxJNqehy7uoogpRvBSje/n+PSSy9l37595Obmcumllx6XmE9JCcJsNuB2qwBkZjageOWL/0BxgW/837fhzAl19j5OMj6EXfsZE9EEG1r++xiHw8Gbb74JQFFREe+99x5z5sw59YkS02DydQ0LIjgE0jvAvh2+7U69a91t37591R82qKrK/v37my7RvHurryd2t/4nrHpv69auLWf16lIANm+u4Lvvihk7NrbGPrGWWK5JvqZJ4/KoHhyqA4/qwWQwoaAQa/bFdU/3TCbNe4BIA6SYFV5//XVJNLdQd3bPZOHOHMwGhes6pOgdjmhB5Fm9GfNqGooCUZaWd8mSEEIIIURbddNNN/G3v/2NhQsXYrX62g44nU4eeeQRbr755oCeOykpiYyMDLZv3w5AYmIiLpeL4uLiGlXN+fn5DB06tHqfgwcPHjfXoUOHSEhIqPU8Vqu1+rEJ/7EqWViNgUv22Ww2Hn744TrvT0qy8sgjHVi1qpRu3cLo1asBFeIRkUfHQcFgqfvnxKBYCFdGnPo5mimTyURoaCh2ux3guCsJmoSiwJ8fgXU/+no0d+tX624DBgwgMTGRvLw8kpOTj1tkLmB+XA7/ft437tYfbpzbNOf1t7z9sH0jtO8OyRm+r+3aDNm7ocdAiIo97hBVU9lYsRGbyUZmcOZJT2Gz1UzXREbqn75xqS7u2XkPWyu3UqVWMTR8KOfEnEP7kPYAtA8PYWRWGjt2+ForRUZG6hitaIz00CAe7CVXOYhTp/8zlahTudtDmMlIh/B6LmLgcsGjj/rG99wDfq6YEUIIIYQQJ/frr7/y1VdfkZqaSu/evmrC9evX43K5GDVqVI1K4yVLlvj13IWFhezfv5+kJN8icv3798dsNvPFF19wySWXAJCbm8umTZt4/PHHARgyZAilpaWsWrWKgQMHAvDzzz9TWlpanYwWbUfXrmF07dqIRZ/GTQGXE4ry4ayJvlYQbYTJZOLBBx/k/fffJzY2liuuuEKfQIJDYMjZJ9zFZrMxf/58cnJySElJaboPjjasPDr+fQ243XAKC6Q2C/k58Phtvp9zswXufMbXKuaFB3ztSpa9A/e+ACE1f4/m7ZnHyrKVKCjMSp/FmVFnHr1zyzpY/q4vQT35eggJpXPnUP7853RWrCilV68wBg2KbLrHWIedVTvZWrkVgHBTOD3DenJ61Ok19rnjjjt4/fXXMZlMTJ8+XY8whRA6kkRzM1bm9tLNFkp6aD37hrndcKRX3pw5kmgWQgghhNBBZGQkkyZNqvG1hraVqKioYMeOHdXbu3fvZt26dURHRxMdHc3cuXOZNGkSSUlJ7Nmzh3vuuYfY2FgmTvT16rTZbFxzzTXcfvvtxMTEEB0dzezZs+nZsyejR48GoGvXrpxzzjlcd911/OMf/wBgxowZnHfeebUuBChEXex2O19//TUR8V04ffKMhi2G18J17dqV+++/X+8w6iUoKKjp+zJ37g2/rfaNs7qeUpLZ7vESYjTo/3O1d5svyQzgdsGebVCQ60syA5QWwcFsaHf0+dOlulhZ5kuya2j8r+R/RxPNbhf88xFwOnzbIWEweQYAY8bEMmbM8dXRekmwJBBkCMKh+mKtrTI7KSmJO++8s4kjCwCvFxY+DptWQZe+cM3dLe9DESF0IInmZszhVeufZBZCCCGEEM3CwoUL/TbX6tWrGTny6EJeR/oiX3XVVSxYsICNGzfy+uuvU1JSQlJSEiNHjuSdd96p0Xv36aefxmQycckll1BVVcWoUaNYtGgRRuPRxX0WL17MLbfcwpgxYwCYMGECzz//vN8ehzgxTdP48ccSnE6VM86IwmQy6B0S4Ivrhx9+wO12c/rpp2M6ST/duXPnsmXLFgBycnKYMmVKU4QpmliFp4JtldvIDM4k2hx9agefdSHEp/h6NPerX9sUTdN47Lc9/FRQSkqwlUf7dCDaqmPCr0MPX99xe7kvKdyxJySkwFdLfMVf8clH22kcZjFYaB/cnp1VOwHoGtL16J1e79HENUBlRVM8igaJNkczr/08fij5gQ4hHRhiG6J3SIGz8WdY95NvvOkX+PWHWhfWFELUJInmZsqlqpgMCqMTT/EPtxBCCCGE0FVVVRWaphES4mt/tnfvXj744AO6detWncitrzPPPLN6wa7aLF++/KRzBAUFMX/+fObPn1/nPtHR0dWLmImmt3BhDh984OuTvXp1GXfe2Q4K8+GL9yAoBM65zNfvuIm9+uqrfPjhhwD88ssvJ6xSVFWVrVu3Vm///vvvgQ5P6KDcU86t224l351PqCGUJzs+SUrQKS4U1uO0U9p9W3klPxX4FsXLrnLyRW4hl2Ymnto5G6hS3YCXEkKVwRiUw1cMR8XC3fNhz1bI6OTbjomHu+ZD3j5f4tl6fMHYw1kP83Xx10SZohgRdUySPSgYLroGPn4douNg7KXHHducdAjpQIeQDnqH4X8VZb52LskZkJp1XOuT47aFELWSRHMz5VE1LAZFKpqFEEIIIVqYCy64gIsuuogbbriBkpISBg4ciMVioaCggKeeeoqZM2fqHaJoZtavLz9+/PLfIHuPb1xeCtNuDdj5d+2q5IUX9gNw001pZGWFHI5lffU+GzZsOOEcBoOB4cOH87///Q9FUTj99NNPuH9A/bAMcvfCwLMgo2OduxW7i1mYuxCn6uTKxCtPPWHaBm2p3EK+Ox8Au2pnTfmagP+/RZpNmBQFz+EP3WKDmqZFZIm6lALvywAEK31IMf3tmKBioM8fetgnpPhudQgzhTEhbkLtd468wHdrA/IdLp7dso8yt4fp7ZPpFx2hd0i+tiVPzoZDuWAwwI0PQZc+LAy6jlUrCunbP5Lrug+g7TUDEuLUNY9rssRxXKqGWTFgM8tnAUIIIYQQLcnatWsZMcJXrfb++++TmJjI3r17ef3113nuued0jk40R4MGHa2UGzzY5hscyj26Q2FeQM//7LP72LbNzrZtdp59dl/114cMGYLH4yE7Oxur1YrT6Tz+4LJiX2J312bmzJnDI488wrPPPsvZZ594Mbr6yMnJYdmyZezZs6f+B634At5+Ab77BJ6/z9feoA7PH3ieb4q/4afSn3hs72PH3b9/v4MNG8pR1bqvKjgVW7du5YknnuD111/H7Xb7Zc6mlhGUQZDBVwxlwEDnkMD3cU8ItnJX90yGxUVyVVYSZyVEBfycAJXqmupxlbYOTfM0yXlbu1d2ZLOhpII9dgeP/75X73B8DuUcfc5VVdi8ljVryliyNZUD0b1ZujuDFStK9Y1RiBZCspjNkKppFDhdtA8LJqGJPq0VQgghhBD+UVlZWd0j+fPPP+eiiy7CYDAwePBg9u5tJm+qRbNQXl7Ogw8+yI4dO+jUaRBTptxM//6Hq/vGTYGPFoHZAqMnnXCexvJ6NbxaKS72UeZx4tJCsShpTJkyhe+++w673c6hQ4eYP38+s2fPPnrgkSrAwnxQFJTr76dXr1NriwBQpW7CQ1GN9gT5+fncdtttVFZWYjabeeqpp8jMzDz5ZHn7j5m4EkoKff10a1HiKakeF3uKa9z3/fdF/N//7UXTNAYNiuS++068aJ7TqfLuu3mUlXm46KIEkpKsf7jfyYMPPojdbgfAaDQyderUkz+eZibeEs+THZ9kddlquoZ2pXNo0ywYOijWxqBYW5Oc64gQQ38qvb5kc7DSG0WR9Ik/eI9pB+XVNDRNO+UFHh1eL//ckU1elYuL0uLpH9PIqui4ZIhLOlrR3LUf3rKaHzB5vf75wEmI1k6eKZuhYpeHcJOJu7u3039FXSGEEEIIcUo6dOjAhx9+yMSJE1m+fDm33XYb4EucRUQ0g0uERbPx5Zdfsn37dgC2bVtJcPCFKEp3351nT4LBo8FkhuCQgMZx001pPPzMl2i4uOyG9RR4D5Bs+ivg++DEZvMl+I6rLD6U60syA2gabN8IPU5jzZoyVq8upU+fcAYNijzhuUvV5Rzy+haeDFK6k2ryVRbv2LGDyspKANxuN5s3b65fonnwaFj5pa+SuVt/SEqvc9dpidOYt2cebs3NNUnX1Ljv++9Lqvuj//xzCQ6Hl6AgY23TAPDqq9l89tkhwNf+5OWXu9e4v6qqqjrJDFBQUHDyx6IzVVUxGI6/CDo9KJ30oLr/X1uLSMP5WEg/3KO5FS9618T+1D6FIpeHUreHa9snNyjn8faeg3yeWwTAljI7bw7tQbCp7t/Pk7IGwawnYPNaSEyD9A6cpmmcc04sv/xSRp8+4QwbFtnw+YVoQyTR3Aw5vSpJwRaGxUee2oFBQbBq1dGxEEIIIYRocg888ACXX345t912G6NGjWLIEF+C4vPPP6dv3746Ryeak2M/eFAU5fgPIsKbpoKza9cwHn7hF7zakareo9W748ePZ/HixSiKwrhx42oemJDiS8rk7QejEboPYPfuSv76152oqsannxbw9793pGvXuhfRqtRWV48d2m+oWhUGJZguXbpgs9koLS0lODiYXr161e/BJKXD3H/5WnrEJ8MJklh9wvvwdo+3UVExKjWTVF26hPDzzyUAZGYGnzDJDJCbe7StyMGDruOqNCMjI7ngggv46KOPqscB8+li36Jm3frDufWvml67di0LFy5kxYoVbNq0CafTidVqpUePHgwZMoTp06fTr18/v4fr0vZTrn6DRUkj3DDS7/M3Roiht94h6KeizNeGprTId4VFt9q/96qmsSynkAKniyizmUirieFxkXUmkJNDrDzVv1PjQvN4q8cuVcOlajR6udRwGww8+vOnKAo33VT3Byrbyyr58EA+8UEWpmQkYjFKZ1ohQBLNzU6Z20OFx8tpMQ14UWk0wmmnfqmaEEIIIYTwn8mTJzN8+HByc3Pp3ftokmLUqFFMnDhRx8hEc3PWWWeRl5fHtm3bOPPMM0lLS9MtlgTDbArUf2IgmFjjddVfv+yyyxg+fDhGo5GkpKSaB5ktvirAbeshIRWS0sn+obi6p7GmaRw44DxhojlE6Y+dlQAEKV0xKL50UXR0NM899xybN2+mY8eOxMfH1//BBIfUuwpcURSMHJ9Enjw5kYQEK4WFbkaNij7pPBMnxvP77xU4nSqXXJJYa5Lt2muvZcqUKQQFBWE0NqL68kR+Ww3/fds33rsd2nXxJZxPYMeOHcyYMYNvvvmGlJQURo8ezRVXXEFERARlZWWsW7eODz74gOeff56RI0fy8ssv06FDB7+Eq2qVZHvvwquVAaDhJcIw2i9zi0b6+DVY95Nv/Mo8+Pu/wXR8Cunfe/J4e+9BdldUUe720isqjA1JFdzUOXDPZ5PT4/mttIK8KhdTMhOxWZo2teVWVR7csJPywwlvBbgyK7lJYxCiuZJEczNS5vZwyOFiQmoss7q2/kuRhBBCCCFaq8TERBITE2t8beDAgTpFI5orRVGaTZ/eEEMv0g3za70vNTX1BAeGQp+h1Zt9+4aTkRHM3r1VJCVZGTjwxO1ibIZzMJOMl0JClaE17ouOjmbYsGH1fxB+NmJE/Red69s3gtdf74nTqRIVZa5zv9DQUH+EVjeno+a2o+qEu7/11ltce+21JCUlsWTJEs4//3xMtSQTPR4PS5cuZfbs2fTq1YtXXnmFKVOmNDpcD4XVSWYAp7ar0XMKPzn2Z8ntAk2tdbfdFb6fsTK3B6eq4tU01pdUBDS0xGArCwZ2Deg5TsTpVauTzACHnC1zcU8hAkESzc1IgcPNsLhI/t63I4aG9GZ2ueDZZ33jv/wFLLKQoBBCCCGEEKLphIaaePrpzhw86CI+3oLFcvLLyUMM9WyL0Yztszt4efsBFEXhemsKqSE6tTLsPQT6jYDNa6Brf992Hd566y2uuOIKrrjiChYsWHDCJLjJZGLixImMGTOGmTNnMnXqVDRN4/LLL29UuGZSCFZ6U6Wtx6AEN7vWGW3auVMhd6+vdcb5V/quYKjFmKQY1hSVE2kx4dXAqCgMjtV3PYICh4tluYXEWs2MTYrx+9pXYWYTF6XFs2R/PhFmExNT4/w6vxAtmaJpWpMvnVlWVlbdb6s1L4gy4vNfcKka8UH1S/huK6vk6qwk7u7RrmEntNsh7PBlaRUVEOhPy4UQQggh/qCtvM4TNcn3/cSWLSvgP/85SEqKldtvzyQ8XOp96kvTNArUf2DXfiFE6U+cYWazXDD91tVb2Xm4srNLRChP9Ouoc0Qntn37dnr37s3kyZNZtGhR9aJ/lZWVFBcXH7d/UlJS9T6qqnL11Vfz/vvvs2HDhka30dA0L052YyYOo9I0fcnrVGn3taS0yppHp6LA4aLU7aHY6cZgUOgXrd/fAU3TuH7VFnKrfH3Tp7VL4pKMhICcy+7xYjUomGpZNFOI1qa+r/Xkt6GZKHS6CTEZGBYXqXcoQgghhBBCCD8pKXHz4ov7yctzsmZNGe+9d1DvkFqUSm0VpeqneLR8ytT/YtdW6B1SrRxe9Zix9wR7Ng/XX389ycnJLFiwoDqBDHDagAGkpqYed7vvvvuq9zEYDCxYsICkpCRmzJjR6FgUxUiQ0uG4JPOS/CVcvPFibtl6C4dch+o9n9frxe32tTLwqCpL9uXz6s5s8h2uEx/4zUdw5xS4ayps+uWUH0dbFhtkoX14CANibbommQGqvGp1khlgZ3llwM4VajJKklmIP5DfiGbAraoUOt1MzUxiRHyk3uEIIYQQQgghRDPV/KqZAW7omEqcAcb8/h1z9q2CqvontwoLXcyfv48XX9xHaWnge72uWbOGb775hieeeOK4dhkFBQW1HlNaWlpjOzQ0lCeeeIJvvvmGtWvX+j3GUk8pi3IX4VAd7Hbs5t2D79bruHXr1jFlyhQuvvhivvjiCxbvyWPhrhw+2H+I+9bvPPHBn70FmubrR/z5e354FEIPISYjpx/Oq5gUhbOTYvQNSIg2Rq7ZagZK3R6irSauaZ/cLC8DE0IIIYQQp+aNN97gpZdeYvfu3axYsYKMjAyeeeYZ2rVrxwUXXKB3eKIJRUaauemmtMOtM4K4+OLAXMLdWoUoA7EZzqfycOuMUGWw3iHVqk90OK/u/QZ+/xp+B/J2wk0P1evYxx/fw++/+xZPO3TIzYMPtg9gpLBo0SJSU1M5//zz69ynb9++3HzzzdXbZ5999nH7TJgwgZSUFBYuXEi/fv38GqNJMWFWzLg0XxVyiDGkXsctXryYqipfC5NXX32Vbvc8Un1fbpUTt6pirqsCNToesvf4xsFh8P7LYLbCmIshuH7nb0vyHS7K3R7ahze//5vZXTO4KC0em9lEbD1bmQoh/EMqmnVW5fVS5PQwPC6KKGvdqxMLIYQQQoiWYcGCBcyaNYvx48dTUlKC9/Bl9JGRkTzzzDP6Bid0MXZsLC+/3J0HH2wv/ZlPkaIoxBlnkGH6J3HGGxpXmPPLt/Cff8HurX6Lr4YDu44Zn6R69hj5+a5ax4GyYsUKRo0ahclU98/ir7/+yjNPPcUPP/xA165dSUtLO24fk8nEqFGjWLlypd9jDDWGcmfGnXQN6cpZUWdxWcJl9TouKioKr1aGSgXR0dGMT47FbPD9zPjGJ0iBzLgPhpwNZ06AsiL4dil88T68/YI/HlKr8mN+CTN+3syta7bx3JZ9eodzHEVRaB8eIklmIXQgiWad5Ttc9IwM44GeDVwAUAghhBBCNCvz58/nn//8J/feey9Go7H66wMGDGDjxo06RiZEG7buJ3jtSV8f3vn3Qkmh/88xdCwcSYQPH1fvw6ZOTcJgUDCZDEyZkuj/uP5g06ZN9OnTp9b78g8d7YW88bffWLhwIUOHDmXRokW17t+nTx+/Pa/9/nsFb7yRw4YN5QAMtA3k8Y6Pc1v6bQQbg+s1xyU3mOg/qpDuQ/O48a7e9I+JYOHg7rw0sAszO6We+OCYBJh6C0y+DoqP6Qmdn93Qh9RqfZFXiFfTAPgyrwivqukckTjC7rXz7sF3+ejQR7jVwLfiEeKP5ON0HamahsurcU5yDOFm+VYIIYQQQrQGu3fvpm/fvsd93Wq1YrfbdYioddq1axc5OTn069ePkJDmd+k2pUW+ZGZae5DFovSXe0zVpcsJRfkQ6eferWecB136gtcDyRn1Pmz06BiGDYtEUSAoyHjyAxpBVVWcTicREbUv2NatWzd+//13LrzgAg4ePMiKw9XKt98+iylTpmC1Wmvsb7PZcDqdqKpaY1HBU7V3bxX33rsDj0fl/fcP8n//14mOHUNPfuAfGCLWctXNviIuq7LFF6PFhM1yiu+3x14CS14BoxFGTzrlOFq7rLBg1hT5PhDICA3CaJAWoM3FvD3zWF+xHoD9jv3cnHbzSY4Qwr8ku6mjEpcHm8XEuGQ/vcAJCoJvvjk6FkIIIYQQTa5du3asW7eOjIyaiab//ve/dOvWTaeoWpfVq1fzt7/9DVVVyczM5KmnnsJsbkZt6LZvghcf9C0q1uM0uP7+o5WuQh8DzoDvP4HyUsjqCmkdAnOehJQGHRYcHNgE8xEGgwGr1UpZWVmt9//6668YjcbqqzFuvPFGFixYQFFRMStWrODMM8+ssX9paSlWq7VRSWaH18Hy39dR4dIIMgShqhp79jgalGgOUrpRqf0CQLDSiOfbkRdA/9PBaILQ8IbP00pd0S6JWKuFEpeH8Smy2F5zsrNqZ61jIZqKJJp1VOn1kh4SREqIn5LCRiP84Q+/EEIIIYRoWnPmzOGmm27C4XCgaRqrVq3i3//+N/PmzeNf//qX3uG1CqtXr0ZVVQD27NlDfn4+KSkNS/AFxKqvfUlmgE2/+Cqbo2L1jamti0uCB16GkgKIS4YT9Cdu7Xr06MG6detqvc9iqdnT9tjfK4fDcdz+69ato2fPng2OxaN6uGvnXWyJ2Mf2oNPJqOxLVmIM/fvXXnF9MomGuyhXvsZAEGHKGQ2OC4CIqMYd34oZFIXxKfKc1hydE3MO7+e/j4LC2Jixeocj2qC2+9dVZ6qmUelRGRxr0zsUIYQQQgjhR9OnT8fj8XDHHXdQWVnJ5ZdfTkpKCs8++yyXXVa/Ba3EifXu3ZvPPvsMTdNITk4mLi5O75BqSjlm/ZXIGAhrWNJM+FlwCASn6x2F7oYMGcIHH3yAx+OpsSDgunXrGDp0KJMnT2bQoEEcPHiQZ55+GgCz2cyAAQNqzOPxePjqq6+YOHFig2PJdeWys2on5jDodse3DHZGcHv/YYSGNixVYVAs2JRzGhyPEC3dVUlXcUbkGZgVMylBzegDWNFmSKJZJ3aPl2CTgfNS/Pii2O2Gl1/2jWfMgOZ0+aAQQgghRBvg8XhYvHgx559/Ptdddx0FBQWoqkp8fLzeobUqQ4YM4bHHHiM7O5tBgwYdV4WpuzPPh6BgOJQLg0eDueHxlZd7ePjhXezd6+Dcc2OZNi3Zj4EKf1m7tow338wlMtLEn/+cTlRU830vNn36dJ5//nmWLl1aI0m8Z88eqqqqeOONN3jjjTdqHDNjxgxiY2tWsH788cdkZ2czffr0BscSZ44jzhzHIfchjEFezurcqcFJZiGET2Zwpt4hiDZM0TStyZcHLSsrw2azUVpaWuciBK3BiM9/waVqxAcd/8Jye3klp8dH8eJpnTH5a3EQux3CwnzjigoIPfWeVkIIIYQQjdFWXuedSEhICJs3bz6uR3NrJt/3wFm8OJe3386t3l6woBupqbIeS1Oxe7zsrqgiIzSozgXcVVXj0ks34HB4ATjrrBhuu615//6fddZZ7N27lw0bNhB6+H3j/v37uXLaFaxY+TNOpxOA9llZXHvddcyePbtG9bPdbqdXr15kZGTw9ddfNyqWQnchP5b8SHpQOn3C+zRqLiGEEIFR39d68lGhDryqhgJMTI3zX5JZCCGEEEI0C4MGDeLXX39tU4lmcVRBgYslS/IJDTUyeXICVmvjXu9brUcXEVQUBYulgYsK7vwd7OXQfYBvbZe2qrICgkKgHu/DytwebluzjXyHi0iziSf7d6q1iEhVNTyeo/VbLpfqt3AdXi/v78unyqsyKS2eaKt/KqVffvllevXqxcyZM1m0aBEGg4G0tDS++fY7vF4vhYWFmM1mIiMjUf6wkKWqqsycOZPc3FyWL1/e4Bhc2n5yvX/FQxGnx1xFpKFPIx9V8+PVyijXvsZELGGG4XqHI4QQASeJZh1UeLyEmox0jwzTOxQhhBBCCOFnN954I7fffjsHDhygf//+1dWCR/Tq1UunyERTeOihnezZUwVASYmbm25qXE/gCRPiyclxsnevg/HjY4mPt576JN8uhfcPt9jrNRhm3NuomFokTYNF/wdrvoeYeLhlnu/fE9hUUkG+w7eoY4nbw5rCMsbVsgCayWTgllvSWbgwm6goM9OmJfkt7Je2Z/NVXhEAm0vtPNW/k1/m7dChA6+88gpTp04FYMGCBdXPVUajsc52P3a7nZkzZ/Lmm2+yePFiOnTo0OAYitS3cWt5ABR4/0WEcg4GpZm1wWkETdPI9t6NS9sHQCyFRBou0Dkq/RxyuDAqit8+LBFCNE+SaG5CmqZR5PJQ4HRxZkIUKcENeJEohBBCCCGatUsvvRSAW265pfpriqKgaRqKouD1evUKTTSB7GxnreOGslgM3HJLI6vjN6w8Ot74sy/pqjSwMrqlytnrSzIDFObDD/+FC6464SEZoUFYDAouVcOgQPvw4Dr3HTkympEjo/0ZMQDZlUd/hg5UOvw695QpU9A0jWuvvZYff/yRJ554ggkTJtRokXGEx+Ph448/Zs6cOeTm5rJ48WKmTJnSqPMbOVp4ZVCCUdCn0t7r1SgudhMdbcZg8N/vhUpldZIZwKFtBtpmonnJvnwW7srBoMAtndMZlej/3xUhRPMgieYmomkae+wOgowGpmQkclPnNIx+/CMmhBBCCCGah927d+sdgtDRpEkJvP12LiaTgQkT/Ljwd2N07g3bNhwdt7UkM0BYhG9RRrevQpnok39vUkKCeKxPR9YWldE9MoxOEU2/Bs6FqXH83+ZKPJrGpDT/Lyp6+eWXM3DgQGZcMolJkyaRkpTEqLPPpk+fPtW9ONetW8dXX31FdnY2Zw0dwvJz+tBh9RJoFw+DRzX43NGGK1Fx4NEKiTZchqLUnmh2artxa7mEKP0wKP7tT263e7j77h3s3l1J+/YhzJvXkeBg/yS8jUooIYbTqFR/AQyEKaf7Zd7mqtjppsTtITM06Lh2Kx/szwdA1eDD/fmSaBaiFZNEcxNwqSqFTjcKMLdnFuelNpMXnEIIIYQQwu+kN3PbNnVqEmPGxGC1GoiIaCZvt8ZeAkkZUFkO/Vt3sqtOtmi4/n746XNIyYTh4+p1WMeIEDpGhNT/POWlsH8HpHWAcFvDYj3GsPhIekSG4VZVYmvpD+0PHWyhfD00nbUdbSzcvJ+VP//EO++8g9PpxGq10rNnTyZOnMj06dPp99MHsGUdOIH3XmpUotmohJJgvO2E+9jVX8j1PgyoWJX2pBr/D0Xx3+/Vzz+Xsnt3JQA7d1byyy+lnH66/5KgSYZ7qVJ+w6REYVHSGjSHy6tyyOkiIchSrzWeirzvUqJ9gIVUEo33YlIiG3TeU7GppIIHN+zEpWoMjbVxV/fMGsnmtNAgSkoqfOMQWcxUiNasmbzyaV00TWNLme+P1UGHC7vHS5jJSNeocIbGReobnBBCCCGECKjXX3/9hPdfeeWVTRSJ0EtcXDPsM9trUK1f/vXXMt577yBxcRZmzEghNFTnt4jbNsCyd3yJ4YuvhxA/rmvTpY/vFijFBfDEbVBWAhGRcMczEBnT6GltlgB/T1Tf4oX94mz0i7PBuVNh3GWoqorhj4nNdV8cHQcHvsLbrq0CfPE5tZ14OIQZ//XATkw82s5SURQSEvzb3lJRjIQoDe/LX+Jyc8evO8itcpIVFsxjfToQbKq74tqtHaJIfQMAB1soUZcQa/xTg89fX1/kFuJSfQti/lRQSrHLU6MX813dM1myLx+zQeGiAFTmCyGaD0k0B8DfNu7mowOHcGsqg2Nt3NI5jc4RIcRYA/yC02qFTz45OhZCCCGEEE3uL3/5S41tt9tNZWUlFouFkJAQSTT7gaZplGqf4tYOEGEYg1XJ0jukFsnlUnn00d04HL6+4aGhRmbMSNUvII8H/vkIVPmKdrAGwWU36RfPiZSXws7fIKUdxB1OfG7b4Esyg+/fbRtg4Ei9Iqy/hBSYcBX88BkkZ8KZEwCOTzIDTJ7h+7eyAs4P/HNZsNKLMpYBYFZSMHH8YoyN0a1bGHPmZLJ2bTkDBkTQuXPTt0c5kRWHSsmt8vXp3lVRxfqSCgbH1l0pr2ACjID38HbT5AUyw4LhYDEAqmkzN2ybh8Vg5s6MO+kZ1pMIs4mr2yc3SSxCCH1JojkAdturcKkqISYj13dIaboqZpMJzj23ac4lhBBCCCFqVVxcfNzXtm/fzsyZM5kzZ44OEbU+ZdpnFHj/AUC59h0Zxn9hVBqfIPr55xLeeecg8fEWbropjfDw1v12ye1WcTrV6m27vfELVf7+++/s27ePgQMHEh19ii0INBUcVUe3K+2Njicg7OXw+K2+CmaLFWY9DqlZkNERzGZwu33/pnfQO9L6GzPZdzuZiCj4052Bj+ewcMMIjNhwk0OYMgRFMZ/8oFN0+unRfm2XAeDV7KiUYVYaV32dEnI0UWxQIOkk7VNMShQJxtsoUT/CoqQSZZjU8JN/9QF8/h7Ep8B19/i+93W4MDWOEKORPIeT/9qfxq5WUqXCKzmv8EynZxoegxCixWndr5x08mifDuRWOTEqCt1tzesTUSGEEEII0fQ6duzIY489xhVXXMGWLVv0DqfFc2kHqseqVoGXUow07nW3w+Hl8cf34HKpbN9uJyrKxPXXN6ynaksRGmpi+vRk3nwzl7g4C5demtCo+X755Rf+9re/oWka7733Hi+88AJBQafQj9Vs8VXMfrjQ13Ji/OWNiidg9u/0JZkBXE7Y/Ksv0ZyYBrOe8FUyd+rl2xaNFmLoBdTefkLTNH4uLEMBBsZEHLcInR6KPb+ytmoGGg6yrJeSZbmv1v0qPV6W5RQSZDQwNikGo+H42HtFhXNXt0w2lFQwMCaCjLDgk54/3HAG4YYzGvcgSovgg1d9491b4Iv/wKRr69xdURTGJvvaxKzeGoHdUQRAqFHyIUK0NZJoDoCkYCtJwTq0rnC7YfFi33jqVN+n6EIIIYQQolkwGo3k5OToHUarEGE4m3LtW1StglDDYL/0bPV6NdxurXr72Erf1mzixAQmTmxcgvmIDRs2oGm+/8P8/Hzy8vLIzMwEYOPGcnbsqGTw4EiSkk7wXumM83w3P3Jqu/Fo+QQrfTAofniflpwBoeG+ymajETp0P3pfWnvfTTSJl7Zn81mOL+l/fkosMzrq2PrlsOUlD6Iq+wCwe18l3XxzrQvyPbJpNxsOL5C3v9LB9XXEPiw+kmHxxx8fUAaj72fbe/gqB3P924DOyZjDqzmvYlJMXJd8XYACFEI0V5Jobk1cLpg+3Te++GJJNAshhBBC6ODjjz+usa1pGrm5uTz//PMMGzZMp6haF6uSRYbxX3gpxUySX6oYQ0NNXH99KosX5xIfb+GyyxL9EGnbctppp/HJJ5/g8XhIS0sjOdnXk3XdujIeeGDn4UrngyxY0BWbrWneq9jVn8n1PgJoBCmdSTE+jqLU0nv4VEREwZynfJXM6R18LTOELlYXlR0zLmeGjrEccdCpEXe4kL/UrdZ5tcW28srq8fZjxs1CuA2mzYKvP/C1zhhzcb0PTQ9KZ27W3ICFJoRo3iTRLIQQQgghhB9deOGFNbYVRSEuLo6zzjqLJ598Up+gWiGjEtrodhlHlJWVsXbtWrp2Teett2q/RL/J7NoMW9dDl77QrrO+sZyiXr168eyzz3LgwAF69+6NxeKrgty82V5d6Vxe7iE729l0iWbtZ8B3boe2FQ+FmIlr/MSxiTBiXOPnEY3SPzqc/+YUVo/1UOWtYo9jD2nWNMJMYQwKu5uPCmcRZKykX+gtdfaVPjsxmqXZBSjAqAT/9oj2iwGn+25CCHEKJNEshBBCCCGEH6lq22i50Fo4HA5mz55Nbm4uRqORv/71r/TqpVOy+cAuePZu3+Xqy9+Bu56r7vObnZ2NxWIhLs4PSVI/0jSN//2vmLIyL6NGRZOenk56enqNfQYNsrFkST4Oh5fU1CCysk7eZ9ZfgpWelPEFAGYlBRN1L2gmWp6ZHVPpGxWOoigMiolo8vOXe8q5ffvt5LpyiTZF82THJxlsG0rPsK/wal4iTHXHNKNjKiMTogkyGkgLPYVe5uKUVHm8BJuMeochRJshiWYhhBBCCCH86K9//SuzZ88mJCSkxterqqp44okneOCBB3SKTNRm//795ObmAuD1evn111/1SzTv33m0J6rHAwd2Q2Iaixcv5u2330ZRFP7yl78watQofeKrxTvv5LF4se//7/vvi3n88U7H7ZOVFcILL3Rh/34nXbuGEhTUdEmfcMNIjEThJocwZTiKcoK3wKu/gyWv+NoG/OkuSEhpsjhbmw3lG/i14lf6hvWlV3jgfp8URWFIXGTA5j+WV6ugSH0TlSqiDZdhVpLYULGBXJfv57/IU8Tq8tWcE3NOvRfB6xgRcvKdRIM4vF7uW7+TrWWV9IwMY27PLCzGRrbNEUKclPyWCSGEEEII4UcPPfQQFRUVx329srKShx56SIeIxImkpqYSHx8PgMFgoE+fPvoF07Uf2A5fQh8dB517A7B06VLAVz386aef1nqopmn88kspq1aVVrepaAq//WavHm/ZYq/z3PHxVvr3jyAkpOkrC0MMfbAZxmNUTlDxqqqw+DkoK4bsPbD09SaLr7XZVbWL+3fdz/v573P/rvvZVbVL75D84pC6gFL1U8rVrw/3/YaMoAzMh1tjKCi0C2qnZ4jiGD8eKmVrma/39caSihr9vJszr+Zlq30rhe5CvUMRokGkojmA9u93UFTkbrLzGars9Dw83rixHDW49V226XKp5Oe7SEmx0qdP018aJYQQQghxMpqm1bo43fr164mOboZ9ONu44OBgnnzySdasWUNGRgYdOnTQL5jIGLjnecjZCyntIMRXFZmZmclvv/0GQEZGRq2HvvJKNh99lA/A+PFxzJyZ1iQhjxgRybp1vgTOsGGRflmYUReKAiYTuF2+bbNF33hasL1Ve1HxvRdVUdlbtZes4Cydo6qbpmk4VSdBxhO3r/Boh46O8Y1Tg1J5tP2jrClfQ8/QnnQObVl91VuzaIvpD9tN0xe+MTRN46FdD/Frxa9YFAsPZT1Ej7AeeoclxCmRRHMAXXvtb+TmOpvsfMFqFT8fc+4qQ9P1Pgs0s1nBYjFgtfpuZrPC++/3btLL7oQQQgghTiQqKgpFUVAUhU6dOtVIuHm9XioqKrjhhht0jFDUJTIysvm0owgNh441Ewv33HMPH330EVar9bjFJo9Ytaq0evzLL6VNlmgeMyaW9u1DKC/30Lu3Poux+YWiwDV3+yqZwyPhwuk17v7yy0KWLSugXbtgrr8+FZOp5sXBleoGyrTlWMggynBxy024+0G/iH4kWBI46DpIgiWBfhH99A6pToXuQu7ZcQ85rhxGRo3ktrTb6vzeRRkuJc87Dw0X0YZp1V/vEtqFLqFdmipk3VR6K1mct5gKbwWXxF9CSlDzbi3TNzqCmR1TWVdczsCYCLrY/LN4bCDlu/L5teJXAFyai++Kv5NEs2hxJNEcQJWVXoxGiItrmk/DDaqBvxnnARAVF4rN0DK/vU6nSlmZh+JiDx06hJCaaiU5OYj4eAvx8RYSEix06dK0vd2EEEIIIU7mmWeeQdM0/vSnP/HQQw9hs9mq77NYLGRmZjJkyBAdIxQtVUREBNOmTTvhPv36RfDpp4eqx02pfftW0me2Sx/f7Q9yc50899w+NE1j61Y7KSlBXHhhfPX9Hq2EXO9DaPiqoY1KKDbl3CYKuvmxmWzM7zSfA84DpFpTCTY23wKo/xb8lxxXDgDfFH/DhXEX1ll9HWroTzvlLcCLQWm+jylQ/pXzL74o8i2sudm+mZe7vqxzRCc3PiWW8SmxeodRb5HmSKJN0RR5igCa9ZUAQtSlZWYiW5AjVbhNdDZWpY8BoPlfFHKUpmlUVakUFbmprFQxmxVsNjMjRkRz333tiI+36h2iEEIIIcRJXXXVVQC0a9eOoUOHYja3pFdkoqW7/vpUevUKR9M0hg6N1Duck9I0DZfLhdXa/F/ru1xqjd7TDoe3xv1eSquTzABuLb/JYqsXlxMsTfv/HGwMpmNIxyY9Z0NEm4+2MzIpJiKMJ/6QxqC03ZYq+a6jP9eH3IdOsKdoKKvByt87/J2vir8ixZrCmVFn6h2SEKdMEs1CVx6PyoEDLhQFUlODOPvsaAYOtNGrVzjh4fLjKYQQQoiW54wzzqgeV1VV4XbXXLMjIkLWmRD+pyhKi0gwA+Tn53PvvfeSl5fHOeecw0033aR3SCeUkRHMpEkJfPZZAVlZwZx7blyN+y2kE244k3L1W0xKHDbDeJ0i/YPyUnjuHsjdB/2Gw/Q7fC1CmrufPodPF0NUHFxzF0QFriJ1XMw4Sj2l7KraxZiYMcRaWk71q19pGuzaDMGhkFx7H/hL4i9ha+VWnKqTKxOvbPQp/533b9aUr2FA+AAuS7ys0fO1FonWRKYmTtU7DCEaTDJ5rYhB9TAk7xsAViSORG2GrTM0TaOw0E1pqQdN870gjo01c889WYweHX1crzMhhBBCiJamsrKSO+64g3fffZfCwuNXjfd6vbUcJfxl7dq1eDweTjvttFbfJ3fPniosFoXk5BMvYtbcfPLJJ+Tl5QGwbNkyLrjgAlJTU3WO6sSuvjqFq68+vietXV1FiboUi5JKrOMVlrznxOt1c/HFbiIjdb6q4aflviQzwNof4MwJkNVV35hOxlEFb78AqgqlRfDZWzD1loCdTlEUpiROqf8Bh3Lhg1d9CfuJf4LYxIDF1qTemg8rvvA9rik3w9Axx+3SK7wXi7svxq25CTU2rt/x6rLVvHXwLQC2Vm6lY0hH+kf0b/B8mqZR5i0j3BiOQQlcTsGlunCpLsJMYQE7hxAtXfPLRIoGM6tu7lp7FwCTz/kBZzNMNOfnu/F4NEaPjqFHj3A6dQqhW7dQaY8hhBBCiFZjzpw5fPPNN7z44otceeWVvPDCC2RnZ/OPf/yDxx57TO/wWrXXX3+d9957D4CxY8dy88036xxR4CxalM1//nMQRVG4+eY0xoxpOZWY0dFH2xVYLBbCwlpm0sarlR5eHM5DlbaO155LZN1K3yKMO3dW8thjnfQN0BZzdGww+BY5bO4MBjAafYlmANMxyXq3y7et5wdIrz8Fu7f4xuUlMOtx/WLxp198BWtomm9cS6IZwGKwYKHx7UOqvFU1t9WqOvY8ObfqZu7uuWyo2EC6NZ3HOjxGuMn/C5NuqtjE33b/jUq1kqkJU6UKW4g6NL9MpGi1qqq8VFR4ueWWdG64oWlWwRZCCCGEaGpLly7l9ddf58wzz+RPf/oTI0aMoEOHDmRkZLB48WKmTpVLYgPl559/rh6vWrVKx0gCb9kyX7W8pmksW1bYohLN559/PuXl5ezbt49x48YRGRkZ0PPt3l3Jjh1V9O0bTmys/3rsqjjQ8FRv5+YeHWdnO/12ngYbdBaUFsLebTDwLIhL0juik7NY4eo58N+3IToOzj38fPnpYlj2DkREwU1/rbO9Q2N4VJUil4cYixmjoY5kdmX50bG9vPZ9WqKMTrDzd984s3ONuzRN8/vVIUNsQxhmG1bdOmOIreEL5W6o2MCGig0A7HPu49vibzk/7nx/hVptSf4SKtVKAN46+BaT4ydjaobFfULoTX4rRJOpqlKJiDBy2WWt5PIiIYQQQohaFBUV0a5dO8DXj7moyLd6/PDhw5k5c6aeobV6ffv2Zd8+X6uAPn36nHjnnL2Qtx8694ZQ/1e/BVpWVjAbN/oSXe3bB+sczakxGo1MmzatSc61daudu+7ajsejYrOZeeGFLths/mlpYVYSiDRMokT9AIuSwpRJ/Zj/bAmqChdfnOCXczSKosDYS/SO4tT1HuK7HVFZ4Us8g6+dxpf/gStn+fWUZW4Pd/66nQOVTjqGh/Bon/YEGY3H7zjxGnjt/3z/txdd49cYdHX9A7DicwgJg8Gjq7/8n/z/8Gbem8SaY5nbbi4pQce3j2kIk8HEXZl3+WWuGHMMCgoavgU74y3xfpn3j+IsR3uzx5hjJMksRB3kN0MElKZplJd7KShw43SqtG8fQkhILX+whRBCCCFaiaysLPbs2UNGRgbdunXj3XffZeDAgSxdujTglZtt3TXXXEO3bt3weDwMGzas7h23b4Ln7wOvFxJS4I5nwNqy+hzfe287PvmkgKAgA+PHt5xqZn8oL/ewZYudjIygk7bg27ixHI/H14ahtNTN7t1V9Onjv97JscariTFchaIopI+E0/p78Ho1oqJ07s+sJ6cDlr4BJQUwehJkNrKFiNkCIaFQafdt26JPvH8D/HSohAOVvir07eWVrC0qZ2hc5PE79jgNnnjH7+fXXUgojJpY40uV3kpey30NDY08Vx7v5L/DrHT/Jvj9ITM4k7sy7uLH0h/pHtqdQbZBATnP9KTpWA1WSjwlXBx/cUDOIURrIIlmETAVFV5ycpyEhho57bQIxoyJ5YwzorBYZME/IYQQQrRe06dPZ/369ZxxxhncfffdnHvuucyfPx+Px8NTTz2ld3itmqIoDB069OQ7/r7al2QGOJgN+dmQ1j6wwflZaKiJSy9te1cKVlR4uO22rRw86CQoyMgTT3QiM7Puiu6+fSP497/zcLlUYmIstG8f4veYjm0rEBEhb7H55E349mPfePtGeOR1MDXi/8VsgZlz4Yv/QHQ8jDv54n2a5qFA/RdObRcRhrFEGEadcP+k4KMfWChAYpD/Wqy0VCbFRJAhqLp/crix+V75MTRyKEMj6/Hc3whBxiD+lPyngJ5DiNZA/gqKgMnNdXLWWdHMnJlGz55hrX7VbyGEEEIIgNtuu616PHLkSLZs2cLq1atp3749vXv31jEyUa1Tb/hyiW/hq+g4iEvWO6IGcblUvF6N4OC2c8Xgjh2VHDzoqzx1OLysWVN2wkRz+/YhPPNMR7bu2kXvnomEh8tb4IArKz46tpeDx924RDNAuy4w4956716qfUap+ikADu8WgpVumJW6e1T3jgrn9q7pbCiuYFCsjaxw/38g0dJYDBbuy7yP9/LfI84Sx9TEtrm+gN3j5f19B3GrGhenJ2CzyHOIECcivyHC78rLPRQWujGZFM47L45evZrvJ59CCCGEEIHkcDhIT08nPT1d71DEsbr2hVlPQN4+6D4AglpWj2OA1atLmTdvN263xg03pDJ+fNzJD2oF0tODCQ01Ybd7UBSFrl1DT7i/pqkYkuaRmbieMoII1x4hSGlkK4cTcbvB3IbbZgCcPQm2rYfyUl/1sQ6/X6pWecyWhorjpMecmRDNmQn+b8vxR6XqZ5Spy7Eq7YkzzERRmu/PS6/wXvQK76V3GLp6bss+fiooBWB3RRWP9Omgc0RCNG+SaG5FPAYTz/R+sHrc1JxOlf37HVitBrp3D+Pcc+M488yoJo9DCCGEEEJPXq+XRx99lJdeeomDBw+ybds2srKyuP/++8nMzOSaa1rRAlItWbvOvtsfeLVSDqkv4dVKiTZeQbDSTYfgTu7tt33tIADeeCO3zSSao6PNPPlkJ1avLqNTpxC6dg074f5ucqjS1gOg4aBc/ZYgYwASzVWV8MIDsGerr4/vdfdCbYvJNYGvir6qXsDtjow7aixi1iRSs+DRN3C791Fm/AGL+j/CDSOaNASb4VwqtbU4tV3YDOdgVdo16fnr4tKyOeR9CdBwaruwKBlEKhfoHZY4gewqZ/X4SB9vIUTdJNHcingNZr5Km6Db+Q8ccNKzZzi33ZbB4ME2aZUhhBBCiDbpkUce4bXXXuPxxx/nuuuuq/56z549efrppyXR3MwVqK9Qof4AQK73YbJMb+kcUe3i4ixs3WqvHrclKSlBpKTUb/FGE9EYlQi8WhlA4BKOq7+FPVvJrgjltUUapu0/cc09g4iJadrvjVN1Mn//fLx4KXAXsDhvMbem39qkMQCoODlguA+vWgKAhuukfZL9yaiEk2p6vMnOV18abkCr3lY1SVw2dxPT4nlu6z40DSanx+sdTpPaXlbJl3lFpIZYOS8lVnI8ol4k0Sz8RtM0zj47hiFDIvUORQghhBBCN6+//jovv/wyo0aN4oYbbqj+eq9evdiyZYuOkYn6UDl6yb2mOdA0FUVpfotZ33hjGjabCYdDZcoU/ywK6HarHDzoIj7e0moW8DYoIaQYH6Nc/QaLkka4YWRgThQeCcDjv/ZjV5kN1itUzt/H3LlNe5m9goJBMeDVfItdGhV9qqo9FOLVSqq3ndoOoOkSzYGmaR4U5dTTKVYlkyjDJZRpy7DSnkjDeQGITvjTqMRoBkRH4NU0oq31b3NS4CpgVdkq2gW3o2to1wBGGBgVbg/3b9iJ3XPkuURhfEqszlGJlkASza2IQfXQ79AKANbGDUFtovYZmqZRUODGaFRo167l9bcTQgghhPCn7OxsOnQ4Prmkqiput1uHiMSpiDZcgUvbi5dSYg3XNcskM0B4uIkbbkjz23x2u4c5c7axf7+DlJQgnniiU6tZOM+ipBFjvDKwJ+kzFC6cTumaKgiPg+AQSks99T9+91b44b8QnwxnTwZDw37uLAYLczLm8FbeW8SYY5iWOO24fexeO7urdpMRlEG4KTDr6ZhJIljpSZW2EQUr4YYzAnKepqZqVeR4H8ChbSHEcBpJhntOOeEcY5xGDMd/X0TzdewCgA6vg88KP8OoGBkXMw6L4firFuxeO7dvv50iTxEKCnPbzaVfRL+mDLnRStye6iQz1GwhIsSJtI5XDgIAs+rmwV9uBWDyOT/gbKJEc36+G7db45prUjj9dOnJLIQQQoi2rXv37vzvf/8jIyOjxtffe+89+vbtq1NUor6sSiYZpn/qHUaTW726jP37fQumZWc7WLWqlFGjYnSOqoUZfRHXWIt55pm9mM0GrroquX7HVdrhxQd8fZ4BTGYYNbHBYQyxDWGIbUit95V6Spm1bRb57nyiTdE81ekpYsz+/z4rioFk419xsgMTcZiU1vGzVK59h0PzXZlSqf5CpfIrocppOkflX/vsDj7LLiAh2MIFqXEYpF1CDU/se4JVZasA2Fm1k1nps47bJ8eZQ5GnCAANjU32TS0u0ZwSbGVwrI2VBaWEm4ycnRj4hTJF6yCJZtEobrdKWZmHG29M45ZbMk5+gBBCCCFEK/fggw8ybdo0srOzUVWVJUuWsHXrVl5//XU++eQTvcMTolYpKUEoioKmaSiKQmpq/Xog19uhXAgNh5ATL97X0o0YEcXw4ZEA9e9nWlVxNMkMUJBX7/N5tCLyvI/iIocow8VEGU6coF5fvp58dz4ARZ4i1pat5eyYs+t9vlOhKCaC6BKQufViomZhlVGxNcl5t5dV4lRVekQG9vfH5VW5Z90OSt2+anyvpjE5PSGg52xpdlTuqHV8rDRrGinWFLKd2ZgUE6dFtLwPIxRF4Z7umeQ5XESaTQSb9GnDI1qe5nkdmGgxSko82GwmLrvMP33hhBBCCCFauvPPP5933nmHzz77DEVReOCBB9i8eTNLly7l7LNPLaHz/fffc/7555OcnIyiKHz44Yc17tc0jblz55KcnExwcDBnnnkmv/32W419nE4nf/7zn4mNjSU0NJQJEyZw4MCBGvsUFxczbdo0bDYbNpuNadOmUVJS0pCHLwJl7Q/w4DXwf7Oh8KDfp+/QIYT778/i3HPjuPfednTuHOq/yV9/Ch6aAQ/8CXa3/j7liqKc2qJZMQkw6HD/4nAbjBhf70OL1fdxaFtRtXIKvQvxaMUn3L9dcDtMh1s9GDGSFZxV/zgFoYZBxBinE2IYQLzxzwQpnQJ+ziX78pm1dht3r9vBS9sOnPyARqjweKuTzAAHKqVdwh+NiRlTPT47uva/6UHGIJ7s+CT3Zt7L852eb5E9msH3XJYUbJUkszglUtEsGqyy0ktJiYdJkxLa3ErXQgghhBB/tGvXLtq1a4eiKIwdO5axY8c2ek673U7v3r2ZPn06kyZNOu7+xx9/nKeeeopFixbRqVMnHn74Yc4++2y2bt1KeLiv9+qtt97K0qVLefvtt4mJieH222/nvPPOY82aNRiNvjePl19+OQcOHGDZsmUAzJgxg2nTprF06dJGPwbhB14vvPE0uF1QmA8fvQZ/usPvpzntNBunnebnCs3SIlj1jW/sqIIflkG71lXl6hfTboULroLgUDDX/72VAWv1WMGIcpK3+GlBaTzW/jF+Lf+VnmE9aR/SvqERt1lRhouI4qImO993+Uc/PPg+v5gbOqUG7FzRVjMjE6L45mAxIUYj45JbR8sTf5qaOJUhtiGYFBPpQel17hdqDGWwbXATRiZE8yCJZtEgmqaRk+OkX78I5s5tf2qf2AshhBBCtEIdO3YkNzeX+Ph4AC699FKee+45EhIaftnxuHHjGDduXK33aZrGM888w7333stFF/mSHq+99hoJCQm89dZbXH/99ZSWlvLKK6/wxhtvMHr0aADefPNN0tLS+PLLLxk7diybN29m2bJlrFy5kkGDBgHwz3/+kyFDhrB161Y6d+7c4PiFnyhKzcXhGrhQnC5CwiAiEspKfNsJgUuStXgRp77eTZThYtwcwq3lEGW4CKNy8sX9Ood2pnOo/F63FN1soeyqqAKgq82PVxrUYVbXDKZkJhJhNhEqlay1kisBhKhbC3qFIpqT/fudRESYuO22DMxm+TESQgghhNA0rcb2Z599ht1uD9j5du/eTV5eHmPGHL2M12q1csYZZ/DTTz8BsGbNGtxud419kpOT6dGjR/U+K1aswGazVSeZAQYPHozNZqveR+jMYICr50BSOnTuDRdcrXdE9We2wC2PwhnnwaRrYXTTVYK2BQYlhETjbNJMTxFmGK53OK3O9rJKvskrovyYdhJN7boOKfylcxozO6ZyZ7fMJjlnUrBVksxCiAaRimZxysrKfH9k7703y/+X1gkhhBBCiHrJy/MtGPbHiumEhAT27t1bvY/FYiEqKuq4fY4cn5eXV12Ffaz4+Pjqff7I6XTidB7t3VlWVtbwByLqp+dA360lSkyDi6/XOwpRC7eWT6n6MUbFRqQyEUWRFMERawrLeGjjLjQgJdjKcwM6YzE2fZGVQVEYnSQtLIQQLYP8FWlFPAYTC3rcWT0OBKdTJTfXxbnnxnL++XEBOYcQQgghREtU2wJgTdFe7I/n0DTtpOf94z617X+ieebNm8dDDz3UgGiFOLnycg9Op0psbIDWgfnoNfhpOaS1h2vuhuCQwJynBcjxPoBbywbAaygl1nitzhE1H2uLyzlynUp2lZPcKicZYcG6xiSEEM2dJJpbEa/BzGeZlwT0HPv3O+nfP4LZszOlL7MQQgghxDE0TePqq6/GavUtzuVwOLjhhhsIDa3ZU3PJkiV+OV9iYiLgq0hOSkqq/np+fn51lXNiYiIul4vi4uIaVc35+fkMHTq0ep+DBw8eN/+hQ4fq7C999913M2vWrOrtsrIy0tLSGv+gRJv3888l/P3ve3C7VS65JJFp05L9e4IDu+CL933jLevgf5/BmMn+PUcLoWle3FpO9bZLO6BjNM1P36hwlh44VF3RnBRsPekxQgjR1klzXVFvZWUeFAUmTIgjJSVI73CEEEIIIZqVq666ivj4eGw2GzabjSuuuILk5OTq7SM3f2nXrh2JiYl88cUX1V9zuVx899131Unk/v37Yzaba+yTm5vLpk2bqvcZMmQIpaWlrFq1qnqfn3/+mdLS0up9/shqtRIREVHjJoQ/fPzxIdxuFYAlS/L9fwKTxbe44hHmAFVNtwCKYiTSMME3xozNcK7OETUvA2IieLJfJ2Z1SeeJfh1PqW3GL4Wl/PmXLdy/fieFTlcAoxRCiOZFKppbEYPmpVvhrwD8HtMXVfFv8/6DB12MHx/HpEkNXzldCCGEEKK1Wrhwod/nrKioYMeOHdXbu3fvZt26dURHR5Oens6tt97Ko48+SseOHenYsSOPPvooISEhXH755QDYbDauueYabr/9dmJiYoiOjmb27Nn07NmT0aNHA9C1a1fOOeccrrvuOv7xj38AMGPGDM477zw6d+7s98ckxImkpFjZsKEcgOTkRlaQ7vgNDh6AXoMh/PCHPImpcMkN8ONySO8Aw8c1MuKWLdZ4LTbDuRgIwajI+jt/1DEihI4Rp9ZaRdU0Hv99Lw6vCnYHr+3KZVbXjABF2Eo4HbD2f2CLhm799Y5GCNEIkmhuRcxeF/NW+hbZmHzODzhN/usfVVXlxWw2MHFiPBaLFMILIYQQQjSF1atXM3LkyOrtI+0qrrrqKhYtWsQdd9xBVVUVN954I8XFxQwaNIjPP/+c8PDw6mOefvppTCYTl1xyCVVVVYwaNYpFixZhNB4tSli8eDG33HILY8aMAWDChAk8//zzTfQodeLxQJX9aAJSNAvXXptKZKSZigovF110/CKVddmzp4qffy6lS5dQevcOh3U/wb/m+e78agncPf9o9fKI8b5bC5Nd6eDHQ6W0CwvitBj//dyalaST7yTqTdPAq2nV2x5VO8HeAoDn74fdW3zjyTPgzPP1jUcI0WCKpmlN/qxXVlaGzWajtLS0VV9mN2LEKlwulfj4prkcy+qp4v1lwwH/J5qzs52EhxtZvrw/QUH+rZQWQgghROvRVl7niZpa3Pe98CA8cxcUF0CfoXDNXTXbKYgWpaDAxcyZm3E4vCiKwsMPd6DX5jd9/ZePuP8lSEjRL8hGKnd7uGHVFsrcHgDu7dGOwbHyIYneXFo2bu0AwUpPDMrRyuf/5RezcGcOURYzc7plkCj9nevmcsKsY/qk9xoEM+7TLx4hRK3q+1pPKprFSamqht3u5cYb0yTJLIQQQgghWr4fl/uSzOCrfM3eDalZ+sbUBmma5pcFxvftc+BweKvn3LGjkl49ToMfl4GqQkomxLTs9n95Va7qJDPAtjJ7gxPNXlXjs5wCyt1ezk2JxWaRtEBDVKm/keO9Dw0PFiWdVOPTGBRfkdmI+ChGxEedZAYBgMUKXfr4FucE6DlIz2hEC6NpGj+W/oiqqQyLHIbRzy1kxamTvyjihNxulbw8F8HBBgYPlk/MhRBCCCFEKxB9TEsGswXCI3ULpa3YWmbnkMPNgJhwgoxGirxvUaS+i1mJJ9n4UKPaN3TpEkpKShDZ2Q7CwkwMGmSDlAS44xk4lANd+oKpZb/1zQgNokN4MDvKqwgyGhgaF9nguV7bncOmH75l0MZv+TwhhYtvvaf5L4qoaVBRBiFhYGweiSS7tgoNX/Lfpe3DzQGstIwPrMrVb/FQQIRydvPozX39A/D7aoiIgnZd9I5GtCD/zPknSwuWArCmfA23pd+mc0SiZf+1FQGVk+OkslIlJsbM8OGRZGT4rxWHEEIIIYQQuhk2FhyVkLMHBo/2LUAlAua7g8X83+a9AHSOCOGxPvEUqf8GwK3lUqy+T7zxzw2ePyTEyNNPd2bnzkpSU4OIjDT77kht57u1Ahajgb/36ci28kqSgi3EWBueGD6Qf4jJX76KyeOBnG1oyzugnHeFH6P1M1WFfz4CG1dBbCL8ZR5ExeodFcFKD0r4ANAwKTGYSdQ7pHopVv9DoXcRAGXKV6QbX/TLlQWNYjZD7yH6xiBapHXl62odC/1IolnUqaLCy7BhkTz9dGdsNrPe4QghhBBCCOEfigKjL9I7ijZjVWFp9XhrWSXlHiOKYkXDCYCR+vX1djgcbNu2jZSUFGJiYmrcFxxspEeP8DqObJnsdjuPPfYYe/bs4dxzz+Wyyy6jR2RYo+c9OzYMo9dXiRtvtaBU2Rs9Z0Dt3eZLMgMU5MHKL2HcZQ2ezu61s7NyJxnBGdhMDa/mDTWcRgqP4mIvocqgGj2amzOHtq167NYOoFKJkVAdIxKi4QbZBrE/f3/1WOhPEs2iVmVlHoKCDFx9dbIkmYUQQgghhBAN1i86gu/zSwBoHxZMpDkMq3YfJeoSTEoiUYZLTzqHw+Fg9uzZ7N27l+DgYB5//HEyMzMDG7gfqJpGudtLhNl4ylWjH3/8MevWrQNg8eLFDB8+nNTU1EbHNKRjB0ovno7py/8QmpgKZ01s9JwBFRHta33iOdyjuhH9tss95dy2/TYOug4SYYzgyY5PkmhteCVysKEHwfRo8PF/lFflZFtZJd1socQGBaadSbhyJnZWAiqhhkEYFUkyi5brqqSr6BXWC4/mYUD4AL3DEUiiuVXxGky82vUv1ePGOHTIxdChUYwYIQsYCCGEEEIIIRpuVGI0cVYzh5xuhsTaUBSFEKUPIYY+9Z5j586d7N3ra79RVVXFypUrm32iudzt4a5fd7Cv0kHPyDAe6pWF2WCo9/Fm89GCH0VRMPmxz7Rt4tVw4VW+6v7mLiYeZtwHv3wL6R1g4Mjjdvn000MsW1ZAVlYIN92UhsVS+//zb/bfOOg6CECZt4w15Ws413puIKOvt+xKB7eu2YbDqxJhNvHcgE6NapFSlzDDENKVBXi1YoKUrn6fX4im1je8r94hiGNIorkV8RjMfND+ykbPU1rqwWg0cO65sfr3ahJCCCGEEEK0eL2iGtfWIiUlhbCwMCoqKgDo1KmTP8IKqO/zS9hX6QBgY0kF64srGBBTvzYhAOeffz779u1j9+7djB8/nsREP/cAbknv9br1991qkZ3t4B//OICmaezZU0VmZhATJ9Ze9ZwZlIlVseLUnBgw0CG4QyCjPiUbiitweFUAytwetpZVMjQuMFXNFiUZlOSAzC2ECKwtpXY+zSkgJdjKxekJGA3N67lcEs3iOMXFbgYMsHHhhfEn31kIIYQQQohWbOPGcr77rphOnUIYM0b/BchamlWlq1iYuxCbycas9FnEWxr2HiOyrIDHh3dnZX4ZHS+cQp++zb+CLc56TEUyEGs9tZaEVquVWbNm+Tmq1sfr1dA0rXrb7dbq3DfRmsjjHR9nTdkauoV2o3No56YIsV662UKxGBRcqkaoyUjH8JbR81kI0XQqPV4e3LCLSq8XAJNBYXJ6w9sJBYIkmlsRg+alfekWAHbauqAqxgbN43ZrdOkSKtXMQgghhBCiTTt0yMWDD+7E7VZZvty34Jy0lqs/TdN4Yt8TOFQHB5wHeDXnVe7KvOvUJ6q0w/P3kVZpJw2g9ADQ/BPNA2Nt3NgxlU2lFQyNjSQzLFjvkFql9PRgLrssif/+t4D27YM577y4E+6fFZxFVnBWE0VXfxlhwTzTvzNbyuz0iAwjLkA9moUQLVeFx1udZAbId7h0jKZ2kmhuRcxeF0/94GudMfmcH3CaTv2FjMejoSgK3brJggBCCCGEEKJtO3TIhdutVm/n5Dh1jKZ+vFoF4MWo2PQO5TgadVeanpC9zJdsPiI/2z8BNYFxKbGMS5FK+ECbOjWJqVOT9A6j0dJCg0gLDdI7DCFEMxUfZOHsxGi+yCsi0mzivJQTf7Cmh/qvRCBaPVXV2L/fQUKCRSo1hBBCCCFEm9epUwi9evl6C8fGWhg5snm/Rq5Qf2SPZxq7PdMoVj/QOxwURWF2+mxSrCl0DenK9KTpDZsoNhH6DfeNQ8Nh2Dn+C1IIIYRoQW7pks7iYT1YOKQb6c3wgympaBaA77K23bsdxMVZuOOOTCIjT61/mBBCCCGEEK2NyWTgb3/rwKFDLqKizFgszbtOp1hdgobn8PhdogwTdY4IBtkGMcg2qHGTKApMvwMumA5hEWBtfm+sWxKntotD3pdQMBJnvBGLkqZ3SEIIIU5BhLn5pnOb9ysl0WTy890EBxt49NEOjB/f/ErvhRBCCCGE0IPBoJCQYG32SWYAs5J4dEzLbyNQg6JATHybSDJXuD28u/cgnxw4hEdVT37AKTrofRqHtpkqbRP53vl+n18IIUTb1fxfLfnZ999/z/nnn09ycjKKovDhhx/qHZLuvF6NkhIPl12WyLBhzftyQCGEEEIIITRNY+nSfBYs2M/OnZV6h6OPNf+D2ZfAPdNg12YA4g03EWm4CJvhXJKM9+ocoGiohzft5o3dufxjRzav7Mzx+/warmPGzb/vuBBCiJajzSWa7XY7vXv35vnnn9c7FN1pmkZBgYudO6vIyAjinHNkkQohhBBCCNH8ffppAS+/fIDPPjvEvffuwG736B1S03v/H+CogrIS+HAhAAYlhFjjdOKMN2BSYvSNr5kpLCykoKBA7zDqZUd5VfV45zFjf4kz3IRJicesJBFrvOG4+91aPh6tyO/nFQGWnwPP3QtP3QF7t9e4S9VUNK2Bi3EKIcQpaL5NPQJk3LhxjBs3Tu8wmoX9+51YLAauvDKJ665LJT7eqndIQgghhBBCnFR2tqN6bLd7KC31EBraxt7ahIRBeenRsajTf//7XxYsWADAjBkzOO+883SO6MTGJEWzNLsABTg7Kdrv84cYepFpeKXW+4rV9yn0vgYYSDDeSrhhpN/Pf6o0TePLoi8p8hQxJnoMUWa5CrdWb78A2zb4xq8/Cfe/BMD3xd/z7P5nMSpG7sq4i34R/XQMsuE8qsp/cwpxqirjk2MJMRn1DkkIUYs29mqsdfMaTLzVcUb1uC4ul8r+/U7MZoVbb81g6tRW1r9NCCGEEEK0amPGxPDdd8WUl3sYOjSSpKQ2WDDxp7vgo0VgscLkGXpH06x98MEH1dWcH374YbNPNM/omMqoxGiCjAZSQvzTk7rU5eE/+w9iVgxMTo8nuI4kXbG65PBIpUT9qFkkmt/Nf5c3894E4Nvib1nQZYHOETVTrmPaoLiPtkd5NfdVXJoLNHg97/UWm2h+aXs2y3MLAVhfXMHferfXOSIhRG0k0dyKeAxm/t35+pPut2+fk65dQ7n++lRGj5ZL6oQQQgghRMvSrl0Ir7zSndJSDwkJFhRF0TukppeSCTfO1TuKFiEtLY3c3NzqcUvQPjzEr/PN+203v5XaAchzOJnTLbPW/Syk4eB331hpHv9XOyp3VI8POA/g8DoIMrb+RSFP2eQZ8Nr/gccNl91U/WWb0Uah25egjTRF6hRc4+0oP9qPf2d5G+3NL0QLIInmNkbTNDRNY9q0JMaOlZ7MQgghhBCi5XG5VF59NZsDB5ycf34cQ4dG6h2SaMZmzZrFf/7zHzRNY9KkSXqHo4sDlc5ax3+UZLyHYnUJChaiDM3j/2pU9Ch+KfsFL15GRI6QJHNdMjvBgy8f9+W7Mu/itdzXMCtmpidP1yEw/zg7KYad2w9Uj4UQzZMkmlsRRVNJq9gNwP6wdmjK8Ws9VlaqWK0GMjKCmzo8IYQQQggh/GLJkoMsW+Zb2G3LFjuLFnXHZjPrHJVorkJDQ7nyyiv1DkNXk9LjeXVnDgYFLkyNq3M/o2Ij1ti8kpGDbYN5qctLlHpK6RTSSe9wWpwkaxJ3Zd6ldxiNdm5KLL0iw3Cpqt8r/oUQ/iOJ5lbE4nXywneXADD5nB9wmmomkzVNIyfHyeDBNnr2lAVDhBBCCCFEy2S3e6vHHo+K06nqGI0Qzd/EtHhGxEViMihEWlrehzKJ1kQSrYm6xlDgcDHvtz3kOVxclpHA+SdI2IvASAuVanYhmrs2l2iuqKhgx46jPZ52797NunXriI6OJj09XcfIAm/PHgdxcRZmz87EbD6+2lkIIYQQQoiW4MIL41m/voIDBxxMnBhPfHwbXAxQiFMUG2TRO4QW7d19B9l2uDfwP3dkc0ZCFBHmU0+plHpKeXzv4+Q587g44WLOiTnHr3GuKF3Bx4c+JtWaynUp12ExyPddCNF02lyiefXq1YwceXTl3FmzZgFw1VVXsWjRIp2iCjyvV8Pj0fjLX9Lp0SNc73CEEEIIIYRosJgYC88910XvMIQQbYjFcLRYy6goGBu4COm7B99lQ8UGAF488CJDbEOwmWx+ifFIEtujedhk30SMOYbLEi/zy9xCCFEfbS7RfOaZZ6Jpmt5hNLm8PBfJyVZGjIjSOxQhhBBCCCGEEKJFmZKZSKHTzUGHi8np8YSajA2aR0GpMTbgv6uNnaoTj+ap3q7wVvhtbiGEqI82l2hui7xejfJyD+PHx5KQIJcVCiGEEEII0dTsdg/79jnIyAgmJKRhCSqhk5y9vn+TM/SNQ+gq1GTkzu6ZjZ7n0oRLyXHmkOvKZXL8ZMJN/rviON4SzyXxl7Dk0BJSralcGHeh3+YWQoj6kERzK6dpGvv2OcjKCuG661L1DkcIIYQQQog2p6jIze23b6WgwEV8vJWnnuqEzdbyFmRrk5a/C0vf8I0nXAVjJusbj2jxwk3hPJD1QMDmn5Y0jWlJ0wI2vxBCnIisCNfK5eW5CAoycOedmWRkBOsdjhBCCCGEEG3Or7+WUVDgAiA/38m6deX1Os6jFVDofYNS9bM22f6vWfhp+dHxis/9O7eqwurvfTdV9e/collxqyq5VU488n0WQrRyUtHcingNJpZkTaseV1R4qKxUueOOTM46K0bn6IQQQgghhGib2rULxmhU8Ho1TCZDvQpANE0j23sPbi0XAK+hjGijLOrV5NI6QGH+4XF7/8797gL4YZlvvG09XP5n/84vmoVyt4c5a7eTXeUkKyyYx/p0ILiB/Z2FEKK5k0RzK+IxmFnY7VYAVFUjJ6eKkSOjmTYtWd/AhBBCCCGEaMOyskJ4+OEOrF9fQd++4WRm1iPRjKM6yQzgZHcgQxR1uXIWtOviG59+rn/n3rLu6Hjrev/OLZqNFQWlZFc5AdhVUcXaonKGxUfqG5QQQgSIJJpbqZISD5GRJu64IxOjUTn5AUIIIYQQQoiA6dEjnB496r/ol0EJJsxwBhXqdyiYiFDODmB0ok4WK4yaGJi5ew6Cbz7yjXsNDsw5hO6Sg63VYwVICrboF4wQQgSYJJpbEUVTiavKAyDbHklaRihZWSE6RyWEEEIIIYRoiATD7UQZLsJIBCYlVu9whL9Nuha69gM06NZf72hEgPSIDOPObpmsLy5nYGwEWeHyHl0I0XpJorkVsXidvPL1+QAM6PIF6enSl1kIIYQQQoiWSlEUrGTpHYYIpG799I5ANIHh8ZEMb4ntMv73Gfy+BrqfBsPP0TsaIUQLIInmVsrr1bDZ5NsrhBBCCCGEEOIPNA2UFtpi0eOB0kKwxYBJ3vMGzJZ18M4C33jjKkhIhY49dA1JCNH8ybNyK2UyKZx+epTeYQghhBBCCCGEaC48Hnj1MV/isHNvuP5+MLegnsGVdnjubjiwG5Iz4NbHICRM76hap7LimtvlJbqE0Rb8WPIjuc5czow6k1iLtEkSLZtB7wBEYCQlWTnrrGi9wxBCCCGEEEK0Brs2wz8fhf/8C9wuvaMRDbVpFWz42VfRvGUdrP1B74hOze+rfUlmgJy9voS5CIw+Q6FDd9+4Uy/oOVDfeFqp5YXLeWzvY7yW9xp37rgTt+rWOyQhGkUqmlupcePiMJnkcwQhhBBCCCFEI7ld8NJDvmpSAJMZLrhK35hEw4RG/GE7vNFT7rc7ePz3Pdg9Xq7vmMqgWFuj56xTbJKv5ceR1h9xSYE7V1tnsfoqxl1O3zgAit3F7Hfsp2NIR4KNwQE5R3O3tXJr9TjfnU+Jp4Q4S5yOEQnROJJobqVmzEjVOwQhhBBCCCFEa+ByHk0yA5QV6ReLaJyOPWDSdb7K5s59oMdpjZ7ylZ3Z7LE7AHh6yz7eHt6z0XPWKbMTXHOXb4G6Ln0hq2vgziV8ApRkznZkM3vHbCq8FaRYU3iq41OEGEMCcq7m7PTI0/mm+Bs8modeYb2INUvrDNGySaK5ldA0jbw8Z/W20dhCF3YQQgghhBBCNC+h4TD2Elj+LtiiYdRFekckGmPkBN/NT0zHLCpoaooFBvsM9d1Ei7aybCUV3goAsp3ZbKvcRp/wPvoGpYM+4X1Y0HkBh9yH6BrSFaWlLtIpxGGSaG4l9u1zEmoyseWsq+jcOQRFVt8VQgghhBBC+Mv50+CcS31tMyQRIo4xo2MqDu8+Kjxermmfonc4ooXoFNIJBQUNjWBDMKnWtntVdqI1kURrot5hCOEXko1sBVwuFa9XY87cznS5aJHe4QghhBBCCCFaI7NF7wj0sXU9/PoDZHaBwaP0jqbZiQ+y8HCfDnqHIVqYnmE9eTjrYbZUbmFgxEBiLdIyQojWQBLNrYDbrWG1GujVq/ELOQghhBBCCCGEOOxQLiyYCx4P/LAMQsKg1yC9oxKiVegV3ote4b30DkMI4UcGvQMQjVdU5CYkxEhUpBEOHfLdNE3vsIQQQgghhBCiZSs+5EsyH3HwgH6xCCGEEM2cJJpbOJdLxeXSuOWWdGKCPRAf77tVVuodmhBCCCGEEEK0bO26QvtuvnF0HAw4Q994hBBCiGZMWme0cAcPukhLC+Lcc2MBp97hCCGEEEIIIUTrYTbDLY/6Kptt0W23T7UQQghRD1LR3II5nSpOp8rllycSGiqfGQghhBBCCCGE3xmNEJsoSWYhhBDiJCTR3IIdOOCkV69wJk9O0DsUIYQQQgghhBBtVIm7hFu33crEDRN5JecVvcMRQgihE0k0t2CapjFhQrxUMwshhBBCCCGE0M3SgqXsrNqJR/Pw4aEP2e/Yr3dIQgghdCCJ5hbK6VQxGBTS0qx6hyKEEEIIIYQQog0LNYZWj40YCTYE6xiNEEIIvUgpbAuVne2kW7dQ+veP0DsUIYQQQgghhBBt2ITYCRxyHWKPYw/jYsYRa4nVOyQhhBA6kERzC6RpGh6PxhlnRNdsm2EywVVXHR0LIYQQQgghhBABZjKYuD71er3DEEIIoTPJRrZATqeG1Wpg8GBbzTusVli0SJeYhBBCCCGEEEII4V9l6tdUaRsIVQYRZhiidzgBoWkaPxeWYQBOi4lAURS9QxJCNJAkmlug0lIPNpuJrKwQvUMRQgghhBCi9dM0WPM/qCiFQaMgWF6HCyECr1JdR773aQDK+Zo05RmsSpbOUfnfC9sOsDy3EIALUuO4tkPKKc+xtczOvN/24PCq3NQplRHxUf4OUwhRD7IYYAtTXu6huNjNmWdGER1trnmnpoHd7rtpmj4BCiGEEEII0dosewcWPQHvvwwvPqh3NEKINsJN3jFbGm4tX7dYAml1UdnRcWHZCfas26KduRQ63dg9XhZsO+Cv0IQQp0gSzS1IdraTggI348fHMnNm2vE7VFZCWJjvVlnZ9AEKIYQQQgjRGu387eh4z1ZQVf1iEW2KVytH1Rx6hyF0EqYMw6L43vsHKZ0JUfrqHFFg9I8OPzqOiWjQHCGmo+mtUJOx0TEJIRpGWme0EC6XitOpcvvtmVx9dTIGg/QsEkIIIYQQokn0Px22rvddNdh3GBikXkcEXpH3XYrUN1AIIsl4LyGGPnqHJJqYUQknzfgcXkowEo2itM7nnps7pdE/OgKDojCogYnmmR1TMSjZVHm8TG+f7OcIhRD11TqfpVqhigovISFGzj47RpLMQgghhBACgLlz56IoSo1bYmJi9f2apjF37lySk5MJDg7mzDPP5Lfffqsxh9Pp5M9//jOxsbGEhoYyYcIEDhyQy45rGHI23PkM3Pw3mH7H0a9rGqz9AX75FrxevaITrZCmaRSr//aNcVCs/kfniIReFMWESYlttUlmAEVRGBoXyeBYW4MXAowNsnBvj3Y83KcD7cOlj74Qemm9z1StiMejceiQm7FjY0hNteodjhBCCCGEaEa6d+9Obm5u9W3jxo3V9z3++OM89dRTPP/88/zyyy8kJiZy9tlnU15eXr3PrbfeygcffMDbb7/NDz/8QEVFBeeddx5eSZzWlJoFXfrAsUmQJa/Aq3+H156EN57WLTTR+iiKgkmJr942Kwk6RiOEEELUj7TOaAE8Ho3gYAOXXJLY4E/3hBBCCCFE62QymWpUMR+haRrPPPMM9957LxdddBEAr732GgkJCbz11ltcf/31lJaW8sorr/DGG28wevRoAN58803S0tL48ssvGTt2bJM+lhZn67rax0L4QbJxLsXqexgII9pwud7hCCGEECclFc0tgNOpYrEYsNnkcwEhhBBCCFHT9u3bSU5Opl27dlx22WXs2rULgN27d5OXl8eYMWOq97VarZxxxhn89NNPAKxZswa3211jn+TkZHr06FG9T22cTidlZWU1bm1Sz0FHx70G6xeHaJXMShLxxluINf4JgxKkdzhCCCHESUnmsgXIz3dxxhlRpKfLiwshhBBCCHHUoEGDeP311+nUqRMHDx7k4YcfZujQofz222/k5eUBkJBQ85L7hIQE9u7dC0BeXh4Wi4WoqKjj9jlyfG3mzZvHQw895OdH0wKdPw069gSPG7oP0DsaIYQQQghdSaK5maus9GKxGLj66pSTt80wGmHy5KNjIYQQQgjRqo0bN6563LNnT4YMGUL79u157bXXGDzYV2H7x9eQmqad9HXlyfa5++67mTVrVvV2WVkZaWlpDXkILV+XPnpHIIQQQgjRLEjrjGbu0CE3HTuGcNppESffOSgI3nvPdwuS6mchhBBCiLYmNDSUnj17sn379uq+zX+sTM7Pz6+uck5MTMTlclFcXFznPrWxWq1ERETUuAkhhBBCiLZNEs3NWEGBC69X4/zz4zCZ5FslhBBCCCFOzOl0snnzZpKSkmjXrh2JiYl88cUX1fe7XC6+++47hg4dCkD//v0xm8019snNzWXTpk3V+wghhBAnU+72sGRfPl/nFaFpmt7hCCF0Iq0zmilN0ygq8jB9ejLTpiXrHY4QQgghhGiGZs+ezfnnn096ejr5+fk8/PDDlJWVcdVVV6EoCrfeeiuPPvooHTt2pGPHjjz66KOEhIRw+eWXA2Cz2bjmmmu4/fbbiYmJITo6mtmzZ9OzZ09Gjx6t86MTjfHzzyUUFro544woQkNb2Nu+Pdtgz1bo2g8SUvSORghRD/et38muiioA8h0uLstM1DkiIYQeWtgrjrajoMBNaKiRc8+Nw2g8SW/mI+x2CAvzjSsqIDQ0cAEKIYQQQgjdHThwgClTplBQUEBcXByDBw9m5cqVZGRkAHDHHXdQVVXFjTfeSHFxMYMGDeLzzz8nPDy8eo6nn34ak8nEJZdcQlVVFaNGjWLRokUYZc2PFmvp0nxefvkAAMuXF/LMM51Pvt5Lc7F7KzxzJ3i9EBIK97wAkTF6RyWEOAG3qlYnmQG2lVfqGI0QQk+SaG5mPB6VffucmM0K06en0KNHmN4hCSGEEEKIZurtt98+4f2KojB37lzmzp1b5z5BQUHMnz+f+fPn+zk6oZdNmyqqx7t2VVJVpRIS0kI+ONi92ZdkBqi0Q86egCaaNc2NXfsFkxJNkNIlYOcRoqnkO1y8siMbDZjePpmkYGvAz2k2GBgeF8kPh0pQgDPiowJ+TiFE8ySJ5mYmO9tFSoqVO+9sx1lnRbecygMhhBBCCCFEszBsWCQrVpSiaRp9+0a0nCQzQLf+8Nlb4KiC6DjI6BTQ0+V451KlbQAg3ngLEYazA3q+tu5ApYNfi8rpZgulfXiI3uG0Ss9s2cfGEt+HTYVON0/2D+zv0BF3dMvgvNJYIswm0kKDmuScQojmRxLNzcjevQ6MRoXJkxMYNUouDxNCCCGEEEKcutNPjyY1NYiiIjd9+oSf/IDmJDEN7n7eV8ncrguEBiZ+t1ulqLiCysgNHKntsWuriEASzYGS73Bx+5rtVHq9mBSF/+vXUZLNAVDm9tQ6DjRFUegeKVdkC9HWGfQOQPgUFblRVY17723Hddel6h2OEEIIIYQQogXLygphwAAbJlMLfMsXEw89B0JYRECmLyx0MXPmZq69ZgfPPnAuHo8v0xyi9AnI+YTProoqKg+3RfFoGlvKpI9vIEzPSibUZCTIaOCaDrKYphCiaUlFczOQm+vE7daYOjWJCy6Il3YZQgghhBBCCBEg335bzMGDTgD2/DaAoq3t6dMrlhBDX50ja926RoQSbTFT5HITYjTSJ0qqXwOhf0wE/x7WA0ByC0KIJieJZp2VlnpwOFTmzMnkyiuT5Q+BEEIIIYQQQgRQUtLRxdHMJhPtEk4nxBD4BdPaOpvFxHMDOrOlzE77sGBigyx6h9RqSV5BCKEXSTTryOvVOHjQxUUXxfsnyWw0wvjxR8dCCCGEEEIIIWoYOjSSm29OZ+tWOyNGRNVIPIvAsllMDIq16R2GEEKIAJFEs45ycpykpgZx220Z/vnEMSgIPv208fMIIYQQQgghRCs2dmwsY8fG6h1G67d9E+Ttg16DwRatdzRCCCECTBLNOvF4NBwOlT/9KYX4ePkEXQghhBBCCCECxl4OufsgORNCQvWOpm3YuApefhg0Db54H+59EaxBekclRJu1q2oXCgrtgtvpHYpoxSTR3MQ0TaOqSqWgwE10tJmzz5ZPdYUQQgghhBAiYIoL4InboKwEYhJgzlMQFqF3VK3f9o2+JDNA0SEoyIOUTF1DEqKt+nfev3nr4FsAXJl4JRcnXKxzRKK1MugdQGu3Z08V27dXVt927KiisNBNeLjJ/9XMdjuEhvpudrv/5hVCCCGEEEKIluq31b4kM0DhQdixSddw2oweA8F0uLYtKR3ik/WNR4g27IuiL6rHXxZ9qWMkorWTiuYAuuKKJLKzndXbwcEGOnUKpXPnEDp0CCEoKAAL9lX+f3t3HhdVuf8B/DNswzACyiKLILhvqCWUoqlZCloqWhYumZb2y8zUbLNMxTatW6Z108y6aJZp1+16cylc0zS3xA1CBRQXEEEFlHWY7+8PLqMDww5zlPm8X695eeac55zzned5wOd8OXOe7No/JhERERER0b3KpzlgZQXo9YCtLeDlp3RElqF1R2D6F8CVS0DrToCtndIREVmsVg6tcDXjKgCgpUNLhaOh+oyJ5jr04ou+SodARERERERk2fxbA698WHQnc7sugEcTpSOyHJ6+RS8iUtRrTV9D+/T2UEGF/q79lQ6H6jEmmomIiIiIiKh+axVQ9CKqiV9/Bo7tB1p1BIY8B6hUSkdUWsoFYOvqoueQP/4MoHFQOiK6C9hZ2SHMPUzpMMgCMNFMRERERERERFSeMyeB/64oWk46C/i1Bro8pGxMpiyOANJTi5bzcoFRkxUNh4gsCycDJCIiIiIiIqI6k60rNP9J01OB1Mu1d7z83BLv80yXU5IIkHHt9vsbacrFQkQWiYlmIiIiIiIiunfo9UpHQJWUX6jHO9FnEb73BF7/6zRyC82UcN67FYgYD7z3YtFjJGpD+0CgW1/AQQvc1x0I6l07x61NKhUwcHTRvxoHIORppSMiIgvDR2fUJ1ZWQO/et5eJiIiIiIjqi1tZwFezgAvxwAMPA6NfvTufkUsGh69l4sSNmwCAuMxs7E29gb5ernV/4j2biu7uBYDffwH6h9f8mCoV8MwUAFNqfqy61PcJoOdjgLUNYMOUDxGZF7OR9YlGA+zaVfTSaJSOhoiIiIiIqPbs+63o2bgiwMGdQOLfSkdEFXCxszV676q2LaNkLfP2N71sKdT2TDITkSL4m6cORUREICEhAVa8u7hMV69exf33348PPvhA6VCIiIiIiOhu5uh8e1mlAhwclYuFKqWtsxZT2zbFwbQMdG7kiPtdnMxz4hGTAE9fQFcA9AkzzzmJiIiJ5rq0fft2JCQkwM3NTelQ7io6nQ5ZWVnIy8uDVquFg4OD0iEREREREdHdruujQFoKcP408EAfwNNH6YgsVk5OIVavTkFurh7DhnnAzc2uzLKPerrgUU8XM0YHwE4NhPL5xERE5sZEcx3z8fFB48aNzXIutU6H73bsAACMe+QR5Jn5qzIigsLCQuh0OhQWFhot5+XlIScnByqVClZWVvD09ET79u3Rp08fPPbYY2aNk4iIiIiI7kEqFTDwGaWjIACLF1/Azp3XAABxcbfw+edtFY6IiCxSxjXg6B9AY++iCTtJcUw01zPO+fl1evycnBwkJyejsLAQKpUKqv9NviEiEBFYW1vD2toaNjY2hn9tbGzg4eGBgIAAtGrVCs2bN0erVq3g5eVVp7ESERERERFRJf21F9ixAfBoAjz9UtFzfstw+XKeyWUiqt9OXL+JrclpaOpgj6f8PGCl5ISsBfnA528VfdMFAMa8VjRRLCmKiWaqkIjg1q1byMjIQGZmJgIDA9G+fXs4OjpCq9UaXg0aNDD53sHBAdbW1kp/DCIiIiIiIjLlZibw/WeATgeciwMaugGDRpdZ/MknPfDJJ+dQWCgID/c0Y6BEpJTMAh3mnEhAnl4PANDYWGOwj7tyAd1Iv51kBoD4U0w03wWYaCYjBQUFyMrKQm5uLnJycgx3Kjs4OMDDwwNDhw7FmDFj0LRpU6VDJSIiIiIiotqgKyhKMhfLyy23eHBwQ6xYEQCdTtCwoW0dB0dEd4PMAp0hyQwAqbl1+436Crk0BvzbFP1xzNoa6BSsbDwEgIlmuoNer0dCQgJcXFzg5eWFVq1aoUWLFvD19UWbNm3QqlUr3plMRERERERU3zR0BQY/C0StARo3Afo9WeEuDRownUBkSXwc7NHHoxF2XrkON7UtHm/ipmxA1tbA5A+BMycAV09OEHuX4P8MBADIy8tDUlISmjRpgqVLl6JFixaG5y8TERERERFRPRfyVNGLiKgM09r54YWWTeBgbQ1rq7sgZ2SnBjoEKR0F3cFK6QBIeRkZGUhKSkKHDh3w5ZdfomXLlkwyExEREREREdUDqfmpOJR5CFm6LKVDoXrA0dbm7kgy012JdzTXI6JS4Yyzs2G5slJTUxESEoJ58+bBwcGhrsIjIiIiIiIiIjNKyk3Ca2deQ64+F41tG2Nh64VoYNNA6bCIqJ5iorkeybe2xrSePau2T34+rK2tMWjQICaZiYiIiIiIiOqRw5mHkasvmtwxtSAVp7NPo4tTF4WjIqL6iolmC5eamgoPDw9069ZN6VCIiIiIiCza8eNZWLbsMhwdrfHKK03h5mandEhEdI9rp20HK1hBDz20Vlr4a/yVDomI6jEmmi2UXq9HcnIydDodxo0bB0dHR6VDIiIiIiKyaPPmJSIrSwcAWLr0It5+u7nCERHRva6dth0+afkJ4rLjEOgYCBdbF6VDIqJ6jInmekRdWIivdu0CALz88MPIs7Y2WS4/Px/nzp2Du7s7XnzxRYwcOdKMURIRERERUUkiAp1ODO8LCqSc0kRElddG2wZttG2UDoOILAATzfWJCDxycgzLxpsE165dw/Xr1wEAHTt2xMcff4wWLVqYO0oiIiIiIipBpVJhypSmWLr0EhwdrfHcc02UDomIiIioSphothDp6enIzs5G//790adPH/Tu3RvOzs5Kh0VERERERP/To0cj9OjRSOkwiIiIiKqFieZ6rLCwEBkZGbh+/Tqsra0RHh6Od999V+mwiIiIiIiIiIiIqJ5hormeSk9Px+WMDDRs2BDdunXDkCFDMGjQIKXDIiIiIiIiIiIionrISukAlLBo0SI0a9YM9vb2CAwMxJ49e5QOqdZlZGRg/Pjx2LBhA/71r39h8ODBUKlUSodFRERERERERERE9ZDFJZpXr16NqVOnYsaMGTh69Ch69uyJAQMGICkpSenQaqywsNCwHBAQgMmTJ8PLy0vBiIiIiIiIiIjIkuTr8xGfHY/swmylQyEiM7O4RPP8+fMxbtw4jB8/Hu3atcOCBQvg6+uLxYsXKx1ajeh0OiQkJuK8VouMJk3w1aJFUKvVSodFREREREREVGXZhdmYGT8TI06OQOTlyBodS0SgF30tRUblySnMwbQz0zD1zFS89PdLSMtPUzokIjIji0o05+fn48iRIwgJCTFaHxISgn379ikUVe24ceMGtO7usP77bzhfvAhHDw+lQyIiIiIiIiKqls1pmxF9Mxo3C29i3dV1SMhJqNZxjmcdx4iTIzDsxDDsuLajlqOkkk7eOonzuecBANd017A/Y7/CERGROVlUojktLQ2FhYXwKJGE9fDwQEpKikJR1UxhYSFSUlKQnp6OwMBA+Pj4KB0SERERERERUY2orW5/Q1cFFexUdtU6zoqUFbilv4UCKcC3l7+trfCoDE3UTWCrsgVQ1G7+Gn9lAyIis7JROgAllJwUT0TuyYny0tPTkZ6ejsaNG2PUqFEYOXKk0iERERERERHRvSrpLLB2KWBrB4RPBNyVm/NngOsAJOUm4WzOWfRz6Qcf++rdVOVs42xYbmjTsJaio7J4q73xYYsPcSDjADo06ICODToqHRIRmZFFJZrd3NxgbW1d6u7l1NTUUnc53+10Oh3S09MxfPhwvPTSS/D09ASys4EOHYoKHDoEODgoGyQRERERERHdO5Z/Cly5VLS8ehEw6X3FQrGxssHLvi/X+DiTfCbBIdkBufpcPOv5bC1ERhVpp22Hdtp2SodBRAqwqESznZ0dAgMDERUVhaFDhxrWR0VFISwsTMHIqkZEkJCQgDZt2txOMhdtAGJibi8TEREREdVDIoJM2YJ8uQAnq35Qq5orHRJR/ZCXa3r5HtbQtiGmNZ2mdBhERBbBohLNADBt2jSMHj0aQUFBCA4OxjfffIOkpCRMmDBB6dAqJScnBxcvXoSrqys++eST20lmIiIiIiILkSlbcLVwMQAgS3bBz/pbWKu0CkdFpDy9XmBlVYPHQg5/Gfjpn0WPznjyhdoLjIiILILFJZrDw8ORnp6O9957D8nJyQgICMDmzZvh5+endGgVEhFcvHgRgYGBmDp1Ktq2bat0SEREREREZpcvFwzLermJQtyANZhoJsv29dcXsHlzGnx81Pjgg1ZwcbGt+kECHgA+XF77wRERkUWwUjoAJUycOBHnzp1DXl4ejhw5gl69eikdUoUKCwtx9uxZNGzYEBMmTMADDzygdEhERERERIpwsuoHK1UDAIDWqits4a1wRETKunAhF5s2XYWI4MKFXPz3v6lKh0RERBbI4u5ovlddu3YNDRs2xJIlS9C5c2elwyEiIiIiUoxa1Rx+1t+iEDdgC2+oVDV4VABRPaDVWsPGxgo6nR4A4OxcjbuZiYiIaoiJ5nuAiODatWt47rnnmGQmIiIiIgJgrdLycRlE/+PiYou33vLHli1p8PPTYOBAN6VDIiIiC8RE8z0gJycH9vb2CAkJKb+gSgUUP2uad3UQERERERFZjG7dGqJbt4ZKh0FERBaMiea7WGFhIVJSUpCdnY1OnTqhXbt25e/g4ACcO2eW2IiIiIiIiIiIiIiKMdF8l8nLy0NWVhaysrJQUFAAT09PTJo0CeHh4XBwcFA6PCIiIiIiIiIiIqJSmGi+i1y9ehWZmZlo2LAhgoODERgYiMGDB8Pbm7NoExERERERERER0d2Liea7RE5ODq5du4bAwEB88803cHR0rM5BgF69ipZ//x3QaGo3SCIiIiIiIiIiIiITrJQOwNKJCBITE5GSkoKgoCD84x//qF6SGQD0euDw4aKXXl+7gRIRERFRvbdo0SI0a9YM9vb2CAwMxJ49e5QOiYiIiIjuEUw0K+zmzZuwsbHB1KlTsXz5cvj4+CgdEhERERFZoNWrV2Pq1KmYMWMGjh49ip49e2LAgAFISkpSOjQiIiIiugcw0ayw4juZR48eDVtbW6XDISIiIiILNX/+fIwbNw7jx49Hu3btsGDBAvj6+mLx4sVKh3ZvSrkIrFgAbIgE8nIrvVt8fDbmzz+HH364jIICfkuRyBIk5CRgftJ8rEhegQJ9gdLh0D1KRLA26Qo+iz2P49ezlA6HLBSf0awgEQEAPP7441Cr1QpHQ0RERESWKj8/H0eOHMH06dON1oeEhGDfvn2lyufl5SEvL8/wPjMzs85jvOcsng2kpxYt5+UC4S9VuEtBgR4zZ55FVpYOACACjB7NicGJ6jOdXodZCbOQocsAAOihxxivMQpHRfeiX5PTsSwhGQCw7+oNfNu1PRqpeUMjmRfvaFZQdnY2bGxs4OXlpXQoRERERGTB0tLSUFhYCA8PD6P1Hh4eSElJKVV+7ty5cHZ2Nrx8fX3NFeq9Qa8Hrqfdfp9+pVK75ebqDUlmALh6Nb+2IyOiu0ye5BmSzACQmp+qYDR0L7uSe/v/jHy94EaBrpzSRHWDiWYzy83NxZUrV3D27FlcuXIFHTt2RLt27ZQOi4iIiIgIKpXK6L2IlFoHAG+//TYyMjIMrwsXLpgrxHuDlRUwYETRsr0G6DesUrs5OtogLKyxYXnw4MZ1FSER3SW01loMdR8KAHC0dsQQ9yHKBkT3rP5ernD73x3MD7k3hL/WXuGIyBLx0RlmotPpcP78eVhbW8PFxQUPPfQQ+vTpg9DQUNjZ2dXeidzcau9YRERERGQR3NzcYG1tXeru5dTU1FJ3OQOAWq3mo98qMmA40OtxwE4N2FZ+vD9+vA+eftoTGo0VbG15XxCRJXje+3kMazwM9lb2sLOqxfwAWRQPjRpLu7bDLZ0eznZM95Ey2PPMJDk5GT4+PpgxYwYeeOABODg41P5JtFrg6tXaPy4RERER1Wt2dnYIDAxEVFQUhg4dalgfFRWFsLAwBSO7x2kdq7WbkxMv04gsjZONk9IhUD1gY2UFZzv+kZKUwxGMGWRnZyMnJwcPPfQQevfurXQ4RERERESlTJs2DaNHj0ZQUBCCg4PxzTffICkpCRMmTFA6NCIiIiK6BzDRXMdu3ryJlJQUdO7cGa+99prS4RARERERmRQeHo709HS89957SE5ORkBAADZv3gw/Pz+lQyMiIiKiewATzXWkoKAA1tbWUKvVCAgIwDPPPAOtVlu3J83JAQYMKFresgXQaOr2fERERERUr0ycOBETJ05UOgwiIiIiugcx0VxHdu3aBZ1OhyeffBLvvPOOydm6a51eD+zefXuZiIiIiIiIiIiIyAz4hPA6cvXqVeTk5CAoKMg8SWYiIiIiIiIiIiIihTDRXAcOHDiAr7/+Gjk5OUqHQkRERERERERERFTn+OiMWqbT6bBq1SqkpKTwTmYiIiIiIiIiIiKyCLyjuRbl5uZizpw52Lp1K7y8vJQOh4iIiIiIiIiIiMgsmGiuRYsXL8aaNWvg7u4OJycnpcMhIiIiIiIiIiIiMgs+OqOWREVFYcWKFWjYsCGcnZ2VC8TBQblzExERERERERERkUViorkWXLp0CcuWLUNOTg6aNGmiXCBaLXDrlnLnJyIiIiIiIiIiIovER2fUgjfeeAOHDx9WNslMREREREREREREpBDe0VxDycnJiI+PR15eHtLT05UOh4iIiIiIiIiIiMjsmGiuIZ1Oh6ZNm8Lb2xt2dnZG26ytreHn52e+YHJzgSefLFpeuxawtzffuYmIiIiIiIiIiMhiMdFcQ76+vvj3v/+tdBhFCguBzZtvLxMRERERERERERGZAZ/RTEREREREREREREQ1wkQzEREREREREREREdUIE81EREREREREREREVCNMNBMRERERERERERFRjTDRTEREREREREREREQ1YqPESUUEAJCZmanE6euvW7duL2dmAoWFysVCREREFql4fFc83iPLwPE9ERERUf1V2TG+Ionm9PR0AICvr68Sp7cM3t5KR0BEREQWLD09Hc7OzkqHQWaSlZUFgON7IiIiovosKyur3DG+IolmFxcXAEBSUlK9vQDJzMyEr68vLly4ACcnJ6XDoRpgW9YvbM/6g21Zf7At65eMjAw0bdrUMN4jy+Dt7Y0LFy7A0dERKpXKLOfk746qYX1VDeur8lhXVcP6qhrWV+WxrqqG9VU1IoKsrCx4V3BjqyKJZiurokdDOzs71/vGdHJyqvef0VKwLesXtmf9wbasP9iW9UvxeI8sg5WVFXx8fBQ5N393VA3rq2pYX5XHuqoa1lfVsL4qj3VVNayvyqvMzcK8AiAiIiIiIiIiIiKiGmGimYiIiIiIiIiIiIhqRJFEs1qtxuzZs6FWq5U4vVlYwme0FGzL+oXtWX+wLesPtmX9wvYkc2FfqxrWV9WwviqPdVU1rK+qYX1VHuuqalhfdUMlIqJ0EERERERERERERER07+KjM4iIiIiIiIiIiIioRphoJiIiIiIiIiIiIqIaYaKZiIiIiIiIiIiIiGqEiWYiIiIiIiIiIiIiqhGzJJqvX7+O0aNHw9nZGc7Ozhg9ejRu3LhR7j7r1q1DaGgo3NzcoFKpEB0dbY5Qq2TRokVo1qwZ7O3tERgYiD179pRbfvfu3QgMDIS9vT2aN2+Or7/+2kyRUkWq0pbr1q1Dv3794O7uDicnJwQHB+PXX381Y7RUkar+bBb7448/YGNjg/vuu69uA6RKq2pb5uXlYcaMGfDz84NarUaLFi3wr3/9y0zRUnmq2pY//vgjOnfuDAcHB3h5eeG5555Denq6maKlsvz+++8YNGgQvL29oVKpsGHDhgr34fiH6kp1/7+vTyIiIqBSqYxenp6ehu0igoiICHh7e0Oj0eDhhx/GqVOnjI6Rl5eHV155BW5ubtBqtRg8eDAuXrxo7o9S6yr6fVVbdVOda927UUX1NXbs2FJ9rVu3bkZlLKW+5s6diwceeACOjo5o3LgxhgwZgri4OKMy7F+3Vaa+2L9uW7x4MTp16gQnJydDvmHLli2G7exbt1VUV+xXChEz6N+/vwQEBMi+fftk3759EhAQIAMHDix3n++//17mzJkjS5cuFQBy9OhRc4RaaatWrRJbW1tZunSpxMTEyJQpU0Sr1cr58+dNlk9ISBAHBweZMmWKxMTEyNKlS8XW1lbWrFlj5sippKq25ZQpU+Tjjz+WgwcPyunTp+Xtt98WW1tb+euvv8wcOZlS1fYsduPGDWnevLmEhIRI586dzRMslas6bTl48GDp2rWrREVFSWJiohw4cED++OMPM0ZNplS1Lffs2SNWVlaycOFCSUhIkD179kiHDh1kyJAhZo6cStq8ebPMmDFD1q5dKwBk/fr15Zbn+IfqSnX/v69vZs+eLR06dJDk5GTDKzU11bB93rx54ujoKGvXrpUTJ05IeHi4eHl5SWZmpqHMhAkTpEmTJhIVFSV//fWX9OnTRzp37iw6nU6Jj1RrKvp9VVt1U51r3btRRfU1ZswY6d+/v1FfS09PNypjKfUVGhoqkZGRcvLkSYmOjpbHH39cmjZtKjdv3jSUYf+6rTL1xf5128aNG2XTpk0SFxcncXFx8s4774itra2cPHlSRNi37lRRXbFfKaPOE80xMTECQP7880/Duv379wsA+fvvvyvcPzEx8a5MND/44IMyYcIEo3Vt27aV6dOnmyz/5ptvStu2bY3Wvfjii9KtW7c6i5Eqp6ptaUr79u1lzpw5tR0aVUN12zM8PFzeffddmT17NhPNd4mqtuWWLVvE2dm51OCBlFfVtvzHP/4hzZs3N1r3xRdfiI+PT53FSFVXmUQzxz9UV2pj/FYflDdu0ev14unpKfPmzTOsy83NFWdnZ/n6669FpOgP7ba2trJq1SpDmUuXLomVlZVs3bq1TmM3p5K/r2qrbmp6rXu3KivRHBYWVuY+llxfqampAkB2794tIuxfFSlZXyLsXxVp1KiRfPvtt+xblVBcVyLsV0qp80dn7N+/H87OzujatathXbdu3eDs7Ix9+/bV9enrRH5+Po4cOYKQkBCj9SEhIWV+pv3795cqHxoaisOHD6OgoKDOYqXyVactS9Lr9cjKyoKLi0tdhEhVUN32jIyMRHx8PGbPnl3XIVIlVactN27ciKCgIHzyySdo0qQJWrdujddffx05OTnmCJnKUJ227N69Oy5evIjNmzdDRHDlyhWsWbMGjz/+uDlCplrE8Q/VhdoYv9UnZ86cgbe3N5o1a4bhw4cjISEBAJCYmIiUlBSjelKr1ejdu7ehno4cOYKCggKjMt7e3ggICKjXdVlbdVMfr3XLs2vXLjRu3BitW7fGCy+8gNTUVMM2S66vjIwMADBcD7J/la9kfRVj/yqtsLAQq1atwq1btxAcHMy+VY6SdVWM/cr8bOr6BCkpKWjcuHGp9Y0bN0ZKSkpdn75OpKWlobCwEB4eHkbrPTw8yvxMKSkpJsvrdDqkpaXBy8urzuKlslWnLUv67LPPcOvWLTz99NN1ESJVQXXa88yZM5g+fTr27NkDG5s6/5VIlVSdtkxISMDevXthb2+P9evXIy0tDRMnTsS1a9f4nGYFVactu3fvjh9//BHh4eHIzc2FTqfD4MGD8eWXX5ojZKpFHP9QXaiN8Vt90bVrV3z//fdo3bo1rly5gg8++ADdu3fHqVOnDHVhqp7Onz8PoOhn1M7ODo0aNSpVpj7XZW3VTX281i3LgAED8NRTT8HPzw+JiYmYOXMmHnnkERw5cgRqtdpi60tEMG3aNDz00EMICAgAwP5VHlP1BbB/lXTixAkEBwcjNzcXDRo0wPr169G+fXtDYpN967ay6gpgv1JKtbMqERERmDNnTrllDh06BABQqVSltomIyfX3kpLxV/SZTJU3tZ7Mr6ptWeynn35CREQE/vOf/5j85UPKqGx7FhYWYuTIkZgzZw5at25trvCoCqrys6nX66FSqfDjjz/C2dkZADB//nwMGzYMX331FTQaTZ3HS2WrSlvGxMRg8uTJmDVrFkJDQ5GcnIw33ngDEyZMwHfffWeOcKkWcfxDdaW647f6ZMCAAYbljh07Ijg4GC1atMDy5csNEx5Vp54spS5ro27q67VuSeHh4YblgIAABAUFwc/PD5s2bcITTzxR5n71vb4mTZqE48ePY+/evaW2sX+VVlZ9sX8Za9OmDaKjo3Hjxg2sXbsWY8aMwe7duw3b2bduK6uu2rdvz36lkGo/OmPSpEmIjY0t9xUQEABPT09cuXKl1P5Xr14t9VeYe4Wbmxusra1L/fUiNTW1zM/k6elpsryNjQ1cXV3rLFYqX3Xastjq1asxbtw4/Pzzz+jbt29dhkmVVNX2zMrKwuHDhzFp0iTY2NjAxsYG7733Ho4dOwYbGxvs2LHDXKFTCdX52fTy8kKTJk0MSWYAaNeuHUSk1MzBZD7Vacu5c+eiR48eeOONN9CpUyeEhoZi0aJF+Ne//oXk5GRzhE21hOMfqgs1Gb/Vd1qtFh07dsSZM2fg6ekJAOXWk6enJ/Lz83H9+vUyy9RHtVU39fFat7K8vLzg5+eHM2fOALDM+nrllVewceNG7Ny5Ez4+Pob17F+mlVVfplh6/7Kzs0PLli0RFBSEuXPnonPnzli4cCH7lgll1ZUplt6vzKXaiWY3Nze0bdu23Je9vT2Cg4ORkZGBgwcPGvY9cOAAMjIy0L1791r5EOZmZ2eHwMBAREVFGa2Piooq8zMFBweXKv/bb78hKCgItra2dRYrla86bQkU3ck8duxYrFy5ks8MvYtUtT2dnJxw4sQJREdHG14TJkww/FX0zucwkXlV52ezR48euHz5Mm7evGlYd/r0aVhZWVU4mKW6U522zM7OhpWV8RDF2toawO27YenewPEP1YXqjt8sQV5eHmJjY+Hl5YVmzZrB09PTqJ7y8/Oxe/duQz0FBgbC1tbWqExycjJOnjxZr+uytuqmPl7rVlZ6ejouXLhgeASSJdWXiGDSpElYt24dduzYgWbNmhltZ/8yVlF9mWLJ/csUEUFeXh77ViUU15Up7FdmUseTDYqISP/+/aVTp06yf/9+2b9/v3Ts2FEGDhxoVKZNmzaybt06w/v09HQ5evSobNq0SQDIqlWr5OjRo5KcnGyOkCu0atUqsbW1le+++05iYmJk6tSpotVq5dy5cyIiMn36dBk9erShfEJCgjg4OMirr74qMTEx8t1334mtra2sWbNGqY9A/1PVtly5cqXY2NjIV199JcnJyYbXjRs3lPoIdIeqtmdJ5c3eTuZV1bbMysoSHx8fGTZsmJw6dUp2794trVq1kvHjxyv1Eeh/qtqWkZGRYmNjI4sWLZL4+HjZu3evBAUFyYMPPqjUR6D/ycrKkqNHj8rRo0cFgMyfP1+OHj0q58+fFxGOf8h8Kvq9Yilee+012bVrlyQkJMiff/4pAwcOFEdHR0M9zJs3T5ydnWXdunVy4sQJGTFihHh5eUlmZqbhGBMmTBAfHx/Ztm2b/PXXX/LII49I586dRafTKfWxakVFv69qq24qc617LyivvrKysuS1116Tffv2SWJiouzcuVOCg4OlSZMmFllfL730kjg7O8uuXbuMrgezs7MNZdi/bquovti/jL399tvy+++/S2Jiohw/flzeeecdsbKykt9++01E2LfuVF5dsV8pxyyJ5vT0dBk1apQ4OjqKo6OjjBo1Sq5fv24cCCCRkZGG95GRkQKg1Gv27NnmCLlSvvrqK/Hz8xM7Ozvp0qWL7N6927BtzJgx0rt3b6Pyu3btkvvvv1/s7OzE399fFi9ebOaIqSxVacvevXub7Jtjxowxf+BkUlV/Nu/ERPPdpaptGRsbK3379hWNRiM+Pj4ybdo0o0E/KaeqbfnFF19I+/btRaPRiJeXl4waNUouXrxo5qippJ07d5b7fyDHP2RO5f1esRTh4eHi5eUltra24u3tLU888YScOnXKsF2v18vs2bPF09NT1Gq19OrVS06cOGF0jJycHJk0aZK4uLiIRqORgQMHSlJSkrk/Sq2r6PdVbdVNZa517wXl1Vd2draEhISIu7u72NraStOmTWXMmDGl6sJS6stUPZXMZ7B/3VZRfbF/GXv++ecN/7e5u7vLo48+akgyi7Bv3am8umK/Uo5KhN9BJSIiIiIiIiIiIqLqq/YzmomIiIiIiIiIiIiIACaaiYiIiIiIiIiIiKiGmGgmIiIiIiIiIiIiohphopmIiIiIiIiIiIiIaoSJZiIiIiIiIiIiIiKqESaaiYiIiIiIiIiIiKhGmGgmIiIiIiIiIiIiohphopmonjh37hxUKhWio6PNds5ly5ahYcOGhvcRERG47777DO/Hjh2LIUOGmC2e+i4iIgIeHh5QqVTYsGGDyXVVqXMl+kxt2rVrF1QqFW7cuKF0KERERERUT5gac9f1+e68hrrXpKSkoF+/ftBqtUbXhkRkmZhoJroHqFSqcl9jx45VJK7w8HCcPn1akXNXRVkJ1XspER4bG4s5c+ZgyZIlSE5OxoABA0yuW7hwIZYtW1apY/r6+iI5ORkBAQG1Gqu5BuVERERE96qxY8eaHNefPXu2Vo5f8oYQqhxT4+vaZM5x8rp16xAaGgo3N7dq3Vzi7++PBQsWVFju888/R3JyMqKjo2v12rCy5yeiu4uN0gEQUcWSk5MNy6tXr8asWbMQFxdnWKfRaHD9+nWzx6XRaKDRaMx+XksUHx8PAAgLC4NKpSpznVqtrvQxra2t4enpWcuREhEREVFl9O/fH5GRkUbr3N3dFYqmbAUFBbC1tVU6DLMwNb6ujruhzm7duoUePXrgqaeewgsvvFBn54mPj0dgYCBatWpVZ+eoifz8fNjZ2SkdBpHF4B3NRPcAT09Pw8vZ2RkqlarUumIJCQno06cPHBwc0LlzZ+zfv9/oWPv27UOvXr2g0Wjg6+uLyZMn49atW2We+9ixY+jTpw8cHR3h5OSEwMBAHD58GEDl75T49NNP4eXlBVdXV7z88ssoKCgwbLt+/TqeffZZNGrUCA4ODhgwYADOnDlj2G7qq2QLFiyAv7+/0brIyEi0a9cO9vb2aNu2LRYtWmTY1qxZMwDA/fffD5VKhYcffhgRERFYvnw5/vOf/xjuINm1axcA4NKlSwgPD0ejRo3g6uqKsLAwnDt3rtzPeOrUKTz++ONwcnKCo6MjevbsaRio6vV6vPfee/Dx8YFarcZ9992HrVu3Gu1f3jkjIiIwaNAgAICVlRVUKpXJdUDpu7T1ej0+/vhjtGzZEmq1Gk2bNsWHH34IwPSd3jExMXjsscfQoEEDeHh4YPTo0UhLSzNsf/jhhzF58mS8+eabcHFxgaenJyIiIgzbi9tl6NChUKlUpdqpWHBwMKZPn2607urVq7C1tcXOnTsBAD/88AOCgoLg6OgIT09PjBw5EqmpqWW2QW30lfz8fEyaNAleXl6wt7eHv78/5s6dW+Y5iYiIiKpLrVYbjek9PT1hbW0NAPjvf/+LwMBA2Nvbo3nz5pgzZw50Op1h3/nz56Njx47QarXw9fXFxIkTcfPmTQBFjxd77rnnkJGRYRjnFo/XTN1R27BhQ8M34orHhz///DMefvhh2Nvb44cffgBQ/hjKlDVr1qBjx47QaDRwdXVF3759DdcdxWPWOXPmoHHjxnBycsKLL76I/Px8w/5bt27FQw89hIYNG8LV1RUDBw40jK+LXbx4EcOHD4eLiwu0Wi2CgoJw4MABw/aK6vFOZY2vKxrLl1dnd6ponLxixQr4+/vD2dkZw4cPR1ZWlmGbiOCTTz5B8+bNodFo0LlzZ6xZs6bc+h89ejRmzZqFvn37llkmIiICTZs2hVqthre3NyZPngygaMx//vx5vPrqq4Y+ZIq/vz/Wrl2L77//3uibthkZGfi///s/Q9s+8sgjOHbsmGG/+Ph4hIWFwcPDAw0aNMADDzyAbdu2GbaXdf7KjPeL+9bcuXPh7e2N1q1bA6jeNR4RVR0TzUT1zIwZM/D6668jOjoarVu3xogRIwyDqRMnTiA0NBRPPPEEjh8/jtWrV2Pv3r2YNGlSmccbNWoUfHx8cOjQIRw5cgTTp0+v0l/nd+7cifj4eOzcuRPLly/HsmXLjB7tMHbsWBw+fBgbN27E/v37ISJ47LHHjJLRFVm6dClmzJiBDz/8ELGxsfjoo48wc+ZMLF++HABw8OBBAMC2bduQnJyMdevW4fXXX8fTTz+N/v37Izk5GcnJyejevTuys7PRp08fNGjQAL///jv27t2LBg0aoH///kYD3ztdunQJvXr1gr29PXbs2IEjR47g+eefN9T7woUL8dlnn+HTTz/F8ePHERoaisGDBxsS6hWd8/XXXzfc7VIcq6l1prz99tv4+OOPMXPmTMTExGDlypXw8PAwWTY5ORm9e/fGfffdh8OHD2Pr1q24cuUKnn76aaNyy5cvh1arxYEDB/DJJ5/gvffeQ1RUFADg0KFDAIouRJKTkw3vSxo1ahR++ukniIhh3erVq+Hh4YHevXsDKEr6vv/++zh27Bg2bNiAxMTEGj8mpqK+8sUXX2Djxo34+eefERcXhx9++KHMZDkRERFRXfj111/xzDPPYPLkyYiJicGSJUuwbNkyw80CQFEi9IsvvsDJkyexfPly7NixA2+++SYAoHv37liwYAGcnJyMxo5V8dZbb2Hy5MmIjY1FaGhohWOokpKTkzFixAg8//zziI2Nxa5du/DEE08Yjf22b9+O2NhY7Ny5Ez/99BPWr1+POXPmGLbfunUL06ZNw6FDh7B9+3ZYWVlh6NCh0Ov1AICbN2+id+/euHz5MjZu3Ihjx47hzTffNGyvTD3eqazxdUVj+bLqrKTyxsnx8fHYsGEDfvnlF/zyyy/YvXs35s2bZ9j+7rvvIjIyEosXL8apU6fw6quv4plnnsHu3bvLaMGKrVmzBp9//jmWLFmCM2fOYMOGDejYsSOAosdu+Pj44L333iv3WuPQoUPo378/nn76aSQnJ2PhwoUQETz++ONISUnB5s2bceTIEXTp0gWPPvoorl27BqCo7R577DFs27YNR48eRWhoKAYNGoSkpKQqnb8sxX0rKioKv/zyS7Wu8YiomoSI7imRkZHi7Oxcan1iYqIAkG+//daw7tSpUwJAYmNjRURk9OjR8n//939G++3Zs0esrKwkJyfH5PkcHR1l2bJllYpl9uzZ0rlzZ8P7MWPGiJ+fn+h0OsO6p556SsLDw0VE5PTp0wJA/vjjD8P2tLQ00Wg08vPPP5s8pojI559/Ln5+fob3vr6+snLlSqMy77//vgQHB4vI7bo5evSoUZkxY8ZIWFiY0brvvvtO2rRpI3q93rAuLy9PNBqN/Prrrybr4e2335ZmzZpJfn6+ye3e3t7y4YcfGq174IEHZOLEiZU+5/r166Xkr2xT6+78TJmZmaJWq2Xp0qUm4ypZLzNnzpSQkBCjMhcuXBAAEhcXJyIivXv3loceeqjUZ3nrrbcM7wHI+vXrTZ6zWGpqqtjY2Mjvv/9uWBccHCxvvPFGmfscPHhQAEhWVpaIiOzcuVMAyPXr10WkdvrKK6+8Io888ohRWxARERHVtjFjxoi1tbVotVrDa9iwYSIi0rNnT/noo4+Myq9YsUK8vLzKPN7PP/8srq6uhvdlXTOYGqc5OztLZGSkiNweHy5YsMCoTEVjqJKOHDkiAOTcuXMmt48ZM0ZcXFzk1q1bhnWLFy+WBg0aSGFhocl9UlNTBYCcOHFCRESWLFkijo6Okp6ebrJ8derR1Pi6orF8WXVmiqn6nz17tjg4OEhmZqZh3RtvvCFdu3YVEZGbN2+Kvb297Nu3z2i/cePGyYgRIyo8Z1nXQp999pm0bt26zGsYPz8/+fzzzys8flhYmIwZM8bwfvv27eLk5CS5ublG5Vq0aCFLliwp8zjt27eXL7/8stzzV2a8P2bMGPHw8JC8vDzDuupc4xFR9fAZzUT1TKdOnQzLXl5eAIDU1FS0bdsWR44cwdmzZ/Hjjz8ayogI9Ho9EhMT0a5du1LHmzZtGsaPH48VK1agb9++eOqpp9CiRYtKx9OhQwfDVwCLYzpx4gSAosk2bGxs0LVrV8N2V1dXtGnTBrGxsZU6/tWrV3HhwgWMGzfO6NljOp3O6JEilVVcR46Ojkbrc3NzS31Vr1h0dDR69uxp8k7vzMxMXL58GT169DBa36NHD8PXx6pzzsqIjY1FXl4eHn300UqVP3LkCHbu3IkGDRqU2hYfH2/42tmdfQwoatPyHmlhiru7O/r164cff/wRPXv2RGJiIvbv34/Fixcbyhw9ehQRERGIjo7GtWvXDHenJCUloX379lU6H1C5vjJ27Fj069cPbdq0Qf/+/TFw4ECEhIRU+VxEREREFenTp4/R2Eer1QIoGpMdOnTI6M7bwsJC5ObmIjs7Gw4ODti5cyc++ugjxMTEIDMzEzqdDrm5ubh165bhODURFBRkWK7OeLtz58549NFH0bFjR4SGhiIkJATDhg1Do0aNjMo4ODgY3gcHB+PmzZu4cOEC/Pz8EB8fj5kzZ+LPP/9EWlqa0VgwICAA0dHRuP/+++Hi4mIyhsrUY0UqM5YvdmedVZW/v7/RtcCd4+uYmBjk5uaiX79+Rvvk5+fj/vvvr/Y5n3rqKSxYsADNmzdH//798dhjj2HQoEGwsalZmujIkSO4efMmXF1djdbn5OQYrm1u3bqFOXPm4JdffsHly5eh0+mQk5NjuKO5pjp27Gj0XOa6ut4iotKYaCaqZ+5Mdt75XLHif1988UXDs7fu1LRpU5PHi4iIwMiRI7Fp0yZs2bIFs2fPxqpVqzB06NAqx1McU3E8csdX5+4kIobYraysSpW787EaxcdaunSpUcIagFGCu7L0ej0CAwONkvHFypqcpTITIpZ8rtmdn7E656yMqk7UqNfrMWjQIHz88celthX/0QIov02rYtSoUZgyZQq+/PJLrFy5Eh06dEDnzp0BFA0+Q0JCEBISgh9++AHu7u5ISkpCaGhomV9vq42+0qVLFyQmJmLLli3Ytm0bnn76afTt27fCZ+ARERERVZVWq0XLli1Lrdfr9ZgzZw6eeOKJUtvs7e1x/vx5PPbYY5gwYQLef/99uLi4YO/evRg3blyFj59TqVTljpfujO3OeICqjbetra0RFRWFffv24bfffsOXX36JGTNm4MCBA4b5U8qLEQAGDRoEX19fLF26FN7e3tDr9QgICDCMBSsa61ZUj1VR3li+WE0S/OWNr4v/3bRpE5o0aWJUrioTgZfk6+uLuLg4REVFYdu2bZg4cSL+8Y9/YPfu3TWayFCv18PLy8sw/82diuf3eeONN/Drr7/i008/RcuWLaHRaDBs2LAKH2NR0Xi/WMm2qKvrLSIqjYlmIgvSpUsXnDp1yuSAtjytW7dG69at8eqrr2LEiBGIjIysdKK5PO3bt4dOp8OBAwfQvXt3AEB6ejpOnz5tuLva3d0dKSkpRoO5Oyev8/DwQJMmTZCQkIBRo0aZPE/xX7MLCwtLrS+5rkuXLli9erVh4orK6NSpE5YvX25ydmknJyd4e3tj79696NWrl2H9vn378OCDD1b7nJXRqlUraDQabN++HePHj6+wfJcuXbB27Vr4+/vX6E4GW1vbUvVqypAhQ/Diiy9i69atWLlyJUaPHm3Y9vfffyMtLQ3z5s2Dr68vABgmoSxLbfQVoKjNwsPDER4ejmHDhqF///64du1amXfLEBEREdWmLl26IC4urswx++HDh6HT6fDZZ5/Byqpo2qWff/7ZqIypcS5QNF6683m3Z86cQXZ2drnxVHYMVZJKpUKPHj3Qo0cPzJo1C35+fli/fj2mTZsGoGjS8ZycHEPC+M8//0SDBg3g4+OD9PR0xMbGYsmSJejZsycAYO/evUbH79SpE7799tsyx2kV1WNlVGYsXxWVHSffqX379lCr1UhKSjLMZVJbNBoNBg8ejMGDB+Pll19G27ZtceLECXTp0qXMPlSRLl26ICUlBTY2NmXOdbJnzx6MHTvWcE158+bNUhPzmTp/ReP98mKqi+stIiqNkwESWZC33noL+/fvx8svv4zo6GicOXMGGzduxCuvvGKyfE5ODiZNmoRdu3bh/Pnz+OOPP3Do0CGTj9iojlatWiEsLAwvvPAC9u7di2PHjuGZZ55BkyZNEBYWBqBoxuGrV6/ik08+QXx8PL766its2bLF6DgRERGYO3cuFi5ciNOnT+PEiROIjIzE/PnzAQCNGzeGRqMxTG6XkZEBoOgrasePH0dcXBzS0tJQUFCAUaNGwc3NDWFhYdizZw8SExOxe/duTJkyBRcvXjT5OSZNmoTMzEwMHz4chw8fxpkzZ7BixQrExcUBKPqL/ccff4zVq1cjLi4O06dPR3R0NKZMmQIA1TpnZdjb2+Ott97Cm2++ie+//x7x8fH4888/8d1335ks//LLL+PatWsYMWIEDh48iISEBPz22294/vnnqzTI9Pf3x/bt25GSkoLr16+XWU6r1SIsLAwzZ85EbGwsRo4cadjWtGlT2NnZ4csvv0RCQgI2btyI999/v9zz1kZf+fzzz7Fq1Sr8/fffOH36NP7973/D09PTcPcFERERUV2bNWsWvv/+e0RERODUqVOIjY3F6tWr8e677wIAWrRoAZ1OZxgnrVixAl9//bXRMfz9/XHz5k1s374daWlphmTyI488gn/+85/466+/cPjwYUyYMKFSd69WNIYq6cCBA/joo49w+PBhJCUlYd26dbh69arRdUR+fj7GjRuHmJgYwzcnJ02aBCsrKzRq1Aiurq745ptvcPbsWezYscOQoC42YsQIeHp6YsiQIfjjjz+QkJCAtWvXYv/+/ZWqx8qqaCxfFZUdJ9/J0dERr7/+Ol599VUsX74c8fHxOHr0KL766qsyJ2MEgGvXriE6OhoxMTEAgLi4OERHRyMlJQUAsGzZMnz33Xc4efKkoR9pNBr4+fkZYv39999x6dIlpKWlVfoz9u3bF8HBwRgyZAh+/fVXnDt3Dvv27cO7775ruHGkZcuWWLduHaKjo3Hs2DGMHDmy1DckTZ2/MuN9U+rqeouITFDm0dBEVF0VTQZ45yQP169fFwCyc+dOw7qDBw9Kv379pEGDBqLVaqVTp06lJrcolpeXJ8OHDxdfX1+xs7MTb29vmTRpkmHiwMpMBlhysr0pU6ZI7969De+vXbsmo0ePFmdnZ9FoNBIaGiqnT5822mfx4sXi6+srWq1Wnn32Wfnwww+NJnwQEfnxxx/lvvvuEzs7O2nUqJH06tVL1q1bZ9i+dOlS8fX1FSsrK8P5U1NTDXVxZz0lJyfLs88+K25ubqJWq6V58+bywgsvSEZGhsl6EhE5duyYhISEiIODgzg6OkrPnj0lPj5eREQKCwtlzpw50qRJE7G1tZXOnTvLli1bjPav6JzVmQyw+NwffPCB+Pn5ia2trTRt2tQwKYqpPnP69GkZOnSoNGzYUDQajbRt21amTp1qmDijd+/eMmXKFKNzlpwAZOPGjdKyZUuxsbEp1U4lbdq0SQBIr169Sm1buXKl+Pv7i1qtluDgYNm4caNRvCUnAxSpeV/55ptv5L777hOtVitOTk7y6KOPyl9//VXuZyAiIiKqKlPj5Dtt3bpVunfvLhqNRpycnOTBBx+Ub775xrB9/vz54uXlZRg/f//996XGRRMmTBBXV1cBILNnzxYRkUuXLklISIhotVpp1aqVbN682eRkgCUnjhOpeLx9p5iYGAkNDRV3d3dRq9XSunVro4neij//rFmzxNXVVRo0aCDjx483mkAuKipK2rVrJ2q1Wjp16iS7du0qNZneuXPn5MknnxQnJydxcHCQoKAgOXDgQKXrsSRT4+uKxvLl1VlJpsbJlZngTq/Xy8KFC6VNmzZia2sr7u7uEhoaKrt37y7zXJGRkQKg1Ku4L6xfv166du0qTk5OotVqpVu3brJt2zbD/vv375dOnTqJWq0uVSd3KnktIFI0Kfkrr7wi3t7eYmtrK76+vjJq1ChJSkoy1FmfPn1Eo9GIr6+v/POf/yx1nVHW+Ssa75f1s1WdazwiqjqVSBkPSSUiIiIiIiIiqmVjx47FjRs3sGHDBqVDISKiWsRHZxARERERERERERFRjTDRTEREREREREREREQ1wkdnEBEREREREREREVGN8I5mIiIiIiIiIiIiIqoRJpqJiIiIiIiIiIiIqEaYaCYiIiIiIiIiIiKiGmGimYiIiIiIiIiIiIhqhIlmIiIiIiIiIiIiIqoRJpqJiIiIiIiIiIiIqEaYaCYiIiIiIiIiIiKiGmGimYiIiIiIiIiIiIhqhIlmIiIiIiIiIiIiIqqR/wftve3wpZ+TjQAAAABJRU5ErkJggg==",
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"# From https://scikit-learn.org/0.21/auto_examples/cluster/plot_kmeans_silhouette_analysis.html\n",
"range_n_clusters = [2, 3, 4, 5, 6]\n",
"\n",
"for n_clusters in range_n_clusters:\n",
" # Create a subplot with 1 row and 2 columns\n",
" fig, (ax1, ax2) = plt.subplots(1, 2)\n",
" fig.set_size_inches(18, 7)\n",
"\n",
" # The 1st subplot is the silhouette plot\n",
" # The silhouette coefficient can range from -1, 1 but in this example all\n",
" # lie within [-0.1, 1]\n",
" ax1.set_xlim([-0.1, 1])\n",
" # The (n_clusters+1)*10 is for inserting blank space between silhouette\n",
" # plots of individual clusters, to demarcate them clearly.\n",
" ax1.set_ylim([0, len(X) + (n_clusters + 1) * 10])\n",
"\n",
" # Initialize the clusterer with n_clusters value and a random generator\n",
" # seed of 10 for reproducibility.\n",
" clusterer = KMeans(n_clusters=n_clusters, random_state=10, n_init='auto')\n",
" cluster_labels = clusterer.fit_predict(X)\n",
"\n",
" # The silhouette_score gives the average value for all the samples.\n",
" # This gives a perspective into the density and separation of the formed\n",
" # clusters\n",
" silhouette_avg = silhouette_score(X, cluster_labels)\n",
" print(\"For n_clusters =\", n_clusters,\n",
" \"The average silhouette_score is :\", silhouette_avg)\n",
"\n",
" # Compute the silhouette scores for each sample\n",
" sample_silhouette_values = silhouette_samples(X, cluster_labels)\n",
"\n",
" y_lower = 10\n",
" for i in range(n_clusters):\n",
" # Aggregate the silhouette scores for samples belonging to\n",
" # cluster i, and sort them\n",
" ith_cluster_silhouette_values = \\\n",
" sample_silhouette_values[cluster_labels == i]\n",
"\n",
" ith_cluster_silhouette_values.sort()\n",
"\n",
" size_cluster_i = ith_cluster_silhouette_values.shape[0]\n",
" y_upper = y_lower + size_cluster_i\n",
"\n",
" color = cm.nipy_spectral(float(i) / n_clusters)\n",
" ax1.fill_betweenx(np.arange(y_lower, y_upper),\n",
" 0, ith_cluster_silhouette_values,\n",
" facecolor=color, edgecolor=color, alpha=0.7)\n",
"\n",
" # Label the silhouette plots with their cluster numbers at the middle\n",
" ax1.text(-0.05, y_lower + 0.5 * size_cluster_i, str(i))\n",
"\n",
" # Compute the new y_lower for next plot\n",
" y_lower = y_upper + 10 # 10 for the 0 samples\n",
"\n",
" ax1.set_title(\"The silhouette plot for the various clusters.\")\n",
" ax1.set_xlabel(\"The silhouette coefficient values\")\n",
" ax1.set_ylabel(\"Cluster label\")\n",
"\n",
" # The vertical line for average silhouette score of all the values\n",
" ax1.axvline(x=silhouette_avg, color=\"red\", linestyle=\"--\")\n",
"\n",
" ax1.set_yticks([]) # Clear the yaxis labels / ticks\n",
" ax1.set_xticks([-0.1, 0, 0.2, 0.4, 0.6, 0.8, 1])\n",
"\n",
" # 2nd Plot showing the actual clusters formed\n",
" colors = cm.nipy_spectral(cluster_labels.astype(float) / n_clusters)\n",
" ax2.scatter(X[:, 0], X[:, 1], marker='.', s=30, lw=0, alpha=0.7,\n",
" c=colors, edgecolor='k')\n",
"\n",
" # Labeling the clusters\n",
" centers = clusterer.cluster_centers_\n",
" # Draw white circles at cluster centers\n",
" ax2.scatter(centers[:, 0], centers[:, 1], marker='o',\n",
" c=\"white\", alpha=1, s=200, edgecolor='k')\n",
"\n",
" for i, c in enumerate(centers):\n",
" ax2.scatter(c[0], c[1], marker='$%d$' % i, alpha=1,\n",
" s=50, edgecolor='k')\n",
"\n",
" ax2.set_title(\"The visualization of the clustered data.\")\n",
" ax2.set_xlabel(\"Feature space for the 1st feature\")\n",
" ax2.set_ylabel(\"Feature space for the 2nd feature\")\n",
"\n",
" plt.suptitle((\"Silhouette analysis for KMeans clustering on sample data \"\n",
" \"with n_clusters = %d\" % n_clusters),\n",
" fontsize=14, fontweight='bold')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"So, the average silhouette score was highest for 3 clusters. So it looks like our \"by eye\" analysis also agrees with this analysis.\n",
"\n",
"## agglomerative clustering\n",
"\n",
"Now let's try a different form of clustering in which we do not need to set, in advance, the number of clusters.\n",
"\n",
"This is *hierarchical agglomerative clustering*."
]
},
{
"cell_type": "code",
"execution_count": 27,
"metadata": {},
"outputs": [],
"source": [
"from sklearn.cluster import AgglomerativeClustering"
]
},
{
"cell_type": "code",
"execution_count": 28,
"metadata": {},
"outputs": [],
"source": [
"from scipy.cluster.hierarchy import dendrogram"
]
},
{
"cell_type": "code",
"execution_count": 29,
"metadata": {},
"outputs": [],
"source": [
"aggclust = AgglomerativeClustering(distance_threshold=0, n_clusters=None)\n",
"aggclust.fit(X);"
]
},
{
"cell_type": "code",
"execution_count": 30,
"metadata": {},
"outputs": [
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAABlkAAANUCAYAAAAwyEuvAAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjkuMiwgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy8hTgPZAAAACXBIWXMAAA9hAAAPYQGoP6dpAAEAAElEQVR4nOzde5xdZX0v/s/kMnESkzEEkxCNiBpTaEABbQh4JEpIQAL14Cm2oREqDXhQaGryokWqIkJQbmKhRaRoUMDYU4vlUmKgCi1CuATSyqX89IgQNAEKQwJkm+v6/cGZaSaZmcxec9lzeb9fr3kx2fuZtZ619tprmOezv89TVxRFEQAAAAAAAKoypNYdAAAAAAAA6I+ELAAAAAAAACUIWQAAAAAAAEoQsgAAAAAAAJQgZAEAAAAAAChByAIAAAAAAFCCkAUAAAAAAKAEIQsAAAAAAEAJQhYAAAAAAIAShCwAAPRLS5cuTV1dXR566KE2n587d27e/va3t3rs7W9/e04++eSe71wPuOuuu1JXV5d/+Id/2G3bk08+eZdj707nnntu6urqOt3+3/7t33LCCSfkLW95S+rr69PY2JhDDz00V111VV577bWWdj39+ixZsiQ//OEPe2Tbv/rVr1JXV5elS5f2yPY7s+/mr+HDh2fcuHF5//vfnz//8z/PY4891ut92lFPX48AAFBLQhYAAAaNm266KZ///Odr3Y0e9/nPfz433XRTrbuRJPniF7+YD37wg/n1r3+dL3/5y7njjjuybNmyHHHEETn33HPzV3/1V73Wl54MWfbaa6/cd999OeaYY3pk+51xxhln5L777svdd9+d7373u/noRz+am2++Oe95z3ty8cUX16xfAAAwkA2rdQcAAKC3HHjggd22raIo8tvf/jYNDQ1d2k6lUunyNnb2zne+s1u3V9b/+T//J+edd15OOeWUXHPNNa2qX44++uicddZZue+++2rYw67btm1btm7dmhEjRuSQQw6paV/e9ra3terDRz7ykXz2s5/N8ccfn7POOivTpk3L0UcfXcMetm/H89jTuuu9CwAAiUoWAAAGkbamo9qwYUMWL16cffbZJ/X19XnLW96ShQsXtprGKknq6urymc98Jt/4xjey7777ZsSIEbnuuuuSJF/60pcyffr07LHHHhkzZkwOOuigXHvttSmKYpf9z507N//4j/+YAw88MG94wxvypS99KUny61//OqeeemomT56c+vr6TJo0Kf/rf/2vPPfcc622sWXLlpxzzjmZNGlSxowZk1mzZuXJJ59s1aat6Zm2b9+eK664Iu9973vT0NCQN73pTTnkkENy8803t7T5/ve/n9mzZ2evvfZKQ0ND9t133/zlX/7lLueis84777yMHTs2f/3Xf93m9GKjR4/O7Nmz2/355inhfvWrX7V6vHnqtLvuuqvlsUceeSRz587N+PHjM2LEiEyaNCnHHHNMnn322SSvv36vvfZarrvuupZptWbOnNny8+vWrctpp52Wt771ramvr88+++yTL33pS9m6dWtLm+ZpuS666KKcf/752WeffTJixIj85Cc/aXO6sOZp1R577LH80R/9URobGzNhwoR88pOfzPr161sd08svv5xTTjkle+yxR974xjfmmGOOyS9/+cvU1dXl3HPP3f3JbkdDQ0OuvfbaDB8+fJdqlmqO+ZJLLslll12WffbZJ2984xszY8aMrFy5cpf9LV26NFOnTs2IESOy77775jvf+c4ubTo6j0ly8803Z8aMGRk5cmRGjx6dI488ss0w7p/+6Z9ywAEHZMSIEXnHO96Rr3/9621OZded791bb701Bx54YMv749Zbb2057n333TejRo3K7/3e77U7jSEAAAOPShYAAPq15k/A72znQdK2bNy4MYcffnieffbZfO5zn8sBBxyQxx57LF/4whfys5/9LHfeeWerAdsf/vCH+bd/+7d84QtfyMSJEzN+/Pgkrw8an3baaXnb296WJFm5cmXOOOOM/PrXv84XvvCFVvt8+OGH88QTT+Sv/uqvss8++2TUqFH59a9/nfe///3ZsmVLSz9efPHF/OhHP0pTU1MmTJjQ8vOf+9zncthhh+Xv/u7vsmHDhvzFX/xFjj322DzxxBMZOnRou8d68skn5/rrr88pp5yS8847L/X19Xn44YdbBRg///nP85GPfCQLFy7MqFGj8p//+Z/56le/mgceeCA//vGPd3s+d7R27do8+uij+fjHP56RI0dW9bPVeu2113LkkUdmn332yd/8zd9kwoQJWbduXX7yk5/klVdeSZLcd999+fCHP5wPfehDLVPGjRkzJsnrYcPv/d7vZciQIfnCF76Qd77znbnvvvty/vnn51e/+lW+/e1vt9rfX//1X+fd7353LrnkkowZMyZTpkzpsH8f+9jH8vGPfzynnHJKfvazn+Xss89OknzrW99K8noAduyxx+ahhx7Kueeem4MOOij33XdfjjrqqG45P5MmTcrBBx+ce++9N1u3bs2wYcOqPua/+Zu/ye/8zu/k8ssvT/L6lHQf+chH8tRTT6WxsTHJ60HDn/zJn+T3f//3c+mll2b9+vU599xzs2nTpgwZsuvn+9o6jzfeeGNOPPHEzJ49O9/73veyadOmXHTRRZk5c2b+5V/+JR/4wAeSJMuXL8/xxx+fD37wg/n+97+frVu35pJLLtkllGzWHe/df//3f8/ZZ5+dc845J42NjfnSl76U448/PmeffXb+5V/+JUuWLEldXV3+4i/+InPnzs1TTz2lWgYAYDAoAACgH/r2t79dJOnwa++99271M3vvvXdx0kkntfz7wgsvLIYMGVI8+OCDrdr9wz/8Q5Gk+Od//ueWx5IUjY2NxUsvvdRhv7Zt21Zs2bKlOO+884px48YV27dvb7X/oUOHFk8++WSrn/nkJz9ZDB8+vHj88cfb3e5PfvKTIknxkY98pNXjf//3f18kKe67776Wx0466aRWx/6v//qvRZLinHPO6bDvO9q+fXuxZcuW4u677y6SFP/+7//e8twXv/jFYnd/SqxcubJIUvzlX/5lp/e58+vT/Bo/9dRTrdo1n4uf/OQnRVEUxUMPPVQkKX74wx92uP1Ro0a12n6z0047rXjjG99YPP30060ev+SSS4okxWOPPVYURVE89dRTRZLine98Z7F58+ZWbZuf+/a3v93yWPN5uuiii1q1Pf3004s3vOENLdfGbbfdViQprrrqqlbtLrzwwiJJ8cUvfrHD42re98UXX9xum49//ONFkuK5554rdcz7779/sXXr1pZ2DzzwQJGk+N73vlcUxevX/aRJk4qDDjqo1TX/q1/9qhg+fHir67G989i8jf3337/Ytm1by+OvvPJKMX78+OLQQw9teez9739/MXny5GLTpk2t2o0bN26Xa7O73rsNDQ3Fs88+2/LY6tWriyTFXnvtVbz22mstj//whz8skhQ333xzh/sDAGBgMF0YAAD92ne+8508+OCDu3w1f+K9I7feemumTZuW9773vdm6dWvL15w5c3aZjipJPvzhD2fs2LG7bOfHP/5xZs2alcbGxgwdOjTDhw/PF77whbz44ot5/vnnW7U94IAD8u53v7vVY7fffns+9KEPZd99991tn4877rhdtpckTz/9dLs/c/vttydJPv3pT3e47V/+8peZN29eJk6c2HIchx9+eJLkiSee2G3fauVd73pXxo4dm7/4i7/IN77xjTz++ONV/fytt96aD33oQ5k0aVKr66B5/ZK77767Vfvjjjsuw4cP7/T223rNfvvb37ZcG83bP+GEE1q1+6M/+qOqjqMjxU6VXdUe8zHHHNOqUmrn6+7JJ5/Mb37zm8ybN69V9dfee++dQw89tM0+7Xwem7cxf/78VpUvb3zjG/Oxj30sK1euzMaNG/Paa6/loYceykc/+tHU19e3anfssce2ua/ueO++973vzVve8paWfze/X2fOnNmqWqv58Y7ekwAADBymCwMAoF/bd9998773vW+XxxsbG7NmzZoOf/a5557LL37xi3YHzP/rv/6r1b/32muvXdo88MADmT17dmbOnJlrrrmmZX2LH/7wh7ngggtSqVR2u40XXnghb33rWzvsa7Nx48a1+nfzQuE772fn7Q8dOjQTJ05st82rr76a//E//kfe8IY35Pzzz8+73/3ujBw5MmvWrMnxxx/f4fbb0jz90lNPPVXVz5XR2NiYu+++OxdccEE+97nPpampKXvttVcWLFiQv/qrv9ptIPLcc8/llltu6dJ10JHdvWYvvvhihg0blj322KNVux2nieuqp59+OiNGjGjZR7XH3JljSNLmNTZx4sRd1tVJdj2Pzdto6/xOmjQp27dvT1NTU4qiSFEUbZ6f9s5Zd7x3d359mgOe9h7/7W9/22ZfAAAYWIQsAAAMWnvuuWcaGhpa1sZo6/kdtbV4+7JlyzJ8+PDceuutecMb3tDy+A9/+MM2t9nWNt785je3LNDeE9785jdn27ZtWbduXbsBwY9//OP85je/yV133dVSvZK8viB7GXvttVf233//rFixIhs3biy1Lkvz+dy0aVOrx3cOAJJk//33z7Jly1IURf7jP/4jS5cuzXnnnZeGhob85V/+ZYf72XPPPXPAAQfkggsuaPP5SZMmtfp3W69hV4wbNy5bt27NSy+91GrAft26dd2y/V//+tdZtWpVDj/88Awb9vqfgNUe8+40hzBt9bm949j5PDZvY+3atbu0/c1vfpMhQ4Zk7NixKYoidXV1ba6/0tl9JdW/dwEAoC2mCwMAYNCaO3du/u///b8ZN25c3ve+9+3y9fa3v32326irq8uwYcNaTaVUqVTy3e9+t9P9OProo/OTn/wkTz75ZJnD6NT2k+Sqq65qt03zIHRzhUKzq6++uvR+P//5z6epqSlnnnnmLtNVJa9Xz6xYsaLdn28+///xH//R6vGbb7653Z+pq6vLe97znnzta1/Lm970pjz88MMtz40YMaLNipy5c+fm0UcfzTvf+c42r4NqA4dqNYda3//+91s9vmzZsi5vu1Kp5E//9E+zdevWnHXWWS2Pd/cxT506NXvttVe+973vtXqtn3766dx7772d3sZb3vKW3Hjjja228dprr+UHP/hBZsyYkZEjR2bUqFF53/velx/+8IfZvHlzS7tXX301t956a6f73B3vXQAAUMkCAMCgtXDhwvzgBz/IBz/4wfz5n/95DjjggGzfvj3PPPNMVqxYkUWLFmX69OkdbuOYY47JZZddlnnz5uXUU0/Niy++mEsuuWSXsKIj5513Xm6//fZ88IMfzOc+97nsv//+efnll7N8+fJ89rOfze/8zu906Tj/x//4H5k/f37OP//8PPfcc5k7d25GjBiRRx55JCNHjswZZ5yRQw89NGPHjs2nPvWpfPGLX8zw4cNzww035N///d9L7/cP/uAP8vnPfz5f/vKX85//+Z855ZRT8s53vjMbN27M/fffn6uvvjof//jHM3v27DZ//v3vf3+mTp2axYsXZ+vWrRk7dmxuuumm3HPPPa3a3Xrrrfnbv/3bfPSjH8073vGOFEWRf/zHf8zLL7+cI488sqXd/vvvn7vuuiu33HJL9tprr4wePTpTp07NeeedlzvuuCOHHnpozjzzzEydOjW//e1v86tf/Sr//M//nG984xudns6tjKOOOiqHHXZYFi1alA0bNuTggw/Offfdl+985ztJ0mp9ko4888wzWblyZbZv357169fnkUceybe+9a08/fTTufTSS1ud5+4+5iFDhuTLX/5y/vRP/zT/83/+zyxYsCAvv/xyzj333A6nqdt5GxdddFFOPPHEzJ07N6eddlo2bdqUiy++OC+//HK+8pWvtOr/Mccckzlz5uTP/uzPsm3btlx88cV54xvfmJdeeqlT++uO9y4AAAhZAAAYtEaNGpV/+7d/y1e+8pV885vfzFNPPZWGhoa87W1vy6xZszpVyfLhD3843/rWt/LVr341xx57bN7ylrdkwYIFGT9+fE455ZRO9eMtb3lLHnjggXzxi1/MV77ylbz44ot585vfnA984AO7rPdQ1tKlS3PQQQfl2muvzdKlS9PQ0JD99tsvn/vc55K8PlXTbbfdlkWLFuWP//iPM2rUqPz+7/9+vv/97+eggw4qvd/zzjsvs2bNyhVXXJFzzjkn//Vf/5WGhob87u/+bj772c/mtNNOa/dnhw4dmltuuSWf+cxn8qlPfSojRozIH/7hH+bKK6/MMccc09JuypQpedOb3pSLLroov/nNb1JfX5+pU6dm6dKlOemkk1raff3rX8+nP/3p/OEf/mE2btyYww8/PHfddVf22muvPPTQQ/nyl7+ciy++OM8++2xGjx6dffbZJ0cddVSbC6Z3pyFDhuSWW27JokWL8pWvfCWbN2/OYYcdluuvvz6HHHJI3vSmN3VqO1dccUWuuOKKDB06NGPGjMk73vGOHHvssVmwYEH222+/Vm174pibr/evfvWrOf744/P2t789n/vc53L33Xfnrrvu6tQ25s2bl1GjRuXCCy/Mxz/+8QwdOjSHHHJIfvKTn+TQQw9taXfUUUflBz/4Qb7whS/k4x//eCZOnJjTTz89v/nNbzpdidId710AAKgr2qrbBwAAoKZuvPHGnHjiifnpT3/aKmCgbVu2bMl73/vevOUtb+lwGjoAAOhOKlkAAABq7Hvf+15+/etfZ//998+QIUOycuXKXHzxxfngBz8oYGnHKaeckiOPPDJ77bVX1q1bl2984xt54okn8vWvf73WXQMAYBARsgAAANTY6NGjs2zZspx//vl57bXXstdee+Xkk0/O+eefX+uu9VmvvPJKFi9enBdeeCHDhw/PQQcdlH/+53/OrFmzat01AAAGEdOFAQAAAAAAlDCk1h0AAAAAAADoj4QsAAAAAAAAJQhZAAAAAAAAShjUC99v3749v/nNbzJ69OjU1dXVujsAAAAAAEANFUWRV155JZMmTcqQIbuvUxnUIctvfvObTJ48udbdAAAAAAAA+pA1a9bkrW99627bDeqQZfTo0UleP1ljxoypcW8AAAAAAIBa2rBhQyZPntySH+zOoA5ZmqcIGzNmjJAFAAAAAABIkk4vMWLhewAAAAAAgBKELAAAAAAAACUIWQAAAAAAAEoQsgAAAAAAAJQgZAEAAAAAAChByAIAAAAAAFCCkAUAAAAAAKAEIQsAAAAAAEAJQhYAAAAAAIAShCwAAAAAAAAlCFkAAAAAAABKELIAAAAAAACUIGQBAAAAAAAoQcgCAAAAAABQgpAFAAAAAACgBCELAAAAAABACUIWAAAAAACAEoQsAAAAAAAAJQhZAAAAAAAAShCyAAAAAAAAlCBkAQAAAAAAKEHIAgAAAAAAUIKQBQAAAAAAoAQhCwAAAAAAQAlCFgAAAAAAgBKELAAAAAAAACUIWQAAAAAAAEoQsgAAAAAAAJQgZAEAAAAAAChByAIAAAAAAFCCkAUAAAAAAKCEYbXuAFCdoihS2bKt1t0AAADolIbhQ1NXV1frbgAA9AghC/QjRVHkf33jvqx6uqnWXQEAAOiU9+09Nv/nUzMELQDAgGS6MOhHKlu2CVgAAIB+5aGnm1TjAwADlkoW6Kce+qtZGVk/tNbdAAAAaNPGzdvyvvPvrHU3AAB6lJAF+qmR9UMzst5bGAAAAACgVkwXBgAAAAAAUIKQBQAAAAAAoAQhCwAAAAAAQAlCFgAAAAAAgBKELAAAAAAAACUIWQAAAAAAAEoQsgAAAAAAAJQgZAEAAAAAAChByAIAAAAAAFCCkAUAAAAAAKAEIQsAAAAAAEAJQhYAAAAAAIAShCwAAAAAAAAlCFkAAAAAAABKELIAAAAAAACUIGQBAAAAAAAoQcgCAAAAAABQgpAFAAAAAACgBCELAAAAAABACUIWAAAAAACAEoQsAAAAAAAAJQhZAAAAAAAAShCyAAAAAAAAlFB1yPLrX/86f/zHf5xx48Zl5MiRee9735tVq1a1PF8URc4999xMmjQpDQ0NmTlzZh577LFW29i0aVPOOOOM7Lnnnhk1alSOO+64PPvss63aNDU1Zf78+WlsbExjY2Pmz5+fl19+uVWbZ555Jscee2xGjRqVPffcM2eeeWY2b95c7SEBAAAAAABUraqQpampKYcddliGDx+e22+/PY8//nguvfTSvOlNb2ppc9FFF+Wyyy7LlVdemQcffDATJ07MkUcemVdeeaWlzcKFC3PTTTdl2bJlueeee/Lqq69m7ty52bZtW0ubefPmZfXq1Vm+fHmWL1+e1atXZ/78+S3Pb9u2Lcccc0xee+213HPPPVm2bFl+8IMfZNGiRV04HQAAAAAAAJ0zrJrGX/3qVzN58uR8+9vfbnns7W9/e8v3RVHk8ssvzznnnJPjjz8+SXLddddlwoQJufHGG3Paaadl/fr1ufbaa/Pd7343s2bNSpJcf/31mTx5cu68887MmTMnTzzxRJYvX56VK1dm+vTpSZJrrrkmM2bMyJNPPpmpU6dmxYoVefzxx7NmzZpMmjQpSXLppZfm5JNPzgUXXJAxY8Z06cQAAAAAAAB0pKpKlptvvjnve9/78gd/8AcZP358DjzwwFxzzTUtzz/11FNZt25dZs+e3fLYiBEjcvjhh+fee+9NkqxatSpbtmxp1WbSpEmZNm1aS5v77rsvjY2NLQFLkhxyyCFpbGxs1WbatGktAUuSzJkzJ5s2bWo1fdmONm3alA0bNrT6AgAAAAAAKKOqkOWXv/xlrrrqqkyZMiU/+tGP8qlPfSpnnnlmvvOd7yRJ1q1blySZMGFCq5+bMGFCy3Pr1q1LfX19xo4d22Gb8ePH77L/8ePHt2qz837Gjh2b+vr6ljY7u/DCC1vWeGlsbMzkyZOrOXwAAAAAAIAWVYUs27dvz0EHHZQlS5bkwAMPzGmnnZYFCxbkqquuatWurq6u1b+LotjlsZ3t3Kat9mXa7Ojss8/O+vXrW77WrFnTYZ8AAAAAAADaU1XIstdee2W//fZr9di+++6bZ555JkkyceLEJNmlkuT5559vqTqZOHFiNm/enKampg7bPPfcc7vs/4UXXmjVZuf9NDU1ZcuWLbtUuDQbMWJExowZ0+oLAAAAAACgjKpClsMOOyxPPvlkq8f+v//v/8vee++dJNlnn30yceLE3HHHHS3Pb968OXfffXcOPfTQJMnBBx+c4cOHt2qzdu3aPProoy1tZsyYkfXr1+eBBx5oaXP//fdn/fr1rdo8+uijWbt2bUubFStWZMSIETn44IOrOSwAAAAAAICqDaum8Z//+Z/n0EMPzZIlS3LCCSfkgQceyDe/+c1885vfTPL69F0LFy7MkiVLMmXKlEyZMiVLlizJyJEjM2/evCRJY2NjTjnllCxatCjjxo3LHnvskcWLF2f//ffPrFmzkrxeHXPUUUdlwYIFufrqq5Mkp556aubOnZupU6cmSWbPnp399tsv8+fPz8UXX5yXXnopixcvzoIFC1SoAAAAAAAAPa6qkOX9739/brrpppx99tk577zzss8+++Tyyy/PiSee2NLmrLPOSqVSyemnn56mpqZMnz49K1asyOjRo1vafO1rX8uwYcNywgknpFKp5IgjjsjSpUszdOjQljY33HBDzjzzzMyePTtJctxxx+XKK69seX7o0KG57bbbcvrpp+ewww5LQ0ND5s2bl0suuaT0yQAAAAAAAOisuqIoilp3olY2bNiQxsbGrF+/XvUL/cLGzVuz3xd+lCR5/Lw5GVlfVU4KAADQa/z9AgD0R9XmBlWtyQIAAAAAAMDrhCwAAAAAAAAlCFkAAAAAAABKELIAAAAAAACUIGQBAAAAAAAoQcgCAAAAAABQgpAFAAAAAACgBCELAAAAAABACUIWAAAAAACAEoQsAAAAAAAAJQhZAAAAAAAAShCyAAAAAAAAlCBkAQAAAAAAKEHIAgAAAAAAUIKQBQAAAAAAoAQhCwAAAAAAQAlCFgAAAAAAgBKELAAAAAAAACUIWQAAAAAAAEoQsgAAAAAAAJQgZAEAAAAAAChByAIAAAAAAFCCkAUAAAAAAKAEIQsAAAAAAEAJQhYAAAAAAIAShCwAAAAAAAAlCFkAAAAAAABKELIAAAAAAACUIGQBAAAAAAAoQcgCAAAAAABQgpAFAAAAAACgBCELAAAAAABACUIWAAAAAACAEoQsAAAAAAAAJQhZAAAAAAAAShCyAAAAAAAAlCBkAQAAAAAAKEHIAgAAAAAAUIKQBQAAAAAAoAQhCwAAAAAAQAlCFgAAAAAAgBKELAAAAAAAACUIWQAAAAAAAEoQsgAAAAAAAJQwrNYdAAAA6C1FUaSyZVutuwGDwsbNW9v8HuhZDcOHpq6urtbdABg0hCwAAMCgUBRF/tc37suqp5tq3RUYdN53/r/UugswaLxv77H5P5+aIWgB6CWmCwMAAAaFypZtAhYABryHnm5StQnQi1SyAAAAg85DfzUrI+uH1robANBtNm7elvedf2etuwEw6AhZAACAQWdk/dCMrPfnEAAA0DWmCwMAAAAAAChByAIAAAAAAFCCkAUAAAAAAKAEIQsAAAAAAEAJQhYAAAAAAIAShCwAAAAAAAAlCFkAAAAAAABKELIAAAAAAACUIGQBAAAAAAAoQcgCAAAAAABQgpAFAAAAAACgBCELAAAAAABACUIWAAAAAACAEoQsAAAAAAAAJQhZAAAAAAAAShCyAAAAAAAAlCBkAQAAAAAAKEHIAgAAAAAAUIKQBQAAAAAAoAQhCwAAAAAAQAlCFgAAAAAAgBKELAAAAAAAACUIWQAAAAAAAEoQsgAAAAAAAJQgZAEAAAAAAChByAIAAAAAAFCCkAUAAAAAAKAEIQsAAAAAAEAJQhYAAAAAAIAShCwAAAAAAAAlCFkAAAAAAABKELIAAAAAAACUIGQBAAAAAAAoQcgCAAAAAABQgpAFAAAAAACgBCELAAAAAABACUIWAAAAAACAEoQsAAAAAAAAJQhZAAAAAAAAShCyAAAAAAAAlCBkAQAAAAAAKEHIAgAAAAAAUIKQBQAAAAAAoAQhCwAAAAAAQAlCFgAAAAAAgBKELAAAAAAAACUIWQAAAAAAAEoQsgAAAAAAAJQgZAEAAAAAAChByAIAAAAAAFCCkAUAAAAAAKAEIQsAAAAAAEAJQhYAAAAAAIAShCwAAAAAAAAlCFkAAAAAAABKELIAAAAAAACUIGQBAAAAAAAooaqQ5dxzz01dXV2rr4kTJ7Y8XxRFzj333EyaNCkNDQ2ZOXNmHnvssVbb2LRpU84444zsueeeGTVqVI477rg8++yzrdo0NTVl/vz5aWxsTGNjY+bPn5+XX365VZtnnnkmxx57bEaNGpU999wzZ555ZjZv3lzl4QMAAAAAAJRTdSXL7/7u72bt2rUtXz/72c9anrvoooty2WWX5corr8yDDz6YiRMn5sgjj8wrr7zS0mbhwoW56aabsmzZstxzzz159dVXM3fu3Gzbtq2lzbx587J69eosX748y5cvz+rVqzN//vyW57dt25Zjjjkmr732Wu65554sW7YsP/jBD7Jo0aKy5wEAAAAAAKAqw6r+gWHDWlWvNCuKIpdffnnOOeecHH/88UmS6667LhMmTMiNN96Y0047LevXr8+1116b7373u5k1a1aS5Prrr8/kyZNz5513Zs6cOXniiSeyfPnyrFy5MtOnT0+SXHPNNZkxY0aefPLJTJ06NStWrMjjjz+eNWvWZNKkSUmSSy+9NCeffHIuuOCCjBkzpvQJAQAAAAAA6IyqK1l+/vOfZ9KkSdlnn33yh3/4h/nlL3+ZJHnqqaeybt26zJ49u6XtiBEjcvjhh+fee+9NkqxatSpbtmxp1WbSpEmZNm1aS5v77rsvjY2NLQFLkhxyyCFpbGxs1WbatGktAUuSzJkzJ5s2bcqqVava7fumTZuyYcOGVl8AAAAAAABlVBWyTJ8+Pd/5znfyox/9KNdcc03WrVuXQw89NC+++GLWrVuXJJkwYUKrn5kwYULLc+vWrUt9fX3Gjh3bYZvx48fvsu/x48e3arPzfsaOHZv6+vqWNm258MILW9Z5aWxszOTJk6s5fAAAAAAAgBZVhSxHH310Pvaxj2X//ffPrFmzcttttyV5fVqwZnV1da1+piiKXR7b2c5t2mpfps3Ozj777Kxfv77la82aNR32CwAAAAAAoD1VTxe2o1GjRmX//ffPz3/+85Z1WnauJHn++edbqk4mTpyYzZs3p6mpqcM2zz333C77euGFF1q12Xk/TU1N2bJlyy4VLjsaMWJExowZ0+oLAAAAAACgjC6FLJs2bcoTTzyRvfbaK/vss08mTpyYO+64o+X5zZs35+67786hhx6aJDn44IMzfPjwVm3Wrl2bRx99tKXNjBkzsn79+jzwwAMtbe6///6sX7++VZtHH300a9eubWmzYsWKjBgxIgcffHBXDgkAAAAAAKBThlXTePHixTn22GPztre9Lc8//3zOP//8bNiwISeddFLq6uqycOHCLFmyJFOmTMmUKVOyZMmSjBw5MvPmzUuSNDY25pRTTsmiRYsybty47LHHHlm8eHHL9GNJsu++++aoo47KggULcvXVVydJTj311MydOzdTp05NksyePTv77bdf5s+fn4svvjgvvfRSFi9enAULFqhOAQAAAAAAekVVIcuzzz6bP/qjP8p//dd/5c1vfnMOOeSQrFy5MnvvvXeS5KyzzkqlUsnpp5+epqamTJ8+PStWrMjo0aNbtvG1r30tw4YNywknnJBKpZIjjjgiS5cuzdChQ1va3HDDDTnzzDMze/bsJMlxxx2XK6+8suX5oUOH5rbbbsvpp5+eww47LA0NDZk3b14uueSSLp0MAAAAAACAzqoriqKodSdqZcOGDWlsbMz69etVwNAvbNy8Nft94UdJksfPm5OR9VXlpAAAg5r/lwJgIPN7DqB7VJsbdGlNFgAAAAAAgMFKyAIAAAAAAFCCkAUAAAAAAKAEIQsAAAAAAEAJQhYAAAAAAIAShCwAAAAAAAAlCFkAAAAAAABKELIAAAAAAACUIGQBAAAAAAAoQcgCAAAAAABQgpAFAAAAAACgBCELAAAAAABACUIWAAAAAACAEoQsAAAAAAAAJQhZAAAAAAAAShCyAAAAAAAAlCBkAQAAAAAAKEHIAgAAAAAAUIKQBQAAAAAAoAQhCwAAAAAAQAlCFgAAAAAAgBKELAAAAAAAACUIWQAAAAAAAEoQsgAAAAAAAJQgZAEAAAAAAChByAIAAAAAAFCCkAUAAAAAAKAEIQsAAAAAAEAJQhYAAAAAAIAShCwAAAAAAAAlCFkAAAAAAABKELIAAAAAAACUIGQBAAAAAAAoQcgCAAAAAABQgpAFAAAAAACgBCELAAAAAABACUIWAAAAAACAEoQsAAAAAAAAJQhZAAAAAAAAShCyAAAAAAAAlCBkAQAAAAAAKEHIAgAAAAAAUIKQBQAAAAAAoAQhCwAAAAAAQAlCFgAAAAAAgBKELAAAAAAAACUIWQAAAAAAAEoQsgAAAAAAAJQgZAEAAAAAAChByAIAAAAAAFCCkAUAAAAAAKAEIQsAAAAAAEAJQhYAAAAAAIAShCwAAAAAAAAlCFkAAAAAAABKELIAAAAAAACUIGQBAAAAAAAoQcgCAAAAAABQgpAFAAAAAACgBCELAAAAAABACUIWAAAAAACAEoQsAAAAAAAAJQhZAAAAAAAAShCyAAAAAAAAlCBkAQAAAAAAKEHIAgAAAAAAUIKQBQAAAAAAoAQhCwAAAAAAQAlCFgAAAAAAgBKELAAAAAAAACUIWQAAAAAAAEoQsgAAAAAAAJQgZAEAAAAAAChByAIAAAAAAFCCkAUAAAAAAKAEIQsAAAAAAEAJQhYAAAAAAIAShCwAAAAAAAAlCFkAAAAAAABKELIAAAAAAACUIGQBAAAAAAAoQcgCAAAAAABQgpAFAAAAAACgBCELAAAAAABACUIWAAAAAACAEoQsAAAAAAAAJQhZAAAAAAAAShCyAAAAAAAAlCBkAQAAAAAAKEHIAgAAAAAAUIKQBQAAAAAAoAQhCwAAAAAAQAlCFgAAAAAAgBKELAAAAAAAACUIWQAAAAAAAEoQsgAAAAAAAJQgZAEAAAAAAChByAIAAAAAAFCCkAUAAAAAAKAEIQsAAAAAAEAJQhYAAAAAAIAShCwAAAAAAAAlCFkAAAAAAABKELIAAAAAAACUIGQBAAAAAAAoQcgCAAAAAABQgpAFAAAAAACghC6FLBdeeGHq6uqycOHClseKosi5556bSZMmpaGhITNnzsxjjz3W6uc2bdqUM844I3vuuWdGjRqV4447Ls8++2yrNk1NTZk/f34aGxvT2NiY+fPn5+WXX27V5plnnsmxxx6bUaNGZc8998yZZ56ZzZs3d+WQAAAAAAAAOqV0yPLggw/mm9/8Zg444IBWj1900UW57LLLcuWVV+bBBx/MxIkTc+SRR+aVV15pabNw4cLcdNNNWbZsWe655568+uqrmTt3brZt29bSZt68eVm9enWWL1+e5cuXZ/Xq1Zk/f37L89u2bcsxxxyT1157Lffcc0+WLVuWH/zgB1m0aFHZQwIAAAAAAOi0UiHLq6++mhNPPDHXXHNNxo4d2/J4URS5/PLLc8455+T444/PtGnTct1112Xjxo258cYbkyTr16/Ptddem0svvTSzZs3KgQcemOuvvz4/+9nPcueddyZJnnjiiSxfvjx/93d/lxkzZmTGjBm55pprcuutt+bJJ59MkqxYsSKPP/54rr/++hx44IGZNWtWLr300lxzzTXZsGFDV88LAAAAAABAh0qFLJ/+9KdzzDHHZNasWa0ef+qpp7Ju3brMnj275bERI0bk8MMPz7333pskWbVqVbZs2dKqzaRJkzJt2rSWNvfdd18aGxszffr0ljaHHHJIGhsbW7WZNm1aJk2a1NJmzpw52bRpU1atWtVmvzdt2pQNGza0+gIAAAAAAChjWLU/sGzZsjz88MN58MEHd3lu3bp1SZIJEya0enzChAl5+umnW9rU19e3qoBpbtP88+vWrcv48eN32f748eNbtdl5P2PHjk19fX1Lm51deOGF+dKXvtSZwwQAAAAAAOhQVZUsa9asyZ/92Z/l+uuvzxve8IZ229XV1bX6d1EUuzy2s53btNW+TJsdnX322Vm/fn3L15o1azrsEwAAAAAAQHuqCllWrVqV559/PgcffHCGDRuWYcOG5e67785f//VfZ9iwYS2VJTtXkjz//PMtz02cODGbN29OU1NTh22ee+65Xfb/wgsvtGqz836ampqyZcuWXSpcmo0YMSJjxoxp9QUAAAAAAFBGVSHLEUcckZ/97GdZvXp1y9f73ve+nHjiiVm9enXe8Y53ZOLEibnjjjtafmbz5s25++67c+ihhyZJDj744AwfPrxVm7Vr1+bRRx9taTNjxoysX78+DzzwQEub+++/P+vXr2/V5tFHH83atWtb2qxYsSIjRozIwQcfXOJUAAAAAAAAdF5Va7KMHj0606ZNa/XYqFGjMm7cuJbHFy5cmCVLlmTKlCmZMmVKlixZkpEjR2bevHlJksbGxpxyyilZtGhRxo0blz322COLFy/O/vvvn1mzZiVJ9t133xx11FFZsGBBrr766iTJqaeemrlz52bq1KlJktmzZ2e//fbL/Pnzc/HFF+ell17K4sWLs2DBAhUqAAAAAABAj6t64fvdOeuss1KpVHL66aenqakp06dPz4oVKzJ69OiWNl/72tcybNiwnHDCCalUKjniiCOydOnSDB06tKXNDTfckDPPPDOzZ89Okhx33HG58sorW54fOnRobrvttpx++uk57LDD0tDQkHnz5uWSSy7p7kMCAAAAAADYRV1RFEWtO1ErGzZsSGNjY9avX6/6hX5h4+at2e8LP0qSPH7enIys7/acFABgwPL/UgAMZH7PAXSPanODqtZkAQAAAAAA4HVCFgAAAAAAgBKELAAAAAAAACUIWQAAAAAAAEoQsgAAAAAAAJQgZAEAAAAAAChByAIAAAAAAFCCkAUAAAAAAKAEIQsAAAAAAEAJQhYAAAAAAIAShCwAAAAAAAAlCFkAAAAAAABKELIAAAAAAACUIGQBAAAAAAAoQcgCAAAAAABQgpAFAAAAAACgBCELAAAAAABACUIWAAAAAACAEoQsAAAAAAAAJQhZAAAAAAAAShCyAAAAAAAAlCBkAQAAAAAAKEHIAgAAAAAAUIKQBQAAAAAAoAQhCwAAAAAAQAlCFgAAAAAAgBKELAAAAAAAACUIWQAAAAAAAEoQsgAAAAAAAJQgZAEAAAAAAChByAIAAAAAAFCCkAUAAAAAAKAEIQsAAAAAAEAJQhYAAAAAAIAShCwAAAAAAAAlCFkAAAAAAABKELIAAAAAAACUIGQBAAAAAAAoQcgCAAAAAABQgpAFAAAAAACgBCELAAAAAABACUIWAAAAAACAEoQsAAAAAAAAJQhZAAAAAAAAShCyAAAAAAAAlCBkAQAAAAAAKEHIAgAAAAAAUIKQBQAAAAAAoAQhCwAAAAAAQAlCFgAAAAAAgBKELAAAAAAAACUIWQAAAAAAAEoQsgAAAAAAAJQgZAEAAAAAAChByAIAAAAAAFCCkAUAAAAAAKAEIQsAAAAAAEAJQhYAAAAAAIAShCwAAAAAAAAlCFkAAAAAAABKELIAAAAAAACUIGQBAAAAAAAoQcgCAAAAAABQgpAFAAAAAACgBCELAAAAAABACUIWAAAAAACAEoQsAAAAAAAAJQhZAAAAAAAAShCyAAAAAAAAlCBkAQAAAAAAKEHIAgAAAAAAUIKQBQAAAAAAoAQhCwAAAAAAQAlCFgAAAAAAgBKELAAAAAAAACUIWQAAAAAAAEoQsgAAAAAAAJQgZAEAAAAAAChByAIAAAAAAFCCkAUAAAAAAKAEIQsAAAAAAEAJQhYAAAAAAIAShCwAAAAAAAAlCFkAAAAAAABKELIAAAAAAACUIGQBAAAAAAAoQcgCAAAAAABQgpAFAAAAAACgBCELAAAAAABACUIWAAAAAACAEoQsAAAAAAAAJQhZAAAAAAAAShCyAAAAAAAAlCBkAQAAAAAAKEHIAgAAAAAAUIKQBQAAAAAAoAQhCwAAAAAAQAlCFgAAAAAAgBKELAAAAAAAACUIWQAAAAAAAEoQsgAAAAAAAJQgZAEAAAAAAChByAIAAAAAAFCCkAUAAAAAAKAEIQsAAAAAAEAJQhYAAAAAAIASqgpZrrrqqhxwwAEZM2ZMxowZkxkzZuT2229veb4oipx77rmZNGlSGhoaMnPmzDz22GOttrFp06acccYZ2XPPPTNq1Kgcd9xxefbZZ1u1aWpqyvz589PY2JjGxsbMnz8/L7/8cqs2zzzzTI499tiMGjUqe+65Z84888xs3ry5ysMHAAAAAAAop6qQ5a1vfWu+8pWv5KGHHspDDz2UD3/4w/n93//9liDloosuymWXXZYrr7wyDz74YCZOnJgjjzwyr7zySss2Fi5cmJtuuinLli3LPffck1dffTVz587Ntm3bWtrMmzcvq1evzvLly7N8+fKsXr068+fPb3l+27ZtOeaYY/Laa6/lnnvuybJly/KDH/wgixYt6ur5AAAAAAAA6JRh1TQ+9thjW/37ggsuyFVXXZWVK1dmv/32y+WXX55zzjknxx9/fJLkuuuuy4QJE3LjjTfmtNNOy/r163Pttdfmu9/9bmbNmpUkuf766zN58uTceeedmTNnTp544oksX748K1euzPTp05Mk11xzTWbMmJEnn3wyU6dOzYoVK/L4449nzZo1mTRpUpLk0ksvzcknn5wLLrggY8aM6fKJAQAAAAAA6EjpNVm2bduWZcuW5bXXXsuMGTPy1FNPZd26dZk9e3ZLmxEjRuTwww/PvffemyRZtWpVtmzZ0qrNpEmTMm3atJY29913XxobG1sCliQ55JBD0tjY2KrNtGnTWgKWJJkzZ042bdqUVatWtdvnTZs2ZcOGDa2+AAAAAAAAyqg6ZPnZz36WN77xjRkxYkQ+9alP5aabbsp+++2XdevWJUkmTJjQqv2ECRNanlu3bl3q6+szduzYDtuMHz9+l/2OHz++VZud9zN27NjU19e3tGnLhRde2LLOS2NjYyZPnlzl0QMAAAAAALyu6pBl6tSpWb16dVauXJn//b//d0466aQ8/vjjLc/X1dW1al8UxS6P7WznNm21L9NmZ2effXbWr1/f8rVmzZoO+wUAAAAAANCeqkOW+vr6vOtd78r73ve+XHjhhXnPe96Tr3/965k4cWKS7FJJ8vzzz7dUnUycODGbN29OU1NTh22ee+65Xfb7wgsvtGqz836ampqyZcuWXSpcdjRixIiMGTOm1RcAAAAAAEAZpddkaVYURTZt2pR99tknEydOzB133NHy3ObNm3P33Xfn0EMPTZIcfPDBGT58eKs2a9euzaOPPtrSZsaMGVm/fn0eeOCBljb3339/1q9f36rNo48+mrVr17a0WbFiRUaMGJGDDz64q4cEAAAAAACwW8Oqafy5z30uRx99dCZPnpxXXnkly5Yty1133ZXly5enrq4uCxcuzJIlSzJlypRMmTIlS5YsyciRIzNv3rwkSWNjY0455ZQsWrQo48aNyx577JHFixdn//33z6xZs5Ik++67b4466qgsWLAgV199dZLk1FNPzdy5czN16tQkyezZs7Pffvtl/vz5ufjii/PSSy9l8eLFWbBggeoUAAAAAACgV1QVsjz33HOZP39+1q5dm8bGxhxwwAFZvnx5jjzyyCTJWWedlUqlktNPPz1NTU2ZPn16VqxYkdGjR7ds42tf+1qGDRuWE044IZVKJUcccUSWLl2aoUOHtrS54YYbcuaZZ2b27NlJkuOOOy5XXnlly/NDhw7NbbfdltNPPz2HHXZYGhoaMm/evFxyySVdOhkAAAAAAACdVVcURVHrTtTKhg0b0tjYmPXr16uAoV/YuHlr9vvCj5Ikj583JyPrq8pJAQAGNf8vBcBA5vccQPeoNjfo8posAAAAAAAAg5GQBQAAAAAAoAQhCwAAAAAAQAlCFgAAAAAAgBKELAAAAAAAACUIWQAAAAAAAEoQsgAAAAAAAJQgZAEAAAAAAChByAIAAAAAAFCCkAUAAAAAAKAEIQsAAAAAAEAJQhYAAAAAAIAShCwAAAAAAAAlCFkAAAAAAABKELIAAAAAAACUIGQBAAAAAAAoQcgCAAAAAABQgpAFAAAAAACgBCELAAAAAABACUIWAAAAAACAEoQsAAAAAAAAJQhZAAAAAAAAShCyAAAAAAAAlCBkAQAAAAAAKEHIAgAAAAAAUIKQBQAAAAAAoAQhCwAAAAAAQAlCFgAAAAAAgBKELAAAAAAAACUIWQAAAAAAAEoQsgAAAAAAAJQgZAEAAAAAAChByAIAAAAAAFCCkAUAAAAAAKAEIQsAAAAAAEAJQhYAAAAAAIAShCwAAAAAAAAlCFkAAAAAAABKELIAAAAAAACUIGQBAAAAAAAoQcgCAAAAAABQgpAFAAAAAACgBCELAAAAAABACUIWAAAAAACAEoQsAAAAAAAAJQhZAAAAAAAAShCyAAAAAAAAlCBkAQAAAAAAKEHIAgAAAAAAUIKQBQAAAAAAoAQhCwAAAAAAQAlCFgAAAAAAgBKELAAAAAAAACUIWQAAAAAAAEoQsgAAAAAAAJQgZAEAAAAAAChByAIAAAAAAFCCkAUAAAAAAKAEIQsAAAAAAEAJQhYAAAAAAIAShCwAAAAAAAAlCFkAAAAAAABKELIAAAAAAACUIGQBAAAAAAAoQcgCAAAAAABQgpAFAAAAAACgBCELAAAAAABACUIWAAAAAACAEoQsAAAAAAAAJQhZAAAAAAAAShCyAAAAAAAAlCBkAQAAAAAAKEHIAgAAAAAAUIKQBQAAAAAAoAQhCwAAAAAAQAlCFgAAAAAAgBKELAAAAAAAACUIWQAAAAAAAEoQsgAAAAAAAJQgZAEAAAAAAChByAIAAAAAAFCCkAUAAAAAAKAEIQsAAAAAAEAJQhYAAAAAAIAShCwAAAAAAAAlCFkAAAAAAABKELIAAAAAAACUIGQBAAAAAAAoQcgCAAAAAABQgpAFAAAAAACgBCELAAAAAABACUIWAAAAAACAEoQsAAAAAAAAJQhZAAAAAAAAShCyAAAAAAAAlCBkAQAAAAAAKEHIAgAAAAAAUIKQBQAAAAAAoAQhCwAAAAAAQAlCFgAAAAAAgBKELAAAAAAAACUIWQAAAAAAAEoQsgAAAAAAAJQgZAEAAAAAAChhWK07AAAAAEDPKYoiRaVS627Qw7Zv3vbf32+sZPvWoTXsDb2lrqEhdXV1te4GDGpCFgAAAIABqiiKPD3vxFQeeaTWXaGH/XZofXLskiTJzw/7QN6wbXONe0RvaDjooOx9w/WCFqihqqYLu/DCC/P+978/o0ePzvjx4/PRj340Tz75ZKs2RVHk3HPPzaRJk9LQ0JCZM2fmsccea9Vm06ZNOeOMM7Lnnntm1KhROe644/Lss8+2atPU1JT58+ensbExjY2NmT9/fl5++eVWbZ555pkce+yxGTVqVPbcc8+ceeaZ2bzZLxAAAACAJCkqFQHLIPGGbZtz+w8X5/YfLhawDCKVhx9WqQY1VlUly913351Pf/rTef/735+tW7fmnHPOyezZs/P4449n1KhRSZKLLrool112WZYuXZp3v/vdOf/883PkkUfmySefzOjRo5MkCxcuzC233JJly5Zl3LhxWbRoUebOnZtVq1Zl6NDXSxnnzZuXZ599NsuXL0+SnHrqqZk/f35uueWWJMm2bdtyzDHH5M1vfnPuueeevPjiiznppJNSFEWuuOKKbjtBAAAAAAPBlJ/ekyENDbXuBtANtlcq+flhH6h1N4BUGbI0Bx7Nvv3tb2f8+PFZtWpVPvjBD6Yoilx++eU555xzcvzxxydJrrvuukyYMCE33nhjTjvttKxfvz7XXnttvvvd72bWrFlJkuuvvz6TJ0/OnXfemTlz5uSJJ57I8uXLs3LlykyfPj1Jcs0112TGjBl58sknM3Xq1KxYsSKPP/541qxZk0mTJiVJLr300px88sm54IILMmbMmC6fHAAAAICBYkhDQ4aMHFnrbgDAgFLVdGE7W79+fZJkjz32SJI89dRTWbduXWbPnt3SZsSIETn88MNz7733JklWrVqVLVu2tGozadKkTJs2raXNfffdl8bGxpaAJUkOOeSQNDY2tmozbdq0loAlSebMmZNNmzZl1apVbfZ306ZN2bBhQ6svAAAAAACAMkqHLEVR5LOf/Ww+8IEPZNq0aUmSdevWJUkmTJjQqu2ECRNanlu3bl3q6+szduzYDtuMHz9+l32OHz++VZud9zN27NjU19e3tNnZhRde2LLGS2NjYyZPnlztYQMAAAAAACTpQsjymc98Jv/xH/+R733ve7s8V1dX1+rfRVHs8tjOdm7TVvsybXZ09tlnZ/369S1fa9as6bBPAAAAAAAA7SkVspxxxhm5+eab85Of/CRvfetbWx6fOHFikuxSSfL888+3VJ1MnDgxmzdvTlNTU4dtnnvuuV32+8ILL7Rqs/N+mpqasmXLll0qXJqNGDEiY8aMafUFAAAAAABQRlUhS1EU+cxnPpN//Md/zI9//OPss88+rZ7fZ599MnHixNxxxx0tj23evDl33313Dj300CTJwQcfnOHDh7dqs3bt2jz66KMtbWbMmJH169fngQceaGlz//33Z/369a3aPProo1m7dm1LmxUrVmTEiBE5+OCDqzksAAAAAACAqg2rpvGnP/3p3Hjjjfmnf/qnjB49uqWSpLGxMQ0NDamrq8vChQuzZMmSTJkyJVOmTMmSJUsycuTIzJs3r6XtKaeckkWLFmXcuHHZY489snjx4uy///6ZNWtWkmTffffNUUcdlQULFuTqq69Okpx66qmZO3dupk6dmiSZPXt29ttvv8yfPz8XX3xxXnrppSxevDgLFixQoQIAAAAAAPS4qkKWq666Kkkyc+bMVo9/+9vfzsknn5wkOeuss1KpVHL66aenqakp06dPz4oVKzJ69OiW9l/72tcybNiwnHDCCalUKjniiCOydOnSDB06tKXNDTfckDPPPDOzZ89Okhx33HG58sorW54fOnRobrvttpx++uk57LDD0tDQkHnz5uWSSy6p6gQAAAAAAACUUVcURVHrTtTKhg0b0tjYmPXr16t+oV/YuHlr9vvCj5Ikj583JyPrq8pJAQAGNf8vBQxG2zduzJMHvT6t+tSHV2XIyJE17hHQHby3oedUmxuUWvgeAAAAAABgsBOyAAAAAAAAlCBkAQAAAAAAKEHIAgAAAAAAUIKQBQAAAAAAoAQhCwAAAAAAQAnDat0BqlQUyZaNte4FtbJ52w7fb0wytGZdocaGj0zq6mrdCwAAAAAY1IQs/UlRJN+ak6y5v9Y9oVaKEUm+/fr3F78rqdtU0+5QQ5MPST65XNACAAAAADUkZOlPtmwUsAxyI+s25VdvmFfrbtAXrFn5+j2hflStewIAAAAAg5aQpb9a/IukfmStewH0ts0bk0veVeteAAAAAAARsvRf9SN9gh0AAAAAAGpoSK07AAAAAAAA0B+pZAEAYMAoiiKVrZVad4M+auOWbTt8X0nqhtawN/R1DcMaUldXV+tuAADQxwlZAAAYEIqiyCdu/0RWv7C61l2hjyq2D0/y5STJzL8/PHVDttS2Q/RpB44/MNcddZ2gBQCADglZAAAYECpbKwIWOlQ3ZEtG7/uXte4G/cQjzz+SytZKRg4fWeuuAADQhwlZAAAYcO464a40DGuodTeAfqiytZKZfz+z1t0AAKCfELIAADDgNAxr8OlzAAAAetyQWncAAAAAAACgPxKyAAAAAAAAlGC6MAAAAACg04qiSFGp1Lobg9r2Hc7/dq9FTdU1NKSurq7W3aCGhCwAAAAAQKcURZGn552YyiOP1Lor/D8/P+wDte7CoNZw0EHZ+4brBS2DmOnCAAAAAIBOKSoVAQvsoPLwwyq7BjmVLAAAAABA1ab89J4MaWiodTegJrZXKqqISCJkAQAAAABKGNLQkCEjR9a6GwA1ZbowAAAAAACAElSyAAAA0C2Kokhla/+ek3zH/vf3Y0mShmENFuIFAOhBQhYAAAC6rCiKfOL2T2T1C6tr3ZVuM/PvZ9a6C1124PgDc91R1wlaAAB6iOnCAAAA6LLK1sqAClgGikeef2RAVOQAAPRVKlkAAADoVnedcFcahjXUuhuDWmVrZUBU4gAA9HVCFhjoiiLZsrHWvaC7bN7Y9vf0f8NHJqbxAGCAaBjWkJHDR9a6GwAA0OOELDCQFUXyrTnJmvtr3RN6wiXvqnUP6E6TD0k+uVzQAgAAANCPWJMFBrItGwUs0F+sWanqDAAAAKCfUckCg8XiXyT1pmyAPmfzRlVJAAAAAP2UkAUGi/qRSf2oWvcCAAAAAGDAMF0YAAAAAABACUIWAAAAAACAEoQsAAAAAAAAJQhZAAAAAAAAShCyAAAAAAAAlCBkAQAAAAAAKEHIAgAAAAAAUIKQBQAAAAAAoAQhCwAAAAAAQAlCFgAAAAAAgBKELAAAAAAAACUIWQAAAAAAAEoQsgAAAAAAAJQgZAEAAAAAAChByAIAAAAAAFCCkAUAAAAAAKCEYbXuAAAAuyqKIpWtlVp3o1/Z8Xw5d9VpGNaQurq6WncDAACg3xGyAAD0MUVR5BO3fyKrX1hd6670WzP/fmatu9CvHDj+wFx31HWCFgAAgCoJWQAA+pjK1oqAhV71yPOPpLK1kpHDR9a6KwAADBBFUaSoDNwK8+07HNv2AXycSVLXoPK9I0IWAIA+7K4T7krDsIZad4MBqrK1ouoHAIBuVxRFnp53YiqPPFLrrvSKnx/2gVp3oUc1HHRQ9r7hekFLO4QsAAB9WMOwBtUFAANAb6+1Vct1qqzzBEBRqQyagGUwqDz8cIpKJXUj/W3aFiELAAB0oLcHRntTLQdhe5MBX2qt1mtt9XbFmnWeANjRlJ/ekyENqvP7o+2VyoCv0ukOQhYAAGhHrQdGe9NAnjbMgC+1NtjW2rLOEwA7GtLQkCEqIBjAhCwADDxFkWzZWOtedM7mjW1/39cNH5kYrGQQGGwDowOVAV/6koG81pZ1ngCAwUjIAsDAUhTJt+Yka+6vdU+qd8m7at2Dzpt8SPLJ5YIWBpWBPDA6UBnwpS+y1hYAwMAiZAFgYNmysX8GLP3NmpWvn+v6UbXuCfQaA6MAdEVRFCkqvb/+1fYd9rm9BvtPkroGa2MBMHAJWQAYuBb/Iqk3INqtNm/sXxU3AAB9QFEUeXreiak88khN+1GrxYsbDjooe99wvaAFgAFJyALAwFU/UqUFAAA1V1QqNQ9Yaqny8MMpKpXUWfgagAFIyAIAAPSYoihS2Vqb6Wl23G+t+tAwzBQ5QGtTfnpPhjQMjjW+tlcqNaueAYDeImSBsori9fUI+rLNG9v+vi8aPtIC2gAwwBRFkU/c/omsfmF1rbuSmX8/syb7PXD8gbnuqOsELUCLIQ0NGaKiAwAGDCELlFEUybfm9K/Ftfv6GgqTD0k+uVzQAgADSGVrpU8ELLX0yPOPpLK1kpHDDagCUF5RFCkqtanK3Nn2HfqxvY/0qVldgwpSoPcJWaCMLRv7V8DSH6xZ+fp5tX4GAAxId51wVxqGDY7pcZLXA6ZaVc8AMLAURZGn553YJ9f16WvTwTUcdFD2vuF6QQvQq4Qs0FWLf/H64tqUs3lj36+yAQC6rGFYg2oOACihqFT6ZMDSF1UefjhFpZI6U/IBvUjIAl1VP1L1BQAAANDjpvz0ngxpGDyVoZ21vVLpc1U1wOAhZAEAAACAfmBIQ0OGqNIA6FOELAAAnVQURSpbe35xzx330Rv7a9YwzEKhAAAAUA0hCwwmRfH64vJ9yeaNbX/flwwfmRh0hEGvKIp84vZPZPULq3t1v725cPaB4w/MdUddJ2gBAACAThKywGBRFMm35iRr7q91T9p3ybtq3YO2TT4k+eRyQQsMcpWtlV4PWHrbI88/ksrWisXJAWAQKIoiRaVnK2a377D97T28r2Z1DSpzAehdQhYYLLZs7NsBS1+2ZuXr569+VK17AvQRd51wVxqGDZwFRytbK71aMQMA1FZRFHl63ompPPJIr+2ztxYlbzjooOx9w/WCFgB6jZAFBqPFv0jqfUp5tzZv7LvVNUBNNQxrUO0BAPRbRaXSqwFLb6o8/HCKSiV1FocHoJcIWWAwqh+pKgMAAIBM+ek9GdLQ/yt0t1cqvVYtAwA7ErIAAAAADFJDGhoyRNUHAJQ2pNYdAAAAAAAA6I+ELAAAAAAAACWYLqw7FUWyZWPPbX/zxra/727DRyZ1dT23fQAAAAAGraIoUlQq3ba97Ttsa3s3breuoSF1xsiA3RCydJeiSL41J1lzf+/s75J39dy2Jx+SfHK5oAUAAACAblUURZ6ed2IqjzzSI9v/+WEf6LZtNRx0UPa+4XpBC9AhIUt32bKx9wKWnrZm5evHUz+q1j0BAAAAYAApKpUeC1i6W+Xhh1NUKqkbObLWXYF2dXdl2I56qkpsZ/29akzI0hMW/yKp74c3380be7ZCBgAA6POKokhla/V/RO/4M2V+vlnDsP79RzYAnTflp/dkSENDrbuxi+2VSrdWxEBP6enKsB315Huiv1eNCVl6Qv1IVSAAAEC/UxRFPnH7J7L6hdVd2s7Mv59Z+mcPHH9grjvqun77RzYAnTekoSFDVIlAaf2pMqwj/b1qTMgCAABAktcrULoasHTVI88/ksrWSkYO759/ZAMA1EJfrQzryECpGhOyAH1PUby+LlCtbd7Y9ve1Mnxk4hOdAEAvueuEu9IwrPf+UK9srXSpAgYA6FhPrt2xs95ay2Nn/X1tj65QGVY7QhagbymK5FtzkjX317onrfWF9YomH5J8crmgBQDoFQ3DGlSTAMAA0Ztrd+ysNysV+vvaHvRPQ2rdAYBWtmzsewFLX7FmZd+o8AEAAAD6lYGydsfuNK/tAb1JJQvQdy3+RVLv05PZvLFvVNIAAAAA/V5fWrujKIoUv/1tl7ezvVLJ/511ZMv33WEwTz1GdYQsQN9VPzKpH1XrXgAAg0xRFKls7dof5zv+fFe31axhmD/0AYCu6ytrdxRFkWd6YAqz7pqezNRjdJaQBQAA4P8piiKfuP0TWf3C6m7bZnct5n7g+ANz3VHX+UOfHlc2aOxquChIBBhc+voUZs1Tj9X1gUCKvk3IAtBVRdGza6Vs3tj29z1h+MjEH7YADGKVrZVuDVi60yPPP5LK1orF6OlR3RU0lgkXBYkAg1dfmsJse6XSbdUwDA5CFoCuKIrkW3OSNff3zv56em2WyYckn1wuaBlIujsE7MnQT8gH9DF3nXBXGobV/o/9ytZKt1XDwO7UMmgUJAIMXn1lCjMoQ8gC0BVbNvZewNIb1qx8/ZishTMw9HQI2N2hn5AP6GMahjUY7GVQ662gUZAIAPRnQhaA7rL4F0l9Px2I2byx56tk6H39LQQU8gFAnyJoBADYPSELQHepH2lwuAzTWfWOvhwCCvkAAACAfkrI0h/11CLbvbW4dn8epAS6l+mseo8QEAAAAKDbCVn6m95aZLsnP1Hcnwcpge5lOisAAAAA+jEhS3/T3wYk22KQEmiL6awAAAAA6GeELP1ZXx6QbItBSqAjprMCAKCfKYoiRaWy23bbd2izvRPt6xoaUmf2BwDoF4Qs/ZkBSQAAAKiJoijy9LwTU3nkkap+7ueHfWC3bRoOOih733C9oAUA+gEhCwAAAECVikql6oClsyoPP5yiUkndyH40ewWd0tnqpx1VWwm1M5VRAD1LyAIA0M8VRZHK1ur/4G624892ZTtJ0jDMH/EADD5TfnpPhjQ0dHk72yuVTlW6DAbVhhFlg4jeDCDKVj/tqMz1oTIKoGcJWQAA+rGiKPKJ2z+R1S+s7pbtzfz7mV36+QPHH5jrjrqu5n/EdzV4atadAdSOhFEAA8uQhoYMUXXSbboaRlQTRPRmANGT1U8dURn133pqHaVmqoYYbMpU5+2oq5V6O6rl+0/IAgDQj1W2VrotYOkOjzz/SCpbKxk5vHZ/xHd38NSsqwHUjvpKGAUAfVFvhhG1CiC6q/qpIyqjWuvJdZSaqRpiMOmO6rwddfV+Vcv3n5AFAGCAuOuEu9IwrGf/WG9PZWulW0OIruhrwVNb+kIYBQD9QU+FEbUOIFQ/9b7eCO9UDTGY1Ko6rz21fP8JWQAABoiGYQ0G7XfSG8FTURT57bbfdqptZWslR//j0S3fd5bpxQAYrIQR9ITuDu9qHdpBrfVGdV57+sL7T8gCAHSvoki2bOx8+80b2/5+d4aPTAw6sxs9HTx1ZWqyaip/TC8GtdeVtZ66Y30nYStA9xHeQfca7O+pqkOWf/3Xf83FF1+cVatWZe3atbnpppvy0Y9+tOX5oijypS99Kd/85jfT1NSU6dOn52/+5m/yu7/7uy1tNm3alMWLF+d73/teKpVKjjjiiPzt3/5t3vrWt7a0aWpqyplnnpmbb745SXLcccfliiuuyJve9KaWNs8880w+/elP58c//nEaGhoyb968XHLJJamvry9xKgCALiuK5FtzkjX3l/v5S97V+baTD0k+uVzQQk311tRkpheD2urOtZ7KTq0obAUA6JuqDllee+21vOc978mf/Mmf5GMf+9guz1900UW57LLLsnTp0rz73e/O+eefnyOPPDJPPvlkRo8enSRZuHBhbrnllixbtizjxo3LokWLMnfu3KxatSpDhw5NksybNy/PPvtsli9fniQ59dRTM3/+/Nxyyy1Jkm3btuWYY47Jm9/85txzzz158cUXc9JJJ6UoilxxxRWlTwgA0AVbNpYPWKq1ZuXr+6sf1Tv7g93oianJ+tJaNzCY9YW1nvpr2NqZCqAylT4qewCAvqLqkOXoo4/O0Ucf3eZzRVHk8ssvzznnnJPjjz8+SXLddddlwoQJufHGG3Paaadl/fr1ufbaa/Pd7343s2bNSpJcf/31mTx5cu68887MmTMnTzzxRJYvX56VK1dm+vTpSZJrrrkmM2bMyJNPPpmpU6dmxYoVefzxx7NmzZpMmjQpSXLppZfm5JNPzgUXXJAxY8bs0r9NmzZl06ZNLf/esGFDxwdbzXQnZaY6Mc0JQO+qdhqrZmWns9rRYLznL/5FUt8DA0GbN1ZX8QK9xJo40DntDbp3ZqC9Lwys98ZaTzvqz2FrmQqgzh6ryh4AoK/o1jVZnnrqqaxbty6zZ89ueWzEiBE5/PDDc++99+a0007LqlWrsmXLllZtJk2alGnTpuXee+/NnDlzct9996WxsbElYEmSQw45JI2Njbn33nszderU3HfffZk2bVpLwJIkc+bMyaZNm7Jq1ap86EMf2qV/F154Yb70pS917mC6Mt1JZwd++ts0J2UHJ5t1xyDljgbjgCVQXlensWpWdnC/v93zu0P9SFUmALTS2UH39gba+8LAukC183qyAqi/VvYAAANPt4Ys69atS5JMmDCh1eMTJkzI008/3dKmvr4+Y8eO3aVN88+vW7cu48eP32X748ePb9Vm5/2MHTs29fX1LW12dvbZZ+ezn/1sy783bNiQyZMnt30wvTHdSX+a5qS7BiebdccnkAfjgGV/1dNVYYnQjd3rzWms2tKf7vkA0EO6OuhuYL3/6q4KoP5c2dObiqJIUWl/6rXtOzy3vYN2SVLXUPsKMgDoy7o1ZGm28y/foih2+wt55zZttS/TZkcjRozIiBEjOuxHm7p7upP+OM1JrQcn22LAsn/ojaqwROhGdXpqGqu29Md7PgD0gmoG3Q2s938qgHpPURR5et6JqTzySKfa//ywD3T4fMNBB2XvG64XtABAO7o1ZJk4cWKS16tM9tprr5bHn3/++Zaqk4kTJ2bz5s1pampqVc3y/PPP59BDD21p89xzz+2y/RdeeKHVdu6/v/WgbVNTU7Zs2bJLhUuXme6ktd4cnGyLAcv+pbcCOqEb1XBfpw27W5i3mkV5+8KaAQB9nUF36BlFpdLpgKUzKg8/nKJSSd1I71cAaqOjCs3OVmf2ZGVmt4Ys++yzTyZOnJg77rgjBx54YJJk8+bNufvuu/PVr341SXLwwQdn+PDhueOOO3LCCSckSdauXZtHH300F110UZJkxowZWb9+fR544IH83u/9XpLk/vvvz/r161uCmBkzZuSCCy7I2rVrWwKdFStWZMSIETn44IO787DYmcFJyuqJgE7o1jm7m7Kts9O0mZaNAarahXl392nqvrBmAP1Dd4V7gj0A2jLlp/dkSEO5adq2Vyq7rXIBgJ5WTYVmR7+3erIys+qQ5dVXX80vfvGLln8/9dRTWb16dfbYY4+87W1vy8KFC7NkyZJMmTIlU6ZMyZIlSzJy5MjMmzcvSdLY2JhTTjklixYtyrhx47LHHntk8eLF2X///TNr1qwkyb777pujjjoqCxYsyNVXX50kOfXUUzN37txMnTo1STJ79uzst99+mT9/fi6++OK89NJLWbx4cRYsWJAxY8Z0+cQAPUBAVxvVTtnWUWhlWjYGqO5emNeaAXRGd4Z7gj0A2jKkoSFDVKDQS3a3FlCzatYESqwLBINdd1Vo9mRlZtUhy0MPPZQPfehDLf9uXkj+pJNOytKlS3PWWWelUqnk9NNPT1NTU6ZPn54VK1Zk9OjRLT/zta99LcOGDcsJJ5yQSqWSI444IkuXLs3QoUNb2txwww0588wzM3v27CTJcccdlyuvvLLl+aFDh+a2227L6aefnsMOOywNDQ2ZN29eLrnkkurPAsBA1p1TtpmWjUGgKwvzWjOAanRnuCfYA+ifdh6U3t3gs8Fm+qpq1wJq1plqKesCdc7uQq5qwi33GvqqMhWavVGZWXXIMnPmzBRF0e7zdXV1Offcc3Puuee22+YNb3hDrrjiilxxxRXtttljjz1y/fXXd9iXt73tbbn11lt322cA/p+yU7aZlo1BxBoB1ELZcE+wB9B/7W5Quq0BIYPN9FXdvRbQjqwLtHvVhly7G3AeSPeazlZY7ajaaqudCal6Tl+t0OzWNVmgW1g7AnqOKdsA+qS+HO7tbt2YjnR2TZmOWG8GGKjKDEobbC6nrUHWzgyiGigtpytrAe3IukCd190h10C515StsNpRmWtwIIVUdI6Qhb7F2hEAAH1GtevGdKRsxY31ZhhM2go1OxNWCiP7v90NShtsLq8zg6ztnVsDpeX01U+aDxZdCbkG2r2mJyusOjJQQio6T8hC39JX1o7ormqaREUNANBvdee6MWVZb4bBojOhZnthpTCy/zMo3XO6MshqoJT+yP2kbd1VYdWRgRZS0XlCFvquWq0d0Z3VNImKGgBgQCi7bkxZ1pthsOlKqCmMhM7p7CCrgVIYeIRP9CQhC31XrdaO6M5qmqRrFTVA32cdKQa4zq7HUe3aG6a26X/68roxMNB0NtQURkJ1DLIC0BOELNCRstU0SdcraqDWdgwPOgoKBnM4UOt1pAZywNPRsXXmuPriMfVDZdfj6MyAX1entuko/Ols4CPo6Rvaey0H4+vYlXMxkM4DQs2u3uO9HxgsiqJIUWn/d+T2HZ7b3kG7ugbvGXpeW9fr7q5R1yb9hZAFOlKrahqotY7Cg52DgsE8JV4t15GqdcDTk6o5tvaOq68dUz/Vk+txdGVqm2rCn44CH2sY1F5nX8vufB13V51Vq6qsrp6LgXg97/hadfS6GFAfWLrjHj8Q3w/0P2UGlJPODyoXRZGn553Y6fVmOpr+rOGgg7L3DdfX/D2z8zkzAD9wdOZ6besa7SvX5mAlyO08IQsAu6omPDAl3ut6ex2pWgY8Pa07jq2vHdMA0F3rcXTH1DbdFf5Yw6D2uuO1rOZ1rLY6qzeqspp19VwMtOu5o9dq59elO16D7grfBD5d19v3BegJZQeUk84PKheVSqcDlt2pPPxwikoldTWcSm1358wAfPforkHzZp0OBUter33h2hysBmKQ25OELDCQdHV6ncQUO+yqvfDAlHit1bLyrbcDnt5U7bH1h2Pqp/rq1DVlwh9rGPRN1b6WZV7HnqjO6onB3GrOxUC9nqt5rbr6GnRn+KaConv1xn0BekJXApAyg8pTfnpPhjRU/2GY7ZVKhwOjvanMOTMAX53uHDRvVmbwvDPXa1+6NvuCjsKx7qyQa7XPARbk9jQhCwwU3TG9TmKKHXZl2ry+byC/RgP52OgWfTX8oXq9/Vp2tTqrJwdzXdettfdadddr0J3hmwqK7uW9wEDQ2QCkK4PKQxoaMmQADV7u7pwZgC+nOwfNm5UZPB9o12tPqyYc62qFXHsGQpDb04QsMFB019RBg3mKnd0tIt6WzlYItUflEABV2HlKI+tUlDfYB2/bmx6rLy4q3puvVdnwTQUF9H87flK8vU+Gl/k0uAHl6jlnPa/soHmzwTR4vrOuVpUk1d1LuiMc62oliffk7glZ6P92HhjvaNB7sAxol5k6aLBPsVPtIuJtKXP+VA5Bv9PRvP19cXCSgWN3Uxr1xDoVDEydnR5rMC4qPpjCt/4UtNWKBX8Hj44+Kb7jQPJgWFeAtnXnWiZ94Z5g0Lyc7qgqScrfS6oNxwZzGNbbhCz0b7sbGN950HuwDGibXqd63bmIeDUGc+UQ9EPVzNs/GAcn6VnVTmlk2iLa09XpsVxb/Z+gbfcs+Du4dPaT4oNhXQF21d1rmbgn9F/dNeVa2XuJcKzvErLQv1U7MG5Am84ou4h4NQZ75RD0U90xb7/BSbpDR1MambaIalQzPZZra+AQtO2eBX8Hr7Y+Ke7T4INbd69l4p4wMJSZcs29ZOASsjBwdDQw3pMD2u2t49GZtToGy/Rl/Y1KoJ7R1nvF9H70Y9XO229wku40mKY0om3NUz21NbVTNVM5uZYQtO3eQF/wt71pkHY3/VFfmPKoJ/ikOB3pylom/eWeQOe4V7AjIQsDRy0Gxju7jkd7Ac9gmb4MOvNeGazT+9FvGZgEaqW9qZ6aB78Hw1ROdB+/z3ZvIA+kdXYapLYGhk15xGA0kO8HQHlCFuiKrq7jYfqygam96qYddabSaUf9vaqjzHul7PujbHVZfz/H0IftuLhyRwsq9+RCyrvrw2BZxLkjbS2CbQHsvml3Uz11x1RO1V4PrgPon7oyDZIpj/qXtiqWBmu1EkB3E7JAd6lmHQ/rcQxcna1u2lFnroWBVNWxu/dKV94fXakuG0jnGPqQjhZX3nnKmZ769H1n+jDYP/nfmUWwB/MC2H3ZjlM9dddUTmWuB9cB9H+dnQbJlEf9T2cqllQrAZQnZOF1u/vkfTWfuh+snwbvT+t4VLs2RrPB+tpWo6vVTe0ZSFVPPfle6cr5H0jnGPqQahZX7qmFlDvTh8GwiHNHurII9mA5dztXdrT3fW9XdPTEVE9lrofBch1Ab2uuPti54qAnKgzamgapvfVaduxLW1RA9C1lK5ZUK7GjHe8H7VVBee/TF+z8u6ujqr3uumaFLH1Zby0SXe0n73f3CXOfBu/byqyN0cxrW51qqpvao+qpvM6e/1qc4x3v7+3d1/tDqFkmsO0Px0WPaW9x5d5cSHnnPgzWRZw70tlFsAfTudtdZceO52GgVXTs7noYTNcBVKMoijYHdaoZzGmv+uDnh32gzQqD9gKZZtUOJJWtfkhUQPRlnalYUq3UNe2Fk7ubnq1ZXwwqOrof7HitlH3v12JQnIFpd7+7dr63ddfvKyFLbyuKtgegdh506s1Forv7k/c+Dd63+aR/7+lP1U0DUV89/x3d33e8r/f1ULNsYNvXj2sQ6431OPrC4sp9oQ99nXO0q75QkVUrrgeoXlsDPM2DOtUM5nRUfbBzhUFHgUyzageSrNcyMA2WhdurXYOmuwbuOxNOJu0HlEnfDCk7ez8o896v1aA4A1O1v7u66/eVkKU3tTUg1TwAtfOgU28uEr2jrnzy3ifu+5++/El/GKg6e3/vqVCzM1U0ye4rTsoGtsLaPsl6HNB5faEii76jOaBuK5Tu7anj6LrumgqnmnCks5qrD9qrMOjMoFJXBpKs19JzOqpA8on9cspUYXXXwH1XwslmfT2kbOt+0JX3fq0GxRn4Ovrd1d2/r4QsvamjAamOBp16cpHonfXVT37TM7zeUFtt3d97MtTsbBVNUl3FSWcC20EY1nZ2/Yak9gNx1uOAzlPZQbP2AurmsE0I3b/01FQ4HYUjRVG0fL+7dVaqqT7YeVCpOwaSBkv1Q2/bXQWST+yXUybo6ImB+86Gk836S0jZk/eD3hwUH6isnfPfevN3l5ClVpoHpDoz6NQXB8LNww/Qdb19f6+m+qSaipO++HuqxqpZvyHp3EBcW9N5Jbuf0qvaAMd6HEBftuO9sL37X28F17sLqIXQ/UtPTYXT3gBPURR55k8+2fLv9tZZKUMg0n/s7rrzif2u213Q0ZMD996Lr2trjar2Bvmds67p6bVzaJ+QpVb684CUefj7lubAqzNr/TA47ByCdmVKKAau9qpPBmHFSU+otjJkdwNxnZnOK2l7Sq9qP0ntU/r9U18aeO5Jg+U4y2irem6gnYuO7oU73v86uu+VWX+qM+dxx4C6mhB6d9d0W/v2Puh53T0VTluKSiW//Y//aPXYYB1Qr9XaGX3NjtedT+x3H4P2tdXeGlUG+XtGT66dQ8eELFTPPPx9R3uBV3tr/TDw7S4E7cqUUDvuQ7DX//XnsL+f6agypLMDcabz+m/tTcM2mAcUu2PguT8YLMdZRlvnZubfzxxw56Kz98L27ntl15/qzHksE1B35preed+1eh90tPZMMvDuwb09KPvOO+/I/511ZK/try+p5doZfU1/DANMS8TutDfob5C/5/XGBwb4b0KWZv3tk9+dWbi4N/ppHv7O6anra3eBl2Br8Kk2BK32GhHsQdW6uzJkME/n1d5AcjI4B9abdXXgub8oe5yD4VP/7Z2b/v6ad6Ste+Hu7ntlA+ueOo+d6c/O+67F+313a88kg/se3B2qWbNhoOkra2dQvVpMS9Qc6nR26qn+or3jSgZWSDXlp/ck2TU4pWfUIrjduTKxbFVid22nNwlZkt755Hd36uzCxb3RT5+E3r3eur52DLwGcrBVTWCV9I1QtFY6CkHLXiOCPQaY9j6Z25cHXHcX2nQ0FU5fPq7O6GhwcSAPJlejzMBzf9TZ4xyM1S93nXBXkrYrMgaSrgbYuwusi6JI06amHP2PRyfp+fvozv3pzPu2t97vZcKg3tJedePO3yf9/3dgX9Zd1Qy1XDujP+krA/K9PS1Re6FOf596qqPjSgZW5VZvBsodvU+SXn6v7OYe2VdCgq7aXWViZ6sSu2s7vU3IkvT8J7+7W2f7W+t+8rreur4GQ+BVbWCV1D4UraWeviYGS7DHgNXRJ3P764Dr7j5t3F+Pqy3Ng4sDMUDoisGypk5nj3OwVPnsaHfBQX8LlntKR9dQLarmyrx3a/F+LxMG9ZTdTf+2c78G0u/AvqQ7qxn643RZva2vDsj31jpG7Q269ufqpt2FVf352Gpld++TpPfeK525R/aVkKCrqq1MbO/a7q7ttNvPHgqqhSw72/mT30WRbPl/J33LxuTrB7z+fW9Py9Wetj6pXs1gZ1FYV6E39URlQV/UmenskuqvszLrAfXHsLGvTAe4O90d4vTWWi/9bXrI/q63X9cq9jMQqyJ2N6DcX4+rLQ3DGlpClma9NVjc1emn+uvaBv39E+ODpcqnPd0dLPfX67gzBuLvh+7Sl4Lcaqd/G+yvXU+xyHLv6qsD8r0dkDWHOgOtumnHsGqgHVtv6sx9qbfeK32pL72po8rEaq7t7tpOs54MqoUsO9tx0LAvTcvVnq4McrZ1fNZV6FmDvdqkO6fe2916QLsLrfrqQHt/uO/0hN5a66WvTw/ZVvDdn4OeWr+uVexnIFZF7Dig3BePqzuCilos9N3V6af669oGA+ET431pcLhZb64X053BQX+9jssYiL8f+qqOgrvdvQ86mv7Na9d7LLLcu7p7QL4/TWk0UKueBupx1dLO96Va3pP6Ul/a013TP3bXtdzd74meDKqFLB0Z6NNydXR8/fWY2qJap5zdVVO0d/6qqTbpynXW3QHjjmo50D5Q7ztF8d/ftxUc9NZaL315esj2gu/+HKj1lde1E/vpi4OvXdWXj6k71sn47bbf1mSh765OP9WX1zboiE+Mt6/sFFy1XC+mq8FBf72Oy+jL99KBpKvTXXqd+oa+OEBcFEWfDwzK6s7zPZimNGrWl9bsoOf0pftSX+pLW7pz+sf+oLuDaiFLZ3V1Wq6+rvn4BtIxJap1yupMNUVnzl971Sa1vs768kD7jgbKfacoku/8/n//e3fBQW+t9dLXpu9r77rsb4Fae2rxuvbx90tbUy/15+l1qtHd62TUaqHvrk4/1ZfWNqiGT4z/t65MwdWV90Gxw4cXiqKo+r7RnQPSnb2Ou1KlQPfpq69DT0132d40h665waGtAcOBGhh01WCb0qgvrdkBfcVgm/6xu0MvIUtnDfRpngbq8Q2Wap3u1pkQojPnrz9cV31toH1H/eH8dcaWjcmvH2r9WEfXT5njbm89jo4q1vry+V38i9f/24cDgqr11vnuwf10ZyhSq6mu+qLuWCejo4W+e1JXB6r76yev+2u/e0J3TcFVzfugKIosuOP/Z++8w6K6nv//Xlh67713FSygqKAYe8Maewlq7BprsEWNn2iiRk2MUaOxRY0lid1oFBWRIorGXrAgXaQjve7vD3/3fBdYYFl2YTHzep48Ady999xT5sydOTMzlf0+7co07O65u17tlibizIeGRikQ0qG5jIO00l3WtNcC8vOssqamk/qNcUK/Ke/N2tAEhdJlVVC5MWkOKY0ayn/NqfQx8DFHpckjlP6x/pCThfjv8LFG68iaqk4ISftPXou5y7Oh/WNk3gNga2vpXrO2ehzNNWKttnpDRJMgbadITYbZ5pBeR9LUSDUhDYO9QCBAUXmRVNpD/DeQxWn+hqTgqs86KCwrxKP0R+z3h2kPK83/hiKLKDtZRSkQ9aMxx6Eha0xajlxp1iFqjtR2Ul/WJ/SleW9p1QeorVC6KOMtd836OItkWVC5MZHG6e7a+lTekEenUn0dCuJ8vjk7KSgqrfGR99RmNdGUsoecLMR/B3k0psur40EYafTbf7WYu7zSlMXVlWSwBilijWgEZOkUaapUV5LQkNRIsmRq0NRKRuembg9RO7Io9l7VMSCcTkvUZ2Vxmv9jiPBpjCg7caMUqqZEI6SLtKJFRCGPETMNrUPUHGlIFEdDo1CkFUEizfoANRkMazLeqrVrB+vDhxA/brxoZ1Gb1rDauxcK6ur/Z8SWYUHl5kRtfSqPxvCGGpOFHYFAw5yB3PXq41AQ5/MAZOqkkLVhuymi0ojmR1PLHnKyNCVNaegkmp7/kuOhsYu509qqmY+xuLowFLFGNABxT29L2ynSVKmuJEFeTwULO1jkoT3yQF2ODGlH+ogb4SSLYu+irjntyjQc7ndY5OcpqqJmGiPKTtz0YlVTotU0nh8rwo4lWUTnydIpKI9rTNLnrSuKojmcAAdqj+KoirQjYOpz72ptaYT6ADXdo/Dff1GRlVWzYff+A7zw9KqxT6RdULk5UVufNldjeE2O/9ocgYBkNV7q61AQ5/MAZOakqMuwLW0aIlMkRVoRdU1Nc4owk4Smlj3kZGkq6jJ0EnXT3A3pje14kBdkXcy9sZ0IwtFIgPxGJHF87MXV5TFirbkgSV2bj4i6Tm8L09hOEXkt2iuPp4KbU1SQLBHHkSHNk+T1iXBqSLH3mhB1zYdpDyutm5qQ5Wn+5k5TridRKdHEGc+PhapOppr2o+ZAc15j4kRRyOvJ/KrU56S+tE+MSyvlTGPUB3AKDwMAkdd0uBKE1z17Vft7TX3SXFPtSJva+rS5IBAIED9pMvs9fvIU2B47+iGdnJiOQECy9VNfh4I4n5e2k6Iuw7a0aey1Jc2IuqakqaM8GpumkD3kZGkqSgtrN3RKiijHAyDfRjJJUmbJwpBek4FR1P2ljawdDxzyMD9kbQRvTCdCbdFIgPxHJEmruLo8zKvmQF0ypin5GOva1JOi8qJaT283FfJctFceUyM1p6ggWSKOI0OaJ8kljXCqT7F3cbk47CL6newn9uflcR43lKo1iiRNtUXrqemo6mQCmn4/kpTmvMaoMHbTnBivicYwrFZ14tT0bx+D46CxqK1P5ZGqJ/0FAgFQWIiihw/Z34oePBC57kU5AoGGOQPrO+/F+TxPVbXa36QV0SDJ2pD36IrGiKhrDJo6yqOxaQrZQ04WeUBcQ2ddp4xrcjwADTeSSVo7pK5oE0lTZknbkF6bgVHU/aVNVceDLKJ0ZDk/5BVpORFqQtxoJKBxIkXqO2+kUVxdnHn1sVIf55I4Mmb8Cdm2tTYHz8dY16YBzj95ioZojPRc8hopI2tqK8oMNO7zi5tqSxKqOjJkfZK8PhFOsjC+kmOgeo2i/2KqrY+J+jgOxU172dDv/BfhjKcCgQCCoiJUFBayqIbGNAg2tjGSojFE09wcB4R4iDrpHz95Cqz37RXr+81lvcRPmlzJaQRIL6KhvmtDIBAgvpGiKxpaawqQbkRdUzqXPhZHcdXUfU2tu5CTpb7IolC5OIZOcU4Zy8pIJqkjRJxoE2mkzJKGIb2udjSmkVFW6a6asxFV0iijhjgR6mugFRWNxH2vMWqDNFWtFXHm1cdIfZ2WYskYGZ1Ora+Dp6nr2kgjMqqBTmV5NdLKIj2XPEfKyJK6ijIDjff84qbaktQQ2tinyGV5P1nXqPhYqBoB0ZiptqrO09qiaKRp3Jelo7KpEXdPqivtpah+kOQ7/1UU1NTAU1OrZgwExDMIijodX9/+rcsY2RxpCiOjvBnl/gsI93lNYyxqLgCNW+dC1En/ogcPICgqquEbzZOqDhaOpohoEBQVNUp0hbRqTUnLkdbUqbs+BkexqDR+4jpEZQU5WepDUxYqr68hU5pGMkkdIfWNNpE0ZZY0TuPX1I6mMDI2RrorSedHU9TBkUWUkfALv6hnkMRA29S1QOSh1kpTG+cbk4Y4LRtbxtTXwdOUc1laEXfN2alcC7IwXstjIfvGOFXd2Om0JG0L1wY1vprYNYM+Vj6mGhWNRX1TpzUUUQb7mqJo6lMHS5L7Vr2evBlRZeEUqkmW1CbLJPlOYyJvUTbi1iqpZiyuqEBiA07Hs/vXYYyUFbJyhDSFkVEejXIfO1X7XNQY1zQXgKarc1FTDZ6PCXlKB8i1B5BNdIW0a03Jqj2i2iIXDkgpRAEJX0sq1xGVxq+JHaLkZKkP8lKoXBxDpqyMZJI6QsSJNhFuc9Vi4tx9ANnXLhCn7xqrQLQkUTpVHSGiThBKMj/kMVICqP96EwiAg4P/73dRzyCvBlpxnVz1mTfC80PCnO2MpnY0NRX1dS41ZT81tRO5LmSx9prA+ddc02/JQyF7aRpexUWa6bQaahCsaQzqMoT+F5B1jYrGNOaKY2CXRnsaOypP1DytKYpGmnNaHp3FtSGOU6ihSJL2UpLvyDJySd6jbGoyTopMNxQwCcWPH1f6fkONQY2V6kWWqXwaUh+gJoMfULvhUR6Nch87gqKiapETVcdY3gzggPRO+suDgbwm5C29mTSjK6pFTwnVoWlOzqX6OiBl4RSXVhRQbc/TWM5UkTWXRPyd67f6Qk4WSWmsQuWiaEoDnaT3rk+0SVPXLqiLxiwQXd8oHVFtOzgE+Dyo4W2Rp0gJQPL1VloAJN2p/Le60tHJQ3RGXU4uYcSdN1UdTtxckQcjcGM5MqVBU8hkSVNqSautDYlqq4+zUBprr5HHRx7Tb4lr2JI0UkaaKZyawpkgrQghaRgExWmLPNUMaiqkHaHRmMZccQ3szT1yqT5jJM05LQ/O4roQxynUUCRxsNX3O9KMXOJSIgp/Xt6jbGoyTooyFgs7WKR1Ol5SY6SotE21fr6RUvnUx2lUm8EPaLrIB6JuxJn/0jCAy0shdXmM0KmKvPSVNBEVPaXaujX7vTk5l+rjgKzLgSEpEkdxinAoNsS53lBEHRqInzwFNkePIH7ceJH9prdzR73uoSC11v7X4Iw2lf6Tn0XarGnK2gXiIM81KES1LSlK+m1a/Or/oiUak0rrTgrrbd6DetxTxutbIABK8qsbn7kXobqcXJJQWljZ4cTNFVFG8IZGudQHzqH0rXll4/omR2Bf38ZtizzC9U/VvvnWvHH6p6b7i3Pv+ny3PmuvagpAKfRBVWOPuEhqPKvqqKjPPWuDM2wJGxu7/dENn/3zmVTuISqFk7SufX3kdWZ8bQwEAgEKSguqOaTEfZbaDIKZRZlSG1M1vlqDIhRkNdcaE2lHaEjTuSfKqVm1z+uSER9D5FJ9xqihc7rqtdSV1OW2tlZVro+8jltjbzWqrJMW0oxcqrqXTLsyrdK6aaz9oKoDoqHy0eFK9YNuTZkHX5ThMW7ceLGf0yk8jDlDpI2CmprYfVObwQ+Qffo0eUSUcbOioEDu9nhxxpgzgDfEkRg3dlwlB01957q0EMc4LbN7i/EuI25fCQQCVBQUVJtjkvRnTZEE0qRqxBrwIWpNFohae7KaZ07hYXD5926NcrguB4Ys21DTXIpu51nj2pPlniIKUYcGih48QEVWltT6jZwshHyz+BWwPPnDf41t1BfH0My1rykcDnUhjgNBFOI8t7L6x+FUVJLh6faanCYl+R/+q5qmqz5OBVk6uRpiQJcWpYUNd2TKwOje6NT0DE3t6G2Iw08WzkJRKQAPDpHsWuyStRt7xEVc45ksHRWyNtbKMoWTNA2vdb1ocs4o7yPeUnFItTRoWen3+l5HUiefONeV1Vz7WGiIMbe+Tk1xZISsjcuymmvyiCgHWEFp0xoh6+sUqsuJJ873Rf3c0HteHHZR7DaImtNV95KHaQ9RVP5/KZykuR/UhCgHRPzkKQ26ZkMdKtI2RooyPBb++6/Y6bLq4whpLDiDX22Gx6ZG1kZYSYybHzONYWiWhLoM5NJEVO0hkfqvGHWeuPkV3c5TKo6r+EmTK10nYcbMen2/vohydksLcZxU0lz/9XFAysqBwbVBOP0a59Str0OxKfeUmuZFQ/uNnCyEfCPtyIWqDoSahJu4hubGinKQBEkcCPJgYBeHpo60qIvanCbfmlePOKiv0VyWTq6aHBxNFaUliSNTlNFd3uZwXYj7DE3t6G2Iw09azkJRKQCTohp0yaLyolqNPeIiyigkyjhV9X6AbE6sy9pYWx8jW2MijtNM2ul7nmQ8kfg60nLyiUJSp5gkht3marxviDG3qLyoXk5NcQzssnQ2ijPX5G0cJW1PTQ4w7yPezcrROC1omsSOYEnGW1zHYVNFLtWX2mRZY558FgdRxjtpGiNlaXhsTJjRsQGRD7KkMaIqmipaojFP8EtKY5+Ur42GRujUB0lqD9XUV9KeX1XlbNV6VdJGlv1dl0NPFutf3HUnSwdGXYcSGupQbIzIvJr6pqH9Rk4W4uOlqiG+oqK6A+HgENGG11pPW0tBSRHXSdDYzgRZP7c0aA6OoLpS3gE1Oy2a2mhetS1N3Q5JHJk11d2pKbKo6ryRByde1VRuQM0Ot6o5yRuzvXU5/GqLKBLHWVjfsZA0gk9GSJKqS5aOClkbthrrJHZ9qeuEdFWkmb5HEsdWfdsrKeLONUnmsSwdRc2Fxk53VxeixqSgtKDWuSZv49iQ9jRGHRQOWcq4h+kPq/1N3PbXJVtqmiM1OQ5lIZdkSX1kmTw4IOqq7SLWNWpxSsqjQ6IhNEYKIklo7KgKWUVLVE2lV1FRIZHxWNop+eqiJoNpc3AQCdMY7RXHuCzN+SUPclaaiHJS1br+xYwgrHQ9KTptGiIz6zqU0BCHYnOPzCMnCwCUCG1ukhinBDWkBWrqwZcHQ2FTIcoQ/9sgyeqVSNvQXB8nwcHBTedMkAcDuyhkkW5IlginvBPHeSJP0VEfQ1o4YaP7IRHrqWpUUU3rc28voDhPumtP3Mi62hwHTe10rG2fERWNU580XpI8W00RfE20H9Z2qr0m41RzqSMgKZIY7BsbadZ0aIoT2+IaeMVtlyQp50QZc+WplkhjRGc05Wl9UUgSoSfqO9x8aorIppraU19kWQelsWScLJx4dc0ReXMc1oWoeSquLJM3B4Qkxkhx0wV9DIgyykn6vLJ01jRGVIUsoiVEnVqPGzNWIudRolA0VpPVSZGhoVoWzo/GiIYSF2nOL2mnU2xqR1ldTipprH9x0ruJS9W0bZLKzJr2J0nHR5qRU03hfCcnCwBsa/N/P9fXOMUZgeStQHNTG96aGlGG+Lf//t/PVY2Wwn1StX/EOaldH+NdfZwEVU+y1/Q5WdBYBvaGGD/l1REkTKWUd3LiPBEXcZ0A8oyw0T1RxHoCKq+pmtZnYhTwnUXNMrS+81iUjD4yqu5nEHWfpnQ61uYIbmgaL2mlrpOT/bC5GadkRX3TKRH1Z2rQ1HobeMU1mjd0Htd1n8aIcpK36IzmxscQ2SRNR2pVZF0Hi6MpnHjylOZLHKde1Xk6N3gu+7m57ckSnQYuKqp3uqDmiiijXNGDBxJFisiyXkRtURVVf5YnA3Jdp9brYzwuqhKN1RR1UmqLLqiopwFXms4aUT8D0jWsS4umTiUqT44ncZF2+q6GOm1ErWlBYXW9vC5qkmnSGJ+GRk41dv0fgJwsoqmPAaepCxDXRGPUVZDXCJ6qiDoFXtVoKXzauqYUYqJoqPFOXCdBTZ8Tvoc89j1Q90n3hvRffR1g8tg/8kxVA3p91oY8I25KtnnVU3KIlKGSzOO6HME1UTUaR9gxI02no7hOI3EdwQ1N49WQZ6ttP2xEo768nWqXB5qbkau5ULXmClC3gVfcOg9qfDWoKv5foUtp1MTg7tNYEQCSpmMTboOsU9zJM5JE6EmrzlVzoz4yjuZX7VR1HtflqBPl7Hqc/n/G3Y9lT27s1EuypiZng6h/r4mGpiCqT70IaRiaRUUcSZqKS5x7cVSdL+I6dUT1r4KaWqUi2I0xTtJCtVWrSr/XxwgrLedHfaLO5KHGjDxEyTWW40kgEKCioEBsh2djOp+k5bQRXovSGttax6cezv6GRk41dv0fgJws/4c0jFPyVEtBGFHPVpPxubaIjqrfl8cIHlHUVQC+au2DpCjx64801JmlrA4oCQmMmvpNlDOhqnOovql4Goo4Dp66jM+yTv31sToJGgtRUQh1rY3m4NgSNyWbcK2T2pwEDZUD9XFAVI3GEXbMSCv6TBKnUV17aF1yuC6k9WzNIfqtDhrjpH9jUdVg35yfRR6pj4FX3DoPDYlIqCuKSRYRAPU9/V7bdYSfW9rOn6Y+ESop/zVHaX3HSVxDvqj5Ne3KNMka2QyQZF1WdR4/THuIgtICsfZDWdY6kyb1dZiISuEkXHhYHqnLyC/K2VBfg5+0TorX5QSoyRhZXzkhqkB5RVaW1A3IIlN+/X+nTX1Ondd0al3a49RYaX6qRtZIaoRtiPOjPkXqRRnWGzslUn3aK9H16ykLZeV44tZFdDtPsdaGPDifJEF4PomMgGyg06qh4yONqL7GdOqSk4VDGgYcznAnbDSXh+iCqs8myoB2cMiHwvDiRnTIawSPLBDXaCyJ8a4hUTQNTcXTEEQ5ePb1/TCHJE1lJAvjpyROAlE0B8eBLBHXCVCTbKnUXxJEX4kbVSFLxHUSSDKPJXFAyLLAuyROo+ZSv0dK7WwqR0djnfSv7f71NYzV9p3maFiUFyeXOEYcSU5q12U0l2ZNjNruIy3jfdUIHUnTVFWNfgGkl/5J3lJp1QdpRQNIyxkmTaqusZrGqa61KM7JfFHz62GaiGjaj4T6RqUII+wwERWBN/7ieOSX5Fe6XnOJWKlaq6Iuh0lVYxhQOYWTLGiIMbcup5Ao415FVpbUDX7iUqcTQFR7CwrqNLLW1wkjLQOyqJRfnNOm1uLcYvS3tFPTiXL6yNpg3VAjrLRTQYlLU/SVLKnNGVgTVSOppBXVV9/aIP+lFI31oSFrQ1ppxxpzbZKTRdrUZHyWJyEnyoCWFAUUZIiI6BDDWSKvETzSomo0RE11EyQx3jUkikYYWRpcRVG13cAHA+y+XpKnMhI3qkcSGtI/YjkOmgBxo86kgbhOgJpki/CcFp4TNTnnqj6bLOppyMpx01jOhoZGhojLRxD5IQukUfNCEuVfnHomdaWcEccgKMqJIMrBU5dhTNR3hHPiVzXYA9IxLMoqKqCpnVzC7ZCVUb6xUujUdR9ptaNqhI400lRdGHqB/SwNJ5uk6cs+JhpidJcFotZYQWlBtXEqKC2odS2Kuk5FRUWt36lP1EVzjYASJffFnfPCckFUBN7DtIfoeLSj3DvsRVH1RH19HCYNNRCLe3K8IYWS66rrIQsa/YR/HUZWSSM+pG0grG2+yEU6KhGphmpzsElDFjaFg0Qa1NhXzdS4L8p5XJezrzGi+hpaG+S/TIOc83JYj6guyMkibURFF8hzZIc0jPPipt5pCE0ZSVB1PMWpm9DYNJbBVRTCc6ghqYwaEtVTFw3pnxodBxKuaVHOEXH/Jvy7rPpKWtQkW5KrrJ+6nHOyqC/VUMfNxxDZJO4zNJcIlUZGkpoXVY2Iws4GSRB10r+uyJC6jPO1OREKSguqOXjqMozVlRNfGGmlc5GmA0LUafPGKGhdF//V+hbC1OVMrIo00wV9eeNL9nNt0VfyGJ0hrzTE6C4ptUWliev4qmstivr3rOKsWr8jrnOxOUdAcUhrXYq6TnOOBJLEYdJQA3GCmFE0NRVKri+NlbolfvIUuTrh31gn3esyatY2XySpr9JQamuvpGnb5BlZOcjlpc6NtBD3eRojqq+htUGAxnf6Vr1HU60LaRWflwcHsDiQk6U+1PfkuKyjC6Rxkr0pjfPiIsogWlM0iSxp7GiR5oKoOSRJX4mM6pG1c7KeqasaOgdEOUdEpemrK3WftCKgGkpthvq6ZIu4zjlhpBVVUavjRox+rK34fFMjEGNOy4tMrQ+yijxqIPVJaVTViFiTs0FcRJ30ryvljDgGQXGcCJIYxur6jrSiJ6TlgKjLgHl95HUEjwiu9PmPBXl4IauLOdfmsJ/FSTMnzeicJxlPKv1ekzFX3qIzmgONVTtDXqLSGsLH4GyV1roUvo6kkUANiUoTNwpEXJriRH3VOhR1GSilkVqpMaj6HM35hL+4NDR9VFM4Lao6w4SNsHWmbZNxfRBpI8v+ba7RODVRqVaImA6K+simqteUVpqxmpDE2SDNFI1N5YCUVvH5xkrJ11BnGDlZhKnNOCXJyXFpOjCqtqU+7Wnup65F1X9pimiSpnZIScOp1hjXBJq+r8RFVOqq2vpBnOeqzRhcNdKtpjR9IlP31cOJ0lgGaXFT6YlCEuecLFLKSeK4EdcpJIw4zo+GUnVfqGlOy4tMrQ9V55qcpOKUpHB7YxkRG3qflgYtK/0uHHlTk2GsNoNVc8mJz1HXSXZVRVV8EfwF+/1jMaBLejpeEsdMQ5w54jo6ZElda0yUw7PquvgY5ow0aSw5Ia5DubnzX5xrkkYCdfujG6YF1T/FWGOkqWlMxDVQNjdj7sd2wr82Gpo+qinqSlR1htVmhG3ucq2hTqGmiIaQB2pzxAkjrmySVq2P+lCXs6Gqw76ioqJaG+sTBSJvNWKaixyu5gybPaeWT1eHnCwcooxTB4f83+9Ncsq+hrYdHAKU5ItvhG2IIbQpqM0YKe/RJLJyWkji5GuKa8oCWfUpIDp1VX3WtSjnpyzqh9SXxjJISzuVXl1OLFnM2Yakw6pJHlWVYVUjk6ruL9KiplpJtTnc5F2mclR9LkAuUnHWlZ5LFPUxIjYk3VBDjZVVjdjiRN7UN7qgOfMxnCIXhSTPJYljRlqpjhrLaSkKcdeYcBs/hhRPwnwMKdHqE5HYnGjquSbvhlBRNcEepNVfJ2qKOiOypLk4T+obPdRcnksUDTGqNxejJoesUoPJuzyqD9JKvSQKeXbg1McRJw5NWetD1DwX5bCPGzO2Whsb+txNSU1yWNrRoA2lmjPsUfU04bVBThYOUcappKimaUtVGpoaSJ5ritTXGCnPERKydFrIIj2UqKiKpkg5VRuN5QgSNjSLG/lVk/NT2vVDJKGxDdKNZahvSme3KETJI1EO+729G39/ER6ToyMrt6e5yFRRSCtlnJSQVeF2jmlB06Rax0US6mPElofoAkmR5Qv4x/RyLwpJHDPSclLJIvJB2o4D4TZ+bM45adeaagpEpV78GGjKudbUDp76ImmKsarP1NwM2s2Vjy16qC6qGtWrOhZqM4w3N+dSnanBJDiZ31gpk2oaB2nrgNJKvSSKmuZaY0cr14Ys5Gxj1/oQNc/rqitT03PLm4OivsizPJd0rpGTRRT1MRiKe8q+LsNtY6SSaeoTy6JO/UvLGNkY/VcXNRmAZRmJ0dyo7zg1Vu0RYUOzuPU26mrb4pfAPKGNsinGvrEM0s3NUC9L6nLYN5YcFh6T5CqndOTlAIEkNCTySMbI4kT9w/TKynZD67hIgiTGx6aMLpAEWRoExbn2x+6EaW7IYy0VeZ0j0q41JU3ErbfxMUTjyBvNzZlYnxRjtRlrm5tBW9bISm41RpFreULUswo7FiSt88DRHA2z9aGxUiaJclBUVFTIzMEjC2eDqLlWUVBQ72dobnVnGqvWh7iIGluRjhk5dlCIizzLc0nnBDlZRCGuwbA+p+xrM9zWlapMWsjaEFqbAb2mU//SMEY2Vv9Jgryk5BI3OkPWbZDXcRJGknobojg6Btjq8X+/N8XYy7FB+j+BKBnWlA6ppna0ywMylIWyPAnd3JwW0uyLxjAuy9IgWNe1m9uJ7/8CoqLTmtJA3BzmSFPLqKpyoj6pHOXRqUbIJ/KW316eaazogf9S9FBNzypJZEOikCOmORpm5RGRDoqsLJnJDFk6BYTnmkTRQyQrG4TYdWXk2EEhCeKkC5TXdHbCkJOlIdTnlH1thlt5TlUmLnUZ0Ovqq4YYI+W5/xorEqMuqjr5xDH4S9sYKc/jJIqGGqRFPWtTjL08RHn9V5G3CB9J21OfiE0OWc61hkQHVqtRNlo6bZIxH2MqG3FoDsblhiLrE9/yGgHRHGhqxwFHc4gKaEoZJUpOFJQWiJ3KUd6cagTxMdDQ4t7iIk+nz2VNXc9aH4dTURVHTHM2zMobH4Pj77+0ruqLvOrVsp53jfHcdc27ulInygvkZGls6jLcNteTxlXrewD1M6BLyxjZXPtP1lR18olj8K9mjKwhbZYkNIdx+hjmZHOJHiLkF3Gj8RprrjU0OrDqPpV8VyrNImRDczAuyzP/BSeVLPmvOjebG3XJCXGdZfLiVJNnKLUaQcgvkhjGPwaHgLxBDormh7gREo0VoScJspx38vLcdaVOlBfIydLY1GW4lbeTzzVR20nipjQqN5f+ayrqMzZVjZGSps0SxX9pnJryWZtb9FBTIA+p9OQZcaPxGmuuSSs6sDk4esVA3JoDxH+T5uykImMuIS3EdZaRU61uqqZWmxs8t+kaQxBEgyGHAEHUHCFRLRVpI0XoyRvylv5N3p3D5GQh6k9dJ4n/Swb05oYkY/ORGCP/89A4ikaWEVv/VZrDXPsI9qn61BwgiOYG1ckgCPmjamq1x+l1134g/hvIawodgiCIuhBZT6egQC6iN4jqyLtzmJwsRP2pmhqsqWpNEI2DvBsjG1Kf4b+EvI9jQ2jIHJBlxNZ/lY95rskRVaMUgJprDhBEc4PqZBCE/EKp1Qhh5CWVDEEQREMQjpCQt+gNovlAThaCIJovDa3PQDR/pDUHmkP0BUHUABm8iI8VmtsEIX9QajVCGDJGEgTxMSDvERJE84CcLETdUKQAIa9Iqz4D0XyR1hyg6AuiGUMGL+JjheY2QRAEQRAEQRDNAXKyELVDkQIEQRAEQRAEQRAEQRAEQRAEIRJyshC1Q5ECBEEQhKygSEmCIAiCIAiCIAiCIJo55GQhCIIgCKLxoUhJgiAIgiAIgiAIgiA+AsjJQhAEQRBE40ORkgRBEARBEARBEARBfASQk4UgCIIgCIIgCIIgCIIgCIIgCEICyMlCEARBEARBEARBEARBEARBEAQhAeRkIQiCIAiCIAiCIAiCIAiCIAiCkAByshAEQRAEQRAEQRAEQRAEQRAEQUgAOVkIgiAIgiAIgiAIgiAIgiAIgiAkgJwsBEEQBEEQBEEQBEEQBEEQBEEQEkBOFoIgCIIgCIIgCIIgCIIgCIIgCAkgJwtBEARBEARBEARBEARBEARBEIQEkJOFIAiCIAiCIAiCIAiCIAiCIAhCAsjJQhAEQRAEQRAEQRAEQRAEQRAEIQHkZCEIgiAIgiAIgiAIgiAIgiAIgpAAcrIQBEEQBEEQBEEQBEEQBEEQBEFIADlZCIIgCIIgCIIgCIIgCIIgCIIgJICcLARBEARBEARBEARBEARBEARBEBJAThaCIAiCIAiCIAiCIAiCIAiCIAgJICcLQRAEQRAEQRAEQRAEQRAEQRCEBJCThSAIgiAIgiAIgiAIgiAIgiAIQgLIyUIQBEEQBEEQBEEQBEEQBEEQBCEB5GQhCIIgCIIgCIIgCIIgCIIgCIKQAHKyEARBEARBEARBEARBEARBEARBSAA5WQiCIAiCIAiCIAiCIAiCIAiCICSAnCwEQRAEQRAEQRAEQRAEQRAEQRASQE4WgiAIgiAIgiAIgiAIgiAIgiAICSAnC0EQBEEQBEEQBEEQBEEQBEEQhASQk4UgCIIgCIIgCIIgCIIgCIIgCEICyMlCEARBEARBEARBEARBEARBEAQhAeRkIQiCIAiCIAiCIAiCIAiCIAiCkAByshAEQRAEQRAEQRAEQRAEQRAEQUgAOVkIgiAIgiAIgiAIgiAIgiAIgiAkgJwsBEEQBEEQBEEQBEEQBEEQBEEQEkBOFoIgCIIgCIIgCIIgCIIgCIIgCAkgJwtBEARBEARBEARBEARBEARBEIQEkJOFIAiCIAiCIAiCIAiCIAiCIAhCAsjJQhAEQRAEQRAEQRAEQRAEQRAEIQHN3smyY8cO2NnZQVVVFZ6enggNDW3qJhEEQRAEQRAEQRAEQRAEQRAE8R+gWTtZjh8/jvnz52PFihW4d+8eunTpgn79+iE+Pr6pm0YQBEEQBEEQBEEQBEEQBEEQxEdOs3aybNmyBVOmTMHnn38ONzc3/Pjjj7CyssLOnTubumkEQRAEQRAEQRAEQRAEQRAEQXzk8Ju6AZJSUlKCu3fvYunSpZX+3rt3b0RERIj8TnFxMYqLi9nvOTk5AID3xQLgfS5QLPjwD8I/c0jyt8b6Dt2b7k33pnvTvenedO96f6cAQHlhOQAg932uyJ856vqbJN+R1nXo3nRvujfdm+5N96Z7N+w75SUC5JV/+Nv73Fz2M0ddf2us79C96d50b7o33ZvuTfdunHvnVXz4u0BQxZ5QAzyBuJ+UM5KTk2FhYYHw8HB07tyZ/f3bb7/Fb7/9hujo6Grf+frrr7FmzZrGbCZBEARBEARBEARBEARBEARBEM2MhIQEWFpa1vm5ZhvJwsHj8Sr9LhAIqv2NY9myZVi4cCH7vaKiApmZmTAwMKjxOwRBEARBEARBEARBEARBEARB/DcQCATIzc2Fubm5WJ9vtk4WQ0NDKCoqIiUlpdLfU1NTYWJiIvI7KioqUFFRqfQ3XV1dWTWRIAiCIAiCIAiCIAiCIAiCIIhmho6OjtifbbaF75WVleHp6YmgoKBKfw8KCqqUPowgCIIgCIIgCIIgCIIgCIIgCEIWNNtIFgBYuHAhJkyYAC8vL3Tq1Am7d+9GfHw8ZsyY0dRNIwiCIAiCIAiCIAiCIAiCIAjiI6dZO1lGjRqFjIwM/O9//8Pbt2/RqlUrXLhwATY2Nk3dNIIgCIIgCIIgCIIgCIIgCIIgPnJ4AoFA0NSNIAiCIAiCIAiCIAiCIAiCIAiCaG4025osBEEQBEEQBEEQBEEQBEEQBEEQTQk5WQiCIAiCIAiCIAiCIAiCIAiCICSAnCwEQRAEQRAEQRAEQRAEQRAEQRASQE4WgiAIgiAIgiAIgiAIgiAIgiAICSAnSxOyceNGBAQE4MCBAxg5ciQCAwObukkAgE2bNsn0+seOHcOYMWMwbtw4jB07FkePHpXp/WSFr68vfv31V+Tl5TV1U6TK+fPnsWTJEoSGhmLEiBE4ceJEUzeJ+Ei5du0aZs6cifv37wMAdu/eLfJzv/32G65cuYLhw4dj9OjR2L59eyO2Uj64fPkyLl++jEuXLsHf3x+XL19u6ibVSnh4OEaNGoUBAwZgwoQJePHihdjfvXHjBmJjYxEQEICxY8fixo0bMmwpQRAEQRAEQRAEQRBEw+A3dQOaipSUFISEhGDgwIHIycnB2bNn0a1bN5w8eRJJSUlwcXHB1KlTUVZWhvfv38PCwgJHjx5FdHQ0Jk+ejN9//x3Dhg3DjRs30Lt3b6xevRqZmZn48ssvkZWVhfbt28PMzAwAsGHDBqioqKB9+/bw8fFBWloafv31Vxw+fBgzZszA8ePH0a5dO8TExFRqY25uLmJjY1FUVAR1dXU8fvwYAwcOhIaGBi5cuICCggLcvXsXY8eOxbp169C3b1/4+Phgw4YNWLVqFWujnZ0dlJWVcerUKRw9ehSrV69Gy5Yt2X3Gjh0LAEhKSoK5uTnu3r2LxYsXAwDS0tJQXl6Oc+fOYezYscjNzcWOHTsQEBCAqKgoaGtro1+/frh+/Tq6deuGt2/fwszMDHFxcdi3bx9mzpyJrVu3wtPTE+rq6mjZsiXWrFkDLy8vzJgxAwYGBhg+fDj+/vtvaGlpYe7cuWjRogVKSkpQXFwMFRUVbNu2DXPnzoWysjLevHmD9PR0pKWlITc3F5aWlvDx8UFERAQsLCzw+eefIyUlBStWrMDo0aPZ35ctWwYAMDc3h7q6Oj7//HP8/fffyMvLw8SJE/Ho0SNcunQJEydOxKpVq9C2bVuMHDmSzQcAUFdXx8SJE7F+/Xp069YNdnZ2MDExwbRp06Ctrc36JDk5GSNGjMDmzZthY2ODTp06oU+fPlBWVsatW7fg7e2NkJAQmJqawsnJCYcOHUJhYSEmTJgAJSUlhISEwM/Pjz33mjVrMHbsWOTk5MDCwgLffPMNsrKy0K9fP5ibm6Nly5b45ptvUFxcjBkzZsDHxwcPHjyAq6sr9u3bh8ePH8PDwwPh4eFYuXIlysvL8eOPPyIvLw/q6uqYNWsWWrRowe63Z88ebNq0CWPHjsXVq1cxadIkDB06FOfPn0f79u1RUlKCffv2ITs7G3w+H9OmTYOLiwsiIiKQkJDA2rZs2TIkJCRg9erVsLS0RGBgIJSVlZGQkAB7e3t06tQJo0ePBo/HQ0ZGBmuT8Dw4e/YsdHV1ceTIkWr/FhERgSdPnqBFixbw8fEB8ME4K/zZyZMnw9bWFkZGRpX6fPfu3Rg8eDCbq0+fPkXbtm2xf/9+DBs2DKqqqti3bx+GDx+OM2fOoLy8HGlpaZg0aRI2bNgAVVVV1tcAUFBQgPPnz+PTTz9l/WRmZoaUlBSUlZVh7969bP4UFRXh6dOn0NHRQUhICIYNG4aMjAw2ttw4ampqsjG8d+8eVFVVERAQwOaVl5cXevfuDWVl5UprBPjgyOzRoweMjIxQUlICACguLsbu3bvZ586ePYvCwkIIBAKMHj2ayUU9PT3s3r0bRUVFsLe3x/Hjx7F69Wo4OTkxmfHDDz9g9uzZle6dmZmJkJAQ8Hg8eHh4IDAwEDExMXB3d8fKlSuhoKDAxvjp06dYt24dfv31V+zbtw/r1q1Damoq7t69i/j4eBw9ehTq6uooKirCxIkTERISAg0NDebwmzdvHkpKSpCRkYHnz58jKSkJb968QUpKCpPdampqTIYIj/2pU6fg5eUFMzMzbNu2DQEBAXj79i2cnJywb98+JhNiY2Ph7e1d6T4xMTEwMjJChw4dsGXLFjg5OcHb2xvfffcdAgMD4eLigr/++gt9+vTB4sWLoaioiHbt2rH2/Prrr9DW1gafz4e6ujratm2Lbdu2oaCgACUlJdXaXlJSwvaAwMBAjB8/HkZGRsjMzMSZM2fQtm1bZGZmIikpCXFxcTA1NYWdnR2TW3p6elixYgXU1NTw/Plz/Pjjj8jJyYGuri46dOgAJSUlvHnzBgkJCTAyMsLy5cvx888/Q0dHB+7u7rCzs0NSUhLi4+Nx584djB07FuvXr0e/fv3g5eWF7777DuXl5SgvL8fKlSuRnJyMq1evYuzYsQgICMDKlSsRHR2NSZMmYeXKlcjKyoKHhwcWLVoEExMTJjM4OX7lyhWcO3cOb9++xd27d7Fw4UJ89tlnmDp1KsrLy5GXl8dkKTe2AHD27FkYGhrC0NAQK1asqLY+ub3sxx9/RHZ2NpPn/fv3x65du6CqqgoXFxeMHz8eMTExuHz5Mt6+fYusrCz4+PjAxcUFoaGhePPmDcrKyuDj44O+ffti0aJFMDQ0hK6ubrXrmZubo1WrVujevTuTKwcPHkRAQACePXsGdXV1XL16Fb1798bKlSsREBCAgQMHYseOHViyZAkKCgqwbNkylJeXw93dHYqKinjx4gUmTZqEH374AU+fPoWdnR3c3Nzw7t07REZGsrWWnZ3N5ElBQQGmTZsGfX19TJ8+HXZ2dsjNzYWpqSm++OILLFu2DIWFhQCArKwsrFq1CgcPHoS5uTlmz56N2NhYFBYW4smTJxgyZAh0dHSqrc+srCz8+OOPeP78OUxNTSEQCKCkpAQ+nw9dXV0UFRXB2dkZU6ZMwfDhw7F169ZKOsiKFStgZWWFGTNmMHn1/Plz1t7nz59j3bp16NevH65cuYKrV68iPT0dKSkpGDVqFExNTXH16lXY29vjxx9/xPjx4/HgwYNqOtEvv/yCMWPGYM+ePXj06BFWrVqFn376Cebm5tiwYQM0NDRw/fp1KCsrM31CIBDAzMwMgYGBrK/09PTYPubi4oI2bdpAUVGRzRGBQIDZs2fj1q1bePToEb755hukpKQgPj4eV65cQU5ODvT19VFSUgKBQIBNmzYhPT0dgYGBEAgEiImJgb29PfT19eHh4YEZM2Yw3aCsrAybNm3C999/j82bN6Nfv37o2bMnNm/ejK+//prNm5KSEqirq2PJkiXYsGEDRo4ciYULF8LGxgaBgYFwcHBgOvC3334LNzc3eHl5MRkNAF26dIG5uTl7rufPnzPdSliX1tPTw/z581FeXg5VVVVMnTqVyQlTU1P88ssvWL16NVavXl2tr4OCgmBlZQVHR0cmO4Q/l56ejmPHjmHAgAFYtGgRBAIBOnfujNjYWJSUlGDatGno3LkzFi1ahC+++AIjRoxgzyi8/lNSUhAeHo7k5GTk5eVh/Pjx+Pnnn5GZmcn0hVmzZuHSpUuYPXs2YmJi2PxTUFBAly5d0KlTJybrzczM2FrlxsbW1pbNtZ9//hlOTk7w9/dnMv7GjRvo168fVqxYgdTUVDx9+hQWFhZMxxAIBCgtLcXbt2/Zms/IyMDnn3+OadOmMdkpEAjY2Ika7z179rA9RVdXF+/evWMyvqioCAAwe/ZsnD59mq2DH3/8EU5OThg5ciS2b9+Ozz//HGfPnmXPwMkwfX19LFy4ENra2tX04n79+sHe3h5Pnz5FZGQkbt26hRUrVmDYsGFsHFauXInMzEzEx8dXa8/z58+RkpJSrQ8SExORmpqKlJQU9h1lZWVMmzYN9vb2WLFiBX766Sds2rQJbm5u6NOnD3799VckJSXBwcEBU6ZMgZqaGvr3719N9pSUlODcuXNsnDidm5PTHTp0QEhICAwNDeHo6IhZs2ZBTU2tWv9t27YNioqKMDIygpmZGebMmYPdu3cjODgYpqamMDc3x7t371BUVMT02N9//x1WVlYYMmQIG8+bN29i//79rE+HDx+O169f4+3bt+Dz+VBUVMSCBQtw8+ZNpqvo6elVewZOF+T2xqdPn+LatWtMJ2/VqhUePnyI8PBwXLp0CZaWligvL8fs2bNx7NgxJCYmYurUqfjjjz+QlpaG+fPnIywsDE5OTujTpw9+++03DBkyhOkLEyZMYO+hvXr1wtSpU2FtbQ1ra2uUlpYiNjaWjWdJSQkmTpwIExMTti5v3LiBR48ewdzcHDk5ORg1ahRGjhzJxqk2PVNbWxuKiopMVnKypaysDL/88gv09PTYXsHJuDdv3rC5xOPxoK+vDz6fj5cvX2Lz5s3Izc2tppMXFhbi6tWrMDMzw7Vr1+Dk5IRFixZV0gW5tRwaGoq1a9fCzs6OjW1CQkI1GW9gYABdXV2UlpYy/W/t2rXV9ARh3atLly7s/fqnn37CmDFj8Ndff7FxjImJwbp166Cjo8OeITY2FmZmZpg8eTLTUZSVlZm8HjNmDAICAjB+/Hjo6elh3759bC0+f/4cHh4eiI2NRUpKCqZOnYqLFy8iOzsbHh4eGD9+PLMHtG3bFjt27ECHDh0QHh4OJycnbNmyBQEBAfjss89Erst169bB2dkZ9+/fx7Rp05CUlISysrJqe3pUVBT8/f1RVFSEv/76C2vXrkV+fj7rH25/NjMzq7bGPDw8qvVFXXt6u3bt2Dz/66+/sHjxYhw+fBhv376tZkN4/fo1nj59iuDgYKabtWvXDjY2Nnj48CF7rm7dulXSSRcuXAglJSWkpqbCwsICLi4umDJlCu7fv8/00PT0dCgoKEBTU5O9O7Vt25aNU0xMDFJTU5GXl4f379/ju+++g6WlJR4+fIjo6Ohq+x2n71Xd36vqzWfPnmXjmJqaioSEBLRq1Qq+vr7V+mX79u1M14mJicH+/fvx+eefs7lmbW3N+oxrr7A8LykpYc9Y1QYwaNAg1p5bt26xtdGpUyf8+uuviI+PZ/plYGAgdHR0MHr0aGzcuBF9+/bFzZs3mYyaP38+1NXVMXXqVCxatAjGxsZo2bIlZs2ahZycHNbnRUVF1XSLhQsXgs/no6ysDKWlpdXkY2RkJIyMjDB48GBYWFhg6dKlUFNTq/Ye4OLiUul5quo/XBu//fZb9rOpqSmTYT179mTv6VXHNi0tDaWlpQgMDMTp06cr7RseHh4YPnw4jhw5gtu3b6OgoACbN2+GkpIS0/s4nb20tJTpDvn5+Uw/+vPPP+Ht7Y0OHTqw59HR0cHmzZvRt29ftkfq6Oiw/uP2/MzMTDY/PTw8qtm6bty4wXRFTh4JywwjIyO0adMG9vb21fQwYZtkjx492LXnzp3L3mdPnDiB7OxsGBoawsPDAyNGjGDvN3fv3mU6E7d///DDD0ym6uvrY9asWdDX12f6RllZGXtH4/R4gUCAZcuWQUVFBcrKypgxYwa+//57JnM+//xzzJs3Dzk5ORg3bhxWrFjB5L2TkxN7T+dkb2BgIP7++284OTnB1dUVixcvhomJCbS1tZlOyu05JSUlbK5t2LCBzWPuOkePHsXIkSNx5MgRtqe1b9+e6Q6cfmRsbFxNTkdERLD3jrVr18Lf3x/v3r1ja15dXR0PHz7E69evmUw0MTGppoMEBQVV0yeq6pe//vorwsLC4Ovri9LSUqSmprK9MTw8HL/88guWL1/O1ve7d++YPUrUe4CzszN+/fVXPH/+nOnIhw8fxpAhQ+Di4sK+8/XXX1eT3T4+Pmwtm5ubV3ouceAJBAKB2J/+iBgyZAgCAgKwZs0aeHp64tq1a1BWVsbw4cOhoKCAlJQUvHr1Cqampnjy5Al0dXWRmZmJ3r17Y8eOHejWrRueP3+O7OxsGBsbo1WrVvD09MTu3bvRq1cv/Pvvv5gxYwaOHDmCpKQk5Ofnw9jYGPr6+rCzs8OcOXMwevRoDB48GEeOHIGtrS3S0tLg7u4OPp+Pfv36YcuWLRAIBCgpKUFhYSH69euHW7du4fPPP8ePP/4IgUCAAQMG4P79+3j+/Dm0tLRQXFyMiooKlJWV4fTp0/jpp59gZGQEHR0dBAcHMyHi6uoKbW1teHp64ujRo5gwYQKOHj2Ky5cvY86cOezeCxYsQGpqKoqLi2FkZIT09HTweDw8fvwYa9aswfr169G5c2fcvn0bZmZmqKioAABkZGSgoqICeXl56NSpE8LDw6GpqQkjIyNYW1tj9OjR2Lt3L96/fw8zMzMcOnQI8+bNw9mzZxEQEIAdO3ZAT08PSkpKiIuLg4ODA0aNGoUjR44gPz8fJiYmaNu2LbKyspCcnAwejweBQICysjLo6OggLi4Orq6uyMnJgYODA0pKSqClpYUnT55AW1sbjx8/RqtWrZCXl4fk5GS0atUKqqqqCAkJgb+/P86cOQM1NTU2H8LCwmBubo6bN29izZo1WLVqFdTV1TFkyBDExMSgqKgIMTExiImJQc+ePREVFYUpU6bg0qVLUFBQwLt371BWVobMzEzo6+sjMzMTDg4OsLe3R3x8PJSUlODg4IBLly7BwMCg0nNbWFggMTERubm5sLOzQ8eOHfH+/XucPXsW6urqMDIywpkzZ7Bs2TJcu3YNffv2xdWrV8Hn82FhYYEWLVogMjIS2dnZUFRURFZWFr766itMnDgRVlZW0NbWRufOnXHr1i107NgRKioq4PF48PX1xfnz55GQkIDCwkJ4enri33//RVlZGSoqKpCcnIx+/fohNDQUzs7OGDRoEOzt7fH9998jIyMDNjY2mDRpEpYsWYI2bdpAT08PioqKGD9+PEaOHIlJkybh+PHj6N27N8LCwhAeHo5jx46hsLAQ3333HZycnPDmzRtoaGigW7du2LVrF9LT07FgwQJoaGigRYsWuHDhAgoLC5GWloZevXrhn3/+Qbdu3WBvbw9DQ0PMmzcPZmZmUFZWRnx8POvziIgIKCoqYt26dTh+/DimT5+OxYsXY+TIkbh69SoKCwtRUVGBjIwMfPLJJ0hOToaRkRHu3bsHgUAAd3d3ZGRkwMzMDHw+H2FhYSgoKGAvDKdPn8axY8cwZ84c3Lx5ExkZGXB2dkZBQQEMDAwwffp0jBkzBh07dkRRURFat24NRUVFFBcXAwAiIiKgoKAAPp+Pb775Bj/99BPU1NTw77//snn17NkzGBsbw9fXFxcvXoSDgwNMTEzYC7e5uTlKS0sRFxeHESNG4ObNm3j37h2MjY2hoqICPT09aGlp4fbt29DU1MSqVavYOo2JiYGxsTHu3r0L4IMh4tWrV+jQoQNsbW1x5MgR2NnZVbp3fn4+OnXqhJMnT8LX15e92NrZ2eHcuXOwtLTEqVOnYGRkhL59+yIhIQEFBQX45ptvMGLECOjr60NVVRVGRkZITU2Furo6vLy88PTpU2hrayM/Px8LFizAyZMnERsbCzU1NSgpKUFNTQ18Ph+amppIS0uDqqoqcnJy4OzsjDt37sDLywvnz59nY3/16lXo6enB0NAQycnJUFVVhZqaGjQ0NNjPz549w/v372FoaAgtLS12n9zcXOjp6aG4uBg8Hg8KCgp4/Pgxli1bhu3bt8Pd3R2pqal49+4dpk6dikOHDsHMzAzx8fHg8XjIycmBm5sbMjMzYWlpidzcXBgbG6OoqAjZ2dms7SNHjmTKCLcHdOzYEWlpaQgICEBgYCB++OEHzJs3D+PGjcMvv/wCb29vPHz4EFpaWkxu7d+/H3w+H19//TUuX77MFFg1NTVcu3YNGhoa0NTUxKtXr9CpUyccP34cn376KV68eAEjIyPExMTAyckJ9+7dw/Tp03H+/HlcunQJ06dPR3l5OVRUVLB//344ODigrKwMpqamOHbsGAICAmBqagoA0NfXB/AhskVFRQVOTk4IDQ2Fi4sLBg0aBCsrKyQkJODJkyfIysqCiooKzp07h86dO8PY2Bh6enoIDQ2Fnp4e8vPzUVhYiJkzZ+LIkSNQUVFhLxYDBw7E9evXUVhYyNbn+fPnoaamBgCYNWsWsrKy0KJFCybPg4ODMWLECDx+/Bj37t2Djo4OVFVVkZKSgv79+yM7O5s5RX19fcHj8ZCfn4+ioiI8efIEmzdvxvr162FoaFjtetxaBoCuXbsyuWJiYoL79+/DwcEBx48fh6enJ3bt2oXAwEA4OTmBx+PBwMAAwAfHaExMDGxtbZGbmwsdHR3cu3cPvr6+mDVrFqZNmwYjIyOYm5sjIyODrTUnJyc4ODhg/fr1cHFxgba2NioqKpixOCcnB3w+HykpKbC0tIRAIEBFRQW++eYbdOnSBd7e3sjNzUV0dDS++eYbrFixghlsOYNAu3bt0L59ewQFBYHP52P06NE4ffo0TE1NoaCggCNHjmDSpElIT09HcHAwfH19ERMTg+TkZNja2kJZWRlt2rRhz5+VlQVvb28EBQVh8ODBCA8PZ+1NTk5GQkIC3NzckJiYyA6mTJw4EadOnYKpqSmOHz+O9u3b499//4WXlxcEAkE1nahLly548uQJjIyMsHTpUgQEBKBTp07Izc2Fubk5PDw8cOHChUr6hLm5ORQUFPD27VvWV1paWhg/fjzmzJkDNTU1aGlp4fHjx2yO6OnpISwsDFpaWhg2bBi2b9+O7t27IyoqCmFhYfjyyy+RmpqK58+fY9y4cTh48CBat27NZMt3332Hr776Cunp6SgoKIC5uTnTDYqLi6GoqIjU1FRs2LABhw4dQkFBAcrKytCmTRs2b+7fv48JEyZgx44d6Nq1K+7fvw87Ozu0aNECp06dgoGBAZYuXYozZ84gJSUF6enplXSDwYMHo6SkBM+ePas09znditMf//jjD/D5fLx79w5mZmbMobtgwQIcOnQIpaWlUFJSgpKSEnR1dZGbm4v8/HwMHz4cFy5cQGZmJrKysgAAS5YswfHjx6Gvr8/GJCUlBUpKSrh37x42b96ML774Ar6+vtDR0cGlS5egra0NX19fNvesra3ZM3bv3h2enp5QUlLC77//zl4AfX198eTJE2RmZsLf3x9BQUHo1asXIiMjERsbCzs7u0rrJTk5GSUlJXjw4AGT9S4uLmytcmOTn5/P5pqzszMUFBRQXl7OZPzLly/Rpk0b3LlzB7q6uli+fDm++OILpmNwMi4jI4OteU1NTTx+/Bg6OjpMdhobG7OxEzXenTt3RlFRETw9PREZGQlzc3O2FjiDSVhYGJsDAQEBaN++PQoLC3H//n32Auvi4gIFBQUkJSUx3UhFRQX5+fno378/k6NRUVFsvJWVlfHy5Us8efIE48aNQ1xcXCXd4cyZM/D394eurm619qxfvx779u2r1geKiopQU1ODubk5+87Vq1ehra2N4uJi5tyzs7NDeno63r9/j8mTJyM/Px+//PILjIyM4OPjgz///LOa7Fm2bBnU1dXRr18/psvk5uYyOW1tbY2lS5fiq6++QqdOnaCoqMh0PuH+Gzx4MFJSUtCmTRvcv38fsbGxsLCwYMZxCwsLmJubw8fHB4WFhTh+/Djy8vKQlZWF8vJyjBw5Eu/evUNBQQHT4Xbv3o1Zs2bB09MTWlpaOH78OKZMmYKbN2/ik08+gba2NoKCgvDixYtqz2BnZwcAuH37NszNzdnc43Ry7jCWvr4+Vq5ciV27dkFHRwc3btxAZGQkli9fjuDgYFhbW2Pq1KmYPXs2m9M3b95Enz598PTpU6SlpaF///54+/Ytew/ldFldXV1YWlpCSUkJ8fHxbDw9PT0RFBSEadOmsXVpb2+PpUuXYujQoZg1axZOnTqFrKwsDB48GIqKirXqmXv27GEOR2HZkp+fDyUlJURHR7O9gtND16xZw+aShoYGUlNT4eHhgaCgIOTn56OgoAB2dnb4/fffcfLkSRw+fBglJSUYMWIEvv32WzaOJSUlTBd88eIFW8tlZWXsMCA3tiUlJdVkPI/HQ3p6Otq0aYO8vDzcuXMHOTk51fSEXr16sTWWl5eHiooK6OrqMhuFqakpG8ecnBwkJCSgqKiIPcPcuXOhoKCAGzduMB1FQUEBampqyMnJgaamJjM4Ojs7Y9q0aTh06BDy8/ORlZUFc3Nz6OjoQFNTE8HBwbh58yYmTpyI/Px8vHjxgtkD7O3twePx8OzZM5w+fRr9+/dH27Zt2bVFrcu//voLHTp0wPPnzzFw4EBcuXIFRkZG1fb0wYMHIzQ0FBs2bMCGDRuQlpaGgoICtm9YW1tDIBCgW7du1daYsrJytb6oa08PCQlh85w7CLd+/Xrs378fjx8/Rq9evdga1NTUxMuXL9GrVy+mm2loaEBdXR1Pnz5lz+Xn58f2pMOHDyM/Px8CgQDTpk3Drl27EBsbCyMjIygqKjI9FAB4PB4OHz7M3p2Ex+nXX3+FmpoaKioqMHLkSKxcuZKt77i4uGr7HXedqvv7J598gsOHD1eSHWZmZnj9+jV27tyJDRs2sL9X7RdhXYd73798+TKbazo6Onj8+DE2b96MHTt2VJPnPB4PPB4PXbt2ZWNnb2+P27dvY/Hixbhx4wZu374NVVVVtjbc3d3x3XffoUePHky/5Prs5MmTGDNmDHMQcTKKey+5fv06nj17hoULF+LChQvQ1taGkpIS+/6VK1eq6Ra+vr7g8/l4//49s6kJy0c3NzcIBAK8ffsWfn5+SEpKwvv376u9B3AHFrnnqar/mJubA/hwMIRr75UrV5gMc3BwQMuWLXHw4MFqY5udnY2xY8diwYIFlfYNTj4mJCRg+/btWL58Ofh8PvLz8/H+/Xum982YMYPJI053+Oeff5h+lJKSAm9vb8TFxTGdoLi4mDmeuD3y/PnzrP9OnjwJf39/5OXlsfn5/v17GBgYQF9fHzExMcxOx+mKwvKIkxnBwcHQ0tLCv//+W00PE7ZJZmVlwcDAAJ06dcKJEyfQv39/hIaGYtCgQcjJyUFeXh7y8/Px/Plz9n7TqVMnpjNx+7ehoSGTqcHBwdDW1kZJSQnTNzp16oTi4mI8fPiQ6fEdO3ZEcXExXF1d8ejRI7x48QIRERGYNm0aFBQUEBISgrNnz6JHjx7o06cP0wX9/PyQmJiIlJQUnDp1CpMmTWLjyO27z549wx9//IE9e/YgPT2drV/hPYdDW1sbWlpayM/PZ9fx8/PD/fv3MWvWLKioqODw4cN49OgR0x04/aigoKCanC4tLYWioiLy8vKYHNbW1mZr3s/PDw8ePMDatWsRERGBoKAguLq6VtNBWrVqVU2fKC8vZ2tDRUUFXbp0weHDh+Hu7g4lJSWUlJQwe05RURGUlJRw584dtr45nb2m9wDOKTd+/HimI3NOxK5du7LveHt7V5PdcXFxbC2vXr0aW7ZswfHjx8X2Nfxn04UZGxtjyJAh6NChA8rLy8Hj8eDj44P09HRkZmayl8ajR4/Cz88P2dnZ8PX1xZYtW2BoaIjx48fD398fVlZW+PTTT6GsrIzp06cDAN6+fQsbGxu4uLhAX18fLVq0wODBg3Hnzh1oaGggODgYe/bsgbe3N3r37o0+ffqgoqICJ0+exNGjR5GZmYk1a9bA19cXDx8+hIqKCvr06QOBQAAvLy9s3boVrq6uaNeuHXN6XL58GcrKyujSpQsGDRqEyZMnIyAgAA8ePEBQUBBOnjyJjIwMeHt7o2fPnjh69Cju37+PEydOYM6cOXB1dYWOjg48PDyQn58PCwsLtGvXDn/99Reio6MRHx+P3bt3482bN+Dz+ejVqxdCQ0Ph6OiIsLAwODg44MmTJ1izZg10dXVha2sLBwcHGBgY4OjRozAwMECvXr3w/v17LF68GPHx8YiLi0NxcTG2bNkC4INjxs/PDz169ED//v2hrKwMJycnjBs3Dtu2bcPx48fh4+MDbW1tREREoKysDDk5OTAyMoKBgQEsLS2hoqICY2NjtG/fHkePHoWSkhJu3LjBDJ9WVlZQUVGBgoICtLW1cfnyZTg5OeH+/fsoLS1FSUkJfvzxR2hpacHX15fNByMjIygoKKCoqIhF7ezduxcZGRlo06YNhg8fjgcPHsDY2Bg//PADBAIB3r9/Dzc3NwwePBhOTk6YNWsWOnTogLi4OFhZWbEUSe3atUO7du2we/du+Pj4MIHCPXdiYiI6deqE/v37Q0tLC4cOHcKqVaugqanJ+jQ1NRVZWVno3LkzEhMT4e7ujuLiYub0cHd3h6+vLz755BN06dIFKioq+Oyzz3Du3DkoKysjLCyMvSgkJSXhxo0bmDBhAnR0dBAYGIi3b99i4sSJsLa2ZmNra2uL33//HQMHDgSfz0dERAQGDhyINm3aQF1dHZqamujWrRs6d+6MBw8esNNJbdu2RWFhIVJTU9G3b1/s3LmTGY7OnDkDFxcXKCoqYu3ataioqIC3tzdbt507d0ZkZCRu3LiBe/fuIS4uDnZ2dujTpw8SExPZZ2NjY5khd/Xq1ejSpUulPh86dCgGDRoEbW1tvHz5EkFBQQCAvn37wsLCgj2jnp4elJWV4e7uDnNzc2hra6NDhw745Zdf2Mtbamoq+vXrhxEjRqB9+/ZYt24dnj17hunTp+PKlSuIj4/H4MGDceXKFejr67P7ubm5ISgoCHp6erh27RoiIyORmZmJ9evXo6CggI2hv78/9PT0oK2tXWlehYWFQVNTEytXroSKigqLKkhJSUGnTp3Qpk0bdOnShZ0w8vT0hLGxMaKjo5Gfn89O3g4fPhz+/v5sPVy8eBHW1tbQ0tJCx44dmcyIiIiApqYmMjMzMWzYMAwYMKDSva2srDB69Gh4eXmx8bayssJ3332Hrl27QkFBATNnzgQAWFpaon379tiyZQuUlZXx2WefITIyEq1bt4aTkxOMjIzQs2dPnD59GmVlZYiKioKdnR2ysrJQUFCAe/fu4f379/D19WURF3Z2dsjMzMS1a9dgY2OD5ORkWFtb4+jRo5XGPiwsDDo6OnBxcYGOjg5iYmLg4eGBnJwcltpq4MCBMDExwatXryrdp0OHDnB3d0eXLl3QsmVLeHh4wMrKCosXL0afPn0QHR0NIyMjCAQCpsT26dMHtra26Nu3L4YPH46QkBD4+PjA1dUVXbp0gb6+PhwcHCq1/ejRo0hKSqq0Bxw4cAAWFhbQ1dWFjo4OhgwZgp49e+Lt27coLi7GxYsXYWRkVElu+fv7o1+/fkxmLl68mEVnurq6wtbWlr1Q7dmzhzlm2rRpAwsLC/To0QO2trZsTO/evYvZs2cjMjISt2/fRkREBADgk08+gZ+fHxQVFfHFF1/g1atXmDlzJh49eoTFixcjOzsb1tbW8PLywpEjR9C/f38mM5YuXYr79+8jLCwMUVFRiIiIgK2tLQIDA8Hj8Zih28LCAhEREXB0dMSGDRugo6MDHo+HTZs2wdLSEjdv3oSysnKl9WllZYXWrVtj+vTpuHHjBp4+fVpJnpeVlbG2hYSEQEtLC97e3rCzs8Pq1avZoQALCws4OTlBWVmZ/c3ExATjxo0Dj8cTeb1WrVrBw8MDXbp0wYMHD2BhYQE7Ozt89dVX6NixI3g8HubMmQNlZWUMHToUnTt3Zvvr7t27cfv2bRQVFeH9+/fQ0tKCk5MTk0H5+fmwt7dHcXExzMzMoKKiUmmtCe97f/75J5SUlODh4QE/Pz/s27cPAoGA6T0KCgpQUFBARUUFiyIxNjaGjY0Nc6JzJ4O5dhgZGeHKlSt4+PAhLC0toaOjw3QIBQUF8Hg8AIBAIICBgQEGDhwIV1dXdOjQATY2Nnj8+DFThE+cOMFODh09ehQrV65EZGRkpfZy8uLo0aOs31RUVLB582b4+fmxvwFgzyBKJ1JSUgIAmJqaokWLFlBSUmLPunv3bmzbtg0lJSWV9AnuBVK4r7h9rLi4GG3atIGzs3OlOZKWlobi4mJ20rp37964desWiouLkZqaioKCAnZyetWqVejevTuTmTwej7WTm2vCukGLFi3g7e0NJSUluLm5QUdHB1ZWVnBwcKg0b5SVlbFq1SqYm5vDzMwM2tra7BSen58f9PT0cOLECezevRuJiYmwsrKqpBtYWFhUm/vCuhWnP/L5fHZIhNunMjIyWNs0NTWhoaEBHo/H+lpPTw/BwcEoKSlhY8/t3dHR0ZXGJCEhAXw+v9J6a9myJcrLy9ncXrlyJSwtLTF06NBKz8i10cXFBXw+HwoKCkxv9fHxgampKXbt2oUrV65AR0cHrVu3Znub8Pzj+kJY1guvVW5shOcatz8Iy3gVFRX8+eef6NOnDwwNDXHixIlKOoa+vj4cHR0rrXlOXxWWncJjJ2q89fT02J7CyQdFRUXo6OiwQynFxcWV1oGlpSVsbGxgY2ODxYsXw8rKij2DsG6kpaUFS0vLSnJUeLwNDQ2Z0ZqbL8K6A9fnotrj7+8PAwODan3A6fiKiorQ1dVFYWEhG/vOnTtj0KBBePToEZvH3bp1g7OzM/766y/cuHEDampqWLlypUjZs3XrVmhoaFTSZYTlNNfXPXr0wL///ouYmBiR/VdeXg5DQ0NkZmZCU1MTpaWlsLS0xMSJE6GgoMDGgdNxtbW12dzv378/OnfujNLSUjx8+BAJCQlQUVHB0KFDYWJiAkNDQ+jp6QEA3r9/zyJc+/XrB0tLS5HP8Pr1a3To0AFGRkZsTIR18rCwMGRmZsLKygre3t4wMDAAn8+HsrIyUlNTUVZWBiUlJejp6aFbt24wMTFh82HChAlwcHCAj48PjIyMsH79+krvoW3atEG/fv3YGjM3N680nty+Ibwuub7k8/lMrnN7QV16prCsFJYtnOwR3is4PVR4/hUWFrLDb23btkXXrl3Z+9bkyZNx8uRJaGtrQ1NTE9bW1uDz+Wy9COuCwmvZ3d2dvctyYyss47lIo4qKChgYGCAzMxMvXryAoaGhSD1BeI1x7yddunRhe4XwOHL7pfAzcPuYsI7CyWsejwcrKyt06NAB7du3R1FREf744w+2FouLi5nM5eZFamoqdHV1YW1tXckewMlFT09PrF27FsXFxezaNa1LKysrXL16Ff3792eHQEXt6Tk5OSgpKYG/vz/rX+F9g9ufz5w5ww4CCK+xqn0hvKeXl5dX29OrzvP27dvD39+fyWThNcitMWHdrGXLlnB2dq70XMJ7EidLi4qKMGPGDJSVlbF+EdZDhY2n3NgKjxMnH42NjTFo0CB06tSJrW9R+x0Akfs7N8+FZQe3Pv39/ZlOK6pfhHUdToYJzzWuz/z9/SvJc24Ncs8oPHavX7+GsbExXFxc2M/CawP4kFVBWL/k5JGHhwd0dXXRpk2bSjKqoqKC6b5KSkrg8XjMDiLc56J0Cy56nmtvVfno7OwMDw8PtG7dGsHBwVBUVBT5HiDcv6L0H+E2cj8Ly7CioiKcO3dO5NhaWlpi0KBBMDY2rrRvcPKxc+fOOHr0KNLT05msE9b7ysvLmTzi9ixh/cjGxgZXr16tpBNw+qfwHincf1zbhOcnpzOpqKjA29sb3377bSVdkZMZfn5+TGZw61KUHiYsg7hrr1y5stLYc1H1nNwSfr8Rfg/n9m9hmcrNEWF9g9O9hPV47m+ZmZmwsbGBmpoaO6jOzXFPT08oKioyXdDIyAgpKSk4evQo258sLS0xePBgFmnl4eHB9Ck9PT22foX3HOG5xo298Hzg3gNOnz4NCwsLaGtrV9IdOP1IlJzm3ju4w+slJSWV1jwnb/z9/dn+LkoHEaVPCK8NLS0t9O7dGwoKCjAxMYG5uTkeP36MoUOHwsDAgM0R4fUtbI8S9R7AyQlhHZl7nxX+Tl5eXjXZLbyWublQH/6z6cI4T3J+fj6cnJxw+/ZttG7dGj/99BO2b9+O1atXQ0Hhgw+qd+/eOHnyJK5evYqRI0di6dKlcHJywq5du+Do6IiysjJERkaiY8eO6N+/P+Lj42FsbMxe8oKCgnDz5k1MmzYNPXr0QK9evRAUFIQ5c+agZ8+eSElJgZ+fHwthf//+Pezt7ZGTk4P169dDIBCwU/3cRFRXV8ekSZMQGBiI/fv347vvvsPy5ctx+vRppKWlYefOnWwDc3V1xc6dO/Hs2TPcvXsXEydOhJKSEku/waGiooLz589j7dq1+Oqrr7B27Vr88MMPKCsrY+ltJkyYgEePHsHNzQ0zZszA559/jq5duyI/Px/ffPMNunbtij/++ANeXl5wdXXFzz//jPXr18PAwADLli3DjRs3sHTpUlhZWeHw4cMAPqQPyM3Nxd27d3HixAnWDxcvXoSysjIUFBTg6+sLIyMjHD58GJ07d8bkyZNx7949dhJm9OjR2LJlC16/fo03b95g586dUFJSwr59+7BlyxacOnUKurq6OHjwIP744w9kZmYyQ1CHDh3g4+ODr7/+Gl27dkXbtm3h4uICDw8PNh8EAgF++eUXGBgY4O+//8aPP/6Ijh07snQRkZGRmDdvHqysrLB3714sXrwY33//PfMkt2zZEsnJyVBUVGRpNcaOHYtWrVohKCgIHh4eUFdXx6FDhzB58mTExMSwaJKBAwdiz549uH//PrZs2YJbt26hf//+6Nq1K+vTefPmITY2FidPnoSCggKOHTuGN2/ewNHREZMnT8arV68AAMOGDcO0adOwdetW8Pl8HDhwAEeOHMGCBQtgYGCA/fv3A/ggkABATU0Nf/zxBz755BMcOXIEJiYm6NSpE1xdXVmNBTs7O7i4uODBgwcIDAzEu3fvoKmpiQcPHmD58uVYvnw58vPzMWrUKKSlpaF169bQ19dnNRcAwM3NDYsWLUJBQQHOnDkDHx8f+Pn54ccff4S7uztGjBiBcePGQUtLCwcPHsSVK1fw4MEDmJmZ4ebNm5g5cyZmzpyJ8vJyjBgxAikpKVBVVcWlS5eQm5uLdevWoaKiAmPHjkXLli3ZKbhhw4bh/fv36NWrFwYOHIiuXbvi1q1bMDIygqurKy5dusRePCdMmIB79+4hPDwcq1atwvbt2+Hm5oazZ89i1apVyM7OxoQJExAbG4v27dtj165dWLNmDW7dugUA4PP58PPzw+jRo9GrVy+sXbsWfD4fn3zyCfbt24c1a9bg/PnzWL58OXbs2IGoqCi8efMGADB58mRs3Lix2rwKCAjA8ePHYWVlha5duyIwMJA5Xnbt2oWCggJ89tlnsLGxYcotAIwePRqTJ0/G/fv3UVBQgBkzZmDYsGF49OgRCgoK4Ovri507d+LJkycwMTHBxIkT0a5dO5w5cwabNm3C3bt38f3332PTpk3s3rdu3YKfnx9UVFTA5/MxatQo5OTk4Msvv8SSJUugoKCArVu3Yty4cXj79i22bdvG1jqXFuLSpUvo168flJSUWCqoIUOGgMfjwd7eHkuWLEFMTAzU1NSwePFinDt3Dvfu3YOpqSl4PB6sra3ZPLexscGQIUOqrTculcGlS5dYqhJXV1c8f/6creWdO3eivLwcACrdx8rKChMnTsScOXNw4MABpKWlYdy4cQAABwcH8Hg8XLhwAa6urnBwcICLiwuWLFmCwsJCBAcHs3QRT548wfDhwzF//nz89NNP2Lt3b6W2f/fdd4iJiYGnpyfbA7g51KtXL3ZPTU1NJCcng8/no2PHjiwknJNbp0+fho+PD4YNGwY3Nzd8++23ePHiBWJiYpiywOPx4OTkhLFjx8LGxgaurq5QUVFBXl4e3Nzc0K5dO0yePBlfffUVxowZw2R969atMWXKFIwbNw7379/HH3/8gYSEBISHh2PWrFn45ZdfsGrVKjg4OMDV1RV8Ph9WVlYAAFtbW7Ro0YKdpAWAqVOnwtXVFVu2bMF3332H77//HkOGDIGGhgZ27tyJCxcuYOTIkfDz84O3tzcLT/fz88OmTZvw7t07jBs3Dunp6Wx9/v7775g5cyYsLCzw008/Yd++fRg0aBCT50OHDsXNmzexfPlyuLu7Y+TIkSgoKMDNmzcxb948FBYWYufOndDT08OWLVtw584dmJqaYufOnQgKCsLIkSPRoUMHfPrpp9WuV1RUhLdv32LZsmW4ePEiHj9+DBMTE7ZGsrOzER4eDnt7e4wdO5aFLnMniz7//HNs27aNKbzW1tbo2bMn7t27h8ePH6NDhw5YtmwZfH19MWfOHBQUFLC1ZmBggC1btrA96dixY9i/fz/OnDmDcePGMcPHsmXLsHLlSpSUlKCiogITJ07ETz/9hG+//RZLly5FUVERhg8fjs8//xzu7u4YPXo0rly5wgw7c+bMwf379zFkyBBs3boVxcXF7EQld4pdU1MTCxYsQPfu3TFu3Dioq6sDAObOncv0j4MHD8LZ2RlKSkpYvHgx5s2bh8DAQNZeTl4oKSlh9erVCA8Ph5eXF+s37kRT79694e/vjy+++EKkTrRmzRpkZ2dj8uTJ2Lt3L4YOHYqwsDAsXboU6urq2Lp1K44fP46tW7cyfUJZWRnm5uaV+io7OxutW7fGkiVLoKysDD6fj5UrV7I5oqGhgYEDB8LCwgIA2CntAQMGsFQB2tra6NSpE4APJxynTZuGUaNGgc/no3v37rCzs0NGRgb27NlTSTfQ1NREZGQkVq9ejV9++QWfffYZEhIS0KVLF5YG46effmIydeHChejZsydGjx6NJ0+eYPny5Vi6dCnOnz+PL7/8EgCwYMECXLt2DStWrGC6QUxMDH7++Wc2l4TnvrD+uGbNGigpKaF79+7Izs7Gxo0bK7VNV1cXx48fx5w5czBlyhQsXboUOjo66NKlC6ZMmYIBAwbA2dmZrYeLFy+yz6mrq2PBggUIDg7GlClTMHLkSPTu3RtlZWV4/PgxDh8+jGPHjuH48eOwsbFBWVkZnj59yp6RM4Jxfezk5AR3d3d8//33GDhwIGxsbLBo0SLk5uZCQ0MDVlZWSExMxPfff19p/iUnJ+Pnn3/GhQsXmKy3tLRka5Ubm5KSEjbXuP3hyy+/ZDKea4uvry86duzIouk5HUNFRQW//vorOnbsCCcnJ9jY2OD169fIyMhgc8XW1haOjo5s7ESNd2ZmJvbu3YuNGzfC2toac+bMYQcKtLS0UFBQgAEDBqBfv35sHXDRKNxL6ejRo2FkZIS0tDRs27aN7fGco0BYjgqPd7du3dga5uSnm5sb0x1KSkqwaNEipKamVmsPAHh4eFTrA09PTwQEBMDCwoJ9hxv7JUuWoKysjM2Va9euoU2bNvjrr7/w888/w93dHQsWLMDx48dFyh7gw/ugsB4VGxvL5HRoaCi+/PJLpKSkYP369eykcdX+i4iIgLKyMtasWYPIyEiUlZXBw8MDI0eORPv27REYGIg5c+agoqICZ86cwebNm3H37l04OzsjNDQUI0eOZCmKv/rqK0ybNg1jx47F8uXL0bp1a0yaNAnjx49HbGws+vfvj379+qFr164IDw/HpEmTqj3DqlWr0K9fPxZBtHjxYty5c4fp5IcOHcK5c+ewbNkyLFq0iB1y8fLywrx582BgYID27dvj9u3bWL58OY4fP45bt26xOV1aWopBgwbBzMwMe/fuxebNm5nMPX78OMLDw7F3715ER0fj999/rzSeAwcOxP379+Hn58fW5ZAhQ7B371506tSJyfXRo0dj3rx5deqZ48aNQ0xMDPbs2YP4+HgmW7hoeV9fX3bN1q1bY+vWrUhMTMTr16+hpaWFd+/eQVtbGwsWLMC7d++goKCAnj17YsuWLXj06BH4fD62bNmCuLg4hIeHY9OmTdi5cycWLFiA0aNHs7XOyW9lZWWYmJggKSkJfD6fje2dO3cwatQoKCoq4pNPPoGdnR2ys7PZHslFz1dUVFTTE3r16sXWWFFREVxdXdGxY0esWbMGWVlZlcZRX18f27ZtY7L70aNHKCkpgbm5eSUdRVdXFxs3bsTmzZsxa9YsLFiwANHR0WjdujWWL1+On376Cb/++iuWL1/O9A53d3e0b98e8+bNQ2ZmJg4cOIDz588zewBnI5g0aRKCg4ORk5ODe/fusawYotaloqIigA/pq4YNG4YpU6Zg7ty51fb0I0eOwMvLCwDQqVMnJCUlYdCgQWzf4Pbn8vJynD59utIas7W1rdYXde3p48ePZ/NcSUkJzs7O7H0hMzMTc+bMqbQGFy9ejLt37zLdLDs7m2X44J5L2O7y4MEDnDlzBn5+fhg5ciT69evH+uXFixdMD+WMvuPHj0dycjK2bduGv/76Cx4eHlixYgWePXuGgIAAlJaW4ssvv8SyZcvw+++/49y5czXud9yeJry/29nZYcuWLWzf5N6TOHtZx44dmU4r3C+ck4bTdTZv3oyvvvqq0lyLjo5GRkYGAGDZsmXV5LmpqSlKS0tRUFDAxi4+Ph56enro2LEjVq1aBT09Pbx48YKtjdu3byMsLAxTpkxh+iUnj3bt2oUNGzaAz+dXklELFy6EgYEBfv75Z7Rt2xampqbMDvLHH3/g5s2bmD9/PiwtLavpFomJiXjw4AG0tbWhrq5eTT6eP38eAGBoaAg3NzdER0dX6jPuPaBVq1asf1+8eFFN/+HaKNze6dOnMxkWHR0NPp8vcmwfPHiAL7/8EseOHYOCggLbN16/fo09e/bg6tWruH79Oktlr6CgAE9PT2zduhWKioqIiYlh8ojTHdavX8/0o7i4OACopBNwa9fW1pbtkVV1s0WLFiEqKorNT2tra0yePBkaGhrIy8uDn58fi+SZM2cOk0fCMoNLfWZra1tNDxO2Se7du5fJfm7s9+7di/nz50NFRYUdWrx16xZ7v/Hw8GA6E7d/czL11q1bEAgEOHLkCJYtW8b0De4drU+fPpV0zJ9++glz5sxh78jz5s0D8KFcwfjx42Fra8tS8vn6+qJz586YOHEiAGDXrl3YunUrHjx4gMWLF+PYsWOIiopCWloa/vzzT9YeXV1d/Pzzz/jrr7/YnmNkZMTm2rNnzzBp0iTweDw2HwwMDDB69Gjk5eXh/Pnz2LJlC9zc3JjuwOlHovSnkJAQREZG4vDhw/jss8/g6enJ5IK9vT2MjIxw7ty5Su+F3GELYR2EswtW1Se4taGiooLt27dj3rx5UFBQwO+//46pU6eia9euiI+Ph6GhIY4fP47169ez9V1WVsbsUdxaFX7XCQoKQlhYGPr27ct0ZO59Vnh9P3nypJrsfv36NVq0aIHnz58DALNhiMt/Nl1YSUkJlJWVMX/+fGRnZyMnJweKiopwc3Nj6aAyMzMxZswY9gLTsWNHmJqaYsSIEcjIyACfz0dFRQWWLVsGgUCAW7duwcXFBQcPHsTw4cMxefJkLFy4kClChoaGyM3NZSeYZ8+eDeBDXk7O+AkAISEhMDExwZw5c8Dn89lp1U8//RQpKSm4ffs25s+fjzZt2mDZsmWs7gp3/aKiIhgZGSE8PBzff/893r17h+TkZJiZmcHe3h6DBg1i6TCEc2sLc+3aNfz5559QU1PD2rVrsWnTJnz11VeV6k0AQGpqKsLCwtCuXTt8/fXXKCkpwZAhQ9ClSxeYmZnhxIkTuHfvHnx8fLBjxw7MnTsXvXv3FvncXG70o0ePorCwED4+Pjhx4gRmzpyJMWPGwM/PD/7+/mjbti0UFBSQn5+PgwcPYv78+SzUjzt5yl23pKQEOTk5ePToEaKiomBpaQkTExNYWVnB1NQUISEhaN++PXR0dLB69Wr4+vpi9erV+Prrr/H7779j9OjRGD58OKs1Ex4ejtWrV0NFRQX6+vqYM2cOO4FQWFiIO3fuMCO9mZkZ1q5di6dPn6J3797w8/NDQUEBwsLCEBsbCwAwMTGBgoICNm/eDHNzc5ZS4tKlSwgLC4Oqqip0dHQwZ84cvH79Grq6utDQ0MD69euhpKTEQv2dnZ1ZvReOwMBAmJqa4uXLlxgzZgy2bt2KsWPHsjojhYWFMDIyYuHzly9fxqBBg9hJ8o0bN8LHxwcBAQEYM2YMQkND8f79e1Y/AQCSk5Px5s0bdspq7ty50NDQQPfu3WFgYIDs7GzmTedOF6Snp+PQoUMsNHPXrl0YP348Ro0ahffv3yMuLo4pkEeOHIGSkhLc3d2xYsUK+Pj4sLDMKVOmoG/fvoiJicGOHTtYPtEVK1agQ4cOAMCKgx8/fhx37tyBi4sL5s6di4ULF0JZWRm6urqsD21tbXHv3j0UFBQgIyMDLi4uaNmyJZvz8fHxsLS0RFJSEktHFhwcjOXLl2PcuHHMWebq6oqDBw/iq6++wrZt2zBq1Cjo6enhzz//xIgRI9C9e3csWbIEqqqqcHd3x/nz51FSUoIZM2YgJycH//zzD0aPHo2ffvoJQ4YMYQb14OBghISEoEWLFti3bx80NDQwb948dO3ala0nLg3isGHDEB4ezl4sSkpK8Omnn+Lrr7/G3LlzYW5ujhMnTmD48OEoKSnBL7/8Uqm933//PXsxNDExYSGb9+7dQ35+PvLy8tC3b18oKysjOTmZhTdzc5DLp3nt2jXk5eXBx8cHeXl5KCwshJOTE06cOAEzMzP4+PhUkykvX76Ek5MTzp8/D2VlZQgEAvz888+YMGECRo4ciY0bN+Lp06cwNDTErVu3mHFq/vz5KCoqwoEDB7Bq1SoEBQXh6NGjzAjl7u6O8vJyZGdno3v37khJSWFRSOfPn4eenh5atmwJTU1N/PPPP3j9+jWsra1ZhAyXwszR0REbN27E27dvIRAIkJSUxOQvABQVFUFVVRUZGRnYsWMH7O3t8fDhQ+Tk5OD06dPo3r07C8feuHEjgA/1sDgDiba2NpYsWYJ+/frhzJkzyMnJYQ4Ubl1yfbRx40Y8efIE+vr6+O233+Dv74/ffvsNX375Jby8vBASEoKCggJ069YNFy5cgIGBAdzd3REZGYlZs2ZBW1sbYWFhcHFxgbW1NWbPno07d+7A0tISjo6OTKkHgE2bNsHDwwMZGRkwMDBgeXR79+4NDw8PzJ07F2PGjIGmpiZyc3NRWFgIY2PjSvvKy5cvoampyca6tLQUf//9N1q2bIkxY8bAwcEBs2fPRnl5OXJzc9G3b19cunSJpQs7cOAAxo8fj4cPHzKjMeeMCg0Nha6uLj799FMm+7/66iuMHj0aUVFRUFJSYvvuy5cv2em6pKQkJCcnVxpDbj3FxMRUkqnAhyg5W1tbBAcHIy4uDs7OznB2dkZ0dDSioqJY7TVOxwgODma1ZACw+mhclFPVNcTNH25/1dDQQGJiIqytrREUFMTWyu7du6Gjo8Nk6/v379ne9/r1a5SVlcHR0RHnz5+HtbU1ysrK2DMK1yg6efIkfHx8cO/ePcTGxmLy5Mm4dOkSOnTowMapqKgIDx48YH1x69YttGjRgukaubm5ePPmDavjVLUfuUiZR48eMdlRXFzMnpW7DgDExcXBxsYGFy5cQGxsLCZNmoTLly+zZ+DS7hw6dAg6OjpMDgEfomHLy8vx5MkTNn+4+wj3C/DhxCDXl1xtIENDQ1haWjL50759e4SFhWHEiBGV5kB6ejoEAgEePXqE/Px8uLu7Izk5Gc7Oznj48CHy8vKgra2Nd+/eISsrq9IeCHyo4fXq1SvY29vj4MGDGDx4MO7evQuBQIDCwkJYWVmx9EbC905OTq4mb4qLi5GSkgIbGxs21zjDofC+m5OTg6ioKDbGly9fhpWVVaV5AQC7d++GtrY20w2E+0IgEFST9cCHVIBPnz5FixYtYGtrW209cSdAhb/D/cyNiZOTE3777TeYmpqiffv2leYQFxXB6WHC1+H0SE4XSUhIYP0n/O/cd4R15JcvXzKdKiEhga0XHo+HgoKCStcRrgHFpefirpeZmYmioiL2fW7tcDn7hceeq4XG/a1qe6ytrdlJd2HZwTkszczMRMoWZWVlnD9/HiYmJtUigIXnD5e2gZN/HMLjcP78ebi5uUFXV5fVdRPWjZydndGqVatqezcnM4X1pBcvXuD27dtMLhYUFCA+Pr7SeHfo0IGNd23jxMkIYVlXVR6VlpZWWiPcnBG+HtcXjx8/Rrt27di9hWW7qPpf3LWE5xU3H6KiopjOk5+fz74r6jtnzpxBUVERmwPcfi48xzi41KQCgQDh4eHIy8uDu7s70tPT2TMKjyd3LQCVap4BqLQ2hNvFtS07O5v1M5daRiAQIDo6ms3pqnXUuDZyaa1fvXqF+Ph4kWuQ++zZs2eZXKtpLr9584almAY+yExuDxIlJwoKCvD69Wu0bNmy0r9HR0ezcS0pKUFeXh5atWqFu3fvolu3buz7wnrAixcvKj0jVzsrIiKiUhtFre+kpCQ8efKk0rzi5vTLly+ho6MDY2NjJCUlVXqX4Hj06BFL88X9nUuDW1hYCDU1NZHzXHi+REZGsv2dW6NcSkknJyecO3cOLVq0YGNdVV8TJc9TU1ORm5tbaVyFxzYiIgKvX79mkWSXL19m8zkmJgaTJ0+GsrIywsPDkZiYyPbaqjKTk2EmJibsfeHcuXPo0KEDoqOjYWZmxp4LQCVZWvUduLi4mJ3IF/6biooKazc3ttza6tu3L+Li4mBtbc3kFPDhQG5iYiK7t0AgqLSGRe1tov4m3Abhn7l/Dw8Pr9S/3Brh2piVlQV/f3+Eh4dX0z8TEhJYGi7hecHJOldXVxQUFLBn4PF4KCwshIqKCszNzSvNxao6HoBqMqO4uBgZGRlMJxCuycvpI5wedu/evWpjwz23m5sbk+ecPDh16hRSU1MxadIkloJSuC6o8P04xySnX3LyUU1NDYWFhdX6gmuv8PwVls2FhYUwNTVFt27dcO3aNWRkZMDV1RUtWrRgczU+Pp49T3JyMrS0tFhf3bt3D5aWlpX2Gm6tlpSUICkpqVpd4ZcvXyIzM5PJiarPCgD//vsvysvLmQ7MyczOnTujoqKi0v3Mzc1x69atajaLqm0DUGlv5GTltWvX8PLlS9b/HFXXWFpaGjQ0NCrJXhMTE7anC19b1L2rjsP58+eRn5/P+kV4bLl9VVinBz68n1RUVCAhIQE6OjpM3+B0RUtLSybbuf28tLQUr1+/hpKSEjp06FBpTZuYmKBbt24IDg7G7du3WRYC4b2aay+3b1QdTwAi9SyOrKwsPH78uJoNRNQa4/T7ixcvssPJBw4cwJAhQyp9VnhsuOtw7yqPHz9GVlYWS1so/B4AfNg/uTlfdS/mnjU8PJxFDlW1HdekZ3FjW1BQUOm9jru38DiVl5fj1atX7PonTpyAiYkJ2rVrV+k9ibPZcvpMUFAQ09m595aqekvVec71LaczVZX3NeklVe3WdfGfdbIsWLAAurq6uHbtGlRVVWFhYcE2URMTE8THx7N80A4ODrh9+zbLFfjq1Svs2bMHGzduhKOjI2JiYtjpohcvXiA+Ph5+fn4oKytDfn4+Xr9+zU4uKCgo4Pvvv8fChQtZ3ZMvvvgCurq6iI+Ph6urK969e4fg4GB4e3uDx+MhOzsbXl5eOHjwIPLy8piB0NbWFrdu3YKTkxPi4+Ph7u6OvLw86OnpQU9PDxkZGeDxeLhz5w6Cg4Ph4+ODTp064cGDB1i1ahU7Fblq1SqMGjUKampqGDt2LAAgNDQUHTp0YKfCCgsLYW5ujiFDhuD06dMwNjZGaWkpbt++zfK5c6HNXK5iTU1NZtjmhO3EiRMxfvx4AB9Ok23bto2Nyfz583Hjxg08fvwYTk5OEAgEsLCwwJw5c3Dq1Cncu3cPkydPxvr16+Hs7IyePXviyJEj6N27N27evMleqLg8vf/73/+wePFiREREMONoQkICMjMzoaSkxNIZJSYmAvggZLiTaEuWLMHo0aNx9epV9O3bFxcvXgTwIbSbewGOjIzEzJkzWR0aACgrK8O9e/fQq1cvAEB5eTkqKiqQkpKC6OhoKCsrY8+ePThw4ACUlZWhpaUFFRUVXLp0CdbW1nj06BEsLCygoKCAAQMGYP/+/ejYsSNCQ0PZmCckJODVq1f49ttvER0djTt37qBTp044f/48DAwM0LlzZzx58gTx8fFQU1NDjx49EBoaiv79+7Och1w9jrdv37I8pN9++y0WLVqEt2/fYtasWdixYwemTp0Kf39/Vmxr8ODBuHz5Mt68eQMbGxu0atUKZ8+eZU6n06dPY9WqVYiKioKJiQm0tLTw/v175OfnIy0tDSoqKlBSUsKzZ88waNAgVo+GKxa3YcMGCAQCJCQkwNzcHHPnzkVMTAzOnDmDsWPHIjExEYmJiXj58iUcHR1RUVGBxMRE7NmzB3///TeOHTuG0tJSmJubw8bGBleuXIG1tTXevn2L8vJy/O9//8P+/fvRtm1blJaWwszMDC9evEBUVBRUVFTYi6uSkhJKS0tZijkuB66BgQGbJ/r6+khJSYGysjIUFRWxefNmrFy5EpqamuxEekhICGbOnIns7Gzs2rULvXv3ZkZ7TU1NZGdnw9nZGaqqqixlWffu3XH27FlMnDgRJ06cwGeffYbU1FQ8evSIfcfFxQU///wzJk2ahMOHD7MT25yzcNGiRVBWVoa9vT34fD5UVFRw8+ZNdlrrzZs36NmzJ0pKShAXF8faO3ToUFy6dAkJCQlwdnZGfHw8S+kSFxfH+kdfXx9xcXGV1gb3QqOvr8+ccdxJkwsXLkBBQQFWVlbQ09NDcnIyiyL89NNPcfLkSVafKCgoCH5+frhy5QqWLVsGc3Nz/PbbbwgICMDEiRPx+eefY8+ePdDV1cVXX32FCxcu4MmTJ7C3t0diYiKUlZXZs9vY2CA+Ph52dna4fv06Hj16xE7aZGVloWfPnrh16xZ69uzJnJrcyaeCggIoKiri5cuX2Lp1KyZNmoQBAwYgODgYvXr1wu3bt1mqibKyMri5uUFbWxtRUVHQ0NCAmpoaHj9+DENDQ1b0nKtRo6KigvLycqxatQoJCQnIyMjAb7/9BmdnZ7i6uuLq1atwc3ODjY0N9uzZAzs7O7x584atS+5Ednp6Oi5dusSKg3fr1g22trbIzMxEYGAgvvvuO7Ru3Rrx8fHw9fXFkSNHkJGRwfaQZ8+eQVlZGba2tuyExq5du+Dp6YkWLVogKioKnTt3RlRUFFJTU6GqqgpHR0eoqanh0aNHsLe3h62tLS5cuIDWrVuzPLuKiopwdHSEnp4e1q1bh9mzZ6O0tJSloLCzs2Ofi4qKYlFDAwcORHBwMGbMmAF9fX0EBQWx05J2dnZ49eoVXF1dER8fj5kzZ0JBQQE7d+6Es7MzRo0ahVOnTiE/P5/lWX7x4gVLy7dkyRKcPn0aY8eOxeHDh1FeXg5PT0+YmJjg7du3ePnyJZSVlaGnp4dJkyZh9erVSEtLg4mJCUsNwuXpVlFRgampKcuJq66ujtatWyMkJITVXmvZsiUMDQ1haGgIbW1tFnLP5XLm8r1yMpKrPcPti9yaVlVVxfjx47F7926YmpoiMTERKioqrL6Pnp4e8vLyEBcXByUlJWhoaCA7OxtGRkYwNTWFsrIy7t69y1IK6evr4/nz56xGUWFhIeLi4qCmpgZnZ2dERETAw8MD9+/fh66uLtzd3REVFYWUlBRWpDclJQUqKiowMzODqakpK/ZeUlKCTp06wdPTE9OmTcOmTZtw9epVJCYmsnRV+vr6SE5ORk5ODtuzudQNXbt2Zf3L1bWIiIhAp06dcPfuXXh4eCA6Ohq2tra4ffs2bG1tWTpVe3t7rFmzptp9kpOTq/XLw4cPWf5sT09PtG7dGtbW1li9enUl3SAhIQHv3r2DiYkJvvnmGyQmJoq8z8OHD1ndN2dnZ2RmZiI3Nxf6+vpsfLniz+PHj8fTp08RFxeHxMRE+Pr6IjQ0FC1atEB6ejq0tbVRUFCA7OxsxMXFsXtzcuLixYsoKytDeXk5evfujcjISCgoKEBFRQUTJ07EmTNnkJubi8DAQFbrSEVFBRERERAIBCL79P79+9DX12cHjtzc3JCXl8fSwtja2iI+Pp5Fd3t6euLOnTto164d9PT0WH00VVVVxMTEsNQIbm5u0NLSqlQbi6s5l5qaClNTU2YcyMnJgbW1NR4+fIjevXuzOfTFF18gJCQEFRUVEAgELKqPu3dISAh69+6Na9euwcDAAPPmzatU4+nff/9ltYOcnZ1haWnJDlf89ddfKC8vh5GREfz9/XHv3j3k5uYiPT0d9vb2iIuLA4/HQ/fu3XHy5El2MCIqKgpZWVlwdnaGjY0NoqKiYGVlBR0dHQwbNozpyI8fP8bSpUvx/fffIy0tDXw+n+lefD4feXl5LI0q94JdXl4OJycn9vJ55swZxMXF4d27d0x2urm5Mdly5MgRpKSkQFNTE/Hx8dDU1GTR8PPmzcPNmzchEAhw9+5dVlMsMzMT5eXlsLOzY3LtwoULMDIywvv37+Hn54ezZ8+y4thlZWXVdCNra2v2PsClXblz5w6ys7NhYGCAVq1a4dmzZ9Xkor6+Pry8vHDo0CE23qqqqixVWm3j5OXlhQEDBuDSpUu4c+cOlJWVmf7KySMuGkBJSYkdXNLU1ISBgQG0tbVZ/6ekpLCaXQYGBmjXrh2TPVxKxsLCQnTu3BnBwcHo3r07S+Girq6O06dPQ01Njc2H9PR0WFpaYsaMGWzMevXqVSntS0hICEsxo6WlhZKSErx58waZmZksLXXbtm1ZDSorKyu8evUKvr6+CAsLQ0BAAMLCwvDw4UOW+ok7Mc3pE2vXrmXpT/39/eHo6Ijvv/+e1Z3IycnB+/fv4ePjAx6Ph40bN7L6m9evX0d5eTlWr16N8+fPw8vLC2vXrq0mK69evcrWxqeffoqgoCAYGRmx95cZM2awNailpVWtr4Tl2t27d2FoaMjG+scff8S8efPwv//9D927d4e+vj7+97//Ydy4cYiPj0deXh6bNwYGBlBRUcHAgQOZTM3NzWX/zqW44RwMXDH7hw8fIi4uDoaGhvDz84OjoyMyMjKQkJDA5iynG3MZBcLCwjB+/Hjo6+vjypUrTL9bunQpYmJi8OTJE1hbW7N5paCgwGqw3rt3D+3atcPdu3fZPOb0Dq621bRp07Bx40YcP34cjo6O0NXVhaenJ3Jycpihl9svtbS0UFFRASsrK7x8+RIqKiooKiqqtFc7ODjg/fv3THZzaU2F17eFhQVMTU2hpqbG1kZ2dnY1eS5cB9XFxQVPnjyppKPo6+sjICAA58+fR1FREXJzc6GlpQV9fX0kJSXhzZs3UFFRgaOjI5uT3F7L2VkSExOhp6fHZJiSkhJat26NO3fusL04Ozub6S2cnBbeLzMyMqClpQUTExNWU4KTs6NGjcLKlSsxd+5cNicnTJiA7OxshIWFQVdXl635vLw8lJeXIz8/Hx07dsTQoUPZerh9+7bIe3P6kUAgqFR71cDAAGpqakhMTIStrS2rFzJ+/Hh2MAcA2w85Oe/i4gJNTU20bNmStTEgIAB///033r59C2tr62r6p7KyMhISElgkHjd/uDnJ4/HQunVr8Hg89gweHh7sOzweD/r6+igtLWUylatJ2bVrV4SGhiIvL4+l6YmMjGT2H0VFRZSXl4PP54PH47F3HM45nZ2dzdK1PX/+nEX8cvfp27cv9PT0UFBQwGxzr169goqKCtasWVNJrnF7VlRUFDQ1NREXF1dNH+MylSgpKaG4uJjJeK6GEnfAbf78+eDz+dVkc0FBAXJzcxEQEIDDhw9Xswfk5ubC0NAQJiYm0NDQQGxsLPT19WFqaoqrV6/CyMgILVu2RIcOHZhsiY+Ph5aWFpN/bdu2xe3bt9n8EQgEaNWqFRuXQYMGsf37yZMnyMvLQ15eHtTU1GBra8vSFl64cAHq6upQUlJCQUEB05G4+deqVStmI/zzzz9Z27y9vWFvb8/WooaGBkpLS5ku+c0337B91cbGBgoKCkzvs7KyQnx8PKunUlX2mpubw93dHYWFhYiNjYWJiUmlfjl8+DDU1NRYKkBuHDiZumfPHuTl5SEhIaGaTs+lszQzM8OVK1cwd+5cZGZmonXr1ti7dy/MzMyQmJgIHx8fBAUFMZ3TyMgIeXl5UFRUZHWFzczMUFZWBkNDQ6Snp+Obb77Bli1bkJubCzU1NWY39Pf3x5MnT3D16lW0atUK2dnZ6NGjBzIyMnDu3Dk2ni9fvsSbN28wfvx49p65atUqPHr0CMnJyXj9+jXatGmDP/74A25ubkhNTYW9vT1evXqFQYMGiVxjnH4v/E7Epdi3srJiY3Px4kUYGhpiwIABIteGoqIi3r59CwUFBXYdZ2fnas8tvM8ZGhri9OnTMDAwYDL+zp070NTUrKQ/cvczMDBgsj87O5vZiRUVFas9A1dv2sfHBxcvXoSTkxNUVVVhYGCAhw8fwtjYmNUE496T2rVrh/v370NHR4e9Fzs4OLBn4Oby48ePmd4yZMgQ2Nvb45tvvmHzpmPHjjh16lSlcRKW91X1kitXrmD37t344osvWMpFcfjPpgvj6nl06dIFSUlJiIuLg4KCAitK3L59eygoKGDEiBEICQlhxceUlJRQWFiIHj16YMOGDTA0NISxsTGsrKzg6OjICpX+8ccfGDZsGDsB//r1axQWFqK0tBS2trbQ1NTEjBkzIBAIEBkZCW9vbxw9ehRhYWEYM2YMFBQU2EkezgvbrVs33Lx5E4cOHcK0adNw9+5dKCkpwdbWFsbGxggODoZAIICPjw9Onz6N4uJi8Pl8djpSIBBAVVUVnp6eGDhwIIYPHw5lZWVoa2tj0qRJMDAwgLq6Ovbs2YNp06Zh9+7dmDlzJlvkALBu3TooKCjg0aNH8PX1RWxsLNq1a4e4uDhUVFQwYxj3YpWYmIgNGzYgIiICDx48QFhYGMLCwthze3h4oHPnzgCAu3fvIjExEbt374adnR3zwJ84cQIGBgbo0KEDysrKkJCQgK+++gqvX7+GqqoqK7ZVWloKR0dHBAcHg8fjITU1lRX75uqbzJ8/H4WFhVBXV8epU6cQERGB2bNno6ysDAoKCrh06RKmTp2K48ePo6CgAL1790ZiYiKmTJmCK1euMKVeXV0dWlpa0NLSQmlpKfbs2QPgQxixoqIiwsPDUVBQwE5VWFtbo3Xr1nj58iU2bNiA1NRU2NjYoLS0FMCHzTA8PBxz585lp04//fRT7N69m+W4Hz58OLZt2wZra2uMHTsWr1+/xoQJE5CVlYWjR4/Czc0Nz549AwDMnj0bFRUViIiIwKFDh/DJJ5+w57lw4QIePnyIOXPmsNRzx48fR0lJCfh8Pm7dusXCevl8PgYNGoSgoCAsX74cBw4cgLm5OVq2bIm4uDjmKNLV1cWbN29YDldPT08oKytj27ZtWLBgAbKystCuXTucPXsWgwcPZmG62dnZsLGxgUAgwLVr1+Dr64vt27ezkxBHjhxhxWd79OiBOXPmoFOnTrC1tcWqVatw4MABREZG4vz588jKykLv3r1RUVGB169fsz7jUoolJSVh5syZ0NTUxN9//w11dXVkZmbCy8sLmZmZaNGiBW7cuIE7d+5g+vTpUFNTw5UrVzBr1izcvHkTISEhLFz+0aNHmD59OgQCAVMuIyMjoaioiIKCAty/f59Fm3H/vnTpUpSUlCAxMRECgYAVSNbT02MG/6CgIPz666+IjY1FWloaBgwYgB49euCLL76At7c3nj59Cj09PfYCJhAIMGPGDNy4cYPVoAgLC0PPnj1x//59dhLFwsICOjo6CAsLw40bNzBt2jSsWbMGBw4cwLNnz1h7IyIikJaWht69e2Pnzp2YMWMGDAwM8PLlS7i4uLD+CQgIQIsWLZCQkMDWRs+ePXH58mVcvXoV7u7u6NWrFwoLC1FUVIRBgwahsLCQrcvWrVuDz+fj7du3GDt2LCtOeOzYMbYhdujQAb///jssLCzg6urKwmnT09Nx4MABeHp64vnz5+z0/OzZs3Hjxg0oKipi586d7GXQ2dmZKae7d+/G9evX4enpievXr8PX1xf//PMPEhMT8f79e6irq0NdXR3GxsYoKCgAj8dDeXk5tmzZgszMTMTGxsLd3R2JiYlo164deDwegoODER0djUGDBuHx48fo2bMngA9RGlwh6vz8fFhbW+PQoUMAAHd3dygqKkJbWxsHDx5E7969MWHCBOjp6SE8PJwZ9u/cuYPZs2ejpKSk0rrs2bMntm3bhs6dO6Nbt27Iy8tDdHQ0y10sEAhYmkEuVeCdO3eYjDh06BCmT5/Orvfu3Ts8f/6cGaIFAgF0dHTQr18/7Ny5EwEBAVBTU0NycjLatGmDW7dusT4fP348WrZsiRs3bmDmzJnIycmBu7s7li1bhhkzZrDnP3DgAK5cuYLo6Gj4+/sjKioK/fr1g7m5Oct1zq0LLsqTS0+jq6uLdu3awcDAAG3atGHrKj8/Hz169EB6ejo7PTp16lRWs4rrx927d+PWrVtMjpw6dQre3t6Ij4+HoqIiXr9+jXbt2kFFRQXv3r3D+vXr2TiWl5fj5cuXKCgoYLpAaGgoLC0tsX37drRr146ddh08eDC2bduGoUOH4p9//oGGhgbu37/Pcs9zxbQrKirg6OjICvPFxcVh2LBhMDU1hbGxMaZPn47Q0FBW6yIzMxMAMHjwYFbPqaysDDt37sTMmTMRGhoKHx8fHDhwAPb29ujVqxeUlJSQnJwMAwMDliebu25+fj7u37+PYcOGwdHREW/fvoWXlxdLgWpgYIBBgwahoqIC8fHxLE3ZnDlzEB4ezoqGzpw5E9evX0f37t2xfft2tG7dGhEREYiIiMDdu3dx8+ZNpKSkYMKECewFkMfj4dGjR+jSpQvbs7mIlsTERHTp0gWhoaHw9vau1J7evXtDVVUV5ubmCAkJYfvhkCFD2KGF3r17V7uPqH5JSUnBzZs3MXDgQFy7dg18Ph+zZs3CuXPnoK6ujqCgICb3r1+/jgcPHuDs2bMi76OoqIhevXohJCQE3bp1Q35+PitcW15eXmkPbNWqFXr06IGTJ0+ic+fOePfuHY4dOwZ7e3u4urqioqKC5Um/e/cuLl++zO7NyQk+n4/o6GhYW1tDV1cXeXl5GDBgAEJDQzF79mw8f/4cioqKWLp0KTthW1FRgXfv3mHEiBEi+5RLC9KxY0c2r6ZPnw51dXWcPHkS165dg4ODA5P1R48eZREgISEhKC4uRlxcHEtzdvnyZURHR2Pw4MGVamN17NgRc+bMYUbK1NRUGBoaQklJCRcuXMDFixfRpk2bSnOIWwdKSkpYunQp5s6dCxMTE6irq7PUdYmJiejWrRsEAkGl51ZTU0NBQQGOHj2Kli1bokWLFmytcNFkfD4furq6ePLkCe7fv48BAwagoqIC+fn5uHPnDkaOHIm///6byQNuPdy4cQMtWrTAnj17MH36dPB4PPz+++/Q19fHs2fPmC42cOBA/PXXX0z/4XSv8vJyNs8PHDiAwYMH4/379/D29kZCQgL+/PNP9OzZE+bm5mjRogXOnj3LZKewbMnLy0NwcDAcHBxQUVEBdXV1ZlTm6qz1798f6enpTM4UFxfD29sbL168YHKtZ8+ebByKi4sxaNAgWFtb49KlS0y+C+tG8fHx7H2AKxKqpKQEU1NTPH78GIsWLYK5uXk1uXjv3j12Sp0b7zFjxuDSpUt1jtP79+/xv//9D/369cPnn3+OS5cuwcXFhckjLgoyNDQUT548gZ2dHfr27YuQkBBcvnyZFcnl8Xjo2LEjcnJyWOoZYdljYWGBAwcOsPc/Pz8//PbbbxgxYgRu3ryJ0tJSKCkpwdfXl82HsLAw9OrVC7Nnz0ZUVBRatGiBvXv3VvtOfn4+mwN5eXlo2bIl3rx5A3t7ezx69AgnT55E//79kZ2dDSsrKxQWFiIkJATl5eWYPXs2nj59ylJOc2tMQ0MD3t7e0NbWBvAhQr6oqAiRkZF4+fIlPDw8wOfzkZWVhb///htOTk64du0aFBQUYGFhAWNjY6SlpcHU1BR8Ph/a2tpsnIyNjavJSs5xOnLkSBw9ehTFxcXM2FVaWlppDRYXF1frqxs3bjC5xs1lLntBTEwM1q5dCyUlJYSEhIDH4+Hdu3d4+PAhFBQUWP05Tg9QUVGpJFMvXbrE/r1Lly4oKSlhMoY7CNCrVy8EBwfj7t276N+/PyIiItC7d2/Y2tqyOVtcXMyekev/HTt2wMfHB1FRUcyQOXDgwEr7OzevlixZgn/++QcPHjyAoqIi1NXV2TzmDH2cXYCTdZGRkQA+ZLMYMmQItm3bBh6Ph5SUFIwZM4btl9zeoqGhwQ7qKSgosP4NCQnB/fv3YWNjw2R3jx49qq3viooKtna4tcH1sbA8v379OiIiIjB9+nRs374dfD6/ko5iZWWF2NhY2NjYgM/nIzw8HC1btmS1ntq0acMOqHJz0svLix004fQaFxcXJsPy8vIAADo6OmwvDg4OZnqLqP3ywoULiI6ORr9+/dje2LVrV2hqauK3337D6dOnUVpayuppcO9WXHQAt+ZfvnwJb29vxMbGQkVFBceOHcPLly9hYmLC3vOr3vvmzZuYM2cOkpKS2HuQ8H7XrVs3jBs3DjNmzEDPnj3Ro0cPXLt2jdX64vbD7t27g8fj4dmzZ9DW1saDBw8QGxvL1v/z58+RkpIiUv/k8/m4du0aPD092R6qoKDA5iQXPZaWlsaeAQD7zsiRI6vJ1ICAAKabeXh4QFNTk2XVEO7fc+fOIS4uDg4ODkxHHjNmDCwsLHDnzh1cvHgR0dHRCAsLY8/t7Oxcbf5xc7CiogJDhw6FkpJSJbnG1eXkDldw/6+qj12/fh3379+Hh4cHOnTowGT848ePq8k9Tj4Iy2Yej4fw8HDMnj0bDx8+rGYP4N5l7O3t0b17dzg7O6O8vBzXr1/H+PHjsW3bNvTv35/pbba2tjA1NUVZWRmysrLYevr0008RHByMnj17oqKiAn369EFgYCBMTEwq7d8pKSnMQN+lSxdW25N7v87OzoaqqipLfxsZGYnr16+zvZizEQq3jdNnhXVkYV3y8ePHUFJSQlZWFl6+fAlPT08WuXL69Gl06dIFaWlpKC0trSZ7vby8EBwcjOfPn7P3BOF7W1lZwcLCAsnJyWwcuIiDgQMH4u+//0ZoaKhInV5YZ+LemQQCATQ1NZGeno4ZM2awTBatWrXC48eP0bp1azg4OEBRURF8Ph/l5eUoKipi9V59fX1RUVGBgQMH4tKlSwgPD0fr1q2Z3ZCTe3w+Hzo6Orhz5w6SkpLQu3dvVvN0+vTpzD4m/J6pra1daV/X1dVFRUUFbt68CQcHB1hYWMDZ2bnGNcaNifA7EWeTzsvLY2NjYmKC6OhoDB8+nNlghfuPe/cRftfj5IDwcwvvc1xEh7CMt7GxgbKyMh4+fFhtLQrrWeXl5cxOHBAQUO0ZOLl/9OhRdkBg+vTp7N85O9GFCxfYexL3bpqYmMjei4WfgXuH4+y/AwcOZPNceN5cuHCByWFunITl/evXryvpJVFRUZgxYwbbo8XlP+tk4YyI2dnZ4PF4MDQ0RHFxMXJzc9GyZUs8evQIJiYmmDBhAnx9fZmixOWj7tKlC8aOHYvs7GyWduLdu3fg8/ksIqRly5ZITU2FtbU1unbtitTUVOjr6+POnTs4evQo1NTUAHyof/Hw4UMAH/LzBQYG4uuvv8b//vc/8Hg8ZGRk4MSJE+DxeGjRogWAD8Zv7rShhoYGwsLCkJeXh4CAAKxdu5ad+F6xYgVmzZqFb7/9FuvWrUNcXByuXr2KwMBAdmJ42LBhGDZsGJKSkphX2d/fH8AHp8qaNWsQERGBli1bsnoTwIcTz6ampujbty+2bt3KQuIWLVqEQ4cOITc3F+rq6lizZg169uzJ0hxx/PDDD8jIyMDatWsBfCiSO2XKFGRlZaGiogLbt2/HgwcP0LFjRyQlJSEhIYEVO9uyZQuCgoLw2WefITY2lp2cMTc3x4gRIxAfH499+/bh3LlzCAwMxPnz53H+/Hk4ODggOTkZampqGDhwIHN0qaqqIikpCV27dsWMGTPg4OAAAOjRowfc3Nzg4uKCqKgoFqnC5eaeMmVKpUJIn376KRYuXAg9PT2cOXMGe/bsYfmYVVVVcebMGURHRyMvLw8ZGRlYtGgRxo4dCy0tLQCAo6Mjtm3bhvbt26N79+4YNmwYvL298e+//+LUqVPIyMjAyJEjUVFRgcDAQPj4+MDY2Bjz5s2rFF6ak5MDe3t7tGvXDsCHmifl5eXo0aMHtLW1WT2OoqIiqKmp4dNPP8Vff/2F7t27IywsDKtWrQIAfPbZZ6xdK1asgKGhIVM80tLSkJOTg9evX+Pvv/9mdVwcHR1x9uxZAGAnEjkHh3B9iy5dusDOzg5aWlq4du0ay8u6fv16GBsbs8gWzlmjpqaGGTNmYM2aNTh16hTMzMxYTZq//voLixcvxqZNmzB16lR24jMpKQkWFhY4ceIETp8+DQCYMGECbGxssHHjRmzduhUODg4wNjbGyZMnkZaWBh8fH6SmpkJHRwdDhw7FiRMn8OrVK+Tl5WH9+vXo1q0bAEBRUZEV9wwPD4e/vz8sLS3RunVrPHjwABMmTEB0dDS8vLygqKgIf39//PDDD1BQUGB5vblTOQUFBejbty+7touLCzMg+/r6wtfXF3v27MHgwYPZdz799FN4enpi6NChmDRpEjw8PJizceTIkTh27Bh4PB66du2KyMhIHDt2jNUI8Pf3Z/3n5+fH2vvzzz+Dz+ezcS8oKMAvv/yCyMhIrFu3jvVPSkoKFixYgJkzZ7K1wdUcmjdvHjstHxoaCnV1daxcuRIvX77E2bNnMX78eJw+fRqFhYUYM2YMW4PcySMzMzMMHjwYv//+O96+fYujR48y+Qh8yAUbHR2NP//8E/v374e3tzdiYmLg6OiI48ePs7V05coVbNq0CatXr8a+ffvQtm1bZGVlITc3FzY2NhgwYAAsLS1Z+kITExNkZGRAQUEBjo6OLE+nl5cXoqOj4efnhxMnTmDjxo3g8/n45ptvWLgx8KEg5bhx4zB//nxYW1tDS0sLf/zxB54/f45ffvkFp0+fRnR0NNatW4edO3fi119/ZfWBtLW1oaSkhDVr1sDf3x9eXl4sPSWPx8Pt27dx7Ngxti65PeDEiROIjo7G8+fP2bq9cuUKjh8/jsDAQCgrK8PMzAzr1q1Dr1690LVrV9bPXCE3Dw8PtGjRAjweD2lpafj2228xd+5c9O3blzlhVFRU2Pi7uLhg8ODB6NatGxwdHTFv3jw2r/79919oaWlh2bJlbP5w3wcAb29v8Pl8ODg4YMeOHVBWVsarV6/A4/HQqlUrhIeHIyIiAj4+PrCwsEDXrl2ZDPvmm28AgKU08/LygqenJ6KjoxEZGYkzZ85g48aNaNmyJVRUVDB48GBMmzYNHTt2RHR0NAQCAZMjtra2OHv2LHr06IFWrVrB1NSUpQzlotNOnz6NIUOGoKioCM7Ozti1axdCQ0ORnZ2Ns2fP4o8//mAGOUdHR/zyyy9QUVFhtdemTZuGH374AT4+PlBUVMTMmTNhY2PD6qOFhoZiwYIF8PT0BPAhX6+/vz8uX76M/fv3szUdGxuLe/fuITU1FbGxsdDU1GSFRQMDA3HixAno6uqyPnZ3d4eqqiouXryIUaNG4fjx49DT00OfPn1YqjvhGkVRUVHIzMzEuXPncPHiRbRo0QKRkZHw8/PDrl27sGvXLixcuBCDBw+Go6MjFi9ezObgvXv3WPQDVztoxIgRyMzMxI4dO9CxY0dUVFQwfevOnTusQPS9e/egqakJc3NzZgz/7rvvEB0djbNnz1ZqT1BQEHuGbt264ezZs2w/7Nu3L9LT06GkpCTyPqL6RU9PD3PnzoWNjQ369euHmzdvIjAwEKGhoVBTU8OwYcNw8uRJvHz5khkvhg0bho0bN1a7j5qaGlq3bg0XFxc8f/6c1YhSVVWFuro62wMTEhIwe/Zs+Pr6wtnZGQcOHICHhwecnJygq6uLf//9F+np6Rg8eDBLzSl8b2E5AQBaWloYNGgQ9u/fj969e+Ps2bMsHRMXGQB8qNnh4OCAwMDAGvt0yZIluHXrVqV5xfWFgYEBZs6cCS8vLyxZsgRRUVGYN28eLC0tsW/fPpY/2szMDP/88w/c3NxYGy0sLPDll19i8ODBmD9/Puzt7eHo6IgNGzbA3d0d3333HbZv346LFy9CQ0ODpUUUnkPTp0+Hq6srBgwYgMzMTCgrK6Ndu3bYv38/+7f+/fvjn3/+X3vnHRfV0f3/D2ChC0uvoqKCglhQEUFAUdQIYkWs2MWGHQuKEQWNFRNDjEZIjKKJBTs2RFEjWCIqRRAptogNSxQUmN8f+d357sIuu4v65Eme83698orMvTNzzplzzr17596ZRHz33XcSes+YMQMhISEICQnB48ePUVBQgEGDBvF7ZC0tLTRr1oy/1ODn58e/SqhXrx7GjBkDV1dXvHnzBgkJCXj06BGPBw0NDb7sq7q6Og4ePMgf+nbp0gUtWrTAzp07MW/ePL5vnPheaPfv34eenh7Px8KG1gcPHsT333+PmJgYpKWl4fnz55g5c6ZE7pw8eTLPLRYWFmjZsiWOHDkCdXV1+Pn58R/U/fv3x/Hjx7Fw4UL88ccfPM9UVlbi4MGD8PPz43ltz549OHbsGN6/f4/ExER88cUXCA0NRXJyMreP+L1Rr169UFhYyH+wX7p0CfPmzUNRURFfw93a2rpaXhS+EBIfb8H/5I3T7t270bhxYyxcuBAWFhZITk5GQkICf+D98uVLZGZmeLGZiQAANa1JREFU8uUWXVxc+NdJAPhvg8rKSjRv3hzOzs6oX78+1NTUJHKP+P5f79+/R0JCAoYPH46YmBhMnToVf/75J1q1aoWZM2dyf3B2dkZ2drbE/ZF4nQ8fPsDOzg5Pnz7lPvD69WtMmTIFpaWl8Pf3x44dO9CzZ08sXLgQYWFh8PPzw6BBgzBjxgwsWbIEnTt3xv379+Hk5CQRYyoqKjh48CA2b96MkydPIiwsDHv27EF6ejoqKytx5coVAH8tqzJmzBgMGjQIqqqq/IGPsP+msD9A//79cfbsWRQWFkIkElXLlRkZGTw2hCU7hXv/r7/+mi+nMX78eKSnp1ezlbm5Oc9rdevWxfr165Gbm8vf4LW2tsYXX3yBZ8+eoaioCLGxsQgJCUFKSorE/nMqKipQU1OTyKm2trb8uHBdtre356tRVFZWcvvVqVMHtra2MDY25rlV8Nk6depwHdu1a4clS5bA2NgYb968weTJk1FRUcHjW11dHaNHj+YrNwi5MjU1FX/++SdsbW0RGxuL4OBgNGvWDFevXuX3Hdra2jzXDR8+HCUlJTA0NMS2bdswefJkXLt2DZWVlRLXy8rKSmRmZqJPnz54/vw51NTU8O233+K7777D7NmzYWlpiaFDh8LAwACTJk2Cs7Mzv/aJx3d6ejpKSkokYqNdu3bV8rmxsTHfB1XQdcaMGfweRVVVFSdOnMDZs2fh4uKC0tJSnDp1CiUlJdDQ0ICKigpmzpyJJk2acJ8Uri+9e/fmL5SePn2a57Dy8nIcPXoUQ4YM4ddi4b6lZcuWSEpKqna9FF5atLa25tdGIb+OHDkSPj4+GDx4MHr27IlWrVrBzc0NgwcPRnh4OB49esRj/sOHDzh48CD8/f0RExODBw8e4KuvvkJhYSEcHR2l9i1c2y5fvsx/BwllkZGRaN26Ndzc3GBtbY2EhATExMRgxYoV6Nu3L4qLi+Ho6IjIyEhs2LABqqqqsLGxQWxsLB48eIDt27cjPDycf31WVlYm9f5TRUUFzs7OMDQ0RK9evfD8+XO8evWK+6S6ujq3qaCDmpoaryP47P79+/k9Xv369fH27VtERkZi5cqV3L6+vr6IjY3l91fCsxkXFxd+PyJ8DVlRUcHHxs3NjeudkZHB+xH8b9CgQfwe+cSJE5g5cyb69+/P89qyZcuwefNmnDt3DvPmzcPr16+l3o9VVFRg5cqVfDlpNTU1REZGYvv27dXyXnZ2drXcLBKJUFpaKvN5gPD1va6uLgoKCmBnZ8fvh4XfZ8IEgJBbHj9+jDt37kjEk3BdSEpKgoODg4SuFhYW/Pp97949vky8YN+ff/6Z/74W9lPdu3cvXrx4gdWrV/NnFlpaWnw5PHHZXr16JbH/qaOjo8S9pHAdmzp1Ki5duoQtW7bw+77Ro0cjNjYW69evx4ULF6rl3t9//533J80u06dPR3BwMGJiYvg4qKqq8pwq/K6Rdk8vfs8k/GYaPHgwnjx5gk6dOvF8EhISwm3w7NkzFBQUoFmzZvw+QXhWa2BgwO+/582bh6ysLJSWlko8NxTy3u3btxETE4P169fj6tWr0NXVlRjPN2/e8Pt84X5u8+bNOHToEBYuXIhly5bB19cXX3/9NYYOHQqRSIS0tDS4u7vLjDFhTMTv38+dOwc3Nzds376dj43gk5GRkRg1alS12GjWrBnKysok2pGmt/CC+OTJk/nX7uI5Xvhit7S0tFosiseyhoYGf07s6upaTQfh92xISAi/305PT0eTJk3QpEkTXLx4kW9rIPxOEn6bCsv7FxcXS+ggXFfEf+OVlJTwr60FvxHPw8I4ief7a9euSdyXTJ48GVOnTuXPORVFVamz/0X4+vri8OHD2L9/P5KTk+Hu7o7ExETs3r0bERER+OGHH2Brawvgr429/f39eZ3k5GRkZmZCR0cH0dHRSExMREREBFasWAFPT09cuXIFO3fuREREBCIjI+Ht7Y358+dj3bp1CAsL459OC1RUVGDjxo3872nTpmH+/Pl8U8B+/fphy5YtmDVrFnbt2gXgr42GtmzZgvDwcCxbtgypqamYMWMGn7BwdHREly5d0LdvX76vjL+/P0JCQrB3717Mnj0bN2/e5OuTA0B8fDwaNWrE7QMAIpEI0dHRuHz5MiIiInDy5EnY2tryz6UMDAzg4eGBtm3b8rKpU6ciNTUVEydO5G37+PjgwoULEmNQUVHB5QXAJ5FCQ0P5m47ChVt4C1Kc7t274+HDhzh16hRSU1Nx6tQpODo6Yvny5XB0dOR6jB49GpcuXUJGRgY6d+6M9PR0BAYG4ptvvsGKFStga2uL6Oho7NmzB3Fxcbxs8+bNfDNi4K/NoLZv346tW7fymxBnZ2duMwBYvnw5RCIRVFRU4O/vD09PT4SHh/MbTX9/f4SGhiIiIgLffvstmjRpgtTUVKSlpQEAQkJCMG7cOGzYsAHp6enQ09ODr68vUlJSkJ6ejh07dsDS0hIbN27Eb7/9BgAYPXo0Vq5ciblz52LNmjUAgC1btqBfv358I/vGjRtzfVasWMGXrhJssXHjRvz4449wcHDA7Nmz+Ybkgs1DQkKwefNmvulWeXk5tmzZgkmTJiE8PBweHh5wc3Pj5yYmJmLnzp24fv063N3dcevWLZSXlyM4OBiHDx/GqFGjsGPHDtjY2CAqKoqP35YtW+Dj44ORI0fC398fAwYM4Es6AMCkSZP4PkcCXbp0wcaNG9GkSRPExMRIjEl8fDwAYMCAAfwrAqGOcPEUbPjLL78gPj4e3t7eyMzMxJAhQxAREYGtW7ciMDAQW7duxePHj/kSd40bN4avry9EIhGPl+DgYLi6uiI4OJj7g5A7BJ8PCQnB2bNnsWHDBhw4cADl5eXYvHkz+vXrh8DAQACAqakpj1ngr/2KlixZIlFn+fLl6NevHz9eUVEBFxcXuLu7Y9asWTx/COP466+/YvHixVizZg2XB4CEvKmpqXxiEwCPIxcXFwn7CF+QiMfGypUrsXjxYpiammL58uXw9PTEnTt3cP/+fZSWliI6OhqTJ09GREQEkpOTMXHiRJ43bW1teQ6MiYnhOgB/rXEdFRXF5bWysoK3tzdEIhFmz56N8ePHIyoqissYHBzMN0qNjo6GSCTCnDlzMH36dJ5b+vTpg+joaInJ3+TkZJw+fRonTpxAaWkpfH190a9fP97fnDlz8Ntvv6Fly5Zo3rw5tmzZgjZt2iAlJYX7Q0BAAGbNmsX9WSQSwdXVFY6OjrydESNG8ElrIVZLS0uxbNkyAICHhwdWrlwJf39/REVFITIyEhYWFhJxGRMTI2GL0tJSflzwr9mzZ2PHjh1o0qQJRCIRzp8/j5EjR0pcQ4QvIQRfyc/Px8aNGxEcHIxGjRrxTUY3b94MkUjEx7t9+/bc5sK4r1mzhustIPiPcG0Q4tHU1BSNGjVCfHw871uIo8uXL2Pfvn3YsWMHSktL+ZeOwv/9/f15XAn6q6urIykpidvH3d0dCxYs4HYMDQ2VyCMJCQmYNWsWhg0bhh49eiAlJQV5eXnw8PCAnp4ezM3NYWdnh9zcXLi5uaGwsBB+fn6IjIzEunXrMHToUIwdOxZlZWVwc3Pjk1p16tRBTk4OysvLERUVhVGjRvFPp8vKypCTk4PS0lIYGBjAzMwMZWVlcHJygouLC3R1dZGbm4v58+cjKCgId+/eRWVlJSwtLVFZWYm2bdsiNTUVbm5u6NGjB19yqGHDhggKCkLDhg3h4uKCli1bIjU1FQMHDoSbmxv09PTQokULaGtrY9GiRfwLhL59+6KoqAhPnjzBqlWrYG5uDmtra3h7e0NHRweurq7o2bMnjhw5AicnJ2RmZuLChQuYOnUqTE1NERkZCVVVVf4ANz4+Hv7+/khKSuKbemtoaGDChAm4ffs2SktL+Vtey5Ytg46ODioqKvgb3O3bt5ewb1BQEExMTNClSxeuQ6dOnRAVFYVly5bB2toar169wpEjR6CtrY2pU6di48aNePv2LUaNGsVfDLh79y68vLzQpk0bbpcBAwbg2rVrsLa2xu7du+Hj44MbN27A0NAQ8+bNQ1paGv/KQkdHB7t370ZQUJDUfoyNjeHj48O/Yp44cSJ/qCwsiebu7g5dXV28e/cOx48f5zlNV1cXOjo6CAwMRGVlJUJDQ5GUlISSkhL06dMHOjo6+OmnnxAUFIT79++jSZMm0NfXh5eXF1xdXTFnzhyMHTsWUVFRmDNnDnR0dKCrq8vfKM/JyUFFRQWioqIwf/58iTHW09PDiBEjUFBQAG9vbwQEBPAlhTQ0NKClpYUBAwZg4MCBuHbtGlq1agUXFxc0b96c74Pz008/4fDhw8jLy4O7uztEIhF69eoFfX19+Pn5IT8/H0uXLsWKFSvw8OFDZGdn82V6CgoKEBISgoyMDEyfPh0mJiZ4+vQpAgICcOrUKVhZWeHEiRO4efMmDAwMMGXKFCxYsABeXl7IzMxEVFQU0tPTUVpaioKCAsTHx8PPzw89evTA3bt3cfToUXh5ecHa2ho9e/aEtbU1Ro4cidTUVHh5eaFx48b4/fff+RrceXl5MDY2Rnl5OYYOHYqePXvyBxdPnjzB/Pnz0b17d+zatQszZ86EpaUlunbtiuPHj+Py5cuYNWsWtLS0cPPmTRQWFuLQoUMICQnBjRs3YGJiAjMzM6SlpXFbNWrUCGFhYSgqKuLyFBcXY/78+dy/vvjiC4hEIrx+/RqOjo48T6xYsQJdu3bF9OnTUVRUBCcnJ763gra2Nn7//XdYWVnh+PHjuHnzJk6fPo0XL17wry3fvHmD8PBwibwmjIPwUFV4YNKmTRu4uLjAyMiI58f+/fvDzc0N9erV43kiMjISampq0NPTw927d9GpUyeJyf6HDx/i+PHjyMjIQGBgIExMTMAYg6GhIby8vNC5c2eZ45Sens6XoaioqEB8fDxcXV3Ru3dv2NnZoXHjxujVqxfu37+P4cOH8xgRvvYdMWIEjh8/jlOnTsHS0hL29vb48ccf4eHhgZs3b8LFxQWRkZGIjo7GnDlz+OoBpaWlfOzz8/O5/fLy8mBubi7hD69fv0ZAQAB0dHRgYWEBIyMj3LlzB15eXmjQoAH3VX19feTn56OyshKGhoYwMzPDnTt3sHjxYowbNw63bt3C6dOnUVRUxMv279+PkJAQTJ8+HcbGxjA0NIS/vz9cXFxgaWmJP/74A6NGjcLx48eRnp6O06dP87g0NjaGiooKJk2ahLp16yInJwcikQhJSUmws7Pjdq6srOR2DgoK4uOkr6+P1NRU2NraIj4+Hi1atJCIDWGT5OPHj/NNiysqKvh4C7YSv5ZoaWlh7dq1OH78OL9OmpiY4OHDh+jevTvfIyQpKQnt27dHUFAQbty4gaFDhyIgIAAlJSXo168fbt26xa81L168wLp16yT8KiEhASNHjoSdnR1MTU0RGBjI87Wenh73r9zcXFhaWqKgoAD79u2Do6Mj/8L69evXOHr0KLp06YLQ0FDo6+vj8ePHaNy4MXR0dNCnTx/o6uri2LFjcHFxQVJSEjp27IgzZ87g2bNn/OuBuXPnIisrC4mJiWjfvj2SkpJQt25dnDlzBg8fPkRKSgoKCwtx7949DBw4EKGhodDU1IS6ujpsbGwQGBiItm3bQkNDA/n5+aioqED37t2Rk5ODvLw8bNy4Efn5+QgMDISmpiZ/o7usrIy/NSwSibBkyRJ4e3vD0NAQixYtQrNmzZCSkoKUlBQ8fvwYKioq/MthU1NT3Lt3DwMGDADw18upq1evxv79+5Geno5+/frx5xkmJiYYNmwYpkyZAisrK4wcORI6OjoYPXo0TExMcOrUKTDGcObMGVhZWWHDhg3Q1tbGgAED0LNnTzx//hwTJkzgXxx5e3vzvTTS0tIwdOhQjB49Gs+ePUOPHj1QWlrKv0aws7NDhw4doK2tDX9/fzRq1Ahjx47F9OnTkZOTg+zsbL7fQ58+fZCbm4vExERcv36dL+k0c+ZMpKen48WLF3jy5Ak6duyIhg0bws7ODtu2bUN6ejrevn2LAQMGYM6cOTAwMOBfsri6usLJyQnh4eFo1KgRMjMzYWpqystGjBiBCxcuICIiAi9fvkTHjh2RkpKC0NBQuLu7Y+zYsTh37hwOHTqEQYMG4cqVK3ByckJwcDC+++47dOjQAa1atcLatWuxZMkSiEQi/rWDg4MD9u3bBzMzM4wdOxb6+vro0KEDunbtyjdyTkpKgpOTE65fv45GjRpJ6CBeR9gPY/78+VBTU8OaNWvQp08fFBYWori4mNtS2JvE398f2dnZyM7ORrdu3RAcHAxDQ0NoaWnB1NQU/fr1Q5s2beDs7MzHJiUlBYsWLYKzszPCwsLQsWNHLF68GF27dkVOTg7y8/Ph4OCAAQMGwNzcHIcOHcL169fRu3dvjBkzBvb29nwJ/0WLFqFx48bIyMhAXl4epk2bBgsLCxQWFmLEiBFYv349hgwZgoCAAGRkZODdu3fo2LEjbt26BW1tbdjZ2fFVABITE2FsbAw9PT20b98eZWVlsLCwwNq1a7Fp0yb+0oCenh7/ktLHxwdDhgzBvXv3oK+vj/r168PR0RFt2rRBcHAw9PT0MHToUBw4cAD9+/fn+8726tULZ86cwaBBg+Dn54esrCyMGTMG586dw5o1a7iuwheZU6ZMgaurK9avX4+ePXtizZo1aNasGZYsWYLhw4ejsLAQt27dwqtXr5CQkIBRo0bBz88PDRo0QHx8PPr3749FixahRYsWaN68OZo0aYJWrVph0aJF0NTU5DZ1d3fnY7d27VqsWbMGhw4dQnR0NIYNGwZbW1sMHz4cPj4+aNasGZo0aYKKigqMGjUKzs7OGDZsGHJzc+Hv74/69eujRYsWuH79Os8zDRs2RPPmzdG0aVOcP38eY8aMgbGxMUJDQ/Hw4UP8+uuvMDY25l8H2tjY4O7du3BwcEC/fv3QokULNGzYEE5OTggNDeUvurRq1QoODg7Q1dVFx44d0aVLF7x79w4DBgzgNpg7dy7atm0LTU1Nnj8DAwORmpqKIUOGYPLkybCyskKfPn3w9u1bNGvWDBMmTECdOnXg4eEBLS0tJCcnc/tVVFQgICAABw4cgJeXF86fP4/+/fvD0NAQx44dw/Xr1zF9+nRYW1vj+vXr2LhxI44cOYI+ffrg8OHD8PLywtWrV/m99OPHjyVirF27dti5cycCAgIAADY2Npg2bRrU1dXRuXNnqKuro6CgAFu2bMGPP/4IIyMj7pPFxcWoX78+mjVrhkePHsHS0hIDBw7kE/DCb1Vvb2+pes+ePRtXrlxBWVmZ1BwfFRWFY8eOoVGjRrCzs8PZs2ehpqYGJycniWuJs7MzgoODUadOHe5XM2fOxKBBg+Do6MiXXA8MDOQTMwMHDoSamhrc3d35su/Dhg1Dz5494eXlBXV1dTx+/BhmZmYoKipCaGgovxb069cPK1asgKGhIUaMGIFDhw6hadOm/LequN+I52Fp+X7t2rVQU1PjY1hYWIjBgwfD2toayvA/uyeLsPcIAL5esfBASbwsJydH6Tqfqh1l6ly4cIGvvyisCdqnT58a2xHq+Pr6Su2zpjrS+pEmj3jbythKmr41ySasNy6+FqqwOVxVecWPKypbbWxV03ny7CtNNnEdpdlcnv2ktSPNFh/jA+J9S+tHmTrydJRnS2XtL09eRW0lTx5F40CZeKrJP5WxSW38pqYYk2U/Zf28NnaujY7y6tcmF8rL54rmFkX1lXXsU+n9Mflc3tgqm/eV0UWazU1NTfnbP97e3jh16hQ8PDwAgO/fcerUKf4FUElJCX8TuqSkBGpqaujatSuOHDkCW1tbvHz5EoGBgdi/fz/fSHvPnj3o2bMnKisroa+vj+zsbCxcuBCxsbEy2/n111/Rq1cvhers2rULvXv3RmpqarWyXr16Ydq0aejduzeKi4t5Ozdu3OAvJyxatAinTp2Crq5uNdkbNWqksN5DhgxBQkICrytLh1u3buHEiRPQ1dWtVkfcVtJ07NWrFxYuXFhNNmNjY5w8eVJqm+KyZWZmVrOVoMOePXsQFhaGkydPSoy34AOXLl3C4sWLFepHvEywqdC3uA7y6ojbMiwsjI/TkCFDsHz5cpiamsrUQdp4yvJPcR+oyVbSxkGaDuJjI9hP3Nek2Vda39L6Eddbnp8L8TJjxgyp8takozQfkVZXlk+K6y0+Jor6zceMg6KyKToO8vqWlifEbS6vb2l15NlFKGvcuHG1fC3LlwQfkRX/iuZCaf2Ix5O08RbkEPfPmzdvKpW3ZOmgaFxKi39ZubtqvqmtPygz3oGBgYiIiKiW18SvJbKul4K8ylyrpY3d2LFjUbduXb4nhJ2dHdzc3KClpYW0tDSpey9aWFhUOy7sz3Xu3DmsW7cO48aNg6urK7S0tJCamsrLXFxcoKOjg5ycHN6O+PGPqSNNnpSUlBp1ULQdkUiES5cuyWxz37593H6urq7Q0dHBkSNHcOfOHXh6ekJPT0+pdjw9PdGgQYMa5RXsIvQjPnbS9BKWkpYnr3g7ZmZmSssrre2cnByYmZnJtIt429JsLs2vFPW/2uhQGx8R71uazyojb9VxkmdfWb4mbbzl+Yiifi4tT4iPnSI6VLV5VR+RJW9Nvq+o/eTZSp680mwhK8Zq0kGZXCjN/+Tltaq2UsTm0vxKnt6C34hEIly7dg1FRUV8oi8hIQHFxcXVcoK02FDU1+Rdk+TFt6L5qKYc/6ni+1P6uaCDrHykaIw9fPgQEyZMwA8//FDtmYQs/me/ZNHU1MTOnTuxc+dOxMfHo1u3blLLalPnU7WjTJ3u3btj+PDh8Pb2RmFhIYYPHy63HaGOrD5rqiOtH3ltK6O3PHtUlU1cHvG+pclbG9lqY6uazlNmTKTpWBv7ybPVp/ABeWOiTB1FY+NT2V+evIraSp48tSmT57M1yfax9vuYGJNXR1E/r42dP3ZM5NVVNBd+qjysqL61yQm1yWu1yefKXJ8+hTzybG5ubg57e3v4+Pjg9u3bKC8vx927d1FcXAxjY2Nelp+fz8tSUlKgqqqKiIgI6OnpoXv37nw94IsXL+Lt27fQ0dHhZUZGRrzOH3/8gbp162Lq1Kk1tiPej7w6AQEBaN68udQyTU1N/m/xdgS9jIyM+L+lya6M3u/evZOoK0uHrKws3l/VOuK2kqWPNNmys7NltileJs1W4n0L7Yi3LdhHmX6k+YM0HeTVEbel+Di9e/cOHTp0qFEHae3I8s+qbcuylaI6SLOfeD/SjkvrW1o/4nrL83PBl2TJW5OO8vxcnk+K610bv/mYcVBUNkXHQZlYlGZzeX3LG6eayqTla1m2kBf/iuZCaf3IisGqcoj7p7J5S5YOH5NbZOXuT+UPyoz327dvpeY1edef2l6rpY2dhYUFDA0NJfaAMzIygr6+Pjw9PavtvTht2jSpx9+8eYPr16/D29sbly5dgoaGBj9PvMzc3JwvbSLt+MfUkSaPPB0UbUdYjkhWm+L2E+Rt3bo1DAwM4Pn/9xFUpB3xOvLkFfqRNnbS9Fq9enWN8kprpzbySmt72rRpNdpFns0VHSdZen8qmyvatzSfVUZeZe0ry9ek1ZHnI4r6ubx4qUkHWTZX1Kfl+ayifX+MvPL6VlQHZXKhorlZWj/K2LymOvLyxOrVq/Hs2TPo6urC19cXe/fuhZmZmdScUJM+H3tNUtTX5OUjeXntY+L7c/i5vHykaIwJe6spw//slyz5+fkSyzw9f/4cL1++rFYmrO+sTJ1P1Y4ydfLz89GgQQNeJv7muKx2hDrC8arn1lRHWj/S5BFvWxlbSdO3JtmE/wttCn1Lk1f8uKKy1cZWNZ0nz77SZBPXUZrN5dlPWjvSbPExPiDet7R+lKkjT0d5tlTW/vLkVdRW8uRRNA6Uiaea/FMZm9TGb2qKMVn2U9bPa2Pn2ugor35tcqG09mqThxXVV9axT6V3TXXl5SN5Y6ts3ldGF2k2v3nzJt8P5ubNm0hJSYG7uzvfC00kElUr69evH/bv3w9tbW0kJSWha9euiIuLw8SJE/nyfOHh4bhz545E2f79+3H37l1cu3YNO3bs4GU1taNInaSkJERFReHkyZMyy6KiorB27VreztmzZ5GSkoKwsDCJf1eVXdgr6VPqXVN/4nVk6Sj0KS6bME41tRkeHo73799Xs5W4DoJs0nxAnq1qskHVvhWxW9UyaX2/f/9epg7KyCir7Zr8qiYdZI2NPPsqaitBb3l+Lu5LstqRFzuy/FyajPL0/li/UXQcFJVNmXFQNBbF84SifUuro2hsyMsDVXVQJP7l5UJ5+aameJKVh5XxgdrG5afIN8r6Q23GW1pek3ZdkJe7a3PNunjxIh4/fgwTExO4uroiISGBbzQv7K0YExPD914MDg7GoUOHqh23tLTk++e4urrysoqKChgbG/MyJycnFBcXw9/fn7cjfvxj6kiTx9LSskYdFG1HqCOrTUHvhIQEGBsbo7i4mLcj2FSRdoQyoZ2a5BXsIpSJj500vfz9/XHx4kWZ8kprR7C5MvJKa1voW5ZdxNuWZnNpfqWo/9VGh9r4iHjf0nxWGXmFcVLUvrJ8Tdp4y/MRRf1cWp4QH7uadJBlc8FH5Pl0Tb4vz37iZdJspai80mwhK8Zq0kGZXCjN/+TlNaEfcR+RZ3NpfiVPb8FvgoODkZ+fj8TERH5uYmIievbsWS0nSIsNRX1N3jVJXnwrmo9qyvEfG9+K+ogyfi7oICsfKRpjwcHBSPj/e7Uqyv/sJAtBEARBEARBEARBEARBEARBEMTH8D+7XBhBEARBEARBEARBEARBEARBEMTHQJMsBEEQBEEQBEEQBEEQBEEQBEEQtYAmWQiCIAiCIAiCIAiCIAiCIAiCIGoBTbIQBEEQBEEQBEEQBEEQBEEQBEHUAppkIQiCIAiCIJSmoKAAKioquH79+t8tCic7OxsuLi5QV1dH69atP1s/cXFx0NPT+2zty8LT0xMzZsz4j/erCEuXLv0kNn/27BmMjY1RUFDw0W1VJSgoCP7+/h/djoqKChISEj66nY+BMYYJEyZAJBJ99jj8XPpK85mlS5fCxMTkv8LG/wRsbGywYcOGz9a+MnH9zTffwM/P77PJQhAEQRAE8d8MTbIQBEEQBEH8AwkKCoKKigpWrlwpUZ6QkAAVFZW/Saq/l/DwcGhpaeH27ds4ffr0Z+snICAAOTk5StX5FBMk+/btQ0RExEe18d9OVFQUfH19YWNj88nbjo6ORlxc3Cdv9+8gMTERcXFxOHz4MB49egQHB4fP1tejR4/Qq1cvhc9XdBJyzpw5EnGalZWFL7/8Eps3b1a6z387f9fEbtUxqonx48fj8uXLOH/+/GeWiiAIgiAI4r8PmmQhCIIgCIL4h6Kuro5Vq1bhxYsXf7con4z379/Xum5eXh7c3NzQsGFDGBgYfEKpJNHQ0ICxsfFna18WIpEIOjo6//F+/1O8e/cOP/zwA8aNG/dR7cjyoQYNGvwtD6o/B3l5eTAzM4OrqytMTU1Rp06dz9aXqakp6tev/8nb1dbWlojTvLw8AEDfvn0/W5//aT58+PB3i/BRVB2jmqhfvz6GDh2Kr7/++jNLRRAEQRAE8d8HTbIQBEEQBEH8Q/H29oapqSmioqJkniNtuZcNGzZIfCkgLKMUGRkJExMT6Onp4csvv0R5eTnmzp0LkUgES0tLbNu2rVr72dnZcHV1hbq6Olq2bInk5GSJ45mZmejduze0tbVhYmKCESNG4OnTp/y4p6cnpk6dilmzZsHQ0BDdu3eXqkdlZSWWLVsGS0tL1K9fH61bt0ZiYiI/rqKigqtXr2LZsmVQUVHB0qVLpbYj9Dd16lTo6enBwMAAYWFhYIzxc168eIGRI0dCX18fmpqa6NWrF3Jzc/nxqm+VCzbevn07bGxs0KBBAwwZMgSvX7/m9j179iyio6OhoqICFRUVFBQU4MWLFxg2bBiMjIygoaGBpk2bIjY2VqrcguziX8PY2NggMjISY8aMgY6ODqytrfH999/LrC+0MX36dMybNw8ikQimpqbVbFVUVIS+fftCW1sburq6GDx4MB4/fixxzsqVK2FiYgIdHR2MHTsWpaWl1fqKjY2Fvb091NXVYWdnh2+//bZG2Y4dO4Y6deqgU6dOEuVnz55Fhw4dUL9+fZiZmWH+/PkoLy+X0EkRH6q6XJgitsjNzUWXLl2grq6OFi1a4OTJk9XaffDgAQICAqCvrw8DAwP07duXL3eWnZ0NTU1N7Ny5k5+/b98+qKur4+bNmzJtUZPOQUFBmDZtGoqKiqCioiLzqx/BTxMSEtCsWTOoq6uje/fuuHfvnsR5MTExaNKkCerVq4fmzZtj+/btEsfFl+4Slgnct28fvLy8oKmpCScnJ/z2228AgOTkZIwePRovX77kvi4rFsVz09KlS+Hr6wsAUFVVlfk1XnJyMlRUVHD69Gk4OztDU1MTrq6uuH37tlI6VUXwjS+//BLGxsbQ1dXFxIkTJSbsEhMT4ebmxvNGnz59+MSQuG1++eUXeHp6Ql1dHT///DOAmmPhY2369u3bGnNATf4ptN+hQwdoaWlBT08PnTt3RmFhYbUxkncuAPj5+SEhIQHv3r2r0d4EQRAEQRD/OhhBEARBEATxj2PUqFGsb9++bN++fUxdXZ3du3ePMcbY/v37mfgtXnh4OHNycpKou379etawYUOJtnR0dNiUKVNYdnY2++GHHxgA5uPjw1asWMFycnJYREQEq1u3LisqKmKMMZafn88AMEtLS7Znzx6WmZnJxo0bx3R0dNjTp08ZY4w9fPiQGRoasgULFrCsrCx27do11r17d+bl5cX79vDwYNra2mzu3LksOzubZWVlSdV33bp1TFdXl8XHx7Ps7Gw2b948VrduXZaTk8MYY+zRo0esZcuWbPbs2ezRo0fs9evXUtsR+gsJCWHZ2dns559/Zpqamuz777/n5/j5+TF7e3t27tw5dv36debj48NsbW3Z+/fvGWOMxcbGsgYNGkjYWFtbm/Xv35/dvHmTnTt3jpmamrKFCxcyxhgrKSlhnTp1YuPHj2ePHj1ijx49YuXl5WzKlCmsdevW7PLlyyw/P5+dPHmSHTx4UOaYe3h4sJCQEP53w4YNmUgkYps2bWK5ubksKiqKqaqqyrSh0Iauri5bunQpy8nJYT/++CNTUVFhJ06cYIwxVllZydq0acPc3NzYlStX2KVLl1jbtm2Zh4cHb2P37t2sXr16bMuWLSw7O5stWrSI6ejoSPjZ999/z8zMzNjevXvZ3bt32d69e5lIJGJxcXEyZQsJCWE9e/aUKLt//z7T1NRkkydPZllZWWz//v3M0NCQhYeHS+ikiA8JMaOoLSoqKpiDgwPz9PRkv//+Ozt79ixr06YNA8D279/PGGPszz//ZE2bNmVjxoxhN27cYJmZmWzo0KGsefPmrKysjDHG2KZNm1iDBg1YQUEBe/DgAROJRGz9+vUy7SBP55KSErZs2TJmaWnJHj16xIqLi6W2Exsby+rWrcucnZ3ZxYsX2ZUrV1iHDh2Yq6srP2ffvn2sbt26bNOmTez27dts7dq1TE1NjSUlJfFzxPUV4t7Ozo4dPnyY3b59mw0cOJA1bNiQffjwgZWVlbENGzYwXV1d7uuyYlE8N71+/ZrFxsYyALyeNM6cOcMAsI4dO7Lk5GSWkZHB3N3dldapKqNGjWLa2tosICCA3bp1ix0+fJgZGRnxGGaMsT179rC9e/eynJwc9vvvvzNfX1/m6OjIKioqJGxjY2PD/f7BgwdyY+FjbCovB8jzzw8fPrAGDRqwOXPmsDt37rDMzEwWFxfHCgsLq42RvHMZY+zNmzdMRUWFJScny7Q1QRAEQRDEvxGaZCEIgiAIgvgHIv7A2MXFhY0ZM4YxVvtJloYNG/KHhYwx1rx5c+bu7s7/Li8vZ1paWiw+Pp4x9n8PBleuXMnP+fDhA7O0tGSrVq1ijDG2ePFi1qNHD4m+7927xwCw27dvM8b+etDdunVrufqam5uzFStWSJS1b9+eTZ48mf/t5OQk8fBdGh4eHsze3p5VVlbystDQUGZvb88YYywnJ4cBYBcuXODHnz59yjQ0NNgvv/zCGJM+yaKpqclevXrFy+bOncs6duwo0a/4BAljjPn6+rLRo0fXrHgV2atOsgwfPpz/XVlZyYyNjVlMTEyNbbi5uUmUtW/fnoWGhjLGGDtx4gRTU1Pjk2mMMZaRkcEAsLS0NMYYY506dWKTJk2SaKNjx44SfmZlZcV27twpcU5ERATr1KmTTNn69u3L/Vhg4cKFrHnz5hLjtWnTJqatrc39VVEfkjbJUpMtjh8/ztTU1PgEJmOMHTt2TGLS4YcffqgmX1lZGdPQ0GDHjx/nZV988QVzd3dn3bp1Y927d5c4vyqK6Fw1hqUhTFpcunSJl2VlZTEALDU1lTHGmKurKxs/frxEvUGDBrHevXvzv6VNsmzdupUfF/xDeLBfNT5kUTU3Vc1d0hAmWU6dOsXLjhw5wgCwd+/eKaxTVUaNGsVEIhH7888/eVlMTIyEzatSXFzMALCbN28yxv7PNhs2bJA4T14sfIxN5eUAef757NkzBkDmpIj4GMk7V0BfX7/GyVSCIAiCIIh/I7RcGEEQBEEQxD+cVatW4ccff0RmZmat22jZsiVUVf/v1tDExASOjo78bzU1NRgYGKC4uFiinvjSTnXq1IGzszOysrIAAFevXsWZM2egra3N/7OzswMAiWV2nJ2da5Tt1atXePjwITp37ixR3rlzZ96XMri4uEgsR9SpUyfk5uaioqICWVlZqFOnDjp27MiPGxgYoHnz5jX2ZWNjI7FfipmZWTVbVSU4OBi7du1C69atMW/ePFy8eFFpXVq1asX/raKiAlNTU7n9itepKmtWVhasrKxgZWXFj7do0QJ6enpc/6ysrGpLeon//eTJE9y7dw9jx46VGPvly5dLjHtV3r17B3V1dYkyoS/x8ercuTPevHmD+/fv8zJ5PiQLebawtraGpaWlVD2Bv3z8zp070NHR4XqKRCKUlpZK6Lpt2zbcuHED165dQ1xcnMzlsJTRWRGEmBSws7OrNpa1iStxu5mZmQGAXL/7lNTUf211cnJygqamJv+7U6dOePPmDV9eLS8vD0OHDkXjxo2hq6uLRo0aAfhreT1xxO2tTCzU1qY15QB5/ikSiRAUFAQfHx/4+voiOjoajx49ktqPoudqaGjg7du3cuUmCIIgCIL4N/H5dkgkCIIgCIIg/iN06dIFPj4+WLhwIYKCgiSOqaqqSuw3AkjfjLlu3boSf6uoqEgtq6yslCuP8HC4srISvr6+WLVqVbVzhIeIAKClpSW3TfF2BRhjNT6srg1VbaVoX7WxVa9evVBYWIgjR47g1KlT6NatG6ZMmYI1a9YoLG9t+q2pjiw9lbG10NaWLVskJquAvybrZGFoaIgXL17I7VcYI/FyRX2oKvJsUZWqslRWVqJdu3bYsWNHtXONjIz4v9PT0/Hnn39CVVUVf/zxB8zNzWXKpKjOiiKtjnhZbeJK3G7i8f6fQl7/nzJXCPV8fX1hZWWFLVu2wNzcHJWVlXBwcJDYtwWQ9EVlYqG2Nq3JhxXxz9jYWEyfPh2JiYnYvXs3wsLCcPLkSbi4uFSro8i5z58/l/B9giAIgiCI/wXoSxaCIAiCIIh/AStXrsShQ4eqfQ1hZGSEP/74Q+KB8fXr1z9Zv5cuXeL/Li8vx9WrV/nXKm3btkVGRgZsbGxga2sr8Z8yD8V1dXVhbm6O8+fPS5RfvHgR9vb2HyWz8HfTpk2hpqaGFi1aoLy8HKmpqfz4s2fPkJOTU6u+BOrVq4eKiopq5UZGRggKCsLPP/+MDRs2yN24/nPTokULFBUVSWyOnpmZiZcvX3L97e3tpdpQwMTEBBYWFrh79261cRfe/pdGmzZtqn2N1aJFC1y8eFHCfy9evAgdHR1YWFh8lK7yEGzx8OFDXiZsRi7Qtm1b5ObmwtjYuJquDRo0APDXQ+egoCAsWrQIo0ePxrBhw2rcGPxT6lxeXo4rV67wv2/fvo2SkhIeo/b29p8srgRk+fp/itrqlJ6eLjEuly5dgra2NiwtLfHs2TNkZWUhLCwM3bp1g729fbUJQWnUNhaqUlubKuKfwF+xt2DBAly8eBEODg7YuXOnzDZrOjcvLw+lpaVo06aN0rISBEEQBEH8k6FJFoIgCIIgiH8Bjo6OGDZsGL7++muJck9PTzx58gRfffUV8vLysGnTJhw7duyT9btp0ybs378f2dnZmDJlCl68eIExY8YAAKZMmYLnz58jMDAQaWlpuHv3Lk6cOIExY8Yo/cBw7ty5WLVqFXbv3o3bt29j/vz5uH79OkJCQpSW+d69e5g1axZu376N+Ph4fP3117ydpk2bom/fvhg/fjzOnz+P9PR0DB8+HBYWFujbt6/SfQnY2NggNTUVBQUFePr0KSorK7FkyRIcOHAAd+7cQUZGBg4fPvxRD7c/Bd7e3mjVqhWGDRuGa9euIS0tDSNHjoSHhwdfBikkJATbtm3Dtm3bkJOTg/DwcGRkZEi0s3TpUkRFRSE6Oho5OTm4efMmYmNjsW7dOpl9+/j4ICMjQ+Lh9eTJk3Hv3j1MmzYN2dnZOHDgAMLDwzFr1iyJ5e0+B97e3mjevDlGjhyJ9PR0pKSkYNGiRRLnDBs2DIaGhujbty9SUlKQn5+Ps2fPIiQkhC/tNWnSJFhZWSEsLAzr1q0DYwxz5syR2e+n1Llu3bqYNm0aUlNTce3aNYwePRouLi7o0KEDgL/iKi4uDt999x1yc3Oxbt067Nu3r0b55GFjY4M3b97g9OnTePr06X986aja6vT+/XuMHTsWmZmZOHbsGMLDwzF16lSoqqpCX18fBgYG+P7773Hnzh0kJSVh1qxZCslTm1ioSm1tKs8/8/PzsWDBAvz2228oLCzEiRMnZE4oK3JuSkoKGjdujCZNmvCybt264ZtvvlFYV4IgCIIgiH8iNMlCEARBEATxLyEiIqLaEkf29vb49ttvsWnTJjg5OSEtLe2jHqBWZeXKlVi1ahWcnJyQkpKCAwcOwNDQEABgbm6OCxcuoKKiAj4+PnBwcEBISAgaNGig9MPi6dOnY/bs2Zg9ezYcHR2RmJiIgwcPomnTpkrLPHLkSLx79w4dOnTAlClTMG3aNEyYMIEfj42NRbt27dCnTx906tQJjDEcPXq02rI8yjBnzhz+pYyRkRGKiopQr149LFiwAK1atUKXLl2gpqaGXbt21bqPT4GKigoSEhKgr6+PLl26wNvbG40bN8bu3bv5OQEBAViyZAlCQ0PRrl07FBYWIjg4WKKdcePGYevWrYiLi4OjoyM8PDwQFxdX49v7jo6OcHZ2xi+//MLLLCwscPToUaSlpcHJyQmTJk3C2LFjERYW9umVr4Kqqir279+PsrIydOjQAePGjcOKFSskztHU1MS5c+dgbW2N/v37w97eHmPGjMG7d++gq6uLn376CUePHsX27dtRp04daGpqYseOHdi6dSuOHj0qtd9PqbOmpiZCQ0MxdOhQdOrUCRoaGhI+5u/vj+joaKxevRotW7bE5s2bERsbC09PT6X7EnB1dcWkSZMQEBAAIyMjfPXVV7VuqzbUVqdu3bqhadOm6NKlCwYPHgxfX18sXboUwF++sGvXLly9ehUODg6YOXMmVq9erZA8tYmFqtTWpvL8U1NTE9nZ2RgwYACaNWuGCRMmYOrUqZg4caLUtuSdGx8fj/Hjx0vUy8vLw9OnTxXWlSAIgiAI4p+ICpO18DRBEARBEARB/Mvw9PRE69atsWHDhr9bFEIKR48exZw5c3Dr1q3P/qXKv524uDjMmDEDJSUlf7co//UEBQWhpKQECQkJf7co/1hu3bqFbt26IScnR2IpMoIgCIIgiP8FaON7giAIgiAIgiD+K+jduzdyc3Px4MEDWFlZ/d3iEAShIA8fPsRPP/1EEywEQRAEQfxPQpMsBEEQBEEQBEH811CbfXYIgvh76dGjx98tAkEQBEEQxN8GLRdGEARBEARBEARBEARBEARBEARRC2ihY4IgCIIgCIIgCIIgCIIgCIIgiFpAkywEQRAEQRAEQRAEQRAEQRAEQRC1gCZZCIIgCIIgCIIgCIIgCIIgCIIgagFNshAEQRAEQRAEQRAEQRAEQRAEQdQCmmQhCIIgCIIgCIIgCIIgCIIgCIKoBTTJQhAEQRAEQRAEQRAEQRAEQRAEUQtokoUgCIIgCIIgCIIgCIIgCIIgCKIW0CQLQRAEQRAEQRAEQRAEQRAEQRBELfh/smD+PJKvyrIAAAAASUVORK5CYII=",
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"# Based on example at https://scikit-learn.org/stable/auto_examples/cluster/plot_agglomerative_dendrogram.html\n",
"def plot_dendrogram(model, **kwargs):\n",
" # Create linkage matrix and then plot the dendrogram\n",
"\n",
" # create the counts of samples under each node\n",
" counts = np.zeros(model.children_.shape[0])\n",
" n_samples = len(model.labels_)\n",
" for i, merge in enumerate(model.children_):\n",
" current_count = 0\n",
" for child_idx in merge:\n",
" if child_idx < n_samples:\n",
" current_count += 1 # leaf node\n",
" else:\n",
" current_count += counts[child_idx - n_samples]\n",
" counts[i] = current_count\n",
"\n",
" linkage_matrix = np.column_stack([model.children_, model.distances_,\n",
" counts]).astype(float)\n",
"\n",
" # Plot the corresponding dendrogram\n",
" dendrogram(linkage_matrix, **kwargs)\n",
"\n",
"plt.figure(figsize=(20,10))\n",
"plt.title('Hierarchical Clustering Dendrogram')\n",
"plot_dendrogram(aggclust)#, truncate_mode='level', p=3)\n",
"plt.xlabel(\"Number of points in node (or index of point if no parenthesis).\");"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"These dendrograms are often used in combination with a display of the gene expression data in a \"heatmap\".\n",
"\n",
"Here is a single example of approximately zillions in the literature. The rows in the heatmap matrix are 1259 genes, the columns are different strains of bacteria.\n",
"\n",
"\n",
"\n",
"Downloaded from [this paper](https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4512144/) [here](https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4512144/bin/ofv09303.jpg).\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Further thoughts and questions\n",
"\n",
"- Does clustering before PCA work better or clustering after PCA?\n",
"- How would you judge this?\n",
"- As discussed in the lecture, PCA is a parameter-free, linear, very fast dimensionality reduction technique and is almost always the first dimensionality reduction technique you should try if you want to look at high dimensional data. If PCA doesn't perform well, there are many other techniques. PCA can give a good first intuition into dimensionality reduction as a broad class of techniques, which is why we do it here. Non-linear techniques in widespread use include ICA (independent component analysis), T-SNE (T stochastic neighbor embedding), and UMAP (Uniform Manifold Approximation and Projection)."
]
}
],
"metadata": {
"celltoolbar": "Create Assignment",
"kernelspec": {
"display_name": "Python 3 (ipykernel)",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.11.10"
}
},
"nbformat": 4,
"nbformat_minor": 4
}